ГЛАВА 7. ИНТЕЛЛЕКТУАЛЬНАЯ ПРИВЯЗКА
НЕКОРРЕКТНЫХ
ССЫЛОК К ЛИТЕРАТУРНЫМ ИСТОЧНИКАМ
В БИБЛИОГРАФИЧЕСКИХ БАЗАХ ДАННЫХ
С ПРИМЕНЕНИЕМ АСК-АНАЛИЗА И СИСТЕМЫ
«ЭЙДОС» (НА ПРИМЕРЕ РОССИЙСКОГО ИНДЕКСА
НАУЧНОГО ЦИТИРОВАНИЯ – РИНЦ)
Адекватная и технологичная оценка
результативности, эффективности и качества научной деятельности конкретных
ученых и научных коллективов является актуальной проблемой для информационного
общества и общества, основанного на знаниях. Решение этой проблемы является
предметом наукометрии и ее целью. Современный этап развития наукометрии
существенно отличается от предыдущих появлением в открытом, а также платном
on-line доступе огромного объема детализированных данных по большому числу
показателей как об отдельных авторах, так и о научных организациях и вузах. В
мире, это известные библиографические базы данных: Web of Science, Scopus,
Astrophysics Data System, PubMed, MathSciNet, zbMATH, Chemical Abstracts,
Springer, Agris или GeoRef. В России это прежде всего Российский индекс
научного цитирования (РИНЦ). РИНЦ – это национальная
информационно-аналитическая система, аккумулирующая более 9 миллионов публикаций
российских ученых, а также информацию о цитировании этих публикаций из более
6000 российских журналов. Данных очень много, это так называемые «Большие
данные» ("Big Data"). Основным первичным наукометрическим
показателем, на основе которого строятся все остальные, такие, например, как
индекс Хирша, является число цитирований
работ автора, размещенных в библиографической базе данных. Это число
цитирований определяется программным обеспечением РИНЦ путем так называемой
«привязки», которая представляет собой грамматический
разбор и поиск в базах данных
работ автора, релевантных (соответствующих) ссылкам на них из источников
литературы в работах различных авторов. Однако проблема состоит в том, что, как показывает опыт, авторы допускают
очень большое количество некорректных и просто неполных ссылок в списках
литературы, очень далеких от ГОСТ. В настоящее время программное обеспечение
РИНЦ не может автоматически привязать эти некорректные ссылки и это требует
вмешательства человека. Но централизованно, силами специалистов РИНЦ, это
сделать не представляется возможным из-за огромного объема работ, а
распределенная работа большого числа специалистов на местах все равно требует
централизованной модерации. В результате работа по привязке ссылок к
литературным источникам ведется очень медленно и огромный объем ссылок
оказывается непривязанными. Это ведет к занижению накометрических показателей
как отдельных авторов, так и научных коллективов, что нельзя признать
приемлемым. Решение этой проблемы
предлагается путем применения автоматизированного системно-когнитивного анализа
(АСК-анализ) и его программного инструментария – интеллектуальной системы
«Эйдос». Приводится численный пример интеллектуальной привязки реальных
некорректных ссылок к работам автора на основе небольшого объема реальных
наукометрических данных, находящихся в открытом бесплатном on-line доступе в
РИНЦ
7.1. Введение
Адекватная и технологичная оценка результативности,
эффективности и качества научной деятельности конкретных ученых и научных коллективов
является актуальной проблемой для информационного общества и общества,
основанного на знаниях. Решение этой проблемы является предметом наукометрии и
ее целью.
Современный этап развития наукометрии существенно отличается
от предыдущих появлением в открытом, а также платном on-line доступе огромного
объема детализированных данных по большому числу показателей как об отдельных
авторах, так и о научных организациях и вузах. В мире, это известные
библиографические базы данных: Web of Science, Scopus, Astrophysics Data
System, PubMed, MathSciNet, zbMATH, Chemical Abstracts, Springer, Agris или
GeoRef.
В России это прежде всего Российский индекс научного цитирования
(РИНЦ). РИНЦ – это национальная информационно-аналитическая система,
аккумулирующая более 9 миллионов публикаций российских ученых, а также
информацию о цитировании этих публикаций из более 6000 российских журналов.
Данных очень много, это так называемые «Большие данные» ("Big Data").
Основным первичным наукометрическим показателем, на
основе которого строятся все остальные, такие, например, как индекс Хирша,
является число цитирований работ автора, размещенных в библиографической
базе данных. Это число цитирований определяется программным обеспечением РИНЦ
путем так называемой «привязки», которая представляет собой грамматический
разбор и поиск в базах данных работ автора, релевантных
(соответствующих) ссылкам на них из источников литературы в работах различных
авторов.
Однако проблема
состоит в том, что, как показывает опыт, авторы допускают очень большое
количество некорректных и просто неполных ссылок в списках литературы, очень
далеких от ГОСТ.
В настоящее время программное обеспечение РИНЦ не
может автоматически привязать эти некорректные ссылки и это требует
вмешательства человека.
Но централизованно, силами специалистов РИНЦ, это
сделать не представляется возможным из-за огромного объема работ, а
распределенная работа большого числа специалистов на местах все равно требует
централизованной модерации. В результате работа по привязке ссылок к
литературным источникам ведется очень медленно и огромный объем ссылок
оказывается непривязанными. Это ведет к занижению накометрических показателей
как отдельных авторов, так и научных коллективов, что нельзя признать
приемлемым.
Решение этой проблемы предлагается путем применения
автоматизированного системно-когнитивного анализа (АСК-анализ) и его
программного инструментария – интеллектуальной системы «Эйдос». Приводится
численный пример интеллектуальной привязки реальных некорректных ссылок к работам
автора на основе небольшого объема реальных наукометрических данных,
находящихся в открытом бесплатном on-line доступе в РИНЦ.
7.2. Методика (кратко об АСК-анализе)
7.2.1. Что такое АСК-анализ
Системный анализ
представляет собой современный метод научного познания, общепризнанный метод
решения проблем [5, 6, 7]. Однако возможности практического применения
системного анализа ограничиваются отсутствием программного инструментария,
обеспечивающего его автоматизацию. Существуют разнородные программные системы,
автоматизирующие отельные этапы или функции системного анализа в различных
конкретных предметных областях.
Автоматизированный
системно-когнитивный анализ (АСК-анализ) представляет собой системный анализ,
структурированный по базовым когнитивным операциям (БКО), благодаря чему
удалось разработать для него математическую модель, методику численных расчетов
(структуры данных и алгоритмы их обработки), а также реализующую их программную
систему – систему «Эйдос» [1-3, 7]. Система «Эйдос» разработана в постановке, не
зависящей от предметной области, и имеет ряд программных интерфейсов с внешними
данными различных типов [3]. АСК-анализ
может быть применен как инструмент, многократно усиливающий возможности
естественного интеллекта во всех областях, где используется естественный
интеллект. АСК-анализ был успешно применен для решения задач идентификации,
прогнозирования, принятия решений и исследования моделируемого объекта путем
исследования его модели во многих предметных областях, в частности в экономике,
технике, социологии, педагогике, психологии, медицине, экологии, ампелографии,
геофизике, энтомологии, криминалистике и др. [8, 9].
7.2.2. Истоки
АСК-анализа
Известно, что системный
анализ является одним из общепризнанных в науке методов решения проблем и
многими учеными рассматривается вообще как метод научного познания. Однако, как
впервые заметил еще в 1984 году проф. И.П. Стабин, на практике применение системного анализа
наталкивается на проблему [10]. Суть этой проблемы в том, что обычно системный
анализ успешно применяется в сравнительно простых случаях, в которых в принципе
можно обойтись и без него, тогда как в действительно сложных ситуациях, когда
он действительно чрезвычайно востребован и у него нет альтернатив, сделать это
удается гораздо реже. Проф. И.П. Стабин предложил и путь решения этой проблемы,
который он видел в автоматизации системного анализа [10].
Однако путь от идеи до
создания программной системы долог и сложен, т.к. включает ряд этапов:
– выбор теоретического
математического метода;
– разработка методики
численных расчетов, включающей структуры данных в оперативной памяти и внешних
баз данных (даталогическую и инфологическую модели) и алгоритмы обработки этих
данных;
– разработка программной
системы, реализующей эти математические методы и методики численных расчетов.
7.2.3. Методика
АСК-анализа
7.2.3.1. Предпосылки решения проблемы
Перегудов Ф.И. и Тарасенко
Ф.П. в своих основополагающих работах 1989 и 1997 годов [5, 6] подробно
рассмотрели математические методы, которые в принципе могли бы быть применены
для автоматизации отдельных этапов системного анализа. Однако даже самые лучшие
математические методы не могут быть применены на практике без реализующих их
программных систем, а путь от математического метода к программной системе
долог и сложен. Для этого необходимо разработать численные методы или методики
численных расчетов (алгоритмы и структуры данных), реализующие математический
метод, а затем разработать программную реализацию системы, основанной на этом
численном методе.
В числе первых попыток
реальной автоматизации системного анализа следует отметить докторскую
диссертацию проф. Симанкова В.С. (2001) [11]. Эта попытка была основана на
высокой детализации этапов системного анализа и подборе уже существующих
программных систем, автоматизирующих эти этапы. Идея была в том, что чем выше
детализация системного анализа, чем мельче этапы, тем проще их
автоматизировать. Эта попытка была реализована, однако, лишь для специального
случая исследования в области возобновляемой энергетики, т.к. системы оказались
различных разработчиков, созданные с помощью различного инструментария и не
имеющие программных интерфейсов друг с другом, т.е. не образующие единой
автоматизированной системы. Эта попытка, безусловно, явилась большим шагом по
пути, предложенному проф. И.П. Стабиным, но и ее нельзя признать обеспечившей
достижение поставленной цели, сформулированной Стабиным И.П. (т.е. создание
автоматизированного системного анализа), т.к. она не привела к созданию единой
универсальной программной системы, автоматизирующий системный анализ, которую
можно было бы применять в различных предметных областях.
Необходимо отметить работы
Дж. Клира по системологии и автоматизации решения системных задач, которые
внесли большой вклад в автоматизацию системного анализа путем создания и
применения универсального решателя системных задач (УРСЗ), реализованного в
рамках оригинальной экспертной системы [12, 13]. Однако в экспертной системе
применяется продукционная модель знаний, для получения которых от эксперта
необходимо участие инженера по знаниям (когнитолога). Этим обусловлены
следующие недостатки экспертных систем:
– они генерируют знания
каждый раз, когда они необходимы для решения задач, и это может занимать
значительно большее время, чем при использовании декларативной формы представления
знаний;
– продукционные модели
обычно построены на бинарной логике (if then else), что вызывает возможность
логического конфликта продукций в процесс логического вывода, что приводит к
необратимому останову логического процесса;
– эксперты - люди чаще
всего заслуженные и их время и знания стоят очень дорого; поэтому привлечение
экспертов для извлечения готовых знаний на длительное время проблематично и
обычно эксперт просто физически не может сообщить очень большой объем знаний, а
иногда и не хочет этого делать и сообщает неадекватные знания;
– чаще всего эксперты
формулируют свои знания неформализуемым путем на основе своей интуиции, опыта и
профессиональной компетенции, т.е. не могут сформулировать свои знания в количественной
форме, а пользуются для их формализации порядковыми или даже номинальными
шкалами, поэтому экспертные знания являются не очень точными и для их
формализации необходим инженер по знаниям (когнитолог).
7.2.3.2. АСК-анализ как решение проблемы
Автоматизированный
системно-когнитивный анализ разработан профессором Е.В. Луценко и предложен в
2002 году [1], хотя разработан он был значительно раньше, причем с программным
инструментарием: системой «Эйдос» [1, 3, 7]. Основная идея, позволившая сделать
это, состоит в рассмотрении системного анализа как метода познания (отсюда и
«когнитивный» от «cognitio» – знание, познание, лат.). Эта идея позволила структурировать
системный анализ не по этапам, как пытались сделать ранее, а по базовым
когнитивным операциям системного анализа (БКОСА), т.е. таким операциям, к
комбинациям которых сводятся остальные. Эти операции образуют минимальную
систему, достаточную для описания системного анализа, как метода познания, т.е.
конфигуратор. Понятие конфигуратора предложено В.А. Лефевром [14]. В 2002 году
Е.В. Луценко был предложен когнитивный конфигуратор [1], включающий 10
базовых когнитивных операций.
Когнитивный конфигуратор:
1) присвоение имен;
2) восприятие (описание
конкретных объектов в форме онтологий, т.е. их признаками и принадлежностью к
обобщающим категориям - классам);
3) обобщение (синтез,
индукция);
4) абстрагирование;
5) оценка адекватности
модели;
6) сравнение, идентификация
и прогнозирование;
7) дедукция и абдукция;
8) классификация и
генерация конструктов;
9) содержательное
сравнение;
10) планирование и
поддержка принятия управленческих решений.
Каждая из этих операций
оказалась достаточно элементарна для формализации и программной реализации.
Компоненты
АСК-анализа:
– формализуемая когнитивная
концепция и следующий из нее когнитивный конфигуратор;
– теоретические основы,
методология, технология и методика АСК-анализа;
– математическая модель
АСК-анализа, основанная на системном обобщении теории информации;
– методика численных
расчетов, в универсальной форме реализующая математическую модель АСК-анализа,
включающая иерархическую структуру данных и 24 детальных алгоритма 10 БКОСА;
– специальное
инструментальное программное обеспечение, реализующее математическую модель и
численный метод АСК-анализа – Универсальная когнитивная аналитическая система
"Эйдос" [3].
Этапы
АСК-анализа:
1) когнитивно-целевая
структуризация предметной области;
2) формализация предметной
области (конструирование классификационных и описательных шкал и градаций и
подготовка обучающей выборки);
3) синтез системы моделей
предметной области (в настоящее время система «Эйдос» поддерживает 3
статистические модели и 7 системно-когнитивных моделей (моделей знаний);
4) верификация (оценка
достоверности) системы моделей предметной области;
5) повышение качества
системы моделей;
6) решение задач
идентификации, прогнозирования и поддержки принятия решений;
7) исследование
моделируемого объекта путем исследования его моделей является корректным, если
модель верно отражает моделируемый объект и включает: кластерно-конструктивный
анализ классов и факторов; содержательное сравнение классов и факторов;
изучение системы детерминации состояний моделируемого объекта; нелокальные
нейроны и интерпретируемые нейронные сети прямого счета; классические
когнитивные модели (когнитивные карты); интегральные когнитивные модели
(интегральные когнитивные карты), прямые обратные SWOT-диаграммы; когнитивные
функции и т.д.
Математические
аспекты АСК-анализа
Математическая модель АСК-анализ основана на теории
информации, точнее на системной теории информации (СТИ), предложенной Е.В.
Луценко [1, 2, 3][1]. Это значит, что в
АСК-анализе все факторы рассматриваются с одной единственной точки зрения:
сколько информации содержится в их значениях о переходе объекта, на который они
действуют, в определенное состояние, и при этом сила и направление влияния всех
значений факторов на объект измеряется в одних общих для всех факторов единицах
измерения: единицах количества информации [8, 9].
Это напоминает подход Дугласа Хаббарда [15], но, в
отличие от него, имеет открытый универсальный программный инструментарий
(систему «Эйдос»), разработанный в постановке, не зависящей от предметной
области [1-3]. К тому же на систему «Эйдос» уже в 1994 году было три патента РФ
[3, 16[2]], а
первые акты ее внедрения датируются 1987 годом [1, 3][3],
тогда как основная работа Дугласа Хаббарда [15] появилась лишь в 2009 году. Это
означает, что идеи АСК-анализа не только появились, но и были доведены до
программной реализации в универсальной форме и применены в различных предметных
областях на 22 с лишним года раньше
появления работ Дугласа Хаббарда.
Поэтому АСК-анализ обеспечивает корректную
сопоставимую обработку числовых и нечисловых данных, представленных в разных
типах измерительных шкал и разных единицах измерения [8, 9]. Метод АСК-анализа
является устойчивым непараметрическим методом, обеспечивающим создание моделей
больших размерностей при неполных и зашумленных исходных данных о сложном
нелинейном динамичном объекте управления. Этот метод является чуть ли не
единственным на данный момент, обеспечивающим многопараметрическую типизацию и
системную идентификацию методов, инструментарий которого (интеллектуальная
система «Эйдос») находится в полном открытом бесплатном доступе [3, 16][4] на
сайте разработчика по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm.
На рисунке 1 приведена карта мира с отображением мест
и времени запуска системы «Эйдос» за период с 9 декабря 2016 года по 10 января
2017 года[5]. Из
этой карты мира видно, что в настоящее время система «Эйдос» чаще запускается в
Европе и США, чем в России.
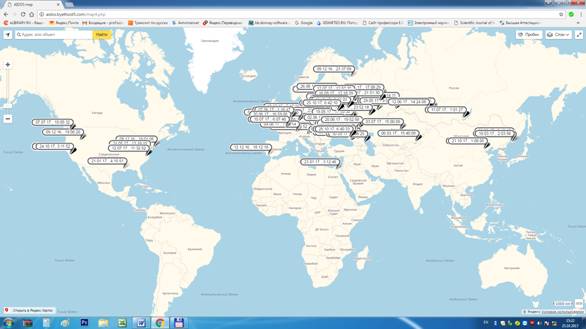
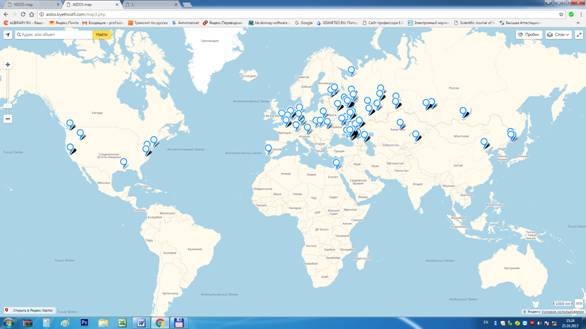
Рисунок 1. Карта мира с отображением мест и времени
запуска системы «Эйдос» за период с 9 декабря 2016 года по 25 октября
2017 года
7.2.4. Некоторые
результаты применения
АСК-анализа в различных предметных областях
Метод системно-когнитивного
анализа и его программный инструментарий интеллектуальная система
"Эйдос" были успешно применены при проведении 6 докторских и 7
кандидатских диссертационных работ в ряде различных предметных областей по
экономическим, техническим, психологическим и медицинским наукам.
АСК-анализ был успешно
применены при выполнении десятков грантов РФФИ и РГНФ различной направленности
за длительный период - с 2002 года по настоящее время (2016 год).
По проблематике АСК-анализа
издана 22 монография, получено 29 патентов на системы искусственного
интеллекта, их подсистемы, режимы и приложения, опубликовано более 200 статей в
изданиях, входящих в Перечень ВАК РФ (по данным РИНЦ). В одном только Научном журнале КубГАУ (входит
в Перечень ВАК РФ с 26-го марта 2010 года) автором АСК-анализа проф.Е.В.Луценко
опубликовано 200 статей, общим объёмом 350,683 у.п.л., в среднем 1,753 у.п.л.
на одну работу.
По этим публикациям,
грантам и диссертационным работам видно, что АСК-анализ уже был успешно
применен в следующих предметных областях и научных направлениях: экономика
(региональная, отраслевая, предприятий, прогнозирование фондовых рынков),
социология, эконометрика, биометрия, педагогика (создание педагогических
измерительных инструментов и их применение), психология (личности,
экстремальных ситуаций, профессиональных и учебных достижений, разработка и
применение профессиограмм), сельское хозяйство (прогнозирование результатов
применения агротехнологий, принятие решений по выбору рациональных
агротехнологий и микрозон выращивания), экология, ампелография, геофизика
(глобальное и локальное прогнозирование землетрясений, параметров магнитного
поля Земли, движения полюсов Земли), климатология (прогнозирование Эль-Ниньо
и Ла-Нинья),
возобновляемая энергетика, мелиорация и управление мелиоративными системами,
криминалистика, энтомология и ряд других областей.
АСК-анализ вызывает большой
интерес во всем мире. Сайт автора АСК-анализа [16] посетило около 500 тыс. посетителей с уникальными
IP-адресами со всего мира. Еще около 500 тыс. посетителей открывали работы по
АСК-анализу в Научном журнале КубГАУ.
Необходимо отметить, что в
развитии различных теоретических основ и практических аспектов АСК-анализа
приняли участие многие ученые: д.э.н.,
к.т.н., проф. Луценко Е.В., Засл. деятель науки РФ, д.т.н., проф. Лойко В.И., к.ф.-м.н., Ph.D., проф., Трунев А.П. (Канада), д.э.н., д.т.н., к.ф.-м.н., проф. Орлов
А.И., к.т.н., доц. Коржаков В.Е., д.э.н., проф. Барановская Т.П., д.э.н.,
к.т.н., проф. Ермоленко В.В., к.пс.н. Наприев И.Л., к.пс.н., доц. Некрасов
С.Д., к.т.н., доц. Лаптев В.Н., к.пс.н, доц. Третьяк В.Г., к.пс.н., Щукин Т.Н.,
д.т.н., проф. Симанков В.С., д.э.н., проф. Ткачев А.Н., д.т.н., проф. Сафронова
Т.И., д.э.н., доц. Горпинченко К.Н., к.э.н., доц. Макаревич О.А., к.э.н., доц.
Макаревич Л.О., к.м.н. Сергеева Е.В. (Фомина Е.В.), Бандык Д.К.
(Белоруссия), Чередниченко Н.А., к.ф.-м.н. Артемов А.А., д.э.н., проф. Крохмаль
В.В., д.т.н., проф. Рябцев В.Г., к.т.н., доц. Марченко
А.Ю., д.т.н., проф. Фролов В.Ю., д.ю.н, проф. Швец С.В., Засл. деятель науки Кубани, д.б.н., проф. Трошин Л.П.,
Засл. изобр. РФ, д.т.н., проф. Серга Г.В., Сергеев А.С., д.б.н., проф.
Стрельников В.В. и другие.
7.2.5. Предлагаемая идея применения АСК-анализа
для решения поставленной в работе проблемы
Казалось бы что здесь сложного?
Ссылка на работу должна совпадать с
библиографическим описанием самой работы и нет никакой проблемы найти ее в базе
данных по точному совпадению тестов ссылки и описания работы. Точно также
делается в любой информационно-поисковой системе (ИПС): отчет формируется из
записей базы данных, в которых все значения полей точно совпадают со
значениями, заданными в запросе.
Но дело в том, что обычно (как правило) текст ссылки
отличается от текста библиографического описания работы и точное их совпадение
наблюдается крайне редко. Поэтому подход, реализуемый в ИПС с точным поиском в
данном случае практически неприменим.
Но есть ИПС с поиском по неполному запросу. В
таких ИПС для каждой записи базы данных определяется степень ее соответствия с
запросу. Эта степень соответствия считается равной числу полей запроса и
записи, значения которых совпали. Для таких ИПС необходим предварительный грамматический
разбор как описания самой работы, так и ссылки на нее. При этом разборе
определяются значения полей библиографических описаний работы (источника) и
ссылки на нее. После этого происходит сравнение значений этих полей. Конечно в
этом случае и сам грамматический разбор является проблемой. При ошибке в
разборе поиск работы ведется уже не там, например при определении сборника
статей конференции как журнала поиск ведется уже в журналах и не дает
результата. Но главное не в этом, а в том, что вес или роль всех полей
библиографического описания считается одинаковым, тогда как в действительности
он разный. Так, например, год издания и Ф.И.О. автора значительно важнее
какого-нибудь слова в названии.
Есть ИПС с нечетким поиском по нечеткому запросу. В таких
ИПС, как и в ИПС по неполному запросу, когда значения некоторых полей могут
отсутствовать, для каждого поля определяется его вес и уже после этого для всех
записей базы данных определяется степень их соответствия запросу уже не просто
по числу совпавших полей, но уже по суммарному весу совпавших полей. В таких
ИПС возникает проблема адекватного определения веса полей при идентификации
записей. Обычно этот вес определяется экспертным путем, т.е. «на основе опыта,
интуиции и профессиональной компетенции»[6], а в
систему вводится вручную. Конечно, при реальных объемах данных РИНЦ как
определение этих весов, так и их ввод в систему вручную совершенно невозможен
из-за огромных объемов данных. Получается, что необходимо и это
автоматизировать.
Автоматизированные системы, которые обеспечивают
автоматическое определение весов признаков и нечеткую идентификацию с их
использованием называются системами распознавания образов. Такие системы могут
рассматриваться как дальнейшее обобщение ИПС с неполным и нечетким запросом.
Универсальная когнитивная аналитическая система
«Эйдос» [3] является такой системой. Более того, система «Эйдос» обеспечивает
широкие возможности применения интеллектуальных технологий для обработки
нечисловых данных, в частности текстов и у авторов имеется большой опыт решения
задач в этой области [17-24].
Предлагается решение поставленной в работе проблемы
путем преобразования данных в информацию, а ее в знания (рисунки 2 и 3) [25,
26][7].
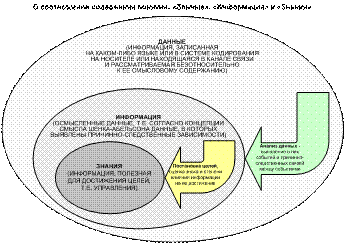
Рисунок 2. О соотношении содержания понятий:
«Данные», «Информация» и «Знания»
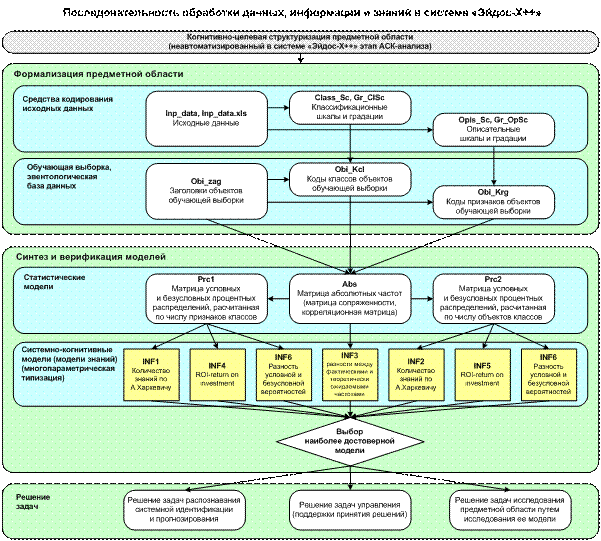
Рисунок 3. Этапы преобразования данных в информацию, а
ее в знания
Данные – это информация, записанная на каком-либо носителе
или находящаяся в каналах связи и представленная на каком-то языке или в
системе кодирования и рассматриваемая безотносительно к ее смысловому
содержанию.
Исходные данные об объекте управления обычно
представлены в форме баз данных, чаще всего временных рядов, т.е. данных,
привязанных ко времени. В соответствии с методологией и технологией
автоматизированного системно-когнитивного анализа (АСК-анализ), развиваемой
проф. Е.В.Луценко, для управления и принятия решений использовать
непосредственно исходные данные не представляется возможным. Точнее сделать это
можно, но результат управления при таком
подходе оказывается мало чем отличающимся от случайного. Для реального же
решения задачи управления необходимо предварительно преобразовать данные в
информацию, а ее в знания о том, какие воздействия на корпорацию к каким ее
изменениям обычно, как показывает опыт, приводят.
Информация есть осмысленные данные.
Смысл данных, в соответствии с концепцией смысла Шенка-Абельсона,
состоит в том, что известны причинно-следственные зависимости между событиями,
которые описываются этими данными. Таким образом, данные преобразуются в
информацию в результате операции, которая называется «Анализ данных», которая
состоит из двух этапов:
1. Выявление событий в данных (разработка
классификационных и описательных шкал и градаций и преобразование с их
использованием исходных данных в обучающую выборку, т.е. в базу событий –
эвентологическую базу).
2. Выявление причинно-следственных зависимостей между
событиями.
В случае систем управления событиями в данных являются
совпадения определенных значений входных факторов и выходных параметров объекта
управления, т.е. по сути, случаи перехода объекта управления в определенные
будущие состояния под действием определенных сочетаний значений управляющих
факторов. Качественные значения входных факторов и выходных параметров
естественно формализовать в форме лингвистических переменных. Если же входные
факторы и выходные параметры являются числовыми, то их значения измеряются с
некоторой погрешностью и фактически представляют собой интервальные числовые
значения, которые также могут быть представлены или формализованы в форме
лингвистических переменных (типа: «малые», «средние», «большие» значения
экономических показателей).
Какие же математические меры могут быть использованы
для количественного измерения силы и направления причинно-следственных зависимостей?
Наиболее очевидным ответом на этот вопрос, который
обычно первым всем приходит на ум, является: «Корреляция». Однако, в статистике
это хорошо известно, что это совершенно не так.
Для преобразования исходных данных в информацию необходимо не только
выявить события в этих данных, но и найти причинно-следственные связи между
этими событиями. В АСК-анализе предлагается 7 количественных мер
причинно-следственных связей, основной из которых является семантическая мера
целесообразности информации по А.Харкевичу.
Знания – это информация,
полезная для достижения целей.
Значит для преобразования информации в знания необходимо:
1. Поставить цель (классифицировать будущие состояния
моделируемого объекта на целевые и нежелательные).
2. Оценить полезность информации для достижения этой
цели (знак и силу влияния).
Второй пункт, по сути, выполнен при преобразовании
данных в информацию. Поэтому остается выполнить только первый пункт, т.к.
классифицировать будущие состояния объекта управления как желательные (целевые)
и нежелательные.
Знания могут быть представлены в различных формах,
характеризующихся различной степенью формализации:
– вообще
неформализованные знания, т.е. знания в своей собственной форме, ноу-хау (мышление
без вербализации есть медитация);
– знания, формализованные в естественном вербальном
языке;
– знания, формализованные в виде различных методик,
схем, алгоритмов, планов, таблиц и отношений между ними (базы данных);
– знания в форме технологий, организационных, производственных,
социально-экономических и политических структур;
– знания, формализованные в виде математических
моделей и методов представления знаний в автоматизированных интеллектуальных
системах (логическая, фреймовая, сетевая, продукционная, нейросетевая, нечеткая
и другие).
Таким образом, для решения сформулированной проблемы
необходимо осознанно и целенаправленно последовательно повышать степень
формализации исходных данных до уровня, который позволяет ввести исходные
данные в интеллектуальную систему, а затем:
– преобразовать исходные данные в информацию;
– преобразовать информацию в знания;
– использовать знания для решения задач управления,
принятия решений и исследования предметной области.
7.3. Результаты
(численный пример
на реальных данных)
Рассмотрим численный пример, основанный на реальных
данных РИНЦ и иллюстрирующий применение АСК-анализа и системы «Эйдос» для
решения поставленной в работе проблемы.
При этом выполним описанные выше этапы АСК-анализа и
этапы преобразования данных в информацию, а ее в знания.
7.3.1. Исходные данные
Исходные данные для численного примера взяты с сайта
РИНЦ: http://elibrary.ru/
по автору: «Елепов Б.С.»
Эти данные состоят из двух файлов:
– Обучающая выборка.doc (6 страниц, 111 источников);
– Тестовая выборка.doc (27 страниц, 588 ссылок на
источники).
Ниже приведены фрагменты этих файлов.
Фрагмент
файла обучающей выборки (работы автора)
РАЗРАБОТКА МОДЕЛИ
ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В
УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов
С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР
ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК:
НОЖНИЦЫ РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И.
Вестник Российской академии естественных наук. Западно-Сибирское отделение.
2016. № 18. С. 198-205.
ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ
БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ:
НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН.
2015. № 8. С. 7-14.
ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО
ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО
ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин
Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32.
ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ
БИБЛИОТЕКА: ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л.
Труды ГПНТБ СО РАН. 2014. № 7. С. 14-22.
ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В
ОБЛАСТИ НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В.,
Елепов Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах
устойчивого развития. 2013. Т. 21. № 4. С. 463-473.
БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л.
Труды ГПНТБ СО РАН. 2013. № 4. С. 7-18.
Фрагмент
файла тестовой выборки
(ссылки на работы автора)
Алексеев A.G, Елепов Б.С., Котов В.Е., Метляев Ю.В.
о программе работ по созданию сети информационно-вычислительных систем
(центров) в Сибирском отделении АН СССР. -Новосибирск, 1987. -27 с. -(Препр./ВЦ
Сиб. отд-ния АН СССР; N 734).
Алексеев
А.С., Елепов Б.С., Бобров JI.K. Развитие инфраструктуры информации Сибирского
отделения РАН//Информационные ресурсы. Интеграция. Технология: 3-я междунар.
конф. ?НТИ-97?, Москва, 26 -28 нояб.
Алексеев
А.С., Елепов Б.С., Бобров Л.К. Развитие инфраструктуры информации Сибирского
отделения РАН//Информационные ресурсы. Интеграция. Технология./Междунар. конф.
НТИ-
Алексеев
А.С., Елепов Б.С., Котов В.Е., Метляев Ю.В. О программе работ по созданию сети
информационно-вычислительных систем (Центров) в Сибирском отделении АН СССР. -
Новосибирск, 1987. - 27 с. - (Препринт / РАН. Сиб. отд-ние. ВЦ; 743).
Алексеев
А.С., Елепов Б.С., Котов В.Е., Метляев Ю.В. О программе работ по созданию сети
информационно-вычислительных систем (центров) в Сибирском отделении АН СССР.
-Новосибирск, 1987, -27 с. -(Препр./ВЦ Сиб. отд-ния АН СССР; N 734)
Древнерусские книжные памятники в Сибири:
цифровое решение проблемы сохранности и доступности/В. Н. Алексеев
//Библиосфера. -2007. -№ 1. -С. 9 -15.
Алексеев В.
Н., Дергачева-Скоп Е. И., Елепов Б. С., Шабанов А. В. Древнерусские книжные
памятники в Сибири: цифровое решение проблемы сохранности и
доступности//Библиосфера. 2007. № 1. С. 9-14.
Алексеев, В.
Н. Древнерусские книжные памятники в Сибири: Цифровое решение проблемы
сохранности и доступности / В. Н. Алексеев, Е. И. Дергачева-Скоп, Б. С. Елепов,
А. В. Шабанов // Библиосфера. - № 1. - 2007
Аристов
Ю.И., Глазнев И.С., Алексеев В.Н., Гордеева Л.Г., Сальникова И.В., Шилова И.А.,
Кундо Л.П., Елепов Б.С., // Библиосфера. 2009. Т. 5. № 1. С. 26.
Открытое
письмо/Арский Ю.М., Елепов Б.С., Зайцев В.Н. и др.//Поиск. -1999.-№43 (545). С.
3.
7.3.2. Когнитивно-целевая
структуризация
предметной области
На этом этапе АСК-анализа мы должны решить, что мы
хотим определять и на основе чего.
В данном случае мы хотим по словам, входящим в
библиографические описания ссылок на литературные источники определять сами эти
источники (идентифицировать их), и, таким образом, привязывать ссылки к
источникам.
В системе «Эйдос» реализована возможность
лемматизации, но мы не будем ей пользоваться, т.к. она хотя и сокращает размерности
моделей и ускоряет обработку, но приводит к некоторой потере информации и
понижению достоверности идентификации.
7.3.3. Формализация предметной
области
Как видно из рисунка 3 этот этап АСК-анализа состоит в
разработке справочников классификационных и описательных шкал и градаций и
кодировании с их помощью исходных данных, в результате чего формируется база
событий или обучающая выборка. По сути этот этап представляет собой
нормализацию исходных данных, т.е. их преобразование в такую форму, которую
удобно обрабатывать на компьютере.
Для небольших задач это можно сделать и вручную. Но
гораздо удобнее воспользоваться специально созданными для этого программными
интерфейсами системы «Эйдос» с внешними базами данных. В системе «Эйдос» есть
довольно много таких интерфейсов (рисунок 4):

Рисунок 4. Программные интерфейсы системы «Эйдос»
с внешними данными различных типов
Для наших целей подходят интерфейсы 2.3.2.2 и особенно
2.3.2.1. Рассмотрим стандарты представления исходных, достоинства и ограничения
этих интерфейсов.
7.3.3.1. Универсальный программный интерфейс
импорта данных из табличных файлов
(режим 2.3.2.2)
Этот программный интерфейс предназначен для ввода
данных из табличных файлов MS Excel или dbf. В таблице 1 приведен фрагмент
исходных данных, подготовленных для интерфейса 2.3.2.2:
Таблица 1 – Исходные данные в стандарте интерфейса
2.3.2.2 (фрагмент)
|
Объект |
Классы |
Признаки |
|
1-РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР |
1-РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР |
РАЗРАБОТКА МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е., Баженов С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о НИР |
|
2-ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И. Вестник Российской академии естественных наук. Западно-Сибирское отделение. 2016. № 18. С. 198-205. |
2-ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И. Вестник Российской академии естественных наук. Западно-Сибирское отделение. 2016. № 18. С. 198-205. |
ПРОБЛЕМЫ КОМПЛЕКТОВАНИЯ НАУЧНЫХ БИБЛИОТЕК: НОЖНИЦЫ РЕФОРМЫ НАУКИ Елепов Б.С., Гуськова А.Е., Босина Л.В., Подкорытова Н.И. Вестник Российской академии естественных наук. Западно-Сибирское отделение. 2016. № 18. С. 198-205. |
|
3-ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ: НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2015. № 8. С. 7-14. |
3-ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ: НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2015. № 8. С. 7-14. |
ГОСУДАРСТВЕННАЯ ПУБЛИЧНАЯ НАУЧНО-ТЕХНИЧЕСКАЯ БИБЛИОТЕКА СИБИРСКОГО ОТДЕЛЕНИЯ РОССИЙСКОЙ АКАДЕМИИ НАУК В ЭЛЕКТРОННОЙ СРЕДЕ: НОВЫЕ НАПРАВЛЕНИЯ ДЕЯТЕЛЬНОСТИ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2015. № 8. С. 7-14. |
|
4-ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32. |
4-ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32. |
ИНТЕГРАЦИЯ ИНФОРМАЦИОННЫХ РЕСУРСОВ СИБИРСКОГО ОТДЕЛЕНИЯ РАН КАК ШАГ К ФОРМИРОВАНИЮ ЕДИНОГО НАУЧНО-ОБРАЗОВАТЕЛЬНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА Елепов Б.С., Жижимов О.Л., Федотов А.М., Шокин Ю.И. Теория и практика общественно-научной информации. 2014. № 22. С. 21-32. |
|
5-ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА: ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2014. № 7. С. 14-22. |
5-ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА: ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2014. № 7. С. 14-22. |
ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ И НАУЧНАЯ БИБЛИОТЕКА: ИНФОРМАЦИОННО-ТЕХНОЛОГИЧЕСКИЙ ПРОГНОЗ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2014. № 7. С. 14-22. |
|
6-ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого развития. 2013. Т. 21. № 4. С. 463-473. |
6-ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого развития. 2013. Т. 21. № 4. С. 463-473. |
ИССЛЕДОВАНИЯ СИБИРСКОГО ОТДЕЛЕНИЯ РАН В ОБЛАСТИ НАНОНАУКИ И НАНОТЕХНОЛОГИИ: БИБЛИОМЕТРИЧЕСКИЙ АНАЛИЗ Бусыгина Т.В., Елепов Б.С., Зибарева И.В., Лаврик О.Л., Шабурова Н.Н. Химия в интересах устойчивого развития. 2013. Т. 21. № 4. С. 463-473. |
|
7-БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2013. № 4. С. 7-18. |
7-БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2013. № 4. С. 7-18. |
БИБЛИОТЕКИ И МИРЪ Елепов Б.С., Лаврик О.Л. Труды ГПНТБ СО РАН. 2013. № 4. С. 7-18. |
На рисунке 5 приведена экранная форма управления
интерфейсом 2.3.2.2 с параметрами для ввода данных из таблицы:
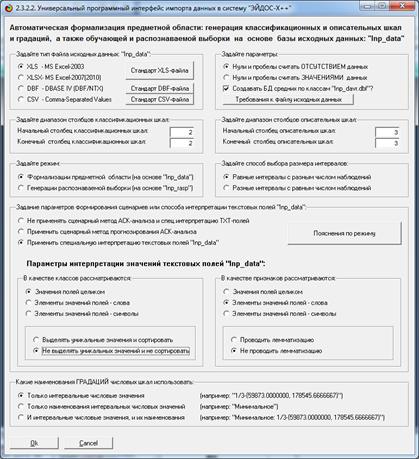
Рисунок 5. Экранная форма управления интерфейсом
2.3.2.2
с параметрами для ввода данных из таблицы 1.
Данный режим формирует классификационные и
описательные шкалы и градации и обучающую выборку на основе исходных данных,
подобных представленным в таблице 1. Работоспособные модели были созданы.
Как классы рассматривалось библиографическое описание
целиком, а как признаки этого описания – слова и числа, из которых оно состоит.
Однако авторы отказались от этого варианта, т.к., как
оказалось, некоторые библиографические описания содержали более 255 символов,
т.е. по длине были больше, чем максимальный размер поля базы данных, и,
поэтому, были обрезаны до 255 символов. Поэтому данный вариант в данной работе не
рассматривается. Отметим лишь, что в системе «Эйдос» есть встроенная лабораторная
работа №3.02 (рисунки 6 и 7), которая как раз предназначена для изучения
студентами этого подхода. Этому же посвящены работы автора [17-23] и ряд
других.
Рисунок 6. Helps по встроенным лабораторным работам
системы «Эйдос»
Рисунок 7. Help по встроенной лабораторной работе 3.02
системы «Эйдос»
7.3.3.2. Программный интерфейс
импорта данных
из текстовых файлов (режим 2.3.2.1)
По этой причине для формализации предметной области
был выбран интерфейс 2.3.2.1, который фактически не имеет ограничения на размер
текстовых файлов обучающей выборки (эти файлы должны быть не более 2 Гб).
Но для импорта исходных данных для обучающей выборки и
распознаваемой выборки из текстовых файлов вида, приведенного в разделе 3.1,
необходимо сначала разбить эти файлы на абзацы и каждый абзац записать в виде
отдельного файла в папки:
– c:\Aidos-X\AID_DATA\Inp_data\ для обучающей выборки
(источников);
– c:\Aidos-X\AID_DATA\Inp_rasp\ для распознаваемой
выборки (тестовой выборки или выборки ссылок на источники).
Экранная форма служебного режима 2.3.2.9,
предназначенного для этого разбиения, приведена на рисунке 8:
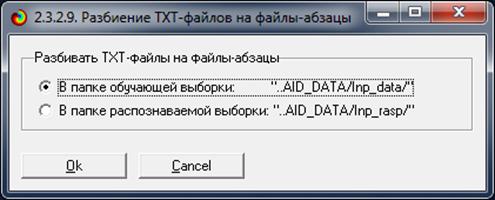
Рисунок 8. Экранная форма управления режимом 2.3.2.9.
Для работы этого режима необходимо с помощью MS Word
преобразовать файл исходных данных в текстовый файл с кодировкой DOS-текст и
поместить его в папку: c:\Aidos-X\AID_DATA\Inp_data\, а затем запустить режим
2.3.2.1.
В результате работы режима с файлом исходных данных,
фрагмент которого приведен в разделе 3.1, а полностью он приведен по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip,
получим 111 текстовых файлов в папке: c:\Aidos-X\AID_DATA\Inp_data\ (рисунок
10):

Рисунок 10. Текстовые файлы с библиографическими
описаниями
литературных источников обучающей выборки (работа автора),
сформированные режимом 2.3.2.9
Ниже приведено содержимое файла: «000001 - Обучающая
выборка.txt»:
РАЗРАБОТКА
МОДЕЛИ ПРОГРАММНО-ТЕХНОЛОГИЧЕСКОЙ ОСНОВЫ ИНФОРМАЦИОННО-БИБЛИОТЕЧНОЙ СИСТЕМЫ СО
РАН В УСЛОВИЯХ МЕНЯЮЩЕЙСЯ КОММУНИКАЦИОННОЙ СРЕДЫ Редькина Н.С., Гуськов А.Е.,
Баженов С.Р., Скарук Г.А., Кулева О.В., Шевченко Л.Б., Паршиков Р.М. отчет о
НИР
Отметим, что файл: «000111 - Обучающая выборка.txt» пустой,
т.к. в файле исходных данных: «Обучающая выборка.txt» в конце был пустой абзац
из одной строки.
Экранная форма управления интерфейсом 2.3.2.1 с параметрами
для ввода данных из текстовых файлов, показанных на рисунке 10, и формирования
классификационных и описательных шкал и градаций и обучающей выборки, приведена
на рисунке 11:
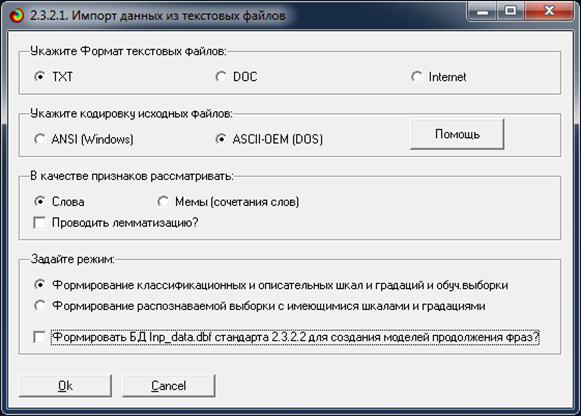
Рисунок 11. Экранная форма интерфейса 2.3.2.1 с параметрами
для ввода
данных из текстовых файлов и формирования классификационных
и описательных шкал и градаций и обучающей выборки
В результате работы данного режима сформированы
классификационные и описательные шкалы и градации и обучающая выборка,
приведенные на рисунках 12, 13 и 14.
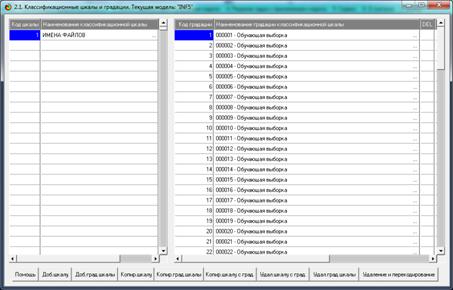
Рисунок 12. Классификационная шкала и ее градации,
т.е. классы
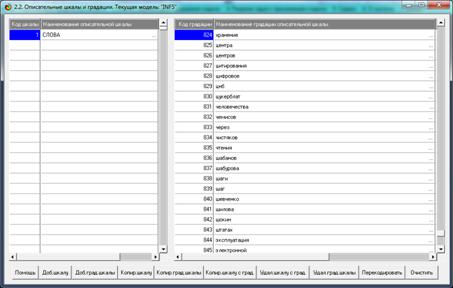
Рисунок 13. Описательная шкала и ее градации, т.е.
признаки – слова
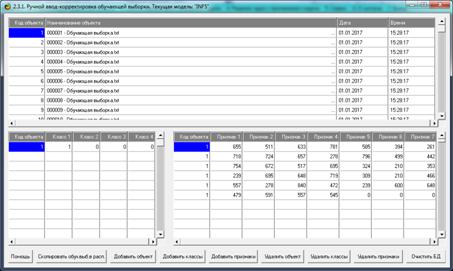
Рисунок 14. Обучающая выборка (фрагмент)
Полностью классификационные и описательные шкалы и
градации и обучающая выборка приведены по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip.
Таким образом режим 2.3.2.1 полностью выполнил все
операции этапа АСК-анализа «Формализация предметной области» и создал все
необходимые условия и предпосылки для выполнения следующего его этапа: «Синтез
и верификация модели предметной области».
После выполнения формализации предметной области для
преобразования исходных данных в информацию остается только осмыслить эти
данные, т.к. выявить причинно-следственные связи между словами и литературными
источниками (см. рисунок 2). Эти причинно следственные связи как раз и отражены
в статистических и системно-когнитивных моделях, создаваемых и проверяемых на
достоверность на следующем этапе АСК-анализа.
7.3.4. Синтез и верификация модели предметной области
7.3.4.1. Частные и интегральные
критерии,
применяемые в АСК-анализе и системе «Эйдос»
В системе «Эйдос» используется 3 статистических модели
(см. рисунок 2) и 7 системно-когнитивных моделей. Различные модели
системно-когнитивные модели отличаются частными критериями знаний.
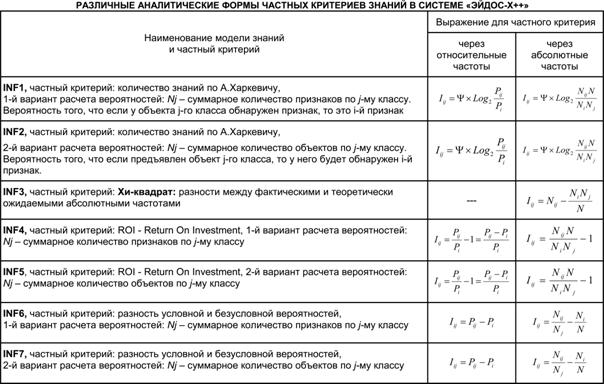
Для решения задач идентификации (классификации,
прогнозирования, распознавания, диагностики) в каждой системно-когнитивной
модели могут применяться два интегральных критерия.


7.3.4.2. Синтез моделей
Для выполнения этого этапа АСК-анализа запустим режим
3.5 системы «Эйдос», при опциях, указанных на рисунке 15:
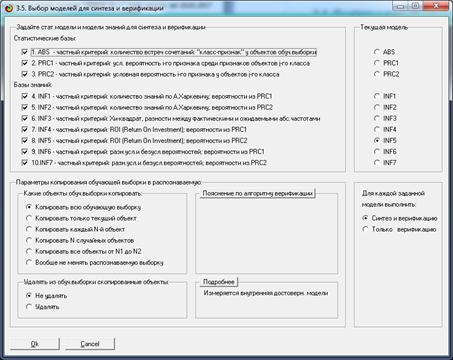
Рисунок 15. Экранная форма режима 3.5 системы «Эйдос»
Процесс синтеза и верификации 10 моделей, представляющих собой матрицы размерностью 111 на 857, шел на компьютере с процессором i7 26 минут 18 секунд (рисунок
16):
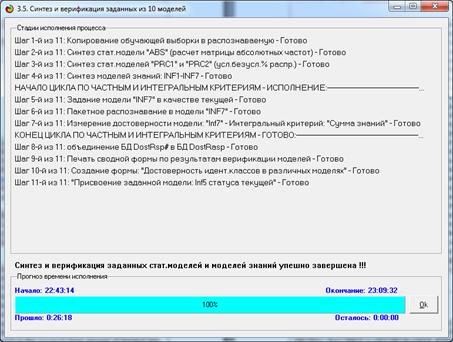
Рисунок 16. Экранная форма прогноза времени исполнения
режима 3.5
Ясно, что синтез модели ABS и 1-й системно-когнитивной
модели на ее основе при тех же исходных данных и на том же компьютере займет
значительно меньшее время (около 26 секунд).
7.3.4.3. Просмотр моделей
В системе «Эйдос» есть режим для просмотра
статистических и системно когнитивных моделей (режим 5.5). На рисунке 17
приведен фрагмент модели INF3:
Рисунок 17. Фрагмент модели INF3
Полностью все статистические и системно когнитивные
модели приведены по ссылке: http://ej.kubagro.ru/2017/01/upload/01.zip.
Здесь же они не приводятся, т.к. каждая из них занимает 128 листов.
7.3.4.4. Достоверность моделей
7.3.4.4.1. По F-критерию Ван Ризбергена
Достоверность созданных моделей оценивалось путем
идентификации во всех созданных моделях библиографических описаний всех 111
источников обучающей выборки. При этом использовалась стандартная мера адекватности
моделей: F-критерий Ван Ризбергена и его мультиклассовое нечеткое обобщение
L-мера проф.Е.В.Луценко, предложенная автором [27].
На рисунке 18 приведена форма по достоверности
моделей, которая отображается в режиме 4.1.3.6:
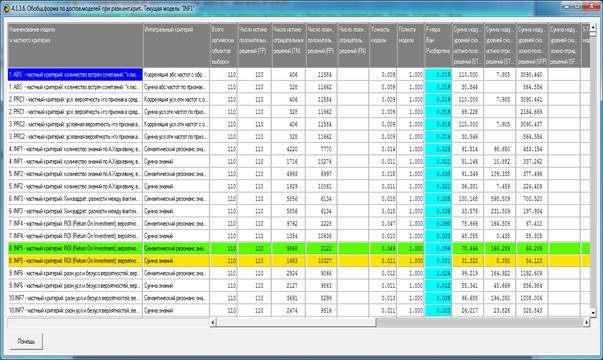
Рисунок 18. Экранная форма по достоверности моделей
(начало)
Из этой формы мы видим, что наиболее достоверной по
F-критерию является модель INF5 с интегральным критерием «Резонанс знаний»
(соответствующая колонка выделена ярко-голубым цветом). Эта модель обеспечивает
100% истинно-положительных решений, 9868 истинно-отрицательных решений и 2122
ложно-положительных решений («ложные срабатывания») при 0% ложно-отрицательных
решений. Точность модели получается равной 0,049, а полнота 1,000, сама F-мера
равна 0,094.
Казалось бы результаты так себе… Но не надо спешить с
выводами.
7.3.4.4.2. По L1-мере проф.Е.В.Луценко
Дело в том, что в стандартной F-мере при
ложно-положительном решении к соответствующему сумматору всегда прибавляется 1,
а если мы посмотрим на рисунке 19 на степень сходства объекта распознаваемой
выборки с классом (т.е. ссылки с источником) при истинно-положительных решениях
(отмечено «птичкой») и при ложно-положительных решениях, то мы увидим, что при
ложно-положительных решениях уровень сходства всегда значительно ниже, чем при
истинно-положительных.
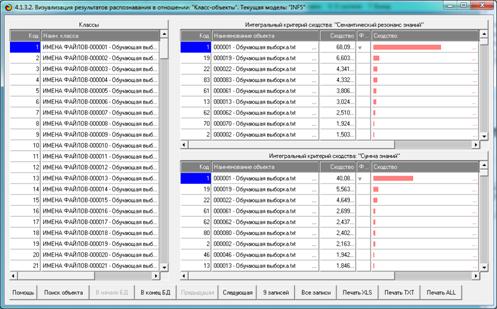
Рисунок 19. Результаты идентификации объектов с
классами
в самой достоверной модели INF5
Такая же картина наблюдается и во всех других
приложениях, опыт создания которых очень велик[8].
Поэтому автором было предложено мультиклассовое
нечеткое обобщение стандартной F-меры Ван Ризбергена, которая была названа
L-мера проф.Е.В.Луценко [27], которая кроме различия уровня сходства объектов с
классами (нечеткость) учитывает также то, что один объект может принадлежать
одновременно к различным классам (мультиклассовость).
На рисунке 20 показано продолжение экранной формы по
достоверности моделей, показывающая ее часть с L-мерой (соответствующая колонка
выделена ярко-зеленым цветом):
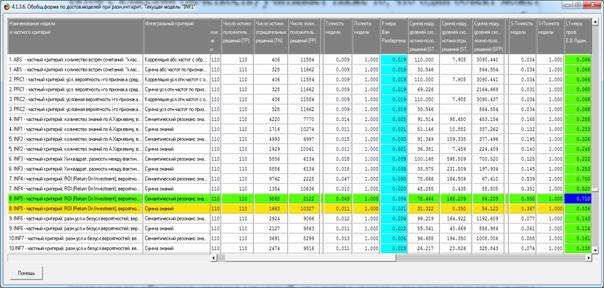
Рисунок 20. Экранная форма по достоверности моделей
(продолжение)
Видно, что с учетом уровня сходства результаты идентификации
значительно лучше, чем по F-критерию: L-мера = 0,710, при этом точность модели
0,550, а полнота 1,000, что уже более менее приемлемо.
Однако, количество ложно-положительных решений («ложных
срабатываний» или ошибочных идентификаций) слишком велико (2122) и не смотря на
то, что они имеют очень низкие уровни сходства их сумма (64,209) все же
почти равна сумме уровней сходства истинно-положительных решений (78,444).
Ясно, что при увеличении числа распознаваемых объектов
сумма
уровней сходства ложно положительных решений может даже превысить сумму
уровней сходства истинно-положительных решений.
Чтобы преодолеть эти проблемы предлагается обобщение предложенного в работе [27] L-критерия
проф.Е.В.Луценко, учитывающее уровень сходства объектов с классами и дающее
оценку достоверности моделей не зависящую
от числа объектов распознаваемой выборки.
7.3.4.4.3. По L2-мере проф.Е.В.Луценко
Автором работы (Е.В.Луценко) предлагается инвариантное
относительно объемов данных обобщение нечеткой мультиклассовой L-меры [27]
достоверности моделей, адекватное для оценки достоверности моделей, построенных
на больших данных.
Понятно, что для того, чтобы устранить зависимость от
числа объектов распознаваемой выборки в L-мере, достаточно вместо сумм
уровней сходства истинно и ложно положительных и отрицательных решений
использовать средние, посчитанные путем деления этих сумм на количество
объектов соответствующих категорий, т.е. на число истинно и ложно
идентифицированных и не идентифицированных объектов.
Это и сделано в новой версии системы «Эйдос» от
12.01.2017. Соответствующая мера достоверности моделей названа: L2-мера, а
предложенная в работе [27], соответственно: L1-мера. Подробному описанию
L2-меры и исследованию зависимости F-меры, L1- и L2-меры от объемов данных планируется
посвятить одну из следующих работ.
В Help режимов
4.1.3.6, 4.1.3.7 и 4.1.3.8 кратко описаны F-мера, а также L1-мера и L2-мера
(рисунок 21):
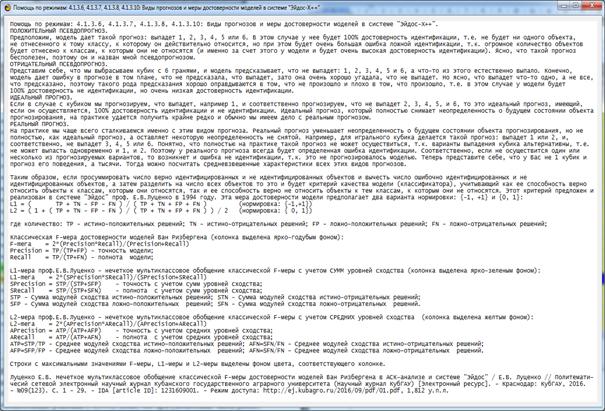
Рисунок 21. Экранная форма Help режимов 4.1.3.6,
4.1.3.7 и 4.1.3.8
На рисунке 22 приведена экранная форма по
достоверности моделей, включающая и L1-меру, и L2-меру.
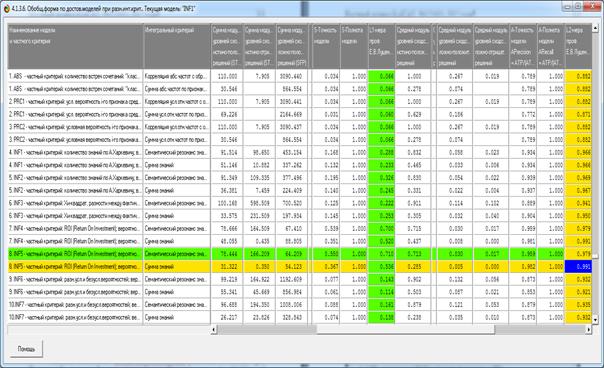
Рисунок 22. Экранная форма по достоверности моделей
(продолжение)
Из этой формы видно, что средний уровень сходства распознаваемых
объектов с классами при истинно-положительных решениях равен 0,285, при
ложно-положительных решениях всего 0,005, что дает точность модели 0,982 при
полноте 1,000 и L2-мере=0,991, что уже вполне прилично.
Все это означает, что если учитывать уровень сходства
объектов с классами в формах идентификации, подобных представленной на рисунке
19, то можно добиться достаточно высокой достоверности идентификации.
Отметим также, что система «Эйдос» сама находит
максимумы в колонках с различными критериями качества моделей и отмечает
соответствующие строки тем же фоном, что и эти колонки.
7.3.5. Выбор наиболее достоверной
модели,
присвоение ей статуса текущей
Продолжим выполнение этапов АСК-анализа и
преобразование данных в информацию, а ее в знания в соответствии с
последовательностью, представленной на рисунке 23.
Для этого:
– выберем наиболее достоверную модель;
– присвоим ей статус текущей модели;
– введем распознаваемую выборку из текстовых файлов в
систему «Эйдос»;
– проведем пакетное распознавание распознаваемой
выборки в текущей модели.
7.3.5.1. Выбор наиболее достоверной модели
Выбор наиболее достоверной модели осуществляется не
сложно. После синтеза и верификации моделей, т.е. после выполнения режима 3.5,
просто запускаем режим 4.1.3.6 и смотрим какая модель находится в строке,
выделенной желтым фоном. Это и есть наиболее достоверная модель по L2-критерию
проф.Е.В.Луценко. В нашем случае это модель INF5. Частный критерий этой модели
приведен в разделе 3.4.1.
7.3.5.2. Присвоение наиболее достоверной модели
статуса текущей модели
Чтобы присвоить модели INF5 запускаем режим 5.6 и
задаем эту модель (рисунки 23):
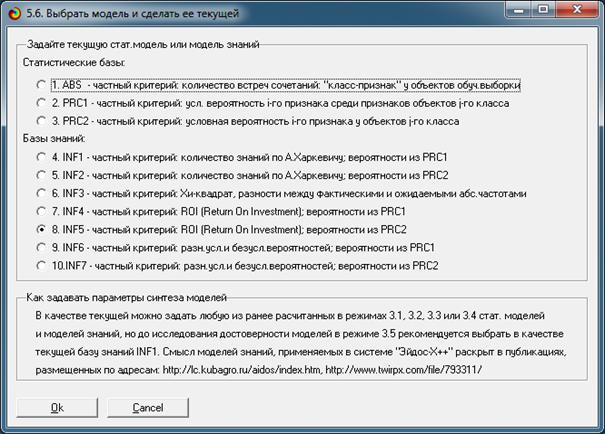
Рисунок 23. Экранные форма режима 5.6, обеспечивающего
присвоение
заданной модели статуса текущей модели (задание и исполнение)
7.3.6. Решение задачи идентификации
(привязки)
ссылок на литературные источники
в наиболее достоверной модели
7.3.6.1. Ввод распознаваемой выборки из текстовых файлов в систему «Эйдос»
Для этого
запишем в MS Word тестовый файл со ссылками на источники как обычный текст
кодировки DOS в папку:
..\Aidos-X\AID_DATA\Inp_rasp\. Каждая ссылка должна быть в отдельном
абзаце.
Затем
запустим служебный режим 2.3.2.9, позволяющий разбить текстовые файлы на абзацы
и каждый абзац записать в виде отельного
файла (рисунок 24):
Рисунок 24.
Экранные форма режима 2.3.2.9
После
исполнения этого режима в папке ..\Aidos-X\AID_DATA\Inp_rasp\ появляется 588 файлов,
часть которых показана на рисунке 25. После формирования этих файлов исходный
файл удаляется из директории.
Затем
запускаем режим 2.3.2.1, который , собственно, и вводит данные из этих файлов в
распознаваемую выборку (рисунок 26). На рисунке 27 приведена экранная форма с
фрагментом этой распознаваемой выборки.
Как уже
указывалось выше, такой подход выбран потому, что на размеры этих файлов по
сути нет ограничения (2Гб), т.е. это могут быть и работы, и даже монографии или
каике-то проекты и отчеты.
Рисунок 25.
Файлы тестовой выборки (фрагмент)
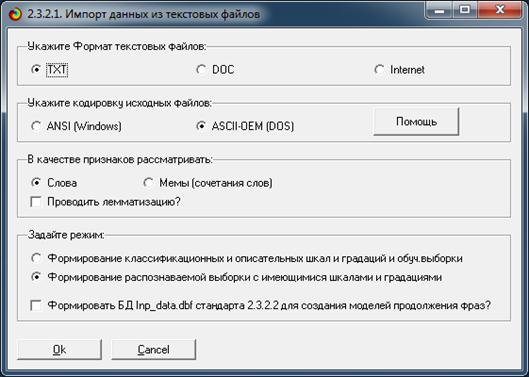
Рисунок 26.
Экранная форма программного интерфейса ввода данных
из текстовых файлов
Рисунок 27.
Экранная форма с отображением фрагмента
распознаваемой выборки
7.3.6.2. Пакетное распознавание распознаваемой
выборки в текущей модели
Далее
запускаем режим 4.1.2, реализующий пакетное распознавание. На рисунке 28
приведена экранная форма с отображением стадии и прогнозом времени исполнения:
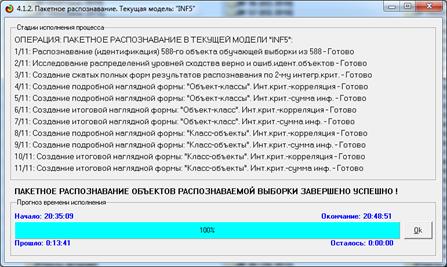
Рисунок 28.
Экранная форма с отображением стадии
и прогнозом времени исполнения
Из этой формы
мы видим, что идентификация 588 объектов в текущей модели заняла 13 минут 41
секунду, т.е. около 1,4 секунды на объект.
7.3.6.3. Краткая характеристика выходных форм
по результатам распознавания
В системе «Эйдос» есть довольно много выходных форм с
выводом различных результатов распознавания (рисунок 29).
Некоторые из них (4.1.3.6, 4.1.3.7, 4.1.3.8, 4.1.3.9,
4.1.3.10, 4.1.3.11) посвящены анализу достоверности моделей и достоверности
распознавания в разрезе по классам и объектам распознаваемой выборки.
Другие (4.1.3.1, 4.1.3.2, 4.1.3.3, 4.1.3.4, 4.1.3.5)
непосредственно содержат результаты распознавания.

Рисунок 29. Выходные формы системы «Эйдос»
по результатам распознавания (режим 4.1.3)
Рассмотрим лишь те из них, которые имеют самое непосредственное
отношение к проблеме, решаемой в данной работе.
7.3.6.4. Создание выходных форм, наиболее удобных
для решения поставленной в работе проблемы
Запустим режим 4.1.3.2. На экране появится экранная
форма, приведенная на рисунке 30.
Если покликать мышкой слева по классам или
воспользоваться стрелками перемещения курсора, то мы увидим два основных
варианта этой формы, приведенные на рисунке 30-а и 30-б.
а)
б)
Рисунок 30. Стандартные экранные формы по результатам
распознавания,
отражающие сходство распознаваемых объектов с заданными классами
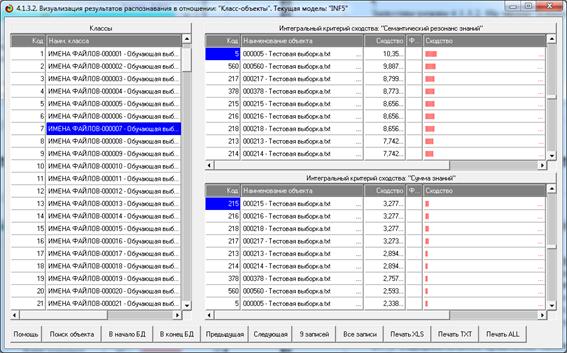
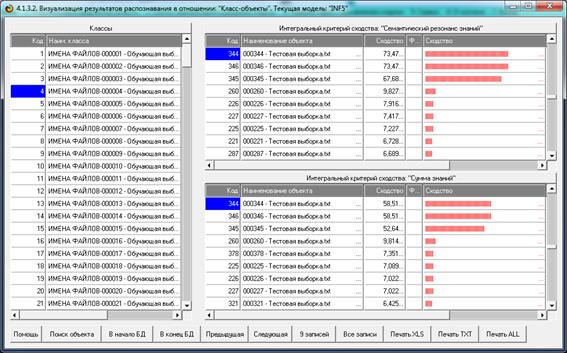
На экранной форме 30-а мы видим (справа), что в
распознаваемой выборке нет объектов имеющих сколько-нибудь заметное сходство с
классом, указанным слева.
На экранной форме 30-б, напротив, мы видим (справа),
что в распознаваемой выборке есть объекты с кодами: 344, 346 и 345, имеющие
сходство около 70% с классом, указанным слева.
Однако с такой формой при решении проблемы,
поставленной в работе, работать неудобно. Можно, конечно, посмотреть на
содержимое файлов обучающей выборки, с библиографическими описаниями работ, и
распознаваемой выборки, содержащей самые разнообразные, в основном некорректные
ссылки на них. Но есть и выходные формы, которые уже содержат эту информацию.
Чтобы получить эти формы кликнем по кнопке «Печать
ALL» на экранной форме, приведенной на рисунке 30. Появится запрос на порог
уровня сходства объектов распознаваемой выборки с классами:
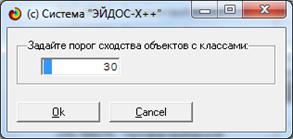
Этот порог используется для того, чтобы принять
решение о том, в какой тип форм включать информацию объектах распознаваемой
выборки: в те, которые содержат информацию о идентифицированных объектах, или в
отчет об неидентифицированных объектах.
В результате формируются выходные формы, информация о
которых приведена на рисунке 31:
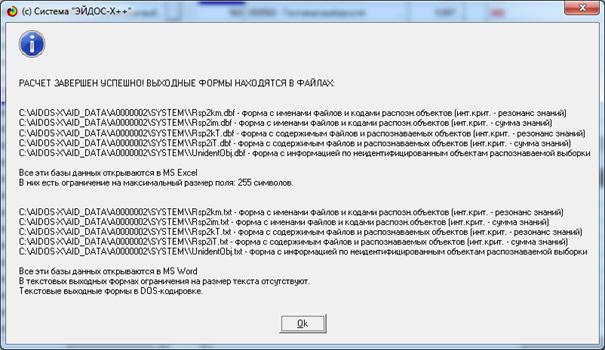
Рисунок 31. Экранная форма с информацией о выходных
формах,
генерируемых по нажатию на кнопе «Печать ALL» в режиме 4.1.3.2.
7.3.6.4.1. Краткие выходные формы
Ниже приведена 1-я страница одной из кратких выходных
форм, содержащих только коды классов и объектов распознаваемой выборки с
уровнями сходства:

7.3.6.4.2. Подробные выходные формы
Ниже приведена 1-я страница одной из подробных
выходных форм, содержащих не только коды классов и объектов распознаваемой
выборки с уровнями сходства, но и полный текст из соответствующих текстовых
файлов:

Отметим, что объем этой выходной формы в модели, используемой
в данной работе, составляет 47 листов.
7.3.6.4.3. Отчет по неидентифицированным ссылкам
Все ссылки, для которых не оказалось источников с
уровнем сходства выше заданного порога оказались вообще неидентифицированными
(непривязанными) и ниже приводится фрагмент отчета по таким ссылкам:

7.3.7. Решение задачи исследования
моделируемой
предметной области
Продолжим выполнение этапов АСК-анализа и кратко
рассмотрим некоторые (не все) возможности исследования моделируемой предметной
области путем исследования ее модели. Это корректно, если модель имеет
достаточно высокую достоверность. В нашем случае по L2-критерию
проф.Е.В.Луценко это именно так.
7.3.7.1. Автоматизированный SWOT-анализ
Система «Эйдос» обеспечивает автоматизированный прямой
и обратный SWOT-анализ [28]. Ниже (в рисунках 32, 33, 34 и 35) приводится
несколько выходных форм соответствующих режимов в модели INF3:
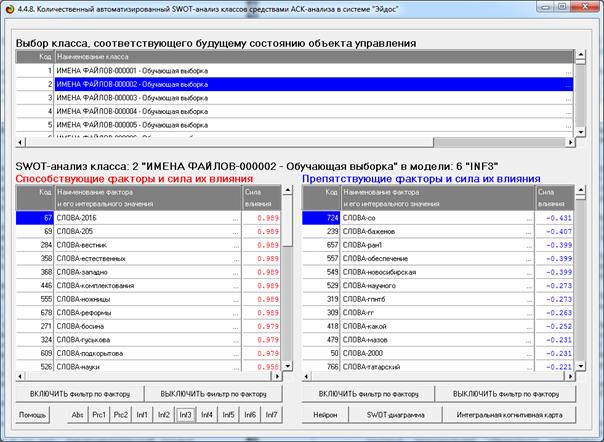
Рисунок 32. Экранная форма управления режимом 4.4.8
(автоматизированный SWOT-анализ классов)
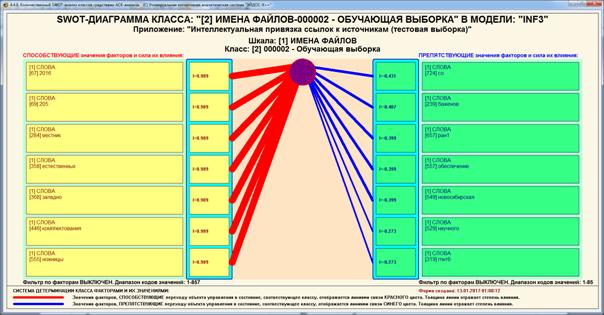
Рисунок 33. SWOT-диаграмма 2-й работы обучающей
выборки
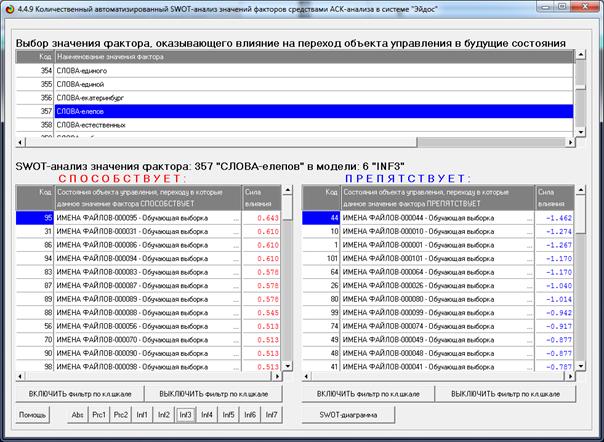
Рисунок 34. Экранная форма управления режимом 4.4.9
(автоматизированный SWOT-анализ значений факторов)
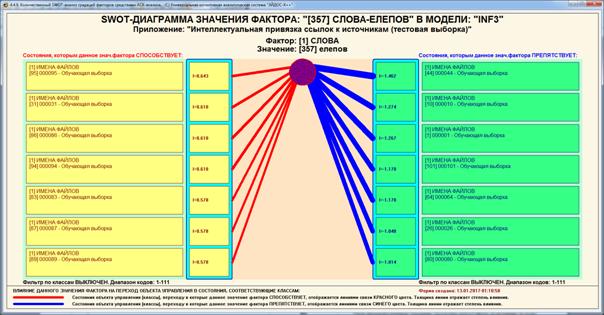
Рисунок 35. SWOT-диаграмма значения фактора: «Елепов»
7.3.7.2. Нелокальные нейроны
Модель представления знаний системы «Эйдос» представляет
собой декларативную нечеткую модель, имеющую сходство с фреймовой и
нейросетевой моделями.
По сравнению с фреймовой моделью модель системы «Эйдос»
имеет существенно упрощенную программную реализацию, связанную с тем, что все
фреймы (классы) имеют общую систему слотов и шпаций, т.е. описательных шкал и
градаций. В тоже время это практически не уменьшает функциональных возможностей
модели представления знаний системы «Эйдос» по сравнению с фреймовой моделью.
По сравнению с нейросетевой моделью модель системы
«Эйдос» обладает тремя основными преимуществами [29]: 1) она является
интерпретируемой, т.е. понятен и хорошо теоретически обоснован смысл весовых
коэффициентов на рецепторах (градациях описательных шкал); 2) она является
нейронной сетью прямого счета, т.е. ее процесс обучения гораздо проще, чем по
алгоритму обратного распространения ошибки; 3) она является нелокальной, т.е.
все нейроны (классы) связаны со всеми, что позволяет моделировать нелинейные
системы [30].
На рисунке 36 приведена экранная форма управления
отображением нелокальных нейронов (режим 4.4.10):
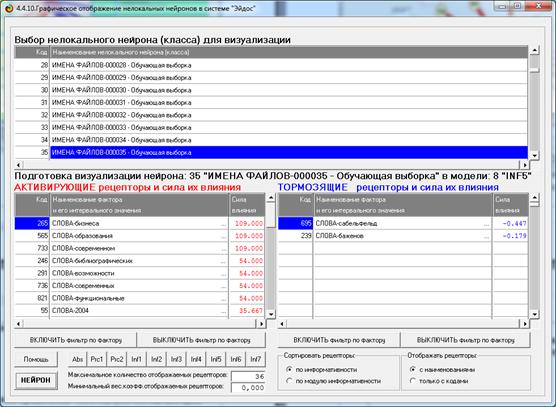
Рисунок 36. Экранная форма управления отображением
нелокальных нейронов (режим 4.4.10 системы «Эйдос»)
Пример отображения нелокального нейрона системы
«Эйдос» приведен на рисунке 37):
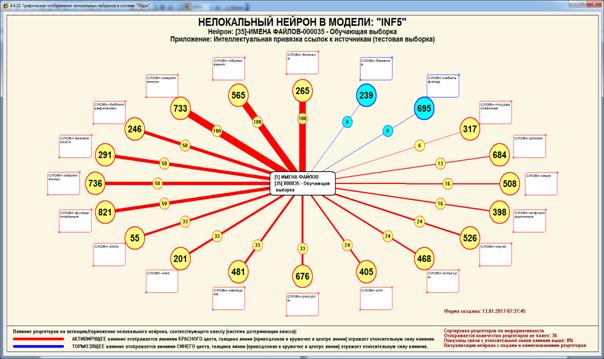
Рисунок 37. Изображение нелокального нейрона (класса)
с указанием весовых коэффициентов на рецепторах (словах)
Пояснения по рисунку приведены на нем самом.
Необходимо отметить, что в системе «Эйдос» нет
принципиальных ограничений на количество нейронов в модели знаний и на
количество рецепторов в них (ограничения накладываются только объемом свободной
внешней памяти и быстродействием компьютеров). Проводились численные эксперименты
с формированием в системе «Эйдос» моделей знаний, содержащих 10000 нейронов,
каждый из которых имел 10000 рецепторов, а программные средства системы «Эйдос»
работы с базами знаний тестировались на размерностях баз знаний до 100000
нейронов с 100000 рецепторов каждый. Правда надо отметить, что такие базы
знаний создавались по полчаса и имели размеры на диске около 200 Гб.
7.3.7.3. Внешнее сравнение текстов
(кластерно-конструктивный анализ)
В режиме 4.2.2.1 создается матрица или подматрица
сходства классов (таблица 2):
Таблица 2 – Матрица сходства классов в модели INF5
(фрагмент)
|
KOD_CLS |
NAME_CLS |
N1 |
N2 |
N3 |
N4 |
N5 |
|
1 |
ИМЕНА ФАЙЛОВ-000001 -
Обучающая выборка |
100,000 |
1,289 |
-1,282 |
-1,879 |
-1,229 |
|
2 |
ИМЕНА ФАЙЛОВ-000002 -
Обучающая выборка |
1,289 |
100,000 |
-0,269 |
-1,836 |
-1,228 |
|
3 |
ИМЕНА ФАЙЛОВ-000003 -
Обучающая выборка |
-1,282 |
-0,269 |
100,000 |
-1,057 |
0,693 |
|
4 |
ИМЕНА ФАЙЛОВ-000004 -
Обучающая выборка |
-1,879 |
-1,836 |
-1,057 |
100,000 |
3,544 |
|
5 |
ИМЕНА ФАЙЛОВ-000005 -
Обучающая выборка |
-1,229 |
-1,228 |
0,693 |
3,544 |
100,000 |
|
6 |
ИМЕНА ФАЙЛОВ-000006 -
Обучающая выборка |
-1,747 |
-1,699 |
-0,874 |
-0,585 |
-1,232 |
|
7 |
ИМЕНА ФАЙЛОВ-000007 -
Обучающая выборка |
-0,821 |
0,254 |
0,697 |
-0,914 |
0,532 |
|
8 |
ИМЕНА ФАЙЛОВ-000008 -
Обучающая выборка |
0,737 |
-0,986 |
-0,228 |
-0,642 |
-0,716 |
|
9 |
ИМЕНА ФАЙЛОВ-000009 -
Обучающая выборка |
-2,103 |
0,222 |
0,066 |
-2,298 |
-1,495 |
|
10 |
ИМЕНА ФАЙЛОВ-000010 -
Обучающая выборка |
-2,366 |
-1,840 |
-1,686 |
-2,575 |
-1,702 |
|
11 |
ИМЕНА ФАЙЛОВ-000011 -
Обучающая выборка |
-1,381 |
-1,340 |
-0,997 |
-1,483 |
-1,000 |
|
12 |
ИМЕНА ФАЙЛОВ-000012 -
Обучающая выборка |
0,020 |
-0,775 |
0,285 |
-0,852 |
0,265 |
|
13 |
ИМЕНА ФАЙЛОВ-000013 -
Обучающая выборка |
1,582 |
-0,877 |
5,231 |
-0,966 |
0,048 |
|
14 |
ИМЕНА ФАЙЛОВ-000014 -
Обучающая выборка |
-1,262 |
-0,388 |
0,413 |
-1,361 |
-0,897 |
|
15 |
ИМЕНА ФАЙЛОВ-000015 -
Обучающая выборка |
-1,411 |
-0,621 |
-1,068 |
-1,565 |
-1,014 |
|
16 |
ИМЕНА ФАЙЛОВ-000016 -
Обучающая выборка |
-1,775 |
-1,724 |
-1,313 |
-1,605 |
-1,290 |
|
17 |
ИМЕНА ФАЙЛОВ-000017 -
Обучающая выборка |
-1,077 |
-1,070 |
-0,712 |
-1,185 |
-0,764 |
|
18 |
ИМЕНА ФАЙЛОВ-000018 -
Обучающая выборка |
-1,138 |
-1,123 |
-0,432 |
-1,251 |
-0,474 |
|
19 |
ИМЕНА ФАЙЛОВ-000019 -
Обучающая выборка |
8,878 |
-1,339 |
-0,569 |
-1,485 |
-0,611 |
|
20 |
ИМЕНА ФАЙЛОВ-000020 -
Обучающая выборка |
-2,152 |
-2,097 |
-1,595 |
-2,062 |
-1,566 |
|
21 |
ИМЕНА ФАЙЛОВ-000021 -
Обучающая выборка |
0,312 |
-1,070 |
-0,773 |
-1,191 |
-0,764 |
|
22 |
ИМЕНА ФАЙЛОВ-000022 -
Обучающая выборка |
6,748 |
-1,358 |
-1,021 |
-1,657 |
-0,955 |
|
23 |
ИМЕНА ФАЙЛОВ-000023 -
Обучающая выборка |
-1,957 |
-1,894 |
-1,454 |
-1,825 |
-1,426 |
|
24 |
ИМЕНА ФАЙЛОВ-000024 - Обучающая
выборка |
-1,428 |
-0,531 |
0,805 |
-0,440 |
-1,049 |
|
25 |
ИМЕНА ФАЙЛОВ-000025 -
Обучающая выборка |
-1,379 |
-1,346 |
-1,045 |
-1,474 |
-1,024 |
|
26 |
ИМЕНА ФАЙЛОВ-000026 -
Обучающая выборка |
-2,064 |
-1,988 |
-1,529 |
-2,225 |
-1,500 |
|
27 |
ИМЕНА ФАЙЛОВ-000027 -
Обучающая выборка |
-0,501 |
-0,587 |
0,233 |
-1,586 |
-1,070 |
|
28 |
ИМЕНА ФАЙЛОВ-000028 -
Обучающая выборка |
-1,263 |
-1,251 |
-0,822 |
-1,362 |
-0,824 |
|
29 |
ИМЕНА ФАЙЛОВ-000029 -
Обучающая выборка |
-1,532 |
-1,258 |
-0,430 |
-1,667 |
-0,503 |
|
30 |
ИМЕНА ФАЙЛОВ-000030 -
Обучающая выборка |
-1,708 |
-1,354 |
-0,793 |
-1,603 |
-1,238 |
|
31 |
ИМЕНА ФАЙЛОВ-000031 -
Обучающая выборка |
-0,843 |
-0,811 |
-0,624 |
-0,908 |
-0,612 |
|
32 |
ИМЕНА ФАЙЛОВ-000032 -
Обучающая выборка |
-0,915 |
-0,734 |
-0,542 |
-1,005 |
-0,550 |
|
33 |
ИМЕНА ФАЙЛОВ-000033 -
Обучающая выборка |
-1,411 |
-1,407 |
-0,493 |
-1,554 |
-0,552 |
|
34 |
ИМЕНА ФАЙЛОВ-000034 -
Обучающая выборка |
0,764 |
1,925 |
-0,479 |
-1,391 |
-0,859 |
|
35 |
ИМЕНА ФАЙЛОВ-000035 -
Обучающая выборка |
-1,640 |
-0,677 |
-0,949 |
-1,775 |
-1,209 |
|
36 |
ИМЕНА ФАЙЛОВ-000036 -
Обучающая выборка |
-1,149 |
-1,116 |
-0,735 |
-1,259 |
6,952 |
|
37 |
ИМЕНА ФАЙЛОВ-000037 -
Обучающая выборка |
-1,592 |
-1,543 |
-1,181 |
-1,724 |
-1,160 |
|
38 |
ИМЕНА ФАЙЛОВ-000038 -
Обучающая выборка |
-1,180 |
-0,478 |
-0,176 |
0,668 |
-0,821 |
|
39 |
ИМЕНА ФАЙЛОВ-000039 -
Обучающая выборка |
-1,786 |
-1,800 |
-1,258 |
-1,718 |
-1,331 |
|
40 |
ИМЕНА ФАЙЛОВ-000040 -
Обучающая выборка |
-1,763 |
-1,526 |
-1,096 |
-1,276 |
-1,269 |
|
41 |
ИМЕНА ФАЙЛОВ-000041 -
Обучающая выборка |
-1,869 |
-1,866 |
-1,105 |
-1,835 |
-0,855 |
|
42 |
ИМЕНА ФАЙЛОВ-000042 -
Обучающая выборка |
-1,030 |
-0,984 |
-0,363 |
-1,089 |
-0,403 |
|
43 |
ИМЕНА ФАЙЛОВ-000043 -
Обучающая выборка |
-1,386 |
-0,607 |
-0,075 |
-1,670 |
-1,043 |
|
44 |
ИМЕНА ФАЙЛОВ-000044 -
Обучающая выборка |
-1,666 |
-1,635 |
-1,007 |
-1,858 |
-1,244 |
|
45 |
ИМЕНА ФАЙЛОВ-000045 -
Обучающая выборка |
-1,834 |
-1,786 |
-0,108 |
-1,981 |
-0,624 |
|
46 |
ИМЕНА ФАЙЛОВ-000046 -
Обучающая выборка |
-1,164 |
-1,689 |
0,009 |
-1,444 |
-0,276 |
|
47 |
ИМЕНА ФАЙЛОВ-000047 -
Обучающая выборка |
-1,529 |
-1,473 |
-1,133 |
-1,624 |
-1,112 |
|
48 |
ИМЕНА ФАЙЛОВ-000048 -
Обучающая выборка |
-1,547 |
-1,491 |
-0,831 |
-1,660 |
-1,108 |
|
49 |
ИМЕНА ФАЙЛОВ-000049 -
Обучающая выборка |
-1,371 |
-1,343 |
-0,647 |
-1,495 |
-0,990 |
|
50 |
ИМЕНА ФАЙЛОВ-000050 -
Обучающая выборка |
-1,466 |
-1,517 |
-0,927 |
-1,675 |
-0,475 |
|
51 |
ИМЕНА ФАЙЛОВ-000051 -
Обучающая выборка |
-1,822 |
-1,655 |
-1,245 |
-1,753 |
-1,361 |
|
52 |
ИМЕНА ФАЙЛОВ-000052 -
Обучающая выборка |
-1,388 |
-2,004 |
-0,954 |
-1,528 |
-0,635 |
|
53 |
ИМЕНА ФАЙЛОВ-000053 -
Обучающая выборка |
0,977 |
-1,072 |
-0,352 |
-1,224 |
-0,401 |
|
54 |
ИМЕНА ФАЙЛОВ-000054 -
Обучающая выборка |
-1,356 |
-1,314 |
-1,007 |
2,124 |
-0,991 |
|
55 |
ИМЕНА ФАЙЛОВ-000055 -
Обучающая выборка |
-1,105 |
-1,277 |
-0,984 |
-1,423 |
-0,932 |
|
56 |
ИМЕНА ФАЙЛОВ-000056 -
Обучающая выборка |
-0,997 |
-1,006 |
-0,733 |
-1,121 |
-0,676 |
|
57 |
ИМЕНА ФАЙЛОВ-000057 -
Обучающая выборка |
-1,208 |
-1,158 |
-0,894 |
-1,287 |
-0,878 |
|
58 |
ИМЕНА ФАЙЛОВ-000058 -
Обучающая выборка |
-0,976 |
-0,931 |
-0,722 |
-1,075 |
-0,710 |
|
59 |
ИМЕНА ФАЙЛОВ-000059 -
Обучающая выборка |
-1,029 |
-1,196 |
0,004 |
-1,293 |
-0,845 |
|
60 |
ИМЕНА ФАЙЛОВ-000060 -
Обучающая выборка |
-1,254 |
-0,665 |
-0,978 |
-1,424 |
-0,960 |
|
61 |
ИМЕНА ФАЙЛОВ-000061 -
Обучающая выборка |
2,134 |
-1,421 |
-1,152 |
-0,655 |
-1,133 |
Фрагменты матрицы сходства могут визуализироваться в
системе «Эйдос» в форме семантических сетей (когнитивных диаграмм). На рисунке
38 приведены экранные формы управления данным режимом (4.2.2.2):
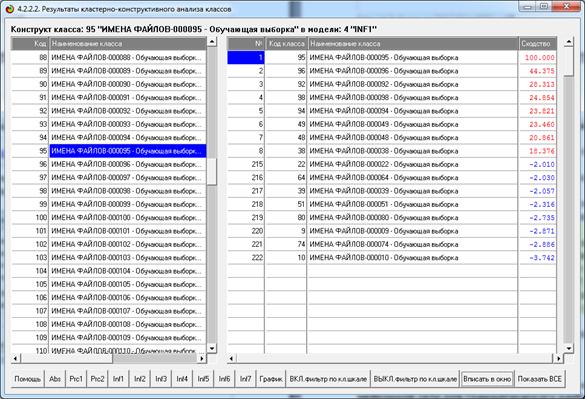
Рисунок 38. Экранные формы управления режимом
кластерно-конструктивный анализ классов системы «Эйдос» (4.2.2.2.)
Пример визуализации конструкта класса с кодом 95
приведен на рисунке 39:
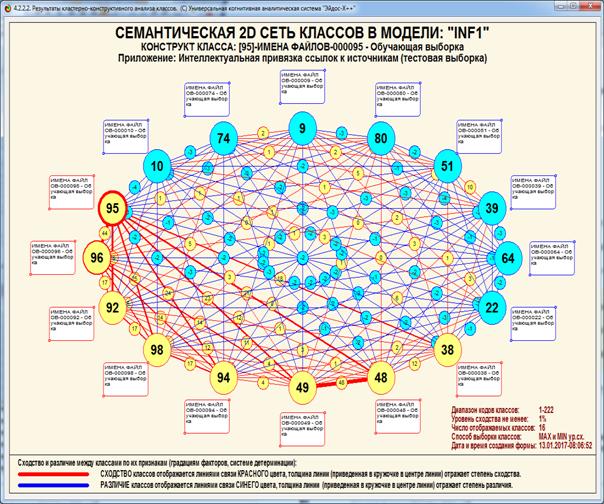
Рисунок 39. Пример визуализации конструкта класса с
кодом 95
Текст объекта обучающей выборки с кодом 95: «НАУЧНЫЕ
БИБЛИОТЕКИ СИБИРИ И ДАЛЬНЕГО ВОСТОКА Елепов Б.С. Новосибирск, 1980.».
Информационный портрет класса 95 приведен на рисунке 40.
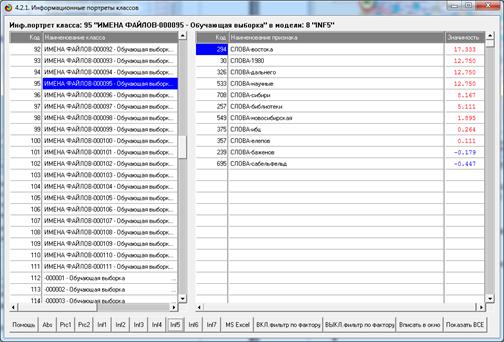
Рисунок 40. Пример визуализации конструкта класса с
кодом 95
Из рисунка 40 видно, что разные слова, входящие в этот
объект, имеют разный вес при его идентификации, т.е. в разной степени
характерны для этого объекта. Мы видим, что наиболее характерным словом для
этого объекта является слово «востока», а за ним идет год работы.
Отметим также, что весовые коэффициенты когнитивной
диаграммы, приведенной на рисунке 39, определяются не «на основе экспертных
оценок», как обычно[9], а рассчитываются
непосредственно на основе моделей знаний, сформированных в системе «Эйдос»
непосредственно на основе эмпирических исходных данных.
7.3.7.4. Содержательное сравнение текстов
(когнитивные диаграммы)
Из когнитивной диаграммы, приведенной на рисунке 39,
мы видим, что некоторые библиографические описания работ в различной степени
сходны друг с другом, а другие в различной степени отличаются. Но из этой
диаграммы мы не видим, чем именно они
сходны и чем отличаются, т.е. того, какие
слова вносят основной вклад в их сходство и различие. Эта информация
приводится в когнитивной диаграмме на рисунке 41:

Рисунок 41. Пример когнитивной диаграммы,
содержательно отражающей
вклад различных слов в сходство-различие двух текстов
На рисунке 42 приведена экранная форма управления режимом
4.2.3, обеспечивающим генерацию когнитивных диаграмм, содержательно отражающих
вклад различных слов в сходство-различие двух текстов.
Рисунок 42. Экранная форма управления режимом 4.2.3,
обеспечивающим
генерацию когнитивных диаграмм, содержательно отражающих вклад
различных слов в сходство-различие двух текстов
По сути эта когнитивная диаграмма раскрывает
внутреннюю структуру каждой линии, показывающей сходство или различие классов
на диаграмме 39. Ниже, на рисунке 43 приведен Help режима 4.2.3, поясняющий,
как формируется когнитивная диаграмма, отображенная на рисунке 41.
Рисунок 43. Help режима 4.2.3, поясняющий, как
формируется
когнитивная диаграмма, отображенная на рисунке 41
Можно представить себе нейронную сеть, построенную на
диаграмме 39 с указанием рецепторов, как на рисунке 37. В DOS-версии системы
«Эйдос» такие диаграммы визуализировались, а в новой аналогичный режим еще не
реализован.
7.3.7.5. Ценность слов для сравнения ссылок
и источников
Различные слова имеют различную ценность для сравнения
источников с источниками и ссылок с источниками.
Если слово встречается с одинаковой вероятностью в
различных источниках, то оно совершенно бесполезно для того, чтобы отличить их
друг от друга. Чем выше вариабельность вероятности[10] (или
одного из частных критериев знаний, приведенных в разделе 3.4.1) встречи
некоторого слова по разным источникам, тем более ценным оно является для их
различения.
На рисунке 44 приведена логистическая кривая
ценности различных слов для решения задачи идентификации текстов
(т.е. ценность слов нарастающим итогом) в модели PRC1[11]:
Рисунок 44. Логистическая кривая ценности различных
слов
для решения задачи идентификации текстов
Из рисунка 44 видно, что 50% слов обеспечивают
суммарно около 75,7% значимости, а 50% суммарной значимости обеспечивается
23,6% слов.
Если подобный анализ провести на моделях, отражающих
не одного автора, а большое их количество, то можно сделать научно обоснованные
выводы о том, какие слова имеет использовать для дифференциации источников и
ссылок и их привязки. Например, можно оставить треть; слов, дающих суммарное
около двух третей значимости. Наряду с лемматизацией, это позволит существенно
уменьшить размерность моделей, вычислительную сложность и время решения задач.
7.4. Обсуждение (некоторые
ограничения предлагаемой
технологии и пути их
преодоления)
7.4.1. Ошибки идентификации и
неидентификации
и как их компенсировать
Ложно-положительные и ложно-отрицательные решения,
т.е. ошибки идентификации и неидентификации, крайне нежелательны и их
обязательно необходимо как-то минимизировать. Ниже в данном разделе рассмотрим
некоторые подходы к решению этой важной и актуальной задачи.
7.4.1.1. Обоснование выбора порога уровней сходства
Обратимся к рисунку 21, на котором раскрываются понятия
положительного и отрицательного псевдопрогнозов.
Из предыдущего изложения, в частности рисунка 30-б в
разделе 3.6.4, ясно, что для достоверности прогноза очень важен выбор порога
положительных уровней сходства, выше которого положительные решения как правило
соответствуют действительности, т.е. являются истинно-положительными, а ниже –
ложно-положительными.
Например, из рисунка 30-б видно, что вероятнее всего к
истинно-положительным решениям относятся те, у которых уровень сходства выше
50%. Но, конечно, по одной форме такие решения принимать нельзя, а также
необходима проверка совпадения прогноза с действительностью, что по этой форме
сделать затруднительно.
Поэтому для выбора порога более корректно использовать
форму, представленную на рисунке 22 и текстовые формы из раздела 3.6.4.
Например, из рисунка 22 видно, что в наиболее
достоверной модели INF5 рационально и обоснованно выбрать порог уровня сходства
выше 30%, т.е. положительные решения, с уровнем сходства выше 30% обоснованно
можно считать истинно-положительными. Соответственно, положительные решения, с
уровнем сходства ниже 30% обоснованно можно считать ложно-положительными или
истинно-отрицательными.
Конечно, речь идет о средних величинах уровней
сходства, причем полученных при идентификации обучающей выборки.
Понятно, что при идентификации объектов как обучающей, так и тестовой выборки
реально могут встретится и истинно-положительные решения с уровнем сходства
ниже 30% и ложно положительные с уровнем сходства выше 30%. Но при таком выборе
порога уровня сходства минимизируется количество ложноположительных и ложноотрицательных
решений.
7.4.1.2. Использование препроцессора в форме
однослойной нейронной сети
для грамматического разбора
и выделения вторичных признаков
По предлагаемой технологии возможно построить модели
измерения сходства-различия библиографических описаний источников и ссылок на
них не по входящим в них словам, а по элементам их библиографических описаний.
В этом случае модели измерения сходства-различия источников и ссылок будут
вторым слоем нейронной сети, в первом слое которой должна решаться задача
разбора некорректного и неполного библиографического описания и
выделения из него этих элементов.
Очень может быть, что такие модели двухслойной
нейронной сети показали покажут высокую достоверность, чем однослойные модели,
основанные на словах, подобные описанной в данной работе.
Однако ожидать этой более высокой достоверности
оправданно только при условии правильного выделения элементов
библиографического описания. А на этапе разбора также возможны ошибки, которые
могут снизить достоверности решения задачи во втором слое.
7.4.1.3. Использование детерминистского
постпроцессора исключающего из отчета
по идентификации точно ошибочные
результаты
Экспертное исследование текстовых выходных форм, приведенных
в разделе 3.6.4, показало, что при очень высоком пороге сходства из списка
ссылок могут пропасть фактические ссылки на источники, а при очень низком в
список ссылок попадает много ссылок на другие источники, сходные по библиографическому
описанию.
Решить эту проблему предлагается путем:
1) выбора низкого порога, что обеспечит исключение
пропусков ссылок;
2) исключения из расширенного списка ссылок тех из
них, которые точно не являются ссылками на данный источник.
Решить 2-ю задачу можно с применением используемого в
настоящее время в программном обеспечении (ПО) РИНЦ алгоритма грамматического
разбора библиографических ссылок, который выделяет год публикации и другие
элементы ее описания. Например, из расширенного списка ссылок можно сразу
исключить ссылки на источники других лет публикации.
7.4.1.4. Использование
предлагаемого подхода
в сочетании с алгоритмами разбора ссылок,
используемыми в ПО РИНЦ настоящее время
Используемый в настоящее время в программном обеспечении
(ПО) РИНЦ алгоритм основан на последовательном грамматическом разборе
библиографических ссылок, выделении элементов их описания и последовательном
сужении круга дальнейшего поиска с учетом результатов предшествующего разбора.
Это очень быстродействующий алгоритм, однако при неверном определении типа
публикации (например она определилась как журнал, а в действительности это
сборник статей) дальнейший поиск ведется уже в публикациях этого типа и обречен
неудачу.
Предлагаемый в данной работе подход решает эту проблему.
Для этого предлагается сначала с очень низким порогом, например 6-7%
сформировать расширенный список работ, на одну из которых может быть
привязываемая ссылка, а затем из этого расширенного списка удаляются варианты,
у которых не совпадают безошибочно определяемые при разборе элементы, такие как
год публикации.
Это предложение напоминает подход, используемый
рыбками: сначала широко закинуть невод и вытащить его со всем, что
туда попало, а потом выкинуть все ненужное и оставить только улов.
7.4.2. Англоязычные ссылки на
русскоязычные
источники и на источники, указанные в транслитерации
Конечно авторы иногда делают странные вещи: например
при публикации в англоязычных журналах помещают в список литературы ссылки на
русскоязычные источники в переводе их на английский язык или в транслитерации,
а не на языке оригинала. Понятно, конечно, что эти англоязычные издания могут
вообще не предусматривать возможности ссылок на русскоязычные источники. Одна с
другой стороны понятно, что если ссылка сделана в переводе или транслитерации,
то предлагаемый подход не найдет их сходства с русскоязычным библиографическим
описание источника.
Предлагается следующее решение этой проблемы: все
русскоязычные библиографические описания источников обучающей выборки перевести
на английский язык и сделать их транслитерацию с применением различных
стандартов транслитерации и дополнить ими обучающую выборку с теми же номерами файлов, что и с
русскоязычным описанием источника.
7.4.3. Повышение скорости
интеллектуальной
привязки
7.4.3.1. Научное исследование
Проведение расчетов по синтезу и верификации моделей
источников, а затем по их применению для привязки ссылок показали, что они
имеют достаточно высокую вычислительную сложность и трудоемкость, требуют
значительных вычислительных ресурсов и затрат времени.
По этим параметрам предлагаемые и описанные выше в
работе подходы не удовлетворяют требованиям, предъявляемым условиями их
практического применения.
Но дело в том, что они и не предназначены для
непосредственного применения на практике. Очень многие аспекты предлагаемых
подходов, освещенные в данной работе не касаются непосредственно практического
применения, а относятся к этапу научного исследования, который предшествует
этапу практического доведения до инновационного уровня и применения любой
разработки.
Самое главное, что мы должны сделать на этапе научного
исследования – это мы должны путем создания и верификации моделей на большом
числе авторов определить наиболее достоверную модель и порог уровня сходства
для определения расширенного списка ссылок или источников.
Можем, при наличии такой возможности и желания,
провести и другие исследования по интересующим направлениям, например,
исследовать, как на скорость и достоверность распознавания и привязки влияет
лемматизация слов или исключение из списка слов двух третей наименее ценных из
них, а также предлагаемые выше препроцессоры и постпроцессоры.
7.4.3.2. Практические применение
Из всего сделанного на этапе научного исследования и
описанного выше, на практике будет применяться лишь небольшая часть:
1) для каждого автора на основе списка его публикаций
в базах данных РИНЦ будет формироваться одна модель, а именно та, которая на
этапе научного исследования показала наивысшую достоверность у наибольшего
числа авторов;
2) в этой модели с порогом уровня сходства,
определенном на этапе научного исследования, будет формироваться расширенный
список ссылок на каждую работу автора;
3) из расширенного списка будут исключаться те из них,
которые не соответствуют хотя бы по одному достоверно установленному элементу
библиографического описания, например, году публикации.
Эти задачи могут на этапе практического применения
могут решаться в десятки раз быстрее, чем аналогичные задачи на этапе научного
исследования.
В результате все это уже может быть вполне может быть
применимым на практике. Тем более, что предлагаемые в работе подходы, включая и
саму систему «Эйдос», могут рассматриваться лишь как прототип для практических
решений на платформе программного обеспечения РИНЦ.
Но на этапе научных исследований они вполне успешно могут
быть применены, собственно говоря, уже применены, что и описано в данной
работе.
7.4.3.3. Применение новых технологий
параллельных вычислений
В наше время существует много подходов эффективного
использования аппаратных средств для высокопроизводительных вычислений. Кроме
очевидной возможности использования суперкомпьютеров с параллельными
процессорами укажем еще на возможность использования видеокарт для
высокопроизводительных вычислений[12] и
кластерные сетевые вычислительные системы с интеллектуальным управлением
задачами и ресурсами[13].
7.5. Выводы
В данной работе предлагается решение проблемы привязки
некорректных ссылок к литературным источникам путем применения
автоматизированного системно-когнитивного анализа (АСК-анализ) и его
программного инструментария – интеллектуальной системы «Эйдос». Приводится
численный пример интеллектуальной привязки реальных некорректных ссылок к
работам автора на основе небольшого объема реальных наукометрических данных,
находящихся в открытом бесплатном on-line доступе в РИНЦ, который
продемонстрировал работоспособность предлагаемого подхода и ряд его преимуществ
перед подходом, применяемым в настоящее время в программном обеспечении РИНЦ.
Таким образом, данная работа является продолжением серии работ автора,
посвященных различным вопросам наукометрии [31, 32, 33] и интеллектуальной
обработки тестов [1-33].
Предлагаются следующие возможные перспективы
дальнейших исследований по теме, которые не удалось в должной мере осветить в данной
работе и которые могут способствовать развитию данного направления исследований
в будущем:
1) использование многослойных нейронных сетей: препроцессором
и постпроцессором в комбинации с предлагаемым подходом;
2) решение задачи выявления фактических научных школ и
сравнения их с формальными научными школами;
3) задача формирования обобщенных образов научных
публикаций авторов, научных коллективов и организаций, как локальных
(традиционных), так и виртуальных.
Отметим также, что наряду с возможностью интеллектуальной
привязки ссылок к литературным источникам в библиографических базах данных
материалы данной работы могут быть использованы при решении ряда других сходных
по сути задач интеллектуальной обработки текстов. Например, предлагаемый подход
можно использовать для поиска аналогов преступлений путем АСК-анализа текстов
фабул преступлений, а также при преподавании дисциплин, связанных с
интеллектуальными технологиями и наукометрией, для проведения лекционных и
лабораторных занятий по этим дисциплинам и при выполнении курсовых и дипломных
работ.