ГЛАВА 6. АВТОМАТИЗИРОВАННЫЙ СИСТЕМНО-КОГНИТИВНЫЙ АНАЛИЗ В ОЦЕНКЕ РЕЗУЛЬТАТОВ НАУЧНОЙ И ПРЕПОДАВАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ
6.1. Синтез адаптивных интеллектуальных
измерительных систем с применением АСК-анализа
и системы «Эйдос», системная идентификация
в эконометрике, биометрии, экологии, педагогике,
психологии и медицине
В разеле предлагается применить автоматизированный системно-когнитивный
анализ (АСК-анализ) и его программный инструментарий систему «Эйдос» как для
синтеза, так и для применения адаптивных интеллектуальных измерительных систем
с целью измерения не значений параметров объектов, а для системной
идентификации состояний сложных
многофакторных нелинейных динамических систем. Кратко
рассматривается математический метод АСК-анализа, реализованный в его программном
инструментарии – универсальной когнитивной аналитической системе «Эйдос-Х++». Математический
метод АСК-анализа основан на системной теории информации (СТИ), которая
создана в рамках реализации программной идеи обобщения всех понятий математики,
в частности - теории информации, базирующихся на теории множеств, путем
тотальной замены понятия множества на более общее понятие системы и тщательного
отслеживания всех последствий этой замены. Благодаря математическому методу,
положенному в основу АСК-анализа, этот метод является непараметрическим и
позволяет сопоставимо обрабатывать десятки
и сотни тысяч градаций факторов и будущих состояний объекта управления
(классов) при неполных (фрагментированных), зашумленных данных числовой и
нечисловой природы измеряемых в различных единицах измерения. Приводится развернутый численный пример
применения АСК-анализа и системы «Эйдос-Х++» как для синтеза
системно-когнитивной модели, обеспечивающей многопараметрическую типизацию
состояний сложных систем, так и для системной идентификации их
состояний, а также для принятии решений об управляющем воздействии, так
изменяющем состав объекта управления, чтобы его качество (уровень системности)
максимально повышалось при минимальных затратах на это. Для численного примера
в качестве сложной системы выбран коллектив фирмы, а его компонент – сотрудники
и кандидаты (персонал). Однако необходимо отметить, что этот пример следует
рассматривать шире, т.к. АСК-анализ и система «Эйдос» разрабатывались и
реализовались в очень обобщенной постановке, постановке, не зависящей от
предметной области, и с успехом могут быть применены и в других областях
«…законы природы являются лишь высказываниями
о пространственно-временных совпадениях…»
Альберт Эйнштейн
6.1.1. Интеллектуальные
измерительные системы,
как закономерный этап развития информационно-измерительных систем
Очевидно, смысл процесса измерения в том, что в его
результате мы получаем определенное количество информации о степени
выраженности тех или иных свойств у измеряемого объекта или о его состоянии.
Информация может рассматриваться с двух точек зрения: с количественной и с
качественной, т.е. содержательной, семантической. Парадокс заключается в том,
что традиционно внимание обращается только на содержание информации, полуденной в процессе измерения, тогда как
на количество этой информации обычно
вообще не обращают никакого внимания. Между тем количество информации
полученной в результате измерений также очень важно, т.к. непосредственно
связано с точностью измерений.
Точность измерений принципиально ограничено соотношением неопределенностей
Гейзенберга, поэтому принципиально ограничено и максимальное количество
информации (Фишера), которое можно получить об объекте в процессе измерений[1].
Например, если в результате измерения температуры с помощью
бытового наружного термометра со стандартной шкалой от -50С° до +50С° мы
получили содержательную информацию о том, что температура воздуха на улице
равна 25С°, то мы получили I=Log2100~7
бит информации, если же мы узнали более точное значение температуры 25,4С°, то
это увеличивает количество полученной информации: I=Log21000~10 бит информации.
Проблема заключается в полном отсутствии универсальных инструментальных
средств для синтеза измерительных систем в различных предметных областях, которые бы позволяли вычислять какое количество информации содержится в
результатах измерения о том, что измеряемая величина примет то или иное
значение.
Вроде бы существуют и учебные пособия по
интеллектуальным измерительным системам [1], и государственный стандарт в этой
области [2]. Однако, сформулированная проблема ими не решается, т.к. в них даже
не ставится задача ее решения. Данный раздел посвящен описанию подхода к
решению данной проблемы, основанного на применении автоматизированного
системно-когнитивного анализа (АСК-анализ) и его программного инструментария –
интеллектуальной системы «Эйдос» [3, 4].
С точки зрения теории информации измерение
представляет собой и процесс
отображения, и результат отображения
одной системы в другой. Процесс
отображения одной системы в другой представляет собой процесс моделирования, результатом которого является модель
измеряемого или отображаемого объекта. В этой связи возникает много сложных
методологических проблем [5, 6]. В соответствии с принципом Эшби более простая система
может адекватно отображаться в более сложной, тогда как более сложная система в
более простой всегда отображается с необратимой потерей информации, т.е.
неадекватно. Значит, что для того чтобы измерительная (управляющая) система
была адекватной она должна быть сложнее измеряемого объекта (объекта управления).
Поэтому вполне естественно и закономерно, что история
измерений – это по сути история эволюция информационно-измерительных систем, в
процессе которой они постоянно усложнялись и становились все более и более
точными. Измерения развивались по двум основным направлениям: с одной стороны
от измерения объективных свойств к социальным и субъективным измерениям, а с
другой стороны от измерения степени выраженности отдельных свойств объектов к
измерению состояний систем в целом.
Первоначально измерения зародись в естественных
науках, но потом постепенно стали проникать, особенно в последнее время, и в гуманитарные науки.
Сначала измерялась степень выраженности объективных свойств объектов,
принадлежащие им по самой их природе (физика: вес, скорость и т.п.), затем
стали измеряться социально-экономические свойства, отражающие отношения людей с
помощью вещей (эконометрика: потребительная и меновая стоимость), а после этого
пришла очередь и субъективных свойств (педагогические измерительные системы,
измеряющие уровень предметной обученности, а также психологические
измерительные системы, обеспечивающие измерение степени выраженности психологических
свойств личности). При этом сначала измерялась степень выраженности свойств
объектов. Затем выяснилось, что не существует совершенно независимых друг от
друга свойств, т.е. все объекты являются в той или иной степени нелинейными, а
представление об абсолютно линейных объектах являются предельной абстракцией,
наподобие математической точки. Но существуют практически линейные объекты, для
которых нелинейностью можно вполне обоснованно пренебречь и для которых измерение
степени выраженности их свойств вполне корректно. Однако для систем с высоким уровнем системности и, соответственно, ярко
выраженной нелинейностью более правильно говорить не об измерении свойств, а об
идентификации состояний систем по их свойствам, т.е. о системной идентификации
[7][2]. Системы с ярко выраженными нелинейными свойствами
широко распространены. Это квантовые природные и технические системы,
качественно изменяющие свое состояние в процессе штатной эксплуатации,
глобальные природные системы [8], биологические и экологические системы, а
также так называемые организационные системы, т.е. все системы с участием
людей: социально-экономические системы, коллективы и отдельные люди – личности.
Например, в медицине, подход к лечению, основанный на
измерении свойств пациента и приведении значений этих свойств к норме,
называется симптоматическим лечением, т.е. лечением клинических признаков, а не
человека, как целостной системы. При таком лечении патологические значения
клинических признаков приводятся к нормальным значениям, но причины заболевания
не устраняются.
Измерение всегда осуществляется во взаимодействии измеряемого
объекта и измерительной системы, поэтому и процесс, и результат отображения
является взаимным, т.е. измерительная
система в процессе оказывает влияние на измеряемый объект и изменяет его и сама
также изменяется в процессе измерения, поэтому она измеряет не состояние
измеряемого объекта «самого по себе», каким оно было до измерения, а то
состояние, которое возникло и стабилизировалось у него в результате
возникновения равновесия в процессе измерения. Казалось бы, подобные
методологические рассуждения играют роль лишь в квантово-механической теории измерений,
но это далеко не так. При измерении состояний сложных нелинейных физических,
социально-экономических, биологических и психологических систем мы часто
наблюдаем существенное, часто необратимое влияние измерительной системы на
измеряемую систему, что совершенно недопустимо ни с какой точки зрения.
Например, мы прекрасно знаем, сколь болезненными для
пациента и небезопасными для него по своим последствиям могут быть медицинские
анализы, в частности гистологические пробы на рак, которые резко активируют
развитие рака. Многие психологические и педагогические измерительные материалы
(тесты) с ложными, неполными и вообще
неверными вариантами ответов, типа ЕГЭ, необратимо
дезориентируют тестируемых в самом
процессе тестирования и поэтому дают закономерное снижение качества результатов
при повторном тестировании, т.е. имеют недопустимо низкую ретестовую
надежность. Но главное даже не в этом, а в том, что само измерение с помощью
подобных грубых измерительных систем необратимо повреждает измеряемый объект, в результате чего он существенно
изменяет свои свойства и по сути становится иным, чем до измерения, а вот это
уже недопустимо. В этом случае сам измерительный инструмент, недопустимо сильно
влияющий на измеряемый объект, следует признать непригодным для измерений (за
исключением случая проведения краш-тестов). Представьте себе, чтобы Вы сказали
о термометре для имения температуры воды, если бы он в процессе измерения эту
воду заморозил бы или вскипятил. Но когда подобными измерительными инструментами
и методами проводятся педагогические измерения уровня предметной обученности у
миллионов школьников нашей страны, то это почему-то считается вполне
приемлемым.
В естественных науках прогресс во многом определяется
совершенствованием технологий измерений
и накопления фактов, а также развитием
методов извлечения знаний из фактов.
Само понятие измерения претерпело значительную
эволюцию [8].
Раньше под измерением понимали сам факт обнаружения и
идентификации объекта или обнаружения (идентификации) у изучаемого объекта
какого-либо свойства, что выражалось качественной,
номинальной или текстовой величиной.
Затем возникло представление о степени выраженности
различных свойств объектов и возможности между ними отношений «больше»,
«меньше».
Позже возникло понятие об отношениях эквивалентности между степенью выраженности
свойства измеряемого объекта с каким-либо эталоном,
который стал рассматриваться как единица измерения. Примером может быть
измерение веса продуктов на весах с помощью гирь. Развитие этих представлений
привело к формированию понятий об измерительных шкалах различных типов [9] и о
единицах измерения и числовых измерениях и тогда под измерением стали понимать
установление количественного значения
некоторого свойства объекта. При этом сначала использовались измерительные
шкалы с условным нулем, а затем и с абсолютным нулем.
Дальнейшее
развитие науки привело к пониманию, что измерение любой количественной величины
всегда осуществляется с некоторой принципиально неустранимой погрешностью. Абсолютно точное значение
измерения недостижимо по ряду причин. Прежде всего, для абсолютно точной записи
любой величины потребовалось бы бесконечное количество знаков, а значит
информационный носитель бесконечной емкости и бесконечное время для записи этой
информации, а также бесконечная скорость передачи информации оп каналу связи и
такая же скорость записи на носитель. С другой стороны сам процесс измерения
всегда занимает некоторое конечное время и за это время возможно получить лишь
ограниченный объем информации Фишера об измеряемом объекте, а сама изменяемая величина,
вообще говоря, может и измениться за это время. Кроме того, в любом реальном
процессе измерения измерительная система взаимодействует
с исследуемым объектом, т.е. не только получает информацию о его состоянии, но
и влияет на него, т.е. изменяет его состояние в процессе измерения. Иначе
говоря, существует принципиально неустранимое влияние наблюдателя на наблюдаемую
им реальность. Следовательно, от самого наблюдателя в определенной степени,
конечно, зависит, что он наблюдает и что он в
принципе может наблюдать. В этой связи возникает много сложных
методологических проблем [5, 6]. Поэтому результаты количественных измерений
стали записывать с указанием погрешностей, а затем и доверительного интервала,
в который с определенной вероятностью (обычно 0.95) попадает истинное значение
измеряемой величины. Таким образом, понимание, что измерение всегда
осуществляется с некоторой погрешностью, привело к переходу к доверительным
интервалам и интервальным оценкам в
измерениях.
Следующий этап развития теории измерений связан с
пониманием того, что измеряемая величина каким-то образом, в общем случае неравномерно, распределена внутри
доверительного интервала. В результате под измерением стали понимать установление
статистических характеристик
вероятностных распределений числовых величин и это ознаменовало следующий
этап развития понятия «Измерение». Чем выше кривизна кривой частот внутри
интервала, тем чаще должны быть расположены точки измерений, чтобы отразить эту
форму (теорема Котельникова об отсчетах). Поэтому в системно-когнитивном
анализе и его программном инструментарии – интеллектуальной системе «Эйдос» [3,
4] возникла и была реализована идея использования интервальных шкал с адаптивным размером интервала, при
котором его размер изменяется таким образом, чтобы внутри разных интервалов
было примерно одинаковое количество наблюдений. В качестве примеров научных
исследований, использующих такой уровень понимания сущности измерений, являются
работа [8].
Но когда стали анализировать эти распределения, то
оказалось, что для того, чтобы сделать обоснованные выводы о характере влиянии
исследуемых факторов на систему
необходимо сравнивать ее поведение под действием этих факторов с какой-то базой сравнения, например с поведением
той же системы в условиях отсутствии действия этих факторов и при прочих равных
условиях, т.е. сравнивать с контрольной
группой. Так появился метод контрольных групп, без которого немыслимо научное
измерение влияния факторов.
Однако в связи с природой самого объекта исследования
реально на практике исследователи чаще всего не имеют возможности изучить
влияние на объект всех возможных сочетаний значений факторов и выделить
контрольную группу. Поэтому приходится сравнивать поведение объектов в
различных группах с его поведением в среднем по всей выборке, для чего были
предложены «метод среднего и отклонений от среднего» и «метод вариабельных
контрольных групп» [8].
Другой проблемой является выделение полезного сигнала из шума, т.к. в общем случае измеряемая
величина является суммой «истинного» значения и шума, и обеспечение сопоставимости изучения влияния факторов
различной природы, как качественных, так
количественных, измеряемых в различных типах измерительных шкал [9, 10] и в
различных единицах измерения. Все эти проблемы решены в новом методе исследования:
системно-когнитивном анализе («АСК-анализ») и его программном инструментарии –
универсальной когнитивной аналитической системе «Эйдос» [3, 4].
Соответственно эволюции понятия «Измерение»
эволюционировали и измерительные системы, технологии и методики их применения.
Для установления фактов, осознанно или нет, но всегда использовался некоторый инструмент и способ или методика его
применения. Исторически первыми такими инструментами стали сами органы
восприятия человека, прежде всего зрение, а способом – наблюдение. Создание новых
инструментов всегда приводило к революции в науке или даже возникновению новых
наук. Достаточно вспомнить, как изменились биология и медицина после изобретения
микроскопа Антони Ван Левенгуком, и как изменилась астрономия после изобретения
телескопа Галилео Галилеем. Последовавшее затем изобретение радиотелескопа
привело к возникновению радиоастрономии, а рентгеновского телескопа, соответственно
– рентгеновской астрономии и т.д. и т.д. Как микроскоп или телескоп многократно
увеличивают возможности естественного зрения, если оно есть, так и системы искусственного интеллекта многократно
увеличивают возможности интеллекта естественного, если он есть. Микроскоп или телескоп не заменяют зрения, а лишь
усиливают возможности естественного зрения или компенсируют его недостатки.
Аналогично и системы искусственного интеллекта не заменяют естественного
интеллект, а лишь усиливают возможности естественного интеллекта или
компенсируют его недостатки.
Адаптивная интеллектуальная измерительная система
(АИИС) также представляет собой новый инструмент исследования, своего рода специфический
микроскоп и телескоп одновременно, появление которого в руках исследователей
может многократно увеличить возможности человека к наблюдению и осмыслению их
результатов, а значит и привести к возникновению новых направлений науки [8,
11, 12, 13]. В качестве источника фактов для АИИС выступают базы знаний,
отражающие свойства систем и характеристику их состояний. В качестве
эффективной системы выделения сверхслабого полезного сигнала из многократно
превосходящего его шума в АИИС применяются методы и технологии искусственного
интеллекта, в частности предлагается применить для этого АСК-анализ и систему
«Эйдос».
В общем случае синтез измерительной системы
представляет собой процесс обучения с учителем системы распознавания образов на
основе примеров и создание базы знаний, отражающей причинно-следственные зависимости
между показаниями датчиков и результатами измерения.
Синтез
измерительной системы предполагает наличие двух
или более параллельных и независимых друг от друга источников и соответствующих
им параллельных каналов передачи информации об измеряемых объектах: источник
априорной информации о сущностных
значениях свойств или измеряемых состояний объектов и источник косвенной информации, получаемой
непосредственно в процессе измерения объектов с помощью датчиков[3]. После
выявления причинно-следственных взаимосвязей
между этими двумя потоками информации измерительная система на основе знания
этих взаимосвязей способна только по косвенной информации, получаемой от
измеряемого объекта в процессе измерения с помощью датчиков, восстановить, реконструировать
априорную информацию и эта реконструированная априорная информация собственно и
является результатом измерения.
Ниже приведены два примера использования знания
причинно-следственных зависимостей для построения измерительных систем.
Пример 1:
пружинные весы. Физики в
лице Гука выявили причинно-следственную взаимосвязь между весом тела,
положенного на пружинные весы, и степенью сжатия пружины под действием этого
веса. Когда весь сравнительно невелик и пружина почти не сжимается, то между ее
сжатием и весом существует практически линейная взаимосвязь, знание которой и
положено в основу принципа действия пружинных весов, которые по степени сжатия пружины определяют вес
тела.
Пример 2:
ртутный или спиртовой термометр. При небольших изменениях температуры жидкости ее
объем изменяется практически линейно от температуры. Знание этой
причинно-следственной зависимости положено в основу действия термометров,
которые по степени расширения жидкости
определяют ее температуру. При этом предполагается, что теплоемкость
термометра пренебрежимо мала по сравнению с теплоемкостью тела, температура
которого измеряется и поэтому в процессе выравнивания
их температур (достижения теплового равновесия) в процессе теплового
взаимодействия температура измеряемого тела практически не изменится за счет
теплового взаимодействия с термометром, а температура последнего станет равной
температуре измеряемого тела. Это в частности означает, что с помощью
макротермометра невозможно измерить температуру капельки тумана или бактерии.
Эмпирические данные, используемые для выявления
причинно-следственных зависимостей в предметной области и необходимые для
синтеза измерительной системы, образуют обучающую выборку, которая является
репрезентативной по отношению к некоторой генеральной совокупности, в пределах
которой действуют те же причинно-следственные зависимости, что и в обучающей
выборке и в пределах которой применение
данной системы методологически корректно.
В естественнонаучных измерениях генеральная
совокупность может быть глобальной,
т.е. в пространстве может включать и другие галактики, а во времени – миллиарды
лет. Когда же измерения производятся в социально-экономических и
социально-психологических системах, то границы генеральной совокупности в
пространстве могут измеряться километрами, а во времени – годами (так
называемые периоды эргодичности), т.е. измерения в этих предметных областях по
необходимости являются локальными.
Для социально-экономических систем не выполняется принцип относительности,
подобный принципу относительности Галилея-Эйнштейна [14]. Поэтому в естественных
науках возможен и успешно применяется подход к построению измерительных систем
на основе заранее известных причинно-следственных связей в предметной области.
Однако этот подход неприменим, например, в социально-экономических и социально-психологических
эмпирических исследованиях, в которых, по этой причине, необходимо иметь инструменты для выявления этих причинно-следственных
связей непосредственно при синтезе
измерительной системы. Этот инструмент необходим также и при применении измерительной системы в адаптивном режиме, т.к. положенные в основу
измерительной системы причинно-следственные связи могут изменяться в
зависимости от места и времени ее применения. Поэтому необходимо адаптировать и
локализовать адаптивные интеллектуальные измерительные системы соответственно к
времени и месту их применения. Это наукоемкая и дорогая процедура, одна без нее
применение неадаптированных и нелокализованных измерительных технологий превращается
в профанацию самой идеи измерений в соответствующих предметных областях.
Понятно, что технология стоит на порядки дороже продуктов ее применения.
Поэтому на практике как правило пользуются неадаптированными и нелокализованными
измерительными инструментами, которые дают неизвестные систематические ошибки
измерений или вообще результаты, близкие к случайным. Таким образом, необходимо
включить инструментарий синтеза измерительной системы в состав самой этой
системы, но для этого надо иметь такой инструментарий и он должен быть достаточно
прост в применении, т.е. должен иметь персональный уровень.
Таким универсальным инструментом, обеспечивающим выявление
причинно-следственных зависимостей в различных предметных областях, является
автоматизированный системно-когнитивный анализ (АСК-анализ) и его программный
инструментарий – интеллектуальная система «Эйдос» [3, 4]. Но АСК-анализ и
система «Эйлос» обеспечивают не только выявление причинно-следственных связей в
различных предметных областях, но и применение знания этих
причинно-следственных зависимостей для измерения степени выраженности
свойств и идентификации состояний объектов в этих предметных областях. Причинно-следственные
связи, выявленные в моделируемой предметной области, отражены в базах
знаний системы «Эйдос» и могут быть наглядно представлены в разнообразных
текстовых и графических формах (которых более 110), в том числе в форме
когнитивных функций [15, 16].
В качестве особо важного этапа развития измерительных
систем необходимо отметить информационно-измерительные системы.
При построении измерительных систем в естественных
науках используются знания причинно следственных зависимостей, полученные в
результате заранее проведенных
длительных фундаментальных исследований и сохраняющих свое значение глобально и на очень длительные периоды
времени, возможно миллионы и даже миллиарды лет. Однако в наше время
потребности практики измерений часто опережают темпы развития фундаментальной
науки, в результате чего возникает проблема синтеза измерительных систем,
обеспечивающих измерение состояний сложных нелинейных объектов на основе
значений их свойств при заранее неизвестном виде причинно-следственных зависимостей между
свойствами и состояниями. В наше время, когда эмпирические измерения все
более проникают в социально-экономические и психологические исследования,
заранее знать причинно-следственные зависимости в измеряемой области не
представляется возможным [14]. Это значит, что в этих областях неприменим
подход, успешно применявшийся в естественных науках.
В автоматизированном системно-когнитивном анализе
(АСК-анализ) предлагается сначала построить интеллектуальные модели, отражающие
эти причинно-следственные взаимосвязи на основе неполных и зашумленных исходных
данных большой размерности, а затем использовать знание этих зависимостей для
системных, т.е. многопараметрических нелинейных измерений.
Обратимся к эпиграфу к статье. Итак, современная
наука, по мнению ее выдающихся представителей, изучает лишь
пространственно-временные совпадения. Неужели уникальные явления, т.е.
то, что не совпадает, и не изучается вовсе? И что вообще означает:
«совпадение»? Ответом на эти вопросы является
системная нечеткая интервальная математика [15]. Ведь ясно, что абсолютно точно ничто не совпадает[4], все всегда совпадет лишь в определенной степени или с определенной точностью и эту степень
всегда можно выбрать такой, что 1) ничего не будет совпадать, или 2) все будет
совпадать, или 3) что-то будет, а что-то не будет совпадать. Третий вариант
открывает путь к исследованию достаточно уникальных явлений и закономерностей,
подчиняющихся принципам относительности лишь локально в определенных доменах
(умвельтах) пространства и времени.
Итак, предлагается применить
автоматизированный системно-когнитивный анализ как для синтеза, так и для
применения адаптивной интеллектуальной измерительной системы с целью измерения
не значений параметров объектов, а для идентификации
состояний измеряемых систем, т.е. для так называемой системной
идентификации [7, 13]. Измерительная система должна быть не проще, чем
измеряемая система (вариант принципа Эшби), иначе она не может быть адекватной.
Значит, для измерения сложных нелинейных систем должны применяться
интеллектуальные технологии, обеспечивающие достаточно высокий уровень
сложности баз знаний. Когда мы проводим
диагностику (квалиметрию) материалов, то стараемся оценить качество каких-либо
параметров в определенных шкалах. Это параметрический подход. Параметрический
подход корректен только для линейных объектов (материалов), в которых отдельные
параметры практически не влияют друг на друга. Для нелинейных материалов
качество надо оценивать не по одному параметру, а по всем сразу. Это суть
системного подхода к квалиметрии, при котором качество рассматривается как
системное (эмерджентное) свойство системы. По мнению автора все без исключения свойства объектов и явлений имеют
системную эмерджентную природу [17]. Это связано с тем, что структура системы
обуславливает на ее макросвойства [18]. Поэтому возникает задача
системной идентификации качества материала на основе значений различных его параметров, которая решается в
АСК-анализе и системе «Эйдос». В
качестве примеров системной идентификации можно привести измерение
сейсмоопасности микрозоны [19] и измерение качества микрозоны для выращивания
пшеницы [20].
Ниже рассмотрим простой
условный численный пример того, как осуществляется синтез измерительной системы в АСК-анализе и его программном
инструментарии – универсальной когнитивной аналитической системе «Эйдос» [3, 4]
и как при этом осуществляется метризация
шкал [9], преобразование данных в информацию, а ее в знания, как выявляются
причинно-следственные зависимости между результатами измерений и их
интерпретацией, и как эта измерительная система применяется для системной идентификации состояний сложных систем, в
частности для многопараметрического измерения их качества. При этом будем
руководствоваться этапами АСК-анализа [3] (когнитивная структуризация и формализация
предметной области; синтез и верификация моделей, определение наиболее
достоверной модели; решение задач идентификации, прогнозирования, принятия
решений и исследования предметной области путем исследования ее модели) и будем
последовательно повышать степень формализации создаваемых моделей, преобразуя
данные в информацию, а ее в знания:
Данные – это информация, записанная на каком-либо носителе
или находящаяся в каналах связи и представленная на каком-то языке или в системе
кодирования и рассматриваемая безотносительно к ее смысловому содержанию.
Исходные данные об объекте управления обычно
представлены в форме баз данных, чаще всего временных рядов, т.е. данных,
привязанных ко времени. В соответствии с методологией и технологией
автоматизированного системно-когнитивного анализа (АСК-анализ) для управления и
принятия решений использовать непосредственно исходные данные не представляется
возможным. Точнее сделать это можно, но результат управления при таком подходе оказывается мало чем
отличающимся от случайного. Для реального же решения задачи управления
необходимо предварительно преобразовать данные в информацию, а ее в знания о
том, какие воздействия на корпорацию к каким ее изменениям обычно, как показывает
опыт, приводят.
Информация есть
осмысленные данные.
Смысл данных, в соответствии с концепцией смысла
Шенка-Абельсона [21], состоит в том, что известны причинно-следственные зависимости
между событиями, которые описываются этими данными. Таким образом, данные
преобразуются в информацию в результате операции, которая называется «Анализ
данных», которая состоит из двух этапов:
1. Выявление событий в данных (разработка
классификационных и описательных шкал и градаций и преобразование с их
использованием исходных данных в обучающую выборку, т.е. в базу событий –
эвентологическую базу).
2. Выявление причинно-следственных зависимостей между
событиями.
В случае систем управления событиями в данных являются
совпадения определенных значений входных факторов и выходных параметров объекта
управления, т.е. по сути, случаи перехода объекта управления в определенные
будущие состояния под действием определенных сочетаний значений управляющих
факторов. Качественные значения входных факторов и выходных параметров
естественно формализовать в форме лингвистических переменных. Если же входные
факторы и выходные параметры являются числовыми, то их значения измеряются с
некоторой погрешностью и фактически представляют собой интервальные числовые
значения, которые также могут быть представлены или формализованы в форме
лингвистических переменных (типа: «малые», «средние», «большие» значения
экономических показателей).
Какие же математические меры могут быть использованы
для количественного измерения силы и направления причинно-следственных зависимостей?
Наиболее очевидным ответом на этот вопрос, который
обычно первым всем приходит на ум, является: «Корреляция». Однако, в статистике
это хорошо известно, что это совершенно не так.
Для преобразования исходных данных в информацию необходимо не только
выявить события в этих данных, но и найти причинно-следственные связи между
этими событиями. В АСК-анализе предлагается 7 количественных мер
причинно-следственных связей, основной из которых является семантическая мера
целесообразности информации по А.Харкевичу.
Знания – это
информация, полезная для достижения
целей [22].
Значит для преобразования информации в знания
необходимо:
1. Поставить цель (классифицировать будущие состояния
моделируемого объекта на целевые и нежелательные).
2. Оценить полезность информации для достижения этой
цели (знак и силу влияния).
Второй пункт, по сути, выполнен при преобразовании
данных в информацию. Поэтому остается выполнить только первый пункт, т.к.
классифицировать будущие состояния объекта управления как желательные (целевые)
и нежелательные.
Знания могут быть представлены в различных формах,
характеризующихся различной степенью формализации:
– вообще
неформализованные знания, т.е. знания в своей собственной форме, ноу-хау
(мышление без вербализации есть медитация);
– знания, формализованные в естественном вербальном
языке;
– знания, формализованные в виде различных методик,
схем, алгоритмов, планов, таблиц и отношений между ними (базы данных);
– знания в форме технологий, организационных,
производственных, социально-экономических и политических структур;
– знания, формализованные в виде математических
моделей и методов представления знаний в автоматизированных интеллектуальных
системах (логическая, фреймовая, сетевая, продукционная, нейросетевая, нечеткая
и другие).
Таким образом, для решения сформулированной проблемы
необходимо осознанно и целенаправленно последовательно повышать степень
формализации исходных данных до уровня, который позволяет ввести исходные
данные в интеллектуальную систему, а затем:
– преобразовать исходные данные в информацию;
– преобразовать информацию в знания;
– использовать знания для решения задач управления,
принятия решений и исследования предметной области.
Исходные данные.
В качестве исходных данных, описывающих различные
состояния объектов для системной идентификации, рассмотрим правильные тела
Платона (таблица 1):
Таблица 1 – ТРЕХМЕРНЫЕ ПРАВИЛЬНЫЕ МНОГОГРАННИКИ
|
№ |
Наименование правильного многогранника |
Изображение |
Количество |
||||
|
Сторон у грани |
Ребер у вершины |
Вершин (всего) |
Ребер (всего) |
Граней (всего) |
|||
|
1 |
|
3 |
3 |
4 |
6 |
4 |
|
|
2 |
|
4 |
3 |
8 |
12 |
6 |
|
|
3 |
|
3 |
4 |
6 |
12 |
8 |
|
|
4 |
|
5 |
3 |
20 |
30 |
12 |
|
|
5 |
|
3 |
5 |
12 |
30 |
20 |
|


Далее осуществим синтез интеллектуальной измерительной
системы в соответствии с этапами АСК-анализа [3, 4]:
1. Когнитивная структуризация предметной области. Это единственный этап АСК-анализа, осуществляемый не
на компьютере. На этом этапе необходимо решить, что мы хотим определять и на
основе чего. В данном случае будем идентифицировать тело Платона на основе его
признаков, приведенных в таблице 1.
Дальнейшие этапы АСК-анализа выполняются в системе
«Эйлос».
2. Формализация предметной области включает: разработку классификационных шкал и
градаций; разработку описательных шкал и градаций; разработку обучающей
выборки, т.е. кодирование исходных данных с применением справочников классификационных
и описательных шкал и градаций. По сути формализация предметной области
представляет собой нормализацию базы
исходных данных.
Таблица 2 – КЛАССИФИКАЦИОННАЯ ШКАЛА И ЕЕ ГРАДАЦИИ
|
Код |
Наименование |
|
1 |
НАИМЕНОВАНИЕ ТЕЛА ПЛАТОНА-Додекаэдр |
|
2 |
НАИМЕНОВАНИЕ ТЕЛА ПЛАТОНА-Икосаэдр |
|
3 |
НАИМЕНОВАНИЕ ТЕЛА ПЛАТОНА-Куб |
|
4 |
НАИМЕНОВАНИЕ ТЕЛА ПЛАТОНА-Октаэдр |
|
5 |
НАИМЕНОВАНИЕ ТЕЛА ПЛАТОНА-Тетраэдр |
Таблица 3 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
|
Код |
Наименование |
|
1 |
СТОРОН У ГРАНИ-3 |
|
2 |
СТОРОН У ГРАНИ-4 |
|
3 |
СТОРОН У ГРАНИ-5 |
|
4 |
РЕБЕР У ВЕРШИНЫ-3 |
|
5 |
РЕБЕР У ВЕРШИНЫ-4 |
|
6 |
РЕБЕР У ВЕРШИНЫ-5 |
|
7 |
ВЕРШИН (ВСЕГО)-12 |
|
8 |
ВЕРШИН (ВСЕГО)-20 |
|
9 |
ВЕРШИН (ВСЕГО)-4 |
|
10 |
ВЕРШИН (ВСЕГО)-6 |
|
11 |
ВЕРШИН (ВСЕГО)-8 |
|
12 |
РЕБЕР (ВСЕГО)-12 |
|
13 |
РЕБЕР (ВСЕГО)-30 |
|
14 |
РЕБЕР (ВСЕГО)-6 |
|
15 |
ГРАНЕЙ (ВСЕГО)-12 |
|
16 |
ГРАНЕЙ (ВСЕГО)-20 |
|
17 |
ГРАНЕЙ (ВСЕГО)-4 |
|
18 |
ГРАНЕЙ (ВСЕГО)-6 |
|
19 |
ГРАНЕЙ (ВСЕГО)-8 |
Используя классификационные и описательные шкалы и
градации (таблицы 2 и 3) закодируем описания тел Платона, приведенные в исходных
данных (таблица 1) в результате чего получим таблицу 4.
Таблица 4 – ОБУЧАЮЩАЯ ВЫБОРКА
|
Наименование объекта |
Код класса |
Коды признаков |
||||
|
Тетраэдр |
5 |
1 |
4 |
9 |
14 |
17 |
|
Куб |
3 |
2 |
4 |
11 |
12 |
18 |
|
Октаэдр |
4 |
1 |
5 |
10 |
12 |
19 |
|
Додекаэдр |
1 |
3 |
4 |
8 |
13 |
15 |
|
Икосаэдр |
2 |
1 |
6 |
7 |
13 |
16 |
3. Синтез и верификация моделей, определение наиболее
достоверной модели.
На основе результатов формализации предметной области
системой «Эйдос» рассчитываются (см. рисунок 1) матрица абсолютных частот
(корреляционная матрица), матрицы условных и безусловных процентных
распределений, а также на их основе матрицы знаний с различными частными
критериями знаний [9].
С применением данных частных критериев знаний
рассчитываются модели знаний, отражающие силу и направление
причинно-следственной взаимосвязи между значениями факторов и принадлежностью
объекта к классам. В таблице 5 приведена одна из 7 моделей знаний:
Таблица 5 – МАТРИЦА ЗНАНИЙ НА ОСНОВЕ ЧАСТНОГО
КРИТЕРИЯ ЗНАНИЙ А.ХАРКЕВИЧА (В МИЛЛИБИТАХ)
|
№ |
Наименование признака |
Наименование класса |
||||
|
Додекаэдр |
Икосаэдр |
Куб |
Октаэдр |
Тетраэдр |
||
|
1 |
СТОРОН У ГРАНИ-3 |
|
368 |
|
368 |
368 |
|
2 |
СТОРОН У ГРАНИ-4 |
|
|
1161 |
|
|
|
3 |
СТОРОН У ГРАНИ-5 |
1161 |
|
|
|
|
|
4 |
РЕБЕР У ВЕРШИНЫ-3 |
368 |
|
368 |
|
368 |
|
5 |
РЕБЕР У ВЕРШИНЫ-4 |
|
|
|
1161 |
|
|
6 |
РЕБЕР У ВЕРШИНЫ-5 |
|
1161 |
|
|
|
|
7 |
ВЕРШИН (ВСЕГО)-12 |
|
1161 |
|
|
|
|
8 |
ВЕРШИН (ВСЕГО)-20 |
1161 |
|
|
|
|
|
9 |
ВЕРШИН (ВСЕГО)-4 |
|
|
|
|
1161 |
|
10 |
ВЕРШИН (ВСЕГО)-6 |
|
|
|
1161 |
|
|
11 |
ВЕРШИН (ВСЕГО)-8 |
|
|
1161 |
|
|
|
12 |
РЕБЕР (ВСЕГО)-12 |
|
|
661 |
661 |
|
|
13 |
РЕБЕР (ВСЕГО)-30 |
661 |
661 |
|
|
|
|
14 |
РЕБЕР (ВСЕГО)-6 |
|
|
|
|
1161 |
|
15 |
ГРАНЕЙ (ВСЕГО)-12 |
1161 |
|
|
|
|
|
16 |
ГРАНЕЙ (ВСЕГО)-20 |
|
1161 |
|
|
|
|
17 |
ГРАНЕЙ (ВСЕГО)-4 |
|
|
|
|
1161 |
|
18 |
ГРАНЕЙ (ВСЕГО)-6 |
|
|
1161 |
|
|
|
19 |
ГРАНЕЙ (ВСЕГО)-8 |
|
|
|
1161 |
|
Подбазы знаний наглядно представляются в форме
когнитивных функций (рисунок 2):
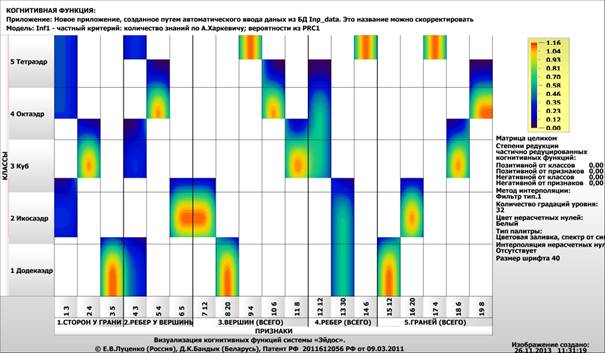
Рисунок 1 – Наглядная визуализация базы знаний Inf1
в форме когнитивной функции
Верификация моделей осуществляется путем решения в них
задачи системной идентификации и подсчета количества ошибок 1-го и 2-го рода
(ошибок неидентификации и ложной идентификации). Модель знаний, приведенная в
таблице 5, показывает 100% достоверность идентификации и неидентификации.
4. Решение задач идентификации, прогнозирования,
принятия решений и исследования предметной области.
Рассмотрим интегральные критерии знаний, используемые в настоящее
время в АСК-анализе и системе «Эйдос-Х++» [23] для верификации моделей и
решения задач идентификации и прогнозирования.
1-й интегральный критерий «Сумма знаний» представляет собой суммарное количество знаний, содержащееся
в системе факторов различной природы, характеризующих сам объект управления,
управляющие факторы и окружающую среду, о переходе объекта в будущие целевые
или нежелательные состояния.
Интегральный критерий представляет собой аддитивную функцию от частных
критериев знаний и имеет вид::
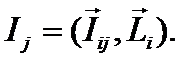
В выражении круглыми скобками обозначено скалярное произведение. В координатной
форме это выражение имеет вид:
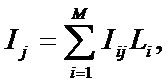
где: M – количество градаций
описательных шкал (признаков);
![]() – вектор состояния j–го класса;
– вектор состояния j–го класса;
![]() – вектор
состояния распознаваемого объекта, включающий все виды факторов,
характеризующих сам объект, управляющие воздействия и окружающую среду (массив–локатор),
т.е.:
– вектор
состояния распознаваемого объекта, включающий все виды факторов,
характеризующих сам объект, управляющие воздействия и окружающую среду (массив–локатор),
т.е.:
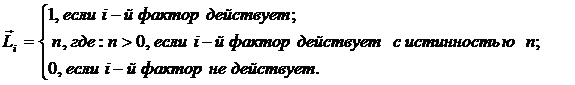
В текущей версии системы «Эйдос-Х++» значения координат вектора
состояния распознаваемого объекта принимались равными либо 0, если признака
нет, или n, если он присутствует у объекта с интенсивностью n, т.е. представлен
n раз (например, буква «о» в слове «молоко» представлена 3 раза, а буква «м» -
один раз).
2-й интегральный критерий «Семантический резонанс
знаний» представляет
собой нормированное суммарное
количество знаний, содержащееся в системе факторов различной природы,
характеризующих сам объект управления, управляющие факторы и окружающую среду,
о переходе объекта в будущие целевые или нежелательные состояния.
Интегральный критерий представляет собой аддитивную функцию от частных
критериев знаний и имеет вид:
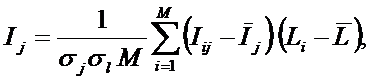
где:
M –
количество градаций описательных шкал (признаков);
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по
вектору объекта;
– среднее по
вектору объекта;
![]() –
среднеквадратичное отклонение частных критериев знаний вектора класса;
–
среднеквадратичное отклонение частных критериев знаний вектора класса;
![]() – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
Результат системной идентификации представляется в
следующем виде (рисунок 3):
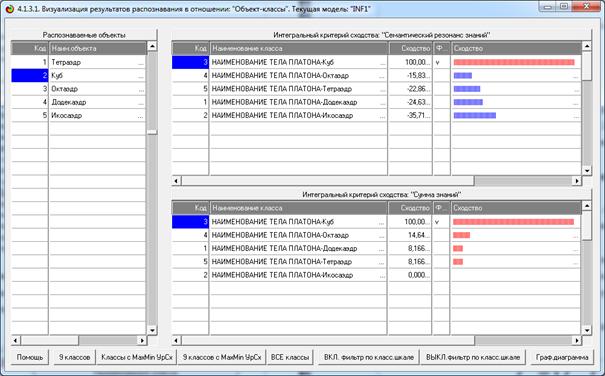
Рисунок 2 – Экранная форма с результатами системной идентификации
в модели знаний INF1
На рисунке 3 показано, что по суммарному количеству
информации, которое содержится в системе признаков объекта «Куб» он больше
всего похож на класс «Куб», а остальные классы не похож в различной степени.
Таким
образом, в АСК-анализе:
1. Рассматривается ряд объектов (фактов),
представляющих в совокупности исследуемую выборку.
2. Каждый из объектов исследуемой выборки представляет
собой систему, имеющую сложную многоуровневую структуру признаков
(экстенсиональное описание).
3. Для каждого из объектов исследуемой выборки
известно, к каким обобщенным категориям (классам) он относится (интенсиональное
описание).
4. Необходимо сформировать модель, обеспечивающую
идентификацию объектов по их признакам, т.е. определение их принадлежности к
обобщенным классам по их признакам.
Если признаки и классы относятся к одному времени, то
имеет место задача идентификации (распознавания). Если же признаки (факторы, причины)
относятся к прошлому, а классы, характеризующие состояния объектов, – к будущему,
то это задача прогнозирования. Математически эти задачи не отличаются.
Совокупность экстенсионального и интенсионального описания каждого объекта
обучающей выборки, по сути, представляет собой его определение через подведение под более общее понятие и выделение специфических
признаков. Иначе
говоря, каждый объект обучающей выборки описывается принадлежностью к более
общей категории (классу) и наличием у него ряда признаков. Например, так
определяется понятие «млекопитающее»: это животное (более общее понятие),
выкармливающее своих детей молоком (специфический признак). На
основе ряда определений конкретных объектов (конкретных онтологий) путем их
обобщения можно получить определения (обобщающие онтологии) обобщенных образов
классов. Если привести в качестве примеров исследуемой выборки
множество различных животных, как млекопитающих, так и других, каждый из таких
примеров определить множеством признаков и построить модель, то окажется, что
наиболее характерным признаком млекопитающих является не наличие шерсти или
когтей, а именно вскармливание детенышей молоком.
Процедура преобразования исходных данных в информацию – это анализ
данных, состоящий из трех шагов:
– разработка справочников фактов и событий;
– выявление в исходных данных фактов или событий и их
кодирование;
– выявление причинно-следственных связей
(зависимостей) между этими событиями.
Фактически для преобразования исходных данных в
информацию необходимо:
1. Разработать классификационные и описательные шкалы
и градации.
2. С использованием классификационных и описательных
шкал и градаций закодировать исходные
данные, в результате чего получится обучающая выборка, состоящая из фактов, представляющих собой примеры в
единстве экстенсионального и интенсионального описания.
3. Произвести расчет матриц абсолютных частот,
условных и безусловных процентных распределений и матрицы информативностей, отражающей
причинно-следственные связи между значениями факторов и принадлежностью
объектов к классам.
Таким образом, информация по задаче – это
исходные данные плюс классификационные и описательные шкалы и градации,
обучающая выборка, а также матрицы частот, процентных распределений и информативностей.
Процедура преобразования информации в знания – это оценка
полезности информации для достижения цели.
Значит знания по задаче – это информация плюс
цель и оценка степени полезности информации для достижения этой цели.
Знания получаются из информации, когда мы
классифицируем будущие состояния объекта управления как желательные (целевые) и
нежелательные.
Банк данных – это базы данных плюс система управления базами данных (СУБД) (стандартные термины). СУБД – это,
по сути, система управления данными.
Информационный банк – это информационные базы плюс информационные системы
(предлагается стандартизировать эти термины). Информационная система – это, по
сути, система управления информацией.
Банк знаний – это базы знаний плюс интеллектуальные системы
(стандартные термины). Интеллектуальная система – это, по сути, система управления знаниями.
Итак, измерение рассматривается как процесс получения информации об объекте
измерения, в частности о степени выраженности тех или иных его свойств или принадлежности
состояния объекта измерения к определенным категориям. Предлагается применить
системно-когнитивный анализ как для синтеза, так и для применения адаптивной
интеллектуальной измерительной системы с целью измерения не значений параметров
объектов, а для идентификации состояний измеряемых систем, т.е. для так
называемой системной идентификации. Измерительная система должна быть не проще,
чем измеряемая система (вариант принципа Эшби), иначе она не может быть адекватной.
Значит, для измерения сложных нелинейных систем должны применяться интеллектуальные
технологии, обеспечивающие достаточно высокий уровень сложности баз знаний. Когда мы проводим диагностику (квалиметрию)
материалов, то стараемся оценить качество каких-либо параметров в определенных
шкалах. Это параметрический подход, который корректен только для линейных
объектов (материалов), в которых отдельные параметры практически не влияют друг
на друга. Для нелинейных материалов качество надо оценивать не по одному
параметру, а по всем сразу и в этом суть
системного подхода к квалиметрии, когда качество рассматривается как системное
(эмерджентное) свойство.
Математические модели
АСК-анализа, применяемые при синтезе и применении адаптивных интеллектуальных
измерительных систем, а также численные примеры системной идентификации, более
подробно рассматриваются в последующих разделах.
6.1.2. Математический метод АСК-анализа –
системная теория информации
Первый раздел данной работы посвящен концептуальным
основам построения интеллектуальных измерительных систем в АСК-анализе, данный
раздел (второй) – математическому методу АСК-анализа, в третьем будет
рассмотрен численный пример синтеза интеллектуальной измерительной системы в
системе «Эйдос-Х++» и ее применения для системной идентификации состояний
сложных систем.
На основе 1-го раздела предлагаются следующие три
принципа построения интеллектуальных измерительных систем в АСК-анализе.
1-й принцип состоит на ясном
осознании того обстоятельства, что
когда мы получаем результаты измерения, то по сути мы получаем некоторое
количество информации о том, в каком состоянии находится измеряемый
объект. Однако традиционно результаты измерения выражаются в определенных
единицах измерения (в частности, единицах измерения физических величин), а не в
единицах измерения информации и этим в определенной степени маскируется или
скрывается смысл самого измерения,
выраженный в 1-м принципе.
2-й принцип, связан с первым и состоит в понимании того, что
когда мы получаем результаты измерения то нас интересует не собственно сам этот
результат, а количество информации, которое содержится в результате измерения о
состоянии объекта измерения, т.е. о том, что нас собственно интересует.
Например, когда врач измеряет температуру пациенту то его интересует не эта
температура сама по себе как некоторые почему-то думают, а возможность на ее
основе сделать выводы о состояния пациента, т.е. о том болен он или нет, и,
если болен, то на сколько серьезно и какой у него диагноз и какой выбрать план
лечения при этом диагнозе.
3-й принцип состоит в том, что при построении измерительной системы на эмпирических примерах
производится градуировка или метризация
измерительных шкал, т.е. нанесение на них делений, соответствующих различным
степеням выраженности измеряемых свойств у объектов измерения. Затем, когда
измерительная система применяется,
т.е. при измерении по ранее полученным шкалам получаются некоторые значения, то
на основании этих значений делается вывод о том, что состояние измеряемого
объекта близко к состоянию тех примеров, которые давали аналогичный результат измерений
при построении шкал. По сути 3-й принцип,
отражающий этап построения или синтеза измерительной системы, функционально
сходен с этапом обучения системы распознавания образов, а этап ее применения
сходен с применением системы распознавания для идентификации состояния объекта
измерения.
Для того, чтобы реализовать сформулированные принципы
в реальной интеллектуальной измерительной системе необходим математический метод, обеспечивающий преобразование данных,
полученных в результате измерений, в информацию о состоянии измеряемого объекта.
Такой метод существует – это математический метод АСК-анализа, основанный на системной нечеткой интервальной математике
(СНИМ) [3, 15] и представляющий собой реализацию идей СНИМ в теории информации.
В этой связи необходимо
определить соотношение содержания терминов: «данные», «информация» и «знание»
(рисунок 4):
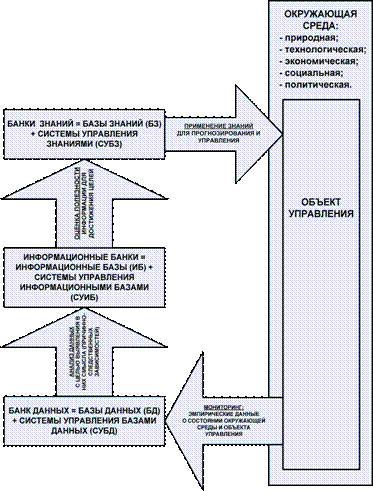
Рисунок 3 – Цикл преобразования эмпирических данных в информацию и
знания и их применения для прогнозирования и принятия управленческих решений в
АСК-анализе
Данные рассматриваются как информация, записанная на
носителях или находящаяся в каналах связи и представленная в определенной системе
кодирования или на определенном языке и рассматриваемая безотносительно к ее
смысловому содержанию.
Смысл данных согласно концепции смысла Шенка-Абельсона [21] известен и
понятен тогда, когда известны причины и следствия меду событиями, которые описываются
этими данными.
Информация представляет
собой осмысленные данные, т.е. данные, описывающие события, между которыми выявлены
причинно-следственные связи.
Знания – это информация, полезная для достижения целей, т.е.
для управления [22].
В этой связи возникает
вопрос о математической количественной мере причинно-следственных связей,
которая бы адекватно отражала их силу и направление. Из вышесказанного
следует, что естественной мерой причинно-следственных связей являются
количественные меры информации и в качестве единицы измерения силы и направления
причинно-следственных связей могут быть использованы единицы измерения
информации. В связи с этой идеей необходимо отметить работу [24], суть которой
в применении теории информации для проверки статистических гипотез. Еще в лемме
Неймана-Пирсона доказывается, что более вероятна та статистическая гипотеза в
пользу которой больше информации. В предисловии к работе [24] А.Н. Колмогоров
высоко оценивал это научное направление, но соответствующий поток работ в СССР
не возник [25]. По-видимому, АСК-анализ мере можно рассматривать как развитие
этого направления прикладной математической статистики, может быть не столько в
чисто-математическом теоретическом плане, сколько в прагматически-прикладном
[25, 26].
Однако известно довольно много различных
количественных мер информации. Поэтому возникает вопрос о том, какая мера
информации является наиболее подходящей в нашем случае. По мнению автора это
семантическая мера целесообразности информации А.Харкевича [3]. Основным
свойством этой меры, предопределяющим ее выбор, является то обстоятельство, что
в ее определение органично входит
понятие цели. В соответствии с изложенными выше и в работе [22]
представлениями автора о соотношении понятий: «Данные», «Информация» и «Знания»
это означает, что по сути А.Харкевич предложил количественную меру знаний. Кроме
того для вычисления меры А.Харкевича достаточно знать изменение вероятности
достижения цели в условиях действия некоторого значения фактора и при его
отсутствии, т.е. она вполне может быть рассчитана непосредственно на основе
эмпирических данных, что очень важно для практических применений (поэтому и
говорят, что эта мера прагматическая).
Операция преобразования данных в информацию называется
«анализ данных», представляет собой процедуру выявления смысла в данных, т.е. согласно концепции смысла Шенка-Абельсона,
выявление причинно-следственных связей между событиями[5], отражаемыми этими данными, и предполагает выполнение
следующих этапов:
1. Разработка справочников, содержащих формальное
кодированное описание с одной стороны будущих состояний объекта управления, а с
другой стороны – факторов их значений, влияющих на этот объект (классификационных
и описательных шкал и градаций в терминологии АСК-анализа).
2. Поиск в исходных данных событий, связанных с
переходами объекта из одного состояния в другое, и значений факторов, под
действием которых эти переходы происходят. При этом в качестве значений
факторов могут выступать и переходы объекта из одного состояния в другое в прошлом.
3. Преобразование базы исходных данных в базу событий,
т.е. кодирование исходных данных с
использованием справочников классов и факторов.
4. Поиск причинно-следственных связей между прошлыми и
будущими событиями в базе событий и формальное представление этих причинно-следственных
связей в виде базы информативностей.
Таким образом, если исходные базы данных представляют
собой временные ряды, то информационная база включает в себя еще дополнительно:
– базы классификационных и описательных шкал и
градаций;
– базу событий (т.е. обучающую выборку),
представляющую собой закодированную с помощью классификационных и описательных
шкал и градаций базу исходных данных;
– базу информативностей, содержащую информацию о силе
и направлении влияния значений факторов на переход объекта управления в
состояния, соответствующие классам.
Основываясь на
работах [3, 16, 18] рассмотрим, математический метод АСК-анализа,
обеспечивающей решение поставленных задач. Очень краткое и несколько упрощенное
описание автоматизированного системно-когнитивного
анализа (АСК-анализ) приведено в работе [27].
В работе [15] (и ряде других) развита идея системного
обобщения математики и обоснована актуальность этой идеи. Эта идея актуальна по
ряду причин разного рода.
Во-первых, потому, что в мире нет ничего кроме систем, а понятие
множества является абстракцией от понятия системы: множество – это система без
внутренней структуры. Поэтому математика, основанная на понятии системы, имеет
некоторые шансы быть более адекватной, чем классическая математика, в очень
большой степени основанная на понятии множества.
Во-вторых, идея системного обобщения математики частично реализована в теории
информации, в результате получена некоторые результаты в области системной
теории информации (СТИ), в частности получен вариант выражения для
семантической меры целесообразности информации А.Харкевича, удовлетворяющий
принципу соответствия с формулой Р.Хартли для равновероятного детерминистского
случая. Этим преодолена искусственная пропасть между «Теорией передачи данных
по каналам связи», как совершенно справедливо называл свою теорию К.Шеннон,
интуитивно понимавший различие между данными и информацией, и семантической
теорией информации А.Харкевича[6].
В-третьих, в созданной системной теории информации получены
разнообразные формы различных коэффициентов эмерджентности: Хартли, Харкевича,
Шеннона, для классических систем, подчиняющихся статистике Л.Больцмана [15] и
квантовых систем подчиняющихся статистикам Ферми-Дирака и Бозе-Эйнштейна [15].
Смысл этих коэффициентов раскрыт в работе [15] и других. Если резюмировать, то
можно сказать, что эти подходы, по-видимому, открывают новые подходы
математического моделирования процессов эволюции систем различного рода и
масштаба от микро до макро и мега уровней [8, 15, 16] и другие[7].
Математический метод АСК-анализа основан на системной теории информации
(СТИ), которая создана в рамках реализации программной идеи обобщения всех понятий
математики, в частности теории информации, базирующихся на теории множеств,
путем тотальной замены понятия множества на более общее понятие системы и тщательного
отслеживания всех последствий этой замены [15]. Благодаря математическому
методу, положенному в основу АСК-анализа, этот метод является непараметрическим
и позволяет в реализующей его системе «Эйдос-Х++» сопоставимо обрабатывать десятки и сотни тысяч градаций
факторов и будущих состояний нелинейных [28] многопараметрических объектов
управления (классов) при неполных (фрагментированных), зашумленных данных
числовой и нечисловой природы измеряемых в различных единицах измерения [3,
15].
Итак, будем считать, что информация содержится не
только в самих базовых элементах системы, но и в ее подсистемах различной
сложности, т.е. состоящих из 2, 3,… m,… M базовых элементов.
Классическая формула Хартли имеет вид [32]:
|
|
( 1
) |
Будем искать ее системное обобщение в виде [3]:
|
|
( 2
) |
где:
W – количество элементов в множестве.
I – количество информации, которое содержится в факте
извлечения одного элемента из множества.
j – коэффициент эмерджентности, названный автором в честь Р.Хартли, коэффициентом эмерджентности
Хартли[8].
Суммарное количество таких подсистем для систем, подчиняющихся
статистике Ферми-Дирака [15, 29], можно принять равным числу сочетаний. Поэтому
примем, что системное обобщение
формулы Хартли имеет вид:
|
|
( 3
) |
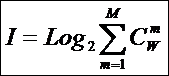
где:
![]() – количество подсистем из m элементов;
– количество подсистем из m элементов;
m – сложность подсистем;
M – максимальная сложность подсистем
(максимальное число элементов подсистемы).
Так как ![]() , то при M=1
система переходит в множество и выражение (3) приобретает вид (1), т.е. для
него выполняется принцип соответствия,
являющийся обязательным для более общей теории.
, то при M=1
система переходит в множество и выражение (3) приобретает вид (1), т.е. для
него выполняется принцип соответствия,
являющийся обязательным для более общей теории.
Учитывая, что при M=W:
|
|
( 4
) |
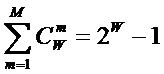
в этом случае получаем:
|
|
( 5
) |
Выражение (5) дает оценку
максимального количества информации в элементе системы. Из выражения (5)
видно, что при увеличении числа элементов W
количество информации I быстро
стремится к W (6) и уже при W>4 погрешность выражения (5) не
превышает 1%:
|
|
( 6
) |
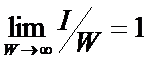
Приравняв правые части выражений (2) и (3):
|
|
( 7 ) |
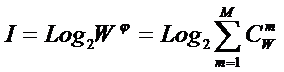
получим выражение для коэффициента эмерджентности Хартли:
|
|
( 8 ) |
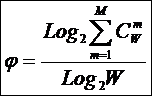
Смысл этого коэффициента весьма интересен и раскрыт в
работах [3, 15] и ряде других[9]. Здесь отметим лишь, что при M®1, когда система асимптотически переходит в множество,
имеем j®1 и (2) ® (1), как и должно быть согласно принципу соответствия,
предложенному Нильсом Бором в 1913 году.
С учетом (8) выражение (2) примет вид:
|
|
( 9 ) |
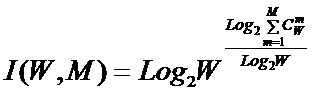
или при M=W и больших W, учитывая (4) и (5):
|
|
( 10 ) |
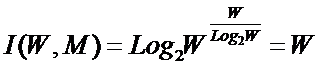
Выражение (9) и представляет собой искомое системное
обобщение классической формулы Хартли, а выражение (10) – его достаточно хорошее
приближение при большом количестве элементов в системе W.
Классическая формула А. Харкевича имеет вид:
|
|
( 11
) |
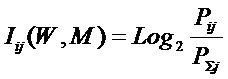
где: – Pij
– условная вероятность перехода объекта в j-е
состояние при условии действия на
него i-го значения фактора;
– ![]() – безусловная вероятность перехода объекта
в j-е состояние (вероятность
самопроизвольного перехода или вероятность перехода, посчитанная по всей
выборке, т.е. при действии любого
значения фактора).
– безусловная вероятность перехода объекта
в j-е состояние (вероятность
самопроизвольного перехода или вероятность перехода, посчитанная по всей
выборке, т.е. при действии любого
значения фактора).
Придадим выражению (11) следующий эквивалентный вид (12),
который и будем использовать ниже. Вопрос об эквивалентности выражений (11) и
(12) рассмотрим позднее.
|
|
( 12
) |
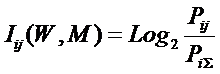
где: – индекс i
обозначает признак (значение фактора): 1£ i £ M;
– индекс j
обозначает состояние объекта или класс: 1£ j £ W;
– Pij
– условная вероятность наблюдения i-го
значения фактора у объектов в j-го
класса;
– ![]() – безусловная вероятность наблюдения i-го значения фактора по всей выборке.
– безусловная вероятность наблюдения i-го значения фактора по всей выборке.
Из (12) видно, что формула
Харкевича для семантической меры информации по сути является логарифмом от
формулы Байеса для апостериорной вероятности (отношение условной
вероятности к безусловной).
Известно, что классическая формула Шеннона для
количества информации для неравновероятных событий преобразуется в формулу Хартли
при условии, что события равновероятны, т.е. удовлетворяет фундаментальному принципу соответствия. Поэтому теория
информации Шеннона справедливо считается обобщением теории Хартли для
неравновероятных событий. Однако, выражения
(11) и (12) при подстановке в них реальных численных значений
вероятностей Pij, ![]() и
и ![]() не дает количества
информации в битах, т.е. для этого выражения не выполняется принцип соответствия, обязательный для
более общих теорий. Возможно, в этом состоит причина довольно сдержанного, а
иногда и скептического отношения специалистов по теории информации Шеннона к
семантической теории информации Харкевича.
не дает количества
информации в битах, т.е. для этого выражения не выполняется принцип соответствия, обязательный для
более общих теорий. Возможно, в этом состоит причина довольно сдержанного, а
иногда и скептического отношения специалистов по теории информации Шеннона к
семантической теории информации Харкевича.
Причину этого мы видим в том, что в выражениях (11) и
(12) отсутствуют глобальные параметры конкретной модели W и M,
т.е. в том, что А. Харкевич в своем выражении для количества информации не
ввел зависимости от мощности пространства
будущих состояний объекта W и количества значений факторов M, обуславливающих
переход объекта в эти состояния.
Поставим задачу получить такое обобщение формулы
Харкевича, которое бы удовлетворяло тому же самому принципу соответствия, что и формула Шеннона, т.е. преобразовывалось в
формулу Хартли в предельном детерминистском равновероятном случае, когда
каждому классу (состоянию объекта) соответствует один признак (значение
фактора), и каждому признаку – один класс, и эти классы (а, значит и признаки),
равновероятны, и при этом каждый фактор однозначно, т.е. детерминистским образом определяет
переход объекта в определенное состояние, соответствующее классу.
В детерминистском случае вероятность Pij наблюдения объекта j-го класса при обнаружении у него i-го признака:
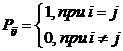 .
.
Будем искать это обобщение (12) в виде:
|
|
( 13
) |
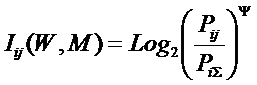
Найдем такое выражение для коэффициента Y, названного
автором в честь А. Харкевича "коэффициентом эмерджентности
Харкевича"[10], которое обеспечивает выполнение для выражения (13)
принципа соответствия с классической формулой Хартли (1) и ее системным
обобщением (2) и (3) в равновероятном
детерминистском случае.
Для этого нам потребуется выразить вероятности Pij, Pj и Pi
через частоты наблюдения признаков по классам (см. табл. 6). В табл. 1 рамкой
обведена область значений, переменные определены ранее.
Таблица 6 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ
|
|
Классы |
Сумма |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения
факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Суммарное количество признаков |
|
|
|
|
|
|
|
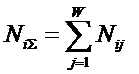
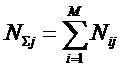
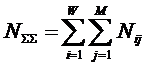
Алгоритм формирования матрицы абсолютных частот.
Объекты обучающей выборки описываются векторами
(массивами) ![]() имеющихся у них
признаков:
имеющихся у них
признаков:
![]()
Первоначально в матрице абсолютных частот все значения
равны нулю. Затем организуется цикл по объектам обучающей выборки. Если
предъявленного объекта, относящегося к j-му
классу, есть i-й признак, то:
![]()
Здесь можно провести очень интересную и важную аналогию
между способом формирования матрицы абсолютных частот и работой многоканальной системы выделения полезного сигнала из шума.
Представим себе, что все объекты, предъявляемые для формирования обобщенного
образа некоторого класса, в действительности являются различными реализациями
одного объекта – "Эйдоса" в смысле Платона [30], по-разному
зашумленного различными случайными обстоятельствами. И наша задача состоит в
том, чтобы подавить этот шум и выделить из него то общее и существенное, что
отличает объекты данного класса от объектов других классов. Учитывая, что шум
чаще всего является "белым" и имеет свойство при суммировании с самим
собой стремиться к нулю, а сигнал при этом, наоборот, возрастает
пропорционально количеству слагаемых, то увеличение объема обучающей выборки
приводит ко все лучшему отношению сигнал/шум в матрице абсолютных частот, т.е.
к выделению полезной информации из шума. Примерно так мы начинаем постепенно
понимать смысл фразы, которую мы сразу не расслышали по телефону и несколько
раз переспрашивали. При этом в повторах шум не позволяет понять то одну, то
другую часть фразы, но в конце концов за счет использования памяти и
интеллектуальной обработки информации мы понимаем ее всю. Так и объекты, описанные признаками, можно
рассматривать как зашумленные фразы, несущие нам информацию об обобщенных
образах классов - "Эйдосах" [30], к которым они относятся. И эту
информацию мы выделяем из шума при синтезе модели.
Для выражения (11):
|
|
( 14 ) |
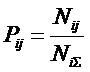
Для выражений (12) и
(13):
|
|
( 15 ) |
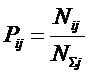
Для выражений (11), (12) и (13):
|
|
( 16 ) |
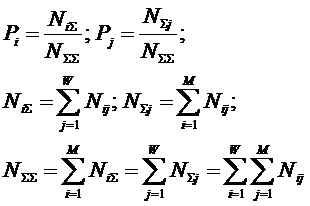
В (16) использованы обозначения:
Nij
– суммарное
количество наблюдений в исследуемой выборке факта:
"действовало i-е значение
фактора и объект перешел в j-е состояние";
![]() – суммарное по всей выборке количество
встреч различных факторов у объектов, перешедших в j-е состояние;
– суммарное по всей выборке количество
встреч различных факторов у объектов, перешедших в j-е состояние;
![]() – суммарное количество встреч i-го фактора у всех объектов исследуемой
выборки;
– суммарное количество встреч i-го фактора у всех объектов исследуемой
выборки;
![]() – суммарное количество встреч различных
значений факторов у всех объектов исследуемой выборки.
– суммарное количество встреч различных
значений факторов у всех объектов исследуемой выборки.
Формирование матрицы условных и безусловных процентных
распределений.
На основе анализа матрицы частот (табл. 1) классы
можно сравнивать по наблюдаемым частотам признаков только в том случае, если
количество объектов по всем классам одинаково, как и суммарное
количество признаков по классам. Если же они отличаются, то корректно
сравнивать классы можно только по условным и безусловным относительным частотам
(оценкам вероятностей) наблюдений признаков, посчитанных на основе матрицы
частот (табл. 1) в соответствии с выражениями (14) и (15), в результате
чего получается матрица условных и безусловных процентных распределений (табл.
7).
При расчете матрицы оценок условных и безусловных
вероятностей Nj из табл. 1
могут браться либо из предпоследней, либо из последней строки. В 1-м случае Nj
представляет собой "Суммарное
количество признаков у всех объектов, использованных для формирования
обобщенного образа j-го класса",
а во 2-м случае - это "Суммарное количество объектов обучающей выборки,
использованных для формирования обобщенного образа j-го класса", соответственно получаем различные, хотя и очень
сходные семантические информационные модели, которые мы называем СИМ-1 и СИМ-2.
Оба этих вида моделей поддерживаются системой "Эйдос".
Таблица 7 – МАТРИЦА УСЛОВНЫХ И БЕЗУСЛОВНЫХ
ПРОЦЕНТНЫХ РАСПРЕДЕЛЕНИЙ
|
|
Классы |
Безусловная вероятность признака |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения
факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Безусловная вероятность класса |
|
|
|
|
|
|
|
Эквивалентность выражений
(11) и (12) устанавливается, если подставить в них выражения относительных частот как оценок
вероятностей Pij, ![]() и
и ![]() через абсолютные
частоты наблюдения признаков по классам из (14), (15) и (16). В обоих случаях из выражений (11) и (12)
получается одно и то же выражение
(17):
через абсолютные
частоты наблюдения признаков по классам из (14), (15) и (16). В обоих случаях из выражений (11) и (12)
получается одно и то же выражение
(17):
|
|
( 17 ) |

А из (13) -
выражение (18), с которым мы и будем далее работать.
|
|
( 18 ) |
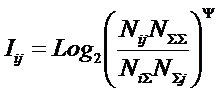
При взаимно-однозначном соответствии классов и
признаков в равновероятном
детерминистском случае имеем (таблица 8):
Таблица 8 – МАТРИЦА ЧАСТОТ В РАВНОВЕРОЯТНОМ
ДЕТЕРМИНИСТСКОМ СЛУЧАЕ
|
|
Классы |
Сумма |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения
факторов |
1 |
1 |
|
|
|
|
1 |
|
... |
|
1 |
|
|
|
1 |
|
|
i |
|
|
1 |
|
|
1 |
|
|
... |
|
|
|
1 |
|
1 |
|
|
M |
|
|
|
|
1 |
1 |
|
|
Сумма |
1 |
1 |
1 |
1 |
1 |
|
|
В этом случае к каждому классу относится один объект,
имеющий единственный признак. Откуда получаем для всех i и j равенства (19):
|
|
( 19 ) |
Таким образом, обобщенная формула А. Харкевича (18) с
учетом (19) в этом случае приобретает вид:
|
|
( 20 ) |
откуда:
|
|
( 21 ) |
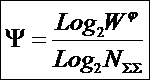
или, учитывая выражение для коэффициента эмерджентности Хартли (8):
|
|
( 22 ) |
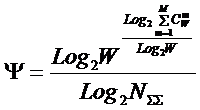
Выражения (21) и (22) получены автором в 2002 году [3]
и названы коэффициентом эмерджентности А.Харкевича, т.к. имеют очевидную связь
с его формулой для количества информации. Эти коэффициенты имеют весьма
глубокий смысл, который автор попытался раскрыть в работах [3, 15] и ряде
других.
Подставив коэффициент эмерджентности А.Харкевича (21)
в выражение (18), получим:
Отметим, что 1-я задача получения системного обобщения
формул Хартли и Харкевича и 2-я задача получения такого обобщения формулы
Харкевича, которая удовлетворяет принципу соответствия с формулой Хартли – это
две разные задачи. 1-я задача является более общей и при ее решении, которое
приведено выше, автоматически
решается и 2-я задача, которая является, таким образом, частным случаем 1-й.
Однако представляет самостоятельный интерес и частный
случай, в результате которого получается формула Харкевича, удовлетворяющая в равновероятном детерминистском случае
принципу соответствия с классической формулой Хартли (1), а не с ее системным
обобщением (2) и (3). Ясно, что эта формула получается из (23) при j=1.
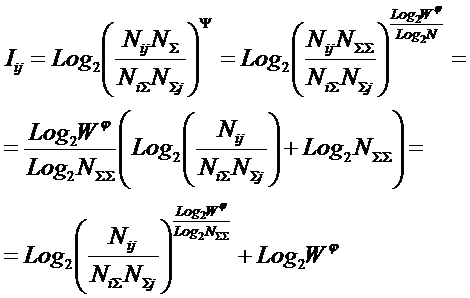
или окончательно:
|
|
( 23 ) |
|
|
( 24 ) |
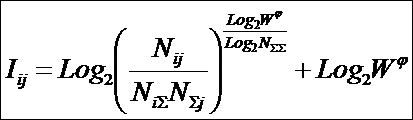
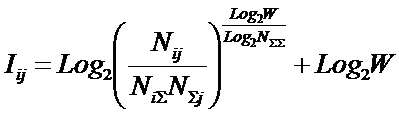
Из выражений (21) и (22) видно, что в этом частном
случае, т.е. когда система эквивалентна множеству (M=1), коэффициент
эмерджентности А.Харкевича приобретает вид:
|
|
( 25 ) |
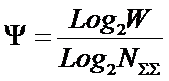
На практике для численных расчетов удобнее пользоваться не выражениями
(23) или (24), а формулой (26),
которая получается непосредственно из (18) после подстановки в него выражения
(25):
|
|
( 26 ) |
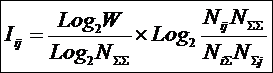
Используя выражение (26) и данные таблицы 1
непосредственно прямым счетом получаем матрицу
знаний (таблица 9):
Таблица 9 – МАТРИЦА ЗНАНИЙ (ИНФОРМАТИВНОСТЕЙ)
|
|
Классы |
Значимость фактора |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения
факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Степень редукции класса |
|
|
|
|
|
|
|
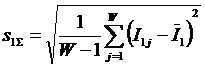
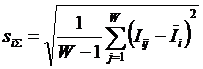
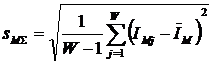
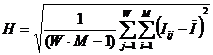
Здесь – ![]() это среднее
количество знаний в i-м значении фактора:
это среднее
количество знаний в i-м значении фактора:

Когда количество информации Iij > 0 – i-й фактор
способствует переходу объекта управления в j-е состояние, когда Iij < 0 –
препятствует этому переходу, когда же Iij = 0 – никак не влияет на это. В
векторе i-го фактора (строка матрицы информативностей) отображается, какое
количество информации о переходе объекта управления в каждое из будущих
состояний содержится в том факте, что данный фактор действует. В векторе j-го
состояния класса (столбец матрицы информативностей) отображается, какое количество
информации о переходе объекта управления в соответствующее состояние содержится
в каждом из факторов.
Таким образом, матрица знаний (информативностей),
приведенная в таблице 6, является обобщенной таблицей решений, в которой входы
(факторы) и выходы (будущие состояния объекта управления) связаны друг с другом
не с помощью классических (Аристотелевых) импликаций, принимающих только
значения: "истина" и "ложь", а различными значениями
истинности, выраженными в битах, и принимающими значения от положительного
теоретически-максимально-возможного ("максимальная степень
истинности"), до теоретически неограниченного отрицательного
("степень ложности"). Это позволяет автоматически формулировать
прямые и опосредованные правдоподобные высказывания с расчетной степенью
истинности.
Фактически предложенная модель позволяет осуществить
синтез обобщенных таблиц решений для различных предметных областей
непосредственно на основе эмпирических исходных данных и продуцировать прямые и
обратные правдоподобные (нечеткие) логические рассуждения по неклассическим
схемам с различными расчетными значениями истинности, являющимися обобщением
классических импликаций.
Таким образом, данная модель позволяет рассчитать,
какое количество информации содержится в любом факте о наступлении любого события
в любой предметной области, причем для этого не требуется повторности этих
фактов и событий. Если данные повторности осуществляются и при этом наблюдается
некоторая вариабельность значений факторов, обуславливающих наступление тех или
иных событий, то модель обеспечивает многопараметрическую типизацию, т.е.
синтез обобщенных образов классов или категорий наступающих событий с
количественной оценкой степени и знака влияния на их наступление различных
значений факторов. Причем эти значения факторов могут быть как количественными,
так и качественными и измеряться в любых единицах измерения, в любом случае в
модели оценивается количество информации, которое в них содержится о
наступлении событий, переходе объекта управления в определенные состояния или,
просто, о его принадлежности к тем или иным классам. Другие способы метризации
приведены в работе [9]. Все они реализованы в системно-когнитивном анализе и
интеллектуальной системе «Эйдос» и обеспечивают сопоставление градациям всех
видов шкал числовых значений, имеющих смысл количества информации в градации о
принадлежности объекта к классу. Поэтому является корректным применение
интегральных критериев, включающих операции умножения и суммирования, для
обработки числовых значений, соответствующих градациям шкал. Это позволяет
единообразно и сопоставимо обрабатывать эмпирические данные, полученные с
помощью любых типов шкал, применяя при этом все математические операции.
Информационный
портрет класса – это список
значений факторов, ранжированных в порядке убывания силы их влияния на переход
объекта управления в состояние, соответствующее данному классу. Информационный
портрет класса отражает систему его детерминации. Генерация информационного
портрета класса представляет собой решение обратной задачи прогнозирования,
т.к. при прогнозировании по системе факторов определяется спектр наиболее
вероятных будущих состояний объекта управления, в которые он может перейти под
влиянием данной системы факторов, а в информационном портрете мы, наоборот, по
заданному будущему состоянию объекта управления определяем систему факторов,
детерминирующих это состояние, т.е. вызывающих переход объекта управления в это
состояние. В начале информационного портрета класса идут факторы, оказывающие
положительное влияние на переход объекта управления в заданное состояние, затем
факторы, не оказывающие на это существенного влияния, и далее – факторы,
препятствующие переходу объекта управления в это состояние (в порядке
возрастания силы препятствования). Информационные портреты классов могут быть
от отфильтрованы по диапазону
факторов, т.е. мы можем отобразить влияние на переход объекта управления в
данное состояние не всех отраженных в модели факторов, а только тех, коды
которых попадают в определенный диапазон, например, относящиеся к определенным
описательным шкалам.
Информационный
(семантический) портрет фактора – это список классов, ранжированный в порядке убывания силы влияния
данного фактора на переход объекта управления в состояния, соответствующие данным
классам. Информационный портрет фактора называется также его семантическим портретом, т.к. в
соответствии с концепцией смысла системно-когнитивного анализа, являющейся
обобщением концепции смысла Шенка-Абельсона [21], смысл фактора состоит в том, какие будущие состояния объекта управления
он детерминирует или обуславливает. Сначала в этом списке идут состояния
объекта управления, на переход в которые данный фактор оказывает наибольшее
влияние, затем состояния, на которые данный фактор не оказывает существенного
влияния, и далее состояния – переходу в которые данный фактор препятствует.
Информационные портреты факторов могут быть от отфильтрованы по диапазону классов, т.е. мы можем отобразить
влияние данного фактора на переход объекта управления не во все возможные
будущие состояния, а только в состояния, коды которых попадают в определенный
диапазон, например, относящиеся к определенным классификационным шкалам.
Прямые и
обратные, непосредственные и опосредованные правдоподобные логические
рассуждения с расчетной степенью истинности в системной теории информации.
|
Перевалов
Михаил Ильич, учитель математики СШ№31 г.Краснодара, примерно
1970 год[11] |
Одним из первых ученых, поднявших и широко обсуждавшим
в своих работах проблематику правдоподобных рассуждений, был известный
венгерский, швейцарский и американский математик Дьердь Пойа [31], книги
которого подарил автору его школьный учитель математики Михаил Ильич
Перевалов, за что автор ему очень благодарен (см. также раздел «Формализация
логики правдоподобных рассуждений Д. Пойа», глава третья, параграф 7,
с.158-163, исходящий из (репрезентативной) теории измерений). Разве мог
он тогда предположить, что через много лет в работе [3][12] им будет
предложена логическая форма представления правдоподобных логических рассуждений
с расчетной степенью истинности, которая определяется в соответствии с
системной теорией информацией непосредственно на основе эмпирических данных. |

В качестве количественной меры влияния факторов,
предложено использовать обобщенную формулу А.Харкевича, полученную на основе
предложенной эмерджентной теории информации. При этом непосредственно из
матрицы абсолютных частот рассчитывается база знаний (табл.4), которая и
представляет собой основу содержательной информационной модели предметной области.
Весовые коэффициенты табл.4 непосредственно
определяют, какое количество информации Iij
система управления получает о наступлении события: "активный объект
управления перейдет в j–е
состояние", из сообщения: "на активный объект управления действует i–й фактор".
Принципиально важно, что эти весовые коэффициенты не
определяются экспертами неформализуемым способом на основе интуиции и профессиональной
компетенции (т.е. фактически «на глазок»), а рассчитываются непосредственно на
основе эмпирических данных и удовлетворяют всем ранее обоснованным в работе [3]
требованиям, т.е. являются сопоставимыми, содержательно интерпретируемыми,
отражают понятия "достижение цели управления" и "мощность
множества будущих состояний объекта управления" и т.д.
В работе [3] обосновано, что предложенная
информационная мера обеспечивает сопоставимость индивидуальных количеств
информации, содержащейся в факторах о классах, а также сопоставимость
интегральных критериев, рассчитанных для одного объекта и разных классов, для
разных объектов и разных классов.
Когда количество информации Iij>0 – i–й фактор
способствует переходу объекта управления в j–е
состояние, когда Iij<0 – препятствует
этому переходу, когда же Iij=0 –
никак не влияет на это. В векторе i–го
фактора (строка матрицы информативностей) отображается, какое количество информации
о переходе объекта управления в каждое из будущих состояний содержится в том
факте, что данный фактор действует. В векторе j–го состояния класса (столбец матрицы информативностей)
отображается, какое количество информации о переходе объекта управления в
соответствующее состояние содержится в каждом из факторов.
Таким образом, матрица информативностей (табл.4)
является обобщенной таблицей решений, в которой входы (факторы) и выходы
(будущие состояния активного объекта управления (АОУ) связаны друг с другом не
с помощью классических (Аристотелевских) импликаций, принимающих только значения:
"Итина" и "Ложь", а различными значениями истинности,
выраженными в битах и принимающими значения от положительного
теоретически-максимально-возможного ("Максимальная степень истинности"),
до теоретически неограниченного отрицательного ("Степень ложности").
Фактически предложенная модель позволяет осуществить
синтез обобщенных таблиц решений для различных предметных областей
непосредственно на основе эмпирических исходных данных и продуцировать на их
основе прямые и обратные правдоподобные (нечеткие) логические рассуждения по
неклассическим схемам с различными расчетными значениями истинности, являющимся
обобщением классических импликаций (табл. 10).
Таблица 10 – Прямые и обратные правдоподобные логические
высказывания с расчетной в соответствии с системной теорией информации (СТИ)
степенью истинности импликаций
Приведем пример более сложного высказывания, которое
может быть рассчитано непосредственно на основе матрицы информативностей –
обобщенной таблицы решений (табл. 4): «Если A, со степенью истинности a(A,B), детерминирует B, и если С, со степенью
истинности a(C,D), детерминирует D, и A совпадает по смыслу с C со
степенью истинности a(A,C), то это вносит вклад в совпадение B с D, равный
степени истинности a(B,D)».
При этом в прямых рассуждениях как предпосылки
рассматриваются факторы, а как заключение – будущие состояния АОУ, а в обратных
– наоборот: как предпосылки – будущие состояния АОУ, а как заключение –
факторы. Степень истинности i-й предпосылки
– это просто количество информации Iij,
содержащейся в ней о наступлении j-го
будущего состояния АОУ. Если предпосылок несколько, то степень истинности наступления
j-го состояния АОУ равна суммарному
количеству информации, содержащемуся в них об этом. Количество информации в i-м факторе о наступлении j-го состояния АОУ, рассчитывается в
соответствии с выражениями системной теории информации (СТИ).
Прямые правдоподобные логические рассуждения позволяют
прогнозировать степень достоверности наступления события по действующим факторам,
а обратные – по заданному состоянию восстановить степень необходимости и
степень нежелательности каждого фактора для наступления этого состояния, т.е.
принимать решение по выбору управляющих воздействий на АОУ, оптимальных для
перевода его в заданное целевое состояние.
Приведем простой пример, когда безупречная
классическая бинарная логика Аристотеля дает сбой. Рассмотрим высказывания:
А) если студент хорошо сдал экзамен по информационным
системам, значит, он умеет хорошо программировать;
Б) если студент умеет хорошо программировать, то он
может стать хорошим специалистом в области прикладной информатики.
Откуда средствами логики предикатов получаем вывод:
В) если студент хорошо сдал экзамен по информационным
системам, то он может стать хорошим специалистом в области прикладной информатики.
Если при рассмотрении каждого высказывания «А» и «Б»
по отдельности у нас не возникает особых возражений, хотя мы сразу чувствуем
здесь какой-то подвох, что это не совсем так или не всегда так и легко можем
привести вполне реальные примеры, когда эти высказывания могут быть и ложными,
то высказывание «В» уже само по себе выглядит очень сомнительным, т.е. проще
говоря ложным, тогда как в логике предикатов
оно является истинным. Интуитивно мы хорошо понимаем, почему так получается.
Дело в том, что в этих высказываниях не отражен контекст, т.е. та
огромная слабо формализованная и вообще неформализованная информация об объекте
моделирования, которой располагает человек, но не располагает логическая
система. Например, в этих двух логических высказываниях не отражена информация,
которой располагает каждый преподаватель и студент, о том, каким образом иногда
сдаются экзамены, когда оценка вообще никак не зависит от знаний. Иначе говоря,
чтобы эти высказывания были истинны необходимо, чтобы оценка определялась
только знаниями. Но и этого мало. Предполагается, что факт получения хорошей
оценки по дисциплине означает полное
ее освоение, хотя все понимают, что для этого достаточно освоения только тех
вопросов, которые были в билете и были заданы преподавателем (кроме того существуют
и весьма распространены и другие варианты).
При решении этой же задачи средами АСК-анализа мы
формулируем эти высказывания в форме правдоподобных рассуждений:
А) если студент хорошо сдал экзамен по информационным
системам, то в этом факте содержится I(A) информации о том, что он умеет хорошо
программировать;
Б) если студент умеет хорошо программировать, то в
этом факте содержится I(Б) информации о том он может стать хорошим специалистом
в области прикладной информатики.
Откуда средствами АСК-анализа получаем результирующее
высказывание:
В) если студент хорошо сдал экзамен по информационным
системам, то в этом факте содержится I(В) информации о том он может стать
хорошим специалистом в области прикладной информатики.
Это высказывание не выглядит как истинное или ложное и
может быть и истинным, и ложным, причем в различной степени, в зависимости от
знака и модуля его расчетной степени истинности I(В)=F(I(A), I(В)). Для расчета этой величины нужны конкретные эмпирические данные, являющиеся
репрезентативными для отражения определенной предметной области (генеральной
совокупности), в которой этот вывод и будет иметь эти значения знака и величины
степени истинности.
Итак, описанная в данном разделе математическая модель
реализована в программном инструментарии АСК-анализа – универсальной когнитивной
аналитической системе «Эйдос-Х++». Как следует из самого названия системы это
сделано в универсальной постановке не зависящей от предметной области. Поэтому
система «Эйдос-Х++» может быть применена, и фактически и была применена, в
самых различных предметных областях для построения интеллектуальных
измерительных систем и интеллектуальных систем управления, а также для решения
задач идентификации, прогнозирования и приятия решений [8, 16, 33-60, 62].
Более подробной численный пример
применения данного математического метода и реализующей его системы «Эйдос-Х++»
для построения интеллектуальной измерительной
системы для системной идентификации состояний сложных
систем приводится ниже.
6.1.3. Применение
АСК-анализа и системы «Эйдос» для интеллектуальных измерений и идентификации
состояний сложных нелинейных систем
В первом разделе данной статьи
предлагается применить автоматизированный системно-когнитивный анализ (АСК-анализ)
как для синтеза, так и для применения адаптивной интеллектуальной измерительной
системы с целью измерения не значений параметров объектов, а для идентификации
состояний сложных систем, т.е. для так называемой системной идентификации.
Применение данного подхода является корректным для измерения состояний сложных многофакторных нелинейных динамических систем.
Во втором разделе статьи кратко
рассматривается математический метод АСК-анализа, реализованный в его
программном инструментарии – универсальной когнитивной аналитической системе
«Эйдос-Х++». Математический метод АСК-анализа основан
на системной теории информации (СТИ), которая создана в рамках реализации
программной идеи обобщения всех понятий математики, в частности теории
информации, базирующихся на теории множеств, путем тотальной замены понятия
множества на более общее понятие системы и тщательного отслеживания всех последствий
этой замены [3, 15]. Благодаря математическому методу, положенному в основу
АСК-анализа, этот метод является непараметрическим и позволяет сопоставимо обрабатывать десятки и сотни тысяч градаций
факторов и будущих состояний нелинейного объекта управления (классов) при
неполных (фрагментированных), зашумленных данных числовой и нечисловой природы
измеряемых в различных единицах измерения.
В данном разделе статьи
приводится численный пример применения АСК-анализа и системы «Эйдос-Х++» как
для синтеза системно-когнитивной модели, обеспечивающей многопараметрическую
типизацию состояний сложных систем, так и для системной идентификации их состояний, а также для
принятии решений об управляющем воздействии, так изменяющем состав объекта управления, чтобы его
качество (уровень системности) максимально повышалось при минимальных затратах
на это[13]. В данном разделе для численного примера в качестве
сложной системы выбран коллектив фирмы, а его компонент – сотрудники и
кандидаты (персонал). Однако необходимо отметить, что этот пример следует
рассматривать шире, т.к. АСК-анализ и система «Эйдос» разрабатывались и
реализовались в очень обобщенной постановке, постановке, не зависящей от
предметной области, и с успехом могут быть применены и в других областях [4,
33-60, 62].
6.1.3.1. Решение 1-й задачи – многопараметрической
типизации
состояний сложных объектов
Решение 1-й задачи является стандартным для системы
«Эйдос», т.е. она предназначена для решения подобных задач и соответствующие
применения описаны в работах автора [33, 60][14]. В соответствии с этапами АСК-анализа и порядком
преобразования данных в информацию, а ее в знания [22], рассмотрим
Excel-таблицу исходных данных (таблица 11).
Таблица 11 – Исходные данные для синтеза
системно-когнитивной
модели управления качеством системы путем управления ее составом[15]
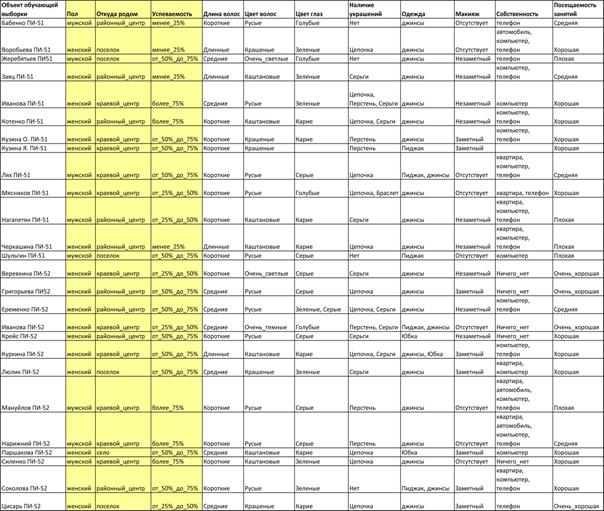
В этой таблице колонки со 2-й по 4-ю являются классификационными
измерительными шкалами, а с 5-й по последнюю – описательными измерительными
шкалами. Каждая классификационная шкала представляет собой должность, а ее
градации (классы) отражают различную степень успешности работы на этой
должности. Описательные шкалы представляют собой личностные и профессиональные
свойства сотрудников, а градации (признаки) – степень их выраженности. Отметим,
что в приведенном упрощенном численном примере классы не являются
профессиональными категориями с указанием степени успешности (например:
МЕНЕДЖЕР ТОРГОВОГО ЗАЛА – хорошо подходит), а признаки респондентов не являются
их личностными свойствами (например: ФАКТОР
А: «ЗАМКНУТОСТЬ – ОБЩИТЕЛЬНОСТЬ» - 8 баллов). Поэтому от читателя
требуется некоторая фантазия, чтобы представить себе, что это так. Но суть
примера от этого не меняется, и он позволяет нам проиллюстрировать излагаемые в
данной работе идеи. Каждому респонденту соответствует строка, в которой он
описан и своими свойствами, и принадлежностью к классам. Таким образом,
исходные данные в содержательной форме, представленные в таблице 1,
эквивалентны такому количеству обучающих выборок, сколько возможно различных
способов группировки данных, описанными описательными шкалами и градациями по
классам. На основе этих данных и решается 1-я задача многопараметрической типизации,
результаты которой отражены в системно-когнитивной модели. В системе
«Эйдос» осуществляется нормализация базы исходных данных
путем автоматической разработки классификационных и описательных шкал и градаций
и кодирования с их использованием исходных данных и представления их в форме
эвентологической базы данных (рисунок 5):
Рисунок 4 – Главная экранная форма для задания
параметров импорта данных в систему
«Эйдос» из внешней базы исходных данных, представленной в таблице 1
Затем в соответствии с этапами АСК-анализа и порядком
преобразования данных в информацию, а ее в знания [22], в режиме 3.5 системы
«Эйдос» выполним синтез и верификацию статистических моделей и моделей знаний
(рисунок 6):

Рисунок 5 – Экранная форма задания параметров
синтеза и верификации моделей (параметры по умолчанию)
Созданные модели, наименования которых приведены на
рисунке 3, отличающиеся частными критериями, представляют собой результат многопараметрической
типизации состояний объектов обучающей выборки, описанных в исходных данных.
Это и есть решение 1-й задачи. По сути, это и есть профессиограммы или ключи теста
на профессиональную пригодность, созданного в инновационной интеллектуальной
технологии «Эйдос». В результате работы режима получены статистические
модели и модели знаний и проведена их верификация. Модель знаний INF1 приведена
на рисунке 7:
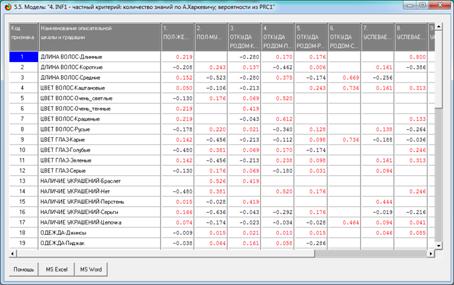
Рисунок 6 – Модель знаний INF1 (фрагмент)
6.1.3.2. Решение 2-й задачи –
системной идентификации
состояний сложных объектов
На рисунках 8 и 9 приведены примеры экранных форм с
результатами системной идентификации. Рисунок 8 дает информацию для
работодателя, проводящего исследование конкретного кандидата на работу, а 9 –
проводящего массовое обследование кандидатов:
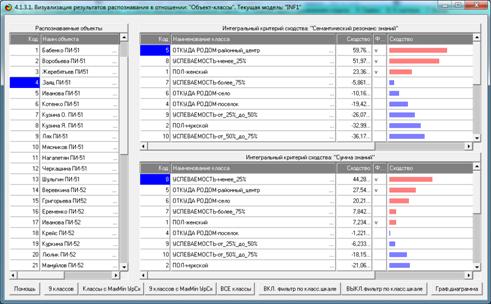
Рисунок 7 – Результаты системной идентификации
конкретного респондента с классами
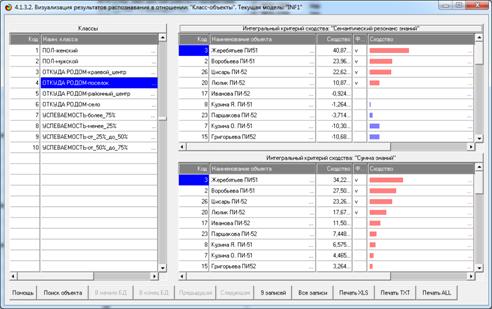
Рисунок 8 – Результаты системной идентификации
конкретного класса с респондентами
При этом достоверность системной идентификации с
применением различных моделей в моделей в системе «Эйдос» оценивается с помощью
предложенной автором метрики, по смыслу сходной с F-критерием.
Метризация шкал – решение проблемы сопоставимости при
системной идентификации
Как показано выше, в АСК-анализе проводится последовательное повышение степени
формализации исходных данных до уровня, обеспечивающего их обработку на
компьютере в программной системе. После выполнения когнитивной
структуризации и формализации предметной области осуществляется синтез
статистических моделей и моделей знаний, в которых все шкалы, в которых описаны
исходные данные, преобразуются к одному типу: числовому, и к одним единицам
измерения: единицам измерения информации, т.е. проводится метризация шкал. В
настоящее время в системе «Эйдос» применяется 7 способов метризации шкал [9].
В работе [3] сформулированы требования к форме представления данных, информации
и знаний, позволяющие оценить степень их
пригодности для решения задач системной идентификации, прогнозирования и
принятия решений, а также исследования предметной области (например,
кластерного анализа).
Прежде всего, результаты решения вышеперечисленных
задач должны быть инвариантны относительно:
– единиц
измерения градаций факторов (признаков);
– типов шкал,
используемых для формализации классов и факторов (номинальные, порядковые и
числовые);
– различных статистических
характеристик исходной выборки: частотных распределений объектов по классам
(обобщенным категориям), частотных распределений градаций факторов, различий в
количестве признаков в описаниях объектов исследуемой выборки, различий в
суммарном количестве признаков по классам.
Кроме того, форма представления должна обеспечивать решение
вышеперечисленных задач с минимальными дополнительными затратами ручного труда,
а это значит, что вся предварительная
обработка должна быть максимально автоматизирована.
Эти требования можно рассматривать и как критерии выбора наиболее подходящей для
решения вышеперечисленных задач формы представления данных, информации и
знаний.
Рассмотрим влияние
единиц измерения в исходной выборке на результаты решения задач прогнозирования
и принятия решений, а также исследования предметной области (например, кластерного
анализа).
Если в исходных данных какие-то значения выражены в
больших единицах измерения, то их числовые значения будут малыми, и наоборот,
если единицы измерения мелкие, то числовые значения – большие. Большие значения
оказывают большее влияние на результаты математической обработки, чем малые, и это приводит к возникновению зависимости
результатов решения задач системной идентификации, прогнозирования и принятия
решений, а также кластерного анализа, от выбранных размерностей исходных данных, что, на взгляд автора, совершенно
неприемлемо и указывает на то, что такое решение нельзя признать корректным и
даже вообще решением. По этой же причине некорректно совместно обрабатывать
сами исходные данные, представленные в различных единицах измерения (натуральных
или ценовых), например, складывать расстояния, представленные в километрах и в
метрах, а затем прибавлять к ним тонны и килограммы, а затем еще и безразмерные
величины. Вроде это очевидно, но, как это ни удивительно, но как показывает
опыт на практике это довольно часто делается, а потом еще на основе подобного
«анализа» делаются и выводы. Очень странно, что обычно на это не обращают никакого внимания при
использовании исходных данных, представленных в различных единицах измерения.
Например, даже в таких популярных (причем, совершенно заслуженно) системах, как
SPSS и Статистика, в подсистеме кластерного анализа приводятся примеры
кластерного анализа над исходными данными, представленными в различных единицах
измерения.
В АСК-анализе факторы формально описываются шкалами, а
значения факторов – градациями шкал. Существует три основных группы факторов:
физические, социально-экономические и психологические (субъективные) и в каждой
из этих групп есть много различных видов факторов, т.е. есть много различных
физических факторов, много социально-экономических и много психологических, но
в АСК-анализе все они рассматриваются с одной единственной точки зрения: сколько информации содержится в их
значениях о переходе объекта, на который они действуют, в определенное
состояние, и при этом сила и направление влияния всех значений факторов на
объект измеряется в одних общих для всех факторов единицах измерения: единицах количества информации. Именно
по этой причине вполне корректно
складывать (в аддитивных интегральных критериях) силу и направление
влияния всех действующих на объект значений факторов, независимо от их природы,
и определять результат совместного
влияния на объект системы значений
факторов. При этом в общем случае объект является нелинейным и факторы внутри него взаимодействуют друг с другом,
т.е. для них не выполняется принцип суперпозиции.
На рисунке 10 приведен пример метризованной
номинальной шкалы в модели INF1. По сути это и есть профессиограмма,
сформированная в среде инновационной интеллектуальной технологии «Эйдос»:
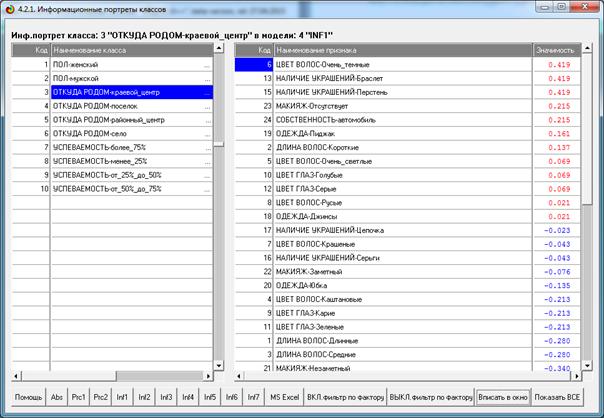
Рисунок 9 – Пример метризованной номинальной
шкалы (профессиограммы)
6.1.3.3.
Решение 3-й задачи – принятия решений об управляющем
воздействии так изменяющем состав
объекта управления,
чтобы его качество максимально повышалось
при минимальных затратах на это
Для решения 3-й задачи предлагается применить выбор
компонент объекта управления по их функциональному назначению с учетом
ресурсов, выделенных на реализацию различных функций, затрат, связанных с
выбором тех или иных компонентов и степени соответствия различных компонент их
функциональному назначению. Фактически предлагается формулировка и решение
нового обобщенного варианта задачи о назначениях:
«Мультипликативный рюкзак»[16], отличающегося от
известного тем, что назначения производится не только с учетом ресурсов и
затрат, но и с учетом степени соответствия компонент их функциональному
назначению, которое предварительно определяется в самой задаче.
Математическая модель,
обеспечивающая решение 1-й задачи и отражающая степень соответствия компонент
их функциональному назначению, а также весь процесс приятия решений по
назначениям, т.е. 2-я задача, реализованы в АСК-анализе и системе «Эйдос-Х++».
6.1.3.3.1. Интегральные критерии системы «Эйдос»
В результате проведения в метризации шкал, т.е. их
преобразования независимо от исходного типа к одному типу: числовому, и
независимо от исходных единиц измерения к одним единицам измерения: количеству
информации, становится возможным корректно совместно обрабатывать результаты
формализации описаний исходных данных в этих шкалах и использовать при этом все
арифметические операции, в т.ч. сложение [9].
Это позволяет использовать аддитивные интегральные
критерии и обоснованно ответить на следующий вопрос. Если нам известно, что объект
обладает не одним, а несколькими признаками, то как посчитать их общий вклад в сходство с теми или иными
классами?
Для этого в системе «Эйдос» используется 2 аддитивных[17] интегральных критерия: «Сумма знаний» и
«Семантический резонанс знаний».
Интегральный критерий «Семантический резонанс знаний» представляет собой суммарное количество знаний,
содержащееся в системе факторов различной природы, характеризующих сам объект
управления, управляющие факторы и окружающую среду, о переходе объекта в будущие
целевые или нежелательные состояния.
Интегральный критерий представляет собой аддитивную
функцию от частных критериев знаний:
![]()
В выражении круглыми скобками обозначено скалярное
произведение. В координатной форме это выражение имеет вид:
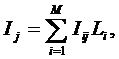 ,
,
где: M – количество градаций описательных шкал
(признаков);
![]() – вектор
состояния j–го класса;
– вектор
состояния j–го класса;
![]() – вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
– вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
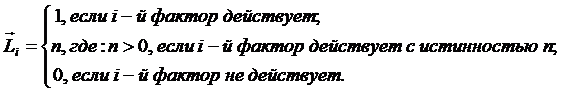 В текущей версии системы «Эйдос-Х++» значения координат
вектора состояния распознаваемого объекта принимались равными либо 0, если
признака нет, или n, если он присутствует у объекта с интенсивностью n, т.е.
представлен n раз (например, буква «о» в слове «молоко» представлена 3 раза, а
буква «м» - один раз).
В текущей версии системы «Эйдос-Х++» значения координат
вектора состояния распознаваемого объекта принимались равными либо 0, если
признака нет, или n, если он присутствует у объекта с интенсивностью n, т.е.
представлен n раз (например, буква «о» в слове «молоко» представлена 3 раза, а
буква «м» - один раз).
Интегральный критерий «Семантический резонанс знаний» представляет собой нормированное суммарное количество знаний, содержащееся в системе
факторов различной природы, характеризующих сам объект управления, управляющие
факторы и окружающую среду, о переходе объекта в будущие целевые или
нежелательные состояния.
Интегральный критерий представляет собой аддитивную
функцию от частных критериев знаний имеет вид:
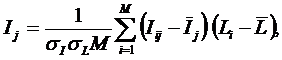
где:
M –
количество градаций описательных шкал (признаков);
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по вектору
объекта;
– среднее по вектору
объекта;
![]() –
среднеквадратичное отклонение частных критериев знаний вектора класса;
–
среднеквадратичное отклонение частных критериев знаний вектора класса;
![]() – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
![]() – вектор
состояния j–го класса;
– вектор
состояния j–го класса;
![]() – вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
– вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
В текущей версии системы «Эйдос-Х++» значения координат вектора
состояния распознаваемого объекта принимались равными либо 0, если признака
нет, или n, если он присутствует у объекта с интенсивностью n, т.е. представлен
n раз (например, буква «о» в слове «молоко» представлена 3 раза, а буква «м» -
один раз).
Приведенное выражение для интегрального критерия «Семантический
резонанс знаний» получается непосредственно из выражения для критерия «Сумма
знаний» после замены координат перемножаемых векторов их
стандартизированными значениями:

Свое наименование интегральный критерий сходства
«Семантический резонанс знаний» получил потому, что по своей математической
форме является корреляцией двух векторов: состояния j–го класса и состояния
распознаваемого объекта.
6.1.3.3.2.
Алгоритм решения 3-й задачи
Алгоритм
назначения объектов на наиболее подходящие классы с учетом ресурсов классов,
затрат на объекты и степени соответствия объектов классам состоит в том, что
назначаем текущий объект на тот класс, удельное сходство с которым максимально,
при условии, что у данного класса есть для этого ресурсы, и делать это до тех
пор, пока есть классы с ресурсами и назначены не все объекты (рисунок 11):

Рисунок 10 – Алгоритм
назначения объектов на наиболее подходящие классы с учетом ресурсов классов,
затрат на объекты и степени соответствия объектов классам
6.1.3.3.3.
Численный пример решения 3-й задачи
Запустим режим 4.1.6 системы «Эйдос»: «Рациональное назначение объектов на классы (задача о ранце)»
(Управление персоналом на основе АСК-анализа и функционально-стоимостного
анализа (задача о назначениях)) (рисунок 12):
Рисунок 11 – Главная
экранная форма режима: 4.1.6. Рациональное
назначение объектов на классы (задача о ранце)
В верхнем левом окне пользователь
может пересоздать базу ресурсов классов, а также корректировать ресурсы
классов. Это возможно либо вручную, либо автоматически. В первом случае
ресурсам присваивается значение по умолчанию. Во втором случае есть несколько
вариантов присвоения значений ресурсов классов.
В верхнем правом окне пользователь
может пересоздать базу затрат на назначение объектов, а также корректировать
затраты объектов. Это возможно либо вручную, либо автоматически. В первом
случае затратам присваивается значение по умолчанию. Во втором случае есть
несколько вариантов присвоения значений затрат на назначение объектов.
При нажатии кнопки «Назначить объекты
на классы» появляется окно, позволяющее задать параметры и цель назначения
(рисунок 13):
Рисунок 12 – Экранная
форма задания параметров и цели
назначений объектов на классы
Опцию: "Назначать не более 1
объекта на класс", имеет смысл использовать при разумной комплектации
какого-либо сложного изделия, например автомобиля, когда каждый элемент
комплектации (объект, деталь) назначается на каждую позицию (класс) 1 раз,
например 1 инжектор, 1 левая фара, и т.д. С аналогичной ситуацией мы
сталкиваемся при назначении кандидатов на такие должности, например, в
спортивной команде, на каждой из которых может быть только один человек.
Опция: «Допускается ли назначать
ранее назначенные объекты» позволяет подать на назначение не все объекты, а
только не назначенные на классы при предыдущих назначениях. Например, если
объектов задано значительно больше, чем классов и была задана опция: «Назначать не более 1
объекта на класс», то при каждом последующем назначении будут получаться автомобили со все более
высокой себестоимостью и все более низкого качества, собранные из деталей, отбракованных при сборке предыдущих
автомобилей. То же самое можно сказать об основном и дополнительном составе
сборной: во 2-ю сборную входят игроки, не вошедшие в 1-ю, в 3-ю сборную - не
вошедшие в 1-ю и 2-ю, и вообще в N-ю - не вошедшие в 1-ю, 2-ю,..., (N-1)-ю.
Если данная опция не установлена, то
все объекты считаются ранее не назначенными. Признак, что объект был ранее
назначен, сбрасывается, при пересоздании базы затрат и при автоматическом
задании затрат. При назначении объектов на классы этот признак устанавливается
для назначенных объектов независимо от того, установлена ли опция:
"Назначать только ранее не назначенные объекты". Но учитывается этот
признак при назначении объектов только в случае, если эта опция установлена.
Опция "Задайте цель управления качеством
системы:" позволяет выбрать одну из четырех целей работы LC-алгоритма,
предложенного автором (рисунок 8):
1. Повышение уровня системности.
2. Понижение уровня системности.
3. Минимизация средних затрат на назначения объектов.
4. Максимизация средних затрат на назначения объектов.
Повышение уровня системности обеспечивает максимальное
повышение качества системы с минимальными затратами на это. Понижение уровня системности обеспечивает
максимальное понижение качества системы с максимальными затратами на это, что
практически означает противодействие системе или даже уничтожение системы
(антисистема). Минимизация средних затрат на назначения объектов приводит к
назначению максимального количества сотрудников без учета степени их
соответствия требованиям должностей с минимальной средней оплатой (всеобщая занятость
населения и высокая скрытая безработица, но не очень эффективная экономика).
Что-то вроде этого получается при сильной социальной политике. Максимизация
средних затрат на назначения объектов приводит к назначению минимального количества
сотрудников без учета степени их соответствия требованиям должностей с максимальной
средней оплатой (низкая занятость населения и высокая реальная безработица).
Аналогичный подход используется руководством при назначении "своих"
людей на руководящие и наиболее хорошо оплачиваемые должности.
На практике приходится применять все четыре подхода в
различных комбинациях в зависимости от обстоятельств. Например, чтобы коллектив
выполнял свою функцию, т.е. вообще работал, сначала используется 1-я цель. Но
так производятся назначения не на все должности, а в основном на
исполнительские. После этого для назначения на престижные руководящие и хорошо
оплачиваемые должности "своих" людей используется 4-я цель. 2-я цель
используется военными и в конкурентной борьбе, а 3-я для того, чтобы не
возникло социального бунта при повышении уровня реальной безработицы.
В нижнем окне на рисунке 9 приводятся
результаты назначения объектов на наиболее подходящие классы с
учетом ресурсов классов, затрат на объекты и степени соответствия объектов
классам, в соответствии с LC-алгоритмом (слева), предложенным автором в работе
[6], и классическим для задачи о Мультипликативном рюкзаке RND-алгоритмом (справа), в котором
ресурсы классов и затраты на объекты учитываются, а степень соответствия
объектов классам не учитывается, т.е. ценность объектов считается независимой
от класса и фактически равна затратам на его назначение. Это и есть основной
итог расчетов, т.е. результат решения задачи, выбранной в качестве примера. Все
результаты расчетов записываются в виде большого количества разнообразных
выходных форм, представляющих собой как текстовые файлы, так и Excel-таблицы.
Фрагмент одной такой формы приведен ниже:
РЕЗУЛЬТАТЫ НАЗНАЧЕНИЙ
ОБЪЕКТОВ НА КЛАССЫ, LC-АЛГОРИТМ
(допускается назначение
более 1 объекта на класс)
(допускается назначение
ранее назначенных объектов)
(Цель - 1. Повышение уровня
системности)
10.05.2015 08:03:35
г.Краснодар
==========================================================================
|ХАРАКТЕРИСТИКИ
ЭФФЕКТИВНОСТИ НАЗНАЧЕНИЯ: |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|СУММА ПО ВСЕМ КЛАССАМ:
|
|Начальный ресурс
класса:............................ 550.0000000 |
|Остаток ресурса после
назначений объектов на классы: 159.9990000 |
|Всего назначено на классы
объектов:................. 26
|
|Суммарное сходство:.................................
1142.1670000 |
|Фактические суммарные
затраты:...................... 390.0010000 |
|Средневзвешенное удельное
сходство:................. 27.4660000
|
|Среднее на объект суммарное
сходство:............... 399.9600000
|
|Средние на объект
фактические суммарные затраты:.... 137.5810000 |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|СРЕДНЕЕ НА КЛАСС:
|
|Начальный ресурс
класса:............................ 55.0000000 |
|Остаток ресурса после
назначений объектов на классы: 15.9999000 |
|В среднем на класс
назначено объектов:.............. 3 |
|Суммарное
сходство:................................. 114.2167000 |
|Фактические суммарные
затраты:...................... 39.0001000 |
|Средневзвешенное удельное
сходство:................. 2.7466000
|
|Среднее на объект суммарное
сходство:............... 39.9960000
|
|Средние на объект
фактические суммарные затраты:.... 13.7581000 |
==========================================================================
==========================================================================
|КЛАСС НАЗНАЧЕНИЯ: |
|Код: 1, наименование: ПОЛ - мужской |
|Начальный ресурс
класса:........................... 100.0000000 |
|Остаток ресурса после
назначений объектов на класс: 19.5120000 |
|Всего на данный класс
назначено объектов:.......... 5 |
|Суммарное
сходство:................................ 233.2890000 |
|Фактические суммарные
затраты:..................... 80.4880000 |
|Средневзвешенное удельное
сходство:................ 2.8980000
|
|Среднее на объект суммарное
сходство:.............. 46.6580000
|
|Средние на объект
фактические суммарные затраты:... 16.0980000 |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по пор.|объекта| объекта
|об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1
| 35 |Мануйлов ПИ-52 | 64.3320000|
11.7070000| 5.4950000|
| 2 |
20 |Шульгин ПИ-51 | 64.9920000|
15.3660000| 4.2300000|
| 3 |
12 |Лях ПИ-51 | 57.3090000|
17.3170000| 3.3090000|
| 4 |
17 |Черкашина ПИ-51| 21.0170000| 16.0980000| 1.3060000|
| 5 |
1 |Бабенко ПИ-51 | 25.6390000|
20.0000000| 1.2820000|
==========================================================================
|КЛАСС НАЗНАЧЕНИЯ:
|
|Код: 2, наименование: ПОЛ - женский |
|Начальный ресурс
класса:........................... 90.0000000 |
|Остаток ресурса после
назначений объектов на класс: 20.4880000 |
|Всего на данный класс назначено
объектов:.......... 5 |
|Суммарное
сходство:................................ 158.5350000 |
|Фактические суммарные
затраты:..................... 69.5120000 |
|Средневзвешенное удельное
сходство:................ 2.2810000
|
|Среднее на объект суммарное
сходство:.............. 31.7070000
|
|Средние на объект
фактические суммарные затраты:... 13.9020000 |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| Номер | Код |
Наименование |Ур-нь сходст| Затраты
на |Удельное сход|
|по пор.|объекта| объекта
|об.с классом|назн. объекта|об. с классом|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1 |
42 |Цисарь ПИ-52 | 44.6200000|
10.0000000| 4.4620000|
| 2 |
24 |Григорьева ПИ52|
38.3090000| 14.3900000| 2.6620000|
| 3 |
33 |Люлик ПИ-52 | 31.7050000|
12.1950000| 2.6000000|
| 4 |
23 |Веревкина ПИ-52|
21.0730000| 14.6340000| 1.4400000|
| 5 |
8 |Иванова ПИ-51 | 22.8280000|
18.2930000| 1.2480000|
==========================================================================
* * *
ДАННЫЕ ПО НЕНАЗНАЧЕННЫМ
ОБЪЕКТАМ (LC-алгоритм):
==========================================================================
|Ном| Код |
Наименование | Код | Наименование
|Ур.сход|Затр.на|Уд.сх.|
| |объек|
объекта |клас.| класса
|об.с кл|объект |об.кл.|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| |
|В СРЕДНЕМ: | | | 0.000|
0.000| 0.000|
==========================================================================
ДАННЫЕ ПО КЛАССАМ, НА
КОТОРЫЕ НЕ БЫЛО НАЗНАЧЕНИЙ ОБЪЕКТОВ (LC-алгоритм):
==========================================================================
|Номер| Код |
Наименование
| Начальный |
| |класса|
класса | ресурс класса |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| 1|
10|УСПЕВАЕМОСТЬ - "5" менее 25%...............| 10.000|
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| |
|
СУММА : |
10.000|
| |
|
СРЕДНЕЕ: | 10.000|
==========================================================================
Универсальная когнитивная аналитическая
система "Эйдос"
По нажатию клавиши выводится более
подробная информация о сравнения результатах эффективности LC-алгоритма и
RND-алгоритма (рисунок 11):
Рисунок 13 – Сравнение
эффективности LC-алгоритма и RND-алгоритма
Из рисунка 11 видно, что при
использовании LC-алгоритма при экономии ресурсов 25% среднее сходство объектов
с классами возрастает примерно на 50%, если за базу сравнения брать
RND-алгоритм. При других исходных данных и параметрах назначения эффективность
LC-алгоритма может меняться, но всегда остается значительно более высокой. Чем
RND-алгоритма. В этом и состоит актуальность постановки задачи и ее решения,
предложенных в данной работе.
6.1.3.3.4.
Различие в подходах психолога и руководителя к назначению и перемещению
персонала
Психологи обычно рекомендуют
назначать сотрудников на должности, которым они больше всего соответствуют по
свои личностным и профессиональным качествам. Руководители же кроме этого еще
учитывают и затраты своих ресурсов на
эти назначения, т.е. то, сколько они готовы платить сотруднику за выполнение
функциональных обязанностей на этой должности. Фактически руководитель
применяет профессиограммы с учетом функционально-стоимостного анализа и метода
«Директ-костинг». Поэтому предлагаемый в работе подход соответствует требованиям
руководителя. Вместе с тем, психологов (специалистов по персоналу) не
интересуют финансовые аспекты назначения персонала, то они могут задать на
классы практически неограниченные ресурсы, а затраты на назначение для всех
респондентов сделать малыми и одинаковыми (например, равными 1). Тогда система
просто назначит сотрудников на должности, которым они больше всего
соответствуют без учета затрат на это. Отметим также, что все выходные формы
записываются в виде файлов. Обычно целью управления качеством является повышение уровня
системности. Однако точно также, т.е. внедряя в определенные систему элементы,
можно не повышать, а понижать ее уровень системности, т.е. по сути, разрушать,
уничтожать данную систему (так и определяется понятие антисистемы[18]).
Итак, качество системы рассматривается, как эмерджентное
свойство систем, обусловленное их
составом и структурой и отражающее их функциональность, надежность и стоимость.
Поэтому при управлении качеством, целью управления является формирование у
объекта управления заранее заданных системных свойств. Чем ярче у объекта
управления выражены системные свойства, тем сильнее у него проявляется нелинейность:
и в зависимости самих управляющих факторов друг от друга, и в зависимости
результатов действия одних факторов, от действия других. Поэтому проблема
управления качеством состоит в том, что в процессе управления сам объект
управления изменяется качественно, т.е. изменяются его уровень системности, степень
детерминированности и сама передаточная
функция. Эта проблема распадается на несколько задач: 1-я состоит в
многопараметрической типизации, 2-я в сопоставимой системной идентификации
состояния объекта управления, а 3-я – в принятии решений об управляющем
воздействии так изменяющем состав объекта управления, чтобы его качество
максимально повышалось при минимальных затратах на это. Для решения 3-й задачи
предлагается применить выбор компонент объекта управления по их функциональному
назначению с учетом ресурсов, выделенных на реализацию различных функций,
затрат, связанных с выбором тех или иных компонентов и степени соответствия
различных компонент их функциональному назначению. Фактически предлагается
формулировка и решение нового обобщения варианта задачи о назначениях: «Мультипликативный рюкзак», отличающееся от известного тем, что
назначения производится не только с учетом ресурсов и затрат, но и с учетом
степени соответствия компонент их функциональному назначению. Математическая
модель, обеспечивающая решение 1-й и 2-й задач и отражающая степень
соответствия компонент их функциональному назначению, а также весь процесс
приятия решений по назначениям, т.е. 3-я задача, реализованы в АСК-анализе и
системе «Эйдос-Х++». Приводится упрошенный численный пример предлагаемого
подхода, связанный с назначением персонала.
6.1.4. Выводы
Материалы данного раздела
могут быть использованы для синтеза и применения интеллектуальных измерительных систем для системной
идентификации в эконометрике, биометрии, экологии, педагогике, психологии,
медицине, ветеринарии и в других предметных областях, а также при преподавании дисциплин: интеллектуальные системы; инженерия знаний и
интеллектуальные системы; интеллектуальные технологии и представление знаний;
представление знаний в интеллектуальных системах; основы интеллектуальных
систем; введение в нейроматематику и методы нейронных сетей; основы
искусственного интеллекта; интеллектуальные технологии в науке и образовании;
управление знаниями; автоматизированный системно-когнитивный анализ и интеллектуальная
система «Эйдос»; которые автор ведет в настоящее время[19], а также и в других дисциплинах,
связанных с преобразованием данных в информацию, а ее – в знания и применением
этих знаний для решения задач идентификации, прогнозирования, принятия решений
и исследования моделируемой предметной области (а это практически все
дисциплины во всех областях науки).
Таким образом, АСК-анализ и
система «Эйдос» представляют собой современную инновационную (готовую к
внедрению) технологию интеллектуального управления качеством систем путем решения обобщенной задачи о
назначениях. Этим
и другим применениям должно способствовать и то, что система «Эйдос» находится
в полном открытом бесплатном доступе (причем с подробно комментированными
открытыми исходными текстами) на сайте автора по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm.
6.2. Хиршамания при оценке результатов научной
деятельности, ее негативные последствия и попытка их преодоления с применением
многокритериального подхода и теории информации
Недавно был начат процесс монетизации
оценки результатов научной деятельности, и возникла потребность в методиках
количественной и сопоставимой оценки эффективности и качества работы ученого.
Появились многочисленные методики материального поощрения за эти результаты.
Общим для всех этих методик является завешенная роль индекса Хирша. Сам по себе
этот индекс вполне обоснован. Однако в связи с практикой применения индекса
Хирша в наших условиях в сознании научного сообщества возникла своеобразная
мания, которую автор предлагает называть «Хиршамания». Эта мания
характеризуется повышенным нездоровым интересом к самому значению индекса
Хирша, особенно к искусственному неадекватному преувеличению этого значения, а
также рядом негативных последствий этого интереса. В данной работе делается
попытка кратко описать некоторые негативные последствия этой новой психической
инфекции, поразившей общественное сознание научного сообщества. А также
наметить пути преодоления хотя бы некоторых причин их возникновения. В этом и
состоит проблема, решаемая в данной работе. Для решения сформулированной
проблемы предлагается применить многокритериальный подход, основанный на теории
информации, а именно тот его вариант, который реализован в автоматизированном
системно-когнитивном анализе (АСК-анализ)
и его программном инструментарии – интеллектуальной системе «Эйдос»
«Индекс Хирша – это наукометрический
показатель, который отражает степень
понимания того, что такое индекс Хирша»
Народная
мудрость периода
Хиршамании
(начало XXI века)
6.2.1.
Проблема, или о том какой урон нанес джин Хирша,
выпущенный из бутылки
Недавно научное сообщество лишилось надбавок за ученые
степени и звания. Был начат процесс монетизации оценки результатов научной деятельности.
Возникла потребность в соответствующих методиках количественной и сопоставимой
оценки эффективности и качества работы ученого. Появились многочисленные
методики материального поощрения за эти результаты. Эти методики отличаются в
разных вузах. Но общим для всех этих методик является большая роль, которая
отводится в них так называемому индексу Хирша. Сам по себе этот индекс вполне
обоснован[20].
Однако в связи с практикой применения индекса Хирша в
наших условиях в сознании научного сообщества возникла своеобразная мания, которую автор предлагает называть
«Хиршамания».
Эта мания характеризуется повышенным нездоровым интересом к самому значению индекса Хирша, особенно к
искусственному неадекватному преувеличению этого значения, а также рядом негативных последствий этого интереса. В
данной работе мы попытаемся кратко описать некоторые негативные последствия
этой новой психической инфекции, поразившей общественное сознание научного сообщества.
А также наметить пути преодоления хотя бы некоторых причин их возникновения. В этом и состоит проблема, решаемая в
данной работе.
Чтобы наметить удачный план лечения, прежде всего надо
поставить правильный диагноз. Мы квалифицируем Хиршаманию как психический
вирус, о которых блестяще писал Ричард Броди [1]. Этот психический вирус может
рассматриваться как инструмент манипуляции общественным сознанием научного
сообщества, что очень хорошо описал в своем бестселлере С.Г. Кара-Мурза [2]. Подобного рода манипуляции, которые
особенно облегчились в связи с появлением глобальной информационной среды
распространения и адресной доставки агента действия, могут использоваться также
для нанесения урона противнику и, по сути, являются информационным оружием [3].
Так что Хиршамания в принципе может быть не таким уж и безобидным явлением.
Так что же собственно произошло? Ученым стали платить
надбавки (материальные поощрения) за те или иные значения индекса Хирша. Ученые
народ неглупый и быстро сообразил, что имеет прямой смысл эти значения
увеличивать. А для этого надо писать научные статьи, монографии,
научно-методические работы и т.д., и т.п., размешать их в Российском индексе
научного цитирования (РИНЦ)[21], и
ссылаться на них. Это ясно из самой природы индекса Хирша. Причем не просто
писать и ссылаться, а писать как можно больше и ссылаться тоже как можно
больше.
Тривиальным является утверждение о том, что статья
должна отражать основные результаты какого-то научного исследования, решение
той или иной научной или прагматической задачи. Но откуда взять столько научных
результатов? Ведь научные исследования требуют инвестиций и имеют длительный
цикл проведения.
Так возникает 1-я
проблема, состоящая в том, что писать то, в общем-то, и не о чем, по
крайней мере, в желаемом количестве, а писать очень надо. В век интернета
решение этой проблемы элементарно. Проводим поиск по ключевым словам, находим
источники, в которых об этом уже кем-то написано, и вставляем тексты из этих
источников в свои статьи. Если мы корректно ссылаемся на эти заимствования, то
они называются «цитированиями», а если нет, то «плагиат». Если ссылаться на все
эти заимствования, то может оказаться, что автор не внес никого личного вклада
в работу, поэтому часто на них не ссылаются. Таким образом, материально
простимулированное применением индекса Хирша для оценки результативности
научной деятельности неоправданное стремление много писать, но не для того,
чтобы отразить результаты реальных исследований, которых или вообще нет, или
недостаточно для удовлетворения амбиций, приводит к распространению плагиата.
Что же такое плагиат с правовой точки зрения? Наверное, это просто воровство, в
частности воровство авторских текстов и идей, нарушение авторских прав на
результаты научной деятельности.
Если есть спрос, то есть и предложение, и вот появляется
система «Антиплагиат»[22] и
много других подобных систем[23].
Подобные системы представляют свои услуги on-line, есть и бесплатные с
ограниченными возможностями, и профессиональные, которые, естественно, платные.
Практически все вузы уже купили профессиональные системы проверки на
антиплагиат, и эта проверка стала нормой. Таким образом, первым отрицательным
последствием Хиршамании является небывалое распространение плагиата в научной
среде и как реакция на это – борьба с плагиатом (а не с его причинами, т.е. как
обычно), причем за деньги самих научных организаций, т.е. косвенно – самих
ученых и с большими затратами труда и времени самих ученых.
Началась борьба с плагиатом, началась и борьба с этой
борьбой. Как грибы после дождя в информационном пространстве вдруг появились
многочисленные ухищрения и «научные рекомендации» для того, чтобы обойти эти
системы, т.е. добиться высокого уровня оригинальности некорректно
заимствованного текста[24].
Прежде всего это различные синонимайзеры[25].
Однако системы антиплагиата работают просто с текстами, поэтому можно их
обойти, если заимствовать не текст, а идеи, т.е. несколько перефразировать
текст, чтобы сам текст стал другим, а его смысл сохранился. Эта процедура
называется «Рерайтинг (rewriting)»[26],
т.е. переписывание и изложение чужих мыслей своими словами. Еще для подобных
целей могут быть использованы программы машинного перевода, т.к. они тоже подбирают
синонимы и перефразируют[27].
Конечно, разработчики систем антиплагиата также принимают меры для обнаружения
признаков борьбы с ними, т.е. признаков искусственного завышения оригинальности
текста (это уже борьба систем антиплагиата с борьбой против них), и т.д., и
т.д. почти до бесконечности.
Автор тоже столкнулся с этим явлением (как поставщик текстов и идей для плагиаторов, как высокопоставленных, так и не очень). Лучше всего об этом написано в статье «Групповой плагиат: от студента до министра»[28]. Чтобы найти многочисленные «труды» плагиаторов, включая диссертации, достаточно в Internet в любой поисковой системе сделать запрос, например: «Коэффициенты эмерджентности Хартли, Харкевича, Шеннона», которые автор системной теории информации (СТИ) проф. Е.В.Луценко назвал так в честь этих выдающихся ученых в области теории информации. При этом автор следовал сложившейся научной традиции называть единицы измерения и математические выражения в честь известных ученых. Причем часто плагиаторы даже не понимают, что сами основоположники и классики теории информации не предлагали этих коэффициентов, а предложены они были в работах автора. Наверное, поэтому они и не считают нужным делать ссылки и пишут, например:
1. «По Харкевичу коэффициент эмерджентности определяет степень детерменированности ситемы…» (подчеркнуто нами, авт., в цитате сохранены орфографические ошибки плагиатора, авт.).
2. «Отсюда строится системная численная мера количества информации в ИС на основе оценки эмерджентности системы (по Хартли и Харкевичу)» (выделено плагиатором, а на самом деле «по Луценко», – авт.).
Эти фразы легко найти в Internet. Так что плагиаторская активность не только продолжается, но и набирает обороты.
Однако индекс Хирша отражает не только число статей,
но и число их цитирований. Поэтому самих статей для повышения значения индекса
Хирша недостаточно, т.е. еще надо, чтобы на них были ссылки. А откуда их взять,
если на твои статьи сам, т.е. по собственной инициативе, никто или почти никто
не ссылается?
Так возникает 2-я
проблема, т.е. проблема увеличения количества ссылок на свои статьи. Но
и эту проблему можно решить. Во-первых, можно самому ссылаться на собственные
статьи, т.е. заниматься самоцитированием. С правовой точки зрения это, конечно,
не плагиат, т.к. нет потерпевшей стороны, т.е. в принципе автор имеет все авторские
права на свой текст и свои идеи и может распоряжаться ими по своему усмотрению.
Но с этической точки зрения чтобы ссылаться на себя, надо иметь на это моральное
право и необходимо, чтобы эта ссылка была оправдана и обоснованна, а не являлась
искусственной, т.е. ссылки ради ссылки, часто даже без сноски на нее из текста.
По мнению автора, такое обоснование может состоять в том, что ряд статей
образует цикл или систему, т.к. они посвящены описанию различных этапов решения
одной проблемы или развитию определенного научного направления, т.е. по сути,
являются продолжением друг друга и взаимосвязаны по своему содержанию[29].
Однако часто у авторов нет возможности для таких обоснованных самоцитирований,
то тогда они занимаются неоправданными (некорректными) самоцитированиями.
Иногда авторов с высоким уровнем самоцитирования обвиняют в том, что они
засоряют информационное пространство дублирующей информацией и как бы продают
многократно один и тот же информационный продукт. Автор не согласен с этой
точкой зрения потому, что если бы она была правильной, то во всем интернет
должно бы быть одно место для харания каждого информационного объекта, а все
остальные просто должны были бы на него ссылаться. Но что мы видим на практике?
Мы видим огромное количество размещений
одного и того информационного объекта на различных сайтах. Кстати, этим
занимаются и различные интеграторы – библиографические базы данных, например
НЭИКОН, КиберЛенинка, Agris, Ulrich’s Periodicals Directory, DOAJ, OALIB (Open Access Library), Scopus, Web of Science, и
даже сам РИНЦ. Смысл таких размещений в новых возможностях в появлении для
читателей новых дополнительных возможностей прочтения публикаций, а также
возможность их статистической обработки и углубленного анализа в базах интегратора.
Но все же как-то неудобно ссылаться только на самого
себя, как будто у тебя и не было предшественников или соавторов. Понятно, что
цитирование соавторами это «почти самоцитирование» и также уязвимо для критики.
Поэтому авторы, не являющиеся соавторами, часто договариваются о взаимных
цитированиях, т.е. я тебя цитирую тебя, а за это – ты меня, что неблаговидно и
с правовой точки зрения является сговором для извлечения дополнительной
необоснованной созданием продукта или услуг прибыли, а этической точки зрения
достойно морального порицания. В век глобальных коммуникаций и эти вопросы
легко решаемы.
И, как всегда, раз наблюдаются искусственные и
необоснованные цитирования, то появляются и средства борьбы с этим
неблаговидным явлением (естественно, как всегда только с самим явлением, а не с
его причинами). В частности появляется идея использовать для количественного
измерения самоцитирований и цитирований соавторами индекс, взятый из экономики,
который в ней используется для количественной оценки степени монополизации
отрасли, – это индекс Херфиндаля[30] и
различные его модификации.
Как же научное сообщество среагировало на
установленные Минобрнауки РФ «правила игры». Да очень просто: все, даже те, кто
уже давно ничего не писал, с готовностью принялись писать научные работы и
цитировать их, можно сказать с энтузиазмом принялись повышать свои индексы цитирования
и индексы Хирша. Правда это не сопровождалось сколь-нибудь заметным или
значительным повышением активности самих научных исследований и инновационных
разработок. А это означает, что народ вполне понял, что от него требуется: не
сама работа, а лишь показатели отчетности о работе. По сути, речь идет о фальсификации деятельности: вместо самой
деятельности и ее результатов учитываются и идут в зачет отчеты с растущими
показателями о якобы имевшей место деятельности и результатах, и эти отчеты и
показатели фактически и принимаются за результаты, а было ли все это на самом
деле о что на сомом деле они отражают, фактически никого особенно не интересует[31].
Налицо явление, которое, в работе [4], названо «виртуализация общества».
Фактическая деятельность в реальной области заменяется, замещается информацией о ней, а потом выясняется, что информация
начинает жить собственной жизнью и замещает
реальную область, при этом она в принципе может и не отражать процессы в
реальной области. В результате масштабной, может быть даже глобальной
фальсификации и виртуализации сама деятельность заменяется отчетностью о ней,
содержащей различные показатели. И народ быстро сообразил, что нет
необходимости в самой деятельности и нет никакого смысла достигать самого
результата деятельности в реальной области: вполне достаточно обеспечить достижение не самого результата деятельности, а
нужных показателей отчетности. Повышения этих показателей все и добиваются.
Но наука в этом плане не оригинальна. В экономике
подобная подмена давно стала нормой: практически все осознают как цель своей
экономической деятельности не создание благ и услуг для потребления их другими
людьми, во что крайне наивно верил Адам Смит и что было беспощадно развенчано
Карлом Марксом, а всего лишь личное обогащение (получение прибыли). В экономике
давно считается нормой, вполне допустимой и не осуждаемой с морально-этической
точки зрения, обогащение без создания реальных благ, например за счет
осуществления спекулятивных операций на фондовом и валютном рынке. В результате
подобных операций создается ничем реально не обеспеченный чисто инфляционный
капитал. И в этом никто не видит ничего аморального или неэтичного. А между тем
это прямой и ничем неприкрытый откровенный грабеж огромных масс людей во всем
мире, покупательная способность которых падает за счет инфляции. Деньги вообще
все замещают и все опошляют и не только в экономике, а вообще везде. Так,
например, любовь они превращают в проституцию. А науку, которая является
общественным институтом и общественной и индивидуальной деятельностью по
познанию человека, общества и природы с целью познания истины (фундаментальная
наука) и повышения эффективности деятельности человека (прикладная наука), – в
искусственное увеличение индекса Хирша путем увеличения потока бессодержательных,
переписанных друг у друга, но при этом широко цитируемых публикаций. В традициях Хиршамании цель достижения
высоких результатов научной деятельности подменяется целью достижения высоких
значений наукометрических показателей, отражающих эти результаты. При этом
в информационном обществе отражение может быть создано и существовать и без
достижения каких-либо реальных результатов и достижений. Таким образом,
фальсификация и виртуализация науки, обусловленная Хиршаманией, по сути,
приводят к ее профанации. Это настолько очевидно, что можно было бы об этом и
не говорить, если бы практически все научное сообщество снизу до верху дружно
бы не занималось именно этим, безропотно приняв правила игры, предложенные
Минобрнауки, причем не просто занималось, но и делало при этом вид, что процесс
идет нормально, т.е. делая хорошую мину при плохой игре[32].
Однако, в отличие от экономики, в науке в соответствии
этикой научных публикаций[33]
подобные действия считаются аморальными, и журналам, допускающим подобные статьи
к публикации практически закрыт путь в такие престижные международные
библиографические базы данных, как Scopus и Web of Science. Из-за действия
подобных этических норм воровать в науке стало так сложно, что иногда начинает
казаться, что ты работаешь. Это звучит как юмор, но им не является, т.е. было
бы смешно, если бы не было грустно. Так, например, рерайтинг – это действительно
сложная и трудоемкая работа, требующая не только профессиональной компетенции в
той предметной области, в которой осуществляется плагиат идей, но и
определенной филологической подготовки: умения быстро и много писать на
правильном русском языке. В работе рерайтера есть почти все, что есть в научной
работе, кроме одного: у рерайтера нет своих новых идей и ему негде
их брать, кроме как заимствовать их у того, у кого они есть. Но у рерайтера не
просто нет своих новых идей, но он и не имеет ни малейшего представления о том,
откуда они вообще берутся. Здесь я не могу отказать себе в удовольствии еще раз
сослаться на статью В.Б.Вяткина [5], хотя плагиаторы-персонажи этой статьи не
удосужились даже переписать мой текст своими словами, т.е. не дотянули до
рерайтеров, а просто привели весь текст целиком, включая «авторскую пунктуацию»,
т.е. изложив все от первого лица, «как было», включая даже мои орфографические
и грамматические ошибки.
Таким образом, можно обоснованно констатировать факт,
состоящий в том, что решение Минобрнауки РФ о монетизации оценки результатов
научной деятельности, в частности
придание неоправданно высокой роли в этом процессе индексам публикационной
активности (само по себе это вчерашний и даже позавчерашний день), а также
индексам цитирования и Хирша, явилось причиной, породившей целый каскад или
снежный ком различных негативных последствий, многие из которых имеют криминальный характер, а некоторые «всего лишь» аморальны
(рисунок 1).
Подобное в новейшей Российской истории было уже не
раз, и, по-видимому, уже есть основания говорить об определенной наметившейся тенденции или закономерности. Достаточно
упомянуть про позорную эпопею с ЕГЭ, которая начиналась за здравие, а
закончилась за упокой и подобную же историю с оценкой эффективности вузов [4].
Очень бы не хотелось, чтобы тоже самое, что случилось с ЕГЭ и с методикой
оценки эффективности вузов случилось бы и с РИНЦ. Однако, к большому сожалению
и объективно говоря пока все идет к тому, что так и получится, т.е. идея
количественной сопоставимой оценки результатов (качества и эффективности)
научной деятельности в наших условиях не реализуема. Может быть, это не дело
только РИНЦ, а дело всего российского научного сообщества, включая Минобрнауки?
Итак, мы сталкиваемся с ситуацией, когда хорошая идея
плохо реализуется, т.к. мы опять впадаем в крайности, относимся к новой (для
нас) идее, как панацее от всех проблем. Но такого, к сожалению, не бывает. А,
как известно, нет лучшего способа дискредитировать хорошую идею, чем довести ее
до абсурда, до крайности, т.к. тогда она становится своей противоположностью.
Получается уже в который раз, что за что боролись, на то и напоролись. В этой
ситуации перефразируя, похоже, что бессмертные слова В.С.Черномырдина,
Минобрнауки может только сказать, что «мы хотели как лучше», а мы уже имеем все
фактические основания констатировать, что опять «получилось как всегда».
Рисунок 1 – Негативные последствия решения о
монетизации оценки
результатов научной деятельности (Хиршамании)
Выше уже упоминалось, что в этой новой истории с
индексом Хирша, ключевая роль принадлежит Российскому индексу научного цитирования
(РИНЦ)[34]. Что
такое РИНЦ сегодня? На сегодня это безусловно самая большая в России
электронная научная библиотека общего доступа. На момент написания данной
статьи в базах РИНЦ содержалось: журналов: 32991, выпусков журналов: 1193672,
полнотекстовых статей: 20325344, издательств: 14976[35].
Данные РИНЦ используются сегодня для оценки рейтингов научных журналов и
результатов научной деятельности, как отдельных ученых, так и вузов и научных
институтов. Безусловно, у РИНЦ много достоинств и в настоящее время ему в России
нет альтернативы. Но и у РИНЦ есть свои недостатки, которые вызывают совершенно
обоснованный и все более громкий ропот в среде научного сообщества. Перечислим
наиболее важные них в контексте проблематики данной статьи.
РИНЦ чрезвычайно инерционная система. Обновление его баз данных происходит раз в неделю, а
некоторые базы данных, например системы SCIENCE INDEX, обновляются раз в 2
месяца. Это означает, что в РИНЦ не выполняется одно из важнейших требований к
базам данных: их актуальность. Проще говоря, если Вы обращаетесь в РИНЦ для
получения тех или иных показателей по отдельным ученым или по вузам научным
организациям, то нужно иметь в виду, что эта информация может быть сильно
устаревшей.
В РИНЦ отсутствует целостность баз данных, т.е. данные в одних графах не подтверждаются данными
в других графах. Как профессор по кафедре компьютерных технологий и систем с
2005 года и программист с почти 40-летним стажем автор может предположить, что
эта особенность РИНЦ обусловлена тем, что разработчики даталогической и
инфологической моделей его баз данных не везде нормализовали его базы данных.
Это означает, что информация РИНЦ нет очень достоверна или, проще говоря,
просто недостоверна.
Программное обеспечение РИНЦ не может идентифицировать
авторов и публикации по их
некорректным, неполным и нестандартным описаниям в списках литературы. Между
тем эта задача решена в общем виде [6]. В результате число работ авторов, число
цитирований этих работ и индекс Хирша авторов в системе РИНЦ оказываются
систематически заниженными[36]. В
качестве выхода из этой проблемной ситуации РИНЦ предлагает нам
регистрироваться в системе SCIENCE INDEX и самим привязывать к себе свои работы
и ссылки на свои работы из списка, предложенного системой РИНЦ. Иначе говоря,
авторам предлагается самим вручную делать работу, которая должна выполняться
полностью автоматически или с участием модератора, т.е. автоматизировано, самим
РИНЦ.
Но и это еще не все. Дело в том, что список работ и
ссылок на них, которые могут принадлежать данному автору, предлагаемый системой
РИНЦ неполон, т.е. иначе говоря, некоторые работы, имея права пользователя
системы SCIENCE INDEX, привязать вообще невозможно. Но это возможно имея права
доступа администратора этой системы. И тут начинается самое интересное. Права
администратора системы SCIENCE INDEX продаются РИНЦ вузам и научным
организациям, причем продаются не дешево. Понятно, что практически все вузы и
научные организации фактически были вынуждены купить эту систему, как, кстати,
немного ранее и доступ к профессиональной версии системы Антиплагиат (которая,
кстати, сейчас интегрируется с системой РИНЦ).
Интересно получается. Ученые должны провести научные исследования и разработки, написать об
этом монографии и статьи, получить авторские свидетельства, разместить их в
РИНЦ, привязать их к себе, как авторам, привязать к себе ссылки на них, причем
должны сделать это все это сами и еще заплатив журналам, Роспатенту и РИНЦ, за
право самим это все сделать. Получается к примеру 5% бюджета времени ученого
уходит на проведение самих научных исследований и разработок, еще 5% – на их
оформление в виде монографий, статей и патентов, и еще 90% на их размещение в
РИНЦ, а также привязку публикаций и ссылок на них к себе, как автору. Разве так мы представляли себе, на что
должен тратить свое творческое время ученый? Причем, как правило, после
ненормированного рабочего дня, потраченного на голосовую нагрузку –
преподавание? Ну то, что журналам за публикацию статей нужно платить, это еще
понять можно. Но почему надо платить еще и РИНЦ за работу, которую мы выполняем
сами за его программную систему, это уже не очень понятно.
Понятно, что покупая
(и не дешево) права доступа администратора системы SCIENCE INDEX, вузы и
научные организации справедливо надеются, что имея эти права, они смогут в
комфортной и дружественной информационной среде полностью решить проблемы с
привязкой статей и ссылок на них, описанные выше. Однако оказывается, что и это
не так.
Прежде всего, надо сказать, что среда далека от
комфортной, переходы из режима в режим плохо продуманы и сделаны неудобно.
Постоянно надо переходить из одного окна в другое, удобнее бывает открыть два
или более окон на большом мониторе, но они мало у кого есть. Реакция системы на клик является
чрезвычайно замедленной: иногда несколько минут. При большом объеме работ это
резко увеличивает общее время работы. Когда администратор системы SCIENCE INDEX
видит список ссылок на работы автора, то те, над которыми ему надо работать, не
отмечены двумя красными треугольниками, и таких довольно много, но приходится
их искать вручную среды отмеченных. При этом ссылки на непривязанные работы и
на привязанные работы, находящиеся на проверке модератора, на экране выглядят
одинаково. Это крайне неудобно. О том, что работа находится на проверке, можно
догадаться потому, что нет ссылки на возможность корректировки ее описания. Но
чтобы узнать есть эта ссылка или нет, надо кликнуть по ссылке на саму
ссылающуюся работу, а потом, если ее нет, вернуться назад в список ссылок,
возможность чего разработчиками не предусмотрена и приходится возвращаться
через авторский указатель. Все это занимает время и раздражает своей
непродуманностью, т.к. решение ведь простое. Надо просто отмечать все ссылки в
специальной отведенной для этого колонке иконками тер типов, отличающимися по
цвету, как сделано с инками, отражающим возможность доступа простого посетителя
РИНЦ к полным текстам публикаций. Есть всего три состояния ссылки на публикацию
автора: 1) привязанная (неважно кем), 2) привязанная администратором
SCIENCE INDEX от организации и находящаяся на проверке у модератора РИНЦ,
3) непривязанная. Я предложил бы непривязанные ссылки отметить красным
цветом, находящиеся на проверке – желтым, а привязанные – зеленым. Это
интуитивно естественно. Желательно было бы иметь возможность сортировки и
фильтрации ссылок по стадии обработки, чтобы было видно только те, над которыми
надо работать, или только те, которые уже привязаны или находящиеся на
проверке.
После привязки ссылки на работу автора в списке
литературы эта корректировка посылается
на проверку модератору. Мне так и не удалось узнать в РИНЦ, установлены ли в
РИНЦ какие-либо нормативы на максимальную длительность его проверки. Не
исключено, что ждать придется годами. Поэтому предлагается ссылки, привязанные
администратором SCIENCE INDEX от организации, не посылать на проверку модератору
РИНЦ, а сразу включать в базы данных РИНЦ, или накапливать а включать в базы
даны раз в неделю. Если РИНЦ заботится о качестве привязки ссылок администратором
SCIENCE INDEX от организации, то пусть сам по своему регламенту проверяет
качество этих привязок, и если они не соответствуют установленным критериям качества,
которые должны быть опубликованы на сайте РИНЦ, то применять к данному администратору
и к его организации санкции (меры воздействия), прописанные в договоре. Например, можно лишать данного администратора
прав доступа на определенное время или требовать от организации его замены и
т.п. Но реакция системы РИНЦ на корректировки администратора SCIENCE INDEX от организации
обязательно должна быть резко ускорена.
Но главное все же не это, хотя это и важно. Главное в
том, что при привязке ссылок в списках литературы возникают безвыходные
ситуации. Даже имея права доступа администратора системы SCIENCE INDEX от
организации, далеко не всегда удается привязать ссылку на работу автора из
списка литературы ссылающейся работы. Мы можем скорректировать эту ссылку на
правильную, но система не привязывает ее, пока не найдет в базах РИНЦ. Это
вообще неприемлемо. Во-первых, потому, что есть работа в базах РИНЦ или ее там
нет, не должно влиять на число ссылок на нее, т.к. это работа автора, на
которую ссылается другой автор, и он эту работу видел, когда ссылался.
Во-вторых, сам поиск не всегда дает положительный результат, т.е. не всегда
способен найти работу, даже если она есть в базах РИНЦ и ссылка на нее
правильная, в т.ч. сформирована самой системой РИНЦ. В этом случае, который
наблюдается примерно в 70% случаев поиска, у администратора SCIENCE INDEX от
организации вообще нет способа привязать эту ссылку. Автор предлагал
администраторам РИНЦ два решения этой проблемы. Первое подробнейшим образом
описано в статье [6]. Работать это решение будет быстро, т.к. у авторов в РИНЦ
не более 300 работ, а чаще всего гораздо меньше. Это решение обеспечивает
ранжирование работ автора в порядке убывания релевантности ссылке. Проведенные
автором численные эксперименты убедительно продемонстрировали, что искомая
работа практически всегда будет на первой позиции, т.е. будет иметь наивысшую
релевантность. Второе решение вообще примитивное и состоит в том, что если
поиск системы РИНЦ не может найти в работах автора, размещенных в РИНЦ ту, на
которую сделана ссылка из списка литературы, то надо просто вывести весь список
его работ и дать возможность администратору SCIENCE INDEX от организации просто
указать в нем нужную работу.
Иначе при работе с РИНЦ слишком часто возникают
безвыходные ситуации и заслуженные ученые, имеющие сотни работ, размещенных в
РИНЦ и индекс Хирша 5 или 6 и видящие, что невозможно его увеличить не только авторам,
но даже имея права администратора SCIENCE INDEX от организации, делают вполне
определенные и легко прогнозируемые выводы и о системе РИНЦ, и о Хирше, и о
всех, кто все это придумал. Все это дискредитирует и систему РИНЦ и основанную
на данных РИНЦ систему оценки
результатов научной деятельности.
Автор данной работы представляет политематический
(мультидисциплинарный) журнал, издаваемый Кубанским агроуниверситетом [7][37]. В
университете (http://kubsau.ru/)
в настоящее время работает 26 факультетов, 85 кафедр, 8 докторских
диссертационных советов по 21 специальностям, около 300 докторов наук, профессоров
и 700 кандидатов наук, доцентов, 1500 преподавателей (а в 2003 году, когда создавался
журнал, кафедр было около 100 и действовало 12 диссертационных советов). Поэтому
естественно, что журнал изначально создавался как мультидисциплинарный (политематический),
т.к. именно такой журнал был нужен университету. Еще отмечу, что наш вуз входит
в тройку крупнейших патентообладателей России и имеет в 4 раза больше патентов,
что все аграрные вузы России ВМЕСТЕ ВЗЯТЫЕ (включая и Темирязевку). За время
существования журнала с 2003 года по сенятбрь 2016 года в свет вышло 120
номеров, в которых опубликовано 6090 статей. Среди 10770 авторов журнала из
России и более 10 стран ближнего и дальнего зарубежья (http://ej.kubagro.ru/geo.asp)
3175 докторов наук, 2832 профессоров, 3447 кандидатов наук, 2505 доцентов (http://ej.kubagro.ru/st.asp).
В среднем ежемесячно в журнале издается 51 статья общим объемом 730 страниц 90
авторов из которых 26 доктора наук, 29 кандидаова наук, 24 профессоров, 21
доцентов. Но в последние годы объем публикаций резко возрос (см.:http://ej.kubagro.ru/st.asp и
работу [7]. Например, в 101-м номере Научного журнала КубГАУ опубликовано
столько статей, сколько в «других журналах» публикуется примерно за 2 – 2.5
года. Как Вы думаете, где будут публиковаться наши ученые – сотрудники
университета: в «других журналах» или в «нашем журнале»? Да у них просто
ФИЗИЧЕСКИ практически нет никакой возможности публиковаться где-то еще. Тем
более, что публикация в нашем журнале БЕСПЛАТНА для сотрудников университета и
аспирантов из любых организаций СНГ. Ну и как это скажется на индексе
Херфиндаля? Понятно, что плохо, точнее очень плохо. По этой причине я ПРОТИВ
модификации методики расчета рейтинга SCIENCE INDEX с учетом индекса Херфиндаля,
т.к. это эквивалентно наказанию крупнейших и наиболее успешных изданий в своей
области (и не только в своей области) и крупнейших издателей. При этом я согласен,
что для мелких и средних по объему изданий его применение может быть вполне
оправдано. Поэтому я предлагаю придавать тем меньший вес индекса Херфиндаля в
определении рейтинга SCIENCE INDEX, чем больше объем номеров издания в станицах за соответствующий период, за
который определяется рейтинг. Для нашего Научного журнала КубГАУ индекс
Херфиндаля практически вообще не должен играть никакой роли.
6.2.2. Идея предлагаемого решения проблемы
Недавно все Российское профессиональное научно-педагогическое сообщество стало свидетелем того, как Министерство образования и науки России начало работу по монетизации оценки результатов научной деятельности (ее качества и эффективности).
В этой связи возникает ряд вопросов, аргументированные ответы на которые представляют большой интерес.
Прежде всего, возникает вопрос о том, что понимается под результатами (качеством и эффективностью) научной деятельности (далее: «результаты»)? Ведь ясно, что прежде чем оценивать результаты научной деятельности было бы неплохо, а на самом деле совершенно необходимо, разобраться с тем, что же это такое. Ясно, что по этому поводу существует много различных мнений, которые в различной степени аргументированы или не аргументированы и отражают позиции руководителей образования и науки, профессионального научно-педагогического сообщества и различных слоев населения. По мнению автора, с научной точки зрения некорректно и неуместно говорить о каких-то критериях оценки результатов научной деятельности, если не определено само это понятие, т.е. отсутствует консенсус в профессиональной среде по поводу того, что же это такое. Очевидно, для достижения такого консенсуса в наше время необходимо широкое обсуждение этого вопроса в научной печати, Internet и СМИ.
Когда консенсус профессионального научно-педагогического сообщества по вопросу о том, что такое «результаты научной деятельности» будет достигнут, на первый план выступает вопрос о том, с помощью какого метода оценивать эти результаты? Для автора вполне очевидно, что этот метод должен представлять собой какой-то вариант метода многокритериальной оценки. Это обусловлено просто тем, что такие сложные и многофакторные системы как наука в принципе невозможно оценивать по одному показателю или критерию. Хиршамания возникла имена благодаря вольному или невольному, сознательному или несознательному игнорированию этого принципа. Чтобы обоснованно выбрать метод оценки результатов научной деятельности необходимо сначала научно обосновать требования к нему, а затем составить рейтинг методов по степени соответствия обоснованным требованиям и выбрать метод, наиболее удовлетворяющий обоснованным требованиям.
Когда метод оценки результатов научной деятельности выбран, необходимо ответить на вопрос о том, на основе каких частных критериев оценивать эти результаты и какой исходной информацией для этого необходимо располагать? Ясно, что эти критерии в общем случае могут иметь как количественную, так и качественную (нечисловую) природу и могут измеряться в различных единицах измерения. Кроме того эти критерии могут иметь различную силу и направление влияния на оценку результатов научной деятельности. Поэтому предварительно надо бы обосновать требования к частным критериям оценки результатов научной деятельности. Это специальная наукоемкая работа, но для автора и сейчас очевидно, что эти критерии должны быть:
– измеримы, т.е. по ним должна быть исходная информация;
– информативны, т.е. обеспечивать разделение измеряемого объекта по категориям (классам) качества и эффективности научной деятельности;
– не управляемы самим объектом, параметры которого измеряются, т.к. иначе он может влиять на результаты измерения в нужном ему направлении.
Индекс Хирша соответствует первым двум требованиям, но не удовлетворяет третьему, т.е. он вполне управляем потому, что вполне понятно, как он формируется, и авторы в состоянии писать статьи и ссылаться на такие свои работы, чтобы индекс Хирша повышался максимально быстро. Поэтому величина индекса Хирша отражает не только результаты научной деятельности, но и степень понимания автором того, что такое индекс Хирша и как он формируется (см. юмористический эпиграф к данному разделу). В психологии считается, что нельзя пользоваться тестом, ключи интерпретации которого рассекречены (опубликованы), т.к. при желании тестируемый может использовать знание этих ключей для того, чтобы так отвечать на тест, чтобы получить нужные ему результаты тестирования. Это ведь элементарно. Непонятно почему такие простые вещи игнорируются системами, вроде РИНЦ.
Представьте себе мальчишку, который не хочет идти в школу и говорит маме, что у него болит голова. Мама сразу достает термометр, чтобы померить ему температуру, сбивает его, ставит своему отпрыску под мышку и бежит на кухню выключать картошку, которую варит. А мальчишка в это время на одно мгновение окунает термометр в чай и сразу кладет его обратно себе под мышку и тихо сидит с грустным видом. Мама прибегает, смотрит термометр и сразу начинает принимать меры для лечения своего мелкого симулянта, а о школе теперь не может быть и речи. Спрашивается, является ли неисправным измерительный инструмент, т.е. термометр? Нет, конечно, он исправен и совершенно правильно измеряет температуру. Но объект измерения (симулянт) заинтересован в тех или иных показаниях и не только в принципе может влиять на показания измерительного инструмента, но и фактически делает это. Примерно тоже самое мы наблюдаем в ситуации с индексом Хирша. Сам по себе это нормальный измерительный инструмент. Но измерительный инструмент, легко управляемый заинтересованной стороной. Поэтому он не пригоден для тех целей, для которых предназначен.
Конечно, возникают вопросы как о способе определения системы критериев оценки результатов научной деятельности, так и о способе определения силы и направления влияния этих критериев на оценку результатов научной деятельности, т.е. по сути, о модели. Но еще более существенным является вопрос: «О способе сопоставимого сведения разнородных по своей природе и измеряемых в различных единицах измерения частных критериев эффективности в один количественный интегральный критерий эффективности вуза».
Автоматизированный системно-когнитивный анализ является одним из современных методов, который предоставляет научно обоснованные ответы на все эти вопросы, но самое существенное, что он оснащен широко и успешно апробированным [8] универсальным программным инструментарием, позволяющим решить эти вопросы не только на теоретическом концептуальном уровне, но и практически. Очень важно, что этот инструментарий и методики его использования для решения сформулированных задач могут быть доступны всем заинтересованным сторонам не только на федеральном уровне, но в самих вузах и НИИ, а также конкретным ученым, т.к. он находится в полном открытом бесплатном доступе (на сайте автора по адресу: http://lc.kubagro.ru/aidos/_Aidos-X.htm ).
Естественно, никто технологию не продает, а если и
продает, то так дорого, что купить ее практически невозможно. Поэтому возникает
вопрос о разработке или поиске подобной технологии в России.
Таким образом, востребованы теоретическое обоснование,
математическая модель, методика численных расчетов (т.е. структуры данных и
алгоритмы их обработки) а также реализующие их инструментальные (программные)
средства, обеспечивающие создание, поддержку, развитие и применение подобных рейтингов.
Данная статья как раз и посвящена рассмотрению
отечественной лицензионной инновационной интеллектуальной технологии,
обеспечивающей решение поставленной проблемы. А именно предлагается применить
для этой цели автоматизированный системно-когнитивный анализ (АСК-анализ) и его
программный инструментарий – интеллектуальную систему «Эйдос».
6.2.3. Автоматизированный
системно-когнитивный
анализ и интеллектуальная система «Эйдос»
как инструментарий решения проблемы
АСК-анализ представляет собой один из современных инновационных методов искусственно интеллекта, который предоставляет научно обоснованные ответы на все эти вопросы, но самое существенное, что он оснащен широко и успешно апробированным универсальным программным инструментарием, позволяющим решить эти вопросы не только как обычно на теоретическом концептуальном уровне, но и на практике [8]. Модели знаний АСК-анализа основаны на нечеткой декларативной модели представления знаний, предложенной автором в 1983 году и являющейся гибридной моделью, сочетающей в себе преимущества фреймовой, нейросетевой и четкой продукционной моделей и обеспечивающей создание моделей очень больших размерностей до 10 млн. раз превышающих максимальные размерности моделей знаний экспертных систем с четкими продукциями:
– от фреймовой модели модель представления знания системы «Эйдос» отличается существенно упрощенной программной реализацией и более высоким быстродействием без потери функциональности;
– от нейросетевой тем, что обеспечивает хорошо обоснованную теоретически содержательную интерпретацию весовых коэффициентов на рецепторах и обучение методом прямого счета;
– от четкой продукционной модели – нечеткими продукциями, представленными в декларативной форме, что обеспечивает эффективное использование знаний без их многократной генерации для решения задач идентификации, прогнозирования, принятия решений и исследования моделируемого объекта.
АСК-анализ является непараметрическим методом, устойчивым к шуму в исходных данных, позволяющий корректно обрабатывать неполные (фрагментированные) исходные данные, описывающие воздействие взаимозависимых факторов на нелинейный объект моделирования.
Суть метода АСК-анализа в том, что он позволяет рассчитать на основе исходных данных какое количество информации содержится в значениях факторов, обуславливающих переходы объекта моделирования в различные будущие состояния, причем как в желательные, так и в нежелательные [9][38].
Он состоит в целенаправленном последовательном повышении степени формализации исходных данных до уровня, который позволяет ввести исходные данные в компьютерную систему, а затем преобразовать исходные данные в информацию; информацию преобразовать в знания; использовать знания для решения задач прогнозирования, принятия решений и исследования предметной области.
Рассмотрим подробнее вопросы выявления, представления и использования знаний в АСК-анализе и системе «Эйдос».
Данные – это информация, записанная на каком-либо носителе
или находящаяся в каналах связи и представленная на каком-то языке или в
системе кодирования и рассматриваемая безотносительно к ее смысловому содержанию.
Исходные данные
об объекте управления обычно представлены в форме баз данных, чаще всего
временных рядов, т.е. данных, привязанных ко времени. В соответствии с
методологией и технологией автоматизированного системно-когнитивного анализа
(АСК-анализ), развиваемой проф. Е.В.Луценко, для управления и принятия решений
использовать непосредственно исходные данные не представляется возможным.
Точнее сделать это можно, но результат управления при таком подходе оказывается мало чем
отличающимся от случайного. Для реального же решения задачи управления
необходимо предварительно преобразовать данные в информацию, а ее в знания о
том, какие воздействия на корпорацию к каким ее изменениям обычно, как
показывает опыт, приводят.
Информация есть осмысленные данные.
Смысл данных, в
соответствии с концепцией смысла Шенка-Абельсона, состоит в том, что известны
причинно-следственные зависимости между событиями, которые описываются этими
данными. Таким образом, данные преобразуются в информацию в результате
операции, которая называется «Анализ данных», которая состоит из двух этапов:
1. Выявление
событий в данных (разработка классификационных и описательных шкал и градаций и
преобразование с их использованием исходных данных в обучающую выборку, т.е. в
базу событий – эвентологическую базу).
2. Выявление
причинно-следственных зависимостей между событиями.
В случае систем
управления событиями в данных являются совпадения определенных значений входных
факторов и выходных параметров объекта управления, т.е. по сути, случаи перехода
объекта управления в определенные будущие состояния под действием определенных
сочетаний значений управляющих факторов. Качественные значения входных факторов
и выходных параметров естественно формализовать в форме лингвистических
переменных. Если же входные факторы и выходные параметры являются числовыми, то
их значения измеряются с некоторой погрешностью и фактически представляют собой
интервальные числовые значения, которые также могут быть представлены или
формализованы в форме лингвистических переменных (типа: «малые», «средние»,
«большие» значения экономических показателей).
Какие же
математические меры могут быть использованы для количественного измерения силы
и направления причинно-следственных зависимостей?
Наиболее
очевидным ответом на этот вопрос, который обычно первым всем приходит на ум,
является: «Корреляция». Однако, в статистике это хорошо известно, что это
совершенно не так. Для преобразования
исходных данных в информацию необходимо не только выявить события в этих
данных, но и найти причинно-следственные связи между этими событиями. В
АСК-анализе предлагается 7 количественных мер причинно-следственных связей,
основной из которых является семантическая мера целесообразности информации по
А.Харкевичу.
Знания –
это информация, полезная для достижения
целей[39].
Значит для
преобразования информации в знания необходимо:
1. Поставить
цель (классифицировать будущие состояния моделируемого объекта на целевые и
нежелательные).
2. Оценить
полезность информации для достижения этой цели (знак и силу влияния).
Второй пункт,
по сути, выполнен при преобразовании данных в информацию. Поэтому остается
выполнить только первый пункт, т.к. классифицировать будущие состояния объекта
управления как желательные (целевые) и нежелательные.
Знания могут
быть представлены в различных формах, характеризующихся различной степенью
формализации:
– вообще неформализованные знания, т.е. знания
в своей собственной форме, ноу-хау (мышление без вербализации есть медитация);
– знания,
формализованные в естественном вербальном языке;
– знания,
формализованные в виде различных методик, схем, алгоритмов, планов, таблиц и
отношений между ними (базы данных);
– знания в
форме технологий, организационных, производственных, социально-экономических и
политических структур;
– знания,
формализованные в виде математических моделей и методов представления знаний в
автоматизированных интеллектуальных системах (логическая, фреймовая, сетевая,
продукционная, нейросетевая, нечеткая и другие).
Таким образом,
для решения сформулированной проблемы необходимо осознанно и целенаправленно последовательно
повышать степень формализации исходных данных до уровня, который позволяет
ввести исходные данные в интеллектуальную систему, а затем:
– преобразовать
исходные данные в информацию;
– преобразовать
информацию в знания;
– использовать
знания для решения задач управления, принятия решений и исследования предметной
области.
АСК-анализ
имеет следующие этапы [8]:
–
когнитивно-целевая структуризация предметной области;
– формализация
предметной области (формирование классификационных и описательных шкал и
градаций и обучающей выборки);
– синтез и
верификация статистических и системно-когнитивных моделей;
– решение задач
идентификации, прогнозирования, принятия решений и исследования предметной
области в наиболее достоверных из созданных моделей.
Единственный
неавтоматизированный в системе «Эйдос» этап – это первый, а остальные приведены
на рисунке 1.
АСК-анализ имеет ряд особенностей, которые обусловили его выбор в качестве метода решения проблемы:
1. Имеет теоретическое обоснование, основой которого является семантическая мера целесообразности информации А.Харкевича.
2. Обеспечивает корректную сопоставимую количественную обработку разнородных по своей природе факторов, измеряемых в различных единицах измерения, высокую точность и независимость результатов расчетов от единиц измерения исходных данных.
3. Обеспечивает построение многомерных моделей объекта моделирования непосредственно на основе неполных и искаженных эмпирических данных о нем.
4. Имеет развитую и доступную программную реализацию в виде универсальной когнитивной аналитической системы «Эйдос».
6.2.4. Частные критерии и
виды моделей
системы «Эйдос»
Частные критерии знаний, используемые в настоящее
время в АСК-анализе и системе «Эйдос-Х++», приведенны в таблице 1.
Таблица 1 – Частные критерии знаний, используемые в
настоящее время
в АСК-анализе и системе «Эйдос-Х++»
|
Наименование модели знаний и частный критерий |
Выражение для частного
критерия |
|
|
через относительные частоты |
через абсолютные частоты |
|
|
INF1, частный критерий:
количество знаний по А.Харкевичу, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков
по j-му классу. Относительная частота
того, что если у объекта j-го класса обнаружен признак, то это i-й признак |
|
|
|
INF2, частный критерий:
количество знаний по А.Харкевичу, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу. Относительная частота
того, что если предъявлен объект j-го класса, то у него будет обнаружен i-й
признак. |
|
|
|
INF3, частный критерий:
Хи-квадрат: разности между фактическими и теоретически ожидаемыми абсолютными
частотами |
--- |
|
|
INF4, частный критерий: ROI -
Return On Investment, 1-й вариант расчета относительных частот: Nj – суммарное количество признаков
по j-му классу |
|
|
|
INF5, частный критерий: ROI -
Return On Investment, 2-й вариант расчета относительных частот: Nj – суммарное количество объектов по j-му классу |
|
|
|
INF6, частный критерий:
разность условной и безусловной относительных частот, 1-й вариант расчета
относительных частот: Nj –
суммарное количество признаков по j-му
классу |
|
|
|
INF7, частный критерий:
разность условной и безусловной относительных частот, 2-й вариант расчета
относительных частот: Nj –
суммарное количество объектов по j-му
классу |
|
|
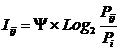
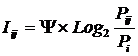
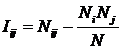
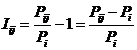
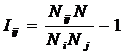
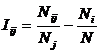
Обозначения:
i – значение прошлого параметра;
j - значение
будущего параметра;
Nij
– количество встреч j-го значения будущего
параметра при i-м значении
прошлого параметра;
M – суммарное число значений всех прошлых параметров;
W - суммарное число значений всех будущих параметров.
Ni – количество
встреч i-м значения прошлого параметра по всей
выборке;
Nj – количество встреч j-го
значения будущего параметра по всей выборке;
N – количество
встреч j-го значения будущего параметра при i-м значении прошлого параметра по
всей выборке.
Iij
– частный критерий знаний: количество знаний в факте
наблюдения i-го значения
прошлого параметра о том, что объект перейдет в состояние, соответствующее j-му значению будущего параметра;
Ψ –
нормировочный коэффициент (Е.В.Луценко, 1979, впервые опубликовано в 1993 году
[15]), преобразующий количество информации в формуле А.Харкевича в биты и
обеспечивающий для нее соблюдение принципа соответствия с формулой Р.Хартли;
Pi – безусловная относительная частота
встречи i-го значения прошлого
параметра в обучающей выборке;
Pij – условная относительная частота встречи
i-го значения прошлого параметра
при j-м значении будущего
параметра.
По сути, частные критерии представляют собой просто
формулы для преобразования матрицы абсолютных частот (таблица 4)[40] в
матрицы условных и безусловных процентных распределений(таблицы 5 и 6) и
матрицы знаний (проф. В.И.Лойко, 2014).
6.2.5. Ценность
описательных шкал и градаций
для решения задач идентификации текстов
и авторов (нормализация
текста)
Для любой из моделей системой «Эйдос» рассчитывается ценность[41] градации
описательной шкалы, т.е. признака, для идентификации или прогнозирования. Количественной
мерой ценности признака в той или иной модели является вариабельность по
классам частного критерия для этого признака (таблица 1) Мер вариабельности может быть много, но
наиболее известными является среднее модулей отклонения от среднего, дисперсия
и среднеквадратичное отклонение. Последняя мера и используется в АСК-анализе и
системе «Эйдос».
В системе «Эйдос» ценность признаков нарастающим
итогов выводится в графической форме.
При большом
объеме обучающей выборки можно без ущерба для достоверности модели удалить из
нее малозначимые признаки (Парето-оптимизация). Для этого в системе «Эйдос» также
есть соответствующие инструменты.
6.2.6. Интегральные критерии системы «Эйдос»
Но если нам известно, что объект обладает не одним, а
несколькими признаками, то как посчитать их общий
вклад в сходство с теми или иными классами? Для этого в системе «Эйдос»
используется 2 аддитивных интегральных критерия: «Сумма знаний» и
«Семантический резонанс знаний».
Интегральный критерий «Семантический резонанс знаний» представляет собой суммарное количество знаний,
содержащееся в системе факторов различной природы, характеризующих сам объект
управления, управляющие факторы и окружающую среду, о переходе объекта в будущие
целевые или нежелательные состояния.
Интегральный критерий представляет собой аддитивную
функцию от частных критериев знаний, представленных в help режима 3.3:
![]()
В выражении круглыми скобками обозначено скалярное
произведение. В координатной форме это выражение имеет вид:
,
где: M – количество градаций описательных шкал
(признаков);
![]() – вектор
состояния j–го класса;
– вектор
состояния j–го класса;
![]() – вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
– вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
В текущей версии системы «Эйдос-Х++» значения
координат вектора состояния распознаваемого объекта принимались равными либо 0,
если признака нет, или n, если он присутствует у объекта с интенсивностью n,
т.е. представлен n раз (например, буква «о» в слове «молоко» представлена 3
раза, а буква «м» - один раз).
Интегральный критерий «Семантический резонанс знаний» представляет собой нормированное суммарное количество знаний, содержащееся в системе
факторов различной природы, характеризующих сам объект управления, управляющие
факторы и окружающую среду, о переходе объекта в будущие целевые или
нежелательные состояния.
Интегральный критерий представляет собой аддитивную
функцию от частных критериев знаний, представленных в help режима 3.3 и
имеет вид:
где:
M –
количество градаций описательных шкал (признаков);
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по
вектору объекта;
– среднее по
вектору объекта;
![]() –
среднеквадратичное отклонение частных критериев знаний вектора класса;
–
среднеквадратичное отклонение частных критериев знаний вектора класса;
![]() – среднеквадратичное
отклонение по вектору распознаваемого объекта.
– среднеквадратичное
отклонение по вектору распознаваемого объекта.
![]() – вектор
состояния j–го класса;
– вектор
состояния j–го класса;
![]() – вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
– вектор состояния распознаваемого объекта, включающий
все виды факторов, характеризующих сам объект, управляющие воздействия и
окружающую среду (массив–локатор), т.е.:
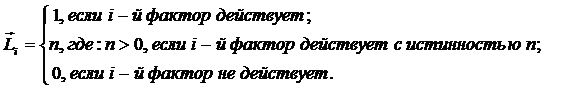
В текущей версии системы «Эйдос-Х++» значения координат вектора
состояния распознаваемого объекта принимались равными либо 0, если признака
нет, или n, если он присутствует у объекта с интенсивностью n, т.е. представлен
n раз (например, буква «о» в слове «молоко» представлена 3 раза, а буква «м» -
один раз).
Приведенное выражение для интегрального критерия «Семантический
резонанс знаний» получается непосредственно из выражения для критерия «Сумма
знаний» после замены координат перемножаемых векторов их
стандартизированными значениями:
Свое наименование интегральный критерий сходства
«Семантический резонанс знаний» получил потому, что по своей математической
форме является корреляцией двух векторов: состояния j–го класса и состояния
распознаваемого объекта.
6.2.7.
Выводы
Недавно был начат процесс монетизации оценки
результатов научной деятельности и возникла потребность в методиках
количественной и сопоставимой оценки эффективности и качества работы ученого.
Появились многочисленные методики материального поощрения за эти результаты.
Общим для всех этих методик является завешенная роль индекса Хирша. Сам по себе
этот индекс вполне обоснован. Однако в связи с практикой применения индекса
Хирша в наших условиях в сознании научного сообщества возникла своеобразная мания, которую автор предлагает называть
«Хиршамания». Эта мания характеризуется повышенным нездоровым интересом к
самому значению индекса Хирша,
особенно к искусственному неадекватному преувеличению этого значения, а также
рядом негативных последствий этого
интереса. В данной работе делается попытка кратко описать некоторые негативные
последствия этой новой психической инфекции, поразившей общественное сознание
научного сообщества. А также наметить пути преодоления хотя бы некоторых причин их возникновения. В этом и
состоит проблема, решаемая в данной работе. Для решения сформулированной проблемы
предлагается применить многокритериальный подход, основанный на теории
информации, а именно тот его вариант, который реализован в автоматизированном системно-когнитивном
анализе (АСК-анализ) и его программном
инструментарии – интеллектуальной системе «Эйдос»
6.3. Количественная оценка
степени манипулирования индексом Хирша и его модификация, устойчивая к
манипулированию
Высшая аттестационная комиссия (ВАК) – это своего рода
отдел технического контроля (ОТК), оценивающий «качество продукции» не только
Министерства образования и науки, но и всех других министерств и ведомств, в
которых есть свои вузы и НИИ. В качестве продукции вузов и НИИ выступают не
только их разработки, но и сами ученые. ВАК, как и ОТК, обеспечивает обратную
связь, информируя управляющую систему о результатах ее работы. Из теории
управления известно, что если информация обратной связи неадекватна, то и
управляющие решения, принимаемые на ее основе, также будут неадекватными. Понятно,
что оценивающая структура не должна находится в подчинении у той структуры,
качество работы которой она оценивает. В противном случае нетрудно догадаться,
как она будет оценивать. В СССР ВАК с 1975 и до самого распада СССР
подчинялась не Министерству образования и науки, а непосредственно Совету
министров СССР, что соответствует этой логике. Однако с тех пор существует устойчивая тенденция постепенного
снижения статуса ВАК. Сегодня ВАК уже не просто входит в Минобрнауки, а
является всего лишь одним из подразделений одной из его структур:
Рособрнадзора. Снижение статуса ВАК неизбежно приводит к снижению как статуса, так и
адекватности присваиваемых им ученых степеней и научных званий. Этот
процесс обесценивания традиционных ученых степеней и званий, присваиваемых ВАК,
дошел до того, что несколько лет назад отменили надбавки к заработной плате за
них. Теперь вместо традиционных ученых степеней и званий, присваиваемых ВАК
практически каждым вузом и НИИ разрабатывается
свои локальные, т.е. несопоставимые
друг с другом наукометрические методики оценки результатов научной и
педагогической деятельности. При всем разнообразии этих методик общим для
всех них является несоразмерно большая роль, которая отводится в них индексу
Хирша. Значение индекса Хирша начинает играть важную роль при защитах, при
рассмотрении конкурсных дел на замещение должностей, а также при определении
величины ежемесячного материального поощрения за результаты научной и
педагогической деятельности. Сам по себе этот индекс теоретически вполне обоснован. Однако в связи с практикой применения индекса Хирша в
наших условиях в сознании научного сообщества возникла своеобразная мания,
которую авторы называют «Хиршамания» [1]. Эта мания характеризуется повышенным
нездоровым интересом к самому значению индекса Хирша, а также к некорректному
манипулированию его значением, т.е. к искусственному неадекватному
преувеличению этого значения, а также рядом негативных последствий этого
интереса.
Возникают естественные вопросы:
1. Возможно ли как-то количественно оценить степень
манипулирования индексом Хирша, т.е. то, в какой степени его значение
«целенаправленно организовано»?
2. Возможно ли получить гипотетическое значение
индекса Хирша каким оно было бы в случае отсутствия манипулирования им?
В данной работе делается попытка найти конкретные
ответы на эти вопросы путем:
– конструирования количественной меры для оценки
степени некорректного манипулирования значением индекса Хирша;
– разработки научно-обоснованной модификации индекса
Хирша, нечувствительной (устойчивая) к попыткам манипулированию им.
Кроме собственно самих идей предлагается также
методика всех численных расчетов, достаточно простая, чтобы ее мог применить
каждый автор.
6.3.1. Что такое индекс Хирша

Рисунок 1 – Распространенное в Internet пояснение к
понятию:
«индекс Хирша»[42]
Если ранжировать все публикации ученого в порядке
убывания числа их цитирований («ранжированный список публикаций»),
то индекс Хирша h – это просто номер публикации в этом списке, процитированной
h раз. За этой публикацией идут публикации, процитированные менее h раз, а до
нее – более h раз.
Таким образом, индекс Хирша является абсциссой точки
пересечения графика числа цитирований для ранжированного списка публикаций с
биссектрисой первого квадранта. Пусть f(h) - число цитирований публикации ранга
h (т.е. публикации с номером h в ранжированном списке публикаций). Тогда для
индекса Хирша h0 справедливы неравенства
f(h) > h при h < h0 и
f(h) < h при h > h0.
6.3.2. Манипулирование индексом Хирша при малом числе публикаций
6.3.2.1. Способ
сформировать максимальное значение индекса Хирша при малом числе публикаций
Из приведенного выше нехитрого алгоритма вычисления
значения индекса Хирша вполне понятно, как получить максимальное значение
индекса Хирша h при минимальном числе публикаций h+1. Для этого достаточно
опубликовать h+1 статей, в каждой из которых сослаться на все остальные [2].
6.3.2.2. Первый
интегральный критерий манипулирования индексом Хирша
Наверное приведенный выше
простой и доступный способ сформировать любое заданное значение индекса Хирша
первым приходит всем авторам на ум. И это дает нам в руки первый наиболее
простой критерий манипулирования индексом Хирша: «Чем более пологим является линейный тренд числа цитирований,
построенный по ранжированному списку публикаций, тем более вероятно, что был
применен описанный выше способ максимизации индекса Хирша при малом числе
публикаций».
Максимальный теоретически
возможный угол наклона линейного тренда, достижимый лишь асимптотически, равен
90°, а минимальный, естественно, равен нулю: 0°. Количественно этот 1-й частный
критерий по сути должен быть какой-то простой функцией от коэффициента наклона
линейного тренда ранжированного списка. Естественным было нормировать 1-й
частный критерий манипулирования индексом Хирша таким образом, чтобы при
наклоне тренда 90° он имел минимальное значение равное 0 (нет манипулирования),
а при наклоне 0° имел максимальное значение, равное 1 (полное манипулирование).
Уравнение линейного тренда
выгладит следующим образом:
![]()
С учетом всех этих
соображений предлагается следующее выражение для 1-го частного критерия
манипулирования индексом Хирша K1
при малом числе публикаций:
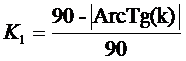 ,
,
где:
k – коэффициент при x в
линейном тренде ранжированного списка публикаций;
ArcTg(k) – арктангенс
коэффициента наклона – угол наклона линейного тренда ранжированного по числу
цитирований списка публикаций (в градусах).
Понятно, что чем более
пологим является линейный тренд графика числа цитирований, тем ближе
коэффициент b в линейном тренде к значению индекса Хирша h:
![]()
Предлагается следующее
выражение для 2-го частного критерия манипулирования индексом Хирша K2 при малом числе
публикаций:
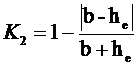 ,
,
где:
b – свободный член в
линейном тренде графика числа цитирований;
he – эмпирическое
значение индекса Хирша, т.е. полученное непосредственно из ранжированного
списка публикаций и построенного по нему графика числа цитирований.
Естественным было
нормировать 2-й частный критерий манипулирования индексом Хирша таким образом,
чтобы при эмпирическом индексе Хирша he=0 он был равен нулю (нет
манипулирования), при свободном члене b равном
эмпирическому индексу Хирша he он был равен 1 (полное
манипулирование), и при увеличении разницы между ними стремился к нулю
(уменьшение степени манипулирования) (таблица 1 и рисунок 2):
Таблица 1 – Зависимость 2-го
частного критерия манипулирования
индексом Хирша от эмпирического значения индекса Хирша
при постоянном свободном члене b=7
|
H |
2-й частный критерий |
H |
2-й частный критерий |
H |
2-й частный критерий |
|
0 |
0,000000 |
13 |
0,700000 |
26 |
0,424242 |
|
1 |
0,250000 |
14 |
0,666667 |
27 |
0,411765 |
|
2 |
0,444444 |
15 |
0,636364 |
28 |
0,400000 |
|
3 |
0,600000 |
16 |
0,608696 |
29 |
0,388889 |
|
4 |
0,727273 |
17 |
0,583333 |
30 |
0,378378 |
|
5 |
0,833333 |
18 |
0,560000 |
31 |
0,368421 |
|
6 |
0,923077 |
19 |
0,538462 |
32 |
0,358974 |
|
7 |
1,000000 |
20 |
0,518519 |
33 |
0,350000 |
|
8 |
0,933333 |
21 |
0,500000 |
34 |
0,341463 |
|
9 |
0,875000 |
22 |
0,482759 |
35 |
0,333333 |
|
10 |
0,823529 |
23 |
0,466667 |
36 |
0,325581 |
|
11 |
0,777778 |
24 |
0,451613 |
37 |
0,318182 |
|
12 |
0,736842 |
25 |
0,437500 |
38 |
0,311111 |
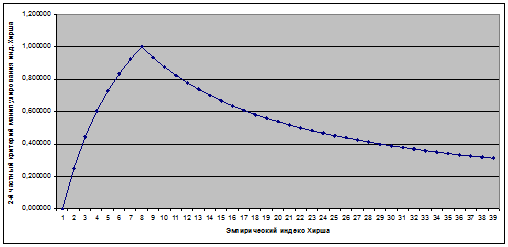
Рисунок 2 – Зависимость 2-го
частного критерия манипулирования
индексом Хирша от эмпирического значения индекса Хирша
при постоянном свободном члене b=7
Если считать, что оба эти
частные критерия K1 и K2 имеют равный вес 0.5, то
можно предложить следующее выражение для 1-го интегрального критерия манипулирования
индексом Хирша при малом числе публикаций:
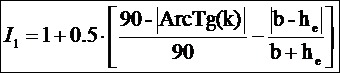 .
.
Все обозначения,
использованные в данном выражении, описаны выше.
Данный 1-й интегральный
критерий принимает значение равное 0 при отсутствии манипулирования и равное 1
при максимальном, т.е. полном манипулировании. Ниже приведена его вербальная
формулировка:
«Чем ближе к нулю коэффициент наклона
линейного тренда числа цитирований, построенного по ранжированному списку публикаций
и чем ближе свободный член в линейном тренде к эмпирическому значению индекса
Хирша, тем более вероятно, что был применен описанный выше способ максимизации
индекса Хирша при малом числе публикаций».
Конечно, понятно, что часть
цитирований могут естественными, не организованными автором, и они вместе тоже
могут формировать достаточно пологий тренд, т.е. понятно, что максимальное
значение индекса манипулирования еще не означает самого факта манипулирования,
а лишь является его признаком. Аналогично и заимствования сами по себе не
означают плагиата, т.к. могут быть снабжены ссылками на источники, а могут быть
и заимствованиями из работ самого автора, которые уже по главам порезаны на
рефераты и разошлись по всему интернету.
6.3.2.3. Примеры
применения первого интегрального критерия манипулирования индексом Хирша на
основе баз данных РИНЦ
Для того, чтобы применить
этот интегральный критерий к публикациям какого-либо автора выполняем следующие
действия:
1. Открываем сайт РИНЦ: http://elibrary.ru/.
2. В меню слева выбираем «Авторский указатель», задаем сортировку по
числу цитирований по убыванию без фильтра по региону. В результате получаем (на
момент написания статьи) (рисунок 3).
3. Выбираем автора, по
которому собираемся анализировать индекс Хирша (Новоселов К.С.), кликаем по
числу его работ (левее гистограммки: ![]() ),
выделяем блоком вместе с заголовком
таблицы первые его 100 публикаций (или все, если их меньше 100),
копируем его в буфер обмена и вставляем
в MS Excel (используем копировать: Ctrl+C, и вставить: Crtl+V или эти
пункты в меню, выскакивающему по клику на правой кнопке мыши).
),
выделяем блоком вместе с заголовком
таблицы первые его 100 публикаций (или все, если их меньше 100),
копируем его в буфер обмена и вставляем
в MS Excel (используем копировать: Ctrl+C, и вставить: Crtl+V или эти
пункты в меню, выскакивающему по клику на правой кнопке мыши).
4. Выделяем блоком весь лист
отменяем объединение ячеек.
5. Переносим колонку D
с числом цитирований в колонку C (если они не в колонке C).
6. Начиная с колонки D
вставляем следующие значения и формулы для построения графика цитирований и
расчета трендов (рисунок 4):
Рисунок 3 – Экранная форма
РИНЦ: «Авторский указатель», сортировка
по числу цитирований по убыванию без фильтра по региону
|
|
|

Рисунок 4 – Значения и
формулы для построения графика цитирований
и расчета трендов
В колонке D просто
подряд пронумерованы строки c 1 до 100. В колонке F в подряд идущих
строках проставлены номера строк, в которых в колонке C приведено число
цитирований: 4, 7, 10, 13 и т.д. с шагом 3. В колонке E приведены
формулы ссылок на ячейки с числом цитирований из колонки C. Все это
сделано для того, чтобы значения числа цитирований для различных публикаций шли
в подряд идущих строках, а не в каждой третьей строке, начиная с 4-й, как это
сделано в РИНЦ. Отметим, что и в РИНЦ шаг 3 между строками с числом цитирований
может нарушаться, хотя это происходит и редко. Например, у автора: Новоселов
К.С. в 64-й публикации (193-я строка в списке РИНЦ) дано не совсем стандартное
описание. Поэтому для 65-й публикации вместо 196 строки указана 201-я, в
которой фактически находится число цитирований 65-й публикации. Далее и до 10-й
публикации они опять идут с стандартным шагом 3. Чтобы не пропустить подобные ситуации рекомендуется проверять
значения числа цитирований не только в первых, но и в последних строках списка.
7. Строим график по числу
цитирований. Для этого выделяем блоком ячейки в колонке E, в которых
есть число цитирований (удобнее это делать снизу вверх), и строим график
(рисунок 5):
Рисунок 5 – График числа цитирований, простроенный по
списку
публикаций Новоселова К.С., ранжированному по числу цитирований
в порядке убывания
8. Строим линейный тренд
графика числа цитирований с выводом формулы тренда и критерия качества
аппроксимации – коэффициента детерминации R2 (рисунок 6):
Рисунок 6 – График числа цитирований публикаций
Новоселова К.С.
с линейным трендом
9. Для расчета частных
критериев и интегрального критерия в MS Excel используем формулы, приведенные
на рисунке 7:
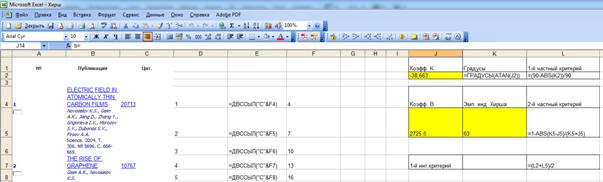
Рисунок 7 – Формулы для
расчета частных критериев и 1-го интегрального
критерия манипулирования индексом Хирша при малом числе публикаций
Значения коэффициентов k и b
из уравнения линейной регрессии, приведенного на рисунке 6, вручную вносим в ячейки J2 и J5
соответственно (выделены на рисунке 7 желтым цветом). В результате получим значения
частных критериев и интегрального критерия манипулирования индексом Хирша для
данного автора (рисунок 8), рассчитанные по приведенным выше формулам.
Из рисунка 8 видно, что все
эти значения очень близки к нулю, что означает полное отсутствие манипулирования в данном случае.
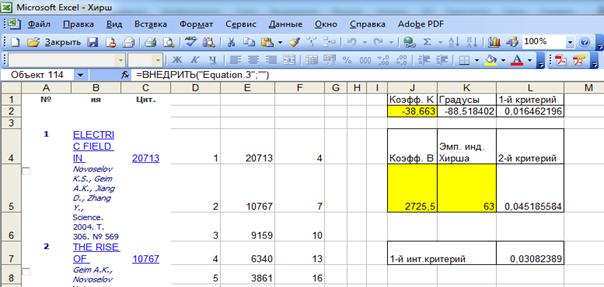
Рисунок 8 – Значения частных
критериев и 1-го интегрального критерия
манипулирования индексом Хирша для автора: Новоселов К.С.
Рассмотрим применение
предлагаемого интегрального критерия на примере 2-го автора, рейтинг,
Ф.И.О. и место работы которого мы не указываем из этических соображений.
На рисунке 9 приведен график числа цитирований с линейным трендом этого 2-го
автора, а в таблице 2 результаты расчета частных критериев и интегрального критерия
:
Рисунок 9 – График числа цитирований публикаций 2-го
автора
с линейным трендом
Таблица 2 – Результаты расчетов частных критериев и 1-го
интегрального
критерия манипулирования индексом Хирша при малом числе публикаций
для 2-го автора
|
Коэфф.
K |
Градусы |
1-й
частный критерий |
|
-0,1778 |
-10,081832 |
0,887979642 |
|
|
|
|
|
Коэфф.
B |
Эмп.
инд. Хирша |
2-й
частный критерий |
|
16,568 |
14 |
0,915990578 |
|
|
|
|
|
1-й
инт.критерий |
|
0,90198511 |
Из таблицы 2 видно, что доля
манипулирования индексом Хирша в данном случае значительно выше, т.к. значение
1-го интегрального критерия близко к 0,9.
Из приведенных графиков и
таблиц мы видим, что для лидера рейтинга РИНЦ по числу цитирований предлагаемый
1-й критерий манипулирования индексом Хирша дает значительно меньшую величину,
чем у 2-го автора. Видно, что этот результат получается за счет того, что у лидера различие между числом цитирований
наиболее и наименее цитируемых работ первой сотни работ. значительно больше, чем у обычного автора.
6.3.3. Манипулирование индексом Хирша при большом числе публикаций
6.3.3.1. Способ
увеличить значение индекса Хирша при большом числе публикаций
Если у автора большое число
публикаций, то очевидно, использовать способ формирования максимального
значения индекса Хирша, который использовался при малом числе публикаций, т.е.
ссылаться во всех публикациях на все, не
представляется возможным по ряду причин. Понятно, что статья, у которой в
списке литературы приведено десятки источников и в основном автора самой этой
статьи, будет выглядеть несколько странно[43].
Во многих журналах просто есть ограничение и на суммарное число источников в
списке литературы и на число источников автора публикации. Но цитирование всех
публикаций данного автора в каждой его публикации не только невозможно
технически[44],
но и не имеет особого смысла, т.к.
увеличение числа цитирований статей, находящихся в ранжированном списке далеко
от значения индекса Хирша, не окажет влияния на его значение ни в ближайшее
время, ни в перспективе (за исключением может быть каких-то научных
«бестселлеров», которые сразу становятся очень цитируемыми и сохраняют
популярность длительное время).
Поэтому многие авторы, у
которых большое количество публикаций, приходят к тому, чтобы увеличивать число ссылок не на все
публикации, а только на те, которые оказывают самое непосредственное
влияние на значение индекса Хирша, т.е. на публикации в окрестности
индекса Хирша в ранжированном списке публикаций. В результате вблизи
значения индекса Хирша, причем как текущего, так и перспективного с точки
зрения этих авторов, формируется характерная «ступенька» или «полочка», показанная
на рисунке 10 красным цветом.
В результате такого
манипулирования индекс Хирша приобретает вместо значения h некоторое большее
значение h2. При этом площадь под кривой числа цитирований, соответствующая
суммарному числу цитирований автора, увеличивается совершенно незначительно, а
значение индекса Хирша за счет этого возрастает довольно заметно, т.е. затраты
на это повышение оказываются весьма эффективными.
Вот как выглядит подобная
«полочка» на реальном графике числа цитирований, построенном по данным РИНЦ[45]
3-го автора (рисунок 11):

Рисунок 10. Результат манипулирования индексом Хирша
при большом числе публикаций: характерная «полочка» в окрестности
индекса Хирша в ранжированном списке публикаций (теория)
Рисунок 11 – Результат манипулирования индексом Хирша
при большом числе публикаций: характерная «полочка» в окрестности
индекса Хирша в ранжированном списке публикаций 3-го автора (факт)
6.3.3.2.
Научно-обоснованная модификация индекса Хирша, нечувствительная (устойчивая) к
попыткам манипулированию им
Идея второго критерия
манипулирования индексом Хирша, применяемого при большом числе публикаций,
основана на том, что при цитирования статей в окрестностях текущего значения
индекса Хирша площадь под кривой числа цитирований, соответствующая суммарному
числу цитирований автора, увеличивается очень незначительно. А это в свою очередь
означает, что, по-видимому, если
аппроксимировать эту кривую с использованием метода наименьших квадратов (МНК),
то эта аппроксимация окажется малочувствительной или устойчивой к появлению
в результате манипулирования этой небольшой «полочки».
Это позволяет сформулировать
гипотезу о том, что значение
индекса Хирша, определенное не по классическому алгоритму, а посчитанное на
основе аппроксимации кривой числа цитирований, окажется менее чувствительным и
более устойчивым к попыткам манипулирования, чем классический индекс Хирша.
Но откуда взять эту
аппроксимацию кривой числа цитирований и как определить значение индекса Хирша
на ее основе? В общем виде все это довольно -просто. Непосредственно из самого
определения классического индекса Хирша следует, что если аппроксимации кривой
числа цитирований выражается в виде уравнения:
![]()
то теоретическим значением индекса Хирша h будет
корень уравнения:
![]() .
.
Такого рода уравнения обычно
легко решаются численно итерационным методом, реализованным в частности, в MS
Excel.
Сам вид функции f() предлагается определять с
использованием аппарата аппроксимации трендов функциями различных видов в MS
Excel.
В принципе можно было бы каждый раз выбирать для аппроксимации тот
вид монотонной[46]
функции, который обеспечивает наивысший коэффициент детерминации R2,
т.е. наиболее хорошее приближение (наилучший тренд). В данном случае для аппроксимации графика числа
цитирований ранжированного списка публикаций уместно использовать лишь
монотонно возрастающие или убывающие функции: линейную, логарифмическую,
степенную, экспоненциальную, но не полиномиальную, т.к. она может иметь точки
перегиба и даже нарушения монотонности и является чувствительной к особенностям
графика, обусловленными манипулированием индексом Хирша.
Но можно выбрать какой-то
один вид функции, который чаще других обеспечивает наилучшее приближение. В
результате многочисленных численных экспериментов по аппроксимации кривых числа
цитирований различных авторов, проведенных по данным РИНЦ, было выявлено, что
наилучшее приближение с коэффициентом детерминации около 0,9 и выше, как
правило обеспечивается трендом в виде степенной функции:
 .
.
Поэтому предлагается
находить теоретическое значение индекса Хирша h путем решения уравнения:
![]() .
.
При этом само уравнение
тренда предлагается формировать в MS Excel непосредственно на основе данных
РИНЦ, как описано выше в разделе 2.3 при формировании линейной регрессии
(примеры приведены ниже).
Решение этого уравнения
легко находится аналитически:
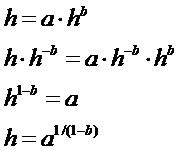
![]() .
.
6.3.3.3. Второй интегральный критерий манипулирования
индексом Хирша
И это дает нам в руки второй
более сложный второй критерий манипулирования индексом Хирша:
«Чем
больше отличаются друг от друга эмпирический индекс Хирша, определенный по
классическому алгоритму, и теоретический индекс Хирша, найденный путем решения
наилучшего уравнения тренда, тем больше вероятность того, что классический
индекс Хирша получен в результате манипулирования (хотя возможны и другие
варианты: шум и несовершенство алгоритма)».
Аналитически 2-й
интегральный критерий манипулирования индексом Хирша, т.е. относительное
превышение эмпирического значения индекса Хирша над теоретическим, может быть
выражен по-разному. Авторы предлагают измерять это превышение в долях от
теоретического значения, как более близкого к истинному:
где:
he – классическое эмпирическое значение индекса Хирша;
ht – классическое эмпирическое значение индекса Хирша.
6.3.3.4.Примеры
определения теоретических значений индекса Хирша путем решения уравнений
трендов
Как и в разделе 2.3 примеры
рассмотрим на примере тех же авторов:
– Новоселов Константин
Сергеевич, имеющий 1-й рейтинг по числу цитирований по данным РИНЦ[47];
– 2-й и 3-й авторы, рейтинг
и Ф.И.О. и место работы которых мы не указываем из этических соображений.
Новоселов Константин Сергеевич.
На графике числа
цитирований, приведенном на рисунке 5, построим тренд в виде степенной функции
(рисунок 12):
Рисунок 12 – График числа цитирований публикаций
Новоселова К.С.
и тренд в виде степенной функции
Мы видим, что уравнение
тренда имеет вид:
![]()
С очень хорошим качеством
аппроксимации: R2 = 0,9747.
Для нахождения
теоретического значения индекса Хирша необходимо решить уравнение тренда:
![]()
Для решения этого уравнения
воспользуемся on-line сервисом Вольфрам-математики по адресу: http://www.wolframalpha.com/. Введя
решаемое уравнение (заменив в нем запятые на точки, добавив знаки операций и
скобки) в окно сервиса, представленное на рисунке 13, получим: h=62.7, что
после округления с точностью до целых совпадает с эмпирическим значением h=63:
Рисунок 13 – Выходной экран
on-line сервиса Вольфрам-математики
с решением уравнения тренда графика числа
цитирований
публикаций Новоселова К.С.
Найденное
on-line решение точно совпадает с полученным аналитически:
![]()
При решении в MS Excel по
этой формуле со значениями коэффициентов: a=59907; b=-1,6581 получаем ![]() или h=62.7087300333721, что совпадает по всем
знакам после запятой с решением, полученным on-line с помощью Вольфрам-математики.
или h=62.7087300333721, что совпадает по всем
знакам после запятой с решением, полученным on-line с помощью Вольфрам-математики.
В разделе 3.3. мы видели,
что 2-й интегральный критерий манипулирования индексом Хирша рассчитывается по
формуле:
где:
he – классическое эмпирическое значение индекса Хирша;
ht – классическое эмпирическое значение индекса Хирша.
Для Новоселова К.С. это дает
значение, весьма близкое к нулю (десятые доли процента):
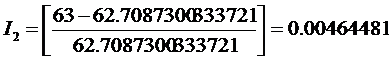 .
.
Фрагменты Excel-файла, в
которых проводятся расчеты по приведенным выше формулам, приведены на рисунках
14 (результаты расчетов) и 15 (формулы):
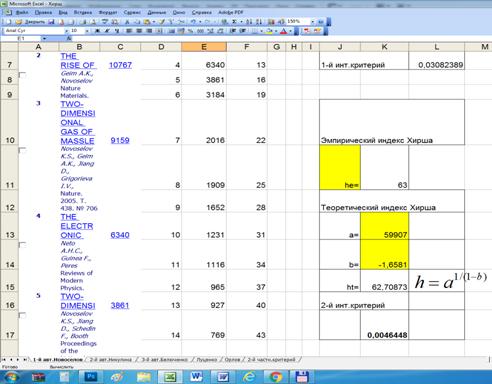
Рисунок 14 – Фрагмент
Excel-файла с расчетами,
представленными в таблице 3 (результаты расчетов)
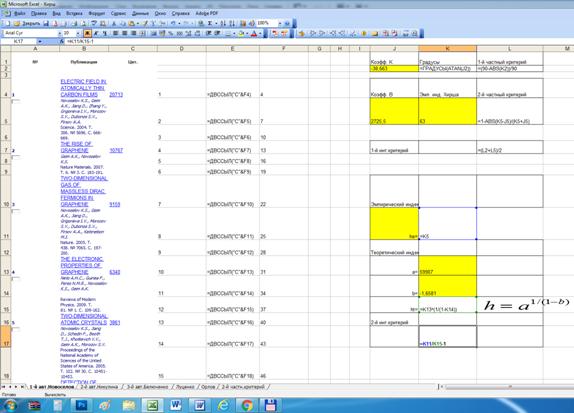
Рисунок 15 – Фрагмент
Excel-файла с расчетами,
представленными в таблице 3 (расчетные формулы)
Для 2-го автора график
числа цитирований публикаций и тренд в виде степенной функции представлены на
рисунке 16:
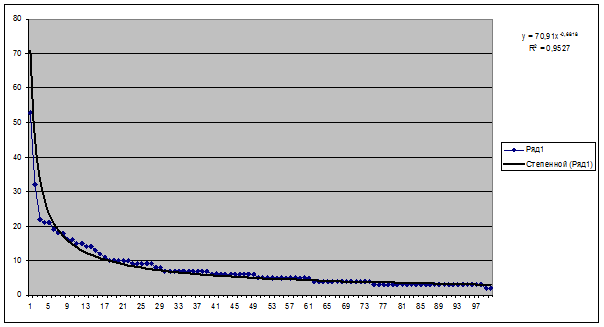
Рисунок 16 – График числа цитирований публикаций 2-го
автора
и тренд в виде степенной функции
Таблица 3 – Эмпирический и
теоретический индексы Хирша и 2-й инт.
критерий манипулирования индексом Хирша для 2-го автора
|
Эмпирический
индекс Хирша |
|
|
he= |
14 |
|
Теоретический
индекс Хирша |
|
|
a= |
70,91 |
|
b= |
-0,6818 |
|
ht= |
12,6017994 |
|
2-й
инт.критерий |
|
|
|
0,11095245 |
Для 2-го автора 2-й
интегральный критерий имеет значение порядка 10%.
Для 3-го автора
график числа цитирований публикаций и тренд в виде степенной функции
представлены на рисунке 17:.
Для 3-го автора эмпирическое
значение индекса Хирша равно 44, а теоретическое 40, что дает значение 2-го
интегрального критерия манипулирования индексом Хирша: I2=(44-40)/40=0.1.
Это значит, что в данном случае манипулирование привело к увеличению индекса
Хирша примерно на 10%.
Интересно, что у некоторых
авторов теоретическое значение индекса Хирша получается не меньше, а больше
эмпирического, т.е. эмпирическое значение «недооценено».
Рисунок 17. График числа цитирований публикаций 3-го
автора
и тренд в виде степенной функции
6.3.4.
Согласованность
1-го и 2-го интегральных критериев
манипулирования индексом Хирша
Рассмотрим сводную таблицу
4, в которой приведем все просчитанные в данной работе частные и интегральные
критерии по всем авторам:
Таблица 4 – Частные и
интегральные критерии по всем авторам
|
Автор |
1-й
частный критерий |
2-й
частный критерий |
1-й
интегральный критерий |
Эмпирический
индекс Хирша |
Теоретический
индекс Хирша |
2-й
интегральный критерий |
|
Новоселов
К.С. |
0,01646 |
0,04518 |
0,03082 |
63 |
62,70873 |
0,00464 |
|
2-й
автор |
0,88797 |
0,91599 |
0,90198 |
14 |
12,60179 |
0,11095 |
|
3-й
автор |
0,60787 |
0,78171 |
0,69479 |
44 |
40 |
0,10000 |
Мы видим, что и частные
критерии, и оба интегральных критерия
манипулирования индексом Хирша дают согласованные, совпадающие по смыслу
результаты, т.е. когда мы не видим манипулирования по 1-му частному критерию,
то не видим его и по 2-му, т.е. эмпирический индекс Хирша практически совпадает
с теоретическим. Возможно это объясняется тем, что авторы, не занимавшиеся
манипулированием индексом Хирша, когда у них было мало публикаций, не начинают
занимаются этим и когда публикаций у них становится большое количество. Это
повышает степень обоснованности и достоверности этих критериев.
6.3.5. Выводы и рекомендации
Итак, на основе вышеизложенного можно считать, что:
1) существует некое неизвестное «истинное значение
индекса Хирша»;
2) есть «эмпирическое (классическое) значение индекса
Хирша», которое является истинным значением, измененным в результате совместного
действия факторов манипулирования (рассматривались в данной статье) а также
естественного шума и несовершенства алгоритма Хирша (в данном разделе эти
факторы только упоминаются);
3) есть «теоретическое значение индекса Хирша», – это
решение уравнения наилучшего тренда графика числа цитирований ранжированного
списка публикаций.
«Теоретическое значение индекса Хирша»
– это новое научное понятие из области наукометрии, которое авторы предлагают
ввести в научный оборот и практику наукометрии по следующим причинам:
– теоретическое значение индекса Хирша является
устойчивым к манипулированию и другим факторам, искажающим истинное значение индекса
Хирша и может обоснованно считаться значительно более близким к истинному
значению индекса Хирша, чем классическое эмпирическое значение;
– технология получения теоретического значения индекса
Хирша (путем решение уравнения наилучшего тренда графика числа цитирований
ранжированного списка публикаций) проста и доступна авторам и организациям.
В статье предлагаются два убедительных количественных
частных критерия манипулирования индексом Хирша при малом числе статей и
основанный на них аддитивный интегральный критерий, основанные на линейном
тренде графика числа цитирований ранжированного списка публикаций.
Степень различия между эмпирическим и теоретическим значениями
индекса Хирша можно считать устойчивым интегральным критерием манипулирования индексом Хирша при любом числе публикаций.
Предлагается:
1. Применить результаты данной статьи при расчетах в
РИНЦ и строить рейтинги авторов, журналов и организаций (подразделений) не
только на основе эмпирического классического индекса Хирша, но и на основе
теоретического индекса Хирша, а также по критериям манипулирования.
2. Не придавать излишне и
неоправданно большого значения классическому эмпирическому значению индекса
Хирша при оценках и принятии решений.
6.4. Синтез и
верификация многокритериальной
системно-когнитивной модели университетского
рейтинга Гардиан и ее применение для сопоставимой
оценки эффективности российских вузов
с учетом направления подготовки
Раздел посвящен решению проблемы,
заключающейся в том, что с одной стороны рейтинг российских вузов востребован,
а с другой стороны пока он не создан. Предлагаемая идея решения проблемы
состоит в применении отечественной лицензионной инновационной интеллектуальной
технологии для этих целей: а именно предлагается применить автоматизированный
системно-когнитивный анализ (АСК-анализ) и его программный инструментарий –
интеллектуальную систему «Эйдос». Эти
методы подробно описываются в этом контексте. Предлагается рассмотреть
возможности применения данного инструментария на примере университетского
рейтинга Гардиан, и рассматриваются его частные критерии (показатели вузов).
Указываются источники данных и методика их подготовки для обработки в системе
«Эйдос». В соответствии с методологией
АСК-анализа описывается установка системы «Эйдос», ввод исходных данных
в нее и формализация предметной области, синтез и верификация модели, их
отображение и применение для решения задач оценки рейтинга Гардиан для
российских вузов и исследования объекта моделирования. Рассматриваются
перспективы и пути создания интегрированного рейтинга российских вузов и эксплуатации
рейтинга в адаптивном режиме. Указываются ограничения предлагаемого подхода и
перспективы его развития
6.4.1. Формулировка
проблемы
Университетские рейтинги давно стали общепринятым в
мире методом оценки эффективности вузов[48].
Этими рейтингами для решения различных задач
пользуются и потенциальные студенты, и их родители, и ученые, и руководители.
Таким образом, они востребованы практически всем обществом.
Недавно и министерство образования и науки РФ
обратилось к идее создания подобного рейтинга для российских вузов, и это в
общем нельзя не приветствовать.
Однако первый опыт создания подобного рейтинга,
по-видимому, приходиться признать неудачным, т.к. он вызвал большой поток
совершенно справедливой и хорошо обоснованной критики со стороны
научно-педагогического сообщества. Возражения вызвали, прежде как сами критерии
оценки эффективности вузов[49], так
и полная непрозрачность процедуры формирования этих критериев, а также то, что
за бортом широкого обсуждения (которого, вообще не было) осталось и само
понятие эффективности вузов, т.е. их основное назначение. А ведь именно тем,
что понимается под эффективностью вузов, определяются и критерии ее оценки. Но
предложенные критерии оказались таковы, что у многих возникло вполне
обоснованное подозрение, что под эффективностью вузов при их формировании
понималось вовсе не качество образования, а нечто другое не свойственное вузам.
Эта критика звучит и на научных конференциях,[50] и в
научных публикациях [1]. А то, о чем не принято говорить на научных
конференциях и писать в научных публикациях, высказывается на форумах и на
личных страницах ученых и педагогов. Например, на своем личном сайте доктор
педагогических наук профессор А.А.Остапенко
пишет: «Основных критериев,
как мы помним пять: средний балл ЕГЭ принятых на обучение студентов; объём
научных работ на одного сотрудника; количество иностранцев-выпускников; доходы
вуза в расчёте на одного сотрудника, а также общая площадь учебно-лабораторных
зданий в расчёте на одного студента. Как они связаны с эффективностью вуза и
что такое эффективность вообще понять, мысля рационально, непросто. Даже
всерьёз обсуждать эти критерии как-то странно» [51]. Но
мы все же выскажем одно соображение. На наш взгляд довольно странно выглядит
попытка сравнения друг с другом вузов разных направленности подготовки, т.е.
например аграрных вузов и вузов, готовящих специалистов для атомной и
ракетно-космической промышленности. Иначе говоря, для вузов разной
направленности должны быть свои рейтинги.
Правда со временем, наверное, в какой-то степени и под
влиянием этой критики, позиция Минобрнауки РФ стала меняться. А то, что к тому
времени уже успели закрыть несколько вузов, как говорят: «имеющих признаки
неэффективности»[52], – это как бы и не так
важно. Динамику этих изменений позиции профильного министерства можно
проследить по Нормативно-правовым документам Минобрнауки РФ, устанавливающим
критерии оценки эффективности деятельности вузов[53].
Таким образом, налицо проблема, которая состоит в том, что с одной стороны рейтинг
российских вузов востребован, а с другой стороны как-то пока не очень получается
его сформировать. То есть, как обычно желаемое не совпадает с действительным, и
«хотели как лучше, а вышло как всегда» (В.С.Черномырдин).
6.4.2. Авторский подход к решению проблемы
6.4.2.1. Идея предлагаемого решения проблемы
Существует
несколько популярных и авторитетных рейтингов вузов1:
–
Университетский рейтинг The Guardian[54];
–
Университетский рейтинг Times[55];
– Мировой рейтинг Times Higher Education[56];
– Рейтинг
мировых вузов Шанхайского Университета[57].
Мы не будем
их здесь описывать, т.к. по ним достаточно информации в общем доступе, в т.ч.
по приведенным ссылкам.
Но хотели бы
отметить, что для поддержки любого подобного рейтинга необходима
соответствующая инфраструктура, оснащенная различными видами обеспечения ее
деятельности (финансовое, кадровое, организационное, техническое, математическое,
программное, информационное и т.д.). Все эти виды обеспечения в совокупности
представляют собой технологию ведения и применения данного рейтинга.
Естественно,
никто технологию не продает, а если и продает, то так дорого, что купить ее
практически невозможно. Поэтому возникает вопрос о разработке или поиске
подобной технологии в России.
Таким
образом, востребованы теоретическое обоснование, математическая модель,
методика численных расчетов (т.е. структуры данных и алгоритмы их обработки) а
также реализующие их инструментальные (программные) средства, обеспечивающие
создание, поддержку, развитие и применение подобных рейтингов.
Данная статья
как раз и посвящена рассмотрению отечественной лицензионной инновационной
интеллектуальной технологии, обеспечивающей решение поставленной проблемы. А
именно предлагается применить для этой цели автоматизированный системно-когнитивный
анализ (АСК-анализ) и его программный инструментарий – интеллектуальную систему
«Эйдос».
6.4.2.2.
Автоматизированный системно-когнитивный анализ и интеллектуальная система
«Эйдос» как инструментарий решения проблемы
Этот подход
кратко описан в статье [2]. Здесь рассмотрим его подробнее.
Прежде всего, возникает вопрос о том, что понимается под эффективностью вузов? Ведь ясно, что прежде чем оценивать эффективность вузов было бы неплохо, а на самом деле совершенно необходимо, разобраться с тем, что же это такое. Причина этого ясна: выбор критериев оценки во многом обуславливается тем, что именно оценивается.
Ясно, что по этому поводу существует много различных мнений, которые в различной степени аргументированы или не аргументированы и отражают позиции руководителей образования и науки, профессионального научно-педагогического сообщества и различных слоев населения. По мнению автора, с научной точки зрения некорректно и неуместно говорить о каких-то критериях оценки эффективности вузов, если не определено само это понятие эффективности, т.е. отсутствует консенсус в профессиональной среде по поводу того, что же это такое.
Очевидно, для достижения такого консенсуса в наше время необходимо широкое обсуждение этого вопроса в научной печати, Internet и СМИ. Однако такое обсуждение не было организовано и критерии оценки эффективности или признаков неэффективности практически неожиданно «свалились научно-педагогическому сообществу как снег на голову».
Уже после этого, как это произошло, началось обсуждение этого вопроса на различных научных конференциях, в научной и периодической прессе, на личных сайтах, формах и т.п. Но пока шло это обсуждение и пока оно не пришло к какому-либо консенсусу в этом вопросе, ряд вузов были закрыты, филиалы сокращены и т.д.
По мнению автора, цель вуза в том, чтобы формировать компетентных и творчески мыслящих специалистов в соответствии с прогнозом социального заказа, т.е. таких, которые будут востребованы обществом в будущем периоде профессиональной деятельности этих специалистов, который составляет 30-40 лет. А должен ли вуз зарабатывать, должен ли он иметь те или иные площади в расчете на одного учащегося – это все нужно знать только для того, чтобы спрогнозировать, сможет ли он выполнить свою основную задачу, т.е. подготовку специалистов. Ни в коем случае нельзя рассматривать эти показатели как самоцель, т.к. достижение тех или иных их значений, вообще говоря, может и ничего не говорить о достижении цели вуза. Несут ли эти критерии какую-либо информацию о достижении цели вуза, и какую именно по величине и знаку, – это еще надо определить в процессе специального исследования, которое, скорее всего не было проведено. Странно, что об этом приходиться писать, но приходиться, т.к. похоже, об этом стали забывать.
Когда консенсус профессионального научно-педагогического сообщества по вопросу о том, что же понимать под «эффективностью вуза» будет достигнут, на первый план выступает вопрос о том, с помощью какого метода оценивать эту эффективность, т.е. как ее измерить.
Для автора вполне очевидно, что этот метод должен представлять собой какой-то вариант метода многокритериальной оценки. Это обусловлено просто тем, что такие сложные и многофакторные системы как вузы в принципе невозможно оценивать по одному показателю или критерию. Чтобы обоснованно выбрать метод оценки эффективности вузов необходимо сначала научно обосновать требования к нему, а затем составить рейтинг методов по степени соответствия обоснованным требованиям и выбрать метод, наиболее удовлетворяющий обоснованным требованиям.
Применение
метода факторного анализа для этих целей, по-видимому, некорректно, т.к. этот
метод, предъявляющий настолько жесткие требования к исходным данным об объекте
моделирования, что их практически невозможно выполнить. Во-первых, факторный
анализ – это параметрический метод,
предполагающий, что исходные данные подчиняются многомерным нормальным распределениям.
Во-вторых, это метод неустойчивый,
т.е. небольшие изменения исходных данных могут привести к значительным
изменениям в модели. Поэтому исходные данные для факторного анализа должны быть
абсолютно точными, что невозможно не только фактически, но даже в принципе.
В-третьих, перед началом факторного
анализа необходимо определить наиболее
важные факторы, которые и будут исследоваться в создаваемой модели. Но при
этом в руководствах по факторному анализу не уточняется, каким способом это
предлагается сделать. А между тем при большом количестве факторов, что является
обычным для большинства реальных задач, это не тривиальная задача, которую вручную
решить невозможно.
Когда метод оценки эффективности вузов выбран, необходимо ответить на вопрос о том, на основе каких частных критериев оценивать эффективность вузов и какой исходной информацией о вузах для этого необходимо располагать?
Ясно, что эти критерии в общем случае могут иметь как количественную, так и качественную природу и могут измеряться в различных единицах измерения. Кроме того эти критерии могут иметь различную силу и направление влияния на интегральную оценку эффективности вузов. Конечно, возникают вопросы как о способе определения системы критериев эффективности вуза, так и о способе определения силы и направления влияния критериев на оценку эффективности вузов.
Но еще более существенным является вопрос: «О способе сопоставимого сведения разнородных по своей природе и измеряемых в различных единицах измерения частных критериев эффективности в один количественный интегральный критерий эффективности вуза».
Отметим, что в материалах Минобрнауки РФ и о критериях оценки эффективности вузов[58] даже не упоминается вопрос о том, что когда значения частных критериев для того или иного вуза установлены, то необходимо каким-то образом на их основе получить обобщающую количественную оценку его эффективности в виде одного числа, т.е. надо как-то объединить значения всех частных критериев в одной формуле, в одном математическом выражении, которое и называется «Интегральный критерий».
Поэтому, наверное, и говорят не об эффективности или неэффективности вуза, а всего лишь «о признаках неэффективности», а признаками являются значения отдельных частных критериев. Если таких признаков неэффективности много, то делают вывод о том, что вуз неэффективен. Фактически такой подход, который может быть и применялся, можно назвать неосознанным применением частных критериев и интегрального критерия, т.е. «неосознанным многокритериальным подходом». При таком подходе все частные критерии имеют одинаковый вес, например принимающий значения 0 (неэффективен) и 1 (эффективен). Когда значения всех частных критериев для вуза установлены, то эти веса суммируются и сумма сравнивается с минимальными и максимальными оценками, полученными для всех вузов. Допустим, в Минобрнауки РФ из каких-то своих соображений решили, что в результате оценки эффективности вузов должно быть закрыто из-за низкой эффективности 1.5% вузов. Тогда все вузы сортируются по убыванию этой суммы и 1.5% с конца рейтинга помещаются в «черный список».
Но такой «неосознанный многокритериальный подход» очень и очень уязвим для критики.
Во-первых, возникает законный вопрос о том, почему все критерии имеют одинаковый вес, хотя даже интуитивно ясно, что они имеют разное значение и по-разному влияют на эффективность вуза (которая, кстати, непонятно в чем заключается).
Во-вторых, непонятно, как можно складывать средний балл ЕГЭ принятых на обучение студентов, объём научных работ на одного сотрудника, количество иностранцев-выпускников, доходы вуза в расчёте на одного сотрудника и общую площадь учебно-лабораторных зданий в расчёте на одного студента. За подобные математические операции ставят двойку по физике в 7-м классе средней школы. Там школьников учат, что перед тем как складывать величины, измеренные в разных единицах измерения, например рост учащихся, выраженный в метрах (1.72) и выраженный в сантиметрах (160), нужно перевести эти величины в одну единицу измерения, например в метры или в сантиметры. А иначе получится: 1.72+160=161.72, т.е. некий результат, не поддающийся разумной содержательной интерпретации[59]. Как бы нечто похожее и на таком же научном уровне не получилось при оценке наличия у вуза «признаков неэффективности». Но научно-педагогическую общественность не поставили в известность о том, каким образом вычисляется интегральная оценка эффективности вуза на основе установленных для него значений частных критериев. Поэтому высказанное опасение остается не снятым.
В развитом осознанном многокритериальном подходе для вычисления значения интегрального критерия нужно знать силу и направление влияния каждого значения частных критериев на величину этого интегрального критерия. Интегральные критерии бывают трех видов: аддитивные, мультипликативные и общего вида. Чаще всего используются аддитивные интегральные критерии, в которых значение интегрального критерия равно просто сумме значений частных критериев. Но чтобы значения частных критериев можно было корректно суммировать необходимо, чтобы они были значениями на числовых измерительных шкалах [3], и чтобы они измерялись в одних и тех же единицах измерения или были безразмерными.
Оба эти требования выполняются в
Автоматизированном системно-когнитивном анализе (АСК-анализ), в котором все
значения всех факторов, независимо от того количественные они или качественные
и в каких единицах они измеряются в исходных данных, в моделях системы «Эйдос»
(системно-когнитивных моделях) они все измеряются в одних и тех же единицах
измерения – единицах количества информации [2, 3]. Поэтому метод АСК-анализа и предлагается для решения
поставленной проблемы.
АСК-анализ представляет собой один из современных методов искусственно интеллекта, который предоставляет научно обоснованные ответы на все эти вопросы, но самое существенное, что он оснащен широко и успешно апробированным универсальным программным инструментарием, позволяющим решить эти вопросы не только как обычно на теоретическом концептуальном уровне, но и на практике [2]. Модели знаний АСК-анализа основаны на нечеткой декларативной модели представления знаний, предложенной автором в 1983 году и являющейся гибридной моделью, сочетающей в себе преимущества фреймовой, нейросетевой и четкой продукционной моделей и обеспечивающей создание моделей очень больших размерностей до 10 млн. раз превышающих максимальные размерности моделей знаний экспертных систем с четкими продукциями:
– от фреймовой модели модель представления знания системы «Эйдос» отличается существенно упрощенной программной реализацией и более высоким быстродействием без потери функциональности;
– от нейросетевой тем, что обеспечивает хорошо обоснованную теоретически содержательную интерпретацию весовых коэффициентов на рецепторах и обучение методом прямого счета [8];
– от четкой продукционной модели – нечеткими продукциями, представленными в декларативной форме, что обеспечивает эффективное использование знаний без их многократной генерации для решения задач идентификации, прогнозирования, принятия решений и исследования моделируемого объекта.
АСК-анализ является непараметрическим методом, устойчивым к шуму в исходных данных, позволяющий корректно обрабатывать неполные (фрагментированные) исходные данные, описывающие воздействие взаимозависимых факторов на нелинейный [7] объект моделирования.
Суть метода АСК-анализа в том, что он позволяет рассчитать на основе исходных данных какое количество информации содержится в значениях факторов, обуславливающих переходы объекта моделирования в различные будущие состояния, причем как в желательные, так и в нежелательные [3].
Он состоит в целенаправленном последовательном повышении степени формализации исходных данных до уровня, который позволяет ввести исходные данные в компьютерную систему, а затем преобразовать исходные данные в информацию; информацию преобразовать в знания; использовать знания для решения задач прогнозирования, принятия решений и исследования предметной области.
Рассмотрим подробнее вопросы выявления, представления и использования знаний в АСК-анализе и системе «Эйдос».
Данные – это информация, записанная на каком-либо носителе или находящаяся в
каналах связи и представленная на каком-то языке или в системе кодирования и
рассматриваемая безотносительно к ее смысловому содержанию.
Исходные
данные об объекте управления обычно представлены в форме баз данных, чаще всего
временных рядов, т.е. данных, привязанных ко времени. В соответствии с
методологией и технологией автоматизированного системно-когнитивного анализа
(АСК-анализ), развиваемой проф. Е.В.Луценко, для управления и принятия решений
использовать непосредственно исходные данные не представляется возможным.
Точнее сделать это можно, но результат управления при таком подходе оказывается мало чем
отличающимся от случайного. Для реального же решения задачи управления
необходимо предварительно преобразовать данные в информацию, а ее в знания о
том, какие воздействия на корпорацию к каким ее изменениям обычно, как
показывает опыт, приводят.
Информация есть осмысленные данные.
Смысл данных,
в соответствии с концепцией смысла Шенка-Абельсона, состоит в том, что известны
причинно-следственные зависимости между событиями, которые описываются этими
данными. Таким образом, данные преобразуются в информацию в результате
операции, которая называется «Анализ данных», которая состоит из двух этапов:
1. Выявление
событий в данных (разработка классификационных и описательных шкал и градаций и
преобразование с их использованием исходных данных в обучающую выборку, т.е. в
базу событий – эвентологическую базу).
2. Выявление
причинно-следственных зависимостей между событиями.
В случае
систем управления событиями в данных являются совпадения определенных значений
входных факторов и выходных параметров объекта управления, т.е. по сути, случаи
перехода объекта управления в определенные будущие состояния под действием
определенных сочетаний значений управляющих факторов. Качественные значения
входных факторов и выходных параметров естественно формализовать в форме лингвистических
переменных. Если же входные факторы и выходные параметры являются числовыми, то
их значения измеряются с некоторой погрешностью и фактически представляют собой
интервальные числовые значения, которые также могут быть представлены или
формализованы в форме лингвистических переменных (типа: «малые», «средние»,
«большие» значения экономических показателей).
Какие же
математические меры могут быть использованы для количественного измерения силы
и направления причинно-следственных зависимостей?
Наиболее
очевидным ответом на этот вопрос, который обычно первым всем приходит на ум,
является: «Корреляция». Однако, в статистике это хорошо известно, что это
совершенно не так. Для преобразования
исходных данных в информацию необходимо не только выявить события в этих
данных, но и найти причинно-следственные связи между этими событиями. В
АСК-анализе предлагается 7 количественных мер причинно-следственных связей,
основной из которых является семантическая мера целесообразности информации по
А.Харкевичу.
Знания –
это информация, полезная для достижения
целей.
Значит для преобразования информации в знания
необходимо:
1. Поставить цель (классифицировать будущие состояния
моделируемого объекта на целевые и нежелательные).
2. Оценить полезность информации для достижения этой
цели (знак и силу влияния).
Второй пункт, по сути, выполнен при преобразовании
данных в информацию. Поэтому остается выполнить только первый пункт, т.к.
классифицировать будущие состояния объекта управления как желательные (целевые)
и нежелательные.
Знания могут быть представлены в различных формах,
характеризующихся различной степенью формализации:
– вообще
неформализованные знания, т.е. знания в своей собственной форме, ноу-хау
(мышление без вербализации есть медитация);
– знания, формализованные в естественном вербальном
языке;
– знания, формализованные в виде различных методик,
схем, алгоритмов, планов, таблиц и отношений между ними (базы данных);
– знания в форме технологий, организационных,
производственных, социально-экономических и политических структур;
– знания, формализованные в виде математических
моделей и методов представления знаний в автоматизированных интеллектуальных
системах (логическая, фреймовая, сетевая, продукционная, нейросетевая, нечеткая
и другие).
Таким образом, для решения сформулированной проблемы
необходимо осознанно и целенаправленно последовательно повышать степень
формализации исходных данных до уровня, который позволяет ввести исходные
данные в интеллектуальную систему, а затем:
– преобразовать исходные данные в информацию;
– преобразовать информацию в знания;
– использовать знания для решения задач управления,
принятия решений и исследования предметной области.
АСК-анализ
имеет следующие этапы [2]:
–
когнитивно-целевая структуризация предметной области;
–
формализация предметной области (формирование классификационных и описательных
шкал и градаций и обучающей выборки);
– синтез и
верификация статистических и системно-когнитивных моделей;
– решение
задач идентификации, прогнозирования, принятия решений и исследования
предметной области в наиболее достоверных из созданных моделей.
Единственный
неавтоматизированный в системе «Эйдос» этап – это первый, а остальные приведены
на рисунке 1.
АСК-анализ имеет ряд особенностей, которые обусловили его выбор в качестве метода решения проблемы:
5. Имеет теоретическое обоснование, основой которого является семантическая мера целесообразности информации А.Харкевича.
6. Обеспечивает корректную сопоставимую количественную обработку разнородных по своей природе факторов, измеряемых в различных единицах измерения, высокую точность и независимость результатов расчетов от единиц измерения исходных данных.
7. Обеспечивает построение многомерных моделей объекта моделирования непосредственно на основе неполных и искаженных эмпирических данных о нем.
8. Имеет развитую и доступную программную реализацию в виде универсальной когнитивной аналитической системы «Эйдос».
Очень важно, что этот инструментарий и методики его использования для решения сформулированных задач могут быть доступны всем заинтересованным сторонам не только на федеральном уровне, но и в самих вузах, что позволит им осуществлять аудиторскую самооценку и видеть свое место и динамику среди других вузов. Это позволит руководителям вузов принимать более осознанные и научно обоснованные решения, направленные на повышение эффективности и рейтинга их вуза. Конечно, для реализации на практике регулярного рейтингового анализа вузов необходимо создание соответствующей достаточно разветвленной инфраструктуры.
Более подробному и конкретному исследованию связанных с этим вопросов и посвящена данная работа, в которой далее кратко расстраивается университетский рейтинг Гардиан (который выбран просто в качестве примера), а затем приводится численный пример его реализации в форме приложения интеллектуальной системы «Эйдос». Отметим, что создание этого приложения не требует программирования [4-6], т.е. система «Эйдос» анализирует исходные данные рейтинга и строит модель, в которой отражено как влияют значения частных критериев на значение интегрального критерия, т.е. на итоговую общую оценку рейтинга вуза.
6.4.2.3. Частные
критерии университетского рейтинга Гардиан
Университетский рейтинг Гардиан[60] выгодно отличается от других тем, что измеряет качество преподавания, использования учебных ресурсов, а также оценивает уровень исследовательской деятельности, что очень полезно для тех, кто интересуется послевузовскими программами – магистратурой, докторантурой и проч.
Как указано на официальном сайте рейтинга10 в нем используются следующие частные критерии:
1. Качество преподавания, которое оценивается
национальным студенческим исследованием (NSS): процент удовлетворенных студентов.
2. Получение обратной связи от преподавателя и качество
заданий. Оценивается опросом NSS, в котором устанавливается процент удовлетворенных
студентов.
3. Результаты опроса NSS, в котором оценивается процент
студентов, удовлетворенных общим качеством выбранной программы.
4. Затраты на студента – оценка по 10-балльной шкале.
5. Соотношение студент – работник вуза: количество
студентов на штатную единицу университета.
6. Карьерные перспективы: процент выпускников, сумевших
найти работу или продолжить обучение в течение полугода после окончания вуза.
7. Уровень прогресса студентов на основе сравнения
университетских результатов с оценками предыдущего сертификата (обычно,
школьного или университетского): оценка по 10-балльной шкале. Данный показатель
демонстрирует, насколько преподавательский состав способен повлиять на улучшение
успеваемости студентов.
8. Проходной балл при поступлении в вуз на основе оценок
предыдущего сертификата обучения (школьный или университетский сертификат).
Отметим,
что считаем важным достоинством данного рейтинга то, что он ведется по
различным направлениям подготовки, которых 45 (таблица 1):
Таблица 1 –
Направления подготовки, по которым проводился
университетский рейтинг Гардиан


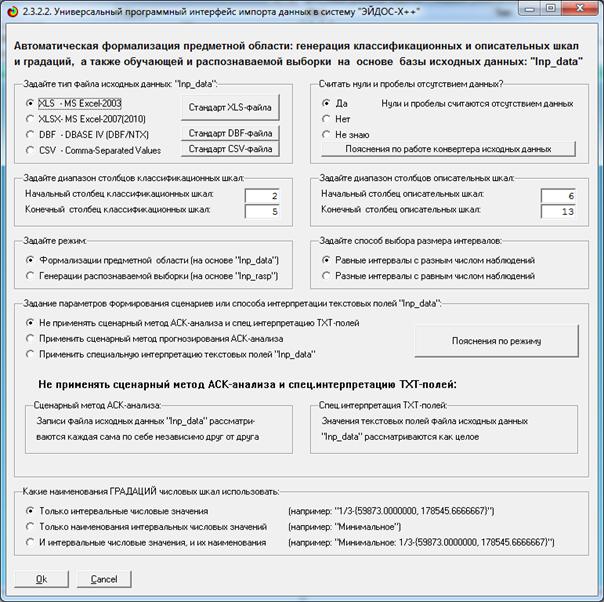
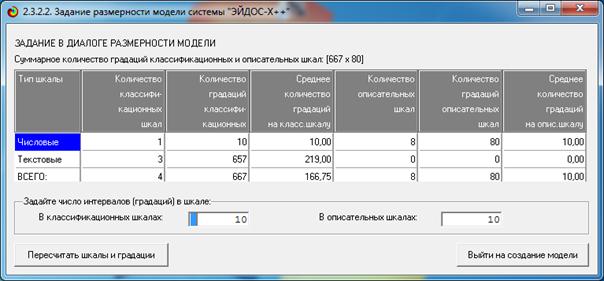
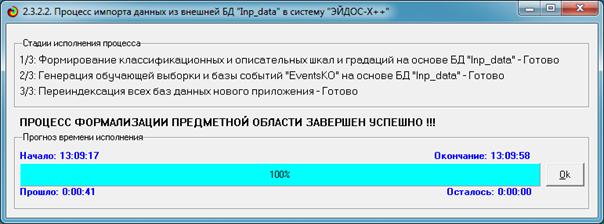
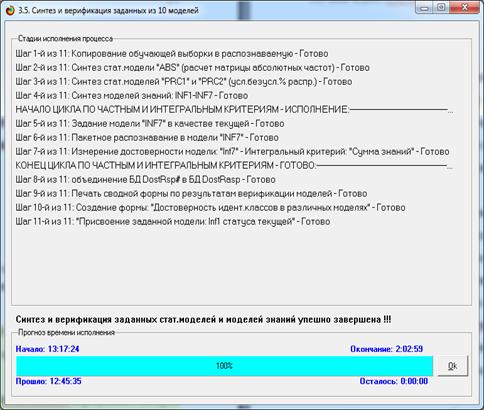
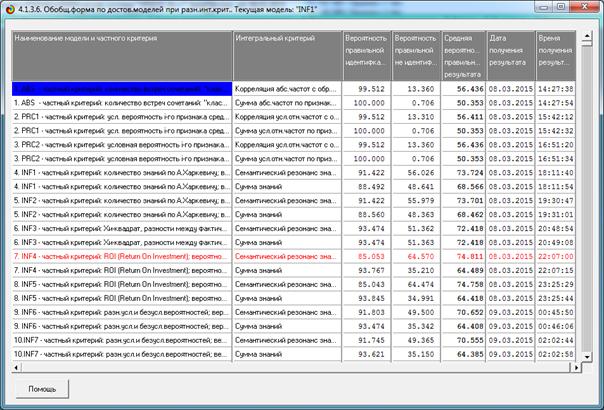
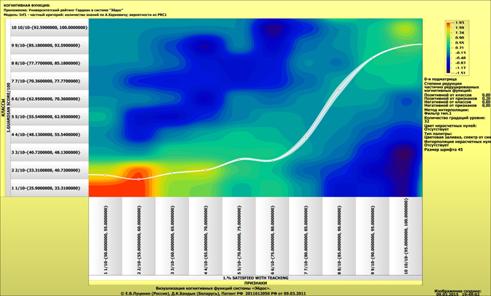
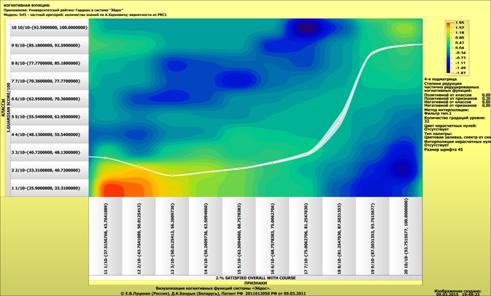
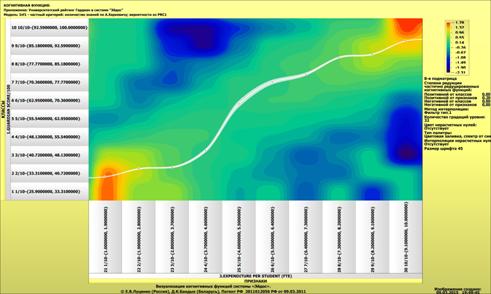
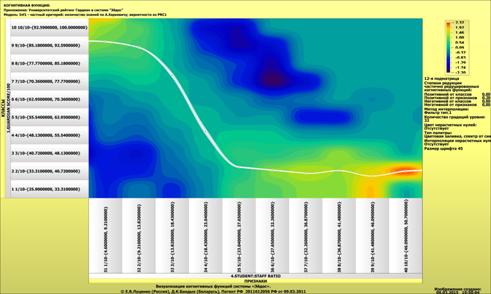
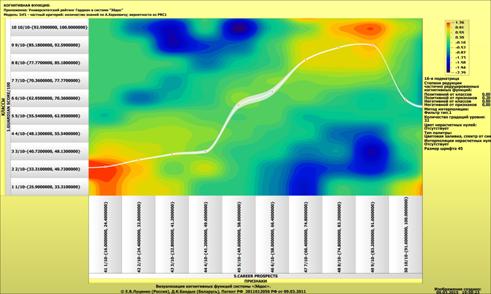
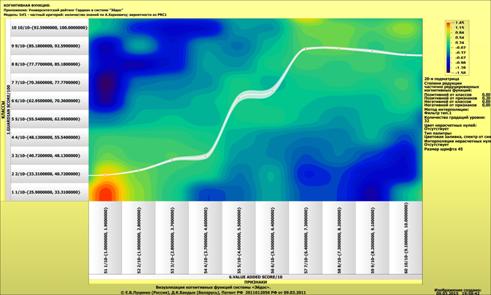
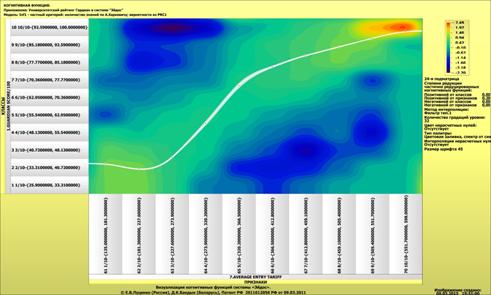
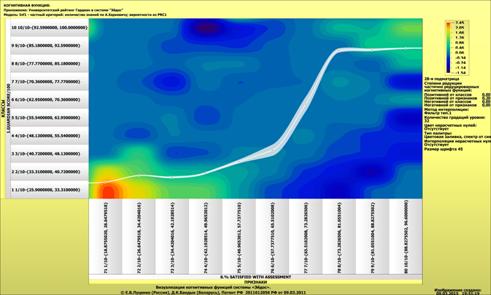
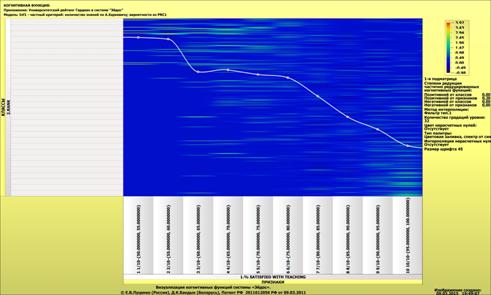
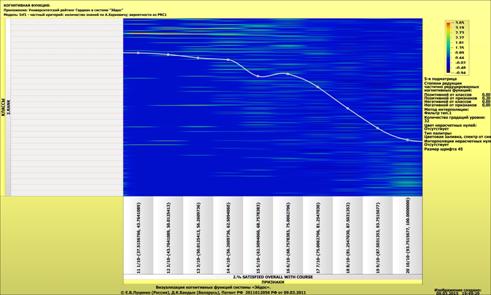

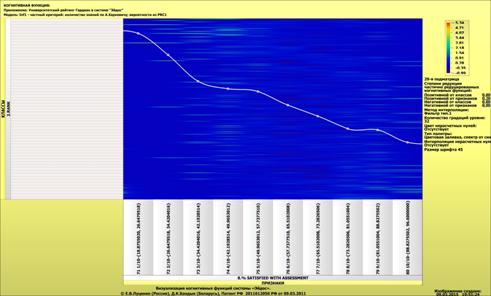

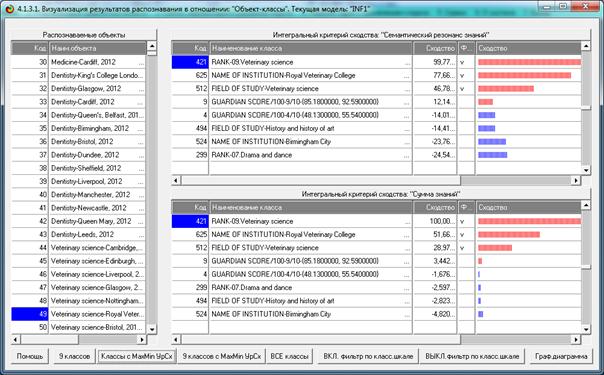


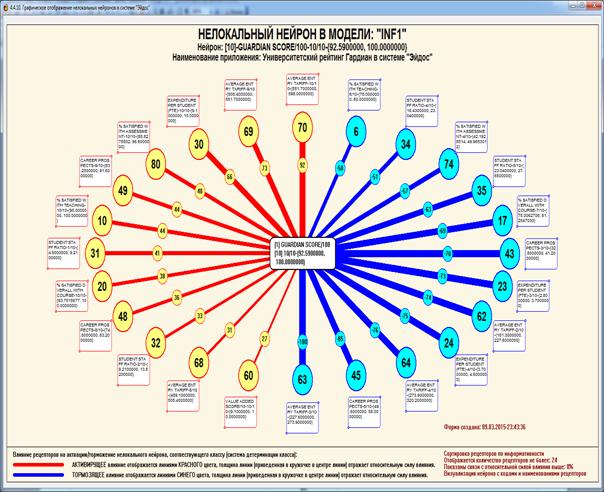
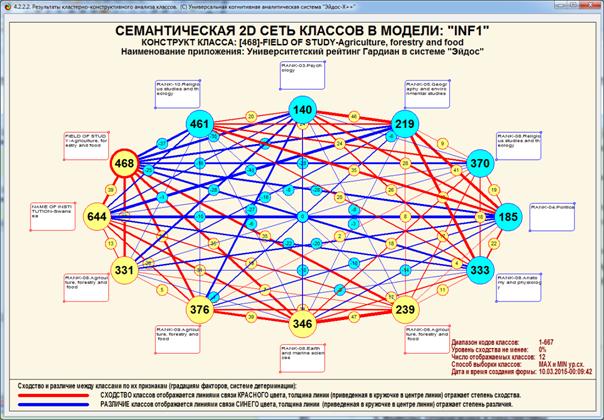

{kind=link}