Автор вел ранее и сейчас ведет много различных учебных
дисциплин: "Теория и техника измерений", "Методы принятия
решений", "Основы теории информации", "Алгоритмы и структуры
данных", "Вычислительные системы и сети", "Базы
данных", "Новые информационные технологии в учебном процессе",
"Комплексные технологии в науке и образовании", "Информационные
системы в экономике", "Математическое моделирование", "Измерения
в экономике (Эконометрика)", "Информатика", "Интеллектуальные
информационные системы", «Представление знаний в информационных системах»,
"Основы теории управления (теория автоматического управления)",
«Компьютерные технологии в строительной науке и образовании (магистратура)»,
«Современные технологии в образовании (магистратура)», «Управление знаниями
(магистратура)», Введение в искусственный интеллект, Системно-когнитивный
анализ, Информационные технологии управления бизнес-процессами / Корпоративные информационные системы
(магистратура), Система искусственного интеллекта «Эйдос», Моделирование социально-экономических
систем / Организационно-управленческие модели
корпорации (магистратура), Введение в нейроматику и методы нейронных
сетей (магистратура), Интеллектуальные и нейросетевые технологии в образовании
(магистратура), Основы искусственного интеллекта, Эффективность АСУ
(магистратура), Функционально-стоимостной анализ системы и технологии
управления персоналом (магистратура), Компьютерная графика.
При проведении лабораторных и практических занятий по
многим из этих дисциплин может успешно использоваться системе «Эйдос-Х++».
Прежде всего, это все дисциплины, связанные с интеллектуальными технологиями и
управлением знаниями, а также с системным анализом, моделированием, управлением
и измерениями. Рассмотрим подробнее некоторые из них.
Учебно-методический комплекс по данной дисцплине в
2011-2012 учебном году составлял около 150 листов: http://www.twirpx.com/user/858406/.
Данная дисциплина обеспечивает
приобретение студентами знаний, умений и навыков по "Интеллектуальные
информационные системы" в соответствии с государственным образовательным
стандартом (ГОС) высшего профессионального образования по специальности
230201.65 - «Информационные системы и технологии». Она входит в цикл специальных дисциплин специальности.
Дисциплина "Интеллектуальные информационные
системы" является теоретическим и прикладным фундаментом для изучения
дисциплин специальности, связанных с обработкой информации при мониторинге,
анализе, прогнозировании и управлении в экономике и юриспруденции. Знания, умения
и навыки, полученные студентами при качественном освоении курса "Интеллектуальные
информационные системы" могут использоваться ими при изучении других
учебных дисциплин, а также при разработке курсовых и дипломных работ.
Изложение учебного материала дисциплины, согласно представленного
в рабочей программе календарно-тематического плана, учитывает специфику
деятельности специалиста в области экономики и юриспруденции. Оно ориентировано
на то, что работа выпускников по данной специальности будет связанна с выявлением
фактов непосредственно из эмпирических данных, накоплением фактов, выявлением
причинно-следственных взаимосвязей между ними и использованием этих знаний для
решения разнообразных задач идентификации, прогнозирования и выработки
рекомендаций по управлению (поддержка принятия управленческих решений). Поэтому
при преподавании дисциплины упор делается на прикладные аспекты эффективного
применения ими интеллектуальных информационных технологий.
Цель – обеспечить высокую профессиональную подготовку
специалистов в области разработки и практического применения интеллектуальных
информационных технологий по профилю будущей специальности.
В результате обучения по дисциплине
"Интеллектуальные информационные системы" студенты должны приобрести
знания, умения и навыки для решения следующих задач:
– формальная постановка задачи, когнитивная структуризация
и формализация предметной области;
– подготовка обучающей выборки и управлению ею;
– синтез модели предметной области, включая ее
Парето-оптимизацию;
– исследование модели на адекватность, сходимость и
устойчивость;
– решение задач идентификации и прогнозирования;
– решение обратных задач идентификации и прогнозирования,
поддержка принятия решений по управлению, информационные портреты классов и
семантические портреты факторов;
– кластерный анализ классов и факторов, графическое отображение
результатов кластерного анализа в форме семантических сетей;
– конструктивный анализ классов и факторов;
– содержательное сравнение обобщенных образов классов
и факторов, отображение результатов содержательного сравнения в графической
форме когнитивных диаграмм;
– решение задач с применением интеллектуальных информационных
технологий в различных предметных областях.
4.2.2.
Требования к уровню освоения содержания дисциплины
В
результате обучения по данной дисциплине студенты должны:
а)
знать:
–
историю, принципы и перспективные направления развития интеллектуальных информационных
систем;
–
критерии выбора математических методов и реализующих их программных средств для
решения конкретных задач в различных предметных областях.
б)
уметь:
ставить
и решать задач, сформулированные в п.1.2 данной рабочей программы, в различных
предметных областях.
в)
иметь представление:
о
перспективах развития интеллектуальных информационных технологий.
Перечень дисциплин, усвоение
которых студентами необходимо для изучения данной дисциплины
(перечень
необходимо согласовать с методической комиссией факультета)
|
Наименование
дисциплины
|
Наименование разделов /тем/
|
|
ОПД.Ф.03. Базы данных
|
Базы
данных (БД). Принципы построения. Жизненный цикл БД. Организация процессов
обработки данных в БД. Информационные хранилища. Проблема создания и сжатия
больших информационных массивов, информационных хранилищ и складов данных.
Управление складами данных.
|
4.2.3.
Содержание дисциплины
Раздел 1. Введение в
интеллектуальные информационные системы
Тема-1.
Интеллектуальные информационные системы, как закономерный и неизбежный этап
развития средств труда.
Основные положения информационно-функциональной теории
развития техники. Информационная теория стоимости. Интеллектуализация –
генеральное направление и развития информационных технологий. Логический
и эвристический методы рассуждения в ИИС. Рассуждения на основе дедукции,
индукции, аналогии. Нечеткий вывод знаний. Немонотонность вывода. Приобретение
знаний. Извлечение знаний из данных.
Тема-2.
Определение и критерии идентификации систем искусственного интеллекта.
Данные, информация, знания. Системно-когнитивный
анализ как развитие концепции смысла Шенка-Абельсона. Понятие: "Система
искусственного интеллекта", место СИИ в классификации информационных
систем. Определение и классификация систем искусственного интеллекта, цели и
пути их создания. Информационная модель деятельности специалиста и место систем
искусственного интеллекта в этой деятельности. Жизненный цикл системы
искусственного интеллекта и критерии перехода между этапами этого цикла. Понятие
интеллектуальной информационной системы (ИИС), основные свойства. Классификация
ИИС.
Раздел 2. Теоретические
основы и применение универсальной когнитивной аналитической системы
"Эйдос"
Тема-3.
Теоретические основы системно-когнитивного анализа.
Системный анализ,
как метод познания. Когнитивная концепция и синтез когнитивного конфигуратора.
СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных
операций. Место и роль СК-анализа в структуре управления.
Тема-4. Системная теория информации и семантическая информационная
модель.
Теоретические
основы системной теории информации. Семантическая информационная модель
СК-анализа. Некоторые свойства математической модели (сходимость, адекватность,
устойчивость и др.). Взаимосвязь математической модели СК-анализа с другими моделями
Тема-5. Методика и технология численных расчетов в СК-анализе
(алгоритмы и структуры данных).
Принципы
формализации предметной области и подготовки эмпирических данных. Иерархическая
структура данных и последовательность численных расчетов в СК-анализе. Обобщенное
описание алгоритмов СК-анализа. Детальные алгоритмы СК-анализа.
Тема-6.
Технология синтеза и эксплуатации приложений в системе «Эйдос».
Назначение и состав
системы "ЭЙДОС". Пользовательский интерфейс, технология разработки и
эксплуатации приложений в системе "ЭЙДОС". Технические характеристики
и обеспечение эксплуатации системы "ЭЙДОС" (версии 12.5). АСК-анализ,
как технология синтеза и эксплуатации рефлексивных АСУ активными объектами.
Раздел 3. Принципы построения
интеллектуальных информационных систем
Тема-7.
Системы с интеллектуальной обратной связью
и
интеллектуальными интерфейсами
Интеллектуальные интерфейсы. Понятие интеллектуального
интерфейса и классификация систем с интеллектуальными интерфейсами. Системы с
биологической обратной связью (БОС). Системы, поведение которых зависит от
психофизиологического состояния пользователя. Использование систем с
биологической обратной связью в медицине для лечения заболеваний путем
осознания ранее не осознаваемых процессов в организме (Фрейд) и освоения
навыков управления ими. Системы с семантическим резонансом (СР). Системы,
поведение которых зависит от состояния сознания пользователя, в частности от
его интересов. Использование систем с семантическим резонансом для тестирования
пользователя и реагирования на его интересы. Компьютерные Y-технологии и интеллектуальный подсознательный интерфейс.
Системы подсознательного тестирования и модификации подсознания пользователя.
Вызванные потенциалы и различие между восприятием и осознанием. Фильтры
сознания (эксперимент со студентами по установке интеллектуальных фильтров на
осознание восприятий, положительные и отрицательные галлюцинации). Возможность
использования подсознательной реакции пользователя на воспринимаемые, но
неосознаваемые изображения для тестирования пользователя и реагирования на его
интересы и принадлежность к тем или иным идентифицируемым группам, в частности
профессиональным группам («профессиограммы»). Возможность сообщения информации
пользователю непосредственно в подсознание, минуя критику и фильтры сознания
(компьютерное нейролингвистическое программирование – НЛП). Виртуальная
реальность. Системы виртуальной реальности и критерии реальности, принцип
эквивалентности виртуальной и истинной реальности. Виртуальные устройства
ввода-вывода. Эффекты присутствия, деперсонализации, модификация сознания
пользователя и переноса центра интересов ценностей и мотиваций в виртуальную
реальность («реалы и виртуалы»). Рассмотрение перспективных и патологических
измененных форм сознания, возникающих в системах с интеллектуальными интерфейсами.
Вопросы соблюдения моральных норм в системах виртуальной реальности и
последствия их несоблюдения. Использование информации, снимаемой с головного
мозга (в частности электроэнцефалограммы), для дистанционного управления кибернетическими
системами с помощью мышления о них, т.е. без использования мышечных усилий:
«телепатический» интерфейс и ментальные игры. Системы с дистанционным
микротелекинетическим интерфейсом, обеспечивающие дистанционное управление
кибернетическими системами без использования физического тела. Проект Vega-72,
история и перспектива. Работы лаборатории Princeton Engineering Anomalies
Research (PEAR) (Princeton
University, at Princeton, N.J. USA): http://www. princeton.edu/~pear/
Тема-8. Автоматизированные системы
распознавания образов
Основные
понятия и определения, связанные с системами распознавания образов. Проблема
распознавания образов. Классификация методов распознавания образов. Применение
распознавания образов для идентификации и прогнозирования. Сходство и различие
в содержании понятий "идентификация" и "прогнозирование".
Роль и место распознавания образов в автоматизации управления сложными
системами. Методы кластерного анализа. Машинное обучение на примерах.
Тема-9.
Математические методы и автоматизированные системы поддержки принятия решений
Многообразие задач принятия решений. Языки описания
методов принятия решений. Выбор в условиях неопределенности. Решение как
компромисс и баланс различных интересов. О некоторых ограничениях
оптимизационного подхода. Экспертные методы выбора. Юридическая ответственность
за решения, принятые с применением систем поддержки принятия решений. Условия
корректности использования систем поддержки принятия решений. Хранилища данных
для принятия решений.
Тема-10.
Экспертные системы
Базовые
понятия. Методика построения. Этап-1 синтеза ЭС: "Идентификация".
Этап-2 синтеза ЭС: "Концептуализация". Этап-3 синтеза ЭС: "Формализация".
Этап-4 синтеза ЭС: "Разработка прототипа". Этап-5 синтеза ЭС:
"Экспериментальная эксплуатация". Этап-6 синтеза ЭС: "Разработка
продукта". Этап-7 синтеза ЭС: "Промышленная эксплуатация". Экспертные
системы. Составные части экспертной системы: база знаний, механизм вывода,
механизмы приобретения и объяснения знаний, интеллектуальный интерфейс.
Организация базы знаний. Этапы проектирования экспертной системы:
идентификация, концептуализация, формализация, реализация, тестирование,
опытная эксплуатация. Участники процесса проектирования: эксперты, инженеры по
знаниям, конечные пользователи. Статические и динамические экспертные системы.
Тема-11.
Нейронные сети
Биологический
нейрон и формальная модель нейрона Маккалоки и Питтса. Возможность решения
простых задач классификации непосредственно одним нейроном. Однослойная нейронная
сеть и персептрон Розенблата. Линейная разделимость и персептронная представляемость.
Многослойные нейронные сети. Проблемы и перспективы нейронных сетей. Модель
нелокального нейрона и нелокальные интерпретируемые нейронные сети прямого
счета. Нейронные сети.
Тема-12.
Генетические алгоритмы и моделирование
биологической эволюции
Основные понятия,
принципы и предпосылки генетических алгоритмов. Пример работы простого
генетического алгоритма. Достоинства и недостатки генетических алгоритмов.
Примеры применения генетических алгоритмов.
Тема-13. Когнитивное моделирование
Определение основных
понятий: "Когнитивное моделирование" и "Классическая когнитивная
карта", их связь с когнитивной психологией и гносеологией. Когнитивная
(познавательно-целевая) структуризация знаний об исследуемом объекте и внешней
для него среды на основе PEST-анализа и SWOT-анализа. Разработка программы
реализации стратегии развития исследуемого объекта на основе динамического
имитационного моделирования (при поддержке программного пакета Ithink).
Тема-14.
Выявление знаний из опыта (эмпирических фактов) и
интеллектуальный
анализ данных (data mining)
Интеллектуальный
анализ данных (data mining). Типы выявляемых закономерностей data mining.
Математический аппарат data mining. Области применения технологий интеллектуального
анализа данных. Автоматизированные системы для интеллектуального анализа данных.
Раздел 4. Применение и
перспективы систем искусственного интеллекта
Тема-15.
Области применения систем искусственного интеллекта.
Обзор опыта
применения АСК-анализа для управления и исследования социально-экономических
систем. Поддержка принятия решений по выбору агротехнологий, культур и пунктов
выращивания. Прогнозирование динамики сегмента рынка. Анализ динамики
макроэкономических состояний городов и районов на уровне субъекта Федерации в
ходе экономической реформы (на примере Краснодарского края) и прогнозирование
уровня безработицы (на примере Ярославской области)
Тема-16.
Перспективы развития систем искусственного интеллекта, в т.ч. в Internet.
Ограничения
АСК-анализа и обоснованное расширение области его применения на основе научной
индукции. Перспективы применения АСК-анализа в управлении. Развитие
АСК-анализа. Другие перспективные области применения АСК-анализа и систем
искусственного интеллекта.
4.2.4.
Практические (семинарские) занятия
|
№ п/п
|
Тема занятия
|
Объём в часах по
формам обучения
|
|
очная
|
заочная
|
|
|
НЕ
ПРЕДУСМАТРИВАЮТСЯ
|
|
|
|
|
|
|
|
4.2.5.
Лабораторный практикум
Лабораторный
практикум включает по выбору преподавателя
любые шесть из десяти перечисленных в
приведенной таблице лабораторных работ разработанных и описанных в авторском
учебном пособии по интеллектуальным информационным системам и
научно0методических статьях автора УМК. Все лабораторные работы основаны на
системе «Эйдос». Каждая работа выполняется 4 часа (две пары), которые, как
правило, идут одна за одной.
Цель проведения лабораторных занятий заключается в закреплении
студентами полученных на лекциях теоретических знаний путем самостоятельного
решения учебных научно-исследовательских задач.
Основной формой проведения лабораторных занятий является
самостоятельного решения студентами учебных научно-исследовательских задач в
реальной системе искусственного интеллекта «Эйдос».
В обязанности преподавателя входят методическое руководство
и консультирование студентов по лабораторным работам.
|
Номер ЛЗ
|
Номер раздела
|
Наименование лабораторной работы (занятия)
|
Объём в часах по форме обучения
|
|
очная
|
заочная
|
|
1
|
2
|
Синтез
и исследование семантической информационной модели: «Прогнозирование
вероятных пунктов назначения
железнодорожных составов»
|
4
|
4
|
|
2
|
2
|
Синтез
и исследование семантической информационной модели: "Прогнозирование
учебных достижений студентов на основе их имеджевых фотороботов"
|
4
|
4
|
|
3
|
2
|
Синтез
и исследование семантической информационной модели: "Прогнозирование учебных достижений
студентов на основе особенностей их почерка"
|
4
|
---
|
|
4
|
2
|
Синтез
и исследование семантической информационной модели: "Прогнозирование учебных достижений
студентов на основе информации об их социальном статусе"
|
4
|
---
|
|
5
|
2
|
Синтез
и исследование семантической информационной моделей: "Идентификация слов
по входящим в них буквам" и "Атрибуция анонимных и псевдонимных текстов"
|
4
|
|
|
6
|
2
|
Синтез
и исследование семантической информационной модели: «Идентификация трехмерных
тел по их проекциям»
|
4
|
---
|
|
7
|
2
|
Синтез
и исследование семантической информационной модели: «Исследование RND-модели
при различных объемах выборки»
|
4
|
---
|
|
8
|
2
|
Синтез
и исследование семантической информационной модели: «Системно-когнитивный подход к синтезу эффективного
алфавита» Синтез и исследование семантической информационной модели:
«Исследование свойств натуральных
чисел»
|
4
|
---
|
|
Общий объём
|
24
|
---
|
Примечание: преподавателем выбираются любые 6 тем лабораторных
работ
4.3. Дисциплина: «Представление знаний
в интеллектуальных информационных системах»
“Истинное знание – это знание причин”
Френсис Бэкон (1561–1626 гг.)
В этом разделе, основанном на работе [127], на
небольшом и наглядном численном примере подробно рассматриваются методологические
аспекты технологии выявления знаний из эмпирических данных, представления
знаний и их использования для решения задач прогнозирования, принятия решений и
исследования предметной области в системно-когнитивном анализе (СК-анализ) и
его программном инструментарии – интеллектуальной системе «Эйдос»
Интеллектуальные системы – это автоматизированные системы,
обеспечивающие выявление знаний из
эмпирических данных, хранение и накопление их в различных формах представления, а также их использование для решения различных
задач. Современный уровень развития теории и практики искусственного интеллекта
и динамика развития этого научного и технологического направления таковы, что,
по-видимому, можно обоснованно говорить о его затяжном кризисе, более того, о
том, что его развитие возможно пошло по тупиковому пути. У автора есть развитые
конкретные глубоко аргументированные представления о путях выхода из этого
кризиса, связанные с решением ключевых вопросов о том, может ли мыслить объект
и какими структурами поддерживается функция мышления у людей и какими
структурами она в принципе может поддерживаться в технических системах.
Парадоксальность ситуации заключается в том, что, казалось бы, само собой
разумеющиеся и очевидные ответы на эти «простые» вопросы, скорее всего,
являются неверными. Однако обсуждение
этих путей и вопросов далеко выходит за рамки данной работы, т.к. требуют
углубленного анализа закономерностей развития человека, технологии и общества,
а также некоторых изменений в современных мировоззренческих концепциях и
научных парадигмах.
Здесь же отметим лишь, что выявление, представление и
использование знаний безусловно является проблемой,
и в различных интеллектуальных системах эта проблема решаются (или не решаются)
по-разному.
Далее рассмотрим вариант решения этой проблемы в автоматизированном
системно-когнитивном анализе (АСК-анализ) и его программном инструментарии – интеллектуальной
системе «Эйдос».
Прежде всего, кратко рассмотрим соотношение содержания
понятий: «данные», «информация» и «знания».
Данные – это
информация, рассматриваемая безотносительно к ее смысловому содержанию,
находящаяся на носителях или в каналах связи и представленная в определенной
системе кодирования или на определенном языке (т.е. в формализованном виде).
Информация –
это осмысленные данные. Смысл,
семантика, содержание (согласно концепции смысла Шенка-Абельсона) – это знание
причинно-следственных зависимостей.
Знания – это
информация, полезная для достижения целей (рисунок 79).
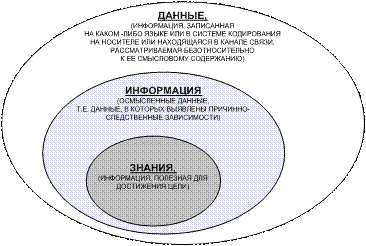
Рисунок 79. Соотношение содержания понятий: «данные»,
«информация», «знания»
Знания могут быть представлены в различных формах, характеризующихся
различной степенью формализации:
– вообще
неформализованные знания, т.е. знания в своей собственной форме, ноу-хау
(мышление без вербализации есть медитация);
– знания, формализованные в естественном вербальном
языке;
– знания, формализованные в виде различных методик,
схем, алгоритмов, планов, таблиц и отношений между ними;
– знания в форме технологий, организационных производственных,
социально-экономических и политических структур;
– знания, формализованные в виде математических
моделей и методов представления знаний в автоматизированных интеллектуальных
системах (логическая, фреймовая, сетевая, продукционная, нейросетевая, нечеткая
и другие).
Таким образом, для решения сформулированной проблемы
необходимо осознанно и целенаправленно последовательно
повышать степень формализации исходных данных до уровня, который позволяет
ввести исходные данные в интеллектуальную систему, а затем:
– преобразовать исходные данные в информацию;
– преобразовать информацию в знания;
– использовать знания для решения задач
прогнозирования, принятия решений и исследования предметной области.
Для этого в АСК-анализе предусмотрены следующие этапы [7]:
1. Когнитивная структуризация предметной области, при
которой определяется, что мы хотим прогнозировать и на основе чего (конструирование
классификационных и описательных шкал).
2. Формализация предметной области (7):
– разработка градаций классификационных и описательных
шкал (номинального, порядкового и числового типа);
– использование разработанных на предыдущих этапах
классификационных и описательных шкал и градаций для формального описания
(кодирования) исследуемой выборки.
3. Синтез и верификация (оценка степени адекватности)
модели.
4. Если модель
адекватна, то ее использование для решения задач идентификации,
прогнозирования и принятия решений, а также для исследования моделируемой
предметной области.
Рассмотрим, как реализуются эти этапы на простом наглядном
примере, который положен в основу лабораторной работы №1 по дисциплине: “Интеллектуальные информационные системы”, преподаваемой автором в Кубанском государственном аграрном
университете. Этот пример интересен тем, что рассматриваемая в нем задача легко
решается также и с помощью «естественного интеллекта», что позволяет сравнить
результаты его работы с работой автоматизированной интеллектуальной системы и увидеть,
как она работает.
Данная задача взята
из книги Д.Мичи и Р.Джонстона "Компьютер – творец",
(c.205-208), в которой она приводится в качестве примера задачи, решаемой
методами искусственного интеллекта. Авторами этой задачи являются Рышард
Михальски и Джеймс Ларсон.
Суть этой задачи
сводится к тому, чтобы выработать правила, обеспечивающие идентификацию
железнодорожных составов и прогнозирование направления их следования на основе
их формализованных или вербальных описаний (рисунок 80).
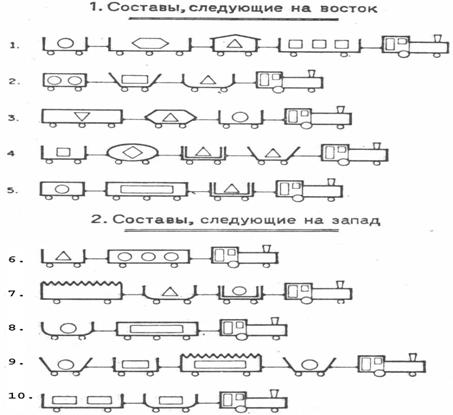
Рисунок 80. Исходные данные по примеру в графическом виде
Выбор данной задачи
не накладывает ограничений на выводы, полученные в результате ее исследования.
Это обусловлено тем, что она имеет ряд характерных особенностей, наблюдающихся
в подобных задачах в самых различных предметных областях. Поэтому ее с полным
основанием можно рассматривать как типовую
для широкого класса задач идентификации и прогнозирования.
Эти особенности
состоят в следующем:
1. Рассматривается
ряд объектов (фактов), представляющих в совокупности исследуемую выборку.
2. Каждый из
объектов исследуемой выборки представляет собой систему, имеющую сложную
многоуровневую структуру признаков (экстенсионально описание).
3. Для каждого из
объектов исследуемой выборки известно, к каким обобщенным категориям (классам)
он относится (интенсионально описание).
4. Необходимо
сформировать модель, обеспечивающую идентификацию объектов по их признакам,
т.е. определение их принадлежности к обобщенным классам.
Если признаки и
классы относятся к одному времени, то имеет место задача идентификации
(распознавания). Если же признаки (факторы, причины) относятся к прошлому, а
классы, характеризующие состояния объектов, – к будущему, то это задача
прогнозирования. Математически эти задачи не отличаются.
Совокупность экстенсионального и интенсинального описания
каждого объекта, по сути, представляет собой его определение через подведение под более общее понятие и выделение специфических
признаков. Например, так определяется понятие «млекопитающее»: это животное
(более общее понятие), выкармливающее своих детей молоком (специфический
признак). На основе ряда определений конкретных объектов путем их обобщения можно получить определения
классов. Если привести в качестве примеров исследуемой выборки множество
различных животных, как млекопитающих, так и других, каждый из таких примеров
определить множеством признаков и построить модель, то окажется, что наиболее
характерным признаком млекопитающих является не наличие шерсти или когтей, а
именно вскармливание детенышей молоком.
Первым делом вручную преобразуем
исходные данные из графической формы, представленной на рисунке 80, в форму
Excel-таблицы исходных данных (таблица 24):
Таблица 24 – Excel-таблица исходных данных
|
Источник
информации
|
Классификационные
шкалы
|
Описательные
шкалы
|
|
Состав
следует на
|
Наименование
состава
|
Форма
вагона
|
Длина
вагона
|
Количество
осей вагона
|
Грузоподъемность вагона
|
Вид стенок
вагона
|
Вид крыши
вагона
|
Вид груза
(кол-во и вид)
|
|
Сост-01,ваг-1
|
ВОСТОК
|
Состав-01
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Отсутствует
|
1 овал
|
|
Сост-02,ваг-1
|
ВОСТОК
|
Состав-02
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Прямая
|
2 овала
|
|
Сост-03,ваг-1
|
ВОСТОК
|
Состав-03
|
Прямоугольная
|
Длинный
|
3
|
80,0
|
Одинарные
|
Прямая
|
1 перевернутый треугольник
|
|
Сост-04,ваг-1
|
ВОСТОК
|
Состав-04
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Отсутствует
|
1 квадрат
|
|
Сост-05,ваг-1
|
ВОСТОК
|
Состав-05
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Прямая
|
1 овал
|
|
Сост-06,ваг-1
|
ЗАПАД
|
Состав-06
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Отсутствует
|
1 треугольник
|
|
Сост-07,ваг-1
|
ЗАПАД
|
Состав-07
|
Прямоугольная
|
Длинный
|
2
|
60,0
|
Одинарные
|
Гофрированная
|
Отсутствует
|
|
Сост-08,ваг-1
|
ЗАПАД
|
Состав-08
|
U-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 овал
|
|
Сост-09,ваг-1
|
ЗАПАД
|
Состав-09
|
V-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 овал
|
|
Сост-10,ваг-1
|
ЗАПАД
|
Состав-10
|
Прямоугольная
|
Длинный
|
2
|
60,0
|
Одинарные
|
Отсутствует
|
2 прямоугольника
|
|
Сост-01,ваг-2
|
ВОСТОК
|
Состав-01
|
Прямоугольная
|
Длинный
|
3
|
80,0
|
Одинарные
|
Отсутствует
|
1 ромб
|
|
Сост-02,ваг-2
|
ВОСТОК
|
Состав-02
|
V-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 прямоугольник
|
|
Сост-03,ваг-2
|
ВОСТОК
|
Состав-03
|
Ромбовидная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Прямая
|
1 треугольник
|
|
Сост-04,ваг-2
|
ВОСТОК
|
Состав-04
|
Овальная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Овальная
|
1 ромб
|
|
Сост-05,ваг-2
|
ВОСТОК
|
Состав-05
|
Прямоугольная
|
Длинный
|
3
|
80,0
|
Одинарные
|
Прямая
|
1 длинный прямоугольник
|
|
Сост-06,ваг-2
|
ЗАПАД
|
Состав-06
|
Прямоугольная
|
Длинный
|
2
|
60,0
|
Одинарные
|
Прямая
|
3 овала
|
|
Сост-07,ваг-2
|
ЗАПАД
|
Состав-07
|
U-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 треугольник
|
|
Сост-08,ваг-2
|
ЗАПАД
|
Состав-08
|
Прямоугольная
|
Длинный
|
3
|
80,0
|
Одинарные
|
Прямая
|
1 длинный прямоугольник
|
|
Сост-09,ваг-2
|
ЗАПАД
|
Состав-09
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Отсутствует
|
1 прямоугольник
|
|
Сост-10,ваг-2
|
ЗАПАД
|
Состав-10
|
U-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 прямоугольник
|
|
Сост-01,ваг-3
|
ВОСТОК
|
Состав-01
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Треугольная
|
1 треугольник
|
|
Сост-02,ваг-3
|
ВОСТОК
|
Состав-02
|
U-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 треугольник
|
|
Сост-03,ваг-3
|
ВОСТОК
|
Состав-03
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Одинарные
|
Отсутствует
|
1 овал
|
|
Сост-04,ваг-3
|
ВОСТОК
|
Состав-04
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Двойные
|
Отсутствует
|
1 треугольник
|
|
Сост-05,ваг-3
|
ВОСТОК
|
Состав-05
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Двойные
|
Отсутствует
|
1 треугольник
|
|
Сост-07,ваг-3
|
ЗАПАД
|
Состав-07
|
Прямоугольная
|
Короткий
|
2
|
40,0
|
Двойные
|
Отсутствует
|
1 овал
|
|
Сост-09,ваг-3
|
ЗАПАД
|
Состав-09
|
Прямоугольная
|
Длинный
|
2
|
60,0
|
Одинарные
|
Гофрированная
|
1 длинный прямоугольник
|
|
Сост-01,ваг-4
|
ВОСТОК
|
Состав-01
|
Прямоугольная
|
Длинный
|
2
|
60,0
|
Одинарные
|
Отсутствует
|
3 квадрата
|
|
Сост-04,ваг-4
|
ВОСТОК
|
Состав-04
|
U-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 треугольник
|
|
Сост-09,ваг-4
|
ЗАПАД
|
Состав-09
|
V-образная
|
Короткий
|
2
|
30,0
|
Одинарные
|
Отсутствует
|
1 овал
|
Итак, исходные данные по задаче – это
Excel-таблица №24.
Процедура преобразования исходных данных в информацию – это
анализ данных, состоящий из двух шагов:
– выявление в исходных данных фактов или событий;
– выявление причинно-следственных связей
(зависимостей) между этими событиями.
Фактически для преобразования исходных данных в информацию
необходимо:
1. Разработать классификационные и описательные шкалы
и градации.
2. С использованием классификационных и описательных
шкал и градаций закодировать исходные
данные, в результате чего получится обучающая выборка, состоящая из фактов, представляющих собой примеры в
единстве экстенсионального и интенсинального описания.
3. Произвести расчет матриц абсолютных частот,
условных и безусловных процентных распределений и матрицы информативностей, отражающей
причинно-следственные связи между значениями факторов и принадлежностью
объектов к классам.
Таким образом, информация по задаче – это
исходные данные плюс классификационные и описательные шкалы и градации,
обучающая выборка, а также матрицы частот, процентных распределений и информативностей.
Процедура преобразования информации в знания – это оценка
полезности информации для достижения цели.
Значит знания по задаче – это информация плюс
цель и оценка степени полезности информации для достижения этой цели.
Знания получаются из информации, когда мы классифицируем
будущие состояния объекта управления как желательные (целевые) и нежелательные.
Банк данных
– это базы данных плюс система управления
базами данных (СУБД) (стандартные термины). СУБД – это, по сути, система управления данными.
Информационный банк – это информационные базы плюс информационные системы (предлагается
стандартизировать эти термины). Информационная система – это, по сути, система управления информацией.
Банк знаний
– это базы знаний плюс интеллектуальные системы (стандартные термины).
Интеллектуальная система – это, по сути, система
управления знаниями.
Существует очевидная параллель между терминами и понятиями,
связанными с данными, информацией и знаниями, наглядно представленная в таблице
25.
Таблица 25 – Параллель между понятиями и терминами,
касающимися данных, информации и знаний
|
Объект
|
Субъект
|
Система
|
|
База данных (БД)
|
Система управления базами
данных (СУБД)
|
Банк данных=БД+СУБД
|
|
Информационная база (ИБ)
|
Информационная система (система управления информационными
базами – СУИБ)
|
Информационный банк=ИБ+СУИБ
|
|
База знаний (БЗ)
|
Интеллектуальная система (система управления базами знаний –
СУБЗ)
|
Банк знаний=БЗ+СУБЗ
|
Автор предлагает «узаконить», т.е. стандартизировать
термины, отмеченные в таблице 25 полужирным
шрифтом. Это позволит упорядочить все эти термины в единой стройной системе,
построенной на основе соотношения содержания понятий «данные», «информация» и
«знания».
Это актуально, т.к. в настоящее время существуют явная
путаница в использовании этих понятий, встречающая даже в названиях соответствующих
дисциплин: «Управление знаниями», «Интеллектуальные информационные системы»,
«Представление знаний в информационных системах». Например, дисциплина
«Управление знаниями» является гуманитарной
и в ней изучаются слабо
формализованные, не основанные на применении автоматизированных
интеллектуальных систем, этапы, формы и методы управления знаниями.
Вместе с тем название этой дисциплины явно соотносится с названием дисциплины
«Управление данными». Интеллектуальные системы часто некорректно называются
интеллектуальными информационными системами, с тем же успехом их можно было бы
называть: «Интеллектуальные СУБД», но лучше и правильнее было бы называть их
как предложено: «Системы управления базами знаний». Дисциплина «Алгоритмы и
структуры данных» соотносится с дисциплиной «Представление знаний в
информационных системах», хотя ясно, что они представляются не в
информационных, а в интеллектуальных системах. В настоящее время дисциплина
«Интеллектуальные информационные системы» по своему содержанию включает
«Представление знаний в информационных системах», тогда как из вышеизложенного
ясно, что они должны соотносится по своему содержанию также, как СУБД и «Модели
баз данных» (в которых обычно преподается лишь одна реляционная модель).
Отметим также, что если применить определение знаний к моделям, описываемым в
дисциплине «Представление знаний в информационных системах», то обнаруживается,
что иногда в ней описываются не модели баз знаний, а модели баз данных или информационные
модели. В частности это видно на примере семантических сетей, которые, по сути,
представляют собой инфологическую модель реляционной базы данных.
По мнению автора дисциплины «Управление знаниями» и
«Представление знаний в интеллектуальных системах» по сути, представляют собой
две части одной дисциплины и должны отражать не способы управления знаниями
различной степени формализации (как в настоящее время), а описание автоматизированных
интеллектуальных систем и баз знаний.
Существует дисциплина: «Алгоритмы и структуры данных».
Предлагается ввести аналогичные дисциплины: «Алгоритмы и информационные
структуры» (в АСК-анализе – это формализация предметной области и синтез
модели) и «Алгоритмы структурирования знаний» (по содержанию близко к
когнитологии, инженерии знаний, представлению знаний)».
Факт наличия причинно-следственных зависимостей может
быть установлен методом хи-квадрат, а ее вид – многофакторным анализом. Однако факторный анализ позволяет
обрабатывать данные лишь очень небольших размерностей (по числу факторов) и
предъявляет чрезвычайно жесткие требования к наличию полных повторностей всех
вариантов сочетаний факторов в исходных данных (т.е. данные не должны быть
фрагментарными), что на практике выполнить удается крайне редко.
Поэтому большой интерес представляют другие подходы к
решению задачи выявления в
эмпирических данных причинно-следственных зависимостей и их вида, отражения
выявленных зависимостей в наглядной графической и аналитической форме.
Рассмотрим вариант решения этой задачи, развиваемый в
СК-анализе и реализованный в системе Эйдос».
Для этого сформулируем требования к форме представления данных, информации и знаний,
позволяющие оценить степень их
пригодности для решения задач прогнозирования и принятия решений, а также
исследования предметной области (например, кластерного анализа).
Прежде всего, результаты решения вышеперечисленных задач
должны быть инвариантны относительно:
– единиц
измерения градаций факторов (признаков);
– типов шкал,
используемых для формализации классов и факторов (номинальные, порядковые и
числовые);
– различных статистических
характеристик исходной выборки: частотных распределений объектов по классам
(обобщенным категориям), частотных распределений градаций факторов, различий в
количестве признаков в описаниях объектов исследуемой выборки, различий в
суммарном количестве признаков по классам.
Кроме того, форма представления должна обеспечивать решение
вышеперечисленных задач с минимальными дополнительными затратами ручного труда,
а это значит, что вся предварительная
обработка должна быть максимально автоматизирована.
Эти требования можно рассматривать и как критерии выбора наиболее подходящей для
решения вышеперечисленных задач формы представления данных, информации и
знаний.
Рассмотрим влияние единиц измерения в исходной выборке
на результаты решения задач прогнозирования и принятия решений, а также
исследования предметной области (например, кластерного анализа).
Если в исходных данных какие-то значения выражены в
больших единицах измерения, то их числовые значения будут малыми, и наоборот,
если единицы измерения мелкие, то числовые значения – большие. Большие значения
оказывают большее влияние на результаты математической обработки, чем малые, и это приводит к возникновению зависимости
результатов решения задач идентификации, прогнозирования и принятия решений, а
также кластерного анализа, от выбранных размерностей исходных данных, что, на
взгляд автора, совершенно неприемлемо и указывает на то, что такое решение
нельзя признать корректным и даже вообще решением. По этой же причине некорректно
совместно обрабатывать сами исходные данные, представленные в различных единицах измерения
(натуральных или ценовых), например, складывать расстояния, представленные в
километрах и в метрах, а затем прибавлять к ним тонны и килограммы, а затем еще
и безразмерные величины. Вроде это очевидно, но, как это ни удивительно, но как
показывает опыт на практике это довольно часто делается, а потом еще на основе
подобного «анализа» делаются и выводы. Очень странно, что обычно на это не обращают никакого внимания при
использовании исходных данных, представленных в различных единицах измерения.
Например, даже в таких популярных (причем, совершенно заслуженно) системах, как
SPSS, в подсистеме кластерного анализа приводятся примеры кластерного анализа
над исходными данными, представленными в различных единицах измерения.
Для решения поставленной задачи в АСК-анализе проводится
последовательное повышение степени
формализации исходных данных до уровня, обеспечивающего их обработку на
компьютере в программной системе. После выполнения когнитивной
структуризации и формализации предметной области осуществляется синтез модели.
Рассмотрим на нашем простом примере, как осуществляется
формализация предметной области и преобразование исходных данных в информацию и
знания.
В системе «Эйдос» есть подсистема _15, содержащая большое
количество различных программных интерфейсов для импорта в систему «Эйдос»
исходных данных из внешних баз данных различных стандартов (рисунок 81):
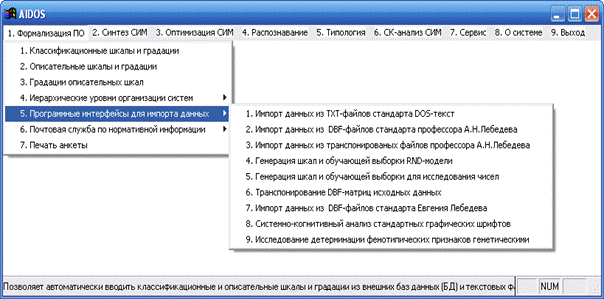
Рисунок 81. Меню выхода на подсистему _15 системы «Эйдос»
Для импорта исходных из таблиц, стандарта таблицы 25 и
автоматизированной формализации
предметной области служит программный интерфейс _152. На рисунке 82
приведен Help этого режима, в котором люъясняются требования к файлу исходных
данных (поэтому в тексте мы повторять их не будем), а на рисунке 83 – меню
задания параметров импорта данных из внешних баз данных в систему «Эйдос». В
первой экранной форме на рисунке 83 задаются параметры преобразования, а на
второй приведена таблица, характеризующая модель, которая будет создана в
результате применения этих параметров. Если пользователя что-либо не устраивает
в этих результатах, то он имеет возможность скорректировать параметры
преобразования.
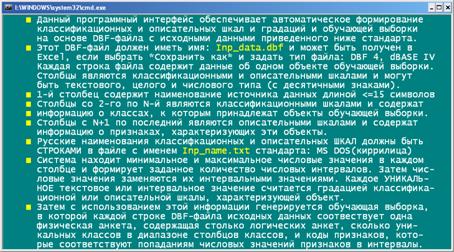
Рисунок 82. Help режима _152 системы «Эйдос»
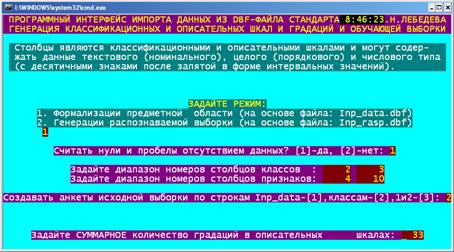
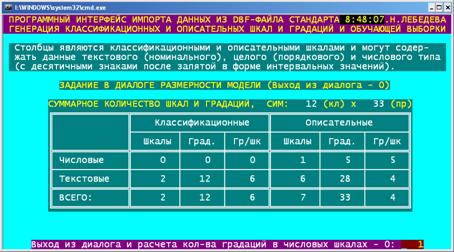
Рисунок 83. Меню режима _152 задания параметров импорта данных из
внешних баз данных в систему «Эйдос»
В результате работы режима _152 системы «Эйдос» на основе
заданных параметров модели автоматически формируются справочники
классификационных и описательных шкал и градаций номинального (текстового),
порядкового (целочисленного) и числового типа (последние – в форме интервальных
значений), а также исходная (обучающая) выборка (таблицы 26-30). На шкалах
номинально типа определены отношения только тождества и различия. На порядковых
шкалах, кроме того, определены отношения больше и меньше между градациями. На
числовых шкалах, кроме того, есть начало отсчета и единица измерения и над
градациями определены все арифметические операции. Необходимо отметить, что
формализация числовых значений в виде интервальных значений является вполне
естественной и хорошо обоснованной, т.к. фактически результатом измерения
является не просто число, а число, заданное с определенной точностью или
погрешностью, т.е. относящееся к некоторому интервалу. Количество интервалов на
числовой шкале должно определяться таким образом, чтобы все они были
представлены как минимум 5 примерами, что считается минимальной статистикой.
Это значит, что если исследуемая выборка мала, то интервалы должны быть велики,
и погрешность модели будет вынужденно велика, и наоборот, если по мере
увеличения объема исходной выборки интервалы могут быть уменьшены и точность
модели возрастает. Иначе говоря, невозможно точно отразить предметную область,
если у нас недостаточно данных. Это можно считать каким-то вариантом теоремы
Котельникова об отсчетах.
Таблица 26 – Справочник классификационных шкал
|
KOD
|
NAME
|
|
1
|
СОСТАВ СЛЕДУЕТ НА
|
|
2
|
НАИМЕНОВАНИЕ
СОСТАВА
|
Таблица 27 – Справочник классификационных шкал и градаций
|
KOD
|
NAME
|
|
1
|
СОСТАВ СЛЕДУЕТ
НА-ВОСТОК
|
|
2
|
СОСТАВ СЛЕДУЕТ
НА-ЗАПАД
|
|
3
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-01
|
|
4
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-02
|
|
5
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-03
|
|
6
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-04
|
|
7
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-05
|
|
8
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-06
|
|
9
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-07
|
|
10
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-08
|
|
11
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-09
|
|
12
|
НАИМЕНОВАНИЕ
СОСТАВА-Состав-10
|
Градации
второй классификационной шкалы, т.е. все градации с 3-й по 12-ю удалены
вручную, т.к. интересует не определение номера состава, а его идентификация с
обобщенными образами классов составов идущих на восток и на запад.
Таблица 28 – Справочник описательных шкал
|
KOD
|
NAME
|
|
1
|
ФОРМА ВАГОНА
|
|
2
|
ДЛИНА ВАГОНА
|
|
3
|
КОЛИЧЕСТВО ОСЕЙ ВАГОНА
|
|
4
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА
|
|
5
|
ВИД СТЕНОК ВАГОНА
|
|
6
|
ВИД КРЫШИ ВАГОНА
|
|
7
|
ВИД ГРУЗА (КОЛ-ВО И ВИД)
|
|
8
|
КОЛИЧЕСТВО ВАГОНОВ В СОСТАВЕ
|
Восьмая
шкала введена вручную, т.к.
соответствующие признаки являются признаками второго уровня иерархии, если
рассматривать состав, как систему, т.е. это не признаки вагонов, а признаки
состава в целом.
Таблица 29 – Справочник описательных шкал и градаций
|
KOD
|
NAME
|
Примечание:
тип шкалы
|
|
1
|
ФОРМА
ВАГОНА-U-образная
|
Номинальный
(текстовый)
|
|
2
|
ФОРМА
ВАГОНА-V-образная
|
|
3
|
ФОРМА
ВАГОНА-Овальная
|
|
4
|
ФОРМА ВАГОНА-Прямоугольная
|
|
5
|
ФОРМА
ВАГОНА-Ромбовидная
|
|
6
|
ДЛИНА
ВАГОНА-Длинный
|
Номинальный
(текстовый)
|
|
7
|
ДЛИНА
ВАГОНА-Короткий
|
|
8
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-002
|
Порядковый
(целочисленный)
|
|
9
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-003
|
|
10
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 1/5-{30.00, 40.00}
|
Числовой
(интервальные
значения)
|
|
11
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 2/5-{40.00, 50.00}
|
|
12
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 3/5-{50.00, 60.00}
|
|
13
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 4/5-{60.00, 70.00}
|
|
14
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 5/5-{70.00, 80.00}
|
|
15
|
ВИД СТЕНОК
ВАГОНА-Двойные
|
Номинальный
(текстовый)
|
|
16
|
ВИД СТЕНОК
ВАГОНА-Одинарные
|
|
17
|
ВИД КРЫШИ
ВАГОНА-Гофрированная
|
|
18
|
ВИД КРЫШИ
ВАГОНА-Овальная
|
|
19
|
ВИД КРЫШИ
ВАГОНА-Отсутствует
|
|
20
|
ВИД КРЫШИ
ВАГОНА-Прямая
|
|
21
|
ВИД КРЫШИ
ВАГОНА-Треугольная
|
|
22
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 длинный прямоугольник
|
Номинальный
(текстовый)
|
|
23
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 квадрат
|
|
24
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 овал
|
|
25
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 перевернутый треугольник
|
|
26
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 прямоугольник
|
|
27
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 ромб
|
|
28
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 треугольник
|
|
29
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 овала
|
|
30
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 прямоугольника
|
|
31
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 квадрата
|
|
32
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 овала
|
|
33
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-Отсутствует
|
Таблица 30 – Исходная (обучающая) выборка
|
Код
объекта
|
Наименование
объекта
|
Коды
классов
|
Коды признаков
|
|
33
|
Состав-01
|
1
|
4
|
7
|
8
|
10
|
11
|
16
|
19
|
24
|
4
|
6
|
9
|
|
|
|
|
16
|
19
|
27
|
4
|
7
|
8
|
10
|
11
|
16
|
21
|
28
|
|
|
|
|
6
|
8
|
12
|
13
|
16
|
19
|
31
|
36
|
|
|
|
|
34
|
Состав-02
|
1
|
4
|
7
|
8
|
10
|
11
|
16
|
20
|
29
|
2
|
7
|
8
|
|
|
|
|
16
|
19
|
26
|
1
|
7
|
8
|
10
|
16
|
19
|
28
|
35
|
|
35
|
Состав-03
|
1
|
4
|
6
|
9
|
14
|
16
|
20
|
25
|
5
|
7
|
8
|
10
|
|
|
|
|
16
|
20
|
28
|
4
|
7
|
8
|
10
|
11
|
16
|
19
|
24
|
|
|
|
|
35
|
|
|
|
|
|
|
|
|
|
|
|
36
|
Состав-04
|
1
|
4
|
7
|
8
|
10
|
11
|
16
|
19
|
23
|
3
|
7
|
8
|
|
|
|
|
11
|
16
|
18
|
27
|
4
|
7
|
8
|
10
|
11
|
15
|
19
|
|
|
|
|
1
|
7
|
8
|
10
|
16
|
19
|
28
|
36
|
|
|
|
|
37
|
Состав-05
|
1
|
4
|
7
|
8
|
10
|
11
|
16
|
20
|
24
|
4
|
6
|
9
|
|
|
|
|
16
|
20
|
22
|
4
|
7
|
8
|
10
|
11
|
15
|
19
|
28
|
|
|
|
|
35
|
|
|
|
|
|
|
|
|
|
|
|
38
|
Состав-06
|
2
|
4
|
7
|
8
|
10
|
11
|
16
|
19
|
28
|
4
|
6
|
8
|
|
|
|
|
13
|
16
|
20
|
32
|
34
|
|
|
|
|
|
|
|
39
|
Состав-07
|
2
|
4
|
6
|
8
|
12
|
13
|
16
|
17
|
33
|
1
|
7
|
8
|
|
|
|
|
16
|
19
|
28
|
4
|
7
|
8
|
10
|
11
|
15
|
19
|
24
|
|
|
|
|
35
|
|
|
|
|
|
|
|
|
|
|
|
40
|
Состав-08
|
2
|
1
|
7
|
8
|
10
|
16
|
19
|
24
|
4
|
6
|
9
|
14
|
|
|
|
|
20
|
22
|
34
|
|
|
|
|
|
|
|
|
|
41
|
Состав-09
|
2
|
2
|
7
|
8
|
10
|
16
|
19
|
24
|
4
|
7
|
8
|
10
|
|
|
|
|
16
|
19
|
26
|
4
|
6
|
8
|
12
|
13
|
16
|
17
|
22
|
|
|
|
|
7
|
8
|
10
|
16
|
19
|
24
|
36
|
|
|
|
|
|
42
|
Состав-10
|
2
|
4
|
6
|
8
|
12
|
13
|
16
|
19
|
30
|
1
|
7
|
8
|
|
|
|
|
16
|
19
|
26
|
34
|
|
|
|
|
|
|
|
Обучающая выборка состоит из трех таблиц баз данных:
– первая включает коды объектов выборки и наименование
источника данных;
– вторая содержит коды классов, к которым принадлежит
объект;
– третья содержит коды признаков объекта.
Первая таблица связана со второй и третьей отношением
«один ко многим».
Объекты исходной выборки формируются путем кодирования
строк таблицы исходных данных с применением справочников классификационных и
описательных шкал и градаций, но при этом могут формироваться и объединенные
объекты из строк по классам. Суммарное количество классификационных и описательных
шкал, с которым работает режим _152, не ограничено, но на практике составляет
не более 256, что связано с ограничением MS Excel 2003. В более поздних версиях
MS Excel это ограничение снято, но из них исключен XLS-DBF-конвертер. Нет никаких
принципиальных проблем снять все эти ограничения и путем разработки небольших
специализированных программ, объединяющих листы MS Excel (что и делалось при
необходимости автором) или использования имеющихся конвертеров. Суммарное
количество градаций классификационных шкал, как и градаций описательных шкал в
текущей версии системы «Эйдос» ограничено 4000, но в будущих версиях это
ограничение планируется снять.
Справочники классификационных и описательных шкал и
градаций и исходные данные, закодированные с их использованием и образующие
обучающую выборку, рассматриваемые совместно
представляют собой результат формализации
предметной области.
После формализации предметной области осуществляется
синтез и верификация (оценка достоверности) модели, а также повышение ее
эффективности [7]. Синтез модели включает расчет на основе эмпирических данных,
представленных в исследуемой выборке, следующих матриц (таблицы 31, 32, 33):
– матрицы абсолютных частот (большинство статических
систем этим и ограничиваются);
– матрицы условных и безусловных процентных распределений
(в некоторых системах это также делается);
– матрицы информативностей или матрицы знаний (что
осуществляется только в АСК-анализе).
Таблица 31 – Матрица абсолютных частот
|
Код
|
Наименование
|
Восток
|
Запад
|
Сумма
|
|
1
|
ФОРМА
ВАГОНА-U-образная
|
2
|
3
|
5
|
|
2
|
ФОРМА
ВАГОНА-V-образная
|
1
|
1
|
2
|
|
3
|
ФОРМА
ВАГОНА-Овальная
|
1
|
|
1
|
|
4
|
ФОРМА
ВАГОНА-Прямоугольная
|
11
|
8
|
19
|
|
5
|
ФОРМА
ВАГОНА-Ромбовидная
|
1
|
|
1
|
|
6
|
ДЛИНА
ВАГОНА-Длинный
|
4
|
5
|
9
|
|
7
|
ДЛИНА
ВАГОНА-Короткий
|
13
|
8
|
21
|
|
8
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-002
|
14
|
12
|
26
|
|
9
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-003
|
3
|
1
|
4
|
|
10
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 1/5-{30.00, 40.00}
|
11
|
6
|
17
|
|
11
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 2/5-{40.00, 50.00}
|
9
|
2
|
11
|
|
12
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 3/5-{50.00, 60.00}
|
1
|
3
|
4
|
|
13
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 4/5-{60.00, 70.00}
|
1
|
4
|
5
|
|
14
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 5/5-{70.00, 80.00}
|
1
|
1
|
2
|
|
15
|
ВИД СТЕНОК
ВАГОНА-Двойные
|
2
|
1
|
3
|
|
16
|
ВИД СТЕНОК
ВАГОНА-Одинарные
|
15
|
11
|
26
|
|
17
|
ВИД КРЫШИ
ВАГОНА-Гофрированная
|
|
2
|
2
|
|
18
|
ВИД КРЫШИ
ВАГОНА-Овальная
|
1
|
|
1
|
|
19
|
ВИД КРЫШИ
ВАГОНА-Отсутствует
|
10
|
9
|
19
|
|
20
|
ВИД КРЫШИ
ВАГОНА-Прямая
|
5
|
2
|
7
|
|
21
|
ВИД КРЫШИ
ВАГОНА-Треугольная
|
1
|
|
1
|
|
22
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 длинный прямоугольник
|
1
|
2
|
3
|
|
23
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 квадрат
|
1
|
|
1
|
|
24
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 овал
|
3
|
4
|
7
|
|
25
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 перевернутый треугольник
|
1
|
|
1
|
|
26
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 прямоугольник
|
1
|
2
|
3
|
|
27
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 ромб
|
2
|
|
2
|
|
28
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 треугольник
|
5
|
2
|
7
|
|
29
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 овала
|
1
|
|
1
|
|
30
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 прямоугольника
|
|
1
|
1
|
|
31
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 квадрата
|
1
|
|
1
|
|
32
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 овала
|
|
1
|
1
|
|
33
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-Отсутствует
|
|
1
|
1
|
|
34
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-2
|
|
3
|
3
|
|
35
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-3
|
3
|
1
|
4
|
|
36
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-4
|
2
|
1
|
3
|
|
|
Кол-во объектов обуч.выборки
|
5
|
5
|
10
|
Матрица абсолютных частот (таблица 31) по сути,
является корреляционной матрицей или таблицей сопряженности.
Рассмотрим,
используя вышеперечисленные критерии, в какой степени эти матрицы пригодны для решения задач прогнозирования
и принятия решений, а также исследования предметной области (например,
кластерного анализа) и какую работу необходимо выполнять вручную и
автоматизировать, чтобы повысить их пригодность для этого.
Матрица абсолютных частот отражает, сколько раз каждая градация факторов
встречается у объектов каждого класса.
Проблема
размерностей при расчете матрицы абсолютных
частот решается тем, что сами размерные
исходные данные с использованием шкал различных типов (номинальных, порядковых
и числовых) заменяются на факты их встречи, т.е. на частоты встреч тех или
иных их интервальных значений в
различных группах, соответствующих классам. Фактом является наблюдение
определенного экстенсионального значения (признака, градации фактора) у объекта
исходной выборки, относящегося к некоторой интенсиональной категории (классу).
Однако вышеперечисленные задачи решать на основе абсолютных
частот можно только в том случае, если по каждому классу в исходных данных было
приведено одинаковое количество
примеров, что на практике встречается крайне редко и является трудно достижимым
при сборе исходных данных, за исключением случая жестко спланированного
управляемого эксперимента (обычно очень небольшой размерности). Можно, конечно,
вручную учитывать это различие, однако реально это возможно сделать только на
моделях очень небольшой размерности и требует специальных усилий (работы).
Чтобы результаты решения вышеперечисленных задач не зависели от количества примеров по
разным классам (т.е. были инвариантны
относительно формы частотных распределений примеров по классам, частотного
распределения признаков и др.), а также от количества признаков у объектов
обучающей выборки, можно с помощью формул (1) перейти от матрицы абсолютных
частот к матрице условных и безусловных процентных распределений (матрице относительных частот или частостей) (таблица
32).
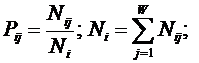 (1)
(1)
где:
Nij –
суммарное количество наблюдений факта: "действовал i-й фактор и объект перешел в j-е
состояние";
Ni – суммарное количество встреч i-го фактора у всех объектов;
W – количество классов (мощность множества
будущих состояний объекта управления).
Таблица 32 – Матрица условных и безусловных
процентных распределений (СИМ-2)
|
Код
|
Наименование
|
В группе:
«Восток»
|
В группе:
«Запад»
|
По всей
выборке
|
|
1
|
ФОРМА
ВАГОНА-U-образная
|
40,0
|
60,0
|
50,0
|
|
2
|
ФОРМА ВАГОНА-V-образная
|
20,0
|
20,0
|
20,0
|
|
3
|
ФОРМА
ВАГОНА-Овальная
|
20,0
|
|
10,0
|
|
4
|
ФОРМА
ВАГОНА-Прямоугольная
|
220,0
|
160,0
|
190,0
|
|
5
|
ФОРМА
ВАГОНА-Ромбовидная
|
20,0
|
|
10,0
|
|
6
|
ДЛИНА
ВАГОНА-Длинный
|
80,0
|
100,0
|
90,0
|
|
7
|
ДЛИНА
ВАГОНА-Короткий
|
260,0
|
160,0
|
210,0
|
|
8
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-002
|
280,0
|
240,0
|
260,0
|
|
9
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-003
|
60,0
|
20,0
|
40,0
|
|
10
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 1/5-{30.00, 40.00}
|
220,0
|
120,0
|
170,0
|
|
11
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 2/5-{40.00, 50.00}
|
180,0
|
40,0
|
110,0
|
|
12
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 3/5-{50.00, 60.00}
|
20,0
|
60,0
|
40,0
|
|
13
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 4/5-{60.00, 70.00}
|
20,0
|
80,0
|
50,0
|
|
14
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 5/5-{70.00, 80.00}
|
20,0
|
20,0
|
20,0
|
|
15
|
ВИД СТЕНОК
ВАГОНА-Двойные
|
40,0
|
20,0
|
30,0
|
|
16
|
ВИД СТЕНОК
ВАГОНА-Одинарные
|
300,0
|
220,0
|
260,0
|
|
17
|
ВИД КРЫШИ
ВАГОНА-Гофрированная
|
|
40,0
|
20,0
|
|
18
|
ВИД КРЫШИ
ВАГОНА-Овальная
|
20,0
|
|
10,0
|
|
19
|
ВИД КРЫШИ
ВАГОНА-Отсутствует
|
200,0
|
180,0
|
190,0
|
|
20
|
ВИД КРЫШИ
ВАГОНА-Прямая
|
100,0
|
40,0
|
70,0
|
|
21
|
ВИД КРЫШИ
ВАГОНА-Треугольная
|
20,0
|
|
10,0
|
|
22
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 длинный прямоугольник
|
20,0
|
40,0
|
30,0
|
|
23
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 квадрат
|
20,0
|
|
10,0
|
|
24
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 овал
|
60,0
|
80,0
|
70,0
|
|
25
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 перевернутый треугольник
|
20,0
|
|
10,0
|
|
26
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 прямоугольник
|
20,0
|
40,0
|
30,0
|
|
27
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 ромб
|
40,0
|
|
20,0
|
|
28
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 треугольник
|
100,0
|
40,0
|
70,0
|
|
29
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 овала
|
20,0
|
|
10,0
|
|
30
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 прямоугольника
|
|
20,0
|
10,0
|
|
31
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 квадрата
|
20,0
|
|
10,0
|
|
32
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 овала
|
|
20,0
|
10,0
|
|
33
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-Отсутствует
|
|
20,0
|
10,0
|
|
34
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-2
|
|
60,0
|
30,0
|
|
35
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-3
|
60,0
|
20,0
|
40,0
|
|
36
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-4
|
40,0
|
20,0
|
30,0
|
|
|
Кол-во объектов обуч.выборки
|
5
|
5
|
10
|
При неограниченном увеличении объема выборки частости
стремятся (сходятся) к теоретическим вероятностям, как своим пределам, поэтому
частости можно считать эмпирическими вероятностями. Способ, которым частости
приближаются к вероятностям, называется сходимостью
модели. В системе «Эйдос» реализован специальный режим, позволяющий исследовать
сходимость модели, в том числе скорость сходимости и погрешность
различия частости и вероятности при различных объемах исследуемой выборки.
Учитывая все это при достаточно больших выборках, по мнению авторов, допустимо
вместо термина «частость» использовать термин «условная вероятность», тем более
что в аналитических выражениях обычно оперируют именно вероятностями.
Однако и при решении вышеперечисленных задач на основе
матрицы условных и безусловных процентных распределений приходится вручную осуществлять сравнение условных
относительных частот, является определенной работой
и реально возможно только на моделях очень малой размерности и требует довольно
больших специальных усилий. Поэтому есть смысл автоматизировать и это сравнение, так, чтобы в нашем распоряжении
была матрица, содержащая уже сами результаты
сравнения условных относительных частот в количественной форме.
Для того чтобы реализовать эту автоматизацию
необходимо выбрать базу сравнения и
способ сравнения, т.е. ответить на два вопроса:
– с чем
сравнивать условные относительные частоты: друг с другом или с безусловными
частотами;
– каким способом
сравнивать условные относительные частоты: с помощью вычитания или с
помощью деления.
Если в модели есть всего два класса, то можно
сравнивать условные относительные частоты как друг с другом, так и с безусловными
частотами, т.к. это одинаково как по трудоемкости (затрачиваемым вычислительным
ресурсам), так и по результатам сравнения. Если же в модели хотя бы три класса,
то уже возникают определенное затруднения в том, как сравнить условные
процентные распределения по ним, а если их сотни или тысячи, то это становится
даже в теоретическом плане непонятным. Поэтому в [7] предлагается использовать в качестве базы для сравнения (нормы) условных относительных частот
их взвешенное среднее по всей исследуемой выборке или безусловные частоты (2):
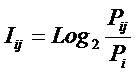 (2)
(2)
где:
– Pij – вероятность перехода
объекта в j-е состояние при условии
действия на него i-го значения
фактора;
– Pi – вероятность наблюдения i-го значения фактора по всей выборке;
Подставим в выражение (2), представляющее собой вариант
формулы А.Харкевича, значения вероятностей, выраженные через фактически
наблюдаемые абсолютные частоты из (3)
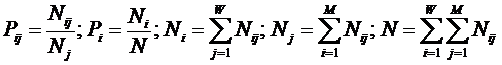 (3)
(3)
где:
W – количество классов (мощность множества
будущих состояний объекта управления)
M – максимальный уровень сложности смешанных
состояний объекта управления;
Nij –
суммарное количество наблюдений факта: "действовал i-й фактор и объект перешел в j-е
состояние";
Nj – в СИМ-1 (семантической информационной
модели) суммарное количество встреч различных факторов у объектов, перешедших в
j-е состояние;
Ni – в суммарное количество встреч i-го фактора у всех объектов;
N – суммарное количество встреч различных
факторов у всех объектов.
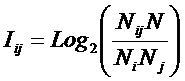 (4)
(4)
Выражение (4) дает количество информации о принадлежности
объекта к j-му классу, если он
обладает i-м признаком, выраженное
через абсолютные частоты из таблицы 8.
Это решение, приводящее к выражению (2), соответствует
принятому в статистике методу средних и отклонений от средних и представляет
собой косвенное или опосредованное сравнение
условных процентных распределений друг с другом, т.к. база сравнения
рассчитывается с их использованием.
Кроме того, важно отметить, что получающееся в
результате этого выражение (4) для количества информации тождественно выражению (6), получающемуся путем сравнения
фактически наблюдаемой абсолютной частоты встреч признака в определенной группе
(классе) с теоретически ожидаемой частотой его наблюдения по методу хи-квадрат
[7],
т.е. если принять, что:
Nij – фактическое количество встреч i-го признака у объектов j-го класса;
Tij
–
теоретически ожидаемое
количество встреч i-го признака у
объектов j-го класса:
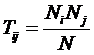 (5)
(5)
Подставив выражение (4) в (3) получаем:
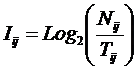 (6)
(6)
или:
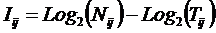 (7)
(7)
Что касается вопроса о том, вычитание или деление для
этого сравнения использовать, то этот вопрос не является принципиальным, т.к.
различие между вычитанием и делением сводится к выбору единиц измерения результатов сравнения: если взять логарифм от отношения, то получится разность логарифмов делимого и делителя.
Из выражения (6) для количества знаний следует:
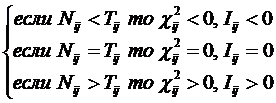
Если фактическая
вероятность наблюдения i-го признака при предъявлении объекта j-го класса
равна теоретически ожидаемой (средней), то наблюдение этого признака не несет
никакой информации о принадлежности объекта к данному классу. Если же она выше
средней – то это говорит в пользу того, что предъявлен объект данного класса,
если же ниже – то другого.
Поэтому наличие
статистической связи (информации) между признаками и классами
распознавания, т.е. отличие вероятностей их
совместных наблюдений от предсказываемого в соответствии со случайным
нормальным распределением, приводит к
увеличению фактической статистики c2
по сравнению с теоретической величиной.
В работе [7, раздел 3.4]
предлагается основанная на выражении (6) и вышеприведенной интерпретации мера
количества знаний в базе знаний, представляющая собой количественную меру степени выраженности закономерностей в предметной
области:
|
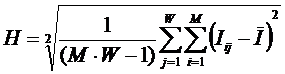
|
(8)
|
где:
|
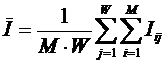
|
– средняя
информативность признаков по матрице информативностей (при увеличении
объема выборки стремится к нулю).
|
Значение данной меры показывает среднее отличие количества
информации в факторах о будущих состояниях активного объекта управления от
среднего количества информации в факторе (которое при больших выборках близко к
0). По своей математической форме эта мера сходна с мерами для значимости
факторов и степени сформированности образов классов и коррелирует с объемом когнитивного пространства
классов и пространства атрибутов.
Интересно отметить, что в американском
Internet-ресурсе

предлагается
следующая метрика для оценки достоверности модели (качества алгоритма):
|

|
(9)
|
Where:
1. i is a
member;
2. n is the
total number of members;
3. p is the
predicted number of days spent in hospital for member i in the test period;
4. a is the actual number of days spent in hospital for
member i in the test period.
5. log is the natural
logarithm function.
Эта метрика (количественная мера) весьма сходна с выражением
(8) из работы [7] и, по существу, содержит под квадратным корнем сумму
квадратов выражения (7), если считать, что теоретически ожидаемое значение
величины – это и есть ее прогнозируемое значение:
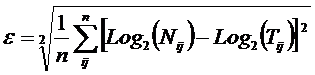 (10)
(10)
Если переписать выражение (9) с учетом вышесказанного
и выражения (7), то получим:
 (11)
(11)
Выражение (11) практически совпадает с выражением (8)
из работы автора [7] (изданной в 2002 году), если учесть, что при увеличении объема выборки среднее по Iij стремится к нулю. Это
значит, что информационная мера сходства, используемая в АСК-анадизе и системе
«Эйдос», тесно связана с энтропийной мерой сходства.
Переход от матрицы абсолютных частот к матрице условных
и безусловных процентных распределений обеспечивает инвариантность результатов
решения вышеперечисленных задач от формы частотного распределения примеров по
классам и признаков по объектам обучающей выборки, однако при этом не решается
вопрос о зависимости этих результатов от размерностей
различных градаций факторов (признаков) и типов шкал, используемых для
формализации факторов.
Проблему размерностей можно было бы решить, перейдя к стандартизированным величинам или отношениям
условных и безусловных вероятностей. Например, формулу Байеса
можно рассматривать как дающую количественную оценку степени влияния фактора на
наступление некоторого события. Отношение условной вероятности наблюдения
некоторого значения фактора в группе (классе) к безусловной вероятности его
наблюдения по всей исследуемой выборке также можно рассматривать как количественную
меру силы и направления его влияния на переход объекта в состояние,
соответствующее классу, т.е. как количественную оценку силы и направления
причинно-следственной связи между ними.
Возникает вопрос о том, каким образом формально
описать влияние на объект не отдельных значений факторов, а всей их системы.
Для того чтобы это сделать введем понятие частных критериев и интегрального критерия.
Частным критерием будем называть выраженное в количественной форме влияние отдельного
значения фактора на переход объекта в различные состояния.
Это значит, что отношение условной вероятности наблюдения
некоторого значения фактора в группе (классе) к безусловной вероятности его
наблюдения по всей исследуемой выборке можно, рассматривать как частный
критерий.
Тогда, если значение фактора способствует переходу объекта в некоторое состояние, то отношение
условной вероятности наблюдения этого значения фактора в группе (классе),
соответствующей данному состоянию, будет больше
безусловной вероятности его наблюдения по всей исследуемой выборке и этот критерий
будет иметь значение больше 1.
Если значение фактора препятствует переходу объекта в
некоторое состояние, то отношение условной вероятности наблюдения этого
значения фактора в группе (классе), соответствующей данному состоянию, будет меньше безусловной вероятности его
наблюдения по всей исследуемой выборке и этот критерий будет иметь значение
меньше 1.
Если же значение фактора никак не влияет на переход объекта в
некоторое состояние, то отношение условной вероятности наблюдения этого
значения фактора в группе (классе), соответствующей данному состоянию, будет равно безусловной вероятности его
наблюдения по всей исследуемой выборке и этот критерий будет иметь значение
равное 1.
Интегральным критерием будем называть некоторое аналитическое
выражение от частных критериев, которое количественно отражает силу влияния системы факторов на переход объекта в
различные состояния.
Моделируемый объект
является линейным, если результат
совместного действия на него совокупности факторов является суммой результатов влияния на него
каждого из этих факторов в отдельности, т.е. выполняется принцип суперпозиции факторов. Чем
меньше интенсивность взаимодействия между факторами в объекте, тем ближе система факторов к множеству [7]
и тем ближе объект к линейному. Таким образом, для линейных объектов можно
обоснованно считать, что взаимодействие между факторами в этих объектах
отсутствует, т.е. по сути можно считать, что на них действует не система
факторов, а множество факторов.
Для линейных объектов интегральный критерий, отражающий совместное влияние
факторов на объект, можно представить в форме суммы влияния каждого из этих факторов в отдельности, т.е. в форме
суммы частных критериев, т.е. для линейных объектов оправданно и обоснованно
использовать аддитивный интегральный
критерий.
Приведенные выше количественные меры силы и направления
причинно-следственных связей очень неудобны для использования подобных в
качестве частных критериев, в основном потому, что в случае отсутствия влияния фактора они равны 1.
В результате в аддитивном интегральном критерии будет присутствовать некое
слагаемое, равное количеству недействующих факторов, и для каждого класса это
слагаемое будет свое. В результате подобный интегральный критерий окажется
просто непригодным для оценки влияния совокупности факторов на поведение
объекта.
Поэтому эти частные критерии необходимо нормировать так, чтобы в случае
отсутствия влияния он принимали значение равное нулю, а не единице. Есть много
вариантов осуществить подобную нормировку, из которых наиболее очевидными являются:
– вычесть 1 из отношения условной вероятности к
безусловной;
– взять логарифм от отношения условной вероятности к
безусловной.
Первый
вариант нормировки приводит к
показателям типа ROI
(количественная оценка степени полезности инвестиций) и различным его
обобщениям.
Второй
вариант сразу приводит к
семантической мере целесообразности информации А.Харкевича. Из этих вариантов
для количественной оценки степени полезности информации для достижения целей по
мнению автора предпочтительным является применение меры А.Харкевича [7]. Это
связано с тем, что использование логарифма в этой мере позволяет привлечь огромный
пласт научных понятий, связанных с данными, информацией и знаниями, что
является для нас очень ценным.
Очень важно,
что этот подход позволяет автоматически решить проблему сопоставимой обработки
многих факторов, измеряемых в различных единицах измерения, т.к. в этом подходе
рассматриваются не сами факторы, какой бы природы они не были и какими бы
шкалами не формализовались, а количество
информации, которое в них содержится о поведении моделируемого объекта (таблица 33):
Таблица 33 – Матрица информативностей (база знаний)
в миллибитах
(СИМ-2)
|
Код
|
Наименование
|
В группе:
«Восток»
|
В группе:
«Запад»
|
Дискрими-
нантная сила
признака
|
|
1
|
ФОРМА
ВАГОНА-U-образная
|
-322
|
263
|
414
|
|
2
|
ФОРМА
ВАГОНА-V-образная
|
|
|
|
|
3
|
ФОРМА
ВАГОНА-Овальная
|
1000
|
|
707
|
|
4
|
ФОРМА
ВАГОНА-Прямоугольная
|
212
|
-248
|
325
|
|
5
|
ФОРМА
ВАГОНА-Ромбовидная
|
1000
|
|
707
|
|
6
|
ДЛИНА
ВАГОНА-Длинный
|
-170
|
152
|
228
|
|
7
|
ДЛИНА
ВАГОНА-Короткий
|
308
|
-392
|
495
|
|
8
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-002
|
107
|
-115
|
157
|
|
9
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-003
|
585
|
-1000
|
1121
|
|
10
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 1/5-{30.00, 40.00}
|
372
|
-503
|
618
|
|
11
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 2/5-{40.00, 50.00}
|
710
|
-1459
|
1534
|
|
12
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 3/5-{50.00, 60.00}
|
-1000
|
585
|
1121
|
|
13
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 4/5-{60.00, 70.00}
|
-1322
|
678
|
1414
|
|
14
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 5/5-{70.00, 80.00}
|
|
|
|
|
15
|
ВИД СТЕНОК
ВАГОНА-Двойные
|
415
|
-585
|
707
|
|
16
|
ВИД СТЕНОК
ВАГОНА-Одинарные
|
206
|
-241
|
316
|
|
17
|
ВИД КРЫШИ
ВАГОНА-Гофрированная
|
|
1000
|
707
|
|
18
|
ВИД КРЫШИ
ВАГОНА-Овальная
|
1000
|
|
707
|
|
19
|
ВИД КРЫШИ
ВАГОНА-Отсутствует
|
74
|
-78
|
107
|
|
20
|
ВИД КРЫШИ
ВАГОНА-Прямая
|
515
|
-807
|
935
|
|
21
|
ВИД КРЫШИ
ВАГОНА-Треугольная
|
1000
|
|
707
|
|
22
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 длинный прямоугольник
|
-585
|
415
|
707
|
|
23
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 квадрат
|
1000
|
|
707
|
|
24
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 овал
|
-222
|
193
|
293
|
|
25
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 перевернутый треугольник
|
1000
|
|
707
|
|
26
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 прямоугольник
|
-585
|
415
|
707
|
|
27
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 ромб
|
1000
|
|
707
|
|
28
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-1 треугольник
|
515
|
-807
|
935
|
|
29
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 овала
|
1000
|
|
707
|
|
30
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-2 прямоугольника
|
|
1000
|
707
|
|
31
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 квадрата
|
1000
|
|
707
|
|
32
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-3 овала
|
|
1000
|
707
|
|
33
|
ВИД ГРУЗА (КОЛ-ВО
И ВИД)-Отсутствует
|
|
1000
|
707
|
|
34
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-2
|
|
1000
|
707
|
|
35
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-3
|
585
|
-1000
|
1121
|
|
36
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-4
|
415
|
-585
|
707
|
|
|
Средне-квадратичное отклонение
|
594
|
608
|
|
Справочники классификационных и описательных шкал и
градаций и исходные данные, закодированные с их использованием и образующие
обучающую выборку, представляют собой результат
формализации предметной области и рассматриваемые совместно с матрицей
информативностей, в соответствии с терминологией, предлагаемой в таблице 25,
являются уже не базой данных, а информационной базой.
Если же среди
классов выделить целевые и нежелательные, то таблица 33 может рассматриваться
уже как база знаний, т.к. содержит количественные оценки степени
полезности (и вредности) информации для достижения целей.
Для расчета таблицы
33 используется СИМ-2, в которой Nj
представляет собой суммарное
количество встреч объектов, относящихся к j-му
классу. Численные эксперименты показали незначительное отличие СИМ-1 от СИМ-2,
но в данной статье в численном примере используется СИМ-2, как более наглядная.
После синтеза модели обязательно осуществляется ее верификация,
т.е. измеряется ее достоверность (валидность, адекватность). Обычно это делают,
решая различные задачи с помощью созданной модели и оценивая качество их
решения. Это могут быть задачи распознавания (идентификации и прогнозирования),
поддержки принятия решений и исследования предметной области.
Идентификация – это количественная оценка степени сходства
конкретного объекта или его состояния с классом по признакам, которые относятся
к тому же моменту времени, что и состояние. Прогнозирование – количественная
оценка степени сходства конкретного объекта или его состояния с классом по
признакам, причем признаки относятся к более раннему времени, чем состояние.
Различие в математической модели алгоритмах решения задач идентификации и
прогнозирования минимальны.
Обычно достоверность модели оценивается путем оценки
качества решения задачи идентификации, как наиболее простых. При этом могут
использоваться различные подходы к выбору объектов для синтеза модели и для
идентификации:
1. Простейшим вариантом является использование всех объектов
исследуемой выборки как для синтеза модели, так и для ее верификации. Этот
подход дает несколько завышенную оценку достоверности модели.
2. Бутстрепный метод предполагает использование
одной части объектов исследуемой выборки
для синтеза модели, а другой для ее
верификации. Причем способов разделения исследуемой выборки на эти две части
также существует много. Объекты, на которых проверяется достоверность модели,
исключаются из выборки, на основе которой она создается, чтобы исключить их
влияние на создаваемую модель. Успешность идентификации таких объектов
означает, что закономерности взаимосвязи между признаками объектов и их
принадлежностью к классам, выявленные на исследуемой выборке, действуют и для
этих объектов. Необходимо отметить, что относительное
влияние новых объектов на модель уменьшается с увеличением объема выборки, поэтому
при больших объемах выборки вполне оправдано использовать первый подход, а
бутстрепный метод актуален только на малых выборках.
3. Наиболее серьезная и убедительная проверка
достоверности модели осуществляется когда для синтеза модели используется
обучающая выборка, а для оценки достоверности модели новые данные, которых вообще не существовало на момент синтеза модели.
В системе «Эйдос» реализованы возможности для всех
этих методов верификации модели. Измерение достоверности созданной модели путем
оценки качества решения задачи идентификации, т.е. численная оценка
эмпирической вероятности ошибок не идентификации и ошибки ложной идентификации
как в целом по всей выборке, так и в разрезе по каждому классу распознавания,
показало, что модель имеет 100% достоверность (рисунок 84):
Если модель адекватна, т.е. верно отражает
моделируемую предметную область, то исследование этой модели корректно считать
исследованием самой моделируемой предметной области. Исследование модели
включает кластерно-конструктивный анализ классов и факторов, семантические
сети, когнитивные диаграммы, классические и обобщенные (интегральные) когнитивные
карты, нелокальные нейроны, когнитивные функции и т.д. Всего система «Эйдос»
генерирует более 62 текстовых форм и более 55 видов различных графических форм,
лишь нескорые из которых имеют аналоги в MS Excel. Вопросы исследования моделей
в АСК-анализе подробно освещены в монографиях и статьях авторов [3-190].
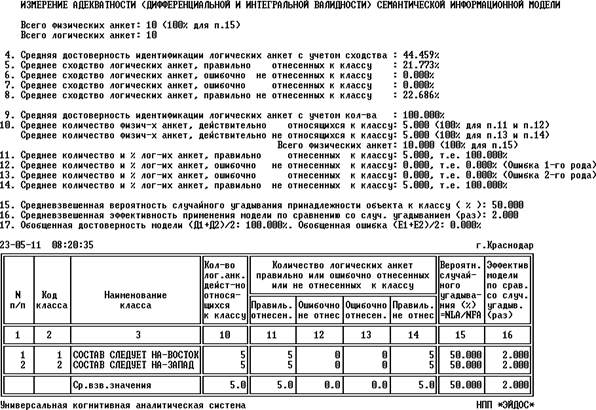
Рисунок 84. Выходная форма системы «Эйдос»
с оценкой достоверности модели
Решение
задачи идентификации
осуществляется в АСК-анализе и системе «Эйдос» на основе леммы Неймана-Пирсона
следующим образом [7]. Количество информации в признаке о
принадлежности обладающего им объекта к классу, рассматривается как частный
критерий. Если известно, что у объекта не один признак, а система
признаков, то считается что интегральным критерием, дающим
количественную оценку степени принадлежности (или непринадлежности) данного
объекта к классам, является суммарное количество информации об этом,
содержащееся в его системе частных критериев, т.е. признаков (1):
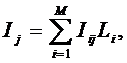 (7)
(7)
где:
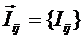 – вектор j–го
состояния объекта управления (j-го
класса), координаты которого, т.е. частные критерии, рассчитываются согласно
выражения (4);
– вектор j–го
состояния объекта управления (j-го
класса), координаты которого, т.е. частные критерии, рассчитываются согласно
выражения (4);
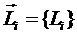 – вектор состояния
предметной области, включающий все виды факторов, характеризующих объект управления,
возможные управляющие воздействия и окружающую среду (массив–локатор), т.е.:
– вектор состояния
предметной области, включающий все виды факторов, характеризующих объект управления,
возможные управляющие воздействия и окружающую среду (массив–локатор), т.е.:
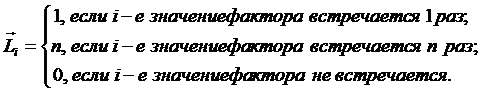
В реализованной модели
значения координат вектора состояния предметной области (объекта обучающей или
распознаваемой выборки) принимались равными либо равным 1 (фактор действует),
либо равным 0 (фактор не действует).
Таким образом,
интегральный критерий (1) представляет собой суммарное количество информации,
содержащееся в факторах различной природы (т.е. факторах характеризующих объект
управления, управляющее воздействие и окружающую среду) о переходе активного
объекта управления в целевое состояние [7]. Важно отметить, что предложенный
интегральный критерий имеет неметрическую
природу (он представляет собой скалярное произведение векторов класса и объекта) и
поэтому его применение корректно в
неортонормированном пространстве с неевклидовой метрикой, каким, как правил и
является когнитивное пространство, построенное на классификационных шкалах, как
осях.
Кроме того, данный интегральный критерий по своей математической форме совпадает с аргументом активационной
функцией нейрона в нейронных сетях, если
интерпретировать весовые коэффициенты на рецепторах как количество информации в
соответствии с выражением (4) [7].
На рисунке 85
представлены некоторые экранные формы результатов идентификации:
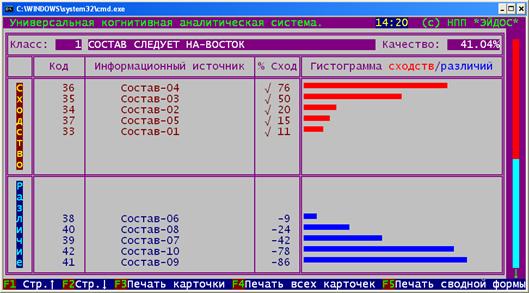
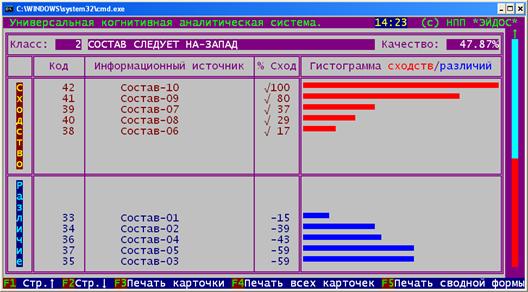
Рисунок 85. Примеры экранных форм результатов идентификации
в системе «Эйдос»
Интегральный критерий (7) имеет и другую
интерпретацию: как весовой коэффициент при разложении вектора идентифицируемого
объекта в ряд по векторам классов [7, раздел 3.5].
Задача
принятия решений является обратной задачей по отношению к задаче
идентификации и прогнозирования, т.е. если при прогнозировании по значениям
факторов определяется степень принадлежности объектов к классам, то при
принятии решений – наоборот, по заданному целевому состоянию (классу)
вырабатываются рекомендации по системе факторов, которые обусловливают переход
системы в состояние, соответствующее этому классу.
В интеллектуальной системе «Эйдос» есть много
различных выходных форм, содержащих результаты решения задачи принятия решений:
нелокальные нейроны, информационные портреты и другие.
Информационный портрет класса – это список факторов, ранжированных в порядке убывания
силы их влияния на переход объекта управления в состояние, соответствующее
данному классу. Информационный портрет класса отражает систему его детерминации.
Генерация информационного портрета класса представляет собой решение обратной
задачи прогнозирования, т.к. при прогнозировании по системе факторов определяется
спектр наиболее вероятных будущих состояний объекта управления, в которые он
может перейти под влиянием данной системы факторов, а в информационном портрете
наоборот, по заданному будущему состоянию объекта управления определяется
система факторов, детерминирующих это состояние, т.е. вызывающих переход
объекта управления в это состояние. В начале информационного портрета класса
идут факторы, оказывающие положительное влияние на переход объекта управления в
заданное состояние, затем факторы, не оказывающие на это существенного влияния,
и далее – факторы, препятствующие переходу объекта управления в это состояние
(в порядке возрастания силы препятствования). Информационные портреты классов
могут быть от отфильтрованы по
диапазону факторов, т.е. мы можем отобразить влияние на переход объекта
управления в данное состояние не всех отраженных в модели факторов, а только
тех, коды которых попадают в определенный диапазон, например, относящиеся к
определенным описательным шкалам.
Информационные портреты классов: «Восток» и «Запад»
приведены в таблицах 34 и 35.
Таблица 34 – Информационный портрет класса: «Восток»
|
NUM
|
KOD
|
NAME
|
INFBIT
|
|
1
|
3
|
ФОРМА ВАГОНА-Овальная
|
0,10415
|
|
2
|
5
|
ФОРМА ВАГОНА-Ромбовидная
|
0,10415
|
|
3
|
18
|
ВИД КРЫШИ ВАГОНА-Овальная
|
0,10415
|
|
4
|
21
|
ВИД КРЫШИ
ВАГОНА-Треугольная
|
0,10415
|
|
5
|
23
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 квадрат
|
0,10415
|
|
6
|
25
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 перевернутый треугольник
|
0,10415
|
|
7
|
27
|
ВИД ГРУЗА (КОЛ-ВО И ВИД)-1
ромб
|
0,10415
|
|
8
|
29
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-2 овала
|
0,10415
|
|
9
|
31
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-3 квадрата
|
0,10415
|
|
10
|
11
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА:
2/5-{40.00, 50.00}
|
0,06710
|
|
11
|
9
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-003
|
0,05103
|
|
12
|
35
|
КОЛИЧЕСТВО ВАГОНОВ В
СОСТАВЕ-3
|
0,05103
|
|
13
|
20
|
ВИД КРЫШИ ВАГОНА-Прямая
|
0,04202
|
|
14
|
28
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 треугольник
|
0,04202
|
|
15
|
15
|
ВИД СТЕНОК ВАГОНА-Двойные
|
0,02928
|
|
16
|
36
|
КОЛИЧЕСТВО ВАГОНОВ В
СОСТАВЕ-4
|
0,02928
|
|
17
|
10
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА:
1/5-{30.00, 40.00}
|
0,02377
|
|
18
|
7
|
ДЛИНА ВАГОНА-Короткий
|
0,01560
|
|
19
|
4
|
ФОРМА
ВАГОНА-Прямоугольная
|
0,00324
|
|
20
|
16
|
ВИД СТЕНОК
ВАГОНА-Одинарные
|
0,00259
|
|
21
|
8
|
КОЛИЧЕСТВО ОСЕЙ
ВАГОНА-002
|
-0,01015
|
|
22
|
19
|
ВИД КРЫШИ
ВАГОНА-Отсутствует
|
-0,01436
|
|
23
|
2
|
ФОРМА ВАГОНА-V-образная
|
-0,02383
|
|
24
|
14
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА:
5/5-{70.00, 80.00}
|
-0,02383
|
|
25
|
6
|
ДЛИНА ВАГОНА-Длинный
|
-0,04558
|
|
26
|
24
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 овал
|
-0,05229
|
|
27
|
1
|
ФОРМА ВАГОНА-U-образная
|
-0,06503
|
|
28
|
22
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 длинный прямоугольник
|
-0,09870
|
|
29
|
26
|
ВИД ГРУЗА (КОЛ-ВО И
ВИД)-1 прямоугольник
|
-0,09870
|
|
30
|
12
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА:
3/5-{50.00, 60.00}
|
-0,15181
|
|
31
|
13
|
ГРУЗОПОДЪЕМНОСТЬ ВАГОНА:
4/5-{60.00, 70.00}
|
-0,19301
|
Таблица 35 – Информационный портрет класса: «Запад»
|
NUM
|
KOD
|
NAME
|
INFBIT
|
|
1
|
17
|
ВИД
КРЫШИ ВАГОНА-Гофрированная
|
0,15535
|
|
2
|
30
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-2 прямоугольника
|
0,15535
|
|
3
|
32
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-3 овала
|
0,15535
|
|
4
|
33
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-Отсутствует
|
0,15535
|
|
5
|
34
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-2
|
0,15535
|
|
6
|
13
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 4/5-{60.00, 70.00}
|
0,11415
|
|
7
|
12
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 3/5-{50.00, 60.00}
|
0,10223
|
|
8
|
22
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-1 длинный прямоугольник
|
0,08049
|
|
9
|
26
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-1 прямоугольник
|
0,08049
|
|
10
|
1
|
ФОРМА
ВАГОНА-U-образная
|
0,06103
|
|
11
|
24
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-1 овал
|
0,05203
|
|
12
|
6
|
ДЛИНА
ВАГОНА-Длинный
|
0,04682
|
|
13
|
2
|
ФОРМА
ВАГОНА-V-образная
|
0,02737
|
|
14
|
14
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 5/5-{70.00, 80.00}
|
0,02737
|
|
15
|
19
|
ВИД
КРЫШИ ВАГОНА-Отсутствует
|
0,01739
|
|
16
|
8
|
КОЛИЧЕСТВО
ОСЕЙ ВАГОНА-002
|
0,01259
|
|
17
|
16
|
ВИД
СТЕНОК ВАГОНА-Одинарные
|
-0,00347
|
|
18
|
4
|
ФОРМА
ВАГОНА-Прямоугольная
|
-0,00436
|
|
19
|
7
|
ДЛИНА
ВАГОНА-Короткий
|
-0,02284
|
|
20
|
10
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 1/5-{30.00, 40.00}
|
-0,03694
|
|
21
|
15
|
ВИД
СТЕНОК ВАГОНА-Двойные
|
-0,04749
|
|
22
|
36
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-4
|
-0,04749
|
|
23
|
20
|
ВИД
КРЫШИ ВАГОНА-Прямая
|
-0,07595
|
|
24
|
28
|
ВИД
ГРУЗА (КОЛ-ВО И ВИД)-1 треугольник
|
-0,07595
|
|
25
|
9
|
КОЛИЧЕСТВО
ОСЕЙ ВАГОНА-003
|
-0,10061
|
|
26
|
35
|
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ-3
|
-0,10061
|
|
27
|
11
|
ГРУЗОПОДЪЕМНОСТЬ
ВАГОНА: 2/5-{40.00, 50.00}
|
-0,15941
|
Из приведенных в таблицах
34 и 35 информационных портретов обобщенных образов классов «Восток» и «Запад»
видно, что система искусственного интеллекта выявила на основе приведенных
примеров (рисунок 80) наиболее характерные и наиболее нехарактерные признаки
этих категорий, которые выявил бы и естественный интеллект. Очень важно
отметить, что в данном случае (т.е. в случае применения АСК-анализа и системы
«Эйдос») результаты работы искусственного
интеллекта понятны и естественны для естественного интеллекта эксперта. При
применении систем искусственного интеллеката так удачно это бывает далеко не
всегда.
С другой стороны
искусственный интеллект способен выявлять знания из эмпирических данных очень большой размерности, на столько большой,
что человеку не хватит и нескольких жизней, чтобы хотя бы только их прочитать,
если тратить на чтение весь рабочий день, не говоря уже о выявлении в них
каких-то закономерностей или знаний [18].
Кроме того, искусственный
интеллект выявляет знания в количественной
форме, тогда как естественный, только на качественном уровне и в
слабо-формализованном виде.
Если мы ставим перед
собой цель найти поезд, идущий на запад по его признакам, то эта степень
характерности признаков (т.е. количество информации, которое в них содержится о
том, что поезд идет на запад или на восток) превращается в знания, позволяющие
нам достичь цели, которую мы ставим.
Если проанализировать
признаки, содержащиеся в таблицах 34 и 35, сравнив содержащееся в них
количество информации о принадлежности или непринадлежности обладающих ими объектов
к тем или иным классам, то можно условно разделить их на три основных группы:
– детерминистские, содержащие очень большое количество информации;
– статистические, содержащие среднее количество информации;
– практически бесполезные, содержащие очень малое количество
информации.
Числовые шкалы
формализуются а системе «Эйдос» в виде интервальных значений, которые
нумеруются от минимального значения к максимальному. Для удобства пользователей
в наименования градаций числовых шкал, как классификационных, так и
описательных, включены условные обозначения номера интервального значения типа:
1/5, что означает: «Первое интервальное значение из пяти».
Необходимо также
отметить, что представление о полностью линейных объектах (системах) является
абстракцией и реально все объекты являются принципиально нелинейными. Вместе с
тем для большинства систем нелинейные эффекты можно считать эффектами второго и
более высоких порядков и такие системы в
первом приближении можно считать линейными. Возможны различные модели взаимодействия факторов, в частности,
развиваемые в форме системного обобщения теории множеств. Этот подход в
перспективе может стать одним из вариантов развития теории нелинейных систем.
Отметим, что
математическая модель АСК-анализа (системная теория информации) органично учитывает принципиальную
нелинейность всех объектов. Это проявляется в нелокальности нейронной сети
системы «Эйдос» [20], приводящей к зависимости всех информативностей от любого
изменения в исходных данных, а не как в методе обратного распространения ошибки. В
результате значения матрицы
информативностей количественно отражают факторы не как множество, а как систему.
Объект может перейти в
некоторое будущее состояние под действием различного количества факторов, но
какая бы система факторов не обусловливала (детерминировала) этот переход, в
ней не может содержаться информации больше, чем можно получить, точно узнав,
что объект переходит в данное состояние. Это количество информации в
АСК-анализе называется «Теоретически максимальное количество информации» и
определяется только количеством классов (будущих состояний объекта), которые в
детерминистском случае равновероятны, т.к. между классами и факторами выполняется
взаимнооднозначное соответствие, когда каждое будущее состояние однозначно
определяется единственным фактором. Формула А.Харкевича видоизменена в работе [7] таким образом, чтобы удовлетворять
принципу соответствия с формулой Р.Хартли в детерминистском случае. Поэтому, чем
меньше факторов, тем жестче ими детерминировано поведение объекта, и наоборот,
чем больше этих факторов, тем меньше влияние каждого из них на поведение
объекта. Например, если переход объекта в некоторое состояние однозначно
определяется единственным фактором, то добавление в модель еще одного точно такого же фактора приводит к тому,
что в сумме эти два фактора будут оказывать тоже самое влияние, которое делится
между ними поровну.
Так в математической
модели АСК-анализа учитывается взаимодействие
факторов и отличие системы факторов
от множества факторов, являющееся
источником нелинейности моделируемого объекта.
Итак, в матрице информативнстей количественно отражены
сила и направление влияния каждого значения фактора на переход объекта в каждое
из состояний, а также учтено, что совокупность факторов является системой, а не
множеством, т.е. учтены взаимодействие факторов и нелинейность моделируемого
объекта. Результаты решения задач идентификации, прогнозирования, принятия
решений и научного исследования моделируемой предметной области (в частности
кластерно-конструктивного анализа), на основе матрицы информативностей
инвариантны относительно формы частотного распределения объектов исследуемой
выборки по классам, единиц измерения значений факторов и типа шкал,
используемых для формализации факторов.
Это позволяет корректно
использовать в АСК-анализе аддитивный интегральный критерий в форме суммы частных критериев не только для
линейных, но и для нелинейных объектов.
Различие между матрицей
информативностей и матрицей знаний. Если в модели отражены лишь
причинно-следственные связи между факторами и будущими состояниями объекта, но
не отражена степень желательности ли нежелательности этих будущих состояний, то
мы имеем дело с матрицей информативностей. Если же некоторые из будущих событий
классифицируются как желательные, т.е. целевые, а другие как нежелательные, то
появляется возможность количественной оценки степени полезности информации о действии факторов для перевода объекта в
эти состояния, т.е. для преобразования информации в знания.
Процесс преобразования информации в знания – это процесс
оценки степени полезности информации для достижения желаемых будущих состояний,
т.е. целей. Таким образом, база знаний количественно отражает степень полезности
(а также бесполезности и вредности) факторов для достижения целей: она содержит
знания в количественной форме о величине и направлении влияния каждого значения
фактора на перевод объекта в каждое из будущих состояний, как желаемое, так и
нежелательное.
Соотношение различных
моделей представления знаний, в т.ч. процедурной и декларативной, таково, что
можно обоснованно говорить о том, что одни и те же знания могут быть более или
менее полно и адекватно представлены с помощью большинства моделей и различие
между ними не столь велико и принципиально, как обычно принято думать.
Это различие можно
сравнить с различием между различными языками, на которых фразы, имеющие один и
тот же смысл, звучат или выглядят (в текстовой форме) совершено по-разному.
Не представляет исключения
и модель представления знаний, принятая в системно-когнитивном анализе и
системе «Эйдос», которая имеет много общего со многими моделями представления
знаний. Например, база знаний (матрица информативностей) системы «Эйдос» очень
напоминает матрицу весовых коэффициентов нейронных сетей, но в отличие от нее
имеет четкую научно обоснованную интерпретацию коэффициентов и рассчитывается
прямым счетом, а не путем итерационного подбора методом обратного
распространения ошибки. Коэффициенты матрицы информативностей представляют
собой количество информации в признаке о принадлежности обладающего им объекта
к классу. О смысле же весовых коэффициентов нейронной сети идут научные
дискуссии. Кроме того база знаний системы «Эйдос» очень напоминает таблицу принятия
решений и на основе нее действительно принимаются решения о принадлежности объектов
к классам (задача идентификации и прогнозирования) или о том, какие значения
факторов необходимы для перевода объекта в заданное целевое состояние (задача
принятия решений) (таблицы 34 и 35).
Из таблиц 36 и 37 видно,
что различные модели представления знаний имеют очень существенное
сходство по смысловому содержанию своих ключевых терминов, т.е. по существу отличаются
друг от друга не очень значительно, по крайней мере намного менее значительно,
чем обычно представляют себе не специалисты области искусственного интеллекта.
Автор даже осмелились бы на утверждение, что по существу все модели
представления знаний могут рассматриваться как разные варианты одной модели,
включающей детализированные и обобщенные описания объектов и их многослойные
иерархические древовидные структуры и различия между этими моделями на
понятийном уровне минимальные и являются в основном терминологическими.
Таким образом, можно обоснованно считать, что модель
знаний АСК-анализа, является гибридной моделью знаний, основанной на
подмножестве фреймовой модели, в которой все фреймы описаны в общей
системе слотов и шпаций (это существенно упрощает программную реализацию без
потери функционала), и нелокальной содержательно интерпретируемой нейронной
сети с алгоритмом обучения прямого счета.
Факт – это единство экстенсионального и
интенсинального описания события,
обнаруженного эмпирическим путем, т.е. по сути, факт это определение события. Пример факта: «Кошка кормит котят
молоком». Пример определения в науке: «Млекопитающее – это животное (более
общее, интенсиональное понятие), вскармливающее своих детей молоком (экстенсиональный
специфический признак)».
Закономерности – это причинно-следственные
зависимости, выявленные на исследуемой выборке и распространяемые лишь на саму
эту выборку.
Эмпирический закон – это закономерности, выявленные на
исследуемой выборке и распространяемые на некоторую более широкую предметную
область, в которой действуют те же причины
их существования, что и в исследуемой выборке. Эта более широкая предметная
область называется генеральной совокупностью,
по отношению к которой исследуемая выборка репрезентативна.
Очень важно понимать, что
генеральная совокупность является более широкой, чем исследуемая выборка, не
только в пространстве, но и во времени.
Периоды времени, в течение
которых закономерности в предметной области существенно не меняются, называются
периодами
эргодичности. Границы между
периодами эргодичности называются точками бифуркации. Используя эту
терминологию можно сказать, что генеральная
совокупность эргодична по отношению к исследуемой выборке, а граница генеральной
совокупности состоит из точек бифуркации.
Большой интерес
представляет анализ глубоких аналогий
и параллелей между рассмотренными выше понятиями автоматизированного
системно-когнитивного анализа и некоторыми базовыми понятиями физики.
Ниже предпринимается попытка сформулировать эти понятия физики в терминах
АСК-анализа. Это сразу позволяет увидеть неожиданные аспекты понимания и
варианты развития этих понятий.
Принцип
относительности Галилея и Эйнштейна формулируется следующим образом: все физические процессы в инерциальных системах отсчёта протекают
одинаково, независимо от того, неподвижна ли система или она находится в
состоянии равномерного и прямолинейного движения.
В терминах АСК-анализа
принцип относительности можно сформулировать следующим образом: закономерности,
выявленные в исследуемой выборке в одной области пространства и времени, выполняются и в других областях, в которых
действуют те же причины их существования,
что и в исследуемой выборке. В частности, эти причины могут состоять в том, что
виртуальная реальность сконструирована таким образом, чтобы в ней выполнялся
принцип относительности.
В фундаментальной теореме
Нетер
доказывается, что причинами существования
законов сохранения являются однородность и изотропность пространства и времени
(их симметрии) (таблица 38):
Таблица 38 – Симметрии пространства и времени
и обусловленные ими законы сохранения
Так как «Инерциальной
называется система отсчёта, по отношению к которой пространство
является однородным
и изотропным,
а время – однородным», то можно сделать вывод: законы
сохранения и инерциальные системы отсчета имеют
общие причины существования –
это симметрии пространства и времени.
Учитывая этот вывод, переформулируем принцип относительности
в АСК-анализе так: закономерности, выявленные в исследуемой выборке в одной
области пространства и времени, тем
точнее выполняются в других областях, чем меньше отличаются свойства пространства и времени (метрические и
топологические) в этих других областях от исследуемой.
Эргодичными по отношению к исследуемой выборке будем называть те
области пространства и времени, в которых действуют те же закономерности, что в
исследуемой выборке.
Неэргодичые области пространства и времени существенно отличаются
по своим свойствам друг от друга и разделены границами, состоящими из точек,
которые мы будем называть точками
бифуркации.
Используя эти термины, принцип относительности в
АСК-анализе можно сформулировать следующим образом: эмпирические закономерности, выявленные на исследуемой выборке в определенной
области пространства и времени будут выполняться и в других областях,
эргодичных по отношению к данной области
и будут нарушаться при переходе в неэргодичные по отношению к ней области.
Таким образом, мы можем сформулировать научную гипотезу «О существовании границ
применимости принципа относительности и законов сохранения»: принцип
относительности и законы сохранения выполняются
для эргодичных по отношению к исследуемой выборке областей пространства и
времени и нарушаются при переходе
через границу бифуркации в неэргодичную по отношению к ней область.
Естественно, возникает вопрос о возможности экспериментальной
проверки этой гипотезы. Для этого необходимо экспериментально выйти к границам
бифуркации исследуемой области пространства и времени и за их границы в
неэргодичную область. Из одной области пространства и времени можно перейти в
другую область путем изменения исследуемых периодов времени, смещения и
поворота в пространстве. Сочетание смещений и поворотов позволяет изменить
пространственно-временной масштаб исследуемой предметной области.
Если эмпирические закономерности в исследуемой выборке
выявлены за определенный период времени,
то они считаются действующими и в другие периоды, в течение которых действуют те же причины существования этих
закономерностей, что и в исследуемой выборке, т.е. в периоды времени,
эргодичные по отношению к исследуемой выборке. Это значит, что вообще говоря на
протяжении очень малых или очень больших периодов времени по сравнению с
исследуемым периодом эти закономерности могут и нарушаться.
Ясно, что неограниченное перемещение в определенном направлении
или изменение пространственного масштаба исследуемой предметной области, в
конце концов, приведет к выходу за границы области эргодичности и это потребует
пересмотра законов, открытых в исследуемой предметной области. Например, при
уменьшении масштаба до размеров атомов и элементарных частиц мы переходим в
область квантовых явлений, а при увеличении масштаба до размеров галактики и
более мы сталкиваемся с явлениями, для объяснения которых необходимо либо пересмотреть
законы гравитации, либо ввести не наблюдаемые в настоящее время сущности, типа
темной материи или энергии.
Но является ли фактически
наше физическое пространство времени однородным и изотропным, и если да или
нет, то на сколько именно, т.е. в какой степени?
Не смотря на то, что на принципе относительности во многом
основана современная наука, он далеко не так очевиден.
Существует легенда,
согласно которой Галилео Галилей
исследовал закономерности свободного падения, сбрасывая шары из разных
материалов одинакового размера, но разной массы с Пизанской башни и измеряя
время падения по собственному пульсу. Однако найденные Галилеем закономерности
свободного падения действовали за миллиарды лет до него и будут действовать
через миллиарды лет после него и не только в Италии, но и в других странах и
даже не только на Земле, и не только в нашей галактике.
Само время изменяет абсолютно все, и даже, наверное,
само себя, поэтому, скорее всего, существуют различные неэргодичные по
отношению друг к другу периоды времени. Нет ничего постоянного в этом мире,
кроме разве что самого этого непостоянства. Возможно, с течением времени
меняется и гравитационная постоянная, и
другие фундаментальные константы. Конечно, это происходит очень и очень
медленно. Тем ни менее есть надежда, что современные сверхточные
информационно-измерительные технологии позволят уловить это изменение. Скорее
всего, есть области Вселенной, в которых значения этих фундаментальных констант
иные, чем в нашей области, да и в любой из этих областей они могут
незначительно изменяться в разных областях.
Если, в соответствии с моделью, принятой в общей
теорией относительности (ОТО) А.Эйнштейна, рассматривать гравитацию как искривление
пространства-времени, то ясно, что структура (метрика, а возможно и топология)
пространства-времени зависит от распределения масс, а оно далеко не равномерно,
значит и пространство-время не однородно и не изотропно на столько же, как и
распределение масс. Следовательно, базовое предположение, на котором основана
теорема Нётер об однородности и изотропности пространства-времени, является
абстракцией и реально выполняется лишь с некоторой точностью или погрешностью,
как, по-видимому, и вытекающие из этих свойств пространства-времени законы
сохранения импульса, энергии и момента количества движения.
Профессор Майкл Лонго с коллегами обобщив,
знания о распределении спиральных галактик в метагалактике, совершили
неожиданное открытие: в северной небесной полусфере Земли более распространены
левозакрученные спирали, а в южной – правозакрученные (хотя для южной части это
и не столь выражено). Результаты этого исследования говорит о том,
структура пространства метагалактики, при детальном ее рассмотрении, является
асимметричной, а не строго однородной и изотропной. Ось вращения Земли
сориентирована в пространстве таким образом, что это различие наибольшее для ее
северного и южного полушарий. Из этого факта следуют далеко идущие выводы. Например,
известно, что сам феномен существования белковой жизни на Земле связан с ярко
выраженной асимметрией (киральностью) белковых молекул.
Эмпирический закон является феноменологическим, т.е.
внешним описанием зависимости последствий от причин, который не раскрывает
механизма или способа, которым реализуется эта зависимость.
Научный закон
– это содержательная интерпретация механизма действия эмпирического закона,
т.е. способа преобразования причин в
следствия. Научный закон является содержательным объяснением и интерпретацией эмпирического закона. Это объяснение,
когда оно разрабатывается, не сразу становится научным законом, а сначала имеет
статус научной гипотезы и приобретает статус научного закона лишь после того,
как на практике, т.е. эмпирически,
подтверждаются предсказания существования новых, ранее неизвестных явлений,
сделанные на основе научной гипотезы. Таким образом, научный закон – это
научная гипотеза, адекватность и прогностическая сила которой подтверждены
(верифицированы) эмпирически. Процесс преобразования научной гипотезы в научный
закон – это процесс подтверждения на практике адекватности этой научной гипотезы.
Необходимо подчеркнуть, что существует принципиальная
возможность создания неограниченного количества различных
моделей, одинаково хорошо (адекватно, верно, достоверно) отражающих одну и
ту же предметную область. Это является еще одной причиной некорректности
гипостазирования лишь одной из них, т.к. реальность одновременно не может быть такой, какой она отражается во всех этих
различных моделях (или может, о чем писал Эверетт).
Иногда такие модели и действительно созданы, тогда это проявляется особенно
наглядно. Естественно возникает вопрос о критериях
выбора одной модели, в определенном смысле или по определенным обоснованным
критериям «наилучшей» из многих. Среди этих критериев следует отметить
адекватность, удовлетворение принципу соответствия и широту адекватно
отражаемой предметной области, а также ее простоту и красоту. Из многих моделей предпочтительная та,
которая более адекватна (точнее), и та, которая адекватно отражает более
широкую предметную область, т.е. включает в себя на основе принципа
соответствия другие известные модели, а также более простая и красивая
модель. Однако часто бывает, что разработка многих моделей (научных теорий)
весьма затруднительна (и может занимать не одну сотню лет) и есть или известна
всего лишь одна-единственная модель. В этом случае эта единственная модель
автоматически начинает считаться наилучшей (из всех известных).
Поэтому ученые, разрабатывающие новые перспективные
модели, стремятся к созданию более общих моделей, т.е. моделей, имеющих более
широкую область адекватности, что обеспечивает этим моделям конкурентные преимущества
перед другими моделями. Обычно более общие модели являются и более точными, чем
частные.
Расширение области адекватности модели осуществляется
путем включения в исходные данные новых (обычно ранее неизвестных, но иногда и
давно всем известных) фактов, не принадлежащих генеральной совокупности, по
отношению к которой исследуемая выборка репрезентативна, с последующим пересинтезом
модели, формулированием новых эмпирических и научных законов.
Это значит, что ученые, действительно стремящиеся к
поиску истины и развитию науки, должны буквально охотиться за такими новыми
фактами, не вписывающимися в традиционные общепринятые научные теории,
концепции и парадигмы реальности. Но в жизни мы часто видим обратное, когда
отрицается само существование подобных фактов на том основании, что «этого не
может быть, т.к. не может быть никогда» или потому, что они «не вписываются» в
частные неоправданно гипостазированные модели. Этот феномен объясняется с
позиций теории научных революций Томаса Куна.
Результаты идентификации и прогнозирования, осуществленные
с помощью модели, путем выполнения когнитивной операции "верификация"
сопоставляются с опытом, после чего определяется целесообразность выполнения
когнитивной операции "обучение". При этом может возникнуть три основных
варианта, которые на рисунке 86 обозначены цифрами:
Рисунок
86. К пояснению смысла понятий:
"Адаптация и синтез когнитивной модели предметной области",
"Внутренняя и внешняя валидность информационной модели",
1. Объект, входит в обучающую выборку и достоверно
идентифицируется (внутренняя валидность, в адаптации нет необходимости).
2. Объект, не входит в обучающую выборку, но входит в
исходную генеральную совокупность, по отношению к которой эта выборка репрезентативна,
и достоверно идентифицируется (внешняя валидность, добавление объекта к
обучающей выборке и адаптация модели приводит к количественному уточнению
смысла признаков и образов классов).
3. Объект не входит в исходную генеральную
совокупность и идентифицируется недостоверно (внешняя валидность, добавление
объекта к обучающей выборке и синтез модели приводит к качественному уточнению
смысла признаков и образов классов, исходная генеральная совокупность
расширяется).
Высшая форма использования информации – это знания,
т.е. ее использование для достижения целей (управления). На рисунке 87
приведена схема автоматизированной системы управления (АСУ), в которой процесс
выявления знаний из предметной области (познание) входит непосредственно в цикл
управления:
Рисунок 87. Структура предметной области и рефлексивной АСУ активными
объектами в АСК-анализе, в которой процесс выявления знаний из предметной
области (познание) входит непосредственно в цикл управления [7]
Подробнее цикл выявления знаний из эмпирических данных
и их применения для прогнозирования и управления (принятия решений) в
АСК-анализе показан на рисунке 88.
Если модель имеет высокую степень адекватности и, особенно,
если нет альтернативных достоверных моделей, то возникает соблазн неоправданно
и необоснованно считать, что реальность
устроена именно таким образом, какой она отражается в этой наилучшей по
сформулированным выше критериям модели или научной теории, т.е. возникает соблазн необоснованно придать онтологический статус абстрактной модели. В
этом состоит широко распространенная малозаметная (когда ее совершаешь) ошибка
познания, называемая «Гипостазирование».
Однако эта ошибка влечет за собой целый шлейф весьма заметных последствий,
важнейшим из которых является отрицание существования фактов, закономерностей и
эмпирических законов, не вписывающихся в те или иные научные теории, даже если
эти факты в буквальном смысле слова очевидны.
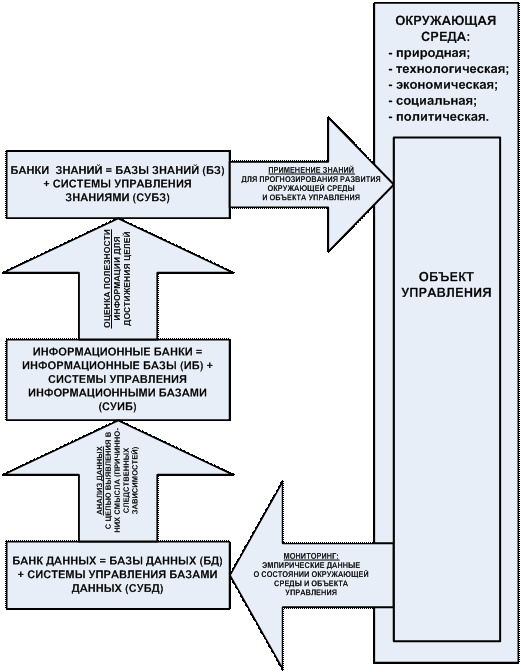
Рисунок 88. Цикл выявления знаний из эмпирических данных
и их применения для прогнозирования и управления
(принятия решений) в АСК-анализе
Например, апологеты воздухоплавания отрицали возможность
создания летательных аппаратов тяжелее воздуха, не смотря на птиц, которые
садились и взлетали перед ними (или даже смотря на них, но не осознавая, что они видят перед собой). При
этом они исходили из того, что принцип действия летальных аппаратов может быть
основан только на законе Архимеда, как это следовало из единственной известной
им научной теории полета. Если бы эти апологеты воздухоплавания отрицали возможность
летательных аппаратов тяжелее воздуха, принцип действия которых основан на
законе Архимеда, то к ним бы не было никаких претензий. Иначе говоря, эти
апологеты упустили из внимания, что могут существовать (а мы уже знаем, что и
действительно существуют) и другие принципы полета: в частности, баллистический,
аэродинамический, ракетный, электромагнитный, на которых может быть основан
принцип действия летательных аппаратов тяжелее воздуха, причем эти аппараты ни в коей мере не нарушают
закон Архимеда (как почему-то думали апологеты и потому отрицали возможность их
создания) и полностью ему подчиняются.
Признание существования факта не зависит от
обнаружения закономерности. Признание существования закономерности не зависит
от обнаружения соответствующего эмпирического закона. Признание существования
эмпирических законов не зависит от наличия верифицированной содержательной
интерпретации или научного закона, а если она есть, то от того, является ли она
«правильной» или «неправильной» по тем или иным критериям или по чьему-то
мнению. Таким образом, признание существования факта не зависит от наличия их
интерпретации или теории, которая его объясняет, и отсутствие такой теории не является основанием для отрицания существования
или непризнания существования факта.
Конечно, часто проще и выгоднее не разрабатывать новые
теоретические объяснения «неудобных» фактов, а просто отрицать само их
существование по принципу: «Есть факт – есть проблема, нет факта – нет
проблемы». Подобное отрицание чаще всего наблюдается на этапе социализации
науки.
От обнаружения фактов до создания адекватной теории их
объясняющей, могут пройти сотни и даже тысячи лет, более того, со временем
меняются и сами критерии достоверности теории или того, что вообще можно
признать «объяснением». Поэтому в разное время различные и даже противоречащие
друг другу теории считаются правильными объяснениями одних и тех же фактов.
Выводы. Целесообразность использования именно матрицы
информативностей (базы знаний) для визуализации когнитивных функций и решения
других задач (идентификации, прогнозирования, поддержки принятия решений и
исследования предметной области) состоит в следующем. На основе сравнения
абсолютных частот можно делать какие-либо выводы только в том случае, когда по
разным классам приведено одинаково количество примеров. В общем случае это
количество примеров по разным классам всегда
разное, поэтому матрица абсолютных частот сама по себе непригодна для
решения вышеперечисленных задач. Но на практике иногда встречается ситуация,
когда это количество мало отличается по разным классам и тогда использование
этой матрицы не дает большой ошибки и позволяет составить более-менее достоверное
представление о предметной области. Получить модель предметной области, инвариантную относительно различий в количестве
примеров по классам, можно перейдя от матрицы абсолютных частот к матрице
условных и безусловных процентных распределений.
Использование матрицы условных и безусловных процентных распределений позволяет
получить такой же уровень достоверности выводов о предметной области, какой
матрица абсолютных частот в случае
равного количества примеров по разным классам. Однако для того, чтобы получить
эти выводы необходимо сравнивать
условные процентные распределения друг с другом. При небольших размерностях моделей
это сравнение может быть проведено вручную, правда лишь на качественном уровне,
однако при реальных встречающихся на практике размерностях вручную это сделать
не представляется возможным. Поэтому в
АСК-анализе принято решение автоматизировать количественное сравнение условных
процентных распределений. При этом возник вопрос о том, как именно их сравнивать:
друг с другом или с какой-то базой сравнения. Если в модели всего два класса,
то приемлем вариант сравнения условных процентных распределений по ним друг с
другом. Но когда классов всего три, то уже не очень понятно как это делать,
если же их сотни, тысячи или десятки тысяч, то это становится вообще непонятным.
В АСК-анализе этот вопрос решен путем сравнения условных процентных
распределений по классам с безусловным процентным распределением по всей
выборке, которое и выступает базой (нормой) сравнения. Кроме того, важно
отметить, что получающееся в результате этого выражение для количества информации
тождественно выражению, получающемуся
путем сравнения фактически наблюдаемой абсолютной частоты встреч признака в
определенной группе к теоретически ожидаемой частоте его наблюдения в методе
хи-квадрат. Таким образом, матрица
информативностей представляет собой результат выполнения процедуры автоматизированного
сравнения условных процентных распределений признаков по классам с их безусловным
процентным распределением по всей выборке. По сути это результат нормировки условных процентных
распределений с использованием в качестве нормы безусловного процентного распределения.
Поэтому использование матрицы информативностей освобождает
исследователя-аналитика от необходимости выполнения огромной рутинной работы (которую
он как правило и не может выполнить вручную, а когда может, то лишь на качественном,
а не количественном уровне) по сравнению условных процентных распределений друг
с другом или с какой-либо базой сравнения и обеспечивает более высокий уровень
достоверности выводов, чем использование матрицы условных и безусловных
процентных распределений.
Таким образом, когнитивные
функции являются адекватным математическим инструментом для формального представления
причинно-следственных зависимостей. Когнитивные функции представляют собой
многозначные интервальные функции многих аргументов, в которых различные
значения функции в различной степени соответствуют различным значениям аргументов,
причем количественной мерой этого соответствия выступает знания, т.е.
информация о причинно-следственных зависимостях в эмпирических данных, полезная
для достижения целей. Многочисленные исследования [3-190] подтверждают, что метод и программный инструментарий визуализации когнитивных функций
позволяют наглядно увидеть такие причинно-следственные закономерности
предметной области, которые другими методами выявить и описать весьма проблематично.
В качестве перспективных направлений исследований и разработок
в области АСК-анализа отметим следующие. Матрица информативностей представляет
собой исчерпывающий перечень (т.е. в декларативной форме представления
знаний) результатов идентификации объектов, описанных одним признаком (градацией описательной шкалы) с классами
(градациями классификационных шкал). С этой точки зрения она состоит из двумерных подматриц, образуемых всеми
сочетаниями описательных и классификационных шкал по две (одна описательная и
одна классификационная шкала). Но матрица информативностей содержит всю
необходимую и достаточную информацию для
расчета (т.е. в процедурной форме
представления знаний) всех возможных результатов
идентификации объектов с классами (градациями классификационных шкал),
описанных не одним, всеми сочетаниями
по два, три, … N признаков из М, где М – количество описательных шкал (если градации в шкалах альтернативные). Если реально выполнить
эти процедуры распознавания для всех возможных объектов, то результаты идентификации можно наглядно
представить в декларативной форме в виде значений элементов многомерных матриц
(когнитивных тензоров или тензоров знаний, описывающих
когнитивное пространство), образованных одной
классификационной шкалой и несколькими описательными. Координатные
плоскости этих многомерных матриц являются подматрицами матрицы информативностей
с общей классификационной шкалой и разными описательными шкалами. Эти
подматрицы визуализируются в базовой системе «Эйдос» (режим _54) и в системе
«Эйдос-астра» в форме когнитивных функций [3-190]. В АСК-анализе в качестве частных критериев принято
рассматривать признаки (градации описательных шкал), точнее не сами признаки, а
количество информации, содержащейся в признаках о принадлежности обладающих ими
объектов к классам, а в качестве интегрального критерия – сумму информативностей частных критериев, т.е. свертку или скалярное
произведение в координатной форме [7].
Многомерные когнитивные структуры в этих подматрицах отражают результаты
идентификации объектов со всеми возможными сочетаниями признаков из n
по m, которые, следуя работе [7], будем называть
Эйдосами, а их визуализацию – многомерными
когнитивными функциями. Это название оправдано тем, что сечения Эйдосов координатными
плоскостями являются уже известными когнитивными функциями [7].
В многомерном когнитивном пространстве можно ввести
понятия, аналогичные понятиям кинематики и динамики. Если в качестве
описательных шкал в семантической информационной модели [7] использовать пространственно-временные координаты,
то АСК-анализ можно будет рассматривать как инструмент для информационного описания физических процессов и явлений, в котором
роль пространства-времени будет играть когнитивное пространство-время. Между
физическим и когнитивным пространством-временем существует тесная взаимосвязь и
вообще между ними больше общего, чем различий [7]. Предлагается также добавить к
пространственно-временным координатам еще две координаты, количественно
отражающие «уровень системности» и «степень детерминированности» системы. В
результате получится наука, которую можно было бы назвать «Информационная динамика систем».
Материалы данной статьи могут быть использованы при
разработке интеллектуальных систем, а также при проведении лабораторных работ
по дисциплинам: «Интеллектуальные информационные системы» для специальности:
080801.65 – Прикладная информатика (по областям) и «Представление
знаний в информационных системах» для специальности: 230201.65 – Информационные
системы и технологии.
В данном
разделе, основанном на работе [128], на небольшом наглядном численном примере
рассматриваются новые математическая модель, алгоритм и результаты
агломеративной кластеризации, основные отличия которых от ранее известных стоят
в том, что:
а) в них
параметры обобщенного образа кластера не вычисляются как средние от исходных
объектов (классов) или центры тяжести, а определяются с помощью той же самой базовой когнитивной
операции АСК-анализа, которая применяется и для формирования обобщенных образов
классов на основе примеров объектов и которая действительно обеспечивает
обобщение;
б) в
качестве критерия сходства используется не евклидово расстояние или его
варианты, а интегральный критерий неметрической природы: «суммарное количество
информации», применение которого теоретически корректно и дает хорошие результаты
в неортонормированных пространствах, которые обычно и встречаются на практике;
в)
кластерный анализ проводится не на основе исходных переменных или матрицы
сопряженности, зависящих от единиц измерения по осям, а в когнитивном пространстве,
в котором по всем осям (описательным шкалам) используется одна единица
измерения: количество информации, и поэтому результаты кластеризации не зависят
от исходных единиц измерения признаков объектов.
Имеется и
ряд других менее существенных отличий. Все это позволяет получить результаты
кластеризации, понятные специалистам и поддающиеся содержательной
интерпретации, хорошо согласующиеся с оценками экспертов, их опытом и интуитивными
ожиданиями, что часто представляет собой проблему для классических методов
кластеризации. Описанные методы теоретически обоснованы в системно-когнитивном
анализе (СК-анализ) и реализованы в его программном инструментарии – интеллектуальной
системе «Эйдос»
«Мышление
– это обобщение, абстрагирование, сравнение, и классификация» (Патанджали,
II в. до
н. э.).
Кластерный
анализ (англ. Data clustering) – это задача
разбиения заданной выборки объектов (ситуаций) на подмножества,
называемые кластерами, так, чтобы каждый кластер состоял из схожих
объектов, а объекты разных кластеров существенно отличались. Кластерный
анализ очень широко применяется как в науке, так и в различных направлениях
практической деятельности. Значение кластерного анализа невозможно переоценить,
оно широко известно и
нет необходимости его специально обосновывать.
Существует большое
количество различных методов кластерного анализа, хорошо описанных в
многочисленной специальной литературе и прекрасных обзорных статьях. Поэтому в
данной статье мы не ставим перед собой задачу дать еще одно подобное описание,
а обратим основное внимание на проблемы,
существующие в кластерном анализе и вариант их решения, предлагаемый в
автоматизированном системно-когнитивном анализе (АСК-анализ). Эти проблемы, в основном, хорошо известны
специалистам, и поэтому наш краткий обзор будет практически полностью основан
на уже упомянутых работах. Необходимо
специально отметить, что специалисты небезуспешно работают над решением этих
проблем, предлагая все новые и новые варианты, которые и являются различными
вариантами кластерного анализа. Мы в данной статье также предложим еще один ранее
не описанный в специальной литературе (т.е. новый, авторский) теоретически
обоснованный и программно-реализованный вариант решения некоторых из этих
проблем, а также проиллюстрируем его на простом численном примере.
Почему же разработано так много различных методов кластерного
анализа, почему это было необходимо? Кажутся почти очевидными мысли о том, что
различные методы кластерного анализа дают результаты различного качества, т.е. одни методы в определенном смысле «лучше», а другие «хуже», и это действительно
так, и, следовательно, по-видимому, должен
существовать только один-единственный метод кластеризации, всегда (т.е. на любых данных) дающий «правильные» результаты, тогда
как все остальные методы являются «неправильными». Однако если задать
аналогичный вопрос по поводу, например, автомобиля или одежды, то становится
ясным, что нет просто наилучшего автомобиля, а есть лучшие по определенным
критериям-требованиям или лучшие для определенных целей. При этом сами критерии также должны быть обоснованы и не
просто могут быть различными, но и должны быть различными при различных целях,
чтобы отражать цель и соответствовать ей. Так автомобиль, лучший для семейного
отдыха не являются лучшим для гонок Формулы-1 или для представительских целей.
Аналогично можно обоснованно утверждать, что одни методы кластерного анализа
являются более подходящими для кластеризации данных определенной структуры, а
другие – другой, т.е. не существует одного наилучшего во всех случаях универсального метода кластеризации, но
существуют методы более универсальные и методы менее универсальные. Но все же
многообразие разработанных методов кластерного анализа на наш взгляд указывает
не только на это, но и на то, что их
можно рассматривать как различные
более или менее успешные варианты решения или попытки решения тех или иных
проблем, существующих в области кластерного анализа.
Для структурирования дальнейшего изложения сформулируем
требования к исходным данным в кластерном анализе и фундаментальные вопросы,
которые решают разработчики различных методов кластерного анализа.
Считается, что
кластерный анализ предъявляет следующие требования
к исходным данным:
1. Показатели не должны коррелировать между собой.
2. Показатели должны быть безразмерными.
3. Распределение показателей должно быть близко к нормальному.
4. Показатели должны отвечать требованию «устойчивости»,
под которой понимается отсутствие влияния на их значения случайных факторов.
5. Выборка должна быть однородна, не содержать «выбросов».
Даже поверхностный анализ сформулированных требований
к исходным данным сразу позволяет утверждать, что на практике они в полной мере никогда не выполняются, а приведение
исходных данных к виду, удовлетворяющему этим требованиям, или очень сложно,
т.е. представляет собой проблему, и
не одну, или даже теоретически невозможно
в полной мере. В любом случае пытаться это делать можно различными способами, хотя чаще
всего на практике этого не делается вообще или потому, что необходимость этого
плохо осознается исследователем, или чаще потому, что в его распоряжении нет
соответствующих инструментов, реализующих необходимые методы.
Конечно, в последнем случае не приходится удивляться тому, что результаты кластерного
анализа получаются мягко сказать «несколько странными», а если они соответствуют
здравому смыслу и точке зрения экспертов, то можно сказать, что это получилось
случайно или потому, что «просто повезло».
Остановимся подробнее на анализе перечисленных требований
к исходным данным, а также проблем, возникающих при попытке их выполнения и
решения.
Первое
требование связано с
использованием в большинстве методов кластеризации евклидова расстояния или различных его вариантов в качестве меры
близости объектов и кластеров. Другими словами это требование означает, что
описательные шкалы, рассматриваемые как оси семантического пространства, должны
быть ортонормированны, т.к. в противном случае применение евклидова
расстояния и большинства других метрик (таблица 39) (кроме расстояния
Махалонобиса) теоретически необоснованно и некорректно.
Таблица 39 – Основные типы метрик при кластер-анализе
|
№
|
Наименование
метрики
|
Тип признаков
|
Формула для оценки меры близости
(метрики)
|
|
1
|
Эвклидово расстояние
|
Количественные
|
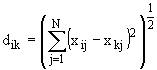
|
|
2
|
Мера сходства Хэмминга
|
Номинальные
(качественные)
|
где  число
совпадающих признаков у образцов — число
совпадающих признаков у образцов — 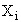 и и 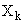
|
|
3
|
Мера сходства Роджерса–Танимото
|
Номинальные
шкалы
|
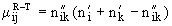
где 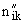 число
совпадающих единичных признаков у образцов — и ; число
совпадающих единичных признаков у образцов — и ;
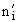 , , 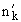 общее число — единичных
признаков у образцов и соответственно; общее число — единичных
признаков у образцов и соответственно;
|
|
4
|
Манхэттенская метрика
|
Количественные
|
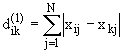
|
|
5
|
Расстояние Махаланобиса
|
Количественные
|
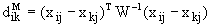 , ,
где W ковариационная матрица выборки; — 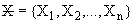 ; ;
|
|
6
|
Расстояние Журавлева
|
Смешанные
|
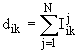 , ,
где 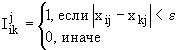
|
Существуют и другие метрики, в частности: квадрат евклидова
расстояния, расстояние городских кварталов (манхэттенское расстояние), расстояние Чебышева, степенное расстояние, процент
несогласия, метрики Рао, Хемминга, Роджерса-Танимото, Жаккара, Гауэра,
Воронина, Миркина, Брея-Кертиса, Канберровская и многие другие. Когда корреляции между переменными равны нулю, расстояние Махаланобиса
эквивалентно квадрату евклидового расстояния. Это означает, что метрику
Махаланобиса можно обоснованно считать обобщением евклидовой метрики для
неортонормированных пространств.
Но на практике это требование никогда в полной мере не выполняется, а для его выполнения
необходимо выполнить операцию ортонормирования семантического пространства, при
которой из модели тем или иным методом
(реализованным в программной системе, в которой проводится кластерный анализ) исключаются все шкалы, коррелирующие
между собой.
Таким образом, первое требование к исходным данным порождает
две проблемы:
Проблема
1.1 выбора метрики, корректной для неортонормированных пространств.
Проблема
1.2 ортонормирования пространства.
Второе
требование (безразмерности
показателей) вытекает из того, что выбор
единиц измерения по осям существенно влияет на результаты кластеризации.
Казалось бы, одного этого должно быть достаточно для того, чтобы не делать
этого, т.к. выбор единиц измерения, по сути, произволен (определяется исследователем),
вследствие чего и результаты кластеризации, вместо того чтобы объективно
отражать структуру данных и описываемой ими объективной реальности, также
становятся произвольными и зависящими не только от самой исследуемой
реальности, но и от произвола исследователя (причем неизвестно от чего больше:
от реальности или исследователя). По сути, автоматизированная
система кластеризации превращается в этих условиях из инструмента исследования
структуры объективной реальности в автоматизированный инструмент рисования
таких дендрограмм, какие больше нравятся пользователю. Непонятно также,
какой содержательный смысл могут иметь, например корни квадратные из сумм
квадратов разностей координат объектов, классов или кластеров, измеряемых в различных единицах измерения.
Разве корректно складывать величины даже
одного рода, измеряемые в различных единицах измерения, а тем более
разного рода? Даже если сложить величины одного рода, но измеренные в разных
единицах измерения, например расстояния
от школы до подъезда дома 1.2 (километра), и от подъезда дома до квартиры 25
(метров), то получится 26,2 непонятно
чего. Если же сложить разнородные по смыслу величины, т.е. величины различной природы, такие,
например, как квадрат разности веса студентов с квадратом разности их роста,
возраста, успеваемости и т.д., а потом еще извлечь из этой суммы квадратный
корень, то получится просто бессмысленная
величина, которая в традиционном кластерном анализе почему-то называется
«Евклидово расстояние». В школе на уроке физики в 8-м классе за подобные
действия сразу бы поставили «Неуд».
Однако, как это ни удивительно, то, что «не прошло бы» на уроке физики в
средней школе является вполне устоявшейся практикой в статистике и ее научных
применениях.
В подтверждение тому, что подобная практика действительно
существует, автор не может удержаться от искушения и не привести пространную
цитату из работы:
«Заметим, что евклидово
расстояние (и его квадрат) вычисляется по исходным, а не по
стандартизованным данным. Это обычный
способ его вычисления, который имеет определенные преимущества (например,
расстояние между двумя объектами не изменяется при введении в анализ нового
объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам
которых вычисляются эти расстояния. К примеру, если одна из осей измерена в
сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то
окончательное евклидово расстояние (или квадрат евклидова расстояния),
вычисляемое по координатам, сильно изменится, и, как следствие, результаты
кластерного анализа могут сильно отличаться от предыдущих.» (выделено нами,
авт.). В этой
работе просто констатируется факт этой ситуации, но ему не дается никакой оценки. Наша же оценка этой практике по
перечисленным выше причинам сугубо отрицательная.
Приведем еще цитату из той же работы: «Степенное расстояние. Иногда
желают (!!!?) прогрессивно увеличить
или уменьшить вес, относящийся к размерности, для которой соответствующие
объекты сильно отличаются. Это может быть достигнуто с использованием
степенного расстояния. Степенное расстояние вычисляется по формуле:
расстояние(x,y) = ( i |xi
- yi|p)1/r
i |xi
- yi|p)1/r
где r и p - параметры, определяемые пользователем.
Несколько примеров вычислений могут показать, как "работает" эта
мера. Параметр p ответственен за
постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание
больших расстояний между объектами. Если оба параметра - r и p,
равны двум, то это расстояние совпадает с расстоянием Евклида».
Мы считаем, что еще какие-то комментарии здесь
излишни.
Таким образом, второе требование к исходным данным порождает
следующую проблему 2.1:
Проблема
2.1 сопоставимой обработки описаний объектов, описанных признаками
различной природы, измеряемыми в различных единицах измерения (проблема
размерностей).
Отметим также, что объекты чаще всего описаны не
только признаками, измеряемыми в различных единицах измерения, но как
количественными, так и качественными признаками, которые соответственно
являются градациями как числовых шкал, так и номинальных (текстовых) шкал.
Существует метрика для номинальных шкал: это «Процент несогласия» [см. там же], однако для количественных шкал
применяются другие метрики. Каким образом и с помощью какой комбинации
классических метрик вычислять расстояния между объектами, описанными как количественными,
так и качественными признаками, а также между кластерами, в которые они входят,
вообще не понятно. Это порождает проблему 2.2.:
Проблема
2.2 формализации описаний объектов, имеющих как количественные, так и
качественные признаки.
Третье
требование (нормальности
распределения показателей) вытекает из того, что статистическое обоснование
корректности вышеперечисленных метрик существенным образом основано на этом предположении, т.е. эти метрики
являются параметрическими. На практике это означает, что перед применением
кластерного анализа с этими метриками необходимо доказать гипотезу о
нормальности исходных данных либо применить процедуру их нормализации. И
первое, и второе, весьма проблематично
и на практике не делается, более того, даже вопрос об этом чаще всего не
ставится. Процедура нормализации (или взвешивания, ремонта) исходных данных обычно предполагает удаление
из исходной выборки тех данных, которые нарушают их нормальность. Ясно, что это
непредсказуемым образом может повлиять на результаты кластеризации, которые,
скорее всего, существенно изменяться и их уже нельзя будет признать результатами
кластеризации исходных данных. Отметим, что на практике исходные данные, не
подчиняющиеся нормальному распределению, встречаются достаточно часто, что и
делает актуальными методы непараметрической статистики.
Таким образом, 3-е требование к исходным данным порождает
проблемы 3.1., 3.2. и 3.3.:
Проблема
3.1 доказательства гипотезы о нормальности исходных данных.
Проблема
3.2 нормализации исходных данных.
Проблема
3.3 применения непараметрических методов кластеризации, корректно
работающих с ненормализованными данными.
Что можно сказать о четвертом и пятом требованиях? Эти
требования взаимосвязаны, т.к. случайные факторы и порождают «выбросы». На
практике, строго говоря, эти требования никогда не выполняются и вообще звучат несколько наивно, если учесть, что как
случайные часто рассматриваются неизвестные факторы, а их влияние даже
теоретически, т.е. в принципе, исключить невозможно. С другой стороны эти требования
«удобны» тем, что неудачные, неадекватные или не интерпретируемые результаты
кластеризации, полученные тем или иным методом кластерного анализа, всегда
можно «списать» на эти неизвестные «случайные» факторы или скрытые параметры и
порожденные ими выбросы. А поскольку ответственность за обеспечение отсутствия
шума и выбросов в исходных данных возложена этими
требованиями на самого исследователя, то получается, что если что-то
получилось не так, то это связано уж не столько с методом кластеризации,
сколько с каким-то недоработками самого исследователя. По этим причинам более
логично и главное, более продуктивно
было бы предъявить эти требования не к исходным данным и обеспечивающему их
исследователю, а к самому методу кластерного анализа, который, по мнению авторов, должен
корректно работать в случае наличия шума
и выбросов в исходных данных.
Таким образом, четвертое и пятое требования приводят к
двум проблемам:
Проблема 4 разработки
такого метода кластерного анализа, математическая модель и алгоритм и которого
органично включали бы фильтр, подавляющий шум в исходных данных, в результате
чего данный метод кластеризации корректно работал бы при наличии шума в исходных
данных.
Проблема 5 разработки метода кластерного анализа, математическая
модель и алгоритм и которого обеспечивали бы выявление «выбросов»
(артефактов) в исходных данных и позволяли либо вообще не показывать их в
дендрограммах, либо показывать, но так, чтобы было наглядно видно, что это
артефакты.
Далее
рассмотрим, как решаются (или не решаются) сформулированные выше проблемы в
классических методах кластерного анализа. Для удобства дальнейшего изложения повторим формулировки этих проблем.
Проблема
1.1 выбора метрики, корректной для неортонормированных пространств.
Проблема
1.2 ортонормирования пространства.
Проблема
2.1 сопоставимой обработки описаний объектов, описанных признаками
различной природы, измеряемыми в различных единицах измерения (проблема
размерностей).
Проблема
2.2 формализации описаний объектов, имеющих как количественные, так и
качественные признаки.
Проблема
3.1 доказательства гипотезы о нормальности исходных данных.
Проблема
3.2 нормализации исходных данных.
Проблема
3.3 применения непараметрических методов кластеризации, корректно
работающих с ненормализованными данными.
Проблема 4 разработки
такого метода кластерного анализа, математическая модель и алгоритм и которого
органично включали бы фильтр, подавляющий шум в исходных данных, в результате
чего данный метод кластеризации корректно работал бы при наличии шума в исходных
данных.
Проблема 5 разработки метода кластерного анализа, математическая
модель и алгоритм и которого обеспечивали бы выявление «выбросов»
(артефактов) в исходных данных и позволяли либо вообще не показывать их в
дендрограммах, либо показывать, но так, чтобы было наглядно видно, что это
артефакты.
Сделать это удобнее
всего, рассматривая какие ответы предлагают классические методы кластерного
анализа на сформулированные вопросы:
– как вычислять координаты кластера из двух более объектов;
– как вычислять расстояние до таких
"полиобъектных" кластеров от "монокластеров" и между
"полиобъектными" кластерами.
Дело в том, что эти вопросы имеют фундаментальное значение
для кластерного анализа, т.к. разнообразные комбинации используемых метрик и
методов вычисления координат и взаимных расстояний кластеров и порождают все
многообразие методов кластерного анализа [7]. Мы бы несколько переформулировали
эти вопросы, а также добавили бы еще один:
1. Каким методом вычислять координаты кластера, состоящего из одного и более объектов, т.е.
каким образом объединять объекты в кластеры.
2. Каким методом сравнивать
кластеры, т.е. как вычислять расстояния
между кластерами, состоящими из различного количества объектов (одного и
более).
3. Каким методом объединять
кластеры, т.е. формировать обобщенные («многообъектные») кластеры.
Вопрос
1-й. Чаше всего
ни в теории и математических моделях кластерного анализа, ни на практике между
кластером, состоящим из одного объекта («моноообъектным» кластером) и самим
объектом не делается никакого различия,
т.е. считается, что это одно и тоже. «В агломеративно-иерархических методах
(aggomerative hierarhical algorithms) … первоначально все объекты (наблюдения)
рассматриваются как отдельные, самостоятельные кластеры состоящие всего лишь из
одного элемента». В работе
также говорится, что древовидная «Диаграмма начинается с каждого объекта в
классе (в левой части диаграммы)». Это решение сразу же порождает многие из вышеперечисленных проблем (1.1., 1.2., 2.1,
2.2), т.к. объекты могут быть описаны как количественными, так и качественными
признаками различной природы, измеряемыми в различных единицах измерения, причем
эти признаки в общем случае взаимосвязаны
(коррелируют) между собой.
Казалось бы,
проблему размерностей (2.1) решает кластеризация не исходных переменных, а
матриц сопряженности, содержащих абсолютные
частоты наблюдения признаков по объектам или классам. Однако при таком
подходе, например при сравнении моделей автомобилей, четыре и два цилиндра у этих моделей, а также четыре и два болта, которыми у них прикручен номер, будут давать
одинаковый вклад в сходство-различие этих моделей, что едва ли разумно и
приемлемо. Тем ни менее матрица сопряженности анализируется в социологических и
социометрических исследованиях, а в статистических системах, в разделах
справки, посвященных кластерному анализу, приводятся примеры подобного рода.
Другое предложение по решению проблемы размерностей
(2.1) основано на четком пожимании того, что изменение единиц измерения переменной
меняет среднее ее значений и их разброс от этого среднего. Например, переход от
сантиметров к миллиметрам увеличивает среднее и среднее отклонение от среднего
в 10 раз. Речь идет о методе нормализации или стандартизации исходных данных,
когда значения переменных заменяются их стандартизированными значения или
z-вкладами. Z-вклад показывает, сколько стандартных отклонений отделяет данное
наблюдение от среднего значения:
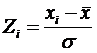 ,
,
где  – значение
данного наблюдения,
– значение
данного наблюдения,  – среднее,
– среднее,  – стандартное
– стандартное
отклонение. Однако этот метод имеет
серьезный недостаток, описанный в специаьной литературе. Дело в том, что
нормализация значений переменных приводит к тому, что независимо от значений их
среднего и вариабельности до нормализации (т.е. значимости, измеряемой
стандартным отклонением), после нормализации среднее становится равным нулю, а
стандартное отклонение 1. Это значит, что нормализация
выравнивает средние и отклонения по всем переменным, снижая, таким
образом, вес значимых переменных, оказывающих большое влияние на объект, и
завышая роль малозначимых переменных, оказывающих меньшее влияние и искажая,
таким образом, картину. На взгляд авторов это на вряд ли приемлемо.
Другой важный недостаток, который в отличие от первого не отмечается в
специальной литературе, состоит в том,
что стандартизированные
значения сложно как-то содержательно интерпретировать, т.е. устранение влияния единиц измерения
достигается ценой потери смысла
переменных, который как раз и содержался в единицах их измерения. В результате
нормализации все переменные становятся как бы «на одно лицо». Это также недопустимо.
Таким образом, можно обоснованно сделать вывод о том, нормализация и стандартизация исходных данных – это весьма радикальное решение проблемы 2.1
«в лоб и в корне», но решение неприемлемо дорогой ценой «при котрой из ванны
вместе с водой выплекскивается и ребенок».
В классических методах кластерного анализа
предлагается два основных варианта ответов
на 1-й вопрос:
1. Вообще не формировать обобщенных классов или кластеров
из объектов, а на всех этапах кластеризации рассматривать только сами первичные
объекты.
2. Формировать обобщенные кластеры путем вычисления
неких статистических характеристик кластера на основе характеристик входящих в
него объектов.
О 1-м варианте ответа в работе
говорится: «Диаграмма начинается с каждого объекта в классе (в левой части
диаграммы). Теперь представим себе, что постепенно (очень малыми шагами) вы
"ослабляете" ваш критерий о том, какие объекты являются уникальными,
а какие нет. Другими словами, вы понижаете порог, относящийся к решению об
объединении двух или более объектов в один кластер. В результате, вы связываете
вместе всё большее и большее число объектов и агрегируете (объединяете)
все больше и больше кластеров, состоящих из все сильнее различающихся элементов».
Этот подход, когда кластеры реально не формируются, т.к. им не соответствуют
какие-либо конструкции математической модели, представляется авторам
сомнительным, т.к., во-первых, как было показано выше, это порождает проблемы
1.1., 1.2., 2.1, 2.2, а во-вторых, никак
не решает проблемы 3.1, 3.2, 3.3, 4 и 5. Между
тем сам способ формирования кластеров из объектов, по мнению авторов, призван
стать средством решения всех этих проблем.
2-й вариант ответа представляется более обоснованным,
однако он сам в свою очередь порождает вопросы о степени корректности и научной
обоснованности того или иного метода вычисления обобщенных характеристик
кластера и главное о том, в какой степени
этот метод позволяет решить сформулированные выше проблемы. Описание
кластера на основе входящих в него объектов традиционно включает центр кластера, в качестве которого
обычно используется среднее или центр тяжести от характеристик входящих
в него объектов [128], а также какую-либо количественную оценку степени
рассеяния объектов кластера от его центра (как правило, это дисперсия). Ответ
на 2-й вопрос является продолжением ответа на 1-й вопрос.
Вопрос 2-й. В работах по кластерному анализу описывается большое
количество различных мер и методов, которые можно применить как для измерения
расстояний между кластерами, так и расстояний от объекта до кластеров.
Например, в невзвешенном центроидном методе при определении расстояния от объекта до кластера, по сути,
определяется расстояние до его центра. В методе невзвешенного попарного
среднего расстояние между двумя кластерами вычисляется как среднее
расстояние между всеми парами объектов в них. При этом, как правило, не
решаются перечисленные выше проблемы, т.к. не
устраняются их причины: а именно средние вычисляются на основе мер
расстояния, корректных только для ортонормированных пространств и при этом
часто используются размерные или нормализованные формы представления признаков
объектов, не формализуется описание объектов, обладающих как количественными,
так и качественными признаками. Ответ на 3-й вопрос является продолжением ответа
на 2-й вопрос.
Вопрос
3-й. При объединении кластеров
характеристики вновь образованного обобщенного кластера обычно пересчитываются
тем же методом, каким они рассчитывались для исходных кластеров. Это сохраняет
нерешенными и все проблемы, которые были при определении характеристик исходных
кластеров и расстояний между этими кластерами.
Далее
рассмотрим вариант решения некоторых из сформулированных выше проблем
кластерного анализа, предлагаемый в АСК-анализе и реализованный в интеллектуальной
системе «Эйдос».
Обратимся к эпиграфам к данной статье: «Мышление – это
обобщение, абстрагирование, сравнение, и классификация» (Патанджали, II в.
до н. э.), «Истинное знание – это знание причин» (Френсис Бэкон, 1561–1626
гг.). Итак, мышление, как процесс это [в том числе] классификация, результатом
же мышления является знание, причем истинное знание есть знание причин.
Истинное мышление есть мышление, дающее истинное знание. Соответственно ложное
мышление – это мышление, приводящее к заблуждениям. Поэтому истинное мышление – это [в том числе] истинная
(правильная, адекватная) классификация объектов по причинам их
поведения, т.е. по системе их детерминации. Правильной классификацией будем
считать ту, которая совпадает с классификацией экспертов, основанной на их
высоком уровне компетенции, профессиональной интуиции и большом практическом
опыте.
Если, как это принято в АСК-анализе [7, 201], факторы
формализовать в виде шкал различного типа (номинальных, порядковых и числовых),
признаки рассматривать как значения факторов, т.е. их интервальные значения,
более или менее жестко детерминирующих поведение объекта, а классы как будущие
состояния, в которые объект переходит под влиянием различных значений этих
факторов, то можно сказать, что признаки
формализуют причины переходов объекта в состояния, соответствующие классам или
кластерам. Если учесть, что классификация – это кластерный анализ, то можно
сделать обоснованные выводы о том, что кластерный анализ это и есть мышление (но
мышление не сводится только к кластерному анализу), а результаты кластерного
анализа представляют собой знания. Степень
истинности этих знаний, полученных в результате кластерного анализа, т.е.
их адекватность или соответствие действительности, полностью определяются степенью истинности метода кластерного анализа,
с помощью которого они получены. Поэтому столь важно решить
сформулированные выше проблемы кластерного анализа. В свою очередь классификация (в т.ч. кластерный анализ) как
процесс основана на обобщении и сравнении. В монографии 2002
года [7] предлагается пирамида иерархической структуры
процесса познания, входящая в базовую когнитивную концепцию (рисунок 89):
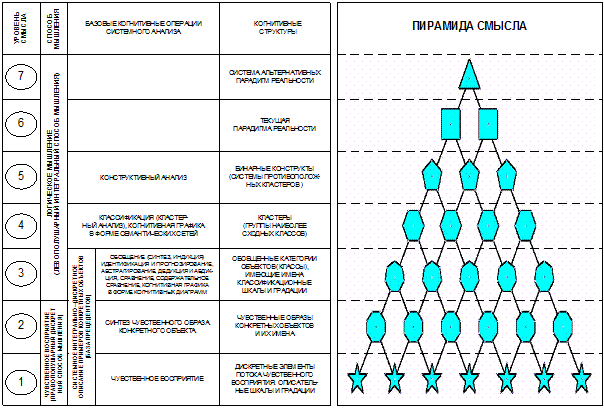
Рисунок 89. Обобщенная схема иерархической структуры процесса познания
согласно базовой формализуемой когнитивной концепции
В этой же монографии [7] предлагается математическая модель, основанная на
семантической теории информации, обеспечивающая высокую степень формализацию
данной когнитивной концепции, достаточную для разработки алгоритмов,
структур данных и программной реализации в виде интеллектуальной программной
системы. Такая система была создана автором и постоянно развивается, это
система «Эйдос» [7, 3-203].
Суть предлагаемых в АСК-анализе решений
сформулированных выше проблем кластерного анализа состоит в следующем.
Основная идея решения проблем кластерного
анализа, состоит в том, что для решения задачи кластеризации предлагается
использовать математическое представление объектов не виде переменных со
значениями, измеряемыми в различных единицах измерения и в шкалах разного типа,
и не матрицу сопряженности с абсолютными частотами встреч признаков по классам
или нормализованными Z-вкладами, а базы
знаний, рассчитанные на основе матрицы сопряженности (матрицы абсолютных
частот) с использованием различных аналитических выражений для частных
критериев. При этом для всех значений всех переменных используется одна и та же размерность – это размерность количества информации (бит, байт и т.д.), что обеспечивает расчет на
основе исходных данных силы и направления влияния на объект всех факторов и их
значений и сопоставимую обработку значений переменных, изначальное (в исходных
данных) представленных в разных единицах измерения и в шкалах разного типа
(количественных – числовых, и качественных – текстовых).
1. Расстояния между объектом и кластером, а также
между кластерами предлагается определять с использованием неметрических
интегральных критериев, корректных для неортормированных пространств, одним и тем же методом: по суммарному количеству информации,
которое содержится (соответственно) в системе признаков объекта о
принадлежности к классу или кластеру, или которое содержится в обобщенных
образах двух классов или кластеров об их принадлежности друг к другу.
2. Координаты
кластера, возникающего как при включении в него одного единственного объекта, так и при объединении многих объектов
в кластеры вычисляются тем же самым
методом, что и координаты кластера, возникающего при объединении нескольких
кластеров, а именно путем применения базовой когнитивной операции (БКОСА):
«Обобщение», «Синтез», «Индукция» (БКОСА-3) АСК-анализа.
3. Объединять
кластеры, т.е. формировать обобщенные
(«многообъектные») кластеры при объединении кластеров предлагается тем же самым методом, что и обобщенные
образы классов при объединении конкретных образов объектов, т.е. путем
применения базовой когнитивной операции (БКОСА): «Обобщение», «Синтез», «Индукция»
(БКОСА-3) АСК-анализа.
Основная идея сводится к тому, чтобы кластеризовать не
размерные переменные, абсолютные или относительные частоты или Z-вклады, а знания.
Предложения 1-3 являются непосредственными ответами на сформулированные выше
фундаментальные вопросы кластерного анализа.
Остановимся
подробнее на математическом и алгоритмическом описании этих предложений и затем
проиллюстрируем их на простом и наглядном численном примере.
Основная
идея. Вспомним
приведенный выше пример кластеризации моделей автомобилей, в котором четыре или
два цилиндра в двигателе давали такой вклад в сходство-различие моделей, как
четыре или два болта, которыми прикручивается регистрационный номер. Из этого
примера ясно, что при сравнении объектов и кластеров основную роль должно
играть не само количество разных
деталей или элементов конструкции, а, например, их влияние на стоимость модели, выраженное в долларах или на
степень ее пригодности (полезности) для
поставленной цели, тоже выраженное в
одних и тех же для всех переменных и их значений единицах измерения. В АСК-анализе предлагается более радикальное
решение: измерять степень и направление влияния всех переменных и их значений
на поведение объекта или принадлежность его к тому или иному классу или
кластеру в одних и тех же универсальных
единицах измерения, а именно единицах измерения количества информации. Ведь по
сути, когда мы узнаем о том, что некий объект обладает определенным признаком,
то мы получаем из этого факта некое количество информации о том, что
принадлежит к определенной категории (классу, кластеру). А уж сами эти категории могут иметь совершенно
различный смысл, в частности классифицировать текущие или будущие состояния
объектов, или степень их полезности для достижения тех или иных целей. И что
очень важно, при этом не играет абсолютно никакой роли в каких единицах
измерения в какой шкале, количественной или качественной, изначально измерялся
этот признак: килограммах, долларах, Омах, джоулях, или еще каких-то других.
Предложение
1-е. В этом смысле в АСК-анализе
исчезает существенное различие между классом и кластером и эти термины можно
использовать как синонимы. Классы в
АСК-анализе могут быть различаться степенью обобщенности: чем больше объектов в
классе и чем выше вариабельность этих объектов по их признакам, тем шире
представляемая ими генеральная совокупность, по отношению к которой они
представляют собой репрезентативную выборку, тем выше степень обобщения в объединяющем
их классе. Классы включают один или насколько объектов. Наименьшей степенью
обобщения обладают классы, включающие лишь один объект, но и они совершенно не
тождественны объекту исходной выборки, т.к. в математической мидели АСК-анализа
у них совершенно различные математические формы представления. Кластеры обычно
являются классами более высокой степени обобщения, т.к. включают один или несколько
классов.
Как реализуется базовая когнитивная операция
АСК-анализа «Обобщение», «Синтез», «Индукция» (БКОСА-3) будет рассмотрено ниже
при кратком изложении математической модели АСК-анализа.
Предложения
2-е и 3-е необходимо рассматривать в комплексе, т.к. их смысл в
том, что объект при когнитивной кластеризации имеет другую математическую
форму, чем объект в исходных данных, а именно такую же форму, как класс и как
кластер, т.е. в АСК-анализе возможны классы и кластеры, включающие как один,
так и много объектов. При этом для формирования класса состоящего из одного
объекта, т.е. при добавлении в пустой кластер первого объекта, используется та
же самая математическая процедура, что и при добавлении в него второго и вообще
любого нового объекта (в АСК-анализе она называется БКОСА-3), и эта же самая
процедура БКОСА-3 используется и при объединении классов или кластеров. При
этом само объединение классов
(кластеров) осуществляется путем создания «с нуля» нового класса
(кластера) из всех объектов, входящих в объединяемые классы (кластеры), а затем
удаления исходных классов (кластеров). Новый объединенный класс (кластер)
создается «с нуля» тем же самым методом (БКОСА-3), каким впервые создается любой новый класс (кластер). Теперь
рассмотрим, как же это реализовано математически и алгоритмически.
Математическая
модель АСК-анализа.
Математическая модель, которая стала основой модели
АСК-анализа, была разработана автором в 1979 году, впервые опубликована в 1993
году, а затем и в последующих статьях и монографиях [7, 3-203], основной из
которых является [7], а также в учебных пособиях [8, 10]. Поскольку эта модель
описана во многих статьях и монографиях, в данной монографии мы лишь кратко изложим
ее суть.
В качестве формальной модели классов и признаков используются
соответственно классификационные и описательные шкалы и градации.
Класс формализуется в виде градации классификационной
шкалы. Если шкала числовая, то градации шкал представляют собой интервальные
значения (числовые интервалы или диапазоны), если же признак качественный, то
градация шкалы представляет собой просто уникальное текстовое наименование. Числовым
интервалам также присваиваются текстовые наименования.
Признак формализуются в виде шкалы, а значения
признака в виде градаций шкалы. Если признак количественный (числовой), то
градации шкал представляют собой интервальные значения (числовые интервалы или
диапазоны), если же признак качественный, то градация шкалы представляет собой
просто уникальное текстовое наименование. Числовым интервалам также
присваиваются текстовые наименования.
Математически и классификационные, и описательные шкалы
представляются в форме векторов, а градации – в форме значений координат этих
векторов, которые могут принимать значения n, где n={0, 1, 2, 3…}, т.е. 0 и натуральные
числа.
Описание объекта исходной выборки формализуется в виде
вектора, координаты которого имеют значение n, если соответствующий признак
встречается n раз, в т.ч. 0, если признак отсутствует
у объекта.
Например, признак: буква «м» присутствует в объекте:
слово «молоко» 1 раз, поэтому значение соответствующего ему элемента вектора
этого объекта будет равно 1, признак: буква «о» присутствует в объекте: слово
«молоко» 3 раза, поэтому значение соответствующего ему элемента вектора этого
объекта будет равно 3, а признак буква «ы» отсутствует
у этого объекта, поэтому значение соответствующего этому признаку элемента вектора
будет равно 0. При программной реализации классификационные и описательные
шкалы и градации представляют собой справочники классов и признаков.
С использованием формального описания всех объектов исходной
выборки рассчитывается таблица сопряженности
классов и признаков или корреляционная матрица, которая в АСК-анализе
называется «матрица абсолютных частот» [7] (таблица 40).
Таблица 40 – Матрица абсолютных частот
|
|
Классы
|
Сумма
|
|
1
|
...
|
j
|
...
|
W
|
|
Значения факторов
|
1
|
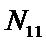
|
|
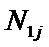
|
|
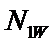
|
|
|
...
|
|
|
|
|
|
|
|
i
|
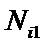
|
|
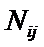
|
|
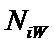
|
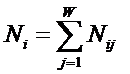
|
|
...
|
|
|
|
|
|
|
|
M
|
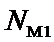
|
|
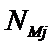
|
|
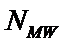
|
|
|
Суммарное
количество
признаков
|
|
|
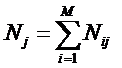
|
|
|
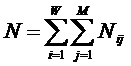
|
|
Суммарное
количество
объектов
обучающей
выборки
|
|
|
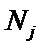
|
|
|
N
|
Алгоритм
формирования матрицы абсолютных частот.
Объекты обучающей
выборки описываются векторами (массивами)
 имеющихся у них
признаков:
имеющихся у них
признаков:
Первоначально в
матрице абсолютных частот все значения равны нулю. Затем организуется цикл по
объектам обучающей выборки. Если предъявленного объекта относящегося к j-му классу есть i-й признак, то:
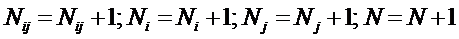
Отметим, что уже при
расчете матрицы абсолютных частот закладываются основы для решения проблем 4 и 5. Способ формирования матрицы
абсолютных частот можно рассматривать как многоканальную систему выделения полезного сигнала из шума. Представим себе, что
все объекты, предъявляемые для формирования обобщенного образа некоторого
класса в действительности являются различными реализациями одного объекта –
"Эйдоса" (в смысле Платона), по-разному зашумленного различными случайными обстоятельствами (по-разному,
т.к. это шум). И наша задача состоит в том, чтобы подавить этот шум и выделить
из него то общее и существенное, что отличает объекты данного класса от
объектов других классов. Учитывая, что шум чаще всего является
"белым" и имеет свойство при суммировании с самим собой стремиться к
нулю, а сигнал при этом наоборот возрастает пропорционально количеству слагаемых,
то увеличение объема обучающей выборки (в случае если сигнал эргодичный, т.е. закономерности
в предметной области не меняются) приводит ко все лучшему отношению сигнал/шум
в матрице абсолютных частот, т.е. к выделению полезной информации из шума.
Примерно так мы начинаем постепенно понимать смысл фразы, которую мы сразу не
расслышали по телефону и несколько раз переспрашивали. При этом в повторах шум
не позволяет понять то одну, то другую часть фразы, но в конце концов за счет
использования памяти и интеллектуальной обработки информации мы понимаем ее
всю. Так и объекты, описанные признаками,
можно рассматривать как зашумленные фразы, несущие нам информацию об обобщенных
образах классов: "Эйдосах" [89], к которым они относятся. И эту информацию мы выделяем из шума при синтезе
модели.
Различные
аналитические формы частных критериев в матрицах знаний и неметрических
интегральных критериев при определении информационных расстояний.
Непосредственно
на основе матрицы абсолютных частот
(таблица 40) рассчитываются матрицы знаний (таблица 42). При этом
используются различные выражения или коэффиценты для преобразования абсолютных
частот в количество знаний (таблица
41), которое в последующем, при решении задач идентификации, прогнозирования,
принятия решений и исследования предметной области используются как частные
критерии знаний в неметрических интегральных критериях.
Таблица 41 – Различные
аналитические формы частных критериев
в матрицах знаний и неметрических интегральных критериях
при определении информационных расстояний
|
Наименование модели знаний
и частный критерий
|
Выражение для частного критерия
|
|
через
относительные частоты
|
через
абсолютные частоты
|
|
СИМ-1, частный критерий: количество
знаний по А.Харкевичу, 1-й вариант расчета вероятностей: Nj – суммарное количество признаков по j-му классу
|
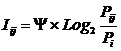
|
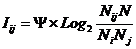
|
|
СИМ-2, частный критерий: количество
знаний по А.Харкевичу, 2-й вариант расчета вероятностей: Nj – суммарное количество объектов по j-му классу
|
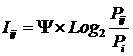
|
|
|
СИМ-3, частный критерий: разности
между фактическими и теоретически ожидаемыми по критерию хи-квадрат абсолютными
частотами
|
---
|
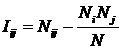
|
|
СИМ-4, частный критерий:
ROI - Return On Investment, 1-й вариант расчета вероятностей
|
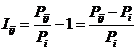
|
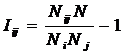
|
|
СИМ-5, частный критерий:
ROI - Return On Investment, 2-й вариант расчета вероятностей
|
|
|
|
СИМ-6, частный критерий: разность
условной и безусловной вероятностей, 1-й вариант расчета вероятностей
|
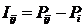
|
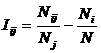
|
|
СИМ-7, частный критерий: разность
условной и безусловной вероятностей, 2-й вариант расчета вероятностей
|
|
|
где:
|

Александр Александрович Харкевич
(21.1(3.2).1904 – 30.3.1965)
|
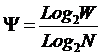 – упрощеннее
выражение для нормировочного коэффициента, переводящего
количество информации в биты, предложенного в Е.В.Луценко в 1979 году, обоснованного
в [7] и названного автором коэффициентом эмерджентности А.А.Харкевича в
честь этого выдающегося советского ученого, внесшего огромный в клад в
создание семантической теории информации и фактически предложившего количественную меру знаний, директора
Института проблем передачи информации АН СССР академика АН СССР. – упрощеннее
выражение для нормировочного коэффициента, переводящего
количество информации в биты, предложенного в Е.В.Луценко в 1979 году, обоснованного
в [7] и названного автором коэффициентом эмерджентности А.А.Харкевича в
честь этого выдающегося советского ученого, внесшего огромный в клад в
создание семантической теории информации и фактически предложившего количественную меру знаний, директора
Института проблем передачи информации АН СССР академика АН СССР.
|
|
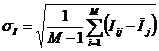
|
Среднеквадратичное
отклонение количества знаний во всех значениях факторов о переходе объекта в j-е состояние от среднего количества
знаний об этом в этих значениях
|
|
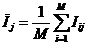
|
Среднее количество знаний
во всех значениях факторов о переходе объекта в j-е состояние
|
|
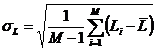
|
Среднеквадратичное
отклонение значений вектора описания объекта от среднего этих значений
|
|
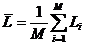
|
Среднее значений вектора описания
объекта
|
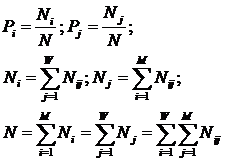
В таблице 41
использованы обозначения:
Nij –
суммарное количество наблюдений в исследуемой выборке факта: "действовало i-е
значение фактора и объект перешел в j-е
состояние";
Nj – суммарное количество встреч различных
значений факторов у объектов, перешедших в j-е
состояние;
Ni – суммарное количество встреч i-го значения фактора у всех объектов исследуемой выборки;
N – суммарное количество встреч различных
значений факторов у всех объектов исследуемой выборки.
Pij
– условная вероятность перехода объекта в j-е
состояние при условии действия на
него i-го значения фактора;
Pj –
безусловная вероятность перехода объекта в j-е
состояние (вероятность самопроизвольного перехода или вероятность перехода,
посчитанная по всей выборке, т.е. при действии любого значения фактора).
Pi –
безусловная вероятность встречи i-го
значения фактора или вероятность его встречи
по всей выборке.
Таблица 42 – Матрица знаний (информативностей)
|
|
Классы
|
Значимость
фактора
|
|
1
|
...
|
j
|
...
|
W
|
|
Значения факторов
|
1
|
|
|
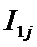
|
|
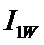
|
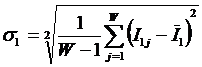
|
|
...
|
|
|
|
|
|
|
|
i
|
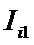
|
|
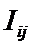
|
|
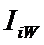
|
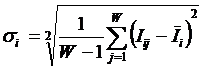
|
|
...
|
|
|
|
|
|
|
|
M
|
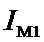
|
|
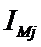
|
|
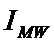
|
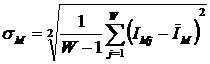
|
|
Степень
редукции
класса
|
s1
|
|
sj
|
|
sW
|
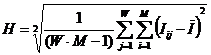
|
Здесь – 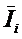 это среднее
количество знаний в i-м значении
фактора:
это среднее
количество знаний в i-м значении
фактора:
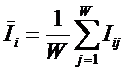
Количественные
значения коэффициентов Iij таблицы 42 являются знаниями о
том, что "объект перейдет в j-е состояние" если "на объект
действует i-е значение фактора".
Утверждение о том,
что это именно знания, а не данные или информация (или что-либо еще), требует
специального серьезного обоснования, которое дано автором в работах [101, 115,
126, 127, 128, 144, 194] и ряде
других работ, начиная с [7] и здесь не приводится в связи с доступностью этих
работ в Internet и достаточно большого объема этого обоснования.
Принципиально
важно, что эти весовые коэффициенты не определяются экспертами на основе опыта
интуитивным неформализуемым способом, а
рассчитываются непосредственно на основе эмпирических данных на основе
теоретически обоснованных моделей, хорошо зарекомендовавших себя на практике
при решении широкого круга задач в различных предметных областях.
Когда количество
информации Iij>0 – i–й фактор способствует переходу
объекта управления в j-е состояние, когда Iij<0
– препятствует этому переходу, когда же Iij=0 – никак не влияет
на это. В векторе i-го фактора (строка матрицы информативностей) отображается,
какое количество информации о переходе объекта управления в каждое из будущих
состояний содержится в том факте, что данный фактор действует. В векторе j-го
состояния класса (столбец матрицы информативностей) отображается, какое
количество информации о переходе объекта управления в соответствующее состояние
содержится в каждом из факторов.
Таким образом, матрица информативностей (таблица 42)
является обобщенной таблицей решений, в которой входы (факторы) и выходы
(будущие состояния объекта управления) связаны друг с другом не с помощью
классических (Аристотелевских) импликаций, принимающих только значения:
"Истина" и "Ложь", а различными
значениями истинности, выраженными в битах и принимающими значения от
положительного теоретически-максимально-возможного ("Максимальная степень
истинности"), до теоретически неограниченного отрицательного
("Степень ложности").
Фактически
предложенная модель позволяет осуществить синтез
обобщенных таблиц решений для различных предметных областей непосредственно
на основе эмпирических исходных данных и продуцировать
на их основе прямые и обратные правдоподобные (нечеткие) логические рассуждения
по неклассическим схемам с различными
расчетными значениями истинности, являющимся обобщением классических
импликаций.
Таким образом,
данная модель позволяет рассчитать какое количество знаний содержится в любом
факте о наступлении любого события в любой предметной области, причем для этого
не требуется повторности этих фактов и событий. Если же эти повторности
осуществляются и при этом наблюдается некоторая вариабельность значений
факторов, обуславливающих наступление тех или иных событий, то модель
обеспечивает многопараметрическую типизацию, т.е. синтез обобщенных образов
классов или категорий наступающих событий с количественной оценкой степени и
знака влияния на их наступление различных значений факторов. Причем эти
значения факторов могут быть как количественными, так и качественными и
измеряться в любых единицах измерения, в любом случае в модели оценивается
количество знаний которое в них содержится о наступлении событий, переходе объекта
управления в определенные состояния или просто о его принадлежности к тем или
иным классам.
Все эти модели (представленные в таблице 41) можно считать
различными вариациями одной базовой модели знаний, в которой мерой
связи между признаком и классом является отношение условной вероятности
наблюдения признака у объектов класса к безусловной вероятности его наблюдения
по всей выборке, так как отличаются
они только способами нормировки частных критериев к нулю при отсутствии причинно-следственной связи между
значением фактора и поведением объекта управления или его принадлежностью к
тому или иному классу. Все эти модели поддерживаются новой версией системой
"Эйдос-Х++".
Нормировать частные критерии к нулю при отсутствии связи
(когда условная вероятность наблюдения признака у объектов класса равно безусловной
вероятности его наблюдения по всей выборке: Pij=Pi)
необходимо, чтобы их было удобно использовать в аддитивном интегральном критерии. Это можно сделать разными
способами. Например, в ROI (СИМ-4) из отношения условной вероятности к
безусловной просто вычитается 1.
Критерий А.Харкевича тесно связан с критерием
хи-квадрат. Рассмотрим выражение для частного критерия через абсолютные частоты
в первой семантической информационной модели (СИМ-1):
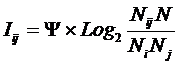
Преобразуем это выражение, учитывая, что логарифм отношения
равен разности логарифмов:
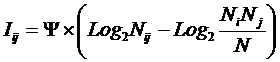
Сравнивая полученное выражение с выражением для частного
критерия на основе хи-квадрат в СИМ-3 из таблицы 41
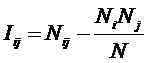
видим,
что они отличаются только шкалой измерения (логарифмическая шкала или нет) и
постоянным множителем, т.е. по сути, единицами измерения. Величина 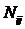 представляет собой
фактическое количество наблюдений i-го
признака у объектов j-го класса, а
представляет собой
фактическое количество наблюдений i-го
признака у объектов j-го класса, а 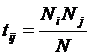 – теоретически
ожидаемое в соответствии с критерием хи-квадрат число таких наблюдений.
– теоретически
ожидаемое в соответствии с критерием хи-квадрат число таких наблюдений.
Также и логарифм отношения условной и безусловной вероятности
СИМ-1 и СИМ-2 является разностью их логарифмов:
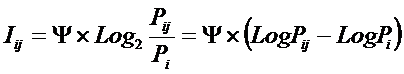
и
отличается от разности этих вероятностей (СИМ-5) только постоянным для каждой
модели множителем и применением логарифмической шкалы вместо линейной.
В настоящее время для каждой модели в АСК-анализе используется
два аддитивных интегральных критерия:
это свертка (сумма частных критериев по тем признакам, которые встречаются у
объекта) и нормированная свертка или корреляция:
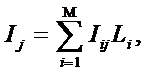
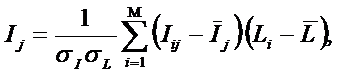
Отметим, что при
расчете интегрального критерия на основе матрицы знаний закладываются основы
для решения проблем 4 и 5.
Дело в том, что по своей математической форме интегральный критерий является
сверткой (скалярным произведением вектора объекта и вектора класса) или нормированной сверткой, т.е. корреляцией.
Это означает, что если эти вектора являются суммой двух сигналов: полезного и
белого шума, то при расчете неметрического
интегрального критерия белый шум будет подавляться, т.к. корреляция белого
шума с самим собой (автокорреляция) стремится к нулю по самому определению
белого шума. Поэтому интегральный критерий сходства объекта со случным набором
признаков с любыми образами классов, или реального объекта с образами классов,
сформированными случайным образом, будет близок нулю. Это означает, что выбранный
интегральный критерий сходства является высокоэффективным средством подавления
белого шума и выделения знаний из шума, который неизбежно присутствует в эмпирических данных.
Важно также
отметить неметрическую природу предложенного в АСК-анализе интегрального
критерия сходства, благодаря чему его
применение является корректным и при
неортонормированном семантическом
информационном пространстве, каким оно в подавляющем количестве случае и
является, т.е. в общем случае. В
этом состоит предлагаемое в АСК-анализе решение проблем 1.1 и 1.2.
Метод кластеризации, реализованный в АСК-анализе, в котором
сравниваются и объединяются когнитивные модели объектов и классов (кластеров),
т.е. их модели, основанные на знаниях и представленные в матрице знаний, будем
называть «Метод когнитивной кластеризации»
или кластеризацией, основанной на
знаниях. Ясно, что кластеризация, основанная на знаниях, может быть
реализована уже не в статистических системах, а только методами искусственного интеллекта, т.е. в интеллектуальных
системах, работающих с базами знаний. При этом, конечно, может быть разработано
много методов кластеризации, основанных на знаниях (не меньше чем уже существующих),
отличающихся способами вычисления и представления знаний в различных интеллектуальных
системах, а также способами использования знаний для формирования кластеров. В
любом случае кластеризация на основе
знаний – это новое перспективное направление исследований и разработок, в
котором уже есть достижения.
Рассмотрим предлагаемый алгоритм когнитивной кластеризации
в графической и текстовой форме (рисунок 90):

Рисунок 90. Алгоритм когнитивной кластеризации
или кластеризации, основанной на знаниях
Дадим необходимые пояснения к приведенному алгоритму.
1. Если не соответствуют размерности баз данных (БД) классов,
признаков и информативностей, то выдать сообщение о необходимости пересинтеза модели.
2. Создать БД абсолютных частот: ABS_KLAS, информативностей:
INF_KLAS, сходства классов: MSK_KLAS, а также БД учета объединения классов
IterObj1.dbf и занести в них начальную информацию по текущей модели.
Данный режим реализован в
модуле _5126 системы «Эйдос» и обеспечивает работу с любой из четырех моделей
или со всеми этими моделями по очереди, поддерживаемых системой и приведенных в
таблице 41. При этом в базах данных этих моделей ничего не изменяется.
3. Цикл по моделям до тех пор, пока есть похожие классы.
4. Рассчитать матрицу сходства классов MSK_KLAS в текущей модели.
Эта матрица
рассчитываемся на основе матрицы знаний модели, заданной при запуске
режима (СИМ-1 – СИМ-4), путем расчета корреляции
обобщенных образов классов (т.е. векторов или профилей классов).
5. Найти пару наиболее похожих классов в матрице сходства.
Здесь определяются два
класса, у которых на предыдущем шаге было обнаружено наивысшее сходство. При этом
при запуске режима задается параметр: «Исключать ли артефакты (выбросы)». Если
задано исключать, то рассматриваются только положительные уровни сходства, если
нет – то и отрицательные, т.е. в этом случае могут быть объединены и непохожие классы, но наименее непохожие
из всех, если других нет. Считается, что непохожие кассы являются исключениями
или «выбросами».
6. Объединить 2 класса с наибольшим уровнем сходства.
Данный пункт алгоритма
требует наиболее детальных пояснений. Как же объединяются классы в методе
когнитивной кластеризации? Сначала суммируются
абсолютные частоты этих классов в таблице 40, причем сумма рассчитывается в
столбце класса с меньшим кодом, а затем частоты класса с большим кодом
обнуляются. После этого в базе знаний (таблица 4) с использованием
частного критерия соответствующей модели (таблица 41) пересчитываются только изменившиеся столбцы и строки,
т.е. пересчитывается столбец класса с меньшим кодом, а столбец класса с большим
кодом обнуляется.
7. Отразить информацию об объединении классов в БД
IterObj1.dbf.
8. Конец цикла итераций. Проверить критерий остановки и
перейти на продолжение итераций (п.9) или на окончание работы (п.10).
9. Пересчитать в базе данных сходства классов (MSK_KLAS) только изменившиеся столбцы и строки. Конец
цикла по моделям.
10. Нарисовать дерево объединения классов, псевдографическое: /TXT/AgKlastK.txt и графическое:
/PCX/AGLKLAST/TrK-#-##.GIF.
Далее рассмотрим работу предлагаемой математической модели и
реализующего ее алгоритма когнитивной кластеризации на простом численном примере.
Численный пример основан на варианте той же задачи из книги Д.Мичи и Р.Джонстона
"Компьютер – творец" эта
задача приводится (на страницах: 205-208) в качестве примера задачи, решаемой
методами искусственного интеллекта. Авторами этой задачи являются Рышард
Михальски и Джеймс Ларсон. Суть этой задачи сводится к тому, чтобы выработать
правила, обеспечивающие идентификацию и классификацию железнодорожных составов
на основе их формализованных описаний (рисунок 91).
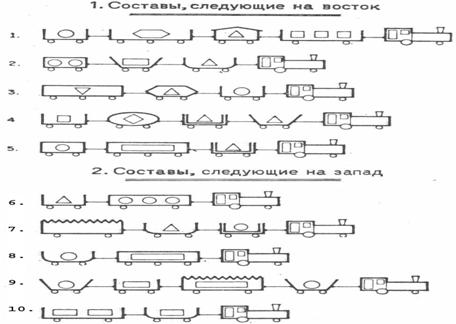
Рисунок 91. Исходные данные по численному примеру
в графическом виде
Важно отметить, что
в данной задаче речь идет о классификации изображений
объектов. Признаки этих объектов в данном случае выявляются человеком, однако в
принципе могут быть разработаны программы, выявляющие подобные признаки непосредственно
из графических файлов с изображениями объектов. Выбор данной задачи не
накладывает ограничений на выводы, полученные в результате ее исследования.
Этапы АСК-анализа предметной области
В работе [7]
предложены следующие этапы АСК-анализа предметной области:
1. Когнитивная структуризация предметной области, при
которой определяется, что мы хотим прогнозировать и на основе чего (конструирование
классификационных и описательных шкал).
2. Формализация предметной области:
– разработка градаций
классификационных и описательных шкал (номинального, порядкового и числового
типа);
– использование разработанных на предыдущих этапах
классификационных и описательных шкал и градаций для формального описания (кодирования)
исходных данных (исследуемой выборки).
3. Синтез и верификация (оценка степени адекватности)
модели.
4. Если модель
адекватна, то ее использование для решения задач идентификации,
прогнозирования и принятия решений, а также для исследования моделируемой
предметной области.
Этап формализации предметной области при небольших
размерностях модели (т.е. когда мало классов и признаков) и небольших объемах
исходных данных может быть выполнен вручную. Однако даже в этом случае
какие-либо изменения на первых этапах создания модели могут быть весьма
трудоемкими. А такие изменения могут быть необходимыми и могут осуществляться многократно, так как качество модели
определяется только на следующем этапе после ее синтеза в процессе верификации.
Если же размерность модели и объем исходных данных велики, то вручную выполнить
этап формализации предметной области весьма проблематично. Поэтому в системе
«Эйдос» реализовано много программных интерфейсов с внешними базами исходных
данных различной структуры, которые позволяют автоматизировать этап формализации
предметной области, т.е. выполнить его автоматически с учетом параметров
формализации, заданных исследователем в диалоге. В численном примере,
приведенном в данной статье, автор воспользовался программным интерфейсом
формализации предметной области системы «Эйдос», реализованным в программном
модуле (режиме) _152, который мы и рассмотрим.
Программный
интерфейс ввода исходных в систему «Эйдос».
Скриншот Help
режима _152 приведен на рисунке 92, а скриншот экранной формы с диалогом
пользователя по заданию параметров формализации предметной области – на
рисунках 93 и 94. Форма представления исходных данных для данного режима,
заполненная реальными данными по рассматриваемому численному примеру, приведена
в таблице 43. Исходные данные представляются в форме денормализованной таблицы
MS Excel, которая затем записывается из самого Excel в виде файла базы данных
стандарта DBF 4 (dBASE IV) (*.dbf), непосредственно воспринимаемого системой
«Эйдос».
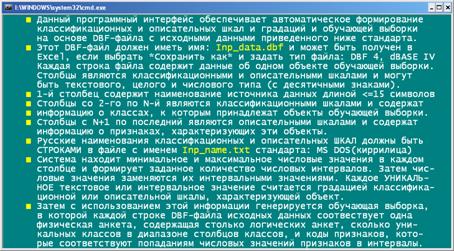
Рисунок 92. Скриншот Help программного интерфейса
формализации предметной области системы «Эйдос» (режим _152)
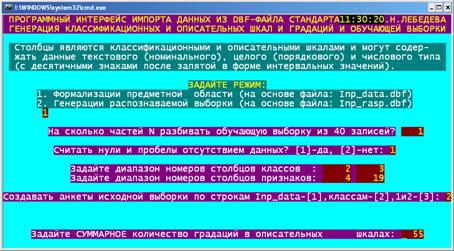
Рисунок 93. Скриншот экранной формы диалога пользователя
по заданию параметров формализации предметной области
системы «Эйдос» (режим _152)
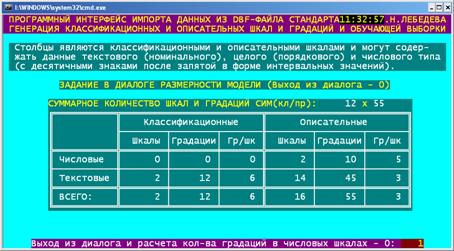
Рисунок 94. Скриншот экранной формы диалога
пользователя
по заданию параметров формализации предметной области
системы «Эйдос» (режим _152)
В результате работы данного режима формируются дендрограммы
результатов когнитивной кластеризации и графики пошагового изменения
межкластерного расстояния, приведенные на рисунках 98 а), б), в) и г):
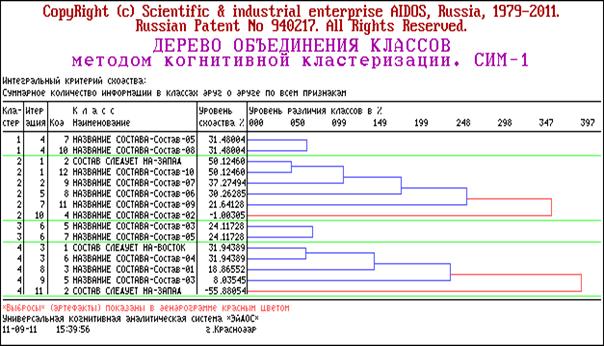
а)
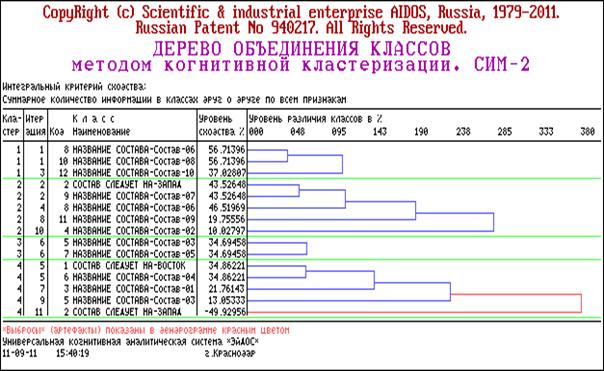
б)
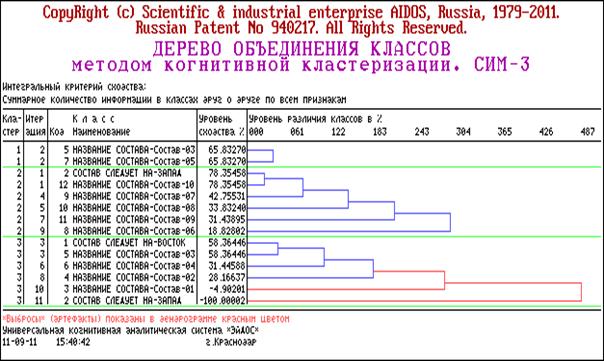
в)
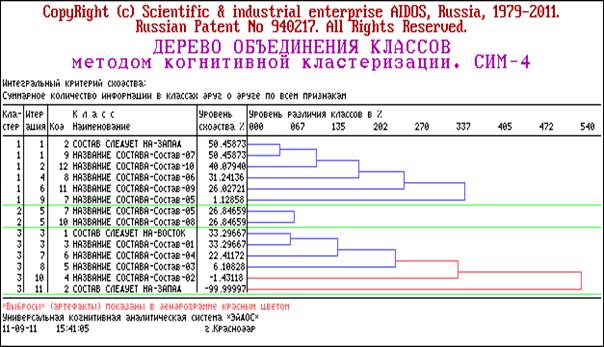
г)
Рисунок 98. Дендрограммы когнитивной кластеризации, полученные
в режиме _5126 системы «Эйдос» на
рассматриваемом
численном примере
Из рисунков 98 мы видим, что когнитивная кластеризация
может начинаться как с монообъектных, так и с полиобъектных классов. Во втором
случае классы создаются путем объединения объектов на основе априорной
информации, источником которой является учитель (эксперт). Поэтому когнитивная
кластеризация представляет собой сочетание обучения с учителем (экспертом) и
без учителя, т.е. самообучения, причем учитель принимает участие лишь в
формировании исходной модели для последующей кластеризации без учителя. На
рисунке 99 приведены графики пошагового изменения межкластерного расстояния при
когнитивной кластеризации в моделях с разными частными критериями знаний,
представленными в таблице 41:
Рисунок 99. Графики пошагового изменения межкластерного расстояния
при когнитивной кластеризации,
полученные в режиме _5126 системы «Эйдос» на рассматриваемом численном примере
Таким образом, у нас есть возможность подвести итоги и
кратко сформулировать, как решаются проблемы кластерного анализа в методе
когнитивной кластеризации, основанном на АСК-анализе и реализованном в интеллектуальной системе «Эйдос» (таблица 56):
Таблица 56 – Проблемы кластеризации и их решения предлагаемые
в системно-когнитивном анализе и системе «Эйдос»
|
№
|
Формулировка
проблемы
кластерного анализа
|
Предлагаемое
в АСК-анализе
и реализованное в системе «Эйдос» решение
|
|
1.
|
Проблема 1.1 выбора метрики, корректной для
неортонормированных пространств.
|
Предлагается применить
неметрический интегральный критерий, представляющий собой суммарное количество
информации в системе признаков о принадлежности объекта к классу
(«информационное расстояние»), никак не основанный на предположении об
ортонормированности пространства и корректно работающий в неортонормированных
пространствах
|
|
2.
|
Проблема 1.2 ортонормирования пространства.
|
Поддерживается
|
|
3.
|
Проблема 2.1 сопоставимой обработки описаний
объектов, описанных признаками различной природы, измеряемыми в различных
единицах измерения (проблема размерностей).
|
Объекты формально
описываются в виде векторов, затем рассчитывается матрица абсолютных частот и
на ее основе – матрица знаний, с использованием которой все признаки измеряются
в одних единицах измерения: единицах измерения количества данных, информации
и знаний – битах, байтах, и т.д.
|
|
|
Проблема 2.2 формализации описаний объектов,
имеющих как количественные, так и качественные признаки.
|
Числовые шкалы
преобразуются в интервальные значения, после чего градации всех типов шкал
обрабатываются единообразно (см.п.3)
|
|
4.
|
Проблема 3.1 доказательства гипотезы о
нормальности исходных данных.
|
Нет необходимости, т.к.
предлагаемые частные и интегральные критерии не предполагают нормальности
исходных данных
|
|
5.
|
Проблема 3.2
нормализации исходных данных.
|
Реализованы режимы ремонта
или взвешивания исходных данных.
|
|
6.
|
Проблема 3.3 применения непараметрических методов
кластеризации, корректно работающих с ненормализованными данными.
|
Предлагаемые методы
являются непараметрическими и корректно работают с ненормализованными данными
|
|
7.
|
Проблема 4 разработки такого метода кластерного
анализа, математическая модель и алгоритм и которого органично включали бы
фильтр, подавляющий шум в исходных данных, в результате чего данный метод
кластеризации корректно работал бы при наличии шума в исходных данных.
|
Предлагаемый метод включает
фильтр подавления шума на уровне формирования матрицы абсолютных частот и
самой математической форме интегрального критерия. Кроме того, реализованы
режимы удаления или корректной обработки артефактов, выбросов (нетипичных
объектов) и малопредставленных данных, по которым нет достаточной статистики
в исходных данных
|
|
8.
|
Проблема 5
разработки метода кластерного анализа, математическая модель и
алгоритм и которого обеспечивали бы выявление «выбросов» (артефактов)
в исходных данных и позволяли либо вообще не показывать их в дендрограммах,
либо показывать, но так, чтобы было наглядно видно, что это артефакты.
|
Поддерживается исключение
выбросов и артефактов из дендрограмм, либо их отображение специальным для них
образом.
|
Отметим, что в АСК-анализе и системе «Эйдос» реализованы
и другие методы кластеризации, также
основанные на знаниях:
– дивизивная кластеризация (см., например: [128]);
– кластерно-конструктивный анализ классов и признаков
[7].
Дивизивная (разделительная, в отличие от
агломартивной, т.е. объединяющей) кластеризация используется в системе «Эйдос»
для того разделять классы на типичную и нетипичную части. Предполагается, что
если объекты не были отнесены к классу, к которому они на самом деле относятся,
то они являются нетипичными для него (исключениями), и это является достаточным
основанием для того, чтобы создать для них новый класс с тем же наименованием и
добавлением номера итерации. Такой подход приводит к резкому уменьшению ошибок
неидентификации при примерно том же уровне ошибок ложной идентификации, что
приводит к существенному улучшению достоверности модели (рисунок 100):
Рисунок 100. Дендрограмма дивизивной кластеризации, полученная в
режиме _34 системы «Эйдос» на рассматриваемом численном примере
Конструкты представляют собой понятия, имеющие противоположные
смысловые полюса, в качестве которых у нас выступают наиболее непохожие кластеры,
а также спектр промежуточных по смыслу классов. Конструкты принадлежат к
наивысшему иерархическому уровню процесса познания, выше которого только
парадигма реальности и их можно рассматривать как оси координат нашего
когнитивного пространства [7]. Система «Эйдос» формирует конструкты на основе
исследования модели предметной области. Роль конструктов невозможно
переоценить, т.к. когда мы познаем мы применяем уже имеющиеся у нас конструкты,
уточняем или расширяем область их применения и создаем новые конструкты (таблица
57).
Таблица 57 – Конструкт: «Запад-Восток»
|
Код
класса
|
Наименование
класса
|
Уровень
сходства
|
|
2
|
СОСТАВ СЛЕДУЕТ НА-ЗАПАД
|
100,00
|
|
12
|
НАЗВАНИЕ СОСТАВА-Состав-10
|
50,12
|
|
9
|
НАЗВАНИЕ СОСТАВА-Состав-07
|
42,73
|
|
8
|
НАЗВАНИЕ СОСТАВА-Состав-06
|
37,65
|
|
11
|
НАЗВАНИЕ СОСТАВА-Состав-09
|
34,55
|
|
10
|
НАЗВАНИЕ СОСТАВА-Состав-08
|
8,70
|
|
4
|
НАЗВАНИЕ СОСТАВА-Состав-02
|
-2,23
|
|
6
|
НАЗВАНИЕ СОСТАВА-Состав-04
|
-15,79
|
|
3
|
НАЗВАНИЕ СОСТАВА-Состав-01
|
-19,88
|
|
5
|
НАЗВАНИЕ СОСТАВА-Состав-03
|
-34,99
|
|
7
|
НАЗВАНИЕ СОСТАВА-Состав-05
|
-44,68
|
|
1
|
СОСТАВ СЛЕДУЕТ НА-ВОСТОК
|
-54,69
|
Таким образом, в данной статье на небольшом численном
примере рассматриваются новые алгоритмы и результаты агломеративной
кластеризации, основные отличия которых от ранее известных стоят в том, что:
а) в них параметры обобщенного образа кластера не вычисляются
как средние от исходных объектов (классов) или центры тяжести, а определяются с
помощью той же самой базовой когнитивной операции АСК-анализа, которая
применяется и для формирования обобщенных образов классов на основе примеров
объектов и которая действительно обеспечивает обобщение;
б) в качестве критерия сходства используется не
евклидово расстояние или его варианты, а интегральный критерий неметрической
природы: «суммарное количество информации», применение которого теоретически
корректно и дает хорошие результаты в неортонормированных пространствах,
которые обычно и встречаются на практике;
в) кластерный анализ проводится не на основе исходных
переменных или матрицы сопряженности, зависящих от единиц измерения по осям, а
в когнитивном пространстве, в котором по всем осям (описательным шкалам)
используется одна единица измерения: количество информации, и поэтому
результаты кластеризации не зависят от исходных единиц измерения признаков объектов.
Имеется и ряд других менее существенных отличий. Все это позволяет получить результаты кластеризации,
понятные специалистам и поддающиеся содержательной интерпретации, хорошо
согласующиеся с оценками экспертов, их опытом и интуитивными ожиданиями, что
часто представляет собой проблему для классических методов кластеризации. Описанные
методы теоретически обоснованы в системно-когнитивном анализе (СК-анализ) и
реализованы в его программном инструментарии – интеллектуальной системе
«Эйдос»,
Основной вывод,
который, по мнению авторов можно обоснованно сделать по материалам данной
статьи, состоит в том, что, не смотря на существование огромного количества
различных методов кластеризации, в этой области существует ряд нерешенных
проблем, ждущих своего решения. Анализ этих проблем позволяет высказать гипотезу, что для их решения необходимо
выйти за пределы понятийного поля чисто математических рассуждений и привлечь
представления из области искусственного интеллекта, в частности основываться на
четкой дефиниции содержания таких основополагающих понятий, как данные, информация
и знания [127]. Данная работа и содержит описание авторского варианта
реализации этой идеи. Здесь же хотелось бы отметить, что кластеризация
классическим методом матрицы знаний, полученной вне статистической системы,
реализующий кластерный анализ, не дает желаемых результатов, т.к. только 1-я
итерация получается соответствующей предлагаемому подходу, а последующие дают
ошибочные результаты, т.к. в статистических системах не реализовано операции
обобщения и добавление объекта к кластеру или объединение классов в кластер
осуществляется иначе, чем формирование самих классов в исходной матрице знаний.
Предлагаемый метод когнитивной кластеризации не лишен
и некоторых недостатков и ограничений, преодоление которых является одним из перспективных направлений развития
этого метода.
Из недостатков
следует прежде всего указать большие затраты вычислительных ресурсов и
машинного времени на решение задачи кластеризации, чем у классических методов,
обусловленные значительным объемом и более высокой сложностью вычислений.
Другим недостатком является нежесткое ограничения текущей версии системы
«Эйдос» на размерности модели, которые планируется преодолеть и которые
постепенно преодолеваются. Версия системы «Эйдос» весны 2011 года обеспечивала
объем обучающей выборки не более 100000 объектов, в текущей версии это
ограничение снято и теперь система может работать с миллионами и даже десятками объектов. Но осталось ограничение
на размерность баз знаний: не более 4000 классов и 4000 градаций факторов. Это
ограничение также в перспективе планируется снять.
В качестве перспективы
автор рассматривает разработку режимов,
обеспечивающих:
– когнитивную кластеризацию признаков;
– двухвходовую кластеризацию (одновременно и классов,
и признаков), что оправдано тем, что при кластеризации классов изменяется и
смысл признаков;
– моделей, основанных на новых частных критериях
знаний (в частности, СИМ-1 – СИМ-7).
Материалы данной статьи могут быть использованы при
разработке интеллектуальных систем, а также при проведении лабораторных работ
по дисциплинам: «Интеллектуальные информационные системы» для специальности:
080801.65 – Прикладная информатика (по областям) и
«Представление знаний в информационных системах» для специальности: 230201.65 –
Информационные системы и технологии.
4.4. Дисциплина:
«Управление знаниями (магистратура)»
В данном разделе показано, что для современного этапа
развития контроллинга характерно все большее его проникновение в средние и
малые фирмы. При этом возникает проблема найти единый, простой в освоении и
недорогой инструментарий контроллера, обеспечивающий создание интеллектуальных
методик для менеджмента на различных уровнях иерархии управления фирмой.
Обосновываются требования к инструментарию контроллера, показано, что всем
сформулированным требованиям
соответствует метод автоматизированного системно-когнитивного анализа и
его инструментарий – система «Эйдос». Приведены примеры применения данного
инструментария для решения задач управления качеством подготовки специалистов,
информационной безопасности, определения номенклатуры и объемов реализуемых
товаров, выбора базовой технологии и управления персоналом.
По вопросу определения целей корпорации в современной
науке не сложилось общепринятой точки зрения и в различных научных направлениях
этот вопрос решается по-разному. Например, в неоклассической теории считается,
что целью корпорации является максимизация дохода, прибыли; в бихевиористской
теории – получение удовлетворительной прибыли и дохода; институциональной
теории – минимизация транзакционных издержек; теории корпорации Дж. Гэлбрейта –
гарантированный уровень прибыли и максимальный темп роста; в предпринимательской
же теории полагают, что цель корпорации зависит от личных целей
предпринимателя [223]. При этом цели корпорации, а также различных связанных с нею социальных
групп людей и государства совпадают лишь частично (рисунок 101):
Рисунок 101. Цели корпорации, а также связанных с ней
социальных групп и государства по С.Ю. Полонскому [223].
Таким образом, наиболее распространенная точка зрения,
состоящая в том, что цель корпорации заключается исключительно в получении
максимальной прибыли, является неоправданно упрощенной. Более того,
максимизация прибыли может быть и нежелательной, например, если это достигается
за счет ущерба целям работников и государства. В любом случае ясно, что для достижения
этих целей необходимо управлять
корпорацией как в целом, так и на различных уровнях ее иерархической структурной
организации.
Современный уровень культуры управления в развитых
странах (в которых уже построено общество, основанное на знаниях) предполагает
использование ряда корпоративных информационных систем (КИС), используемых на
различных уровнях иерархии обработки информации (рисунок 102):
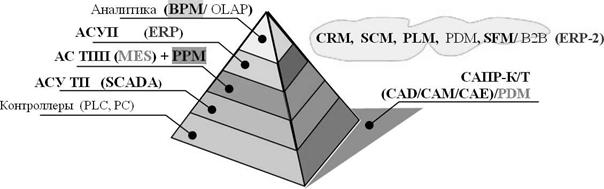
Рисунок 102. Корпоративные
информационные системы
(КИС - CALS), по А.Г. Киселеву [224]
На рисунке 102 использованы следующие обозначения [224]:
– аналитика для высшего менеджмента предприятия - управление
эффективностью бизнеса (BPM) - инструмент OLAP;
– автоматизированная система управления (АСУ) предприятия
в целом на уровне бизнес - процессов (АСУП или ERP);
– автоматизированная система (АС) технологической подготовки
производства (ТПП), и как расширение - управление производством в целом на
уровне производственных процессов (АС ТПП или MES) + аналитика цехового менеджмента для управления
эффективностью производства (PPM);
– АСУ технологическими процессами (ТП) в реальном времени
(АСУ ТП или SCADA);
– системы автоматического управления (САУ)
техническими системами и контроллеры технических устройств (PLC, PC);
– системы автоматизированного проектирования разработчика-конструктора
(САПР-К или CAD/CAM) и технолога
(САПР-Т или CAE), а также им соответствующие инженерные и технологические базы
знаний и система управления ими (PDM);
– внешние по отношению к предприятию информационные
системы (ERP-2): управление отношениями с клиентами (CRM, в т.ч. электронный
бизнес B2B), управление цепями поставок (SCM), управление жизненным циклом
произведенного изделия (PLM) и продажами (SFM).
Из рисунка 102 видно, что:
– в фундаменте пирамиды обработки информации корпорации
находятся автоматические системы управления чисто техническими объектами
управления (САУ, т.е. по сути системы управления машинами);
– на среднем уровне мы имеем дело уже с автоматизированными
системами управления (АСУ) человеко-машинными объектами управления от АСУ ТП,
до АС ТПП и АСУП;
– на верхнем уровне расположены автоматизированные системы
организационного управления (АСОУ) и аналитические системы, в которых объектом
управления выступают как конкретные люди, так и коллективы.
Не во всех корпорациях представлены нижние уровни, приведенные
на рисунке 102, например,
нижние уровни более характерны для производственных компаний, оснащенных достаточно
современным технологическим оборудованием.
Если проанализировать «долю» человека и техники в объектах
управления различных иерархических уровней корпорации, то окажется, что в ее
фундаменте находятся чисто технические системы, с повышением уровня иерархии
доля человека в объектах управления возрастает, а доля техники соответственно
уменьшается, и в вершине пирамиды техники уже вообще нет, а остается только
человек.
Эта ситуация, по-видимому, обусловлена тем, что на
различных уровнях иерархии корпорации на практике используются знания различной
степени формализации:
– на самом верхнем уровне – это интуитивные знания и
опыт, т.е. знания вообще неформализованные, не выраженные на каком-либо языке
или в какой-либо системе кодирования (ноу-хау);
– на промежуточных уровнях знания частично формализованы,
например вербализованы, т.е. представлены с помощью слов в звуковой или
текстовой форме, а также научных книг, учебников и методических указаний с
иерархическим структурированным
содержанием;
– на самом низком уровне представлены хорошо формализованные
знания, т.е. знания в форме математических моделей и баз знаний (БЗ) интеллектуальных
систем.
В этой связи отметим, что для американской,
германской, китайской и российской традиций контролинга характерна различная
степень формализации знаний, которая наиболее высока именно в российском
контроллинге, а самая низкая в китайском, в котором считается, что для
достижения цели достаточно верно определить направление движения (С.Г.Фалько),
т.к т.еллектуальных систем.
«первым достигнет финиша не тот, кто бежит быстрее, а тот, кто бежит к финишу».
Однако проблема состоит в том, что приобретение, внедрение
и использование всех систем, приведенных на рисунке 102, является
целесообразным лишь для достаточно крупных корпораций, тогда как для средних и
малых фирм, которых большинство, это
вряд ли возможно. Это обусловлено как высокой стоимостью этих систем, так и
сложностью их освоения, внедрения и применения, избыточностью функций,
отсутствием информационных взаимосвязей между ними, многообразием разработчиков
и программных инструментальных средств, с помощью которых они созданы.
Сложилась парадоксальная ситуация, состоящая в том,
что внедрение корпоративных информационных систем
на практике часто осуществляется не
системно, т.е. они фактически не
образуют целостной корпоративной информационной системы, аналогично тому, как
до возникновения локальных компьютерных сетей не образовывали единой системы не
связанные друг с другом автоматизированные рабочие места (АРМы).
Традиционным общественным институтом, нацеленным на
выявление новых знаний, является наука.
Также традиционно инженеры, используя
эти научные знания, разрабатывают
новые технологии, которые уже и применяются на практике.
Для управления на уровне машин и технологий (так называемые
системы автоматического управления – САУ и АСУ ТП) используются знания, добытые за сотни или даже тысячи
лет фундаментальной наукой, прежде
всего физикой и химией.
Однако на уровне управления человеко-машинными системами
и коллективами людей (АС ТПП и АСОУ) таких знаний нет, что определяется самой
природой этих объектов управления.
Одна из современных тенденций развития контроллинга состоит
в том, что он проникает в фирмы все меньшего и меньшего масштаба деятельности,
т.е. в этих фирмах появляются небольшие подразделения или даже просто отдельные
сотрудники, выполняющие функции контроллинга. Достигнутый в настоящее время
уровень развития управления фирмами требует более оперативного и конкретного
подхода к контроллингу, при котором знания о деятельности фирмы выявляются в самой фирме с учетом ее динамики и в
фирме же доводятся до уровня технологий и используются на практике. Это и есть
основная задача контроллинга [225]. Таким образом, контроллер, – это, по сути, ученый,
профессионально занимающийся непрерывным исследованием своей фирмы и
производящий инновационный интеллектуальный продукт в форме знаний различной
степени формализации, готовых по своей
степени коммерциализации для внедрения и практического использования
менеджментом корпорации. Соответственно подразделение контроллинга в фирме
является ее инновационным научным подразделением, призванным создать и поддерживать
в адекватном состоянии модель этой фирмы, обеспечивающую решение задач
прогнозирования ее развития и поддержки принятия управленческих решений,
направленных на достижение целей фирмы и разумного баланса интересов фирмы, ее
сотрудников и акционеров, а также государства.
Менеджмент же призван использовать на практике
методики, разработанные контроллерами, т.е. фактически менеджеры являются
пользователями и исполнителями инновационных технологий и методик их применения,
разработанных контроллерами.
Информационная
модель деятельности менеджера, представленная на рисунке 103, разработана на
основе модели, впервые предложенной В.Н. Лаптевым (1984).
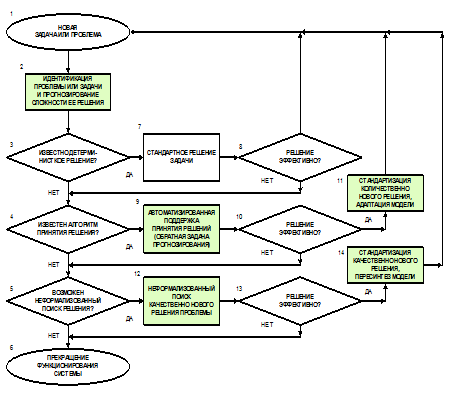
Рисунок 103. Информационная модель деятельности
менеджера
и место систем искусственного интеллекта в этой деятельности
по В.Н.Лаптеву
На вход
системы управления поступает задача или проблема. Толкование различия между
ними также дано В.Н. Лаптевым и состоит в следующем. Ситуация, при которой
фактическое состояние системы не совпадает с желаемым (целевым) называется проблемной ситуацией и представляет собой:
– задачу, если способ перевода системы из
фактического состояния в желаемое точно известен, и необходимо лишь применить
его;
– проблему, если способ перевода системы
из фактического состояния в желаемое не известен, и необходимо сначала его разработать
и только после этого применить.
Таким
образом, можно считать, что проблема –
это задача, способ решения которой неизвестен. Это означает, что если этот способ разработать, то этим самым
проблема сводится к задаче, переводится в класс задач. Проще говоря,
проблема – это сложная задача, а задача – это простая проблема.
Но и проблемы
различаются по уровню сложности:
– для решения
одних достаточно автоматизированной
системы поддержки принятия решений;
– для решения
других – обязательным является творческое неформализуемое на современном этапе
развития технологий искусственного интеллекта участие людей: в первую очередь контроллеров, экспертов, а также
менеджеров.
Рассмотрим
подробнее, т.е. по блокам, информационную
модель деятельности менеджера, представленную на рисунке 103.
Блок 1. На вход системы поступает задача или проблема, что
именно неясно, т.к. чтобы это выяснить необходимо идентифицировать ситуацию и обратиться к базе данных стандартных решений
с запросом, существует ли стандартное решение для данной ситуации.
Блок 2. Далее осуществляется идентификация проблемы или
задачи и прогнозирование сложности ее решения. На этом этапе применяется
интеллектуальная система, относящаяся к классу систем распознавания образов,
идентификации и прогнозирования или эта функция реализуется менеджером
самостоятельно "вручную" по методике, разработанной конроллером.
Блок 3. Если в результате идентификации задачи или проблемы
по ее признакам установлено, что имеется стандартное решение, то это означает,
что на вход системы поступила задача, которая ранее уже встречалась. Для
установления этого достаточно информационно-поисковой системы, осуществляющей
поиск по точному совпадению параметров запроса и в применении интеллектуальных
систем нет необходимости. Тогда происходит переход на блок 7, а иначе на
блок 4.
Блок 4. Если установлено, что точно такой задачи не встречалось,
но встречались сходные, аналогичные,
которые могут быть найдены в результате обобщенного (нечеткого) поиска системой
распознавания образов, то решение может быть найдено с помощью
автоматизированной системы поддержки принятия решений путем решения обратной задачи прогнозирования. Это
значит, что на вход системы поступила не задача, а проблема, имеющая
количественную новизну по сравнению с решаемыми ранее (т.е. не очень сложная
проблема). В этом случае осуществляется переход на блок 9, иначе – на блок 5.
Блок 5. Если установлено, что сходных проблем не встречалось,
то необходимо качественно новое решение, поиск которого требует существенного
творческого участия человека-эксперта. В этом случае происходит переход на блок
12, а иначе – на блок 6.
Блок 6. Переход на этот блок означает, что возможности поиска
решения или выхода из проблемной ситуации системой исчерпаны и решения не
найдено. В этом случае система обычно терпит ущерб целостности своей структуре
и полноте функций, вплоть до разрушения и прекращения функционирования.
Блок 7. На этом этапе осуществляется реализация стандартного
решения, соответствующего установленной задаче, а затем проверяется эффективность
решения на блоке 8.
Блок 8. Если стандартное решение оказалось эффективным, это
означает, что на этапах 2 и 3 идентификация задачи и способа решения осуществлены
правильно и система может переходить к разрешению следующей проблемной ситуации (переход на
блок 1). Если же стандартное решение оказалось неэффективным, то это
означает, что проблемная ситуация идентифицирована как стандартная задача
неверно и необходимо продолжить попытки ее разрешения с использованием более
общих подходов, основанных на применении систем искусственного интеллекта (переход
на блок 4), например, систем поддержки принятия решений.
Блок 9. Применяется автоматизированная система поддержки
принятия решений, обеспечивающая решение обратной задачи прогнозирования.
Отличие подобных систем от информационно-поисковых состоит в том, что они
способны производить обобщение, выявлять силу и направление влияния различных
факторов на поведение системы, и, на основе этого, по заданному целевому
состоянию вырабатывать рекомендации по системе факторов, которые могли бы
перевести систему в это состояние (обратная задача прогнозирования).
Блок 10. Если решение, полученное с помощью системы поддержки
принятия решений, оказалось неэффективным, то это означает, что проблемная
ситуация идентифицирована как аналогичная ранее встречавшимся неверно.
Следовательно, что на вход системы поступила качественно новая, по сравнению с
решаемыми ранее, т.е. сложная проблема. В этом случае необходимо продолжить
попытки разрешения проблемы с использованием творческих неформализованных
подходов с участием человека-эксперта и перейти на блок 5, иначе – на блок 11.
Блок 11. Информация об условиях и результатах решения проблемы
заносится в базу знаний, т.е. стандартизируется.
После чего база знаний количественно (не принципиально) изменяется, т.е.
осуществляется ее адаптация. В результате
адаптации при встрече в будущем точно таких же проблемных ситуаций, как
разрешенная, система уже будет разрешать ее не как проблему, а как стандартную
задачу.
Блок 12. На этом этапе с использованием неформализованных (на
данном этапе развития автоматизированных интеллектуальных технологий)
творческих подходов и опыта осуществляется поиск качественно нового решения
проблемы, не встречавшейся ранее, после чего управление передается блоку 13.
Блок 13. Если решение, полученное контроллерами и экспертами с
помощью неформализованных подходов, оказалось неэффективным, то это означает,
что система терпит крах (осуществляется переход на блок 6). Если же адекватное
решение найдено, то происходит переход на блок 14.
Блок 14. Стандартизация качественно нового решения, проблемы
и пересинтез модели. Информация об условиях и результатах творческого решения
проблемы заносится в базу знаний, т.е. стандартизируется.
После этого база знаний качественно,
принципиально изменяется, т.е. фактически осуществляется ее пересоздание
(пересинтез). В результате пересинтеза
базы знаний при встрече в будущем проблемных ситуаций, аналогичных разрешенной,
система уже будет реагировать на них как проблемы, решаемые автоматизированными
системами поддержки принятия решений.
Блоки, в
которых могут применяться интеллектуальные технологии, т.е. современные системы
искусственного интеллекта, на рисунке 103 показаны с затемненным фоном:
– блоки 2 и 12: система
распознавания образов, идентификации и прогнозирования;
– блоки 9, 11, 12 и 14:
автоматизированная система поддержки принятия решений.
Теперь можно
уже более конкретно и обоснованно сформулировать, что задачей контроллеров
является с применением этих интеллектуальных систем создание и верификация
соответствующих интеллектуальных приложений, т.е. конкретных моделей, на основе
которых могут решаться задачи идентификации, прогнозирования и поддержки
принятия решений в корпорации. Задачей же менеджеров является применение на
практике разработанных контроллерами интеллектуальных приложений. Конечно, в
задачи контроллера входит и обучение менеджеров, и контроль за их работой с
применением данных технологий.
Итак, одна из важнейших современных тенденций развития
технологии контроллинга состоит в том, что эти технологии все больше и больше
проникают в фирмы все меньшего размера. Однако для того, чтобы контроллер мог
соответствовать этим требованиям времени ему необходим соответствующий
адекватный инструмент, обеспечивающий
возможно наиболее полную автоматизацию его функций. По сути дела ему необходима
своего рода интеллектуальная автоматизированная система научных исследований
(ИАСНИ), т.е. система, обеспечивающая поддержку тех интеллектуальных,
познавательных (когнитивных) функций и операций, которые ученый выполняет в
процессе познания и научного исследования предметной области. Современный уровень
развития систем искусственного интеллекта и интеллектуальных автоматизированных
систем правления позволяет ставить и решать задачу создания таких систем.
Вышесказанное позволяет обоснованно сформулировать ряд
общих требований к методам решения различных задач интеллектуального управления
современной фирмой, ориентированной на экономику знаний, которые в перспективе
могли бы стать адекватным инструментом автоматизированной поддержки основных
функций контроллера в малых и средних фирмах.
Первое
требование. Метод должен
обеспечивать решение сформулированной проблемы в условиях неполной (фрагментированной)
зашумленной исходной информации большой размерности, не отражающей всех
ограничений и ресурсов и не содержащей полных повторений всех вариантов
сочетаний прибыли, рентабельности, номенклатуры и объемов продукции, причем получение
недостающей информации представляется принципиально невозможным.
Второе
требование. Метод должен
быть недорогим в приобретении и использовании, т.е. для этого должно быть достаточно
одного стандартного персонального компьютера, недорогого лицензионного
программного обеспечения и одного сотрудника, причем курс обучения этого
сотрудника должен быть несложным для него, т.е. не предъявлять к нему каких-то
сверхжестких нереалистичных требований.
Третье
требование. Вся
необходимая и достаточная исходная информация для применения метода должна быть
в наличии в бухгалтерии, планово-экономических и других подразделениях фирмы.
Четвертое
требование. Метод должен
быть адаптивным, т.е. оперативно учитывать изменения во всех компонентах моделируемой
системы.
Наконец можно выдвинуть и пятое требование. Для решения различных задач управление фирмой на
всех иерархических уровнях информационной пирамиды корпорации, приведенных на
рисунке 102, возможно за исключением 1-го, должен использоваться один математический метод, один алгоритм его реализации и единый программный инструментарий для
осуществления этого алгоритма, т.е. одна
система.
Для разработки адаптивной методики, необходимой для решения
рассмотренных здесь проблем управления фирмой, выбран метод автоматизированного
системно-когнитивного анализа (АСК-анализ), удовлетворяющий всем обоснованным
выше требованиям.
Этот выбор был обусловлен тем, что данный метод
является непараметрическим, позволяет корректно и сопоставимо обрабатывать
тысячи градаций факторов и будущих состояний объекта управления при неполных
(фрагментированных), зашумленных данных различной природы, т.е. измеряемых в
различных единицах измерения. Для метода АСК-анализа разработаны и методика
численных расчетов, и соответствующий программный инструментарий, а также
технология и методика их применения. Они прошли успешную апробацию при решении
ряда задач в различных предметных областях [7]. Наличие инструментария АСК-анализа (базовая система
"Эйдос") [7] позволяет
не только осуществить синтез семантической информационной модели (СИМ), но и
периодически проводить адаптацию и синтез ее новых версий, обеспечивая тем
самым ее локализацию для других месть применения и отслеживание динамики предметной
области сохраняя тем самым высокую адекватность модели в изменяющихся условиях.
Важной особенностью АСК-анализа является возможность единообразной числовой
обработки разнотипных по смыслу и единицам измерения числовых и нечисловых данных
(в т.ч. текстовых и графических). Это обеспечивается тем, что нечисловым
величинам тем же методом, что и числовым, приписываются сопоставимые в
пространстве и времени, а также между собой, количественные значения, имеющие
смысл количества информации или знаний, что позволяет сопоставимо обрабатывать
их как числовые. При этом на первых двух этапах АСК-анализа числовые величины
сводятся к интервальным оценкам, как и информация об объектах нечисловой
природы (фактах, событиях) (этот этап реализуется и в методах интервальной
статистики); на третьем этапе АСК-анализа всем этим величинам по единой методике,
основанной на системном обобщении семантической теории информации
А. Харкевича, сопоставляются количественные величины (имеющие смысл количества
информации или знаний в признаке о принадлежности объекта к классу), с которыми
в дальнейшем и производятся все операции моделирования (этот этап является
уникальным для АСК-анализа).
АСК-анализ
обеспечивает:
– выявление
знаний о поведении сложной многопараметрической системы под действием большого
количества факторов различной природы (измеряемых в различных единицах
измерения) из эмпирических данных;
– формализацию
этих знаний в форме баз знаний (с оценкой степени их адекватности);
– применение
этих знаний для решения задач прогнозирования и поддержки принятия решений,
т.е. управления.
Метод автоматизированного системно-когнитивного
анализа и его программный инструментарий – система «Эйдос» обеспечивают
выявление причинно-следственных зависимостей из эмпирических данных. В качестве
инструментария для формального представления причинно-следственных зависимостей
используются когнитивные функции, представляющие собой многозначные
интервальные функции многих аргументов, в которых различные значения функции в
различной степени соответствуют различным значениям аргументов, причем
количественной мерой этого соответствия выступает знания, т.е. информация о
причинно-следственных зависимостях в эмпирических данных, полезная для достижения
целей [117, 125].
В работе [7] приведен перечень этапов
системно-когнитивного анализа, которые необходимо выполнить, чтобы осуществить
синтез модели объекта управления, решить с ее применением задачи
прогнозирования и поддержки принятия решений, а также провести исследование
объекта моделирования путем исследования его модели. Учитывая эти этапы
СК-анализа выполним декомпозицию цели работы в последовательность задач,
решение которых обеспечит ее поэтапное достижение:
1. Когнитивная структуризация предметной области и формальная
постановка задачи, проектирование структуры и состава исходных данных.
2. Формализация предметной области.
2.1. Получение исходных данных запланированного
состава в той форме, в которой они накапливаются в поставляющей их организации
(обычно в форме базы данных какого-либо стандарта или Excel-формы).
2.2. Разработка стандартной Excel-формы для
представления исходных данных.
2.3. Преобразование исходных данных из исходных баз данных
в стандартную электронную Excel-форму.
2.4. Контроль достоверности исходных данных и исправление
ошибок.
2.5. Использование стандартного программного
интерфейса системы «Эйдос» для преобразования исходных данных из стандартной
Excel-формы в базы данных системы "Эйдос" (импорт данных).
3. Синтез семантической информационной модели (СИМ),
отражающей силу и направление влияния факторов на переход объекта управления в
будущие состояния.
4. Измерение адекватности СИМ.
5. Повышение эффективности СИМ.
6. Решение с помощью СИМ задач прогнозирования и поддержки
принятия решений, а также научного исследования предметной области.
7. Разработка принципов оценки экономической эффективности
разработанных технологий при их применении в торговой фирме.
8. Исследование ограничений разработанной технологии и
перспектив ее развития.
Рассмотрим подробнее пять различных задач управления
знаниями фирмы на различных иерархических уровнях управления, для решения
которых обоснованно и эффективно применен метод системно-когнитивного анализа с
использованием его программного инструментария – универсальной когнитивной аналитической
системы «Эйдос» (система «Эйдос») [15, 16].
В работах [15, 16] рассматривается специфика
применения автоматизированных систем управления (АСУ) в вузе для управления
качеством подготовки менеджеров, предлагается двухконтурная модель АСУ, на 1-м
контуре которой осуществляется управление студентом с помощью образовательного
процесса, а на 2-м – управление самим образовательным процессом, при этом
рефлексивная АСУ качеством подготовки менеджеров рассматривается авторами как
АСУ технологическими процессами (ТП) в образовании. Работа поддержана грантом
КубГАУ за 2006 год по созданию программы мониторинга качества образования.
Классическая схема автоматизированной
системы управления (АСУ) включает управляемый объект и управляющую систему,
находящиеся в некоторой окружающей среде и взаимодействующие друг с другом за
счет управляющих и обратных связей (рисунок 104).
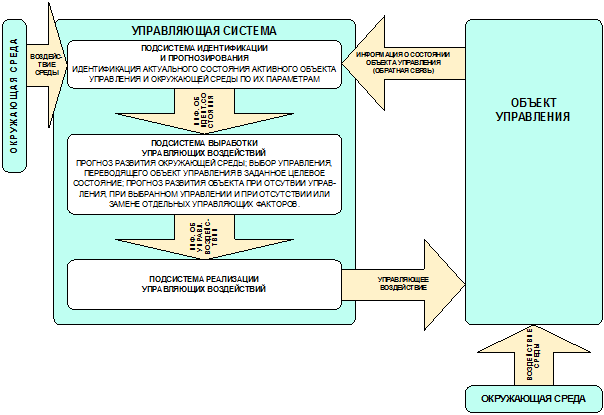
Рисунок 104. Структура типовой АСУ
Традиционно АСУ применялись при управлении
различными техническими системами и технологическими
процессами (АСУ ТП). В экономике известны АСУ организационного
управления (АСОУ), в которых осуществляется управление людьми, выполняющими различные функции по производству
материального продукта.
Возникает вопрос о том, можно ли осуществить
перенос огромных наработок в этих областях на новую предметную область: синтез
рефлексивной АСУ качеством подготовки
менеджеров? Для обоснованного ответа на этот вопрос, как минимум,
необходимо сравнить АСУ в вузе с АСУ
на производстве и в экономике, т.е. по сути, провести некоторую аналогию
(конечно, насколько это корректно и возможно) между вузом и заводом, сравнить,
что в этих случаях является сырьем, управляющими факторами, конечным продуктом,
окружающей средой (таблица 58):
Таблица 58 – Сравнение рефлексивной асу качеством подготовки менеджеров
с АСУ ТП и АСОУ
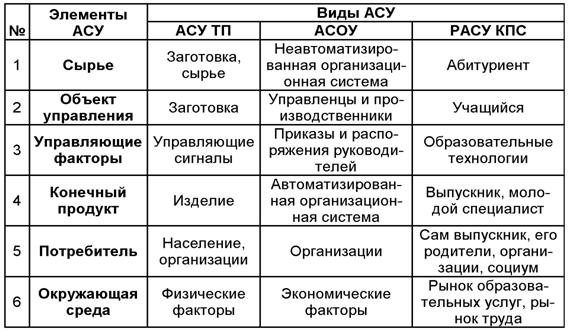
В таблице 58
приведены АСУ, в которых объектом управления является некий объект, на
начальном этапе представляющий собой сырье,
а на конечном, благодаря воздействию определенной технологии, преобразующийся в конечный продукт, выпускаемый организацией и потребляемый некоторым внешним
потребителем.
Конечно,
абитуриент обладает определенными предпосылками для того, чтобы стать или не
стать хорошим студентом или менеджером, но можно ли на этом основании в каком-то
смысле сравнивать его с сырьем или какой-нибудь заготовкой для будущей детали? Если при этом сравнении упускается специфика
абитуриента, как активной системы, то такое сравнение безусловно некорректно,
если же характеристика конституционных и социально-обусловленных личностных
свойств абитуриента (в том числе таких как его оценка и самооценка, мотивации,
ценностные ориентации и т.д.) входит в систему исследуемую факторов, влияющих
на его переход в будущие состояния, как это предлагается в данной работе, то
такое сравнение не только обоснованно, но и целесообразно.
Чтобы
сформулировать концепцию управления в рефлексивной АСУ качеством подготовки
менеджеров рассмотрим упрощенную формальную модель. Процесс управления состоит из последовательных циклов управления, каждый из которых включают следующие этапы:
–
количественное сопоставимое измерение параметров и идентификация состояния
объекта управления;
– оценка
эффективности (качества) предыдущего управляющего воздействия;
– если
предыдущее управляющее воздействие не обеспечило приближения цели, то выработка
новых или корректировка (адаптация) имеющихся методов принятия решений;
– иначе –
выработка нового управляющего воздействия на основе имеющихся методов принятия
решений;
– реализация
управляющего воздействия.
При этом
объектами управления, в соответствии с технологией QFD (развертывания функций
качества) на различных уровнях являются:
– потребительские
свойства продукта;
– свойства
его компонент;
–
технологический процесс;
– элементы
(операции) технологического процесса (рисунок 105) [13]:
Рисунок 105. Обобщенная схема QFD-технологии
(развертывание функций качества) согласно Б. Робертсону
Конкретизируем
общие положения QFD-технологии (развертывание функций качества) для случая
рефлексивной АСУ качеством подготовки менеджеров. Из этой технологии следует,
что на макроуровне в этой АСУ должно быть по крайней мере два уровня:
– 1-й уровень
– управление качеством конечной продукции;
– 2-й уровень
– управление качеством технологии производства конечной продукции.
Такие АСУ,
которые управляют производством конечного продукта организации, будем называть
АСУ группы "Б" (АСУ средств потребления). Применительно к
рефлексивной АСУ качеством подготовки менеджеров, АСУ группы "Б" –
это АСУ управления студентом с помощью образовательных технологий (рисунок 106):
Рисунок 106. Обобщенная схема АСУ КПС группы "Б"
Обычно
влияние тех или иных традиционных образовательных технологий на свойства
выпускника считается известным. Это
положение не подвергается в данной работе сомнению, однако необходимо отметить,
что само понятие "известно" существенно отличается в гуманитарной и
технических областях, т.е. в этих областях приняты различные критерии для классификации исследуемых
закономерностей на "известные" и "неизвестные". Это
приводит к тому, что в ряде случаев то, что "гуманитарии" считают для
себя известным не является таковым для "естественников", т.е. они, конечно, имеют эти знания, но они
их не устраивают. Как правило, гуманитариев устраивает качественная оценка связи, в результате они часто
оперируют нечеткими высказываниями типа: "Наличие хороших учебных
помещений положительно сказывается на качестве образования". И это для них
приемлемо. Однако для создания АСУ необходима количественная модель предметной области, отражающая знания о взаимосвязях
образовательных технологий и уровнях предметной обученности и воспитанности
студентов, т.е. знаний, выраженных в такой качественной форме недостаточно, требуется количественная
формулировка.
Что значит
"хорошее учебное помещение", что "значит качество
образования", в каких сопоставимых
единицах измерения и каким способом
(и каким измерительным инструментом)
можно измерять эти величины, в каких
единицах измерения измеряется взаимосвязь между ними, носит ли она детерминистский
или статистический характер и т.д. и т.п. Вот лишь некоторые вопросы, которые
задают себе проектировщики АСУ. В результате в одной и той же ситуации
гуманитарий может считать, что ему "известна та или иная
зависимость", а менеджер по созданию АСУ, предъявляющий к себе значительно
более жесткие требования, не может себе позволить так считать, что ему это известно,
а значит, будет ставить вопрос о проведении специальных исследований для
выявления и количественного измерения этих связей.
Поэтому при
создании рефлексивной АСУ качеством подготовки менеджеров возникают проблемы:
–
количественного измерения различных параметров образовательных процессов,
предметной обученности и воспитанности студентов и выпускников;
– выявления
количественных зависимостей между параметрами образовательных процессов
(управляющими воздействиями) и предметной обученностью и воспитанностью
студентов и выпускников.
Во всех
случаях внедрение АСУ означает прежде всего изменение (совершенствование)
технологии воздействия на объект управления (рисунок 106 и таблица 58). Таким
образом, сам процесс внедрения АСУ можно рассматривать как процесс управления
совершенствованием технологии производства конечного продукта вуза, т.е.
выпускника, молодого менеджера.
АСУ, в
которых сама образовательная технология является объектом управления, мы отнесем
к группе "А" (таблица 59).
В
технических, производственных и (в меньшей степени) в экономических системах
АСУ группы "А" являются чем-то экзотическим, т.к. объект управления,
как правило, представляет собой систему с медленноменяющимися параметрами. В
этих областях АСУ после внедрения работают достаточно длительное время без
существенных изменений.
Таблица 59 – Компоненты АСУ образовательными технологиями
|
№
|
Элементы
АСУ
|
Рефлексивная
АСУ
качеством подготовки менеджеров
|
|
1
|
Сырье
|
Образовательный
процесс и ППС до внедрения рефлексивной
АСУ качеством подготовки менеджеров
|
|
2
|
Объект
управления
|
Образовательный
процесс и преподаватели
|
|
3
|
Управляющие
факторы
|
Материально-техническое
и научно-методическое обеспечение образовательного процесса, повышение квалификации
ППС
|
|
4
|
Конечный
продукт
|
Образовательный
процесс и ППС после внедрения рефлексивной
АСУ качеством подготовки менеджеров
|
|
5
|
Потребитель
|
Сам
выпускник, его родители, организации, социум
|
|
6
|
Окружающая
среда
|
Рынок труда
и образовательных услуг
|
В рефлексивной АСУ качеством подготовки
менеджеров ситуация кардинально иная: и сами учащиеся, и условия окружающей
среды, являются весьма динамичными, из чего с необходимостью следует и высокая
динамичность образовательных технологий. Следовательно, рефлексивная АСУ качеством подготовки
менеджеров группы "Б" фактически не только не может быть
внедрена, но даже и разработана без одновременной разработки и внедрения рефлексивной АСУ качеством подготовки
менеджеров группы "А", которая бы обеспечила ей высокий
уровень адаптивности, достаточный для обеспечения поддержки адекватности модели
как при количественных, так и при качественных изменениях предметной области,
т.е. как на детерминистских, эргодичных периодах, на которых закономерности
предметной области остаются практически неизменными или изменяются лишь количественно,
так и после прохождения системой точек бифуркации, после чего они изменяются
качественно.
Обобщенная
схема рефлексивной АСУ качеством
подготовки менеджеров группы "А" приведена на рисунке 107:
Рисунок 107. Обобщенная схема рефлексивной АСУ
качеством подготовки менеджеров группы "А"
Объединение рефлексивной АСУ качеством подготовки менеджеров
групп "А" и "Б" приводит к схеме двухуровневой АСУ, в которой первый контур
управления включает управление студентом, а второй контур управления
обеспечивает управление самой образовательной технологией, оказывающей
управляющее воздействие на студента.
Но и
управление образовательными технологиями будет беспредметным без обратной
связи, содержащей информацию об эффективности, как традиционных педагогических
методов, так и педагогических инноваций, т.е. без учета их влияния на качество
образования.
Кроме того, рефлексивная АСУ качеством подготовки менеджеров
включает ряд обеспечивающих систем,
работа которых направлена на создание наиболее благоприятных условий для
выполнения основной функции этой АСУ, т.е. обеспечение международного уровня качества
образования. Это так называемые обеспечивающие подсистемы:
–
стратегическое управление (включая совершенствование организационной структуры
университета и демократизацию управления);
– управление
инновационной деятельностью (НИР, ОКР, внедрение);
– управление
информационными ресурсами (локальные и корпоративные сети, Internet);
– управление
планово-экономической, финансовой и хозяйственной деятельностью, и др.
Необходимо
также отметить, что рефлексивная АСУ
качеством подготовки менеджеров работает в определенной окружающей
среде, которая, в частности, включает:
–
социально-экономическую среду;
– рынок
труда;
– рынок
образовательных услуг;
– рынок
наукоемкой продукции.
Учитывая
вышесказанное, в данном исследовании предлагается следующая обобщенная модель рефлексивной АСУ качеством подготовки менеджеров,
включающую в качестве базовых подсистем
АСУ групп "А" и "Б", а также обеспечивающие подсистемы
(рисунок 108).
Необходимо
отметить, что двухуровневая схема рефлексивной АСУ качеством подготовки
менеджеров является обобщением структуры типовой АСУ для вуза, а не обобщением
структуры рефлексивной АСУ активными объектами [7]. Чтобы рассматривать ее
именно как рефлексивную АСУ необходимо иметь в виду, что и образовательный
процесс, и студент, являются активными
объектами и управляющие воздействия на них имеют информационный характер. При этом информационные потоки обуславливают
соответствующие финансовые, энергетические и вещественные потоки, изучаемые
методами логистики.
Рисунок 108. Обобщенная схема двухуровневой рефлексивной АСУ качеством
подготовки менеджеров
4.4.4.3. Двухуровневая рефлексивная АСУ качеством подготовки менеджеров, как АСУ ТП
в образовании: сходство и различие
Итак, объединение рефлексивных АСУ качеством подготовки
менеджеров групп "А" и "Б" приводит к схеме двухуровневой
АСУ. Из сравнения рефлексивной АСУ качеством подготовки менеджеров с
АСУ ТП, то можно сделать следующие выводы:
– аналогом сырья в вузе является абитуриент;
– объектом управления в вузе является студент, который
представляет собой систему несопоставимо более сложную, чем любая техническая
система или любой производственный процесс;
– технологический процесс в вузе – это образовательный
процесс, где использование технических средств является вспомогательным, а
основным является прямое воздействие профессорско-преподавательского состава.
Вуз, если
рассматривать его как производственную систему, имеет весьма специфический
конечный продукт – это выпускник, молодой менеджер.
Рефлексивная АСУ качеством подготовки
менеджеров имеет еще одну ярко выраженную специфическую особенность по
сравнению с АСУ ТП: эта особенность – очень
большая длительность технологического процесса "по выпуску одного
изделия", т.е. время прохождения студента вдоль обрабатывающих центров
(преподавателей) по образовательному конвейеру до выпускника (от 4 до 7 лет,
обычно 5 лет). В производственных АСУ ТП это время измеряется минутами,
реже часами или днями. Эта особенность привела к тому, что на различных стадиях
образовательного процесса традиционно сложились свои циклы управления, вложенные во внешний цикл управления
более высокого уровня, включающие образовательное управляющее воздействие и контроль
его результатов в течение каждого семестра или даже занятия. При этом сами
обрабатывающие центры (преподаватели) не автоматизированы и практически все
управляющее воздействие представляет собой "ручной труд".
Кроме того, в
связи с тем, что качество результата во многом предопределяется качеством
"сырья", т.е. абитуриентов, многие вузы пришли к тому, что создали
свои собственные системы довузовского образования или наладили тесные шефские
связи с уже существующими средними образовательными учреждениями.
Для повышения
качества образования также очень важно иметь регулярную, систематическую
информацию обратной связи о начале и
продолжении трудового пути выпускников, молодых менеджеров, об их оценке потребителями. Для получения подобной
информации вуз должен быть заинтересован в том, чтобы не терять связь со своими
выпускниками на протяжении их трудового и жизненного пути, организуя с этой
целью различные товарищества выпускников, регулярные встречи выпускников и т.п.
и т.д.
Следовательно,
создание учебных заведений нового типа, интегрирующих в единую систему системы
довузовского, вузовского и послевузовского образования, т.е. университетских комплексов, весьма
перспективно. Поэтому обобщенную схему двухуровневой рефлексивной АСУ качеством подготовки менеджеров, представленную на
рисунке 109, имеет смысл представить в виде "Технологической схемы
управления", более традиционной для АСУ ТП.
|
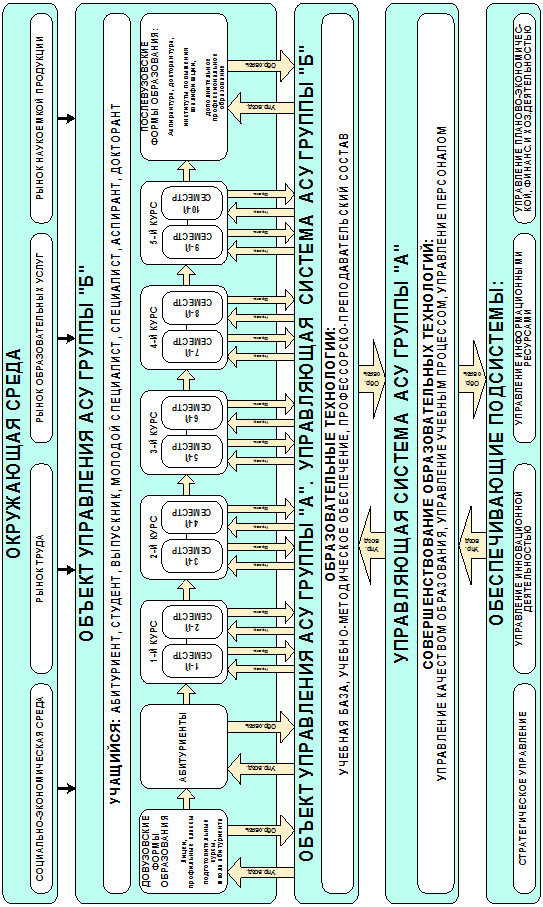
|
Рисунок 109. Детализированная
схема рефлексивной АСУ качеством подготовки менеджеров,
как двухуровневой АСУ ТП
|
Цель рефлексивной АСУ качеством подготовки менеджеров
Традиционно, цель применения АСУ можно представить в
виде некоторой суперпозиции трех
подцелей:
1.
Стабилизация состояния объекта управления в динамичной или агрессивной внешней
среде.
2. Перевод
объекта в некоторое конечное (целевое) состояние, в котором он приобретает
определенные заранее заданные свойства.
3. Повышение
качества функционирования самой АСУ (адаптация и синтез модели,
совершенствование технологии воздействия на объект управления в соответствии с
принципом дальности управления Фельдбаума).
Для рефлексивной АСУ качеством
подготовки менеджеров, очевидно, наиболее актуальными являются второй и
третий аспекты цели АСУ, причем если второй аспект реализуется путем применения
образовательных технологий, то третий – за счет реализации в составе рефлексивной АСУ качеством подготовки
менеджеров подсистемы управления образовательным процессом. На этом
моменте стоит остановиться подробнее. Если существующая образовательная
технология позволяет достичь поставленной перед ней цели, то она просто применяется
и эта задача решается. Если же нет, то задача превращается в проблему, которая
может быть решена только путем совершенствования самой образовательной технологии.
Как правило,
АСУ действует в определенной окружающей среде, которая является общей и для
субъекта, и для объекта управления (система управления находится вне среды
объекта управления в случае автоматизированных систем дистанционного
управления, рассмотрение которых выходит за рамки данной работы). Граница между тем, что считается окружающей
средой, и тем, что считается объектом управления относительна и зависит
от уровня развития технологий, т.к. определяется возможностью подсистемы
управления оказывать на них воздействие: на объект управления управляющее
воздействие может быть оказано, а на среду нет.
Окружающая
среда включает несколько "слоев": социально-экономическая среда;
рынок труда; рынок образовательных услуг; рынок наукоемкой продукции и т.д.
В
определенном аспекте студент, очевидно, может с полным основанием
рассматриваться как объект управления, на который преподавателями в течение
длительного времени систематически оказывается определенное целенаправленное
управляющее воздействие, призванное, в конце концов, превратить вчерашнего
школьника в профессионала в некоторой предметной области.
Конечно,
подобный подход является очень упрощенным, т.к. человек является не просто
сложнейшей системой обработки информации, но и обладает свободой воли.
С формальной
точки зрения это означает, что человек, как объект управления, представляет
собой активную систему. Внешние параметры подобных систем слабым и очень
сложным образом связаны с их результирующим (целевым) состоянием. Выразить в
аналитической форме эти зависимости в настоящее время практически не
представляется возможным. Эти обстоятельства привели к тому, что традиционные
подходы к синтезу систем управления состоянием человека, разрабатываемые в основном
в медицине, не дали ощутимых результатов. Сложноразрешимые проблемы возникают
как на этапе идентификации состояния объекта управления, так и на этапе
выработки управляющего воздействия.
Проблема обеспечения информационной безопасности является
системной и далеко выходит за рамки чисто технической или инженерной проблемы.
В частности вся серьезность возможных последствий ошибок в обеспечении
информационной безопасности часто не вполне осознается не только системным администратором,
но и руководством фирмы. Одной из причин этого, по-видимому, является то, что
примеры, приводящиеся в специальной литературе, редко бывают убедительными,
т.к. чаще всего описанные в них фирмы мало напоминают нашу конкретную небольшую
фирму. В тоже время для обоснованного принятия решения о целевом финансировании
работ по обеспечению информационной безопасности руководителю любой фирмы
необходима информация, как о стоимости этих работ, так и о возможных финансовых
и иных последствиях отказа от их проведения.
Однако проблема состоит в том, что получить подобную информацию
в настоящее время весьма затруднительно, т.к. на Российском рынке программного
обеспечения отсутствуют доступные небольшим фирмам и понятные рядовому
системному администратору и его руководителю методики оценки последствий ошибок
в конфигурировании системы безопасности их компьютеров.
Для определенности ограничимся рассмотрением системы
безопасности операционной системы MS Windows.
Одним из стандартных средств централизованной проверки
компьютеров под управлением MS Windows, которое традиционно применяется для
выявления типичных ошибок конфигурации системы безопасности и создания
отдельного отчета по результатам проверки каждого компьютера под управлением
операционной системы MS Windows, является Microsoft Baseline Security Analyzer
(MBSA).
Однако данное средство не содержит какого-либо
аппарата прогнозирования возможных последствий фактически имеющейся
конфигурации системы безопасности.
Поэтому для решения поставленной здесь проблемы требуется
разработка адаптивной методики прогнозирования возможных финансовых и иных
последствий ошибок в настройках системы информационной безопасности. Применение
АСК-анализа для решения поставленной проблемы рассматривается в работе [16].
Руководство любой небольшой торговой фирмы постоянно
решает проблему определения номенклатуры и объемов товаров, реализация которых
обеспечила бы увеличение прибыли и рентабельности фирмы при известных
ограничениях на оборотные средства, транспорт, складские и торговые помещения,
но при неизвестной емкости рынка.
При решении поставленной проблемы руководство традиционно
исходит из следующих простых и очевидных соображений, отражающих две крайние
ситуации:
– если закупить товары, которые не пользуются спросом,
то они не будут проданы и затраты на их приобретение, доставку, хранение и
попытку продажи станут убытками;
– если же закупать наиболее востребованные рынком
товары, то они будут реализованы, но это может и не увеличивать прибыль фирмы
или даже принести убытки, т.к. по этим товарам выручка может очень
незначительно покрывать или даже не покрывать затраты на их приобретение,
доставку, хранение и продажу.
Как правило, на практике традиционно закупаются те
товары и в тех количествах, которые были реализованы в предыдущий период.
Однако при этом остается открытым и нерешенным вопрос о том, насколько
номенклатура и объем этих товаров эффективны с точки зрения достижения цели
фирмы: повышения ее прибыли и рентабельности. Это означает, что традиционный способ
решения поставленной проблемы на неформализованном интуитивном уровне обычно не
позволяет решить ее достаточно эффективно.
Применение компьютерных технологий, в частности задачи
линейного программирования и других оптимизационных методов, для решения
подобных задач наталкивается на ряд сложностей связанных с тем, что как сами
математические модели, так и реализующий их программный инструментарий, а также
исходная информация для их использования не удовлетворяют сформулированным выше
требованиям:
– эти системы недостаточно технологичны для их применения
в небольших торговых фирмах;
– существующие системы разработаны за рубежом или в мегаполисах
(в основном в Москве и Санкт-Петербурге) и очень слабо отражают региональную
специфику и также специфику конкретной фирмы (т.е. не локализованы). Точнее
сказать – они вообще ее не отражают, из-за чего и имеют очень низкую достоверность
прогнозирования, близкую и статистически незначимо отличающуюся от вероятности
случайного угадывания без использования этих систем или другой априорной
информации. Этим обусловлена и низкая эффективность рекомендуемых ими решений;
– эти системы не обладают адаптивностью и не учитывают
динамику предметной области, которая чрезвычайно высока, особенно в Южном Федеральном
Округе (ЮФО). В результате даже первоначально хорошо работающие
(локализованные) системы очень быстро теряют адекватность модели и качество прогнозов
и рекомендуемых решений;
– стоимость этих систем настолько высока, что их
приобретение и использование чаще всего мало или вообще нерентабельно, особенно
для небольших торговых фирм.
Необходимо еще раз отметить, что если ограничения
фирмы известны ее руководству, то емкость рынка по номенклатуре товаров в сфере
действия фирмы, вообще говоря, остается неизвестной, что не позволяет применить
задачу линейного программирования. Для определения этой емкости обычно
необходимо регулярно проводить специальные достаточно дорогостоящие
маркетинговые исследования. Но даже если бы это удалось, то было бы получено
тривиальное решение: торговать одним товаром, обеспечивающим наибольшее
превышение выручки над затратами. Однако этого решение является неверным, т.к.
чтобы торговля этим товаром принесла прибыль, сопоставимую с прибылью от
торговли широким спектром товаров, он должен реализоваться в таких количествах,
которые обычно намного превышают реальный спрос на него. Кроме того, ясно, что
один товар, каким бы он не был замечательным, по своим потребительским
свойствам не может заменить спектра товаров.
Как это понятно, для решения поставленной здесь
проблемы тоже требуется разработка адаптивной методики прогнозирования влияния,
но уже номенклатуры и объемов реализуемой продукции на прибыль и рентабельность
фирмы, и, на этой основе, поддержки принятия решений о выборе таких сочетаний
этих факторов, которые обеспечили бы достижение цели фирмы. Применение
АСК-анализа для решения поставленной проблемы рассматривается в работе [16].
Как уже отмечалось во введении цель фирмы,
производящей те или иные виды продукции или оказывающей услуги, по крайней
мере, как ее осознает собственник, как правило, состоит в повышении прибыли, а
также рентабельности. Наиболее очевидным способом увеличения прибыли является простое
увеличение объема производства или оказанных услуг, т.е. экстенсивный путь,
основанный на увеличении затрат. Повышение рентабельности также позволяет
повысить прибыль, но без увеличения затрат, или получить ту же прибыль но с
меньшими затратами. По своему экономическому смыслу рентабельность представляет
собой эффективность используемого в фирме способа получения прибыли и обычно
увеличение рентабельности предполагает технологическую модернизацию
производства и его организации, внедрение инновационных технологий, т.е. его
интенсификацию, поэтому этот путь называется интенсивным. Таким образом, путь
достижения поставленной цели, а именно путь повышения прибыли фирмы, включает
много различных компонент, определяющей из которых является выбор конкретной
технологии, обеспечивающей получение заданного результата.
Подчеркнем еще раз, что сам путь от ситуации,
фактически сложившейся в фирме, к целевой ситуации, как правило, является
далеко не идеальным.
Руководство любой фирмы постоянно решает проблему поиска
и получения в свое распоряжение технологии, обеспечивающей увеличение прибыли и
рентабельности фирмы при имеющихся и известных руководству фирмы ограничениях
на оборотные средства, транспорт, сырье и материалы, средства их обработки,
складские и торговые помещения, и других ограничениях. Однако эта проблема
решается при неизвестной руководству емкости рынка на тот период будущего
времени, когда продукция будет произведена и предметно станет вопрос о ее
реализации.
При решении поставленной проблемы руководство традиционно
исходит из методик и рекомендаций, разработанных учеными и практиками для
подобных по объему и направлению деятельности фирм.
Однако при этом остается открытым и нерешенным вопрос
о том, насколько эти рекомендации эффективны с точки зрения достижения цели для
данной конкретной фирмы.
Будем предполагать, что эти методики и рекомендации разработаны
именно для достижения поставленной цели, а не какой-либо другой. Об этом
приходится говорить явно, т.к. такое несоответствие целей фирмы и целей методик
и рекомендаций на практике встречается сплошь и рядом.
Первый вопрос состоит в том, насколько полно и верно
эти методики и рекомендации учитывают как специфику конкретной фирмы, так и специфику
того региона, в котором данная фирма действует. Это вопрос о том, соответствуют
ли эти рекомендации месту их применения, т.е. о том, насколько они
локализованы.
Второй не менее важный вопрос – это вопрос о степени
соответствия этих методик и рекомендаций времени их применения, т.е. о том, как
полно и верно они отражают последние новейшие мировые и отечественные
достижения и тенденции в этой области, т.е. как они адаптированы ко времени их
предполагаемого применения.
Таким образом, методики и рекомендации,
удовлетворяющие всем сформулированным требованиям, практически недоступны
фирмам, чаще всего по той причине, что они просто не существуют или разработаны
давно и в основном за рубежом. В свою очередь создание их отечественных
аналогов или локализация и адаптация являются чрезвычайно наукоемким и дорогим
делом, да и коллективов, которые могли бы взяться за него, очень мало. Поэтому
на практике чаще всего применяются неадаптированные и нелокализованные
методики, созданные вообще для других целей, чем те, для достижения которых их
применяют. Это означает, что традиционный способ решения поставленной проблемы
– это ее решение на неформализованном уровне управления знаниями, т.к. почти
«вручную» или практически «на глазок», и обычно это не позволяет решить ее на
должном уровне и достаточно эффективно.
Применение компьютерных технологий для решения подобных
задач наталкивается на ряд сложностей связанных с тем, что как сами
математические модели, так и реализующий их программный инструментарий, а также
исходная информация для их использования не удовлетворяют сформулированным выше
требованиям.
Как это видно здесь опять возникает необходимость разработки
адаптивной методики, обеспечивающей:
– на основе анализа бизнес-процессов выявление знаний
о влиянии технологических факторов на объемы и качество производимой продукции и
оказанных услуг, а также на прибыль и рентабельность фирмы;
– использование этих знаний для прогнозирования и поддержки
принятия решений о выборе таких сочетаний технологических факторов, которые
обеспечили бы достижение цели фирмы.
Применение АСК-анализа для решения поставленной проблемы
рассматривается в работе [16].
Системно-когнитивный
анализ и система «Эйдос» позволяют разработать профессиограммы, т.е. на основе
ретроспективной базы данных определить, какие признаки респондентов (первичные,
устанавливаемые непосредственно, вторичные, т.е. расчетные) наиболее характерны
для работников, успешно работающих по тем или иным должностям [16]. Аналогично,
могут быть разработаны профессиограммы, отражающие успешность обучения по тем
или иным специальностям, дисциплинам и циклам дисциплин [16]. Во всех этих
случаях можно и решить задачу о назначениях, т.е. распределить кандидатов,
претендующих на ту или иную оплату труда (затраты), на должности, в
соответствии с ограничениями на фонд оплаты труда по этим должностям, причем
сделать это таким образом, что и для каждого работника, и по каждой должности,
и по организации в целом, будет получена максимальная польза.
Применение АСК-анализа для решения поставленной проблемы
рассматривается в работе [16].
Все сформулированные выше задачи были успешно решены
для рассмотренных здесь проблем управления фирмой. С описанием решений по
проблеме управления качеством подготовки специалистов можно ознакомиться в
работе [16], информационной безопасности [16], по проблеме определения
номенклатуры и объемов реализуемых товаров в [16], по проблеме выбора технологии
в [16], по управлению персоналом в [16].
Заключение
Таким образом, можно сделать следующие выводы:
1. Применение системно-когнитивного анализа и его
инструментария – системы «Эйдос» позволяет создать полнофункциональную двух
уровневую систему управлению качеством подготовки специалистов, на первом
уровне которой осуществляется управление учащимися с целью сделать их
специалистами, а на втором – управление учебным процессом с целью повышения его
эффективности.
2. Применение системно-когнитивного анализа для выявления
знаний о последствиях ошибок в конфигурировании системы безопасности по отчету
Microsoft Baseline Security Analyzer (MBSA) и использования этих знаний для
прогнозирования последствий дало желаемые результаты.
3. Применение системно-когнитивного анализа
бизнес-процессов реальной торговой фирмы позволило создать методики
прогнозирования и поддержки принятия решений по такому выбору номенклатуры и
объемов реализуемой продукции, которые обеспечивают получение максимальной
прибыли и рентабельности.
4. Применение системно-когнитивного анализа и его
инструментария – системы «Эйдос» позволило создать интеллектуальную
консалтинговую систему, обеспечивающую как выявление технологических знаний,
так и поддержку принятия решений по эффективному применению этих знаний с целью
достижения заданных показателей хозяйственно-экономической эффективности;
5.
Системно-когнитивный анализ и его инструментарий – система «Эйдос» являются
адекватным средством для решения для решения ранее не встречавшегося в
литературе обобщения задачи о назначениях персонала фирмы, учитывающего не
только различную потенциальную полезность сотрудников на разных должностях,
различные затраты на оплату труда сотрудников и фонды заработной платы
должностей, но и обеспечивающего автоматическое определение степени этой
полезности сотрудников на разных должностях на основе их признаков путем
решения задачи распознавания.
В заключение
автор выражает искреннюю благодарность ведущему российскому ученому и
организатору в области контроллинга профессору Сергею Григорьевичу Фалько за
мастер-класс, прошедший 15 октября 2010 на кафедре общего, стратегического и
информационного менеджмента Кубанского государственного университета,
вдохновивший авторов на написание этой работы.
4.5. Дисциплина: «Функционально-стоимостной
анализ системы и технологии управления персоналом (магистратура)»
В данном разделе на
примере применения функционально-стоимостного анализа для решения задачи
управления персоналом рассматривается задача
о назначениях (рюкзаках) в различных все более общих постановках, учитывающих:
1) размер грузов и объемы рюкзаков; 2) различную полезность грузов, зависящую
только от грузов, но одинаковую для всех рюкзаков, и различные затраты на их
размещение, а также ограничения на ресурсы, связанные с рюкзаками, затрачиваемые
на грузы при их размещении; 3) различную полезность каждого груза для разных
рюкзаков, различные затраты на размещение грузов и различные ресурсы хозяев
рюкзаков. Более подробно рассматриваются технология и методика применения
системно-когнитивного анализа и его инструментария – системы «Эйдос» для решения
ранее не встречавшегося в литературе обобщения задачи о назначениях,
обеспечивающего автоматическое прогнозирование степени полезности грузов для
разных рюкзаков на основе признаков грузов путем решения задачи распознавания с
применением модели, основанной на базе прецедентов.
Различные варианты
задачи о назначениях
часто встречаются в самых различных предметных областях, от управления запасами
на стационарных складах и воздушных, водных и подводных судах до управления
очередями заданий в различных системах массового обслуживания (СМО), например в
супермаркетах и многопроцессорных системах.
Рассмотрим на
уровне неформальной постановки и
алгоритмов решения различные варианты задачи о назначениях (рюкзаках или ранцах) во
все более общих постановках, учитывающих:
Задача-1: различные размеры грузов и объемы рюкзаков;
Задача-2: различную полезность
грузов, зависящую только от грузов и различные затраты на их размещение, а
также ограничения на ресурсы, связанные с рюкзаками, затрачиваемые на грузы при
их размещении;
Задача-3: различную полезность каждого груза для разных
рюкзаков, различные затраты на размещение грузов и различные ресурсы хозяев
рюкзаков.
Задача-4: тоже, что в 3-й задаче, плюс автоматическое прогнозирование
степени полезности грузов для разных рюкзаков на основе признаков этих грузов
путем решения задачи распознавания с применением модели, основанной на базе
прецедентов.
Для решения 4-й
задачи, впервые встречающейся в литературе, применим технологию и методику
системно-когнитивного анализа и его инструментарий – систему «Эйдос».
Задача-1.
Дано: размеры грузов и объемы рюкзаков;
Необходимо: разместить грузы по рюкзакам так, чтобы для размещения
наиболее важные грузы были размещены в первую очередь и при этом было
использовано минимальное количество рюкзаков, причем рюкзаки были максимально
заполнены (т.е. остатки пустого места минимальны). Будем считать, что важность
грузов пропорциональна их размерам.
Алгоритм решения
(LPT-longest processing time): Заполняем
рюкзак грузами в порядке убывания их размера до тех пор, пока не превышен объем
рюкзака, иначе берем самый большой новый пустой рюкзак и продолжаем процесс,
или подробнее по шагам:
Шаг-1. Сортируем
рюкзаки в прядке убывания их размеров.
Шаг-2. Сортируем
грузы в поинимальныны при этом рядке
убывания их размера.
Шаг-3. Организуем
цикл по рюкзакам в порядке убывания их размера.
Шаг-4. Размещаем
самый большой предмет из еще не размещенных, который помещается в оставшемся
свободном месте текущего рюкзака. Вычисляем остаток свободного места в рюкзаке.
Шаг-5. Если остаток
свободного места в текущем рюкзаке позволяет разместить в нем по крайней мере
самый маленький груз из еще не размещенных, то переход на шаг-4, иначе – на
шаг-6.
Шаг 6. Остались еще
остались незаполненные рюкзаки? Если да, то переход на шаг-7, иначе – на шаг-8.
Шаг-7. Берем
следующий (очередной) рюкзак, самый большой и оставшихся и переходим на шаг-4.
Шаг-8. Выход.
Задача-2
Дано:
– различная
полезность грузов;
– различные затраты
на размещение грузов;
– ограничения на
ресурсы, связанные с рюкзаками, затрачиваемые на грузы при их размещении.
Необходимо: разместить грузы по рюкзакам так, чтобы наиболее полезные
грузы были размещены в первую очередь и при этом было использовано минимальное
количество рюкзаков, причем рюкзаки имели максимальную суммарную полезность и
минимальный вес.
Алгоритм: Заполняем рюкзак грузами в порядке убывания их удельной полезности до тех пор, пока для
этого остаются ресурсы рюкзака, если же ресурсов нет, то берем следующий самый
большой по ресурсам новый пустой рюкзак и продолжаем процесс, или подробнее по
шагам:
Шаг-1. Находим
удельную полезность каждого груза (полезность/затраты),
т.е. полезность единицы затрат при размещении данного груза.
Шаг-2. Сортируем
грузы в порядке убывания удельной полезности.
Шаг-3. Сортируем
рюкзаки в прядке убывания их ресурсов.
Шаг-3. Организуем
цикл по рюкзакам в порядке убывания их ресурсов.
Шаг-4. Организуем
цикл по грузам в порядке убывания их удельной полезности.
Шаг-5. Размещаем
груз с наибольшей удельной полезностью из еще не размещенных, на который в
текущем рюкзаке есть ресурсы. Вычисляем остаток ресурсов рюкзака (вычитаем из его
текущих ресурсов затраты на размещение текущего груза).
Шаг-6. Если остаток
ресурсов текущего рюкзака позволяет разместить в нем по крайней мере груз с
наименьшими затратами из еще не размещенных, то переход на шаг-5, иначе – на
шаг-7.
Шаг 7. Остались еще
незаполненные рюкзаки? Если да, то переход на шаг-8, иначе – на шаг-9.
Шаг-8. Берем
следующий очередной рюкзак, самый большой по ресурсам из оставшихся, и
переходим на шаг-4.
Шаг-9. Выход.
Задача-3
Дано:
– различная
полезность каждого груза для разных рюкзаков;
– различные затраты
на размещение грузов;
– ограничения на
ресурсы, связанные с рюкзаками, затрачиваемые на грузы при их размещении.
Необходимо: разместить грузы по рюкзакам наиболее эффективно,
т.е. так, чтобы суммарная полезность всей системы рюкзаков была максимальна, а
суммарные затраты на размещение грузов – минимальны.
Алгоритм: Помещаем грузы в рюкзаки, для которых их удельная
полезность максимальна, до тех пор, пока не распределены все грузы и это
позволяют ресурсы рюкзаков, или подробнее по шагам:
Шаг-1. Находим
удельную полезность каждого груза для каждого рюкзака: (полезность для
рюкзака)/затраты, т.е. полезность единицы затрат для каждого варианта размещении каждого груза в
каждом рюкзаке.
Шаг-2. Сортируем варианты размещения грузов в порядке
убывания удельной полезности для всех
грузов и рюкзаков. В этой базе данных каждый груз будет встречаться столько
раз, сколько есть рюкзаков, но размещаться будет только один из них.
Шаг-3. Организуем
цикл по вариантам размещения грузов в порядке убывания их удельной полезности.
Шаг-5. Размещаем
груз с наибольшей удельной полезностью из еще не размещенных, в рюкзаке, для
которого удельная полезность максимальна при условии, что это позволяют ресурсы
рюкзака. Иначе данный вариант размещения больше не рассматривается. Вычисляем
остаток ресурсов рюкзака (вычитаем из его текущих ресурсов затраты на
размещение текущего груза).
Шаг-6. Остались еще
не рассмотренные варианты размещения грузов по рюкзакам? Если да – то переход
на шаг-5, иначе – на шаг 7.
Шаг-7. Выход.
Задача-4
Дано:
– различные
признаки грузов и база прецедентов, в которой содержится информация о том, на
сколько грузы с теми или иными признаками ранее были полезными (или нет) и для
тех или иных рюкзаков;
– различные затраты
на размещение грузов;
– ограничения на
ресурсы, связанные с рюкзаками, затрачиваемые на грузы при их размещении.
Необходимо:
– на основе базы
прецедентов (обучающей выборки) разработать модель, которая отражала бы влияние
признаков грузов на степень их полезности для различных рюкзаков;
– на основе
созданной модели определить или спрогнозировать степень полезности каждого
груза для каждого из рюкзаков, т.е. для каждого варианта размещения;
– разместить грузы
по рюкзакам наиболее эффективно, т.е. так, чтобы суммарная полезность всей
системы рюкзаков была максимальна, а суммарные затраты на размещение грузов – минимальны.
Обобщенный
алгоритм:
Этап-1. Синтез
модели, отражающей влияние признаков грузов на их полезность для разных
рюкзаков.
Этап-2.
Прогнозирование степени полезности грузов для разных рюкзаков на основе
признаков этих грузов путем решения задачи распознавания с применением модели,
основанной на базе прецедентов.
Этап-3. Размещение
грузов в рюкзаки, для которых их удельная полезность максимальна, до тех пор,
пока не распределены все грузы и это позволяют ресурсы рюкзаков, или подробнее
по шагам:
Возможны различные
подходы к решению этой задачи. Первые два этапа могут быть реализованы с
помощью различных технологий искусственного интеллекта. Известно, что
третий этап может быть реализован с применением методов линейного, нелинейного
и динамического программирования.
Однако у этих
подходов есть свои проблемы:
1.
Труднодоступность или фактическое отсутствие программного обеспечения,
позволяющего строить на основе прецедентов и применять для прогнозирования
модели влияния признаков объектов на
их полезность для различных применений.
2. Очень значительные затраты
вычислительных ресурсов (прежде всего времени) при решении подобных задач, даже
при очень ограниченных размерностях, весьма и далеких от реальных.
По поводу 1-й проблемы можно сказать, что не вполне ясен, даже чисто в
научном плане, общий подход к определению полезности, тем более в
количественной форме, тем более при большом количестве объектов и их применений
(классов). Таким образом, полезность даже определить трудно, но ясно одного определения
самого по себе еще совершенно недостаточно, т.к. для решения задачи на практике
необходимо еще и ввести эту полезность
в соответствующие базы данных, что вручную сделать в большинстве реальных
случаев практически невозможно. Следовательно, необходимо специальное программное
обеспечение, позволяющее не только количественно определять полезность
большого количества объектов для значительного количества их применений на
основе признаков этих объектов, но и автоматически вводить эту информацию
(наряду с другой, указанной в условиях задачи) в соответствующие базы данных, а
также имеющее режимы, непосредственно обеспечивающие решение задачи о
назначениях в универсальной форме, независящей от предметной области.
Причиной 2-й проблемы, т.е. большой
вычислительной трудоемкости решения подобных задач, по мнению авторов, является
так называемая проблема «комбинаторного взрыва». Поясним
эту проблему на шуточном примере, имеющим, те ни менее, v yb vtyttсамое непосредственное отношение ом примереак называемая проблема
комбинаторного взк рассматриваемым задачам.
Дано:
У Мальвины есть ящик разных яблок: больших и маленьких,
красных и зеленых, сладких и кислых, блестящих и матовых, ароматных и не очень
и т.д.
Буратино любит
большие сладкие, ароматные и блестящие красные яблоки, т.к. они веселят его, а
Пьеро больше нравятся маленькие,
кислые, матовые, зеленые и не очень ароматные яблоки, т.к. от них он становится
еще более грустным.
Но яблок, практически полностью удовлетворяющих этим
идеальным для Буратино и Пьеро стандартам, в ящике всего несколько, а остальные
занимают промежуточное между ними положение.
Мальвина решила немного подзаработать на этой ситуации
и для каждого яблока объявила свою цену по своему усмотрению.
Остается добавить, что и у Буратино, и у Пьеро еще
оставалось по нескольку золотых, которые они еще просто не успели или забыли
зарыть в стране дураков.
Необходимо:
так распределить яблоки между Буратино и Пьеро, чтобы на имеющиеся у каждого из
них деньги он получил максимум удовлетворения, т.е. чтобы суммарная польза от
распределения яблок была максимальна, а затраты минимальны.
Решение:
При попытке решения этой задачи методом прямого перебора
всех возможных вариантов распределения блок между Буратино и Пьеро даже при
небольшом количестве яблок возникает сложноразрешимая проблема комбинаторного взрыва:
– если бы яблоко было одно, то было бы всего два варианта,
кому его отдать (по числу подсистем);
– если появляется еще одно яблоко, то количество вариантов
удваивается, т.к. каждый из ранее существовавших вариантов «расщепляется» на
два в зависимости от того, кому отдано второе яблоко;
– третье яблоко приводит к расщеплению на два каждого
из вариантов, возникших на предыдущем этапе;
– и вообще, если дано N объектов, которые необходимо
распределить на две подсистемы, то получается 2 в степени N различных вариантов
этого распределения.
Если же еще появится Некто (с котором Буратино не
хотел делиться яблоками), то каждый предыдущий вариант будет расщепляться не на
2, а на 3 варианта. И вообще, если имеется K подсистем, по которым
распределяется N объектов, то возможно KN (K в степени N) различных
вариантов распределения. Это очень много даже для сравнительно небольшого
количества подсистем и распределяемых объектов. Например, существует 510=9765625
различных вариантов распределить 10 объектов по 5 классам. Поэтому необходим
какой-то нетривиальный подход, не основанный на полном переборе вариантов,
чтобы решить эту задачу.
Для решения сформулированных проблем в данной работе все эти этапы, включая и 3-й,
предлагается осуществлять с помощью системно-когнитивного анализа (СК-анализ) и
его инструментария – универсальной когнитивной аналитической системы «Эйдос»
(система «Эйдос») [7]. Алгоритм 3-го этапа не отличается от алгоритма задачи-3.
Сформулируем (на
неформальном уровне) общую постановку задачи о назначениях в традиционной
терминологии СК-анализа. Размещаемые грузы будем называть объектами или элементами,
а рюкзаки классами или подсистемами. В
качестве количественной меры «пользы» от размещения объекта в классе (для
самого класса и системы в целом) будем рассматривать сходство образа данного
конкретного объекта с обобщенным образом класса, т.е. по сути, количество
информации, содержащееся в системе признаков объекта о его принадлежности к
данному классу.
Дано:
1. Элементы имеют свойства и в разной степени подходят
для различных подсистем, но в какой именно степени подходят – это надо еще
определить (это задача распознавания).
2. На включение элементов в состав подсистем затрачиваются
определенные ресурсы подсистем, т.е. каждому элементу соответствуют затраты, а
подсистемам – ресурсы.
3. Все элементы различны.
4. Каждый элемент может быть назначен единственной подсистеме.
Необходимо:
максимизировать суммарный системный эффект (пользу) от распределения элементов
по подсистемам и желательно при этом минимизировать суммарные затраты.
Далее на условном
примере небольшой размерности рассмотрим подробнее как реализуются все эти
этапы в системе «Эйдос». Размерность примера выбрана таким образом, чтобы
необходимые базы данных можно было полностью привести в работе.
В режиме _154
(рисунок 110) сгенерируем случайную модель
с параметрами, представленными на рисунке 111:
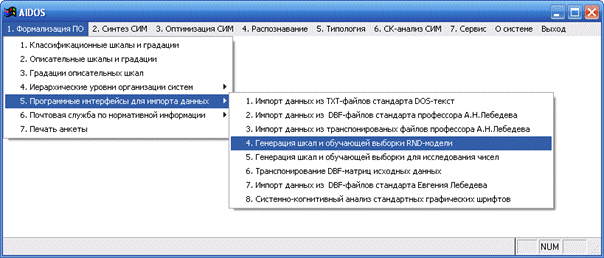
Рисунок 110. Экранная форма вызова режима _154
системы «Эйдос»
Рисунок 111. Параметры случайной модели
При каждом запуске
этого режима автоматически формируются разные случайные модели с заданными
параметрами. В примере, рассматриваем в данной работе, сформированы следующие
базы данных (таблицы 60-62):
Таблица 60 – Справочник классов
|
KOD
|
NAME
|
|
1
|
Klass_1
|
|
2
|
Klass_2
|
|
3
|
Klass_3
|
|
4
|
Klass_4
|
|
5
|
Klass_5
|
Таблица 61 – Справочник признаков
|
KOD
|
NAME
|
|
1
|
Atr_1
|
|
2
|
Atr_2
|
|
3
|
Atr_3
|
|
4
|
Atr_4
|
|
5
|
Atr_5
|
|
6
|
Atr_6
|
|
7
|
Atr_7
|
|
8
|
Atr_8
|
|
9
|
Atr_9
|
|
10
|
Atr_10
|
Таблица 62 – Обучающая выборка (база прецедентов)
|
Код
объекта
|
Наименование
объекта
|
Коды классов
|
Коды признаков
|
|
Klass1
|
Klass2
|
Klass3
|
Atr1
|
Atr2
|
Atr3
|
Atr4
|
Atr5
|
|
1
|
Ist-00001
|
2
|
3
|
4
|
2
|
3
|
5
|
6
|
8
|
|
2
|
Ist-00002
|
1
|
2
|
4
|
1
|
7
|
8
|
9
|
10
|
|
3
|
Ist-00003
|
1
|
3
|
5
|
1
|
2
|
3
|
4
|
6
|
|
4
|
Ist-00004
|
1
|
3
|
5
|
3
|
4
|
6
|
9
|
10
|
|
5
|
Ist-00005
|
1
|
2
|
4
|
5
|
6
|
7
|
8
|
10
|
|
6
|
Ist-00006
|
1
|
2
|
5
|
2
|
3
|
6
|
7
|
8
|
|
7
|
Ist-00007
|
1
|
4
|
5
|
1
|
3
|
5
|
6
|
9
|
|
8
|
Ist-00008
|
2
|
3
|
5
|
5
|
6
|
7
|
9
|
10
|
|
9
|
Ist-00009
|
2
|
3
|
5
|
1
|
3
|
5
|
6
|
8
|
|
10
|
Ist-00010
|
1
|
3
|
4
|
1
|
2
|
5
|
7
|
10
|
|
11
|
Ist-00011
|
1
|
3
|
4
|
1
|
2
|
3
|
8
|
9
|
|
12
|
Ist-00012
|
1
|
3
|
5
|
1
|
2
|
3
|
6
|
9
|
|
13
|
Ist-00013
|
2
|
3
|
4
|
1
|
4
|
5
|
7
|
10
|
|
14
|
Ist-00014
|
1
|
2
|
3
|
1
|
2
|
3
|
4
|
5
|
|
15
|
Ist-00015
|
1
|
2
|
5
|
1
|
3
|
7
|
9
|
10
|
|
16
|
Ist-00016
|
2
|
3
|
5
|
2
|
4
|
6
|
9
|
10
|
|
17
|
Ist-00017
|
1
|
2
|
4
|
4
|
6
|
8
|
9
|
10
|
|
18
|
Ist-00018
|
1
|
4
|
5
|
3
|
4
|
7
|
9
|
10
|
|
19
|
Ist-00019
|
1
|
3
|
4
|
1
|
2
|
4
|
7
|
8
|
|
20
|
Ist-00020
|
1
|
4
|
5
|
1
|
2
|
3
|
6
|
8
|
|
21
|
Ist-00021
|
1
|
3
|
5
|
2
|
3
|
4
|
8
|
10
|
|
22
|
Ist-00022
|
3
|
4
|
5
|
2
|
3
|
5
|
6
|
7
|
|
23
|
Ist-00023
|
1
|
3
|
5
|
4
|
6
|
8
|
9
|
10
|
|
24
|
Ist-00024
|
2
|
3
|
4
|
1
|
2
|
6
|
8
|
9
|
|
25
|
Ist-00025
|
2
|
4
|
5
|
1
|
3
|
4
|
6
|
7
|
|
26
|
Ist-00026
|
2
|
3
|
4
|
3
|
5
|
6
|
9
|
10
|
|
27
|
Ist-00027
|
2
|
3
|
4
|
1
|
4
|
5
|
7
|
10
|
|
28
|
Ist-00028
|
1
|
3
|
5
|
1
|
2
|
6
|
8
|
10
|
|
29
|
Ist-00029
|
1
|
2
|
5
|
1
|
2
|
3
|
6
|
8
|
|
30
|
Ist-00030
|
1
|
2
|
4
|
1
|
4
|
6
|
8
|
10
|
|
31
|
Ist-00031
|
1
|
3
|
4
|
1
|
6
|
7
|
8
|
9
|
|
32
|
Ist-00032
|
1
|
2
|
3
|
1
|
2
|
7
|
8
|
10
|
|
33
|
Ist-00033
|
2
|
3
|
5
|
1
|
3
|
5
|
8
|
9
|
|
34
|
Ist-00034
|
1
|
4
|
5
|
1
|
2
|
5
|
7
|
8
|
|
35
|
Ist-00035
|
1
|
4
|
5
|
3
|
5
|
6
|
7
|
10
|
|
36
|
Ist-00036
|
1
|
2
|
4
|
1
|
2
|
5
|
6
|
7
|
|
37
|
Ist-00037
|
1
|
3
|
4
|
5
|
7
|
8
|
9
|
10
|
|
38
|
Ist-00038
|
1
|
3
|
4
|
2
|
4
|
5
|
7
|
10
|
|
39
|
Ist-00039
|
1
|
2
|
3
|
1
|
2
|
6
|
9
|
10
|
|
40
|
Ist-00040
|
1
|
2
|
4
|
1
|
3
|
5
|
7
|
8
|
|
41
|
Ist-00041
|
1
|
3
|
5
|
3
|
4
|
7
|
8
|
9
|
|
42
|
Ist-00042
|
1
|
2
|
4
|
3
|
5
|
8
|
9
|
10
|
|
43
|
Ist-00043
|
2
|
4
|
5
|
2
|
6
|
8
|
9
|
10
|
|
44
|
Ist-00044
|
2
|
4
|
5
|
1
|
4
|
5
|
9
|
10
|
|
45
|
Ist-00045
|
1
|
2
|
5
|
1
|
2
|
4
|
6
|
8
|
|
46
|
Ist-00046
|
2
|
3
|
5
|
1
|
2
|
3
|
4
|
7
|
|
47
|
Ist-00047
|
2
|
3
|
5
|
1
|
2
|
5
|
7
|
8
|
|
48
|
Ist-00048
|
1
|
2
|
5
|
3
|
4
|
5
|
7
|
10
|
|
49
|
Ist-00049
|
3
|
4
|
5
|
3
|
4
|
6
|
8
|
9
|
|
50
|
Ist-00050
|
1
|
2
|
5
|
1
|
4
|
5
|
6
|
10
|
|
51
|
Ist-00051
|
1
|
2
|
5
|
2
|
4
|
5
|
6
|
10
|
|
52
|
Ist-00052
|
1
|
3
|
5
|
3
|
7
|
8
|
9
|
10
|
|
53
|
Ist-00053
|
2
|
4
|
5
|
1
|
3
|
8
|
9
|
10
|
|
54
|
Ist-00054
|
1
|
2
|
3
|
4
|
5
|
6
|
8
|
10
|
|
55
|
Ist-00055
|
1
|
2
|
5
|
2
|
3
|
4
|
5
|
9
|
|
56
|
Ist-00056
|
1
|
3
|
4
|
2
|
3
|
4
|
8
|
10
|
|
57
|
Ist-00057
|
2
|
3
|
5
|
2
|
3
|
4
|
6
|
9
|
|
58
|
Ist-00058
|
1
|
2
|
4
|
2
|
5
|
6
|
7
|
8
|
|
59
|
Ist-00059
|
1
|
2
|
3
|
3
|
4
|
8
|
9
|
10
|
|
60
|
Ist-00060
|
2
|
4
|
5
|
2
|
3
|
4
|
7
|
8
|
|
61
|
Ist-00061
|
1
|
3
|
4
|
2
|
4
|
8
|
9
|
10
|
|
62
|
Ist-00062
|
2
|
3
|
5
|
1
|
5
|
7
|
9
|
10
|
|
63
|
Ist-00063
|
1
|
2
|
3
|
2
|
6
|
8
|
9
|
10
|
|
64
|
Ist-00064
|
1
|
4
|
5
|
1
|
5
|
6
|
8
|
10
|
|
65
|
Ist-00065
|
1
|
3
|
5
|
2
|
3
|
7
|
8
|
10
|
|
66
|
Ist-00066
|
1
|
2
|
5
|
3
|
5
|
7
|
8
|
9
|
|
67
|
Ist-00067
|
1
|
2
|
3
|
5
|
6
|
8
|
9
|
10
|
|
68
|
Ist-00068
|
1
|
2
|
5
|
3
|
4
|
6
|
7
|
10
|
|
69
|
Ist-00069
|
2
|
3
|
5
|
3
|
4
|
5
|
6
|
10
|
|
70
|
Ist-00070
|
1
|
4
|
5
|
1
|
3
|
6
|
7
|
8
|
|
71
|
Ist-00071
|
1
|
4
|
5
|
1
|
3
|
4
|
7
|
10
|
|
72
|
Ist-00072
|
1
|
3
|
5
|
1
|
4
|
5
|
7
|
10
|
|
73
|
Ist-00073
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
74
|
Ist-00074
|
1
|
3
|
4
|
2
|
3
|
7
|
8
|
9
|
|
75
|
Ist-00075
|
2
|
3
|
5
|
1
|
3
|
4
|
8
|
10
|
|
76
|
Ist-00076
|
2
|
3
|
5
|
1
|
2
|
4
|
6
|
7
|
|
77
|
Ist-00077
|
3
|
4
|
5
|
3
|
4
|
5
|
8
|
9
|
|
78
|
Ist-00078
|
1
|
2
|
3
|
3
|
5
|
6
|
8
|
10
|
|
79
|
Ist-00079
|
1
|
2
|
3
|
1
|
5
|
6
|
8
|
9
|
|
80
|
Ist-00080
|
2
|
4
|
5
|
1
|
4
|
7
|
8
|
10
|
|
81
|
Ist-00081
|
1
|
2
|
4
|
1
|
4
|
5
|
6
|
7
|
|
82
|
Ist-00082
|
1
|
2
|
3
|
1
|
3
|
4
|
8
|
9
|
|
83
|
Ist-00083
|
2
|
3
|
4
|
1
|
3
|
7
|
9
|
10
|
|
84
|
Ist-00084
|
1
|
2
|
5
|
1
|
4
|
5
|
7
|
8
|
|
85
|
Ist-00085
|
3
|
4
|
5
|
2
|
3
|
6
|
7
|
8
|
|
86
|
Ist-00086
|
1
|
4
|
5
|
2
|
3
|
4
|
7
|
8
|
|
87
|
Ist-00087
|
1
|
3
|
5
|
5
|
6
|
7
|
8
|
9
|
|
88
|
Ist-00088
|
1
|
2
|
5
|
4
|
5
|
6
|
9
|
10
|
|
89
|
Ist-00089
|
1
|
3
|
5
|
1
|
2
|
3
|
9
|
10
|
|
90
|
Ist-00090
|
1
|
3
|
5
|
1
|
2
|
3
|
6
|
8
|
|
91
|
Ist-00091
|
1
|
3
|
4
|
1
|
2
|
6
|
8
|
10
|
|
92
|
Ist-00092
|
2
|
4
|
5
|
1
|
2
|
7
|
8
|
10
|
|
93
|
Ist-00093
|
2
|
3
|
5
|
1
|
4
|
5
|
9
|
10
|
|
94
|
Ist-00094
|
2
|
3
|
5
|
2
|
3
|
4
|
5
|
9
|
|
95
|
Ist-00095
|
2
|
3
|
4
|
1
|
2
|
4
|
5
|
7
|
|
96
|
Ist-00096
|
2
|
4
|
5
|
1
|
3
|
4
|
6
|
10
|
|
97
|
Ist-00097
|
1
|
2
|
4
|
2
|
4
|
5
|
7
|
10
|
|
98
|
Ist-00098
|
1
|
2
|
3
|
1
|
2
|
3
|
7
|
10
|
|
99
|
Ist-00099
|
1
|
4
|
5
|
1
|
3
|
8
|
9
|
10
|
|
100
|
Ist-00100
|
2
|
3
|
5
|
6
|
7
|
8
|
9
|
10
|
После формализации
предметной области был запущен режим _25 системы «Эйдос» (рисунок 112), который
сформировал базу абсолютных частот (таблица 63), базу знаний (таблица 64), а
также базу данных результатов идентификации образов конкретных объектов с
обобщенными образами классов (таблица 65):
Рисунок 112. Экранная форма выбора режима _25
системы «Эйдос»
Таблица 63 – База абсолютных частот
|
Коды признаков
|
Коды классов
|
|
1
|
2
|
3
|
4
|
5
|
|
1
|
34
|
35
|
30
|
28
|
32
|
|
2
|
31
|
25
|
31
|
22
|
26
|
|
3
|
34
|
28
|
31
|
24
|
39
|
|
4
|
30
|
33
|
28
|
21
|
32
|
|
5
|
29
|
34
|
26
|
22
|
24
|
|
6
|
34
|
33
|
29
|
22
|
32
|
|
7
|
33
|
30
|
26
|
29
|
29
|
|
8
|
43
|
33
|
35
|
31
|
32
|
|
9
|
28
|
27
|
31
|
19
|
27
|
|
10
|
39
|
37
|
33
|
27
|
32
|
Таблица 64 – База знаний (в сантибитах: Бит×0,01)
|
Коды
признаков
|
Коды классов
|
|
1
|
2
|
3
|
4
|
5
|
|
1
|
-1,380
|
1,495
|
-1,850
|
2,390
|
-0,326
|
|
2
|
0,883
|
-3,993
|
4,386
|
-0,072
|
-1,723
|
|
3
|
-0,775
|
-4,985
|
-0,204
|
-1,900
|
6,560
|
|
4
|
-2,207
|
2,773
|
-0,894
|
-3,598
|
2,820
|
|
5
|
-1,235
|
5,770
|
-1,198
|
-0,072
|
-4,264
|
|
6
|
0,470
|
1,477
|
-1,076
|
-3,417
|
1,524
|
|
7
|
0,164
|
-0,908
|
-3,902
|
5,995
|
-0,960
|
|
8
|
3,214
|
-3,235
|
0,182
|
2,759
|
-3,188
|
|
9
|
-1,635
|
-0,836
|
5,100
|
-4,013
|
0,189
|
|
10
|
1,228
|
1,511
|
-0,572
|
-0,513
|
-2,074
|
Режим _25 системы
«Эйдос» сформировал также базу данных результатов идентификации образов конкретных
объектов с обобщенными образами классов (таблица 68):
Таблица 65 – База данных результатов идентификации образов
конкретных объектов с обобщенными образами классов
|
Результаты
идентификации
объектов
с 1-м классом
|
Результаты
идентификации
объектов
со 2-м классом
|
Результаты
идентификации
объектов
с 3-м классом
|
Результаты
идентификации
объектов
с 4-м классом
|
Результаты
идентификации
объектов
с 5-м классом
|
|
Код объекта
|
Код класса
|
Сходство
|
Факт
|
Код объекта
|
Код класса
|
Сходство
|
Факт
|
Код объекта
|
Код класса
|
Сходство
|
Факт
|
Код объекта
|
Код класса
|
Сходство
|
Факт
|
Код объекта
|
Код класса
|
Сходство
|
Факт
|
|
65
|
1
|
61,8
|
√
|
50
|
2
|
76,6
|
√
|
61
|
3
|
56,8
|
√
|
34
|
4
|
72,0
|
√
|
25
|
5
|
62,1
|
√
|
|
28
|
1
|
58,4
|
√
|
44
|
2
|
63,5
|
√
|
43
|
3
|
55,6
|
|
47
|
4
|
72,0
|
|
57
|
5
|
60,6
|
√
|
|
91
|
1
|
58,4
|
√
|
93
|
2
|
63,5
|
√
|
63
|
3
|
55,6
|
√
|
32
|
4
|
69,4
|
|
4
|
5
|
58,5
|
√
|
|
43
|
1
|
55,4
|
|
88
|
2
|
63,4
|
√
|
11
|
3
|
52,8
|
√
|
92
|
4
|
69,4
|
√
|
3
|
5
|
57,5
|
√
|
|
63
|
1
|
55,4
|
√
|
13
|
2
|
63,1
|
√
|
57
|
3
|
50,7
|
√
|
40
|
4
|
61,3
|
√
|
96
|
5
|
55,4
|
√
|
|
32
|
1
|
54,8
|
√
|
27
|
2
|
63,1
|
√
|
55
|
3
|
49,8
|
|
10
|
4
|
52,7
|
√
|
49
|
5
|
51,8
|
√
|
|
92
|
1
|
54,8
|
|
72
|
2
|
63,1
|
|
94
|
3
|
49,8
|
√
|
19
|
4
|
51,2
|
√
|
68
|
5
|
51,6
|
√
|
|
6
|
1
|
53,1
|
√
|
81
|
2
|
62,9
|
√
|
16
|
3
|
48,1
|
√
|
84
|
4
|
51,2
|
|
18
|
5
|
43,6
|
√
|
|
85
|
1
|
53,1
|
|
54
|
2
|
49,8
|
√
|
89
|
3
|
47,6
|
√
|
80
|
4
|
48,6
|
√
|
46
|
5
|
42,6
|
√
|
|
5
|
1
|
51,7
|
√
|
51
|
2
|
45,5
|
√
|
24
|
3
|
46,7
|
√
|
2
|
4
|
46,2
|
√
|
12
|
5
|
41,7
|
√
|
|
58
|
1
|
47,7
|
√
|
62
|
2
|
42,6
|
√
|
12
|
3
|
44,1
|
√
|
65
|
4
|
44,1
|
|
82
|
5
|
40,7
|
|
|
100
|
1
|
47,1
|
|
64
|
2
|
42,5
|
|
39
|
3
|
41,5
|
√
|
98
|
4
|
42,0
|
|
71
|
5
|
40,5
|
√
|
|
78
|
1
|
40,9
|
√
|
8
|
2
|
42,5
|
√
|
74
|
3
|
38,6
|
√
|
70
|
4
|
41,5
|
√
|
41
|
5
|
36,9
|
√
|
|
1
|
1
|
36,9
|
|
69
|
2
|
39,8
|
√
|
59
|
3
|
25,1
|
√
|
58
|
4
|
37,8
|
√
|
69
|
5
|
31,8
|
√
|
|
20
|
1
|
35,2
|
√
|
84
|
2
|
36,1
|
√
|
42
|
3
|
23,0
|
|
36
|
4
|
35,6
|
√
|
59
|
5
|
30,2
|
|
|
29
|
1
|
35,2
|
√
|
73
|
2
|
36,0
|
√
|
49
|
3
|
21,6
|
√
|
5
|
4
|
35,2
|
√
|
75
|
5
|
27,1
|
√
|
|
90
|
1
|
35,2
|
√
|
38
|
2
|
31,9
|
|
77
|
3
|
20,8
|
√
|
95
|
4
|
34,6
|
√
|
7
|
5
|
26,5
|
√
|
|
21
|
1
|
34,4
|
√
|
97
|
2
|
31,9
|
√
|
21
|
3
|
20,1
|
√
|
13
|
4
|
32,0
|
√
|
70
|
5
|
26,0
|
√
|
|
56
|
1
|
34,4
|
√
|
95
|
2
|
31,8
|
√
|
56
|
3
|
20,1
|
√
|
27
|
4
|
32,0
|
√
|
55
|
5
|
25,8
|
√
|
|
64
|
1
|
33,9
|
√
|
67
|
2
|
29,3
|
√
|
17
|
3
|
19,0
|
|
72
|
4
|
32,0
|
|
94
|
5
|
25,8
|
√
|
|
52
|
1
|
32,7
|
√
|
79
|
2
|
29,2
|
√
|
23
|
3
|
19,0
|
√
|
37
|
4
|
31,7
|
√
|
60
|
5
|
25,4
|
√
|
|
67
|
1
|
30,9
|
√
|
5
|
2
|
28,9
|
√
|
53
|
3
|
18,5
|
|
62
|
4
|
29,5
|
|
86
|
5
|
25,4
|
√
|
|
74
|
1
|
28,7
|
√
|
48
|
2
|
26,3
|
√
|
99
|
3
|
18,5
|
|
31
|
4
|
29,1
|
√
|
15
|
5
|
24,7
|
√
|
|
37
|
1
|
27,4
|
√
|
30
|
2
|
25,5
|
√
|
67
|
3
|
16,9
|
√
|
6
|
4
|
27,0
|
|
83
|
5
|
24,7
|
|
|
70
|
1
|
26,9
|
√
|
10
|
2
|
24,7
|
|
4
|
3
|
16,4
|
√
|
85
|
4
|
27,0
|
√
|
14
|
5
|
22,8
|
|
|
34
|
1
|
26,4
|
√
|
36
|
2
|
24,5
|
√
|
82
|
3
|
16,2
|
√
|
60
|
4
|
26,0
|
√
|
20
|
5
|
21,4
|
√
|
|
47
|
1
|
26,4
|
|
26
|
2
|
19,3
|
√
|
1
|
3
|
14,6
|
√
|
86
|
4
|
26,0
|
√
|
29
|
5
|
21,4
|
√
|
|
2
|
1
|
25,7
|
√
|
7
|
2
|
19,2
|
|
26
|
3
|
14,3
|
√
|
46
|
4
|
23,8
|
|
90
|
5
|
21,4
|
√
|
|
24
|
1
|
25,3
|
|
35
|
2
|
18,9
|
|
33
|
3
|
14,1
|
√
|
66
|
4
|
23,5
|
|
89
|
5
|
20,1
|
√
|
|
61
|
1
|
24,5
|
√
|
37
|
2
|
15,7
|
|
20
|
3
|
10,0
|
|
74
|
4
|
23,5
|
√
|
21
|
5
|
18,7
|
√
|
|
54
|
1
|
24,3
|
√
|
96
|
2
|
15,5
|
√
|
29
|
3
|
10,0
|
|
71
|
4
|
21,2
|
√
|
56
|
5
|
18,7
|
|
|
30
|
1
|
22,7
|
√
|
87
|
2
|
15,5
|
|
90
|
3
|
10,0
|
√
|
52
|
4
|
20,9
|
|
6
|
5
|
17,6
|
√
|
|
60
|
1
|
22,1
|
|
17
|
2
|
12,2
|
√
|
88
|
3
|
9,5
|
|
15
|
4
|
18,7
|
|
85
|
5
|
17,6
|
√
|
|
86
|
1
|
22,1
|
√
|
23
|
2
|
12,2
|
|
79
|
3
|
8,1
|
√
|
83
|
4
|
18,7
|
√
|
77
|
5
|
17,0
|
√
|
|
17
|
1
|
19,7
|
√
|
80
|
2
|
11,9
|
√
|
28
|
3
|
7,5
|
√
|
38
|
4
|
17,4
|
√
|
48
|
5
|
16,8
|
√
|
|
23
|
1
|
19,7
|
√
|
14
|
2
|
8,7
|
√
|
91
|
3
|
7,5
|
√
|
97
|
4
|
17,4
|
√
|
26
|
5
|
16,0
|
|
|
80
|
1
|
19,1
|
|
16
|
2
|
7,9
|
√
|
7
|
3
|
5,4
|
|
73
|
4
|
17,0
|
|
11
|
5
|
13,4
|
|
|
45
|
1
|
18,7
|
√
|
76
|
2
|
7,4
|
√
|
45
|
3
|
5,3
|
|
76
|
4
|
14,8
|
|
98
|
5
|
13,2
|
|
|
87
|
1
|
18,7
|
√
|
78
|
2
|
5,7
|
√
|
51
|
3
|
4,6
|
|
81
|
4
|
14,8
|
√
|
76
|
5
|
12,4
|
√
|
|
31
|
1
|
17,0
|
√
|
9
|
2
|
5,6
|
√
|
52
|
3
|
4,3
|
√
|
87
|
4
|
14,6
|
|
53
|
5
|
11,3
|
√
|
|
42
|
1
|
16,6
|
√
|
4
|
2
|
2,3
|
|
44
|
3
|
4,1
|
|
28
|
4
|
14,0
|
|
99
|
5
|
11,3
|
√
|
|
19
|
1
|
15,1
|
√
|
71
|
2
|
2,0
|
|
93
|
3
|
4,1
|
√
|
64
|
4
|
14,0
|
√
|
22
|
5
|
11,2
|
√
|
|
53
|
1
|
14,9
|
|
68
|
2
|
1,9
|
√
|
3
|
3
|
2,6
|
√
|
91
|
4
|
14,0
|
√
|
74
|
5
|
9,6
|
|
|
99
|
1
|
14,9
|
√
|
25
|
2
|
1,8
|
√
|
41
|
3
|
2,0
|
√
|
100
|
4
|
12,0
|
|
35
|
5
|
9,1
|
√
|
|
73
|
1
|
12,0
|
√
|
39
|
2
|
0,7
|
√
|
14
|
3
|
1,8
|
√
|
22
|
4
|
10,3
|
√
|
16
|
5
|
8,8
|
√
|
|
11
|
1
|
10,9
|
√
|
77
|
2
|
-0,3
|
|
66
|
3
|
-0,1
|
|
35
|
4
|
7,7
|
√
|
52
|
5
|
7,5
|
√
|
|
9
|
1
|
10,8
|
|
34
|
2
|
-2,3
|
|
65
|
3
|
-0,7
|
√
|
48
|
4
|
6,7
|
|
9
|
5
|
6,2
|
√
|
|
98
|
1
|
8,7
|
√
|
47
|
2
|
-2,3
|
√
|
100
|
3
|
-1,8
|
√
|
9
|
4
|
5,8
|
|
17
|
5
|
-0,0
|
|
|
75
|
1
|
8,3
|
|
58
|
2
|
-2,4
|
√
|
37
|
3
|
-2,6
|
√
|
20
|
4
|
5,8
|
√
|
23
|
5
|
-0,0
|
√
|
|
40
|
1
|
7,2
|
√
|
55
|
2
|
-4,6
|
√
|
60
|
3
|
-2,9
|
|
29
|
4
|
5,8
|
|
45
|
5
|
-1,0
|
√
|
|
35
|
1
|
5,7
|
√
|
94
|
2
|
-4,6
|
√
|
86
|
3
|
-2,9
|
|
90
|
4
|
5,8
|
|
33
|
5
|
-1,9
|
√
|
|
59
|
1
|
5,3
|
√
|
45
|
2
|
-5,8
|
√
|
18
|
3
|
-3,2
|
|
25
|
4
|
4,1
|
√
|
1
|
5
|
-2,2
|
|
|
66
|
1
|
4,3
|
√
|
42
|
2
|
-7,4
|
√
|
6
|
3
|
-4,1
|
|
41
|
4
|
2,7
|
|
81
|
5
|
-2,9
|
|
|
10
|
1
|
3,4
|
√
|
33
|
2
|
-7,5
|
√
|
85
|
3
|
-4,1
|
√
|
11
|
4
|
2,3
|
√
|
30
|
5
|
-3,1
|
|
|
39
|
1
|
2,3
|
√
|
40
|
2
|
-7,9
|
√
|
87
|
3
|
-6,1
|
√
|
33
|
4
|
2,3
|
|
65
|
5
|
-4,0
|
√
|
|
22
|
1
|
1,7
|
|
2
|
2
|
-8,6
|
√
|
2
|
3
|
-7,1
|
|
75
|
4
|
2,1
|
|
78
|
5
|
-4,3
|
|
|
79
|
1
|
0,8
|
√
|
100
|
2
|
-8,7
|
√
|
15
|
3
|
-9,8
|
|
53
|
4
|
-0,3
|
√
|
66
|
5
|
-5,7
|
√
|
|
51
|
1
|
-2,6
|
√
|
31
|
2
|
-8,8
|
|
83
|
3
|
-9,8
|
√
|
99
|
4
|
-0,3
|
√
|
88
|
5
|
-6,5
|
√
|
|
49
|
1
|
-3,4
|
|
75
|
2
|
-11,2
|
√
|
31
|
3
|
-10,6
|
√
|
45
|
4
|
-4,2
|
|
40
|
5
|
-8,8
|
|
|
8
|
1
|
-4,3
|
|
18
|
2
|
-11,2
|
|
58
|
3
|
-11,0
|
|
8
|
4
|
-4,7
|
|
50
|
5
|
-9,6
|
√
|
|
36
|
1
|
-5,3
|
√
|
22
|
2
|
-12,3
|
|
8
|
3
|
-11,3
|
√
|
24
|
4
|
-6,7
|
√
|
39
|
5
|
-10,1
|
|
|
68
|
1
|
-5,6
|
√
|
28
|
2
|
-13,0
|
|
32
|
3
|
-12,0
|
√
|
79
|
4
|
-6,7
|
|
31
|
5
|
-12,3
|
|
|
38
|
1
|
-6,1
|
√
|
91
|
2
|
-13,0
|
|
92
|
3
|
-12,0
|
|
30
|
4
|
-6,8
|
√
|
42
|
5
|
-12,4
|
|
|
97
|
1
|
-6,1
|
√
|
3
|
2
|
-15,7
|
|
22
|
3
|
-13,7
|
√
|
1
|
4
|
-8,7
|
√
|
19
|
5
|
-16,0
|
|
|
41
|
1
|
-7,0
|
√
|
15
|
2
|
-18,5
|
√
|
19
|
3
|
-14,3
|
√
|
78
|
4
|
-11,3
|
|
24
|
5
|
-16,8
|
|
|
16
|
1
|
-7,2
|
|
83
|
2
|
-18,5
|
√
|
98
|
3
|
-14,7
|
√
|
14
|
4
|
-12,0
|
|
44
|
5
|
-17,6
|
√
|
|
84
|
1
|
-9,3
|
√
|
61
|
2
|
-18,8
|
|
38
|
3
|
-15,0
|
√
|
21
|
4
|
-12,4
|
|
93
|
5
|
-17,6
|
√
|
|
89
|
1
|
-12,0
|
√
|
19
|
2
|
-19,3
|
|
97
|
3
|
-15,0
|
|
56
|
4
|
-12,4
|
√
|
51
|
5
|
-18,0
|
√
|
|
33
|
1
|
-13,6
|
|
66
|
2
|
-21,2
|
√
|
34
|
3
|
-16,4
|
|
68
|
4
|
-13,0
|
|
80
|
5
|
-18,1
|
√
|
|
26
|
1
|
-15,1
|
|
59
|
2
|
-24,5
|
√
|
47
|
3
|
-16,4
|
√
|
42
|
4
|
-14,8
|
√
|
61
|
5
|
-19,6
|
|
|
76
|
1
|
-16,6
|
|
82
|
2
|
-24,6
|
√
|
62
|
3
|
-16,7
|
√
|
18
|
4
|
-16,6
|
√
|
73
|
5
|
-20,1
|
|
|
15
|
1
|
-20,3
|
√
|
49
|
2
|
-24,7
|
|
46
|
3
|
-16,9
|
√
|
89
|
4
|
-17,0
|
|
95
|
5
|
-22,4
|
|
|
83
|
1
|
-20,3
|
|
1
|
2
|
-25,6
|
√
|
78
|
3
|
-19,7
|
√
|
82
|
4
|
-18,5
|
|
100
|
5
|
-22,8
|
√
|
|
12
|
1
|
-20,8
|
√
|
43
|
2
|
-26,2
|
√
|
10
|
3
|
-21,6
|
√
|
54
|
4
|
-21,3
|
|
13
|
5
|
-24,5
|
|
|
69
|
1
|
-21,7
|
|
63
|
2
|
-26,2
|
√
|
76
|
3
|
-23,0
|
√
|
50
|
4
|
-23,5
|
|
27
|
5
|
-24,5
|
|
|
77
|
1
|
-23,1
|
|
24
|
2
|
-26,3
|
√
|
75
|
3
|
-23,0
|
√
|
43
|
4
|
-23,8
|
√
|
72
|
5
|
-24,5
|
√
|
|
96
|
1
|
-23,4
|
|
32
|
2
|
-26,5
|
√
|
95
|
3
|
-23,8
|
√
|
63
|
4
|
-23,8
|
|
54
|
5
|
-26,8
|
|
|
82
|
1
|
-24,8
|
√
|
92
|
2
|
-26,5
|
√
|
54
|
3
|
-24,5
|
√
|
67
|
4
|
-23,8
|
|
43
|
5
|
-27,3
|
√
|
|
48
|
1
|
-25,3
|
√
|
57
|
2
|
-29,0
|
√
|
36
|
3
|
-25,1
|
|
61
|
4
|
-24,9
|
√
|
63
|
5
|
-27,3
|
|
|
62
|
1
|
-25,7
|
|
46
|
2
|
-29,3
|
√
|
69
|
3
|
-27,2
|
√
|
39
|
4
|
-26,0
|
|
8
|
5
|
-29,2
|
√
|
|
4
|
1
|
-26,4
|
√
|
53
|
2
|
-31,7
|
√
|
9
|
3
|
-28,6
|
√
|
44
|
4
|
-27,0
|
√
|
36
|
5
|
-30,2
|
|
|
71
|
1
|
-27,0
|
√
|
99
|
2
|
-31,7
|
|
30
|
3
|
-29,0
|
|
93
|
4
|
-27,0
|
|
28
|
5
|
-30,4
|
√
|
|
3
|
1
|
-27,4
|
√
|
70
|
2
|
-32,3
|
|
64
|
3
|
-31,1
|
|
3
|
4
|
-31,7
|
|
91
|
5
|
-30,4
|
|
|
50
|
1
|
-28,7
|
√
|
89
|
2
|
-36,0
|
|
96
|
3
|
-31,7
|
|
77
|
4
|
-33,0
|
√
|
84
|
5
|
-31,2
|
√
|
|
18
|
1
|
-29,9
|
√
|
12
|
2
|
-36,2
|
|
50
|
3
|
-38,6
|
|
7
|
4
|
-34,1
|
√
|
79
|
5
|
-32,1
|
|
|
57
|
1
|
-30,4
|
|
98
|
2
|
-36,4
|
√
|
5
|
3
|
-45,3
|
|
12
|
4
|
-34,1
|
|
38
|
5
|
-32,9
|
|
|
46
|
1
|
-30,9
|
|
41
|
2
|
-38,2
|
|
68
|
3
|
-45,9
|
|
96
|
4
|
-34,3
|
√
|
97
|
5
|
-32,9
|
|
|
88
|
1
|
-31,7
|
√
|
21
|
2
|
-42,4
|
|
48
|
3
|
-46,7
|
|
59
|
4
|
-35,6
|
|
2
|
5
|
-33,9
|
|
|
13
|
1
|
-32,3
|
|
56
|
2
|
-42,4
|
|
70
|
3
|
-47,3
|
|
51
|
4
|
-38,0
|
|
87
|
5
|
-35,9
|
√
|
|
27
|
1
|
-32,3
|
|
52
|
2
|
-45,4
|
|
73
|
3
|
-47,6
|
√
|
17
|
4
|
-44,6
|
√
|
62
|
5
|
-40,3
|
√
|
|
72
|
1
|
-32,3
|
√
|
20
|
2
|
-49,9
|
|
35
|
3
|
-48,0
|
|
23
|
4
|
-44,6
|
|
67
|
5
|
-42,6
|
|
|
25
|
1
|
-35,7
|
|
29
|
2
|
-49,9
|
√
|
40
|
3
|
-48,1
|
|
69
|
4
|
-48,8
|
|
32
|
5
|
-45,4
|
|
|
95
|
1
|
-36,3
|
|
90
|
2
|
-49,9
|
|
80
|
3
|
-48,6
|
|
55
|
4
|
-49,7
|
|
92
|
5
|
-45,4
|
√
|
|
81
|
1
|
-41,0
|
√
|
60
|
2
|
-56,1
|
√
|
71
|
3
|
-51,3
|
|
94
|
4
|
-49,7
|
|
64
|
5
|
-45,7
|
√
|
|
7
|
1
|
-45,3
|
√
|
86
|
2
|
-56,1
|
|
84
|
3
|
-52,9
|
|
26
|
4
|
-51,2
|
√
|
58
|
5
|
-47,4
|
|
|
14
|
1
|
-47,1
|
√
|
11
|
2
|
-63,0
|
|
25
|
3
|
-54,7
|
|
49
|
4
|
-52,7
|
√
|
5
|
5
|
-49,5
|
|
|
55
|
1
|
-50,1
|
√
|
65
|
2
|
-63,3
|
|
13
|
3
|
-58,1
|
√
|
16
|
4
|
-61,3
|
|
10
|
5
|
-51,8
|
|
|
94
|
1
|
-50,1
|
|
6
|
2
|
-63,5
|
√
|
27
|
3
|
-58,1
|
√
|
88
|
4
|
-61,3
|
|
37
|
5
|
-57,5
|
|
|
44
|
1
|
-53,1
|
|
85
|
2
|
-63,5
|
|
72
|
3
|
-58,1
|
√
|
57
|
4
|
-69,4
|
|
34
|
5
|
-58,5
|
√
|
|
93
|
1
|
-53,1
|
|
74
|
2
|
-76,6
|
|
81
|
3
|
-61,6
|
|
4
|
4
|
-72,0
|
|
47
|
5
|
-58,5
|
√
|
В нашем примере
режим _25 автоматически скопировал обучающую выборку в распознаваемую выбору,
но при реальном решении задачи о назначениях она вручную вводится в режиме _41,
а распознавание ее, т.е. количественное определение меры сходства всех объектов
со всеми классами, осуществляется в режиме _42 (рисунок 113):
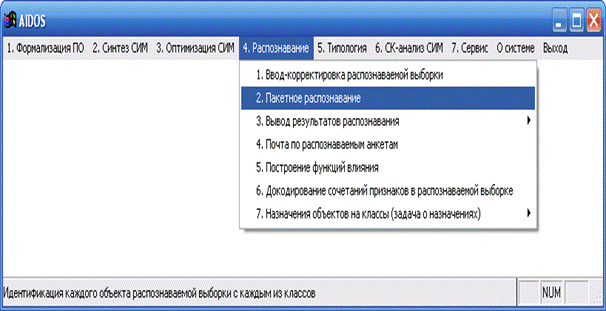
Рисунок 113. Экранная форма выбора режима _42
системы «Эйдос»
Когда эти базы
сформированы, запускается режим _47, обеспечивающий решение задачи о
назначениях (рисунок 114):
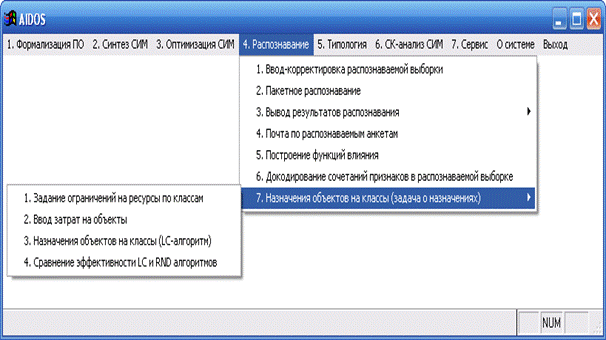
Рисунок 114. Экранная форма выбора режима _47
системы «Эйдос»
Далее в режиме _471
(рисунок 115) вводятся вручную или автоматически ресурсы классов, а в режиме
_472 (рисунок 116), также вручную или автоматически, затраты на объекты в результате
чего формируются базы данных, представленные в таблицах 66 и 67:
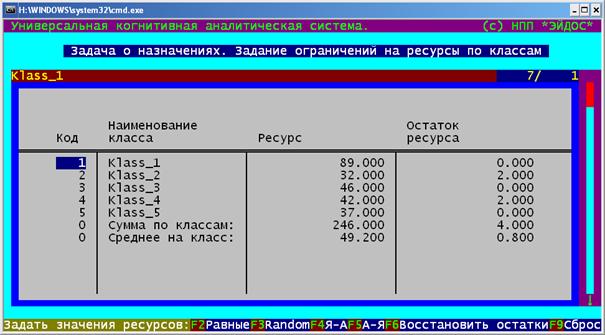
Рисунок 115. Экранная форма режима _471 ввода-корректировки
ресурсов классов
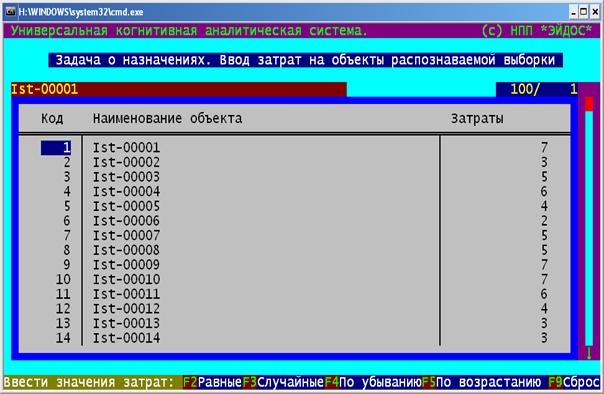
Рисунок 116. Экранная форма режима _472 ввода-корректировки
затрат объектов
Таблица 66 – база данных ресурсов классов
|
Код
класса
|
Наименование
класса
|
Ресурс
|
|
1
|
Klass_1
|
89,000
|
|
2
|
Klass_2
|
32,000
|
|
3
|
Klass_3
|
46,000
|
|
4
|
Klass_4
|
42,000
|
|
5
|
Klass_5
|
37,000
|
|
|
Сумма по классам:
|
246,000
|
|
|
Среднее на класс:
|
49,200
|
Таблица 67 – База данных затрат на объекты
|
KOD
|
NAME
|
ZATRATI
|
KOD
|
NAME
|
ZATRATI
|
|
1
|
Ist-00001
|
7
|
51
|
Ist-00051
|
9
|
|
2
|
Ist-00002
|
3
|
52
|
Ist-00052
|
10
|
|
3
|
Ist-00003
|
5
|
53
|
Ist-00053
|
6
|
|
4
|
Ist-00004
|
6
|
54
|
Ist-00054
|
8
|
|
5
|
Ist-00005
|
4
|
55
|
Ist-00055
|
10
|
|
6
|
Ist-00006
|
2
|
56
|
Ist-00056
|
9
|
|
7
|
Ist-00007
|
5
|
57
|
Ist-00057
|
4
|
|
8
|
Ist-00008
|
5
|
58
|
Ist-00058
|
2
|
|
9
|
Ist-00009
|
7
|
59
|
Ist-00059
|
4
|
|
10
|
Ist-00010
|
7
|
60
|
Ist-00060
|
10
|
|
11
|
Ist-00011
|
6
|
61
|
Ist-00061
|
3
|
|
12
|
Ist-00012
|
4
|
62
|
Ist-00062
|
6
|
|
13
|
Ist-00013
|
3
|
63
|
Ist-00063
|
4
|
|
14
|
Ist-00014
|
3
|
64
|
Ist-00064
|
4
|
|
15
|
Ist-00015
|
6
|
65
|
Ist-00065
|
8
|
|
16
|
Ist-00016
|
7
|
66
|
Ist-00066
|
4
|
|
17
|
Ist-00017
|
9
|
67
|
Ist-00067
|
7
|
|
18
|
Ist-00018
|
5
|
68
|
Ist-00068
|
7
|
|
19
|
Ist-00019
|
3
|
69
|
Ist-00069
|
10
|
|
20
|
Ist-00020
|
6
|
70
|
Ist-00070
|
3
|
|
21
|
Ist-00021
|
1
|
71
|
Ist-00071
|
4
|
|
22
|
Ist-00022
|
3
|
72
|
Ist-00072
|
5
|
|
23
|
Ist-00023
|
8
|
73
|
Ist-00073
|
5
|
|
24
|
Ist-00024
|
3
|
74
|
Ist-00074
|
5
|
|
25
|
Ist-00025
|
6
|
75
|
Ist-00075
|
8
|
|
26
|
Ist-00026
|
7
|
76
|
Ist-00076
|
10
|
|
27
|
Ist-00027
|
6
|
77
|
Ist-00077
|
8
|
|
28
|
Ist-00028
|
5
|
78
|
Ist-00078
|
9
|
|
29
|
Ist-00029
|
5
|
79
|
Ist-00079
|
6
|
|
30
|
Ist-00030
|
5
|
80
|
Ist-00080
|
3
|
|
31
|
Ist-00031
|
6
|
81
|
Ist-00081
|
3
|
|
32
|
Ist-00032
|
5
|
82
|
Ist-00082
|
10
|
|
33
|
Ist-00033
|
8
|
83
|
Ist-00083
|
5
|
|
34
|
Ist-00034
|
4
|
84
|
Ist-00084
|
3
|
|
35
|
Ist-00035
|
8
|
85
|
Ist-00085
|
5
|
|
36
|
Ist-00036
|
5
|
86
|
Ist-00086
|
5
|
|
37
|
Ist-00037
|
7
|
87
|
Ist-00087
|
5
|
|
38
|
Ist-00038
|
7
|
88
|
Ist-00088
|
8
|
|
39
|
Ist-00039
|
7
|
89
|
Ist-00089
|
7
|
|
40
|
Ist-00040
|
8
|
90
|
Ist-00090
|
1
|
|
41
|
Ist-00041
|
7
|
91
|
Ist-00091
|
9
|
|
42
|
Ist-00042
|
2
|
92
|
Ist-00092
|
3
|
|
43
|
Ist-00043
|
2
|
93
|
Ist-00093
|
5
|
|
44
|
Ist-00044
|
5
|
94
|
Ist-00094
|
3
|
|
45
|
Ist-00045
|
7
|
95
|
Ist-00095
|
1
|
|
46
|
Ist-00046
|
8
|
96
|
Ist-00096
|
7
|
|
47
|
Ist-00047
|
4
|
97
|
Ist-00097
|
1
|
|
48
|
Ist-00048
|
9
|
98
|
Ist-00098
|
9
|
|
49
|
Ist-00049
|
1
|
99
|
Ist-00099
|
4
|
|
50
|
Ist-00050
|
4
|
100
|
Ist-00100
|
10
|
Варианты
автоматического формирования и ввода в базы данных ресурсов и затрат в этих
режимах видны из рисунков 115 и 116.
После ввода
ресурсов классов и затрат на объекты запускается режим _473 (рисунок 117),
который собственно и осуществляет назначения объектов на классы согласно
алгоритма задачи 4, т.е. максимизируя пользу по классам и в целом по системе и
при этом минимизируя остатки ресурсов классов, затраты по классам и общие
затраты.
В результате работы
данного режима формируются выходные формы, представленная в таблицах 68 и 69:
Таблица 68 – База данных ресурсов классов
|
Код
класса
|
Наименование
класса
|
Ресурс
|
Остаток
ресурса
|
Количество
объектов
|
Суммарная
польза
|
Сумма
затрат
|
Средне-
взвешенная
удельная
польза
|
Средняя
польза
|
Средние
затраты
|
|
1
|
Klass_1
|
89,000
|
0,000
|
17,000
|
712,5022397
|
89,000
|
8,0056431
|
41,9118965
|
5,235
|
|
2
|
Klass_2
|
32,000
|
2,000
|
8,000
|
467,2168469
|
30,000
|
15,5738949
|
58,4021059
|
3,750
|
|
3
|
Klass_3
|
46,000
|
0,000
|
11,000
|
518,6988525
|
46,000
|
11,2760620
|
47,1544411
|
4,182
|
|
4
|
Klass_4
|
42,000
|
2,000
|
11,000
|
617,5542042
|
40,000
|
15,4388551
|
56,1412913
|
3,636
|
|
5
|
Klass_5
|
37,000
|
0,000
|
9,000
|
408,5936439
|
37,000
|
11,0430715
|
45,3992938
|
4,111
|
|
|
Сумма
по классам:
|
246,000
|
4,000
|
56,000
|
2724,5657872
|
242,000
|
61,3375266
|
249,0090286
|
20,914
|
|
|
Среднее
на класс:
|
49,200
|
0,800
|
11,200
|
544,9131574
|
48,400
|
12,2675053
|
49,8018057
|
4,183
|
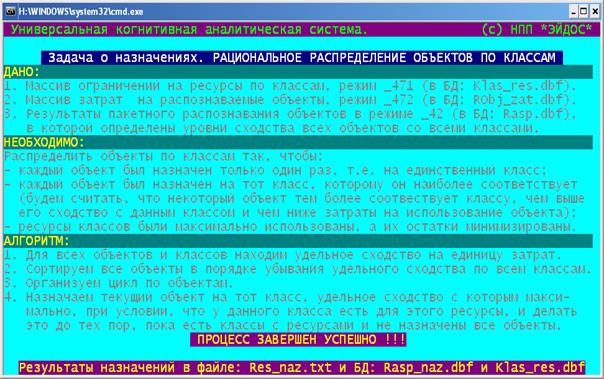
Рисунок 117. Экранная форма режима _473
назначения объектов на классы
Таблица 69 – Результаты назначений объектов
распознаваемой выборки на классы
13-08-09 11:25:35 г.Краснодар
==========================================================================
|ХАРАКТЕРИСТИКИ
ЭФФЕКТИВНОСТИ НАЗНАЧЕНИЯ: |
|СУММА ПО ВСЕМ
КЛАССАМ:
|
|Начальный ресурс:
246, остаток: 4 |
|Суммарное сходство:................................2724.5657872 |
|Фактические
суммарные затраты:.....................242 |
|Средневзвешенное
удельное сходство:................61.3375266 |
|Среднее на объект
суммарное сходство:..............249.0090286 |
|Средние на объект
фактические суммарные затраты:...21 |
|Всего
назначено:...................................56 объекта(ов) |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|СРЕДНЕЕ НА
КЛАСС:
|
|Начальный ресурс:
49.200, остаток: 0.800 |
|Суммарное сходство:................................544.9131574 |
|Фактические
суммарные затраты:.....................48.400 |
|Средневзвешенное
удельное сходство:................12.2675053 |
|Среднее на объект
суммарное сходство:..............49.8018057 |
|Средние на объект
фактические суммарные затраты:...4.183 |
|В среднем на
класс назначено:......................11.200 объекта(ов) |
==========================================================================
|КЛАСС
НАЗНАЧЕНИЯ:
|
|Код: 1,
наименование: Klass_1, начальный ресурс: 89, остаток: 0 |
|Суммарное сходство:................................712.5022397 |
|Фактические
суммарные затраты:.....................89 |
|Средневзвешенное
удельное сходство:................8.0056431 |
|Среднее на объект
суммарное сходство:..............41.9118965 |
|Средние на объект
фактические суммарные затраты:...5.235 |
|Всего на данный
класс назначено:...................17 объекта(ов): |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по
пор.|объекта| объекта |об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
90 |Ist-00090 | 35.2205677| 1|
35.2205677|
| 2 |
21 |Ist-00021 | 34.4137661| 1|
34.4137661|
| 3 |
6 |Ist-00006 | 53.0519770| 2|
26.5259885|
| 4 |
58 |Ist-00058 | 47.7400114| 2|
23.8700057|
| 5 |
5 |Ist-00005 | 51.7322895| 4|
12.9330724|
| 6 |
28 |Ist-00028 | 58.3606532| 5|
11.6721306|
| 7 |
85 |Ist-00085 | 53.0519770| 5|
10.6103954|
| 8 |
65 |Ist-00065 | 61.8074476| 8| 7.7259310|
| 9 |
29 |Ist-00029 | 35.2205677| 5| 7.0441135|
| 10 |
91 |Ist-00091 |
58.3606532| 9| 6.4845170|
| 11 |
20 |Ist-00020 | 35.2205677| 6| 5.8700946|
| 12 |
1 |Ist-00001 | 36.8947308| 7| 5.2706758|
| 13 |
100 |Ist-00100 | 47.1043333| 10| 4.7104333|
| 14 |
78 |Ist-00078 | 40.8870089| 9| 4.5430010|
| 15 |
30 |Ist-00030 | 22.6644450| 5| 4.5328890|
| 16 |
86 |Ist-00086 | 22.1189613| 5| 4.4237923|
| 17 |
87 |Ist-00087 | 18.6522823| 5| 3.7304565|
==========================================================================
|КЛАСС
НАЗНАЧЕНИЯ:
|
|Код: 2,
наименование: Klass_2, начальный ресурс: 32, остаток: 2 |
|Суммарное сходство:................................467.2168469 |
|Фактические
суммарные затраты:.....................30 |
|Средневзвешенное
удельное сходство:................15.5738949 |
|Среднее на объект
суммарное сходство:..............58.4021059 |
|Средние на объект
фактические суммарные затраты:...3.750 |
|Всего на данный
класс назначено:...................8 объекта(ов): |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по
пор.|объекта| объекта |об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
97 |Ist-00097 | 31.9232794| 1|
31.9232794|
| 2 |
13 |Ist-00013 | 63.1013633| 3|
21.0337878|
| 3 |
81 |Ist-00081 | 62.9062481| 3|
20.9687494|
| 4
| 50 |Ist-00050 |
76.6495522| 4| 19.1623881|
| 5 |
44 |Ist-00044 | 63.5108619| 5|
12.7021724|
| 6 |
93 |Ist-00093 | 63.5108619| 5|
12.7021724|
| 7 |
72 |Ist-00072 | 63.1013633| 5|
12.6202727|
| 8 |
64 |Ist-00064 | 42.5133168| 4|
10.6283292|
==========================================================================
|КЛАСС
НАЗНАЧЕНИЯ: |
|Код: 3,
наименование: Klass_3, начальный ресурс: 46, остаток: 0 |
|Суммарное сходство:................................518.6988525 |
|Фактические
суммарные затраты:.....................46 |
|Средневзвешенное
удельное сходство:................11.2760620 |
|Среднее на объект
суммарное сходство:..............47.1544411 |
|Средние на объект
фактические суммарные затраты:...4.182 |
|Всего на данный
класс назначено:...................11 объекта(ов): |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по
пор.|объекта| объекта |об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
43 |Ist-00043 | 55.5838012| 2|
27.7919006|
| 2 |
61 |Ist-00061 | 56.8425916| 3|
18.9475305|
| 3 |
94 |Ist-00094 | 49.8391402| 3|
16.6130467|
| 4 |
24 |Ist-00024 | 46.7424653| 3|
15.5808218|
| 5 |
63 |Ist-00063 | 55.5838012| 4|
13.8959503|
| 6 |
42 |Ist-00042 | 22.9821121| 2|
11.4910561|
| 7 |
12 |Ist-00012 | 44.0710764| 4|
11.0177691|
| 8 |
11 |Ist-00011 | 52.7766247| 6| 8.7961041|
| 9 |
74 |Ist-00074 | 38.5802769| 5| 7.7160554|
| 10 |
16 |Ist-00016 | 48.1370433| 7| 6.8767205|
| 11 |
89 |Ist-00089 | 47.5599196| 7| 6.7942742|
==========================================================================
|КЛАСС
НАЗНАЧЕНИЯ: |
|Код: 4,
наименование: Klass_4, начальный ресурс: 42, остаток: 2 |
|Суммарное сходство:................................617.5542042 |
|Фактические
суммарные затраты:.....................40 |
|Средневзвешенное
удельное сходство:................15.4388551 |
|Среднее на объект
суммарное сходство:..............56.1412913 |
|Средние на объект
фактические суммарные затраты:...3.636 |
|Всего на данный
класс назначено:...................11 объекта(ов): |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по
пор.|объекта| объекта |об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
95 |Ist-00095 | 34.5572497| 1|
34.5572497|
| 2 |
92 |Ist-00092 | 69.4227545| 3|
23.1409182|
| 3 |
34 |Ist-00034 |
72.0227334| 4| 18.0056834|
| 4 |
47 |Ist-00047 | 72.0227334| 4|
18.0056834|
| 5 |
19 |Ist-00019 | 51.2415712| 3|
17.0805237|
| 6 |
84 |Ist-00084 | 51.2415712| 3|
17.0805237|
| 7 |
80 |Ist-00080 | 48.6415923| 3|
16.2138641|
| 8 |
2 |Ist-00002 | 46.1955575| 3|
15.3985192|
| 9 |
32 |Ist-00032 | 69.4227545| 5|
13.8845509|
| 10 |
70 |Ist-00070 | 41.5353662| 3|
13.8451221|
| 11 |
40 |Ist-00040 | 61.2503203| 8| 7.6562900|
==========================================================================
|КЛАСС
НАЗНАЧЕНИЯ:
|
|Код: 5,
наименование: Klass_5, начальный ресурс: 37, остаток: 0 |
|Суммарное сходство:................................408.5936439 |
|Фактические
суммарные затраты:.....................37 |
|Средневзвешенное
удельное сходство:................11.0430715 |
|Среднее на объект
суммарное сходство:..............45.3992938 |
|Средние на объект
фактические суммарные затраты:...4.111 |
|Всего на данный
класс назначено:...................9 объекта(ов): |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по
пор.|объекта| объекта |об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
49 |Ist-00049 | 51.8183980| 1|
51.8183980|
| 2 |
57 |Ist-00057 | 60.6187779| 4|
15.1546945|
| 3 |
3 |Ist-00003 | 57.5283765| 5|
11.5056753|
| 4 |
25 |Ist-00025 | 62.1137448| 6|
10.3522908|
| 5 |
71 |Ist-00071 | 40.4988661| 4|
10.1247165|
| 6 |
4 |Ist-00004 | 58.5112721| 6|
9.7518787|
| 7 |
18 |Ist-00018 | 43.5892675| 5| 8.7178535|
| 8 |
14 |Ist-00014 | 22.7546711| 3| 7.5848904|
| 9 |
22 |Ist-00022 | 11.1602699| 3| 3.7200900|
==========================================================================
===============================================
|СПИСОК
НЕНАЗНАЧЕННЫХ ОБЪЕКТОВ: |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование | Затраты на |
|по
пор.|объекта| объекта |назн. объекта|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
7 |Ist-00007 | 5|
| 2 |
8 |Ist-00008 | 5|
| 3 |
9 |Ist-00009 | 7|
| 4 |
10 |Ist-00010 | 7|
| 5 |
15 |Ist-00015 | 6|
| 6 |
17 |Ist-00017 | 9|
| 7 |
23 |Ist-00023 | 8|
| 8 |
26 |Ist-00026 | 7|
| 9 |
27 |Ist-00027 |
6|
| 10 |
31 |Ist-00031 | 6|
| 11 |
33 |Ist-00033 | 8|
| 12 |
35 |Ist-00035 | 8|
| 13 |
36 |Ist-00036 | 5|
| 14 |
37 |Ist-00037 | 7|
| 15 |
38 |Ist-00038 | 7|
| 16 |
39 |Ist-00039 | 7|
| 17 |
41 |Ist-00041 | 7|
| 18 |
45 |Ist-00045 | 7|
| 19 |
46 |Ist-00046 | 8|
| 20 |
48 |Ist-00048 | 9|
| 21 |
51 |Ist-00051 | 9|
| 22 |
52 |Ist-00052 | 10|
| 23 |
53 |Ist-00053 | 6|
| 24 |
54 |Ist-00054 | 8|
| 25 |
55 |Ist-00055 |
10|
| 26 |
56 |Ist-00056 | 9|
| 27 |
59 |Ist-00059 | 4|
| 28 |
60 |Ist-00060 | 10|
| 29 |
62 |Ist-00062 | 6|
| 30 |
66 |Ist-00066 | 4|
| 31 |
67 |Ist-00067 | 7|
| 32 |
68 |Ist-00068 | 7|
| 33 |
69 |Ist-00069 | 10|
| 34 |
73 |Ist-00073 | 5|
| 35 |
75 |Ist-00075 | 8|
| 36 |
76 |Ist-00076 | 10|
| 37 |
77 |Ist-00077 | 8|
| 38 |
79 |Ist-00079 | 6|
| 39 |
82 |Ist-00082 | 10|
| 40 |
83 |Ist-00083 | 5|
| 41 |
88 |Ist-00088 |
8|
| 42 |
96 |Ist-00096 | 7|
| 43 |
98 |Ist-00098 | 9|
| 44 |
99 |Ist-00099 | 4|
===============================================
Универсальная
когнитивная аналитическая система
НПП *ЭЙДОС*
Итак, выполнено
назначение объектов на классы, максимизирующее пользу по классам и в целом по
системе и при этом минимизирующее остатки ресурсов классов, затраты по классам
и общие затраты, при заданных затратах на каждый объект и ограничениях на
ресурсы классов.
Теперь остается
рассмотреть вопрос об эффективности этого назначения, как по времени,
затраченному на расчет, так и по его результатам. Ведь не нужно забывать о том,
что для него использован эвристический, а не оптимизизационный алгоритм, т.е.
ожидается хороший, рациональный вариант назначения, но его оптимальность строго
не доказана и неизвестно, реализуется ли она.
Что касается времени расчета при той размерности задачи,
которая используется в качестве примера в работе, т.е. 5 классов и 100
объектов, то оно занимает не более нескольких десятых долей секунды
(субъективно оценивается как «мгновенно»). Более точную оценку времени
исполнения мы дадим чуть позже. Необходимо отметить, что количество вариантов
распределения 100 объектов по 5 классам составляет огромное число 5100,
которое настолько велико, что даже не может быть вычислено стандартными
средствами (например в Excel или на калькуляторе).
Конечно, наиболее
убедительную оценку качества результатов распределения согласно предложенного
алгоритма могло быть дать их сравнение с результатами распределения с использованием
оптимизационного метода. Однако, сделать это не представляется возможным из-за
ранее сформулированных проблем: труднодоступности соответствующего программного
обеспечения и очень больших затрат времени на расчет. Поэтому предлагается
сравнить результаты распределения с случайными распределениями (которые
используются в качестве «контрольной группы» или «базы сравнения»), когда
объекты назначаются на классы случайным образом. С целью осуществления такого
сравнения в системе «Эйдос» реализован специальный режим _474 (рисунок 118):
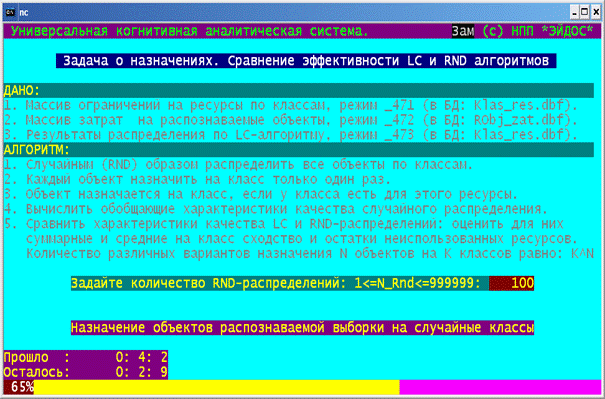
Рисунок 118. Экранная форма режима _474 системы «Эйдос»
С использованием
данного режима сгенерировано 100 случайных распределений 100 объектов по 5
классам. При этом затраты на объекты и ресурсы классов взяты из баз данных рассматриваемого
в работе примера.
Генерация этих 100
случайных примеров назначения проводилось в режиме _474 практически по тому же
алгоритму, что и реальное назначение в режиме _473 с тем лишь отличием, что
вместо пользы объектов для классов, определенной системой «Эйдос» на основе
базы прецедентов по признакам объектов, использовалась равномерно
распределенная случайная величина. Обобщенные результаты случайных
распределений и их сравнение с результатами работы LC-алгоритма приведены в
таблицах 70 и 71:
Таблица 70 – Суммарные результаты случайных распределений
и их сравнение с результатами работы LC-алгоритма
|
Наименование
|
Ресурс
|
Остаток
ресурса
|
Количество
объектов
|
Суммарная
польза
|
Сумма
затрат
|
Средне-
взвешенная
удельная
польза
|
Средняя
польза
|
Средние
затраты
|
|
Сумма по классам RND-распределения 1:
|
246,00
|
1,00
|
48,00
|
1337,55
|
245,00
|
28,47
|
141,30
|
25,06
|
|
Сумма по классам RND-распределения 2:
|
246,00
|
5,00
|
47,00
|
1333,13
|
241,00
|
26,93
|
140,92
|
26,55
|
|
Сумма по классам RND-распределения 3:
|
246,00
|
1,00
|
47,00
|
1335,69
|
245,00
|
27,48
|
147,26
|
27,02
|
|
Сумма по классам RND-распределения 4:
|
246,00
|
2,00
|
48,00
|
1319,55
|
244,00
|
27,67
|
135,57
|
26,52
|
|
Сумма по классам RND-распределения 5:
|
246,00
|
0,00
|
48,00
|
1082,86
|
246,00
|
23,28
|
113,05
|
24,86
|
|
Сумма по классам RND-распределения 6:
|
246,00
|
1,00
|
46,00
|
1184,75
|
245,00
|
24,19
|
129,85
|
26,83
|
|
Сумма по классам RND-распределения 7:
|
246,00
|
0,00
|
49,00
|
1392,75
|
246,00
|
28,86
|
144,68
|
25,53
|
|
Сумма по классам RND-распределения 8:
|
246,00
|
1,00
|
45,00
|
1433,77
|
245,00
|
30,07
|
164,93
|
27,60
|
|
Сумма по классам RND-распределения 9:
|
246,00
|
2,00
|
45,00
|
1144,47
|
244,00
|
24,32
|
124,96
|
26,59
|
|
Сумма по классам RND-распределения 10:
|
246,00
|
1,00
|
46,00
|
1235,11
|
245,00
|
23,74
|
126,54
|
27,15
|
|
Сумма по классам RND-распределения 11:
|
246,00
|
3,00
|
47,00
|
1235,82
|
243,00
|
25,05
|
131,00
|
26,68
|
|
Сумма по классам RND-распределения 12:
|
246,00
|
2,00
|
46,00
|
1150,55
|
244,00
|
25,19
|
126,40
|
26,04
|
|
Сумма по классам RND-распределения 13:
|
246,00
|
0,00
|
46,00
|
1443,05
|
246,00
|
31,34
|
162,17
|
26,15
|
|
Сумма по классам RND-распределения 14:
|
246,00
|
2,00
|
47,00
|
1377,03
|
244,00
|
30,07
|
153,09
|
25,84
|
|
Сумма по классам RND-распределения 15:
|
246,00
|
4,00
|
45,00
|
1071,00
|
242,00
|
21,57
|
113,22
|
27,27
|
|
Сумма по классам RND-распределения 16:
|
246,00
|
2,00
|
48,00
|
1352,60
|
244,00
|
28,64
|
141,21
|
25,08
|
|
Сумма по классам RND-распределения 17:
|
246,00
|
0,00
|
46,00
|
1192,05
|
246,00
|
24,38
|
132,99
|
27,34
|
|
Сумма по классам RND-распределения 18:
|
246,00
|
4,00
|
47,00
|
1305,87
|
242,00
|
25,90
|
131,19
|
27,66
|
|
Сумма по классам RND-распределения 19:
|
246,00
|
4,00
|
48,00
|
1276,37
|
242,00
|
26,19
|
130,96
|
25,08
|
|
Сумма по классам RND-распределения 20:
|
246,00
|
0,00
|
47,00
|
1364,36
|
246,00
|
28,74
|
148,78
|
26,62
|
|
Сумма по классам RND-распределения 21:
|
246,00
|
1,00
|
49,00
|
1467,36
|
245,00
|
32,90
|
153,76
|
24,74
|
|
Сумма по классам RND-распределения 22:
|
246,00
|
3,00
|
46,00
|
1263,43
|
243,00
|
25,27
|
135,44
|
27,24
|
|
Сумма по классам RND-распределения 23:
|
246,00
|
2,00
|
47,00
|
1483,08
|
244,00
|
28,89
|
152,49
|
27,24
|
|
Сумма по классам RND-распределения 24:
|
246,00
|
4,00
|
47,00
|
1350,79
|
242,00
|
29,40
|
146,97
|
25,90
|
|
Сумма по классам RND-распределения 25:
|
246,00
|
5,00
|
42,00
|
912,46
|
241,00
|
18,68
|
108,12
|
29,21
|
|
Сумма по классам RND-распределения 26:
|
246,00
|
2,00
|
47,00
|
1453,99
|
244,00
|
31,79
|
170,61
|
27,18
|
|
Сумма по классам RND-распределения 27:
|
246,00
|
6,00
|
50,00
|
1474,66
|
240,00
|
32,06
|
148,25
|
23,43
|
|
Сумма по классам RND-распределения 28:
|
246,00
|
3,00
|
47,00
|
1354,09
|
243,00
|
29,53
|
156,32
|
26,93
|
|
Сумма по классам RND-распределения 29:
|
246,00
|
2,00
|
45,00
|
1194,80
|
244,00
|
26,17
|
131,29
|
27,18
|
|
Сумма по классам RND-распределения 30:
|
246,00
|
3,00
|
49,00
|
1320,09
|
243,00
|
27,27
|
132,84
|
24,75
|
|
Сумма по классам RND-распределения 31:
|
246,00
|
0,00
|
46,00
|
1375,79
|
246,00
|
26,50
|
142,02
|
27,87
|
|
Сумма по классам RND-распределения 32:
|
246,00
|
1,00
|
47,00
|
1245,26
|
245,00
|
26,04
|
133,22
|
26,50
|
|
Сумма по классам RND-распределения 33:
|
246,00
|
1,00
|
49,00
|
1241,44
|
245,00
|
25,27
|
124,00
|
24,71
|
|
Сумма по классам RND-распределения 34:
|
246,00
|
1,00
|
46,00
|
1433,66
|
245,00
|
29,70
|
156,91
|
26,99
|
|
Сумма по классам RND-распределения 35:
|
246,00
|
1,00
|
48,00
|
1308,69
|
245,00
|
28,40
|
140,32
|
25,49
|
|
Сумма по классам RND-распределения 36:
|
246,00
|
3,00
|
47,00
|
1186,47
|
243,00
|
22,82
|
122,27
|
27,22
|
|
Сумма по классам RND-распределения 37:
|
246,00
|
3,00
|
50,00
|
1405,86
|
243,00
|
28,23
|
133,53
|
24,77
|
|
Сумма по классам RND-распределения 38:
|
246,00
|
2,00
|
45,00
|
1131,40
|
244,00
|
24,44
|
131,54
|
26,98
|
|
Сумма по классам RND-распределения 39:
|
246,00
|
1,00
|
48,00
|
1286,78
|
245,00
|
25,38
|
130,82
|
26,19
|
|
Сумма по классам RND-распределения 40:
|
246,00
|
0,00
|
51,00
|
1419,23
|
246,00
|
29,27
|
139,29
|
23,92
|
|
Сумма по классам RND-распределения 41:
|
246,00
|
1,00
|
45,00
|
1181,37
|
245,00
|
24,75
|
135,71
|
27,88
|
|
Сумма по классам RND-распределения 42:
|
246,00
|
0,00
|
49,00
|
1259,25
|
246,00
|
25,89
|
123,92
|
25,23
|
|
Сумма по классам RND-распределения 43:
|
246,00
|
3,00
|
48,00
|
1200,58
|
243,00
|
23,36
|
117,87
|
26,13
|
|
Сумма по классам RND-распределения 44:
|
246,00
|
1,00
|
46,00
|
1296,91
|
245,00
|
27,31
|
143,35
|
26,52
|
|
Сумма по классам RND-распределения 45:
|
246,00
|
2,00
|
48,00
|
1204,11
|
244,00
|
25,06
|
129,57
|
26,10
|
|
Сумма по классам RND-распределения 46:
|
246,00
|
1,00
|
47,00
|
1270,15
|
245,00
|
26,50
|
135,34
|
25,89
|
|
Сумма по классам RND-распределения 47:
|
246,00
|
3,00
|
41,00
|
977,97
|
243,00
|
19,75
|
110,34
|
30,81
|
|
Сумма по классам RND-распределения 48:
|
246,00
|
0,00
|
47,00
|
1361,09
|
246,00
|
26,91
|
139,57
|
26,80
|
|
Сумма по классам RND-распределения 49:
|
246,00
|
1,00
|
48,00
|
1369,46
|
245,00
|
28,07
|
143,21
|
25,94
|
|
Сумма по классам RND-распределения 50:
|
246,00
|
2,00
|
50,00
|
1474,56
|
244,00
|
30,75
|
149,38
|
24,44
|
|
Сумма по классам RND-распределения 51:
|
246,00
|
1,00
|
51,00
|
1440,30
|
245,00
|
32,61
|
153,54
|
23,81
|
|
Сумма по классам RND-распределения 52:
|
246,00
|
2,00
|
46,00
|
1207,79
|
244,00
|
24,99
|
132,45
|
27,07
|
|
Сумма по классам RND-распределения 53:
|
246,00
|
2,00
|
46,00
|
1339,79
|
244,00
|
28,04
|
145,81
|
27,00
|
|
Сумма по классам RND-распределения 54:
|
246,00
|
0,00
|
46,00
|
1230,21
|
246,00
|
23,26
|
125,24
|
27,10
|
|
Сумма по классам RND-распределения 55:
|
246,00
|
0,00
|
52,00
|
1568,95
|
246,00
|
33,32
|
153,27
|
23,67
|
|
Сумма по классам RND-распределения 56:
|
246,00
|
1,00
|
47,00
|
1367,95
|
245,00
|
26,09
|
135,18
|
27,04
|
|
Сумма по классам RND-распределения 57:
|
246,00
|
3,00
|
47,00
|
1233,70
|
243,00
|
25,71
|
130,14
|
26,00
|
|
Сумма по классам RND-распределения 58:
|
246,00
|
0,00
|
42,00
|
1293,03
|
246,00
|
26,50
|
152,81
|
29,75
|
|
Сумма по классам RND-распределения 59:
|
246,00
|
2,00
|
49,00
|
1286,35
|
244,00
|
26,89
|
131,97
|
24,65
|
|
Сумма по классам RND-распределения 60:
|
246,00
|
0,00
|
50,00
|
1374,77
|
246,00
|
28,67
|
143,03
|
24,83
|
|
Сумма по классам RND-распределения 61:
|
246,00
|
2,00
|
47,00
|
1421,14
|
244,00
|
31,38
|
153,01
|
25,30
|
|
Сумма по классам RND-распределения 62:
|
246,00
|
2,00
|
50,00
|
1427,58
|
244,00
|
29,72
|
144,71
|
25,81
|
|
Сумма по классам RND-распределения 63:
|
246,00
|
4,00
|
47,00
|
1034,05
|
242,00
|
21,56
|
109,90
|
26,63
|
|
Сумма по классам RND-распределения 64:
|
246,00
|
0,00
|
47,00
|
1442,41
|
246,00
|
30,42
|
153,76
|
25,40
|
|
Сумма по классам RND-распределения 65:
|
246,00
|
1,00
|
49,00
|
1562,19
|
245,00
|
30,90
|
155,11
|
25,42
|
|
Сумма по классам RND-распределения 66:
|
246,00
|
3,00
|
43,00
|
1101,76
|
243,00
|
20,12
|
117,85
|
29,59
|
|
Сумма по классам RND-распределения 67:
|
246,00
|
3,00
|
49,00
|
1419,75
|
243,00
|
30,31
|
150,90
|
24,96
|
|
Сумма по классам RND-распределения 68:
|
246,00
|
2,00
|
46,00
|
1461,10
|
244,00
|
30,12
|
158,81
|
26,37
|
|
Сумма по классам RND-распределения 69:
|
246,00
|
0,00
|
45,00
|
1283,34
|
246,00
|
25,78
|
137,29
|
27,21
|
|
Сумма по классам RND-распределения 70:
|
246,00
|
2,00
|
50,00
|
1390,90
|
244,00
|
28,43
|
135,46
|
25,18
|
|
Сумма по классам RND-распределения 71:
|
246,00
|
3,00
|
47,00
|
1318,17
|
243,00
|
25,93
|
130,03
|
27,62
|
|
Сумма по классам RND-распределения 72:
|
246,00
|
0,00
|
43,00
|
1199,83
|
246,00
|
22,94
|
131,41
|
29,54
|
|
Сумма по классам RND-распределения 73:
|
246,00
|
1,00
|
49,00
|
1499,65
|
245,00
|
31,64
|
158,98
|
25,19
|
|
Сумма по классам RND-распределения 74:
|
246,00
|
1,00
|
48,00
|
1268,48
|
245,00
|
25,77
|
129,26
|
26,32
|
|
Сумма по классам RND-распределения 75:
|
246,00
|
0,00
|
47,00
|
1338,61
|
246,00
|
27,70
|
141,88
|
26,98
|
|
Сумма по классам RND-распределения 76:
|
246,00
|
0,00
|
46,00
|
1134,79
|
246,00
|
20,81
|
114,72
|
27,87
|
|
Сумма по классам RND-распределения 77:
|
246,00
|
2,00
|
48,00
|
1310,69
|
244,00
|
26,47
|
134,37
|
25,74
|
|
Сумма по классам RND-распределения 78:
|
246,00
|
3,00
|
45,00
|
1122,43
|
243,00
|
24,73
|
127,79
|
26,44
|
|
Сумма по классам RND-распределения 79:
|
246,00
|
2,00
|
46,00
|
1206,27
|
244,00
|
23,69
|
127,57
|
27,27
|
|
Сумма по классам RND-распределения 80:
|
246,00
|
0,00
|
49,00
|
1469,15
|
246,00
|
30,29
|
155,41
|
26,19
|
|
Сумма по классам RND-распределения 81:
|
246,00
|
0,00
|
46,00
|
1253,88
|
246,00
|
26,63
|
139,59
|
26,76
|
|
Сумма по классам RND-распределения 82:
|
246,00
|
1,00
|
45,00
|
971,91
|
245,00
|
18,91
|
102,90
|
27,55
|
|
Сумма по классам RND-распределения 83:
|
246,00
|
0,00
|
44,00
|
1302,34
|
246,00
|
26,76
|
148,66
|
28,24
|
|
Сумма по классам RND-распределения 84:
|
246,00
|
1,00
|
46,00
|
1304,72
|
245,00
|
26,53
|
147,42
|
27,49
|
|
Сумма по классам RND-распределения 85:
|
246,00
|
5,00
|
48,00
|
1364,88
|
241,00
|
26,97
|
136,91
|
25,97
|
|
Сумма по классам RND-распределения 86:
|
246,00
|
3,00
|
48,00
|
1255,29
|
243,00
|
26,90
|
132,98
|
25,57
|
|
Сумма по классам RND-распределения 87:
|
246,00
|
1,00
|
51,00
|
1323,92
|
245,00
|
26,35
|
129,54
|
24,75
|
|
Сумма по классам RND-распределения 88:
|
246,00
|
3,00
|
49,00
|
1405,94
|
243,00
|
30,77
|
141,11
|
25,13
|
|
Сумма по классам RND-распределения 89:
|
246,00
|
1,00
|
45,00
|
1361,47
|
245,00
|
29,55
|
152,78
|
26,78
|
|
Сумма по классам RND-распределения 90:
|
246,00
|
1,00
|
44,00
|
1036,20
|
245,00
|
22,66
|
121,81
|
27,89
|
|
Сумма по классам RND-распределения 91:
|
246,00
|
1,00
|
48,00
|
1401,40
|
245,00
|
29,46
|
147,33
|
25,25
|
|
Сумма по классам RND-распределения 92:
|
246,00
|
0,00
|
45,00
|
1385,08
|
246,00
|
27,94
|
150,72
|
26,91
|
|
Сумма по классам RND-распределения 93:
|
246,00
|
3,00
|
49,00
|
1183,22
|
243,00
|
26,38
|
128,46
|
25,08
|
|
Сумма по классам RND-распределения 94:
|
246,00
|
2,00
|
48,00
|
1417,80
|
244,00
|
27,81
|
144,07
|
26,38
|
|
Сумма по классам RND-распределения 95:
|
246,00
|
2,00
|
46,00
|
1227,37
|
244,00
|
24,68
|
133,60
|
27,87
|
|
Сумма по классам RND-распределения 96:
|
246,00
|
3,00
|
48,00
|
1343,12
|
243,00
|
27,93
|
143,96
|
25,82
|
|
Сумма по классам RND-распределения 97:
|
246,00
|
0,00
|
50,00
|
1543,65
|
246,00
|
32,33
|
155,89
|
24,40
|
|
Сумма по классам RND-распределения 98:
|
246,00
|
3,00
|
49,00
|
1633,35
|
243,00
|
33,88
|
169,17
|
25,45
|
|
Сумма по классам RND-распределения 99:
|
246,00
|
0,00
|
46,00
|
1187,66
|
246,00
|
24,67
|
131,48
|
26,60
|
|
Сумма по классам RND-распределения 100:
|
246,00
|
0,00
|
48,00
|
1097,35
|
246,00
|
22,49
|
110,71
|
25,78
|
|
Сумма по всем RND-распределениям:
|
24600,00
|
165,00
|
4711,00
|
130228,78
|
24435,00
|
2692,84
|
13799,08
|
2635,23
|
|
Среднее сумм по всем RND-распределениям:
|
246,00
|
1,65
|
47,11
|
1302,29
|
244,35
|
26,93
|
137,99
|
26,35
|
|
Ср.кв.откл. сумм по всем RND-распределениям:
|
0,00
|
1,40
|
2,02
|
135,97
|
1,40
|
3,21
|
13,96
|
1,33
|
|
Сумма из LC-распределения:
|
246,00
|
4,00
|
56,00
|
2724,57
|
242,00
|
61,34
|
249,01
|
20,91
|
|
Эффективность LC-алгоритма по сравнению с RND в
%:
|
100,00
|
242,42
|
118,87
|
209,21
|
99,04
|
227,78
|
180,45
|
79,36
|
Таблица 71 – Средние результаты случайных распределений
и их сравнение с результатами работы LC-алгоритма
|
Наименование
|
Ресурс
|
Остаток
ресурса
|
Количество
объектов
|
Суммарная
польза
|
Сумма
затрат
|
Средне-
взвешенная
удельная
польза
|
Средняя
польза
|
Средние
затраты
|
|
Среднее на класс RND-распределения 1:
|
49,20
|
0,20
|
9,60
|
267,51
|
49,00
|
5,69
|
28,26
|
5,01
|
|
Среднее на класс RND-распределения 2:
|
49,20
|
1,00
|
9,40
|
266,63
|
48,20
|
5,39
|
28,18
|
5,31
|
|
Среднее на класс RND-распределения 3:
|
49,20
|
0,20
|
9,40
|
267,14
|
49,00
|
5,50
|
29,45
|
5,40
|
|
Среднее на класс RND-распределения 4:
|
49,20
|
0,40
|
9,60
|
263,91
|
48,80
|
5,53
|
27,11
|
5,31
|
|
Среднее на класс RND-распределения 5:
|
49,20
|
0,00
|
9,60
|
216,57
|
49,20
|
4,66
|
22,61
|
4,97
|
|
Среднее на класс RND-распределения 6:
|
49,20
|
0,20
|
9,20
|
236,95
|
49,00
|
4,84
|
25,97
|
5,37
|
|
Среднее на класс RND-распределения 7:
|
49,20
|
0,00
|
9,80
|
278,55
|
49,20
|
5,77
|
28,94
|
5,11
|
|
Среднее на класс RND-распределения 8:
|
49,20
|
0,20
|
9,00
|
286,75
|
49,00
|
6,01
|
32,99
|
5,52
|
|
Среднее на класс RND-распределения 9:
|
49,20
|
0,40
|
9,00
|
228,89
|
48,80
|
4,86
|
24,99
|
5,32
|
|
Среднее на класс RND-распределения 10:
|
49,20
|
0,20
|
9,20
|
247,02
|
49,00
|
4,75
|
25,31
|
5,43
|
|
Среднее на класс RND-распределения 11:
|
49,20
|
0,60
|
9,40
|
247,16
|
48,60
|
5,01
|
26,20
|
5,34
|
|
Среднее на класс RND-распределения 12:
|
49,20
|
0,40
|
9,20
|
230,11
|
48,80
|
5,04
|
25,28
|
5,21
|
|
Среднее на класс RND-распределения 13:
|
49,20
|
0,00
|
9,20
|
288,61
|
49,20
|
6,27
|
32,43
|
5,23
|
|
Среднее на класс RND-распределения 14:
|
49,20
|
0,40
|
9,40
|
275,41
|
48,80
|
6,01
|
30,62
|
5,17
|
|
Среднее на класс RND-распределения 15:
|
49,20
|
0,80
|
9,00
|
214,20
|
48,40
|
4,31
|
22,64
|
5,46
|
|
Среднее на класс RND-распределения 16:
|
49,20
|
0,40
|
9,60
|
270,52
|
48,80
|
5,73
|
28,24
|
5,02
|
|
Среднее на класс RND-распределения 17:
|
49,20
|
0,00
|
9,20
|
238,41
|
49,20
|
4,88
|
26,60
|
5,47
|
|
Среднее на класс RND-распределения 18:
|
49,20
|
0,80
|
9,40
|
261,17
|
48,40
|
5,18
|
26,24
|
5,53
|
|
Среднее на класс RND-распределения 19:
|
49,20
|
0,80
|
9,60
|
255,27
|
48,40
|
5,24
|
26,19
|
5,02
|
|
Среднее на класс RND-распределения 20:
|
49,20
|
0,00
|
9,40
|
272,87
|
49,20
|
5,75
|
29,76
|
5,32
|
|
Среднее на класс RND-распределения 21:
|
49,20
|
0,20
|
9,80
|
293,47
|
49,00
|
6,58
|
30,75
|
4,95
|
|
Среднее на класс RND-распределения 22:
|
49,20
|
0,60
|
9,20
|
252,69
|
48,60
|
5,05
|
27,09
|
5,45
|
|
Среднее на класс RND-распределения 23:
|
49,20
|
0,40
|
9,40
|
296,62
|
48,80
|
5,78
|
30,50
|
5,45
|
|
Среднее на класс RND-распределения 24:
|
49,20
|
0,80
|
9,40
|
270,16
|
48,40
|
5,88
|
29,39
|
5,18
|
|
Среднее на класс RND-распределения 25:
|
49,20
|
1,00
|
8,40
|
182,49
|
48,20
|
3,74
|
21,62
|
5,84
|
|
Среднее на класс RND-распределения 26:
|
49,20
|
0,40
|
9,40
|
290,80
|
48,80
|
6,36
|
34,12
|
5,44
|
|
Среднее на класс RND-распределения 27:
|
49,20
|
1,20
|
10,00
|
294,93
|
48,00
|
6,41
|
29,65
|
4,69
|
|
Среднее на класс RND-распределения 28:
|
49,20
|
0,60
|
9,40
|
270,82
|
48,60
|
5,91
|
31,26
|
5,39
|
|
Среднее на класс RND-распределения 29:
|
49,20
|
0,40
|
9,00
|
238,96
|
48,80
|
5,23
|
26,26
|
5,44
|
|
Среднее на класс RND-распределения 30:
|
49,20
|
0,60
|
9,80
|
264,02
|
48,60
|
5,45
|
26,57
|
4,95
|
|
Среднее на класс RND-распределения 31:
|
49,20
|
0,00
|
9,20
|
275,16
|
49,20
|
5,30
|
28,40
|
5,58
|
|
Среднее на класс RND-распределения 32:
|
49,20
|
0,20
|
9,40
|
249,05
|
49,00
|
5,21
|
26,64
|
5,30
|
|
Среднее на класс RND-распределения 33:
|
49,20
|
0,20
|
9,80
|
248,29
|
49,00
|
5,05
|
24,80
|
4,94
|
|
Среднее на класс RND-распределения 34:
|
49,20
|
0,20
|
9,20
|
286,73
|
49,00
|
5,94
|
31,38
|
5,40
|
|
Среднее на класс RND-распределения 35:
|
49,20
|
0,20
|
9,60
|
261,74
|
49,00
|
5,68
|
28,06
|
5,10
|
|
Среднее на класс RND-распределения 36:
|
49,20
|
0,60
|
9,40
|
237,29
|
48,60
|
4,56
|
24,45
|
5,45
|
|
Среднее на класс RND-распределения 37:
|
49,20
|
0,60
|
10,00
|
281,17
|
48,60
|
5,65
|
26,71
|
4,95
|
|
Среднее на класс RND-распределения 38:
|
49,20
|
0,40
|
9,00
|
226,28
|
48,80
|
4,89
|
26,31
|
5,40
|
|
Среднее на класс RND-распределения 39:
|
49,20
|
0,20
|
9,60
|
257,36
|
49,00
|
5,08
|
26,16
|
5,24
|
|
Среднее на класс RND-распределения 40:
|
49,20
|
0,00
|
10,20
|
283,85
|
49,20
|
5,85
|
27,86
|
4,78
|
|
Среднее на класс RND-распределения 41:
|
49,20
|
0,20
|
9,00
|
236,27
|
49,00
|
4,95
|
27,14
|
5,58
|
|
Среднее на класс RND-распределения 42:
|
49,20
|
0,00
|
9,80
|
251,85
|
49,20
|
5,18
|
24,78
|
5,05
|
|
Среднее на класс RND-распределения 43:
|
49,20
|
0,60
|
9,60
|
240,12
|
48,60
|
4,67
|
23,57
|
5,23
|
|
Среднее на класс RND-распределения 44:
|
49,20
|
0,20
|
9,20
|
259,38
|
49,00
|
5,46
|
28,67
|
5,30
|
|
Среднее на класс RND-распределения 45:
|
49,20
|
0,40
|
9,60
|
240,82
|
48,80
|
5,01
|
25,91
|
5,22
|
|
Среднее на класс RND-распределения 46:
|
49,20
|
0,20
|
9,40
|
254,03
|
49,00
|
5,30
|
27,07
|
5,18
|
|
Среднее на класс RND-распределения 47:
|
49,20
|
0,60
|
8,20
|
195,59
|
48,60
|
3,95
|
22,07
|
6,16
|
|
Среднее на класс RND-распределения 48:
|
49,20
|
0,00
|
9,40
|
272,22
|
49,20
|
5,38
|
27,91
|
5,36
|
|
Среднее на класс RND-распределения 49:
|
49,20
|
0,20
|
9,60
|
273,89
|
49,00
|
5,61
|
28,64
|
5,19
|
|
Среднее на класс RND-распределения 50:
|
49,20
|
0,40
|
10,00
|
294,91
|
48,80
|
6,15
|
29,88
|
4,89
|
|
Среднее на класс RND-распределения 51:
|
49,20
|
0,20
|
10,20
|
288,06
|
49,00
|
6,52
|
30,71
|
4,76
|
|
Среднее на класс RND-распределения 52:
|
49,20
|
0,40
|
9,20
|
241,56
|
48,80
|
5,00
|
26,49
|
5,41
|
|
Среднее на класс RND-распределения 53:
|
49,20
|
0,40
|
9,20
|
267,96
|
48,80
|
5,61
|
29,16
|
5,40
|
|
Среднее на класс RND-распределения 54:
|
49,20
|
0,00
|
9,20
|
246,04
|
49,20
|
4,65
|
25,05
|
5,42
|
|
Среднее на класс RND-распределения 55:
|
49,20
|
0,00
|
10,40
|
313,79
|
49,20
|
6,66
|
30,65
|
4,73
|
|
Среднее на класс RND-распределения 56:
|
49,20
|
0,20
|
9,40
|
273,59
|
49,00
|
5,22
|
27,04
|
5,41
|
|
Среднее на класс RND-распределения 57:
|
49,20
|
0,60
|
9,40
|
246,74
|
48,60
|
5,14
|
26,03
|
5,20
|
|
Среднее на класс RND-распределения 58:
|
49,20
|
0,00
|
8,40
|
258,61
|
49,20
|
5,30
|
30,56
|
5,95
|
|
Среднее на класс RND-распределения 59:
|
49,20
|
0,40
|
9,80
|
257,27
|
48,80
|
5,38
|
26,39
|
4,93
|
|
Среднее на класс RND-распределения 60:
|
49,20
|
0,00
|
10,00
|
274,95
|
49,20
|
5,73
|
28,61
|
4,97
|
|
Среднее на класс RND-распределения 61:
|
49,20
|
0,40
|
9,40
|
284,23
|
48,80
|
6,28
|
30,60
|
5,06
|
|
Среднее на класс RND-распределения 62:
|
49,20
|
0,40
|
10,00
|
285,52
|
48,80
|
5,94
|
28,94
|
5,16
|
|
Среднее на класс RND-распределения 63:
|
49,20
|
0,80
|
9,40
|
206,81
|
48,40
|
4,31
|
21,98
|
5,33
|
|
Среднее на класс RND-распределения 64:
|
49,20
|
0,00
|
9,40
|
288,48
|
49,20
|
6,08
|
30,75
|
5,08
|
|
Среднее на класс RND-распределения 65:
|
49,20
|
0,20
|
9,80
|
312,44
|
49,00
|
6,18
|
31,02
|
5,08
|
|
Среднее на класс RND-распределения 66:
|
49,20
|
0,60
|
8,60
|
220,35
|
48,60
|
4,02
|
23,57
|
5,92
|
|
Среднее на класс RND-распределения 67:
|
49,20
|
0,60
|
9,80
|
283,95
|
48,60
|
6,06
|
30,18
|
4,99
|
|
Среднее на класс RND-распределения 68:
|
49,20
|
0,40
|
9,20
|
292,22
|
48,80
|
6,02
|
31,76
|
5,27
|
|
Среднее на класс RND-распределения 69:
|
49,20
|
0,00
|
9,00
|
256,67
|
49,20
|
5,16
|
27,46
|
5,44
|
|
Среднее на класс RND-распределения 70:
|
49,20
|
0,40
|
10,00
|
278,18
|
48,80
|
5,69
|
27,09
|
5,04
|
|
Среднее на класс RND-распределения 71:
|
49,20
|
0,60
|
9,40
|
263,63
|
48,60
|
5,19
|
26,01
|
5,52
|
|
Среднее на класс RND-распределения 72:
|
49,20
|
0,00
|
8,60
|
239,97
|
49,20
|
4,59
|
26,28
|
5,91
|
|
Среднее на класс RND-распределения 73:
|
49,20
|
0,20
|
9,80
|
299,93
|
49,00
|
6,33
|
31,80
|
5,04
|
|
Среднее на класс RND-распределения 74:
|
49,20
|
0,20
|
9,60
|
253,70
|
49,00
|
5,15
|
25,85
|
5,26
|
|
Среднее на класс RND-распределения 75:
|
49,20
|
0,00
|
9,40
|
267,72
|
49,20
|
5,54
|
28,38
|
5,40
|
|
Среднее на класс RND-распределения 76:
|
49,20
|
0,00
|
9,20
|
226,96
|
49,20
|
4,16
|
22,94
|
5,57
|
|
Среднее на класс RND-распределения 77:
|
49,20
|
0,40
|
9,60
|
262,14
|
48,80
|
5,29
|
26,87
|
5,15
|
|
Среднее на класс RND-распределения 78:
|
49,20
|
0,60
|
9,00
|
224,49
|
48,60
|
4,95
|
25,56
|
5,29
|
|
Среднее на класс RND-распределения 79:
|
49,20
|
0,40
|
9,20
|
241,25
|
48,80
|
4,74
|
25,51
|
5,45
|
|
Среднее на класс RND-распределения 80:
|
49,20
|
0,00
|
9,80
|
293,83
|
49,20
|
6,06
|
31,08
|
5,24
|
|
Среднее на класс RND-распределения 81:
|
49,20
|
0,00
|
9,20
|
250,78
|
49,20
|
5,33
|
27,92
|
5,35
|
|
Среднее на класс RND-распределения 82:
|
49,20
|
0,20
|
9,00
|
194,38
|
49,00
|
3,78
|
20,58
|
5,51
|
|
Среднее на класс RND-распределения 83:
|
49,20
|
0,00
|
8,80
|
260,47
|
49,20
|
5,35
|
29,73
|
5,65
|
|
Среднее на класс RND-распределения 84:
|
49,20
|
0,20
|
9,20
|
260,94
|
49,00
|
5,31
|
29,48
|
5,50
|
|
Среднее на класс RND-распределения 85:
|
49,20
|
1,00
|
9,60
|
272,98
|
48,20
|
5,39
|
27,38
|
5,19
|
|
Среднее на класс RND-распределения 86:
|
49,20
|
0,60
|
9,60
|
251,06
|
48,60
|
5,38
|
26,60
|
5,11
|
|
Среднее на класс RND-распределения 87:
|
49,20
|
0,20
|
10,20
|
264,78
|
49,00
|
5,27
|
25,91
|
4,95
|
|
Среднее на класс RND-распределения 88:
|
49,20
|
0,60
|
9,80
|
281,19
|
48,60
|
6,15
|
28,22
|
5,03
|
|
Среднее на класс RND-распределения 89:
|
49,20
|
0,20
|
9,00
|
272,29
|
49,00
|
5,91
|
30,56
|
5,36
|
|
Среднее на класс RND-распределения 90:
|
49,20
|
0,20
|
8,80
|
207,24
|
49,00
|
4,53
|
24,36
|
5,58
|
|
Среднее на класс RND-распределения 91:
|
49,20
|
0,20
|
9,60
|
280,28
|
49,00
|
5,89
|
29,47
|
5,05
|
|
Среднее на класс RND-распределения 92:
|
49,20
|
0,00
|
9,00
|
277,02
|
49,20
|
5,59
|
30,14
|
5,38
|
|
Среднее на класс RND-распределения 93:
|
49,20
|
0,60
|
9,80
|
236,64
|
48,60
|
5,28
|
25,69
|
5,02
|
|
Среднее на класс RND-распределения 94:
|
49,20
|
0,40
|
9,60
|
283,56
|
48,80
|
5,56
|
28,81
|
5,28
|
|
Среднее на класс RND-распределения 95:
|
49,20
|
0,40
|
9,20
|
245,47
|
48,80
|
4,94
|
26,72
|
5,57
|
|
Среднее на класс RND-распределения 96:
|
49,20
|
0,60
|
9,60
|
268,62
|
48,60
|
5,59
|
28,79
|
5,16
|
|
Среднее на класс RND-распределения 97:
|
49,20
|
0,00
|
10,00
|
308,73
|
49,20
|
6,47
|
31,18
|
4,88
|
|
Среднее на класс RND-распределения 98:
|
49,20
|
0,60
|
9,80
|
326,67
|
48,60
|
6,78
|
33,83
|
5,09
|
|
Среднее на класс RND-распределения 99:
|
49,20
|
0,00
|
9,20
|
237,53
|
49,20
|
4,93
|
26,30
|
5,32
|
|
Среднее на класс RND-распределения 100:
|
49,20
|
0,00
|
9,60
|
219,47
|
49,20
|
4,50
|
22,14
|
5,16
|
|
Сумма средних по всем RND-распределениям:
|
4920,00
|
33,00
|
942,20
|
26045,76
|
4887,00
|
538,57
|
2759,82
|
527,05
|
|
Среднее средних по всем RND-распределениям:
|
49,20
|
0,33
|
9,42
|
260,46
|
48,87
|
5,39
|
27,60
|
5,27
|
|
Ср.кв.откл. средних по всем RND-распределениям:
|
0,00
|
0,28
|
0,40
|
27,19
|
0,28
|
0,64
|
2,79
|
0,27
|
|
Среднее из LC-распределения:
|
49,20
|
0,80
|
11,20
|
544,91
|
48,40
|
12,27
|
49,80
|
4,18
|
|
Эффективность LC-алгоритма по сравнению с RND в
%:
|
100,00
|
242,42
|
118,87
|
209,21
|
99,04
|
227,78
|
180,45
|
79,37
|
Из этих таблиц видно,
что использование
LC-алгоритма более чем в 2 раза повышает среднюю пользу по системе по сравнению
со случайным назначением.
В реальных примерах
это превышение может быть значительно большим, т.к. в приме ре, рассматриваемом
в данной работе, объекты обладают случайными
признаками и случайным образом
отнесены к классам, в реальных задачах есть закономерности связи признаков с
классами.
Кратко рассмотрим
возможные применения задачи о назначениях в области педагогики и психологии.
СК-анализ и система «Эйдос» позволяют разработать профессиограммы, т.е. на
основе ретроспективной базы данных определить, какие признаки респондентов
(первичные, устанавливаемые непосредственно, вторичные, т.е. расчетные)
наиболее характерны для работников, успешно работающих по тем или иным
должностям [16]. Аналогично, могут быть разработаны профессиограммы, отражающие
успешность обучения по тем или иным специальностям, дисциплинам и циклам
дисциплин. Во всех этих случаях можно и
решить задачу о назначениях, т.е. распределить кандидатов, претендующих на ту
или иную оплату труда (затраты), на должности, в соответствии с ограничениями
на фонд оплаты труда по эти должностям, причем сделать это таким образом, что и
для каждого работника, и по каждой должности, и по организации в целом, будет
получена максимальная польза.
Выводы. На основе
вышеизложенного на наш взгляд можно обоснованно предположить, что
системно-когнитивный анализ и его инструментарий – система «Эйдос» являются
адекватным средством для решения для решения ранее не встречавшегося в
литературе обобщения задачи о назначениях, учитывающего не только различную
полезность одного и того же груза для разных рюкзаков, различные затраты на
грузы и ресурсы рюкзаков, но и обеспечивающего автоматическое определение
степени этой полезности на основе признаков груза путем решения задачи распознавания.
Материалы данной работы могут стать основой для нескольких лабораторных работ
по дисциплинам: «Интеллектуальные информационные системы», «Представление
знаний», «Интеллектуальные
информационные технологии», «Системы управления знаниями», «Человеко-машинное
взаимодействие» и может применяться в
вузах, готовящих специалистов по
специальностям «Прикладная информатика» и «Информационные системы и
технологии».
4.6. Дисциплина: «Основы теории
управления (теория автоматического управления)"
В данном разделе рассмотрим глубокую взаимосвязь между
теорией автоматизированного и автоматического управления и системно-когнитивным
анализом и его программным инструментарием – системой «Эйдос» в их применении
для интеллектуального управления сложными (многофакторными) нелинейными системами
[136]. Предлагается технология, позволяющая на практике
реализовать интеллектуальное автоматизированное и даже автоматическое
управление сложными нелинейными объектами управления, для которых ранее
управление реализовалось лишь на слабоформализованном уровне, как правило, без
применения математических моделей и компьютеров. К таким объектам управления
относятся, например, технические системы, штатно качественно-изменяющиеся в
процессе управления, биологические и экологические системы,
социально-экономические и психологические системы. Достичь этого применение
ск-анализа и системы «эйдос» для синтеза когнитивной матричной передаточной
функции сложного объекта управления на основе эмпирических данных
Управление – это достижение цели путем принятия и реализации
решений об определенных действиях, способствующих достижению этой цели. Цели
управления обычно заключаются в том, чтобы определенная система, которая
называется объектом управления, находилась в определенном целевом (желаемом) состоянии
или эволюционировала по определенному заранее известному или неизвестному
сценарию. Действия, способствующие достижению цели, называются управляющими
воздействиями. Решения об управляющих воздействиях принимаются управляющей
системой. Управляющее воздействие вырабатывается управляющей системой на основе
модели объекта управления и информации обратной связи о его состоянии и
условиях окружающей среды (рисунок 119):
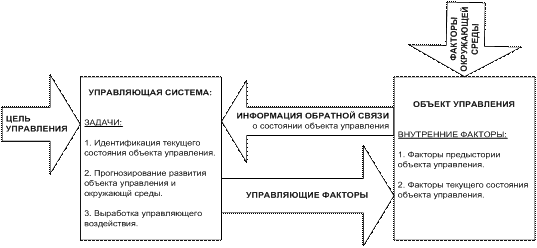
Рисунок 119. Цикл управления в замкнутых автоматизированных
и автоматических системах управления (АСУ и САУ)
Автоматизированные и автоматические системы управления
отличаются друг от друга степенью
формализации и степенью автоматизации процесса выработки решения об
управляющем воздействии:
– считается, что
в системах автоматического управления (САУ) процесс выработки управляющего
воздействия полностью автоматизирован, т.е. оно принимается управляющей
системой автоматически, без участия человека [7];
– в автоматизированных системах управления (АСУ) решение
об управляющем воздействии принимается управляющей системой с участием человека
в процессе их взаимодействия [7].
Однако, по мнению авторов, методологически неверно
представлять себе дело таким образом, как будто САУ принимают решение полностью
самостоятельно, без какого-либо участия человека. Гораздо правильнее было бы
сказать, что в случае САУ решение принимаемся человеком, который сконструировал
и создал эти САУ и «заложил» в них определенные математические модели и
реализующие их алгоритмы принятия решений, которые в процессе работы САУ просто
используются на практике. Разве это
не является участием человека? Следовательно, точнее было бы говорить не об
участии или неучастии человека в принятии управляющих решений, а об его участии
в реальном времени в случае АСУ и отсроченном участии в случае САУ.
Естественно, далеко не для всех видов объектов
управления удается построить их достаточно полную адекватную математическую
модель, являющуюся основой для принятия управляющих решений. В более-менее
полной мере это удается сделать лишь для достаточно простых, в основном чисто
технических систем, и
именно для них удается построить САУ. Для технологических же систем, а также
других систем, включающих не только техническую компоненту, но людей в качестве
элементов, это удается сделать лишь в неполной мере, т.е. степень формализации управления такими системами ниже, чем в САУ. В
этом случае в процессе выработки решения об управляющем воздействии остаются
вообще неформализованные или слабо формализованные этапы, которые пока не
поддаются автоматизации, и, поэтому, решения об управляющем воздействии не
удается принять на полностью формализованном уровне и тем самым полностью
передать эту функцию системе управления. Этим и обусловлена необходимость включения
человека непосредственно в цикл управления, что и приводит к созданию АСУ, в
которых математические модели и алгоритмы используются не для принятия решений,
а для создания человеку комфортных информационных условий, в которых он мог бы
принимать решения на основе своего опыта и профессиональной компетенции.
Поэтому и говорят, что АСУ не принимают решений, а лишь поддерживают принятие решений. Еще сложнее поддаются
математическому моделированию и формализации биологические и экологические, а
также социально-экономические и психологические системы, включающие отдельных
людей и их коллективы, т.е. сложные системы.
Поэтому сложные системы обычно являются слабо формализованными и на этой их
особенности практически основано их определение.
Конечно, управление такими системами тоже осуществляется, но уже практически
без использования математических моделей и компьютерных технологий, т.е.
преимущественно на слабо формализованном интуитивном уровне на основе опыта и
профессиональной компетенции экспертов и лиц, принимающих решения (ЛПР). При
этом в соответствии с принципом Эшби управляемость сложных
систем является неполной.
Таким образом, виды управления различными объектами
управления можно классифицировать по степени формализации процесса принятия
решений об управляющих воздействиях и, соответственно, по степени участия человека
в этом процессе:
– САУ:
автоматическое принятие решения без непосредственного участия человека в
реальном времени;
– АСУ:
поддержка принятия решений, т.е. создание комфортных информационных условий для
принятия решений человеком в реальном времени;
– менеджмент:
управление на слабо формализованном уровне практически без применения
математических моделей [16].
Перспектива развития методов управления сложными системами, по
мнению авторов, состоит в повышении
степени формализации процессов принятия решений при выборе вариантов
управляющих воздействий. Однако на пути реализации этой перспективы необходимо
решить проблему разработки
технологии, обеспечивающей создание формальной
количественной модели сложного объекта
управления на основе эмпирических данных о его поведении под действием
различных факторов, модели, пригодной для решения задач прогнозирования и
принятия решений.
В стационарных САУ и АСУ объект управления не изменяется качественно в процессе
управления и, поэтому, его модель, созданная на этапе проектирования и создания
системы управления не теряет адекватность и в процессе ее применения. Иначе
обстоит дело в случае, когда объект
управления изменяется качественно непосредственно в процессе управления, т.е.
является динамичным. В этом случае модель объекта управления быстро теряет
адекватность, как и управляющие воздействия, выработанные на ее основе.
Реализация таких неадекватных управляющих воздействий приводит уже не к
достижению цели управления, а к срыву управления. Поэтому проблема состоит не
только в том, чтобы создать адекватную модель сложного объекта управления, но и
в том, чтобы сохранить ее адекватность
при существенном изменении этого объекта, т.е. при изменении характера
взаимосвязей между воздействующими факторами и поведением объекта управления.
Это означает, что система
управления сложными динамичными объектами должна быть интеллектуальной,
т.к. именно системы этого класса позволяют проводить обучение, адаптацию или
настройку модели объекта управления за счет накопления и анализа информации о поведении
этого объекта при различных сочетаниях действующих на него факторов. Таким
образом, решив первую проблему, т.е. разработав технологию создания модели
сложного объекта управления, мы этим самым создаем основные предпосылки и для
решения и второй проблемы, т.к. для этого
достаточно применить эту технологию непосредственно в цикле управления.
Кратко рассмотрим, какие решения поставленной проблемы
предлагаются в теории управления и в
теории автоматизированного и автоматического управления.
Чисто лингвистически термин: «Теория управления» является
более общим, чем «Теория автоматического управления», т.е. теория управления
должна включать в себя все методы управления: и слабо формализованные, и
среднего (АСУ), и наивысшего уровня формализации (САУ). Однако если
ознакомиться с соответствующей специальной литературой, то становится ясным,
что в настоящее время под теорией управления фактически понимаются лишь слабо
формализованные подходы к управлению, развиваемые в менеджменте и контроллинге.
Но это именно те методы, степень формализации которых авторы и предлагают
повышать в данной и других работах.
Поэтому нам остается, по сути, попытаться перенести в
теорию управления сложными динамичными биологическими, социально-экономическими
и психологическими системами опыт решения подобных проблем из теории АСУ и
особенно, как наиболее математизированной и детально разработанной, – теории
САУ, т.е. теории автоматического управления (ТАУ). Для этого, основываясь на
работах [226, 227, 228], кратко приведем необходимые для дальнейшего изложения
ведения из ТАУ.
В ТАУ принята следующая модель объекта управления (рисунок
120):
Рисунок 120. Модель многоканального объекта управления в ТАУ
согласно [228]
На рисунке 123 использованы следующие обозначения [228]:
«– управляющие воздействия
u1, ... , um – это входные сигналы объекта
управления, с помощью которых влияют на режим работы объекта;
– выходные переменные y1,
... , ym – это измеряемые выходные сигналы динамической системы;
– переменные состояния x1, ... , xn – это внутренние, как правило, недоступные измерению
переменные, которые определяют состояние объекта в каждый момент времени;
причем 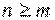 ;
;
– возмущающие воздействия M1, ..., Ml – отражают случайные воздействия окружающей среды на
объект управления и обычно недоступны измерению. Требование парирования их
влияния и приводит к необходимости создания систем автоматического управления».
При этом цель управления задается с
помощью входных (задающих)
воздействий (сигналов), поступающих на вход системы управления и определяющих требуемые
законы изменения выходных переменных (сигналов) объекта управления [228].
«Все
переменные, которые характеризуют объект, удобно представить в векторной форме:

Входные воздействия
на систему (или задание на регулятор) принято обозначать буквой v. Их
число обычно совпадает с числом выходных переменных и изображается следующим
вектором:
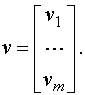
В зависимости от
числа входных и выходных переменных выделяют:
– одноканальные объекты (или системы) – объекты, в которых есть только
одна выходная переменная (m=1);
– многоканальные
(многосвязные, многомерные, взаимосвязные) объекты (или системы) – объекты, в
которых число выходных переменных больше единицы (m>1)» [228].
В системах автоматического управления (САУ) математической моделью объекта
управления, которая отражает его реакцию (отклик) на воздействие различных
факторов, является передаточная функция.
Согласно,
«если  –
входной сигнал одноканальной линейной стационарной системы, а
–
входной сигнал одноканальной линейной стационарной системы, а  –
её выходной сигнал, то передаточная функция
–
её выходной сигнал, то передаточная функция
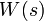 имеет вид:
имеет вид:
где: 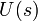 и
и 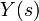 –
преобразования Лапласа для сигналов и соответственно:
–
преобразования Лапласа для сигналов и соответственно:
Для дискретных
систем вводится понятие дискретной передаточной функции. Пусть 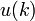 –
входной дискретный сигнал такой системы, а
–
входной дискретный сигнал такой системы, а 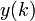 –
её дискретный выходной сигнал,
–
её дискретный выходной сигнал, 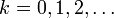 .
Тогда передаточная функция
.
Тогда передаточная функция  такой
системы записывается в виде:
такой
системы записывается в виде:
где  и
и 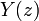 –
z-преобразования для
сигналов и соответственно:
–
z-преобразования для
сигналов и соответственно:
Естественно, сложные системы являются многоканальными.
Для таких систем передаточная функция «представляет собой матрицу со следующими компонентами:
где 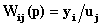 - скалярные передаточные функции,
которые представляют собой отношение выходной величины к входной в
символической форме при нулевых начальных условиях
- скалярные передаточные функции,
которые представляют собой отношение выходной величины к входной в
символической форме при нулевых начальных условиях 
Собственными передаточными функциями i-го канала называются компоненты передаточной матрицы 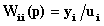 , которые
находятся на главной диагонали. Составляющие, расположенные выше или ниже
главной диагонали, называются передаточными
функциями перекрестных связей между каналами» [228].
, которые
находятся на главной диагонали. Составляющие, расположенные выше или ниже
главной диагонали, называются передаточными
функциями перекрестных связей между каналами» [228].
Рассмотрим теперь конструкции матричной математической
модели АСК-анализа в сопоставлении с
приведенными моделями из ТАУ [7].
Знание передаточной функции объекта управления позволяет:
– по входным параметрам определить выходные, т.е.
решать задачу прогнозирования (прямая
задача);
– по заданным целевым (желательным) выходным параметрам
определять входные, т.е. принимать
решения по выбору управляющих воздействий (обратная задача прогнозирования).
Факторы,
воздействующие на поведение объекта управления, можно классифицировать на три
основных группы:
1. Внутренние
факторы, описывающие предысторию и текущее состояние объекта управления
и определяющие его собственное движение при отсутствии внешних воздействий
(«самодвижение»).
2. Внешние
факторы.
2.1. Управляющие
или технологические факторы, – это внешние факторы, зависящие от
управляющей системы.
2.2. Факторы
окружающей среды, т.е. внешние «возмущающие» факторы, не зависящие от
управляющей системы (при данном уровне развития технологий).
Необходимо отметить, что приведенная классификация факторов
является классификацией по признакам, не имеющим отношения к их влиянию на
поведение объекта управления, и это значит, что в этом отношении или с этой точки зрения они могут рассматриваться
совершенно одинаково (однотипно, одним способом), т.е. все вместе, что и принято в автоматизированном системно-когнитивном
анализе (АСК-анализ) [7]. Поэтому в
АСК-анализе модель объекта управления, принятая в ТАУ и приведенная на рисунке 120, модифицируется следующим образом (рисунок 121):
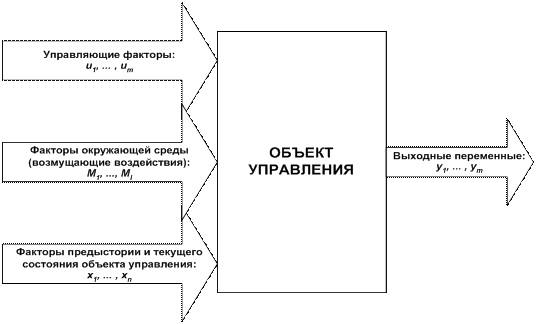
Рисунок 121. Модель многоканального объекта управления
в АСК-анализе [136]
Конечно, из общих
соображений понятно, что управляющие факторы и факторы окружающей среды влияют
на выходные параметры объекта управления не непосредственно, а опосредованно
его внутренним состоянием, т.е. сначала под их влиянием изменяется состояние
объекта управления, а уже после этого и
вследствие этого
соответствующим образом изменяется его поведение и выходные параметры. Поэтому
в работе [229] обоснованно вводятся следующие матричные модели (матрицы):
А - матрица состояния системы (объекта), характеризует динамические
свойства системы;
В - матрица
управления (входа),
характеризует воздействие входных переменных на переменные состояния;
С - матрица
выхода по состоянию, характеризует связь выходных координат (как
правило, это измеряемые переменные) с
переменными состояния;
D - матрица
выхода по управлению, характеризующая непосредственное воздействие
входов на выходы.
АСК-анализ подобный подход
может быть реализован при создании многоуровневых семантических информационных
моделей, эквивалентных многослойным нейронным сетям (см., например: [20, 59]). Рассмотрим теперь, как в
АСК-анализе формируется матричная модель объекта управления, являющаяся аналогом матричной
передаточной функции (1) и напрямую связывающая выходные параметры объекта
управления с входными, причем входные параметры в соответствии с моделью
объекта управления, представленной на рисунке 121, включают управляющие
факторы, факторы окружающей среды и факторы внутреннего состояния объекта
управления (матрицы C и D).
В соответствии с моделью
объекта управления, представленной на рисунке 121, введем вектор входных
параметров , который мы будем называть «массив-локатор»: Li=n, если i-й признак встречается у объекта n раз.
Такой подход
соответствует использованию номинальных и
порядковых шкал для формализации качественных (в т.ч. текстовых)
переменных, которые в АСК-анализе метризуются до интервальных числовых шкал (шкал отношений) для формализации
числовых значений входных переменных [201]. Каждый входной фактор любого из
трех типов, приведенных на рисунке 121, формализуется с помощью отдельной
порядковой или числовой шкалы с градациями, которые мы будем называть «признаками».
Таким образом, текстовые и числовые переменные в АСК-анализе обрабатываются однотипно.
Возникает естественный
вопрос о том, а не является ли этот подход, основанный на замене чисел их
интервальными значениями, каким-либо ограничением при формализации числовых
переменных? Здесь необходимо отметить, что числа всегда отражают реальность с
определенной погрешностью. По сути, вместо точных числовых значений всегда
используются округленные с некоторой точностью, или, фактически, интервальные
значения, включающие точные значения и погрешности их измерений. Аналогичный
смысл имеет доверительный интервал. Поэтому диапазон значений любой числовой
шкалы, используемой для формализации теоретически непрерывной
числовой величины, на практике всегда делится на некоторое конечное число интервалов N,
количество которых по формуле I=Log2N
определяет максимальное
количество информации I, получаемое
при измерении, т.е. непрерывная величина заменяется дискретным набором
интервальных значений и это не является
каким-либо ограничением.
В этой связи кратко
рассмотрим требования, предъявляемые в статистике к исходным данным:
1. Данные должны быть
максимально полными, но не отрывочными, случайно выхваченными.
2. Данные должны быть
абсолютно достоверными и точными.
3. Данные должны
соответствовать принципу единообразия, сопоставимости.
4. Данные должны
соответствовать принципу своевременности (сбор должен быть организован только в
строго определенное время, но кроме
этого, данные должны быть представлены так же в срочном порядке).
являются в принципе не выполнимыми.
Первое требование для реальных сложных динамичных объектов управления
фактически никогда не удается выполнить по причине большой размерности таких
объектов и сложности получения информации по всем их параметрам.
Второе требование еще менее выполнимо, т.к. абсолютно точное измерение соответствует бесконечному количеству возможных
вариантов результатов измерения N, и,
соответственно (по формуле: I=Log2N),
порождает бесконечное количество информации I.
Понятно, что такое измерение должно будет занять бесконечное количество времени при любом сколь угодно высоком
конечном трафике информационного канала, созывающего датчик измерительной
системы с носителем информации. Кроме того: а) за бесконечное время измерения
измеряемый объект со всеми его параметрами, скорее всего, изменится или вообще перестанет существовать, как, впрочем, и
измерительная система; б) для записи результата измерения потребуется носитель
информации бесконечной емкости. Понятно, что если говорить не о бесконечной, а
лишь об определенной точности, то она также зависит от времени измерения и эта
связь раскрывается в принципе неопределенности Гейзенберга. Это принцип
применим не только на микроувроне к квантовым явлениям, но и к макроскопическим,
вполне классическим явлениям. Например, бессмысленно говорить о частотном
спектре сигнала в какой-либо момент
времени. Точность определения частоты тем выше, чем дольше мы наблюдаем за
сигналом, теряя, таким образом, точность определения самого времени. С
аналогичной ситуацией мы сталкиваемся, когда пытаемся определить скорость в
какой-то определенный момент времени
или в какой-то точке траектории, т.к.
измерение скорости само занимает некоторое время и в принципе не может быть
осуществлено мгновенно, и за время измерения объект измерения сместится.
Поэтому из принципа неопределенности Гейзенберга следует принципиальное
ограничение на максимальное количество информации, которое может быть получено
в результате измерения (так называемая «информация Фишера»).
Третье требование сложно выполнимо для сложных систем, которые описываются
значительным количеством разнородных по своей природе количественных и
качественных параметров, измеряемых в различных единицах измерения. В АСК-анализе проблема сопоставимой в пространстве
и времени обработки подобных данных решается путем отказа от обработки значений
параметров и перехода к рассмотрению количества информации, которое содержится
в этих значениях о поведении и выходных параметрах объекта управления.
Четвертое требование тесно связано со вторым и находится с ним в явном
противоречии, т.к. чем более «своевременными» (или как обычно говорят «актуальными»)
являются исходные данные, тем, очевидно, меньше их будет.
Таким образом, строго говоря, требования к исходным данным, предъявляемые
в статистике, выполнить крайне сложно, если это вообще возможно, и, поэтому,
корректность применения статистических методов для обработки подобных данных (неудовлетворяющих
требованиям) находится под большим вопросом. Тем ни менее эти методы все равно
применяются, и когда это делается над исходными данными, не удовлетворяющими сформулированным требованиям (а это типичная
ситуация), то это делается некорректно. Метод АСК-анализа не является статистическим
методом, не предъявляет столь жестких требований к исходным данным и предлагает
способ решения этой проблемы на основе применения теории информации.
Исходной матрицей для построения матричной модели сложного
динамичного объекта управления в АСК-анализе является матрица абсолютных
частот, являющаяся корреляционной матрицей или матрицей сопряженности (таблица 72):
Таблица 72 – Матрица абсолютных частот
(матрица сопряженности)
|
|
Классы
(целевые и нежелательные состояния
объекта управления)
|
Сумма
|
|
1
|
…
|
j
|
…
|
W
|
|
Факторы и их интервальные
значения
|
Управляющие
факторы
|
1
|
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
|
Факторы
окружающей
среды
|
…
|
|
|
|
|
|
|
|
i
|
|
|
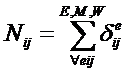
|
|
|
|
|
…
|
|
|
|
|
|
|
|
Факторы
состояния
объекта
управления
|
…
|
|
|
|
|
|
|
|
M
|
|
|
|
|
|
|
|
Суммарное
количество
признаков
|
|
|
|
|
|
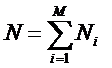
|
|
Суммарное
количество
объектов
обучающей
выборки
|
|
|
|
|
|
N
|
В данной таблице
использованы обозначения [7]:
Nij –
суммарное количество наблюдений в исследуемой выборке факта: "действовало i-е
значение фактора и объект перешел в j-е
состояние";
Nj – суммарное количество встреч различных
значений факторов у объектов, перешедших в j-е
состояние;
Ni – суммарное количество встреч i-го значения фактора у всех объектов исследуемой выборки;
N – суммарное количество встреч различных
значений факторов у всех объектов исследуемой выборки.
Первоначально при
синтезе модели в матрице абсолютных частот все значения равны нулю. Затем
организуется цикл по всем объектам обучающей выборки (e), каждый из которых описан
двумя векторами: вектором входных параметров (значения факторов или признаки) и
вектором выходных параметров (будущие состояния или классы). В каждом объекте
организуется цикл по всем его признакам (i) и всем классам (j), к которым он
относится (2):
где:
– 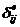 : напоминает дельта-функцию Дирака:
: напоминает дельта-функцию Дирака:

– M:
суммарное количество значений факторов (признаков) в модели;
– W:
суммарное количество классов в модели;
– E: количество объектов обучающей выборки.
Затем в матрице абсолютных частот рассчитываются суммы
по строкам (3), столбцам (4) и всей матрице (5):
После этого на основе матрицы абсолютных частот с использованием
выражений (6) рассчитывается матрица относительных частот или частостей
(таблица 73), которую мы для удобства
будем называть матрицей уловных и безусловных вероятностей.
|
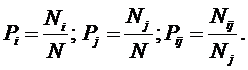
|
(12)
|
где:
– индекс i обозначает признак (значение фактора): 1£ i £ M;
– индекс j обозначает состояние объекта или
класс: 1£ j £ W;
– Pij – условная вероятность
наблюдения i-го значения фактора у
объектов в j-го класса или, что тоже самое, условная вероятность перехода
объекта в j-е состояние при условии действия на него i-го значения фактора;
– Pi – безусловная вероятность
наблюдения i-го значения фактора по
всей выборке;
– Pj – безусловная вероятность
перехода объекта в j-е состояние
(вероятность самопроизвольного перехода или вероятность перехода, посчитанная
по всей выборке, т.е. при действии любого
значения фактора).
Таблица 73 – Матрица уловных и безусловных
процентных распределений
|
|
Классы
(целевые и нежелательные состояния
объекта управления)
|
Безусловная
вероятность
признака
|
|
1
|
…
|
j
|
…
|
W
|
|
Факторы и их интервальные
значения
|
Управляющие
факторы
|
1
|
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
|
Факторы
окружающей
среды
|
…
|
|
|
|
|
|
|
|
i
|
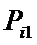
|
|
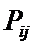
|
|
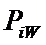
|
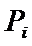
|
|
…
|
|
|
|
|
|
|
|
Факторы
состояния
объекта
управления
|
…
|
|
|
|
|
|
|
|
M
|
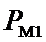
|
|
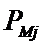
|
|
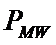
|
|
|
Безусловная
вероятность
класса
|
|
|
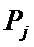
|
|
|
|
Придадим таблице 73 вид, сходный с видом матричной передаточной
функции многоканального объекта управления. Для этого подставим в таблицу 73
выражения для вероятностей через абсолютные частоты с использованием (12)
(таблица 74):
Таблица 74 – Матрица уловных и безусловных процентных распределений
в форме, аналогичной матричной передаточной функции (1)
|
|
Классы
(целевые и нежелательные состояния
объекта управления)
|
Безусловная
вероятность
признака
|
|
1
|
…
|
j
|
…
|
W
|
|
Факторы и их интервальные
значения
|
Управляющие
факторы
|
1
|
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
|
Факторы
окружающей
среды
|
…
|
|
|
|
|
|
|
|
i
|
|
|
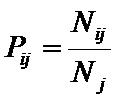
|
|
|
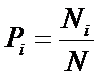
|
|
…
|
|
|
|
|
|
|
|
Факторы
состояния
объекта
управления
|
…
|
|
|
|
|
|
|
|
M
|
|
|
|
|
|
|
|
Безусловная
вероятность
класса
|
|
|
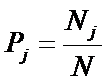
|
|
|
|
Сравнивая выражения
для матричной передаточной функции (7) с таблицей 74 мы видим, что элементы таблицы 74 по своей математической форме весьма напоминают скалярные передаточные функции Wij(p)= yi/uj,
представляющие собой отношение выходной величины к входной в
символической форме при нулевых начальных условиях [228]. Это является вполне достаточным основанием для проведения
глубокой аналогии между матрицей
условных и безусловных вероятностей (таблица 74), с одной стороны, и матричной
передаточной функцией (7), с другой стороны.
Очевидно, эта аналогия может быть
проведена, если считать:
– входной величиной uj – суммарное количество встреч i-го
значения фактора по всей исследуемой выборке Ni;
– выходной величиной yi – суммарное
количество встреч i-го значения фактора у объектов j-го класса Nij;
– скалярной передаточной функцией Wij(p)
– условную вероятность (частость) встречи встреч i-го значения
фактора у объектов j-го класса
или, что тоже самое, условную
вероятность перехода объекта управления в j-е
состояние при условии действия на
него i-го значения фактора Pij.
Но почему же это все не более чем аналогия или метафора?
Дело в том, что передаточная функция
непрерывной одноканальной системы представляет собой отношение преобразования
Лапласа выходной величины (3) к преобразованию Лапласа входной величины (2),
что в символической форме при нулевых начальных условиях аналитически
представляется в форме выражения (1). В дискретных системах, которые только и
встречаются на практике, преобразование Лапласа заменяется его дискретным
аналогом – z-преобразованием или преобразованием Лорана для
входного (5) и выходного (6) сигналов, в результате чего выражение (1)
преобразуется в выражение для дискретной передаточной функции (4).
Для многоканальной
дискретной системы элементы матричной передаточной функции представляют собой
передаточные функции одноканальных дискретных подсистем для соответствующих
каналов и перекрестных связей. Поэтому получим аналитическую форму для
дискретной передаточной функции, выраженную непосредственно через входные и
выходные сигналы (13). Для этого подставим в выражение (4) формулы для их
z-преобразований (5) и (6):
Далее, подставим в таблицу 74 значения абсолютных
частот с использованием выражений: (8), (9), (10), (11) и в результате получим
таблицу 75:
Таблица 75 – Матрица уловных и безусловных процентных распределений
в форме, аналогичной матричной передаточной функции
с использованием аналога z-преобразования Лорана
|
|
Классы
(целевые и нежелательные состояния
объекта управления)
|
Безусловная
вероятность
признака
|
|
1
|
…
|
j
|
…
|
W
|
|
Факторы и их интервальные
значения
|
Управляющие
факторы
|
1
|
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
|
Факторы
окружающей
среды
|
…
|
|
|
|
|
|
|
|
i
|
|
|
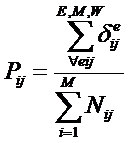
|
|
|
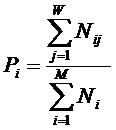
|
|
…
|
|
|
|
|
|
|
|
Факторы
состояния
объекта
управления
|
…
|
|
|
|
|
|
|
|
M
|
|
|
|
|
|
|
|
Безусловная
вероятность
класса
|
|
|
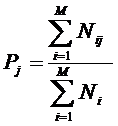
|
|
|
|
Сравнивая выражение (13) с выражениями для Pij, Pi, Pj (их смысл расшифрован выше) из таблицы 75, мы
видим, что весьма похожи, но не тождественны, по своей математической форме. Сходство состоит в том, что все они
представляют собой отношения сумм значений различных сигналов, которые могут
быть интерпретированы как входные и выходные, а различие в том, что в z-преобразовании слагаемые в суммах
умножаются на z-k, где k – индекс суммирования. Кроме того, в
z-преобразовании суммирование ведется до бесконечности, тогда как в реальных
моделях, оно ограничено размерностью матриц модели.
Кратко рассмотрим смысл
самого z-преобразовании и этого степенного множителя и предложим аналогию,
которая на взгляд авторов позволяет обоснованно предположить, что при определенных
условиях матрица условных и безусловных вероятностей, представленная в таблице 75,
является аналогом матричной передаточной функции многоканальной дискретной системы (7).
Рассмотрим простой численный
пример z-преобразования, приведенный в электронном источнике: http://www.inkcanon.com/predmet/cufr-obr-sig/page21.html.
Удобным способом представления цифровых последовательностей
является Z-преобразование (Z-transform). Смысл его заключается в том, что
последовательности чисел {x(k)} становится в соответствие функция
комплексной переменной Z, которая определяется таким образом:

 .
.
Разумеется, функция X(z) определена только для тех
значений z, при которых записанный ряд сходится. Область, в которой
Z-преобразование сходится, называется областью сходимости.
Определим Z-преобразование для последовательности, изображенной
на рисунке 122.
Рисунок 122. График дискретной функции для z-преобразования
Данная дискретная функция может быть представлена таблично:
Z-преобразование данной функции имеет вид:
Данный ряд расходится, т.е. x(k) = ? при z = 0.
Следовательно, область сходимости – вся плоскость z, кроме точки z = 0. Поэтому
слагаемое, соответствующее этой точке, отбрасываем и получаем:
Из приведенного примера видно, что коэффициенты z-преобразования являются
значениями дискретной функции, подвергаемой этому преобразованию. Если пытаться
понять смысл этих коэффициентов,
анализируя их роль в результате z-преобразования, т.е. в функции X(z), то они отражают степень, в которой
в этой функции представлены комплексные экспоненты, то есть гармонические осцилляции различных частот
и скоростей нарастания/затухания. Тот же смысл этих коэффициентов и в
преобразовании Лапласа. В этом плане z-преобразование аналогично преобразованиям
Фурье и Лапласа. Но преобразованиям Фурье определено на области: [–∞,
+∞], тогда как одностороннее преобразование Лапласа на области: [0,
+∞]. Поэтому считается, что преобразование Лапласа и z-преобразование
больше, чем преобразование Фурье, подходят для формального математического
представления причинно-следственных зависимостей, но, конечно, только при том условии, что входные и выходные сигналы интерпретируются
как функции времени. Кроме того, в разложении функции в ряд Фурье коэффициенты
этого ряда, имеющие совершенно аналогичный смысл, вычисляются, а не задаются в качестве исходных значений дискретной
функции, как в преобразованиях Лапласа и z-преобразовании, а исходной является
функция, разлагаемая в ряд Фурье.
Если в
выражении (13) положить z=1, то оно примет математическую форму, не
отличающуюся от выражений для Pij, Pi, Pj из таблицы 75. Из вышеизложенного ясно, что матрицу условных и безусловных вероятностей можно обоснованно считать
матричной передаточной функцией, в которой рассматриваются отклики объекта
управления не на гармонические осцилляции различных частот и скоростей нарастания/затухания,
а на единичные прямоугольные импульсы.
Z-преобразование получается из одностороннего дискретного
преобразования Лапласа простой заменой переменных (14) [18]:
где:
– s – комплексный аргумент: s = iω
– T – период
дискретизации.
Согласно [230]
смысл этой замены в том, чтобы все бесконечные периодические повторения нулей и
полюсов дискретного фильтра в комплексной
плоскости s преобразовать в одну точку в комплексной плоскости z (рисунок 123).
Рисунок 123. Отображение комплексной s-плоскости
в комплексную z-плоскость согласно [18]
Обратная экспонента под
суммой выражения (13) имеет два смыла: математический и физический. Математический смысл состоит в
том, что добавление такого сомножителя к слагаемым некоторого ряда делает его
сходящимся для широкого класса функций, возрастающих медленее экспоненты. Физический смысл состоит в более
или менее быстром затухании последствий любого события с течением времени,
причем, как правило, закон затухания
имеет экспоненциальный характер. Если бы это было иначе, то сколь угодно
слабые воздействия могли бы приводить к сколь угодно большим последствиям, что
приводило бы к хаосу и неустойчивости реальности, подобно «эффекту бабочки», описанного
в рассказе Рэя Бредбери «И грянул гром».
Однако подобной хаотичности и неустойчивости на практике не наблюдается,
следовательно «эффекта бабочки» не существует и последствия событий затухают с
течением времени не медленнее экспоненты.
Сравним z-преобразование
с представлением числа в виде ряда в позиционной системе счисления.
Для этого продолжим рассмотрение вышеприведенного примера Z-преобразования
дискретной функции (рисунок 123), представленной таблично:
Z-преобразование данной
функции имеет вид:
где
z≠0.
Целое число x
в системе счисления с основанием b представляется в виде конечной
линейной комбинации цифр и степеней числа b:
где: ak –
это целые числа, называемые цифрами,
удовлетворяющие неравенству 0 ≤ ak ≤ (b-1). Каждая
степень bk в такой записи называется весовым
коэффициентом разряда.
Из сравнения выражений
(15) и (16) мы видим, что если произвести в них представленные в таблице 76
замены переменных, то получим одно и тоже математическое выражение, что означает
эквивалентность выражений (15) и (16) как по форме, так и по содержанию.
Таблица 76 – Замены переменных в выражениях
для z-преобразования и представления числа в виде ряда
Основываясь на
приведенной аналогии можно сделать два вывода:
1. Значения
z-преобразования некоторой дискретной функции могут рассматриваться как числа,
записанные в позиционной системе счисления с основанием 1/z = e-sT (см. выражение
(14)), при этом роль цифр играют значения дискретной функции.
2. Числа в любой
позиционной системе счисления могут рассматриваться как значения
z-преобразования дискретных функций, значения которых представлены цифрами, с
помощью которых записываются эти числа.
Продолжим дальнейшее
рассмотрение синтеза семантической информационной модели в системно-когнитивном
анализе. Далее, непосредственно на основе матрицы абсолютных частот или с
использованием матрицы условных и безусловных процентных распределений с
использованием количественных мер знаний (таблица 77) [7, 127] получаем базу знаний (таблица 78):
Таблица 77 – Различные аналитические формы
частных количественных критериев знаний согласно [7, 127]
|
Наименование модели знаний
и частный критерий
|
Выражение для частного критерия
|
|
через
относительные частоты
|
через
абсолютные частоты
|
|
СИМ-1,
частный критерий: количество знаний по А.Харкевичу, 1-й вариант расчета
вероятностей: Nj – суммарное количество
признаков по j-му классу (предпоследняя
строка таблицы 2)
|
|
|
|
СИМ-2,
частный критерий: количество знаний по А.Харкевичу, 2-й вариант расчета
вероятностей: Nj – суммарное
количество объектов по j-му классу
(последняя строка таблицы 2)
|
|
|
|
СИМ-3,
частный критерий: разности между фактическими и теоретически ожидаемыми по
критерию хи-квадрат абсолютными частотами
|
---
|
|
|
СИМ-4,
частный критерий: ROI - Return On Investment, 1-й вариант расчета
вероятностей
|
|
|
|
СИМ-5,
частный критерий: ROI - Return On Investment, 2-й вариант расчета
вероятностей
|
|
|
|
СИМ-6, частный критерий: разность
условной и безусловной вероятностей, 1-й вариант расчета вероятностей
|
|
|
|
СИМ-7, частный критерий: разность
условной и безусловной вероятностей, 2-й вариант расчета вероятностей
|
|
|
Таблица 78 – Матрица знаний
|
|
Классы
(целевые и нежелательные состояния
объекта управления)
|
Значимость
фактора
|
|
1
|
…
|
j
|
…
|
W
|
|
Факторы и их интервальные значения
|
Управляющие
факторы
|
1
|
|
|
|
|
|
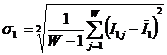
|
|
…
|
|
|
|
|
|
|
|
Факторы
окружающей
среды
|
…
|
|
|
|
|
|
|
|
i
|
|
|
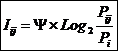
|
|
|
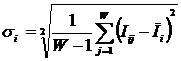
|
|
…
|
|
|
|
|
|
|
|
Факторы
состояния
объекта
управления
|
…
|
|
|
|
|
|
|
|
M
|
|
|
|
|
|
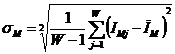
|
|
Степень
редукции
класса
|
s1
|
|
sj
|
|
sW
|
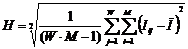
|
Здесь – это среднее
количество знаний в i-м значении
фактора:
На основе
анализа математической формы выражений для количественных мер знаний (таблица 77)
можно высказать гипотезу о том, что каждое из этих выражений, по сути, представляет
собой вариант скалярной передаточной функции, аналогичной элементу матричной
передаточной функции (78), и, следовательно, база знаний (таблица 78) представляет собой вариант матричной
передаточной функции.
Эта гипотеза основывается на следующих аналогиях и
предположениях
(таблица 78):
– входная величина uj аналогична или
подобна (~) Pi ,
т.е. безусловной вероятности наблюдения i-го
значения фактора по всей выборке;
– выходная величина yi ~ Pij – условной вероятности наблюдения i-го значения фактора у объектов в j-го класса или, что тоже самое, условной вероятности перехода объекта в j-е состояние при условии действия на него i-го
значения фактора;
– скалярная передаточная функция Wij(p)
~ Iij – знанию о том, что "объект перейдет в j-е
состояние" если "на объект действует i-е значение фактора".
Общее между скалярной передаточной функцией из матрицы (7) и
количественными мерами знаний состоит в том, что во все их выражения входят
отношения, а различие – в том, что частные
количественные меры знаний нормированы к 0 (при отсутствии влияния значения
фактора на переход объекта управления в j-е состояние), а в передаточной
функции в этом случае, т.е. когда выходное воздействие тождественно входному,
частные критерии равны 1. Однако, как мы увидим ниже, это различие не
принципиально и вообще несущественно.
Для этой нормировки используется логарифм, вычитание
единицы и другие способы. Подобное нормирование удобно при использовании аддитивного интегрального критерия. Однако при
использовании мультипликативного интегрального критерия, если частные критерии
равны 1 в случае отсутствия воздействия как, например, в случае передаточной
функции в которой выходной сигнал равен входному, то в этой нормировке к 0 нет
необходимости.
Взятие логарифма от частных критериев может рассматриваться
как формальный математически прием, обеспечивающий нужную нормировку. Но в этом
есть и более глубокий смысл. Мультипликативный интегральный критерий преобразуется в
аддитивный просто взятием логарифма от произведения (18):
При этом частные критерии, равные 1 при отсутствии воздействия,
преобразуются в количественные меры знаний СИМ-1 и СИМ-2.
Казалось бы, аддитивный интегральный критерий предполагает
линейность объекта управления, т.к. выполнение для него принципа суперпозиции, в этом случае
результирующее воздействие на линейный объект управления совокупности факторов является суммой
влияний на него каждого из этих факторов в отдельности. Проще говоря, если объект управления линейный, то факторы
не взаимодействуют друг с другом внутри объекта управления, т.е. являются не
системой, а множеством факторов. Однако в случае модели
системно-когнитивного анализа это не так, т.е. не смотря на логарифмический вид
частных критериев знаний и аддитивный интегральный критерий модель СК-анализа
позволяет учесть нелинейные эффекты
взаимодействия факторов.
Это осуществляется
следующим образом: из таблицы 77 мы видим, что в математические выражения для
всех частных критерий знаний входят величины, зависящие не
только Nij и N, но и от Nj и N.
Благодаря этому и математической форме частных критериев знаний, если добавить
в модель еще один фактор, тождественный одному из уже имеющихся, то количество
знаний в каждом из них будет меньше, чем до этого.
Итак, количественные значения коэффициентов Iij
таблицы 78 являются знаниями о том, что "объект перейдет в j-е состояние"
если "на объект действует i-е значение фактора".
Когда количество
знаний Iij > 0 – i–й
фактор способствует переходу объекта
управления в j-е состояние, когда Iij < 0 – препятствует этому переходу, когда же Iij = 0 – никак не влияет на это.
В векторе i-го фактора (строка матрицы знаний)
отображается, какое количество знаний о переходе объекта управления в каждое из
будущих состояний содержится в том факте, что данное значение фактора действует.
В векторе j-го состояния класса (столбец матрицы
знаний) отображается, какое количество знаний о переходе объекта управления в
соответствующее состояние содержится в каждом из значений факторов, представленных
в модели.
Таким
образом, матрица знаний функционально эквивалента матричной передаточной
функции (7), в которой входы (значения факторов) и выходы (будущие состояния
объекта управления) связаны друг с другом знаниями, выраженными в битах.
Такую
матричную передаточную функцию, в которой элементами являются не скалярные
передаточные функции, представляющие собой отношение выходной величины к
входной в символической форме при нулевых начальных условиях, а знания, будем
называть когнитивной матричной
передаточной функцией.
Фактически предложенная модель позволяет осуществить синтез когнитивной матричной передаточной
функции для различных предметных областей непосредственно на основе эмпирических
исходных данных и продуцировать на их
основе прямые и обратные правдоподобные (нечеткие) логические рассуждения по
неклассическим схемам с различными расчетными значениями истинности,
являющимся обобщением классических импликаций [7].
Таким образом,
данная модель позволяет рассчитать какое
количество знаний содержится в любом факте о наступлении любого события в любой
предметной области, причем для этого не требуется повторности этих фактов.
Если же эти повторности осуществляются и при этом наблюдается некоторая вариабельность
значений факторов, обуславливающих наступление тех или иных событий, то модель
обеспечивает многопараметрическую
типизацию, т.е. синтез обобщенных образов классов или категорий наступающих
событий с количественной оценкой силы и направления влияния на их наступление
различных значений факторов. Причем эти значения факторов могут быть как количественными,
так и качественными и измеряться в любых единицах измерения, в любом случае в
модели оценивается количество знаний, которое в них содержится о наступлении
событий, переходе объекта управления в определенные состояния или просто о его
принадлежности к тем или иным классам.
Принципиально важно, что эти элементы когнитивной
матричной передаточной функции не
определяются экспертами на основе опыта интуитивным неформализуемым способом, а рассчитываются непосредственно на
основе эмпирических данных и теоретически обоснованной модели, хорошо
зарекомендовавшей себя на практике при решении широкого круга задач в самых
различных предметных областях.
В этой связи кратко
рассмотрим информационную модель деятельности специалиста и место систем
искусственного интеллекта в этой деятельности [10]. Специалист, и тем более менеджер, в своей работе
постоянно сталкивается с необходимостью решения интеллектуальных задач,
связанных с идентификацией, прогнозированием и принятием решений (управлением)
(рисунок 124):
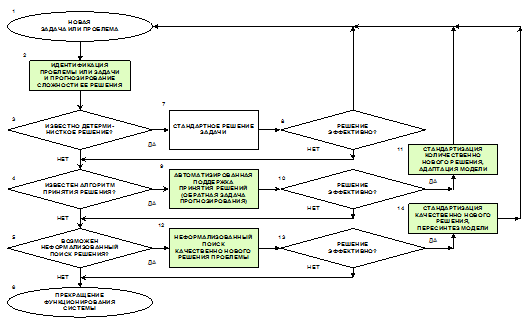
Рисунок 124. Информационная модель деятельности специалиста
и место систем искусственного интеллекта в этой деятельности
Дадим краткие
пояснения к информационной модели деятельности специалиста, представленной на
рисунке 124.
Блок 1. На
вход системы поступает задача или проблема. Что именно неясно, т.к. чтобы это
выяснить необходимо идентифицировать ситуацию и обратиться к базе данных
стандартных решений с запросом, существует ли стандартное решение для данной
ситуации.
Блок 2.
Далее осуществляется идентификация проблемы или задачи и прогнозирование
сложности ее решения. На этом этапе применяется интеллектуальная система,
относящаяся к классу систем распознавания образов, идентификации и прогнозирования
или эта функция реализуется специалистом самостоятельно "вручную".
Блок 3.
Если в результате идентификации задачи или проблемы по ее признакам
установлено, что точно имеется стандартное решение, то это означает, что на
вход системы поступила точно такая же
задача, как уже когда-то ранее встречалась. Для установления этого достаточно
информационно-поисковой системы, осуществляющей поиск по точному совпадению
параметров запроса и в применении интеллектуальных систем нет необходимости.
Тогда происходит переход на блок 7, а иначе на блок 4.
Блок 4.
Если установлено, что точно такой задачи не встречалось, но встречались сходные, аналогичные, которые могут быть
найдены в результате обобщенного (нечеткого) поиска системой распознавания образов,
то решение может быть найдено с помощью автоматизированной системы поддержки
принятия решений путем решения обратной
задачи прогнозирования. Это значит, что на вход системы поступила не
задача, а проблема, имеющая количественную новизну по сравнению с решаемыми
ранее (т.е. не очень сложная проблема). В этом случае осуществляется переход на
блок 9, иначе – на блок 5.
Блок 5.
Если установлено, что сходных проблем не встречалось, то необходимо качественно
новое решение, поиск которого требует существенного творческого участия
человека-эксперта. В этом случае происходит переход на блок 12, а иначе – на
блок 6.
Блок 6.
Переход на этот блок означает, что возможности поиска решения или выхода из
проблемной ситуации системой исчерпаны и решения не найдено. В этом случае
система обычно терпит ущерб целостности своей структуре и полноте функций,
вплоть до разрушения и прекращения функционирования.
Блок 7.
На этом этапе осуществляется реализация стандартного решения, соответствующего
точно установленной задаче, а затем проверяется эффективность решения на блоке
8.
Блок 8.
Если стандартное решение оказалось эффективным, это означает, что на этапах 2 и
3 идентификация задачи и способа решения осуществлены правильно и система может
переходить к разрешению следующей проблемной
ситуации (переход на блок 1). Если же стандартное решение оказалось
неэффективным, то это означает, что проблемная ситуация идентифицирована как
стандартная задача неверно и необходимо продолжить попытки ее разрешения с
использованием более общих подходов, основанных на применении систем
искусственного интеллекта (переход на блок 4), например, систем поддержки принятия
решений.
Блок 9.
Применяется автоматизированная система поддержки принятия решений,
обеспечивающая решение обратной задачи прогнозирования. Отличие подобных систем
от информационно-поисковых состоит в том, что они способны производить обобщение,
выявлять силу и направление влияния различных факторов на поведение системы, и,
на основе этого, по заданному целевому состоянию вырабатывать рекомендации по
системе факторов, которые могли бы перевести систему в это состояние (обратная
задача прогнозирования).
Блок 10.
Если решение, полученное с помощью системы поддержки принятия решений,
оказалось неэффективным, то это означает, что проблемная ситуация
идентифицирована как аналогичная ранее встречавшимся неверно. Следовательно, что
на вход системы поступила качественно новая, по сравнению с решаемыми ранее,
т.е. сложная проблема. В этом случае необходимо продолжить попытки разрешения
проблемы с использованием творческих неформализованных подходов с участием
человека-эксперта и перейти на блок 5, иначе – на блок 11.
Блок 11.
Информация об условиях и результатах решения проблемы заносится в базу знаний,
т.е. стандартизируется. После чего база знаний количественно (не принципиально)
изменяется, т.е. осуществляется ее адаптация. В результате адаптации при встрече в будущем точно таких же проблемных
ситуаций, как разрешенная, система уже будет разрешать ее не как проблему, а
как стандартную задачу.
Блок 12.
На этом этапе с использованием неформализованных творческих подходов
осуществляется поиск качественно нового решения проблемы, не встречавшейся
ранее, после чего управление передается блоку 13.
Блок 13.
Если решение, полученное экспертами с помощью неформализованных подходов,
оказалось неэффективным, то это означает, что система терпит крах
(осуществляется переход на блок 6). Если же адекватное решение найдено, то
происходит переход на блок 14.
Блок 14.
Стандартизация качественно нового решения, проблемы и пересинтез модели.
Информация об условиях и результатах творческого решения проблемы заносится в
базу знаний, т.е. стандартизируется. После этого база знаний качественно,
принципиально изменяется, т.е. фактически осуществляется ее пересоздание
(пересинтез). В результате пересинтеза
базы знаний при встрече в будущем проблемных ситуаций, аналогичных разрешенной,
система уже будет реагировать на них как проблемы, решаемые автоматизированными
системами поддержки принятия решений.
Блоки
информационной модели деятельности специалиста, в которых в принципе могут использоваться системы искусственного интеллекта,
на рисунке 124 показаны со светло-зеленой заливкой:
– блоки 2 и 12: система
распознавания образов, идентификации и прогнозирования;
– блоки 9, 11, 12 и 14:
автоматизированная система поддержки принятия решений.
Однако в настоящее
время специалист, как правило, решает все вышеперечисленные задачи без использования систем искусственного
интеллекта (СИИ). Но чтобы эта принципиальная
возможность применения СИИ превратилась в практическую возможность необходимо, чтобы существовала программная
система искусственного интеллекта, созданная в универсальной постановке, не
зависящей от предметной области. Благодаря универсальной постановке такая
система поддерживала бы решение вышеперечисленных задач, решаемых управляющей
системой САУ и АСУ, но не только для технических объектов управления, а в
широком круге предметных областей, в том числе при управлении биологическими,
экономическими и социально-психологическими системами. Это именно те области, в
которых в настоящее время в основном применяются слабо формализованные методы
управления без использования компьютерных технологий. Причины этого вполне
понятны. Они связаны с тем, что применение
математического аппарата матричных передаточных функций, развитого в теории САУ
и АСУ, для управления столь сложными объектами управления представляется в настоящее
время фактически невозможным из-за практической невозможности адекватного
математического описания этих объектов управления. Между тем подобные системы давно существуют, например,
Универсальная когнитивная аналитическая система «Эйдос» [7], обеспечивающая формирование когнитивных матричных
передаточных функций сложных объектов управления на основе эмпирических данных.
Однако чтобы эта практическая возможность стала действительностью необходимо с помощью системы «Эйдос» разработать
соответствующие интеллектуальные приложения, а затем применить эти приложения
на практике. Это в очень многих случаях уже сделано [7], в
том числе и автором с соавторами, но поле деятельности в этом направлении
вообще не ограничено.
Есть два способа принятия
решения о многофакторном управляющем воздействии, при которых выбирается
система значений факторов для воздействия на объект управления:
– многократное решение задачи
прогнозирования при различных сочетаниях значений управляющих факторов;
– решение обратной задачи
прогнозирования (а затем замена значений факторов с использованием результатов
кластерного анализа, прогнозирование и принятие окончательного решения о выборе
управляющего воздействия).
Выработка управляющего воздействия
путем прогнозирования поведения объекта управления в результате воздействия на
него различных сочетаний значений факторов приводит к комбинаторному взрыву и огромным затратам вычислительных ресурсов и
времени. В результате весьма вероятна ситуация, когда принятие решения путем
многократного прогнозирования и выбора наиболее подходящего варианта может
занимать больше времени, чем длительность цикла управления, что вообще неприемлемо.
Например, если в модели всего 3 описательных шкалы по 10 градаций в каждой, то
выбор варианта управляющего воздействия путем прогнозирования поведения объекта
управления при различных вариантах значений управляющих факторов потребовал бы
1000 прогнозов. Отметим, что на практике при решении реальных задач факторов
(шкал) может быть не 3, а сотни и тысячи. Это делает выбор управляющего
воздействия путем перебора вариантов прогнозов практически неосуществимым.
Выработка управляющего
воздействия путем решения обратной задачи
прогнозирования. Если при прогнозировании на основе знаний о системе
действующих значений факторов определяется будущее поведение объекта
управления, то при решении обратной задачи прогнозирования, наоборот, по
заданному целевому состоянию объекта управления определяется такая система
значений факторов, которая при воздействии на объект управления с наибольшей
степенью обусловленности переводит его в это целевое состояние. Решение
обратной задачи прогнозирования представляет собой просто выборку всех знаний
из матрицы знаний о воздействии различных значений факторов на переход объекта
управления в целевое состояние и сортировку этих значений факторов в порядке
убывания количеств знаний в них. Если какие-либо значения факторов не удается
использовать на практике из-за их высокой стоимости или фактической недоступности
соответствующих технологий, то можно используя результаты кластерного анализа [128]
заменить эти значения факторов другими, сходными по действию на поведение
объекта управления, но более доступными, а затем решить задачу прогнозирования
с новым набором значений факторов. Если результат прогнозирования
удовлетворительный, то принимается решение о выборе данного управляющего
воздействия.
Рассмотрим, как в
предлагаемой модели реализуются задачи идентификации, прогнозирования и
принятия решений.
Рассмотрим
поведение объекта управления при воздействии на него не одного, а целой системы значений факторов:
|
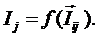
|
(18)
|
В теории принятия
решений скалярная функция Ij векторного
аргумента называется интегральным критерием. Основная
проблема состоит в выборе такого аналитического вида функции интегрального критерия, который обеспечил бы
эффективное решение задач, решаемых управляющей системой САУ и АСУ.
Учитывая, что частные критерии (таблица 77) имеют
смысл количества знаний, а знания, как и информация, является аддитивной функцией, предлагается ввести
интегральный критерий, как аддитивную
функцию от частных критериев в виде:
|
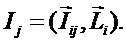
|
(19)
|
В выражении (19)
круглыми скобками обозначено скалярное произведение, т.е. свертка. В координатной
форме это выражение имеет вид:
|
,
|
(20)
|
где:
– вектор j-го класса-состояния объекта
управления;
– вектор состояния предметной области (объекта управления),
включающий все виды факторов, характеризующих объект управления, возможные
управляющие воздействия и окружающую среду (массив-локатор), т.е. Li=n, если i-й признак встречается у объекта n раз.
Таким образом,
предложенный интегральный критерий
представляет собой суммарное количество знаний, содержащихся в системе значений
факторов различной природы (т.е. факторах, характеризующих объект управления,
управляющее воздействие и окружающую среду) о переходе объекта управления в то
или иное будущее состояние.
В
многокритериальной постановке задача прогнозирования состояния объекта
управления, при оказании на него заданного многофакторного управляющего
воздействия Ij, сводится к
максимизации интегрального критерия:
|
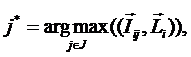
|
(21)
|
т.е.
к выбору такого состояния объекта управления, для которого интегральный
критерий максимален.
Результат прогнозирования поведения объекта управления, описанного данной
системой факторов, представляет собой список его возможных будущих состояний, в
котором они расположены в порядке убывания суммарного количества знаний о переходе
объекта управления в каждое из них.
Задача принятия решения о выборе наиболее эффективного управляющего
воздействия является обратной задачей
по отношению к задаче максимизации интегрального критерия (идентификации и
прогнозирования), т.е. вместо того, чтобы по набору факторов прогнозировать
будущее состояние объекта, наоборот, по заданному (целевому) состоянию объекта
определяется такой набор факторов, который с наибольшей эффективностью перевел
бы объект управления в это состояние.
Предлагается еще
одно обобщение фундаментальной леммы Неймана-Пирсона, основанное на косвенном
учете корреляций между информативностями в векторе состояний при использовании
средних по векторам. Соответственно, вместо простой суммы количеств информации
предлагается использовать корреляцию между векторами состояния и объекта
управления, которая количественно измеряет степень сходства этих векторов:
|
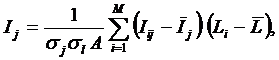
|
(22)
|
где:
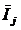 – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
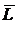 – среднее по
вектору идентифицируемой ситуации (объекта).
– среднее по
вектору идентифицируемой ситуации (объекта).
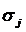 – среднеквадратичное
отклонение информативностей вектора класса;
– среднеквадратичное
отклонение информативностей вектора класса;
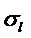 – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
Выражение (22) получается
непосредственно из (20) после замены координат перемножаемых векторов их
стандартизированными значениями:
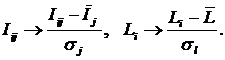
Необходимо
отметить, что выражение для интегрального критерия сходства (22) по своей
математической форме является корреляцией
двух векторов. Это означает, что если эти вектора являются суммой двух
сигналов: полезного и белого шума, то при достаточно большой выборке при расчете интегрального критерия белый шум
практически не будет играть никакой роли, т.е. его корреляция с самими
собой равна нулю по определению. Поэтому интегральный критерий сходства объекта
со случным набором признаков с любыми образами классов, или реального объекта с
образами классов, сформированными случайным образом, будет равен нулю. Это
означает, что выбранный интегральный
критерий сходства является высокоэффективным средством подавления белого шума и
выделения полезной информации из шума, который неизбежно присутствует в
эмпирических данных.
Важно также
отметить неметрическую природу
предложенного интегрального критерия сходства, благодаря чему его применение является корректным и при
неортонормированном семантическом информационном пространстве, каким оно в подавляющем
количестве случае и является, т.е. в общем случае.
Если применить предлагаемые модели для конкретизации
схемы цикла управления, представленного на рисунке 119, и информационной модели
деятельности специалиста (рисунок 124), то получим представленную на рисунке 125
параметрическая модель рефлексивной АСУ активными объектами (системами), впервые
приведенную в работе [7]. В работах [6, 15, 16] приведены подобные схемы ряда
конкретных применений системно-когнитивного анализа и системы «Эйдос» для
интеллектуального управления сложными системами.
Рисунок 125. Параметрическая модель рефлексивной АСУ
активными объектами (системами)
Рассмотренные выше матрицы условных и безусловных вероятностей,
а также матрица знаний, могут рассматриваться не только как аналоги матричной
передаточной функции, но и как матричные
коэффициенты передачи,
элементы которых являются коэффициентами передачи между значениями факторов и
классами, соответствующими переходам объекта управления в будущие состояния.
Безразмерные относительные коэффициенты передачи используются и в экономике и
называются эластичность [21] и также могут быть использованы качестве меры знаний. Согласно [228]
«передаточные функции принято записывать в стандартной форме:
|
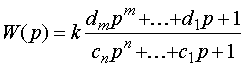 , ,
|
(24)
|
где 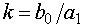 – коэффициент передачи».
Таким образом, можно сделать вывод, что коэффициент передачи – это матричная
передаточная функция при начальных условиях.
– коэффициент передачи».
Таким образом, можно сделать вывод, что коэффициент передачи – это матричная
передаточная функция при начальных условиях.
Выводы.
Таким образом, в разделе рассмотрена глубокая
взаимосвязь между теорией автоматизированного и автоматического управления и
системно-когнитивным анализом и его программным инструментарием – системой
«Эйдос» в их применении для интеллектуального управления сложными системами.
Предлагается технология, позволяющая на практике реализовать интеллектуальное
автоматизированное и даже автоматическое управление такими объектами
управления, для которых ранее управление реализовалось лишь на
слабоформализованном уровне, как правило, без применения математических моделей
и компьютеров. К таким объектам управления относятся, например, технические системы,
штатно качественно-изменяющиеся в процессе управления, биологические и
экологические системы, социально-экономические и психологические системы.
О применении САУ для управления подобными сложными
системами в настоящее время не может быть
речи из-за практической невозможности их адекватного описания с
применением дифференциальных уравнений. Вместе с тем, перспектива развития
методов управления сложными системами состоит в повышении степени формализации процессов принятия решений при выборе
вариантов управляющих воздействий. Предлагается технология, обеспечивающая создание формальной количественной
модели сложного объекта управления на
основе эмпирических данных о его поведении под действием различных факторов, модели,
пригодной для решения задач прогнозирования и принятия решений. В предлагаемой
технологии есть ряд аналогий с методами САУ и АСУ, рассмотрению которых и
посвящена статья. Естественно, предложенная технология не рассматривается авторами
как альтернатива САУ и АСУ в тех областях, где их применение хорошо освоено и
предлагается лишь как вариант повышения степени формализации при управлении
сложными системами, управление которыми, как правило, осуществляется вообще без
использования математических моделей и компьютерных технологий.
Сформулированы и обоснованы гипотезы о том, что матрица
условных и безусловных процентных распределений и матрицы знаний с различными
количественными мерами знаний, могут рассматриваться как матричные передаточные
функции, т.е. модели сложных многофакторных динамичных объектов управления, на
основе которых могут успешно решаться основные задачи, решаемые с применением
матричных передаточных функций: задача прогнозирования поведения объекта
управления под действием системы
факторов и задача выработки такого управляющего воздействия, которое переведет
объект управления в заранее заданное целевое состояние.
Материалы статьи могут быть использованы при проведении
лекционных и лабораторных занятий по дисциплинам: «Основы теории управления
(теория автоматического управления) (ТАУ)», «Автоматизированные системы
управления (АСУ)», «Эффективность АСУ», «Интеллектуальные информационные
системы» и «Концепции современного естествознания» для различных
специальностей, а также для решения перечисленных в начале статьи и других
задач того же типа в различных предметных областях.
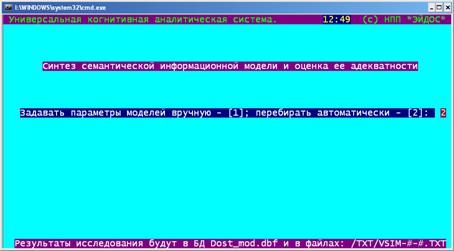

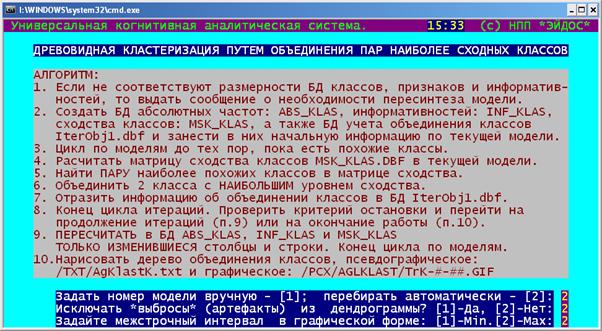
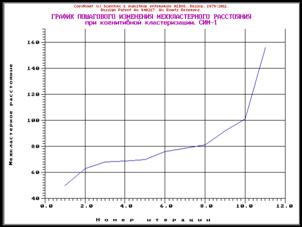
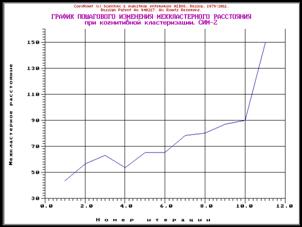
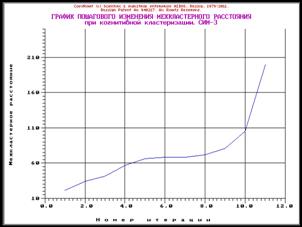
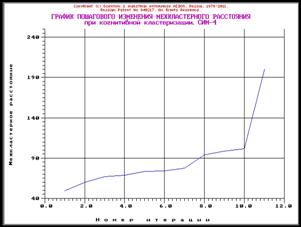
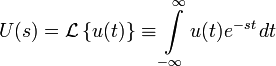
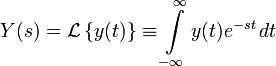
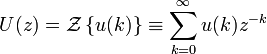
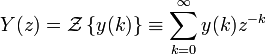
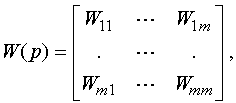
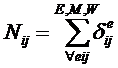
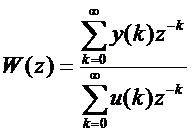
 ,
,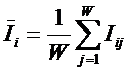 .
.