ГЛАВА 6. ПРИМЕНЕНИЕ АСК-АНАЛИЗА И ИНТЕЛЛЕКТУАЛЬНОЙ
СИСТЕМЫ "ЭЙДОС" ДЛЯ РЕШЕНИЯ В ОБЩЕМ ВИДЕ
ЗАДАЧИ ИДЕНТИФИКАЦИИ ЛИТЕРАТУРНЫХ
ИСТОЧНИКОВ И АВТОРОВ ПО СТАНДАРТНЫМ,
НЕСТАНДАРТНЫМ И НЕКОРРЕКТНЫМ
БИБЛИОГРАФИЧЕСКИМ ОПИСАНИЯМ
Проблемы идентификации авторов и
литературных источников по библиографическим описаниям в списках литературы в
последнее время приобретает все большее значение научное и практическое
значение. Это связано в частности с политикой Министерства образования и науки
Российской Федерации в области оценки качества результатов научной
деятельности, которая предполагает использование количества ссылок на
публикации авторов и индекса Хирша. В России создаются соответствующие
аналитические инструменты и сервисы для оценки результатов научной деятельности,
функционально аналогичные известным зарубежным библиографическим базам данных
Scopus, Web of Science и другим. В настоящее время наиболее известным в России
сервисом подобного назначения является Российский индекс научного цитирования
(РИНЦ): http://elibrary.ru/. Однако, как показывает опыт, часто ссылки
в списках литературы публикаций сделаны с нарушением ГОСТ 7.1—2003, а
также с ошибочными выходными данными, например, неверно указанными номерами
страниц, наименованием издательства и т.п. На практике это приводит к тому, что
программная система библиографической базы не может определить, на какую работу
сделана данная ссылка и кто авторы этой работы. В результате для этих авторов
теряется цитирование, что приводит к занижению их индексов Хирша и оценки
результатов их научной деятельности руководством. Понятно, что эти отрицательные
последствия желательно преодолеть. Данная работа посвящена изложению подхода,
который позволяет решить эту проблему путем применения АСК-анализа и
интеллектуальной системы «Эйдос», представляющих собой современную
инновационную интеллектуальную технологию (готовую к внедрению).
6.1. Описание проблемы и идея ее решения
Проблемы идентификации авторов и литературных
источников по библиографическим описаниям в списках литературы в последнее
время приобретает все большее значение научное и практическое значение. Это
связано в частности с политикой Министерства образования и науки Российской
Федерации в области оценки качества результатов научной деятельности, которая
предполагает использование количества ссылок на публикации авторов и индекса
Хирша. В России создаются соответствующие аналитические
инструменты и сервисы для оценки результатов научной деятельности,
функционально аналогичные известным зарубежным библиографическим базам данных
Scopus, Web of Science и другим. В настоящее время наиболее известным в России
сервисом подобного назначения является Российский индекс научного цитирования
(РИНЦ): http://elibrary.ru/. Однако, как
показывает опыт, часто ссылки в списках литературы публикаций сделаны с
нарушением ГОСТ 7.1—2003, а также с
ошибочными выходными данными, например, неверно указанными номерами страниц,
наименованием издательства и т.п. На практике это приводит к тому, что
программная система библиографической базы не может определить на какую работу,
из находящихся в ней, сделана данная ссылка и кто авторы этой работы. В
результате для этих авторов теряется цитирование, что приводит к занижению их
индексов Хирша и оценки результатов их научной деятельности чиновниками. Понятно,
что эти отрицательные последствия желательно преодолеть.
Традиционно данная проблема решается с помощью
алгоритма шинглов[1]. Данная работа посвящена
изложению идеи решения этой проблему путем применения Автоматизированного
системно-когнитивного анализа (АСК-анализ) и его программного инструментария –
интеллектуальной системы «Эйдос», которые представляют собой современную инновационную
интеллектуальную технологию (готовую к внедрению). В ней рассматривается алгоритм,
основанный на вычислении количества информации в словах
библиографической ссылки о том, что это ссылка на данную работу и данных
авторов, а также ценность слов для идентификации статей и авторов (т.е.
вариабельность количества информации в словах по работам и авторам).
Предлагаемый алгоритм имеет ряд отличий от алгоритма
шинглов, за счет чего может иметь определенные преимущества перед ним. Рассмотрим
эти различия подробнее.
Этапы алгоритма шинглов1,
которые проходит текст, подвергшийся сравнению:
– канонизация текста;
– разбиение на шинглы;
– вычисление хэшей шинглов;
– случайная выборка 84
значений контрольных сумм;
– сравнение, определение
результата.
Рассмотрим, каким образом реализуются или не
реализуются (т.к. в этом нет необходимости) подобные этапы в АСК-анализе и его
программном инструментарии – системе «Эйдос» (таблица 1):
Таблица 1 – Сравнение алгоритма шинглов и алгоритма
АСК-анализа, реализованного в системе «Эйдос»
|
Алгоритм
шинглов |
Алгоритм
АСК-анализа, реализованный в системе «Эйдос» |
|
Канонизация текста |
|
|
Канонизация текста приводит оригинальный
текст к единой нормальной форме.
Текст очищается от предлогов, союзов, знаков
препинания, HTML тегов, и прочего ненужного «мусора», который не должен участвовать в сравнении. В
большинстве случаев также предлагается удалять из текста прилагательные, так
как они не несут смысловой нагрузки. |
Так
как вычисляется количество информации в словах библиографической ссылки
о том, что это ссылка на данную работу и данных авторов, а также ценность
слов для идентификации статей и авторов (т.е. вариабельность количества
информации в словах по работам и авторам), то в этапе канонизации текста нет
необходимости. |
|
Также на этапе канонизации текста можно
приводить существительные к именительному падежу, единственному числу, либо
оставлять от них только корни. |
Лемматизация
текста[2]
на основе морфологического анализа, т.е. приведение слов к их исходной форме.
Это целесообразно, но в настоящее время не реализовано. |
|
Разбиение на шинглы |
|
|
Шинглы (англ. – «чешуйки») – выделенные
из работы подпоследовательности слов. Необходимо из сравниваемых текстов
выделить подпоследовательности слов, идущих друг за другом по 10 штук (длина
шингла). Выборка происходит внахлест, а не встык. Таким образом, разбивая
текст на подпоследовательности, мы получим набор шинглов в количестве равному
количеству слов минус длина шингла плюс один. |
Система
«Эйдос» обеспечивает использование в качестве признаков текста последовательностей
подряд идущих слов по 2, 3,…, N слов, т.е. шинглов, но это не имеет смысла
делать при решении проблемы идентификации текстов и авторов по нестандартным
и некорректным библиографическим описаниям, т.к. в них
как раз эти последовательности могут быть нарушены, что приведет к понижению
достоверности идентификации алгоритма шинглов. Кроме того использование
таких подпоследовательностей само требует затрат вычислительных ресурсов, а
также резко увеличивает количество признаков текста, размерность моделей и
время идентификации. |
|
Вычисление хэшей
шинглов |
|
|
Принцип алгоритма шинглов заключается в
сравнении случайной выборки контрольных сумм шинглов (подпоследовательностей)
двух текстов между собой. |
Тексты
сравниваются не по случайному подмножеству своих признаков, а по всем признакам, в качестве которых
выступают слова. Считается идентифицированными тот источник и те авторы, о
которых в словах ссылки содержится максимальное количество информации. Это
может обеспечить более высокую достоверность алгоритма. |
|
Проблема
быстродействия алгоритма |
|
|
Проблема алгоритма заключается в количестве
сравнений, ведь это напрямую отражается на производительности. Увеличение
количества шинглов для сравнения характеризуется экспоненциальным ростом операций, что критически отразится на
производительности. |
Проблема
алгоритма заключается в количестве сравнений, ведь это напрямую отражается на
производительности. Увеличение количества слов в библиографических ссылках,
используемых для сравнения, приводит к линейному
росту числа операций сравнения. |
Таким образом, есть надежда, что предлагаемый алгоритм
будет иметь более высокую достоверность и быстродействие, чем алгоритм шинглов.
6.2. Предыстория и задел для решения проблемы
идентификации текстов и авторов в АСК-анализе
и системе «Эйдос»
Автор на протяжении многих лет периодически
возвращался к проблематике атрибуции анонимных и псевдонимных текстов,
идентификации текстов и их авторов [1, 2]. С 2006 года на базе системы «Эйдос»
проводятся лабораторные работы, в которых изучается применение интеллектуальных
технологий для решения этих задач [3] (см. лаб.работы №1 и №6).
В новой версии системы «Эйдос-Х++» этой теме посвящена
лабораторная работа 3.02 (рисунок 1):
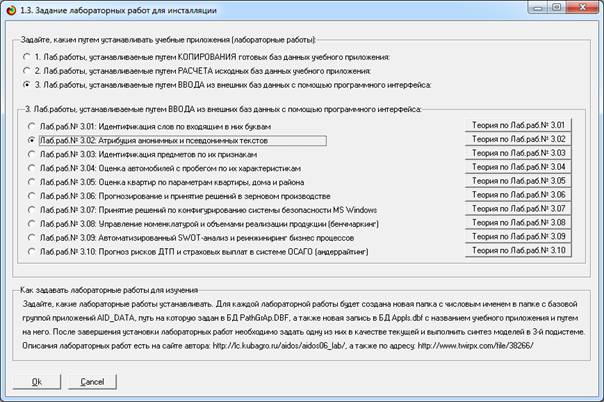
Рисунок 1. Экранная формы выбора лабораторной работы
3-го типа
На рисунке 2 приведен Help этой лабораторной работы:
Рисунок 2. Экранная формы Help лабораторной работы
3.02
Кроме того есть опыт анализ проблематики научного
журнала в динамике с использованием технологии обработки текстов в интеллектуальной
системе «Эйдос» [4].
6.3. Описание предлагаемого решения проблемы
6.3.1. Этапы АСК-анализа и
преобразование
исходных данных в информацию,
а ее в знания в системе "Эйдос"
АСК-анализ представляет собой современную
инновационную (т.е. полностью готовую к внедрению и использованию) широко и
успешно апробированную интеллектуальную технологию [5, 6, 7, 8].
АСК-анализ
включает следующие этапы:
1. Когнитивная структуризация предметной области
(неформализованный этап). На этом
этапе решается, что мы хотим прогнозировать и на основе чего. В нашей задаче мы
хотим прогнозировать продолжительность жизни пациента после перенесенного им
инфаркта на основе анализа эхокардиограммы.
2. Формализация предметной области. На этом этапе разрабатываются классификационные и
описательные шкалы и градации, а затем с их использованием исходные данные
кодируются и представляются в форме баз событий, между которыми могут быть
выявлены причинно-следственные связи.
3. Синтез и верификация моделей (оценка достоверности, адекватности). Повышение
качества модели. Выбор наиболее достоверной модели для решения в ней задач.
4. Решение задач идентификации и прогнозирования.
5. Решение задач принятия решений и управления.
6. Решение задач исследования моделируемой предметной
области путем исследования ее модели.
На рисунке 3 приведены автоматизированные в системе
«Эйдос» этапы АСК-анализа, которые обеспечивают последовательное повышение
степени формализации модели путем преобразования исходных данных в информацию,
а далее в знания:
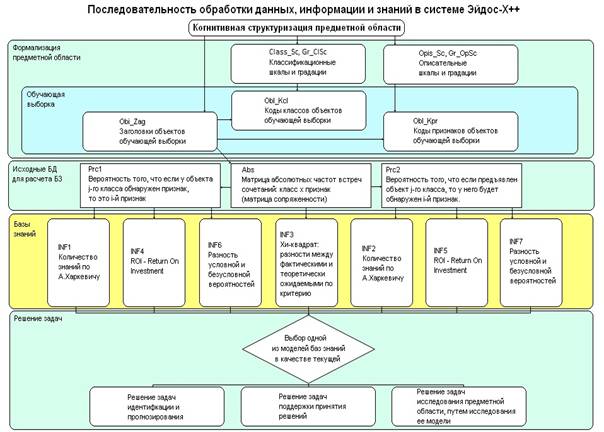
Рисунок 3. Этапы последовательного преобразования
данных в информацию, а ее в знания в системе "Эйдос"
Подробно этот процесс описан в работах [9, 10]. Суть
этого процесса в следующем:
1. Информация
рассматривается как осмысленные исходные данные.
2. Смысл,
согласно концепции Шенка-Абельсона [11] считается известным, когда выявлены
причинно-следственные связи.
3. Анализ –
это операция выявления смысла из исходных данных.
4. Причинно-следственные связи существуют не между элементами
исходных данных, а между реальными событиями, которые они отражают
(моделируют), т.е. причинно-следственные связи – это характеристика реальной
области, а не абстрактных моделей. Иначе говоря, анализ самих исходных данных
невозможен, а возможен только анализ событий, описанных этими исходными
данными.
5. Поэтому перед анализом исходных данных необходимо
предварительно преобразовать их в базы событий, т.е. в эвентологические базы.
6. Это преобразование осуществляется с помощью
справочников событий, факторов и их значений, т.е. с помощью классификационных
и описательных шкал и градаций, которые также необходимо разработать.
7. Формализация предметной области представляет собой
разработку справочников классификационных и описательных шкал и градаций и преобразование
с их помощью баз исходных данных в базы событий (т.е. обучающую выборку), и
является первым автоматизированным в системе «Эйдос» этапом АСК-анализа.
8. Затем следуют остальные перечисленные выше этапы
АСК-анализа:
– синтез и верификация моделей и выбор наиболее
достоверной из них;
– решение в ней задач идентификации, прогнозирования,
принятия решений и исследования предметной области, т.е. преобразование информации
в знания.
Этап синтеза и верификации моделей завершает процесс
анализа исходных данных и преобразования их в информацию, а ее в знания.
В АСК-анализе есть несколько режимов, обеспечивающих
решение задачи принятия решений для управления
или достижения целей, которая
представляет собой обратную задачу прогнозирования: это и режим 4.2.1,
позволяющий формировать информационные портреты классов, а также режим 4.4.8,
поддерживающий количественный автоматизированный SWOT и –PEST анализ, включая
построение SWOT и –PEST матриц и диаграмм [12], а также режим 4.4.10,
визуализирующий нейросетевую интерпретацию модели знаний системы «Эйдос» [13].
Эти режимы обеспечивают преобразование информации в знания, т.к. знания
представляют собой информацию, полезную для достижения целей, т.е. по сути технологию,
в частности ноу-хау [5]. Наличие цели является ключевым моментом для
преобразования информации в знания. А постановка целей (целеполагание) не
мыслима без мотивации, которая в настоящее время является слабо формализованным
этапом.
Итак, в процессе анализа
исходные данные представляются в форме базы событий, между которыми выявляются
причинно-следственные связи, и, таким образом, исходные данные преобразуются в
информацию, представляющую собой осмысленные данные (смысл есть знание причинно-следственных
связей), а затем информация используется для достижения целей (управления),
т.е. преобразуется в знания.
Формализация предметной области включает разработку
классификационных и описательных шкал и градаций и преобразование с их использованием
исходных данных (таблица 2) в обучающую выборку. Этот этап полностью автоматизируется программным интерфейсом системы «Эйдос»
с внешними табличными базами исходных данных (режим 2.3.2.2).
Но перед выполнением этого этапа АСК-анализа,
естественно, необходимо сначала скачать и установить систему «Эйдос».
6.3.2. Скачивание
и инсталляция системы «Эйдос»
Для скачивания и инсталляции системы «Эйдос»
необходимо по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm
открыть и выполнить следующую инструкцию[3]:
ИНСТРУКЦИЯ
по скачиванию и установке системы «Эйдос» (объем около 100 Мб)
|
Система не
требует инсталляции, не меняет никаких системных файлов и содержимого папок
операционной системы, 1. Скачать
самую новую на текущий момент полную версию системы «Эйдос-Х++» (около 100 Мб) с сайта разработчика
по ссылкам: 2.
Разархивировать этот архив в любую папку с правами на запись с коротким
латинским именем и путем доступа, . 3. Запустить
систему. Файл запуска: 4. Задать имя: 1 и пароль: 1 (потом их можно поменять в режиме 1.2). 5. Перед тем как запустить новый режим НЕОБХОДИМО ЗАВЕРШИТЬ предыдущий (Help можно не закрывать). Окна закрываются в порядке, обратном порядку их открытия. |
|
Разработана
программа: «
Если библиотеки (*.DLL) системы «Эйдос-Х++» расположены
в папке, на которую прописан путь поиска (скачиваются по п.1), то вместо
выполнения пунктов 1,2,3 можно просто запускать файл: «
При запуске программы
1. Программа
2. После завершения процесса скачивания появляется диалоговое окно с сообщением, что надо сначала разархивировать систему, заменяя все файлы (опция: «Yes to All» или «OwerWrite All»), и только затем закрыть данное окно.
3. Потом программа
4. После закрытия диалогового окна с инструкцией (см. п.2), происходит запуск обновленной версии системы «Эйдос» на исполнение.
5. Если Вы собираетесь работать с текстами, то необходимо скачать базу данных для лемматизации “Lemma.DBF” по ссылке: http://lc.kubagro.ru/Lemma.rar и разархивировать ее в папку с системой «Эйдос-Х++» (архив имеет размер около 10 Мб, сама база около 200 Мб). База для лемматизации сделана на основе словаря Зализняка и работы: https://habrahabr.ru/company/realweb/blog/265375/ Сейчас эта база входит в комплект поставки. Если Вы не собираетесь работать с текстами, то эта база не нужна и можно удалить ее и индексный массив Lemma.ntx из директории с системой. На работу остальных функций системы это не повилияет, а размер директории с системой заметно сократится.
Примечания: 1. Если 2. Если Вам не нужны лабораторные работы, то можно удалить папку: ..:\Aidos-X\AID_DATA\LabWorks\. На работу остальных функций системы это не повлияет, а размер директории с системой заметно сократится.
|
|
Лицензия: Автор отказывается от какой бы то ни было ответственности за Ваш выбор или не выбор системы «Эйдос» и последствия применения или не применения Вами системы «Эйдос». Проще говоря, пользуйтесь если понравилось, а если не понравилось – не пользуйтесь: решайте сами и сами же несите ответственность за Ваше решение. |
По этим ссылкам
всегда размещена наиболее полная на момент скачивания незащищенная от
несанкционированного копирования портативная (portable) версия системы (не
требующая инсталляции) с исходными текстами, находящаяся в полном
открытом бесплатном доступе (объем около 50 Мб). Обновление имеет
объем около 3 Мб.
Далее запускаем систему "Эйдос" из папки
"Aidos-X" файлом _aidos-x.exe. Система попросит ввести логин и пароль
(рисунок 9). Необходимо ввести: логин – 1, пароль – 1.
Далее запускаем систему "Эйдос" из папки
"Aidos-X" файлом _aidos-x.exe. Система попросит ввести логин и пароль
(рисунок 4).
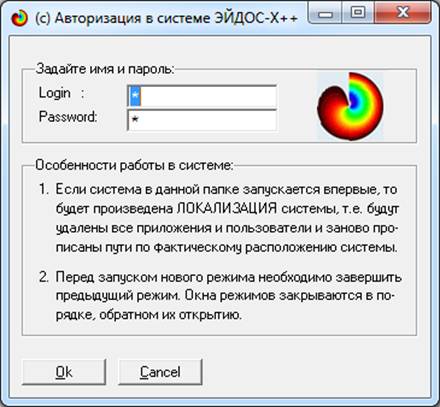
Рисунок 4. Экранная форма авторизации в системе
"Эйдос"
Здесь необходимо ввести: логин – 1, пароль – 1. В
результате откроется главное окно системы (рисунок 5):
Рисунок 5 – Главное окно системы "Эйдос"
В последующем имя и пароль можно изменить в режиме
1.2.
В качестве исходных данных для примера решения задачи
идентификации текстов и авторов, рассмотренного в данной работе, использована
выборка из баз данных Научного журнала КубГАУ [14, 4] за весь период его
существования с 2003 года по настоящее время (точнее по 100-й номер). За это
время в журнале издано 3949 статей.
Файл выборки организован следующим образом (таблица
2):
Таблица 2 – Исходные данные (фрагмент)
|
Объект |
Работа |
Автор |
Библиографическая
ссылка |
|
10301001 |
IDA10301001 |
Кацко_И_А,
Креймер_А_С |
Кацко И.
А. Принятие решения о структуре системы автономного энергоснабжения с использованием
когнитивного подхода / И. А. Кацко, А. С. Креймер // Политематический сетевой
электронный научный журнал Кубанского государственного аграрного университета
(Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. –
№01(001) С. 1 – 2. IDA [article ID]: 0010301001 – Режим доступа:
http://ej.kubagro.ru/2003/01/01.pdf, 0,063 у.п.л., импакт-фактор РИНЦ=0,346 |
|
10301002 |
IDA10301002 |
Богатырев_Н_И,
Креймер_А_С |
Богатырев
Н. И. Имитационное моделирование ветроэнергетической установки / Н. И. Богатырев,
А. С. Креймер // Политематический сетевой электронный научный журнал Кубанского
государственного аграрного университета (Научный журнал КубГАУ) [Электронный
ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 3 – 8. IDA [article ID]:
0010301002 – Режим доступа: http://ej.kubagro.ru/2003/01/02.pdf, 0,313
у.п.л., импакт-фактор РИНЦ=0,346 |
|
10301004 |
IDA10301004 |
Хисамов_Ф_Г |
Хисамов
Ф. Г. Методика оптимизации структуры перспективных аппаратных средств криптографической
защиты информации в автоматизированных системах управления / Ф. Г. Хисамов //
Политематический сетевой электронный научный журнал Кубанского государственного
аграрного университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2003. – №01(001) С. 9 – 15. IDA [article ID]: 0010301004 – Режим
доступа: http://ej.kubagro.ru/2003/01/04.pdf, 0,375 у.п.л., импакт-фактор
РИНЦ=0,346 |
|
10301005 |
IDA10301005 |
Луценко_Е_В |
Луценко
Е. В. Численный расчет эластичности объектов информационной безопасности на
основе системной теории информации / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2003. – №01(001) С. 16 – 27. IDA [article ID]: 0010301005 – Режим
доступа: http://ej.kubagro.ru/2003/01/05.pdf, 0,688 у.п.л., импакт-фактор
РИНЦ=0,346 |
|
10301006 |
IDA10301006 |
Федоренко_М_А |
Федоренко
М. А. Исследование порога целесообразности применения самолета АН-2 на
работах в аграрном секторе / М. А. Федоренко // Политематический сетевой
электронный научный журнал Кубанского государственного аграрного университета
(Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. –
№01(001) С. 28 – 40. IDA [article ID]: 0010301006 – Режим доступа:
http://ej.kubagro.ru/2003/01/06.pdf, 0,75 у.п.л., импакт-фактор РИНЦ=0,346 |
|
10301007 |
IDA10301007 |
Безродный_О_К,
Лойко_В_И |
Безродный
О. К. Система инвестиционного управления автодорожной отраслью региона / О.
К. Безродный, В. И. Лойко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. – №01(001) С. 41 –
54. IDA [article ID]: 0010301007 – Режим доступа:
http://ej.kubagro.ru/2003/01/07.pdf, 0,813 у.п.л., импакт-фактор РИНЦ=0,346 |
|
10301008 |
IDA10301008 |
Луценко_Е_В,
Третьяк_В_Г |
Луценко
Е. В. Анализ профессиональных траекторий специалистов c применением системы
«Эйдос» / Е. В. Луценко, В. Г. Третьяк // Политематический сетевой
электронный научный журнал Кубанского государственного аграрного университета
(Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2003. –
№01(001) С. 55 – 58. IDA [article ID]: 0010301008 – Режим доступа:
http://ej.kubagro.ru/2003/01/08.pdf, 0,188 у.п.л., импакт-фактор РИНЦ=0,346 |
В данной работе исследовано две выборки статей:
полная, включающая 3949 статей, и сокращенная, представляющая собой 100 статей,
выбранных из полной случайным образом. Программа, осуществившая выборку 100
статей из полной, приведена ниже (язык xBase++):
=====================================================
FUNCTION
CLOSE ALL
USE Inp_data EXCLUSIVE
NEW;N_Obj = RECCOUNT()
aNumRec := {} // Массив
номеров записей, которые останутся в БД Inp_data.dbf
N_Rec = 100 //
Количество записей, которые останутся в БД Inp_data.dbf
SELECT Inp_data
DELETE ALL
// Сформировать массив кодов случайных объектов обучающей
выборки без повторов из N элементов
DO WHILE LEN(aNumRec) < N_Rec // В массиве еще нет aNumRec
элементов?
// Случайный номер
записи от 1 до N_Rec
mRndRec =
1+INT(RANDOM()%N_Obj)
IF
ASCAN(aNumRec, mRndRec) = 0 //
Номер этого объекта еще не разыгрывался?
AADD (aNumRec, mRndRec)
ENDIF
ENDDO
ASORT(aNumRec)
FOR j=1 TO LEN(aNumRec)
DBGOTO(aNumRec[j])
RECALL
NEXT
PACK
LB_Warning( aNumRec, 'Удаление записей из БД
"Inp_data.dbf"' )
LB_Warning( 'В базе даннных: "Inp_data.dbf" осталось
'+ALLTRIM(STR(N_Rec))+' случайных записей', 'Удаление записей из БД
"Inp_data.dbf"' )
CLOSE ALL
RETURN NIL
=====================================================
Далее везде, где это специально не оговорено,
рассматривается модель, основанная на 100 работах.
6.3.3. Автоматизированная
формализация предметной
области путем импорта исходных данных
из внешних баз данных в систему "Эйдос"
Для преобразования исходных данных в базы данных
системы "Эйдос" необходимо файл MS Excel, который содержит базу
исходных данных, скопировать в папку: ..Aidos-X\AID_DATA\Inp_data и присвоить
ему имя: «Inp_data.xls». Само преобразование осуществляется в универсальном
программном интерфейсе импорта данных из внешних баз данных в систему «Эйдос»
(режима 2.3.2.2), Help которого приведен на рисунке 6:
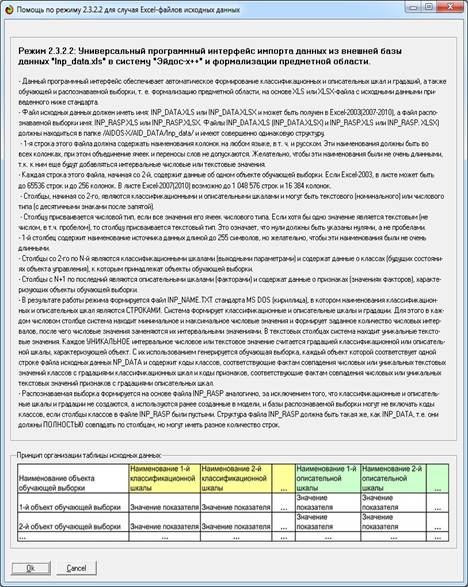
Рисунок 6. Help режима 2.3.2.2 системы «Эйдос»
Экранная форма задания параметров режима 2.3.2.2
приведена на рисунке 7:
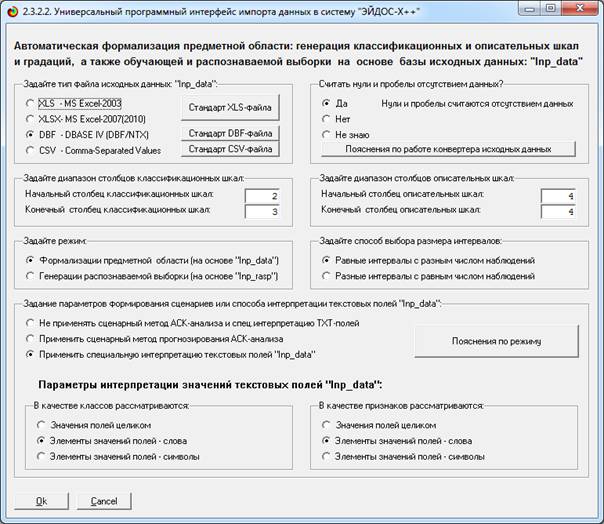
Рисунок 7 – Экранная форма Универсального программного
интерфейса импорта данных в систему "Эйдос" (режим 2.3.2.2.)
В экранной форме, приведенной на рисунке 7, необходимо
задать настройки, показанные на рисунке:
-
"Задайте тип
файла исходных данных Inp_data": "XLS - MS Excel-2003";
-
"Задайте
диапазон столбцов классификационных шкал": "Начальный столбец
классификационных шкал" – 2, "Конечный столбец классификационных
шкал" – 3;
-
"Задайте
диапазон столбцов описательных шкал": "Начальный столбец описательных
шкал" – 4, "Конечный столбец описательных шкал" – 4;
-
"Задание
параметров формирования сценариев или способа интерпретации текстовых
полей": "Применить сценарный метод АСК-анализа и спец.интерпретацию
TXT-полей";
-
«Параметры
интерпретации текстовых полей Inp_data»: В качестве классов рассматривать
элементы значений полей – слова, В качестве признаков рассматривать элементы
значений полей – слова.
Затем кликнуть кнопку "ОК". Далее
открывается окно, где размещена информация о размерности модели (рисунок 8).
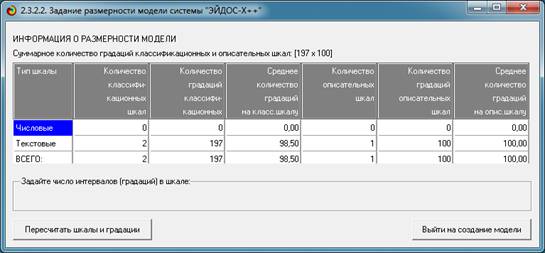
Рисунок 8. Информация о размерности модели системы
"Эйдос"
В этом окне необходимо нажать кнопку "Выйти на
создание модели".
Далее открывается окно, отображающее стадию процесса
импорта данных из внешней БД "Inp_data.xls" в систему
"Эйдос" (рисунок 9), а также прогноз времени завершения этого
процесса. В том окне необходимо дождаться завершения формализации предметной
области и нажать кнопку "ОК".
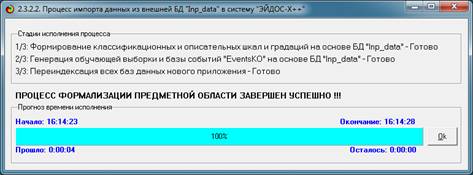
Рисунок 9. Процесс импорта данных из внешней БД
"Inp_data.xls"
в систему "Эйдос"
Для просмотра классификационных шкал и градаций
необходимо запустить режим 2.1 (рисунок 10):
Рисунок 10. Классификационные шкалы и градации
(фрагменты)
Для просмотра описательных шкал и градаций необходимо
запустить режим 2.2 (рисунок 11):
Рисунок 11. Описательные шкалы и градации (фрагмент)
Для просмотра обучающей выборки необходимо запустить
режим 2.3.1. (рисунок 12):
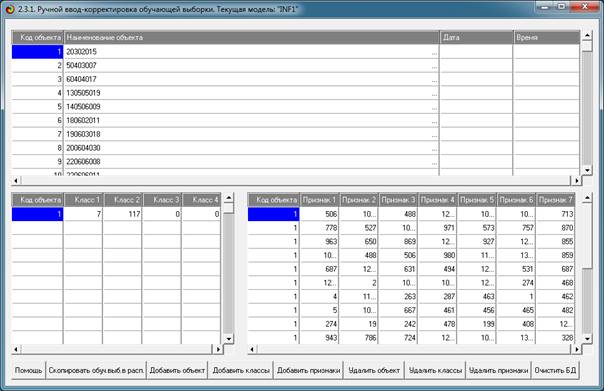
Рисунок 12. Обучающая выборка (фрагмент)
Тем самым создаются все необходимые и достаточные
предпосылки для выявления силы и направления причинно-следственных связей между
значениями факторов и результатами их совместного системного воздействия (с
учетом нелинейности системы [15]).
6.3.4. Синтез и верификация статистических
и интеллектуальных моделей
Далее запускаем режим 3.5, в котором происходит выбор
моделей для синтеза и верификации (рисунок 13) и нажмем кнопку "ОК".
После успешного завершения, также необходимо нажать кнопку "ОК"
(рисунок 14).
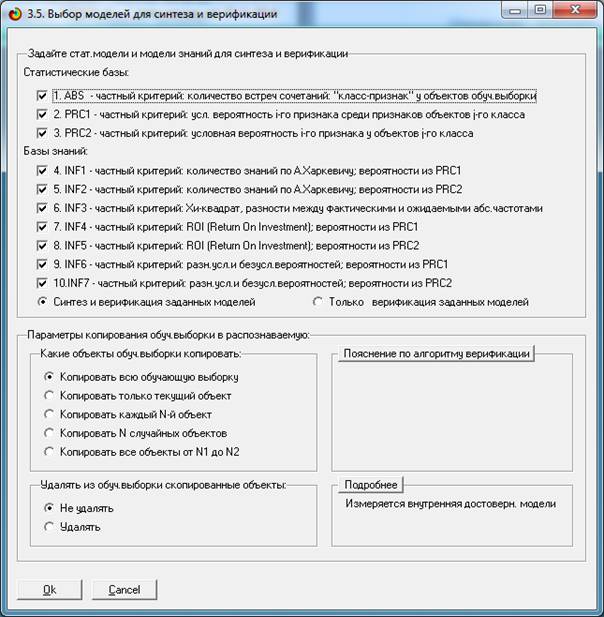
Рисунок 13. Выбор моделей для синтеза и верификации
В данном режиме имеется много различных методов
верификации моделей, в том числе и поддерживающие бутстрепный метод. Но мы используем
параметры по умолчанию, приведенные на рисунке 13.
В результате выполнения режима 3.5 (рисунок 14)
созданы все модели, со всеми частными критериями, перечисленные на рисунке 13,
но ниже мы приведем лишь некоторые из них (таблицы 3-5).
Предварительно рассмотрим частные и интегральные
критерии, применяемые в настоящее время в системе «Эйдос».
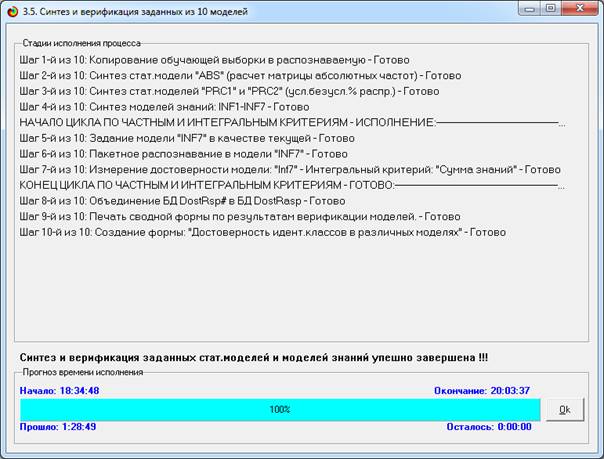
Рисунок 14. Синтез и верификация статистических
моделей
и моделей знаний
Отметим, что синтез и верификация всех 10 моделей на выборке
100 статей заняли около полутора часов (процессор i7).
6.3.5. Частные критерии и виды моделей
системы «Эйдос»
Рассмотрим решение задачи идентификации на примере
модели INF1, в которой рассчитано количество информации по А.Харкевичу, которое
мы получаем о принадлежности идентифицируемого объекта к каждому из классов,
если знаем, что у этого объекта есть некоторый признак. Это так называемые частные критерии сходства, приведенные в
таблице 3.
Таблица 3 – Частные критерии знаний, используемые в
настоящее время
в АСК-анализе и системе «Эйдос-Х++»
|
Наименование модели знаний |
Выражение для частного критерия |
|
|
через |
через |
|
|
INF1, частный критерий: количество знаний по
А.Харкевичу, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков по j-му классу. Относительная частота того, что если у объекта j-го
класса обнаружен признак, то это i-й признак |
|
|
|
INF2, частный критерий: количество знаний по
А.Харкевичу, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу. Относительная частота того, что если предъявлен
объект j-го класса, то у него будет обнаружен i-й признак. |
|
|
|
INF3, частный критерий: Хи-квадрат: разности
между фактическими и теоретически ожидаемыми абсолютными частотами |
--- |
|
|
INF4, частный критерий: ROI - Return On
Investment, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков по j-му классу |
|
|
|
INF5, частный критерий: ROI - Return On
Investment, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу |
|
|
|
INF6, частный критерий: разность условной и безусловной
относительных частот, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков
по j-му классу |
|
|
|
INF7, частный критерий: разность условной и безусловной
относительных частот, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу |
|
|
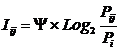
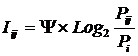
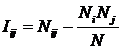
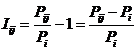
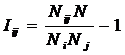
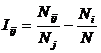
Обозначения:
i – значение прошлого параметра;
j - значение
будущего параметра;
Nij
– количество встреч j-го значения будущего
параметра при i-м значении
прошлого параметра;
M – суммарное число значений всех прошлых параметров;
W - суммарное число значений всех будущих параметров.
Ni – количество
встреч i-м значения прошлого параметра по всей
выборке;
Nj – количество встреч j-го
значения будущего параметра по всей выборке;
N – количество
встреч j-го значения будущего параметра при i-м значении прошлого параметра по
всей выборке.
Iij
– частный критерий знаний: количество знаний в факте
наблюдения i-го значения прошлого
параметра о том, что объект перейдет в состояние, соответствующее j-му значению будущего параметра;
Ψ –
нормировочный коэффициент (Е.В.Луценко, 1979, впервые опубликовано в 1993 году
[15]), преобразующий количество информации в формуле А.Харкевича в биты и
обеспечивающий для нее соблюдение принципа соответствия с формулой Р.Хартли;
Pi – безусловная относительная частота
встречи i-го значения прошлого
параметра в обучающей выборке;
Pij – условная относительная частота встречи
i-го значения прошлого параметра
при j-м значении будущего
параметра.
По сути, частные критерии представляют собой просто
формулы для преобразования матрицы абсолютных частот (таблица 4)[4] в
матрицы условных и безусловных процентных распределений (таблицы 5 и 6) и матрицы
знаний (проф. В.И.Лойко, 2014).
Таблица 4 – Матрица абсолютных частот (модель ABS)
(фрагмент)
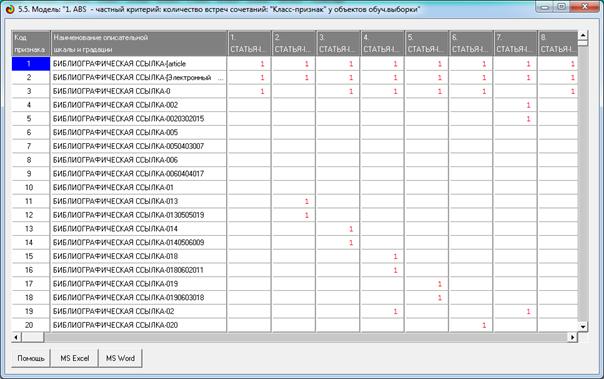
Таблица 5 – Матрица информативностей (модель INF1) в
битах (фрагмент)
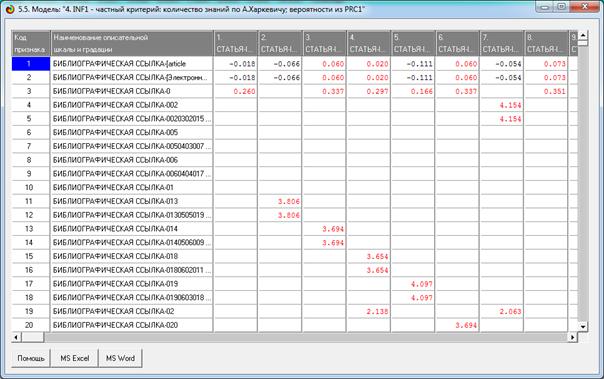
Таблица 6 – Матрица знаний (модель INF3) (фрагмент)
6.3.6. Ценность описательных шкал и градаций
для решения задач идентификации текстов
и авторов (нормализация текста)
Для любой из моделей системой «Эйдос» рассчитывается ценность[5] градации
описательной шкалы, т.е. признака, для идентификации или прогнозирования. Количественной
мерой ценности признака в той или иной модели является вариабельность по
классам частного критерия для этого признака (таблица 3) Мер вариабельности может быть много, но
наиболее известными является среднее модулей отклонения от среднего, дисперсия
и среднеквадратичное отклонение. Последняя мера и используется в АСК-анализе и
системе «Эйдос».
В системе «Эйдос» ценность признаков нарастающим
итогов выводится в графической форме.
При большом
объеме обучающей выборки можно без ущерба для достоверности модели удалить из
нее малозначимые признаки (Парето-оптимизация). Для этого в системе «Эйдос
«также есть соответствующие инструменты.
Как показывает опыт, в результате такого удаления из
текста малозначимых признаков (нормализации текста) из него прежде всего будут
удалены различные предлоги, междометия и слова, состоящие из очень малого числа
букв (от 1 до 3), а также отдельно стоящие символы типа наклонной черты (флеш)
и т.п.
6.3.7. Интегральные критерии системы «Эйдос»
Но если нам известно, что объект обладает не одним, а
несколькими признаками, то как посчитать их общий
вклад в сходство с теми или иными классами? Для этого в системе «Эйдос»
используется 2 аддитивных интегральных критерия: «Сумма знаний» и
«Семантический резонанс знаний».
Интегральный критерий «Семантический резонанс знаний» представляет собой суммарное
количество знаний, содержащееся в системе факторов различной природы,
характеризующих сам объект управления, управляющие факторы и окружающую среду,
о переходе объекта в будущие целевые или нежелательные состояния.
Интегральный критерий представляет собой аддитивную функцию от частных
критериев знаний, представленных в help режима 3.3:
![]()
В выражении круглыми скобками обозначено скалярное произведение. В
координатной форме это выражение имеет вид:
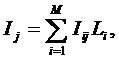 ,
,
где: M – количество градаций описательных шкал (признаков);
![]() – вектор состояния j–го класса;
– вектор состояния j–го класса;
![]() – вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
– вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
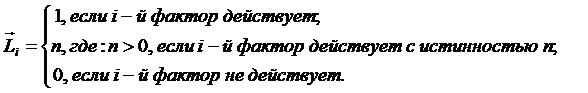
В текущей версии системы «Эйдос-Х++» значения координат вектора состояния
распознаваемого объекта принимались равными либо 0, если признака нет, или n, если
он присутствует у объекта с интенсивностью n, т.е. представлен n раз (например,
буква «о» в слове «молоко» представлена 3 раза, а буква «м» - один раз).
Интегральный критерий «Семантический резонанс знаний» представляет собой нормированное суммарное количество
знаний, содержащееся в системе факторов различной природы, характеризующих сам
объект управления, управляющие факторы и окружающую среду, о переходе объекта в
будущие целевые или нежелательные состояния.
Интегральный критерий представляет собой аддитивную функцию от частных
критериев знаний, представленных в help режима 3.3 и имеет вид:
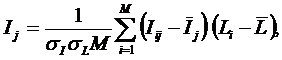
где:
M –
количество градаций описательных шкал (признаков);
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по
вектору объекта;
– среднее по
вектору объекта;
![]() – среднеквадратичное
отклонение частных критериев знаний вектора класса;
– среднеквадратичное
отклонение частных критериев знаний вектора класса;
![]() – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
![]() – вектор состояния j–го класса;
– вектор состояния j–го класса;
![]() – вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
– вектор состояния
распознаваемого объекта, включающий все виды факторов, характеризующих сам
объект, управляющие воздействия и окружающую среду (массив–локатор), т.е.:
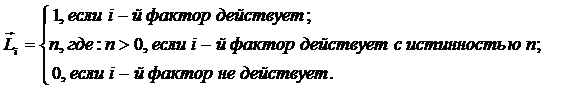
В текущей версии системы «Эйдос-Х++» значения координат вектора состояния
распознаваемого объекта принимались равными либо 0, если признака нет, или n,
если он присутствует у объекта с интенсивностью n, т.е. представлен n раз
(например, буква «о» в слове «молоко» представлена 3 раза, а буква «м» - один
раз).
Приведенное выражение для интегрального критерия «Семантический резонанс
знаний» получается непосредственно из выражения для критерия «Сумма
знаний» после замены координат перемножаемых векторов их
стандартизированными значениями:
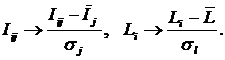
Свое наименование интегральный критерий сходства «Семантический резонанс
знаний» получил потому, что по своей математической форме является корреляцией
двух векторов: состояния j–го класса и состояния распознаваемого объекта.
6.3.8. Результаты
верификации моделей
Результаты верификации (оценки достоверности) моделей,
отличающихся частными критериями (таблица 3) с двумя приведенными выше
интегральными критериями приведены на рисунке 15:
Рисунок 15. Результаты верификации моделей
Наиболее достоверной в данном приложении оказались модели
INF4 при интегральном критерии «Резонанс знаний» (на рисунке 15 эта модель
выделена красным цветом). Данная модель обеспечивает 100% достоверность
идентификации работы и ее авторов по библиографическому описанию этой работы
(достоверность отнесения объекта к классу, к которому он действительно
относится), и 98% достоверность не отнесения работы и ее авторов к тем классам,
к которым они не относятся.
Для оценки достоверности моделей в АСК-анализе и системе
«Эйдос» используется метрика, предложенная автором, сходная с F-критерием[6] и
дающая те же результаты ранжирования моделей по их качеству (рисунок 16):
Рисунок 16. Виды прогнозов и принцип определения
достоверности моделей по авторскому варианту метрики, сходной с F-критерием
Кроме того в системе «Эйдос» используют уточненную
F-меру, учитывающую не только сам факт идентификации или не идентификации, но и
уровень сходства-различия при этом.
Также обращает на себя внимание, что статистические
модели, как правило, дают более низкую средневзвешенную достоверность
идентификации и не идентификации, чем модели знаний, и практически никогда –
более высокую. Этим и оправдано применение моделей знаний.
6.4. Решение задач идентификации текстов
и их авторов в наиболее достоверной модели
6.4.1. Присвоение наиболее достоверной модели
статуса
текущей и решение в ней задач идентификации
В соответствии со схемой этапов последовательного преобразования
данных в информацию, а ее в знания в системе "Эйдос", приведенной на
рисунке 3, присвоим статус текущей модели INF4, наиболее достоверной модели по
данным верификации (рисунок 15). Для этого в режиме 5.6 системы «Эйдос»
зададим эту модель и кликнем по кнопке Ok (рисунок 17):
Рисунок 17. Экранные формы режима присвоения модели
статуса текущей
Затем произведем идентификацию и авторов в текущей модели.
Для этого запустим режим 4.1.2 системы «Эйдос» (рисунок 18):
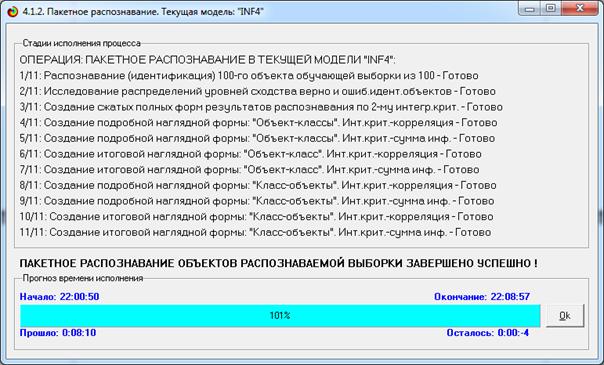
Рисунок 18. Экранная форма режима идентификации
текстов и их авторов
Из рисунка 18 видно, что идентификация 100 статей в
наиболее достоверной модели INF4 заняла 8 минут, т.е. 4.8 секунды на одну работу.
6.4.2. Отображение результатов идентификации
Режим 4.1.3 системы «Эйдос» обеспечивает отображение
результатов идентификации в различных формах:
1. Подробно наглядно: "Объект – классы".
2. Подробно наглядно: "Класс – объекты".
3. Итоги наглядно: "Объект – классы".
4. Итоги наглядно: "Класс – объекты".
5. Подробно сжато: "Объект – классы".
6. Обобщенная форма по достоверности моделей при разных
интегральных критериях.
7. Обобщенный статистический анализ результатов идентификации
по моделям и интегральным критериям.
8. Статистический анализ результатов идентификации по
классам, моделям и интегральным критериям.
9. Распознавание уровня сходства при разных моделях и
интегральных критериях.
10.Достоверность идентификации классов при разных моделях
и интегральных критериях.
Рассмотрим некоторые из них.
На рисунке 19 приведен пример идентификации работы и
ее авторов в наиболее достоверной модели INF4:
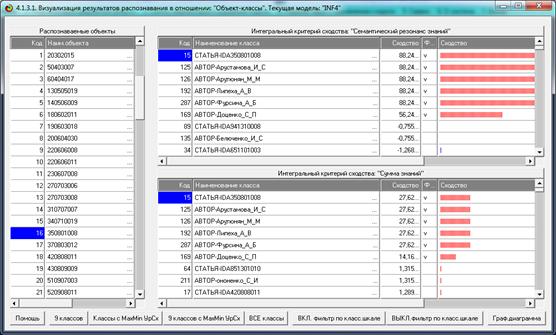
Рисунок 19. Экранная форма результатов идентификации
работы и ее авторов
На рисунке 20 приведены результаты идентификации
автора данной работы по библиографическим описаниям его статей.
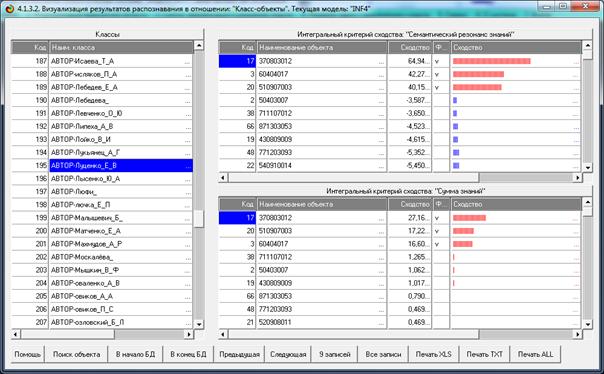
Рисунок 20. Результаты идентификации автора данной работы
по библиографическим описаниям его статей
Результаты решения проблемы, поставленной в работе, приведенные
на рисунках 19 и 20 можно признать очень хорошими.
Однако возникает закономерный вопрос о том, а будет ли
вообще работать предлагаемый алгоритм и инструментарий на больших базах данных
и о том, как он будет работать. Для ответа на этот вопрос был проведен
численный эксперимент на выборке 3949 работы. Результат идентификации статей
приведен на рисунках 21.
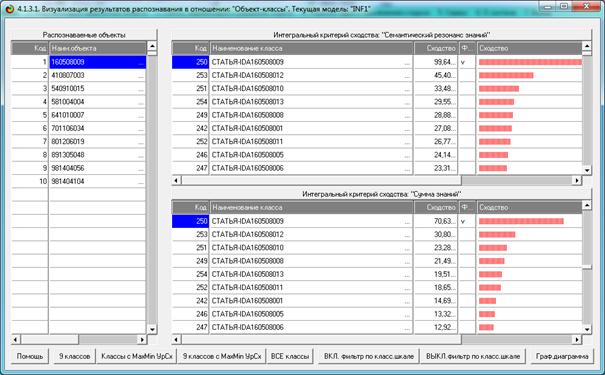
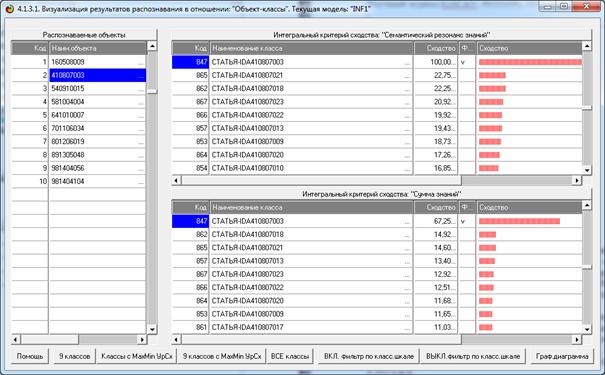
|
|
|
|
|
|
|
|
|
|
|
|
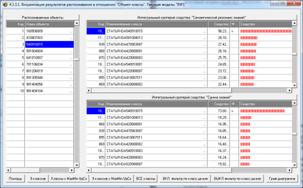
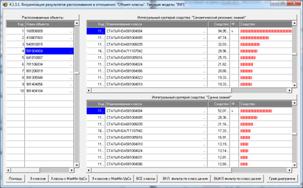
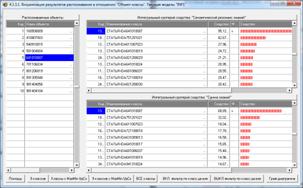
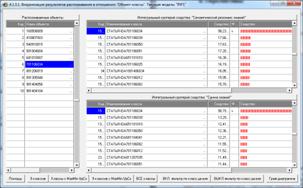
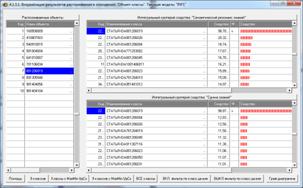
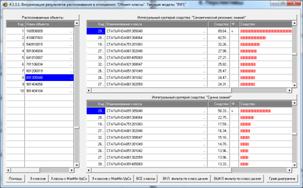
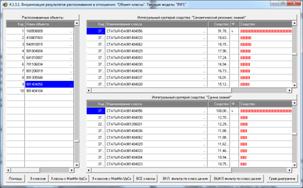
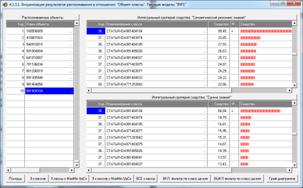
Рисунок 21. Экранные формы с результатами
идентификации статей
в модели INF1: 3949 статей, 19989 слов
Из рисунка 21 мы видим, что все 10 статей, выбранных
для идентификации случайным образом, идентифицированы по их стандартному
библиографическому описанию абсолютно верно, причем со значительным, в разы,
превышением уровня сходства с правильной работей по сравнению со следующей за
ней наиболее сходной. Это означает, что поставленная в работе задача успешно
решена. Если же различие в уровне сходства наиболее сходной работы и следующей
за ней незначительное, то информацию об этих работах необходимо предоставить
для принятия решения специалисту.
Рассмотрим теперь идентификацию
статей с нестандартными и некорректными библиографическими описаниями в
модели INF1, созданной на основе 3949 библиографических описаний
статей.
Для формирования некорректных библиографических ссылок
возьмем стандартную ссылку на работу автора (1-я строка таблицы 7) и будем,
начиная с конца библиографического описания, последовательно удалять из него элементы
описания и создавать новые строки с неполными библиографическими
описаниями. Две последних строки получены не путем удаления элементов
библиографического описания, что приводит к неполноте описания, а путем
добавления лишних элементов (шума, выделено желтым фоном):
наклонной черты после имени автора и неверного указания страниц. Как показывает
опыт, в настоящее время подобные описания не идентифицируются программным
обеспечением РИНЦ.
В результате получим таблицу 7:
Таблица 7 – Распознаваемая выборка с некорректными
(неполными ) библиографическими описаниями
|
№ |
Объект |
Работа |
Автор |
Библиографическая
ссылка |
|
1 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 154 – 185. – Шифр Информрегистра: 04208000120031,
IDA [article ID]: 0370803012 – Режим доступа:
http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л., импакт-фактор РИНЦ=0,346 |
|
2 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 154 – 185. – Шифр Информрегистра: 04208000120031,
IDA [article ID]: 0370803012 – Режим доступа:
http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л. |
|
3 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного университета
(Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. –
№03(037) С. 154 – 185. – Шифр Информрегистра: 04208000120031, IDA [article
ID]: 0370803012 |
|
4 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 154 – 185. – Шифр Информрегистра: 04208000120031 |
|
5 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 154 – 185. |
|
6 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) |
|
7 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. |
|
8 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) |
|
9 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Неформальная постановка и обсуждение задач, возникающих при
системном обобщении теории множеств на основе системной теории информации
(Часть 1-я: задачи 1-3) |
|
10 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. / Неформальная постановка и обсуждение задач,
возникающих при системном обобщении теории множеств на основе системной
теории информации (Часть 1-я: задачи 1-3) / Е. В. Луценко // Политематический
сетевой электронный научный журнал Кубанского государственного аграрного
университета (Научный журнал КубГАУ) [Электронный ресурс]. – Краснодар:
КубГАУ, 2008. – №03(037) С. 154 – 185. – Шифр Информрегистра: 04208000120031,
IDA [article ID]: 0370803012 – Режим доступа:
http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л., импакт-фактор РИНЦ=0,346 |
|
11 |
370803012 |
IDA370803012 |
Луценко_Е_В |
Луценко Е. В. /
Неформальная постановка и обсуждение задач, возникающих при системном
обобщении теории множеств на основе системной теории информации (Часть 1-я:
задачи 1-3) / Е. В. Луценко // Политематический сетевой электронный научный
журнал Кубанского государственного аграрного университета (Научный журнал
КубГАУ) [Электронный ресурс]. – Краснодар: КубГАУ, 2008. – №03(037) С. 1154 – 2185. – Шифр Информрегистра:
04208000120031, IDA [article ID]: 0370803012 – Режим доступа:
http://ej.kubagro.ru/2008/03/12.pdf, 1,938 у.п.л., импакт-фактор РИНЦ=0,346 |
Распознаваемую выборку из некорректных (неполных и
зашумленных) библиографических описаний введем в систему «Эйдос» с помощью
универсального программного интерфейса с внешними базами данных 2.3.2.2 при
параметрах, показанных на рисунке 22:
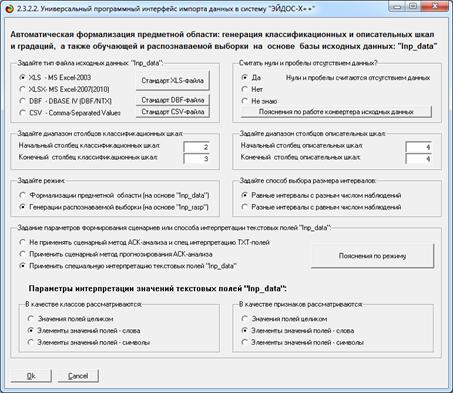
Рисунок 22. Экранная форма универсального программного
интерфейса
с внешними базами данных для ввода распознаваемой выборки
В результате получена распознаваемая выборка, которую
можно просмотреть в режиме 4.1.2 (рисунок 23).
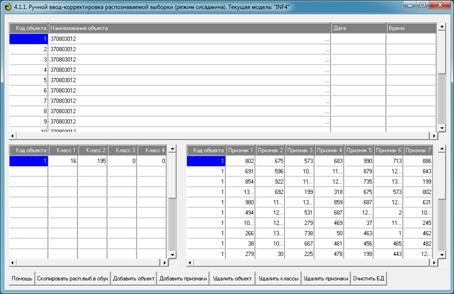
Рисунок 23. Экранная форма распознаваемой выборки
некорректных библиографических описаний
Процесс распознавания проведем в режиме 4.2.1 в модели
INF1, созданной на основе библиографических описаний всех 3949 статей
(рисунок 24):
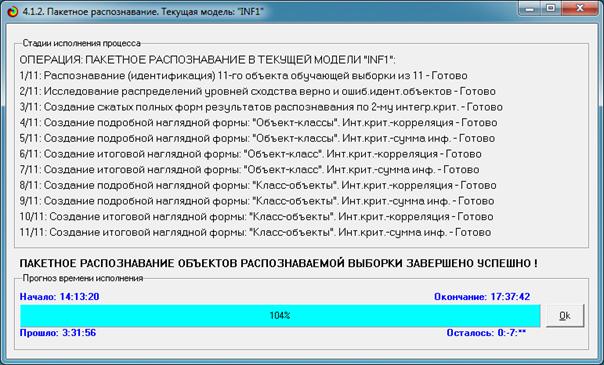
Рисунок 24. Экранная форма отображения стадии процесса
идентификации нестандартных и некорректных библиографических описаний
Как видно из рисунка 24, процесс идентификации 11
статей в этой модели занял примерно три с половиной часа или около 20 минут на
одно описание.
Результаты распознавания приведены на рисунках 25:
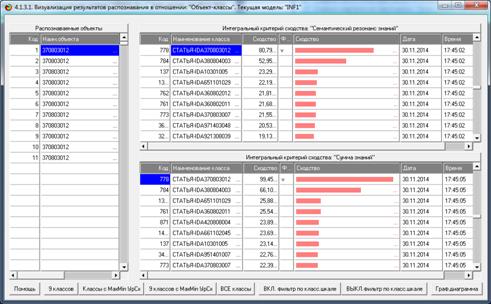
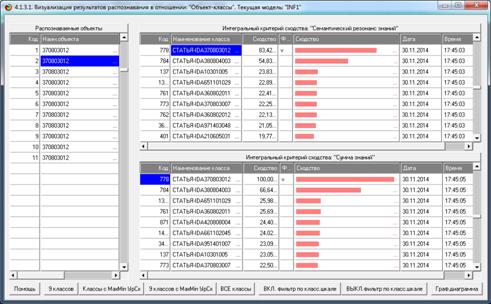
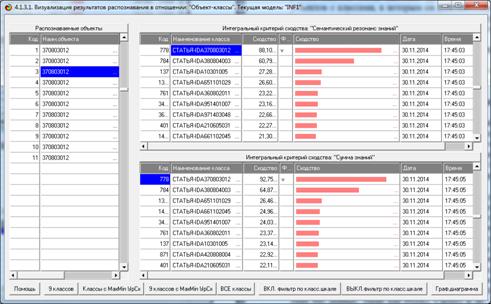
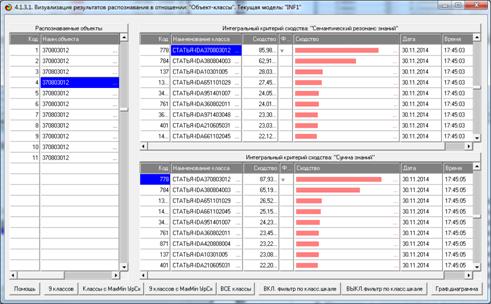
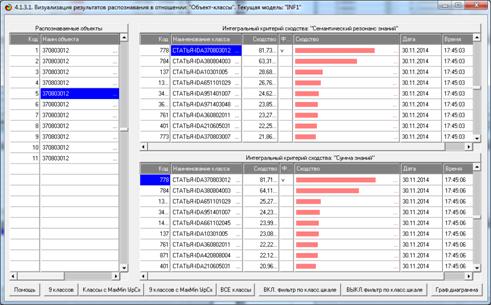
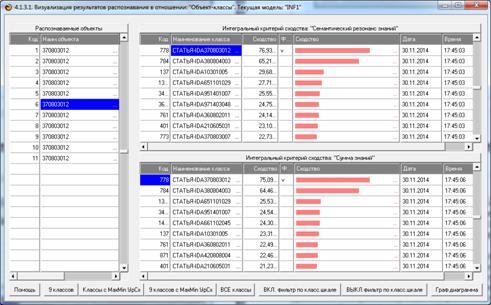
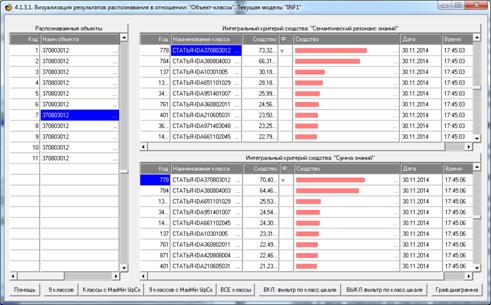
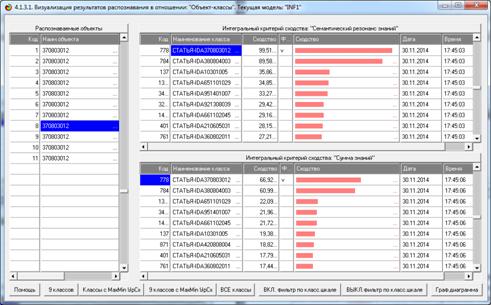
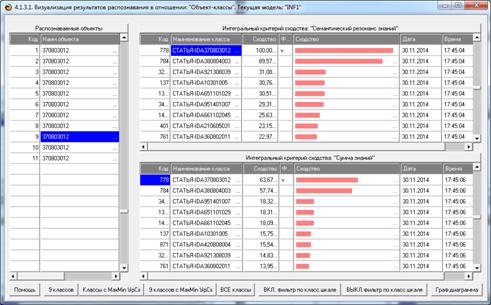
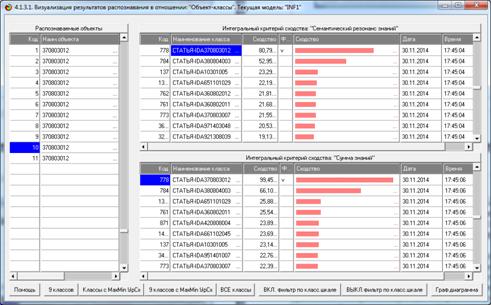
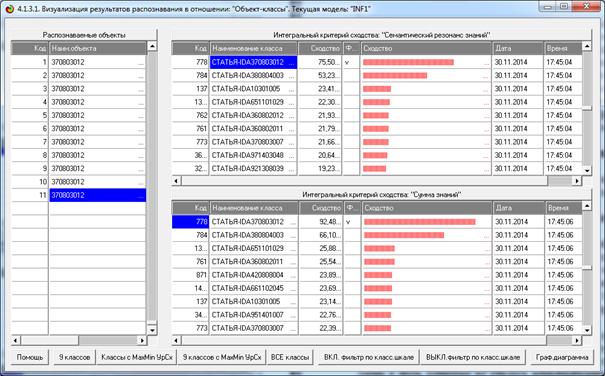
Рисунок 25. Экранная форма отображения результатов
идентификации
нестандартных и некорректных библиографических описаний
Из рисунков 25 видно, что в модели INF1, созданной на
основе 3949 статей Научного журнала КубГАУ за 2003-2014 годы, верно
идентифицированы все тестовые библиографические описания из таблицы 7:
и стандартное из строки 1, и все 10 нестандартные и
некорректные (неполные и зашумленные), приведенные в строках 2-11.
6.5. Выводы
На основе выше изложенного можно сделать обоснованный
вывод о том, что АСК-анализ и его программный инструментарий интеллектуальная
система «Эйдос», обеспечивают решение задачи идентификации текстов и авторов на
основе библиографических описаний публикаций, в том числе нестандартных и
некорректных, неполных и зашумленных. При этом обеспечивается очень высокий
уровень достоверности идентификации объектов с классами, к которым он
действительно принадлежат (100%) и очень высокий уровень достоверности не
идентификации объектов с классами, к которым они действительно не принадлежат
(около 98%).
Некоторые
недостатки и перспективы предлагаемого подхода
Конечно, предлагаемый подход не лишен и некоторых недостатков
и ограничений, в преодолении которых состоят некоторые перспективы его
развития.
6.6.1. Повышение быстродействия алгоритмов
Основной недостаток предлагаемых решений, выявленный
на приведенных в данной работе примерах, состоит в довольно значительных
затратах вычислительных ресурсов, внешней памяти и времени на создание
моделей, их верификацию и решение в этих моделях задач идентификации. Особенно
это заметно на примере со 3949 статей, 19989 слов.
Таким образом, как обычно возникает вопрос о том, что
делать в этих условиях.
Прежде всего, возникает мысль о том, что в больших
библиографических базах типа РИНЦ, Скопус и т.п., предлагаемые в данной работе решения
целесообразно
применять не ко всем работам и авторам, а лишь к тем, которые не удалось
идентифицировать с помощью более простых и быстродействующих алгоритмов,
уже реализованных в программном обеспечении этих систем. Иначе говоря применять
их в тех случаях, в которых ранее было необходимо участие человека.
Следующая очевидная мысль состоит в том, что
необходимо оптимизировать предлагаемые решения алгоритмы и решения
специально для их реализации в программном обеспечении больших
библиографических баз данных, таких как РИНЦ, Скопус и др. Для того, чтобы это
сделать необходимо предварительно разобраться с причинами возникновения этой
ситуации. Мы видим две такие основные причины:
Во-первых,
это универсальность и независимость от предметной области алгоритма,
реализованного в системе «Эйдос». В процессе синтеза и верификации моделей в
системе производится расчет большого количества различных выходных форм,
которые не нужны при решении задач, поставленных в работе.
Во-вторых,
это отсутствие морфологического анализатора в текущей версии системы «Эйдос», в
результате чего слова не приводятся к начальной форме и используются все
словоформы, реально встретившиеся в библиографических ссылках. Это на порядок
увеличивает размерность моделей и время их создания и использования для решения
задач.
Соответственно, представляется, что есть два основных
пути повышения быстродействия предложенных алгоритмов при их использовании для
решения задач идентификации литературных источников и авторов на основе
библиографических описаний:
1) оптимизация алгоритма специально для очень больших
библиографических баз данных, типа РИНЦ и Скопус;
2) лемматизация текста[7] на
основе морфологического анализа, т.е. приведение слов к их исходной форме, и
сокращение за счет этого размерностей баз данных на порядок и такое же
повышение быстродействия алгоритма.
Кроме того, на взгляд автора, для повышения
быстродействия алгоритмов обработки матриц чрезвычайно перспективным является
применение в системе «Эйдос» технологии CUDA[8] или
другой функционально аналогичной, но более универсальной и менее зависимой от
аппаратного обеспечения технологии, обеспечивающей высокопроизводительные
параллельные неграфические вычисления на графических
процессорах, обладающих огромными
вычислительными ресурсами, на порядки превосходящими ресурсы центрального
процессора.
Отметим,
что быстродействие работы предложенных алгоритмов на работах одного автора,
которых редко бывает больше 200-400, является вполне достаточным для его
использования модератором.
6.6.2. Перспективы применения АСК-анализа
и системы «Эйдос» для решения задач
идентификации и прогнозирования на основе
анализа Internet-контента
Описанная в работе технология может быть применена для
решения задач выявления взаимосвязей между динамикой Internet-контента и
событиями в области экономики, политики, культуры и в других областях.
Особенное значение это приобретает в условиях жесткого информационного
противоборства, если не сказать информационной войны, ведущих центров влияния в
мире.
Например, в работе [16] тотальная
ложь рассматривается как стратегическое информационное оружие общества периода
глобализации и дополненной реальности. Рассматривается возможность применения в
современном обществе принципа наблюдаемости, как общепринятого в физике
критерия реальности. Показано, в каких случаях применение данного принципа в исследованиях
общества приводит к общественным иллюзиям, а когда дает адекватные результаты.
Предлагаются понятие: «Степень виртуализации общества» и количественная шкала
для ее измерения, а также вводится понятие «Общественный умвельт» под которым
понимается область общества, существенно отличающаяся от остальных своими
фундаментальными закономерностями.
В работах [17] и [18] рассматриваются применение
технологий нейролингвистического программирования (НЛП) для астротурфинга[9]
и манипулирования сознанием больших масс людей и различных целевых групп
населения.
Язык программирования Аляска xBase++, на котором
написана система «Эйдос-Х++» позволяет реализовать все существующие в настоящее
время возможности взаимодействия с Internet-ресурсами, но для этого необходима
библиотека Xb2net.dll, которая у автора есть только в демо-версии (функционально-ограниченная).