4.2. ОПИСАНИЕ АЛГОРИТМОВ БАЗОВЫХ КОГНИТИВНЫХ ОПЕРАЦИЙ СИСТЕМНОГО АНАЛИЗА
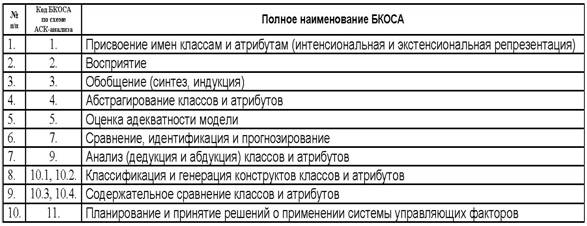
В данном разделе приведены 24 детальных алгоритма всех 10 базовых когнитивных операций системного анализа (таблица 4.1), коды которых полностью соответствуют схеме АСК-анализа (рисунок 2.16).
|
Таблица 4. 1 – БАЗОВЫЕ КОГНИТИВНЫЕ ОПЕРАЦИИ |
|
|
В таблице
4.2 приведена структура каждой базовой когнитивной операции и даны наименования
программных модулей и функций Универсальной когнитивной аналитической системы
"Эйдос", реализующих данные когнитивные
операции. (подробнее данная
система описана в главе 5.).
|
Таблица 4. 2 – СООТВЕТСТВИЕ БКОСА ПРОГРАММНЫМ МОДУЛЯМ, ПРОЦЕДУРАМ И ФУНКЦИЯМ СИСТЕМЫ "Эйдос" |
|
|
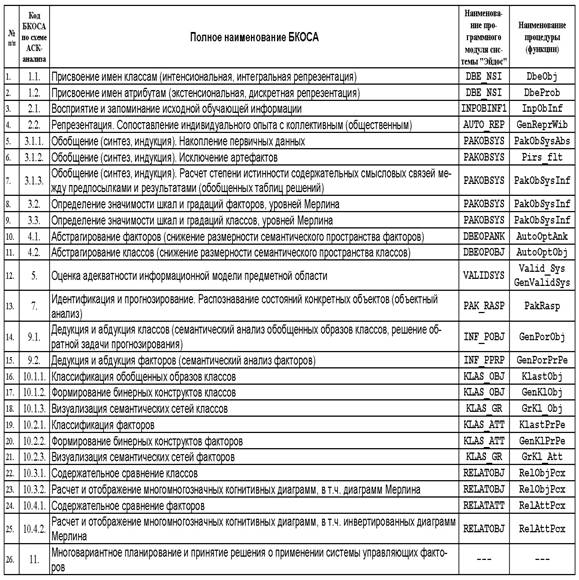
Детальные алгоритмы базовых когнитивных операций системного анализа приведены на рисунках 4.2 – 4.25.
БКОСА-2.1. "Восприятие и запоминание исходной обучающей информации"
В базы данных вводятся двухвекторные (дискретно-интегральные) описания объектов, включающие как их описание на языке признаков, так и принадлежность к определенным классификационным категориям – классам.
БКОСА-2.2. "Репрезентация. Сопоставление индивидуального опыта с коллективным (общественным)"
В ряде случаев, особенно при проведении политологических исследований, необходимо, чтобы исследуемая выборка корректно представляла генеральную совокупность не только в смысле традиционно понимаемой репрезентативности, но и по распределению респондентов по категориям (т.е. структурно) соответствовала ей. Добиться этого путем подбора объектов для исследования затруднительно, т.к. каждый объект может относится одновременно ко многим классификационным категориям. Данный алгоритм обеспечивает выборку из исследуемого множества объектов последовательных подмножеств, наиболее близких по частотному распределению объектов по категориям к заданному распределению. Данная операция называется также "взвешивание или ремонт данных".
БКОСА-3.1.1. "Обобщение (синтез, индукция). Накопление первичных данных"
На основе анализа обучающей выборки обеспечивается накопление в базах данных первичных элементов смысла, т.е. фактов, состоящих в том, что определенный признак встретился у объекта определенного класса.
БКОСА-3.1.2. "Обобщение (синтез, индукция). Исключение артефактов"
При отсутствии статистики невозможно отличить закономерные факты от не вписывающихся в общую складывающуюся картину и искажающих ее, т.е. артефактов. При накоплении же достаточной статистики это возможно и данный алгоритм позволяет выявить и исключить из дальнейшего анализа артефакты. Необходимо отметить, что в результате действия данного алгоритма существенно повышается качество содержательной модели предметной области, в частности ее валидность.
БКОСА-3.1.3. "Обобщение (синтез, индукция). Расчет степени истинности содержательных смысловых связей между предпосылками и результатами (обобщенных таблиц решений)"
Непосредственно на основе матрицы абсолютных частот позволяет вычислить количество информации, содержащейся в факте наблюдения у некоторого объекта определенного признака о том, что данный объект принадлежит к определенной классификационной категории.
БКОСА-3.2. "Определение значимости шкал и градаций факторов, уровней Мерлина"
Рассчитывается среднее количество информации, которое система управления получает о поведении АОУ из фактов о действии тех или иных факторов и их значений. Кроме того, если факторы классифицированы независимым способом по уровням Мерлина, то определяется и значимость этих уровней.
БКОСА-3.3. "Определение значимости шкал и градаций классов, уровней Мерлина"
Рассчитывается среднее количество информации, которое система управления получает из одного признака, если известен класс. Если классы относятся к уровням Мерлина, то определяется и их значимость.
БКОСА-4.1. "Абстрагирование факторов (снижение размерности семантического пространства факторов)"
С помощью метода последовательных приближений (итерационный алгоритм) при заданных граничных условиях снижается размерность пространства атрибутов без существенного уменьшения его объема. Критерий остановки итерационного процесса – достижение одного из граничных условий.
БКОСА-4.2. "Абстрагирование классов (снижение размерности семантического пространства классов)"
С помощью метода последовательных приближений (итерационный алгоритм) при заданных граничных условиях снижается размерность пространства классов без существенного уменьшения его объема. Критерий остановки итерационного процесса – достижение одного из граничных условий.
БКОСА-5. "Оценка адекватности информационной модели предметной области"
Осуществляется идентификация объектов обучающей выборки (классификационный вектор которых уже известен) и затем рассчитывается средневзвешенная погрешность идентификации (интегральная валидность), а также погрешность идентификации с каждым классом (дифференциальная валидность). Если модель имеет приемлемый уровень адекватности, то принимается решение о возможности ее использования в адаптивном режиме на объектах, не входящих в обучающую выборку, но относящихся к генеральной совокупности, по отношению к которой эта выборка репрезентативна. Если же модель недостаточно адекватна, то продолжаются работы по синтезу адекватной модели путем увеличения количества классов и факторов, а также корректировки описаний объектов обучающей выборки и увеличения их количества.
БКОСА-7. "Сравнение, идентификация и прогнозирование. Распознавание состояний конкретных объектов (объектный анализ)"
Рассчитывается количество информации, содержащееся в описании идентифицируемого объекта о его принадлежности к каждому из классов. Все классы ранжируются в порядке убывания количества информации о принадлежности к ним в описании данного объекта. Таким образом вектор объекта разлагается в ряд по векторам классов. Кроме того все объекты ранжируются в порядке убывания сходства с каждым классом. Таким образом вектор класса разлагается в ряд по векторам объектов.
БКОСА-9.1. "Дедукция и абдукция классов (семантический анализ обобщенных образов классов, решение обратной задачи прогнозирования)"
Координаты вектора класса (т.е. факторы) ранжируются в порядке убывания их значений. Таким образом, в начале списка оказываются факторы, оказывающие наиболее сильное влияние на переход АОУ в состояние, соответствующее данному классу, а в конце списка – препятствующие этому. Это позволяет выбрать факторы для управляющего воздействия, целью которого является перевод АОУ в состояние, соответствующее данному классу. Механизм фильтрации позволяет "изолированно" рассматривать влияние различных групп факторов: например, факторов, характеризующих объект управления, управляющую систему или окружающую среду.
БКОСА-9.2. "Дедукция и абдукция факторов (семантический анализ факторов)"
Классы ранжируются в порядке убывания влияния данного фактора на переход АОУ в состояния, соответствующие этим классам. В начале списка оказываются состояния, на переход в которые данный фактор оказывает наибольшее влияние, а в конце – на переход в которые данный фактор препятствует. Этот список является развернутой характеристикой смысла фактора.
БКОСА-10.1.1. "Классификация обобщенных образов классов"
Сравниваются вектора классов и формируется диагональная матрица сходства классов, в которой по обоим осям расположены коды классов а в клетках находятся нормированные коэффициенты, численно отражающие степень сходства или различия векторов соответствующих классов.
БКОСА-10.1.2. "Формирование бинерных конструктов классов"
На основе матрицы сходства классов для каждого из них формируется ранжированный список остальных, в котором они расположены в порядке убывания сходства с данным классом. Такие списки представляют собой бинарные конструкты, а их полюса соответствуют кластерам.
БКОСА-10.1.3. "Визуализация семантических сетей классов"
На основе матрицы сходства классов визуализируются ориентированные графы, вершинам которых соответствуют классы, а ребрам – степени их сходства или различия. Знак связи обозначается цветом: красный цвет – сходство, синий – различие, толщина линии соответствует модулю (силе) связи. Необходимо отметить, что для подобных графов в литературе пока нет устоявшегося общепринятого названия: в данном исследовании, как и в предшествующих работах автора, они согласно [244] называются семантическими сетями, в литературе по когнитивному анализу их называют когнитивными картами, а в литературе по когнитивному анализу – когнитивными картами или схемами [177].
БКОСА-10.2.1. "Классификация факторов"
Сравниваются вектора факторов и формируется диагональная матрица сходства факторов, в которой по обоим осям расположены коды факторов а в клетках находятся нормированные коэффициенты, численно отражающие степень сходства или различия векторов соответствующих факторов.
БКОСА-10.2.2. "Формирование бинерных конструктов факторов"
На основе матрицы сходства факторов для каждого из них формируется ранжированный список остальных, в котором они расположены в порядке убывания сходства с данным фактором. Такие списки представляют собой бинарные конструкты, а их полюса соответствуют кластерам.
БКОСА-10.2.3. "Визуализация семантических сетей факторов"
На основе матрицы сходства факторов визуализируются ориентированные графы, вершинам которых соответствуют заданные факторы, а ребрам – степени их сходства или различия. Знак связи обозначается цветом: красный цвет – сходство, синий – различие, толщина линии соответствует модулю (силе) связи.
БКОСА-10.3.1. "Содержательное сравнение классов"
Каждая связь между классами в семантической сети, отражающая степень их сходства или различия, имеет определенную структуру, описанную в разделе 3.2.3 исследования. Эта структура включает ряд элементов, каждый из которых соответствует одному слагаемому обобщенной меры сходства векторов классов.
БКОСА-10.3.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. диаграмм Вольфа Мерлина"
Из всех составляющих связи между классами выбираются 8 наиболее сильных и отображаются в форме линий, цвет которых означает знак, а толщина – модуль силы связи. Классы изображаются в форме наиболее значимых фрагментов их информационных портретов. При этом учитываются корреляции между факторами.
БКОСА-10.4.1. "Содержательное сравнение факторов"
Каждая связь между факторами в семантической сети, отражающая степень их сходства или различия, имеет определенную структуру, описанную в разделе 3.2.3 исследования. Эта структура включает ряд элементов, каждый из которых соответствует одному слагаемому обобщенной меры сходства векторов факторов.
БКОСА-10.4.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. инвертированных диаграмм Мерлина"
Из всех составляющих связи между факторами выбираются 16 наиболее сильных и отображаются в форме линий, цвет которых означает знак, а толщина – модуль силы связи. Факторы отображаются в форме наиболее значимых фрагментов их семантических портретов. При этом учитываются корреляции между классами.
БКОСА-11. "Многовариантное планирование и принятие решения о применении системы управляющих факторов"
Выполняется в несколько этапов:
1) выполняется прогноз развития АОУ в условиях отсутствия управляющих воздействий, т.е. реализуется БКОСА-7 ("движение по инерции");
2) если в соответствии с прогнозом по п.1 АОУ достигает заданного целевого состояния (т.е. прогноз "удовлетворительный"), то планирование прекращается (переход на п.6); иначе – выполняется п.3;
3) путем решения обратной задачи прогнозирования (БКОСА-9.1) определяется набор факторов, оптимальный для перевода АОУ в заданное целевое состояние;
4) если все эти факторы есть возможность использовать для управления, то на этом планирование прекращается (переход п.6); иначе переход на п.5;
5) используя результаты кластерно-конструктивного анализа факторов (БКОСА 10.2.1, 10.2.2, 10.2.3) последовательно ищется замена для факторов, которые нет возможности использовать и после каждой замены выполняется прогнозирование (БКОСА-7); если результаты прогнозирования удовлетворительные – окончание планирования (переход на п.6); иначе принятие решения о невозможности выработки корректного управляющего воздействия;
6) окончание планирования.