ГЛАВА
III.
ИНФОРМАЦИОННАЯ ТЕХНОЛОГИЯ ПРИМЕНЕНИЯ СИСТЕМЫ
“ЭЙДОС”
В данном разделе излагается авторский подход к решению сформулированных
выше проблем и задач. Данный подход реализован в универсальной автоматизированной
системе распознавания образов “ЭЙДОС-
Описание технологии работы в системе “ЭЙДОС” включает
следующие вопросы:
· разработка
оптимальной методики тестирования;
· проведение
массовых обследований в промышленном режиме;
· углубленный
анализ результатов тестирования;
· вопросы
интерпретации результатов и возможности использования стандартных тестов;
· исследования
динамики и территориальных зависимостей.
Рассмотрим эти вопросы подробнее.
3.1.
РАЗРАБОТКА ОПТИМАЛЬНОЙ МЕТОДИКИ ТЕСТИРОВАНИЯ
Для разработки оптимальной методики тестирования прежде
всего необходимо владеть основными принципами формализованного описания
предметной области. Сама разработка включает следующие работы:
· разработка
и ввод максимальной анкеты;
· управление
обучающей выборкой и обучение Системы;
· оптимизация
максимальной анкеты;
· ортонормирование системы классов распознавания;
· перекодирование.
3.1.1. ОСНОВНЫЕ ПРИНЦИПЫ
ФОРМАЛИЗОВАННОГО ОПИСАНИЯ ПРЕДМЕТНОЙ ОБЛАСТИ
Основными объектами обработки информации в Системе являются классы распознавания и признаки.
Попытка строгого прямого определения этих краеугольных
понятий (обычно путем указания более общего понятия и
выделения специфического признака) неизбежно наталкивается на фундаментальные
трудности почти философского характера, а также на чисто лингвистические
проблемы, т.к. дискретный звуковой и
письменный язык, которым в частности написана и данная работа, сами состоят из
слов, обозначающих те самые классы распознавания и признаки, которые необходимо определить с их
помощью. Очевидно мы имеем здесь классическую форму известного парадокса
Рассела, что указывает на принципиальную неполноту самого языка, как формальной
системы (обобщение теоремы Геделя), и,
следовательно, невозможность разрешения этой проблемы без выхода за пределы
самого языка.
Из этого краткого рассуждения очевидно, что определение этих
понятий должно быть операционным, т.е. основанным на том, как формируются данные
понятия и как ими пользоваться.
Классы распознавания - это обобщенные образы, эталонные
описания которых формируются Системой на основе предъявления ей в качестве
примеров конкретных реализаций объектов (их состояний или ситуаций), которые по
мнению экспертов, относятся к данным классам. Класс распознавания представляет
собой обобщенную категорию, которой пользователь дает имя, и в которой
каким-либо образом выявлено все наиболее существенное и повторяющееся у всех
конкретных реализаций данной категории, т.е. то, что в первую очередь отличает
данную категорию от других категорий.
Система “ЭЙДОС” обеспечивает
формирование обобщенных образов классов распознавания различных иерархических уровней обобщения,
например (выделены различными шрифтами):
Отличник по математике 8-а класса СШ №
Отличник по математике 8-б класса СШ №
Отличник по математике 8-в класса СШ №
Отличник по математике 8-г класса СШ №
Отличник по математике восьмого класса
СШ №
Отличник по математике 8-а класса СШ №
Отличник по математике 8-б класса СШ №
Отличник по математике 8-в класса СШ №
Отличник по математике 8-г класса СШ №
Отличник по математике восьмого класса
СШ №
Отличник по математике восьмого класса
г.Краснодара
Отличник по математике 9-а класса СШ №
Отличник по математике 9-б класса СШ №
Отличник по математике 9-в класса СШ №
Отличник по математике 9-г класса СШ №
Отличник по математике девятого класса
СШ №
Отличник по математике 9-а класса СШ №
Отличник по математике 9-б класса СШ №
Отличник по математике 9-в класса СШ №
Отличник по математике 9-г класса СШ №
Отличник по математике девятого класса
СШ №
Отличник по математике девятого класса
г.Краснодара
...............................................................................................................
Отличник по математике г.Краснодара
...............................................................................................................
3.1.1.1.
ТИПЫ ИЗМЕРИТЕЛЬНЫХ ШКАЛ
Полное
описание типов измерительных шкал дается в [35, 56, 84]. В приведенной ниже
таблице дана характеристика измерительных шкал согласно [35].
ХАРАКТЕРИСТИКА
И ПРИМЕРЫ ИЗМЕРИТЕЛЬНЫХ ШКАЛ
|
Тип
шкалы |
Характеристики |
Примеры |
|
Номинальная (наименований) |
Объекты
классифицированы, классам присвоены словесные наименования или условные
номера - коды. То, что номер одного класса больше или меньше другого, еще
ничего не говорит о свойствах объектов, относящихся к этим классам, за
исключением того, что они различаются. |
Раса,
Национальность, цвет глаз, номера на футболках, пол, клинические диагнозы,
автомобильные номера, номера страховок. |
|
Порядковая |
Объекты
классифицированы, а классы обозначены номерами (закодированы). Значения чисел, присваиваемые классам,
качественно отражают степень выраженности определенных свойств предметов,
принадлежащих этим классам. То есть большим значениям кодов классов
соответствует и большая степень выраженности измеряемого свойства, на
основании чего классы можно ранжировать. |
Твердость
минералов, награды за заслуги, ранжирование по индивидуальным чертам
личности, военные и гражданские ранги, должности и звания. |
|
Интервальная |
Существует
единица измерения, при помощи которой классы можно не только упорядочить, но
и приписать им числа так, чтобы равные разности чисел присвоенных классам,
отражали равные различия в количествах измеряемых свойств. Нулевая точка интервальной
шкалы произвольна (условна) и не указывает на отсутствие свойства. |
Календарное
время, шкалы температур по Фаренгейту и Цельсию. |
|
Отношений |
Числа,
присвоенные классам, обладают всеми свойствами интервальной шкалы, но помимо
этого на шкале существует абсолютный нуль, соответствующий полному отсутствию
измеряемого свойства. Отношения чисел, присвоенных классам или объектам при
измерении, отражают количественные отношения измеряемого свойства. |
Рост,
вес, время, цена, количество информации, температура по Кельвину (есть
абсолютный нуль). |
Конечно,
наименования могут быть присвоены градациям всех видов измерительных шкал.
3.1.1.2.
КЛАССЫ РАСПОЗНАВАНИЯ И ШКАЛЫ
Очень плодотворным является
представление классов распознавания, как некоторых областей в фазовом
пространстве, в котором в качестве осей координат выступают некоторые шкалы.
Классы распознавания могут рассматриваться, также, как градации (конкретные
значения, заданные с некоторой точностью, или диапазоны - зоны), заданные на
этих шкалах. Количество шкал, тип шкал и количество градаций на них в системе
“ЭЙДОС” задает сам пользователь (причем на количество шкал и градаций не
накладывается ограничений, кроме суммарного количества классов)
Например:
шкала “Возраст” содержит 6 градаций:
менее 20 лет;
от 20 до 30 лет;
от 30 до 40 лет;
от 40 до 50 лет;
от 50 до 60 лет;
более 60 лет.
шкала “Пол” - 2 градации:
мужчина;
женщина.
шкала “Социальный статус” - 6 градаций:
безработный;
домохозяйка;
рабочий;
крестьянин;
служащий;
предприниматель.
Если представить эти шкалы как оси
координат, то, очевидно, наиболее обобщенным классам распознавания
соответствуют зоны на самих осях, перечень которых приведен выше (всего
6+2+6=14 классов распознавания).
Кроме того возможно всего 3 варианта
сочетаний по 2 оси, соответствующие областям на координатных плоскостях:
ВОЗРАСТ х ПОЛ (6 х 2 = 12 сочетаний
градаций типа: “Мужчина от 20 до 30 лет”, “Женщина моложе 20 лет” и т.п.);
ВОЗРАСТ х СОЦИАЛЬНЫЙ СТАТУС (6 х 6 = 36
сочетаний градаций, например “Предприниматель 30 - 40 лет”);
ПОЛ х СОЦИАЛЬНЫЙ СТАТУС (2 х 6 = 12
сочетаний градаций, например: “Деловая женщина (женщина предприниматель)”,
“Мужчина - безработный” ).
Таким образом, в нашем примере
существует всего: 12+36+12=60 сочетаний градаций, соответствующие более
детализированным классам распознавания.
Кроме того существуют области в фазовом
пространстве, образованные сочетаниями градаций сразу всех трех шкал. Всего
существует: 6х2х6=72 таких зон, соответствующих наиболее детализированным
классам распознавания, возможным в нашем примере (типа: “Безработный мужчина в
возрасте 40 - 50 лет”).
Итак, в результате мы имеем:
14 классов распознавания максимальной
обобщенности;
60 классов распознавания средней
степени обобщения;
72 детализированных класса
распознавания;
всего: 14+60+72=146 классов
распознавания различных уровней обобщения. Естественно, пользователь может
исследовать только те классы, которые его интересуют, сознательно принимая
решение не рассматривать остальных. Но он должен знать, что и остальные классы
также могут быть сформированы и исследованы, а для этого нужно иметь их
классификацию, принцип разработки которой мы только что рассмотрели.
Конкретными реализациями обобщенных
категорий могут быть объекты, их состояния или ситуации (но применять мы, как
правило, будем термин “объекты”, всегда имея в виду и остальные возможные варианты).
Синонимами понятия “класс распознавания” являются
применяющиеся в специальной литературе термины “объекты”, “категории”, “образы”, “эталоны”,
“типы”, “профили”.
Когда классы распознавания сформированы с ними могут осуществляться три
основные операции:
вывод на печать в виде таблиц или
графических диаграмм;
сравнение друг с другом на основе
сопоставления их информационного содержания;
сравнение с любыми конкретными
объектами, их состояниями или ситуациями.
Примеры классов
распознавания:
· в правоохранительной сфере - это прежде всего
статьи уголовного кодекса и нарушений ПДД, аналоги
преступлений (или аналоги фабул), аналоги проверок, обобщенные фотороботы криминогенных и некриминогенных типов различной направленности деятельности,
типология оперативных ситуаций, индивидуальные фотороботы состоящих на учете
лиц, оптимальные и неоптимальные абитуриенты, слушатели специальных учебных
заведений и сотрудники ОВД по всему спектру должностей и специальностей, сферы
криминальных интересов, неоправданно высокие степени риска при залоге и
кредитовании, криминальные типы экономической и финансовой деятельности (в
различных сфера), и т.п.;
·
в
медицине - это нозологические образы (диагнозы конкретных заболеваний при
дифференциальной диагностике или целые классы заболеваний при общей
диагностике), или клинические состояния
больного, в гомеопатии - гомеопатические
типы;
·
в
психосоциальной диагностике и анализе общественного мнения
- это различные политические, социальные, возрастные, образовательные,
профессиональные, территориальные и иные группы, различные формальные и
неформальные объединения граждан;
·
в
службах занятости, профориентации и определения профессиональной пригодности -
это различные профессии и конкретные должности, каждая со своей шкалой (типа:
“подходит” - “не подходит” или более подробной);
·
в
области выявления специальных способностей различной
направленности это будут наименования самих этих способностей.
Какие именно классы распознавания должны обрабатываться Системой определяет сам пользователь,
исходя из своих конкретных целей и задач.
3.1.1.3. ПРИЗНАКИ
И ШКАЛЫ
Конкретные объекты, предъявляемые
Системе в качестве примеров или реализаций некоторых обобщенных классов
(прецедентов), описываются на языке признаков.
Признаки могут иметь любую природу, в частности:
объективную - физическую, химическую и
др. (вес, температура, рост);
социально-экономическую (стоимость,
степень износа, процент дивидендов);
эмоционально-психологическую
(привлекательный, предупредительный, резкий).
Система признаков двухуровневая, что
позволяет формализовать (шкалировать) не только
качественные (да/нет), но и количественные (числовые) признаки, а также
позволяет обрабатывать вопросы со многими, в том числе и неальтернативными вариантами ответов. Вопрос с вариантами
ответов можно рассматривать как шкалу с градациями. Такое понимание позволяет
“ввести в оборот” хорошо разработанную теорию шкалирования, что является весьма
ценным. В системе “ЭЙДОС” нет ограничений на тип и количество шкал, а также на
количество градаций в них (за исключением суммарного общего количества
градаций, которое не должно превышать 4000). Нет в системе “ЭЙДОС” и таких
искусственных ограничений, как, например, необходимость одинакового количества
градаций во всех шкалах, или необходимость использовать только шкалы только
одного какого-либо типа, и т.п., которые, как правило, встречаются в других системах.
В принципе могут быть сконструированы
системы признаков, представляемые деревьями трех и более уровней, однако
программно реализовывать их нецелесообразно, т.к. они все сводятся к
двухуровневым деревьям (вопросы с вариантами ответов).
Длина наименования шкалы (вопроса): до
195 символов, длина наименования градации (варината ответа): до 195 символов.
Данная структура системы признаков
относится к опросникам закрытого типа с множественным выбором [46].
Это также не является ограничением, т.к. к данной системе могут быть сведены
результаты тестирования с помощью тестов других видов: как открытых, так и закрытых,
как с вербальным стимульным материалом, так и с невербальным (рисуночные
тесты, тесты на конструирование, на ассоциации и т.п.). В этом смысле система “ЭЙДОС” является системой обработки
результатов тестирования и их анализа, а не системой предъявления стимульного материала. Это значит, что стимульный материал
оформляется оптимально исходя из целей тестирования и система не является здесь
ограничением.
В системе “ЭЙДОС” формальное описание
объекта представляет собой совокупность его интенсионального и
экстенсионального описаний. Интенсиональное (дискретное) описание - это
последовательность кодов тех и только тех признаков, которые реально фактически
встретились у данного конкретного объекта. Экстенсиональное (континуальное)
описание состоит из кодов тех классов распознавания, для
формирования образов которых по мнению экспертов целесообразно использовать
интенсиональное описание данного конкретного объекта. Именно взаимодействие и
взаимная дополнительность этих двух взаимоисключающих видов описания объектов
формирует смысл.
Таким образом формальное описание
объекта в системе “ЭЙДОС” состоит из
двух векторов. Первый вектор описывает к каким обобщенным категориям
(классам распознавания) относится
объект с точки зрения экспертов (вектор субъективной, смысловой, человеческой
оценки). Второй же вектор содержит информацию о том, какими признаками обладает
данный объект (вектор объективных характеристик). Необходимо особо подчеркнуть,
что связь этих двух векторов друг с другом имеет вообще
говоря не детерминистский, а вероятностный, статистический характер.
Если объект описан обоими векторами, то
это описание можно использовать для формирования обобщенных образов классов
распознавания, а также для
проверки степени успешности выполнения этой задачи.
Если объект описан только вторым
вектором - вектором признаков, то его можно использовать только для решения
задачи распознавания (идентификации), которую можно рассматривать как задачу восстановления вектора
классов данного объекта по его известному вектору признаков.
Необходимо отметить, что в статистических системах, таких
как SPSS, STATGRAPHICS, STATISTICA, описание объекта состоит только из одного вектора характеристик.
В системе “ЭЙДОС” этот вариант
описания предметной области получается как некоторое подмножество из возможных в ней вариантов, определяемое
двумя ограничениями:
1.
справочник классов распознавания тождественно совпадает со справочником признаков;
2.
наличие какого-либо признака у объекта
обучающей выборки однозначно (детерминистским образом)
определяет принадлежность этого объекта к соответствующему классу распознавания.
Очевидно, эти ограничения приводят и к соответствующим
ограничениям, накладываемым в свою очередь на варианты обработки информации и
анализа данных в подобных системах.
Примеры признаков:
· в правоохранительной сфере - это обычные
криминалистические признаки (прямые и, особенно, косвенные улики), а также
признаки, психофизиологического, социального, финансового, экономического,
имущественного, психологического,
культурного, религиозного, этнического и биографического характера,
данные уголовного, секретного и личного дела, оценка коллег и сослуживцев,
специальные признаки, применяемые для криминогенной идентификации личности
(формализованные признаки фоторобота, группы крови
и других возможных выделений, характеристика отпечатков пальцев, почерка
преступления и т.п.);
·
в
медицине - это симптомы и синдромы, факторы риска различного рода;
·
в
психосоциальной диагностике и анализе общественного мнения
- это вопросы, позволяющие отнести респондента к определенной возрастной, профессиональной,
национальной, имущественной, образовательной и т.д. группе населения, а также вопросы самого
различного содержания, прямо или косвенно связанные с теми проблемами, которые
лидеры политических партий и движений поднимают в своих программных и
предвыборных выступлениях;
·
в
службах занятости, областях профориентации и определения профессиональной пригодности - это
вопросы и другие данные, позволяющие получить информацию о квалификации,
профессиональных возможностях и перспективах респондента;
·
в
области выявления специальных способностей различной
направленности - это признаки самой различной природы, выявленные как наиболее
значимые для решения поставленной задачи в результате проведенного
предварительного (пилотажного) исследования.
3.1.1.4. УРОВНИ СИСТЕМНОЙ
ОРГАНИЗАЦИИ КЛАССОВ
Классы распознавания могут относится к различным уровням иерархии какой-либо системы.
Например, это могут быть конкретные студенты, группы, курсы,
факультеты, учебные заведения, районы, регионы и т.д.
В системе “ЭЙДОС-
Работа с уровнями предоставляет ряд преимуществ, по
сравнению с использованием диапазонов кодов:
1.
классы распознавания, относящиеся к
одному уровню, могут идти в справочнике в любом порядке;
2.
изменять коды уровней значительно
легче, чем переделывать справочники, к тому же это не требует перекодирования
обучающей выборки;
3.
уровни классов имеют самостоятельный
смысл, тогда как выделение диапазонов кодов выглядит более искусственным
приемом.
3.1.1.5. УРОВНИ СИСТЕМНОЙ
ОРГАНИЗАЦИИ ПРИЗНАКОВ
В системе “ЭЙДОС-
Работа с уровнями предоставляет ряд преимуществ, по
сравнению с использованием диапазонов кодов:
1.
признаки, относящиеся к одному уровню,
могут идти в справочнике в любом порядке;
2.
изменять коды уровней значительно
легче, чем переделывать справочники, к тому же это не требует перекодирования
обучающей выборки;
3.
уровни признаков имеют самостоятельный
смысл, тогда как выделение диапазонов кодов выглядит более искусственным
приемом.
3.1.2. ПРИНЦИПЫ ФОРМИРОВАНИЯ
СПИСКА КЛАССОВ РАСПОЗНАВАНИЯ
В качестве классов распознавания пользователь может выбрать те категории, с
применением которых он собирается идентифицировать (прогнозировать) объекты или
ситуации исследуемой предметной области.
На начальном этапе (этапе пилотного исследования) могут быть заданы все категории,
использование которых с точки зрения
исследователя представляется целесообразным. Дальнейший анализ с использованием автоматизированной
системы покажет, насколько оправданным было применение тех или иных
категорий, соответствует ли им какое-либо реальное содержание. Если окажется,
что некоторым категориям реально в предметной области ничего не соответствует,
то они могут быть просто исключены из списка категорий, либо объединены с другими
аналогичными по смыслу.
3.1.3. РАЗРАБОТКА И ВВОД
МАКСИМАЛЬНОЙ АНКЕТЫ
Максимальная анкета представляет собой
первоначальный набор признаков, который используется для описания объектов
обучающей выборки и для обучения Системы решению задачи
распознавания.
Универсальная система распознавания образов поддерживает двухуровневую организацию признаков. Это позволяет, как уже
отмечалось ранее, формализовать (шкалировать) не только
качественные (да/нет), но и количественные (числовые) признаки, а также
позволяет обрабатывать вопросы со многими, в том числе и неальтернативными вариантами ответов.
Например:
ВОЗРАСТ:
· до
18 лет,
· от
18 до 25 лет,
· от
26 до 40 лет,
· от
40 до 50 лет,
· от
50 до 65 лет,
· старше
65 лет.
При разработке максимальной анкеты
возникает вопрос об источниках, из которых можно было бы почерпнуть систему
признаков, а также связанный с ним вопрос о возможности использовании для этих
целей стандартных методик тестирования и диагностики, которые уже используются
в данной предметной области.
3.1.3.1.
ИСТОЧНИКИ ИНФОРМАЦИИ.
Для того, чтобы придумать как можно
больше различных вопросов, среди которых, возможно окажутся и очень значимые,
разработчики рекомендуют применить метод “мозгового штурма”, т.е. свободного,
некритического, с раскрепощенной фантазией генерирования вопросов. Если в этой системе признаков
окажутся не очень ценные для решения задачи распознавания, то в этом
нет ничего страшного, т.к. Система на этапе оптимизации сама выявит и выбросит
их, но хуже если в первоначальной системе признаков не окажется значимых
вопросов. Поэтому первоначально пусть их будет как можно больше, тогда
оптимальная методика получится более качественной.
3.1.3.2.
ИСПОЛЬЗОВАНИЕ СТАНДАРТНЫХ МЕТОДИК
Могут быт использованы также системы
признаков (анкеты), применяемые в стандартных методиках тестирования,
литературные данные и др.
Очень интересной возможностью,
предоставляемой Системой, является возможность использования в качестве ВХОДНОЙ
информации РЕЗУЛЬТАТОВ работы стандартных методик тестирования, диагностики или
анализа. Особенно удобно использовать эту
возможность, если тест выдает результаты тестирования в формализованном виде
(т.е. не просто текстовка, а какая-либо
заранее известная классификация и связанная с ней текстовка). Так, например, в
максимальную анкету можно включить результаты теста Кеттела (16PF-опросник):
Фактор “A” -
“ЗАМКНУТОСТЬ - ОБЩИТЕЛЬНОСТЬ”
· низкая
оценка,
· норма,
· высокая
оценка.
Фактор “B” -
“ИНТЕЛЛЕКТ”
· низкая
оценка,
· норма,
· высокая
оценка.
Фактор “C” - “ЭМОЦИОНАЛЬНАЯ
НЕУСТОЙЧИВОСТЬ - ЭМОЦИОНАЛЬНАЯ УСТОЙЧИВОСТЬ”
· низкая
оценка,
· норма,
· высокая
оценка.
Фактор “Е” -
“ПОДЧИНЕННОСТЬ - ДОМИНАНТНОСТЬ”
· низкая
оценка,
· норма,
· высокая
оценка.
и т.д. до фактора MD, всего 17 факторов с уже
известной их интерпретацией но неизвестной значимостью для решения задач
тестирования и диагностики в других областях, кроме той, для которой
предназначен тест Кеттела (выявление интеллектуальных, эмоционально-волевых
и коммуникативных особенностей личности и групп).
Таким образом стандартные методики
могут быть использованы В КАЧЕСТВЕ ИСТОЧНИКА ИНФОРМАЦИИ об объектах (т.е.
средства измерения их признаков) для Универсальной автоматизированной системы
распознавания образов “ЭЙДОС”. В этом смысле Система “ЭЙДОС” является интегратором стандартных тестов.
Подобную роль в медицинской области могут играть лабораторные исследования или
использование аппаратных диагностических методик (таких, например, как оценка
общей работоспособности, психофизиологические тесты, и т.п.).
Ряд параметров респондента может установлен непосредственно с помощью
простейших методов (например анкеты), не требующих какой-либо обработки. Такие
параметры респондента будем называть “первичными параметрами”.
Параметры респондента, которые
могут быть установлены только с использованием специальных методик, тестов и соответствующих процедур математической
обработки “первичных параметров”, будем называть “вторичными параметрами”.
Первичные параметры респондента как правило фиксируют мелкие, фрагментарные легко
наблюдаемые, на первый взгляд малозначительные характеристики, которые взятые
сами по себе мало что говорят. Однако взятые в совокупности, обработанные
специальными методами эти “первичные параметры” позволяют получить
представление об интегральных и фундаментальных (конституционных)
характеристиках личности в целом, развитии интеллекта, эмоциональной сферы,
мотиваций и т.п., то есть
получить “вторичные параметры” личности.
Для
технологии и системы “ЭЙДОС”
не играет никакой роли, каким образом получены те характеристики личности,
которые используются для принятия решения о принадлежности данной личности к
тем или иным категориям - классам (идентификация личности), то есть нет никакой принципиальной разницы между
первичными и вторичными параметрами. Это означает, что технология и система
“ЭЙДОС” позволяет строить как “одноступенчатые тесты прямого действия”, осуществляющие
идентификацию личности непосредственно на основе первичных параметров, так и
“двухступенчатые тесты опосредованного действия”, которые осуществляют
идентификацию личности на основе ее вторичных параметров. Принципиально важно отметить,
что могут быть созданы и комбинированные тесты, включающие в качестве исходной
информации о личности как первичные, так и вторичные параметры.
Использование результатов работы
стандартных тестов в качестве источника информации о респондентах для системы “ЭЙДОС” обеспечивает
возможность выявить взаимосвязи между качествами личности, которые измеряются
стандартными тестами, и фактическими проявлениями личности в тех или иных
ситуациях, которые интересуют заказчика или исследователя. Эта возможность
представляется интересной как в научном, так и в практическом плане.
После обработки результатов
исследования может быть выявлено, что результаты тестирования, выдаваемые
некоторыми тестами, играют основную роль в идентификации респондентов по категориям (классам распознавания), тогда как
другие практически не играют никакой роли. Очевидно последние могут быть исключены
из процессов сбора и обработки информации без ущерба для качества работы приложения.
С другой стороны, очевидно,
предварительная обработка данных с помощью тестов “первой ступени” с целью получения вторичных
параметров для ввода в систему “ЭЙДОС” может быть
сама по себе достаточно трудоемка. Поэтому для практических (прагматических) целей
вполне достаточно иметь полученный с помощью системы “ЭЙДОС” оптимальный тест
прямого действия, обеспечивающий идентификацию личности вообще без
использования стандартных тестов.
Другой важной и интересной возможностью
является возможность использования системы “ЭЙДОС” для реализации стандартных
тестов в качестве приложений системы “ЭЙДОС”. Необходимо особо отметить, что
для реализации этой возможности совершенно не требуется программирования. Кроме
того в одном приложении могут быть одновременно реализовано сразу несколько
стандартных тестов, а также, например, новый тест профессиональной диагностки.
Рассмотрим эту возможность на примере
интеграции 16PF-опросника Кеттела и самоактуализационного теста (САТ).
Каждый фактор опросника Кеттелла
является по сути шкалой с десятью (или тремя) градациями, которые называются
стенами. Каждая шкала имеет название, каждая градация имеет свою стандартную
интерпретацию, приведенную в специальной литературе.
НАИМЕНОВАНИЯ ШКАЛ 16PF-опросника Кеттела:
A: замкнутость - общительность
B: интеллект
С: эмоциональная неустойчивость -
устойчивость
E: подчиненность - доминантность
F: сдержанность - агрессивность
G: подверженность чувствам - высокая
нормативность
H: робость - смелость
I: жесткость - чувствительность
L: доверчивость - подозрительность
M: практичность - развитое воображение
N: прямолинейность -
дипломатичность
O: уверенность в себе - тревожность
Q1: консерватизм - радикализм
Q2: конформизм - нонконформизм
Q3: низкий самоконтроль - высокий
Q4: расслабленность - напряженность.
В тесте САТ имеется 14 шкал, каждая из
которых также имеет свое название и стандартную интерпретацию:
Шкала ориентации во времени
Шкала поддержки
Шкала ценностной ориентации
Шкала гибкости поведения
Шкала сензитивности
Шкала спонтанности
Шкала самоуважения
Шкала самопринятия
Шкала представлений о природе человека
Шкала синергичности
Шкала принятия агрессии
Шкала контактности
Шкала познавательных потребностей
Шкала креативности
Кроме того шкалы объединены в блоки:
3+4
Ценностные ориентации
5+6
Чувства
7+8
Cамовосприятие
9+10 Концепция человека
11+12 Межличностная чувствительность
13+14 Отношение к познанию.
Для реалиазции 16PF-опросника Кеттела и
теста САТ в системе “ЭЙДОС” прежде всего сформируем справочник классов распознавания,
в котором названия классов будут соотвествовать названиям факторов
16PF-опросника и названиям шкал и блоков шкал САТ.
На втором этапе сформируем справочник
признаков, который по сути дела будет состоять из текста опросника Кеттела и
опросника САТ (вопросы с вариантами ответов).
На третьем этапе, используя ключи
интерпретации этих тестов сформируем анкеты обучающей выборки, соответствующие
ключам.
КЛЮЧИ 16pf-опросника
Кеттелла (вариант с 187 вопросами):
A: 3а,
3б, 26б, 26в, 27б, 27в, 51б, 51в, 52а, 52б, 76б, 76в, 101а, 101б, 126а, 126б,
151б, 151в, 176а, 176б
B: 28б,
53б, 54б, 77в, 78б, 102в, 103б, 127в, 128б, 152а, 153в, 177а, 178а,
F: 8б,
8в, 33а, 33б, 58а, 58б, 82б, 82в, 83а, 83б, 107б, 107в, 108б, 108в, 132а, 132б,
133а, 133б, 157б, 157в, 158б, 158в, 182а, 182б, 183а, 183б,
H: 10а,
10б, 35б, 35в, 36а, 36б, 60б, 60в, 61б, 61в, 85б, 85в, 86б, 86в, 110а, 110б,
111а, 111б, 135а, 135б, 136а, 136б, 161б, 161в, 186а, 186б,
L: 13б,
13в, 38а, 38б, 63б, 63в, 64б, 64в, 88б, 88в, 89б, 89в, 113а, 113б, 114а, 114б,
139б, 139в, 164а, 164б,
N: 16б,
16в, 17а, 17б, 41б, 41в, 42а, 42б, 66б, 66в, 67б, 67в, 92б, 92в, 117а, 117б,
142а, 142б, 167а, 167б,
Q1: 20а,
20б, 21б, 21в, 45б, 45в, 46а, 46б, 70а, 70б, 95б, 95в, 120б, 120в, 145а, 145б,
169а, 169б, 170б, 170в,
Q3: 23б,
23в, 24б, 24в, 48а, 48б, 73а, 73б, 98а, 98б, 123б, 123в, 147б, 147в, 148а,
148б, 172б, 172в, 173а, 173б,
C: 4а,
4б, 5б, 5в, 29б, 29в, 30а, 30б, 55а, 55б, 79б, 79в, 80б, 80в, 104а, 104б, 105а,
105б, 129б, 129в, 130а, 130б, 154б, 154в, 179а, 179б,
E: 6б,
6в, 7а, 7б, 31б, 31в, 32б, 32в, 56а, 56б, 57б, 57в, 81б, 81в, 106б, 106в, 131а,
131б, 156а, 156б,
G: 9б,
9в, 34б, 34в, 59б, 59в, 84б, 84в, 109а, 109б, 134а, 134б, 159б, 159в, 160а,
160б, 184а, 184б, 185а, 185б,
I: 11б,
11в, 12а, 12б, 37а, 37б, 62б, 62в, 87б, 87в, 112а, 112б, 137б, 137в, 138а,
138б, 162б, 162в, 163а, 163б,
M: 14б,
14в, 15б, 15в, 39а, 39б, 40а, 40б, 65а, 65б, 90б, 90в, 91а, 91б, 115а, 115б,
116а, 116б, 140а, 140б, 141б, 141в, 165б, 165в, 166б, 166в,
O: 18а,
18б, 19б, 19в, 43а, 43б, 44б, 44в, 68б, 68в, 69а, 69б, 93б, 93в, 94а, 94б,
118а, 118б, 119а, 119б, 143а, 143б, 144б, 144в, 168б, 168в,
Q2: 22б,
22в, 47а, 47б, 71а, 71б, 72а, 72б, 96б, 96в, 97б, 97в, 121б, 121в, 122б, 122в,
146а, 146б, 171а, 171б,
Q4: 25б,
25в, 49а, 49б, 50а, 50б, 74а, 74б, 75б, 75в, 99а, 99б, 100б, 100в, 124а, 124б,
125б, 125в, 149а, 149б, 150б, 150в, 174а, 174б, 175б, 175в
КЛЮЧИ теста САТ:
1.
11а, 16б, 18б, 21а, 28б, 38б, 40б, 41б,
45б, 60б, 64б, 71б, 76б, 82б, 91б, 106б, 126б,
2.
1б, 2б, 3а, 4а, 5б, 7б, 8а, 9а, 10а,
12б, 14б, 15б, 17а, 19а, 22б, 23а, 25б, 26б, 27б, 29а, 31б, 32а, 33б, 34а, 35б,
36б, 39б, 42а, 43а, 44б, 46а, 47б, 49б, 50б, 51б, 52а, 53а, 55а, 56а, 57а, 59а,
61б, 62б, 65б, 66а, 67б, 68а, 69б, 70а, 72б, 73а, 74б, 75б, 77а, 80а, 81а, 83а,
85б, 86а, 87б, 88б, 89б, 90а, 93а, 94а, 95б, 96а, 97а, 98а, 99б, 100а, 102а,
103б, 104а, 105б, 108б, 109а, 110а, 111б, 113а, 114а, 115а, 116б, 117б, 118а,
119б, 120а, 122а, 123б, 125б,
3.
17а, 29а, 42а, 49б, 50б, 53а, 56а, 59а,
67б, 68а, 69б, 80а, 81а, 90а, 93а, 97а, 99б, 113а, 114а, 122а,
4.
3а, 9а, 12б, 33б, 36б, 38б, 40б, 47б,
50б, 51б, 61б, 62б, 65б, 68а, 70а, 74б, 82б, 85б, 95б, 97а, 99б, 102а, 105б,
123б
5.
2б, 5б, 10а, 43а, 46а, 55а, 73а, 77а,
83а, 89б, 103б, 119б, 122а,
6.
5б, 14б, 15б, 26б, 42а, 62б, 67б, 74б,
77а, 80а, 81а, 83а, 95б, 114а
7.
2б, 3а, 7б, 23а, 29а, 44б, 53а, 66а,
69б, 98а, 100а, 102а, 106б, 114а, 122а,
8.
1б, 8а, 14б, 22б, 31б, 32а, 34а, 39б,
53а, 61б, 71б, 75б, 86а, 87б, 104а, 105б, 106б, 110а, 111б, 116б, 125б,
9.
23а, 25б, 27б, 50б, 66а, 90а, 94а, 97а,
99б, 113а,
10. 50б,
68а, 91б, 93а, 97а, 99б, 113а,
11. 5б,
8а, 10а, 15б, 19а, 29а, 39б, 43а, 46а, 56а, 57б, 67б, 85б, 93а, 94а, 115а,
12. 5б,
7б, 17а, 23б, 26б, 36б, 46а, 65б, 70а, 73а, 74б, 75б, 79б, 96а, 99б, 103б,
108б, 109а, 120а, 123б,
13. 13а,
20б, 37а, 48а, 63б, 66а, 78б, 82б, 92а, 107б, 121б,
14. 6б,
24а, 30а, 42а, 54а, 58а, 59а, 68а, 84а, 101а, 105б, 112б, 123б, 124б,
Каждая анкета будет соотвествовать одному ключу - классу
распознавания. Таким образом всего получится
16 анкет по ключам Кеттелла и 14 по ключам САТ. В каждой анкете будут
приведены коды коды вариантов ответов, соответствующих данному ключу.
На следующем этапе осуществляется обучение системы “ЭЙДОС”.
В результате она вычисляет свои “весовые коэффициенты”, представляющие собой
количество информации, которое мы получаем о выраженности данного фактора или
шкалы у респондента при получении положительного ответа на данный вопрос.
После этого, если мы введем в качестве распознаваемой,
анкету, заполненную некоторым респондентом, ответившим на опросники Кеттелла и
САТ, то в результате распознавания мы получим карточку, на которой будет
показано какие факторы и шкалы у него представлены, т.е. какие личностные
качества у него имеются.
Если бы кроме наименований шкал в справочник классов
распознавания были бы введены и наименования профессиональных категорий
(например, с градациями “подходит”, “неопределенно”, “не подходит”), а
обучающей выборке были бы анкеты, заполненные представителями этих
профессиональных категорий, то в результате обучения система “ЭЙДОС” сформировала
бы и их обобщенные образы. Тогда в результате кластерно-конструктивного анализа
мы бы увидели, какие факторы и шкалы (т.е. психологические свойства)
коррелируют или антикоррелируют с обобщенными образами профессиональных
категорий. Это еще один подход к формированию профессиограмм в системе “ЭЙДОС”.
Первый вариант формирования профессиограмм рассмотрен кратко выше и основан
просто на включении в справочник признаков психологических свойств, измеряемых
с помощью стандартных тестов. Этот подход автоматизирован в системе окружения “ЭЙДОС-Y“ (подробнее
см. в разделе 3.1.3. данной работы).
Таким образом:
стандартные тесты могут быть
использованы в качестве источника информации о психологических свойствах
респондентов в ситуации тестирования;
любой стандартный тест с известными
ключами интерпретации может быть реализован в качестве приложения системы
“ЭЙДОС”;
могут быть созданы приложения системы
“ЭЙДОС”, автоматизирующие сразу “целый пакет” стандартных тестов и являющееся
по сути дела супертестом (аналогично популярному супертесту MMPI);
причем для этого не требуется никакого
программирования.
3.1.3.3.
ПОНЯТИЕ О МЕТОДИКАХ КОСВЕННОЙ ДИАГНОСТИКИ
Фактически, все методики измерения
относятся к методикам косвенного измерения, т.к. измерения любой величины мы осуществляем не
для того, чтобы узнать ее значение само по себе, а для того, чтобы по этому
значению сделать вывод о том, что нас интересует. Например, когда врач измеряет
температуру больного, то он это делает не для того, чтобы узнать его температуру,
а для того, чтобы по величине этой температуры сделать вывод о возможном диагнозе
и методе лечения.
Косвенное тестирование, - это способ
получения информации о сущностных свойствах объектов по их внешним проявлениям
(свойствам). Например, когда мы спрашиваем респондента об одном, чтобы узнать
совсем о другом, то мы применяем косвенное тестирование. Но для того, чтобы
уметь это делать необходимо знать, как корреляционно связаны те или иные ответы
на наши вопросы с тем, что мы в действительности хотим узнать о респонденте,
т.е. мы должны располагать инструментом для косвенных измерений. Чтобы узнать
эти корреляционные зависимости и построить на их основе методику косвенных
измерений необходимо располагать соответствующей технологией, позволяющей
выявить корреляционные зависимости между наблюдаемыми параметрами объектов и их
сущностной характеристикой, причем, очевидно, эту последнюю необходимо уметь
определять другим независимым от наших вопросов методом, например на основе
экспертных оценок или по верифицированным (т.е. точно известным из опыта)
данным.
Таким образом, когда мы задаем
респонденту те или иные вопросы, то в действительности мы
меньше всего хотим выяснить то, о чем вроде-бы идет речь в этих вопросах (как
обычно полагает респондент). В
действительности нам важна лишь та иная реакция различных типов респондентов на эти вопросы, а Система уже сама выявит взаимосвязи между вариантами этой реакции и
типами респондентов, и, на этой основе,
позволит нам решать поставленные задачи идентификации, прогнозирования и т.п. При этом совершенно не играет роли мотивация
респондента при ответах: т.е. является ли респондент
искренним, или старается “изощренно” лгать, спокоен он или возбужден и т.п., - играет роль
лишь то, чтобы это состояние мотивации было однотипным и для респондентов
обучающей выборки, и для тестируемых.
Таким образом Система “ЭЙДОС” обеспечивает
конструирование методик косвенного тестирования, позволяющих получать
информацию о том, что нас интересует, спрашивая респондента о таких вещах,
которые по-видимому (на первый взгляд) не имеют ни малейшего отношения к
предмету наших интересов, или имеют, но совершенно не ясно какое.
В ряде случаев системами косвенной
диагностики являются единственным способом получить о респонденте необходимую достоверную информацию, которую
невозможно получить в качестве ответа на прямой вопрос (например, если
спросить: “Ты будешь брать взятки, если закончишь обучение?”. Естественно,
слушатель ответит “Нет”, и искренне улыбнется).
В связи с вышеизложенным вопросы
(обобщенные признаки) максимальной анкеты могут относиться к следующим
категориям:
корректные с точки зрения грамматики
и/или содержания предметной области;
некорректные с точки зрения грамматики
и/или содержания предметной области.
Варианты ответов на вопросы
максимальной анкеты, в свою очередь, могут относиться к следующим категориям:
правильные и полные ответы (с точки
зрения содержания предметной области);
правильные но неполные ответы (с точки
зрения содержания предметной области);
неправильные ответы (с точки зрения
содержания предметной области). В частности, эти ответы могут отражать распространенные
заблуждения;
корректные с точки зрения грамматики;
грубо или “изящно” некорректные с точки
зрения “академической” грамматики, построенные на базе слогана, сленга или просто жаргона;
ответы, рассчитанные на наличие у
респондента чувства юмора или каких-либо других качеств,
например на знание иностранных языков или языков народов бывшего СССР.
Примером может быть ставший уже
классическим вопрос “из социологического обследования одесситов”: “Каково оно?”
со следующими тремя вариантами ответов: “1.регулярно; 2.не помню; 3.а я всю
субботу работал на даче с тещей”.
Вопросы и ответы всех этих типов могут
дать ценную информацию для классификации и распознавания респондентов, поэтому
включение таких вопросов в максимальную анкету является совершенно оправданным.
С каждым признаком может быть связана
его интерпретация, если она заранее известна (из стандартных методик, на основе
ранее проведенных исследований или из других источников). В последующем эта
информация будет использована для автоматизированной интерпретации эталонных
описаний классов распознавания.
Режимы ввода-корректировки первичных и
обобщенных признаков системы “ЭЙДОС” обеспечивают
автоматическое кодирование признаков и автоматическое ведение их ссылок друг на
друга с возможностью корректировки ссылок в одну сторону при вводе первичных признаков.
3.1.3.4.
АВТОМАТИЧЕСКИЙ ВВОД СИСТЕМЫ ПРИЗНАКОВ ИЗ ФАЙЛОВ
Если у пользователя есть текстовые
файлы с необходимыми вопросами, то нет необходимости
вводить их в Систему вручную, т.к. предусмотрен режим их автоматического ввода.
Причем как первичные признаки могут рассматриваться:
1.
строки,
2.
предложения,
3.
слова,
4.
семантически оправданные сочетания слов: 1-е слово со 2-м, 1-е
слово с 3-м, 1-е слово с 4-м, ... , 1-е слово со N-м.
1.
Первый
вариант особенно удобен при вводе опросников со сканера с применением систем распознавания текстов.
2.
Третий
вариант интересен для определения смысловой нагрузки слов в текстах
и для решения задач сравнения неформализованных фабул преступлений и автоматизированной
атрибуции текстов.
3.
Четвертый
вариант целесообразно применять для ввода информации из текстовых
файлов, формируемых,
например, некоторыми стандартными тестами, дающими формализованные результаты
тестирования, а также астрологическими
системами.
4.
Например,
фрагмент текстового файла, формируемого
астрологической системой STAR v.5.5 (автор: O.Nicolajchuk, 1991) имеет вид:
Cardinal : mer ura
plu
Fixed : sun hea
tai nep
Mutable : moo ven
mar jup sat
Fire : sat
Earth : sun hea
ura plu
Air : moo mer
mar
Water : tai ven
jup nep
Exaltation(5): jup
Relation(4): ura nep
Enmity(2): ven
Fall(1):
Expatriation(0): plu
5.
В результате его обработки в режиме
“сочетания слов” система “ЭЙДОС” формирует
следующий справочник признаков:
|
1 2 Air : 3 Air mar 4 Air mer 5 Air moo 6 Cardinal : 7 Cardinal mer 8 Cardinal plu 9 Cardinal ura 10
Earth : |
11
Earth hea 12
Earth plu 13
Earth sun 14
Earth ura 15
Enmity(2): ven 16
Exaltation(5): jup 17
Expatriation(0): plu 18
Fall(1): 19
Fire : 20
Fire sat |
21
Fixed : 22
Fixed hea 23
Fixed nep 24
Fixed sun 25
Fixed tai 26
House(6): mer 27
Mutable : 28
Mutable jup 29
Mutable mar 30
Mutable moo |
31
Mutable sat 32
Mutable ven 33
Relation(4): nep 34
Relation(4): ura 35
Water : 36
Water jup 37
Water nep 38
Water tai 39
Water ven |
Если бы для формирования справочника
признаков использовалось большое количество фрагментов текстовых файлов, подобных вышеприведенному, то
справочник астрологических признаков включал бы более 300 наименований.
С использованием данного справочника
признаков исходный фрагмент текстового файла представляется системой “ЭЙДОС” в следующем стандартном для нее
виде:
А
Н К Е
Т А обучающей выборки
N° 1 0001-SID.TXT
15.05.96 14:09:29
г.Краснодар
==============================================================================
|
Код | Наименования
классов распознавания |
==============================================================================
|
1 | Сидоров Иван Петрович |
==============================================================================
| К о д ы
п е р в и ч н ы х п р и з н а к
о в |
==============================================================================
|
6 7 9
8 21 24
22 25 23
27 30 32
29 28 31 |
|
19 20 10
13 11 14 12
2 5 4
3 35 38
39 36 |
|
37 26 16
34 33 15
18 17 |
==============================================================================
Универсальная когнитивная аналитическая
система НПП *ЭЙДОС*
Данная технология позволяет без ручного ввода генерировать признаки
из текстовых файлов, кодировать
эти текстовые файлы и добавлять их закодированные описания к
анкетам обучающей и распознаваемой выборки. После обучения
системы, оптимизации системы признаков и проверки на валидность, получается
новая методика, обеспечивающая достижение поставленных целей на основе выявленных
взаимосвязей между астрологическими данными и с тем, что интересует заказчика.
В более техническом плане механизм
автоматического кодирования и ввода признаков из текстовых файлов будет описан ниже.
3.1.4. УПРАВЛЕНИЕ ОБУЧАЮЩЕЙ ВЫБОРКОЙ
И ОБУЧЕНИЕ СИСТЕМЫ
Для обучения Системы решению задачи
распознавания необходимо следующее:
1. Принять
решение о том, какие объекты использовать для обучения Системы, т.е.
сформировать обучающую выборку,
2. Описать
объекты обучающей выборки на языке признаков с использованием максимальной
анкеты,
3. Ввести
в Систему информацию обучающей выборки, приняв специальные меры для обеспечения
высокого качества ввода,
4. Принять
решение об окончании процесса обучения Системы на основе обоснованных
количественных критериев.
Рассмотрим эти этапы подробнее.
3.1.4.1.
ПРИНЦИПЫ ФОРМИРОВАНИЯ ОБУЧАЮЩЕЙ ВЫБОРКИ
Должен быть определен КОМПЕТЕНТНЫЙ
СОВЕТ ЭКСПЕРТОВ, имеющий полномочия РЕШАТЬ:
- какие объекты отобрать в обучающую выборку,
- для формирования обобщенных эталонных
образов каких классов распознавания какие объекты использовать,
- когда прекращать процесс обучения
Системы.
Полномочия Совета Экспертов должны быть
оформлены юридически.
В Совет Экспертов могут входить
эксперты, имеющие различные полномочия.
Так, например, если Система
используется для разработки оптимальной методики тестирования для подбора и
расстановки кадров на крупном предприятии, то справочник классов распознавания будет представлять собой по сути дела
штатно-должностной список в котором каждая должность будет представлена,
например, в двух вариантах: подходит и не подходит. Очевидно, подбор конкретных работников для обучающей выборки, являющихся яркими представителями
данных классов распознавания является делом компетенции тех членов Совета
Экспертов, которые принимают решение о приеме на работу и увольнении работников
данных должностей.
Для качественного формирования
эталонных описаний классов распознавания по каждому классу распознавания должно быть
представлено ДОСТАТОЧНОЕ количество объектов, являющихся ЯРКИМИ И ТИПИЧНЫМИ
ПРЕДСТАВИТЕЛЯМИ данного класса (так, чтобы вариабельность объектов по признакам, т.е. разброс между объектами одного класса был минимальным).
Необходимо особо подчеркнуть,
что для обучения Системы “ЭЙДОС” фамилия и
другие адресные данные лиц, анкеты которых по решению экспертов используются
для формирования образов, совершенно не существенны (если, конечно, не
изучается влияние первой и других букв имени, отчества и
фамилии), поэтому указывать их нет необходимости. Чтобы не происходило утечки конфиденциальной
информации о том, как оценивают эксперты, которые как правило являются
руководителями) тех или иных лиц, анкеты должны быть обезличены, либо фамилии
конкретных лиц заменены условными шифрами в соответствии с таблицей, которая
есть только у самого эксперта или руководителя.
Удачный выбор экспертов имеет решающее
значение для достижения высокой эффективности разрабатываемой методики, т.к.
при обучении Система просто подбирает решающие правила таким образом, чтобы
принимать автоматизированные решения в максимальной степени совпадающие с
коллегиальными решениями Совета экспертов.
Примечание: понятие эксперта в
технологии «ЭЙДОС» и в экспертных системах существенно отличаются. В первом
случае от эксперта требуется лишь сообщить системе на основе достоверной
информации о принадлежности объекта обучающей выборки к том или иным классам.
Во втором случае от эксперта, как правило, требуют, чтобы он вербализовал, да
еще как правило в логической форме, принципы принятия решений, которыми он
руководствуется. Это обычно наталкивается на значительные сложности, т.к.
эксперты принимают решения обычно не на основе логических рассуждений.
Интересен также вопрос о том, кого обычно выбирают экспертами при формализации
знаний в экспертных системах. Если это, например, профессора, то и система
учится принимать решения как профессора.
Вопрос о соотношении этих решений с действительностью как бы и не возникает. Но
дело в том, что и профессора ошибаются в довольно большом проценте случаев, что
выясняется, когда их решения сравнивают с действительностью. Строго говоря,
профессора, например, в области медицинской диагностики, это не те врачи,
которые лучше ставят диагноз, а те, которые лучше знают, как стать
профессорами. Соответственно, если профессоров-диагностов пригласить
экспертами, то и экспертная система будет ставить диагноз не так, как лучшие
диагносты, а так, как карьеристы и коньюктурщики, т.е. профессора. Так не лучше ли обучать систему не
подсказывая ей те или иные модели действительности, которые могут быть неадекватными,
а просто вводя в нее информацию о самой действительности? Модель же
действительности пусть система формирует сама (если может, естественно).
Этот подход и реализован в системе «ЭЙДОС», которая, таким образом,
функционально полнее экспертных систем.
3.1.4.2.
ДОКУМЕНТАЛЬНАЯ ФОРМАЛИЗАЦИЯ ОБУЧАЮЩЕЙ ВЫБОРКИ
Этот процесс представляет собой
описание объектов обучающей выборки на языке признаков.
Для проведения данной работы
назначается ОРГАНИЗАТОР АНКЕТИРОВАНИЯ, имеющий
соответствующие полномочия и подчиненных для непосредственной работы с корреспондентами
обучающей выборки.
С помощью Системы распечатываются следующие
документы:
1.
анкета с текстовкой вопросов;
2.
анкеты-пустографки для описания
объектов обучающей выборки.
3.1.4.2.1.
Инструкция ОРГАНИЗАТОРУ анкетирования:
1-й вариант: - анкету с текстовкой вопросов размножьте и раздайте
корреспондентам, предупредив их о том, чтобы они не делали в них никаких меток
и обращались с анкетами аккуратно,
2-й вариант: - анкету с текстовкой вопросов РАСШЕЙТЕ и раздайте листы участникам анкетируемой группы, чтобы они
могли отвечать на вопросы одновременно, меняясь листами между собой, коды вопросов, на которые корреспонденты
отвечают “ДА”, должны быть записаны ими в данную пустографку, при этом
ОСОБОЕ ВНИМАНИЕ корреспондентов должно быть обращено на ЧЕТКОСТЬ заполнения.
Это очень важно для качественной работы операторов, которым, к сожалению,
слишком часто приходится просто догадываться, что же все-таки написано в
бланке, а от этого зависит и качество всей работы в целом. Заполнение всех
полей и подписей данного титульного листа является обязательным.
3.1.4.2.2.
Инструкция УЧАСТНИКУ АНКЕТИРУЕМОЙ ГРУППЫ (респонденту):
1.
если Вы согласны с утверждением, т.е.
отвечаете на вопрос “ДА”, то АККУРАТНО, ЧЕТКО, ПЕЧАТНЫМ ШРИФТОМ, запишите код
данного вопроса в пустографку. Для
заполнения анкеты использовать только шариковую ручку (карандаш не допускается).
2.
если Вы не согласны с утверждением,
отвечаете на вопрос “НЕТ” или у Вас нет определенного мнения по данному
вопросу, то просто пропустите его.
3.
на вопросы со многими вариантами
ответов можно отвечать “ДА” одновременно на несколько вариантов (нет
необходимости обязательно выбирать только один из них).
4.
если Вы записали код ответа в
пустографку ошибочно, то просто зачеркните его,
5.
после ответа на все вопросы некоторого
листа анкеты (если она расшита) зачеркните N° этого листа в таблице, подобной
этой:
|
1 |
2 |
3 |
4 |
5 |
|
6 |
7 |
8 |
9 |
10 |
а затем попросите у других опрашиваемых те листы анкеты, на которые Вы еще не ответили.
3.1.4.3.
ВВОД, КОНТРОЛЬ И КОРРЕКТИРОВКА ОБУЧАЮЩЕЙ ИНФОРМАЦИИ
В данном режиме имеется двух-оконный
интерфейс.
3.1.4.3.1. РУЧНОЕ КОДИРОВАНИЕ
КЛАССОВ РАСПОЗНАВАНИЯ
В левом окне
вводится информация, характеризующая анкету в целом (заголовок анкеты). Это
номер анкеты, который формируется Системой автоматически, а также коды классов
распознавания, для формирования обобщенных образов которых
будет использоваться данная анкета, вводимые пользователем. Каждый столбец для
ввода кода класса распознавания соответствует некоторой шкале классификации
классов, а сам код - градации соответствующей шкалы.
Физическая анкета
- это анкета, заполненная респондентом. Но этот
респондент может относится одновременно ко многим
градациям шкал классификации классов распознавания (см.2.1.1.1, 2.1.1.2), т.е.
быть одновременно, например, мужчиной, иметь определенный возраст, определенную
национальность, определенную форму занятости и т.д., и т.п. Следовательно одну физическую анкету можно
использовать для формирования обобщенных образов каждой из этих категорий, к
которым относится заполнявший ее респондент. Это и означает, что одна
физическая анкета рассматривается как включающая некоторое количество логических
анкет.
В правом окне
подряд в любом порядке вводятся коды признаков, которые были установлены у
объекта обучающей выборки (из анкеты). Активное окно обведено
двойной рамкой. Переход из одного окна в другое по нажатию клавиши TAB.
В процессе ввода Системой отображаются
наименования классов распознавания и признаков, коды которых введены
пользователем. При вводе кода объекта или признака, которых нет в справочниках
Системой подается специальный звуковой сигнал. В каждом окне есть свое
функциональное меню со многими возможностями, среди которых есть и
контекстно-зависимая подсказка.
После окончания ввода анкет обучающей выборки необходимо проверить правильность
ввода. Это обусловлено тем, что этот этап работ является ключевым и во многом
определяет качество работы Системы в будущем. Проверка проводится путем зачитывания кодов вслух с анкет, заполненных
корреспондентами и сверки их с введенными в Систему на экране или на
распечатках анкет. При обнаружении неверно введенного кода при сверке на экране
он сразу корректируется, а при сверке
по распечатке анкеты - отмечается карандашом, а корректируются отдельно.
После окончания ввода анкет обучающей выборки и сверки правильности их ввода необходимые
анкеты могут быть продублированы.
3.1.4.3.2. ПОЛУАВТОМАТИЧЕСКОЕ И АВТОМАТИЧЕСКОЕ КОДИРОВАНИЕ
КЛАССОВ РАСПОЗНАВАНИЯ В СООТВЕТСТВИИ С КОДАМИ ПРИЗНАКОВ, ВВЕДЕННЫХ В АНКЕТЫ
ОБУЧАЮЩЕЙ ВЫБОРКИ
Этот режим разработан специально для
обработки социологической информации, т.к. социологические анкеты как правило
сконструированы таким образом, что классы распознавания определяются на основе
ответов на вопросы анкеты. Например: пол, возраст, национальность,
профессиональная принадлежность, политическая ориентация и т.п. Для этих целей Системе необходимо указать, как
связаны классы распознавания и признаки. Делается это при вводе справочников
классов распознавания и первичных признаков путем задания необходимых кодов в
соответствующем столбце.
Всего существует три варианта таких
связей, которые в системе “ЭЙДОС-
1.
одному классу распознавания соответствует один признак
(взаимно-однозначное соответствие, как в системе SPSS),
2.
один признак соответствует нескольким
классам распознавания (например: признак с кодом 15 “национальность
- иранец” соответствует классам 22 - “национальность - иранец” и 30 -
“национальность - нерусский”),
3.
один класс распознавания соответствует нескольким признакам (например:
класс распознавания 7 “пенсионер” соответствует признакам 45 “возраст 65-75
лет” и признаку 46 “возраст 75 и более лет”).
Если связи классов распознавания и признаков заданы (в режимах ввода соответствующих
справочников), то в режиме ввода обучающей информации кодирование классов распознавания
происходит полуавтоматически при нажатии
клавиши TAB и переходе из окна ввода признаков в окно ввода классов. При этом
вводятся только новые коды классов, каждый класс вводится лишь один раз, уже
введенные ранее коды классов не меняются, все коды классов располагаются в
порядке возрастания, вводится не более некоторого максимального количества
кодов классов, заданного в базе данных SETUP.DBF перед созданием всех баз данных.
Кроме того в системе “ЭЙДОС-
*
сбросить все ранее введенные коды
классов и полностью сформировать их заново на основе ссылок классов на признаки
и признаков на классы;
*
дополнить ранее введенные классы
распознавания (независимо от способа, каким они были введены: вручную или
автоматически), отсутствующими классами, сформированными на основе ссылок.
Данный
режим значительно повышает адаптивные возможности системы.
Например, если уже после ввода обучающей выборки и проведения расчетов по ней,
у Вас возникла мысль дополнить классы распознавания новыми обобщающими
классами, сформировать эти образы и провести их дальнейший анализ, то для этого
достаточно ввести в справочник классов их наименования, указать ссылки на
признаки (или/и признаков на эти классы), а затем выполнить данный режим и переобучить
систему.
В версии 5.1 системы “ЭЙДОС” это
перекодирование можно было осуществить только в полуавтоматическом режиме, т.е.
пройдя по всем анкетам обучающей выборки и нажимая на каждой клавишу TAB. Это
было довольно трудоемко, особенно при больших объемах обучающей выборки.
3.1.4.4.
АВТОМАТИЧЕСКИЙ ВВОД ОБУЧАЮЩЕЙ ИНФОРМАЦИИ ИЗ ТЕКСТОВЫХ ФАЙЛОВ
Если в окне ввода первичных признаков
нажать клавишу: “F7 Ввод из файлов”, то появится
новое функциональное меню, в котором будут следующие варианты:
·
нажав клавишу F5 - автоматически
закодировать тот текстовый файл, на котором
Вами установлен курсор, и ввести коды признаков в ту анкету, с заголовка
которой Вы перешли в правое окно. Имя файла может иметь любое расширение.
·
нажав клавишу F6 - автоматически
закодировать и ввести в анкеты коды признаков всех текстовых файлов с именами вида: ####-???.*, где: #### - номера
анкет {0001,0002,...,NNNN}, ??? - произвольные символы, .* - расширение. При
этом коды признаков ДОПОЛНЯТ анкеты с соответствующими номерами. Если же таких
анкет нет, то они будут созданы.
В обоих случаях предварительно
необходимо задать, что считать первичным признаками: строки, предложения, слова
или сочетания слов. Далее `процесс идет` автоматически с наглядным отображением
его стадии.
Текстовые файлы с обучающей информацией должны находиться в поддиректории DOB.
3.1.4.5.
ПАРАМЕТРИЧЕСКОЕ ЗАДАНИЕ ПОДМНОЖЕСТВА АНКЕТ ОБУЧАЮЩЕЙ ВЫБОРКИ
Данный режим предназначен для выделения из обучающей выборки некоторого подмножества анкет, удовлетворяющих заданным параметрам.
Параметры задаются путем ввода анкеты-маски, в которой
указываются коды тех классов распознавания, которые
должны быть исследованы, или/и коды определенных вопросов опросника. В дальнейшей
обработке будут участвовать только те анкеты обучающей выборки, которые относятся к указанным классам
распознавания и содержат одновременно коды всех вопросов, присутствующих в анкете-маске.
Если анкета-маска пуста, то будут обработаны все анкеты
обучающей выборки. Если в анкете-маске вообще не задано
классов распознавания или признаков, то, соответственно, будут
обрабатываться анкеты обучающей выборки, относящиеся к любым классам
распознавания, или с любыми наборами признаков.
При вызове данного режима из
соответствующего пункта меню подсистемы обучения после выделения подмножества анкет происходит переформирование баз данных
статистики, тогда как при вызове из пункта функционального меню F6 МАСКА при
вводе анкет обучающей выборке осуществляется лишь фильтрация анкет и
связанных с ними справочников классов распознавания и признаков.
После выделения подмножества далее Система работает таким образом, как
будто других анкет вообще не было введено. Это проявляется и выполнении таких
режимов, как “Формирование статистических характеристик обучающей выборки”, при формировании информационных
портретов и конструктов и т.д.
При выходе из данного режима
автоматически переформировываются простейшие частотные распределения:
распределение респондентов по
категориям (классам распознавания);
распределение ответов респондентов на
вопросы анкеты, содержащееся в справочнике первичных признаков.
3.1.4.6.
ПОЛУЧЕНИЕ СТАТИСТИЧЕСКИХ ХАРАКТЕРИСТИК ОБУЧАЮЩЕЙ ВЫБОРКИ. ОБЪЕДИНЕНИЕ КЛАССОВ
РАСПОЗНАВАНИЯ (ручной ремонт обучающей выборки)
Обучающая выборка должна быть
представительной (репрезентативной) по всем классам
распознавания. Прежде всего
это означает, что если мы хотим делать обоснованные, взвешенные выводы по
изучаемой предметной области, то мы должны стремиться к тому, чтобы при сборе
исходной информации по каждому классу распознавания было достаточное количество
обучающих анкет. Скажем, если изучается мнение различных национальностей по какому-либо
вопросу, то некорректным будет вывод о целом народе по одному - двум его представителям
почему-то попавшим в поле зрения исследователя.
Однако, часто исследователь работает с
информацией, на сбор которой он не мог повлиять. Таким образом часто возникает
ситуация, при которой статистические характеристики обучающей выборки не могут контролироваться исследователем и даже могут быть ему вообще
неизвестны.
В этой связи, следовательно, возникает
несколько взаимосвязанных задач:
·
узнать сколько анкет представлено в обучающей выборке по каждому классу распознавания (всего и в % к общему количеству физических и
логических анкет в обучающей выборке), т.е. сгенерировать частотное распределение анкет по классам распознавания;
·
если по каким-либо классам
распознавания анкет представлено значительно меньше, чем по
другим, то объединить такие классы распознавания, создав некие обобщенные
классы из нескольких родственных по смыслу, но очень слабо представленных;
·
после объединения слабо представленных
классов распознавания в более крупные, сформировать кодировку новых классов распознавания;
·
сформировать новый справочник классов
распознавания;
·
перекодировать обучающую выборку в соответствии с новым справочником
классов распознавания (при этом каждый “новый” класс распознавания в
анкете будет встречаться не более одного раза, хотя он и соответствует нескольким
“старым” классам распознавания, которых в данной анкете могло быть несколько),
а также заново сгенерировать и рассчитать статистические базы данных (т.е.
использовать перекодированную обучающую выборку для обучения Системы распознавания).
Выполнение всех этих задач вместе
социологи часто справедливо называют “ремонтом данных мониторинга”.
Все эти задачи решаются в описываемом
режиме просто нажатием соответствующих функциональных клавиш (описание которых
приводится в Help данного режима). Здесь же необходимо лишь сообщить, что
нажатием клавиш Ctrl+Insert Системой запоминается наименование класса
распознавания той строки, на которой в данный момент стоит
курсор (при этом подается характерный звуковой сигнал), а при нажатии просто
клавиши Insert (что также сопровождается своим звуковым сигналом), это значение
переносится из памяти в поле наименования той записи, на которой установлен
курсор. Этот механизм позволяет очень удобно без затрат лишних усилий
переименовать старые классы распознавания в новые (набрав каждое новое наименование
лишь один раз).
Кроме того при выполнении данного
режима рассчитываются некоторые частотные распределения:
частотное распределение встреч
признаков, как абсолютное, так и в % к числу физических анкет. Данное частотное
распределение визуализируется в справочнике первичных признаков (подсистема
“Словари”), а также в его распечатке и файле PRIZ_PER.TXT (рекомендуемый порядок сортировки
- по кодам признаков);
частотное распределение анкет обучающей выборки по классам распознавания, для
формирования обобщенных образов которых они используются. Выходная форма с
именем ANK_OBJ.TXT формируется автоматически в поддиректории TXT.
3.1.4.7.
АВТОМАТИЧЕСКИЙ РЕМОНТ ОБУЧАЮЩЕЙ ВЫБОРКИ
При проведении практических социологических и
психологических исследований возникает следующая серьезная проблема. Обычно
заказчики исследования и его руководители ставят перед собой цель извлечь из
опроса респондентов и анализа его результатов определенные выводы,
которые можно было бы с известной и контролируемой уверенностью распространить
на всех работников некоторого предприятия, или на все население определенного
региона, т.е. на некоторую общность, которую называют “генеральная
совокупность” и которая, собственно, и изучается.
Необходимое условие, обеспечивающее возможность корректного
распространения выводов, сделанных на основе исследования некоторой выборки на
генеральную совокупность, называется репрезентативностью исследуемой выборки. Чаще всего руководители
работ требует от опрашивающих искать и находить таких респондентов и в таком количестве, чтобы они составляли
репрезентативную выборку, т.е. ставится задача организационного управления процессом опроса
респондентов и формирования исследуемой выборки. Однако опыт показывает,
что достижение репрезентативности организационными (и юридическими) мерами
является очень трудоемким, сложным и вообще проблематичным.
Таким образом, возникает идея добиться репрезентативности другим, гораздо более технологичным и реальным
путем, а именно: выделить из исходной (достаточно большой) выборки анкет всех
опрошенных респондентов такое подмножество, которое
удовлетворяло бы заданным условиям репрезентативности. Математически эта задача
является достаточно сложной (и трудоемкой в вычислительном отношении), т.к.
каждая физическая анкета, заполненная респондентом, может
включать в себя несколько логических анкет, т.е. каждый респондент может относится ко многим категориям одновременно.
Автоматический ремонт обучающей выборки - это операция, которая выделяет из
всех анкет обучающей выборки такое подмножество,
которое дает частотное распределение логических анкет по классам
распознавания в наименьшей степени отличающееся от заданного
частотного распределения (т.е. распределения генеральной совокупности). Такое
подмножество называется РЕПРЕЗЕНТАТИВНЫМ,
т.е. считается,
что оно в определенном смысле ПРЕДСТАВЛЯЕТ генеральную совокупность, а значит
выводы, сделанные на основе обработки данных этой выборки, можно с определенной
уверенностью отнести ко всей генеральной совокупности.
Первоначальное выделение анкет репрезентативной выборки является ЛОГИЧЕСКИМ, т.е. осуществляется без физического удаления введенных
данных, которое производится только по нажатию F8.
Пользовательский интерфейс данной подсистемы реализован в виде двух окон.
В верхнем окне
отображается фактическое частотное распределение логических анкет по классам
распознавания. Вы можете
всегда заново сгенерировать его, нажав клавишу F9-Сброс. В столбце [% Ген.выборка] Вы можете
ввести частотное распределение, которое
желательно для Вас. Обычно это частное распределение, соответствующее (по
имеющимся данным) генеральной совокупности.
Однако, следует иметь в виду, что в столбце [% Ген.выборка] недопустимо
задавать СТРОГО равномерное распределение (“почти” - можно).
Затем, нажав клавишу F6-РЕПРЕЗЕНТАЦИЯ, Вы можете запустить
процесс выделения максимально репрезентативных анкетных подмножеств из обучающей выборки. Первоначально это выделение является
логическим.
По окончании процесса происходит переход в нижнее окно (а
также по нажатию Shift-F1).
По нажатию клавиши Insert Вы можете перенести значения из
поля [% Обуч.выборка] в поле [%
Ген.выборка].
По одновременному нажатию клавиш Ctrl-Insert Вы можете
занести значение поля [% Ген.выборка] в буфер, из
которого по нажатию клавиши Insert значение будет заноситься в поле [%
Ген.выборка], на котором установлен курсор.
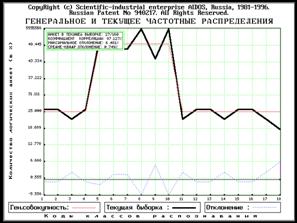
В нижнем окне
представлены результаты выполнения системой “ЭЙДОС” алгоритма
выделения наиболее репрезентативного подмножества из обучающей выборки. Анкеты в БД расположены в таком порядке, что постоянно
обеспечивается наилучшее соответствие их суммарного частотного распределения (с
1-й анкеты и по текущую) частотному распределению генеральной совокупности.
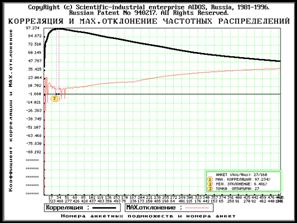
Для каждого подмножества указаны коэффициент корреляции частотных
распределений и их максимальное отклонение друг от друга. В графе “Min/Max”
дается словесное сообщение: “MIN.отклонение”, “MAX.корреляция” и
“Оптимум-MinMax” (на основе анализа ВСЕЙ БД ИТОГОВ).
Чтобы логически выделить некоторое подмножество анкет, пользователю достаточно подвести курсор
к последней анкете этого подмножества и нажать: F6-Логическая маркировка. Результат
такого выделения виден в верхнем окне (переход в него по нажатию Shift-F1), а
также НА ГРАФИКАХ. Если все нормально, т.е. результат устраивает (OK), то
физическое сжатие всех БД осуществляется по F8-Физ.сжатие.
Подсистема формирует две графические формы, которые при
воспроизведении автоматически записываются в поддиректории PCX\REPAIR в виде PCX-файлов с уникальными именами вида GEN-####.PCX и
KORR####.PCX, где: #### - порядковый номер файла в данной поддиректории. Эти
файлы можно включить в качестве иллюстраций в текст документа (как это сделано
и в данной работе).
|
|
|
Данные формы имеют
вид:
3.1.4.8.
КРИТЕРИЙ ОСТАНОВКИ ПРОЦЕССА ОБУЧЕНИЯ
Вопрос о достаточности информации
обучающей выборки для такого обучения системы, которое
обеспечивает качественное решение задачи распознавания возникает совершенно естественно, т.к. если
обучающая выборка должна быть очень велика, т.е. Система
обучается слишком медленно, то возникает вопрос о целесообразности всей затеи
использовать данную Систему. Во всяком случае очевидно, что вопрос о
трудоемкости процесса обучения очень важен.
В системе имеется критерий, который
позволяет решить когда можно прекратить процесс обучения Системы.
После окончания ввода любой анкеты
могут быть сброшены базы данных статистики в режиме: “СЕРВИС”, “Генерация баз
данных”, “Генерация БД статистики”. Это приводит к тому, что
полностью теряются результаты обучения Системы на предыдущей обучающей выборке. Следовательно, если проводить
обучение Системы на различных по объему обучающих выборках, (что не занимает много времени), по мере
сбора и ввода обучающей информации, то мы
увидим динамику процесса обучения и на определенном этапе этого процесса можем
обнаружить, что ДОБАВЛЕНИЕ НОВЫХ АНКЕТ ОБУЧАЮЩЕЙ ВЫБОРКИ УЖЕ ПРАКТИЧЕСКИ НИЧЕГО
НЕ МЕНЯЕТ. Тут уже ясно, что эти новые анкеты можно было бы с равным
успехом и не добавлять в обучающую выборку.
Но что же меняет или не меняет
добавление этих новых анкет? “На что же, так сказать, надо смотреть”. Прежде
всего это сама максимальная анкета, как она видна в режиме “ОПТИМИЗАЦИЯ” или в
распечатке. Во-вторых, это информационные (ранговые) портреты
классов распознавания. В-третьих,
это характеристики базы данных конструктов, прежде всего
ее коэффициент редукции (это аналог характеристики “интегральная
информативность”, но не для
отдельного признака, а для всей базы данных конструктов в целом). И, наконец,
это просто само качественное и надежное решение задачи распознавания объектов
обучающей выборки, предъявленных Системе в режиме
распознавания. Для того, чтобы “перекачать” обучающую выборку в базы данных распознаваемых анкет
служит режим:
“F6 Об.инф. -> Расп.анкеты”
на который имеется выход из окна
заголовков анкет “ВВОД-КОРРЕКТИРОВКА ОБУЧАЮЩЕЙ ВЫБОРКИ”. После выполнения этого
режима можно просто запустить пакетное распознавание и посмотреть его результаты в режиме:
“РАСПОЗНАВАНИЕ” или (что предпочтительнее) измерить ВАЛИДНОСТЬ Системы распознавания в подсистеме “Анализ”.
Примечание:
в режиме “Исключение артефактов (статистический фильтр Пирсона) мы можем
определить, набрана ли достаточная статистика, чтобы было оправданным говорить
о вступлении в силу “закона больших чисел”. Конечно, наличие статистики
желательно для достижения устойчивости образов (их независимости от добавления
новых обучающих анкет). Но математическая модель Системы
“ЭЙДОС” такова, что
в случае предъявления Системе для обучения анкет типичных и ярких
представителей классов распознавания (а достижение этого - задача экспертов),
образы очень быстро “сходятся” к некоторым предельным
значениям, которые можно считать сформированными. Практически это означает, что
адекватность образов как правило будет достигаться в Системе до набора
достаточной статистики.
3.1.4.9.
ВОЗМОЖНЫЕ ПРИЧИНЫ НИЗКОЙ ОБУЧАЕМОСТИ СИСТЕМЫ
После осуществления указанной выше
проверки работоспособности Системы может выясниться, что результаты
распознавания неудовлетворительны, т.е. не соответствуют
ожиданиям пользователя. Естественно, возникает вопрос о возможных причинах этого.
Первое и простейшее предположение,
состоящее в том, что “Система не работает”, мы рассматривать не будем: т.к.
разработчики на многочисленных приложениях в течение достаточно многих лет (с
1981 года) систематически убеждались в обратном, т.е. в том, что Система
работает, и работает нормально.
Естественно, что и сами ожидания
пользователя должны быть корректны, т.е. пользователь должен иметь адекватное
понимание того, что в действительности делает Система и чего она не делает. Необходимой
предпосылкой этого является наличие у пользователя адекватного тезауруса
(понятийного аппарата), который обеспечил бы ему понимание действительного
смысла терминов, применяемых в Системе.
Реально, причины по которым Система
может плохо обучаться можно разделить на объективные и субъективные (само это
деление, конечно, довольно условно, а “для Системы” вообще важны лишь
статистические характеристики обучающей выборки, а не причины, по которым они именно
такие, а не другие).
К объективным причинам прежде всего
можно отнести реальное отсутствие каких-либо достаточно выраженных
закономерностей в той предметной области, в которой с помощью Системы “ЭЙДОС”
разрабатывается данное приложение. Под “закономерностями” в данном случае
понимается наличие взаимосвязей между признаками объектов (или их состояний) и
классами распознавания. Таким
образом, если к некоторому классу распознавания реально относятся объекты
(состояния) с очень различными свойствами и у них отсутствуют свойства,
встречающиеся с большей вероятностью, чем у объектов других классов, то Система
будет “плохо” обучаться распознаванию данного класса. Конечно, нужно понимать, что
это “не вина Системы”, т.к. в этом случае
просто обучаться нечему.
В принципе не может быть Системы
распознавания, которая
могла бы обучиться распознаванию классов, для формирования обобщенных
(эталонных) образов которых, т.е. для обучения, предъявлялись бы объекты
(состояния) со случайным набором признаков. Естественно, это может иметь место
только при достаточно больших выборках, при которых начинает работать “Закон
больших чисел”, т.е. можно говорить о статистике. Поэтому при малых выборках
классы распознавания, сформированные на основе объектов, выбранных случайным
образом, распознаются ничуть не хуже, чем сформированные осмысленно.
К субъективным причинам медленной
обучаемости Системы распознавания может быть отнесена низкая взаимная
согласованность тех решений экспертов, которые используются при обучении
Системы, а также низкий уровень компетентности экспертов в той предметной области,
в которой разрабатывается конкретное приложение. Достаточно очевидно, что если
экспертная группа будет давать Системе противоречивые решения о принадлежности
объектов (состояний) к тем или иным классам распознавания, то Система
выработает некоторую обобщенную точку зрения, как бы “равнодействующую” для
всей группы экспертов. Эта “равнодействующая” будет менее четко выраженной
(т.е. более близкой к той, которая сформировалась бы при случайной обучающей выборке) при большем разбросе в решениях экспертов по одному и тому же вопросу.
И наоборот, она была бы четко выраженной при совпадении решений различных
экспертов в сходных ситуациях.
Для большей наглядности, доведем эту
ситуацию “до абсурда”. Пусть, например, некоторый эксперт будет “несколько не в
себе” и принимает решения о принадлежности тех или иных объектов (состояний) к
классам распознавания не очень вникая в то, что это за объекты, и
что это за классы. Это может быть, грубо говоря, “от фонаря”, либо случайным
образом. Очевидно, если такой эксперт будет обучать Систему распознавания, то в
результате она также будет “несколько не в себе”, но в этом случае все
претензии, конечно, не к ней.
3.1.4.10.
ЗАПУСК ПРОЦЕССА ОБУЧЕНИЯ И ЕГО КОНТРОЛЬ
После ввода обучающей выборки необходимо запустить процессы, с
помощью которых Система “ЭЙДОС” использует
обучающую выборку для формирования статистики встреч признаков
по классам распознавания и на этой основе рассчитает какое количество
информации каждый признак содержит о каждом классе распознавания и какова
интегральная информативность каждого признака (его селективная сила).
Для этого необходимо выполнить
следующее:
·
в режиме F7-Сервис, “Генерация баз
данных”, “Создание баз данных статистики” создать базы данных статистики (т.е.
базу абсолютных частот и базу информативностей),
·
в режиме F2-Обучение, “Пакетная обработка”, “Пакетное обучение системы”, “Обучение базы абсолютных
частот” обучить базу абсолютных частот,
·
в режиме F2-Обучение, “Пакетная обработка”, “Пакетное обучение системы”, “Расчет информативностей признаков” рассчитать базу информативностей.
Необходимо обратить внимание на то, что
в процессе расчета базы абсолютных частот Система осуществляет довольно полную
проверку корректности информации в обучающей выборке, состоящую из следующих проверок:
·
указан ли в обучающей анкете по крайней мере один код класса
распознавания, для обучения
эталонного образа которого предназначена данная анкета,
·
все ли коды классов распознавания, указанные в
анкете, соответствуют реально имеющимся в справочнике и в базах статистики,
·
введены ли в данную анкету коды
первичных признаков,
·
все ли коды признаков, введенные в
данную анкету, соответствуют реально имеющимся в справочнике первичных
признаков и базах статистики.
При обнаружении этих явных ошибок в
обучающей выборке Системой подаются звуковые сигналы
различной тональности, чтобы обратить внимание пользователя на наличие этих ошибок.
В этом случае в поддиректории TXT в файле с именем ERR_OBI.TXT формируется ПРОТОКОЛ
ОШИБОК ОБУЧАЮЩЕЙ ВЫБОРКИ, который может быть распечатан из любого текстового
редактора и использован для исправления ошибок.
Исправление ошибки осуществляется после
установки курсора на поле с ошибочной информацией. Установку курсора на нужное
поле лучше всего осуществлять с помощью функции F4-Поиск, в которой необходимо
ввести ошибочный код.
После исправления ошибок необходимо
сбросить базы данных статистики и повторить обучение.
3.1.4.11.
ИСКЛЮЧЕНИЕ АРТЕФАКТОВ (СТАТИСТИЧЕСКИЙ ФИЛЬТР ПИРСОНА)
При формировании обучающей выборки возможны случаи, когда в одной или
очень малом числе анкет, относящихся к некоторым классам распознавания, встречаются
совершенно уникальные признаки. В соответствии с математической моделью эти
признаки неизбежно оказываются весьма информативными и имеют большой вес в
образах тех классов распознавания, в которых они встречаются. Однако, всерьез
принимать эти признаки часто нет оснований, т.к. они не удовлетворяют условию
минимальной достаточной статистики Пирсона (например, встречаются реже 5 раз на класс распознавания
). Таким образом появление этих признаков в анкетах обучающей выборки целесообразно
рассматривать как случайное и лишь искажающее картину. Такие признаки принято
называть артефактами.
Естественно, возникают вопросы:
о выявлении артефактов и принятии решения об их исключении;
о выполнении самой операции исключения
артефактов из процесса формирования обобщенных образов и
последующего анализа.
Примечание:
Конечно для исключения артефактов необходимо иметь достаточно большую обучающую выборку, т.к. только в этом случае вообще
можно говорить о статистике. В противном случае практически все признаки
формально невозможно отличить от артефактов. Очевидно, необходимым условием,
при выполнении которого статистика может сформироваться, - достаточно большое
количество анкет обучающей выборки. Точнее - минимальное количество
анкет, приходящихся на один класс распознавания, должно быть
достаточно велико (эту информацию можно получить в режиме: “Статистика
обучающей выборки”). Кстати, из этого следует, что условия достаточной
статистики можно добиться не только увеличивая объем обучающей выборки, но и
объединяя классы распознавания в режиме “Ручной ремонт обучающей выборки”.
Данная ситуация напоминает какой-то вариант теоремы “Котельникова” об отсчетах,
в которой доказывается, что чем
детальнее мы хотим прорисовать кривую, тем больше нам нужно опорных точек. Если
достаточного количества опорных точек нет и не предвидится, то приходится
согласиться с вариантом меньшей детализации; В нашем случае это вариант с
меньшим количеством, но зато более обобщенных, “укрупненных” классов
распознавания. Из этого следует один практический вывод: не следует увлекаться особенно высокими степенями детализации при
разработке справочника классов распознавания, т.к. это может потребовать очень
большой обучающей выборки.
|
|
Исключение артефактов осуществляется в подрежиме: “Исключение
артефактов (фильтр Пирсона)” режима:
Пакетное обучение системы” подсистемы: “Обучение
системы”. При запуске этого режима Система вычисляет частотное распределение
абсолютных частот встреч признаков (по базе данных абсолютных частот) и выводит
это частотное распределение на дисплей в графическом виде (а также записывает в
виде PCX-файла в поддиректории PCX).
|
|
Здесь приведены примеры двух таких
видеограмм: первая для
случая, когда статистики нет, а вторая - когда она есть. В зависимости от
характеристик конкретного частотного распределения Система предлагает пользователю
считать артефактами признаки, встретившиеся определенное
соответствующее число раз. От пользователя требуется только подтвердить свое согласие
с консультацией Системы или самому задать минимальное количество встреч
признака на класс распознавания, которое (по
его мнению) является достаточным, чтобы можно было действительно говорить о
некоторой закономерности (обычно это 5 или более). После этого из матрицы
абсолютных частот исключаются все частоты, меньше заданной и затем
пересчитывается матрица информативностей признаков.
3.1.4.12.
РАСЧЕТ МАТРИЦЫ УСЛОВНЫХ ПРОЦЕНТНЫХ РАСПРЕДЕЛЕНИЙ ПРИЗНАКОВ ПО КЛАССАМ
РАСПОЗНАВАНИЯ
В данном режиме осуществляется расчет
матрицы, содержащей количество признаков, встретившихся по данным обучающей выборки по каждому классу распознавания в процентах к числу респондентовт, относящихся
к данному классу распознавания.
3.1.4.13.
АВТОМАТИЗИРОВАННЫЙ РЕЖИМ ОБУЧЕНИЯ СИСТЕМЫ
Этот режим предназначен для
автоматического последовательного выполнения следующих функций:
·
создание пустых баз данных статистики в
соответствии с размерностями справочников классов распознавания и признаков;
·
расчет базы данных абсолютных частот на
основе обучающей выборки;
·
расчет и отображение в виде графика
частотного распределения частот признаков и применение фильтра артефактов (фильтра Пирсона), если это
уместно;
·
расчет матрицы информативностей признаков, построение списка признаков в
порядке убывания интегральной информативности (ценности для решения задачи распознавания) и списка
классов распознавания в порядке убывания степени сформированности образов;
·
расчет матрицы процентных распределений
признаков по классам распознавания;
·
расчет абсолютного и процентного
частотного распределения анкет обучающей выборки по классам распознавания;
·
расчет абсолютного и процентного
частотного распределения признаков по данным обучающей выборки.
3.1.5.
ОПТИМИЗАЦИЯ МАКСИМАЛЬНОЙ АНКЕТЫ
После окончания процесса обучения
Системы осуществляется оптимизация анкеты. Этот процесс заключается в
постепенном уменьшении размерности баз данных статистики, путем выбрасывания из обучающей выборки наименее значимых признаков и при
одновременном соблюдении заданных пользователем граничных условий.
3.1.5.1.
ТРИ ИТЕРАЦИОННЫХ АЛГОРИТМА ОПТИМИЗАЦИИ
Наиболее очевидным алгоритмом
уменьшения размерности системы признаков представляется алгоритм,
основанный на отсечении, отбрасывании такого количества наименее значимых признаков,
чтобы в осталось столько признаков, сколько необходимо (из соображений
избыточности и размера анкеты). Однако такой простой подход оказывается
неприемлемым по той причине, что все признаки вообще говоря являются
корреляционно-взаимосвязанными друг с другом и отбрасывание даже одного из них, пусть даже и наименее
информативного, может таким образом поменять порядок признаков, расположенных
по убыванию их интегральной информативности, что
предпоследний признак может переместиться куда-нибудь в середину списка. Вероятность
этого тем больше, чем короче список признаков.
Поэтому напрашивается “итерационный алгоритм с переменным шагом”, т.е. количеством
признаков, отбрасываемых за одни проход. Причем это количество отбрасываемых
признаков должно постепенно уменьшаться при приближении к оптимальному состоянию.
В настоящее время в Системе реализовано
три итерационных алгоритма оптимизации:
1.
с отбрасыванием такого количества наименее значимых признаков,
которые вносят некоторый заданный пользователем процент интегральной
информативности в базу данных конструктов,
2.
с отбрасыванием определенного процента от оставшегося
количества признаков,
3.
с отбрасыванием некоторого фиксированного количества признаков.
Выход на эти режимы оптимизации
осуществляется по нажатию функциональной клавиши “F5 Оптимизация анкеты” из
режима: “ОПТИМИЗАЦИЯ”.
После этого Система запрашивает:
·
вариант выбора шага оптимизации,
·
какое минимальное количество признаков
должно остаться в описании каждого класса распознавания,
·
какое минимальное количество признаков
должно остаться в анкете после завершения процесса оптимизации,
|
|
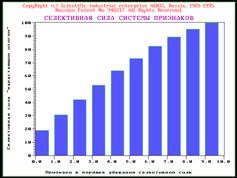
Граничное условие фильтра Пирсона вычисляется Системой автоматически (для исключения артефактов). Последнее
граничное условие практически приводит к удалению наиболее информативных признаков, если по
ним нет достаточной статистики (т.е. артефактов). Считается, что эти признаки
оказались весьма информативными случайно именно из-за отсутствия по ним
статистики и принимать их во внимание нет достаточных оснований (си. также
“Исключение артефактов (фильтр Пирсона)” в предыдущем разделе).
После задания этих параметров
осуществляется процесс оптимизации с отображением удаленных обобщенных и
первичных признаков и текущих характеристик базы данных конструктов. Имеется режим
вывода на дисплей логистической гистограммы, которая наглядно
отображает суммарную интегральную информативность системы признаков (“нарастающим итогом”).
Необходимо отметить, что этот процесс
при реальных объемах и размерностях данных требует значительных вычислительных
ресурсов компьютера и его желательно проводить на виртуальном диске большой емкости на компьютерах класса
486DX. Успокаивать здесь может только то, что эта операция выполняется редко и
ее результатом является новая оптимальная методика тестирования, которая (кто
знает), может быть в будущем будет стандартизирована и станет такой же
известной, как тест Кеттела или Люшера.
3.1.5.2.
ВЛИЯНИЕ ОПТИМИЗАЦИИ НА ВАЛИДНОСТЬ
Под валидностью системы распознавания в данной работе понимается способность системы
давать соответствующие действительности результаты идентификации и прогнозирования.
Естественно, чтобы на практике
определить валидность системы, необходимо выполнить соответствующие
вполне определенные операции. В [46] приводится классификация методов
определения валидности, каждый из
которых, как обычно обладает своими плюсами минусами. Само понятие
“соответствие действительности”, также нуждается в уточнении. Можно понимать
его как соответствие точке зрения экспертов, как соответствие литературным
данным или результатом работы других, уже общепризнанных диагностических
методов и основанных на них систем.
Различают дифференциальную валидность, т.е.
способность системы правильно идентифицировать объекты с определенным классом
распознавания, и интегральную
валидность, которая представляет собой взвешенное среднее дифференциальных валидностей.
Опыт применения системы “ЭЙДОС” показывает,
что после оптимизации системы признаков, т.е. после корректного удаления
признаков с низкой селективной силой, валидность Системы распознавания закономерно возрастает.
Так, например, в реальном приложении из
области Public Relations с 18 классами распознавания и 386 признаками в максимальной анкете при
обучающей выборке в 495 физических и 2951 логических
анкет интегральная валидность Системы (т.е. валидность по всем классам
распознавания вместе) составила 90.58% (т.е. верно было распознано 2673 анкеты,
ошибочно 278). Дифференциальная валидность (т.е. валидность по каждому классу
распознавания) варьировалась от 100% до 84%.
После оптимизации анкеты до 200
признаков интегральная валидность составила 94.88% (верно: 2800, ошибочно: 151),
валидность по классам от 100% до 87%. При оптимизации до 77 признаков -
интегральная валидность - 96.14% (верно: 2837, ошибочно: 114), по классам - от
100% до 91%.
Корректным считается такое удаление незначимых признаков, в результате которого оставшейся
системы признаков достаточно для надежного решения задачи идентификации и
прогнозирования. При дальнейшем удалении признаков валидность системы начнет уменьшаться. Очевидно, что если
удалить слишком много признаков, то корректная работа системы вообще может
стать невозможной.
3.1.5.3.
ПЕРЕКОДИРОВАНИЕ
После завершения процесса оптимизации
целесообразно выполнить операцию перекодирования.
Перекодирование предназначено для удаления пропусков в
кодировке первичных признаков, которые возникают после
оптимизации анкеты (удаления незначимых признаков).
Операция перекодирования НЕОБРАТИМА, поэтому рекомендуем Вам перед ее
выполнением обязательно обновить архивы БД!
Перекодируются справочники первичных и обобщенных признаков,
анкеты обучающей и распознаваемой выборки и статистические базы
данных.
Таким образом перекодированием ЗАВЕРШАЕТСЯ разработка оптимальной методики
тестирования.
3.1.6.
ОРТОНОРМИРОВАНИЕ СИСТЕМЫ КЛАССОВ РАСПОЗНАВАНИЯ
Как мы уже видели при рассмотрении
перспективной когнитивной концепции, аморфные образы, как правило
обобщающие несколько более жестких образов, естественно являются сильно
связанными с другими образами. В этих условиях, естественно, говорить об ортонормируемости базовых образов (по которым осуществляется
разложение в ряд при распознавании) не
приходится. Но в ряде случаев представляет интерес выделить из всей системы образов такую подсистему, в которой образы
были бы наименее связаны друг с другом, т.е. подсистему ортонормированных образов.
В системе “ЭЙДОС” в подсистеме
“Оптимизация” имеется режим, обеспечивающий эту возможность.
3.1.6.1.
ТРИ ИТЕРАЦИОННЫХ АЛГОРИТМА ОРТОНОРМИРОВАНИЯ
Аналогично режиму исключения незначимых признаков, рассмотренному выше, в данном
режиме также имеется три итерационных алгоритма ортонормирования:
|
|
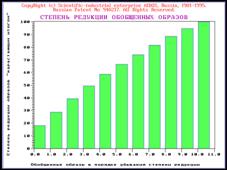
1.
с отбрасыванием такого количества наиболее аморфных образов,
которые вносят некоторый заданный пользователем процент в степень редукции базы
данных конструктов,
2.
с отбрасыванием определенного процента от оставшегося
количества классов распознавания,
3.
с отбрасыванием некоторого фиксированного количества классов
распознавания.
Кроме того также задается граничное условие: сколько классов распознавания должно остаться в системе после
ортонормирования.
3.1.6.2.
ВЛИЯНИЕ ОРТОНОРМИРОВАНИЯ НА ВАЛИДНОСТЬ И РЕЗУЛЬТАТЫ КЛАСТЕРНО-КОНСТРУКТИВНОГО
АНАЛИЗА
Изучение влияния степени
ортонормирования образов на валидность системы распознавания показало, что существенного изменения
валидности не происходит. Но поскольку обобщенные образы становятся более детерминистскими, то можно
сделать общий вывод: чем выше степень
ортонормированности образов, тем более детерминистскими становятся
признаки, тем Система “ЭЙДОС” ближе к детерминистским система
распознавания (построенных, например, на алгоритмах “прототипа” или
“k-ближайших соседей”) и к информационно-поисковым системам и дальше от статистических
систем распознавания, работающих с “размытыми” обобщенными образами.
Результаты кластерно-конструктивного
анализа показали, что при увеличении степени ортонормированности образов их связь в кластерах и конструктах ослабевает.
Интересно отметить, в исследовании где первоначально было 300 образов было
обнаружено, что средний уровень силы корреляционной связи между наиболее
похожими образами оказался числено примерно равен количеству классов
распознавания, которое
остается после операции ортонормирования: например при
60 образах - это 60%, при 30 - 30%, при 10 - 10%.
3.1.6.3.
ПЕРЕКОДИРОВАНИЕ
Операция перекодирования позволяет устранить пропуски в кодировании
образов, возникшие при исключении аморфных образов. При этом одновременно
перекодируется обучающая выборка и статистические базы данных.
3.1.7.
УДАЛЕНИЕ КЛАССОВ РАСПОЗНАВАНИЯ И ПРИЗНАКОВ, ПО КОТОРЫМ НЕДОСТАТОЧНО ДАННЫХ
Данный режим позволяет исключить из справочников и
статистических баз данных те классы распознавания и признаки, по которым в обучающей выборке не оказалось достаточно данных.
Это означает, что если некоторый класс распознавания или
признак встретился в менее, чем заданном проценте случаев от количества анкет в
обучающей выборке, то он будет удален из соответствующих справочников и
статистических матриц и не будет никаким образом участвовать в дальнейшем
анализе. При удалении очень редких (недостаточно представленных) классов и
признаков надежность и качество выводов, которые делаются на основе анализа,
возрастает. При удачно подобранном пороге распределение Пирсона принимает вид
“с куполом”, характерный для случая, когда имеет место достаточная статистика.
ТИПИЧНЫЙ
ВИД РАСПРЕДЕЛЕНИЙ ПИРСОНА
В СЛУЧАЯХ, КОГДА СТАТИСТИКИ НЕТ, И КОГДА ОНА ЕСТЬ
|
|
|
|
Статистики
нет |
Статистика
есть |
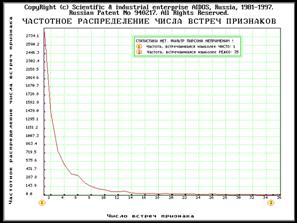
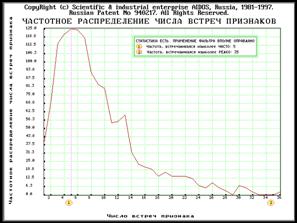
Очевидно, что именно очень редкие классы распознавания и
признаки являются основным источником артефактов (или исключений), т.е.
признаков, которые нарушают статистически значимые закономерности.
3.2.
ПРОВЕДЕНИЕ МАССОВЫХ ОБСЛЕДОВАНИЙ В ПРОМЫШЛЕННОМ РЕЖИМЕ
Данный вид работ
включает:
·
ввод анкет для распознавания,
·
возможное параметрическое задание
подмножества распознаваемых анкет,
·
пакетное распознавание,
·
вывод результатов распознавания.
3.2.1. ВВОД
АНКЕТ ДЛЯ РАСПОЗНАВАНИЯ
3.2.1.1. РУЧНОЙ ВВОД РАСПОЗНАВАЕМЫХ АНКЕТ
Подобно режиму ввода обучающей выборки, режим ввода анкет для распознавания включает следующие этапы работ:
·
Документальная формализация анкет распознаваемой выборки,
·
Ввод, контроль и корректировка анкет
распознаваемой выборки,
·
Автоматический ввод анкет
распознаваемой выборки из текстовых файлов,
·
которые и выполняются совершенно
аналогично. Поэтому здесь их нет смысла особенно подробно рассматривать.
В данном режиме реализован двух -
оконный интерфейс, подобный
тому, который использовался в режиме ввода обучающей выборки и с аналогичным сервисом.
3.2.1.2.
АВТОМАТИЧЕСКИЙ ВВОД РАСПОЗНАВАЕМЫХ АНКЕТ ИЗ ТЕКСТОВЫХ ФАЙЛОВ
Если в окне ввода первичных признаков
нажать клавишу: “F7 Ввод из файлов”, то появится
новое функциональное меню, в котором будут следующие варианты:
·
нажав клавишу F5 - автоматически
закодировать тот текстовый файл, на котором
Вами установлен курсор, и ввести коды признаков в ту анкету, с заголовка
которой Вы перешли в правое окно. Имя файла может иметь любое расширение.
·
нажав клавишу F6 - автоматически
закодировать и ввести в анкеты коды признаков всех текстовых файлов с именами вида: ####-???.*, где: #### - номера
анкет {0001,0002,...,NNNN}, ??? - произвольные символы, .* - расширение. При
этом коды признаков ДОПОЛНЯТ анкеты с соответствующими номерами. Если же таких
анкет нет, то они будут созданы.
В обоих случаях предварительно
необходимо задать, что считать первичным признаками: строки, предложения, слова
или сочетания слов. Далее `процесс идет` автоматически с наглядным отображением
его стадии.
Текстовые файлы с распознаваемой информацией должны находиться
в поддиректории DRS.
3.2.2.
ПАРАМЕТРИЧЕСКОЕ ЗАДАНИЕ ПОДМНОЖЕСТВА АНКЕТ РАСПОЗНАВАЕМОЙ ВЫБОРКИ
Данный режим предназначен для выделения
из распознаваемой выборки подмножества анкет, удовлетворяющих заданным параметрам.
Параметры задаются путем ввода
анкеты-маски, в которой могут быть указаны номера анкет для распознавания, а также коды
определенных вопросов опросника. В дальнейшей
обработке будут участвовать только те анкеты распознаваемой выборки, которые
имеют заданные номера и содержат одновременно коды всех вопросов, присутствующих
в анкете-маске.
Если анкета-маска пуста, то будут
обработаны все анкеты распознаваемой выборки. Если в анкете-маске вообще не
задано номеров анкет или признаков, то, соответственно, будут обрабатываться
анкеты распознаваемой выборки с любыми номерами или с любыми признаками.
3.2.3.
ПАКЕТНОЕ РАСПОЗНАВАНИЕ
Выполняется в подсистеме:
“РАСПОЗНАВАНИЕ”, режиме “ПАКЕТНОЕ РАСПОЗНАВАНИЕ” с отображением текущей стадии
этого процесса и выводом номеров неидентифицируемых анкет и классов распознавания.
В данном режиме система подсчитывает,
какое количество информации содержится в системе признаков, описывающих каждый
распознаваемой объект, о принадлежности данного объекта к каждому из классов
распознавания. Кроме того
учитывается общая форма профиля объекта, т.е. корреляции между признаками.
В системе “ЭЙДОС-
работа алгоритма осуществляется
примерно в семь раз быстрее;
снято ограничение на количество анкет в
распознаваемой выборке (которых в версии 5.1 могло быть чуть больше 1000);
для работы алгоритма используется
значительно меньшее количество дисковой памяти.
3.2.4. ВЫВОД
РЕЗУЛЬТАТОВ РАСПОЗНАВАНИЯ И ИХ ОЦЕНКА
Реализуется в подсистеме:
“РАСПОЗНАВАНИЕ”, в режиме: “ВЫВОД РЕЗУЛЬТАТОВ”. При этом отображается меню с
двумя вариантами:
один объект - много классов;
один класс - много объектов.
Здесь имеется в виду распознаваемый
объект, описанный анкетой распознаваемой выборки.
Оба варианта дополняют друг друга. Так,
например, если первый вариант отвечает на вопрос пользователя: “На какую
должность больше всего подходит данный тестируемый?”, то второй
вариант соответствует ответу на вопрос: “Кто из всей группы тестируемых лучше всего подходит на данную должность?”.
В каждом из этих режимов сначала
отображается сводная форма, соответственно, дающая информацию в виде:
“один объект - один класс распознавания”;
“один класс распознавания - один объект”.
В первом случае в сводной форме каждому
распознаваемому объекту поставлен в соответствие некоторый класс распознавания, с которым он
имеет наибольшее сходство. Во втором случае, наоборот, каждому классу
распознавания поставлен в соответствие некоторый распознаваемый объект, имеющий
с данным классом наибольшее сходство.
Оба эти вида сводных форм очень похожи,
т.к. дают информацию об отношении “один к одному”, однако в них разный порядок
и размеры полей. Но в них отличается количество строк, т.к. в первой форме оно
равно количеству объектов в распознаваемой выборке, а во второй - количеству
сформированных классов распознавания. Кроме того в
первом случае в сводной форме выводится интегральная оценка достоверности
распознавания каждой анкеты.
Сама сводная форма в обоих случаях
служит в качестве меню для просмотра более подробной информации по результатам
распознавания.
Результатом распознавания некоторого объекта является список всех
классов распознавания, рассортированный в порядке убывания сходства с этим
объектом.
Результатом идентификации
распознаваемых объектов с некоторым классом распознавания, является
список объектов, рассортированный в порядке убывания сходства с этим классом.
Система выдает соответствующие формы,
содержащие эту информацию в удобном для восприятия виде, которая называется
“Карточка распознавания”. Эта форма
выдается по нажатию клавиши F1 при просмотре обобщенной формы и содержит
информацию, соответствующую текущей строке.
В карточке распознавания объекта кроме уровня его сходства с каждым
классом распознавания дается также интегральная количественная оценка качества
распознавания данного объекта в целом.
Эта оценка представляет собой
эвристический критерий, который представляет собой нормированную к 100%
модифицированную дисперсию уровней сходства. Модификация заключается в том, что
введен весовой коэффициент, уменьшающий вклад уровней сходства в данную оценку
в зависимости от их ранга.
Высокий уровень интегрального качества
распознавания означает близость ситуации к детерминистскому
варианту, когда для Системы не представляет проблемы однозначная идентификация
распознаваемой анкеты с одним определенным классом распознавания.
При распознавании обучающей выборки (измерение валидности Системы) эта ситуация характерна для
незначительных по количеству анкет обучающих выборок и при небольшом количестве классов
распознавания, т.е. для тех
случаев, когда мало сказывается статистический разброс по признакам внутри объектов (состояний),
относящихся к одному классу распознавания.
Низкий уровень интегрального качества
распознавания означает, что распознаваемая анкета по
каким-либо причинам оказалась либо вообще не сходной ни с одним из классов распознавания,
либо напротив, - похожа сразу на несколько различных классов. Соответственно, в
этой ситуации системе “ЭЙДОС” сложнее
принять решение об идентификации распознаваемой анкеты с одним-единственным
классом распознавания.
Наиболее очевидной причиной низкой
распознаваемости некоторых анкет может являться то, что
описанные в них объекты (состояния) действительно не относятся ни к одному из
классов, для распознавания которых обучалась Система. В этом случае (при необходимости) данные
анкеты могут быть переписаны из распознаваемой выборки в обучающую и после корректировки справочника классов
распознавания и перегенерации баз данных статистики использована для
дообучения Системы. Второй
причиной может быть то, что эти анкеты заполнены случайным образом, т.е.
объективно не относится ни к каким классам распознавания вообще (кстати, в
системе “ЭЙДОС” имеется
режим оценки анкет по “шкале лживости”).
При значительных по количеству анкет
обучающих выборках и большом количестве классов
распознавания начинает сказываться реально существующий
разброс по признакам между объектами (состояниями),
использованными в процессе обучения для формирования обобщенных (эталонных)
образов классов распознавания. Это сказывается на том, что ни одна анкета
обучающей выборки вообще говоря не является на 100%
сходной с образом того класса распознавания, для формирования которого она была
использована. (Как говорилось выше, 100%
сходство не достигается и тогда, когда класс распознавания обучен на одной
анкете, т.к. анкета представляется в виде меандра на множестве {0,1}, а профиль класса распознавания
из базы эталонов - это кривая общего вида).
Соответственно, в этом случае уровень сходства конкретной анкеты и класса
распознавания становится ниже (обычно около 20% - 30%), понижается и оценка
интегрального качества распознавания, которое отражает эти реально существующие
статистические характеристики. Это является совершенно естественным. Система рассчитана на работу с такого рода
данными и именно в этом одно из ее основных отличий от детерминистских систем,
работающих только с четкими запросами (например информационно-поисковых).
Необходимо специально отметить, что в подобных ситуациях Система “ЭЙДОС” работает со
стабильной валидностью на уровне 90%-100%.
3.3.
УГЛУБЛЕННЫЙ АНАЛИЗ РЕЗУЛЬТАТОВ ТЕСТИРОВАНИЯ
Этот анализ проводится с классами
распознавания и признаками и включает:
·
информационный (ранговый) анализ,
·
кластерный и конструктивный анализ,
·
содержательное сравнение информационных
портретов.
3.3.1.
ИНФОРМАЦИОННЫЙ (РАНГОВЫЙ) АНАЛИЗ
Система формирует информационные
(ранговые) портреты
обобщенных эталонных образов классов распознавания и признаков.
Портреты классов распознавания представляют собой списки признаков в порядке
убывания содержащегося в них количества информации о принадлежности к этим
классах. Информационный портрет класса распознавания показывает нам, каков
информационный вклад каждого признака в общий объем информации, содержащейся в
данном образе.
Например,
при классах распознавания - профессиональных типах и использовании в качестве
источников информации о респондентах стандартных психологических тестов и опросников,
информационные портреты классов
представляют собой, по сути профессиограммы, т.е. содержат
информацию о том, какими психологическими характеристиками и личностными
качествами фактически обладают респонденты, успешно работающие на определенных
должностях или по определенным профессиям (в отличие от других профессий).
Портреты признаков представляют собой
списки классов распознавания в порядке убывания количества информации о
них, которое содержит данный признак. По своей сути информационный портрет
признака раскрывает нам смысл данного признака, т.е. его семантическую нагрузку.
Информационные портреты могут быть
просмотрены на дисплее в виде текстовых форм и в виде графических круговых
диаграмм в подсистеме “Типология”, а также распечатаны.
В режиме просмотра информационного
портрета класса распознавания пользователь имеет возможность по нажатию
клавиши “F7-Интерпретация” получить на дисплее, а при необходимости распечатать
интерпретацию информационного портрета с общей статистикой по портрету в целом,
а также с абсолютными (в Бит) и относительными (в %) весами каждого признака.
По клавише “F6-Фильтрация” пользователь
имеет возможность оставить в ранговом портрете только признаки, коды которых
попадают в заданный диапазон или только относящиеся к заданному диапазону
уровней системной организации. В режиме F2-Сортировка задается какую часть
информационного портрета выводить:
·
полный информационный портрет,
·
положительная часть информационного
портрета: информативности > 0,
·
отрицательная часть информационного
портрета: информативности < 0.
Нажатие клавиши F5 инициирует вывод на дисплей круговой диаграммы
информационного портрета класса распознавания.
Фильтрация и сортировка влияют на
содержание круговых диаграмм, которые имеют следующий вид:
|
|
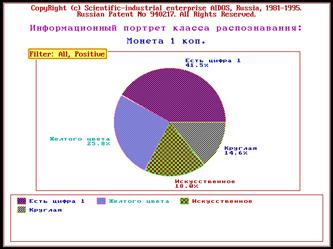
В правой части круговых диаграмм
имеется графическое (кнопочное) меню, предоставляющее пользователю следующие
варианты выбора:
· PCX
- запись в виде PCX-файла в поддиректории Pcx\Object - для круговых диаграмм
информационных портретов классов распознавания, или в
поддиректории Pcx\Attribute - для круговых диаграмм информационных портретов признаков;
· Ibm -
печать круговой диаграммы на матричном принтере, работающем в стандарте IBM или
EPSON, причем при выборе данного пункта меню предоставляется два варианта
печати: инвертированная печать (негатив), либо позитивная печать но в
виде, экономящем красящую ленту;
· Las
- печать на лазерном принтере. При выборе данного варианта меню пользователю
предоставляется три варианта печати круговой диаграммы: “Inv” и “Max”
аналогичны описанным режимам печати на матричном принтере, а “Min” печатается
уменьшенный экономный вариант видеограммы.
|
|
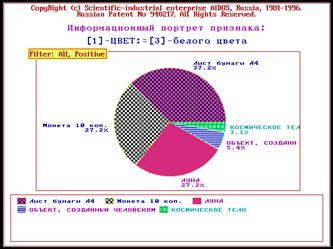
При записи круговых диаграмм в виде
PCX-файлов им присваиваются имена, представляющие собой порядковый номер
файла в поддиректории. Эти
видеограммы могут быть считаны и скорректированы в
графической системе PaintBrash, входящей в состав системы WINDOWS, и записаны в
графическом формате PCX или BMP, которые доступны для редактора WINWORD. В
результате эти видеограммы могут быть включены в отчеты и распечатаны на
лазерном принтере в составе отчета (таким же способом они включены и в состав
данной работы).
Кроме оперативного просмотра
информационных портретов классов распознавания на дисплее пользователь может (нажав клавишу
“F5-Генерация информационных портретов”) сформировать задание на генерацию
информационных портретов и запустить его на исполнение. Это задание может содержать
неограниченное количество строк в каждой из которых пользователь задает для
какого диапазона классов распознавания какой диапазон признаков его интересует.
Бланк задания и само задание распечатываются (примеры приведены в приложении №2
Образцы входных и выходных форм системы “ЭЙДОС”).
В режиме формирования информационных
портретов признаков также имеется возможность пакетной генерации информационных портретов всех
признаков, однако без формирования специального задания.
3.3.2.
КЛАСТЕРНО-КОНСТРУКТИВНЫЙ АНАЛИЗ И СЕМАНТИЧЕСКИЕ СЕТИ
Кластеры представляют собой такие
группы объектов (или признаков) внутри которых они наиболее схожи друг с
другом, а между которыми наиболее различны.
При формировании кластеров используются матрицы сходства объектов и
признаков, формируемые на основе базы данных конструктов. Сразу после
расчета матриц сходства система создает соотвествующие выходные формы с именами
Korr_obj.txt и Korr_att.txt в поддиректории TXT.
Система формирует кластеры для заданного диапазона кодов классов
распознавания (признаков) или заданных диапазонов уровней
системной организации, с различными критериями включения объекта (признака) в
кластер.
Эти критерии формируются автоматически
в зависимости от количества заданных пользователем уровней кластеризации, либо
задается пользователем непосредственно. В последнем уровне кластеризации, в
частности при задании одного уровня Система включает в кластеры не только
похожие, но и все непохожие объекты (признаки), и таким образом, формирует
конструкты классов распознавания и признаков.
Конструктом является понятие, имеющее противоположные по
смыслу полюса и целый спектр промежуточных смысловых значений, а также
количественную шкалу для измерения этих значений. Так, например, конструкт “Температура” имеет полюса “Горячее” -
“Холодное”, а для количественного измерения температуры применяется, например,
шкала Цельсия. Конструкт “Вес” имеет полюса “Легкий” - “Тяжелый” и количественную
шкалу в граммах, килограммах и т.д.
Когда мы познаем какой-либо объект, то
этот процесс представляет собой, ВО-ПЕРВЫХ, подбор подходящих для его
описания конструктов и определение на шкалах этих конструктов
положения данного объекта. Таким образом если конструкты рассматривать как оси координат некоторого
многомерного фазового пространства, то каждый объект в таком пространстве
представляет собой точку, а его эволюция - фазовую траекторию. Конструкт тем
больше подходит для описания объектов, чем он четче выражен, т.е. чем дальше
отстоят друг от друга его полюса, чем длиннее его шкала. Когда некоторый
конструкт имеет слабо разведенные полюса, то его
применение для описания различных объектов мало что может изменить в этом описании
и не позволяет четко различать эти объекты, таким образом такие конструкты
почти ничего не означают и практически бесполезны [127].
Степень разведения полюсов конструкта называется степенью его редукции и для
конструктов - признаков совпадает с интегральной информативностью признака, его значимостью для решения задачи
распознавания. Этот термин
введен автором [74] и представляет интерес, т.к. вызывает глубокие ассоциации с
понятием “редукция волновой функции” из квантовой теории поля (КТП). Редукция
волновой функции по очень многим своим особенностям напоминает процесс
осознания мысли, перехода ее из невербальной формы существования в вербализованную [115]. Мышление есть функция ментального тела человека, также, как эмоции - функция
астрального, а движение - функция физического. Это означает, что “чистое
мышление”, мышление как таковое не может быть осознано при астральной и
физической формах сознания. Следовательно, при физическом и астральном
сознании, то, что осознается и понимается при данных формах сознания как
процесс мышления, в действительности представляет собой лишь процесс
воплощения мысли в те языковые формы, которые осознаются при этих формах сознания. Так, например, при
физической форме сознания считается, что мышление представляет собой процесс
генерации внутренней или внешней речи (звуковой, текстовой или другой), т.е.
процесс вербализации. Медитация
есть мышление без вербализации и возможно только при ментальном сознании. При астральном же и физическом
сознании как мышление осознается (и под ним понимается) не оно само, а лишь его
результат, т.е. вербализация [67]. В этой связи необходимо отметить, что
скорочтение представляет собой способ восприятия
вербализованной мысли (т.е. чтения) без ее повторной
вербализации (даже в форме внутренней речи).
Похоже,
когда люди начали строить Вавилонскую башню - они понимали друг друга
«без слов», т.е. общались на уровне медитации, по-видимому, в ментальном или по
крайней мере астральном сознании. Возникновение условных звуковых и других
языков связано с грехопадением людей, т.е. их переходом на физический план в
физическое сознание. В будущем, при переходе в высшие формы сознания, люди
смогут начать строительство «новой Вавилонской башни».
Понятия “кластер” и “конструкт”
взаимосвязаны. Положительный
и отрицательный полюса конструкта представляет собой кластеры в наибольшей степени отличающиеся друг от
друга. Конструкт может рассматриваться как кластер с нечеткими границами,
включающий в различной степени, причем не только положительной, но
отрицательной, все объекты (признаки).
Используя эти понятия можно утверждать,
что, ВО-ВТОРЫХ, процесс познания представляет собой процесс редукции уже
существующих конструктов, а также процесс
создания новых конструктов и повышения их степени редукции.
Универсальная автоматизированная
система распознавания образов “ЭЙДОС” позволяет
решать обе эти важнейших задачи познания:
· в режимах кластерного и конструктивного анализа создавать новые
конструкты,
· в режимах оптимизации базы
конструктов повышать их степень редукции.
Таким образом Система “ЭЙДОС” представляет
собой систему искусственного интеллекта и является средством автоматизации
процесса познания.
Вход в режимы кластерного анализа объектов и признаков осуществляется из
подсистемы “ТИПОЛОГИЯ”. При этом первоначально рассчитываются матрицы сходства
объектов и признаков, и уже на их основе генерируются кластеры (конструкты), которые
затем просматриваются и печатаются. Имеются режимы раздельно реализующие эти
функции, а также автоматический режим, реализующий их все вместе.
Здесь уместно специально обратить
внимание пользователей на то, что конструктивный анализ, проведенный по данным
ответов некоторой группы на вопросы психологической ориентации позволяет с
одной стороны измерить степень однородности (а значит и надежности
группы), а с другой, выделить в данной группе относительно автономные подгруппы
со своими лидерами и их реальными конкурентами. Кроме того для каждого члена
группы выявляется, какие члены группы его поддерживают, а какие нет и
насколько. Одной из общепризнанных аксиом прикладной психологии считается
следующее положение: “Чем выше однородность
группы, т.е. чем больше сходства обнаруживается у членов группы по данным
индивидуально - психологическим свойствам, тем
выше оценка надежности групповой деятельности и меньше внутригрупповая напряженность.”
[82, с.81].
Таким
образом Система позволяет с одной стороны выявлять и прогнозировать
индивидуальные характеристики членов группы, а с другой стороны подбирать коллективы
в соответствии с принципом “информационной пирамиды”, т.е. под руководителя
подбирается его ближайшее окружение (“заместители”), под них подбирается их
окружение и т.д.
Ниже приводится Help-фрагмент режима, позволяющего решать
задачи реструктуризации коллектива.
ДАННЫЙ РЕЖИМ ОБЕСПЕЧИВАЕТ:
· формирование
нового справочника классов распознавания, в котором
классы распознавания соответствуют кластерам;
· автоматический
ввод в анкеты обучающей выборки кодов тех классов распознавания, для
формирования обобщенных образов которых должны быть использованы данные анкеты
(на основе информации из кластеров);
· формирование
баз данных статистики в соответствии с новым справочником классов распознавания и переобучение Системы.
ПРИМЕНЕНИЕ:
данный режим может быть применен, например, для формирования групп из массы
респондентов по сходству, определенному на основе тестирования.
Для этого необходимо:
1.
ввести в обучающую выборку анкеты респондентов,
2.
с помощью режима *F8CopyObj* (в режиме ввода анкет обучающей выборки) сформировать справочник классов распознавания, в котором
каждой анкете будет соответствовать свой класс,
3.
обучить Систему,
4.
выполнить кластерно-конструктивный
анализ с исключением кластеров с ТОЖДЕСТВЕННЫМ набором классов,
5.
выполнить данный режим, нажав клавишу *F8 Формирование классов на основе
кластеров* в подсистеме кластерно-конструктивного
анализа классов распознавания (генерация кластеров).
Данный режим может выполняться при
различных значениях граничных условий (с удалением кластеров из одного объекта или без удаления, при
различных пороговых уровнях сходства включения в кластер), а также
может повторяться уже не для классов “один класс - одна анкета”, а для классов
- групп.
После того, как конструкты классов или
признаков сформированы, в режиме: “Вывод
2d-диаграмм” имеется возможность отображения их в графическом виде
(см.рис.).
Необходимо отметить, что диаграммы
смыслового сходства-различия классов (признаков) соответствуют определению семантических сетей, т.е. представляют
собой ориентированные графы, в которых признаки соединены линиями,
соответствующими их смысловому сходству (различию).
|
|
|
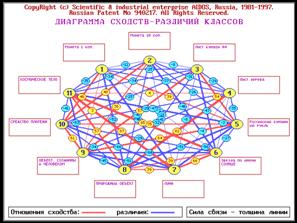
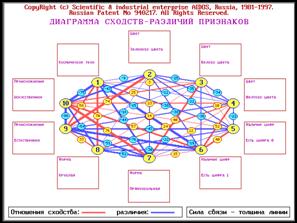
Кроме того система позволяет вывести
диаграммы сходств/различий любых заданных классов (признаков). На одной
диаграмме может быть отображено от 3 до 12 классов (признаков).
2d-диаграммы конструктов классов
записываются в поддиректорию PCX\KLAS-OBJ с именами вида: KOBJ###.PCX, где ####
- код класса распознавания (на диаграмме в центре).
2d-диаграммы конструктов признаков
записываются в поддиректорию PCX\KLAS-ATT с именами вида: KATT###.PCX, где ####
- код признака (на диаграмме в центре).
3.3.3. СОДЕРЖАТЕЛЬНОЕ СРАВНЕНИЕ
В системе “ЭЙДОС” версии 6.2 в
обобщенной постановке реализованы режимы, обеспечивающие содержательное
сравнение классов распознавания и признаков. В чем же состоит суть этих режимов?
В
информационных портретах классов распознавания мы видим, какое количество информации о
принадлежности (и не принадлежности) к данному классу мы получаем, обнаружив у
некоторого объекта признаки, содержащиеся в информационном портрете. В кластерно-конструктивном
анализе мы получаем результаты сравнения классов распознавания друг с другом,
т.е. мы видим на сколько они сходны и насколько отличаются. Но мы
не видим, какими признаками они похожи и какими отличаются, и какой
вклад каждый признак вносит в сходство или различие некоторых двух классов.
Эту информацию мы могли бы получить, если бы проанализировали два информационных
портрета. Эту работу и осуществляет режим содержательного сравнения классов
распознавания.
Аналогично, в информационных портретах признаков мы видим, какое
количество информации о принадлежности (и не принадлежности) к различным
классам распознавания мы получаем, обнаружив у некоторого объекта
данный признак. В кластерно-конструктивном
анализе мы получаем результаты сравнения признаков друг с другом, т.е. мы видим
на сколько они сходны и насколько отличаются. Но мы не видим, какими
классами они похожи и какими отличаются, и какой вклад каждый класс
вносит в смысловое сходство или различие некоторых двух признаков. Эту
информацию мы могли бы получить, если бы проанализировали информационные
портреты двух признаков. Эту работу и осуществляет режим содержательного
(смыслового) сравнения признаков.
3.3.3.1.
СОДЕРЖАТЕЛЬНОЕ СРАВНЕНИЕ КЛАССОВ.
КОГНИТИВНЫЕ ДИАГРАММЫ (В Т.Ч. ДИАГРАММЫ МЕРЛИНА)
Постановка проблем.
Существующий в настоящее время психометрический инструментарий, как правило,
позволяет исследовать какой-либо один из аспектов или уровней организации
личности, как целостной системы, а не всю систему в целом.
Например,
по мнению автора, самоактуализационный тест (САТ) измеряет прежде всего
социально-обусловленные качества респондентов, тогда как опросник 16 PF
Р.Б.Кеттелла - конституционные психические качества, детерминируемые более
фундаментальными и устойчивыми генотипическими факторами.
Для
целей практической работы КЮИ МВД РФ
по подготовке профессионалов МВД необходимо иметь развернутые профессиограммы
по всем базовым специальностям. Эти профессиограммы должны содержать требования
как к индивидуальным, так и психодинамическим, и социально-психологическим
свойствам личности в их взаимосвязи,
на что неоднократно обращал внимание В.С.Мерлин [3].
Сегодня
же никто не в состоянии обоснованно сказать, какие качества личности и в каком
сочетании должны быть у обучаемого КЮИ МВД РФ, который готовится по той или
иной специальности, между тем эти требования, по-видимому, отличаются по
различным специальностям.
Отсюда
следует актуальность решения первой
проблемы: разработать профессиограммы
по базовым специальностям КЮИ МВД РФ.
Но
даже если бы эти профессиограммы и существовали бы, то возникла бы вторая проблема, т.е. проблема практического применения
профессиограмм в практике приема обучаемых, определения их специализации и обучения
в КЮИ МВД РФ.
Для
решения второй проблемы необходимо, по крайней мере:
1. регулярно
(согласно регламента) измерять у каждого конкретного обучаемого те качества
личности, которые есть в профессиограммах, т.е. формировать индивидуальные интегральные
образы обучаемых;
2. количественно
сравнивать “индивидуальный интегральный образ” каждого обучаемого с
профессиограммами;
3. вырабатывать
рекомендации по коррекции личности обучаемых либо по их профессиональной переориентации.
Традиционные пути решения
проблем.
Разработка профессиограмм длительный процесс весьма значительной
трудоемкости и наукоемкости. В целом этот процесс в настоящее время не
формализован и практически не оснащен адекватным техническим и методическим
инструментарием. Осуществляется он, в основном, путем применения значительного
количества слабо адаптированных или вообще не адаптированных по месту и времени
применения тестов зарубежного производства, предназначенных не для тех целей,
которые ставятся перед разработчиками профессиограмм.
В.С.Мерлин
говорил как о перспективной задаче для будущих разработчиков, о создании автоматизированных систем,
обеспечивающих комплексное измерение разноуровневых качеств личности и изучение
взаимосвязей этих качеств, характерных для различных вариантов фактического проявления
личности. При этом он отмечал, что для выявления такого рода взаимосвязей
недостаточно изучения отдельных конкретных индивидуальностей, а необходимо
обобщение значительных массивов данных, основанных на репрезентативных
представительных выборках.
Концепция решения проблем
автором. Автор предлагает конкретные
успешно опробированные методики и компьютерные технологии решения
сформулированных выше проблем, воплощенные в когнитивной аналитической системе
“ЭЙДОС-
Кратко,
суть этих методик и технологий заключается в следующем:
·
проектируется представительная по
количеству респондентов выборка;
·
респонденты тестируются с применением
батареи стандартных тестов с помощью системы окружения “ЭЙДОС-Y”;
·
классификаторы и результаты
тестирования экспортируются в когнитивную аналитическую систему “ЭЙДОС-
·
когнитивная аналитическая система
“ЭЙДОС-
1. автоматическое
взвешивание или ремонт исходных данных, то есть выборка из массива респондентов
такого подмножества, которое в наибольшей степени соответствует заданной
генеральной совокупности (обеспечение структурной репрезентативности обучающей
выборки);
2. формирование
обобщенных образов исследуемых профессиональных категорий респондентов, т.е. профессиограмм;
3. определение
вклада психологических свойств, измеряемых с помощью стандартных тестов, в
различие профессиограмм;
4. исключение
тех психологических свойств, которые вносят наименьший вклад в различие профессиограмм
;
5. вывод
сформированных профессиограмм и профилей психологических качеств в удобной для
восприятия и анализа текстовой и графической форме;
6. сравнение
индивидуальных интегральных образов респондентов с профессиограммами и
определение спектра профессиональных предпочтений для данного респондента;
7. сравнение
профессиограмм (и профилей психологических качеств) друг с другом, формирование кластеров и конструктов;
8. содержательное
сравнение профессиограмм (и профилей психологических качеств) друг с другом, в том числе стандартные и инвертированные
(термин авт.) диаграммы В.С.Мерлина;
9. расчет
частотных распределений профессиограмм и психологических, а также двумерных матриц сопряженности на основе критерия c2
и коэффициентов Пирсона, Чупрова и Крамера.
В данной работе
невозможно рассмотреть все эти технологические этапы и концепции, на которых
они основаны [1, 2], поэтому мы остановимся только на вопросах формирования и содержательного
анализа профессиограмм.
Формирование и отображение
профессиограмм. Система “ЭЙДОС-
Профессиограммы представляют собой
списки психологических свойств в порядке убывания содержащегося в них
количества информации о принадлежности к данным профессиональным типам.
Профессиограммы
содержат информацию о том, какими психологическими характеристиками и
личностными качествами фактически обладают респонденты, успешно или не успешно
работающие на определенных должностях или по определенным профессиям (в отличие
от других должностей и профессий). Профессиограмма показывает информационный
вклад каждого психологического свойства в общий объем информации, содержащейся
в образе данной профессии.
Профили
психологических свойств представляют собой списки профессиональных типов в порядке убывания
количества информации о принадлежности к ним, которое содержит данное психологическое
свойство.
По
своей сути профиль психологического свойства раскрывает нам его смысл, т.е. его семантическую нагрузку.
Профессиограммы
и профили психологических свойств могут быть просмотрены на дисплее в виде
текстовых форм и в виде графических круговых диаграмм, а также записаны в виде
файлов.
Пользователь
имеет возможность выделить в профессиограмме или профиле психологического
свойства только те психологические свойства, которые относятся к заданному диапазону
уровней системной организации личности (уровни Мерлина).
Этот
аппарат был успешно применен кандидатом психологических наук подполковником
В.Г.Третьяком в исследовании, предметом которого было изучение взаимосвязи
между учебной активностью и индивидуальными особенностями обучаемых
юридического института МВД РФ [5].
Кластерный и конструктивный
анализ. Кластеры представляют собой
такие группы профессиональных типов (психологических свойств) внутри которых
они наиболее схожи друг с другом, а между которыми наиболее различны.
Система
формирует конструкты для заданных диапазонов уровней системной
организации (в т.ч. уровней Мерлина) профессиограмм (психологических свойств) и
с различными критериями их включения в конструкт.
Конструктом является понятие,
имеющее противоположные по смыслу полюса и целый спектр промежуточных смысловых
значений, а также количественную шкалу для измерения этих значений.
Так,
например, конструкт “Температура” имеет полюса “Горячее” -
“Холодное”, а для количественного измерения температуры применяется, например,
шкала Цельсия. Конструкт “Вес” имеет полюса “Легкий” - “Тяжелый” и
количественную шкалу в граммах, килограммах и т.д.
Когда
мы познаем какой-либо объект, то этот процесс представляет собой, во-первых, подбор подходящих для
его описания конструктов и определение на шкалах этих конструктов
положения данного объекта. Таким образом если конструкты рассматривать как оси координат некоторого
многомерного фазового пространства, то каждый объект в таком пространстве представляет
собой точку, а его эволюция - фазовую траекторию.
Понятия
“кластер” и “конструкт”
взаимосвязаны.
Положительный и отрицательный полюса конструкта представляет собой кластеры в наибольшей степени отличающиеся друг от
друга. Конструкт может рассматриваться как кластер с нечеткими границами,
включающий в различной степени, причем не только положительной, но
отрицательной, все объекты (признаки).
Конструкт
тем больше подходит для описания объектов, чем сильнее отличаются друг от друга
его полюса, чем длиннее его шкала, т.е. чем выше степень редукции конструкта.
Используя
эти понятия можно утверждать, что, во-вторых,
процесс познания представляет собой процесс повышения степени редукции уже
существующих конструктов, а также процесс
создания новых конструктов.
Универсальная
когнитивная аналитическая система “ЭЙДОС-6.2” позволяет
решать обе эти важнейших задачи познания:
·
в режимах кластерного и конструктивного анализа создавать новые
конструкты,
·
в режимах оптимизации базы конструктов повышать степень их редукции.
Таким образом система “ЭЙДОС” представляет собой средство
автоматизации процесса познания, т.е. является когнитивной системой. Кроме того, система “ЭЙДОС” основана на
принципах адаптивного семантического анализа и работает не только с абсолютными
и относительными, т.е. процентными распределениями, но и с аналитической формой
информации, формируемой на основе сопоставительного
анализа процентных распределений и измеряемой в Bit. Таким образом, система “ЭЙДОС” является аналитической системой.
Здесь
уместно специально обратить внимание пользователей на то, что конструктивный
анализ, проведенный по данным ответов некоторой группы на вопросы
психологической ориентации позволяет с одной стороны измерить степень однородности (а значит и надежности
группы), а с другой, выделить в данной группе относительно автономные подгруппы
со своими лидерами и их реальными конкурентами. Кроме того для каждого члена
группы выявляется, какие члены группы его поддерживают, а какие нет и
насколько.
Таким
образом Система позволяет с одной стороны выявлять и прогнозировать индивидуальные
характеристики членов группы, а с другой стороны подбирать коллективы в соответствии
с принципом “информационной пирамиды”, т.е. под руководителя подбирается его ближайшее
окружение (“заместители”), под них подбирается их окружение и т.д.
В системе “ЭЙДОС” версии 6.0 в обобщенной постановке реализованы режимы,
обеспечивающие содержательное сравнение профессиограмм друг с другом и профилей
психологических свойств друг с другом.
Из
профессиограммы мы видим, какое количество информации о
принадлежности (и не принадлежности) к данному профессиональному типу мы
получаем, обнаружив у некоторого респондента психологические свойства,
содержащиеся в профессиограмме. В кластерно-конструктивном
анализе мы получаем результаты сравнения профессиограмм друг с другом, т.е. мы
видим на сколько они сходны и насколько отличаются. Но мы не видим, какими психологическими свойствами они похожи и
какими отличаются, и какой вклад каждое свойство вносит в сходство или
различие некоторых двух профессиональных типов. Эту информацию мы могли бы
получить, если бы проанализировали две профессиограммы. Эту работу и осуществляет
режим содержательного сравнения профессиональных типов.
Аналогично,
в профилях психологических свойств мы видим, какое количество информации
о принадлежности (и не принадлежности) к различным профессиональным типа мы получаем, обнаружив у некоторого
респондента данное свойство. В кластерно-конструктивном
анализе мы получаем результаты сравнения профилей психологических свойств друг
с другом, т.е. мы видим на сколько они сходны и насколько отличаются по своему
смыслу. Но мы не видим, информацией о
каких профессиональных типах они похожи и какими отличаются, и какой вклад
каждый профессиональный тип вносит в смысловое сходство или различие некоторых
двух психологических свойств. Эту информацию мы могли бы получить, если бы
проанализировали профили двух психологических свойств. Эту работу и
осуществляет режим содержательного (смыслового) сравнения психологических
свойств системы “ЭЙДОС”.
Содержательное сравнение
профессиограмм. Данный режим автоматизирует содержательное
сравнение пар профессиограмм.
При этом автоматически выполняются
следующие этапы:
1. Формируются
две профессиограммы: например для J-го
и L-го профессиональных типов (классов).
2. Выявляются
психологические свойства (признаки), которые есть по крайней мере в одной из
профессиограмм. Такие свойства называются связями,
т. к. благодаря тому, что они либо тождественны друг другу, либо между ними
имеется определенное сходство или различие по смыслу, они вносят определенный
вклад в отношения сходства/различия
между профессиональными типами.
3. Список
выявленных связей сортируется в порядке убывания модуля силы связи и на
графической диаграмме отображается не более заданного пользователем количества
связей.
Пусть, например:
·
у J-го
класса обнаружен i-й признак,
·
у L-го
класса обнаружен k-й признак.
Следуя
математической модели, изложенной в работе автора [1], приведем вывод формулы,
дающей количество информации о принадлежности некоторого респондента к классу J, которое мы получаем, узнав, что этот
респондент обладает признаком I.
Введем обозначения:
|
W |
количество
классов в списке классов; |
|
A |
количество
признаков в списке признаков; |
|
|
количество
встреч i-го признака у объектов
(конкретных реализаций) j-го класса; |
|
|
суммарное
количество наблюдений i-го
признака по всем классам; |
|
|
суммарное
количество признаков, обнаруженных у объектов j-го класса; |
|
|
суммарное
количество признаков, обнаруженное у предъявленных объектов по всем классам; |
|
|
вероятность
встретить i-й признак при
предъявлении какого-либо объекта из имеющихся в обучающей выборке; |
|
|
вероятность
встретить i-й признак при
предъявлении объекта, принадлежащего к
j-му классу; |
|
|
количество
информации в i-м признаке о
принадлежности к j-му классу. |
На
основе обучающей выборки системой рассчитывается матрица абсолютных частот
встреч признаков по классам, которая имеет вид:
|
|
К л а с с ы |
|
||||
|
Признаки |
... |
j |
... |
l |
... |
Сумма |
|
... |
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
Сумма |
|
|
|
|
|
|
Верхний
индекс обозначает класс, а нижний - признак.
Средняя
вероятность встретить i-й признак
при случайном предъявлении вообще какого-либо объекта, из имеющихся в обучающей выборке:
![]() ...................................................( H )
...................................................( H )
Вероятность
встретить i-й признак при
предъявлении объекта, относящегося к j-му классу:
![]() .........................................................( I )
.........................................................( I )
Если
вероятность встретить i-й признак
при предъявлении объекта j-го класса
такая же, как и в среднем:
![]()
то
обнаружение данного признака не дает системе никакой информации о том, к какому
классу относится предъявленный объект.
Если
у объектов j-го класса i-й признак встречается с большей
вероятностью, чем в среднем по всем классам:
![]()
то
при обнаружении данного признака система получает некоторую информацию в пользу
того, что предъявлен объект, относящийся к j-му
классу.
Если
у объекта, относящегося к j-му
классу, i-й признак встречается с
меньшей вероятностью, чем в среднем по всем классам:
![]()
то
при обнаружении данного признака система получает некоторую информацию в пользу
того, что предъявлен объект НЕ ОТНОСЯЩИЙСЯ к j-му классу (при этом количество информации отрицательное).
Всем
этим достаточно убедительным соображениям удовлетворяет так называемая семантическая мера целесообразности
информации А.А.Харкевича [4, с.56], которая в наших обозначениях выглядит
следующим образом:
![]() ................................................( J )
................................................( J )
Подставив
![]() и
и ![]() из (1) и (2) получим:
из (1) и (2) получим:
![]() ................................( K )
................................( K )
Окончательное
выражение для расчета количества информации в i-м признаке о принадлежности некоторого конкретного объекта к j-му классу имеет вид:
![]() ...........................( L )
...........................( L )
где:
![]()
-
нормировочный коэффициент, переводящий количество информации
в двоичные единицы информации - Биты.
Непосредственно
на основе матрицы частот встреч признаков ![]() система “ЭЙДОС”
формирует матрицу информативностей
признаков
система “ЭЙДОС”
формирует матрицу информативностей
признаков ![]() , которая имеет структуру, аналогичную структуре матрицы
абсолютных частот.
, которая имеет структуру, аналогичную структуре матрицы
абсолютных частот.
Обобщенным
образом (профилем) класса распознавания является столбец матрицы
информативностей, т.е. совокупность всех информативностей признаков данного
класса. Обобщенным образом (профилем) признака является строка матрицы
информативностей, т.е. совокупность всех информативностей данного признака.
Аналогично,
формула для количества информации в k-м
признаке о принадлежности к L-му
классу имеет вид:
![]() ...................................( M )
...................................( M )
Вклад
некоторого признака i в сходство/различие
двух классов j и l равен соответствующему слагаемому корреляции образов этих
классов, т.е. просто произведению информативностей:
![]() ............................................( N )
............................................( N )
Классический
коэффициент корреляции Пирсона, количественно определяющий степень сходства
двух классов: j и l, на основе учета вклада каждой связи,
образованной i-м признаком,
рассчитывается по формуле:
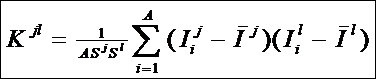 .........................( O )
.........................( O )
где:
|
|
средняя
информативность признаков j-го
класса; |
|
|
средняя
информативность признаков L-го
класса; |
|
|
среднеквадратичное
отклонение информативностей признаков j-го
класса; |
|
|
среднеквадратичное
отклонение информативностей признаков L-го
класса; |
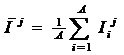
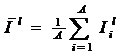
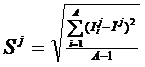
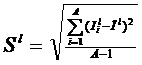
Проанализируем,
насколько классический коэффициент корреляции Пирсона (8) пригоден для решения важных задач:
1. содержательного
сравнения классов;
2. изучения
внутренней многоуровневой структуры класса.
Упростим
анализ, считая, что средние информативности признаков по обоим классам близки к
нулю, что близко к истине.
Каждое
слагаемое (7) суммы (8) отражает связь между классами, образованную одним i-м признаком. I-я связь
существует в том и только в том случае, если i-й признак есть у обоих классов. Поэтому эти связи уместно назвать
одно-однозначными. Но это означает,
что данной подход не позволяет сравнивать классы, описанные различными, т.е.
непересекающимися наборами признаков. Но даже если общие признаки и есть, то
невозможность учета вклада остальных признаков, по мнению автора, является
недостатком классического подхода, т.к. из содержательного анализа связей
неконтролируемо исключается потенциально существенная информация. Таким
образом, классический подход имеет ограниченную применимость при решении задачи
№1. Для решения задачи №2 подход, основанный на формуле (8) вообще не применим, т.к. различные уровни
системной организации классов образованы различными признаками и,
следовательно, между уровнями не будет ни одной одно-однозначной связи.
Основываясь на этих соображениях,
автор предлагает, в общем случае учитывать вклад в сходство/различие двух
классов, который вносят не только общие, но и остальные признаки. Логично
предположить, что этот вклад (при прочих равных условиях) будет тем меньше, чем
меньше корреляция между этими признаками. Таким образом, для обобщения
выражения для силы связи (7) необходимо умножить произведение информативностей
признаков на коэффициент корреляции между ними, отражающий степень сходства или
различия признаков по смыслу.
Таким образом, будем считать, что
любые два психологических свойства (i,k) вносят определенный вклад в
сходство/различие двух классов (j,l), определяемый сходством/различием
признаков и количеством информации о принадлежности к этим классам, которое
содержится в данных признаках:
![]() ....................................( P )
....................................( P )
где:
![]() - классический коэффициент
корреляции Пирсона, количественно определяющий степень сходства по смыслу двух
признаков: i и k, на основе учета вклада каждой связи, образованной содержащейся в
них информацией о принадлежности к j-му
классу:
- классический коэффициент
корреляции Пирсона, количественно определяющий степень сходства по смыслу двух
признаков: i и k, на основе учета вклада каждой связи, образованной содержащейся в
них информацией о принадлежности к j-му
классу:
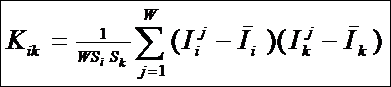 .................( Q )
.................( Q )
где:
|
|
средняя
информативность профиля i-го
признака; |
|
|
средняя
информативность профиля k-го
признака; |
|
|
среднеквадратичное
отклонение информативностей профиля |
|
|
среднеквадратичное
отклонение информативностей профиля |
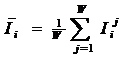
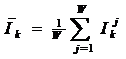
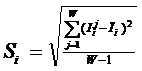
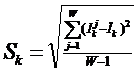
Коэффициент
корреляции между признаками (10) рассчитывается на основе всей обучающей выборки, а не только объектов двух сравниваемых
классов.
Так как коэффициент корреляции
между признаками (10) практически всегда не равен нулю, то каждый признак i образует связи со всеми признаками k, где k={1,...,A}, а каждый признак k
в свою очередь связан со всеми остальными признаками. Это означает, что
выражение (9) является обобщением (7) на случай много-многозначных связей.
На
основе этих представлений сформулируем выражение для обобщенного коэффициента корреляции Пирсона (термин автора)
между двумя классами: j и l, учитывающего вклад в их сходство/различие
не только одно-однозначных, но и много-многозначных связей, образуемых
коррелирующими признаками.
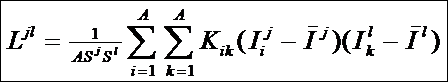 .............( R )
.............( R )
Поясним эту формулу на упрощенном
примере: допустим и у меня, и у Вас темно-карие
глаза. Ясно, что в этом заключается определенное сходство между нами. Теперь
допустим, что мне неизвестен цвет Ваших глаз, но зато известно, что Вы жгучий
брюнет. Можно ли сказать, что имеющаяся информация о цвете моих глаз и Ваших
волос говорит в пользу того, что мы похожи. Учитывая, что обычно брюнеты имеют
темно-карие глаза (корреляция между этими признаками составляет »0,95),
на этот вопрос можно ответить утвердительно. Практически это означает, что
информация о наличии признака “брюнет” вносит вклад в сходство с обладателями “карих глаз”, причем лишь в 0,9 раз меньше,
чем информация и самом признаке “карие глаза”. Аналогично, информация о том,
что я блондин вносит определенный вклад в различие с обладателями темно-карих
глаз, т.к. эти признаки находятся в антикорреляции.
Сравним
классический (8) и обобщенный (11) коэффициенты корреляции Пирсона друг с
другом.
Очевидно,
при i=k (11) преобразуется в (8),
т.е. соблюдается принцип соответствия. Отметим, что пользователь имеет
возможность задавать минимальный коэффициент корреляции (порог) между
признаками, образующих отображаемые на диаграмме связи. При пороге 100%
отображаются только одно-однозначные связи, учитываемые в классическом
коэффициенте корреляции (8).
Из
выражений (8) и (11) видно, что:
![]() ........................................................( S )
........................................................( S )
т.к.
в обобщенном коэффициенте корреляции учитываются связи между классами, образованные
за счет учета корреляций между различными признаками. Ясно, что отношение:
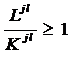 ..........................................................( T )
..........................................................( T )
отражает
степень избыточности описания
классов. В системе “ЭЙДОС” имеется возможность исключения из системы признаков
наименее ценных из них для идентификации классов. При этом в первую очередь
удаляются сильно коррелирующие друг с другом признаки. В результате степень
избыточности системы признаков уменьшается и она становится ближе к ортонормированной [2].
Рассмотрим
вопрос о единицах измерения, в
которых количественно выражаются связи между классами.
Сходство
двух признаков ![]() выражается величиной
от — 1 до +1.
выражается величиной
от — 1 до +1.
Максимальная
теоретически-возможная информативность
признака в Bit выражается формулой:
![]() ...........................................( U )
...........................................( U )
где:
- Nobj - количество
классов.
Таким
образом, максимальная
теоретически-возможная сила связи Rmax равна:
![]() ................................................................(
V )
................................................................(
V )
Сила связи в диаграммах
выражается в процентах от максимальной теоретически возможной силы связи.
На
диаграмме отображается 8 наиболее
сильных по модулю связей, рассчитанных согласно формуле (11), причем знак связи
изображается цветом (красный +, синий — ), а величина - толщиной линии.
Запись
отображаемых диаграмм в виде PCX-файлов осуществляется автоматически.
Распечатывать диаграммы рекомендуется в системе Windows (PaintBrash, WinWord и
др.). Система формирует также текстовый файл, содержащий всю информацию о
связях двух заданных профессиограмм при заданных условиях фильтрации в
процентах от максимальной теоретически-возможной силы связи.
|
|
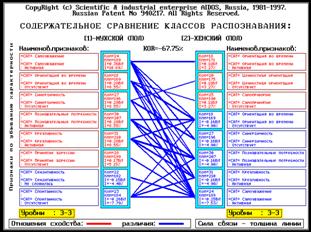
В
качестве примера приводятся диаграмма, наглядно показывающая вклад психологических
свойств, измеряемых самоактуализационным тестом (САТ) в сходство/различие двух
классов: “мужчины” и “женщины”:
Диаграммы
могут быть автоматически сформированы для любых двух профессиональных типов,
для пар наиболее похожих и непохожих профессиональных типов, для их всех
возможных сочетаний, а также диаграммы В.С.Мерлина [3 ].
Диаграммы
Мерлина представляют собой частный
случай диаграмм содержательного сравнения классов, т.е. диаграммы Мерлина
это диаграммы содержательного сравнения классов, формируемые системой “ЭЙДОС-
1. класс
сравнивается сам с собой;
2. выбрана
фильтрация левой и правой профессиограммы по уровням системной организации
признаков (в данном случае - уровням Мерлина);
3. левый
класс отображается с фильтрацией по одному уровню системной организации, а
правый - по другому.
4. Диалог
задания вида диаграмм предоставляет пользователю возможность задать следующие
параметры:
·
способ нормирования толщины линий,
отображающих связи: нормирование по текущей диаграмме или по всем диаграммам;
·
способ фильтрации признаков в
профессиограммах диаграммы: по диапазону признаков или по диапазону уровней
системной организации (уровням Мерлина);
·
сами диапазоны признаков или уровней
для левой и правой профессиограмм;
·
максимальное количество связей,
отображаемых на диаграмме;
·
уровень сходства признаков, образующих
одну связь, отображаемую на диаграмме: от 0 до 100%. При уровне сходства 100% в
портретах отображаются только связи, образованные теми признаками, которые есть
в профессиограммах одновременно, т.е. взаимно-однозначные связи. При уровне
сходства менее 100% вообще говоря связи становятся много-многозначными, т.к.
каждый признак корреляционно связан со всеми остальными;
·
уровень сходства классов, отображаемых
на диаграмме.
На
приведенных в примере диаграммах Мерлина для классов: “Мужчина” и “Женщина”
показаны положительные взаимосвязи между конституционными психологическими
свойствами личности, измеряемыми 16PF опросником Р.Кеттелла и
социально-обусловленными свойствами личности, измеряемыми самоактуализационным
тестом (САТ).
|
|
|


Обращает
на себя внимание, что если образ мужчины имеет позитивное содержание, т.е.
может быть охарактеризован в терминах типа: “для мужчин характерны такие-то и
такие-то психологические свойства”, то обобщенный образ женщин в основном
состоит из психологических свойств, которые не характерны для женщин. То есть, если о мужчинах можно сказать какими
свойствами они обладают, то о женщинах лишь то, какими они не обладают.
3.3.3.2.
СОДЕРЖАТЕЛЬНОЕ (СМЫСЛОВОЕ) СРАВНЕНИЕ ПРИЗНАКОВ.
КОГНИТИВНЫЕ ДИАГРАММЫ (В Т.Ч.ИНВЕРТИРОВАННЫЕ ДИАГРАММЫ МЕРЛИНА)
Данный режим автоматизирует содержательное сравнение пар
информационных портретов признаков.
После того, как оба признака выбраны, Вы можете с помощью клавиши:
F5 *Диаграмма* получить диаграмму
отношений информационных портретов выбранных признаков. Запись диаграммы в виде
PCX-файла в поддиректорию: PCX/REL-ATT
осуществляется автоматически. Распечатывать диаграммы рекомендуется в системе
WINDOWS (PaintBrash, WinWord и др.).
В режиме F5
*Диаграмма* перед отображением графической диаграммы система формирует в
поддиректории TXT файл Rel_att.txt, содержаший ВСЮ информацию о связях двух заданных информационных портретов при
заданных условиях фильтрации в процентах от максимальной теоретически-возможной
силы связи.
В данном режиме реализуются следующие
функции:
1.
Формируются информационные портреты
двух признаков (психологических свойств).
2.
Выявляются классы, которые есть по
крайней мере в одном из профилей. Такие классы называются связями, т. к. благодаря тому, что они либо тождественны друг
другу, либо между ними имеется определенное сходство или различие, они вносят
определенный вклад в отношения
сходства/различия между признаками по смыслу.
3.
Все связи между признаками сортируются
в порядке убывания модуля, после чего отображаются на диаграмме в соответствии
с ограничениями, заданными пользователем.
Для каждого класса известно, какое количество информации о
принадлежности к нему содержит данный признак - это информативность.
Если бы классы были тождественны друг другу, т.е. это был бы
один класс, то его вклад в
сходство/различие двух признаков был бы просто равен соответствующему данному
классу слагаемому корреляции этих
признаков, т.е. просто произведению информативностей.
Но поскольку это вообще говоря могут быть различные классы,
то, очевидно, необходимо умножить произведение информативностей на коэффициент
корреляции между классами.
Таким образом, будем считать, что любые два класса (j,l) вносят определенный вклад в сходство/различие
двух признаков (i,k), определяемый сходством/различием этих классов и
количеством информации о принадлежности к ним, которое содержится в данных признаках.
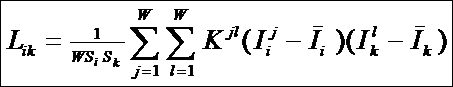 .............( W )
.............( W )
Вывод формулы (14) обобщенного коэффициента корреляции
Пирсона для двух признаков, совершенно аналогичен выводу формулы (11), поэтому
он здесь не приводится. Формулы для всех входящих в (14) величин приведены
выше.
Также, как и в режиме содержательного сравнения классов, в
данном режиме сила связи выражается в процентах от максимальной
теоретически-возможной силы связи.
На диаграмме отображается 16 наиболее значимых связей,
рассчитанных согласно этой формуле, причем знак связи изображается цветом
(красный +, синий — ), а величина - толщиной линии.
Запись диаграмм в виде PCX-файлов осуществляется
автоматически. Распечатывать диаграммы рекомендуется в системе Windows
(PaintBrash, WinWord и др.).
Система формирует также текстовый файл, содержащий всю информацию о связях двух заданных
информационных портретов при заданных условиях фильтрации в процентах от
максимальной теоретически-возможной силы связи.
В качестве примера ниже приводятся две диаграммы, наглядно
показывающие вклад каждого класса в сходство и/или различие двух признаков:
|
|
|


Система позволяют автоматически получить файлы диаграмм для
любых двух заданных признаков, для пар наиболее похожих и непохожих признаков,
для всех их возможных сочетаний, а также инвертированные диаграммы Мерлина.
Понятие “инвертированная диаграмма Мерлина” предлагается
автором в данной статье. Эти диаграммы представляют собой частный случай диаграмм содержательного сравнения признаков,
формируемых системой “ЭЙДОС-
1.
признак сравнивается сам с собой;
2.
выбрана фильтрация левого и правого
профиля по уровням системной организации классов (аналог уровней Мерлина для
свойств);
3.
левый профиль отображается с
фильтрацией по одному уровню системной организации классов, а правый - по
другому.
4.
Диалог задания вида диаграмм
предоставляет пользователю возможность задать следующие параметры:
· способ
нормирования толщины линий, отображающих связи: нормирование по текущей диаграмме
или по всем диаграммам;
· способ
фильтрации классов в профилях диаграммы: по диапазону кодов классов или по диапазону
уровней системной организации;
· сами
диапазоны классов или уровней для левого и правого профилей;
· максимальное
количество связей, отображаемых на диаграмме;
· уровень
сходства классов, образующих одну связь, отображаемую на диаграмме: от 0 до
100%. При уровне сходства 100% в профилях отображаются только связи,
образованные теми классами, о которых есть информация в обоих признаках, т.е.
взаимно-однозначные связи. При уровне сходства менее 100% вообще говоря связи
становятся много-многозначными, т.к. каждый класс корреляционно связан со всеми
остальными;
· уровень
сходства признаков, отображаемых на диаграмме.
Приведем пример инвертированной диаграммы Мерлина для
признака: “Самоуважение: активное” с фильтрами по группам классов: “Мужчины” и
“Женщины”.
|
|
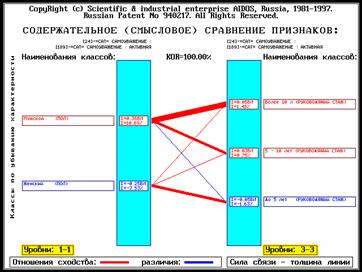
Из данной диаграммы следует, что данное психологическое
свойство характерно для мужчин и нехарактерно для женщин, характерно для имеющих большой руководящий стаж, и
нехарактерно для не имеющих его. Для мужчин характерен руководящий стаж в
основном более 10 лет и от 5 до 10 лет, тогда как для женщин - до 5 лет
(мужчины с таким стажем тоже есть, но для них это скорее исключение, т.е. он
для них не характерен).
3.3.4. АНАЛИЗ
РАБОТОСПОСОБНОСТИ СИСТЕМЫ
3.3.4.1.
АНАЛИЗ ДОСТОВЕРНОСТИ ЗАПОЛНЕНИЯ АНКЕТ
Матрица сходства признаков
(рассчитанная в режиме кластерного анализа признаков), содержит информацию о том,
насколько коррелируют различные признаки друг с другом по данным
обучающей выборки.
Если измерить эти корреляции в отдельной анкете (все равно
из обучающей выборки или распознаваемой) и сравнить с
корреляциями, имевшими место в обучающей выборке, то мы получим количественную
оценку достоверности заполнения данной анкеты. Если анкету заполнять “от
фонаря”, то корреляции между признаками в ней наверняка будут нарушены и это моментально
обнаружится.
Существует еще одна причина того, что в
анкете будут “нарушены” корреляции между признаками, т.е. они будут ИНЫМИ, чем
в обучающей выборке. Эта причина заключается в том, что
объект, описанный данной анкетой, не относится ни к одному из классов
распознавания, на которых
обучалась Система.
Выход на режим анализа достоверности
заполнения анкет осуществляется из подсистемы “АНАЛИЗ”.
3.3.4.2.
ИЗМЕРЕНИЕ ВАЛИДНОСТИ СИСТЕМЫ РАСПОЗНАВАНИЯ
Как уже упоминалось выше, валидность Системы распознавания - это способность Системы правильно
распознавать обучающую выборку (при ее предъявлении на распознавание), т.е. способность
относить объекты, описанные анкетами, анкеты к тем категориям, к которым их
относили или отнесли бы эксперты.
При измерении валидности рассматриваются логические анкеты.
Физическая анкета
- это анкета, заполненная респондентом. Но этот
респондент может относится одновременно ко многим
градациям шкал классификации классов распознавания (см.2.1.1.1, 2.1.1.2), т.е.
быть одновременно, например, мужчиной, иметь определенный возраст, определенную
национальность, определенную форму занятости и т.д., и т.п. Следовательно одну физическую анкету можно
использовать для формирования обобщенных образов каждой из этих категорий, к
которым относится заполнявший ее респондент. Это и означает, что одна
физическая анкета рассматривается как включающая некоторое количество логических
анкет.
Логическая анкета считается распознанной
правильно, если по данным обобщенной формы по результатам распознавания (по отчету “Итоговые результаты
распознавания”) она отнесена Системой к классу, к которому ее относили и
эксперты и для формирования обобщенного образа которого данная анкета использовалась.
В Системе “ЭЙДОС” имеется
режим, предназначенный для прямого измерения валидности Системы распознавания. Выход на
него осуществляется по нажатию клавиши F6 “Анализ” из главного меню. Конечно
результаты работы данного режима корректны, если обучающая выборка была переписана в распознаваемую (F2
“Обучение”, “Ввод - корректировка обучающей информации”, F6 “Копирование обучающей выборки
в распознаваемые анкеты”), а затем был выполнен режим пакетного распознавания.
В режиме измерения валидности Системы имеется возможность сгенерировать отчет по валидности Системы распознавания в целом по всем классам распознавания, а также
по каждому классу отдельно, просмотреть этот отчет в различных вариантах
сортировки, а также распечатать его диск (в директорию TXT) и на принтер.
3.3.5.
ПРОСМОТР ПРОФИЛЕЙ КЛАССОВ РАСПОЗНАВАНИЯ И ПРИЗНАКОВ
В данном режиме пользователь имеет возможность (нажав
клавишу F2) загрузить в специальную базу данных, предназначенную специально для
просмотра, одну из баз, содержащих статистическую информацию (абсолютные
частоты, процентные распределения или информативности).
После этого он может просматривать профили классов
распознавания и признаков на экране в виде таблицы, а также
может вывести на дисплей и записать в виде PCX-файлов в поддиректории PCX\DIAGR-2D и PCX\DIAGR-3D многочисленные
варианты графического представления профилей в двухмерном (2d) и трехмерном
(3d) представлении (нажав соответственно клавиши F4 и F5). При этом для
ограничения отображаемой информации теми аспектами, которые интересуют
пользователя в данный момент предусмотрена фильтрация классов распознавания и
признаков, а также задание диапазонов классов и признаков.
Для удобства пользователей (чтобы они могли сами
"повернуть" графическую диаграмму так, как им удобнее для просмотра),
предусмотрен режим ручной установки вида проекции, который запускается перед
показом диаграмм. При этом на экране на белом фоне появляется пустой голубой
параллелепипед, положением которого по отношению к плоскости экрана может
управлять непосредственно сам пользователь.
Управление видом
проекции осуществляется с помощью клавиш:
'x' - переключение на настройку параметра X0.
'y' - переключение на настройку параметра Y0.
'o' - переключение на настройку параметра XOZ.
'-' - уменьшение заданного параметра.
'+' - увеличение заданного параметра.
Esc - выход из режима настройки вида проекции.
Ниже приводятся примеры некоторых видов 3d-диаграмм,
генерируемых данным режимом Системы “ЭЙДОС-
|
|
|
|
|
|
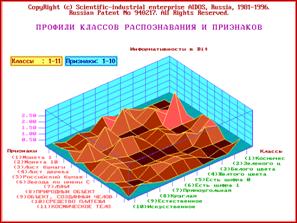

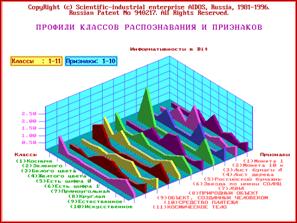
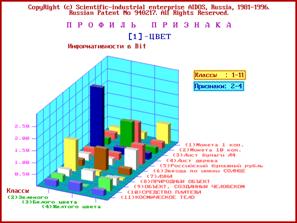
Всего же система
“ЭЙДОС-
3.3.6. РАСЧЕТ
ОДНОМЕРНЫХ ЧАСТОТНЫХ РАСПРЕДЕЛЕНИЙ И МАТРИЦ СОПРЯЖЕННОСТИ КЛАССОВ РАСПОЗНАВАНИЯ
И ПРИЗНАКОВ
В подсистеме анализа имеется пункт
меню: “Измерение НЕЗАВИСИМОСТИ классов распознавания и признаков”, обеспечивающий реализацию
следующих функций:
·
печать бланков задания на расчет
одномерных частотных распределений и матриц сопряженности,
·
ввод - корректировка и печать
заполненного задания,
·
расчет и печать на диск в поддиректорию TXT одномерных частотных распределений суммы ответов по
вопросам суммарно по всем категориям опрошенных,
·
расчет и печать на диск двумерных матриц сопряженности классов распознавания и признаков,
·
расчет и печать итоговой формы по
расчету матриц сопряженности (на основе задания), которая включает
теоретическое и фактическое значение критерия Х2, коэффициентов
Пирсона (Р), Чупрова (Т) и Крамера (К) для каждой строки задания.
Кроме того имеется возможность задания
уровня значимости, используемого при расчете, а также фильтрации заданий, для
которых на заданном уровне значимости была установлена связь между классами и признаками, или наоборот, не
было ее установлено.
Критерий Х2 рассчитывается
Системой для заданий размерностями до 340 степеней свободы (в таблицах обычно не
более 30). Остальные коэффициенты рассчитываются на основе Х2. Формы
снабжены текстовой информацией, облегчающей интерпретацию и принятие решений.
3.4.
ВОПРОСЫ ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ И ИСПОЛЬЗОВАНИЕ СТАНДАРТНЫХ МЕТОДИК ТЕСТИРОВАНИЯ
Сегодня нам неизвестны прямые аналоги
системы на Российском рынке программных систем. Системы статистической
обработки информации и экспертные системы не поддерживают когнитивных функций, описанных в разделе 1.3.1. настоящего
исследования, и поэтому, не могут рассматриваться как аналоги Системы “ЭЙДОС-
Преимуществом предлагаемой системы
перед стандартными методиками тестирования, является то, что она содержит
инструментальную (технологическую) подсистему, позволяющую СОЗДАВАТЬ новые
оптимальные методики тестирования в самых различных предметных областях, тогда
как стандартные методики представляют собой лишь РЕЗУЛЬТАТ подобной технологии.
Стандартные методики часто не адекватны
нашим условиям по своим решающим правилам (имеют очень низкую валидность), а значит
требуют адаптации даже при их использовании для тех целей, для которых они
предназначены.
Кроме того стандартные методики
создавались для решения вполне определенных задач, но в наших условиях часто
вынуждено используются для достижения других целей, т.к. специально
предназначенные для этого методики вообще отсутствуют. Но это бывает не всегда
оправданным и в любом случае требует обоснования (которое также обычно
отсутствует).
Естественно, Система может быть с
успехом применена в областях, для которых подобные методы ранее не применялись,
вообще отсутствуют, или применявшиеся методики еще не стандартизированы.
Не требует комментариев также широко
распространенная в России практика рассекречивания решающих правил и способов интерпретации
стандартных методик тестирования на различных факультетах и курсах прикладной
психологии, что делает их применение для реальных исследований совершенно
методологически неоправданным, т.к. всем желающим уже известно
как на них отвечать, чтобы получить заранее необходимые результаты. Практически
это означает, что большинство стандартных методик могут использоваться (у нас и
в настоящее время) только в качестве учебных пособий. Естественно, это нарушает
и авторские права разработчиков этих тестов, т.к. лишает
их потенциальной прибыли, на которую те, возможно, рассчитывали, когда разрабатывали
свои тесты.
Для пользователей предлагаемой системы
все эти проблемы автоматически и корректным образом снимаются.
Системы обработки статистической
информации, работающие на частотах признаков и дающие на основе этого
процентные отношения ответивших положительно или отрицательно на те или иные
вопросы анкеты строго говоря относятся к другому классу систем и не должны
сопоставляться с системой “ЭЙДОС-
Таким образом она просто автоматизирует
БОЛЬШЕ, чем статистические системы “с частотами и процентами”, т.е.
предоставляет специалисту по интерпретации “менее сырой” и более обработанный,
более пригодный для аналитического исследования и принятия решений КОЛИЧЕСТВЕННЫЙ
материал там, где обычно господствовали интуитивно-неформализуемые оценки
экспертов.
В то же время необходимо подчеркнуть,
что предлагаемая система позволяет использовать результаты тестирования,
проведенного с использованием стандартных тестов, для сбора
ИСХОДНОЙ информации об объектах, предъявляемых системе как в режиме обучения,
так и в режиме распознавания, а также ДЛЯ
ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ стандартного тестирования.
Итак, на этапе обучения универсальная система
распознавания образов количественно определяет значимость
личностных свойств, выявляемых с использованием стандартных методик, для
решения задачи классификации тестируемых по заданным классам распознавания, а на этапах
распознавания и анализа результатов позволяет дать более развернутую, разностороннюю
и углубленную характеристику распознаваемых объектов и эталонных описаний
классов распознавания с точки зрения различных подходов психологии и социологии.
Таким образом предлагаемая
универсальная система распознавания образов позволяет на высоком методологическом
уровне корректно решить задачу расширения области применения стандартных
методик тестирования, их своеобразной “привязки” или
адаптации для решения задач тестирования и диагностики в любой предметной
области, исключить из этого процесса субъективизм и произвол. Сейчас же, чаще
всего, после проведения стандартного тестирования, начинается неформализованная “магия” интерпретации его результатов, в
результате которой психолог пытается дать ответ, каким образом полученные
результаты проливают свет на решение тех вопросов, ради решения которых
заказчик и оплачивал всю работу.
3.5.
ИССЛЕДОВАНИЕ ДИНАМИКИ И ТЕРРИТОРИАЛЬНЫХ ЗАВИСИМОСТЕЙ
Так как обучение Системы может
проводиться периодически и в различных регионах, то могут исследоваться
территориальные и динамические зависимости эталонных описаний классов
распознавания (а не только различия в процентах ответов на
те или иные вопросы), что представляет специальный интерес.
3.6.
ПРИМЕНЕНИЕ СИСТЕМЫ “ЭЙДОС” ВО ВЗАИМОДЕЙСТВИИ С СИСТЕМОЙ
WINDOWS
Система Windows и системы, работающие в
среде Windows, предоставляют своим пользователям чрезвычайно большое
разнообразие различных ценных возможностей. Не воспользоваться этими возможностями
было бы крайне неразумно.
Естественно, для этого с технической
точки зрения необходимо прежде всего обеспечить обмен данными между системами
“ЭЙДОС” и Windows. Существует всего два направления передачи данных:
|
|
“ЭЙДОС” |
® |
Windows; |
|
|
Windows |
® |
“ЭЙДОС”. |
Система “ЭЙДОС” генерирует три основных
видов файлов:
текстовые файла стандарта: “текст MS
DOS”;
графические файлы в стандарте “PCX”;
файлы баз данных в стандарте “DBF dBase
IV”.
Данные во всех этих стандартах легко
могут быть загружены и использованы следующими приложениями Windows:
MS DOS и PCX - текстовым редактором
WinWord
PCX - графическим редактором
PaintBrash;
DBF - электронными таблицами Excel.
Excel позволяет генерировать различные
графические диаграммы по данным баз данных, полученных из системы “ЭЙДОС”, и
передавать эти диаграммы в Winword для отчетов.
Кроме того, Excel позволяет производить
различные расчеты в электронных таблицах, которые затем могут быть записаны в
стандарте DBF dBase IV и с помощью простой программы (которую, однако,
необходимо разработать, например, на Clipper, Fox или dBase) преобразованы в
стандарты системы “ЭЙДОС”. Это позволяет организовать в системе “ЭЙДОС”
обработку данных, которые накапливались в Excel.
3.6.1. ПЕРЕДАЧА ТЕКСТОВЫХ И
ГРАФИЧЕСКИХ ФОРМ ИЗ “ЭЙДОС” В WINWORD
Система “ЭЙДОС” генерирует 42 вида
текстовых форм в стандарте “текст MS DOS”, которые записываются в поддиректории
TXT в виде TXT-файлов. Эти файлы могут быть загружены редактором WinWord и
записаны уже как DOC-файлы (файлы WinWord).
Для того, чтобы эти формы имели
нормальный вид необходимо установить для таблиц шрифт Courier New Cyr нужного
кегля, а также выбрать лист книжный или журнальный. Система “ЭЙДОС”
обеспечивает автоматическое листование текстовых форм для удобства вывода на
лазерный принтер, причем обеспечивается настройка на тип принтера. Подробнее об
этом говорится далее в разделе 2.1.7.5.
Как уже упоминалось выше, система
“ЭЙДОС” генерирует PCX-файлы 44-х различных видов двухмерных и трехмерных
графических форм. Эти формы записываются в виде PCX-файлов (16 цветов, 640х480
пикселов) в поддиректории директории PCX, которая создается системой “ЭЙДОС” в
текущей директории (т.е. в той, в которой она работает). Эти файлы также могут
быть непосредственно загружены редактором WinWord как рисунок и вставлены в заранее
созданный кадр или в ячейку таблицы.
3.6.2. ПЕРЕДАЧА ГРАФИЧЕСКИХ ФОРМ
ИЗ “ЭЙДОС” В PAINTBRASH
PCX-файлы, созданные системой “ЭЙДОС” могут
непосредственно загружаться графическим редактором PaintBrash, в котором их
можно редактировать.
3.6.3. ПЕРЕДАЧА БАЗ ДАННЫХ ИЗ
“ЭЙДОС” В EXCEL
Excel позволяет непосредственно
загрузить любую базу данных системы “ЭЙДОС”, но наибольший смысл это имеет делать
с базой INF.DBF, в которой хранятся обобщенные образы классов распознавания и
признаков. Представляют интерес также:
база Perc.dbf, содержащая условные
процентные распределения, т.е., например, проценты положительно ответивших на
некоторый вопрос от числа респондентов, относящихся к данной категории (по всем
вопросам и категориям);
информационные портреты классов
(Port_obj.dbf);
информационные портреты признаков
(Port_prp.dbf);
базы кластерного анализа (Klas_obj.dbf
и Klas_prp.dbf) и др.
Данные этих и других баз данных системы
“ЭЙДОС” можно обрабатывать в Excel его средствами, в частности очень интересной
возможностью является использование мастера диаграмм для получения графических
иллюстраций.
3.6.4. СОЗДАНИЕ ГРАФИЧЕСКИХ
ДИАГРАММ В EXCEL И ИХ ПЕРЕДАЧА В WINWORD И PAINTBRASH
Excel имеет великолепные графические
возможности, однако существует целый ряд причин, по которым в ряде случаев
применение графической подсистемы “ЭЙДОС” является предпочтительным:
многие формы, генерируемые системой
“ЭЙДОС” вообще не могут быть непосредственно получены из баз данных системы;
эти формы содержат такое оформление,
которое или практически невозможно, или довольно трудоемко сделать в Excel;
система “ЭЙДОС” работает и на
компьютерах, на которых или не может быть установлена или отсутствует система
Windows и Excel;
Excel требует от пользователя умения
загружать базы данных системы “ЭЙДОС”, строить по ним диаграммы и передавать их
через буфер обмена в WinWord для использования в отчете “как есть” или в
PaintBrash для редактирования. Это значит, что все же для многих пользователей
будет проще непосредственно воспользоваться графическими формами системы
“ЭЙДОС”.
Однако для более квалифицированных
пользователей несомненно имеет смысл освоить технологию, о которой говориться в
п.4. Дело в том, что Excel позволяет отобразить по крайней мере в 14 различных
графических видах любую строку или группу строк любых баз данных системы
“ЭЙДОС”. Это открывает практически неограниченные возможности по графическому
отображению результатов анализа, проведенного с помощью системы “ЭЙДОС”.
Графические формы безупречны, но требуют дополнительного пояснения в тексте
(что обозначают строки и столбцы диаграмм и т.п.).
Опишем поэтапно эту технологию.
3.6.4.1.
ЗАГРУЗКА В EXCEL БАЗ ДАННЫХ СИСТЕМЫ “ЭЙДОС”
Запустить систему Windows и Excel. В
меню “Файл” выбрать пункт “Открыть”. Появится окно выбора директории. Перейти в
текущую директорию системы “ЭЙДОС”. В
списке “Тип файла” выбрать “Файлы dBase (DBF)”. В левом окне появится список
файлов баз данных. Выбрать курсором нужную базу и щелкнуть на кнопке OK. База
сразу будет загружена в Excel.
После этого целесообразно сохранить ее
в формате Excel выбрав в меню “Файл” пункт “Сохранить как...”, а затем задав
нужную директорию и списке “Тип файла” указав тип “Рабочая книга Microsoft
Excel.
3.6.4.2.
ПОСТРОЕНИЕ ГРАФИЧЕСКИХ ДИАГРАММ В EXCEL
Для удобства просмотра загруженной базы
данных на экране можно отметить ее всю целиком блоком нажав клавиши Alt+A, а
затем уменьшив ширину столбца до минимальной, при которой числа видны в
выбранном формате. Можно также уменьшить количество разрядов после запятой,
используя кнопку “Уменьшить разрядность” и использовать уменьшенный масштаб отображения
на экране.
После этого с помощью мыши выделить
блоком тот фрагмент базы данных, который Вы хотели бы отобразить в графическом
виде. Это может быть, например, строка или часть строки, столбец или часть
столбца, любой прямоугольный фрагмент таблицы.
Затем с помощью мыши нажать на кнопку
“Мастер диаграмм”. Курсор примет вид маленькой диаграммы, которую Вы можете
переместить в любую часть экрана и нажать левую кнопку мыши. Сразу же в этом
месте появиться рамка с графической диаграммой, принятой по умолчанию. Кроме
того появится меню управления типом диаграммы. Развернув список возможных
вариантов диаграмм Вы можете выбрать любой из них. Кроме того можно изменить
положение и размер созданного Вами окна с диаграммой, работая с ее рамкой. При
увеличении размера появляются более подробные надписи по осям координат.
Щелкнув мышью на диаграмме дважды, Вы получаете возможность редактировать ее
выбирая различные цвета ее фрагментов изображения и фона и т.д.
Аналогично Вы можете сделать сразу
несколько диаграмм по различным фрагментам загруженной базы данных.
После построения диаграмм файл надо еще
раз записать, выбрав в меню “Файл” пункт “Сохранить” (или нажав Ctrl+S).
3.6.4.3.
ПЕРЕДАЧА ГРАФИЧЕСКИХ ДИАГРАММ ИЗ EXCEL В WINWORD
Эта операция осуществляется через буфер
обмена, т.е. часть оперативной памяти, которая доступна всем приложениям
Windows.
Чтобы поместить графическую диаграмму в
буфер обмена необходимо щелкнуть мышью один раз на диаграмме, после чего ее
рамка активизируется. После этого в меню “Правка” необходимо выбрать пункт
“Вырезать”, при этом диаграмма на экране исчезнет. Но более удобно
воспользоваться кнопкой “с ножницами”.
Примечание:
Может показаться, что лучше выбрать пункт меню “Копировать”, однако при этом
будет скопирована в буфер обмена вся база данных и диаграмма, либо выделенный
блоком фрагмент базы данных, но не одна диаграмма, как нам надо.
После этого необходимо выйти из Excel,
нажав клавиши Alt+F4. При вопросе системы записать ли измененный файл, надо
выбрать “Нет”, чтобы сохранить на диске вариант файла с диаграммами.
Затем надо сразу загрузить WinWord а
затем либо в меню “Вставка” создать кадр, либо нажав кнопку “Вставка таблицы”
вставить в текст таблицу. Потом в меню “Правка” выбрать пункт “Вставить”, или,
что удобнее, нажать на кнопку “с портфельчиком”. В результате в кадре или
выбранной ячейке таблицы появится графическая диаграмма из Excel, отображающая
часть базы данных системы “ЭЙДОС”.
Приведенные ниже диаграммы вставлены в
текст работы именно по описанной технологии. Для того, чтобы в ячейке таблицы
была возможность сделать надписи, необходимо перед тем, как поместить туда
диаграмму несколько раз нажать в ячейке Enter для создания пустых строк. Если
перед выводом диаграммы или после этого скорректировать разрядность отображаемых
данных, ширину столбцов с надписями или сами надписи, то соответствующие изменения
сразу же произойдут и в диаграмме.
|
ПРОФИЛИ
ПРИЗНАКОВ
|
КОНСТРУКТ
“ПРОИСХОЖДЕНИЕ”
|
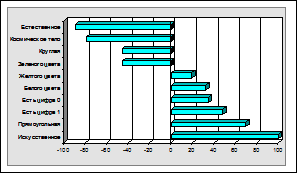
3.6.4.4.
ПЕРЕДАЧА ГРАФИЧЕСКИХ ДИАГРАММ ИЗ EXCEL В PAINTBRASH
Эту операцию выполняют тогда, когда
необходимо скорректировать само изображение графической диаграммы, используя
растровую графику, т.е. практически вообще без ограничений.
Данная операция осуществляется
совершенно аналогично передаче изображения в WinWord, с той разницей, что
вставка изображения осуществляется после загрузки графического редактора
PaintBrash (в меню “Редактирование” пункт “Вставка”).
После вставки изображения оно
появляется в поле графического редактора в блоке, положение которого можно
изменить просто нажав и удерживая клавишу мыши и перемещая ее таким образом,
чтобы освободить место, например, для надписей (легенды). При этом необходимо
учитывать, что часть изображения, закрываемая панелью инструментов или палитрой
не сохраняется, поэтому перед осуществлением вставки и сдвига диаграммы
необходимо сначала убрать панель и палитру в меню “Вид” щелкнув на пунктах
“Панель инструментов” и “Палитра”. Если что-то получилось не так, достаточно
просто выйти из PaintBrash без сохранения файла, опять войти в PaintBrash и
повторить операцию вставки, т.к. диаграмма сохраняется в буфере обмена.
После корректировки изображения
необходимо записать его в меню “Файл” “Сохранить как...” в виде PCX-файла (или
BMP), для последующего использования в WinWord или распечатки.
3.6.5. ПРИМЕНЕНИЕ EXCEL ДЛЯ
СОЗДАНИЯ СИСТЕМ ОКРУЖЕНИЯ СИСТЕМЫ “ЭЙДОС-6.2”
В разделе 2.1.1.3 пункте “Использование
стандартных методик” уже упоминалось о возможности создания с помощью системы
“ЭЙДОС” двухступенчатых тестов, т.е. тестов, в которых в качестве признаков
объектов выступают так называемые “вторичные параметры”, получающиеся в
результате определенной математической обработки непосредственно фиксируемых
“первичных параметров”.
В качестве примеров систем окружения,
предназначенных для генерации вторичных параметров, можно привести системы “ЭЙДОС-фонд” и система “ЭЙДОС-Y“,
описанные в разделах 3.1.2 и 3.1.3 данной работы.
Система “ЭЙДОС-фонд” представляет собой программный
интерфейс между биржевыми базами данных, содержащими первичную информацию о
торгах, и специально разработанным приложением системы “ЭЙДОС-
Система “ЭЙДОС-Y“
представляет собой программный интерфейс между стандартными психологическими
тестами, оперирующими непосредственно ответами респондентов на вопросы, и
приложениями системы “ЭЙДОС-
Как показывает опыт, довольно часто
данные об объектах анализа накапливаются в базах данных Excel.
Используя возможность производить в
Excel различные расчеты по накапливаемым данным, можно организовать
непосредственную генерацию в Excel баз данных обучающей выборки системы
“ЭЙДОС”, а именно:
базы заголовков анкет обучающей выборки
ObInfZag.dbf;
базы кодов признаков анкет обучающей
выборки ObInfKpr.dbf.
Автору представляется наиболее
целесообразным организовать расчет данных для этих баз на двух отдельных
листах, так чтобы каждая строка соответствовала одной анкете и номер строки
соответствовал номеру анкеты.
Аналогично, на Excel можно подготовить
листы вторичных параметров для распознаваемого объекта (объектов) на основе
введенных первичных данных, для баз данных распознаваемой выборки RsAnkZag.dbf
(заголовки) и RsAnkKpr.dbf (признаки).
Эти листы затем могут быть записаны в
стандарте DBF dBase IV и с помощью простой программы (которую, однако,
необходимо написать, например, на Clipper, Fox или dBase) преобразованы в
стандарты системы “ЭЙДОС”.
Это позволяет организовать в системе
“ЭЙДОС” обработку данных, которые накапливались в Excel, по технологии,
полностью исключающей ручную подготовку вторичных параметров, ручное
кодирование и ручной ввод данных в систему “ЭЙДОС”. Следовательно, на Excel могут быть созданы эффективные
приложения, являющиеся системами окружения для системы “ЭЙДОС-
Таким образом, система Windows и ее
приложения являются средой, существенно повышающей возможности и эффективность
применения системы “ЭЙДОС”.
3.7. ИНСТАЛЛЯЦИЯ И НАСТРОЙКА
СИСТЕМЫ
Различается лицензионная и
пользовательская инсталляция системы “ЭЙДОС”
В системе предусмотрена общая
настройка, настройка цветов пользовательского интерфейса и настройка печати
текстовых форм.
3.7.1.
ЛИЦЕНЗИОННАЯ ИНСТАЛЛЯЦИЯ
Система “ЭЙДОС-
После лицензионной инсталляции пользователь может сделать
архивы файлов системы и в дальнейшем осуществлять пользовательские инсталляции.
3.7.2.
ПОЛЬЗОВАТЕЛЬСКИЕ ИНСТАЛЛЯЦИИ
Пользовательские инсталляции - это установка системы на
компьютер, где уже была осуществлена лицензионная инсталляция.
Это процесс осуществляется просто путем копирования файлов
системы в новую директорию из директории, в которой была осуществлена
лицензионная инсталляция, или путем восстановления из архивов лицензионной
инсталляции данного компьютера, которые могут храниться на гибких дисках.
3.7.3.
ОБЩАЯ НАСТРОЙКА ПАРАМЕТРОВ СИСТЕМЫ В БАЗЕ ДАННЫХ SETUP.DBF
База данных SETUP.DBF создается системой автоматически при
первом запуске со следующими параметрами по умолчанию:
СТРУКТУРА SETUP.DBF
|
№ |
Имя |
Значение по умолчанию |
Смысл параметра |
|
1
|
N_field |
11 |
Количество полей
для кодов признаков в базе данных OBINFKPR.DBF |
|
2
|
N_prp |
12 |
Максимальное
количество градаций на одну шкалу, т.е. максимальное количество вариантов
ответов на вопрос PRIZ_OB.DBF |
|
3
|
N_obj |
20 |
Максимальное
количество кодов классов распознавания в анкете обучающей выборки
OBINFZAG.DBF |
|
4
|
Shrift |
F |
В версиях системы
“ЭЙДОС” до 5.2 этот параметр означал включение (T) или не включение (F) в
текст выходных форм ESC-последовательностей управления принтерами в стандарте
EPSON |
|
5
|
Color |
15 |
Номер цвета для
фона графических выходных форм |
|
6
|
Sort |
T |
Флаг сортировки
кодов классов распознавания в анкетах обучающей выборки при нажатии клавиши
TAB или при их автоматическом формировании |
|
7
|
Lag |
50 |
Величина
“скользящего среднего” в пикселах для сглаживания распределения частот
ответов Пирсона |
|
8
|
DelayArc |
0 |
Количество дней,
через которое делать архив баз данных при запуске системы (0 - не делать
архива вообще) |
В дальнейшем квалифицированный пользователь может изменить
эти параметры с помощью программы DBU.EXE, входящей в комплект поставки, а
затем в сервисной подсистеме (F7) запустить режим “Создание всех баз данных”. В
результате вышеперечисленные базы данных будут пересозданы с новыми
структурами, соответствующими заданным значениям параметров.
Так можно настроить систему “ЭЙДОС” таким образом, что она
будет обеспечивать ввод и обработку, например, 100 вариантов ответов на
вопросы. Или сможет обрабатывать анкеты обучающей выборки, содержащие заданное
(например, 100) количество логических анкет, т.е. кодов классов распознавания.
Однако без необходимости не следует задавать слишком большие
значения этих параметров, т.к. это уменьшает эффективность использования
внешней памяти и других ресурсов системы.
3.7.4.
НАСТРОЙКА ЦВЕТОВ В БАЗЕ ДАННЫХ SETCOLOR.DBF
База данных SETCOLOR.DBF создается системой автоматически
при первом запуске со следующими параметрами по умолчанию:
БАЗА ДАННЫХ
SETCOLOR.DBF
|
№ |
Название цвета |
Обозначение |
Красный |
Зеленый |
Синий |
|
1.
|
Черный |
N |
0 |
0 |
0 |
|
2.
|
Синий |
B |
0 |
0 |
42 |
|
3.
|
Зеленый |
G |
0 |
42 |
0 |
|
4.
|
Голубой |
GB |
0 |
42 |
42 |
|
5.
|
Красный |
R |
42 |
0 |
0 |
|
6.
|
Сиреневый |
RB |
42 |
0 |
42 |
|
7.
|
Коричневый |
RG |
42 |
21 |
0 |
|
8.
|
Белый |
W |
60 |
60 |
50 |
|
9.
|
Темносерый |
N+ |
21 |
21 |
21 |
|
10. |
Светлосиний |
B+ |
21 |
21 |
63 |
|
11. |
Светлозеленый |
G+ |
21 |
63 |
21 |
|
12. |
Светлоголубой |
GB+ |
21 |
63 |
63 |
|
13. |
Яркокрасный |
R+ |
63 |
21 |
21 |
|
14. |
Светлосереневый |
RB+ |
63 |
21 |
63 |
|
15. |
Желтый |
RG+ |
63 |
63 |
21 |
|
16. |
Яркобелый |
W+ |
63 |
63 |
63 |
Числа от 0 до 63 означают яркость лучей “RGB”: красного,
зеленого и синего (0 - луч погашен, 63 - луч имеет максимальную яркость).
Изменяя яркости этих трех лучей пользователь может изменять фактический цвет на
экране того цвета, который указан в графе “Название цвета”. Легко видеть, что
каждый из 16 базовых цветов имеет 64х64х64=262144 вариантов отображения на
экране. Этого вполне достаточно для цветовой настройки пользовательского интерфейса
системы “ЭЙДОС-
3.7.5.
НАСТРОЙКА ПАРАМЕТРОВ ПЕЧАТИ ВХОДНЫХ И ВЫХОДНЫХ ФОРМ В БАЗЕ ДАННЫХ SET-TEXT.DBF
База данных SET-TEXT.DBF создается системой автоматически
при первом запуске (и при несоотвествии параметров новой версии с текущей базой
данных) со следующими параметрами по умолчанию:
ПАРАМЕТРЫ ФОРМАТИРОВАНИЯ ВЫХОДНЫХ
ФОРМ ДЛЯ РЕДАКТОРА WINWORD
|
1 |
Abs.txt |
65 |
6 |
АЛЬБОМНЫЙ=> |
Матрица абсолютных частот |
|
2 |
Anketa.txt |
59 |
10 |
Книжный |
Анкета |
|
3 |
AnkObKod.txt |
0 |
10 |
Книжный |
Анкеты обучающей выборки с кодами признаков |
|
4 |
AnkObNam.txt |
0 |
10 |
Книжный |
Анкеты обучающей выборки с наим.признаков |
|
5 |
AnkObZer.txt |
0 |
10 |
Книжный |
Анкеты обучающей выборки - пустографки |
|
6 |
Ank.txt |
0 |
9 |
Книжный |
Распределение анк.об.выб.по классам распознавания |
|
7 |
Arep_it.txt |
65 |
9 |
Книжный |
Итог ремонта обучающей выборки (взвешивания данных) |
|
8 |
Arep_zad.txt |
53 |
8 |
АЛЬБОМНЫЙ |
Задание на ремонт обучающей выборки - част.распр.ГС |
|
9 |
Dost_ank.txt |
53 |
8 |
АЛЬБОМНЫЙ |
Оценка анкет об.выборки по =шкале лживости= |
|
10 |
Inf.txt |
65 |
6 |
АЛЬБОМНЫЙ=> |
Матрица информативностей |
|
11 |
Ipo_####.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Информационный портрет объекта-класса с кодом #### |
|
12 |
Ipo_blf.txt |
59 |
10 |
Книжный |
Задание на формирование инф.портретов классов |
|
13 |
Ipo_blz.txt |
59 |
10 |
Книжный |
Бланк задания на формирование инф.портретов классов |
|
14 |
Ipp_####.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Информационный портрет признака с кодом #### |
|
15 |
Ips_obi.txt |
59 |
10 |
Книжный |
Обучающая база данных дискрипторной ИПС |
|
16 |
Ips_rsi.txt |
59 |
10 |
Книжный |
Распознаваемая база данных дискрипторной ИПС |
|
17 |
Klas_obj.txt |
74 |
8 |
Книжный |
Кластеры и конструкты объектов (классов) |
|
18 |
Klas_prp.txt |
74 |
8 |
Книжный |
Кластеры и конструкты признаков |
|
19 |
Matr_sf.txt |
43 |
10 |
АЛЬБОМНЫЙ |
Задание и сводная форма матриц сопряженности X^2 |
|
20 |
Matr_sp1.txt |
48 |
9 |
АЛЬБОМНЫЙ |
Одномерные частотные распределения X^2 |
|
21 |
Matr_sp2.txt |
0 |
6 |
АЛЬБОМНЫЙ |
Двухмерные частотные распределения X^2 |
|
22 |
Matr_sz.txt |
0 |
10 |
Книжный |
Бланк задания на формирование матриц сопряженности |
|
23 |
Object.txt |
84 |
7 |
Книжный |
Справочник классов распознавания |
|
24 |
Objs_int.txt |
59 |
10 |
Книжный |
Интерпретация инф.портретов классов (объектов) |
|
25 |
Opt_ank.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Вопросы в порядке убывания селективной силы |
|
26 |
Opt_obj.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Классы в порядке убывания сформированности |
|
27 |
Perc.txt |
65 |
6 |
АЛЬБОМНЫЙ=> |
Матрица условных процентных распределений |
|
28 |
Port_obj.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Информационные портреты классов (объектов) |
|
29 |
Port_prp.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Информационные портреты признаков |
|
30 |
Priz_int.txt |
59 |
10 |
Книжный |
Справочник интерпретации первичных признаков |
|
31 |
Priz_ob.txt |
59 |
7 |
АЛЬБОМНЫЙ |
Справочник обобщенных признаков (шкал, вопросов) |
|
32 |
Priz_per.txt |
84 |
7 |
Книжный |
Справочник первичных признаков (градаций, ответов) |
|
33 |
Rasp_it1.txt |
59 |
7 |
АЛЬБОМНЫЙ |
Итоговая форма по результатам распознавания N°1 |
|
34 |
Rasp_it2.txt |
59 |
7 |
АЛЬБОМНЫЙ |
Итоговая форма по результатам распознавания N°2 |
|
35 |
RspKart1.txt |
0 |
10 |
АЛЬБОМНЫЙ |
Карта результатов идентификации инф.источника |
|
36 |
RspKart2.txt |
0 |
9 |
Книжный |
Карта результатов идентификации инф.источников |
|
37 |
RsAnkKod.txt |
0 |
10 |
Книжный |
Анкеты распознаваемой выборки с кодами ответов |
|
38 |
RsAnkNam.txt |
0 |
10 |
Книжный |
Анкеты расп.выборки с наименованиями ответов |
|
39 |
RsAnkZer.txt |
0 |
10 |
Книжный |
Анкеты-пустографки расп.выборки для заполнения |
|
40 |
Stat_obi.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Статистическая характеристика обучающей выборки |
|
41 |
ValidSys.txt |
65 |
6 |
АЛЬБОМНЫЙ |
Отчет по интегральной и дифференциальной валидности |
|
42 |
Err_obi.txt |
65 |
9 |
Книжный |
Протокол ошибок обучающей выборки |
|
43 |
Merl_att.txt |
50 |
14 |
Книжный |
Наименования уровней иерархии признаков |
|
44 |
Merl_obj.txt |
50 |
14 |
Книжный |
Наименования уровней иерархии классов |
|
45 |
Ipp_blf.txt |
59 |
10 |
Книжный |
Задание на формирование инф.портретов признаков |
|
46 |
Ipp_blz.txt |
59 |
10 |
Книжный |
Бланк задания на формиров-е инф.портретов признаков |
|
47 |
Korr_obj.txt |
59 |
10 |
Книжный |
Корреляционная матрица классов |
|
48 |
Korr_att.txt |
59 |
10 |
Книжный |
Корреляционная матрица признаков |
|
49 |
Rel_obj.txt |
59 |
10 |
Книжный |
Матрица связей информационных портретов классов |
|
50 |
Rel_att.txt |
59 |
10 |
Книжный |
Матрица связей информационных портретов признаков |
Данная форма играет роль памятки для пользователя-оператора,
который выводит формы системы на принтере.
Более опытный пользователь должен предварительно подобрать
размер шрифта и тип листа для каждой формы, учитывая требования к виду форм и характеристики своего принтера, и
занести найденные параметры в базу данных SET-TEXT.DBF с использованием программы
DBU.EXE или любой другой, позволяющей корректировать DBF-файлы.
Если удалить SET-TEXT.DBF и запустить систему, то эта база
будет создана с параметрами для HP LJ IIIP, который принят в системе “ЭЙДОС”
как принтер по умолчанию.
Наименования файлов для выходных форм квалифицированный
пользователь также, при желании, может поменять на другие.
Перед печатью выходных форм для большего удобства в работе
рекомендуем задать в редакторе WINWORD шрифт Courier New Cyr и наиболее часто
встречающийся размер шрифта (кегль) ПО УМОЛЧАНИЮ в меню *ФОРМАТ-ШРИФТ*.
Если рекомендуется тип страницы: АЛЬБОМНАЯ=> , то надо
немного уменьшить правое поле листа.