3.1. Количественная
оценка степени
манипулирования индексом Хирша
и его модификация, устойчивая
к манипулированию
В СССР ВАК с
1975 и до самого распада СССР подчинялась не Министерству образования и науки,
а непосредственно Совету министров СССР. Однако с тех пор существует устойчивая
тенденция постепенного снижения статуса ВАК. Сегодня ВАК уже не просто входит в
Минобрнауки, а является всего лишь одним из подразделений одной из его
структур: Рособрнадзора. Снижение статуса ВАК неизбежно приводит к снижению как
статуса, так и адекватности присваиваемых им ученых степеней и научных званий.
Этот процесс обесценивания традиционных ученых степеней и званий, присваиваемых
ВАК, дошел до того, что несколько лет назад отменили надбавки к заработной
плате за них. Теперь вместо них каждым вузом и НИИ разрабатывается свои
локальные, т.е. несопоставимые друг с другом наукометрические методики оценки
результатов научной и педагогической деятельности. При всем разнообразии этих
методик, общим для всех них является несоразмерно большая роль, которая отводится
в них индексу Хирша. Значение индекса Хирша начинает играть важную роль при
защитах, при рассмотрении конкурсных дел на замещение должностей, а также при
определении величины ежемесячного материального поощрения за результаты научной
и педагогической деятельности. Сам по себе, этот индекс теоретически вполне
обоснован. Однако, в связи с практикой его применения в наших условиях, в коллективном
сознании научного сообщества возникла своеобразная мания, которую авторы
называют «Хиршамания». Эта мания характеризуется повышенным нездоровым
интересом к самому значению индекса Хирша, а также к некорректному
манипулированию его значением, т.е. к искусственному неадекватному
преувеличению этого значения, а также рядом негативных последствий этого
интереса. В данной работе делается попытка сконструировать количественную меру
для оценки степени некорректного манипулирования значением индекса Хирша, а
также предлагается научно-обоснованная модификация индекса Хирша, нечувствительная
(устойчивая) к манипулированию им. Приводится методика всех численных расчетов,
которая достаточно проста, чтобы ее мог применить любой автор
Высшая
аттестационная комиссия (ВАК) – это своего рода отдел технического контроля
(ОТК), оценивающий «качество продукции» не только Министерства образования и
науки, но и всех других министерств и ведомств, в которых есть свои вузы и НИИ.
В качестве продукции вузов и НИИ выступают не только их разработки, но и сами
ученые. ВАК, как и ОТК, обеспечивает обратную связь, информируя управляющую систему
о результатах ее работы. Из теории управления известно, что если информация
обратной связи неадекватна, то и управляющие решения, принимаемые на ее основе,
также будут неадекватными. Понятно, что оценивающая структура не должна
находится в подчинении у той структуры, качество работы которой она оценивает.
В противном случае нетрудно догадаться, как она будет оценивать. В СССР
ВАК с 1975 и до самого распада СССР подчинялась не Министерству образования и
науки, а непосредственно Совету министров СССР, что соответствует этой логике.
Однако с тех пор существует устойчивая
тенденция постепенного снижения статуса ВАК. Сегодня ВАК уже не просто
входит в Минобрнауки, а является всего лишь одним из подразделений одной из его
структур: Рособрнадзора. Снижение статуса ВАК неизбежно приводит к
снижению как статуса, так и адекватности присваиваемых им ученых степеней и научных
званий. Этот процесс обесценивания традиционных ученых степеней и
званий, присваиваемых ВАК, дошел до того, что несколько лет назад отменили
надбавки к заработной плате за них. Теперь вместо традиционных ученых степеней
и званий, присваиваемых ВАК практически
каждым вузом и НИИ разрабатывается свои локальные,
т.е. несопоставимые друг с другом наукометрические методики оценки результатов
научной и педагогической деятельности. При всем разнообразии этих методик
общим для всех них является несоразмерно большая роль, которая отводится в них
индексу Хирша. Значение индекса Хирша начинает играть важную роль при защитах,
при рассмотрении конкурсных дел на замещение должностей, а также при определении
величины ежемесячного материального поощрения за результаты научной и
педагогической деятельности. Сам по себе этот индекс теоретически вполне обоснован. Однако в связи с практикой применения индекса Хирша в
наших условиях в сознании научного сообщества возникла своеобразная мания, которую
авторы называют «Хиршамания» [1]. Эта мания характеризуется повышенным
нездоровым интересом к самому значению индекса Хирша, а также к некорректному
манипулированию его значением, т.е. к искусственному неадекватному преувеличению
этого значения, а также рядом негативных последствий этого интереса.
Возникают
естественные вопросы:
1. Возможно
ли как-то количественно оценить степень манипулирования индексом Хирша, т.е.
то, в какой степени его значение «целенаправленно организовано»?
2. Возможно
ли получить гипотетическое значение индекса Хирша каким оно было бы в случае
отсутствия манипулирования им?
В данной
работе делается попытка найти конкретные ответы на эти вопросы путем:
–
конструирования количественной меры для оценки степени некорректного
манипулирования значением индекса Хирша;
– разработки
научно-обоснованной модификации индекса Хирша, нечувствительной (устойчивая) к
попыткам манипулированию им.
Кроме
собственно самих идей предлагается также методика всех численных расчетов,
достаточно простая, чтобы ее мог применить каждый автор.
3.1.1. Что такое индекс Хирша
Если
ранжировать все публикации ученого в порядке убывания числа их цитирований («ранжированный
список публикаций»), то индекс Хирша h – это просто номер публикации в
этом списке, процитированной h раз. За этой публикацией идут публикации,
процитированные менее h раз, а до нее – более h раз.
Таким
образом, индекс Хирша является абсциссой точки пересечения графика числа
цитирований для ранжированного списка публикаций с биссектрисой первого
квадранта (рис. 1).
Пусть f(h) -
число цитирований публикации ранга h (т.е. публикации с номером h в
ранжированном списке публикаций). Тогда для индекса Хирша h0
справедливы неравенства
f(h) >
h при h < h0 и f(h) < h при h > h0.
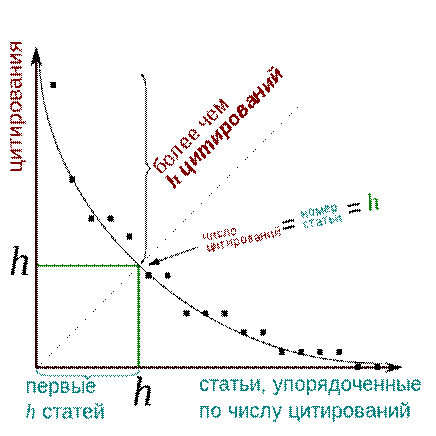
Рисунок 1.
Распространенное в Internet пояснение к понятию:
«индекс Хирша»[1]
3.1.2. Манипулирование индексом Хирша
при малом числе публикаций
Из
приведенного выше нехитрого алгоритма вычисления значения индекса Хирша вполне
понятно, как получить максимальное значение индекса Хирша h при минимальном
числе публикаций h+1. Для этого достаточно опубликовать h+1 статей, в каждой из
которых сослаться на все остальные [2].
Наверное приведенный выше простой и доступный способ сформировать любое
заданное значение индекса Хирша первым приходит всем авторам на ум. И это дает
нам в руки первый наиболее простой критерий манипулирования индексом Хирша: «Чем более пологим является линейный тренд
числа цитирований, построенный по ранжированному списку публикаций, тем более
вероятно, что был применен описанный выше способ максимизации индекса Хирша при
малом числе публикаций».
Максимальный теоретически возможный угол наклона линейного тренда,
достижимый лишь асимптотически, равен 90°, а минимальный, естественно, равен
нулю: 0°. Количественно этот 1-й частный критерий по сути должен быть какой-то
простой функцией от коэффициента наклона линейного тренда ранжированного
списка. Естественным было нормировать 1-й частный критерий
манипулирования индексом Хирша таким образом, чтобы при наклоне тренда 90° он
имел минимальное значение равное 0 (нет манипулирования), а при наклоне 0° имел
максимальное значение, равное 1 (полное манипулирование).
Уравнение линейного тренда выгладит следующим образом:
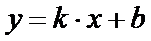
С учетом всех этих соображений предлагается следующее выражение для 1-го
частного критерия манипулирования индексом Хирша K1 при малом числе публикаций:
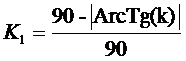 ,
,
где:
k – коэффициент при x в линейном тренде ранжированного списка публикаций;
ArcTg(k) – арктангенс коэффициента наклона – угол наклона линейного
тренда ранжированного по числу цитирований списка публикаций (в градусах).
Понятно, что чем более пологим является линейный тренд графика числа
цитирований, тем ближе коэффициент b в линейном тренде к значению индекса Хирша
h:
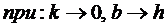
Предлагается следующее выражение для 2-го частного критерия
манипулирования индексом Хирша K2
при малом числе публикаций:
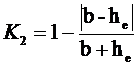 ,
,
где:
b – свободный член в линейном тренде графика числа цитирований;
he – эмпирическое значение индекса Хирша, т.е. полученное
непосредственно из ранжированного списка публикаций и построенного по нему
графика числа цитирований.
Естественным было нормировать 2-й частный критерий манипулирования
индексом Хирша таким образом, чтобы при эмпирическом индексе Хирша he=0
он был равен нулю (нет манипулирования), при свободном члене b равном эмпирическому индексу Хирша he
он был равен 1 (полное манипулирование), и при увеличении разницы между ними
стремился к нулю (уменьшение степени манипулирования) (таблица 1 и рисунок 2):
Таблица 1 – Зависимость 2-го частного критерия манипулирования индексом
Хирша от эмпирического значения индекса Хирша
при постоянном свободном члене b=7
|
B
|
H
|
2-й
частный
критерий
|
B
|
H
|
2-й
частный
критерий
|
B
|
H
|
2-й
частный
критерий
|
|
7
|
0
|
0,000000
|
7
|
13
|
0,700000
|
7
|
26
|
0,424242
|
|
7
|
1
|
0,250000
|
7
|
14
|
0,666667
|
7
|
27
|
0,411765
|
|
7
|
2
|
0,444444
|
7
|
15
|
0,636364
|
7
|
28
|
0,400000
|
|
7
|
3
|
0,600000
|
7
|
16
|
0,608696
|
7
|
29
|
0,388889
|
|
7
|
4
|
0,727273
|
7
|
17
|
0,583333
|
7
|
30
|
0,378378
|
|
7
|
5
|
0,833333
|
7
|
18
|
0,560000
|
7
|
31
|
0,368421
|
|
7
|
6
|
0,923077
|
7
|
19
|
0,538462
|
7
|
32
|
0,358974
|
|
7
|
7
|
1,000000
|
7
|
20
|
0,518519
|
7
|
33
|
0,350000
|
|
7
|
8
|
0,933333
|
7
|
21
|
0,500000
|
7
|
34
|
0,341463
|
|
7
|
9
|
0,875000
|
7
|
22
|
0,482759
|
7
|
35
|
0,333333
|
|
7
|
10
|
0,823529
|
7
|
23
|
0,466667
|
7
|
36
|
0,325581
|
|
7
|
11
|
0,777778
|
7
|
24
|
0,451613
|
7
|
37
|
0,318182
|
|
7
|
12
|
0,736842
|
7
|
25
|
0,437500
|
7
|
38
|
0,311111
|
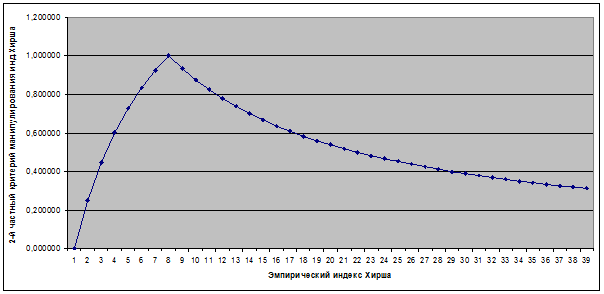
Рисунок 2. Зависимость 2-го частного критерия манипулирования
индексом Хирша от эмпирического значения индекса Хирша
при постоянном свободном члене b=7
Если считать, что оба эти частные критерия K1 и K2
имеют равный вес 0.5, то можно предложить следующее выражение для 1-го интегрального
критерия манипулирования индексом Хирша при малом числе публикаций:
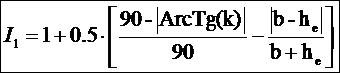 .
.
Все обозначения, использованные в данном выражении, описаны выше.
Данный 1-й интегральный критерий принимает значение равное 0 при
отсутствии манипулирования и равное 1 при максимальном, т.е. полном
манипулировании. Ниже приведена его вербальная формулировка:
«Чем ближе к нулю коэффициент наклона линейного тренда числа
цитирований, построенного по ранжированному списку публикаций и чем ближе
свободный член в линейном тренде к эмпирическому значению индекса Хирша, тем
более вероятно, что был применен описанный выше способ максимизации индекса
Хирша при малом числе публикаций».
Конечно, понятно, что часть цитирований могут естественными, не
организованными автором, и они вместе тоже могут формировать достаточно пологий
тренд, т.е. понятно, что максимальное значение индекса манипулирования еще не
означает самого факта манипулирования, а лишь является его признаком.
Аналогично и заимствования сами по себе не означают плагиата, т.к. могут быть
снабжены ссылками на источники, а могут быть и заимствованиями из работ самого
автора, которые уже по главам порезаны на рефераты и разошлись по всему
интернету.
Для того, чтобы применить этот интегральный критерий к публикациям
какого-либо автора выполняем следующие действия:
1. Открываем сайт РИНЦ: http://elibrary.ru/.
2. В меню слева выбираем «Авторский указатель», задаем сортировку по числу цитирований по убыванию без фильтра по
региону. В результате получаем (на момент написания статьи) (рисунок 3):
Рисунок 3. Экранная форма РИНЦ: «Авторский указатель»,
сортировка по числу цитирований по убыванию
без фильтра по региону
3. Выбираем автора, по которому собираемся анализировать индекс Хирша
(Новоселов К.С.), кликаем по числу его работ (левее гистограммки: 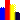 ),
выделяем блоком вместе с заголовком
таблицы первые его 100 публикаций (или все, если их меньше 100),
копируем его в буфер обмена и вставляем
в MS Excel (используем копировать: Ctrl+C, и вставить: Crtl+V или эти
пункты в меню, выскакивающему по клику на правой кнопке мыши).
),
выделяем блоком вместе с заголовком
таблицы первые его 100 публикаций (или все, если их меньше 100),
копируем его в буфер обмена и вставляем
в MS Excel (используем копировать: Ctrl+C, и вставить: Crtl+V или эти
пункты в меню, выскакивающему по клику на правой кнопке мыши).
4. Выделяем блоком весь лист отменяем объединение ячеек.
5. Переносим колонку D с числом цитирований в колонку C
(если они не в колонке C).
6. Начиная с колонки D вставляем следующие значения и формулы для
построения графика цитирований и расчета трендов (рисунок 4):
Рисунок 4. Значения и формулы для построения графика
цитирований и расчета трендов
В колонке D просто подряд пронумерованы строки c 1 до 100. В колонке
F в подряд идущих строках проставлены номера строк, в которых в колонке C
приведено число цитирований: 4, 7, 10, 13 и т.д. с шагом 3. В колонке E
приведены формулы ссылок на ячейки с числом цитирований из колонки C.
Все это сделано для того, чтобы значения числа цитирований для различных публикаций
шли в подряд идущих строках, а не в каждой третьей строке, начиная с 4-й, как
это сделано в РИНЦ. Отметим, что и в РИНЦ шаг 3 между строками с числом
цитирований может нарушаться, хотя это происходит и редко. Например, у автора:
Новоселов К.С. в 64-й публикации (193-я строка в списке РИНЦ) дано не совсем
стандартное описание. Поэтому для 65-й публикации вместо 196 строки указана
201-я, в которой фактически находится число цитирований 65-й публикации. Далее
и до 10-й публикации они опять идут с стандартным шагом 3. Чтобы не пропустить подобные ситуации рекомендуется проверять значения
числа цитирований не только в первых, но и в последних строках списка.
7. Строим график по числу цитирований. Для этого выделяем блоком ячейки в
колонке E, в которых есть число цитирований (удобнее это делать снизу
вверх), и строим график (рисунок 5):
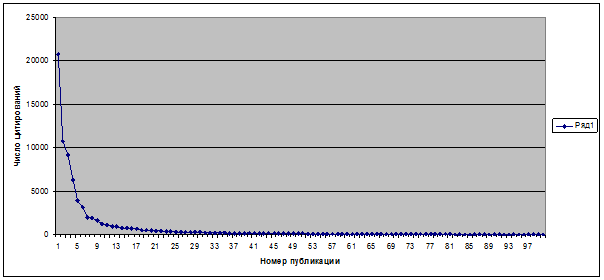
Рисунок 5.
График числа цитирований, простроенный по списку
публикаций Новоселова К.С., ранжированному по числу цитирований в порядке
убывания
8. Строим линейный тренд графика числа цитирований с выводом формулы
тренда и критерия качества аппроксимации – коэффициента детерминации R2
(рисунок 6):
Рисунок 6.
График числа цитирований публикаций Новоселова К.С. с линейным трендом
9. Для расчета частных критериев и интегрального критерия в MS Excel
используем формулы, приведенные на рисунке 7:
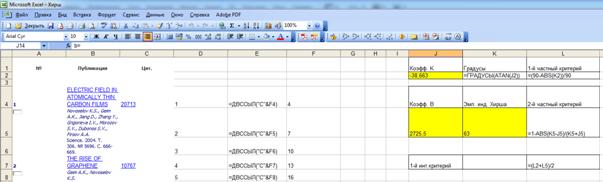
Рисунок 7. Формулы для расчета частных критериев и 1-го
интегрального критерия манипулирования индексом Хирша
при малом числе публикаций
Значения коэффициентов k и b из уравнения линейной регрессии,
приведенного на рисунке 6, вручную
вносим в ячейки J2 и J5 соответственно (выделены на рисунке 7
желтым цветом). В результате получим значения частных критериев и интегрального
критерия манипулирования индексом Хирша для данного автора (рисунок 8),
рассчитанные по приведенным выше формулам.
Из рисунка 8 видно, что все эти значения очень близки к нулю, что
означает полное отсутствие манипулирования
в данном случае.
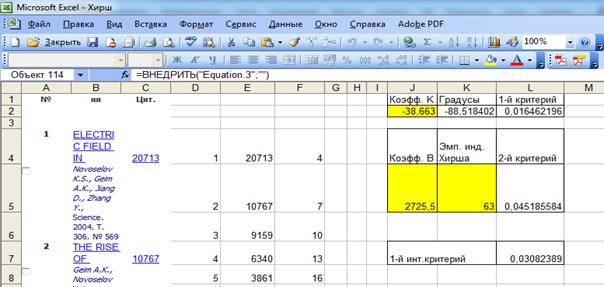
Рисунок 8. Значения частных критериев и 1-го интегрального критерия манипулирования
индексом Хирша для автора:
Новоселов К.С.
Рассмотрим применение предлагаемого интегрального критерия на примере 2-го
автора, рейтинг, Ф.И.О. и место работы которого мы не указываем из
этических соображений.
На рисунке 9 приведен график числа
цитирований с линейным трендом этого 2-го автора, а в таблице 2 результаты
расчета частных критериев и интегрального критерия :
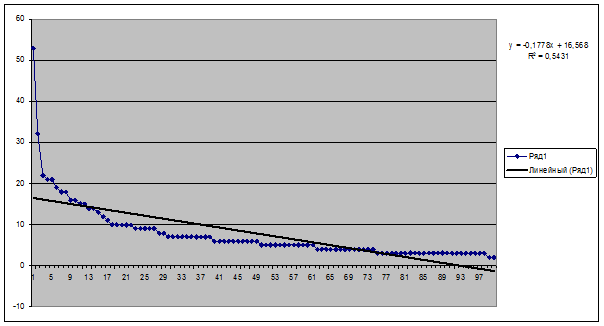
Рисунок 9.
График числа цитирований публикаций 2-го автора
с линейным трендом
Таблица 2 – Результаты расчетов частных критериев и 1-го
интегрального критерия манипулирования индексом Хирша при малом числе
публикаций для 2-го автора
|
Коэфф. K
|
Градусы
|
1-й частный критерий
|
|
-0,1778
|
-10,081832
|
0,887979642
|
|
|
|
|
|
Коэфф. B
|
Эмп. инд. Хирша
|
2-й частный критерий
|
|
16,568
|
14
|
0,915990578
|
|
|
|
|
|
1-й инт.критерий
|
|
0,90198511
|
Из таблицы 2 видно, что доля манипулирования индексом Хирша в данном
случае значительно выше, т.к. значение 1-го интегрального критерия близко к
0,9.
Из приведенных графиков и таблиц мы видим, что для лидера рейтинга РИНЦ
по числу цитирований предлагаемый 1-й критерий манипулирования индексом Хирша
дает значительно меньшую величину, чем у 2-го автора. Видно, что этот результат
получается за счет того, что у лидера
различие между числом цитирований наиболее и наименее цитируемых работ первой
сотни работ. значительно
больше, чем у обычного автора.
3.1.3. Манипулирование индексом Хирша
при большом числе публикаций
Если у автора большое число публикаций, то очевидно, использовать способ
формирования максимального значения индекса Хирша, который использовался при
малом числе публикаций, т.е. ссылаться во всех публикациях на все, не представляется возможным по ряду
причин. Понятно, что статья, у которой в списке литературы приведено десятки
источников и в основном автора самой этой статьи, будет выглядеть несколько
странно. Во многих журналах просто есть ограничение и на суммарное число
источников в списке литературы и на число источников автора публикации. Но
цитирование всех публикаций данного автора в каждой его публикации не только
невозможно технически, но и не имеет особого смысла,
т.к. увеличение числа цитирований статей, находящихся в ранжированном списке
далеко от значения индекса Хирша, не окажет влияния на его значение ни в
ближайшее время, ни в перспективе (за исключением может быть каких-то научных
«бестселлеров», которые сразу становятся очень цитируемыми и сохраняют
популярность длительное время).
Поэтому многие авторы, у
которых большое количество публикаций, приходят к тому, чтобы увеличивать число ссылок не на все
публикации, а только на те, которые оказывают самое непосредственное
влияние на значение индекса Хирша, т.е. на публикации в окрестности
индекса Хирша в ранжированном списке публикаций. В результате вблизи
значения индекса Хирша, причем как текущего, так и перспективного с точки
зрения этих авторов, формируется характерная «ступенька» или «полочка», которую
предлагается называть: «горб Хирша», показанная на рисунке 10 красным
цветом. К росту этого «горба Хирша» приводит и привязка ссылок к публикациям,
которую осуществляют администраторы системы Science Index, которые привязывают не все публикации подряд, а в первую очередь те,
которые в наибольшей степени влияют на значение индекса Хирша. Так совместными
усилиями авторов и администраторов этот горб и выращивается.
В результате такого манипулирования индекс Хирша приобретает вместо
значения h некоторое большее значение h2. При этом площадь под кривой числа
цитирований, соответствующая суммарному числу цитирований автора, увеличивается
совершенно незначительно, а значение индекса Хирша за счет этого возрастает
довольно заметно, т.е. затраты на это повышение оказываются весьма
эффективными.
Вот как выглядит подобная «полочка» на реальном графике числа
цитирований, построенном по данным РИНЦ 3-го автора (рисунок 11):
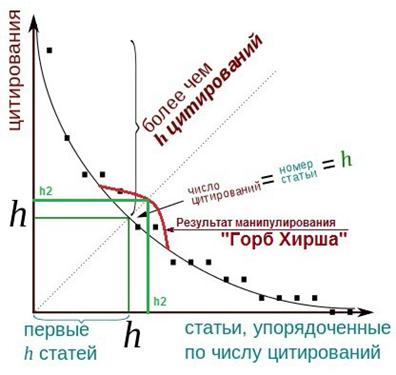
Рисунок 10.
Результат манипулирования индексом Хирша при большом числе публикаций:
характерная «полочка» в окрестности
индекса Хирша («горб Хирша») в ранжированном списке публикаций (теория)
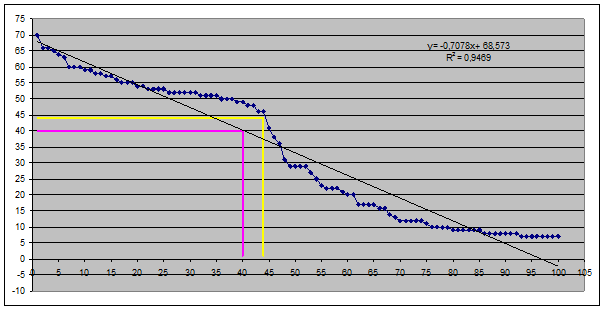
Рисунок 11.
Результат манипулирования индексом Хирша
при большом числе публикаций: характерная «полочка» в окрестности
индекса Хирша («горб Хирша») в ранжированном списке публикаций
3-го автора (факт)
Идея второго критерия манипулирования индексом Хирша, применяемого при
большом числе публикаций, основана на том, что при цитирования статей в
окрестностях текущего значения индекса Хирша площадь под кривой числа
цитирований, соответствующая суммарному числу цитирований автора, увеличивается
очень незначительно. А это в свою очередь означает, что, по-видимому, если аппроксимировать эту кривую с использованием
метода наименьших квадратов (МНК), то эта аппроксимация окажется малочувствительной
или устойчивой к появлению в результате манипулирования этой небольшой
«полочки».
Это позволяет сформулировать гипотезу о том, что значение индекса Хирша, определенное не по
классическому алгоритму, а посчитанное на основе аппроксимации кривой числа
цитирований, окажется менее чувствительным и более устойчивым к попыткам
манипулирования, чем классический индекс Хирша.
Но откуда взять эту аппроксимацию кривой числа цитирований и как
определить значение индекса Хирша на ее основе? В общем виде все это довольно
просто. Непосредственно из самого определения классического индекса Хирша
следует, что если аппроксимации кривой числа цитирований выражается в виде уравнения:
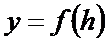
то теоретическим значением
индекса Хирша h будет корень уравнения:
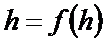 .
.
Такого рода уравнения обычно легко решаются численно итерационным
методом, реализованным в частности, в MS Excel.
Сам вид функции f() предлагается
определять с использованием аппарата аппроксимации трендов функциями различных видов
в MS Excel.
В принципе можно было бы каждый
раз выбирать для аппроксимации тот вид монотонной функции, который обеспечивает наивысший коэффициент
детерминации R2, т.е. наиболее хорошее приближение (наилучший тренд). В данном случае для аппроксимации графика числа
цитирований ранжированного списка публикаций уместно использовать лишь монотонно
возрастающие или убывающие функции: линейную, логарифмическую, степенную,
экспоненциальную, но не полиномиальную, т.к. она может иметь точки перегиба и
даже нарушения монотонности и является чувствительной к особенностям графика,
обусловленными манипулированием индексом Хирша.
Но можно выбрать какой-то один вид функции, который чаще других
обеспечивает наилучшее приближение. В результате многочисленных численных
экспериментов по аппроксимации кривых числа цитирований различных авторов,
проведенных по данным РИНЦ, было выявлено, что наилучшее приближение с
коэффициентом детерминации около 0,9 и выше, как правило обеспечивается трендом
в виде степенной функции:
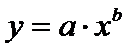 .
.
Поэтому предлагается находить теоретическое значение индекса Хирша h
путем решения уравнения:
 .
.
При этом само уравнение тренда предлагается формировать в MS Excel
непосредственно на основе данных РИНЦ, как описано выше в разделе 2.3 при
формировании линейной регрессии (примеры приведены ниже).
Решение этого уравнения легко находится аналитически:
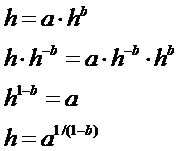
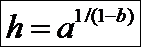 .
.
И это дает нам в руки второй более сложный второй критерий
манипулирования индексом Хирша:
«Чем больше отличаются друг от друга
эмпирический индекс Хирша, определенный по классическому алгоритму, и теоретический
индекс Хирша, найденный путем решения наилучшего уравнения тренда, тем больше
вероятность того, что классический индекс Хирша получен в результате манипулирования
(хотя возможны и другие варианты: шум и несовершенство алгоритма)».
Аналитически 2-й интегральный критерий манипулирования индексом Хирша,
т.е. относительное превышение эмпирического значения индекса Хирша над
теоретическим, может быть выражен по-разному. Авторы предлагают измерять это
превышение в долях от теоретического значения, как более близкого к истинному:
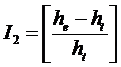
где:
he – классическое эмпирическое значение индекса Хирша;
ht – теоретическое значение индекса Хирша.
Как и в разделе 2.3 примеры рассмотрим на примере тех же авторов:
– Новоселов Константин Сергеевич, имеющий 1-й рейтинг по числу
цитирований по данным РИНЦ;
– 2-й и 3-й авторы, рейтинг и Ф.И.О. и место работы которых мы не
указываем из этических соображений.
Новоселов
Константин Сергеевич.
На графике числа цитирований, приведенном на рисунке 5, построим тренд в
виде степенной функции (рисунок 12):
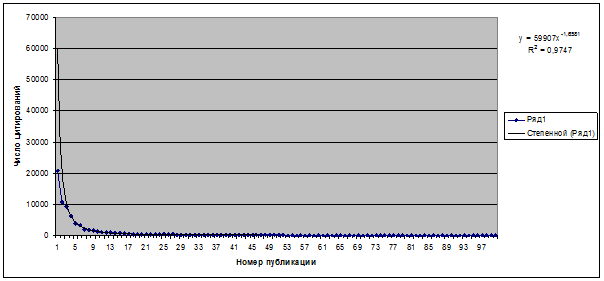
Рисунок 12.
График числа цитирований публикаций
Новоселова К.С. и тренд в виде степенной функции
Мы видим, что уравнение тренда имеет вид:
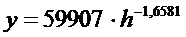
С очень хорошим качеством аппроксимации: R2 = 0,9747.
Для нахождения теоретического значения индекса Хирша необходимо решить
уравнение тренда:
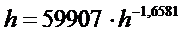
Для решения этого уравнения воспользуемся on-line сервисом
Вольфрам-математики по адресу: http://www.wolframalpha.com/. Введя решаемое уравнение (заменив в нем запятые на точки, добавив знаки
операций и скобки) в окно сервиса, представленное на рисунке 13, получим:
h=62.7, что после округления с точностью до целых совпадает с эмпирическим значением
h=63:
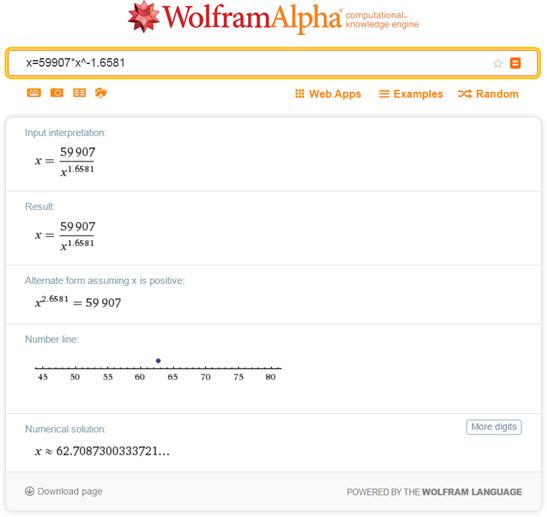
Рисунок 13. Выходной экран on-line сервиса Вольфрам-математики с решением
уравнения тренда графика числа цитирований публикаций Новоселова К.С.
Найденное on-line решение точно совпадает с полученным
аналитически:
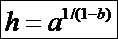
При решении в MS Excel по этой формуле со значениями коэффициентов:
a=59907; b=-1,6581 получаем 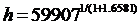 или h=62.7087300333721,
что совпадает по всем знакам после запятой с решением, полученным on-line с
помощью Вольфрам-математики.
или h=62.7087300333721,
что совпадает по всем знакам после запятой с решением, полученным on-line с
помощью Вольфрам-математики.
В разделе 3.3. мы видели, что 2-й интегральный критерий манипулирования
индексом Хирша рассчитывается по формуле:
где:
he – классическое эмпирическое значение индекса Хирша;
ht – теоретическое значение индекса Хирша.
Для Новоселова К.С. это дает значение, весьма близкое к нулю (десятые
доли процента):
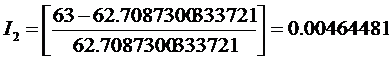 .
.
Фрагменты Excel-файла, в которых проводятся расчеты по приведенным выше
формулам, приведены на рисунках 14 (результаты расчетов) и 15 (формулы):
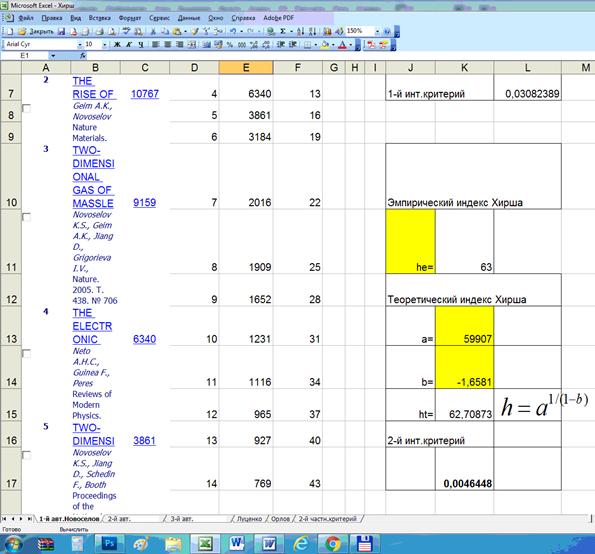
Рисунок 14. Фрагмент Excel-файла с расчетами,
представленными в таблице 3 (результаты расчетов)
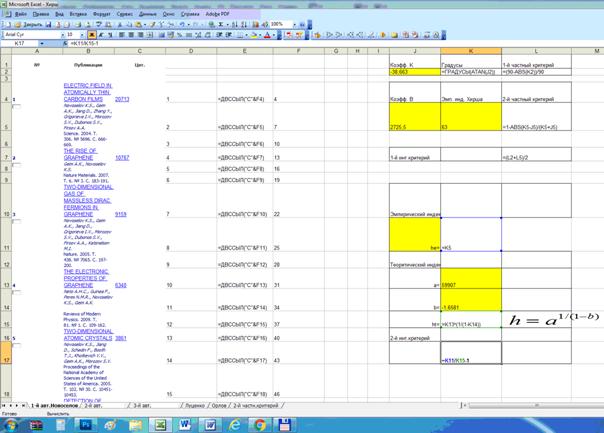
Рисунок 15. Фрагмент Excel-файла с расчетами,
представленными в таблице 3 (расчетные формулы)
Для 2-го
автора график числа
цитирований публикаций и тренд в виде степенной функции представлены на рисунке
16:
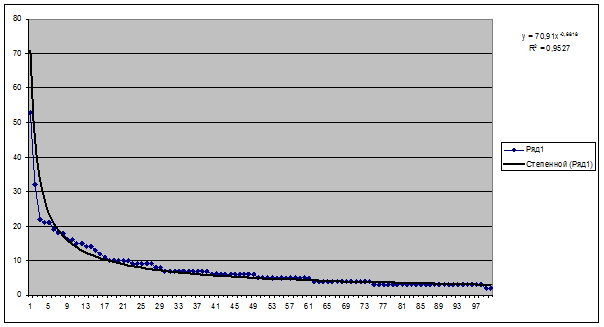
Рисунок 16.
График числа цитирований публикаций 2-го автора
и тренд в виде степенной функции
Таблица 3 – Эмпирический и теоретический индексы Хирша и 2-й инт. критерий
манипулирования индексом Хирша для 2-го автора
|
Эмпирический индекс Хирша
|
|
|
he=
|
14
|
|
Теоретический индекс Хирша
|
|
|
a=
|
70,91
|
|
b=
|
-0,6818
|
|
ht=
|
12,6017994
|
|
2-й инт.критерий
|
|
|
|
0,11095245
|
Для 2-го автора 2-й интегральный критерий имеет значение порядка 10%.
Для 3-го
автора график числа цитирований публикаций и тренд в виде
степенной функции представлены на рисунке 17:
Рисунок 17.
График числа цитирований публикаций 3-го автора (вырастившего внушительный «горб
Хирша»)
и тренд в виде линейной функции
Для 3-го автора использован линейный тренд, т.к. он дает приближение с
более высоким коэффициентом детерминации, чем степенная функция. Для 3-го
автора эмпирическое значение индекса Хирша равно 44, а теоретическое 40, что
дает значение 2-го интегрального критерия манипулирования индексом Хирша: I2=(44-40)/40=0.1.
Это значит, что в данном случае манипулирование привело к увеличению индекса
Хирша примерно на 10%.
Интересно, что у некоторых авторов теоретическое значение индекса Хирша
получается не меньше, а больше эмпирического, т.е. эмпирическое значение
«недооценено».
3.1.4. Согласованность 1-го и 2-го интегральных
критериев манипулирования индексом Хирша
Рассмотрим сводную таблицу 4, в которой приведем все просчитанные в
данной статье частные и интегральные критерии по всем авторам:
Таблица 4 – Частные и интегральные критерии по всем авторам
|
Автор
|
1-й частный критерий
|
2-й частный критерий
|
1-й интегральный критерий
|
Эмпирический индекс Хирша
|
Теоретический индекс Хирша
|
2-й интегральный критерий
|
|
Новоселов К.С.
|
0,01646
|
0,04518
|
0,03082
|
63
|
62,70873
|
0,00464
|
|
2-й автор
|
0,88797
|
0,91599
|
0,90198
|
14
|
12,60179
|
0,11095
|
|
3-й автор
|
0,60787
|
0,78171
|
0,69479
|
44
|
40
|
0,10000
|
Мы видим, что и частные критерии, и оба интегральных
критерия манипулирования индексом Хирша дают согласованные, совпадающие по
смыслу результаты, т.е. когда мы не видим манипулирования по 1-му частному
критерию, то не видим его и по 2-му, т.е. эмпирический индекс Хирша практически
совпадает с теоретическим. Возможно это объясняется тем, что авторы, не
занимавшиеся манипулированием индексом Хирша, когда у них было мало публикаций,
не начинают занимаются этим и когда публикаций у них становится большое
количество. Это повышает степень обоснованности и достоверности этих критериев.
3.1.5. Выводы и рекомендации
Итак, на основе
вышеизложенного можно считать, что:
1) существует
некое неизвестное «истинное значение индекса Хирша»;
2) есть
«эмпирическое (классическое) значение индекса Хирша», которое является истинным
значением, измененным в результате совместного действия факторов
манипулирования (рассматривались в данной статье) а также естественного шума и
несовершенства алгоритма Хирша (в данной статье эти факторы только
упоминаются);
3) есть
«теоретическое значение индекса Хирша», – это решение уравнения наилучшего
тренда графика числа цитирований ранжированного списка публикаций.
«Теоретическое
значение индекса Хирша» – это новое научное понятие из области
наукометрии, которое авторы предлагают ввести в научный оборот и практику
наукометрии по следующим причинам:
– теоретическое
значение индекса Хирша является устойчивым к манипулированию и другим факторам,
искажающим истинное значение индекса Хирша и может обоснованно считаться
значительно более близким к истинному значению индекса Хирша, чем классическое
эмпирическое значение;
– технология
получения теоретического значения индекса Хирша (путем решение уравнения
наилучшего тренда графика числа цитирований ранжированного списка публикаций)
проста и доступна авторам и организациям.
В статье
предлагаются два убедительных количественных частных критерия манипулирования
индексом Хирша при малом числе статей и основанный на них аддитивный
интегральный критерий, основанные на линейном тренде графика числа цитирований
ранжированного списка публикаций.
Степень
различия между эмпирическим
и теоретическим значениями индекса Хирша можно считать устойчивым интегральным критерием манипулирования индексом Хирша
при любом числе публикаций.
Предлагается:
1. Применить
результаты данной статьи при расчетах в РИНЦ и строить рейтинги авторов,
журналов и организаций (подразделений) не только на основе эмпирического
классического индекса Хирша, но и на основе теоретического индекса Хирша, а
также по критериям манипулирования.
2. Не придавать излишне и неоправданно большого значения классическому
эмпирическому значению индекса Хирша при оценках и принятии решений.
3.2. Наукометрическая
интеллектуальная
измерительная система по данным РИНЦ
на основе АСК-анализа и системы "Эйдос"
Адекватная
и технологичная оценка результативности, эффективности и качества научной
деятельности конкретных ученых и научных коллективов является актуальной
проблемой для информационного общества и общества, основанного на знаниях.
Решение этой проблемы является предметом наукометрии и ее целью. Современный
этап развития наукометрии существенно отличается от предыдущих появлением в открытом,
а также платном on-line доступе огромного объема детализированных данных по
большому числу показателей как об отдельных авторах, так и о научных
организациях и вузах. В мире, это известные библиографические базы данных: Web
of Science, Scopus, Astrophysics Data System, PubMed, MathSciNet, zbMATH,
Chemical Abstracts, Springer, Agris или GeoRef. В России это прежде всего
Российский индекс научного цитирования (РИНЦ). РИНЦ – это национальная
информационно-аналитическая система, аккумулирующая более 9 миллионов
публикаций российских ученых, а также информацию о цитировании этих публикаций
из более 6000 российских журналов. Данных очень много, это так называемые
«Большие данные» ("Big Data"). Но проблема состоит в том, чтобы
осмыслить эти большие данные, точнее, выявить смысл значений наукометрических
показателей) и тем самым преобразовать их в большую информацию («great
information»), а затем применить эту информацию для достижения цели наукометрии,
т.е. преобразовать ее в большие знания («great knowledge») о конкретных ученых
и научных коллективах. Решение этой проблемы предлагается путем создания
«Наукометрической интеллектуальной измерительной системы» на основе применения
автоматизированного системно-когнитивного анализа и его программного
инструментария – интеллектуальную систему «Эйдос». Приводится численный пример
создания и применения Наукометрической интеллектуальной измерительной системы,
на основе небольшого объема реальных наукометрических данных, находящихся в
открытом бесплатном on-line доступе в РИНЦ.
3.2.1. Формулировка
проблемы
Адекватная и
технологичная оценка результативности, эффективности и качества научной
деятельности конкретных ученых и научных коллективов была важной всегда, но
особенно актуальной она стала в информационном обществе и обществе, основанном
на знаниях.
Однако
реализация этой оценки на практике является как научной, так и чисто
технологической проблемой, не решенной и в настоящее время [1].
Решение этой
проблемы является предметом наукометрии и ее целью. В современной наукометрии
огромное количество проблем и нерешенных вопросов, по которым идет интенсивная
очень содержательная и богатая идеями научная дискуссия [1]. По мнению авторов
источником подавляющего большинства этих проблем является принципиально новая
особенность современной наукометрии, существенно качественно отличающая ее от
предыдущих этапов ее развития, которая заключается в появлении в открытом (а также платном) on-line доступе огромного объема
детализированных данных по большому числу накометрических показателей как об
отдельных авторах, так и о научных организациях и вузах.
В мире
наукометрические данные содержатся в известных библиографических базах данных:
Web of Science, Scopus, Astrophysics Data System, PubMed, MathSciNet, zbMATH,
Chemical Abstracts, Springer, Agris, GeoRef и др. В России также есть много
библиографических баз данных из которых выделяется Российский индекс научного
цитирования (РИНЦ) (http://elibrary.ru/).
Так что
исходных наукометрических данных уже очень и очень много, это так называемые
«Большие данные» ("Big Data"). А большие данные [34] – это само по
себе большие проблемы, которые «часто разделяют на три основные группы: объем,
скорость, неоднородность (так называемые «3 V»: Volume, Velocity, Variety) [2]».
Первые две из этих проблем скорее относятся к аппаратному обеспечению
поддержки больших данных и обеспечения доступа к ним, но третья проблема
касается уже научно-методологических, математических, алгоритмических и программных
(инструментальных) средств обработки больших данных.
В работе [2]
третья проблема характеризуется следующим образом: «проблема неоднородности
состоит в том, что данные зачастую происходят из разных источников и бывают в
разных форматах и разного качества. Их невозможно просто сложить вместе и
обработать – требуются сложная работа, чтобы привести их в пригодный для анализа вид».
Здесь
говорится о малопригодности этих данных для анализа в сыром виде, но ничего не
говорится о цели этого анализа и его методах и способах. Поэтому авторы
предлагают разбить третью проблему на две части: в первой части конкретнее описать
технические причины малопригодности сырых больших данных для обработки; а во
второй части описать цель этой обработки.
Авторская формулировка третьей проблемы обработки
больших наукометрических данных («Big
scientometric data»):
–
наукометрические показатели, содержащиеся в библиографических базах данных,
зашумлены, фрагментированы (не полны), представлены в разных типах
измерительных шкал (номинальных, порядковых и количественных) и в разных
единицах измерения, зависят друг от друга, т.е. описывают нечисловые [35] и/или
нелинейные объекты, вследствие чего не подчиняются нормальному распределению
[36];
– цель обработки больших наукометрических
данных состоит в том, чтобы осмыслить эти зашумленные,
фрагментированные взаимозависимые большие данные, измеряемые в разных типах
шкал и в разных единицах измерения, точнее, выявить смысл в значениях
наукометрических показателей, и тем самым преобразовать их в большую информацию
(«great information»), а затем применить эту информацию для достижения цели
наукометрии, т.е. преобразовать ее в
большие знания («great knowledge») о результатах, эффективности и качестве
научной деятельности конкретных ученых и научных коллективов.
3.2.2. Требования к методу решения проблемы
и недостатки традиционных методов
Из
вышеприведенной авторской формулировки проблемы обработки больших
наукометрических данных вытекают следующие требования к методу их обработки,
также состоящие из двух частей, обеспечивающих соответственно решение технических
аспектов проблемы и достижение цели обработки. Этот метод должен обеспечивать:
– корректную
сопоставимую обработку числовых и нечисловых данных, представленных в разных
типах измерительных шкал и разных единицах измерения и являться устойчивым к
шуму в исходных данных непараметрическим методом, обеспечивающим создание
моделей больших размерностей при неполных и зашумленных исходных данных о
сложном нелинейном динамическом объекте моделирования, имеющим программный
инструментарий;
–
преобразование данных в информацию, а ее в знания о результатах, эффективности
и качестве научной деятельности конкретных ученых и научных коллективов и
решение на этой основе задач многопараметрической типизации и системной идентификации,
а также задач исследования моделируемого объекта путем создания и анализа его
модели.
Факторный
анализ – один из наиболее популярных методов выявления причинно-следственных
зависимостей в исходных данных [37]. Он является параметрическим методом,
требующим абсолютно точных исходных данных, полных повторностей всех возможных
сочетаний значений независимых друг от друга факторов, которых должно быть не
более 5-6, измеряемых в числовых шкалах и одних единицах измерения. Факторный
анализ не обеспечивает преобразование исходных данных в информацию, а ее в
знания и решение задач многопараметрической типизации и системной
идентификации, а также исследования моделируемого объекта путем исследования
его модели. Таким образом, факторный анализ не удовлетворяет практически ни
одному из требований, предъявляемы к методу обработки.
3.2.3. Идея решения
проблемы с применением
наукометрической интеллектуальной
измерительной системы
Всем
обоснованным выше требованиям к методу решения поставленной проблемы
соответствует автоматизированный системно-когнитивный анализ (АСК-анализ) [13]
и его программного инструментарий – интеллектуальная система «Эйдос» [14].
Метод АСК-анализа является
устойчивым к шуму и неполноте в исходных данных непараметрическим методом и обеспечивает
создание моделей больших размерностей сложных нелинейных объектов моделирования
на основе корректной сопоставимой обработки числовых и нечисловых данных о них,
представленных в различных типах измерительных шкал и разных единицах измерения
[15] и имеет программный инструментарий – интеллектуальную систему «Эйдос».
Этот метод обеспечивает преобразование данных в информацию, а ее в знания о
результатах, эффективности и качестве научной деятельности конкретных ученых и
научных коллективах и решение на этой основе задач многопараметрической типизации
и системной идентификации, а также исследования моделируемого объекта путем
исследования его модели.
Поэтому метод
АСК-анализа и будет использован для решения поставленной в статье проблемы.
По сути
проблема состоит в поиске или разработке адекватных частных критериев
результатов научной деятельности и методов интеграции этих частных критериев
для оценки результатов как отдельных ученых, так и научных коллективов. В настоящее
время практика наукометрии, или, может быть, даже точнее сказать
«псевдонаукометрии», сильно опережает теорию, так как и сами частные критерии,
и методы их интеграции и применения вызывают большую и хорошо обоснованную критику
[1, 3-11].
Ясно, что
разные значения частных наукометрических критериев характеризует разное
качество результатов научной деятельности, что и заложено в наукометрических
методиках. Но не понятно, откуда их разработчики этих методик взяли именно сами
эти значения. Скорее всего они сделали это на основе экспертных оценок, т.е. на
основе интуиции, опыта и профессиональной компетенции.
Конечно,
разработчики частных наукометрических критериев старались сконструировать их
таким образом, чтобы они адекватно отражали определенные признаки степени
успешности научной деятельности. Но возникает закономерный и существенный
вопрос о том, на сколько или в какой степени это действительно удалось им
сделать. Это вопрос о том, на сколько те или иные частные наукометрические
критерии действительно «работают» и выполняют свою функцию индикаторов
результатов научной деятельности.
Какими
способами это можно проверить и кто это проверял?
По-видимому,
способом проверки адекватности частных наукометрических критериев является сравнение
результатов оценки результатов научной
деятельности ученых по этим частным критериям с экспертными оценками этих же
результатов. Если эти оценки совпадают, то критерии адекватны, если же нет,
то значит они не работают и не пригодны для тех целей, для которых были
разработаны.
Мысли о
подобной проверке высказывались (см., например, [55]), но никто не осуществлял
попыток такой проверки. В данной работе фактически впервые это также будет сделано.
Но даже если
частные наукометрические критерии не выполняют своей функции, которая
планировалась при их конструировании, то можно узнать в количественной форме,
какую функцию они фактически выполняют и использовать их в этом качестве. Это
же касается и критериев, которые работают. Что имеется в виду?
Авторы
предлагают на основе экспертных оценок оценивать не сами частные критерии, а
значения интегральных критериев для различных категорий авторов, отличающихся
результативностью научной деятельности, и на основе этого строить модель,
определяющую смысл различных значений частных критериев, т.е. количество
информации в их значениях о различных результатах научной деятельности.
Суть
предлагаемого подхода в том, что частные наукометрические критерии
рассматриваются не сами по себе, как это обычно делается, а сначала на основе эмпирических данных об
общих наукометрических показателях различных ученых (в нашем случае данных
РИНЦ) и экспертных оценок результатов их деятельности создается и верифицируется модель, в которой рассчитывается, какое
количество информации содержится в частных критериях о значениях интегральных
критериев (результативности деятельности ученого), а затем эта модель применяется для оценки результатов
деятельности других ученых, данные о которых не входили в обучающую выборку.
Естественно, эти другие ученые должны входить в генеральную совокупность, по
отношению к которой обучающая выборка репрезентативна, для чего они, например,
должны относиться к тому же направлению науки. Для оценки результатов деятельности
ученого с помощью модели рассчитывается суммарное количество информации,
которое содержится в его наукометрических показателях о различных результатах деятельности, и
считается, что у него скорее всего наиболее ценны те результаты, о которых в
его наукометрических показателях содержится наибольшее суммарное количество
информации. Эта оценка с помощью аддитивного интегрального критерия является сопоставимой количественной оценкой
результатов научной деятельности различных ученых. В идеале наукометрическая
интеллектуальная измерительная система должна оценивать ученых на основе их
наукометрических показателей и модели так же, как эксперты на основе своей
интуиции, опыта и профессиональной компетенции.
В этом и
состоит суть предлагаемой наукометрической интеллектуальной измерительной
системы [12], в которой значения частных наукометрических критериев будут
рассчитываться непосредственно на основе эмпирических данных и экспертных
оценок значений интегральных критериев по научно обоснованной методике на
основе применения АСК-анализа [13] и системы «Эйдос» [14].
3.2.4. Краткое описание АСК-анализа, как метода решения
проблемы
3.2.4.1. Кратко
об АСК-анализе
Системный анализ представляет собой современный метод научного
познания, общепризнанный метод решения проблем [13, 16, 19, 20]. Однако
возможности практического применения системного анализа ограничиваются
отсутствием программного инструментария, обеспечивающего его автоматизацию.
Существуют разнородные программные системы, автоматизирующие отдельные этапы
или функции системного анализа в различных конкретных предметных областях.
Автоматизированный системно-когнитивный анализ
(АСК-анализ) представляет собой системный анализ, структурированный по базовым
когнитивным операциям (БКО), благодаря чему удалось разработать для него
математическую модель, методику численных расчетов (структуры данных и
алгоритмы их обработки), а также реализующую их программную систему – систему
«Эйдос» [13, 16, 17]. Система «Эйдос» разработана в постановке, не зависящей от предметной
области, и имеет ряд программных интерфейсов с внешними данными различных типов
[17]. АСК-анализ может быть применен как инструмент, многократно усиливающий
возможности естественного интеллекта во всех областях, где используется естественный
интеллект. АСК-анализ был успешно применен для решения задач идентификации,
прогнозирования, принятия решений и исследования моделируемого объекта путем
исследования его модели во многих предметных областях, в частности в экономике,
технике, социологии, педагогике, психологии, медицине, экологии, ампелографии,
геофизике, энтомологии, криминалистике и многих других [13, 14].
Известно, что системный анализ является одним из общепризнанных в науке
методов решения проблем и многими учеными рассматривается вообще как метод
научного познания. Однако, как впервые заметил еще в 1984 году проф. И.П.
Стабин, на практике применение системного анализа наталкивается на проблему
[24]. Суть этой проблемы в том, что обычно системный анализ успешно применяется
в сравнительно простых случаях, в которых в принципе можно обойтись и без него,
тогда как в действительно сложных ситуациях, когда он действительно чрезвычайно
востребован и у него нет альтернатив, сделать это удается гораздо реже. Проф.
И.П. Стабин предложил и путь решения этой проблемы, который он видел в
автоматизации системного анализа [24].
Однако путь от идеи до создания программной системы долог и сложен,
т.к. включает ряд этапов:
– выбор теоретического математического метода;
– разработка методики численных расчетов, включающей структуры данных в
оперативной памяти и внешних баз данных (даталогическую и инфологическую
модели) и алгоритмы обработки этих данных;
– разработка программной системы, реализующей эти математические методы
и методики численных расчетов.
Перегудов Ф.И. и Тарасенко Ф.П. в своих основополагающих работах 1989 и
1997 годов [19, 20] подробно рассмотрели математические методы, которые в
принципе могли бы быть применены для автоматизации отдельных этапов системного
анализа. Однако даже самые лучшие математические методы не могут быть применены
на практике без реализующих их программных систем, а путь от математического
метода к программной системе долог и сложен. Для этого необходимо разработать
численные методы или методики численных расчетов (алгоритмы и структуры
данных), реализующие математический метод, а затем разработать программную
реализацию системы, основанной на этом численном методе.
В числе первых попыток реальной автоматизации системного анализа
следует отметить докторскую диссертацию проф. Симанкова В.С. (2001) [25]. Эта
попытка была основана на высокой детализации этапов системного анализа и
подборе уже существующих программных систем, автоматизирующих эти этапы. Идея
была в том, что чем выше детализация системного анализа, чем мельче этапы, тем
проще их автоматизировать. Эта попытка была реализована, однако, лишь для
специального случая исследования в области возобновляемой энергетики, т.к.
системы оказались различных разработчиков, созданные с помощью различного
инструментария и не имеющие программных интерфейсов друг с другом, т.е. не
образующие единой автоматизированной системы. Эта попытка, безусловно, явилась
большим шагом по пути, предложенному проф. И.П. Стабиным, но и ее нельзя признать
обеспечившей достижение поставленной цели, сформулированной Стабиным И.П. (т.е.
создание автоматизированного системного анализа), т.к. она не привела к созданию
единой универсальной программной системы, автоматизирующий системный анализ,
которую можно было бы применять в различных предметных областях.
Необходимо отметить работы Дж. Клира по системологии и автоматизации
решения системных задач, которые внесли большой вклад в автоматизацию
системного анализа путем создания и применения универсального решателя
системных задач (УРСЗ), реализованного в рамках оригинальной экспертной системы
[26, 27]. Однако в экспертной системе применяется продукционная модель знаний,
для получения которых от эксперта необходимо участие инженера по знаниям
(когнитолога). Этим обусловлены следующие недостатки экспертных систем:
– они генерируют знания каждый раз, когда они необходимы для решения
задач, и это может занимать значительно большее время, чем при использовании
декларативной формы представления знаний;
– продукционные модели обычно построены на бинарной логике (if then
else), что вызывает возможность логического конфликта продукций в процесс
логического вывода, что приводит к необратимому останову логического процесса
при противоречивых исходных данных;
– эксперты - люди чаще всего заслуженные и их время и знания стоят
очень дорого; поэтому привлечение экспертов для извлечения готовых знаний на
длительное время проблематично и обычно эксперт просто физически не может
сообщить очень большой объем знаний, а иногда и не хочет этого делать по тем
или иным причинам («ноу-хау», нарушение морально-этических норм или даже ГК или
УК, конфликт интересов) и сознательно сообщает неадекватные знания;
– чаще всего эксперты формулируют свои знания неформализуемым путем на
основе своей интуиции, опыта и профессиональной компетенции, т.е. не могут
сформулировать свои знания в количественной форме, а пользуются для их
формализации порядковыми или даже номинальными шкалами, поэтому экспертные
знания являются не очень точными и для их формализации необходим инженер по
знаниям (когнитолог).
Автоматизированный системно-когнитивный анализ разработан профессором
Е.В. Луценко и предложен в 2002 году [13], хотя разработан он был значительно
раньше, причем с программным инструментарием: системой «Эйдос» [17]. Основная
идея, позволившая сделать это, состоит в рассмотрении системного анализа как
метода познания (отсюда и «когнитивный» от «cognitio» – знание, познание,
лат.). Эта идея позволила структурировать системный анализ не по этапам, как
пытались сделать ранее, а по базовым когнитивным операциям системного анализа
(БКОСА), т.е. таким операциям, к комбинациям которых сводятся остальные. Эти
операции образуют минимальную систему, достаточную для описания системного
анализа, как метода познания, т.е. конфигуратор. Понятие конфигуратора
предложено В.А. Лефевром [28]. В 2002 году Е.В. Луценко был предложен когнитивный
конфигуратор [13], включающий 10 базовых когнитивных операций.
1) присвоение имен;
2) восприятие (описание конкретных объектов в форме онтологий, т.е. их
признаками и принадлежностью к обобщающим категориям - классам);
3) обобщение (синтез, индукция);
4) абстрагирование;
5) оценка адекватности модели;
6) сравнение, идентификация и прогнозирование;
7) дедукция и абдукция;
8) классификация и генерация конструктов;
9) содержательное сравнение;
10) планирование и поддержка принятия управленческих решений.
Каждая из этих операций оказалась достаточно элементарна для
формализации и программной реализации.
– формализуемая когнитивная концепция и следующий из нее когнитивный
конфигуратор;
– теоретические основы, методология, технология и методика АСК-анализа;
– математическая модель АСК-анализа, основанная на системном обобщении
теории информации;
– методика численных расчетов, в универсальной форме реализующая
математическую модель АСК-анализа, включающая иерархическую структуру данных и
24 детальных алгоритма 10 БКОСА;
– специальное инструментальное программное обеспечение, реализующее
математическую модель и численный метод АСК-анализа – Универсальная когнитивная
аналитическая система "Эйдос".
1) когнитивно-целевая структуризация предметной области;
2) формализация предметной области (конструирование классификационных и
описательных шкал и градаций и подготовка обучающей выборки);
3) синтез системы моделей предметной области (в настоящее время система
«Эйдос» поддерживает 3 статистические модели и 7 системно-когнитивных моделей
(моделей знаний);
4) верификация (оценка достоверности) системы моделей предметной
области;
5) повышение качества системы моделей;
6) решение задач идентификации, прогнозирования и поддержки принятия
решений;
7) исследование моделируемого объекта путем исследования его моделей
является корректным, если модель верно отражает моделируемый объект и включает:
кластерно-конструктивный анализ классов и факторов; содержательное сравнение
классов и факторов; изучение системы детерминации состояний моделируемого
объекта; нелокальные нейроны и интерпретируемые нейронные сети прямого счета;
классические когнитивные модели (когнитивные карты); интегральные когнитивные модели
(интегральные когнитивные карты), прямые обратные SWOT-диаграммы; когнитивные
функции и т.д.
Суть метода АСК-анализа состоит в последовательном повышении степени
формализации модели и преобразовании данных в информацию, а ее в знания и
решении на основе этих знаний задач идентификации (распознавания, классификации
и прогнозирования), поддержки принятия решений и исследования моделируемой
предметной области (рисунки 1 и 2):
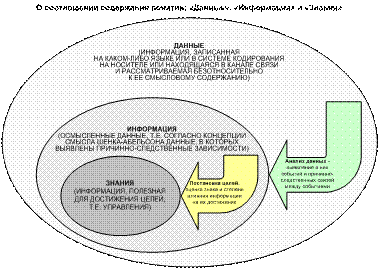
Рисунок 1. О
соотношении содержания понятий:
«данные», «информация» и «знания» в АСК-анализе
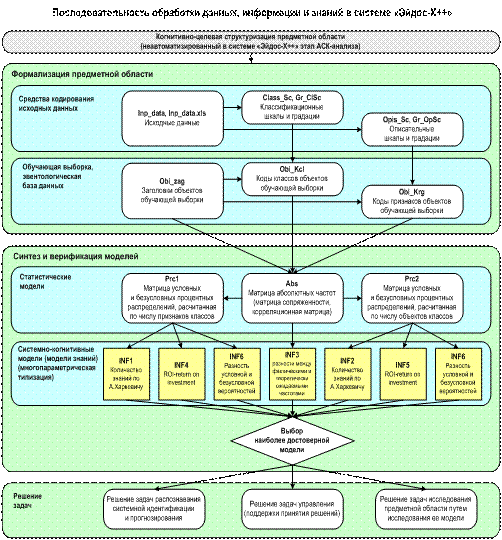
Рисунок 2.
Последовательность преобразования данных
в информацию, а ее в знания и решения задач
в АСК-анализе и системе «Эйдос»
Математическая
модель АСК-анализ основана на теории информации, точнее на системной теории
информации (СТИ), предложенной Е.В. Луценко [13, 16]. Это значит,
что в
АСК-анализе все факторы рассматриваются с одной единственной точки зрения:
сколько информации содержится в их значениях о переходе объекта, на который они
действуют, в определенное состояние, и при этом сила и направление влияния всех
значений факторов на объект измеряется в одних общих для всех факторов единицах
измерения: единицах количества информации [8, 9].
Это
напоминает подход Дугласа Хаббарда [15], но, в отличие от него, имеет открытый
универсальный программный инструментарий (систему «Эйдос»), разработанный в
постановке, не зависящей от предметной области [13, 14]. К тому же на систему
«Эйдос» уже в 1994 году было три патента РФ [13, 14], а первые
акты ее внедрения датируются 1987 годом [13, 14], тогда как
основная работа Дугласа Хаббарда [29] появилась лишь в 2009 году. Это означает,
что идеи АСК-анализа не только появились, но и были доведены до программной
реализации в универсальной форме и применены в различных предметных областях на
22 с лишним года раньше появления
работ Дугласа Хаббарда.
Поэтому
АСК-анализ обеспечивает корректную сопоставимую обработку числовых и нечисловых
данных, представленных в разных типах измерительных шкал и разных единицах
измерения [13, 23]. Метод АСК-анализа является устойчивым непараметрическим
методом, обеспечивающим создание моделей больших размерностей при неполных и
зашумленных исходных данных о сложном нелинейном динамичном объекте управления.
Этот метод является чуть ли не единственным на данный момент, обеспечивающим
многопараметрическую типизацию и системную идентификацию методов,
инструментарий которого (интеллектуальная система «Эйдос») находится в полном
открытом бесплатном доступе [13, 14].
Система Эйдос
обеспечивает:
1.
Многопараметрическую типизацию, т.е. формирование обобщенных образов классов на
основе конкретных примеров объектов, которые к ним относятся.
2. Системную
идентификацию, т.е. определение степени сходства образа конкретного объекта с
обобщенными образами классов (сравнение конкретных объектов с обобщенными образами
классов).
3.
Формирование кластеров классов (сравнение обобщенных образов классов друг с
другом).
4.
Формирование конструктов кластеров (сравнение кластеров друг с другом и
формирование конструктов).
5.
Исследование моделируемой предметной области путем исследования ее модели.
Метод системно-когнитивного анализа и его программный инструментарий
интеллектуальная система "Эйдос" были успешно применены при
проведении 6 докторских и 7 кандидатских диссертационных работ в ряде различных
предметных областей по экономическим, техническим, психологическим и медицинским
наукам.
АСК-анализ был успешно применены при выполнении десятка грантов РФФИ и
РГНФ различной направленности за длительный период - с 2002 года по настоящее
время (2016 год).
По проблематике АСК-анализа издано 24 монографии, получено 29 патентов
на системы искусственного интеллекта, их подсистемы, режимы и приложения,
опубликовано более 236 статей в изданиях, входящих в Перечень ВАК РФ (по данным
РИНЦ). В одном только Научном журнале
КубГАУ (входит в Перечень ВАК РФ с 26-го марта 2010 года) автором АСК-анализа
Луценко Е.В. опубликовано 208, общим объёмом 373,621 у.п.л., в среднем 1,796
у.п.л. на одну статью.
По этим публикациям, грантам и диссертационным работам видно, что
АСК-анализ уже был успешно применен в следующих предметных областях и научных
направлениях: экономика (региональная, отраслевая, предприятий, прогнозирование
фондовых рынков), социология, эконометрика, биометрия, педагогика (создание
педагогических измерительных инструментов и их применение), психология
(личности, экстремальных ситуаций, профессиональных и учебных достижений,
разработка и применение профессиограмм), сельское хозяйство (прогнозирование
результатов применения агротехнологий, принятие решений по выбору рациональных
агротехнологий и микрозон выращивания), экология, ампелография, геофизика
(глобальное и локальное прогнозирование землетрясений, параметров магнитного поля
Земли, движения полюсов Земли), климатология (прогнозирование Эль-Ниньо и Ла-Нинья), возобновляемая энергетика, мелиорация и управление мелиоративными
системами, криминалистика, энтомология и ряд других областей.
АСК-анализ вызывает большой интерес во всем мире. Сайт автора
АСК-анализа [16] посетило около 500 тыс. посетителей с уникальными
IP-адресами со всего мира. Еще около 500 тыс. посетителей открывали статьи по
АСК-анализу в Научном журнале КубГАУ.
Необходимо отметить, что в развитии различных теоретических основ и
практических аспектов АСК-анализа приняли участие многие ученые: д.э.н., к.т.н., проф. Луценко Е.В.,
Засл. деятель науки РФ, д.т.н., проф. Лойко В.И., к.ф.-м.н.,
Ph.D., проф., Трунев А.П. (Канада),
д.э.н., д.т.н., к.ф.-м.н., проф. Орлов А.И., к.т.н., доц. Коржаков В.Е.,
д.э.н., проф. Барановская Т.П., д.э.н., к.т.н., проф. Ермоленко В.В., к.пс.н.
Наприев И.Л., к.пс.н., доц. Некрасов С.Д., к.т.н., доц. Лаптев В.Н., к.пс.н,
доц. Третьяк В.Г., к.пс.н., Щукин Т.Н., д.т.н., проф. Симанков В.С., д.э.н.,
проф. Ткачев А.Н., д.т.н., проф. Сафронова Т.И., д.э.н., доц. Горпинченко К.Н.,
к.э.н., доц. Макаревич О.А., к.э.н., доц. Макаревич Л.О., к.м.н. Сергеева Е.В.
(Фомина Е.В.), Бандык Д.К. (Белоруссия), Чередниченко Н.А., к.ф.-м.н. Артемов
А.А., д.э.н., проф. Крохмаль В.В., д.т.н., проф. Рябцев В.Г., к.т.н., доц. Марченко
А.Ю., д.т.н., проф. Фролов В.Ю., д.ю.н, проф. Швец С.В., Засл. деятель науки Кубани, д.б.н., проф. Трошин Л.П.,
Засл. изобр. РФ, д.т.н., проф. Серга Г.В., Сергеев А.С., д.б.н., проф.
Стрельников В.В. и другие.
В заключение
отметим, что программный инструментарий АСК-анализа – интеллектуальная система
«Эйдос» находится в полном открытом бесплатном доступе на сайте автора (вместе
с исходными текстами) по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm.
3.2.5. Численный пример синтеза и применения
наукометрической интеллектуальной
измерительной системы
Рассмотрим численный пример решения поставленной проблемы в
соответствии с приведенными выше в разделе 3.3.2 и на рисунке 2 этапами
АСК-анализа:
1) когнитивно-целевая структуризация предметной области;
2) формализация предметной области (конструирование классификационных и
описательных шкал и градаций и подготовка обучающей выборки);
3) синтез системы моделей предметной области (в настоящее время система
«Эйдос» поддерживает 3 статистические модели и 7 системно-когнитивных моделей
(моделей знаний);
4) верификация (оценка достоверности) системы моделей предметной
области;
5) повышение качества системы моделей;
6) решение задач идентификации, прогнозирования и поддержки принятия
решений;
7) исследование моделируемой предметной области путем исследования ее
модели.
Содержание этого этапа АСК-анализа, единственного неформализованного и не
реализованного в системе «Эйдос», состоит в том, что необходимо определиться что
мы будем рассматривать в качестве факторов, а что в качестве результатов их
влияния.
В данном случае ясно, что на основе значений общих наукометрических
показателей авторов необходимо оценивать результаты их научной деятельности.
Таким образом данный этап выполнен.
На этом этапе АСК-анализа создаются классификационные и описательные
шкалы и градации, а затем с их использованием кодируются исходные данные и в
результате чего формируются база событий и обучающая выборка (рис. 2). По сути
этап формализации предметной области является нормализацией базы исходных данных, в результате чего степень
формализации исходных данных возрастает до уровня, необходимого и достаточного
для их обработки на компьютере в программной системе.
Исходные данные любезно предоставлены в удобной для проведения
исследования форме Глуховым Виктором Алексеевичем, – к.т.н., зам. директора по
научной работе ИНИОН РАН, руководителем Фундаментальной библиотеки, г. Москва.
Необходимо отметить, что все эти исходные данные находятся в полном открытом
бесплатном доступе на сайте РИНЦ http://elibrary.ru/ в авторском указателе и представляют собой ни что иное, как «Общие
показатели» по каждому автору.
Исходные данные представляются в форме Excel-таблицы, в которой каждая
строка описывает один объект обучающей выборки. В первой колонке этой таблицы
содержится идентифицирующая информация об объекте обучающей выборки, затем идут
колонки, являющиеся классификационными шкалами, а затем колонки, являющиеся
описательными шкалами.
Классификационные и описательные шкалы могут быть текстового и числового
типа. Если они текстового типа, то значениями градаций шкал являются уникальные
текстовые наименования в них. Если шкалы числового типа, то в них ищется минимальное
и максимальное числовое значение, а затем диапазон изменения числовой величины
делится на заданное пользователем (в диалоге) число интервальных числовых
значений, которые и являются градациями шкал. Градации классификационных шкал
являются классами и по ним проводится группировка строк базы исходных данных и
обобщение. Градации описательных шкал являются значениями факторов,
характеризующих объекты обучающей выборки. Требования к файлу исходных данных
приведены на рис. 3:
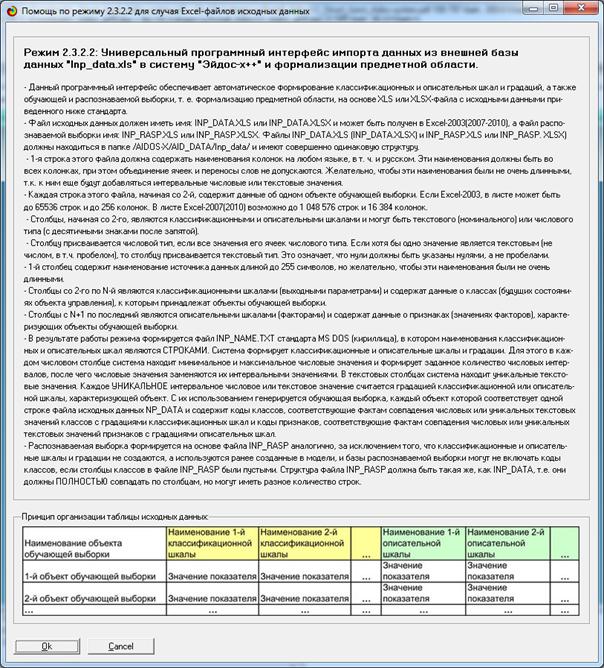
Рисунок 3. Требования к файлу исходных данных
Сами исходные данные приведены в таблице 1.
Синтез и верификация модели осуществляется в режиме 3.5 системы «Эйдос»
(рис. 4):
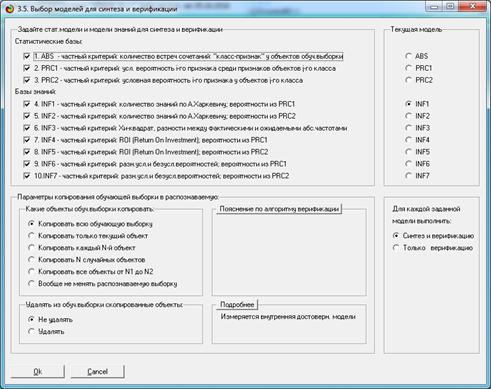
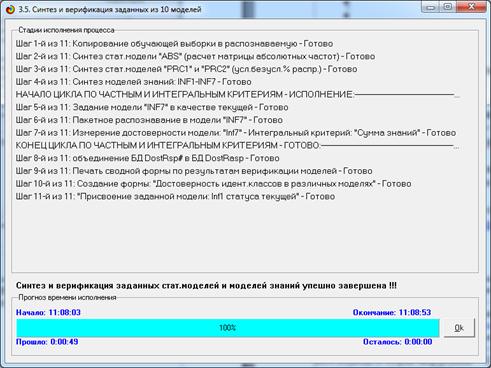
Рисунок 4. Экранные формы режима синтеза
и верификации модели системы «Эйдос»
В соответствии с последовательностью преобразования данных в информацию,
а ее в знания и решения задач в АСК-анализе и системе «Эйдос», приведенной на
рис. 2, в режиме 3.5 созданы и проверены на достоверность следующие модели,
отличающиеся частными критериями:
Частные
модели ABS, PRC#, INF#, отличаются друг друга частными критериями знаний [15]
(табл. 5).
Таблица 5 –
Частные критерии знаний, используемые
в настоящее время в АСК-анализе и системе «Эйдос-Х++»
|
Наименование модели знаний
и частный критерий
|
Выражение для частного критерия
|
|
через
относительные
частоты
|
через
абсолютные частоты
|
|
ABS, частный критерий: абсолютная
частота встречаемости i-го признака
в j-м классе
|
---
|
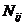
|
|
PRC1, частный критерий: относительная
частота встречи i-го признака в j-м классе, где Nj – суммарное количество признаков по j-му классу.
|
---
|
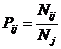
|
|
PRC2, частный критерий: относительная
частота встречи i-го признака в j-м классе, где Nj – суммарное количество объектов по j-му классу.
|
|
|
|
INF1, частный критерий: количество знаний
по А. Харкевичу, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков
по j-му классу. Относительная
частота того, что если у объекта j-го класса обнаружен признак, то это i-й признак
|
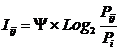
|
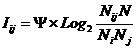
|
|
INF2, частный критерий: количество знаний
по А. Харкевичу, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу. Относительная частота
того, что если предъявлен объект j-го класса, то у него будет обнаружен i-й
признак.
|
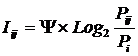
|
|
|
INF3, частный критерий: Хи-квадрат:
разности между фактическими и теоретически ожидаемыми абсолютными частотами
|
---
|
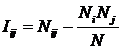
|
|
INF4, частный критерий: ROI - Return
On Investment, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков по j-му классу
|
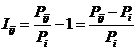
|
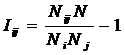
|
|
INF5, частный критерий: ROI - Return
On Investment, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу
|
|
|
|
INF6, частный критерий: разность
условной и безусловной относительных частот, 1-й вариант расчета
относительных частот: Nj –
суммарное количество признаков по j-му
классу
|
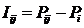
|
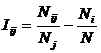
|
|
INF7, частный критерий: разность
условной и безусловной относительных частот, 2-й вариант расчета
относительных частот: Nj –
суммарное количество объектов по j-му
классу
|
|
|
Обозначения:
i – значение прошлого параметра;
j - значение
будущего параметра;
Nij – количество встреч j-го значения будущего
параметра при i-м значении
прошлого параметра;
M – суммарное число значений всех прошлых параметров;
W - суммарное число значений всех будущих параметров;
Ni – количество встреч i-м значения прошлого
параметра по всей выборке;
Nj – количество встреч j-го значения будущего
параметра по всей выборке;
N – количество встреч j-го значения будущего
параметра при i-м значении
прошлого параметра по всей выборке;
Iij – частный критерий знаний: количество знаний в факте
наблюдения i-го значения
прошлого параметра о том, что объект перейдет в состояние, соответствующее j-му значению будущего параметра;
Ψ – нормировочный коэффициент (Е.В. Луценко,
2002), преобразующий количество информации в формуле А.Харкевича в биты и
обеспечивающий для нее соблюдение принципа соответствия с формулой Р.Хартли;
Pi
– безусловная
относительная частота встречи i-го
значения прошлого параметра в обучающей выборке;
Pij
– условная
относительная частота встречи i-го
значения прошлого параметра при j-м значении
будущего параметра.
Все эти
способы метризации с применением 7 частных критериев знаний (табл. 5)
реализованы в системно-когнитивном анализе и интеллектуальной системе «Эйдос» и
обеспечивают сопоставление градациям всех видов шкал числовых значений, имеющих
смысл количества информации в градации о принадлежности объекта к классу.
Поэтому является корректным применение интегральных критериев, включающих
операции умножения и суммирования, для обработки числовых значений, соответствующих
градациям шкал. Это позволяет единообразно и сопоставимо обрабатывать
эмпирические данные, полученные с помощью любых типов шкал, применяя при этом
все математические операции.
На рис. 5 приведены фрагменты созданных моделей ABS, PRC2, INF1:
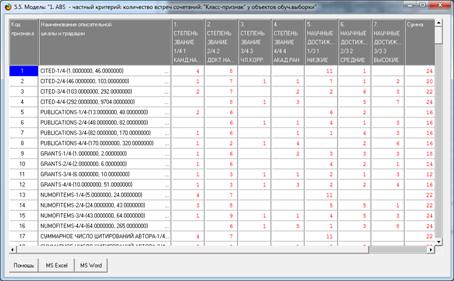
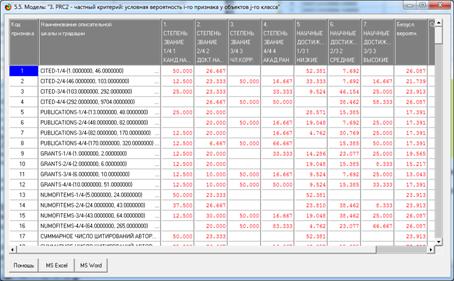
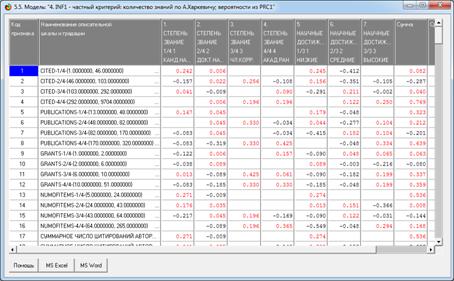
Рисунок 5. Экранные формы просмотра моделей:
ABS, PRC2, INF1 (фрагменты)
Различные результаты верификации (оценки достоверности) моделей приведены
на рис. 5 – 9:
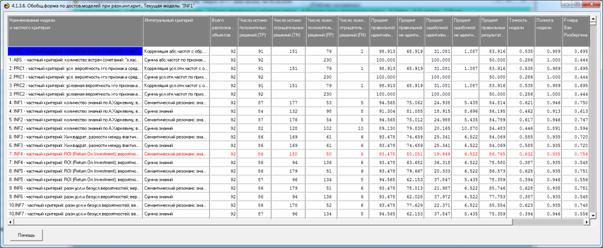
Рисунок 5. Экранная форма режима оценки достоверности моделей при разных
интегральных критериях (сокращенный вариант)
Сами модели отличаются друг от друга частными критериями, а результаты
классификации в них – интегральными критериями.
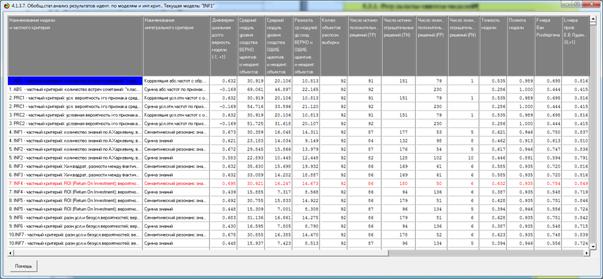
Рисунок 6. Экранная форма режима оценки достоверности моделей при разных
интегральных критериях (полный вариант)
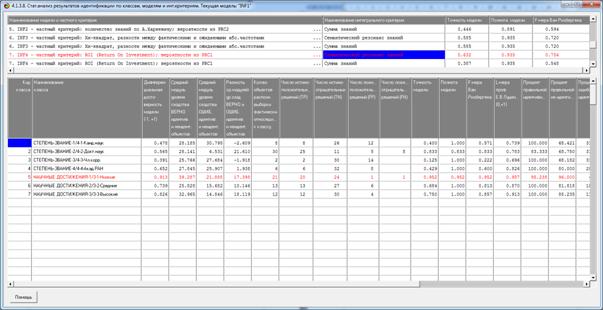
Рисунок 7. Экранная форма режима оценки достоверности
идентификации объектов с разными классами
в различных моделях и при разных интегральных критериях
Из этой формы видно, что в любой из моделей одни классы идентифицируются
лучше, а другие хуже.
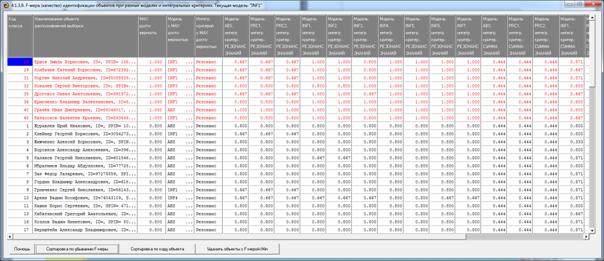
Рисунок 8. Экранная форма режима оценки достоверности
идентификации объектов с разными классами
в различных моделях и при разных интегральных критериях
Из этой формы видно, что одни объекты идентифицируются с классами лучше,
а другие хуже.
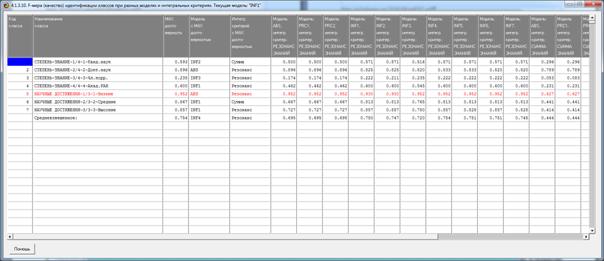
Рисунок 9. Экранная форма режима оценки достоверности
идентификации классов в различных моделях
и при разных интегральных критериях
Из этой формы видно, что одни классы идентифицируются лучше в одной
модели, а другие в другой.
При оценке достоверности моделей используется F-критерий Ван Ризбергена, сходный критерий, предложенный проф. Е.В. Луценко в 1994 году, а также
эффективность классификации в модели по сравнению со случайным угадыванием.
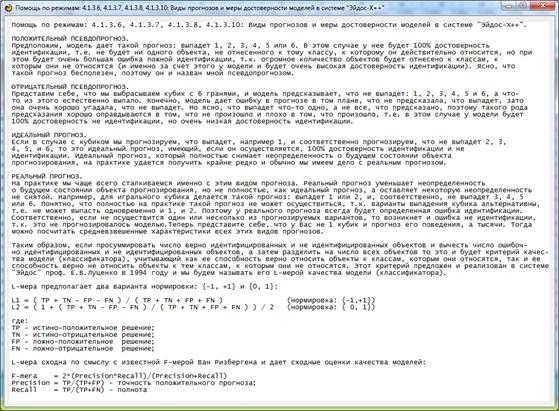
Рисунок 10. Экранная форма режима помощи по оценке достоверности
По результатам оценки достоверности созданных моделей можно сделать вывод
о том, что по F-критерию Ван Ризбергена их достоверность достаточно высока, а
значит оценки и решения на их основе будут хорошо совпадать с оценками
экспертов (в области репрезентативности моделей).
Рассмотрим решение задач классификации, поддержки принятия решений и
исследования предметной области путем исследования ее модели.
Мы видим, что по F-критерию достоверности моделей Ван Ризбергена
достоверность созданных моделей достаточно высока, чтобы решение этих задач на
основе моделей можно было бы считать корректным.
В соответствии с математической моделью АСК-анализа, реализованной в
системе «Эйдос», объект распознаваемой выборки считается относящимся к тому
классу, о принадлежности к которому в его системе признаков содержится
максимальное количество информации. Таким образом в системе «Эйдос» используется
аддитивный интегральный критерий.
Интегральный
критерий «Сумма знаний» представляет собой суммарное
количество знаний, содержащееся в системе факторов различной природы,
характеризующих сам объект управления, управляющие факторы и окружающую среду,
о переходе объекта в будущие целевые или нежелательные состояния.
Интегральный
критерий представляет собой аддитивную функцию от частных критериев знаний [13]
и имеет вид:
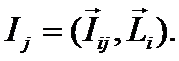
В этом
выражении круглыми скобками обозначено скалярное произведение. В координатной
форме указанное выражение имеет вид:
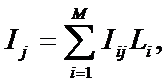
где: M –
количество градаций описательных шкал (значений факторов);
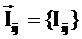 – вектор состояния j–го класса;
– вектор состояния j–го класса;
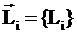 – вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
– вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:

В текущей версии системы «Эйдос-Х++» значения
координат вектора состояния распознаваемого объекта принимались равными либо 0,
если признака нет, или n, если он
присутствует у объекта с интенсивностью n, т.е. представлен n раз (например,
буква «о» в слове «молоко» представлена 3 раза, а буква «м» - один раз).
Интегральный
критерий «Семантический резонанс знаний» представляет
собой нормированное суммарное количество знаний, содержащееся в системе
факторов различной природы, характеризующих сам объект управления, управляющие
факторы и окружающую среду, о переходе объекта в будущие целевые или
нежелательные состояния.
Интегральный
критерий представляет собой аддитивную функцию от частных критериев знаний [21]
и имеет вид:
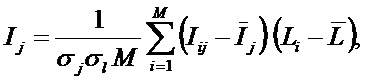
где:
M – количество градаций описательных шкал
(признаков);
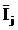 – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
 – среднее по
вектору объекта;
– среднее по
вектору объекта;
 – среднеквадратичное отклонение частных
критериев знаний, рассчитанное по вектору класса;
– среднеквадратичное отклонение частных
критериев знаний, рассчитанное по вектору класса;
 – среднеквадратичное отклонение по вектору
распознаваемого объекта.
– среднеквадратичное отклонение по вектору
распознаваемого объекта.
– вектор состояния j–го класса;
– вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
Приведенное
выражение для интегрального критерия «Семантический резонанс знаний» получается
непосредственно из выражения для критерия «Сумма знаний» после замены координат
перемножаемых векторов их стандартизированными значениями:
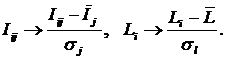
Свое
наименование интегральный критерий сходства «Семантический резонанс знаний»
получил потому, что по своей математической форме является корреляцией двух
векторов: состояния j–го класса и состояния распознаваемого объекта.
Таким
образом, в АСК-анализе и системе «Эйдос» используется одно общее математическое
выражение для частных критериев, как способствующих, так и препятствующих
переходу объекта моделирования в некоторое состояние, а также вообще не
влияющих на это, и аддитивный интегральный критерий, что обеспечивает
сопоставимость измерений и результатов системной идентификации.
На рис. 11 и 12 приведены экранные формы с результатами классификации
некоторых авторов на основе их общих наукометрических показателей РИНЦ с
использованием наиболее достоверных из созданных моделей:
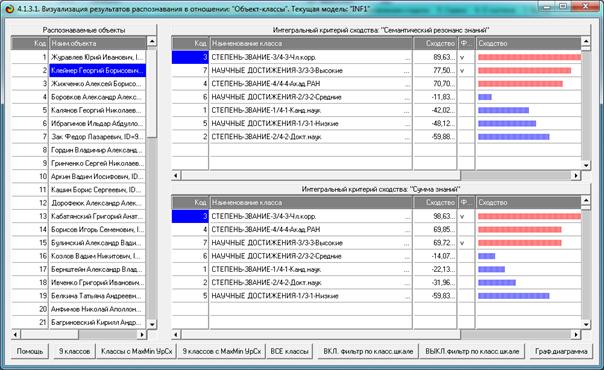
Рисунок 11. Экранная форма с результатами классификации автора:«Чл.-кор.
РАН Клейнер Г.Б.»
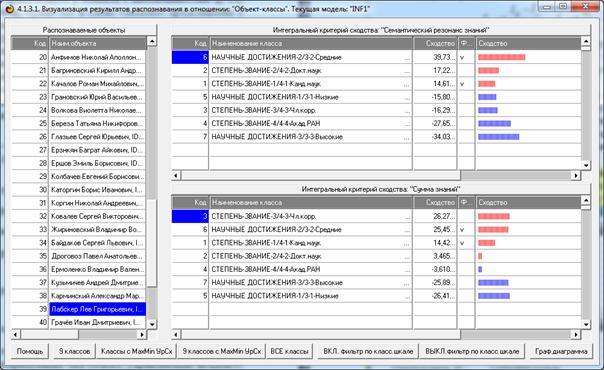
Рисунок 12. Экранная форма с результатами классификации автора:«Канд.
наук Лабскер Л.Г.»
В результатах классификации Чл.-кор. РАН Г.Б. Клейнера отметим его очень
высокий уровень сходства по значениям наукометрических показателям с
академиками РАН («без 5 минут академик»).
В результатах классификации канд.наук Л.Г. Лабскера отметим, что по
значениям его наукометрических показателей он имеет более высокий уровень
сходства с докторами наук, чем с кандидатами («не защитившийся доктор»).
Задача поддержки принятия решений является обратной по отношению к задаче
прогнозирования (классификации): при прогнозировании по значениям факторов
определяется будущее состояние, а при принятии решений, наоборот, по целевому
будущему состоянию определяется, какие значения факторов его обуславливают.
В системе «Эйдос» есть возможность вывести значения наукометрических
показателей, наиболее характерных для любого заданного результата научной
деятельности. Например, на рис. 13 приведен информационный портрет результата
«Научные достижения – высокие»:
Конечно, это звучит несколько цинично, но в соответствии с созданными
моделями получается, что для того, чтобы эксперты оценили результаты научной
деятельности автора как высокие, ему нужно иметь следующие наукометрические
показатели (приведены в порядке убывания силы влияния на этот результат
оценки):
– очень большое количество публикаций в РИНЦ;
– очень большое число самоцитирований;
– очень большое суммарное число цитирований;
– очень большое или большое значение индекса Хирша.
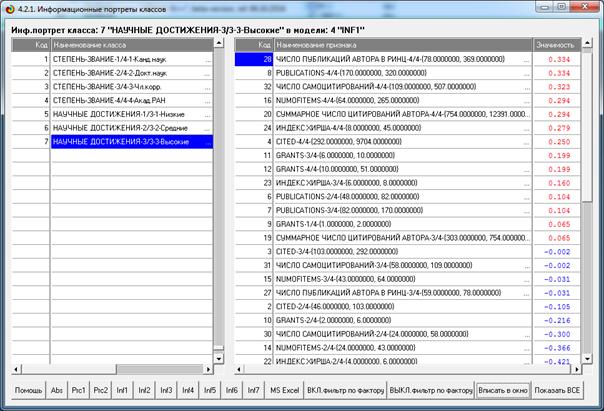
Рисунок 13. Информационный портрет результата:
«Научные достижения – высокие»
К
самоцитированию следует относиться положительно.
Странным является отрицательное отношение к самоцитированию отдельных
авторов, публикующихся по вопросам оценки эффективности научной деятельности.
Анализ предшественников может быть нужен в начале цикла исследований, когда нет
собственных публикаций и, как следствие, самоцитирование невозможно. После
получения новых самостоятельных результатов исследователь (или
исследовательский коллектив) опережает других, и его новые работы опираются на
ранее созданную им самим базу, а не на работы со стороны. Другими словами, для
дальнейших статей «посторонних предшественников» попросту нет. А вот ссылок на
собственные предыдущие работы объективно становится много. Необходимо указать
связи новых результатов с ранее полученными тем же автором (исследовательским
коллективом). Чем больше сделано, тем больше связей надо указать,
следовательно, тем больше ссылок на собственные работы.
Таким образом, самоцитирование – это хорошо. Это значит, что ученый
строит свою область. А отсутствие самоцитирования означает, что для автора эта
статья - первая по новой для него тематике. Либо он – начинающий, либо
"срывает яблоки из чужих садов". Типовая ситуация – научный деятель
берет чужую работу и изучает, конспектирует или пересказывает ее своими словами
– получается собственное произведение.
В качестве примера можно рассмотреть статью [38] по выбору средних в
соответствии со шкалами измерения. В ней систематизированы публикации,
порожденные работами 70-х годов одного из авторов настоящей статьи. Но из
обзора [38] было неясно, в каких работах получены основополагающие результаты,
а какие публикации являются всего лишь комментариями. Пришлось опубликовать
отдельную статью на эту тему [39].
Второй пример – статья [40]. Ее авторы взяли работу [51] одного из
авторов настоящей статьи, заменили условие дифференцируемости на условие
непрерывности – и получили новый научный результат. Поясним сложившуюся
традицию в простых и понятных терминах: один человек построил дом, другой покрасил
дверь в нем. И теперь надо ссылаться на второго из них (как на получившего
более продвинутые результаты), в лучшем случае добавляя "который развил
(или улучшил) первоначальные соображения первого".
Критика научного журнала за самоцитирование выглядит особенно нелепо,
поскольку противоречит естественному процессу научных исследований. Вполне
естественно, что авторы, работающие по одной и той же тематике, имеют тенденцию
публиковаться в одном и том же журнале и ссылаться друг на друга.
Рассмотрим некоторые
возможности исследования моделируемой предметной области путем исследования ее
модели, предоставляемые системой «Эйдос». Результаты, полученные путем
исследования модели, вполне корректно считать результатами исследования самой
моделируемой предметной области, так как модель достоверна, т.е. хорошо и
правильно отражает моделируемую предметную область.
Каждое значение
наукометрического показателя имеет некоторую ценность для решения задачи
классификации авторов по обобщающим категориям (классам). В системе «Эйдос» в качестве количественной
меры ценности значения показателя используется его вариабельность в наиболее
достоверной базе знаний. В качестве меры вариабельности используется
среднеквадратичное отклонение (но с тем же успехом могли бы быть использованы и
другие меры, например среднее отклонение модуля отклонения от среднего).
На рис. 14 приведена накопительная кривая ценности всех значений всех
показателей, ранжированных в порядке убывания ценности в модели INF1:
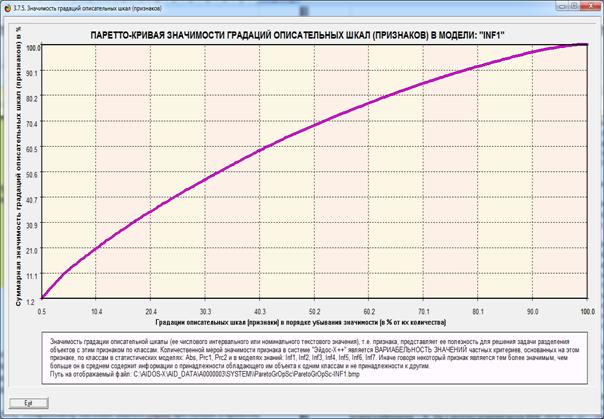
Рисунок 14. Накопительная кривая ценности всех значений всех
показателей, ранжированных в порядке убывания ценности в модели INF1
Из рис. 14 видно, что 50% значений наукометрических показателей
обеспечивает более 70% суммарной ценности, а 50% ценности обеспечивается 30%
наиболее ценных значений показателей.
Ценность показателя считается в системе «Эйдос» как
среднее ценностей его градаций.
В табл. 6 приведен список всех использованных в созданных моделях
наукометрических показателей, ранжированный в порядке убывания ценности:
Таблица 6 – Общие наукометрические показатели РИНЦ
в порядке убывания их ценности для классификации
(исходная модель INF1)
|
№
|
Код
|
Наименование
шкалы
|
Значимость
шкалы
|
|
Бит
|
Бит
нар.ит.
|
%
|
%
нар.ит
|
|
1
|
28
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ЖУРНАЛОВ ИЗ ПЕРЕЧНЯ
ВАК
|
0,192
|
0,192
|
2,664
|
2,664
|
|
2
|
14
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ЖУРНАЛАХ ИЗ ПЕРЕЧНЯ
ВАК
|
0,184
|
0,376
|
2,561
|
5,225
|
|
3
|
52
|
NUMOFLIBRARYITEMS
|
0,180
|
0,556
|
2,494
|
7,719
|
|
4
|
34
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ ЖУРНАЛОВ С НЕНУЛЕВЫМ
ИМПАКТ-ФАКТОРОМ
|
0,179
|
0,735
|
2,488
|
10,207
|
|
5
|
7
|
ЧИСЛО ПУБЛИКАЦИЙ АВТОРА В РИНЦ
|
0,176
|
0,911
|
2,440
|
12,647
|
|
6
|
48
|
ГОД ПЕРВОЙ ПУБЛИКАЦИИ
|
0,175
|
1,086
|
2,434
|
15,081
|
|
7
|
24
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ЖУРНАЛОВ
|
0,175
|
1,261
|
2,429
|
17,510
|
|
8
|
10
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ЖУРНАЛАХ
|
0,171
|
1,432
|
2,378
|
19,888
|
|
9
|
55
|
ИНДЕКС ХИРША ПО ЯДРУ РИНЦ
|
0,168
|
1,600
|
2,335
|
22,223
|
|
10
|
18
|
ЧИСЛО ЦИТИРОВАНИЙ СОАВТОРАМИ
|
0,167
|
1,767
|
2,320
|
24,543
|
|
11
|
20
|
ЧИСЛО ПУБЛИКАЦИЙ АВТОРА, ПРОЦИТИРОВАННЫХ ХОТЯ БЫ
ОДИН РАЗ
|
0,164
|
1,931
|
2,277
|
26,820
|
|
12
|
8
|
ЧИСЛО САМОЦИТИРОВАНИЙ
|
0,160
|
2,091
|
2,218
|
29,038
|
|
13
|
44
|
ЧИСЛО СОАВТОРОВ
|
0,159
|
2,250
|
2,207
|
31,245
|
|
14
|
42
|
ЧИСЛО ПУБЛИКАЦИЙ, ПРОЦИТИРОВАВШИХ РАБОТЫ АВТОРА
|
0,157
|
2,407
|
2,184
|
33,429
|
|
15
|
4
|
NUMOFITEMS
|
0,153
|
2,560
|
2,119
|
35,548
|
|
16
|
49
|
ЧИСЛО ССЫЛОК НА САМУЮ ЦИТИРУЕМУЮ ПУБЛИКАЦИЮ
|
0,149
|
2,709
|
2,065
|
37,613
|
|
17
|
32
|
ЧИСЛО ПУБЛИКАЦИЙ В ЖУРНАЛАХ С НЕНУЛЕВЫМ
ИМПАКТ-ФАКТОРОМ
|
0,147
|
2,855
|
2,035
|
39,648
|
|
18
|
53
|
ЧИСЛО ЦИТИРОВАНИЙ ПУБЛИКАЦИЙ, ВХОДЯЩИХ В ЯДРО РИНЦ
|
0,146
|
3,001
|
2,031
|
41,678
|
|
19
|
5
|
СУММАРНОЕ ЧИСЛО ЦИТИРОВАНИЙ АВТОРА
|
0,144
|
3,146
|
2,004
|
43,682
|
|
20
|
54
|
LIBRARYCITED
|
0,144
|
3,290
|
2,004
|
45,685
|
|
21
|
23
|
ЧИСЛО ПУБЛИКАЦИЙ ЗА ПОСЛЕДНИЕ 5 ЛЕТ (%)
|
0,141
|
3,431
|
1,956
|
47,641
|
|
22
|
31
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ПЕРЕВОДНЫХ ЖУРНАЛОВ
(%)
|
0,139
|
3,570
|
1,926
|
49,567
|
|
23
|
12
|
ЧИСЛО ПУБЛИКАЦИЙ В ЗАРУБЕЖНЫХ ЖУРНАЛАХ
|
0,138
|
3,707
|
1,912
|
51,479
|
|
24
|
3
|
GRANTS
|
0,136
|
3,843
|
1,884
|
53,363
|
|
25
|
50
|
ЧИСЛО ПУБЛИКАЦИЙ, ВХОДЯЩИХ В ЯДРО РИНЦ
|
0,134
|
3,977
|
1,867
|
55,231
|
|
26
|
35
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ ЖУРНАЛОВ С НЕНУЛЕВЫМ
ИМПАКТ-ФАКТОРОМ (%)
|
0,134
|
4,112
|
1,866
|
57,097
|
|
27
|
37
|
ЧИСЛО ЦИТИРОВАНИЙ ПУБЛИКАЦИЙ АВТОРА ИЗ ВСЕХ
ПУБЛИКАЦИЙ ЗА ПОСЛЕДНИЕ 5 ЛЕТ
|
0,134
|
4,245
|
1,854
|
58,951
|
|
28
|
27
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ ЗАРУБЕЖНЫХ ЖУРНАЛОВ (%)
|
0,131
|
4,377
|
1,822
|
60,773
|
|
29
|
47
|
ИНДЕКС ХИРША С УЧЕТОМ ТОЛЬКО СТАТЕЙ В ЖУРНАЛАХ
|
0,129
|
4,505
|
1,785
|
62,558
|
|
30
|
6
|
ИНДЕКС ХИРША
|
0,126
|
4,631
|
1,749
|
64,308
|
|
31
|
41
|
СРЕДНЕВЗВЕШЕННЫЙ ИМПАКТ-ФАКТОР ЖУРНАЛОВ, В КОТОРЫХ
БЫЛИ ПРОЦИТИРОВАНЫ СТАТЬИ
|
0,125
|
4,757
|
1,742
|
66,050
|
|
32
|
17
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ПЕРЕВОДНЫХ ЖУРНАЛАХ
(%)
|
0,124
|
4,881
|
1,728
|
67,778
|
|
33
|
46
|
ИНДЕКС ХИРША БЕЗ УЧЕТА САМОЦИТИРОВАНИЙ
|
0,124
|
5,005
|
1,715
|
69,494
|
|
34
|
22
|
ЧИСЛО ПУБЛИКАЦИЙ ЗА ПОСЛЕДНИЕ 5 ЛЕТ
|
0,121
|
5,126
|
1,680
|
71,174
|
|
35
|
16
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ПЕРЕВОДНЫХ ЖУРНАЛАХ
|
0,121
|
5,246
|
1,675
|
72,849
|
|
36
|
9
|
ЧИСЛО САМОЦИТИРОВАНИЙ (%)
|
0,120
|
5,366
|
1,671
|
74,520
|
|
37
|
13
|
ЧИСЛО ПУБЛИКАЦИЙ В ЗАРУБЕЖНЫХ ЖУРНАЛАХ (%)
|
0,120
|
5,486
|
1,664
|
76,184
|
|
38
|
33
|
ЧИСЛО ПУБЛИКАЦИЙ В ЖУРНАЛАХ С НЕНУЛЕВЫМ
ИМПАКТ-ФАКТОРОМ (%)
|
0,118
|
5,604
|
1,639
|
77,823
|
|
39
|
30
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ПЕРЕВОДНЫХ ЖУРНАЛОВ
|
0,115
|
5,719
|
1,592
|
79,415
|
|
40
|
2
|
PUBLICATIONS
|
0,114
|
5,833
|
1,586
|
81,001
|
|
41
|
26
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ ЗАРУБЕЖНЫХ ЖУРНАЛОВ
|
0,113
|
5,946
|
1,570
|
82,571
|
|
42
|
43
|
ЧИСЛО ЦИТИРОВАНИЙ ПУБЛИКАЦИЙ АВТОРА В РИНЦ
|
0,113
|
6,059
|
1,564
|
84,136
|
|
43
|
25
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ЖУРНАЛОВ (%)
|
0,108
|
6,167
|
1,506
|
85,641
|
|
44
|
1
|
CITED
|
0,105
|
6,272
|
1,457
|
87,098
|
|
45
|
11
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ЖУРНАЛАХ (%)
|
0,104
|
6,376
|
1,441
|
88,539
|
|
46
|
19
|
ЧИСЛО ЦИТИРОВАНИЙ СОАВТОРАМИ (%)
|
0,104
|
6,480
|
1,440
|
89,980
|
|
47
|
36
|
СРЕДНЕВЗВЕШЕННЫЙ ИМПАКТ-ФАКТОР ЖУРНАЛОВ, В КОТОРЫХ
БЫЛИ ОПУБЛИКОВАНЫ СТАТЬИ
|
0,104
|
6,583
|
1,440
|
91,420
|
|
48
|
29
|
ЧИСЛО ЦИТИРОВАНИЙ ИЗ РОССИЙСКИХ ЖУРНАЛОВ ИЗ ПЕРЕЧНЯ
ВАК (%)
|
0,102
|
6,685
|
1,411
|
92,830
|
|
49
|
21
|
ЧИСЛО ПУБЛИКАЦИЙ АВТОРА, ПРОЦИТИРОВАННЫХ ХОТЯ БЫ
ОДИН РАЗ (%)
|
0,097
|
6,782
|
1,344
|
94,174
|
|
50
|
51
|
ЧИСЛО ПУБЛИКАЦИЙ, ВХОДЯЩИХ В ЯДРО РИНЦ (%)
|
0,087
|
6,869
|
1,204
|
95,378
|
|
51
|
40
|
ЧИСЛО ЦИТИРОВАНИЙ РАБОТ АВТОРА, ОПУБЛИКОВАННЫХ ЗА
ПОСЛЕДНИЕ 5 ЛЕТ (%)
|
0,085
|
6,953
|
1,179
|
96,557
|
|
52
|
15
|
ЧИСЛО ПУБЛИКАЦИЙ В РОССИЙСКИХ ЖУРНАЛАХ ИЗ ПЕРЕЧНЯ
ВАК (%)
|
0,083
|
7,037
|
1,154
|
97,711
|
|
53
|
38
|
ЧИСЛО ЦИТИРОВАНИЙ ПУБЛИКАЦИЙ АВТОРА ИЗ ВСЕХ
ПУБЛИКАЦИЙ ЗА ПОСЛЕДНИЕ 5 ЛЕТ (%)
|
0,081
|
7,117
|
1,124
|
98,835
|
|
54
|
39
|
ЧИСЛО ЦИТИРОВАНИЙ РАБОТ АВТОРА, ОПУБЛИКОВАННЫХ ЗА
ПОСЛЕДНИЕ 5 ЛЕТ
|
0,081
|
7,198
|
1,119
|
99,954
|
|
55
|
45
|
INDICATORYEAR
|
0,003
|
7,201
|
0,046
|
100,000
|
Отметим, что в разных моделях, и даже в одной модели при изменении
параметров ее синтеза, приведенные характеристики значимости наукометрических
критериев и их рейтинг изменяются.
Из табл. 6 можно сделать научно-обоснованный вывод о том, что индекс
Хирша не всегда является наиболее значимым наукометрическим показателем и его
роль в современных наукометрических методиках может быть несколько
преувеличена. Об этом авторы из общетеоретических соображений писали ранее в
своих работах [3, 4, 7, 9, 11, 55].
В соответствии с пониманием соотношения содержания понятий: «данные,
информация, знания», представленным на рис. 1 и 2, знания – это информация,
полезная для достижения целей, т.е. используемая для управления (т.к. управление
– это деятельность по достижению цели).
Поэтому если мы используем созданные модели для достижения целей, то они
становятся моделями знаний (когнитивными моделями). Таким образом, если мы
выберем целевое состояние и на основе созданных моделей оценим влияние
различных значений факторов по степени их влияния на способствование и достижение
и препятствование достижению этого целевого состояния, то это будет
использование данных моделей как моделей знаний. По сути это и делается в
количественном автоматизированном SWOT- и PEST-анализе средствами системы
«Эйдос» [31] (рис. 15, 16):
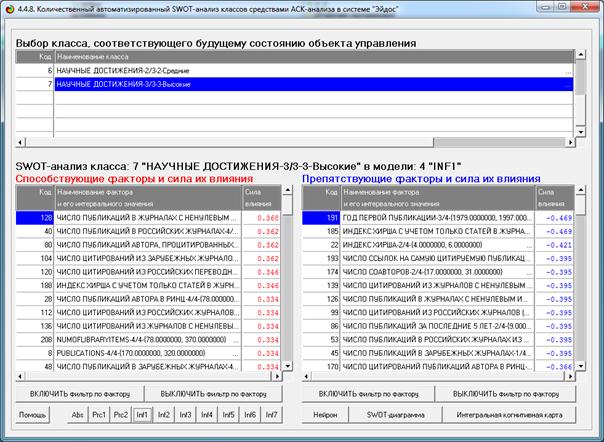
Рисунок 15. Табличная выходная форма количественного автоматизированного
SWOT- и PEST-анализа средствами системы «Эйдос»
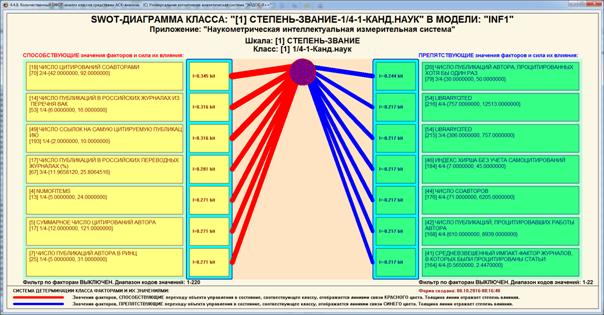
Рисунок 16. Графическая выходная форма количественного автоматизированного
SWOT- и PEST-анализа средствами системы «Эйдос»
Когнитивные функции предложены проф. Е.В. Луценко в 2005 году [32] и
наглядно отражают какое количество информации содержится в значениях аргумента
о значении функции [16, 32, 33] (рис. 17 и 18):
Рисунок 17. Экранная форма режима визуализации
когнитивных функций
Программный модуль визуализации когнитивных функций разработан по
постановке проф. Е. В. Луценко разработчиком интеллектуальных систем Д. К.
Бандык из Белоруссии.
В когнитивных функциях количество информации в значениях аргумента о
значениях функции отображается цветом (красным максимальное, синим
минимальное), линией соединены значения функции о которых в значении аргумента
содержится максимальное количество информации, ширина линии (аналог доверительного
интервала) отражает степень неопределенности значения функции, которое тем
ниже, чем больше информации о нем в значении функции (рис. 18–21):
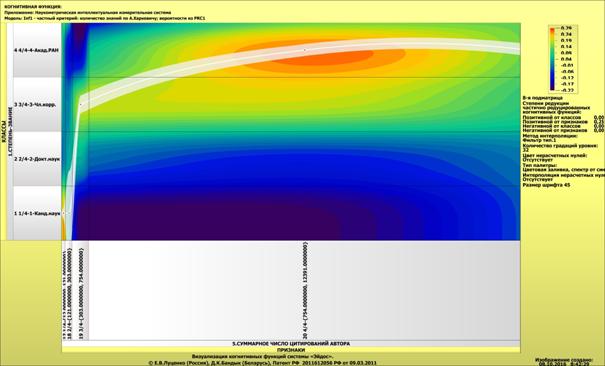
Рисунок 18. Когнитивная функция, отражающая взаимосвязь суммарного числа
цитирований автора и его ученой степени-звания
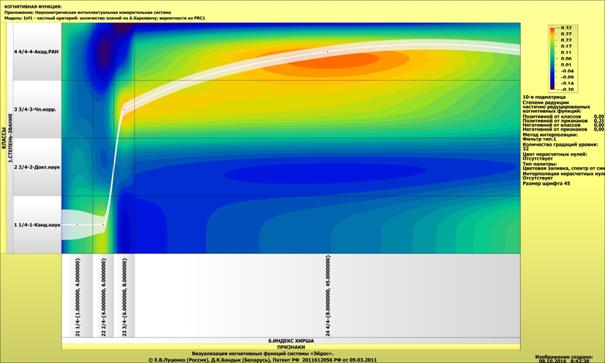
Рисунок 19. Когнитивная функция, отражающая взаимосвязь
индекса Хирша автора и его ученой степени-звания
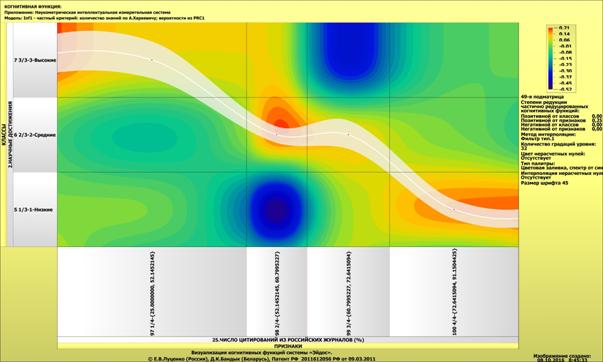
Рисунок 20. Когнитивная функция, отражающая зависимость научных достижений
автора от доли (%) его цитирований из российских журналов
Из когнитивной функции, представленной на рис. 20, видно, что у авторов с
высокими научными достижениями доля цитирований из зарубежных научных изданий
выше, чем у авторов с другими научными достижениями.
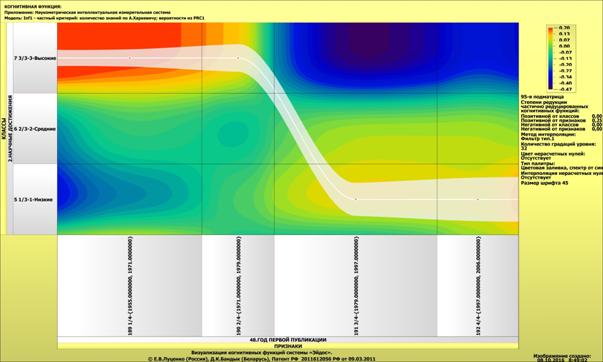
Рисунок 21. Когнитивная функция, отражающая зависимость научных достижений
автора от года первой публикации
Из этой функции на рисунке 21 мы видим, что высокие научные достижения
тесно связаны с длительной научной работой.
Приведено лишь несколько примеров когнитивных функций, т.к. в каждой
модели (которых 10) генерируется 110 когнитивных функций, отражающих
описательных шкал, которых 55, на классификационные шкалы, которых 2.
Результаты сравнения классов по системе характерных для них значений
общих наукометрических показателей РИНЦ приведены на рис. 22:
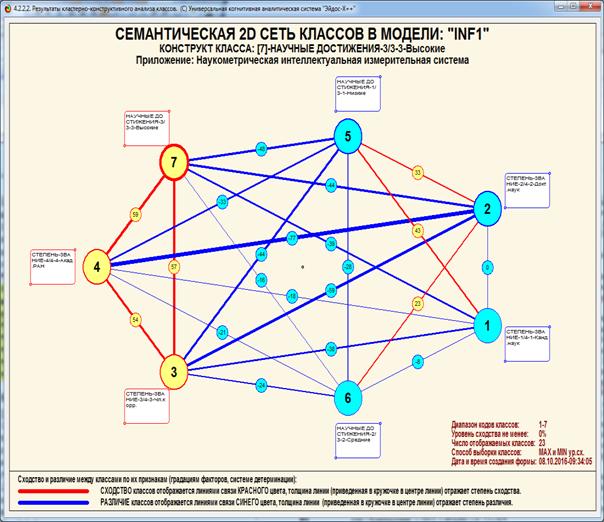
Рисунок 22. Результаты сравнения классов по системе характерных для них
значений общих наукометрических показателей РИНЦ
Из когнитивной диаграммы, приведенной на рисунке 22, мы видим, что как и
ожидалось, для академиков и членов-корреспондентов РАН характерны высокие
научные достижения, средние достижения характерны для докторов наук, а низкие
для кандидатов наук. Мы видим также, что академики и члены-корреспонденты
образуют с авторами высоких научных достижений один кластер, с низкой
вариабельностью внутри него, а доктора и кандидаты наук образуют противоположный
кластер с более высокой вариабельностью объектов, внутри него. Кластер высоких
научных достижений противоположен по характерным для него значениям общих
наукометрических показателей кластеру средних и низких научных достижений, и
они образуют полюса конструкта: «Уровень научных достижений».
Отметим также, что приведенная когнитивная диаграмма формируется системой
«Эйдос» автоматически на основе созданных моделей.
3.2.6. Выводы,
перспективы и рекомендации
Предлагается:
1. Построить
с применением результатов данной статьи наукометрическую интеллектуальную
измерительную систему на основе баз данных РИНЦ и экспертных оценок и включить
ее в состав программного обеспечения РИНЦ.
2. Применить
результаты данной статьи при расчетах в РИНЦ и строить рейтинги авторов,
журналов и организаций (подразделений) не только на основе эмпирического
классического индекса Хирша, но и на основе теоретического индекса Хирша [4], а
также по критериям манипулирования, по общему числу цитирований [9] и другим
показателям.
3. Не придавать излишне и неоправданно большого значения классическому
эмпирическому значению индекса Хирша при оценках и принятии решений.
Проблемы идентификации авторов и литературных
источников по библиографическим описаниям в списках литературы в последнее
время приобретает все большее значение научное и практическое значение. Это
связано в частности с политикой Министерства образования и науки Российской
Федерации в области оценки качества результатов научной деятельности, которая
предполагает использование количества ссылок на публикации авторов и индекса
Хирша. В России создаются соответствующие аналитические инструменты и сервисы
для оценки результатов научной деятельности, функционально
аналогичные известным зарубежным библиографическим базам данных Scopus, Web of
Science и другим. В настоящее время наиболее известным в России сервисом
подобного назначения является Российский индекс научного цитирования (РИНЦ): http://elibrary.ru/. Однако, как
показывает опыт, часто ссылки в списках литературы публикаций сделаны с
нарушением ГОСТ 7.1—2003, а также с
ошибочными выходными данными, например, неверно указанными номерами страниц,
наименованием издательства и т.п. На практике это приводит к тому, что
программная система библиографической базы не может определить, на какую статью
сделана данная ссылка и кто авторы этой статьи. В результате для этих авторов
теряется цитирование, что приводит к занижению их индексов Хирша и оценки
результатов их научной деятельности руководством. Понятно, что эти
отрицательные последствия желательно преодолеть. Данная статья посвящена изложению
подхода, который позволяет решить эту проблему путем применения АСК-анализа и
интеллектуальной системы «Эйдос», представляющих собой современную
инновационную интеллектуальную технологию (готовую к внедрению).
СОДЕРЖАНИЕ
1. Описание проблемы и идея ее решения.. 239
2. Предыстория и задел для решения проблемы
идентификации текстов и авторов в АСК-анализе и системе «Эйдос». 242
3. Описание предлагаемого решения проблемы... 243
3.1.
Этапы АСК-анализа и преобразование исходных
данных в информацию, а ее в знания в системе "Эйдос" 243
3.2. Скачивание и
инсталляция системы «Эйдос» 247
3.3.
Автоматизированная формализация предметной области путем импорта исходных
данных из внешних баз данных в систему "Эйдос" 252
3.4.
Синтез и верификация статистических и
интеллектуальных моделей 258
3.5. Частные критерии и
виды моделей системы «Эйдос» 260
3.6. Ценность
описательных шкал и градаций для решения
задач идентификации текстов и авторов
(нормализация текста) 263
3.7. Интегральные
критерии системы «Эйдос» 263
3.8. Результаты
верификации моделей 266
4. Решение задач идентификации текстов и их авторов в наиболее достоверной модели 268
4.1. Присвоение наиболее
достоверной модели статуса текущей и решение
в ней задач идентификации 268
4.2.
Отображение результатов идентификации 270
5. Выводы... 282
6. Некоторые недостатки и перспективы... 283
6.1. Повышение
быстродействия алгоритмов 283
3.3.1. Описание
проблемы и идея ее решения
Проблемы
идентификации авторов и литературных источников по библиографическим описаниям
в списках литературы в последнее время приобретает все большее значение научное
и практическое значение. Это связано в частности с политикой Министерства
образования и науки Российской Федерации в области оценки качества результатов
научной деятельности, которая предполагает использование количества ссылок на
публикации авторов и индекса Хирша. В России создаются соответствующие аналитические инструменты и сервисы для
оценки результатов научной деятельности,
функционально аналогичные известным зарубежным библиографическим базам данных
Scopus, Web of Science и другим. В настоящее время наиболее известным в России
сервисом подобного назначения является Российский индекс научного цитирования
(РИНЦ): http://elibrary.ru/. Однако, как
показывает опыт, часто ссылки в списках литературы публикаций сделаны с
нарушением ГОСТ 7.1—2003, а также с
ошибочными выходными данными, например, неверно указанными номерами страниц,
наименованием издательства и т.п. На практике это приводит к тому, что
программная система библиографической базы не может определить на какую статью,
из находящихся в ней, сделана данная ссылка и кто авторы этой статьи. В
результате для этих авторов теряется цитирование, что приводит к занижению их
индексов Хирша и оценки результатов их научной деятельности чиновниками. Понятно,
что эти отрицательные последствия желательно преодолеть.
Традиционно
данная проблема решается с помощью алгоритма шинглов. Данная
статья посвящена изложению идеи решения этой проблему путем
применения Автоматизированного системно-когнитивного анализа (АСК-анализ) и его
программного инструментария – интеллектуальной системы «Эйдос», которые
представляют собой современную инновационную интеллектуальную технологию
(готовую к внедрению). В ней рассматривается алгоритм, основанный на
вычислении количества информации в словах библиографической ссылки о
том, что это ссылка на данную статью и данных авторов, а также ценность
слов для идентификации статей и авторов (т.е. вариабельность количества информации
в словах по статьям и авторам).
Предлагаемый
алгоритм имеет ряд отличий от алгоритма шинглов, за счет чего может иметь
определенные преимущества перед ним. Рассмотрим эти различия подробнее.
Этапы алгоритма шинглов1, которые проходит текст,
подвергшийся сравнению:
– канонизация текста;
– разбиение на шинглы;
– вычисление хэшей шинглов;
– случайная выборка 84 значений контрольных сумм;
– сравнение, определение результата.
Рассмотрим,
каким образом реализуются или не реализуются (т.к. в этом нет необходимости)
подобные этапы в АСК-анализе и его программном инструментарии – системе «Эйдос»
(таблица 1):
Таблица 1 –
Сравнение алгоритма шинглов и алгоритма
АСК-анализа, реализованного в системе «Эйдос»
|
Алгоритм шинглов
|
Алгоритм
АСК-анализа, реализованный в системе «Эйдос»
|
|
Канонизация
текста
|
|
Канонизация текста приводит оригинальный текст к единой нормальной форме. Текст очищается от
предлогов, союзов, знаков препинания, HTML тегов, и прочего
ненужного «мусора», который не должен
участвовать в сравнении. В большинстве случаев также предлагается удалять из
текста прилагательные, так как они не несут смысловой нагрузки.
|
Так как
вычисляется количество информации в словах библиографической ссылки о
том, что это ссылка на данную статью и данных авторов, а также ценность
слов для идентификации статей и авторов (т.е. вариабельность количества
информации в словах по статьям и авторам), то в этапе канонизации текста нет
необходимости.
|
|
Также на этапе канонизации текста можно приводить существительные
к именительному падежу, единственному числу, либо оставлять от них только
корни.
|
Лемматизация
текста на основе морфологического анализа, т.е. приведение слов к их
исходной форме. Это целесообразно, но в настоящее время не реализовано.
|
|
Разбиение на шинглы
|
|
Шинглы (англ. – «чешуйки») – выделенные из статьи
подпоследовательности слов. Необходимо из сравниваемых текстов выделить
подпоследовательности слов, идущих друг за другом по 10 штук (длина шингла).
Выборка происходит внахлест, а не встык. Таким образом, разбивая текст на
подпоследовательности, мы получим набор шинглов в количестве равному количеству
слов минус длина шингла плюс один.
|
Система «Эйдос»
обеспечивает использование в качестве признаков текста последовательностей
подряд идущих слов по 2, 3,…, N слов, т.е. шинглов, но это не имеет смысла
делать при решении проблемы идентификации текстов и авторов по нестандартным
и некорректным библиографическим описаниям, т.к. в них
как раз эти последовательности могут быть нарушены, что приведет к понижению
достоверности идентификации алгоритма шинглов. Кроме того использование
таких подпоследовательностей само требует затрат вычислительных ресурсов, а
также резко увеличивает количество признаков текста, размерность моделей и
время идентификации.
|
|
Вычисление хэшей
шинглов
|
|
Принцип алгоритма шинглов заключается в сравнении случайной
выборки контрольных сумм шинглов (подпоследовательностей) двух текстов между
собой.
|
Тексты
сравниваются не по случайному подмножеству своих признаков, а по всем признакам, в качестве которых
выступают слова. Считается идентифицированными тот источник и те авторы, о
которых в словах ссылки содержится максимальное количество информации. Это
может обеспечить более высокую достоверность алгоритма.
|
|
Проблема
быстродействия алгоритма
|
|
Проблема алгоритма заключается в количестве сравнений, ведь
это напрямую отражается на производительности. Увеличение количества шинглов
для сравнения характеризуется экспоненциальным
ростом операций, что критически отразится на производительности.
|
Проблема
алгоритма заключается в количестве сравнений, ведь это напрямую отражается на
производительности. Увеличение количества слов в библиографических ссылках,
используемых для сравнения, приводит к линейному
росту числа операций сравнения.
|
Таким
образом, есть надежда, что предлагаемый алгоритм будет иметь более высокую
достоверность и быстродействие, чем алгоритм шинглов.
3.3.2. Предыстория и
задел для решения проблемы идентификации текстов и авторов в АСК-анализе и
системе «Эйдос»
Автор на
протяжении многих лет периодически возвращался к проблематике атрибуции
анонимных и псевдонимных текстов, идентификации текстов и их авторов [1, 2]. С
2006 года на базе системы «Эйдос» проводятся лабораторные работы, в которых
изучается применение интеллектуальных технологий для решения этих задач [3]
(см. лаб.работы №1 и №6).
В новой
версии системы «Эйдос-Х++» этой теме посвящена лабораторная работа 3.02
(рисунок 1):
Рисунок 1.
Экранная формы выбора лабораторной работы
3-го типа
На рисунке 2
приведен Help этой лабораторной работы:
Рисунок 2.
Экранная формы Help лабораторной работы 3.02
Кроме того
есть опыт анализ проблематики научного журнала в динамике с использованием
технологии обработки текстов в интеллектуальной системе «Эйдос» [4].
3.3.3. Описание
предлагаемого решения проблемы
АСК-анализ
представляет собой современную инновационную (т.е. полностью готовую к
внедрению и использованию) широко и успешно апробированную интеллектуальную
технологию [5, 6, 7, 8].
АСК-анализ включает следующие этапы:
1.
Когнитивная структуризация предметной области (неформализованный этап). На этом
этапе решается, что мы хотим прогнозировать и на основе чего. В нашей задаче мы
хотим прогнозировать продолжительность жизни пациента после перенесенного им
инфаркта на основе анализа эхокардиограммы.
2.
Формализация предметной области. На этом
этапе разрабатываются классификационные и описательные шкалы и градации, а
затем с их использованием исходные данные кодируются и представляются в форме
баз событий, между которыми могут быть выявлены причинно-следственные связи.
3. Синтез
и верификация моделей (оценка достоверности,
адекватности). Повышение качества модели. Выбор наиболее достоверной модели для
решения в ней задач.
4. Решение
задач идентификации и прогнозирования.
5. Решение
задач принятия решений и управления.
6. Решение
задач исследования моделируемой предметной области путем
исследования ее модели.
На рисунке 3
приведены автоматизированные в системе «Эйдос» этапы АСК-анализа, которые
обеспечивают последовательное повышение степени формализации модели путем преобразования
исходных данных в информацию, а далее в знания:
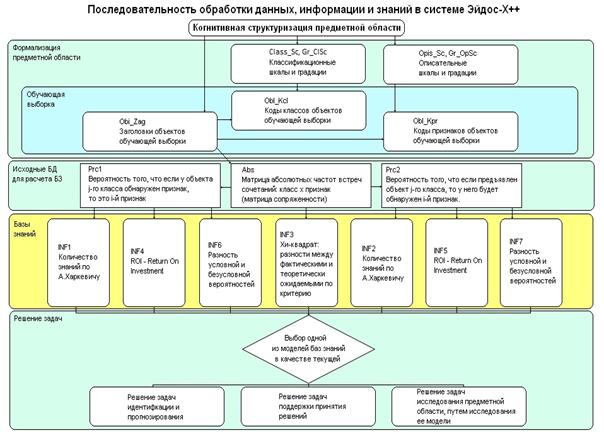
Рисунок 3.
Этапы последовательного преобразования данных в информацию, а ее в знания в
системе "Эйдос"
Подробно этот
процесс описан в работах [9, 10]. Суть этого процесса в следующем:
1. Информация рассматривается как
осмысленные исходные данные.
2. Смысл, согласно концепции
Шенка-Абельсона [11] считается известным, когда выявлены причинно-следственные
связи.
3. Анализ – это операция выявления смысла
из исходных данных.
4.
Причинно-следственные связи существуют не между элементами исходных данных, а
между реальными событиями, которые они отражают (моделируют), т.е. причинно-следственные
связи – это характеристика реальной области, а не абстрактных моделей. Иначе
говоря, анализ самих исходных данных невозможен, а возможен только анализ
событий, описанных этими исходными данными.
5. Поэтому
перед анализом исходных данных необходимо предварительно преобразовать их в
базы событий, т.е. в эвентологические базы.
6. Это
преобразование осуществляется с помощью справочников событий, факторов и их
значений, т.е. с помощью классификационных и описательных шкал и градаций,
которые также необходимо разработать.
7.
Формализация предметной области представляет собой разработку справочников
классификационных и описательных шкал и градаций и преобразование с их помощью
баз исходных данных в базы событий (т.е. обучающую выборку), и является первым
автоматизированным в системе «Эйдос» этапом АСК-анализа.
8. Затем
следуют остальные перечисленные выше этапы АСК-анализа:
– синтез и
верификация моделей и выбор наиболее достоверной из них;
– решение в
ней задач идентификации, прогнозирования, принятия решений и исследования
предметной области, т.е. преобразование информации в знания.
Этап синтеза
и верификации моделей завершает процесс анализа исходных данных и
преобразования их в информацию, а ее в знания.
В АСК-анализе
есть несколько режимов, обеспечивающих решение задачи принятия решений для управления или достижения целей, которая представляет собой
обратную задачу прогнозирования: это и режим 4.2.1, позволяющий формировать
информационные портреты классов, а также режим 4.4.8, поддерживающий количественный
автоматизированный SWOT и –PEST анализ, включая построение SWOT и –PEST матриц
и диаграмм [12], а также режим 4.4.10, визуализирующий нейросетевую интерпретацию
модели знаний системы «Эйдос» [13]. Эти режимы обеспечивают преобразование
информации в знания, т.к. знания представляют собой информацию,
полезную для достижения целей, т.е. по сути технологию, в частности ноу-хау
[5]. Наличие цели является ключевым моментом для преобразования информации
в знания. А постановка целей (целеполагание) не мыслима без мотивации, которая
в настоящее время является слабо формализованным этапом.
Итак, в
процессе анализа исходные данные
представляются в форме базы событий, между которыми выявляются
причинно-следственные связи, и, таким образом, исходные данные преобразуются в
информацию, представляющую собой осмысленные данные (смысл есть знание
причинно-следственных связей), а затем информация используется для достижения
целей (управления), т.е. преобразуется в знания.
Формализация
предметной области включает разработку классификационных и описательных шкал и
градаций и преобразование с их использованием исходных данных (таблица 2) в
обучающую выборку. Этот этап полностью
автоматизируется программным интерфейсом системы «Эйдос» с внешними табличными
базами исходных данных (режим 2.3.2.2).
Но перед
выполнением этого этапа АСК-анализа, естественно, необходимо сначала скачать и
установить систему «Эйдос».
3.3.3.2. Скачивание и
инсталляция системы «Эйдос»
Для
скачивания и инсталляции системы «Эйдос» необходимо по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm открыть и
выполнить следующую инструкцию:
ИНСТРУКЦИЯ
по скачиванию и установке системы «Эйдос» (объем около 100 Мб)
|
Система не требует инсталляции, не меняет никаких
системных файлов и содержимого папок операционной системы,
т.е. является портативной (portable)
программой. Но чтобы она работала необходимо аккуратно выполнить следующие
пункты.
1. Скачать самую новую на текущий момент полную версию
системы «Эйдос-Х++» (около 100
Мб) с сайта разработчика по ссылкам:
http://lc.kubagro.ru/a.rar или: http://lc.kubagro.ru/Aidos-X.exe (ссылки для обновления системы даны в режиме 6.2).
Вариант без лабораторных работ и базы лемматизации: http://lc.kubagro.ru/a-min.rar (около 30
Мб). Скачивание самой новой версии системы «Эйдос» из облака.
2. Разархивировать этот архив в любую папку с правами на
запись с коротким латинским именем и путем доступа, .
включающим только папки с такими же именами (лучше всего в корневой
каталог какого-нибудь диска).
3. Запустить систему. Файл запуска:  _AIDOS-X.exe. _AIDOS-X.exe.
4. Задать имя: 1 и пароль: 1 (потом их можно поменять в
режиме 1.2).
5. Перед тем как запустить новый режим НЕОБХОДИМО
ЗАВЕРШИТЬ предыдущий (Help можно не закрывать). Окна закрываются в порядке,
обратном порядку их открытия.
|
|
Разработана программа: « _START_AIDOS.exe»,
полностью снимающая с пользователя системы «Эйдос-Х++» заботу о проверке
наличия и скачивании обновлений. Эту программу надо просто скачать по ссылке: http://lc.kubagro.ru/_START_AIDOS.exe, поместить в папку с исполнимым модулем системы и всегда запускать
систему с помощью этого файла. _START_AIDOS.exe»,
полностью снимающая с пользователя системы «Эйдос-Х++» заботу о проверке
наличия и скачивании обновлений. Эту программу надо просто скачать по ссылке: http://lc.kubagro.ru/_START_AIDOS.exe, поместить в папку с исполнимым модулем системы и всегда запускать
систему с помощью этого файла.
Если библиотеки (*.DLL) системы «Эйдос-Х++» расположены в папке, на
которую прописан путь поиска (скачиваются по п.1), то вместо выполнения
пунктов 1,2,3 можно просто запускать файл: «_START_AIDOS.exe»
и он сам все скачает, развернет и даже запустит систему «Эйдос-Х++».
При запуске программы _START_AIDOS.exe
система «Эйдос-Х++» не
должна быть запущена, т.к. она содержится в файле обновлений и при его
разархивировании возникнет конфликт, если система будет запущена.
1. Программа _START_AIDOS.exe
определяет дату исполнимого модуля системы «Эйдос» в текущей папке: _AIDOS-X.exe и дату обновлений на FTP-сервере
разработчика не скачивая их,
и, если исполнимый модуль системы «Эйдос» в текущей папке устарел, то
скачивает минимальные обновления Downloads.exe объемом около 5 Мб. Если же в
текущей папке вообще нет исполнимого модуля системы «Эйдос»: _AIDOS-X.exe,
то программа _START_AIDOS.exe
скачивает полную инсталляцию системы «Эйдос» объемом около 100 Мб в виде
самораспаковывающегося архива Update.exe.
Процесс скачивания отображается в виде диалогового с соответствующим
сообщением.
2. После завершения процесса
скачивания появляется
диалоговое окно с сообщением, что надо сначала разархивировать систему, заменяя все
файлы (опция: «Yes to All» или «OwerWrite All»), и только затем закрыть данное окно.
3. Потом программа _START_AIDOS.exe
запускает скачанные обновления на разархивирование. После окончания
разархивирования окно архиватора с отображением стадии процесса исчезает.
4. После закрытия диалогового окна
с инструкцией (см. п.2), происходит запуск обновленной версии системы «Эйдос»
на исполнение.
5. Если Вы собираетесь работать с
текстами, то необходимо скачать базу данных для лемматизации “Lemma.DBF” по
ссылке: http://lc.kubagro.ru/Lemma.rar и разархивировать ее в папку с системой «Эйдос-Х++» (архив имеет
размер около 10 Мб, сама база около 200 Мб). База для лемматизации сделана на
основе словаря Зализняка и
статьи: https://habrahabr.ru/company/realweb/blog/265375/ Сейчас эта база
входит в комплект поставки. Если Вы не собираетесь работать с текстами, то
эта база не нужна и можно удалить ее и индексный массив Lemma.ntx из
директории с системой. На работу остальных функций системы это не повилияет,
а размер директории с системой заметно сократится.
Примечания:
1. Если _START_AIDOS.exe
запускается в папке с уже ранее установленной системой устаревшей версии, то
при разархивировании будут возникать конфликты при попытке разархивирования
библиотек (DLL-файлов), которые используются самим модулем_START_AIDOS.exe.
Поэтому, если мы хотим их обновить, надо выйти из этого модуля и разархивировать
скачанный архив Update.exe,
запустив его вручную. Если этого не делать, то просто останутся предыдущие
версии библиотек. Так что достаточно один раз сделать это вручную или
поместить библиотеки в папку, на которую прописан путь доступа.
2. Если Вам не нужны лабораторные
работы, то можно удалить папку: ..:\Aidos-X\AID_DATA\LabWorks\. На работу
остальных функций системы это не повлияет, а размер директории с системой
заметно сократится.
|
|
Лицензия:
Автор отказывается от какой бы то ни было
ответственности за Ваш выбор или не выбор системы «Эйдос» и последствия
применения или не применения Вами системы «Эйдос».
Проще говоря, пользуйтесь если
понравилось, а если не понравилось – не пользуйтесь: решайте сами и сами же
несите ответственность за Ваше решение.
|
По этим ссылкам всегда размещена наиболее полная на
момент скачивания незащищенная от несанкционированного копирования портативная
(portable) версия системы (не требующая инсталляции) с исходными текстами,
находящаяся в полном открытом бесплатном доступе (объем около
50 Мб). Обновление имеет объем около 3 Мб.
Далее
запускаем систему "Эйдос" из папки "Aidos-X" файлом
_aidos-x.exe. Система попросит ввести логин и пароль (рисунок 9). Необходимо
ввести: логин – 1, пароль – 1.
Далее
запускаем систему "Эйдос" из папки "Aidos-X" файлом
_aidos-x.exe. Система попросит ввести логин и пароль (рисунок 4).
Рисунок 4.
Экранная форма авторизации в системе "Эйдос"
Здесь
необходимо ввести: логин – 1, пароль – 1. В результате откроется главное окно
системы (рисунок 5):
Рисунок 5 –
Главное окно системы "Эйдос"
В последующем
имя и пароль можно изменить в режиме 1.2.
В качестве
исходных данных для примера решения задачи идентификации текстов и авторов,
рассмотренного в данной статье, использована выборка из баз данных Научного
журнала КубГАУ [14, 4] за весь период его существования с 2003 года по
настоящее время (точнее по 100-й номер). За это время в журнале издано 3949
статей.
Файл выборки
организован следующим образом (таблица 2):
Таблица 2 –
Исходные данные (фрагмент)
|
Объект
|
Статья
|
Автор
|
Библиографическая ссылка
|
|
10301001
|
IDA10301001
|
Кацко_И_А, Креймер_А_С
|
Кацко И. А. Принятие решения о
структуре системы автономного энергоснабжения с использованием когнитивного
подхода / И. А. Кацко, А. С. Креймер // Политематический сетевой электронный
научный журнал Кубанского государственного аграрного университета (Научный
журнал КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С.
1 – 2. IDA [article ID]: 0010301001 – Режим доступа:
http://ej.kubagro.ru/2003/01/01.pdf, 0,063 у.п.л., импакт-фактор РИНЦ=0,346
|
|
10301002
|
IDA10301002
|
Богатырев_Н_И, Креймер_А_С
|
Богатырев Н. И. Имитационное
моделирование ветроэнергетической установки / Н. И. Богатырев, А. С. Креймер
// Политематический сетевой электронный научный журнал Кубанского
государственного аграрного университета (Научный журнал КубГАУ) [Электронный
ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 3 – 8. IDA [article ID]:
0010301002 – Режим доступа: http://ej.kubagro.ru/2003/01/02.pdf, 0,313
у.п.л., импакт-фактор РИНЦ=0,346
|
|
10301004
|
IDA10301004
|
Хисамов_Ф_Г
|
Хисамов Ф. Г. Методика оптимизации
структуры перспективных аппаратных средств криптографической защиты
информации в автоматизированных системах управления / Ф. Г. Хисамов //
Политематический сетевой электронный научный журнал Кубанского государственного
аграрного университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2003. – №01(001) С. 9 – 15. IDA [article ID]: 0010301004 – Режим
доступа: http://ej.kubagro.ru/2003/01/04.pdf, 0,375 у.п.л., импакт-фактор
РИНЦ=0,346
|
|
10301005
|
IDA10301005
|
Луценко_Е_В
|
Луценко Е. В. Численный расчет
эластичности объектов информационной безопасности на основе системной теории
информации / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 16 –
27. IDA [article ID]: 0010301005 – Режим доступа:
http://ej.kubagro.ru/2003/01/05.pdf, 0,688 у.п.л., импакт-фактор РИНЦ=0,346
|
|
10301006
|
IDA10301006
|
Федоренко_М_А
|
Федоренко М. А. Исследование порога
целесообразности применения самолета АН-2 на работах в аграрном секторе / М.
А. Федоренко // Политематический сетевой электронный научный журнал
Кубанского государственного аграрного университета (Научный журнал КубГАУ)
[Электронный ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 28 – 40. IDA
[article ID]: 0010301006 – Режим доступа:
http://ej.kubagro.ru/2003/01/06.pdf, 0,75 у.п.л., импакт-фактор РИНЦ=0,346
|
|
10301007
|
IDA10301007
|
Безродный_О_К, Лойко_В_И
|
Безродный О. К. Система
инвестиционного управления автодорожной отраслью региона / О. К. Безродный,
В. И. Лойко // Политематический сетевой электронный научный журнал Кубанского
государственного аграрного университета (Научный журнал КубГАУ) [Электронный
ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 41 – 54. IDA [article ID]:
0010301007 – Режим доступа: http://ej.kubagro.ru/2003/01/07.pdf, 0,813
у.п.л., импакт-фактор РИНЦ=0,346
|
|
10301008
|
IDA10301008
|
Луценко_Е_В, Третьяк_В_Г
|
Луценко Е. В. Анализ
профессиональных траекторий специалистов c применением системы «Эйдос» / Е.
В. Луценко, В. Г. Третьяк // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал КубГАУ)
[Электронный ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 55 – 58. IDA
[article ID]: 0010301008 – Режим доступа: http://ej.kubagro.ru/2003/01/08.pdf,
0,188 у.п.л., импакт-фактор РИНЦ=0,346
|
В данной
работе исследовано две выборки статей: полная, включающая 3949 статей, и
сокращенная, представляющая собой 100 статей, выбранных из полной случайным
образом. Программа, осуществившая выборку 100 статей из полной, приведена ниже
(язык xBase++):
=========================================================
FUNCTION
Main()
CLOSE ALL
USE Inp_data
EXCLUSIVE NEW;N_Obj = RECCOUNT()
aNumRec :=
{} // Массив номеров записей, которые
останутся в БД Inp_data.dbf
N_Rec =
100 // Количество записей,
которые останутся в БД Inp_data.dbf
SELECT
Inp_data
DELETE ALL
//
Сформировать массив кодов случайных объектов обучающей выборки без повторов из
N элементов
DO WHILE
LEN(aNumRec) < N_Rec // В
массиве еще нет aNumRec элементов?
// Случайный номер записи от 1 до N_Rec
mRndRec = 1+INT(RANDOM()%N_Obj)
IF ASCAN(aNumRec, mRndRec) = 0 // Номер этого объекта еще не
разыгрывался?
AADD (aNumRec, mRndRec)
ENDIF
ENDDO
ASORT(aNumRec)
FOR j=1 TO
LEN(aNumRec)
DBGOTO(aNumRec[j])
RECALL
NEXT
PACK
LB_Warning(
aNumRec, 'Удаление записей из БД "Inp_data.dbf"' )
LB_Warning( 'В
базе даннных: "Inp_data.dbf" осталось '+ALLTRIM(STR(N_Rec))+'
случайных записей', 'Удаление записей из БД "Inp_data.dbf"' )
CLOSE ALL
RETURN NIL
=========================================================
Далее везде,
где это специально не оговорено, рассматривается модель, основанная на 100
статьях.
Для
преобразования исходных данных в базы данных системы "Эйдос"
необходимо файл MS Excel, который содержит базу исходных данных, скопировать в
папку: ..Aidos-X\AID_DATA\Inp_data и присвоить ему имя: «Inp_data.xls». Само
преобразование осуществляется в универсальном программном интерфейсе импорта
данных из внешних баз данных в систему «Эйдос» (режима 2.3.2.2), Help которого
приведен на рисунке 6:
Рисунок 6.
Help режима 2.3.2.2 системы «Эйдос»
Экранная
форма задания параметров режима 2.3.2.2 приведена на рисунке 7:
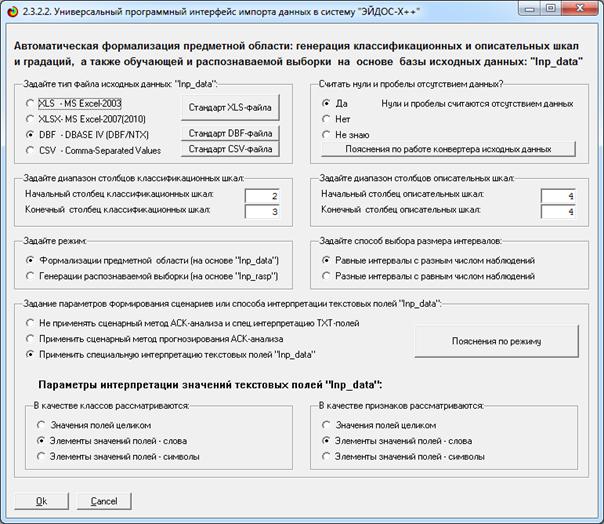
Рисунок 7 –
Экранная форма Универсального программного интерфейса импорта данных в систему
"Эйдос" (режим 2.3.2.2.)
В экранной
форме, приведенной на рисунке 7, необходимо задать настройки, показанные на
рисунке:
- "Задайте тип файла исходных данных
Inp_data": "XLS - MS Excel-2003";
- "Задайте диапазон столбцов классификационных
шкал": "Начальный столбец классификационных шкал" – 2,
"Конечный столбец классификационных шкал" – 3;
- "Задайте диапазон столбцов описательных
шкал": "Начальный столбец описательных шкал" – 4, "Конечный
столбец описательных шкал" – 4;
- "Задание параметров формирования сценариев или способа
интерпретации текстовых полей": "Применить сценарный метод
АСК-анализа и спец.интерпретацию TXT-полей";
- «Параметры интерпретации текстовых полей Inp_data»: В
качестве классов рассматривать элементы значений полей – слова, В качестве
признаков рассматривать элементы значений полей – слова.
Затем
кликнуть кнопку "ОК". Далее открывается окно, где размещена
информация о размерности модели (рисунок 8).
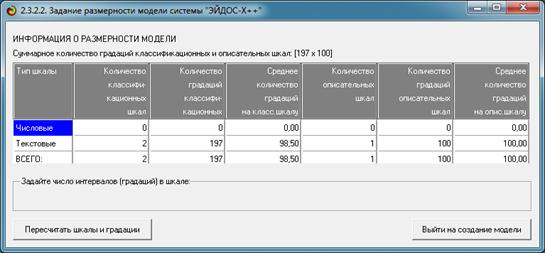
Рисунок 8.
Информация о размерности модели системы "Эйдос"
В этом окне
необходимо нажать кнопку "Выйти на создание модели".
Далее
открывается окно, отображающее стадию процесса импорта данных из внешней БД
"Inp_data.xls" в систему "Эйдос" (рисунок 9), а также
прогноз времени завершения этого процесса. В том окне необходимо дождаться
завершения формализации предметной области и нажать кнопку "ОК".
Рисунок 9.
Процесс импорта данных из внешней БД "Inp_data.xls"
в систему "Эйдос"
Для просмотра
классификационных шкал и градаций необходимо запустить режим 2.1 (рисунок 10):
Рисунок 10.
Классификационные шкалы и градации (фрагменты)
Для просмотра
описательных шкал и градаций необходимо запустить режим 2.2 (рисунок 11):
Рисунок 11.
Описательные шкалы и градации (фрагмент)
Для просмотра
обучающей выборки необходимо запустить режим 2.3.1. (рисунок 12):
Рисунок 12.
Обучающая выборка (фрагмент)
Тем самым
создаются все необходимые и достаточные предпосылки для выявления силы и
направления причинно-следственных связей между значениями факторов и
результатами их совместного системного воздействия (с учетом нелинейности
системы [15]).
Далее
запускаем режим 3.5, в котором происходит выбор моделей для синтеза и
верификации (рисунок 13) и нажмем кнопку "ОК". После успешного
завершения, также необходимо нажать кнопку "ОК" (рисунок 14).
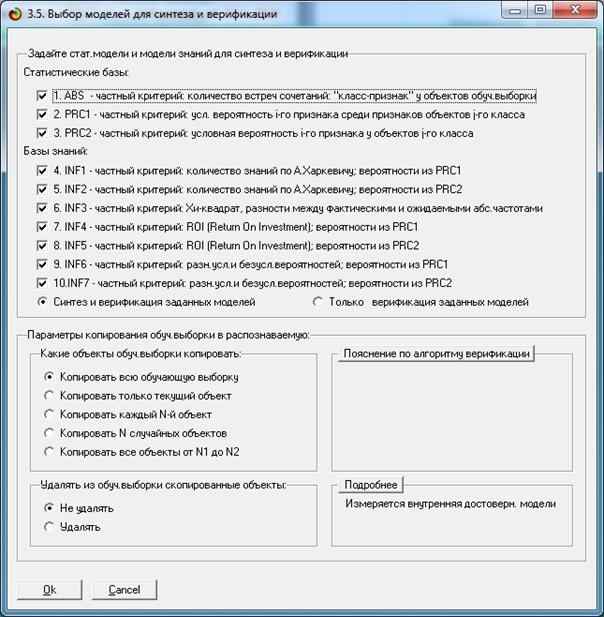
Рисунок 13.
Выбор моделей для синтеза и верификации
В данном
режиме имеется много различных методов верификации моделей, в том числе и
поддерживающие бутстрепный метод. Но мы используем параметры по умолчанию,
приведенные на рисунке 13.
В результате
выполнения режима 3.5 (рисунок 14) созданы все модели, со всеми частными
критериями, перечисленные на рисунке 13, но ниже мы приведем лишь некоторые из
них (таблицы 3-5).
Предварительно
рассмотрим частные и интегральные критерии, применяемые в настоящее время в
системе «Эйдос».
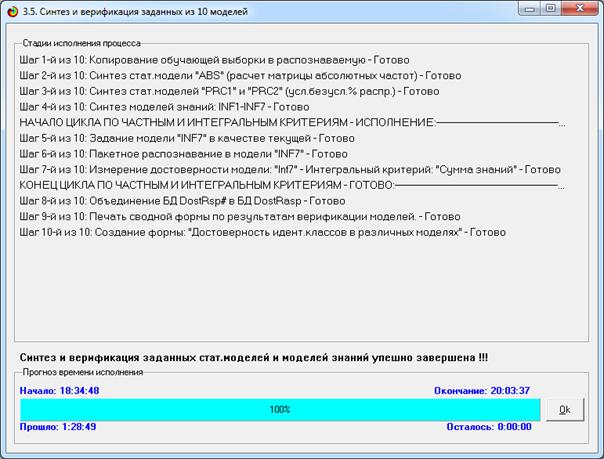
Рисунок 14. Синтез
и верификация статистических моделей
и моделей знаний
Отметим, что
синтез и верификация всех 10 моделей на выборке 100 статей заняли около
полутора часов (процессор i7).
3.3.3.5. Частные критерии и виды моделей
системы «Эйдос»
Рассмотрим
решение задачи идентификации на примере модели INF1, в которой рассчитано
количество информации по А.Харкевичу, которое мы получаем о принадлежности
идентифицируемого объекта к каждому из классов, если знаем, что у этого объекта
есть некоторый признак. Это так называемые частные
критерии сходства, приведенные в таблице 3.
Таблица 3 –
Частные критерии знаний, используемые в настоящее время
в АСК-анализе и системе «Эйдос-Х++»
|
Наименование модели знаний
и частный критерий
|
Выражение для частного критерия
|
|
через
относительные частоты
|
через
абсолютные частоты
|
|
INF1, частный критерий: количество знаний по А.Харкевичу, 1-й
вариант расчета относительных частот:
Nj – суммарное количество признаков по j-му классу. Относительная частота того, что если у объекта j-го
класса обнаружен признак, то это i-й признак
|
|
|
|
INF2, частный критерий: количество знаний по А.Харкевичу, 2-й
вариант расчета относительных частот: Nj
– суммарное количество объектов по j-му
классу. Относительная частота того, что если предъявлен объект j-го класса,
то у него будет обнаружен i-й признак.
|
|
|
|
INF3, частный критерий: Хи-квадрат: разности между фактическими и
теоретически ожидаемыми абсолютными частотами
|
---
|
|
|
INF4, частный критерий: ROI - Return On Investment, 1-й вариант
расчета относительных частот: Nj –
суммарное количество признаков по j-му
классу
|
|
|
|
INF5, частный критерий: ROI - Return On Investment, 2-й вариант
расчета относительных частот: Nj –
суммарное количество объектов по j-му
классу
|
|
|
|
INF6, частный критерий: разность условной и безусловной
относительных частот, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков
по j-му классу
|
|
|
|
INF7, частный критерий: разность условной и безусловной
относительных частот, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу
|
|
|
Обозначения:
i –
значение прошлого параметра;
j
- значение будущего параметра;
Nij –
количество встреч j-го значения будущего параметра при i-м значении прошлого параметра;
M
– суммарное число значений всех прошлых
параметров;
W -
суммарное число значений всех будущих
параметров.
Ni –
количество встреч i-м значения прошлого параметра по всей
выборке;
Nj –
количество встреч j-го значения будущего параметра по
всей выборке;
N
– количество встреч j-го
значения будущего параметра при i-м
значении прошлого параметра по всей выборке.
Iij – частный
критерий знаний: количество знаний в факте наблюдения i-го значения прошлого параметра о том, что объект перейдет в
состояние, соответствующее j-му значению
будущего параметра;
Ψ
– нормировочный коэффициент (Е.В.Луценко, 1979, впервые опубликовано в 1993
году [15]), преобразующий количество информации в формуле А.Харкевича в биты и
обеспечивающий для нее соблюдение принципа соответствия с формулой Р.Хартли;
Pi – безусловная относительная частота встречи i-го значения прошлого параметра в обучающей выборке;
Pij – условная относительная частота встречи i-го значения прошлого параметра при j-м значении будущего параметра.
По сути,
частные критерии представляют собой просто формулы для преобразования матрицы
абсолютных частот (таблица 4) в матрицы
условных и безусловных процентных распределений (таблицы 5 и 6) и матрицы
знаний (проф. В.И.Лойко, 2014).
Таблица 4 –
Матрица абсолютных частот (модель ABS) (фрагмент)
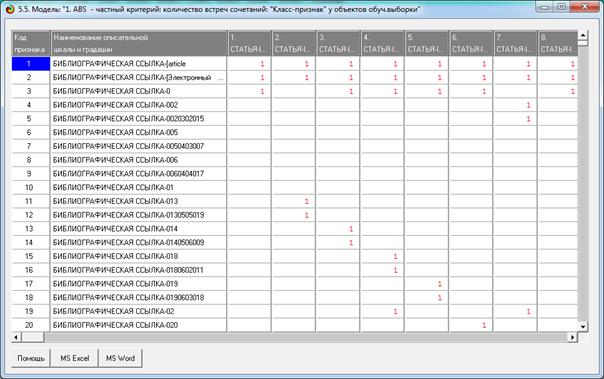
Таблица 5 –
Матрица информативностей (модель INF1) в битах (фрагмент)
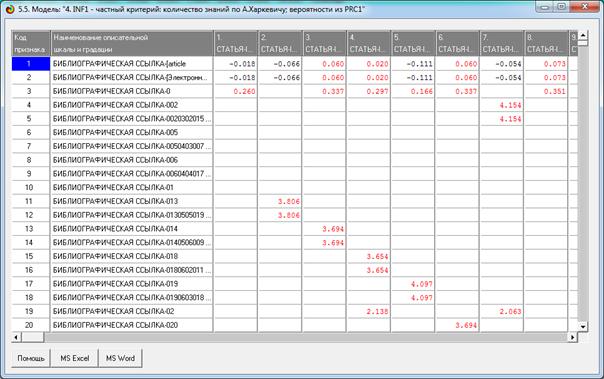
Таблица 6 –
Матрица знаний (модель INF3) (фрагмент)
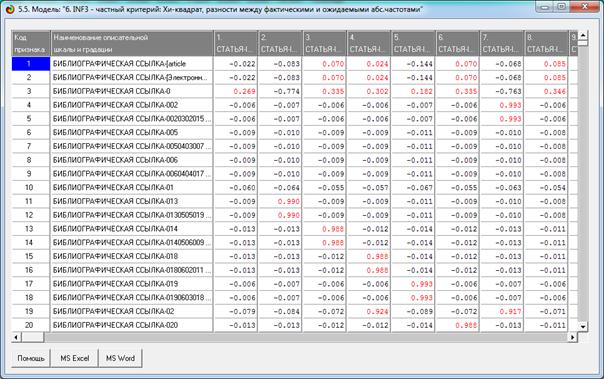
3.3.3.6. Ценность описательных шкал и градаций
для решения задач идентификации текстов
и авторов (нормализация текста)
Для любой из
моделей системой «Эйдос» рассчитывается ценность градации
описательной шкалы, т.е. признака, для идентификации или прогнозирования. Количественной
мерой ценности признака в той или иной модели является вариабельность по
классам частного критерия для этого признака (таблица 3) Мер вариабельности может быть много, но
наиболее известными является среднее модулей отклонения от среднего, дисперсия
и среднеквадратичное отклонение. Последняя мера и используется в АСК-анализе и
системе «Эйдос».
В системе
«Эйдос» ценность признаков нарастающим итогов выводится в графической форме.
При большом объеме обучающей выборки можно без
ущерба для достоверности модели удалить из нее малозначимые признаки
(Парето-оптимизация). Для этого в системе «Эйдос «также есть соответствующие инструменты.
Как
показывает опыт, в результате такого удаления из текста малозначимых признаков
(нормализации текста) из него прежде всего будут удалены различные предлоги,
междометия и слова, состоящие из очень малого числа букв (от 1 до 3), а также
отдельно стоящие символы типа наклонной черты (флеш) и т.п.
3.3.3.7. Интегральные критерии системы «Эйдос»
Но если нам
известно, что объект обладает не одним, а несколькими признаками, то как
посчитать их общий вклад в сходство с
теми или иными классами? Для этого в системе «Эйдос» используется 2 аддитивных
интегральных критерия: «Сумма знаний» и «Семантический резонанс знаний».
Интегральный критерий
«Семантический резонанс знаний» представляет собой суммарное количество знаний, содержащееся в системе
факторов различной природы, характеризующих сам объект управления, управляющие
факторы и окружающую среду, о переходе объекта в будущие целевые или
нежелательные состояния.
Интегральный критерий
представляет собой аддитивную функцию от частных критериев знаний,
представленных в help режима 3.3:
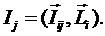
В выражении круглыми скобками
обозначено скалярное произведение. В координатной форме это выражение имеет
вид:
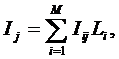 ,
,
где: M – количество градаций
описательных шкал (признаков);
– вектор
состояния j–го класса;
– вектор состояния распознаваемого объекта, включающий все виды факторов,
характеризующих сам объект, управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
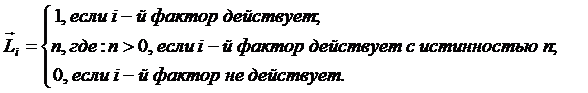
В текущей версии системы
«Эйдос-Х++» значения координат вектора состояния распознаваемого объекта
принимались равными либо 0, если признака нет, или n, если он присутствует у
объекта с интенсивностью n, т.е. представлен n раз (например, буква «о» в слове
«молоко» представлена 3 раза, а буква «м» - один раз).
Интегральный критерий
«Семантический резонанс знаний» представляет собой нормированное
суммарное количество знаний, содержащееся в системе факторов различной природы,
характеризующих сам объект управления, управляющие факторы и окружающую среду,
о переходе объекта в будущие целевые или нежелательные состояния.
Интегральный критерий
представляет собой аддитивную функцию от частных критериев знаний,
представленных в help режима 3.3 и имеет вид:
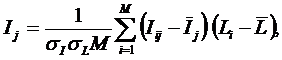
где:
M –
количество градаций описательных шкал (признаков);
– средняя
информативность по вектору класса;
– среднее по
вектору объекта;
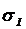 – среднеквадратичное
отклонение частных критериев знаний вектора класса;
– среднеквадратичное
отклонение частных критериев знаний вектора класса;
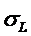 – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
– вектор
состояния j–го класса;
– вектор состояния распознаваемого объекта, включающий все виды факторов,
характеризующих сам объект, управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
В текущей версии системы
«Эйдос-Х++» значения координат вектора состояния распознаваемого объекта
принимались равными либо 0, если признака нет, или n, если он присутствует у
объекта с интенсивностью n, т.е. представлен n раз (например, буква «о» в слове
«молоко» представлена 3 раза, а буква «м» - один раз).
Приведенное выражение для
интегрального критерия «Семантический резонанс знаний» получается
непосредственно из выражения для критерия «Сумма знаний» после замены
координат перемножаемых векторов их стандартизированными значениями:
Свое наименование интегральный
критерий сходства «Семантический резонанс знаний» получил потому, что по своей
математической форме является корреляцией двух векторов: состояния j–го класса
и состояния распознаваемого объекта.
Результаты
верификации (оценки достоверности) моделей, отличающихся частными критериями
(таблица 3) с двумя приведенными выше интегральными критериями приведены на
рисунке 15:
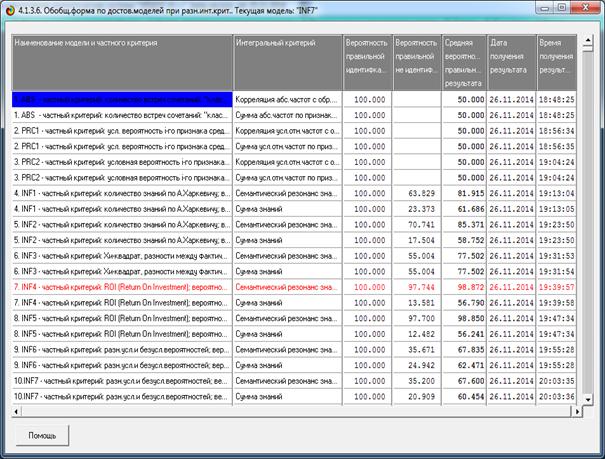
Рисунок 15.
Результаты верификации моделей
Наиболее
достоверной в данном приложении оказались модели INF4 при интегральном критерии
«Резонанс знаний» (на рисунке 15 эта модель выделена красным цветом). Данная
модель обеспечивает 100% достоверность идентификации статьи и ее авторов по
библиографическому описанию этой статьи (достоверность отнесения объекта к
классу, к которому он действительно относится), и 98% достоверность не
отнесения статьи и ее авторов к тем классам, к которым они не относятся.
Для оценки
достоверности моделей в АСК-анализе и системе «Эйдос» используется метрика,
предложенная автором, сходная с F-критерием и дающая те
же результаты ранжирования моделей по их качеству (рисунок 16):
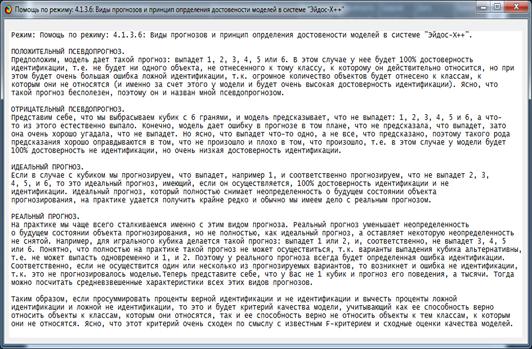
Рисунок 16.
Виды прогнозов и принцип определения достоверности моделей по авторскому
варианту метрики, сходной с F-критерием
Кроме того в
системе «Эйдос» используют уточненную F-меру, учитывающую не только сам факт
идентификации или не идентификации, но и уровень сходства-различия при этом.
Также
обращает на себя внимание, что статистические модели, как правило, дают более
низкую средневзвешенную достоверность идентификации и не идентификации, чем
модели знаний, и практически никогда – более высокую. Этим и оправдано
применение моделей знаний.
3.3.4. Решение задач
идентификации текстов
и их авторов в наиболее достоверной модели
В
соответствии со схемой этапов последовательного преобразования данных в
информацию, а ее в знания в системе "Эйдос", приведенной на рисунке
3, присвоим статус текущей модели INF4, наиболее достоверной модели по данным
верификации (рисунок 15). Для этого в режиме 5.6 системы «Эйдос» зададим
эту модель и кликнем по кнопке Ok (рисунок 17):
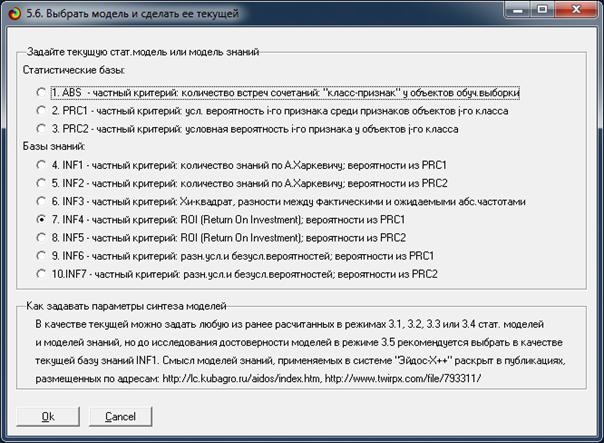
Рисунок 17. Экранные формы режима присвоения модели статуса текущей
Затем
произведем идентификацию и авторов в текущей модели. Для этого запустим режим
4.1.2 системы «Эйдос» (рисунок 18):
Рисунок 18.
Экранная форма режима идентификации текстов и их авторов
Из рисунка 18
видно, что идентификация 100 статей в наиболее достоверной модели INF4 заняла 8
минут, т.е. 4.8 секунды на одну статью.
Режим 4.1.3
системы «Эйдос» обеспечивает отображение результатов идентификации в различных
формах:
1. Подробно наглядно: "Объект – классы".
2. Подробно наглядно: "Класс – объекты".
3. Итоги наглядно: "Объект – классы".
4. Итоги наглядно: "Класс – объекты".
5. Подробно сжато: "Объект – классы".
6. Обобщенная форма по достоверности моделей при разных
интегральных критериях.
7. Обобщенный статистический анализ результатов идентификации
по моделям и интегральным критериям.
8. Статистический анализ результатов идентификации по
классам, моделям и интегральным критериям.
9. Распознавание уровня сходства при разных моделях и интегральных
критериях.
10.
Достоверность
идентификации классов при разных моделях и интегральных критериях.
Рассмотрим
некоторые из них.
На рисунке 19
приведен пример идентификации статьи и ее авторов в наиболее достоверной модели
INF4:
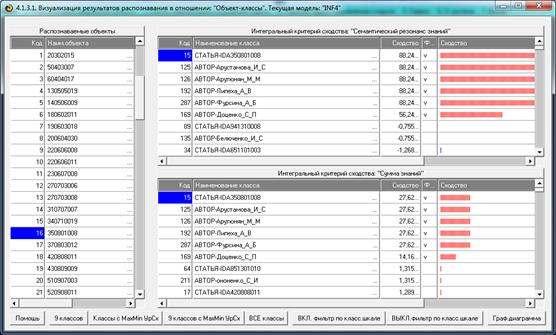
Рисунок 19.
Экранная форма результатов идентификации
статьи и ее авторов
На рисунке 20
приведены результаты идентификации автора данной статьи по библиографическим
описаниям его статей.
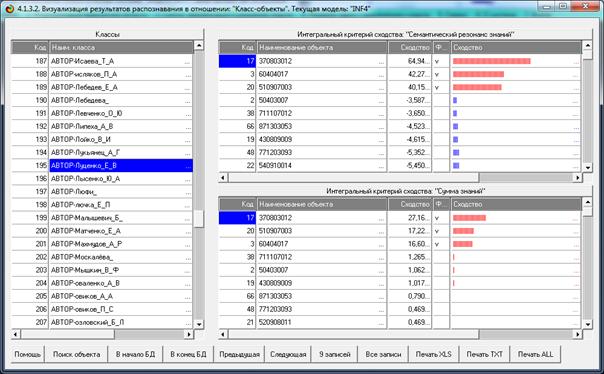
Рисунок 20.
Результаты идентификации автора данной статьи
по библиографическим описаниям его статей
Результаты
решения проблемы, поставленной в статье, приведенные на рисунках 19 и 20 можно
признать очень хорошими.
Однако
возникает закономерный вопрос о том, а будет ли вообще работать предлагаемый
алгоритм и инструментарий на больших базах данных и о том, как он будет
работать. Для ответа на этот вопрос был проведен численный эксперимент на
выборке 3949 статьи. Результат идентификации статей приведен на рисунках 21.
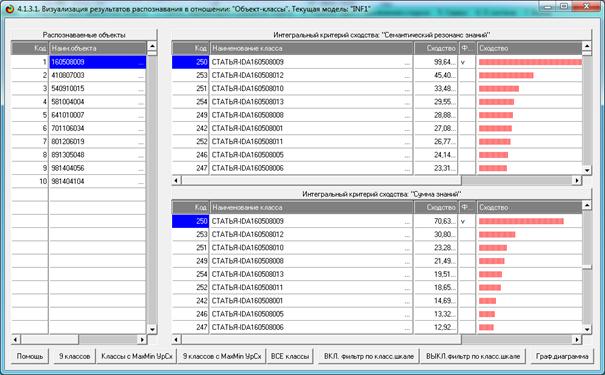
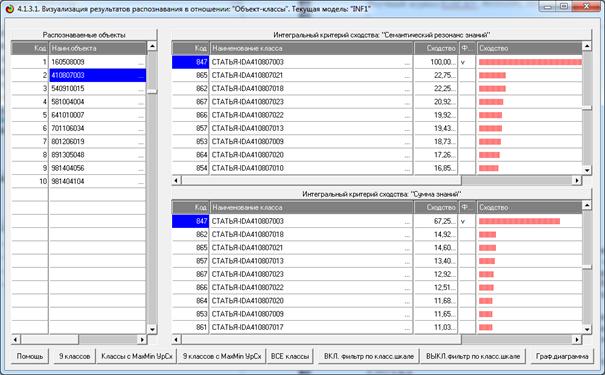
Рисунок 21.
Экранные формы с результатами идентификации статей
в модели INF1: 3949 статей, 19989 слов
Из рисунка 21
мы видим, что все 10 статей, выбранных для идентификации случайным образом,
идентифицированы по их стандартному библиографическому описанию абсолютно
верно, причем со значительным, в разы, превышением уровня сходства с правильной
статьей по сравнению со следующей за ней наиболее сходной. Это означает, что
поставленная в статье задача успешно решена. Если же различие в уровне сходства
наиболее сходной статьи и следующей за ней незначительное, то информацию об
этих статьях необходимо предоставить для принятия решения специалисту.
Рассмотрим
теперь идентификацию статей с нестандартными
и некорректными библиографическими описаниями в модели INF1, созданной на основе 3949 библиографических описаний
статей.
Для
формирования некорректных библиографических ссылок возьмем стандартную ссылку
на статью автора (1-я строка таблицы 7) и будем, начиная с конца
библиографического описания, последовательно удалять из него элементы
описания и создавать новые строки с неполными библиографическими описаниями.
Две последних строки получены не путем удаления элементов библиографического
описания, что приводит к неполноте описания, а путем добавления лишних
элементов (шума, выделено желтым фоном): наклонной черты после имени
автора и неверного указания страниц. Как показывает опыт, в настоящее время
подобные описания не идентифицируются программным обеспечением РИНЦ.
В результате
получим таблицу 7:
Таблица 7 –
Распознаваемая выборка с некорректными
(неполными ) библиографическими описаниями
|
№
|
Объект
|
Статья
|
Автор
|
Библиографическая ссылка
|
|
1
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 –
185. – Шифр Информрегистра: 04208000120031, IDA [article ID]: 0370803012 –
Режим доступа: http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л.,
импакт-фактор РИНЦ=0,346
|
|
2
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я: задачи
1-3) / Е. В. Луценко // Политематический сетевой электронный научный журнал
Кубанского государственного аграрного университета (Научный журнал КубГАУ)
[Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 – 185. –
Шифр Информрегистра: 04208000120031, IDA [article ID]: 0370803012 – Режим
доступа: http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л.
|
|
3
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 –
185. – Шифр Информрегистра: 04208000120031, IDA [article ID]: 0370803012
|
|
4
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 –
185. – Шифр Информрегистра: 04208000120031
|
|
5
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 –
185.
|
|
6
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037)
|
|
7
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном обобщении
теории множеств на основе системной теории информации (Часть 1-я: задачи 1-3)
/ Е. В. Луценко // Политематический сетевой электронный научный журнал
Кубанского государственного аграрного университета (Научный журнал КубГАУ)
[Электронный ресурс]. – Краснодар: КубГАУ, 2008.
|
|
8
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В.
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3)
|
|
9
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Неформальная
постановка и обсуждение задач, возникающих при системном обобщении теории
множеств на основе системной теории информации (Часть 1-я: задачи 1-3)
|
|
10
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В. /
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 154 –
185. – Шифр Информрегистра: 04208000120031, IDA [article ID]: 0370803012 –
Режим доступа: http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л.,
импакт-фактор РИНЦ=0,346
|
|
11
|
370803012
|
IDA370803012
|
Луценко_Е_В
|
Луценко Е. В. / Неформальная постановка и обсуждение
задач, возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 1154 – 2185.
– Шифр Информрегистра: 04208000120031, IDA [article ID]: 0370803012 – Режим доступа:
http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л., импакт-фактор РИНЦ=0,346
|
Распознаваемую
выборку из некорректных (неполных и зашумленных) библиографических описаний
введем в систему «Эйдос» с помощью универсального программного интерфейса с внешними
базами данных 2.3.2.2 при параметрах, показанных на рисунке 22:
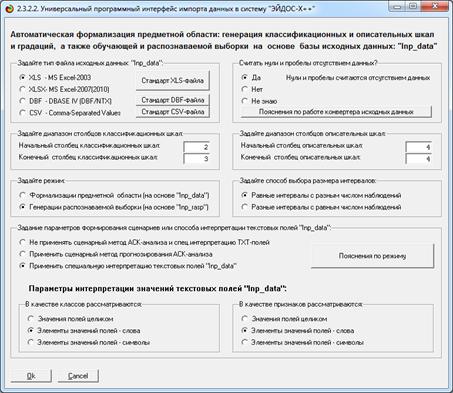
Рисунок 22.
Экранная форма универсального программного интерфейса
с внешними базами данных для ввода распознаваемой выборки
В результате
получена распознаваемая выборка, которую можно просмотреть в режиме 4.1.2
(рисунок 23).
Рисунок 23.
Экранная форма распознаваемой выборки
некорректных библиографических описаний
Процесс
распознавания проведем в режиме 4.2.1 в модели INF1, созданной на основе
библиографических описаний всех 3949 статей (рисунок 24):
Рисунок 24.
Экранная форма отображения стадии процесса идентификации нестандартных и
некорректных библиографических описаний
Как видно из
рисунка 24, процесс идентификации 11 статей в этой модели занял примерно три с
половиной часа или около 20 минут на одно описание.
Результаты
распознавания приведены на рисунках 25:
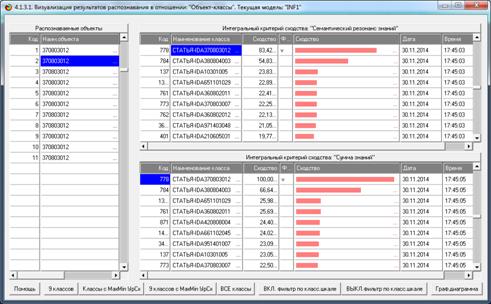
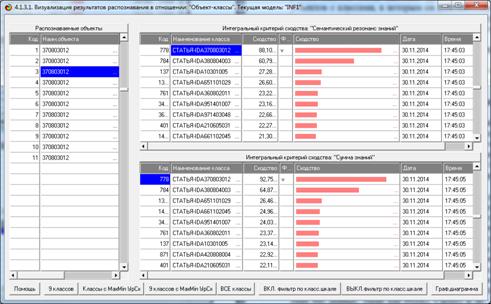
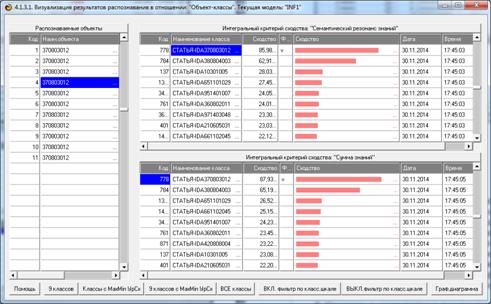
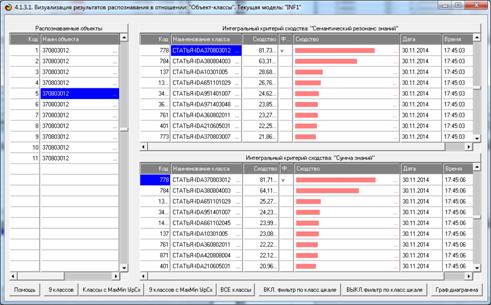
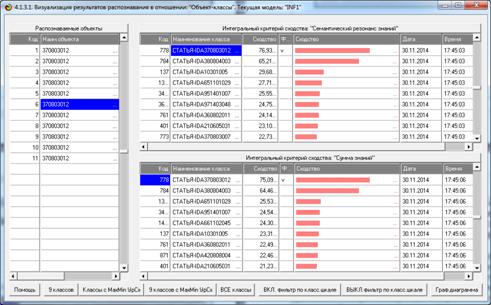
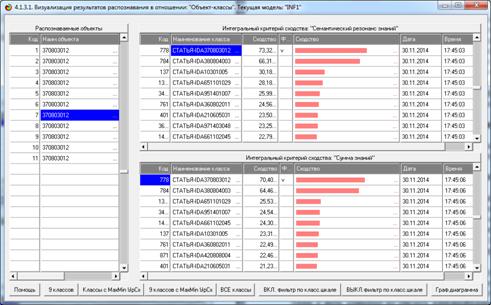
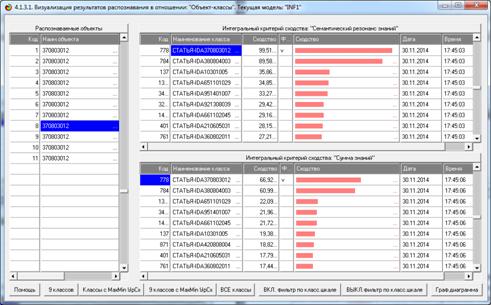
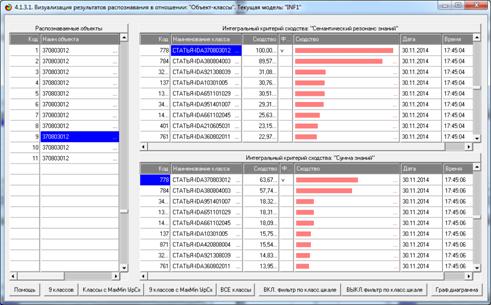
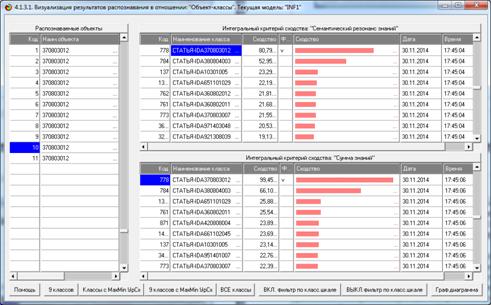
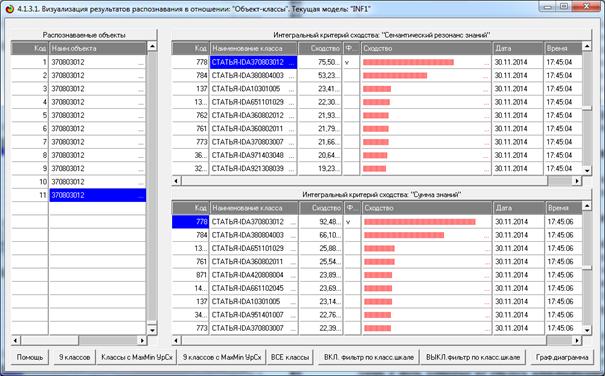
Рисунок 25.
Экранная форма отображения результатов идентификации
нестандартных и некорректных библиографических описаний
Из рисунков
25 видно, что в модели INF1, созданной на основе 3949 статей Научного журнала
КубГАУ за 2003-2014 годы, верно идентифицированы все тестовые
библиографические описания из таблицы 7: и стандартное из строки 1, и все
10 нестандартные и некорректные (неполные и зашумленные), приведенные в строках
2-11.
На основе
выше изложенного можно сделать обоснованный вывод о том, что АСК-анализ и его
программный инструментарий интеллектуальная система «Эйдос», обеспечивают
решение задачи идентификации текстов и авторов на основе библиографических
описаний публикаций, в том числе нестандартных и некорректных, неполных и
зашумленных. При этом обеспечивается очень высокий уровень достоверности
идентификации объектов с классами, к которым он действительно принадлежат (100%)
и очень высокий уровень достоверности не идентификации объектов с классами, к
которым они действительно не принадлежат (около 98%).
3.3.6. Некоторые
недостатки и перспективы
Конечно,
предлагаемый подход не лишен и некоторых недостатков и ограничений, в
преодолении которых состоят некоторые перспективы его развития.
Основной
недостаток предлагаемых решений, выявленный на приведенных в данной статье
примерах, состоит в довольно значительных затратах вычислительных ресурсов,
внешней памяти и времени на создание моделей, их верификацию и решение в этих
моделях задач идентификации. Особенно это заметно на примере со 3949 статей,
19989 слов.
Таким
образом, как обычно возникает вопрос о том, что делать в этих условиях.
Прежде всего,
возникает мысль о том, что в больших библиографических базах типа РИНЦ, Скопус
и т.п., предлагаемые в данной статье решения целесообразно применять не ко
всем статьям и авторам, а лишь к тем, которые не удалось идентифицировать с
помощью более простых и быстродействующих алгоритмов, уже реализованных
в программном обеспечении этих систем. Иначе говоря применять их в тех случаях,
в которых ранее было необходимо участие человека.
Следующая
очевидная мысль состоит в том, что необходимо оптимизировать предлагаемые
решения алгоритмы и решения специально для их реализации в программном
обеспечении больших библиографических баз данных, таких как РИНЦ, Скопус и др.
Для того, чтобы это сделать необходимо предварительно разобраться с причинами
возникновения этой ситуации. Мы видим две такие основные причины:
Во-первых, это
универсальность и независимость от предметной области алгоритма, реализованного
в системе «Эйдос». В процессе синтеза и верификации моделей в системе
производится расчет большого количества различных выходных форм, которые не
нужны при решении задач, поставленных в статье.
Во-вторых, это
отсутствие морфологического анализатора в текущей версии системы «Эйдос», в
результате чего слова не приводятся к начальной форме и используются все
словоформы, реально встретившиеся в библиографических ссылках. Это на порядок
увеличивает размерность моделей и время их создания и использования для решения
задач.
Соответственно,
представляется, что есть два основных пути повышения быстродействия предложенных
алгоритмов при их использовании для решения задач идентификации литературных
источников и авторов на основе библиографических описаний:
1)
оптимизация алгоритма специально для очень больших библиографических баз
данных, типа РИНЦ и Скопус;
2) лемматизация
текста на основе
морфологического анализа, т.е. приведение слов к их исходной форме, и
сокращение за счет этого размерностей баз данных на порядок и такое же повышение
быстродействия алгоритма.
Кроме того,
на взгляд автора, для повышения быстродействия алгоритмов обработки матриц
чрезвычайно перспективным является применение в системе «Эйдос» технологии CUDA или другой
функционально аналогичной, но более универсальной и менее зависимой от
аппаратного обеспечения технологии, обеспечивающей высокопроизводительные
параллельные неграфические вычисления на графических
процессорах, обладающих огромными
вычислительными ресурсами, на порядки превосходящими ресурсы центрального
процессора.
Отметим, что быстродействие работы
предложенных алгоритмов на работах одного автора, которых редко бывает больше
200-400, является вполне достаточным для его использования модератором.
Описанная в
статье технология может быть применена для решения задач выявления взаимосвязей
между динамикой Internet-контента и событиями в области экономики, политики, культуры и
в других областях. Особенное значение это приобретает в условиях жесткого
информационного противоборства, если не сказать информационной войны, ведущих
центров влияния в мире.
Например, в работе [16] тотальная ложь
рассматривается как стратегическое информационное оружие общества периода
глобализации и дополненной реальности. Рассматривается возможность применения в
современном обществе принципа наблюдаемости, как общепринятого в физике
критерия реальности. Показано, в каких случаях применение данного принципа в исследованиях
общества приводит к общественным иллюзиям, а когда дает адекватные результаты.
Предлагаются понятие: «Степень виртуализации общества» и количественная шкала
для ее измерения, а также вводится понятие «Общественный умвельт» под которым
понимается область общества, существенно отличающаяся от остальных своими
фундаментальными закономерностями.
В работах
[17] и [18] рассматриваются применение технологий нейролингвистического
программирования (НЛП) для астротурфинга и манипулирования
сознанием больших масс людей и различных целевых групп населения.
Язык
программирования Аляска xBase++, на котором написана система «Эйдос-Х++»
позволяет реализовать все существующие в настоящее время возможности
взаимодействия с Internet-ресурсами, но для этого необходима библиотека
Xb2net.dll, которая у автора есть только в демо-версии (функционально-ограниченная).
3.4. Интеллектуальная
привязка некорректных
ссылок к литературным источникам
в библиографических базах данных
с применением АСК-анализа и системы
«Эйдос» (на примере российского индекса
научного цитирования – РИНЦ)
Адекватная и технологичная оценка результативности,
эффективности и качества научной деятельности конкретных ученых и научных коллективов
является актуальной проблемой для информационного общества и общества,
основанного на знаниях. Решение этой проблемы является предметом наукометрии и
ее целью. Современный этап развития наукометрии существенно отличается от
предыдущих появлением в открытом, а также платном on-line доступе огромного
объема детализированных данных по большому числу показателей как об отдельных
авторах, так и о научных организациях и вузах. В мире, это известные библиографические
базы данных: Web of Science, Scopus, Astrophysics Data System, PubMed,
MathSciNet, zbMATH, Chemical Abstracts, Springer, Agris или GeoRef. В России это
прежде всего Российский индекс научного цитирования (РИНЦ). РИНЦ – это
национальная информационно-аналитическая система, аккумулирующая более 9
миллионов публикаций российских ученых, а также информацию о цитировании этих
публикаций из более 6000 российских журналов. Данных очень много, это так
называемые «Большие данные» ("Big Data"). Основным первичным
наукометрическим показателем, на основе которого строятся все остальные, такие,
например, как индекс Хирша, является число
цитирований работ автора, размещенных в библиографической базе данных. Это
число цитирований определяется программным обеспечением РИНЦ путем так
называемой «привязки», которая представляет собой грамматический разбор и поиск
в базах данных работ автора, релевантных (соответствующих) ссылкам на них из
источников литературы в работах различных авторов. Однако проблема состоит в том, что, как показывает опыт, авторы допускают
очень большое количество некорректных и просто неполных ссылок в списках
литературы, очень далеких от ГОСТ. В настоящее время программное обеспечение
РИНЦ не может автоматически привязать эти некорректные ссылки и это требует
вмешательства человека. Но централизованно, силами специалистов РИНЦ, это
сделать не представляется возможным из-за огромного объема работ, а распределенная
работа большого числа специалистов на местах все равно требует централизованной
модерации. В результате работа по привязке ссылок к литературным источникам
ведется очень медленно и огромный объем ссылок оказывается непривязанными. Это
ведет к занижению накометрических показателей как отдельных авторов, так и
научных коллективов, что нельзя признать приемлемым. Решение этой проблемы предлагается путем применения
автоматизированного системно-когнитивного анализа (АСК-анализ) и его
программного инструментария – интеллектуальной системы «Эйдос». Приводится
численный пример интеллектуальной привязки реальных некорректных ссылок к
работам автора на основе небольшого объема реальных наукометрических данных,
находящихся в открытом бесплатном on-line доступе в РИНЦ
Адекватная и
технологичная оценка результативности, эффективности и качества научной
деятельности конкретных ученых и научных коллективов является актуальной
проблемой для информационного общества и общества, основанного на знаниях.
Решение этой проблемы является предметом наукометрии и ее целью.
Современный
этап развития наукометрии существенно отличается от предыдущих появлением в
открытом, а также платном on-line доступе огромного объема детализированных
данных по большому числу показателей как об отдельных авторах, так и о научных
организациях и вузах. В мире, это известные библиографические базы данных: Web
of Science, Scopus, Astrophysics Data System, PubMed, MathSciNet, zbMATH,
Chemical Abstracts, Springer, Agris или GeoRef.
В России это
прежде всего Российский индекс научного цитирования (РИНЦ). РИНЦ – это
национальная информационно-аналитическая система, аккумулирующая более 9
миллионов публикаций российских ученых, а также информацию о цитировании этих
публикаций из более 6000 российских журналов. Данных очень много, это так
называемые «Большие данные» ("Big Data").
Основным
первичным наукометрическим показателем, на основе которого строятся все
остальные, такие, например, как индекс Хирша, является число цитирований работ автора,
размещенных в библиографической базе данных. Это число цитирований определяется
программным обеспечением РИНЦ путем так называемой «привязки», которая
представляет собой грамматический разбор и поиск в базах данных работ автора,
релевантных (соответствующих) ссылкам на них из источников литературы в работах
различных авторов.
Однако проблема состоит в том, что, как
показывает опыт, авторы допускают очень большое количество некорректных и
просто неполных ссылок в списках литературы, очень далеких от ГОСТ.
В настоящее
время программное обеспечение РИНЦ не может автоматически привязать
эти некорректные ссылки и это требует вмешательства человека.
Но
централизованно, силами специалистов РИНЦ, это сделать не представляется
возможным из-за огромного объема работ, а распределенная работа большого числа
специалистов на местах все равно требует централизованной модерации. В результате
работа по привязке ссылок к литературным источникам ведется очень медленно и
огромный объем ссылок оказывается непривязанными. Это ведет к занижению
накометрических показателей как отдельных авторов, так и научных коллективов,
что нельзя признать приемлемым.
Решение этой
проблемы предлагается путем применения автоматизированного
системно-когнитивного анализа (АСК-анализ) и его программного инструментария –
интеллектуальной системы «Эйдос». Приводится численный пример интеллектуальной
привязки реальных некорректных ссылок к работам автора на основе небольшого
объема реальных наукометрических данных, находящихся в открытом бесплатном
on-line доступе в РИНЦ.
3.4.2. Методика (кратко об АСК-анализе)
3.4.2.1. Что такое АСК-анализ
Системный анализ представляет собой современный метод научного
познания, общепризнанный метод решения проблем [5, 6, 7]. Однако возможности
практического применения системного анализа ограничиваются отсутствием
программного инструментария, обеспечивающего его автоматизацию. Существуют
разнородные программные системы, автоматизирующие отельные этапы или функции
системного анализа в различных конкретных предметных областях.
Автоматизированный системно-когнитивный анализ
(АСК-анализ) представляет собой системный анализ, структурированный по базовым
когнитивным операциям (БКО), благодаря чему удалось разработать для него
математическую модель, методику численных расчетов (структуры данных и
алгоритмы их обработки), а также реализующую их программную систему – систему
«Эйдос» [1-3, 7].
Система «Эйдос» разработана в постановке, не зависящей от предметной области, и
имеет ряд программных интерфейсов с внешними данными различных типов [3].
АСК-анализ может быть применен как
инструмент, многократно усиливающий возможности естественного интеллекта во
всех областях, где используется естественный интеллект. АСК-анализ был успешно
применен для решения задач идентификации, прогнозирования, принятия решений и
исследования моделируемого объекта путем исследования его модели во многих
предметных областях, в частности в экономике, технике, социологии, педагогике,
психологии, медицине, экологии, ампелографии, геофизике, энтомологии, криминалистике
и др. [8, 9].
Известно, что системный анализ является одним из общепризнанных в науке
методов решения проблем и многими учеными рассматривается вообще как метод
научного познания. Однако, как впервые заметил еще в 1984 году проф. И.П.
Стабин, на практике применение
системного анализа наталкивается на проблему [10]. Суть этой проблемы в том,
что обычно системный анализ успешно применяется в сравнительно простых случаях,
в которых в принципе можно обойтись и без него, тогда как в действительно
сложных ситуациях, когда он действительно чрезвычайно востребован и у него нет
альтернатив, сделать это удается гораздо реже. Проф. И.П. Стабин предложил и
путь решения этой проблемы, который он видел в автоматизации системного анализа
[10].
Однако путь от идеи до создания программной системы долог и сложен,
т.к. включает ряд этапов:
– выбор теоретического математического метода;
– разработка методики численных расчетов, включающей структуры данных в
оперативной памяти и внешних баз данных (даталогическую и инфологическую
модели) и алгоритмы обработки этих данных;
– разработка программной системы, реализующей эти математические методы
и методики численных расчетов.
Перегудов Ф.И. и Тарасенко Ф.П. в своих основополагающих работах 1989 и
1997 годов [5, 6] подробно рассмотрели математические методы, которые в
принципе могли бы быть применены для автоматизации отдельных этапов системного
анализа. Однако даже самые лучшие математические методы не могут быть применены
на практике без реализующих их программных систем, а путь от математического
метода к программной системе долог и сложен. Для этого необходимо разработать
численные методы или методики численных расчетов (алгоритмы и структуры
данных), реализующие математический метод, а затем разработать программную
реализацию системы, основанной на этом численном методе.
В числе первых попыток реальной автоматизации системного анализа следует
отметить докторскую диссертацию проф. Симанкова В.С. (2001) [11]. Эта попытка
была основана на высокой детализации этапов системного анализа и подборе уже
существующих программных систем, автоматизирующих эти этапы. Идея была в том,
что чем выше детализация системного анализа, чем мельче этапы, тем проще их
автоматизировать. Эта попытка была реализована, однако, лишь для специального
случая исследования в области возобновляемой энергетики, т.к. системы оказались
различных разработчиков, созданные с помощью различного инструментария и не
имеющие программных интерфейсов друг с другом, т.е. не образующие единой
автоматизированной системы. Эта попытка, безусловно, явилась большим шагом по
пути, предложенному проф. И.П. Стабиным, но и ее нельзя признать обеспечившей
достижение поставленной цели, сформулированной Стабиным И.П. (т.е. создание
автоматизированного системного анализа), т.к. она не привела к созданию единой
универсальной программной системы, автоматизирующий системный анализ, которую
можно было бы применять в различных предметных областях.
Необходимо отметить работы Дж. Клира по системологии и автоматизации
решения системных задач, которые внесли большой вклад в автоматизацию
системного анализа путем создания и применения универсального решателя системных
задач (УРСЗ), реализованного в рамках оригинальной экспертной системы [12, 13].
Однако в экспертной системе применяется продукционная модель знаний, для
получения которых от эксперта необходимо участие инженера по знаниям
(когнитолога). Этим обусловлены следующие недостатки экспертных систем:
– они генерируют знания каждый раз, когда они необходимы для решения
задач, и это может занимать значительно большее время, чем при использовании
декларативной формы представления знаний;
– продукционные модели обычно построены на бинарной логике (if then
else), что вызывает возможность логического конфликта продукций в процесс
логического вывода, что приводит к необратимому останову логического процесса;
– эксперты - люди чаще всего заслуженные и их время и знания стоят
очень дорого; поэтому привлечение экспертов для извлечения готовых знаний на
длительное время проблематично и обычно эксперт просто физически не может
сообщить очень большой объем знаний, а иногда и не хочет этого делать и сообщает
неадекватные знания;
– чаще всего эксперты формулируют свои знания неформализуемым путем на
основе своей интуиции, опыта и профессиональной компетенции, т.е. не могут
сформулировать свои знания в количественной форме, а пользуются для их
формализации порядковыми или даже номинальными шкалами, поэтому экспертные
знания являются не очень точными и для их формализации необходим инженер по
знаниям (когнитолог).
Автоматизированный системно-когнитивный анализ разработан профессором Е.В.
Луценко и предложен в 2002 году [1], хотя разработан он был значительно раньше,
причем с программным инструментарием: системой «Эйдос» [1, 3, 7]. Основная
идея, позволившая сделать это, состоит в рассмотрении системного анализа как
метода познания (отсюда и «когнитивный» от «cognitio» – знание, познание,
лат.). Эта идея позволила структурировать системный анализ не по этапам, как
пытались сделать ранее, а по базовым когнитивным операциям системного анализа
(БКОСА), т.е. таким операциям, к комбинациям которых сводятся остальные. Эти
операции образуют минимальную систему, достаточную для описания системного
анализа, как метода познания, т.е. конфигуратор. Понятие конфигуратора
предложено В.А. Лефевром [14]. В 2002 году Е.В. Луценко был предложен когнитивный
конфигуратор [1], включающий 10 базовых когнитивных операций.
1) присвоение имен;
2) восприятие (описание конкретных объектов в форме онтологий, т.е. их
признаками и принадлежностью к обобщающим категориям - классам);
3) обобщение (синтез, индукция);
4) абстрагирование;
5) оценка адекватности модели;
6) сравнение, идентификация и прогнозирование;
7) дедукция и абдукция;
8) классификация и генерация конструктов;
9) содержательное сравнение;
10) планирование и поддержка принятия управленческих решений.
Каждая из этих операций оказалась достаточно элементарна для
формализации и программной реализации.
– формализуемая когнитивная концепция и следующий из нее когнитивный
конфигуратор;
– теоретические основы, методология, технология и методика АСК-анализа;
– математическая модель АСК-анализа, основанная на системном обобщении
теории информации;
– методика численных расчетов, в универсальной форме реализующая
математическую модель АСК-анализа, включающая иерархическую структуру данных и
24 детальных алгоритма 10 БКОСА;
– специальное инструментальное программное обеспечение, реализующее
математическую модель и численный метод АСК-анализа – Универсальная когнитивная
аналитическая система "Эйдос" [3].
1) когнитивно-целевая структуризация предметной области;
2) формализация предметной области (конструирование классификационных и
описательных шкал и градаций и подготовка обучающей выборки);
3) синтез системы моделей предметной области (в настоящее время система
«Эйдос» поддерживает 3 статистические модели и 7 системно-когнитивных моделей
(моделей знаний);
4) верификация (оценка достоверности) системы моделей предметной
области;
5) повышение качества системы моделей;
6) решение задач идентификации, прогнозирования и поддержки принятия
решений;
7) исследование моделируемого объекта путем исследования его моделей
является корректным, если модель верно отражает моделируемый объект и включает:
кластерно-конструктивный анализ классов и факторов; содержательное сравнение
классов и факторов; изучение системы детерминации состояний моделируемого
объекта; нелокальные нейроны и интерпретируемые нейронные сети прямого счета;
классические когнитивные модели (когнитивные карты); интегральные когнитивные
модели (интегральные когнитивные карты), прямые обратные SWOT-диаграммы;
когнитивные функции и т.д.
Математическая
модель АСК-анализ основана на теории информации, точнее на системной теории
информации (СТИ), предложенной Е.В. Луценко [1, 2, 3]. Это значит,
что в
АСК-анализе все факторы рассматриваются с одной единственной точки зрения:
сколько информации содержится в их значениях о переходе объекта, на который они
действуют, в определенное состояние, и при этом сила и направление влияния всех
значений факторов на объект измеряется в одних общих для всех факторов единицах
измерения: единицах количества информации [8, 9].
Это
напоминает подход Дугласа Хаббарда [15], но, в отличие от него, имеет открытый
универсальный программный инструментарий (систему «Эйдос»), разработанный в
постановке, не зависящей от предметной области [1-3]. К тому же на систему
«Эйдос» уже в 1994 году было три патента РФ [3, 16], а первые
акты ее внедрения датируются 1987 годом [1, 3], тогда как основная
работа Дугласа Хаббарда [15] появилась лишь в 2009 году. Это означает, что идеи
АСК-анализа не только появились, но и были доведены до программной реализации в
универсальной форме и применены в различных предметных областях на 22 с лишним
года раньше появления работ Дугласа
Хаббарда.
Поэтому
АСК-анализ обеспечивает корректную сопоставимую обработку числовых и нечисловых
данных, представленных в разных типах измерительных шкал и разных единицах
измерения [8, 9]. Метод АСК-анализа является устойчивым непараметрическим
методом, обеспечивающим создание моделей больших размерностей при неполных и
зашумленных исходных данных о сложном нелинейном динамичном объекте управления.
Этот метод является чуть ли не единственным на данный момент, обеспечивающим
многопараметрическую типизацию и системную идентификацию методов,
инструментарий которого (интеллектуальная система «Эйдос») находится в полном
открытом бесплатном доступе [3, 16] на сайте
разработчика по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm.
На рисунке 1
приведена карта мира с отображением мест и времени запуска системы «Эйдос» за
период с 9 декабря 2016 года по 10 января 2017 года.
Из этой карты
мира видно, что в настоящее время, к сожалению, система «Эйдос» больше
востребована в Европе и США, чем в России.
Рисунок 1.
Карта мира с отображением мест и времени запуска системы «Эйдос» за период с 9
декабря 2016 года по 20 июня 2017 года
Метод системно-когнитивного анализа и его программный инструментарий
интеллектуальная система "Эйдос" были успешно применены при
проведении 6 докторских и 7 кандидатских диссертационных работ в ряде различных
предметных областей по экономическим, техническим, психологическим и медицинским
наукам.
АСК-анализ был успешно применены при выполнении десятков грантов РФФИ и
РГНФ различной направленности за длительный период - с 2002 года по настоящее
время (2016 год).
По проблематике АСК-анализа издана 22 монография, получено 29 патентов
на системы искусственного интеллекта, их подсистемы, режимы и приложения,
опубликовано более 200 статей в изданиях, входящих в Перечень ВАК РФ (по данным
РИНЦ). В одном только Научном журнале КубГАУ
(входит в Перечень ВАК РФ с 26-го марта 2010 года) автором АСК-анализа
проф.Е.В.Луценко опубликовано 200 статей, общим объёмом 350,683 у.п.л., в
среднем 1,753 у.п.л. на одну статью.
По этим публикациям, грантам и диссертационным работам видно, что АСК-анализ
уже был успешно применен в следующих предметных областях и научных
направлениях: экономика (региональная, отраслевая, предприятий, прогнозирование
фондовых рынков), социология, эконометрика, биометрия, педагогика (создание
педагогических измерительных инструментов и их применение), психология
(личности, экстремальных ситуаций, профессиональных и учебных достижений,
разработка и применение профессиограмм), сельское хозяйство (прогнозирование
результатов применения агротехнологий, принятие решений по выбору рациональных
агротехнологий и микрозон выращивания), экология, ампелография, геофизика
(глобальное и локальное прогнозирование землетрясений, параметров магнитного поля
Земли, движения полюсов Земли), климатология (прогнозирование Эль-Ниньо и Ла-Нинья), возобновляемая энергетика, мелиорация и управление мелиоративными
системами, криминалистика, энтомология и ряд других областей.
АСК-анализ вызывает большой интерес во всем мире. Сайт автора
АСК-анализа [16] посетило около 500 тыс. посетителей с уникальными
IP-адресами со всего мира. Еще около 500 тыс. посетителей открывали статьи по
АСК-анализу в Научном журнале КубГАУ.
Необходимо отметить, что в развитии различных теоретических основ и
практических аспектов АСК-анализа приняли участие многие ученые: д.э.н., к.т.н., проф. Луценко Е.В.,
Засл. деятель науки РФ, д.т.н., проф. Лойко В.И., к.ф.-м.н.,
Ph.D., проф., Трунев А.П. (Канада),
д.э.н., д.т.н., к.ф.-м.н., проф. Орлов А.И., к.т.н., доц. Коржаков В.Е.,
д.э.н., проф. Барановская Т.П., д.э.н., к.т.н., проф. Ермоленко В.В., к.пс.н.
Наприев И.Л., к.пс.н., доц. Некрасов С.Д., к.т.н., доц. Лаптев В.Н., к.пс.н,
доц. Третьяк В.Г., к.пс.н., Щукин Т.Н., д.т.н., проф. Симанков В.С., д.э.н.,
проф. Ткачев А.Н., д.т.н., проф. Сафронова Т.И., д.э.н., доц. Горпинченко К.Н.,
к.э.н., доц. Макаревич О.А., к.э.н., доц. Макаревич Л.О., к.м.н. Сергеева Е.В.
(Фомина Е.В.), Бандык Д.К. (Белоруссия), Чередниченко Н.А., к.ф.-м.н. Артемов
А.А., д.э.н., проф. Крохмаль В.В., д.т.н., проф. Рябцев В.Г., к.т.н., доц. Марченко
А.Ю., д.т.н., проф. Фролов В.Ю., д.ю.н, проф. Швец С.В., Засл. деятель науки Кубани, д.б.н., проф. Трошин Л.П.,
Засл. изобр. РФ, д.т.н., проф. Серга Г.В., Сергеев А.С., д.б.н., проф. Стрельников
В.В. и другие.
Казалось бы
что здесь сложного?
Ссылка на
работу должна совпадать с библиографическим описанием самой работы и нет
никакой проблемы найти ее в базе данных по точному совпадению тестов ссылки и
описания работы. Точно также делается в любой информационно-поисковой системе
(ИПС): отчет формируется из записей базы данных, в которых все значения полей
точно совпадают со значениями, заданными в
запросе.
Но дело в
том, что обычно (как правило) текст ссылки отличается от текста
библиографического описания работы и точное их совпадение наблюдается крайне
редко. Поэтому подход, реализуемый в ИПС с точным поиском в данном случае
практически неприменим.
Но есть ИПС с
поиском по неполному запросу. В таких ИПС для каждой записи базы данных
определяется степень ее соответствия с запросу. Эта степень соответствия
считается равной числу полей запроса и записи, значения которых совпали. Для
таких ИПС необходим предварительный грамматический разбор как описания самой
работы, так и ссылки на нее. При этом разборе определяются значения полей
библиографических описаний работы (источника) и ссылки на нее. После этого
происходит сравнение значений этих полей. Конечно в этом случае и сам
грамматический разбор является проблемой. При ошибке в разборе поиск работы
ведется уже не там, например при определении сборника статей конференции как
журнала поиск ведется уже в журналах и не дает результата. Но главное не в
этом, а в том, что вес или роль всех полей библиографического описания считается
одинаковым, тогда как в действительности он разный. Так, например, год издания
и Ф.И.О. автора значительно важнее какого-нибудь слова в названии.
Есть ИПС с
нечетким поиском по нечеткому запросу. В таких ИПС, как и в ИПС по неполному
запросу, когда значения некоторых полей могут отсутствовать, для каждого поля
определяется его вес и уже после этого для всех записей базы данных определяется
степень их соответствия запросу уже не просто по числу совпавших полей, но уже
по суммарному весу совпавших полей. В таких ИПС возникает проблема адекватного
определения веса полей при идентификации записей. Обычно этот вес определяется
экспертным путем, т.е. «на основе опыта, интуиции и профессиональной
компетенции», а в систему
вводится вручную. Конечно, при реальных объемах данных РИНЦ как определение
этих весов, так и их ввод в систему вручную совершенно невозможен из-за
огромных объемов данных. Получается, что необходимо и это автоматизировать.
Автоматизированные
системы, которые обеспечивают автоматическое определение весов признаков и
нечеткую идентификацию с их использованием называются системами распознавания
образов. Такие системы могут рассматриваться как дальнейшее обобщение ИПС с
неполным и нечетким запросом.
Универсальная
когнитивная аналитическая система «Эйдос» [3] является такой системой. Более
того, система «Эйдос» обеспечивает широкие возможности применения
интеллектуальных технологий для обработки нечисловых данных, в частности текстов
и у авторов имеется большой опыт решения задач в этой области [17-24].
Предлагается
решение поставленной в работе проблемы путем преобразования данных в
информацию, а ее в знания (рисунки 2 и 3) [25, 26].
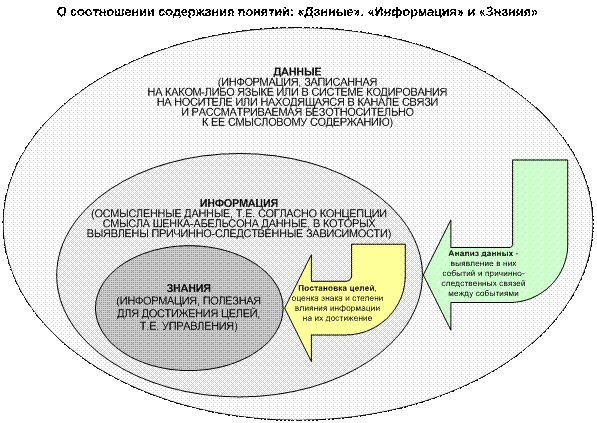
Рисунок 2. О
соотношении содержания понятий:
«Данные», «Информация» и «Знания»
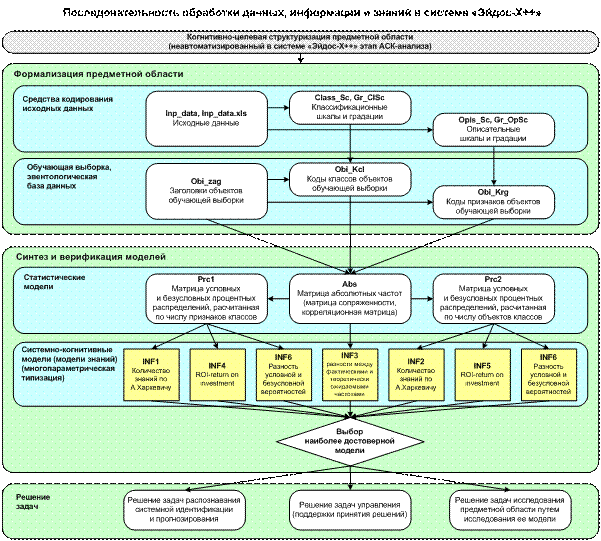
Рисунок 3.
Этапы преобразования данных в информацию, а ее в знания
Данные – это
информация, записанная на каком-либо носителе или находящаяся в каналах связи и
представленная на каком-то языке или в системе кодирования и рассматриваемая безотносительно
к ее смысловому содержанию.
Исходные
данные об объекте управления обычно представлены в форме баз данных, чаще всего
временных рядов, т.е. данных, привязанных ко времени. В соответствии с
методологией и технологией автоматизированного системно-когнитивного анализа
(АСК-анализ), развиваемой проф. Е.В.Луценко, для управления и принятия решений
использовать непосредственно исходные данные не представляется возможным.
Точнее сделать это можно, но результат управления при таком подходе оказывается мало чем
отличающимся от случайного. Для реального же решения задачи управления
необходимо предварительно преобразовать данные в информацию, а ее в знания о
том, какие воздействия на корпорацию к каким ее изменениям обычно, как показывает
опыт, приводят.
Информация есть
осмысленные данные.
Смысл данных,
в соответствии с концепцией смысла Шенка-Абельсона, состоит в том, что известны
причинно-следственные зависимости между событиями, которые описываются этими
данными. Таким образом, данные преобразуются в информацию в результате
операции, которая называется «Анализ данных», которая состоит из двух этапов:
1. Выявление
событий в данных (разработка классификационных и описательных шкал и градаций и
преобразование с их использованием исходных данных в обучающую выборку, т.е. в
базу событий – эвентологическую базу).
2. Выявление
причинно-следственных зависимостей между событиями.
В случае
систем управления событиями в данных являются совпадения определенных значений
входных факторов и выходных параметров объекта управления, т.е. по сути, случаи
перехода объекта управления в определенные будущие состояния под действием
определенных сочетаний значений управляющих факторов. Качественные значения
входных факторов и выходных параметров естественно формализовать в форме лингвистических
переменных. Если же входные факторы и выходные параметры являются числовыми, то
их значения измеряются с некоторой погрешностью и фактически представляют собой
интервальные числовые значения, которые также могут быть представлены или
формализованы в форме лингвистических переменных (типа: «малые», «средние»,
«большие» значения экономических показателей).
Какие же
математические меры могут быть использованы для количественного измерения силы
и направления причинно-следственных зависимостей?
Наиболее
очевидным ответом на этот вопрос, который обычно первым всем приходит на ум,
является: «Корреляция». Однако, в статистике это хорошо известно, что это совершенно
не так. Для преобразования исходных
данных в информацию необходимо не только выявить события в этих данных, но и
найти причинно-следственные связи между этими событиями. В АСК-анализе
предлагается 7 количественных мер причинно-следственных связей, основной из
которых является семантическая мера целесообразности информации по А.Харкевичу.
Знания – это
информация, полезная для достижения
целей.
Значит для
преобразования информации в знания необходимо:
1. Поставить
цель (классифицировать будущие состояния моделируемого объекта на целевые и
нежелательные).
2. Оценить
полезность информации для достижения этой цели (знак и силу влияния).
Второй пункт,
по сути, выполнен при преобразовании данных в информацию. Поэтому остается
выполнить только первый пункт, т.к. классифицировать будущие состояния объекта
управления как желательные (целевые) и нежелательные.
Знания могут
быть представлены в различных формах, характеризующихся различной степенью
формализации:
– вообще неформализованные знания, т.е. знания
в своей собственной форме, ноу-хау (мышление без вербализации есть медитация);
– знания,
формализованные в естественном вербальном языке;
– знания,
формализованные в виде различных методик, схем, алгоритмов, планов, таблиц и
отношений между ними (базы данных);
– знания в
форме технологий, организационных, производственных, социально-экономических и
политических структур;
– знания,
формализованные в виде математических моделей и методов представления знаний в
автоматизированных интеллектуальных системах (логическая, фреймовая, сетевая,
продукционная, нейросетевая, нечеткая и другие).
Таким образом,
для решения сформулированной проблемы необходимо осознанно и целенаправленно
последовательно повышать степень формализации исходных данных до уровня, который
позволяет ввести исходные данные в интеллектуальную систему, а затем:
–
преобразовать исходные данные в информацию;
–
преобразовать информацию в знания;
–
использовать знания для решения задач управления, принятия решений и
исследования предметной области.
Рассмотрим
численный пример, основанный на реальных данных РИНЦ и иллюстрирующий
применение АСК-анализа и системы «Эйдос» для решения поставленной в работе
проблемы.
При этом
выполним описанные выше этапы АСК-анализа и этапы преобразования данных в
информацию, а ее в знания.
Исходные
данные для численного примера взяты с сайта РИНЦ: http://elibrary.ru/ по автору:
«Елепов Б.С.»
Эти данные
состоят из двух файлов:
– Обучающая
выборка.doc (6 страниц, 111 источников);
– Тестовая выборка.doc
(27 страниц, 588 ссылок на источники).
Ниже
приведены фрагменты этих файлов.
Фрагмент
файла обучающей выборки (работы автора)
РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ
ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ
СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук Г.А., Кулева О.В.,
Шевченко Л.Б., Паршиков Р.М. отчет о НИР
ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ
НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина
Л.В., Подкорытова Н.И. Вестник Российской академии естественных наук.
Западно-Сибирское отделение. 2016. № 18. С. 198-205.
ГОСУДАРСТВЕННАЯ
ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ
АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ: НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С.,
Лаврик О.Л. Труды ГПНТБ СО РАН. 2015. № 8. С. 7-14.
ИНТЕГРАЦИЯ
ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО
НАУЧНО-ОБРАЗОВАТЕЛЬНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л.,
Федотов А.М., Шокин Ю.И. Теория и практика общественно-научной информации.
2014. № 22. С. 21-32.
ФОРМЫ ПРЕДСТАВЛЕНИЯ
ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА: ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С.,
Лаврик О.Л. Труды ГПНТБ СО РАН. 2014. № 7. С. 14-22.
ИССЛЕДОВАНИЯ СИБИРСКОГО
ОТДЕЛЕНИЯ РАН В ОБЛАСТИ НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ
Бусыгина Т.В., Елепов Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в
интересах устойчивого развития. 2013. Т. 21. № 4. С. 463-473.
БИБЛИОТЕКИ И МИРЪ Елепов
Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2013. № 4. С. 7-18.
Фрагмент файла тестовой выборки
(ссылки на работы автора)
Алексеев
A.G, Елепов Б.С., Котов В.Е., Метляев Ю.В. о программе работ по созданию сети
информационно-вычислительных систем (центров) в Сибирском отделении АН СССР.
-Новосибирск, 1987. -27 с. -(Препр./ВЦ Сиб. отд-ния АН СССР; N 734).
Алексеев А.С., Елепов Б.С., Бобров JI.K.
Развитие инфраструктуры информации Сибирского отделения РАН//Информационные
ресурсы. Интеграция. Технология: 3-я междунар. конф. ?НТИ-97?, Москва, 26 -28
нояб. 1997 г.:
Материалы конф. М., 1997. -С. 15-16.
Алексеев А.С., Елепов Б.С., Бобров Л.К.
Развитие инфраструктуры информации Сибирского отделения РАН//Информационные
ресурсы. Интеграция. Технология./Междунар. конф. НТИ-97. М., 26 -28 ноября 1997 г. -М., 1997. -С. 15
-16.
Алексеев А.С., Елепов Б.С., Котов В.Е.,
Метляев Ю.В. О программе работ по созданию сети информационно-вычислительных
систем (Центров) в Сибирском отделении АН СССР. - Новосибирск, 1987. - 27 с. -
(Препринт / РАН. Сиб. отд-ние. ВЦ; 743).
Алексеев А.С., Елепов Б.С., Котов В.Е.,
Метляев Ю.В. О программе работ по созданию сети информационно-вычислительных
систем (центров) в Сибирском отделении АН СССР. -Новосибирск, 1987, -27 с.
-(Препр./ВЦ Сиб. отд-ния АН СССР; N 734)
Древнерусские книжные памятники в Сибири:
цифровое решение проблемы сохранности и доступности/В. Н. Алексеев
//Библиосфера. -2007. -№ 1. -С. 9 -15.
Алексеев В. Н., Дергачева-Скоп Е. И., Елепов
Б. С., Шабанов А. В. Древнерусские книжные памятники в Сибири: цифровое решение
проблемы сохранности и доступности//Библиосфера. 2007. № 1. С. 9-14.
Алексеев, В. Н. Древнерусские книжные
памятники в Сибири: Цифровое решение проблемы сохранности и доступности / В. Н.
Алексеев, Е. И. Дергачева-Скоп, Б. С. Елепов, А. В. Шабанов // Библиосфера. - №
1. - 2007
Аристов Ю.И., Глазнев И.С., Алексеев В.Н.,
Гордеева Л.Г., Сальникова И.В., Шилова И.А., Кундо Л.П., Елепов Б.С., // Библиосфера.
2009. Т. 5. № 1. С. 26.
Открытое письмо/Арский Ю.М., Елепов Б.С.,
Зайцев В.Н. и др.//Поиск. -1999.-№43 (545). С. 3.
На этом этапе
АСК-анализа мы должны решить, что мы хотим определять и на основе чего.
В данном
случае мы хотим по словам, входящим в библиографические описания ссылок на
литературные источники определять сами эти источники (идентифицировать их), и,
таким образом, привязывать ссылки к источникам.
В системе
«Эйдос» реализована возможность лемматизации, но мы не будем ей пользоваться,
т.к. она хотя и сокращает размерности моделей и ускоряет обработку, но приводит
к некоторой потере информации и понижению достоверности идентификации.
Как видно из
рисунка 3 этот этап АСК-анализа состоит в разработке справочников
классификационных и описательных шкал и градаций и кодировании с их помощью
исходных данных, в результате чего формируется база событий или обучающая выборка.
По сути этот этап представляет собой нормализацию исходных данных, т.е. их
преобразование в такую форму, которую удобно обрабатывать на компьютере.
Для небольших
задач это можно сделать и вручную. Но гораздо удобнее воспользоваться
специально созданными для этого программными интерфейсами системы «Эйдос» с
внешними базами данных. В системе «Эйдос» есть довольно много таких интерфейсов
(рисунок 4):

Рисунок 4.
Программные интерфейсы системы «Эйдос»
с внешними данными различных типов
Для наших
целей подходят интерфейсы 2.3.2.2 и особенно 2.3.2.1. Рассмотрим стандарты
представления исходных, достоинства и ограничения этих интерфейсов.
Этот
программный интерфейс предназначен для ввода данных из табличных файлов MS
Excel или dbf. В таблице 1 приведен фрагмент исходных данных, подготовленных
для интерфейса 2.3.2.2:
Таблица 1 –
Исходные данные в стандарте интерфейса 2.3.2.2 (фрагмент)
|
Объект
|
Классы
|
Признаки
|
|
1-РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ
ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ
КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук Г.А.,
Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР
|
1-РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ
ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ
КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук
Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР
|
РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ
ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ
КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук
Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР
|
|
2-ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ
РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И.
Вестник Российской академии естественных наук. Западно-Сибирское отделение.
2016. № 18. С. 198-205.
|
2-ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ
РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И.
Вестник Российской академии естественных наук. Западно-Сибирское отделение.
2016. № 18. С. 198-205.
|
ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ
РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И.
Вестник Российской академии естественных наук. Западно-Сибирское отделение.
2016. № 18. С. 198-205.
|
|
3-ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ
БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ:
НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН.
2015. № 8. С. 7-14.
|
3-ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ
БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ:
НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН.
2015. № 8. С. 7-14.
|
ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ
БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ:
НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН.
2015. № 8. С. 7-14.
|
|
4-ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО
ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО
ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин
Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32.
|
4-ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО
ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО
ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин
Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32.
|
ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО ОТДЕЛЕНИЯ
РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО ИНФОРМАЦИОННОГО
ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин Ю.И. Теория и
практика общественно-научной информации. 2014. № 22. С. 21-32.
|
|
5-ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА:
ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО
РАН. 2014. № 7. С. 14-22.
|
5-ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА:
ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО
РАН. 2014. № 7. С. 14-22.
|
ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА:
ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО
РАН. 2014. № 7. С. 14-22.
|
|
6-ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ
НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов
Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого
развития. 2013. Т. 21. № 4. С. 463-473.
|
6-ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ
НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов
Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого
развития. 2013. Т. 21. № 4. С. 463-473.
|
ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ
НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов
Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого
развития. 2013. Т. 21. № 4. С. 463-473.
|
|
7-БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды
ГПНТБ СО РАН. 2013. № 4. С. 7-18.
|
7-БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды
ГПНТБ СО РАН. 2013. № 4. С. 7-18.
|
БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды
ГПНТБ СО РАН. 2013. № 4. С. 7-18.
|
На рисунке 5
приведена экранная форма управления интерфейсом 2.3.2.2 с параметрами для ввода
данных из таблицы:
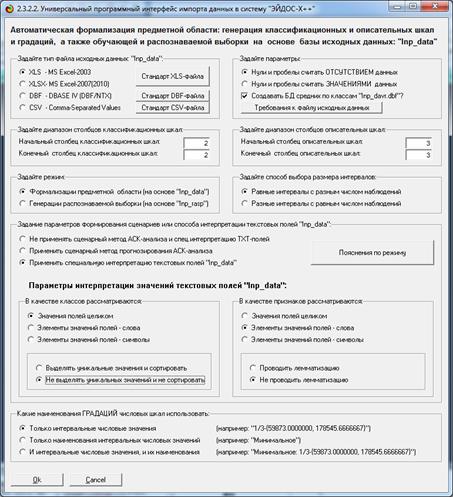
Рисунок 5.
Экранная форма управления интерфейсом 2.3.2.2
с параметрами для ввода данных из таблицы 1.
Данный режим
формирует классификационные и описательные шкалы и градации и обучающую выборку
на основе исходных данных, подобных представленным в таблице 1. Работоспособные
модели были созданы.
Как классы
рассматривалось библиографическое описание целиком, а как признаки этого
описания – слова и числа, из которых оно состоит.
Однако авторы
отказались от этого варианта, т.к., как оказалось, некоторые библиографические
описания содержали более 255 символов, т.е. по длине были больше, чем
максимальный размер поля базы данных, и, поэтому, были обрезаны до 255 символов.
Поэтому данный вариант в данной статье не рассматривается. Отметим лишь, что в
системе «Эйдос» есть встроенная лабораторная работа №3.02 (рисунки 6 и 7),
которая как раз предназначена для изучения студентами этого подхода. Этому же посвящены
работы автора [17-23] и ряд других.
Рисунок 6.
Helps по встроенным лабораторным работам системы «Эйдос»
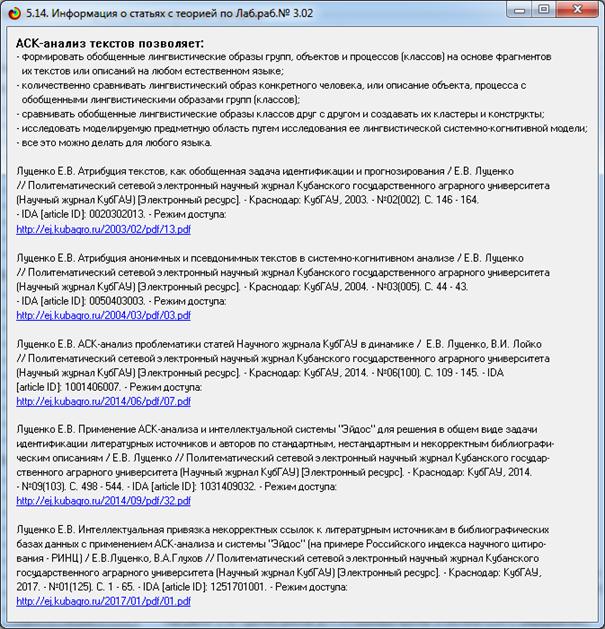
Рисунок 7.
Help по встроенной лабораторной работе 3.02 системы «Эйдос»
По этой
причине для формализации предметной области был выбран интерфейс 2.3.2.1,
который фактически не имеет ограничения на размер текстовых файлов обучающей
выборки (эти файлы должны быть не более 2 Гб).
Но для импорта исходных данных для
обучающей выборки и распознаваемой выборки из текстовых файлов вида, приведенного
в разделе 3.1, необходимо сначала разбить эти файлы на абзацы и каждый абзац
записать в виде отдельного файла в папки:
– c:\Aidos-X\AID_DATA\Inp_data\ для
обучающей выборки (источников);
– c:\Aidos-X\AID_DATA\Inp_rasp\ для
распознаваемой выборки (тестовой выборки или выборки ссылок на источники).
Экранная форма служебного режима
2.3.2.9, предназначенного для этого разбиения, приведена на рисунке 8:
Рисунок 8. Экранная форма управления
режимом 2.3.2.9.
Для работы этого режима необходимо с
помощью MS Word преобразовать файл исходных данных в текстовый файл с кодировкой
DOS-текст и поместить его в папку: c:\Aidos-X\AID_DATA\Inp_data\, а затем запустить
режим 2.3.2.1.
В результате работы режима с файлом
исходных данных, фрагмент которого приведен в разделе 3.1, а полностью он приведен
по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip, получим 111 текстовых файлов в папке: c:\Aidos-X\AID_DATA\Inp_data\ (рисунок
10):

Рисунок 10.
Текстовые файлы с библиографическими описаниями
литературных источников обучающей выборки (работа автора),
сформированные режимом 2.3.2.9
Ниже
приведено содержимое файла: «000001 - Обучающая выборка.txt»:
РАЗРАБОТКА МОДЕЛИ
ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В
УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов
С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР
Отметим, что
файл: «000111 - Обучающая выборка.txt» пустой, т.к. в файле исходных данных:
«Обучающая выборка.txt» в конце был пустой абзац из одной строки.
Экранная
форма управления интерфейсом 2.3.2.1 с параметрами для ввода данных из
текстовых файлов, показанных на рисунке 10, и формирования классификационных и
описательных шкал и градаций и обучающей выборки, приведена на рисунке 11:
Рисунок 11.
Экранная форма интерфейса 2.3.2.1 с параметрами для ввода
данных из текстовых файлов и формирования классификационных
и описательных шкал и градаций и обучающей выборки
В результате
работы данного режима сформированы классификационные и описательные шкалы и
градации и обучающая выборка, приведенные на рисунках 12, 13 и 14.
Рисунок 12.
Классификационная шкала и ее градации, т.е. классы
Рисунок 13.
Описательная шкала и ее градации, т.е. признаки – слова
Рисунок 14.
Обучающая выборка (фрагмент)
Полностью
классификационные и описательные шкалы и градации и обучающая выборка приведены
по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip.
Таким образом
режим 2.3.2.1 полностью выполнил все операции этапа АСК-анализа «Формализация
предметной области» и создал все необходимые условия и предпосылки для
выполнения следующего его этапа: «Синтез и верификация модели предметной
области».
После
выполнения формализации предметной области для преобразования исходных данных в
информацию остается только осмыслить эти данные, т.к. выявить
причинно-следственные связи между словами и литературными источниками (см.
рисунок 2). Эти причинно следственные связи как раз и отражены в статистических
и системно-когнитивных моделях, создаваемых и проверяемых на достоверность на
следующем этапе АСК-анализа.
В системе
«Эйдос» используется 3 статистических модели (см. рисунок 2) и 7
системно-когнитивных моделей. Различные модели системно-когнитивные модели
отличаются частными критериями знаний.
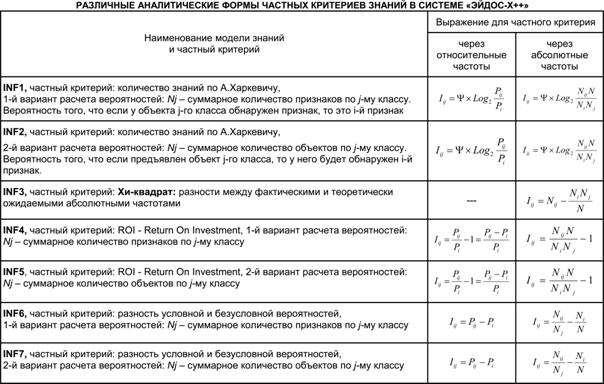
Для решения
задач идентификации (классификации, прогнозирования, распознавания,
диагностики) в каждой системно-когнитивной модели могут применяться два
интегральных критерия.


Для
выполнения этого этапа АСК-анализа запустим режим 3.5 системы «Эйдос», при
опциях, указанных на рисунке 15:
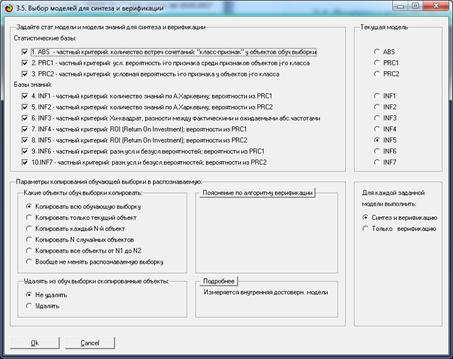
Рисунок 15.
Экранная форма режима 3.5 системы «Эйдос»
Процесс
синтеза и верификации 10 моделей,
представляющих собой матрицы размерностью 111
на 857, шел на компьютере с
процессором i7 26 минут 18 секунд (рисунок 16):
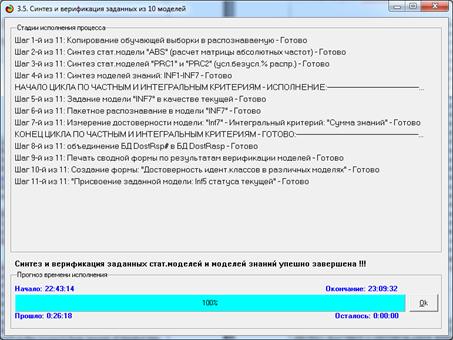
Рисунок 16.
Экранная форма прогноза времени исполнения режима 3.5
Ясно, что
синтез модели ABS и 1-й системно-когнитивной модели на ее основе при тех же
исходных данных и на том же компьютере займет значительно меньшее время (около
26 секунд).
В системе
«Эйдос» есть режим для просмотра статистических и системно когнитивных моделей
(режим 5.5). На рисунке 17 приведен фрагмент модели INF3:
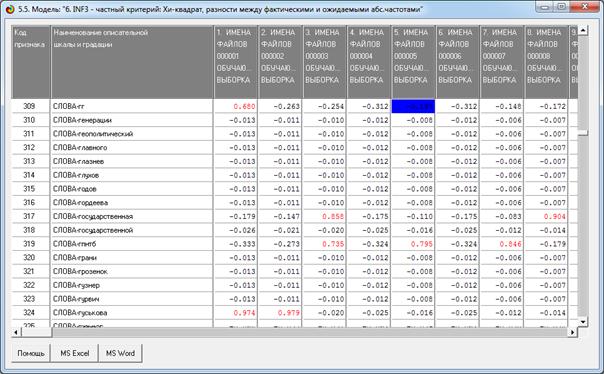
Рисунок 17.
Фрагмент модели INF3
Полностью все
статистические и системно когнитивные модели приведены по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip. Здесь же
они не приводятся, т.к. каждая из них занимает 128 листов.
Достоверность
созданных моделей оценивалось путем идентификации во всех созданных моделях
библиографических описаний всех 111 источников обучающей выборки. При этом использовалась
стандартная мера адекватности моделей: F-критерий Ван Ризбергена и его
мультиклассовое нечеткое обобщение L-мера проф.Е.В.Луценко, предложенная
автором [27].
На рисунке 18
приведена форма по достоверности моделей, которая отображается в режиме
4.1.3.6:
Рисунок 18.
Экранная форма по достоверности моделей (начало)
Из этой формы
мы видим, что наиболее достоверной по F-критерию является модель INF5 с
интегральным критерием «Резонанс знаний» (соответствующая колонка выделена
ярко-голубым цветом). Эта модель обеспечивает 100% истинно-положительных
решений, 9868 истинно-отрицательных решений и 2122 ложно-положительных решений
(«ложные срабатывания») при 0% ложно-отрицательных решений. Точность модели получается
равной 0,049, а полнота 1,000, сама F-мера равна 0,094.
Казалось бы
результаты так себе… Но не надо спешить с выводами.
Дело в том,
что в стандартной F-мере при ложно-положительном решении к соответствующему
сумматору всегда прибавляется 1, а если мы посмотрим на рисунке 19 на степень
сходства объекта распознаваемой выборки с классом (т.е. ссылки с источником)
при истинно-положительных решениях (отмечено «птичкой») и при
ложно-положительных решениях, то мы увидим, что при ложно-положительных
решениях уровень сходства всегда значительно ниже, чем при
истинно-положительных.
Рисунок 19.
Результаты идентификации объектов с классами
в самой достоверной модели INF5
Такая же
картина наблюдается и во всех других приложениях, опыт создания которых очень
велик.
Поэтому
автором было предложено мультиклассовое нечеткое обобщение стандартной F-меры
Ван Ризбергена, которая была названа L-мера проф.Е.В.Луценко [27], которая
кроме различия уровня сходства объектов с классами (нечеткость) учитывает также
то, что один объект может принадлежать одновременно к различным классам
(мультиклассовость).
На рисунке 20
показано продолжение экранной формы по достоверности моделей, показывающая ее
часть с L-мерой (соответствующая колонка выделена ярко-зеленым цветом):
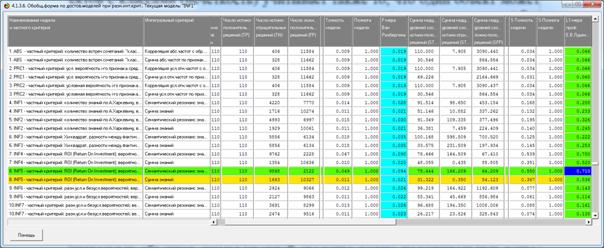
Рисунок 20.
Экранная форма по достоверности моделей (продолжение)
Видно, что с
учетом уровня сходства результаты идентификации значительно лучше, чем по
F-критерию: L-мера = 0,710, при этом точность модели 0,550, а полнота 1,000,
что уже более менее приемлемо.
Однако, количество
ложно-положительных решений («ложных срабатываний» или ошибочных идентификаций)
слишком велико (2122) и не смотря на то, что они имеют очень низкие уровни
сходства их сумма (64,209) все же почти равна сумме уровней сходства
истинно-положительных решений (78,444).
Ясно, что при
увеличении числа распознаваемых объектов сумма уровней сходства ложно
положительных решений может даже превысить сумму уровней сходства истинно-положительных
решений.
Чтобы
преодолеть эти проблемы предлагается
обобщение предложенного в работе [27] L-критерия проф.Е.В.Луценко, учитывающее
уровень сходства объектов с классами и дающее оценку достоверности моделей не зависящую от числа объектов распознаваемой
выборки.
Автором
работы (Е.В.Луценко) предлагается инвариантное относительно объемов данных
обобщение нечеткой мультиклассовой L-меры [27] достоверности моделей,
адекватное для оценки достоверности моделей, построенных на больших данных.
Понятно, что для
того, чтобы устранить зависимость от числа объектов распознаваемой выборки в
L-мере, достаточно вместо сумм уровней сходства истинно и ложно положительных
и отрицательных решений использовать средние, посчитанные путем деления
этих сумм на количество объектов соответствующих категорий, т.е. на
число истинно и ложно идентифицированных и не идентифицированных объектов.
Это и сделано
в новой версии системы «Эйдос» от 12.01.2017. Соответствующая мера
достоверности моделей названа: L2-мера, а предложенная в работе [27],
соответственно: L1-мера. Подробному описанию L2-меры и исследованию зависимости
F-меры, L1- и L2-меры от объемов данных планируется посвятить одну из следующих
работ.
В Help режимов 4.1.3.6, 4.1.3.7 и 4.1.3.8
кратко описаны F-мера, а также L1-мера и L2-мера (рисунок 21):
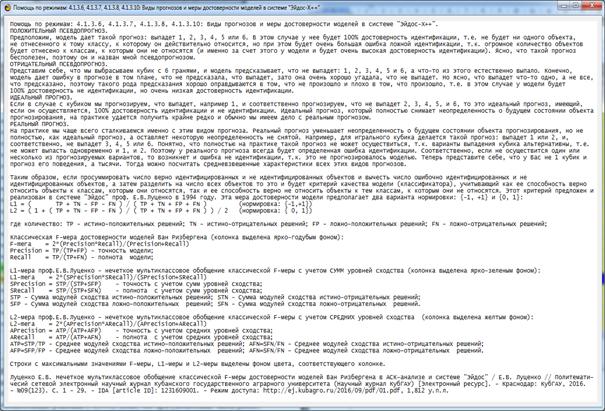
Рисунок 21.
Экранная форма Help режимов 4.1.3.6, 4.1.3.7 и 4.1.3.8
На рисунке 22
приведена экранная форма по достоверности моделей, включающая и L1-меру, и
L2-меру.
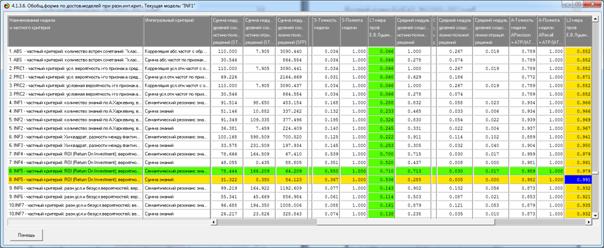
Рисунок 22.
Экранная форма по достоверности моделей
(продолжение)
Из этой формы
видно, что средний уровень сходства распознаваемых объектов с классами при
истинно-положительных решениях равен 0,285, при ложно-положительных решениях
всего 0,005, что дает точность модели 0,982 при полноте 1,000 и L2-мере=0,991,
что уже вполне прилично.
Все это
означает, что если учитывать уровень сходства объектов с классами в формах
идентификации, подобных представленной на рисунке 19, то можно добиться
достаточно высокой достоверности идентификации.
Отметим
также, что система «Эйдос» сама находит максимумы в колонках с различными
критериями качества моделей и отмечает соответствующие строки тем же фоном, что
и эти колонки.
Продолжим
выполнение этапов АСК-анализа и преобразование данных в информацию, а ее в
знания в соответствии с последовательностью, представленной на рисунке 23.
Для этого:
– выберем
наиболее достоверную модель;
– присвоим ей
статус текущей модели;
– введем
распознаваемую выборку из текстовых файлов в систему «Эйдос»;
– проведем
пакетное распознавание распознаваемой выборки в текущей модели.
Выбор наиболее
достоверной модели осуществляется не сложно. После синтеза и верификации
моделей, т.е. после выполнения режима 3.5, просто запускаем режим 4.1.3.6 и
смотрим какая модель находится в строке, выделенной желтым фоном. Это и есть
наиболее достоверная модель по L2-критерию проф.Е.В.Луценко. В нашем случае это
модель INF5. Частный критерий этой модели приведен в разделе 3.4.1.
Чтобы
присвоить модели INF5 запускаем режим 5.6 и задаем эту модель (рисунки 23):
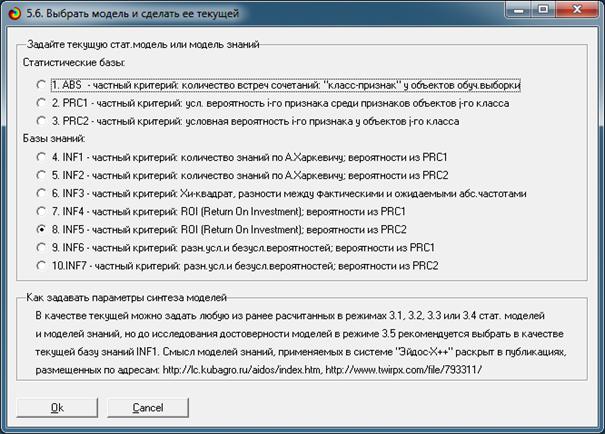
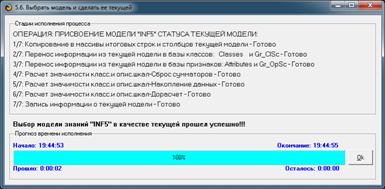
Рисунок 23.
Экранные форма режима 5.6, обеспечивающего присвоение
заданной модели статуса текущей модели (задание и исполнение)
Для этого запишем в MS Word тестовый файл со ссылками
на источники как обычный текст кодировки DOS в папку: ..\Aidos-X\AID_DATA\Inp_rasp\. Каждая ссылка
должна быть в отдельном абзаце.
Затем запустим служебный режим 2.3.2.9, позволяющий
разбить текстовые файлы на абзацы и каждый абзац записать в виде отельного файла (рисунок 24):
Рисунок 24. Экранные форма режима 2.3.2.9
После исполнения этого режима в папке
..\Aidos-X\AID_DATA\Inp_rasp\ появляется 588 файлов, часть которых показана на
рисунке 25. После формирования этих файлов исходный файл удаляется из
директории.
Затем запускаем режим 2.3.2.1, который , собственно, и
вводит данные из этих файлов в распознаваемую выборку (рисунок 26). На рисунке
27 приведена экранная форма с фрагментом этой распознаваемой выборки.
Как уже указывалось выше, такой подход выбран потому,
что на размеры этих файлов по сути нет ограничения (2Гб), т.е. это могут быть и
статьи, и даже монографии или каике-то проекты и отчеты.

Рисунок 25. Файлы тестовой выборки (фрагмент)
Рисунок 26. Экранная форма программного интерфейса
ввода данных
из текстовых файлов
Рисунок 27. Экранная форма с отображением фрагмента
распознаваемой выборки
Далее запускаем режим 4.1.2, реализующий пакетное распознавание.
На рисунке 28 приведена экранная форма с отображением стадии и прогнозом
времени исполнения:
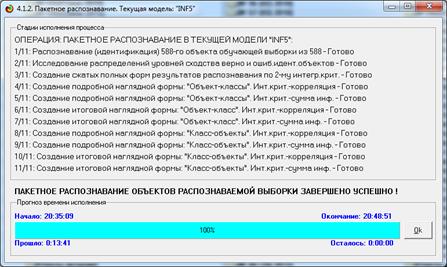
Рисунок 28. Экранная форма с отображением стадии
и прогнозом времени исполнения
Из этой формы мы видим, что идентификация 588 объектов
в текущей модели заняла 13 минут 41 секунду, т.е. около 1,4 секунды на объект.
В системе
«Эйдос» есть довольно много выходных форм с выводом различных результатов
распознавания (рисунок 29).
Некоторые из
них (4.1.3.6, 4.1.3.7, 4.1.3.8, 4.1.3.9, 4.1.3.10, 4.1.3.11) посвящены анализу
достоверности моделей и достоверности распознавания в разрезе по классам и
объектам распознаваемой выборки.
Другие
(4.1.3.1, 4.1.3.2, 4.1.3.3, 4.1.3.4, 4.1.3.5) непосредственно содержат
результаты распознавания.

Рисунок 29.
Выходные формы системы «Эйдос»
по результатам распознавания (режим 4.1.3)
Рассмотрим
лишь те из них, которые имеют самое непосредственное отношение к проблеме,
решаемой в данной работе.
Запустим
режим 4.1.3.2. На экране появится экранная форма, приведенная на рисунке 30.
Если покликать
мышкой слева по классам или воспользоваться стрелками перемещения курсора, то
мы увидим два основных варианта этой формы, приведенные на рисунке 30-а и 30-б.
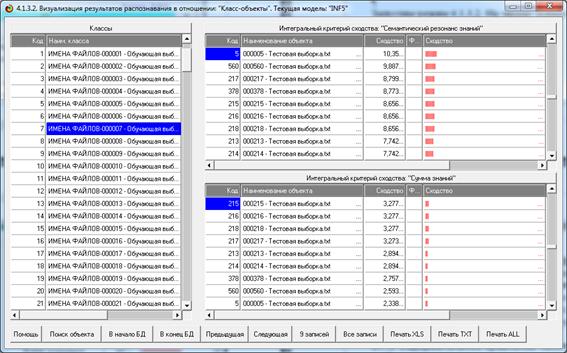
а)
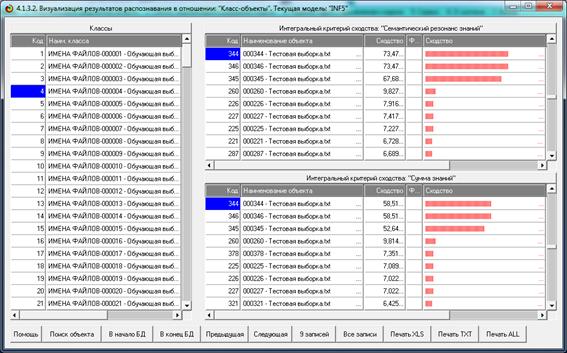
б)
Рисунок 30.
Стандартные экранные формы по результатам распознавания,
отражающие сходство распознаваемых объектов с заданными классами
На экранной
форме 30-а мы видим (справа), что в распознаваемой выборке нет объектов имеющих
сколько-нибудь заметное сходство с классом, указанным слева.
На экранной
форме 30-б, напротив, мы видим (справа), что в распознаваемой выборке есть
объекты с кодами: 344, 346 и 345, имеющие сходство около 70% с классом, указанным
слева.
Однако с
такой формой при решении проблемы, поставленной в работе, работать неудобно.
Можно, конечно, посмотреть на содержимое файлов обучающей выборки, с
библиографическими описаниями работ, и распознаваемой выборки, содержащей самые
разнообразные, в основном некорректные ссылки на них. Но есть и выходные формы,
которые уже содержат эту информацию.
Чтобы
получить эти формы кликнем по кнопке «Печать ALL» на экранной форме,
приведенной на рисунке 30. Появится запрос на порог уровня сходства объектов
распознаваемой выборки с классами:
Этот порог
используется для того, чтобы принять решение о том, в какой тип форм включать
информацию объектах распознаваемой выборки: в те, которые содержат информацию о
идентифицированных объектах, или в отчет об неидентифицированных объектах.
В результате
формируются выходные формы, информация о которых приведена на рисунке 31:
Рисунок 31.
Экранная форма с информацией о выходных формах,
генерируемых по нажатию на кнопе «Печать ALL» в режиме 4.1.3.2.
Ниже
приведена 1-я страница одной из кратких выходных форм, содержащих только коды
классов и объектов распознаваемой выборки с уровнями сходства:

Ниже
приведена 1-я страница одной из подробных выходных форм, содержащих не только
коды классов и объектов распознаваемой выборки с уровнями сходства, но и полный
текст из соответствующих текстовых файлов:

Отметим, что
объем этой выходной формы в модели, используемой в данной работе, составляет 47
листов.
Все ссылки,
для которых не оказалось источников с уровнем сходства выше заданного порога
оказались вообще неидентифицированными (непривязанными) и ниже приводится
фрагмент отчета по таким ссылкам:

Продолжим
выполнение этапов АСК-анализа и кратко рассмотрим некоторые (не все)
возможности исследования моделируемой предметной области путем исследования ее
модели. Это корректно, если модель имеет достаточно высокую достоверность. В
нашем случае по L2-критерию проф.Е.В.Луценко это именно так.
Система «Эйдос»
обеспечивает автоматизированный прямой и обратный SWOT-анализ [28]. Ниже (в
рисунках 32, 33, 34 и 35) приводится несколько выходных форм соответствующих режимов
в модели INF3:
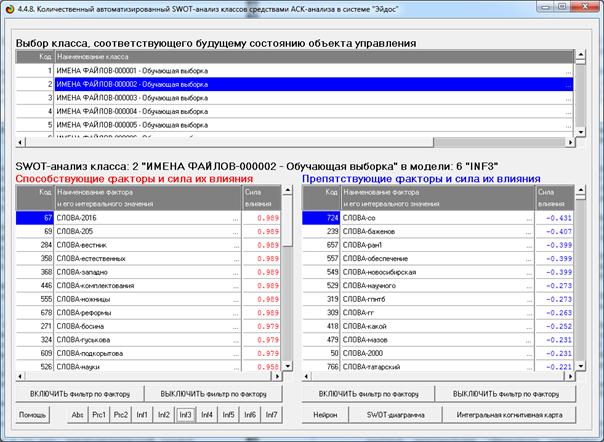
Рисунок 32.
Экранная форма управления режимом 4.4.8
(автоматизированный SWOT-анализ классов)
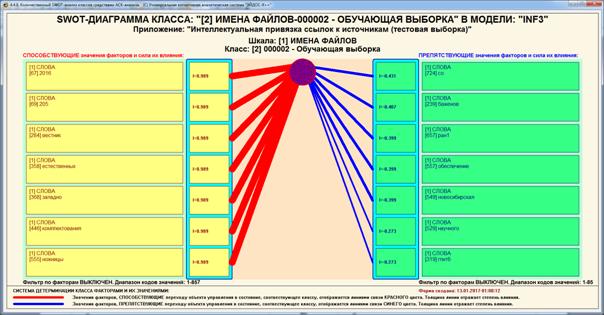
Рисунок 33.
SWOT-диаграмма 2-й работы обучающей выборки
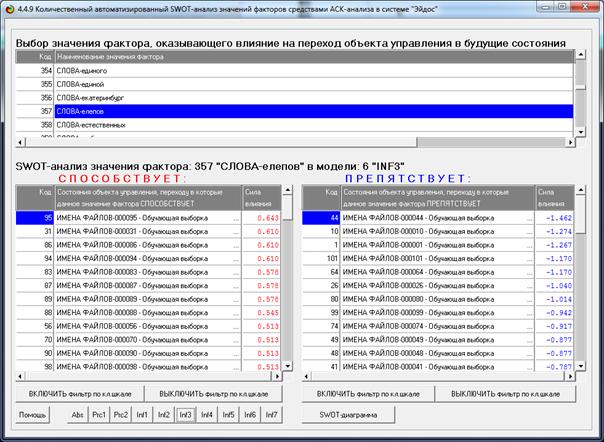
Рисунок 34.
Экранная форма управления режимом 4.4.9
(автоматизированный SWOT-анализ значений факторов)
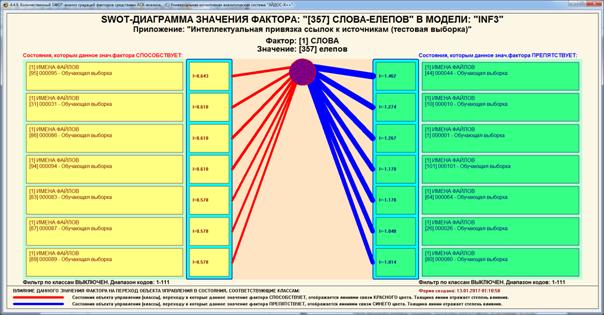
Рисунок 35.
SWOT-диаграмма значения фактора: «Елепов»
Модель
представления знаний системы «Эйдос» представляет собой декларативную нечеткую
модель, имеющую сходство с фреймовой и нейросетевой моделями.
По сравнению
с фреймовой моделью модель системы «Эйдос» имеет существенно упрощенную программную
реализацию, связанную с тем, что все фреймы (классы) имеют общую систему слотов
и шпаций, т.е. описательных шкал и градаций. В тоже время это практически не
уменьшает функциональных возможностей модели представления знаний системы
«Эйдос» по сравнению с фреймовой моделью.
По сравнению
с нейросетевой моделью модель системы «Эйдос» обладает тремя основными
преимуществами [29]: 1) она является интерпретируемой, т.е. понятен и хорошо
теоретически обоснован смысл весовых коэффициентов на рецепторах (градациях
описательных шкал); 2) она является нейронной сетью прямого счета, т.е. ее
процесс обучения гораздо проще, чем по алгоритму обратного распространения
ошибки; 3) она является нелокальной, т.е. все нейроны (классы) связаны со
всеми, что позволяет моделировать нелинейные системы [30].
На рисунке 36
приведена экранная форма управления отображением нелокальных нейронов (режим
4.4.10):
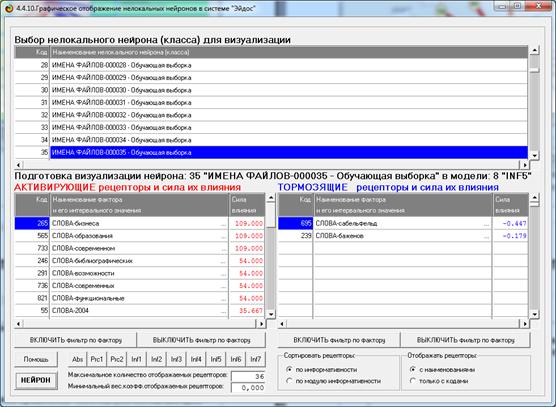
Рисунок 36.
Экранная форма управления отображением
нелокальных нейронов (режим 4.4.10 системы «Эйдос»)
Пример
отображения нелокального нейрона системы «Эйдос» приведен на рисунке 37):
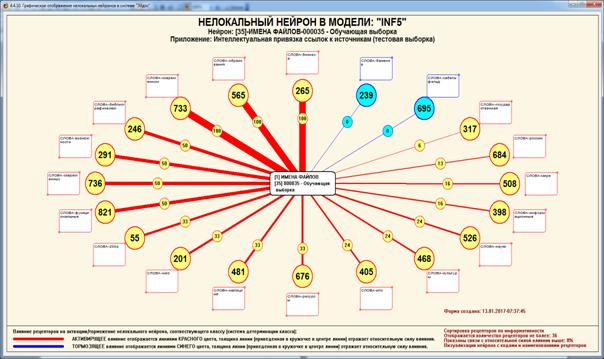
Рисунок 37.
Изображение нелокального нейрона (класса)
с указанием весовых коэффициентов на рецепторах (словах)
Пояснения по
рисунку приведены на нем самом.
Необходимо
отметить, что в системе «Эйдос» нет принципиальных ограничений на количество
нейронов в модели знаний и на количество рецепторов в них (ограничения
накладываются только объемом свободной внешней памяти и быстродействием
компьютеров). Проводились численные эксперименты с формированием в системе
«Эйдос» моделей знаний, содержащих 10000 нейронов, каждый из которых имел 10000
рецепторов, а программные средства системы «Эйдос» работы с базами знаний
тестировались на размерностях баз знаний до 100000 нейронов с 100000 рецепторов
каждый. Правда надо отметить, что такие базы знаний создавались по полчаса и
имели размеры на диске около 200 Гб.
В режиме
4.2.2.1 создается матрица или подматрица сходства классов (таблица 2):
Таблица 2 –
Матрица сходства классов в модели INF5 (фрагмент)
|
KOD_CLS
|
NAME_CLS
|
N1
|
N2
|
N3
|
N4
|
N5
|
|
1
|
ИМЕНА ФАЙЛОВ-000001 - Обучающая выборка
|
100,000
|
1,289
|
-1,282
|
-1,879
|
-1,229
|
|
2
|
ИМЕНА ФАЙЛОВ-000002 - Обучающая выборка
|
1,289
|
100,000
|
-0,269
|
-1,836
|
-1,228
|
|
3
|
ИМЕНА ФАЙЛОВ-000003 - Обучающая выборка
|
-1,282
|
-0,269
|
100,000
|
-1,057
|
0,693
|
|
4
|
ИМЕНА ФАЙЛОВ-000004 - Обучающая выборка
|
-1,879
|
-1,836
|
-1,057
|
100,000
|
3,544
|
|
5
|
ИМЕНА ФАЙЛОВ-000005 - Обучающая выборка
|
-1,229
|
-1,228
|
0,693
|
3,544
|
100,000
|
|
6
|
ИМЕНА ФАЙЛОВ-000006 - Обучающая выборка
|
-1,747
|
-1,699
|
-0,874
|
-0,585
|
-1,232
|
|
7
|
ИМЕНА ФАЙЛОВ-000007 - Обучающая выборка
|
-0,821
|
0,254
|
0,697
|
-0,914
|
0,532
|
|
8
|
ИМЕНА ФАЙЛОВ-000008 - Обучающая выборка
|
0,737
|
-0,986
|
-0,228
|
-0,642
|
-0,716
|
|
9
|
ИМЕНА ФАЙЛОВ-000009 - Обучающая выборка
|
-2,103
|
0,222
|
0,066
|
-2,298
|
-1,495
|
|
10
|
ИМЕНА ФАЙЛОВ-000010 - Обучающая выборка
|
-2,366
|
-1,840
|
-1,686
|
-2,575
|
-1,702
|
|
11
|
ИМЕНА ФАЙЛОВ-000011 - Обучающая выборка
|
-1,381
|
-1,340
|
-0,997
|
-1,483
|
-1,000
|
|
12
|
ИМЕНА ФАЙЛОВ-000012 - Обучающая выборка
|
0,020
|
-0,775
|
0,285
|
-0,852
|
0,265
|
|
13
|
ИМЕНА ФАЙЛОВ-000013 - Обучающая выборка
|
1,582
|
-0,877
|
5,231
|
-0,966
|
0,048
|
|
14
|
ИМЕНА ФАЙЛОВ-000014 - Обучающая выборка
|
-1,262
|
-0,388
|
0,413
|
-1,361
|
-0,897
|
|
15
|
ИМЕНА ФАЙЛОВ-000015 - Обучающая выборка
|
-1,411
|
-0,621
|
-1,068
|
-1,565
|
-1,014
|
|
16
|
ИМЕНА ФАЙЛОВ-000016 - Обучающая выборка
|
-1,775
|
-1,724
|
-1,313
|
-1,605
|
-1,290
|
|
17
|
ИМЕНА ФАЙЛОВ-000017 - Обучающая выборка
|
-1,077
|
-1,070
|
-0,712
|
-1,185
|
-0,764
|
|
18
|
ИМЕНА ФАЙЛОВ-000018 - Обучающая выборка
|
-1,138
|
-1,123
|
-0,432
|
-1,251
|
-0,474
|
|
19
|
ИМЕНА ФАЙЛОВ-000019 - Обучающая выборка
|
8,878
|
-1,339
|
-0,569
|
-1,485
|
-0,611
|
|
20
|
ИМЕНА ФАЙЛОВ-000020 - Обучающая выборка
|
-2,152
|
-2,097
|
-1,595
|
-2,062
|
-1,566
|
|
21
|
ИМЕНА ФАЙЛОВ-000021 - Обучающая выборка
|
0,312
|
-1,070
|
-0,773
|
-1,191
|
-0,764
|
|
22
|
ИМЕНА ФАЙЛОВ-000022 - Обучающая выборка
|
6,748
|
-1,358
|
-1,021
|
-1,657
|
-0,955
|
|
23
|
ИМЕНА ФАЙЛОВ-000023 - Обучающая выборка
|
-1,957
|
-1,894
|
-1,454
|
-1,825
|
-1,426
|
|
24
|
ИМЕНА ФАЙЛОВ-000024 - Обучающая выборка
|
-1,428
|
-0,531
|
0,805
|
-0,440
|
-1,049
|
|
25
|
ИМЕНА ФАЙЛОВ-000025 - Обучающая выборка
|
-1,379
|
-1,346
|
-1,045
|
-1,474
|
-1,024
|
|
26
|
ИМЕНА ФАЙЛОВ-000026 - Обучающая выборка
|
-2,064
|
-1,988
|
-1,529
|
-2,225
|
-1,500
|
|
27
|
ИМЕНА ФАЙЛОВ-000027 - Обучающая выборка
|
-0,501
|
-0,587
|
0,233
|
-1,586
|
-1,070
|
|
28
|
ИМЕНА ФАЙЛОВ-000028 - Обучающая выборка
|
-1,263
|
-1,251
|
-0,822
|
-1,362
|
-0,824
|
|
29
|
ИМЕНА ФАЙЛОВ-000029 - Обучающая выборка
|
-1,532
|
-1,258
|
-0,430
|
-1,667
|
-0,503
|
|
30
|
ИМЕНА ФАЙЛОВ-000030 - Обучающая выборка
|
-1,708
|
-1,354
|
-0,793
|
-1,603
|
-1,238
|
|
31
|
ИМЕНА ФАЙЛОВ-000031 - Обучающая выборка
|
-0,843
|
-0,811
|
-0,624
|
-0,908
|
-0,612
|
|
32
|
ИМЕНА ФАЙЛОВ-000032 - Обучающая выборка
|
-0,915
|
-0,734
|
-0,542
|
-1,005
|
-0,550
|
|
33
|
ИМЕНА ФАЙЛОВ-000033 - Обучающая выборка
|
-1,411
|
-1,407
|
-0,493
|
-1,554
|
-0,552
|
|
34
|
ИМЕНА ФАЙЛОВ-000034 - Обучающая выборка
|
0,764
|
1,925
|
-0,479
|
-1,391
|
-0,859
|
|
35
|
ИМЕНА ФАЙЛОВ-000035 - Обучающая выборка
|
-1,640
|
-0,677
|
-0,949
|
-1,775
|
-1,209
|
|
36
|
ИМЕНА ФАЙЛОВ-000036 - Обучающая выборка
|
-1,149
|
-1,116
|
-0,735
|
-1,259
|
6,952
|
|
37
|
ИМЕНА ФАЙЛОВ-000037 - Обучающая выборка
|
-1,592
|
-1,543
|
-1,181
|
-1,724
|
-1,160
|
|
38
|
ИМЕНА ФАЙЛОВ-000038 - Обучающая выборка
|
-1,180
|
-0,478
|
-0,176
|
0,668
|
-0,821
|
|
39
|
ИМЕНА ФАЙЛОВ-000039 - Обучающая выборка
|
-1,786
|
-1,800
|
-1,258
|
-1,718
|
-1,331
|
|
40
|
ИМЕНА ФАЙЛОВ-000040 - Обучающая выборка
|
-1,763
|
-1,526
|
-1,096
|
-1,276
|
-1,269
|
|
41
|
ИМЕНА ФАЙЛОВ-000041 - Обучающая выборка
|
-1,869
|
-1,866
|
-1,105
|
-1,835
|
-0,855
|
|
42
|
ИМЕНА ФАЙЛОВ-000042 - Обучающая выборка
|
-1,030
|
-0,984
|
-0,363
|
-1,089
|
-0,403
|
|
43
|
ИМЕНА ФАЙЛОВ-000043 - Обучающая выборка
|
-1,386
|
-0,607
|
-0,075
|
-1,670
|
-1,043
|
|
44
|
ИМЕНА ФАЙЛОВ-000044 - Обучающая выборка
|
-1,666
|
-1,635
|
-1,007
|
-1,858
|
-1,244
|
|
45
|
ИМЕНА ФАЙЛОВ-000045 - Обучающая выборка
|
-1,834
|
-1,786
|
-0,108
|
-1,981
|
-0,624
|
|
46
|
ИМЕНА ФАЙЛОВ-000046 - Обучающая выборка
|
-1,164
|
-1,689
|
0,009
|
-1,444
|
-0,276
|
|
47
|
ИМЕНА ФАЙЛОВ-000047 - Обучающая выборка
|
-1,529
|
-1,473
|
-1,133
|
-1,624
|
-1,112
|
|
48
|
ИМЕНА ФАЙЛОВ-000048 - Обучающая выборка
|
-1,547
|
-1,491
|
-0,831
|
-1,660
|
-1,108
|
|
49
|
ИМЕНА ФАЙЛОВ-000049 - Обучающая выборка
|
-1,371
|
-1,343
|
-0,647
|
-1,495
|
-0,990
|
|
50
|
ИМЕНА ФАЙЛОВ-000050 - Обучающая выборка
|
-1,466
|
-1,517
|
-0,927
|
-1,675
|
-0,475
|
|
51
|
ИМЕНА ФАЙЛОВ-000051 - Обучающая выборка
|
-1,822
|
-1,655
|
-1,245
|
-1,753
|
-1,361
|
|
52
|
ИМЕНА ФАЙЛОВ-000052 - Обучающая выборка
|
-1,388
|
-2,004
|
-0,954
|
-1,528
|
-0,635
|
|
53
|
ИМЕНА ФАЙЛОВ-000053 - Обучающая выборка
|
0,977
|
-1,072
|
-0,352
|
-1,224
|
-0,401
|
|
54
|
ИМЕНА ФАЙЛОВ-000054 - Обучающая выборка
|
-1,356
|
-1,314
|
-1,007
|
2,124
|
-0,991
|
|
55
|
ИМЕНА ФАЙЛОВ-000055 - Обучающая выборка
|
-1,105
|
-1,277
|
-0,984
|
-1,423
|
-0,932
|
|
56
|
ИМЕНА ФАЙЛОВ-000056 - Обучающая выборка
|
-0,997
|
-1,006
|
-0,733
|
-1,121
|
-0,676
|
|
57
|
ИМЕНА ФАЙЛОВ-000057 - Обучающая выборка
|
-1,208
|
-1,158
|
-0,894
|
-1,287
|
-0,878
|
|
58
|
ИМЕНА ФАЙЛОВ-000058 - Обучающая выборка
|
-0,976
|
-0,931
|
-0,722
|
-1,075
|
-0,710
|
|
59
|
ИМЕНА ФАЙЛОВ-000059 - Обучающая выборка
|
-1,029
|
-1,196
|
0,004
|
-1,293
|
-0,845
|
|
60
|
ИМЕНА ФАЙЛОВ-000060 - Обучающая выборка
|
-1,254
|
-0,665
|
-0,978
|
-1,424
|
-0,960
|
|
61
|
ИМЕНА ФАЙЛОВ-000061 - Обучающая выборка
|
2,134
|
-1,421
|
-1,152
|
-0,655
|
-1,133
|
Фрагменты
матрицы сходства могут визуализироваться в системе «Эйдос» в форме
семантических сетей (когнитивных диаграмм). На рисунке 38 приведены экранные
формы управления данным режимом (4.2.2.2):
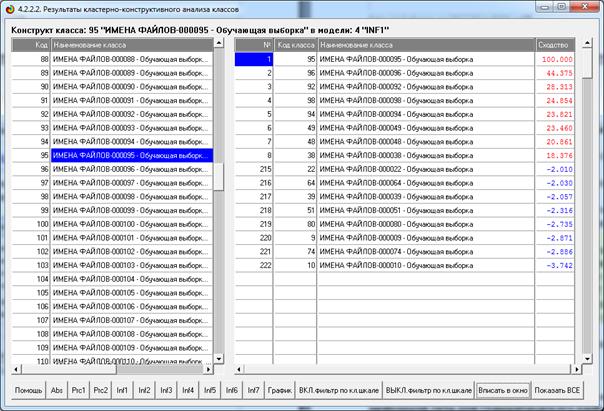
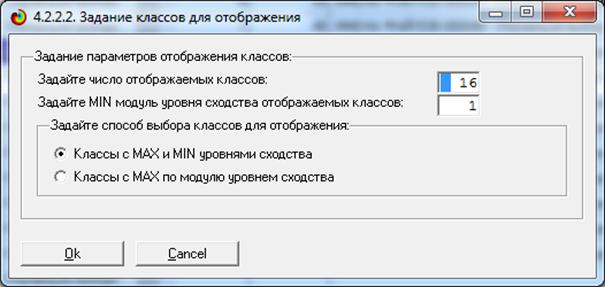
Рисунок 38.
Экранные формы управления режимом кластерно-конструктивный анализ классов
системы «Эйдос» (4.2.2.2.)
Пример
визуализации конструкта класса с кодом 95 приведен на рисунке 39:
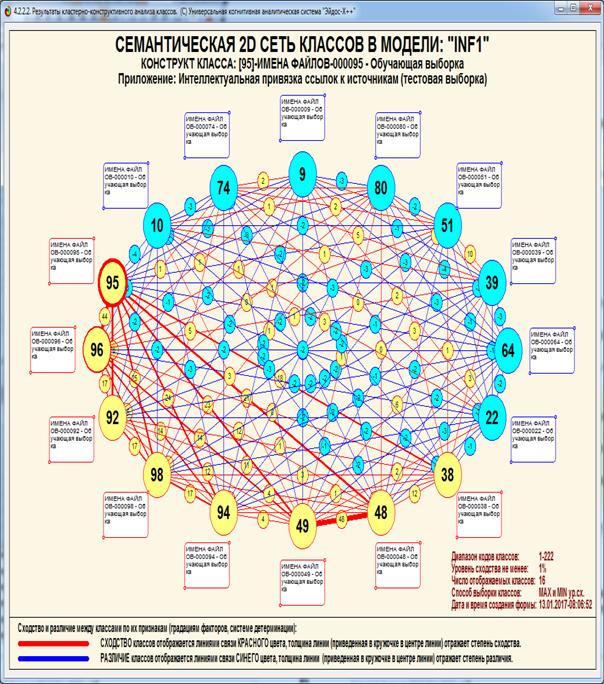
Рисунок 39.
Пример визуализации конструкта класса с кодом 95
Текст объекта
обучающей выборки с кодом 95: «НАУЧНЫЕ БИБЛИОТЕКИ СИБИРИ И ДАЛЬНЕГО ВОСТОКА
Елепов Б.С. Новосибирск, 1980.». Информационный портрет класса 95 приведен на
рисунке 40.
Рисунок 40.
Пример визуализации конструкта класса с кодом 95
Из рисунка 40
видно, что разные слова, входящие в этот объект, имеют разный вес при его
идентификации, т.е. в разной степени характерны для этого объекта. Мы видим,
что наиболее характерным словом для этого объекта является слово «востока», а
за ним идет год работы.
Отметим
также, что весовые коэффициенты когнитивной диаграммы, приведенной на рисунке
39, определяются не «на основе экспертных оценок», как обычно, а
рассчитываются непосредственно на основе моделей знаний, сформированных в системе
«Эйдос» непосредственно на основе эмпирических исходных данных.
Из
когнитивной диаграммы, приведенной на рисунке 39, мы видим, что некоторые
библиографические описания работ в различной степени сходны друг с другом, а
другие в различной степени отличаются. Но из этой диаграммы мы не видим, чем именно они сходны и чем
отличаются, т.е. того, какие слова вносят
основной вклад в их сходство и различие. Эта информация приводится в
когнитивной диаграмме на рисунке 41:

Рисунок 41.
Пример когнитивной диаграммы, содержательно отражающей
вклад различных слов в сходство-различие двух текстов
На рисунке 42
приведена экранная форма управления режимом 4.2.3, обеспечивающим генерацию
когнитивных диаграмм, содержательно отражающих вклад различных слов в
сходство-различие двух текстов.
Рисунок 42.
Экранная форма управления режимом 4.2.3, обеспечивающим
генерацию когнитивных диаграмм, содержательно отражающих вклад
различных слов в сходство-различие двух текстов
По сути эта
когнитивная диаграмма раскрывает внутреннюю структуру каждой линии,
показывающей сходство или различие классов на диаграмме 39. Ниже, на рисунке 43
приведен Help режима 4.2.3, поясняющий, как формируется когнитивная диаграмма,
отображенная на рисунке 41.
Рисунок 43.
Help режима 4.2.3, поясняющий, как формируется
когнитивная диаграмма, отображенная на рисунке 41
Можно
представить себе нейронную сеть, построенную на диаграмме 39 с указанием
рецепторов, как на рисунке 37. В DOS-версии системы «Эйдос» такие диаграммы
визуализировались, а в новой аналогичный режим еще не реализован.
Различные
слова имеют различную ценность для сравнения источников с источниками и ссылок
с источниками.
Если слово
встречается с одинаковой вероятностью в различных источниках, то оно совершенно
бесполезно для того, чтобы отличить их друг от друга. Чем выше вариабельность вероятности (или одного
из частных критериев знаний, приведенных в разделе 3.4.1) встречи некоторого
слова по разным источникам, тем более ценным оно является для их различения.
На рисунке 44
приведена логистическая кривая ценности различных слов для решения задачи
идентификации текстов (т.е. ценность слов нарастающим итогом) в
модели PRC1:
Рисунок 44.
Логистическая кривая ценности различных слов
для решения задачи идентификации текстов
Из рисунка 44
видно, что 50% слов обеспечивают суммарно около 75,7% значимости, а 50% суммарной
значимости обеспечивается 23,6% слов.
Если подобный
анализ провести на моделях, отражающих не одного автора, а большое их
количество, то можно сделать научно обоснованные выводы о том, какие слова
имеет использовать для дифференциации источников и ссылок и их привязки.
Например, можно оставить треть; слов, дающих суммарное около двух третей
значимости. Наряду с лемматизацией, это позволит существенно уменьшить
размерность моделей, вычислительную сложность и время решения задач.
3.4.4. Обсуждение (некоторые ограничения предлагаемой
технологии и пути их преодоления)
Ложно-положительные
и ложно-отрицательные решения, т.е. ошибки идентификации и неидентификации,
крайне нежелательны и их обязательно необходимо как-то минимизировать. Ниже в
данном разделе рассмотрим некоторые подходы к решению этой важной и актуальной
задачи.
Обратимся к
рисунку 21, на котором раскрываются понятия положительного и отрицательного
псевдопрогнозов.
Из
предыдущего изложения, в частности рисунка 30-б в разделе 3.6.4, ясно, что для
достоверности прогноза очень важен выбор порога положительных уровней сходства,
выше которого положительные решения как правило соответствуют действительности,
т.е. являются истинно-положительными, а ниже – ложно-положительными.
Например, из
рисунка 30-б видно, что вероятнее всего к истинно-положительным решениям
относятся те, у которых уровень сходства выше 50%. Но, конечно, по одной форме
такие решения принимать нельзя, а также необходима проверка совпадения прогноза
с действительностью, что по этой форме сделать затруднительно.
Поэтому для
выбора порога более корректно использовать форму, представленную на рисунке 22
и текстовые формы из раздела 3.6.4.
Например, из
рисунка 22 видно, что в наиболее достоверной модели INF5 рационально и
обоснованно выбрать порог уровня сходства выше 30%, т.е. положительные решения,
с уровнем сходства выше 30% обоснованно можно считать истинно-положительными.
Соответственно, положительные решения, с уровнем сходства ниже 30% обоснованно
можно считать ложно-положительными или истинно-отрицательными.
Конечно, речь
идет о средних величинах уровней сходства, причем полученных при
идентификации обучающей выборки. Понятно, что при идентификации объектов как
обучающей, так и тестовой выборки реально могут встретится и истинно-положительные
решения с уровнем сходства ниже 30% и ложно положительные с уровнем сходства
выше 30%. Но при таком выборе порога уровня сходства минимизируется количество
ложноположительных и ложноотрицательных решений.
По
предлагаемой технологии возможно построить модели измерения сходства-различия
библиографических описаний источников и ссылок на них не по входящим в них
словам, а по элементам их библиографических описаний. В этом случае модели
измерения сходства-различия источников и ссылок будут вторым слоем нейронной
сети, в первом слое которой должна решаться задача разбора
некорректного и неполного библиографического описания и выделения из него этих
элементов.
Очень может
быть, что такие модели двухслойной нейронной сети показали покажут высокую
достоверность, чем однослойные модели, основанные на словах, подобные описанной
в данной работе.
Однако
ожидать этой более высокой достоверности оправданно только при условии
правильного выделения элементов библиографического описания. А на этапе разбора
также возможны ошибки, которые могут снизить достоверности решения задачи во
втором слое.
Экспертное
исследование текстовых выходных форм, приведенных в разделе 3.6.4, показало,
что при очень высоком пороге сходства из списка ссылок могут пропасть
фактические ссылки на источники, а при очень низком в список ссылок попадает много
ссылок на другие источники, сходные по библиографическому описанию.
Решить эту
проблему предлагается путем:
1) выбора
низкого порога, что обеспечит исключение пропусков ссылок;
2) исключения
из расширенного списка ссылок тех из них, которые точно не являются ссылками на
данный источник.
Решить 2-ю
задачу можно с применением используемого в настоящее время в программном
обеспечении (ПО) РИНЦ алгоритма грамматического разбора библиографических
ссылок, который выделяет год публикации и другие элементы ее описания.
Например, из расширенного списка ссылок можно сразу исключить ссылки на
источники других лет публикации.
Используемый
в настоящее время в программном обеспечении (ПО) РИНЦ алгоритм основан на
последовательном грамматическом разборе библиографических ссылок, выделении элементов
их описания и последовательном сужении круга дальнейшего поиска с учетом
результатов предшествующего разбора. Это очень быстродействующий алгоритм, однако
при неверном определении типа публикации (например она определилась как журнал,
а в действительности это сборник статей) дальнейший поиск ведется уже в
публикациях этого типа и обречен неудачу.
Предлагаемый
в данной работе подход решает эту проблему. Для этого предлагается сначала с
очень низким порогом, например 6-7% сформировать расширенный список работ, на одну
из которых может быть привязываемая ссылка, а затем из этого расширенного
списка удаляются варианты, у которых не совпадают безошибочно определяемые при
разборе элементы, такие как год публикации.
Это
предложение напоминает подход, используемый рыбками: сначала широко закинуть невод
и вытащить его со всем, что туда попало, а потом выкинуть все ненужное и
оставить только улов.
Конечно
авторы иногда делают странные вещи: например при публикации в англоязычных
журналах помещают в список литературы ссылки на русскоязычные источники в
переводе их на английский язык или в транслитерации, а не на языке оригинала.
Понятно, конечно, что эти англоязычные издания могут вообще не предусматривать
возможности ссылок на русскоязычные источники. Одна с другой стороны понятно,
что если ссылка сделана в переводе или транслитерации, то предлагаемый подход
не найдет их сходства с русскоязычным библиографическим описание источника.
Предлагается
следующее решение этой проблемы: все русскоязычные библиографические описания
источников обучающей выборки перевести на английский язык и сделать их транслитерацию
с применением различных стандартов транслитерации и дополнить ими обучающую
выборку с теми же номерами файлов, что и
с русскоязычным описанием источника.
Проведение
расчетов по синтезу и верификации моделей источников, а затем по их применению
для привязки ссылок показали, что они имеют достаточно высокую вычислительную
сложность и трудоемкость, требуют значительных вычислительных ресурсов и затрат
времени.
По этим
параметрам предлагаемые и описанные выше в работе подходы не удовлетворяют
требованиям, предъявляемым условиями их практического применения.
Но дело в
том, что они и не предназначены для непосредственного применения на практике.
Очень многие аспекты предлагаемых подходов, освещенные в данной работе не
касаются непосредственно практического применения, а относятся к этапу научного
исследования, который предшествует этапу практического доведения до
инновационного уровня и применения любой разработки.
Самое
главное, что мы должны сделать на этапе научного исследования – это мы должны
путем создания и верификации моделей на большом числе авторов определить
наиболее достоверную модель и порог уровня сходства для определения расширенного
списка ссылок или источников.
Можем, при
наличии такой возможности и желания, провести и другие исследования по
интересующим направлениям, например, исследовать, как на скорость и
достоверность распознавания и привязки влияет лемматизация слов или исключение
из списка слов двух третей наименее ценных из них, а также предлагаемые выше
препроцессоры и постпроцессоры.
Из всего
сделанного на этапе научного исследования и описанного выше, на практике будет
применяться лишь небольшая часть:
1) для
каждого автора на основе списка его публикаций в базах данных РИНЦ будет
формироваться одна модель, а именно та, которая на этапе научного
исследования показала наивысшую достоверность у наибольшего числа авторов;
2) в этой
модели с порогом уровня сходства, определенном на этапе научного исследования,
будет формироваться расширенный список ссылок на каждую работу автора;
3) из
расширенного списка будут исключаться те из них, которые не соответствуют хотя
бы по одному достоверно установленному элементу библиографического описания,
например, году публикации.
Эти задачи
могут на этапе практического применения могут решаться в десятки раз быстрее,
чем аналогичные задачи на этапе научного исследования.
В результате
все это уже может быть вполне может быть применимым на практике. Тем более, что
предлагаемые в работе подходы, включая и саму систему «Эйдос», могут
рассматриваться лишь как прототип для практических решений на платформе
программного обеспечения РИНЦ.
Но на этапе
научных исследований они вполне успешно могут быть применены, собственно
говоря, уже применены, что и описано в данной работе.
В наше время
существует много подходов эффективного использования аппаратных средств для
высокопроизводительных вычислений. Кроме очевидной возможности использования суперкомпьютеров
с параллельными процессорами укажем еще на возможность использования видеокарт
для высокопроизводительных вычислений и кластерные
сетевые вычислительные системы с интеллектуальным управлением задачами и ресурсами.
В данной
работе предлагается решение проблемы привязки некорректных ссылок к
литературным источникам путем применения автоматизированного системно-когнитивного
анализа (АСК-анализ) и его программного инструментария – интеллектуальной
системы «Эйдос». Приводится численный пример интеллектуальной привязки реальных
некорректных ссылок к работам автора на основе небольшого объема реальных наукометрических
данных, находящихся в открытом бесплатном on-line доступе в РИНЦ, который
продемонстрировал работоспособность предлагаемого подхода и ряд его преимуществ
перед подходом, применяемым в настоящее время в программном обеспечении РИНЦ.
Таким образом, данная работа является продолжением серии работ автора,
посвященных различным вопросам наукометрии [31, 32, 33] и интеллектуальной
обработки тестов [1-33].
Предлагаются
следующие возможные перспективы дальнейших исследований по теме, которые не
удалось в должной мере осветить в данной работе и которые могут способствовать
развитию данного направления исследований в будущем:
1)
использование многослойных нейронных сетей: препроцессором и постпроцессором в
комбинации с предлагаемым подходом;
2) решение
задачи выявления фактических научных школ и сравнения их с формальными научными
школами;
3) задача
формирования обобщенных образов научных публикаций авторов, научных коллективов
и организаций, как локальных (традиционных), так и виртуальных.
Отметим
также, что наряду с возможностью интеллектуальной привязки ссылок к
литературным источникам в библиографических базах данных материалы данной
работы могут быть использованы при решении ряда других сходных по сути задач
интеллектуальной обработки текстов. Например, предлагаемый подход можно
использовать для поиска аналогов преступлений путем АСК-анализа текстов фабул
преступлений, а также при преподавании дисциплин, связанных с интеллектуальными
технологиями и наукометрией, для проведения лекционных и лабораторных занятий
по этим дисциплинам и при выполнении курсовых и дипломных работ.
Статья
посвящена решению проблемы, заключающейся в том, что с одной стороны рейтинг
российских вузов востребован, а с другой стороны пока он не создан.
Предлагаемая идея решения проблемы состоит в применении отечественной
лицензионной инновационной интеллектуальной технологии для этих целей: а именно
предлагается применить автоматизированный системно-когнитивный анализ
(АСК-анализ) и его программный инструментарий – интеллектуальную систему
«Эйдос». Эти методы подробно описываются
в этом контексте. Предлагается рассмотреть возможности применения данного
инструментария на примере университетского рейтинга Гардиан, и рассматриваются
его частные критерии (показатели вузов). Указываются источники данных и
методика их подготовки для обработки в системе «Эйдос». В соответствии с методологией АСК-анализа описывается установка системы
«Эйдос», ввод исходных данных в нее и формализация предметной области, синтез и
верификация модели, их отображение и применение для решения задач оценки рейтинга
Гардиан для российских вузов и исследования объекта моделирования.
Рассматриваются перспективы и пути создания интегрированного рейтинга
российских вузов и эксплуатации рейтинга в адаптивном режиме. Указываются
ограничения предлагаемого подхода и перспективы его развития
СОДЕРЖАНИЕ
1. Формулировка проблемы... 356
2. Авторский подход к решению проблемы... 358
2.1. Идея предлагаемого решения проблемы... 141
2.2. Автоматизированный системно-когнитивный анализ
и интеллектуальная система «Эйдос» как инструментарий решения проблемы... 145
2.3. Частные критерии университетского рейтинга
Гардиан.. 371
3. Численный пример.. 374
3.1. Источники исходных данных.. 374
3.2. Подготовка исходных данных для системы «Эйдос». 375
3.3. Установка системы «Эйдос». 382
3.4. Ввод исходных данных в систему «Эйдос» с
помощью одного и ее программных интерфейсов.. 385
3.5. Синтез и верификация многокритериальной
системно-когнитивной модели университетского рейтинга Гардиан, учитывающей
направления подготовки.. 394
3.6. Наглядное отображение подматриц системно-когнитивных
моделей университетского рейтинга Гардиан в виде когнитивных функций 401
3.7. Интегральный критерий и решение задачи оценки
рейтинга вуза в системно-когнитивной модели университетского рейтинга Гардиан 408
3.8. Исследование многокритериальной
системно-когнитивной модели университетского рейтинга Гардиан, учитывающей
направления подготовки 412
4. Интеграция различных рейтингов в одном «супер рейтинге» – путь к
использованию рейтинга Гардиан для оценки российских вузов 419
4.1. Пилотное исследование и Парето-оптимизация.. 419
4.2. Эксплуатация методики в адаптивном режиме.. 423
3.5.1. Формулировка проблемы
Университетские
рейтинги давно стали общепринятым в мире методом оценки эффективности вузов.
Этими
рейтингами для решения различных задач пользуются и потенциальные студенты, и
их родители, и ученые, и руководители. Таким образом, они востребованы
практически всем обществом.
Недавно и
министерство образования и науки РФ обратилось к идее создания подобного
рейтинга для российских вузов, и это в общем нельзя не приветствовать.
Однако первый
опыт создания подобного рейтинга, по-видимому, приходиться признать неудачным,
т.к. он вызвал большой поток совершенно справедливой и хорошо обоснованной
критики со стороны научно-педагогического сообщества. Возражения вызвали,
прежде как сами критерии оценки эффективности вузов, так и
полная непрозрачность процедуры формирования этих критериев, а также то, что за
бортом широкого обсуждения (которого, вообще не было) осталось и само понятие
эффективности вузов, т.е. их основное назначение. А ведь именно тем, что
понимается под эффективностью вузов, определяются и критерии ее оценки. Но
предложенные критерии оказались таковы, что у многих возникло вполне
обоснованное подозрение, что под эффективностью вузов при их формировании
понималось вовсе не качество образования, а нечто другое не свойственное вузам.
Эта критика
звучит и на научных конференциях, и в научных
публикациях [1]. А то, о чем не принято говорить на научных конференциях и
писать в научных публикациях, высказывается на форумах и на личных страницах
ученых и педагогов.
Например, на
своем личном сайте доктор педагогических наук профессор А.А.Остапенко пишет: «Основных критериев, как мы помним пять: средний балл ЕГЭ
принятых на обучение студентов; объём научных работ на одного сотрудника; количество
иностранцев-выпускников; доходы вуза в расчёте на одного сотрудника, а также
общая площадь учебно-лабораторных зданий в расчёте на одного студента. Как они
связаны с эффективностью вуза и что такое эффективность вообще понять, мысля
рационально, непросто. Даже всерьёз обсуждать эти критерии как-то странно»[41].
Но мы все же
выскажем одно соображение. На наш взгляд довольно странно выглядит попытка
сравнения друг с другом вузов разных направленности подготовки, т.е. например
аграрных вузов и вузов, готовящих специалистов для атомной и
ракетно-космической промышленности. Иначе говоря, для вузов разной
направленности должны быть разные критерии и основанные на них рейтинги. Для
агарного вуза естественно, что у него есть учебные подсобные хозяйства, фермы, поля,
сады, виноградники, посадки орехов, машинно-тракторные станции и т.п. и т.д. Можете
себе представить что получится, если разделить прибыль аграрного вуза на его
площадь?
Правда со
временем, наверное, в какой-то степени и под влиянием этой критики, позиция
Минобрнауки РФ стала меняться. А то, что к тому времени уже успели закрыть
несколько вузов, как говорят: «имеющих признаки
неэффективности», – это как
бы и не так важно. Кроме того вузы, имевшие много филалов, отказались от них,
т.к. они в основном были малоэтажными и «увеличивали признаки неэффективности».
Естественно, эти филиалы сразу же стали филиалами московских вузов, после чего
об этих одиозных критериях эффективности вузов как-то потихоньку и забыли,
наверное потому, что они уже выполнили свою функцию: перераспределение
собственности вузов от периферии в пользу центра. Динамику этих изменений
позиции профильного министерства можно проследить по Нормативно-правовым документам
Минобрнауки РФ, устанавливающим критерии оценки эффективности деятельности вузов.
Таким
образом, налицо проблема, которая
состоит в том, что с одной стороны рейтинг российских вузов востребован, а с
другой стороны как-то пока не очень получается его сформировать. То есть, как
обычно желаемое не совпадает с действительным, и «хотели как лучше, а вышло как
всегда» (В.С.Черномырдин).
3.5.2. Авторский подход к решению проблемы
Идея решения проблемы проста: обратиться к мировому
опыту в этой области, творчески его переосмыслить применительно к российским
реалиям и разработать свои научно-обоснованные подходы, с учетом всего лучшего,
что есть в мировом опыте.
Существует несколько популярных и авторитетных рейтингов
вузов1:
– Университетский рейтинг The Guardian[44];
– Университетский рейтинг Times[45];
– Мировой рейтинг Times Higher Education[46];
– Рейтинг мировых вузов Шанхайского Университета[47].
Мы не будем их здесь описывать, т.к. по ним достаточно
информации в общем доступе, в т.ч. по приведенным ссылкам.
Но хотели бы отметить, что для поддержки любого подобного
рейтинга необходима соответствующая инфраструктура, оснащенная различными
видами обеспечения ее деятельности (финансовое, кадровое, организационное,
техническое, математическое, программное, информационное и т.д.). Все эти виды
обеспечения в совокупности представляют собой технологию ведения и применения
данного рейтинга.
Естественно, никто технологию не продает, а если и
продает, то так дорого, что купить ее практически невозможно. Поэтому возникает
вопрос о разработке или поиске подобной технологии в России.
Таким образом, востребованы теоретическое обоснование,
математическая модель, методика численных расчетов (т.е. структуры данных и
алгоритмы их обработки) а также реализующие их инструментальные (программные)
средства, обеспечивающие создание, поддержку, развитие и применение подобных рейтингов.
Данная статья как раз и посвящена рассмотрению отечественной
лицензионной инновационной интеллектуальной технологии, обеспечивающей решение
поставленной проблемы. А именно предлагается применить для этой цели
автоматизированный системно-когнитивный анализ (АСК-анализ) и его программный
инструментарий – интеллектуальную систему «Эйдос».
Этот подход кратко описан в статье [2]. Здесь
рассмотрим его подробнее.
Прежде всего, возникает вопрос о том, что
понимается под эффективностью вузов? Ведь ясно, что прежде чем
оценивать эффективность вузов было бы неплохо, а на самом деле совершенно
необходимо, разобраться с тем, что же это такое. Причина этого ясна: выбор
критериев оценки во многом обуславливается тем, что именно оценивается.
Ясно, что по этому поводу существует много различных
мнений, которые в различной степени аргументированы или не аргументированы и
отражают позиции руководителей образования и науки, профессионального
научно-педагогического сообщества и различных слоев населения. По мнению
автора, с научной точки зрения некорректно и неуместно говорить о каких-то
критериях оценки эффективности вузов, если не определено само это понятие
эффективности, т.е. отсутствует консенсус в профессиональной среде по поводу
того, что же это такое.
Очевидно, для достижения такого консенсуса в наше
время необходимо широкое обсуждение этого вопроса в научной печати, Internet и
СМИ. Однако такое обсуждение не было организовано и критерии оценки
эффективности или признаков неэффективности практически неожиданно «свалились
научно-педагогическому сообществу как снег на голову».
Уже после этого, как это произошло, началось
обсуждение этого вопроса на различных научных конференциях, в научной и
периодической прессе, на личных сайтах, формах и т.п. Но пока шло это
обсуждение и пока оно не пришло к какому-либо консенсусу в этом вопросе, ряд
вузов были закрыты, филиалы сокращены и т.д.
По мнению автора, цель вуза в том, чтобы формировать
компетентных и творчески мыслящих специалистов в соответствии с прогнозом
социального заказа, т.е. таких, которые будут востребованы обществом в будущем
периоде профессиональной деятельности этих специалистов, который составляет
30-40 лет. А должен ли вуз зарабатывать, должен ли он иметь те или иные площади
в расчете на одного учащегося – это все нужно знать только для того, чтобы
спрогнозировать, сможет ли он выполнить свою основную задачу, т.е. подготовку
специалистов. Ни в коем случае нельзя рассматривать эти показатели как
самоцель, т.к. достижение тех или иных их значений, вообще говоря, может и
ничего не говорить о достижении цели вуза. Несут ли эти критерии какую-либо
информацию о достижении цели вуза, и какую именно по величине и знаку, – это
еще надо определить в процессе специального исследования, которое, скорее всего
не было проведено. Странно, что об этом приходиться писать, но приходиться,
т.к. похоже, об этом стали забывать.
Когда консенсус профессионального
научно-педагогического сообщества по вопросу о том, что же понимать под
«эффективностью вуза» будет достигнут, на первый план выступает вопрос о том, с
помощью
какого метода оценивать эту эффективность, т.е. как
ее измерить.
Для автора вполне очевидно, что этот метод должен представлять
собой какой-то вариант метода многокритериальной оценки. Это обусловлено просто
тем, что такие сложные и многофакторные системы как вузы в принципе невозможно
оценивать по одному показателю или критерию.
Чтобы обоснованно выбрать метод оценки эффективности вузов необходимо
сначала научно обосновать требования к нему, а затем составить рейтинг методов
по степени соответствия обоснованным требованиям и выбрать метод, наиболее удовлетворяющий
обоснованным требованиям.
Применение метода факторного анализа для этих целей,
по-видимому, некорректно, т.к. этот метод, предъявляющий настолько жесткие
требования к исходным данным об объекте моделирования, что их практически
невозможно выполнить. Во-первых, факторный анализ – это параметрический метод, предполагающий, что исходные данные
подчиняются многомерным нормальным распределениям. Во-вторых, это метод неустойчивый, т.е. небольшие изменения
исходных данных могут привести к значительным изменениям в модели. Поэтому
исходные данные для факторного анализа должны быть абсолютно точными, что
невозможно не только фактически, но даже в принципе. В-третьих, перед началом факторного анализа
необходимо определить наиболее важные
факторы, которые и будут исследоваться в создаваемой модели. Но при этом в
руководствах по факторному анализу не уточняется, каким способом это
предлагается сделать. А между тем при большом количестве факторов, что является
обычным для большинства реальных задач, это не тривиальная задача, которую
вручную решить невозможно.
Когда метод оценки эффективности вузов выбран, необходимо
ответить на вопрос о том, на основе каких частных критериев
оценивать эффективность вузов и какой исходной информацией о вузах для этого
необходимо располагать?
Ясно, что эти критерии в общем случае могут иметь как
количественную, так и качественную природу и могут измеряться в различных единицах
измерения. Кроме того эти критерии могут иметь различную силу и направление
влияния на интегральную оценку эффективности вузов. Конечно, возникают вопросы
как о
способе определения системы критериев эффективности вуза, так и о
способе определения силы и направления влияния критериев на оценку
эффективности вузов.
Но еще более существенным является вопрос: «О
способе сопоставимого сведения разнородных по своей природе и измеряемых в
различных единицах измерения частных критериев эффективности в один
количественный интегральный критерий эффективности вуза».
Отметим, что в материалах Минобрнауки РФ и о критериях
оценки эффективности вузов даже не упоминается вопрос о том, что когда значения
частных критериев для того или иного вуза установлены, то необходимо каким-то
образом на их основе получить обобщающую количественную оценку его эффективности
в виде одного числа, т.е. надо
как-то объединить значения всех частных критериев в одной формуле, в одном
математическом выражении, которое и называется «Интегральный критерий».
Поэтому, наверное, и говорят не об эффективности или неэффективности
вуза, а всего лишь «о признаках неэффективности», а признаками являются
значения отдельных частных критериев. Если таких признаков неэффективности
много, то делают вывод о том, что вуз неэффективен. Фактически такой подход,
который может быть и применялся, можно назвать неосознанным применением частных
критериев и интегрального критерия, т.е. «неосознанным многокритериальным
подходом». При таком подходе все частные критерии имеют одинаковый вес,
например принимающий значения 0 (неэффективен) и 1 (эффективен). Когда значения
всех частных критериев для вуза установлены, то эти веса суммируются и сумма
сравнивается с минимальными и максимальными оценками, полученными для всех
вузов. Допустим, в Минобрнауки РФ из каких-то своих соображений решили, что в
результате оценки эффективности вузов должно быть закрыто из-за низкой
эффективности 1.5% вузов. Тогда все вузы сортируются по убыванию этой суммы и
1.5% с конца рейтинга помещаются в «черный список».
Но такой «неосознанный многокритериальный подход»
очень и очень уязвим для критики.
Во-первых, возникает законный вопрос о том, почему все критерии
имеют одинаковый вес, хотя даже интуитивно ясно, что они имеют разное значение
и по-разному влияют на эффективность вуза (которая, кстати, непонятно в чем
заключается).
Во-вторых, непонятно, как можно складывать средний балл ЕГЭ принятых на обучение
студентов, объём научных работ на одного сотрудника, количество
иностранцев-выпускников, доходы вуза в расчёте на одного сотрудника и общую
площадь учебно-лабораторных зданий в расчёте на одного студента. За подобные
математические операции ставят двойку по физике в 7-м классе средней школы. Там
школьников учат, что перед тем как складывать величины, измеренные в разных
единицах измерения, например рост учащихся, выраженный в метрах (1.72) и выраженный
в сантиметрах (160), нужно перевести эти величины в одну единицу измерения,
например в метры или в сантиметры. А иначе получится: 1.72+160=161.72, т.е.
некий результат, не поддающийся разумной содержательной интерпретации. Как бы нечто похожее и на таком же научном уровне не
получилось при оценке наличия у вуза «признаков неэффективности». Но
научно-педагогическую общественность не поставили в известность о том, каким
образом вычисляется интегральная оценка эффективности вуза на основе установленных
для него значений частных критериев. Поэтому высказанное опасение остается не
снятым.
В развитом осознанном многокритериальном подходе для
вычисления значения интегрального критерия нужно знать силу и направление
влияния каждого значения частных критериев на величину этого интегрального
критерия. Интегральные критерии бывают трех видов: аддитивные,
мультипликативные и общего вида. Чаще всего используются аддитивные
интегральные критерии, в которых значение интегрального критерия равно просто
сумме значений частных критериев. Но чтобы значения частных критериев можно
было корректно суммировать необходимо, чтобы они были значениями на числовых
измерительных шкалах [3], и чтобы они измерялись в одних и тех же единицах
измерения или были безразмерными.
Оба эти требования выполняются в Автоматизированном
системно-когнитивном анализе (АСК-анализ), в котором все значения всех
факторов, независимо от того количественные они или качественные и в каких
единицах они измеряются в исходных данных, в моделях системы «Эйдос»
(системно-когнитивных моделях) они все измеряются в одних и тех же единицах
измерения – единицах количества информации [2, 3]. Поэтому метод АСК-анализа и предлагается для решения
поставленной проблемы.
АСК-анализ представляет собой один из современных методов
искусственно интеллекта, который предоставляет научно обоснованные ответы на
все эти вопросы, но самое существенное, что он оснащен широко и успешно
апробированным универсальным программным инструментарием, позволяющим решить
эти вопросы не только как обычно на теоретическом концептуальном уровне, но и
на практике [2]. Модели знаний АСК-анализа основаны на нечеткой декларативной
модели представления знаний, предложенной автором в 1983 году и являющейся
гибридной моделью, сочетающей в себе преимущества фреймовой, нейросетевой и
четкой продукционной моделей и обеспечивающей создание моделей очень больших
размерностей до 10 млн. раз превышающих максимальные размерности моделей знаний
экспертных систем с четкими продукциями:
– от фреймовой модели модель представления знания системы
«Эйдос» отличается существенно упрощенной программной реализацией и более
высоким быстродействием без потери функциональности;
– от нейросетевой тем, что обеспечивает хорошо обоснованную
теоретически содержательную интерпретацию весовых коэффициентов на рецепторах и
обучение методом прямого счета [8];
– от четкой продукционной модели – нечеткими продукциями,
представленными в декларативной форме, что обеспечивает эффективное
использование знаний без их многократной генерации для решения задач
идентификации, прогнозирования, принятия решений и исследования моделируемого
объекта.
АСК-анализ
является непараметрическим методом, устойчивым к шуму в исходных данных,
позволяющий корректно обрабатывать неполные (фрагментированные) исходные
данные, описывающие воздействие взаимозависимых факторов на нелинейный [7]
объект моделирования.
Суть метода АСК-анализа в том, что он позволяет рассчитать
на основе исходных данных какое количество
информации содержится в значениях факторов, обуславливающих переходы
объекта моделирования в различные будущие состояния, причем как в желательные,
так и в нежелательные [3].
Он состоит в целенаправленном последовательном повышении степени
формализации исходных данных до уровня, который позволяет ввести
исходные данные в компьютерную систему, а затем преобразовать исходные данные в информацию; информацию преобразовать в знания; использовать знания для решения задач прогнозирования, принятия
решений и исследования предметной области.
Рассмотрим подробнее вопросы выявления, представления
и использования знаний в АСК-анализе и системе «Эйдос».
Данные – это
информация, записанная на каком-либо носителе или находящаяся в каналах связи и
представленная на каком-то языке или в системе кодирования и рассматриваемая
безотносительно к ее смысловому содержанию.
Исходные данные об объекте управления обычно представлены
в форме баз данных, чаще всего временных рядов, т.е. данных, привязанных ко
времени. В соответствии с методологией и технологией автоматизированного системно-когнитивного
анализа (АСК-анализ), развиваемой проф. Е.В.Луценко, для управления и принятия
решений использовать непосредственно исходные данные не представляется
возможным. Точнее сделать это можно, но результат управления при таком подходе оказывается мало чем
отличающимся от случайного. Для реального же решения задачи управления
необходимо предварительно преобразовать данные в информацию, а ее в знания о
том, какие воздействия на корпорацию к каким ее изменениям обычно, как показывает
опыт, приводят.
Информация есть
осмысленные данные.
Смысл данных, в соответствии с концепцией смысла Шенка-Абельсона,
состоит в том, что известны причинно-следственные зависимости между событиями,
которые описываются этими данными. Таким образом, данные преобразуются в
информацию в результате операции, которая называется «Анализ данных», которая
состоит из двух этапов:
1. Выявление событий в данных (разработка классификационных
и описательных шкал и градаций и преобразование с их использованием исходных
данных в обучающую выборку, т.е. в базу событий – эвентологическую базу).
2. Выявление причинно-следственных зависимостей между
событиями.
В случае систем управления событиями в данных являются
совпадения определенных значений входных факторов и выходных параметров объекта
управления, т.е. по сути, случаи перехода объекта управления в определенные
будущие состояния под действием определенных сочетаний значений управляющих факторов.
Качественные значения входных факторов и выходных параметров естественно
формализовать в форме лингвистических переменных. Если же входные факторы и
выходные параметры являются числовыми, то их значения измеряются с некоторой погрешностью
и фактически представляют собой интервальные числовые значения, которые также
могут быть представлены или формализованы в форме лингвистических переменных
(типа: «малые», «средние», «большие» значения экономических показателей).
Какие же математические меры могут быть использованы
для количественного измерения силы и направления причинно-следственных зависимостей?
Наиболее очевидным ответом на этот вопрос, который
обычно первым всем приходит на ум, является: «Корреляция». Однако, в статистике
это хорошо известно, что это совершенно не так.
Для преобразования исходных данных в информацию необходимо не только
выявить события в этих данных, но и найти причинно-следственные связи между
этими событиями. В АСК-анализе предлагается 7 количественных мер
причинно-следственных связей, основной из которых является семантическая мера
целесообразности информации по А.Харкевичу.
Знания – это
информация, полезная для достижения целей.
Значит для преобразования информации в знания необходимо:
1. Поставить цель (классифицировать будущие состояния
моделируемого объекта на целевые и нежелательные).
2. Оценить полезность информации для достижения этой
цели (знак и силу влияния).
Второй пункт, по сути, выполнен при преобразовании данных
в информацию. Поэтому остается выполнить только первый пункт, т.к.
классифицировать будущие состояния объекта управления как желательные (целевые)
и нежелательные.
Знания могут быть представлены в различных формах, характеризующихся
различной степенью формализации:
– вообще
неформализованные знания, т.е. знания в своей собственной форме, ноу-хау
(мышление без вербализации есть медитация);
– знания, формализованные в естественном вербальном
языке;
– знания, формализованные в виде различных методик,
схем, алгоритмов, планов, таблиц и отношений между ними (базы данных);
– знания в форме технологий, организационных, производственных,
социально-экономических и политических структур;
– знания, формализованные в виде математических
моделей и методов представления знаний в автоматизированных интеллектуальных
системах (логическая, фреймовая, сетевая, продукционная, нейросетевая, нечеткая
и другие).
Таким образом, для решения сформулированной проблемы
необходимо осознанно и целенаправленно последовательно повышать степень
формализации исходных данных до уровня, который позволяет ввести исходные
данные в интеллектуальную систему, а затем:
– преобразовать исходные данные в информацию;
– преобразовать информацию в знания;
– использовать знания для решения задач управления, принятия
решений и исследования предметной области.
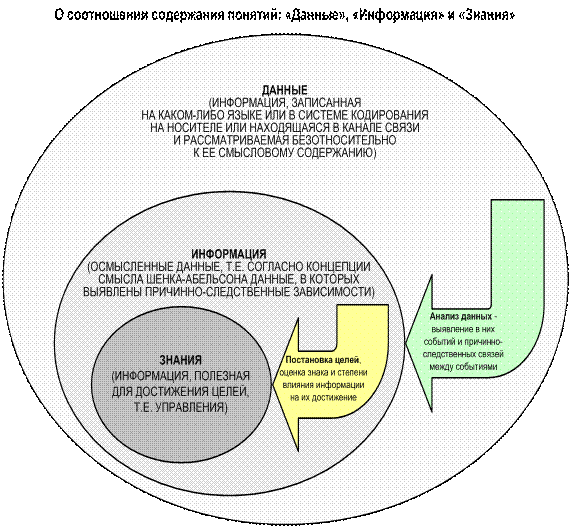
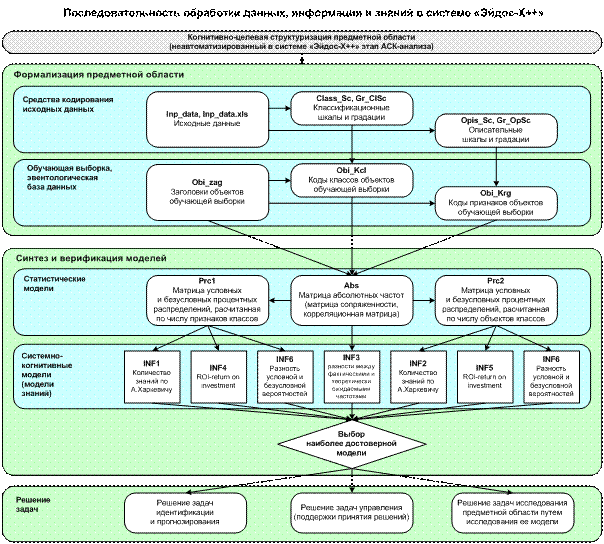
Рисунок 1.
Соотношение содержания понятий: «Данные», «Информация»,
«Знания» и этапы последовательного повышения степени формализации
модели от данных к информации, а от нее к знаниям
АСК-анализ имеет следующие этапы [2]:
– когнитивно-целевая структуризация предметной
области;
– формализация предметной области (формирование классификационных
и описательных шкал и градаций и обучающей выборки);
– синтез и верификация статистических и
системно-когнитивных моделей;
– решение задач идентификации, прогнозирования, принятия
решений и исследования предметной области в наиболее достоверных из созданных моделей.
Единственный
неавтоматизированный в системе «Эйдос» этап – это первый, а остальные приведены
на рисунке 1.
АСК-анализ имеет ряд
особенностей, которые обусловили его выбор в качестве метода решения проблемы:
1. Имеет теоретическое обоснование, основой
которого является семантическая
мера целесообразности информации А.Харкевича.
2. Обеспечивает корректную сопоставимую количественную
обработку разнородных по своей природе факторов, измеряемых в различных
единицах измерения, высокую точность и независимость результатов
расчетов от единиц измерения исходных данных.
3. Обеспечивает построение многомерных моделей объекта
моделирования непосредственно на основе неполных и искаженных эмпирических
данных о нем.
4. Имеет развитую и доступную программную реализацию в
виде универсальной когнитивной аналитической системы «Эйдос».
Очень важно, что этот инструментарий и методики его использования
для решения сформулированных задач могут быть доступны всем заинтересованным
сторонам не только на федеральном уровне, но и в самих вузах, что позволит им
осуществлять аудиторскую самооценку и видеть свое место и динамику среди других
вузов. Это позволит руководителям вузов принимать более осознанные и научно
обоснованные решения, направленные на повышение эффективности и рейтинга их
вуза. Конечно, для реализации на практике регулярного рейтингового анализа
вузов необходимо создание соответствующей достаточно разветвленной инфраструктуры.
Более подробному и конкретному исследованию связанных
с этим вопросов и посвящена данная работа, в которой далее кратко
расстраивается университетский рейтинг Гардиан (который выбран просто в
качестве примера), а затем приводится численный пример его реализации в форме
приложения интеллектуальной системы «Эйдос». Отметим, что создание этого приложения
не требует программирования [4-6],
т.е. система «Эйдос» анализирует исходные данные рейтинга и строит модель, в
которой отражено как влияют значения частных критериев на значение
интегрального критерия, т.е. на итоговую общую оценку рейтинга вуза.
Университетский
рейтинг Гардиан выгодно отличается от других тем, что измеряет
качество преподавания, использования учебных ресурсов, а также оценивает
уровень исследовательской деятельности, что очень полезно для тех, кто
интересуется послевузовскими программами – магистратурой, докторантурой и проч.
Как указано
на официальном сайте рейтинга10 в нем используются следующие частные критерии:
1. Качество преподавания, которое оценивается национальным
студенческим исследованием (NSS): процент удовлетворенных студентов.
2. Получение обратной связи от преподавателя и качество
заданий. Оценивается опросом NSS, в котором устанавливается процент удовлетворенных
студентов.
3. Результаты опроса NSS, в котором оценивается процент
студентов, удовлетворенных общим качеством выбранной программы.
4. Затраты на студента – оценка по 10-балльной шкале.
5. Соотношение студент – работник вуза: количество студентов
на штатную единицу университета.
6. Карьерные перспективы: процент выпускников, сумевших
найти работу или продолжить обучение в течение полугода после окончания вуза.
7. Уровень прогресса студентов на основе сравнения университетских
результатов с оценками предыдущего сертификата (обычно, школьного или
университетского): оценка по 10-балльной шкале. Данный показатель
демонстрирует, насколько преподавательский состав способен повлиять на
улучшение успеваемости студентов.
8. Проходной балл при поступлении в вуз на основе оценок
предыдущего сертификата обучения (школьный или университетский сертификат).
Отметим, что считаем важным
достоинством данного рейтинга то, что он ведется по различным направлениям
подготовки, которых 45 (таблица 1):
Таблица 1 – Направления подготовки, по которым
проводился
университетский рейтинг Гардиан
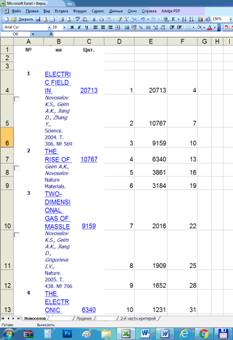
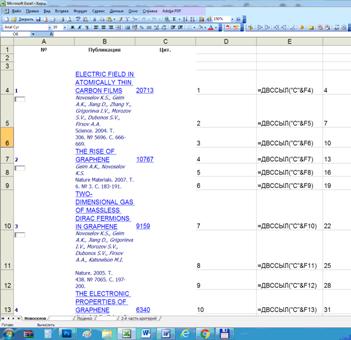
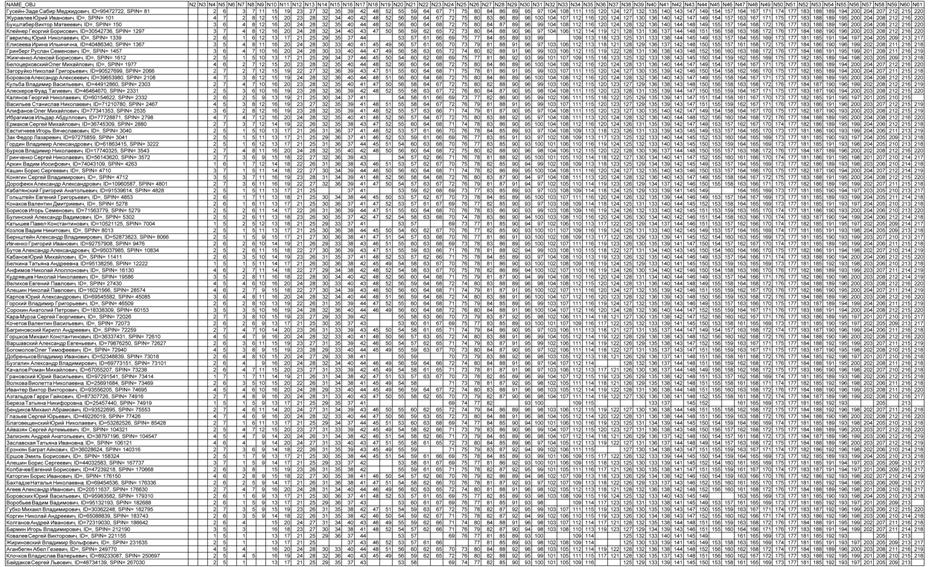
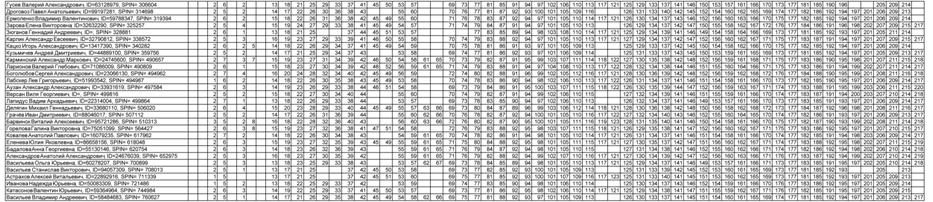
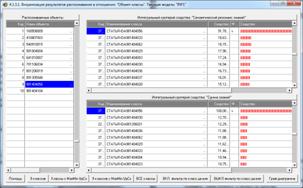
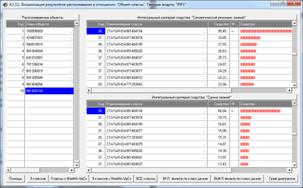


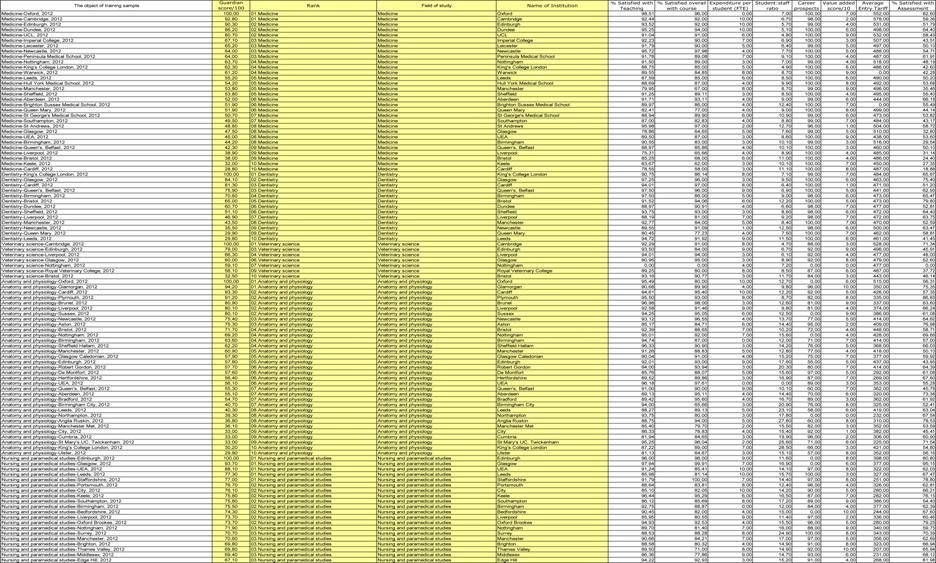

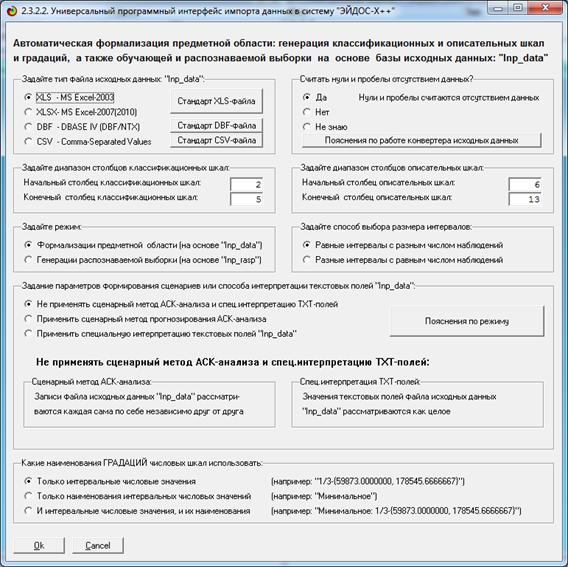
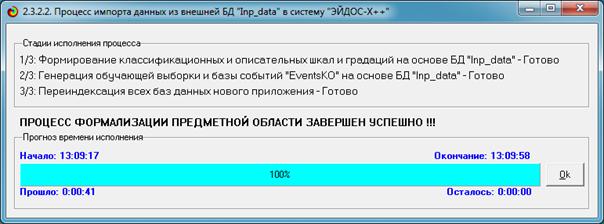
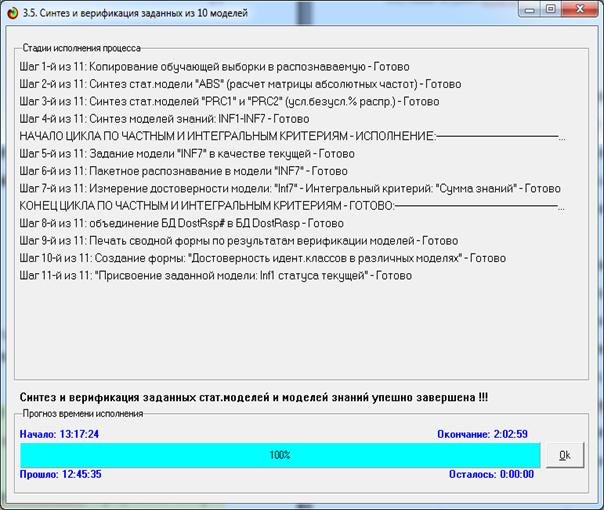
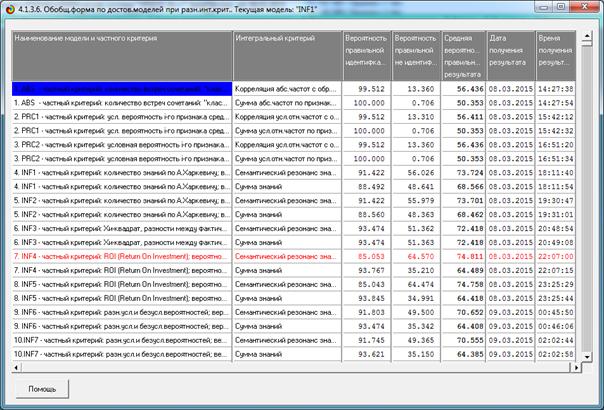
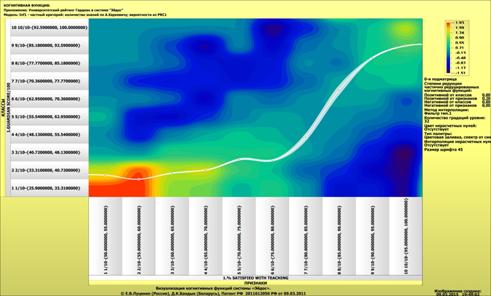
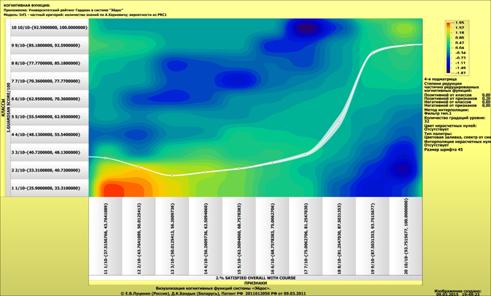
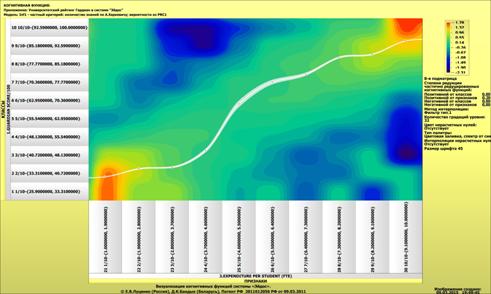
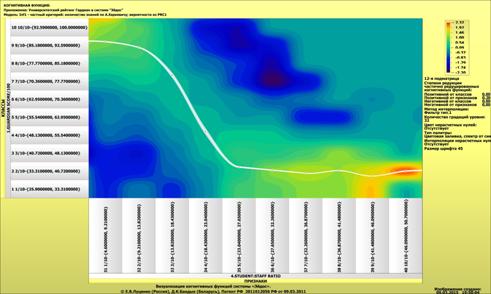
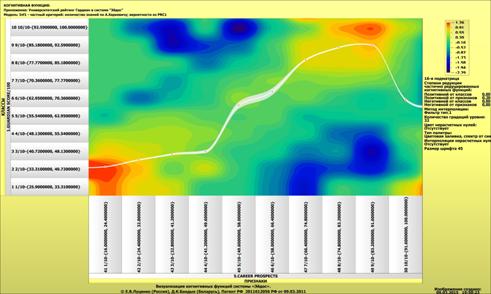
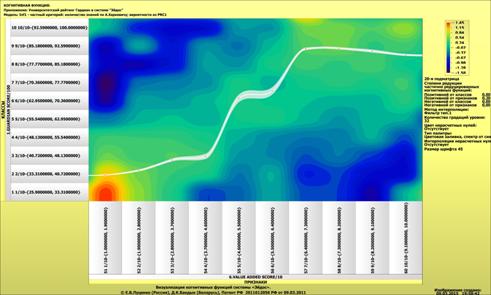
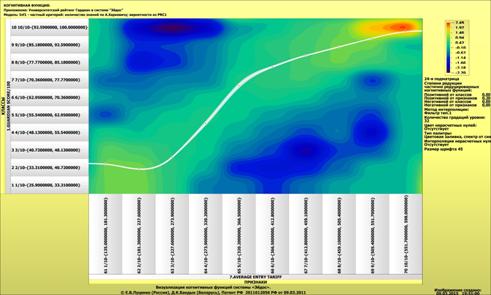
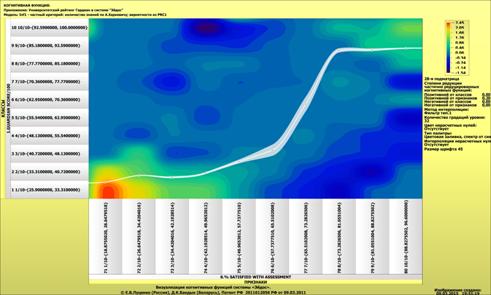
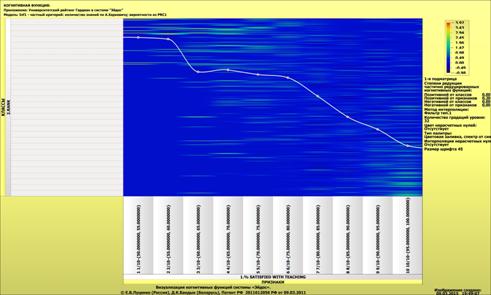
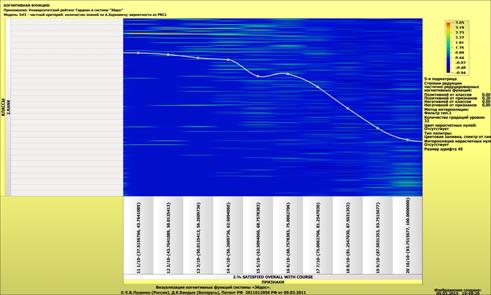
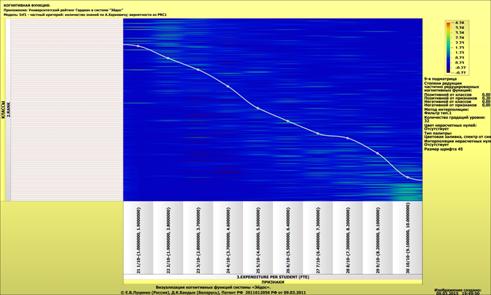
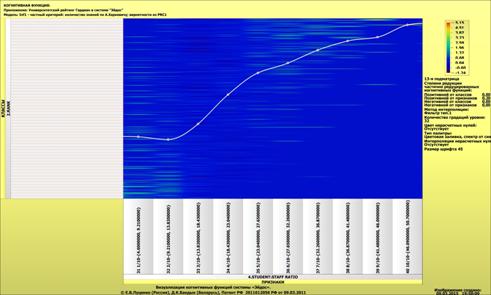
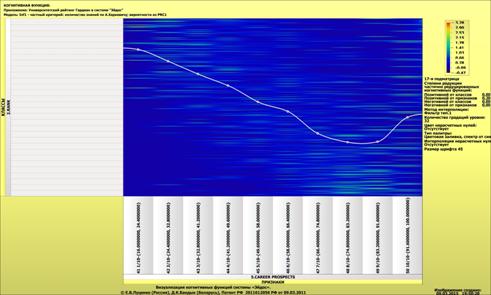

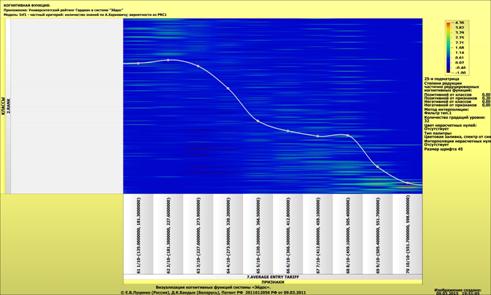
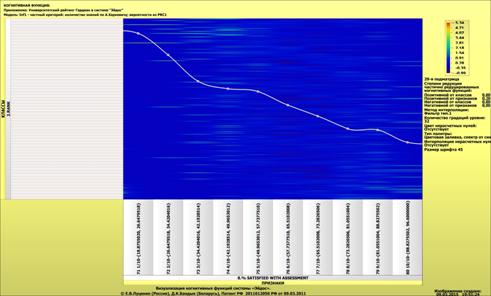
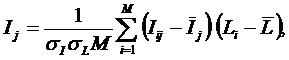

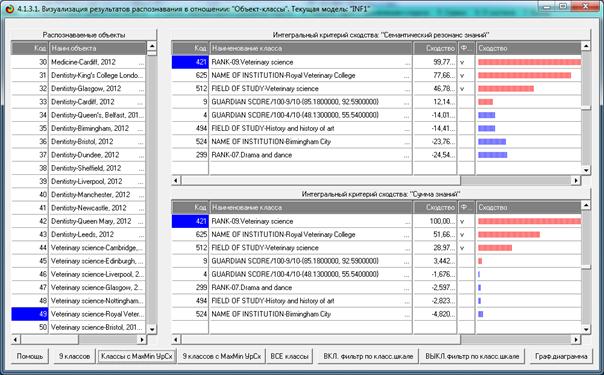
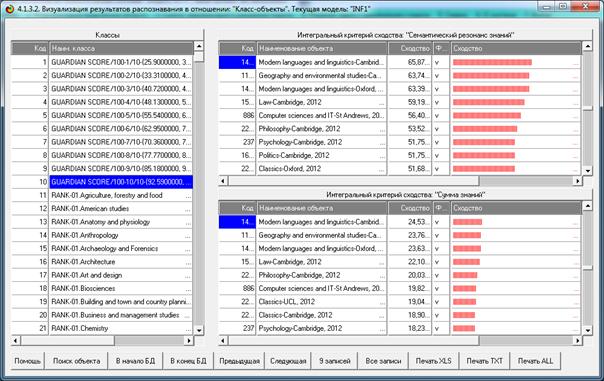
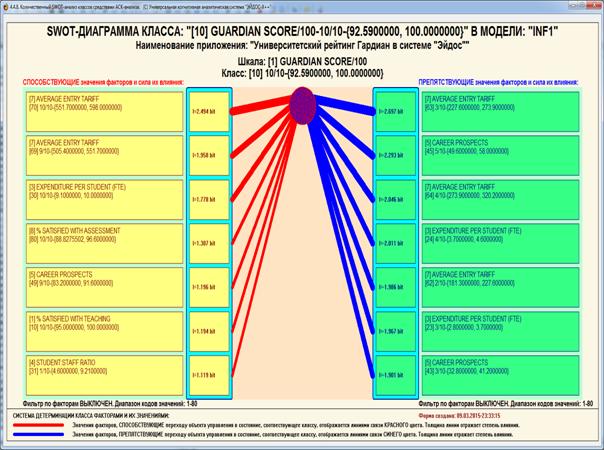
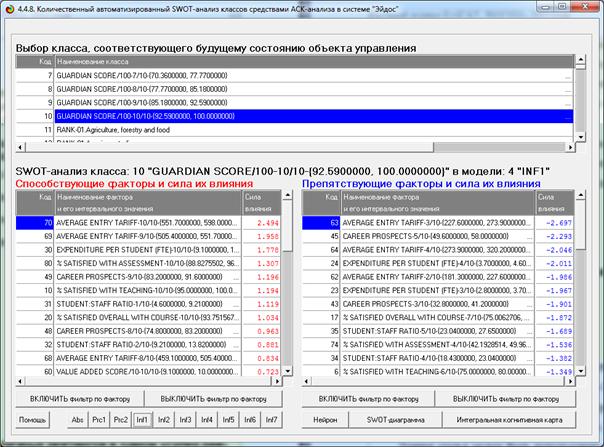
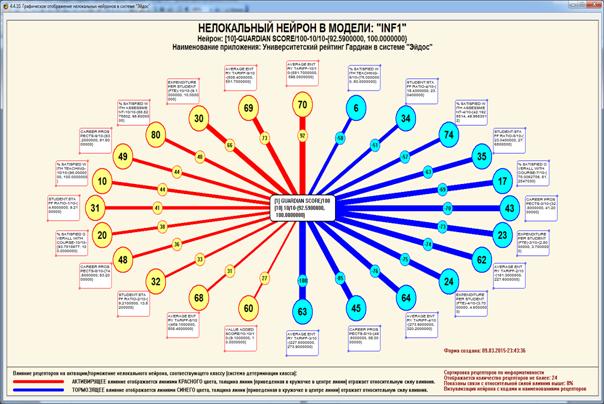
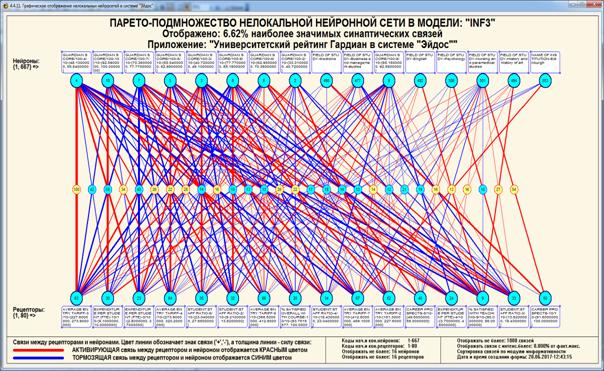
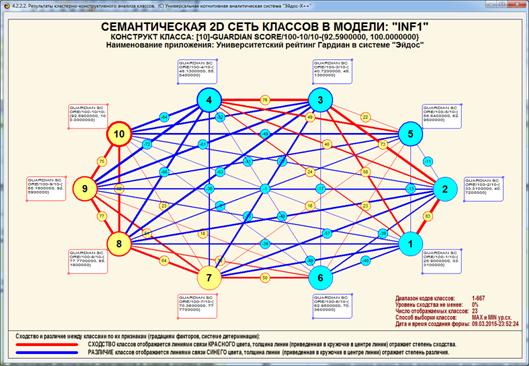
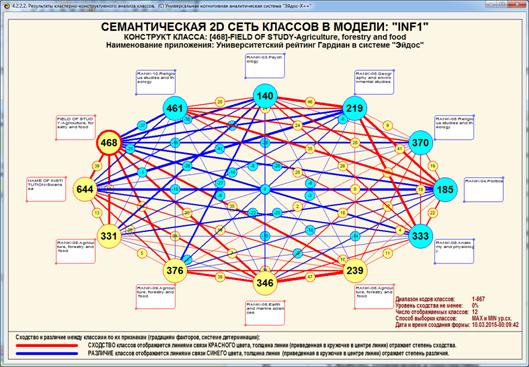
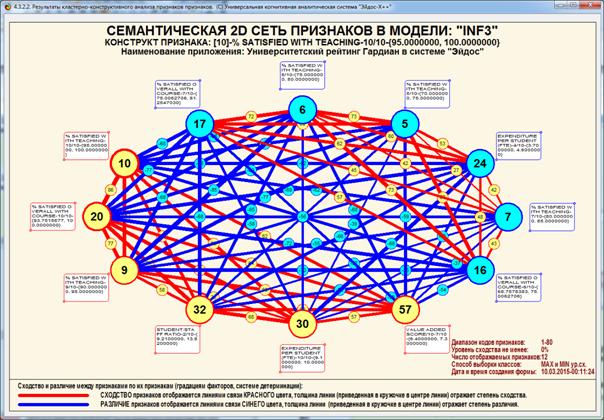
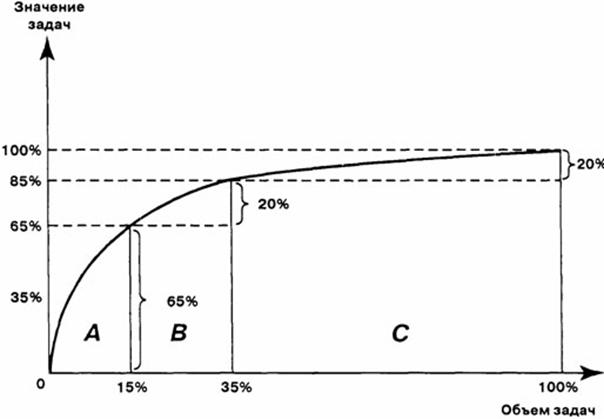
{kind=link}
{kind=link}