ГЛАВА 3. КОНКРЕТНЫЕ ОБЛАСТИ МАТЕМАТИЧЕСКИХ И ИНСТРУМЕНТАЛЬНЫХ
МЕТОДОВ КОНТРОЛЛИНГА
Бросив общий взгляд на математические
и инструментальные методы контроллинга, рассмотрев "с птичьего полета"
эту обширную область теоретических и прикладных исследований, вполне естественно
проанализировать ранее выделенные крупные научные направления. Двигаясь "сверху
вниз", мы получим возможность обсуждать конкретные алгоритмы расчетов, однако
за подробностями часто будем отсылать к соответствующим публикациям. По нашей оценке,
современный этап развития науки характеризуется тем, что конкретные методы достаточно
хорошо описаны в традиционных бумажных изданиях и в Интернет-ресурсах. Недостаточно
проработан следующий иерархический этап - анализ совокупностей методов, предназначенных
для решения задач в рамках конкретных научных направлений. Необходимо развитие методологии
[50] математических и инструментальных методов контроллинга, т.е. организации деятельности
в этой области исследований. Именно развитию методологии посвящена настоящая часть
монографии. Начнем с анализа выделенных в предыдущей части точек роста.
3.1. Современное состояние непараметрической
статистики
Непараметрическая статистика – одна из пяти точек роста
прикладной математической статистики и математических методов экономики в целом
(включая контроллинг). Специалистам хорошо известно большое число публикаций по
конкретным вопросам непараметрической статистики - статей и книг, полностью или
частично посвященных этой тематике. Однако приходится констатировать, что внутренняя
структура научного направления "Непараметрическая статистика" остается
до настоящего времени непроявленной. Цель настоящего раздела – на основе сложившегося
в практике научной деятельности определения непараметрической статистики рассмотреть
ее деление на области и систематизировать исследования по непараметрическим статистическим
методам.
Непараметрическая статистика – одна из пяти точек роста
прикладной математической статистики, выделенных в разделе 2.3 (см. также статьи
[67, 154, 155]). Она занимает важное место среди математических методов исследования.
Однако, несмотря на большое число публикаций по конкретным вопросам непараметрической
статистики, внутренняя структура этого научного направления оставалась до сих пор
непроявленной. На основе сложившегося в практике научной деятельности определения
непараметрической статистики проведем ее деление на области и сделаем первоначальную
попытку систематизировать публикации по непараметрическим статистическим методам.
Как известно, непараметрика, или - подробнее - непараметрическая
статистика, позволяет делать статистические выводы, в частности, оценивать характеристики
распределения и проверять статистические гипотезы, без, как правило, слабо обоснованных
предположений о том, что функция распределения элементов выборки входит в то или
иное параметрическое семейство. Например, широко распространена вера в то, что статистические
данные часто подчиняются нормальному распределению. Как говорят (частично в шутку,
частично всерьез - распространенная фраза из научного фольклора), математики думают,
что это - экспериментальный факт, установленный в прикладных исследованиях, в то
время как прикладники уверены, что математики доказали нормальность результатов
наблюдений. Между тем анализ конкретных результатов наблюдений, в частности, погрешностей
измерений, приводит всегда к одному и тому же выводу - в подавляющем большинстве
случаев реальные распределения существенно отличаются от нормальных [121]. Некритическое
использование гипотезы нормальности часто приводит к значительным ошибкам, например,
при отбраковке резко выделяющихся результатов наблюдений (выбросов) [156], при статистическом
контроле качества и в других случаях. Поэтому целесообразно использовать непараметрические
методы, в которых на функции распределения результатов наблюдений наложены лишь
весьма слабые требования. Обычно предполагается лишь их непрерывность. На основе
обобщения многочисленных исследований можно констатировать, что к настоящему времени
с помощью непараметрических методов можно решать практически тот же круг задач,
что ранее решался параметрическими методами. Являются несостоятельными встречающиеся
в литературе заявления о том, что непараметрические методы имеют меньшую мощность
или требуют большего объема выборки, чем параметрические. При этом в непараметрике,
как и в математической статистике в целом, шире - во всей обширной области математических
методов исследования, остается ряд нерешенных задач, некоторые из которых сформулированы
в статье [157].
3.1.1. Параметрические и непараметрические
гипотезы
Начнем обсуждение понятия «непараметрическая статистика»
с постановок задач проверки статистических гипотез, следуя подходу, зафиксированному
в справочнике [60]. Уточнение исходных понятий необходимо, поскольку в литературе
распространены неполные или даже неверные формулировки.
Статистическая гипотеза – любое предположение, касающееся неизвестного распределения
случайных величин (элементов). Приведем формулировки нескольких статистических гипотез:
1. Результаты наблюдений имеют нормальное распределение
с нулевым математическим ожиданием.
2. Результаты наблюдений имеют функцию стандартного нормального
распределения c нулевым математическим ожиданием и единичной дисперсией (обычно
такое распределение обозначается N(0,1)).
3. Результаты наблюдений имеют нормальное распределение.
4. Результаты наблюдений в двух независимых выборках имеют
одно и то же нормальное распределение.
5. Результаты наблюдений в двух независимых выборках имеют
одно и то же распределение.
Различают нулевую и альтернативную гипотезы. Нулевая гипотеза
– гипотеза, подлежащая проверке. Альтернативная гипотеза – каждая допустимая гипотеза,
отличная от нулевой. Нулевую гипотезу обозначают Н0, альтернативную
– Н1 (от Hypothesis – «гипотеза» (англ.)). Выбор тех или
иных нулевых или альтернативных гипотез определяется стоящими перед менеджером,
экономистом, инженером, исследователем прикладными задачами. Рассмотрим примеры.
Пример 1. Пусть
нулевая гипотеза – гипотеза 2 из приведенного выше списка, а альтернативная – гипотеза
1. Сказанное означает, что реальная ситуация описывается вероятностной моделью,
согласно которой результаты наблюдений рассматриваются как реализации независимых
одинаково распределенных случайных величин с функцией распределения N(0,σ),
где параметр σ (среднее квадратичное отклонение) неизвестен статистику. В рамках
этой модели нулевую гипотезу записывают так:
Н0: σ = 1,
а альтернативную так:
Н1: σ ≠ 1.
Пример 2. Пусть
нулевая гипотеза – по-прежнему гипотеза 2 из приведенного выше списка, а альтернативная
– гипотеза 3 из того же списка. Тогда в вероятностной модели управленческой, экономической
или производственной ситуации предполагается, что результаты наблюдений образуют
выборку из нормального распределения N(m, σ) при некоторых значениях
m и σ. Гипотезы записываются так:
Н0: m = 0, σ = 1
(оба параметра принимают фиксированные значения);
Н1: m ≠ 0 и/или σ ≠ 1
(т.е. либо m ≠ 0, либо σ ≠ 1, либо
и m ≠ 0, и σ ≠ 1).
Пример 3. Пусть
Н0 – гипотеза 1 из приведенного выше списка, а Н1
– гипотеза 3 из того же списка. Тогда вероятностная модель – та же, что в примере
2,
Н0: m = 0, σ произвольно;
Н1: m ≠ 0, σ произвольно.
Пример 4. Пусть
Н0 – гипотеза 2 из приведенного выше списка, а согласно Н1
результаты наблюдений имеют функцию распределения F(x), не совпадающую
с функцией стандартного нормального распределения Ф(х). Тогда
Н0: F(х) = Ф(х) при всех х
(записывается как тождество F(х) ≡ Ф(х));
Н1: F(х0) ≠ Ф(х0)
при некотором х0 (т.е. неверно, что F(х)
≡ Ф(х)).
Примечание. Здесь
символ "≡" - знак тождественного совпадения функций (т.е. совпадения
при всех возможных значениях аргумента х).
Пример 5. Пусть
Н0 – гипотеза 3 из приведенного выше списка, а согласно Н1
результаты наблюдений имеют функцию распределения F(x), не являющуюся нормальной.
Тогда
![]()
при некоторых m, σ;
Н1: для любых m, σ найдется х0
= х0(m, σ) такое, что
![]() .
.
Пример 6. Пусть
Н0 – гипотеза 4 из приведенного выше списка, согласно вероятностной
модели две выборки извлечены из совокупностей с функциями распределения F(x)
и G(x), являющихся нормальными с параметрами m1,
σ1 и m2, σ2 соответственно, а
Н1 – отрицание Н0. Тогда
Н0: m1 = m2, σ1
= σ2, причем m1 и σ1 произвольны;
Н1: m1 ≠ m2 и/или
σ1 ≠ σ2.
Пример 7. Пусть
в условиях примера 6 дополнительно известно, что σ1 = σ2.
Тогда
Н0: m1 = m2, σ >
0, причем m1 и σ произвольны;
Н1: m1 ≠ m2, σ
> 0.
Пример 8. Пусть
Н0 – гипотеза 5 из приведенного выше списка, согласно вероятностной
модели две выборки извлечены из совокупностей с функциями распределения F(x)
и G(x) соответственно, а Н1 – отрицание Н0.
Тогда
Н0: F(x) ≡ G(x), где
F(x) – произвольная функция распределения;
Н1: F(x) и G(x) - произвольные
функции распределения, причем
F(x) ≠
G(x) при некоторых х.
Пример 9. Пусть
в условиях примера 7 дополнительно предполагается, что функции распределения F(x)
и G(x) отличаются только сдвигом, т.е. G(x) = F(x
- а) при некотором а. Тогда
Н0: F(x) ≡ G(x), где
F(x) – произвольная функция распределения;
Н1: G(x) = F(x - а), а ≠
0, где F(x) – произвольная функция распределения.
Пример 10. Пусть
в условиях примера 4 дополнительно известно, что согласно вероятностной модели ситуации
F(x) - функция нормального распределения с единичной дисперсией, т.е.
имеет вид N(m, 1). Тогда
Н0: m = 0 (т.е. F(х) = Ф(х)
при всех х, F(х) ≡ Ф(х));
Н1: m ≠ 0
(т.е. неверно, что F(х) ≡ Ф(х)).
Пример 11. При
статистическом регулировании технологических, экономических, управленческих или
иных процессов [97, 158] рассматривают выборку, извлеченную из совокупности с нормальным
распределением и известной дисперсией, и гипотезы
Н0: m = m0,
Н1: m = m1,
где значение параметра m = m0
соответствует налаженному ходу процесса, а переход к m = m1
свидетельствует о разладке.
Пример 12. При
статистическом приемочном контроле [16, 159, 160] число дефектных единиц продукции
в выборке подчиняется гипергеометрическому распределению, неизвестным параметром
является p = D/N – уровень дефектности, где N – объем партии продукции,
D – общее число дефектных единиц продукции в партии. Используемые в нормативно-технической
и коммерческой документации (стандартах, договорах на поставку и др.) планы контроля
часто нацелены на проверку гипотезы
Н0: p < AQL
против альтернативной гипотезы
Н1: p > LQ,
где AQL – приемочный уровень дефектности, LQ
– браковочный уровень дефектности (очевидно, что AQL < LQ).
Пример 13. В
качестве показателей стабильности технологического, экономического, управленческого
или иного процесса используют ряд характеристик распределений контролируемых показателей,
в частности, коэффициент вариации v = σ/M(X). Требуется
проверить нулевую гипотезу
Н0: v < v0
при альтернативной гипотезе
Н1: v > v0,
где v0 – некоторое заранее заданное граничное
значение.
Пример 14. Пусть
вероятностная модель двух выборок – та же, что в примере 8, математические ожидания
результатов наблюдений в первой и второй выборках обозначим М(Х) и
М(У) соответственно. В ряде ситуаций проверяют нулевую гипотезу
Н0: М(Х) = М(У)
против альтернативной гипотезы
Н1: М(Х) ≠ М(У).
Пример 15. В
статье [161] отмечалось большое значение в математической статистике функций распределения,
симметричных относительно 0. При проверке симметричности
Н0: F(-x) = 1 – F(x) при всех
x, в остальном F произвольна;
Н1: F(–x0) ≠ 1 – F(x0)
при некотором x0, в остальном F произвольна.
В вероятностно-статистических методах принятия решений
используются и многие другие постановки задач проверки статистических гипотез.
Конкретная задача проверки статистической гипотезы полностью
описана, если заданы нулевая и альтернативная гипотезы. Выбор метода проверки статистической
гипотезы, свойства и характеристики методов определяются как нулевой, так и альтернативной
гипотезами. Для проверки одной и той же нулевой гипотезы при различных альтернативных
гипотезах следует использовать, вообще говоря, различные методы. Так, в примерах
4 и 10 нулевая гипотеза одна и та же, а альтернативные – различны. Поэтому в условиях
примера 4 следует применять методы проверки согласия с фиксированным распределением
(например, критерии Колмогорова или омега-квадрат), а в условиях примера 10 - критерий
Стьюдента. Если в условиях примера 4 использовать критерий Стьюдента, то он не будет
решать поставленных задач (не сможет обнаружить все варианты альтернативных гипотез).
Если в условиях примера 10 использовать критерий согласия Колмогорова, то он, напротив,
будет решать поставленные задачи, хотя, возможно, и хуже, чем специально приспособленный
для этого случая критерий Стьюдента.
При обработке реальных данных большое значение имеет правильный
выбор гипотез Н0 и Н1. Принимаемые предположения,
например, нормальность распределения, должны быть тщательно обоснованы, в частности,
статистическими методами. Отметим, что в подавляющем большинстве конкретных прикладных
постановок распределение результатов наблюдений отлично от нормального [121].
Часто возникает ситуация, когда вид нулевой гипотезы вытекает
из постановки прикладной задачи, а вид альтернативной гипотезы не ясен. В таких
случаях следует рассматривать альтернативную гипотезу наиболее общего вида и использовать
методы, решающие поставленную задачу при всех возможных Н1. В
частности, при проверке гипотезы 2 (из приведенного выше списка) как нулевой следует
в качестве альтернативной гипотезы использовать Н1 из примера
4, а не из примера 10, если нет специальных обоснований нормальности распределения
результатов наблюдений при альтернативной гипотезе.
Статистические гипотезы разделяют на два класса - параметрические
и непараметрические. Дадим определения этим терминам. Предположение, которое касается
неизвестного значения параметра распределения, входящего в некоторое параметрическое
семейство распределений, называется параметрической гипотезой (отметим, что
параметр может быть и многомерным). Предположение, при котором вид распределения
неизвестен (т.е. не предполагается, что оно входит в некоторое априори заданное
параметрическое семейство распределений), называется непараметрической гипотезой.
Таким образом, если распределение F(x) результатов наблюдений в выборке
согласно принятой вероятностной модели входит в некоторое параметрическое семейство
{F(x;θ), θ![]() Θ}, т.е. F(x)
= F(x;θ0) при некотором θ0
Θ}, т.е. F(x)
= F(x;θ0) при некотором θ0![]() Θ, то рассматриваемая
гипотеза – параметрическая, в противном случае – непараметрическая.
Θ, то рассматриваемая
гипотеза – параметрическая, в противном случае – непараметрическая.
Если и Н0 и Н1 – параметрические
гипотезы, то задача проверки статистической гипотезы – параметрическая. Если
хотя бы одна из гипотез Н0 и Н1 – непараметрическая,
то задача проверки статистической гипотезы – непараметрическая. Другими словами,
если вероятностная модель ситуации – параметрическая, т.е. полностью описывается
в терминах того или иного параметрического семейства распределений вероятностей,
то и задача проверки статистической гипотезы – параметрическая. Если же вероятностная
модель ситуации – непараметрическая, т.е. ее нельзя полностью описать в терминах
какого-либо параметрического семейства распределений вероятностей, то и задача проверки
статистической гипотезы – непараметрическая. В примерах 1 - 3, 6, 7, 10 - 12 даны
постановки параметрических задач проверки гипотез, а в примерах 4, 5, 8, 9, 13 -
15 – непараметрических. Непараметрические задачи проверки гипотез делятся на два
класса: в одном из них речь идет о проверке утверждений, касающихся функций распределения
(примеры 4, 5, 8, 9, 15), во втором – о проверке утверждений, касающихся характеристик
распределений (примеры 13, 14).
Статистическая гипотеза называется простой, если она однозначно
задает распределение результатов наблюдений, вошедших в выборку. В противном случае
статистическая гипотеза называется сложной. Гипотеза 2 из приведенного выше списка,
нулевые гипотезы в примерах 1, 2, 4, 10, нулевая и альтернативная гипотезы в примере
11 – простые, все остальные упомянутые выше гипотезы – сложные.
Однозначно определенный способ проверки статистических
гипотез называется статистическим критерием. Статистический критерий строится
с помощью статистики U(x1, x2, …,
xn) – функции от результатов наблюдений x1,
x2, …, xn. В пространстве значений статистики U
выделяют критическую область Ψ, т.е. область со следующим свойством:
если значения применяемой статистики принадлежат данной области, то отклоняют (иногда
говорят - отвергают) нулевую гипотезу, в противном случае – не отвергают (т.е. принимают).
Статистику U, используемую при построении определенного
статистического критерия, называют статистикой этого критерия. Например, в задаче проверки статистической гипотезы, приведенной
в примере 4, применяют критерий Колмогорова, основанный на статистике
![]() .
.
При этом Dn называют статистикой критерия
Колмогорова.
Частным случаем статистики U является векторзначная
функция результатов наблюдений U0(x1, x2,
…, xn) = (x1, x2, …, xn),
значения которой – набор результатов наблюдений. Если xi – числа,
то U0 – набор n чисел, т.е. точка n–мерного
пространства. Ясно, что статистика критерия U является функцией от U0,
т.е. U = f(U0). Поэтому можно считать, что Ψ – область
в том же n–мерном пространстве, нулевая гипотеза отвергается, если (x1,
x2, …, xn)![]() Ψ, и принимается
в противном случае.
Ψ, и принимается
в противном случае.
В вероятностно-статистических методах обработки данных
и принятия решений статистические критерии, как правило, основаны на статистиках
U, принимающих числовые значения, и критические области имеют вид
Ψ = {U(x1, x2,
…, xn) > C}, (1)
где С – некоторые числа.
Статистические критерии делятся на параметрические
и непараметрические: параметрические критерии используются в параметрических задачах
проверки статистических гипотез, а непараметрические
– в непараметрических задачах.
При проверке статистической гипотезы возможны ошибки. Есть
два рода ошибок. Ошибка первого рода заключается в том, что отвергают нулевую гипотезу,
в то время как в действительности эта гипотеза верна. Ошибка второго рода состоит
в том, что принимают нулевую гипотезу, в то время как в действительности эта гипотеза
неверна.
Вероятность ошибки первого рода называется уровнем значимости
и обозначается α. Таким образом, α = P{U![]() Ψ | H0},
т.е. уровень значимости α – это вероятность события {U
Ψ | H0},
т.е. уровень значимости α – это вероятность события {U![]() Ψ}, вычисленная
в предположении, что верна нулевая гипотеза Н0.
Ψ}, вычисленная
в предположении, что верна нулевая гипотеза Н0.
Уровень значимости однозначно определен, если Н0
– простая гипотеза. Если же Н0 – сложная гипотеза, то уровень
значимости, вообще говоря, зависит от функции распределения результатов наблюдений,
удовлетворяющей Н0. Статистику критерия U обычно строят
так, чтобы вероятность события {U![]() Ψ} не зависела
от того, какое именно распределение (из удовлетворяющих нулевой гипотезе Н0)
имеют результаты наблюдений. Для статистик критерия U общего вида под уровнем
значимости понимают максимально возможную ошибку первого рода. Максимум (точнее,
супремум) берется по всем возможным распределениям, удовлетворяющим нулевой гипотезе
Н0, т.е. α = sup P{U
Ψ} не зависела
от того, какое именно распределение (из удовлетворяющих нулевой гипотезе Н0)
имеют результаты наблюдений. Для статистик критерия U общего вида под уровнем
значимости понимают максимально возможную ошибку первого рода. Максимум (точнее,
супремум) берется по всем возможным распределениям, удовлетворяющим нулевой гипотезе
Н0, т.е. α = sup P{U![]() Ψ | H0}.
Ψ | H0}.
Если критическая область имеет вид, указанный в формуле
(1), то
P{U >
C | H0} = α.
(2)
Если С задано, то из последнего соотношения определяют
α. Часто поступают по иному - задавая α (обычно α = 0,05, иногда
α = 0,01 или α = 0,1, другие значения α используются гораздо реже),
определяют С из уравнения (2), обозначая его Сα, и
используют критическую область Ψ = {U > Cα} с заданным
уровнем значимости α.
Вероятность ошибки второго рода есть P{U![]() Ψ | H1}.
Обычно используют не эту вероятность, а ее дополнение до 1, т.е. P{U
Ψ | H1}.
Обычно используют не эту вероятность, а ее дополнение до 1, т.е. P{U![]() Ψ | H1}
= 1 – P{U
Ψ | H1}
= 1 – P{U![]() Ψ | H1}.
Эта величина носит название мощности критерия. Итак, мощность критерия –
это вероятность того, что нулевая гипотеза будет отвергнута, когда альтернативная
гипотеза верна.
Ψ | H1}.
Эта величина носит название мощности критерия. Итак, мощность критерия –
это вероятность того, что нулевая гипотеза будет отвергнута, когда альтернативная
гипотеза верна.
Понятия уровня значимости и мощности критерия объединяются
в понятии функции мощности критерия – функции, определяющей вероятность того, что
нулевая гипотеза будет отвергнута. Функция мощности зависит от критической области
Ψ и действительного распределения результатов наблюдений. В параметрической
задаче проверки гипотез распределение результатов наблюдений задается параметром
θ. В этом случае функция мощности обозначается М(Ψ, θ) и зависит
от критической области Ψ и действительного значения исследуемого параметра
θ. Если
Н0: θ = θ0,
Н1: θ = θ1,
то
М(Ψ, θ0)
= α,
М(Ψ, θ1)
= 1 – β,
где α – вероятность ошибки первого рода, β - вероятность ошибки второго рода. В статистическом
приемочном контроле α – риск изготовителя, β – риск потребителя. При статистическом
регулировании технологического процесса α – риск излишней наладки, β –
риск незамеченной разладки.
Функция мощности М(Ψ, θ) в случае одномерного
параметра θ обычно достигает минимума, равного α, при θ = θ0,
монотонно возрастает при удалении от θ0 и приближается к 1 при |θ
- θ0| → ∞.
В ряде вероятностно-статистических методов принятия решений
используется оперативная характеристика L(Ψ, θ) - вероятность принятия
нулевой гипотезы в зависимости от критической области Ψ и действительного значения
исследуемого параметра θ. Ясно, что
L(Ψ, θ)
= 1 - М(Ψ, θ).
Основной характеристикой статистического критерия является
функция мощности. Для многих задач проверки статистических гипотез разработан не
один статистический критерий, а целый ряд. Чтобы выбрать из них определенный критерий
для использования в конкретной практической ситуации, проводят сравнение критериев
по различным показателям качества [16, приложение 3], прежде всего с помощью их
функций мощности. В качестве примера рассмотрим лишь два показателя качества критерия
проверки статистической гипотезы – состоятельность и несмещенность.
Пусть объем выборки n растет, а Un
и Ψn – статистики критерия и критические области соответственно.
Критерий называется состоятельным, если
![]()
т.е. вероятность отвергнуть нулевую гипотезу стремится
к 1, если верна альтернативная гипотеза.
Статистический критерий называется несмещенным,
если для любого θ0, удовлетворяющего Н0, и любого
θ1 , удовлетворяющего Н1, справедливо неравенство
P{U![]() Ψ | θ0}
< P{U
Ψ | θ0}
< P{U![]() Ψ | θ1},
Ψ | θ1},
т.е. при справедливости Н0 вероятность
отвергнуть Н0 меньше, чем при справедливости Н1.
При наличии нескольких статистических критериев в одной
и той же задаче проверки статистических гипотез следует использовать состоятельные
и несмещенные критерии. Предлагаемый из каких-либо соображений критерий, предназначенный
для определенной задачи проверки статистических гипотез, подлежит проверке – является
ли он состоятельным и несмещенным. Можно поставить вопрос иначе: для какой задачи
проверки статистических гипотез предназначен определенный критерий, т.е. для какой
задачи он является состоятельным?
3.1.2. Место непараметрической статистики
в истории прикладной статистики
Типовые примеры раннего этапа применения статистических
методов описаны в Ветхом Завете (см., например, Книгу Чисел). Там, в частности,
описана перепись военнообязанных – подсчет числа воинов в различных племенах. С
математической точки зрения дело сводилось к подсчету числа попаданий значений наблюдаемых
признаков в определенные градации [110].
В дальнейшем результаты обработки статистических данных
стали представлять в виде таблиц и диаграмм, как это и сейчас делают органы государственной
статистики. Надо признать, что по сравнению с Ветхим Заветом есть прогресс – в Библии
не было таблиц и диаграмм. Однако нет продвижения по сравнению с работами российских
статистиков конца XIX – начала XX вв.
Сразу после возникновения теории вероятностей (Паскаль,
Ферма, XVII в.) вероятностные модели стали использоваться при обработке статистических
данных. Например, изучалась частота рождения мальчиков и девочек, было установлено
отличие вероятности рождения мальчика от вероятности рождения девочки (и от 0,5),
анализировались причины того, что в парижских приютах эта вероятность не та, что
в самом Париже, и т.д. Имеется достаточно много публикаций по истории теории вероятностей
с описанием раннего этапа развития статистических методов исследований; к лучшим
из них относится очерк [162].
В
Отсчет современного этапа развития статистических методов
можно начать с
Разработанную в первой трети ХХ в. теорию статистического
анализа данных называют параметрической статистикой, поскольку ее основной объект
изучения – это выборки из распределений, описываемых одним или небольшим числом
параметров. Наиболее общим является семейство кривых Пирсона, задаваемых четырьмя
параметрами. Как правило, нельзя указать каких-либо веских причин, по которым распределение
результатов конкретных наблюдений должно входить в то или иное параметрическое семейство.
Исключения хорошо известны: если вероятностная модель предусматривает суммирование
независимых случайных величин, то сумму естественно описывать нормальным распределением;
если же в модели рассматривается произведение таких величин, то итог, видимо, приближается
логарифмически нормальным распределением, и т.д. Однако подобных моделей нет в подавляющем
большинстве реальных ситуаций, и приближение реального распределения с помощью кривых
из семейства Пирсона или его подсемейств – чисто формальная операция. Именно из
таких соображений критиковал параметрическую статистику академик АН СССР С.Н. Бернштейн
в
В первой трети ХХ в., одновременно с параметрической статистикой,
в работах Спирмена и Кендалла появились первые непараметрические методы, основанные
на коэффициентах ранговой корреляции, носящих ныне имена этих статистиков. Но непараметрика,
не делающая нереалистических предположений о том, что функции распределения результатов
наблюдений принадлежат тем или иным параметрическим семействам распределений, стала
заметной частью статистики лишь со второй трети ХХ века. В 1930-е годы появились
работы А.Н. Колмогорова и Н.В. Смирнова, предложивших и изучивших статистические
критерии, носящие в настоящее время их имена. Эти критерии основаны на использовании
так называемого эмпирического процесса. (Как известно, эмпирический процесс – это
разность между эмпирической и теоретической функциями распределения, умноженная
на квадратный корень из объема выборки.) В работе А.Н. Колмогорова
После Второй мировой войны развитие непараметрической статистики
пошло быстрыми темпами. Большую роль сыграли работы американского статистика Ф.
Вилкоксона и его школы (см., в частности, [72, 73]). Итог таков: по мнению ведущих
специалистов по математической статистике к настоящему времени с помощью непараметрических
методов можно решать практически тот же круг статистических задач, что и с помощью
параметрических. В нашей стране непараметрические методы получили достаточно большую
известность после выхода в
Наше представление об основных этапах развития прикладной
математической статистики представлено в табл.1. Названия этапов даны по впервые
разработанным подходам. Вновь появляющиеся этапы не вытесняют полностью статистические
методы, разработанные на предыдущих. В настоящее время активно используются методы
всех четырех этапов.
Таблица 4 – Основные этапы развития прикладной
математической статистики
|
№ |
Этапы |
Характерные черты |
Годы |
|
1 |
Описатель-ная статистика |
Тексты, таблицы, графики. Отдельные расчетные приемы
(МНК) |
До 1900 |
|
2 |
Параметри-ческая статистика |
Модели параметрических семейств распределений –
нормальных, гамма и др. Теория оценивания параметров и проверки гипотез |
1900 - 1933 |
|
3 |
Непарамет-рическая статистика |
Произвольные непрерывные распределения. Непараметрические
методы оценивания и проверки гипотез |
1933 - 1979 |
|
4 |
Нечисловая статистика |
Выборка – из элементов произвольных пространств.
Использование показателей различия и расстояний |
С 1979 |
В табл. 4 исходим из деления прикладной математической
статистики на четыре области (табл.2). Статистику нечисловых данных (статистику
объектов нечисловой природы, нечисловую статистику), ставшую знаменем современного
четвертого этапа развития статистических методов (после непараметрической статистики),
не рассматриваем в настоящем разделе. Этой области прикладной математической статистики
посвящен специальный раздел настоящей монографии, а также достаточно много публикаций,
в том числе монографий [5, 36] и обзоров [82, 163].
Таблица 5 – Области прикладной математической статистики
|
№ |
Вид статистических данных |
Область прикладной статистики |
|
1 |
Числа |
Статистика (случайных) величин |
|
2 |
Конечномерные вектора |
Многомерный статистический анализ |
|
3 |
Функции |
Статистика случайных процессов и временных рядов |
|
4 |
Объекты нечисловой природы |
Статистика нечисловых данных |
3.1.3. Три основные области непараметрической
статистики
Исходя из практики статистического анализа данных, опишем
структуру непараметрической статистики, выделив основные ее области. Их, по нашему
мнению, три:
- область на стыке параметрических и непараметрических
методов;
- ранговые статистические методы;
- непараметрические оценки функций, прежде всего плотности
распределения, регрессионной зависимости, а также статистик, используемых в теории
классификации.
3.1.3.1. Сопоставление параметрических
и непараметрических методов анализа данных
Рассмотрим эти области. Первая из них относится прежде
всего к статистике (случайных) величин (см. табл. 2), поскольку обсуждаются различные
семейства распределений случайных величин, в то время как для случайных векторов
широко известно лишь одно параметрическое семейство - многомерных нормальных распределений.
Многие алгоритмы анализа данных рассматривают как в параметрической,
так и в непараметрической статистике. Например, выборочное среднее арифметическое
и выборочная дисперсия являются оценками максимального правдоподобия (т.е. в определенном
смысле наилучшими) для математического ожидания и дисперсии соответственно, если
результаты наблюдения - выборка из нормального распределения. В непараметрической
постановке они являются состоятельными оценками математического ожидания и дисперсии.
Однако не всегда наилучшими - для оценивания центра распределения в ряде ситуаций
предпочтительнее медиана [164]. Непараметрические и параметрические оценки характеристик
распределения сопоставлены в статье [165].
Метод моментов проверки согласия с параметрическим семейством
распределений [166], например, с нормальным семейством с помощью критериев асимметрии
и эксцесса, основан на асимптотической нормальности выборочных моментов для выборок
из произвольных распределений. Разработано много критериев согласия [167]. Однако
достаточно достоверно отличить нормальное распределение от распределения другого
типа можно лишь по выборкам, объем которых - сотни [168] или даже тысячи [5]. Часто
критерии согласия применяются с ошибками (см. примеры в [60, 74, 75]. Констатируем,
что в наиболее распространенном случае, когда объем выборки - не более нескольких
десятков результатов измерений (наблюдений, испытаний, анализов, опытов), невозможно
обосновать выбор определенного распределения из того или иного параметрического
семейства.
Что происходит, если не выполнены предпосылки, при которых
разработаны параметрические методы? Например, для проверки однородности двух независимых
выборок в случае нормальности распределений и равенства дисперсий рекомендуют двухвыборочный
критерий Стьюдента. Если же предпосылки нарушены, то для проверки равенства математических
ожиданий следует использовать критерий Крамера-Уэлча [71]. Крайняя неустойчивость
параметрических методов отбраковки резко выделяющихся наблюдений делает невозможным
их практическое применение [156]. В то же время доверительные границы для математического
ожидания в непараметрическом случае отличаются от таковых в случае нормального распределения
только использованием квантилей нормального распределения вместо квантилей распределения
Стьюдента, т.е. при росте объемов выборки различие исчезает (ср. с выводами в статье
[165]).
Довольно часто предполагают, что погрешности (отклонения,
ошибки, невязки) в методе наименьших квадратов имеют нормальное распределение. Однако
это предположение не является обязательным. Так, непараметрическому оцениванию точки
пересечения регрессионных прямых посвящены работы [169, 170], непараметрический метод наименьших квадратов для
восстановления линейной зависимости с периодической составляющей разработан в статьях
[119, 171].
3.1.3.2. Ранговые
статистические методы
В этих методах используют не сами результаты измерений,
а их ранги, т.е. места в упорядоченных рядах. Примерами являются критерии Колмогорова,
Смирнова, омега-квадрат, коэффициенты ранговой корреляции Спирмена и Кендалла [69,
75, 117]. Все ранговые статистики измерены в порядковой шкале [5, 36, 82, 163],
т.е. их значения не меняются при любом строго возрастающем преобразовании шкалы
измерения.
Разработка и изучение ранговых статистик продолжается.
Так. в [72, 73] разобраны два мифа, связанные с критерием Вилкоксона (Манна - Уитни)
- о том, что этот критерий является состоятельным для проверки тождественного совпадения
двух функций распределения (т.н. абсолютной однородности) или хотя бы для проверки
равенства их медиан. Несмотря на выявленные недостатки, этот непараметрический критерий
полезен для построения карт контроля качества
продукции [172]. Состоятельные критерии проверки абсолютной однородности независимых
выборок описаны в [173]. Интересный (как теоретически, так и практически) факт существенного
различия реальных и номинальных уровней
значимости в задачах проверки статистических гипотез с помощью непараметрических
критериев выявлен в статье [174].
3.1.3.3. Непараметрические
оценки функций
Базовыми являются непараметрические оценки плотности распределения
в пространствах произвольной природы [118, 175]. На их основе разработаны методы
непараметрического оценивания регрессионных зависимостей, классификации (распознавания
образов, дискриминантного и кластерного анализов) [120, 176]. Эти методы, входящие
в статистику нечисловых данных [5, 36, 82, 163], имеют большое прикладное значение.
Непараметрический дискриминантный анализ (синонимы: непараметрические
методы диагностики, непараметрические методы распознавания образов) используется
в задачах управления качеством [177], диагностики
электрорадиоизделий [178]. Цикл работ [179 - 182] посвящен непараметрическим
методам классификации текстовых документов.
3.1.3.4. О развитии
непараметрической статистики
Проведенный анализ показывает, что к настоящему времени
с помощью непараметрических методов можно решать практически тот же круг задач,
что ранее решался параметрическими методами. Все большую роль играют непараметрические
оценки плотности, непараметрические методы регрессии и распознавания образов (дискриминантного
анализа).
Непараметрические методы не используют априорных (и в большинстве
практических ситуаций недоступных проверке) предположений о том, что распределения
результатов измерений (наблюдений, испытаний, анализов, опытов) входят в то или
иное параметрическое семейство, а потому являются более обоснованными, чем параметрические.
В непараметрике, как и в математической статистике в целом,
остается ряд нерешенных задач. Для обеспечения широкого внедрения непараметрических
методов необходимо провести еще целый комплекс теоретических и пилотных (т.е. пробных)
прикладных работ.
Методология современных статистических методов предполагает,
что при решении конкретной прикладной задачи необходимо прежде всего построить (выбрать,
описать) вероятностно-статистическую модель. А уже в рамках модели разрабатывается
(подбирается, используется) соответствующий ей метод, согласно которому создаются
алгоритмы и проводятся расчеты, делаются выводы и принимаются управленческие решения.
Часто полезны иерархические системы моделей. Такая система на примере проверки однородности
двух независимых выборок построена в статье [71], в которой, в частности, продемонстрирована
польза несостоятельных критериев проверки статистических гипотез [166].
Непараметрическая статистика является лучше соответствует
потребностям практики, представляет собой более передовой и более мощный (результативный,
продуктивный) подход, чем параметрическая. Поэтому она должна применяться более
широко, чем сейчас, вытеснять параметрическую из несвойственных последней областей
использования. Преподавание математической статистики также должно быть приведено
в соответствие с современными требованиями, место непараметрической статистики должно
быть основным при рассмотрении задач статистики случайных величин, многомерного
статистического анализа, статистики случайных процессов и временных рядов. Примером
адекватного соотношения различных подходов, по нашему мнению, является учебник [5],
соответствующий современному уровню развития прикладной математической статистики.
3.2. Подход к изучению устойчивости выводов
в математических моделях экономики
Раздел 3.2 основан на применении общей схемы изучения устойчивости
выводов, полученных с помощью математических методов и моделей, относительно допустимых
отклонений исходных данных и предпосылок моделей. Рассмотрены конкретные постановки
задач устойчивости: по отношению к изменению данных, их объема и распределений,
к допустимым преобразованиям шкал измерения, к временным характеристикам (моменту
начала реализации проекта, горизонту планирования). Уменьшение неопределенности
может проводиться путем изменения вида данных, т.е. путем перехода к нечисловым
данным. Обсуждаются модели конкретных процессов управления промышленными предприятиями
на примерах устойчивости характеристик инвестиционных проектов к изменению коэффициентов
дисконтирования и устойчивости к изменению коэффициентов модели и объемов партий
продукции в моделях управления запасами.
Математические модели дают лишь приближенное представление
о реальных явлениях и процессах. Исходные данные известны лишь с некоторой точностью,
математические зависимости всегда несколько отличаются от реальных. Поэтому изучение
устойчивости выводов относительно допустимых отклонений исходных данных и предпосылок
модели – один из этапов построения математической модели (см. [50, с.288-303], [183]
и др.). Представим разработанный нами подход к изучению устойчивости выводов в математических
моделях, используя примеры в основном из области математического моделирования процессов
управления промышленными предприятиями. Рассмотрим общую схему устойчивости, выделим
классы устойчивых моделей, приведем решения ряда конкретных задач.
Процессы управления промышленными предприятиями реализуются
в реальных ситуациях с достаточно высоким уровнем неопределенности [9, 184]. Велика
роль нечисловой информации как на «входе», так и на «выходе» процесса принятия управленческого
решения. Неопределенность и нечисловая природа управленческой информации должны
быть отражены при анализе устойчивости экономико-математических методов и моделей.
3.2.1. Основные понятия и базовые положения
подхода к изучению устойчивости выводов
в математических моделях социально-экономических явлений и процессов
Применение экономико-математических методов и моделей при
разработке инструментария повышения эффективности управления промышленными предприятиями
обычно предполагает последовательное осуществление трех этапов исследования. Первый
- от исходной практической проблемы до теоретической чисто математической задачи.
Второй – внутриматематическое изучение и решение этой задачи. Третий – переход от
математических выводов обратно к практической проблеме.
Целесообразно выделять четверки проблем:
ЗАДАЧА – МОДЕЛЬ - МЕТОД - УСЛОВИЯ ПРИМЕНИМОСТИ.
Обсудим каждую из только что выделенных составляющих.
Задача, как
правило, порождена потребностями той или иной прикладной области. Разрабатывается
одна из возможных математических формализаций реальной ситуации. Например, при изучении
предпочтений потребителей возникает вопрос: различаются ли мнения двух групп потребителей.
При математической формализации мнения потребителей в каждой группе обычно моделируются
как независимые случайные выборки, т.е. как совокупности независимых одинаково распределенных
случайных величин, а вопрос маркетологов переформулируется в рамках этой модели
как вопрос о проверке той или иной статистической гипотезы однородности. Речь может
идти об однородности характеристик, например, о проверке равенства математических
ожиданий, или о полной (абсолютной однородности), т.е. о совпадении функций распределения,
соответствующих двух совокупностям.
Модель может
быть порождена также обобщением потребностей (задач) ряда прикладных областей. Приведенный
выше пример иллюстрирует эту ситуацию: к необходимости проверки гипотезы однородности
приходят и медики при сравнении двух групп пациентов, и инженеры при сопоставлении
результатов обработки деталей двумя способами, и т.д. Таким образом, одна и та же
математическая модель может применяться для решения самых разных по
своей прикладной сущности задач. Важно подчеркнуть, что выделение перечня задач
находится вне математики.
Метод, используемый
в рамках определенной математической модели - это уже во многом, если не в основном,
дело математиков. В вероятностно-статистических моделях речь идет, например, о методе
оценивания, о методе проверки гипотезы, о методе доказательства той или иной теоремы,
и т.д. В первых двух случаях алгоритмы разрабатываются и исследуются математиками,
но используются прикладниками, в то время как метод доказательства касается лишь
самих математиков.
Отнюдь не все модели и методы непосредственно связаны с
математикой. В организационно-экономических исследованиях широко используются графические
модели описания спроса и предложения, равновесных цен. Предпочтения потребителей
могут быть выявлены различными методами – выборочным опросом потребителей, путем
наблюдения за их поведением, с помощью различных экспертных процедур. Ясно, что
для решения той или иной задачи в рамках одной и той же принятой исследователем
модели может быть предложено много методов.
Наконец, рассмотрим последний элемент четверки - условия
применимости. При использовании математической модели он - полностью внутриматематический.
С точки зрения математика замена условия (кусочной) дифференцируемости некоторой
функции на условие ее непрерывности может представляться существенным научным достижением,
в то время как экономист или менеджер оценить это достижение не смогут. Для них,
как и во времена Ньютона и Лейбница, непрерывные функции мало отличаются от (кусочно)
дифференцируемых. Точнее, они одинаково хорошо (или одинаково плохо) могут быть
использованы для описания и решения реальных проблем.
Взаимоотношения моделей и методов заслуживают обсуждения.
В процессе познания не всегда метод следует за математической моделью. Метод может
быть разработан на основе эвристических соображений, словесной модели. Свойства
метода можно изучать лишь в рамках той или иной модели. В рамках одной математической
модели метод может быть оптимальным, в рамках другой – несостоятельным. Проблема
состоит в создании или выборе модели, адекватной изучаемому явлению или процессу.
С точки зрения практической деятельности модели и методы
нужны не сами по себе, а как инструменты разработки управленческих решений, которые
могут описываться как выводы, заключения, планы мероприятий. Рассмотрим цепочку:
ДАННЫЕ – МЕТОД (их обработки) – ВЫВОДЫ.
Как обосновать адекватность выводов? Один из критериев
– устойчивость метода обработки данных. Устойчивость можно изучать лишь в рамках
определенной модели.
Для обоснованного практического применения математических
моделей процессов управления промышленными предприятиями и основанных на них экономико-математических
методов должна быть изучена устойчивость получаемых с их помощью выводов по отношению
к допустимым отклонениям исходных данных и предпосылок моделей. Возможные применения
результатов подобного исследования:
- заказчик научно-исследовательской работы получает представление
о точности предлагаемого решения;
- удается выбрать из многих моделей наиболее адекватную;
- по известной точности определения отдельных параметров
модели удается указать необходимую точность нахождения остальных параметров;
- переход к случаю «общего положения» позволяет получать
более сильные с математической точки зрения результаты.
Можно рекомендовать обрабатывать данные несколькими способами
(методами). Выводы, общие для всех способов, скорее всего отражают реальность (являются
объективными). Выводы, меняющиеся от метода к методу, субъективны, зависят от исследователя,
выбравшего тот или иной метод анализа данных. Здесь речь идет об устойчивости выводов
по отношению к выбору метода.
3.2.2. Общая схема устойчивости
Проблемы устойчивости обсуждались многими авторами и с
разных точек зрения. Так, случай «общего положения» соответствует переходу к «мягкой
модели» в терминологии В.И. Арнольда [185]. В настоящем разделе рассматривается
только система научных результатов, к которым авторы настоящей монографии имеют
отношение, следовательно, она не претендует на обзор различных постановок задач
изучения устойчивости.
Необходим математический аппарат для описания проблем устойчивости
выводов, получаемых на основе математических моделей социально-экономических явлений
и процессов. Предлагаем использовать следующие базовые понятия, впервые введенные
в монографии [7].
Определение 1. Общей схемой устойчивости называется кортеж {A, B, f, d, E}, где:
A – множество,
интерпретируемое как пространство исходных данных;
B – множество,
называемое пространством решений;
f – способ получения
выводов, т.е. однозначное отображение ![]() ;
;
d – показатель
устойчивости, т.е. неотрицательная функция, определенная на подмножествах У
множества B и такая, что из ![]() вытекает
вытекает ![]() ;
;
![]() – совокупность допустимых отклонений, т.е. система
подмножеств множества A такая, что каждому элементу множества исходных данных
– совокупность допустимых отклонений, т.е. система
подмножеств множества A такая, что каждому элементу множества исходных данных
![]() и каждому значению параметра
и каждому значению параметра ![]() из некоторого множества параметров
из некоторого множества параметров ![]() соответствует подмножество
соответствует подмножество ![]() ) множества исходных
данных. Оно называется множеством допустимых отклонений в точке х при значении
параметра, равном
) множества исходных
данных. Оно называется множеством допустимых отклонений в точке х при значении
параметра, равном ![]() .
.
Способ получения выводов иногда будем для краткости называть
моделью. Во многих конкретных постановках устойчивости выводы получают с
помощью определенного метода, основанного на некоторой модели. С прикладной точки
зрения модель первична, метод – вторичен, поскольку результаты его применения определяются
свойствами модели. Это соображение оправдывает принятую нами в [7] терминологию
общей схемы устойчивости.
Часто показатель устойчивости d(Y) определяется
с помощью метрики, псевдометрики или показателя различия (меры близости) ![]() как диаметр множества У, т.е.
как диаметр множества У, т.е. ![]() Т.е. в пространстве решений с помощью показателя
устойчивости вокруг образа исходных данных сформирована система окрестностей. В
пространстве исходных данных подобная система – это Е, т.е. совокупность
допустимых отклонений,
Т.е. в пространстве решений с помощью показателя
устойчивости вокруг образа исходных данных сформирована система окрестностей. В
пространстве исходных данных подобная система – это Е, т.е. совокупность
допустимых отклонений, ![]() - окрестность радиуса
- окрестность радиуса ![]() вокруг точки х.
вокруг точки х.
Определение 2. Показателем устойчивости в точке х при значении параметра, равном
![]() , называется
число
, называется
число
![]() ,
,
т.е. диаметр образа множества допустимых отклонений при
отображении, рассматриваемом в качестве модели (способа получения выводов).
Определение 3. Абсолютным показателем устойчивости в точке х называется число
![]() .
.
Рассмотрим два конкретных типа математических моделей.
В теории измерений (см., например, [7]) окрестностью исходных данных являются все
те вектора, что получаются из исходного путем преобразования координат с помощью
допустимого преобразования шкалы, которое берется из соответствующей группы допустимых
преобразований. В статистике интервальных данных [5, 83] под окрестностью исходных
данных естественно понимать – при описании выборки – куб с ребрами ![]() и центром в исходном векторе. В обоих случаях максимальное
сужение не означает сужение к точке.
и центром в исходном векторе. В обоих случаях максимальное
сужение не означает сужение к точке.
Определение 4. Абсолютным показателем устойчивости на пространстве исходных данных
А по мере ![]() называется число
называется число
![]() .
.
Определение 5. Максимальным абсолютным показателем устойчивости называется
![]() .
.
Определение 6. Модель f называется абсолютно ![]() –устойчивой, если
–устойчивой, если
![]() , где
, где
![]() – максимальный абсолютный показатель
устойчивости.
– максимальный абсолютный показатель
устойчивости.
Пример. Если
показатель устойчивости формируется с помощью метрики ![]() , а совокупность допустимых
отклонений E – это совокупность всех окрестностей всех точек пространства
исходных данных A, то 0–устойчивость модели f эквивалентна непрерывности
модели f на множестве A.
, а совокупность допустимых
отклонений E – это совокупность всех окрестностей всех точек пространства
исходных данных A, то 0–устойчивость модели f эквивалентна непрерывности
модели f на множестве A.
Типовая проблема в общей схеме устойчивости – проверка ![]() –устойчивости данной
модели f относительно данной системы допустимых отклонений E.
–устойчивости данной
модели f относительно данной системы допустимых отклонений E.
Проблема А (проблема характеризации устойчивых моделей).
Даны пространство исходных данных A, пространство решений B, показатель
устойчивости d, совокупность допустимых отклонений E и неотрицательное
число ![]() . Описать достаточно
широкий класс
. Описать достаточно
широкий класс ![]() – устойчивых моделей f. Или:
найти все
– устойчивых моделей f. Или:
найти все ![]() –устойчивые модели
среди моделей, обладающих данными свойствами, т.е. входящих в данное множество моделей.
–устойчивые модели
среди моделей, обладающих данными свойствами, т.е. входящих в данное множество моделей.
Проблема Б (проблема характеризации систем допустимых отклонений). Даны пространство
исходных данных A, пространство решений B, показатель устойчивости
d, модель f и неотрицательное число ![]() . Описать достаточно
широкий класс систем допустимых отклонений E, относительно которых модель
f является
. Описать достаточно
широкий класс систем допустимых отклонений E, относительно которых модель
f является ![]() –устойчивой.
Или: найти все такие системы допустимых отклонений E среди совокупностей
допустимых отклонений, обладающих данными свойствами, т.е. входящих в данное множество
совокупностей допустимых отклонений.
–устойчивой.
Или: найти все такие системы допустимых отклонений E среди совокупностей
допустимых отклонений, обладающих данными свойствами, т.е. входящих в данное множество
совокупностей допустимых отклонений.
Пример. Определение
устойчивости по Ляпунову решения ![]() нормальной автономной системы дифференциальных
уравнений
нормальной автономной системы дифференциальных
уравнений ![]() с начальными условиями
с начальными условиями ![]() выразим в терминах общей схемы устойчивости.
выразим в терминах общей схемы устойчивости.
Здесь пространство исходных данных A – конечномерное
евклидово пространство, множество допустимых отклонений ![]() - окрестность радиуса
- окрестность радиуса ![]() точки
точки ![]() , пространство решений
B – множество функций на луче
, пространство решений
B – множество функций на луче ![]() с метрикой
с метрикой
![]() .
.
Модель f – отображение, переводящее начальные условия
х в решение системы дифференциальных уравнений с этими начальными условиями
![]() .
.
В терминах общей схемы устойчивости положение равновесия
а называется устойчивым по Ляпунову, если ![]() .
.
Для формулировки определения асимптотической устойчивости
по Ляпунову надо ввести в пространстве решений B псевдометрику
![]() .
.
Положение равновесия а называется асимптотически
устойчивым, если ![]() для некоторого
для некоторого ![]() , где показатель устойчивости
, где показатель устойчивости
![]() рассчитан с использованием псевдометрики
рассчитан с использованием псевдометрики ![]() .
.
Таким образом, общая схема устойчивости является обобщением
классических постановок задач устойчивости по Ляпунову в теории дифференциальных
уравнений. Соотношение общей схемы устойчивости с подходами других авторов обсуждается
в [184, гл.8], [7, гл.1] и др. Отметим только структурную устойчивость (грубость
динамических систем), введенную А. А. Андроновым и Л. С. Понтрягиным в
Непосредственно из общей схемы устойчивости вытекает ряд
практически полезных рекомендаций [7, гл.1], в частности, принцип уравнивания
погрешностей, согласно которому целесообразно уравнять вклад
погрешностей различной природы в общую погрешность. Принцип уравнивания погрешностей
позволяет установить:
- рациональный объем
выборки в статистике интервальных данных (см., например, [5, 83]);
- число градаций
в анкетах, предназначенных для опроса потребителей [7, 57];
- необходимую точность
оценивания параметров (платы за доставку и платы за дефицит) в моделях управления
запасами (см., например, [54, 57]).
Перечислим ряд конкретных постановок проблем устойчивости
в математических методах и моделях, в частности, используемых службами контроллинга
при информационно-аналитической поддержке процессов управления деятельностью промышленных
предприятий и организаций других отраслей народного хозяйства.
3.2.3. Устойчивость по отношению
к неопределенностям исходных данных
Исходные данные могут быть известны лишь с некоторыми неопределенностями
(погрешностями, ошибками, невязками), присущими результатам измерений (наблюдений,
испытаний, анализов, опытов). Для учета влияния неопределенностей на свойства процедур
анализа данных используют модель сгруппированных данных [188, 189], статистику интервальных
([5, гл.12], [36, гл.4], [83] и др.) и нечетких [85, 190] данных.
Развернутый анализ различных подходов к учету неопределенностей
исходных данных проведен в работах по системной нечеткой интервальной математике
[32, 33], поэтому в настоящей книге мы ограничимся приведенными выше замечаниями
и литературными ссылками.
3.2.4. Устойчивость к изменению объема данных
(объема выборки)
Асимптотические методы математической статистики нацелены
на получение выводов, не меняющихся при изменении объемов данных, лишь бы эти объемы
были достаточно велики. Отметим, что выводы, устойчивые к изменению объема выборки,
т.е. полученные в результате предельного перехода, зачастую являются более общими,
чем те, которые можно получить при рассмотрении конкретного объема выборки. Так,
согласно Центральной предельной теореме теории вероятностей распределение центрированного
и нормированного среднего арифметического независимых одинаково распределенных случайных
величин приближается к вполне определенному распределению (нормальному распределению
с математическим ожиданием 0 и дисперсией 1), каким бы ни было распределение слагаемых
(в предположении, что дисперсия этого распределения конечна и отлична от 0).
Как писали Б.В. Гнеденко и А.Н. Колмогоров, «познавательная
ценность теории вероятностей раскрывается только предельными теоремами» [191]. В
этом полемически заостренном утверждении подчеркивается принципиальная важность
получения выводов, устойчивых к изменению объема выборки.
Многообразие работ по асимптотическим методам математической
статистики необозримо, включает в себя сотни тысяч статей и книг на различных языках.
Полученные нами решения ряда задач асимптотической статистики рассмотрены, в частности,
в монографиях [5, 7]. Проблемы изучения устойчивости к изменению объема данных (объема выборки) рассмотрены также в
следующем разделе настоящнй монографии, посвященном компьютерно-статистическим технологиям.
3.2.5. Устойчивость (робастность) к изменению
распределений данных
До сих пор в книгах и статьях, выполненных в рамках старой
парадигмы математических методов экономики, часто рассматривают различные параметрические
семейства распределений числовых случайных величин. А именно – изучают семейства
нормальных распределений, логарифмически нормальных, экспоненциальных, гамма-распределений,
распределений Вейбулла – Гнеденко и др. Все они зависят от одного, двух или трех
параметров. Поэтому для полного описания распределения достаточно знать или оценить
одно, два или три числа. Широко развита и представлена в литературе параметрическая
теория математической статистики, в которой предполагается, что распределения результатов
наблюдений принадлежат тем или иным параметрическим семействам.
К сожалению, параметрические семейства существуют лишь
виртуально, в теории, а именно, в моделях, созданных исследователями. Анализ конкретных
данных показывает, что погрешности наблюдений (измерений, испытаний, анализов, опытов)
в большинстве случаев имеют распределения, отличные от нормальных и от распределений
из других параметрических семейств. Так, в научной школе метролога проф. П. В. Новицкого
проведены исследования законов распределения различного рода погрешностей измерения.
Изучены распределения погрешностей электромеханических приборов на кернах, электронных
приборов для измерения температур и усилий, цифровых приборов с ручным уравновешиванием.
Объем выборок экспериментальных данных для каждого экземпляра составлял 100–400
отсчетов. Оказалось, что 46 из 47 распределений значимо отличались от нормального.
Исследована форма распределения погрешностей у 25 экземпляров цифровых вольтметров
Щ-1411 в 10 точках диапазона. Результаты аналогичны. Дальнейшие сведения содержатся
в монографии [192].
В лаборатории прикладной математики Тартуского государственного
университета проанализировано 2500 выборок из архива реальных статистических данных.
В 92% случаев гипотезу нормальности пришлось отвергнуть [16].
Анализ, проведенный в [5, 16], показал, что распределения
реальных данных почти всегда отличаются от тех, которые включены в параметрические
семейства. Отличия могут быть большими или меньшими, но они всегда есть. Каково
влияние этих отличий на свойства процедур анализа данных? Иногда оно исчезает при
росте объемов данных, как для доверительного оценивания математического ожидания,
иногда является заметным (как при оценивании высших моментов), иногда делает процедуру
полностью необоснованной (как для отбраковки выбросов) [5]. Следовательно, надо
либо использовать непараметрические процедуры (в которых на функции распределения
наложены лишь внутриматематические условия регулярности, например, условие непрерывности),
в частности, при решении задач прогнозирования [193], либо изучать устойчивость
основанных на параметрических моделях процедур по отношению к отклонениям распределений
результатов наблюдений от предпосылок модели. Как говорят, изучать робастность статистических
процедур (от robust (англ.) – крепкий, грубый) с использованием моделей и методов,
приведенных в [7, 122, 194 – 197] и др. Статистику интервальных данных ([5, гл.12],
[83], [36, гл.4]) также можно отнести к робастной статистике.
3.2.6. Устойчивость по отношению к допустимым
преобразованиям шкал измерения
Борьба с неопределенностью может проводиться путем изменения
вида данных, т.е. путем перехода к нечисловым данным, например, к более слабым шкалам
измерения.
Таблица 6 – Основные шкалы измерения
|
Тип шкалы |
Определение шкалы |
Примеры |
Группа допустимых преобразований |
|
Шкалы
качественных признаков |
|||
|
Наи-мено-ваний |
Числа используют для различения объектов |
Номера телефонов, паспортов, пол, ИНН, штрих-коды,
УДК |
Все взаимно-однозначные преобразования |
|
По-рядко-вая |
Числа используют для упорядочения объектов |
Оценки экспертов, баллы ветров, отметки в школе,
полезность, номера домов |
Все строго возрастающие преобразования |
|
Шкалы
количественных признаков (описываются
началом отсчета и единицей измерения) |
|||
|
Интервалов |
Начало отсчета и единица измерения произвольны |
Потенциальная энергия, положение точки, температура
по шкалам Цельсия и Фаренгейта[1] |
Все линейные преобразования φ(x) = ax
+ b, a и b произвольны, а>0 |
|
Отношений |
Начало отсчета задано, единица измерения произвольна |
Масса, длина, мощность, напряжение, сопротивление,
темпе-ратура по Кельвину, цены |
Все подобные преобразования φ(x) = ax,
а произвольно, а>0 |
|
Разностей |
Начало произ-вольно, единица измерения задана |
Время[2]** |
Все преобразования сдвига φ(x) = x
+ b, b произвольно |
|
Абсолютная |
Начало отсчета и единица измерения заданы |
Число людей в данном помещении |
Только тождественное преобразование φ(x)
= x |
Примером нечисловых
данных являются результаты измерений в шкалах, отличных от абсолютной. Теория измерений
[198] – один из разделов нечисловой статистики [36, 82, 163]. Типы основных шкал
измерения, их определения, примеры величин, измеренных в этих шкалах, группы допустимых
преобразований приведены в табл.1.
Основное требование
к статистическим алгоритмам: выводы, сделанные на основе данных, измеренных
в шкале определенного типа, не должны меняться при допустимом преобразовании шкалы
измерения этих данных. В частности, выводы могут быть адекватны реальности
только тогда, когда они не зависят от того, какую единицу измерения предпочтет исследователь.
Это требование
позволяет, например, указать вид допустимой средней величины в зависимости от шкалы,
в которой измерены данные (табл.2). Определим термины.
Общее понятие
средней величины введено Огюстеном Луи Коши: средней величиной (средним по Коши)
является любая функция f(X1, X2,...,Xn)
такая, что при всех возможных значениях аргументов значение этой функции не меньше,
чем минимальное из чисел X1, X2,...,Xn,
и не больше, чем максимальное из этих чисел.
Для чисел X1,
X2,...,Xn средним
по Колмогорову является
G{(F(X1) + F(X2)
+...+ F(Xn))/n},
где F - строго монотонная функция
(т.е. строго возрастающая или строго убывающая), G - функция, обратная к
F.
Конкретизацией
основного требования к алгоритмам анализа данных является условие устойчивости результата
сравнения средних (УУРСС): неравенства
f(Y1, Y2,...,Yn)
< f(Z1, Z2,...,Zn).
f(![]() (Y1),
(Y1), ![]() (Y2),...,
(Y2),..., ![]() (Yn)) < f(
(Yn)) < f(![]() (Z1),
(Z1), ![]() (Z2),...,
(Z2),..., ![]() (Zn)),должны быть равносильны для любых
чисел Y1, Y2,...,Yn, Z1,
Z2,...,Zn и любого допустимого преобразования
(Zn)),должны быть равносильны для любых
чисел Y1, Y2,...,Yn, Z1,
Z2,...,Zn и любого допустимого преобразования ![]() из группы допустимых
преобразований
из группы допустимых
преобразований ![]() , задающей шкалу.
, задающей шкалу.
На основе математической
теории, развитой в [7, 198, 200], получен цикл теорем, кратко описанный в табл.2.
Правила выбора алгоритмов анализа данных в зависимости от шкал, в которых эти данные
измерены, заслуживают дальнейшего изучения.
Таблица 7 – Выбор средних в зависимости
от шкалы измерения
|
Тип шкалы |
Вид средних |
Средние, удовлетворяющие УУРСС |
|
Порядковая |
По Коши |
Члены вариационного ряда. Медианы |
|
Интервальная |
По Колмогорову |
Среднее арифметическое |
|
Отношений |
По Колмогорову |
Степенные средние с F(X)=XC,
С |
3.2.7. Нечисловая статистика как часть теории
устойчивости
В многообразии моделей и методов анализа данных нами выделена
и развита как самостоятельная область нечисловая статистика [36] (синонимы: статистика
объектов нечисловой природы [7, 163], статистика нечисловых данных [5]). Примерами
объектов нечисловой природы (напомним здесь, чтобы не обращаться к другим разделам
настоящей монографии), являются значения качественных признаков, т.е. результаты
кодировки объектов с помощью заданного перечня категорий (градаций); упорядочения
(ранжировки) экспертами образцов продукции (при оценке её технического уровня и
конкурентоспособности)) или заявок на проведение научных работ (при проведении конкурсов
на выделение грантов); классификации (отношения эквивалентности), т.е. разбиения
объектов на группы сходных между собой (кластеры); толерантности, т.е. бинарные
отношения, описывающие сходство объектов между собой, например, сходство организационных
структур промышленных предприятий; результаты парных сравнений или контроля качества
продукции по альтернативному признаку («годен» - «брак»), т.е. последовательности
из 0 и 1; множества (обычные или нечеткие), например, перечни рекомендуемых к осуществлению
инновационных проектов, составленные экспертами независимо друг от друга; слова,
предложения, тексты; вектора, координаты которых - совокупность значений разнотипных
признаков, например, результат составления отчета о деятельности промышленного предприятия
или анкета эксперта, в которой ответы на часть вопросов носят качественный характер,
а на часть - количественный; ответы на вопросы экспертной, маркетинговой или социологической
анкеты, часть из которых носит количественный характер (возможно, интервальный),
часть сводится к выбору одной из нескольких подсказок, а часть представляет собой
тексты; графы [201] и т.д. Интервальные данные также можно рассматривать как пример
объектов нечисловой природы, а именно, как частный случай нечетких множеств. Отметим,
что теория нечетких множеств тесно связана с теорией случайных множеств, а именно,
нечеткие множества естественно рассматривать как «проекции» случайных множеств,
за каждой системой нечетких множеств видеть систему случайных множеств [5, 7, 16,
36, 85, 190].
В чем принципиальная новизна нечисловой статистики? Для
классической статистики характерна операция сложения. При расчете выборочных характеристик
распределения (выборочное среднее арифметическое, выборочная дисперсия и др.), в
регрессионном анализе и других областях этой научной дисциплины постоянно используются
суммы. Математический аппарат - законы больших чисел, Центральная предельная теорема
и другие теоремы - нацелены на изучение сумм. В нечисловой же статистике нельзя
использовать операцию сложения, поскольку элементы выборки лежат в пространствах,
где нет операции сложения. Методы обработки нечисловых данных основаны на принципиально
ином математическом аппарате - на применении различных расстояний в пространствах
объектов нечисловой природы.
Как показали многочисленные опыты, человек более правильно
(и с меньшими затруднениями) отвечает на вопросы качественного, например, - сравнительного,
характера, чем количественного. Так, ему легче сказать, какая из двух гирь тяжелее,
чем указать их примерный вес в граммах [144]. Поэтому нечисловая статистика отражает
потребности экспертных оценок [52, 135, 202] и технологий управления (менеджмента),
в частности, контроллинга [21, 28].
3.2.8. Устойчивость по отношению к временным
характеристикам (моменту начала реализации
проекта, горизонту планирования)
Перейдем к применению математических методов исследования
для модернизации управления предприятиями и организациями. Для решения задач управления
используют экономико-математические методы и модели. В качестве первого примера
рассмотрим математические задачи, решенные для обоснования стратегического планирования.
При разработке стратегии развития промышленного предприятия
одна из основных проблем – целеполагание. Поскольку естественных целей обычно несколько,
то при построении формализованных экономико-математических моделей приходим к задачам
многокритериальной оптимизации. Поскольку одновременно по нескольким критериям оптимизировать
невозможно (например, невозможно добиться максимальной прибыли при минимуме затрат),
то для адекватного применения экономико-математических методов и моделей необходимо
тем или иным образом перейти к однокритериальной постановке (либо, выделив множество
оптимальных по Парето альтернатив, применить экспертные технологии выбора). При
выборе вида единого критерия целесообразно использовать следующую полученную нами
характеризацию моделей с дисконтированием.
Пусть динамику развития рассматриваемой экономической системы
можно описать последовательностью ![]() , где переменные xj,
j = 1, 2, ..., m, лежат в некотором пространстве Х, возможно,
достаточно сложной природы. Положение экономической системы в следующий момент не
может быть произвольным, оно связано с положением в предыдущий момент. Проще всего
принять, что существует некоторое множество К такое, что
, где переменные xj,
j = 1, 2, ..., m, лежат в некотором пространстве Х, возможно,
достаточно сложной природы. Положение экономической системы в следующий момент не
может быть произвольным, оно связано с положением в предыдущий момент. Проще всего
принять, что существует некоторое множество К такое, что ![]() . Результат экономической
деятельности за j-й период описывается величиной
. Результат экономической
деятельности за j-й период описывается величиной ![]() . Зависимость не только
от начального и конечного положения, но и от номера периода объясняется тем, что
через номер периода осуществляется связь с общей (внешней) экономической ситуацией.
Желая максимизировать суммарные результаты экономической деятельности, приходим
к постановке стандартной задачи динамического программирования:
. Зависимость не только
от начального и конечного положения, но и от номера периода объясняется тем, что
через номер периода осуществляется связь с общей (внешней) экономической ситуацией.
Желая максимизировать суммарные результаты экономической деятельности, приходим
к постановке стандартной задачи динамического программирования:
![]()
![]() . (1)
. (1)
При обычных математических предположениях максимум достигается.
Часто применяются
модели, приводящие к частному случаю задачи (1):
![]()
![]() . (2)
. (2)
Это - модели с дисконтированием (![]() - дисконт-фактор).
Естественно выяснить, какими «внутренними» свойствами выделяются задачи типа (2)
из всех задач типа (1).
- дисконт-фактор).
Естественно выяснить, какими «внутренними» свойствами выделяются задачи типа (2)
из всех задач типа (1).
Представляет интерес изучение и сравнение между собой планов
возможного экономического поведения на k шагов ![]() и
и ![]() . Естественно сравнение
проводить с помощью описывающих результаты экономической деятельности функций, участвующих
в задачах (1) и (2): план Х1 лучше плана Х2
при реализации с момента i, если
. Естественно сравнение
проводить с помощью описывающих результаты экономической деятельности функций, участвующих
в задачах (1) и (2): план Х1 лучше плана Х2
при реализации с момента i, если
![]()
![]() (3)
(3)
Будем писать Х1R(i)Х2,
если выполнено неравенство (3), где R(i) - бинарное отношение на множестве
планов, задающее упорядочение планов отношением «лучше при реализации с момента
i».
Ясно, что упорядоченность планов на k шагов, определяемая
с помощью бинарного отношения R(i), может зависеть от i,
т.е. «хорошесть» плана зависит от того, с какого момента i он начинает осуществляться.
С точки зрения реальной экономики это вполне понятно. Например, планы действий,
вполне рациональные для периода стабильного развития, нецелесообразно применять
в период гиперинфляции. И наоборот, операции, приемлемые в период гиперинфляции,
не принесут эффекта в стабильной обстановке.
Однако, как легко видеть, в моделях с дисконтированием
(2) все упорядочения R(i) совпадают, i = 1,2, …,
m - k. Оказывается, верно и обратное: если упорядочения совпадают, то мы имеем
дело с задачей (2) - с задачей с дисконтированием, причем достаточно совпадения
только при k = 1,2. Сформулируем более подробно предположения об устойчивости
упорядочения планов.
(I). Пусть ![]() . Верно одно из двух:
либо
. Верно одно из двух:
либо ![]() для всех
для всех ![]() , либо
, либо ![]() для всех
для всех ![]() .
.
(II). Пусть ![]() . Верно одно из двух:
либо
. Верно одно из двух:
либо ![]() для всех
для всех ![]() , либо
, либо ![]() для всех
для всех ![]() .
.
Нами установлено [7, 203], что из условий устойчивости
упорядоченности планов (I) и (II) следует существование констант ![]() и
и ![]() , таких, что
, таких, что ![]() . Поскольку прибавление
константы не меняет точки, в которой функция достигает максимума, то последнее соотношение
означает, что условия устойчивости упорядоченности планов (I) и (II) характеризуют
(другими словами, однозначно выделяют) модели с дисконтированием среди всех моделей
динамического программирования. Другими словами, устойчивость хозяйственных решений
во времени эквивалентна использованию моделей с дисконтированием; применяя модели
с дисконтированием, предполагаем, что экономическая среда стабильна; если прогнозируем
существенное изменение взаимоотношений хозяйствующих субъектов, то вынуждены отказаться
от использования моделей типа (2).
. Поскольку прибавление
константы не меняет точки, в которой функция достигает максимума, то последнее соотношение
означает, что условия устойчивости упорядоченности планов (I) и (II) характеризуют
(другими словами, однозначно выделяют) модели с дисконтированием среди всех моделей
динамического программирования. Другими словами, устойчивость хозяйственных решений
во времени эквивалентна использованию моделей с дисконтированием; применяя модели
с дисконтированием, предполагаем, что экономическая среда стабильна; если прогнозируем
существенное изменение взаимоотношений хозяйствующих субъектов, то вынуждены отказаться
от использования моделей типа (2).
Перейдем к проблеме горизонта планирования. Только
задав интервал времени, можно на основе экономико-математических методов и моделей
принять оптимальные решения и рассчитать ожидаемую прибыль. Проблема «горизонта
планирования» состоит в том, что оптимальное поведение зависит от того, на какое
время вперед планируют, а выбор этого горизонта зачастую не имеет рационального
обоснования. Однако от него зависят принимаемые решения и соответствующие этим решениям
экономические результаты. Например, при коротком периоде планирования целесообразны
лишь инвестиции (капиталовложения) в оборотные фонды предприятия, и лишь при достаточно
длительном периоде – в основные фонды. Однозначный выбор горизонта планирования
обычно не может быть обоснован, это – нечисловая экономическая величина. Предлагаем
справиться с противоречием путем использования асимптотически оптимальных планов.
Рассмотрим модель (2) с ![]() , т.е. модель без дисконтирования
, т.е. модель без дисконтирования
![]()
![]()
При каждом m существует оптимальный план ![]() , при котором достигает
максимума оптимизируемая функция. Поскольку выбор горизонта планирования, как правило,
нельзя рационально обосновать, хотелось бы построить план действий, близкий к оптимальному
плану при различных горизонтах планирования. Это значит, что целью является построение
бесконечной последовательности
, при котором достигает
максимума оптимизируемая функция. Поскольку выбор горизонта планирования, как правило,
нельзя рационально обосновать, хотелось бы построить план действий, близкий к оптимальному
плану при различных горизонтах планирования. Это значит, что целью является построение
бесконечной последовательности ![]() такой, что ее начальный отрезок длины m, т.е.
такой, что ее начальный отрезок длины m, т.е.
![]() , дает примерно такое
же значение оптимизируемого функционала, как и значение для оптимального плана
, дает примерно такое
же значение оптимизируемого функционала, как и значение для оптимального плана ![]() . Бесконечную последовательность
. Бесконечную последовательность
![]() с указанным свойством назовем асимптотически
оптимальным планом.
с указанным свойством назовем асимптотически
оптимальным планом.
Выясним, можно ли использовать для построения асимптотически
оптимального плана непосредственно оптимальный план. Зафиксируем k и рассмотрим
последовательность ![]() , m = 1, 2,
... . Примеры показывают, что, во-первых, элементы в этой последовательности будут
меняться; во-вторых, они могут не иметь пределов. Следовательно, оптимальные планы
могут вести себя крайне нерегулярно, а потому в таких случаях их нельзя использовать
для построения асимптотически оптимальных планов.
, m = 1, 2,
... . Примеры показывают, что, во-первых, элементы в этой последовательности будут
меняться; во-вторых, они могут не иметь пределов. Следовательно, оптимальные планы
могут вести себя крайне нерегулярно, а потому в таких случаях их нельзя использовать
для построения асимптотически оптимальных планов.
Нами установлено [7, 54, 204] существование асимптотически
оптимальных планов: можно указать такие бесконечные последовательности ![]() , что
, что
![]()
С помощью такого подхода решается проблема горизонта планирования
- надо использовать асимптотически оптимальные планы, не зависящие от горизонта
планирования. Оптимальная траектория движения состоит из трех участков - начального,
конечного и основного, а основной участок - это движение по магистрали (аналогия
с типовым движением автотранспорта).
3.2.9. Устойчивость в моделях конкретных
процессов управления промышленными
предприятиями
В качестве примера рассмотрим устойчивость к изменению
коэффициентов модели и объемов партий в моделях управления запасами. Так, для классической
модели Вильсона управления материальными ресурсами в результате строгой постановки
задачи оптимизации в ее естественной общности выявлен ряд неклассических эффектов
[54].
Пусть ![]() - интенсивность спроса, s – плата за хранение
единицы товара в течение единицы времени, g – плата за доставку одной партии,
T – интервал (горизонт) планирования. По известной «формуле квадратного корня»
- интенсивность спроса, s – плата за хранение
единицы товара в течение единицы времени, g – плата за доставку одной партии,
T – интервал (горизонт) планирования. По известной «формуле квадратного корня»
![]()
Найдем неотрицательное целое число n такое, что
![]()
Наименьшее из f(Q1) и f(Q2)
– минимальные средние издержки, а то из Q1 и Q2,
на котором достигается минимум – оптимальный размер партии,
![]() .
.
Таким образом, «формула квадратного корня», как правило,
не дает оптимальный план, а только асимптотически оптимальный.
По статистическим данным можно оценить возможные отклонения
![]() интенсивности спроса
интенсивности спроса ![]() , а затем найти рациональную
точность
, а затем найти рациональную
точность ![]() определения платы за хранение s и рациональную
точность
определения платы за хранение s и рациональную
точность ![]() определения платы за доставку g согласно
принципу уравнивания погрешностей:
определения платы за доставку g согласно
принципу уравнивания погрешностей:
![]()
Стремиться к более точному определению параметров s
и g нецелесообразно, как следствие, нет необходимости выбирать между конкурирующими
методиками их расчета.
Изучение устойчивости позволило получить практически полезные
выводы. Так, для кальцинированной соды на Реутовской химбазе Московской области
вызванное отклонениями параметров модели максимальное относительное увеличение
суммарных затрат не превосходило 26% (колебания по кварталам от 22,5% до 25,95%).
Фактические издержки составляли от 260% до 349% от оптимального уровня. внедрение
модели Вильсона в практику управления запасами на Реутовской химбазе дает возможность
снизить издержки по доставке и хранению кальцинированной соды в 2,1 раза.
Разработана [54, 205] двухуровневая модель управления материальными
ресурсами промышленного предприятия для случая нестационарного спроса, найдены оптимальные
значения управляющих параметров, установлена их устойчивость относительно изменения
горизонта (интервала) планирования. В этой модели размеры заявок Xj
независимы и одинаково распределены, τ(Т) – число заявок за время Т.
Оптимальные уровни (при ![]() ) таковы:
) таковы:
![]() ,
, ![]() ,
,
где h – издержки от дефицита единицы товара в течение
единицы времени.
3.2.10. Устойчивость характеристик инвестиционных
проектов к изменению коэффициентов
дисконтирования с течением времени
Эта задача – частный случай постановок задач устойчивости
в рамках статистики интервальных данных ([5, разд.12.7], [206]). Другой частный
случай – применение линейного регрессионного анализа интервальных данных при анализе
и прогнозировании затрат предприятия ([36, разд.4.4], [207]).
***
Подведем итоги раздела. Нами разработана общая схема устойчивости,
позволяющая проводить разработку и развитие математических методов и моделей на
основе единого методологического подхода к изучению устойчивости выводов по отношению
к допустимым отклонениям исходных данных и предпосылок модели. Возможности общего
подхода продемонстрированы на примере восьми конкретных постановок задач устойчивости.
Рассмотрена устойчивость по отношению к изменению данных (как частный случай - устойчивость
характеристик инвестиционных проектов к изменению коэффициентов дисконтирования
с течением времени), к изменению объема данных (объема выборки), к изменению распределений
данных. Поскольку борьба с неопределенностью может проводиться путем изменения
вида данных, т.е. путем перехода к нечисловым данным, то рассмотрены основные идеи
нечисловой статистики, в том числе теории измерений. Обсуждается устойчивость по
отношению к временным характеристикам (моменту начала реализации проекта, горизонту
планирования) и устойчивость в моделях конкретных процессов управления промышленными
предприятиями (на примере устойчивости к изменению коэффициентов модели и объемов
партий в моделях управления запасами).
Для обоснованного практического применения математических
и моделей процессов управления должна быть изучена устойчивость получаемых с их
помощью выводов по отношению к допустимым отклонениям исходных данных и предпосылок
моделей. Это требование вытекает из нужд практики и находится вне математики, оно
относится к методологии [50] и философии математики [208]. В настоящем разделе описаны
подходы к решению этой проблемы и приведены примеры, демонстрирующие теоретическую
значимость и практическую пользу получаемых при изучении устойчивости научных результатов.
Очевидна связь многих результатов настоящего раздела с новой областью теоретической
и вычислительной математики – системной нечеткой интервальной математикой [32, 33].
3.3. Информационно-коммуникационные технологии
- инструменты контроллинга
Проанализируем современное состояние основных компьютерно-статистических
методов, обсудим достижения и имеющиеся проблемы, наметим перспективы дальнейшего
движения, сформулируем научные проблемы, которые следует решить в будущем. Основное
внимание уделим обсуждению методов статистических
испытаний (Монте-Карло), датчиков псевдослучайных чисел, имитационного моделирования,
методов размножения выборок (будем их кратко называть "бутстреп-методы"),
места среди автоматизированного системно-когнитивного анализа (АСК-анализа),
имея в виду, что подробное обсуждение АСК-анализа будет дано в дальнейших разделах
настоящей монографии. Рассмотрим применение компьютерной статистики в контроллинге и свойства статистических пакетов
как инструментов исследователя.
Одним из отличительных признаков новой парадигмы математической
[63] и прикладной [114] статистики, анализа данных и других статистических методов
[115], математических методов экономики [116] является широкое применение компьютерно-статистических
методов. В старой парадигме они применялись при вычислении выборочных характеристик,
а при разработке инструментов статистического анализа данных - только для расчета
таблиц (т.е. информационные технологии фактически находились вне статистической
теории). Согласно новой парадигме информационные технологии – эффективные инструменты
получения выводов (имеются в виду датчики псевдослучайных чисел, размножение выборок,
в т.ч. бутстреп, автоматизированный системно-когнитивный анализ и др.). Наряду с
математическими методами получения научных результатов, прежде всего с предельными
теоремами теории вероятностей и математической статистики [209], компьютерно-статистические
технологии позволяют изучать скорость сходимости распределений статистик, применяемых
при оценивании параметров и проверке гипотез в статистике случайных величин, многомерном
статистическом анализе, анализе временных рядов и нечисловой статистике, решать
другие теоретические и прикладные задачи. Поэтому для дальнейшего развития и широкого
использования статистических методов необходимо проанализировать современное состояние
основных компьютерно-статистических методов, выявить достижения и имеющиеся проблемы,
наметить перспективы дальнейшего движения, сформулировать задачи, которые следует
решить.
3.3.1. Методы статистических испытаний
(Монте-Карло)
Многие информационные технологии в области прикладной статистики
опираются на использование методов статистических испытаний. Этот термин применяется
для обозначения компьютерных технологий, в которых в модель реального явления или
процесса искусственно вводится большое число случайных элементов. Обычно моделируется
последовательность независимых одинаково распределенных случайных величин или же
последовательность, построенная на ее основе, например, последовательность накапливающихся
(кумулятивных) сумм.
Необходимость в методе статистических испытаний возникает
потому, что чисто теоретические методы дают точное решение, как правило, лишь в
исключительных случаях. Либо тогда, когда исходные случайные величины имеют вполне
определенные функции распределения, например, нормальные, чего, как правило, не
бывает. Либо когда объемы выборок очень велики (с практической точки зрения - бесконечны).
Не только в задачах обработки данных возникает необходимость
в методе статистических испытаний. Она не менее актуальна и при экономико-математическом
моделировании технических, социально-экономических, медицинских и иных процессов.
Представим себе всем знакомый объект - торговый зал самообслуживания по продаже
продовольственных товаров. Сколько нужно работников в зале, сколько касс? Необходимо
просчитать загрузку в разное время суток, в разные сезоны года, с учетом замены
товаров и смены сотрудников. Нетрудно увидеть, что теоретическому анализу, например,
с помощью теории массового обслуживания, подобная система не поддается, поскольку
не выполнены необходимые для применения теории предположения, а компьютерному -
вполне.
Методы статистических испытаний стали развиваться после
второй мировой войны с появлением компьютеров. Второе название - методы Монте-Карло
- они получили по наиболее известному игорному дому, а точнее, по его рулетке, поскольку
исходный материал для получения случайных чисел с произвольным распределением -
это случайные натуральные числа.
В методах статистических испытаний можно выделить две составляющие.
Базой являются датчики псевдослучайных чисел. Результатом работы таких датчиков
являются последовательности чисел, которые обладают некоторыми свойствами последовательностей
случайных величин (в смысле теории вероятностей). Надстройкой являются различные
алгоритмы, использующие последовательности псевдослучайных чисел.
Что же это могут быть за алгоритмы? Приведем примеры. Пусть
мы изучаем распределение некоторой статистики при заданном объеме выборки. Тогда
естественно много раз (например, 100000 раз) смоделировать выборку заданного объема
(т.е. набор независимых одинаково распределенных случайных величин) и рассчитать
значение статистики. Затем по 100000 значениям статистики можно достаточно точно
построить функцию распределения изучаемой статистики, оценить ее характеристики.
Однако эта схема годится лишь для так называемой «свободной от распределения» статистики,
распределение которой не зависит от распределения элементов выборки. Если же такая
зависимость есть, то одной точкой моделирования не обойдешься, придется много раз
моделировать выборку, беря различные распределения, меняя параметры. Чтобы общее
время моделирования было приемлемым, возможно, придется сократить число моделирований
в одной точке, зато увеличив общее число точек. Точность моделирования может быть
оценена по общим правилам выборочных обследований.
Второй пример - частично описанное выше моделирование работы
торгового зала самообслуживания по продаже продовольственных товаров. Здесь одна
последовательность псевдослучайных чисел описывает интервалы между появлениями покупателей,
вторая, третья и т.д. связаны с выбором ими первого, второго и т.д. товаров в зале
(например, число - номер в перечне товаров). Короче, все действия покупателей, продавцов,
работников предприятия разбиты на операции, каждая операция, в продолжительности
или иной характеристике которой имеется случайность, моделируется с помощью соответствующей
последовательности псевдослучайных чисел. Затем итоги работы сотрудников торговой
организации и зала в целом выражаются через характеристики случайных величин. Формулируется
критерий оптимальности, решается задача оптимизации и находятся оптимальные значения
параметров. В частности, оптимальные планы статистического контроля строятся на
основе вероятностно-статистических моделей [16].
3.3.2. Датчики псевдослучайных чисел
Теперь обсудим свойства датчиков псевдослучайных чисел.
Здесь стоит слово «псевдослучайные», а не «случайные». Это весьма важно. Дело в
том, что за последние 50 лет обсуждались в основном три принципиально разных варианта
получения последовательностей чисел, которые в дальнейшем использовались в методах
статистических испытаний.
Первый - таблица случайных чисел. К сожалению, объем любой
таблицы конечен, и сколько-нибудь сложные расчеты с ее помощью невозможны. Через
некоторое время приходится повторять уже использованные числа. Кроме того, обычно
обнаруживались те или иные отклонения от случайности.
Второй - физические датчики случайных чисел, в которых
в качестве случайного числа рассматривается результат измерения некоторой физической
величины. Основной недостаток - нестабильность, непредсказуемые отклонения от заданного
распределения (обычно - равномерного).
Третий - расчетный. В простейшем случае каждый следующий
член последовательности рассчитывается по предыдущему. Например, так:
![]()
где z0 - начальное значение (заданное
целое положительное число), M - параметр алгоритма (заданное целое положительное
число), P = 2m, где
m - число двоичных разрядов представления чисел, с которыми манипулирует
компьютер. Знак ![]() здесь означает теоретико-числовую операцию сравнения,
т.е. взятие дробной части от числа
здесь означает теоретико-числовую операцию сравнения,
т.е. взятие дробной части от числа ![]() и отбрасывание целой части.
и отбрасывание целой части.
В настоящее время обычно применяется именно третий вариант.
Совершенно ясно, что он не соответствует интуитивному представлению о случайности.
Например, интуитивно очевидно, что по предыдущему элементу случайной последовательности
с независимыми элементами нельзя предсказать значение следующего элемента. А приведенная
выше формула как раз и дает способ такого предсказания. Расчетный путь получения
последовательности псевдослучайных чисел противоречит не только интуиции, но и подходу
к определению случайности на основе теории алгоритмов, развитому акад. А.Н. Колмогоровым
и его учениками в 1960-х гг. [210]. Однако во многих прикладных задачах он работает,
и это основное.
Методу статистических
испытаний посвящена обширная литература (см., например, монографии [211 – 213]).
Время от времени обнаруживаются недостатки у популярных датчиков псевдослучайных
чисел. Так, например, в середине 1980-х гг. выяснилось, что для одного из наиболее
известных датчиков три последовательных значения связаны линейной зависимостью
![]()
После этого в
Итоги можно подвести так. Во многих случаях решаемая методом
статистических испытаний задача сводится к оценке вероятности попадания в некоторую
область в многомерном пространстве фиксированной размерности. Тогда из чисто
математических соображений теории чисел следует, что с помощью датчиков псевдослучайных
чисел поставленная задача решается корректно. Сводка соответствующих математических
обоснований приведена, например, в работе С.М. Ермакова [214].
В других случаях приходится рассматривать вероятности попадания
в области в пространствах переменной размерности. Типичным примером является
ситуация, когда на каждом шагу проводится проверка соответствующей статистической
гипотезы, и по ее результатам либо остаемся в данном пространстве, либо переходим
в пространство большей размерности. Например, в регрессионном анализе при оценивании
степени многочлена либо останавливаемся на данной степени, либо увеличиваем степень,
переходя в параметрическое пространство большей размерности [216]. Так вот, вопрос
об обоснованности применения метода статистических испытаний (а точнее, о свойствах
датчиков псевдослучайных чисел) в случае пространств переменной размерности остается
в настоящее время открытым. О важности этой проблемы вдохновенно говорил академик
РАН Ю.В. Прохоров на Первом Всемирном Конгрессе Общества математической статистики
и теории вероятностей им. Бернулли (Ташкент,
3.3.3. Имитационное моделирование
Поскольку постоянно обсуждаем проблемы моделирования, приведем
несколько общих формулировок.
«Модель в общем смысле (обобщенная модель) - это создаваемый
с целью получения и (или) хранения информации специфический объект (в форме мысленного
образа, описания знаковыми средствами либо материальной системы), отражающей свойства,
характеристики и связи объекта-оригинала произвольной природы, существенные для
задачи, решаемой субъектом» (это определение взято из монографии [6, с.44]).
Например, в менеджменте производственных систем используют:
- модели технологических процессов (контроль и управление
по технико-экономическим критериям, АСУ ТП - автоматизированные системы управления
технологическими процессами);
- модели управления качеством продукции (в частности, модели
оценки и контроля надежности);
- модели массового обслуживания (теории очередей);
- модели управления запасами (в современной терминологии
- модели логистики, т.е. теории и практики управления материальными, финансовыми
и информационными потоками);
- имитационные и эконометрические модели деятельности предприятия
(как единого целого) и управления им (АСУ предприятием) и др.
Согласно академику РАН Н.Н. Моисееву [217, с.213], имитационная
система - это совокупность моделей, имитирующих протекание изучаемого процесса,
объединенная со специальной системой вспомогательных программ и информационной базой,
позволяющих достаточно просто и оперативно реализовать вариантные расчеты. Другими
словами, имитационная система - это совокупность имитационных моделей. А имитационная
модель предназначена для ответов на вопросы типа: «Что будет, если…» Что будет,
если параметры примут те или иные значения? Что будет с ценой на продукцию, если
спрос будет падать, а число конкурентов расти? Что будет, если государство резко
усилит вмешательство в экономику? Что будет, если остановку общественного транспорта
перенесут на
При имитационном моделировании часто используется метод
статистических испытаний (Монте-Карло). Теорию и практику машинных имитационных
экспериментов с моделями экономических систем еще более 40 лет назад подробно разобрал
Т. Нейлор в обширной классической монографии [220]. Рассмотрим применение датчиков
псевдослучайных чисел в рамках статистических технологий.
3.3.4. Методы размножения выборок
(бутстреп-методы)
Прикладная статистика бурно развивается последние десятилетия.
Серьезным (хотя, разумеется, не единственным и не главным) стимулом является стремительно
растущая производительность вычислительных средств. Поэтому понятен острый интерес
к статистическим методам, интенсивно использующим компьютеры. Одним из таких методов
является так называемый «бутстреп», предложенный в
Сам термин «бутстреп» - это английское слово «bootstrap»,
записанное русскими буквами. Оно буквально означает что-то вроде: «вытягивание себя
(из болота) за шнурки от ботинок». Термин специально придуман и заставляет вспомнить
о подвигах барона Мюнхгаузена.
В истории прикладной статистики было несколько более или
менее успешно осуществленных рекламных кампаний. В каждой из них «раскручивался»
тот или иной метод, который, как правило, отвечал нескольким условиям:
- по мнению его пропагандистов, полностью решал актуальную
научную задачу;
- был понятен (при постановке задачи, при ее решении и
при интерпретации результатов) широким массам потенциальных пользователей;
- использовал современные возможности вычислительной техники.
Пропагандисты метода, как правило, избегали беспристрастного
сравнения его возможностей с возможностями иных статистических методов. Если сравнения
и проводились, то с заведомо слабым «противником».
В нашей стране в условиях отсутствия массового систематического
образования в области прикладной статистики подобные рекламные кампании находили
особо благоприятную почву, поскольку у большинства затронутых ими специалистов не
было достаточных знаний в области методологии построения моделей прикладной статистики
для того, чтобы составить самостоятельное квалифицированное мнение.
Речь идет о таких методах и постановках, как бутстреп,
нейронные сети, генетические алгоритмы, метод группового учета аргументов, робастные
оценки по Тьюки-Хуберу, асимптотика пропорционального роста числа параметров и объема
данных и др. Бывали локальные всплески неоправданного энтузиазма. Например, московские
социологи в 1980-х гг. весьма активно пропагандировали так называемый «детерминационный
анализ» - простой эвристический метод анализа таблиц сопряженности. Хотя в Новосибирске
в это время давно уже было разработано (под руководством Г.С. Лбова) продвинутое
математическое и программное обеспечение анализа векторов разнотипных признаков,
включающее в себя «детерминационный анализ» как весьма частный случай.
Однако даже на фоне всех остальных рекламных кампаний судьба
бутстрепа исключительна. Во-первых, признанный его автор Б. Эфрон с самого начала
признавался, что в математико-статистической теории он ничего принципиально нового
не сделал. Его исходная статья (первая в сборнике [131]) называлась: «Бутстреп-методы:
новый взгляд на методы складного ножа». Тем самым Б. Эфрон честно признавал первенство
за М. Кенуем – автором методов «складного ножа». Во вторых, сразу появились статьи
и дискуссии в научных изданиях, публикации рекламного характера, и даже в научно-популярных
журналах. Бурные обсуждения на конференциях, спешный выпуск книг. В 1980-е гг. финансовая
подоплека всей этой активности, связанная с добыванием грантов на научную деятельность,
содержание учебных заведений и т.п., была мало понятна отечественным специалистам,
для которых упомянутые реалии науки и образования в капиталистических странах были
практически незнакомы.
В чем основная идея группы методов «размножения выборок»,
наиболее известным представителем которых является бутстреп?
Пусть дана выборка ![]() . В вероятностно-статистической
теории предполагаем, что это - набор независимых одинаково распределенных случайных
величин. Пусть эконометрика интересует некоторая статистика
. В вероятностно-статистической
теории предполагаем, что это - набор независимых одинаково распределенных случайных
величин. Пусть эконометрика интересует некоторая статистика ![]() Как изучить ее свойства? Подобными проблемами мы
занимались на протяжении всей профессиональной научной жизни и знаем, насколько
это непросто. Идея, которую предложил в
Как изучить ее свойства? Подобными проблемами мы
занимались на протяжении всей профессиональной научной жизни и знаем, насколько
это непросто. Идея, которую предложил в
![]()
![]()
![]() ;
;
…
![]() ;
;
…
![]() ;
;
![]()
Всего n новых (размноженных) выборок объемом (n
- 1) каждая. По каждой из них можно рассчитать значение интересующей
эконометрика статистики (с уменьшенным на 1 объемом выборки):
![]()
![]()
![]()
…
![]()
…
![]()
![]()
Полученные значения статистики позволяют судить о ее распределении
и о характеристиках распределения - о математическом ожидании, медиане, квантилях,
разбросе и др. Значения статистики, построенные по размноженным подвыборкам, не
являются независимыми. Однако, как показано, например, в [57, гл.6] на примере ряда
статистик, возникающих в методе наименьших квадратов и в кластер-анализе (при обсуждении
возможности объединения двух кластеров), при росте объема выборки влияние зависимости
может ослабевать, а потому со значениями статистик типа ![]() можно обращаться как с независимыми случайными
величинами.
можно обращаться как с независимыми случайными
величинами.
Однако и без всякой вероятностно-статистической теории
разброс величин ![]() дает наглядное представление о том, какую точность
может дать рассматриваемая статистическая оценка.
дает наглядное представление о том, какую точность
может дать рассматриваемая статистическая оценка.
Сам М. Кенуй и его последователи использовали размножение
выборок в основном для построения оценок с уменьшенным смещением. А вот Б. Эфрон
предложил новый способ размножения выборок, существенно использующий датчики псевдослучайных
чисел. А именно, он предложил строить новые выборки, моделируя выборки из эмпирического
распределения. Другими словами, Б. Эфрон предложил взять конечную совокупность
из n элементов исходной выборки ![]() и с помощью датчика псевдослучайных чисел сформировать
из нее любое число размноженных выборок. Процедура, хотя и нереальна без ЭВМ, проста
с точки зрения программирования. По сравнению с описанной выше процедурой Кенуя
появляются новые недостатки - неизбежные совпадения элементов размноженных выборок
и зависимость от качества датчиков псевдослучайных чисел. Однако существует математическая
теория, позволяющая (при некоторых предположениях и безграничном росте объема выборки)
обосновать процедуры бутстрепа (см. сборник статей [131]).
и с помощью датчика псевдослучайных чисел сформировать
из нее любое число размноженных выборок. Процедура, хотя и нереальна без ЭВМ, проста
с точки зрения программирования. По сравнению с описанной выше процедурой Кенуя
появляются новые недостатки - неизбежные совпадения элементов размноженных выборок
и зависимость от качества датчиков псевдослучайных чисел. Однако существует математическая
теория, позволяющая (при некоторых предположениях и безграничном росте объема выборки)
обосновать процедуры бутстрепа (см. сборник статей [131]).
Есть много способов развития идеи размножения выборок (см.,
например, статью [132]). Можно по исходной выборке построить эмпирическую функцию
распределения, а затем каким-либо образом от кусочно-постоянной функции перейти
к непрерывной функции распределения, например, соединив точки ![]() отрезками прямых. Другой вариант - перейти к непрерывному
распределению, построив непараметрическую оценку плотности [118]. После этого рекомендуется
брать размноженные выборки из этого непрерывного распределения (являющегося состоятельной
оценкой исходного), непрерывность защитит от совпадений элементов в этих выборках.
отрезками прямых. Другой вариант - перейти к непрерывному
распределению, построив непараметрическую оценку плотности [118]. После этого рекомендуется
брать размноженные выборки из этого непрерывного распределения (являющегося состоятельной
оценкой исходного), непрерывность защитит от совпадений элементов в этих выборках.
Другой вариант построения размноженных выборок - более
прямой. Исходные данные не могут быть определены совершенно точно и однозначно.
Поэтому предлагается к исходным данным добавлять малые независимые одинаково распределенные
погрешности. При таком подходе соединяем вместе идеи устойчивости и бутстрепа. При
внимательном анализе многие идеи прикладной статистики тесно друг с другом связаны
(см. статью [132]).
В каких случаях целесообразно применять бутстреп, а в каких
- другие методы прикладной статистики? В период рекламной кампании встречались,
в том числе в научно-популярных журналах, утверждения о том, что и для оценивания
математического ожидания полезен бутстреп. Как показано в статье [132], это совершенно
не так. При росте числа испытаний методом Монте-Карло бутстреп-оценка приближается
к классической оценке - среднему арифметическому результатов наблюдений. Другими
словами, бутстреп-оценка отличается от классической оценки только шумом псевдослучайных
чисел.
Аналогичной является ситуация и в ряде других случаев.
Там, где эконометрическая теория хорошо развита, где найдены методы анализа данных,
в том или иной смысле близкие к оптимальным, бутстрепу делать нечего. А вот в новых
областях со сложными алгоритмами, свойства которых недостаточно ясны, он представляет
собой ценный инструмент для изучения ситуации.
3.3.5. Автоматизированный системно-когнитивный
анализ
В предисловии к переводу на русский язык книги С. Кульбака
«Теория информации и статистика» [126] А.Н. Колмогоров писал: «... навыки мысли
и аналитический аппарат теории информации должны, по-видимому, привести к заметной
перестройке здания математической статистики» (с. 5 – 6). Однако по неясным причинам этого
не произошло. Несмотря на рекомендацию А.Н. Колмогорова, поток исследований, имеющих
целью указанную перестройку математико-статистической теории и практики, в СССР
и мире не возник. Работы Е.В. Луценко по разработке и применению автоматизированного
системно-когнитивного анализа (см., например [127 - 130]) можно рассматривать как
развитие указанного А.Н. Колмогоровым направления прикладной математической статистики,
не только и не столько в чисто-математическом плане, сколько в прагматически-прикладном.
Реализуется рекомендация А.Н. Колмогорова: «По-видимому, внедрение предлагаемых
методов в практическую статистику будет облегчено, если тот же материал будет изложен
более доступно и проиллюстрирован на подробно разобранных содержательных примерах».
Отметим оригинальность подхода и результатов Е.В. Луценко (по сравнению с книгой
C. Кульбака), так что речь выше идет об идейных связях, а не о конкретике. Математический
метод автоматизированного системно-когнитивного анализа (АСК-анализ) реализован
в его программном инструментарии – универсальной когнитивной аналитической системе
Эйдос-Х++. АСК-анализ
основан на системной теории информации, которая создана в рамках реализации
программной идеи обобщения всех понятий математики, в частности теории информации,
базирующихся на теории множеств, путем тотальной замены понятия множества на более
общее понятие системы и тщательного отслеживания всех последствий этой замены (см.,
например, [32, 33]). Благодаря математическим основам АСК-анализа этот метод является
непараметрическим и позволяет сопоставимо обрабатывать десятки и сотни тысяч градаций
факторов и будущих состояний объекта управления (классов) при неполных (фрагментированных),
зашумленных данных числовой и нечисловой природы, измеряемых в различных единицах
измерения. За дальнейшей информацией – теоретическими разработками и многочисленными
примерами успешного практического использования АСК-анализа отошлем к публикациям
проф. Е.В. Луценко и его сотрудников, прежде всего в «Научном журнале КубГАУ».
3.3.6. Компьютерная статистика в контроллинге
В качестве примера применения компьютерной статистики рассмотрим
конкретную прикладную область – контроллинг, т.е. современный подход к управлению
организацией [1, 2, 4, 29, 30, 86, 221]. Контроллеру и сотрудничающему с ним статистику
нужна разнообразная экономическая и управленческая информация, не менее нужны удобные
инструменты ее анализа. Следовательно, информационная поддержка контроллинга необходима
для успешной работы контроллера. Без современных компьютерных инструментов анализа
и управления, основанных на продвинутых эконометрических и экономико-математических
методах и моделях, невозможно эффективно принимать управленческие решения. Недаром
специалисты по контроллингу большое внимание уделяют проблемам создания, развития
и применения компьютерных систем поддержки принятия решений. Высокие статистические
технологии и эконометрика - неотъемлемые части любой современной системы поддержки
принятия экономических и управленческих решений.
Важная часть прикладной статистики - применение высоких
статистических технологий к анализу конкретных экономических данных. Такие исследования
зачастую требуют дополнительной теоретической работы по «доводке» статистических
технологий применительно к конкретной ситуации. Большое значение для контроллинга
имеют не только общие методы, но и конкретные эконометрические модели, например,
вероятностно-статистические модели тех или иных процедур экспертных оценок или эконометрики
качества, имитационные модели деятельности организации, прогнозирования в условиях
риска. И конечно, такие конкретные применения, как расчет и прогнозирование индекса
инфляции. Сейчас уже многим специалистам ясно, что годовой, квартальный или месячный
бухгалтерский баланс предприятия может быть использован для оценки его финансово-хозяйственной
деятельности только с привлечением данных об инфляции. Различные области экономической
теории и практики в настоящее время еще далеко не согласованы. При оценке и сравнении
инвестиционных проектов принято использовать такие характеристики, как чистая текущая
стоимость, внутренняя норма доходности, основанные на введении в рассмотрение изменения
стоимости денежной единицы во времени (это осуществляется с помощью дисконтирования).
А вот при анализе финансово-хозяйственной деятельности организации на основе данных
бухгалтерской отчетности изменение стоимости денежной единицы во времени по традиции
не учитывают.
Специалисты по контроллингу должны быть вооружены современными
средствами информационной поддержки, в том числе средствами на основе высоких статистических
технологий и эконометрики. Очевидно, преподавание должно идти впереди практического
применения. Ведь как применять то, чего не знаешь?
Статистические технологии применяют для анализа данных
двух принципиально различных типов. Один из них - это результаты измерений (наблюдений,
испытаний, анализов, опытов и др.) различных видов, например, результаты управленческого
или бухгалтерского учета, данные Госкомстата и др. Короче, речь идет об объективной
информации. Другой - это оценки экспертов, на основе своего опыта и интуиции делающих
заключения относительно экономических явлений и процессов. Очевидно, это - субъективная
информация. В стабильной экономической ситуации, позволяющей рассматривать длинные
временные ряды тех или иных экономических величин, полученных в сопоставимых условиях,
данные первого типа вполне адекватны. В быстро меняющихся условиях приходятся опираться
на экспертные оценки. Такая новейшая часть прикладной статистики, как статистика
нечисловых данных, была создана как ответ на запросы теории и практики экспертных
оценок.
Для решения каких экономических задач могут быть полезны
статистические методы? Практически для всех, использующих конкретную информацию
о реальном мире. Только чисто абстрактные, отвлеченные от реальности исследования
могут обойтись без нее. В частности, статистические методы необходима для прогнозирования,
в том числе поведения потребителей, а потому и для планирования. Выборочные исследования,
в том числе выборочный контроль, основаны на статистические методы. Но планирование
и контроль - основа контроллинга. Поэтому статистические методы - важная составляющая
инструментария контроллера, воплощенного в компьютерной системе поддержки принятия
решений. Прежде всего оптимальных решений, которые предполагают опору на адекватные
модели прикладной статистики. В производственном менеджменте это может означать,
например, использование моделей экстремального планирования эксперимента (судя по
накопленному опыту их практического использования, такие модели позволяют повысить
выход полезного продукта на 30-300%).
Высокие статистические технологии предполагают адаптацию
применяемых методов к меняющейся ситуации. Например, параметры прогностического
индекса меняются вслед за изменением характеристик используемых для прогнозирования
величин. Таков метод экспоненциального сглаживания. В соответствующем алгоритме
расчетов значения временного ряда используются с весами. Веса уменьшаются по мере
удаления в прошлое. Многие методы дискриминантного анализа основаны на применении
обучающих выборок. Например, для построения рейтинга надежности банков можно с помощью
экспертов составить две обучающие выборки - надежных и ненадежных банков. А затем
с их помощью решать для вновь рассматриваемого банка, каков он - надежный или ненадежный,
а также оценивать его надежность численно, т.е. вычислять значение рейтинга.
Автоматизированный системно-когнитивный анализ является
перспективным инструментом контроллинга и менеджмента [29, 30, 86].
Один из способов построения адаптивных статистических моделей
- нейронные сети (см., например, монографию [222]). При использовании нейронных
сетей упор делается не на формулировку адаптивных алгоритмов анализа данных, а -
в большинстве случаев - на построение виртуальной адаптивной структуры. Термин «виртуальная»
означает, что «нейронная сеть» - это специализированная компьютерная программа,
«нейроны» используются лишь при общении человека с компьютером. Методология нейронных
сетей идет от начальных идей кибернетики 1940 - 50-х гг. В компьютере создается
модель мозга человека (весьма примитивная с точки зрения физиолога). Основа модели
- весьма простые базовые элементы, называемые нейронами. Они соединены между собой,
так что нейронные сети можно сравнить с хорошо знакомыми экономистам и инженерам
блок-схемами. Каждый нейрон находится в одном из заданного множества состояний.
Он получает импульсы от соседей по сети, изменяет свое состояние и сам рассылает
импульсы. В результате состояние множества нейтронов изменяется, что соответствует
проведению статистических вычислений.
Нейроны обычно объединяются в слои (как правило, два-три).
Среди них выделяются входной и выходной слои. Перед началом решения той или иной
задачи производится настройка. Во-первых, устанавливаются связи между нейронами,
соответствующие решаемой задаче. Во-вторых, проводится обучение, т.е. через нейронную
сеть пропускаются обучающие выборки, для элементов которых требуемые результаты
расчетов известны. Затем параметры сети модифицируются так, чтобы получить максимальное
соответствие выходных значений заданным величинам.
С точки зрения точности расчетов (и оптимальности в том
или ином статистическом смысле) нейронные сети не имеют преимуществ перед другими
адаптивными системами прикладной статистики. Однако они более просты для восприятия,
поэтому привлекательны для тех, кто плохо знаком с математико-статистической теорией.
Надо отметить, что в прикладной статистике используются
и модели, промежуточные между нейронными сетями и «обычными» системами регрессионных
уравнений (одновременных и с лагами). Они тоже используют блок-схемы, как, например,
универсальный метод моделирования связей социально-экономических факторов ЖОК (этот
метод подробно разработан в [5, 54, 57]).
Профессионалу в области контроллинга полезны многочисленные
интеллектуальные инструменты анализа данных, относящиеся к высоким статистическим
технологиям [51] и эконометрике [16]. В частности, заметное место в математико-компьютерном
обеспечении принятия решений в контроллинге занимают методы теории нечеткости [190],
входящие в системную нечеткую интервальную математику [32, 33].
3.3.7. Статистические пакеты – инструменты
исследователя
Рассмотрим проблемы разработки, внедрения и использования
статистических пакетов (статистических программных продуктов) в России за последние
25 лет, дадим критический анализ популярных в настоящее время пакетов в сопоставлении
с результатами современных научных исследований, наметим перспективы развития работ
в области статистического программного обеспечения (ср. [223]).
Очевидно, что математические методы исследования, в том
числе методы статистического анализа данных, требуют больших вычислений и зачастую
невозможны без компьютеров. Продвинутое применение высоких статистических технологий
(см., например, раздел 2.3 настоящей монографии и [51]) предполагает использование
соответствующих программных продуктов. Статистические пакеты – постоянно используемые
интеллектуальные инструменты исследователей, инженеров, управленцев, занимающихся
анализом больших массивов данных.
В разделе «Математические методы исследования» журнала
«Заводская лаборатория» (основном отечественном издании по статистическим методам)
неоднократно рассматривались вопросы разработки и применения статистических пакетов.
Так, более 20 статистических пакетов, разработанных Всесоюзным центром статистических
метолов и информатики (директор – А.И. Орлов), в том числе пакеты СПК, АТСТАТ-ПРП,
СТАТКОН, АВРОРА-РС, ЭКСПЛАН, ПАСЭК, НАДИС, проанализированы в [224, 225]. Перечисленные
семь пакетов рассмотрены также в [226]. Сравнительному анализу четырех диалоговых
систем по статистическому контролю посвящена статья [227], и т.д.
Однако наряду с очевидной пользой статистические пакеты
могут приносить вред неискушенному пользователю. Например, в них зачастую пропагандируется
применение двухвыборочного критерия Стьюдента (много раз этот критерий упомянут
в статье [228], посвященной программному обеспечению статистического анализа данных),
когда условия его применимости не проверены, а зачастую и не выполнены. Между тем
хорошо известно, каковы последствия использования критерия Стьюдента вне сферы его
применимости, а также и то, что применять его нет необходимости поскольку разработаны
более адекватные критерии [71].
Другой пример. Малограмотность переводчиков в русифицированной
версии MS Excel (по крайней мере в разделе «Анализ данных») шокирует специалиста
по прикладной статистике: например, «объем выборки» именуется «счет». С сожалением
приходится констатировать, что не соответствует современным требованиям и электронный
учебник – обзор методов, реализованных в пакете STATISTICA6, о котором идет речь
в статье [228].
К сожалению, анализ допущенных в документации к пакету
недочетов занял бы не меньше места, чем сама документация. В [47] продемонстрировано,
насколько трудоемким оказался критический анализ всего лишь нескольких десятков
ГОСТов по статистическим методам управления качеством. Это замечание касается, конечно,
не только пакетов. Из одной публикации в другую кочуют одни и те же ошибки. Для
разоблачения каждой нужна развернутая публикация. Например, распространенная ошибка
при использовании критериев Колмогорова и омега-квадрат разобрана в [74, 75], ошибочные
утверждения о том, какие гипотезы можно проверять с помощью двухвыборочного критерия
Вилкоксона, разоблачены в [72, 73].
Основное противоречие в области разработки статистических
пакетов таково. Те, кто программирует, не являются специалистами по прикладной статистике,
поскольку это не входит в их профессиональные обязанности. С другой стороны, специалисты
по статистическим методам не берутся реализовывать их в пакетах, поскольку такая
работа, весьма трудоемкая и ответственная, обычно не соответствует их профессиональным
устремлениям. Судя по опыту Всесоюзного центра статистических методов и информатики,
стоимость разработки (на профессиональном уровне) пакета среднего уровня сложности
– порядка 70 тыс. руб. (в ценах
В нашей стране активная работа по созданию развернутой
системы отечественных статистических пакетов развернулась в 80-х годах [225, 226].
Как уже отмечалось, только Всесоюзным центром статистических метолов и информатики
было разработано более 20 программных продуктов по прикладной статистике и другим
статистическим методам. Эта работа проводилась в рамках более широкого проекта,
нацеленного на объединение усилий специалистов по статистическим методам с целью
повышения эффективности теоретических и прикладных исследований. Важным промежуточным
итогом было создание в
Развал СССР, либерализация цен и гиперинфляция начала 90-х
положили конец рассматриваемому проекту. Из плана работ реализована только подготовка
современных учебников ([5, 16, 52, 54] и др. (см. также раздел 2.1 настоящей монографии),
составленных на основе статей, опубликованных в «Заводской лаборатории» (учебники
выложены в свободном доступе на сайте «Высокие статистические технологии» http://orlovs.pp.ru
и на странице Лаборатории экономико-математических методов в контроллинге http://ibm.bmstu.ru/nil/biblio.html
). Предприятия и организации, лишившись оборотных средств из-за инфляции, перестали
покупать статистические программные продукты, коллективы разработчиков распались,
перестали поддерживать статистические пакеты в условиях быстрого обновления технических
средств и базового программного обеспечения. В результате многообразие продуктов
на отечественном рынке статистических пакетов резко сократилось, и монополистами
оказались SPSS, STATISTICA, STATGRAPHICS (и немногие другие), о которых идет речь
в статье О.С. Смирновой [228].
На опасность бездумного применения статистических пакетов
В.В. Налимов обращал внимание более 40 лет назад [231]. Он имел в виду прежде всего
склонность к проведению расчетов без знакомства с сутью применяемых методов. Необходимо
обратить внимание также на научно-технический уровень самих пакетов и сопровождающей
документации. Дополнительно к сказанному в начале этого подраздела приходится констатировать,
что в популярных в настоящее время в России статистических пакетах нет примерно
половины того, что разработано представителями отечественной вероятностно-статистической
научной школы и включено в современные учебники [5, 16, 52, 54], подготовленные
в соответствии с рекомендациями Всесоюзной статистической ассоциации и – позже -
Российской ассоциации статистических методов. Сказанное легко проверить, сопоставив
содержание указанных учебников и перечень методов, включенных в распространенные
пакеты. Поэтому преподаватели МГТУ им. Н.Э. Баумана сознательно избегаем использования
в учебном процессе пакетов SPSS, STATISTICA, STATGRAPHICS, чтобы не приучать студентов
к статистике 60-70-х годов прошлого века. Однако, поскольку нет современных пакетов,
приходится для практических расчетов использовать устаревшие программные продукты.
Тиражи пакетов и учебников сопоставимы. Пакет STATGRAPHICS
имеет более 40 тыс. зарегистрированных пользователей, учебник «Прикладная статистика»
[5] выпущен тиражом 3 тыс. экземпляров, электронную версию только с сайта «Высокие
статистические технологии» скачали 45,7 тыс. пользователей (по состоянию на 04.02.2015).
Поэтому состав пакетов и качество документации имеют большое значение. Они во многом
определяют качество прикладных научных работ и обоснованность хозяйственных решений.
Отметим, что по сравнению с 1980-ми годами к настоящему
времени наметился рост внимания к статистическим технологиям [51], а не только к
их составляющим – конкретным методам обработки данных. В этом суть популярного ныне
подхода Data Mining (на русском - «добыча данных», «интеллектуальный анализ данных»).
Термин Data Mining введен эмигрантом
из СССР Г. Пятецким-Шапиро в
Еще более выражена отмеченная тенденция в технологии «Шесть
сигм» [232]. Эта технология, первоначально позиционированная как «революционный
метод управления качеством», основана на применении теории принятия решений [54]
и прикладной статистики [5]. Мы ее рассматриваем как подход к совершенствованию
бизнеса [25] и как новую систему внедрения математических методов исследования [233].
Итак, статистические пакеты – интеллектуальные инструменты,
необходимые широким кругам научных работников, инженеров, менеджеров. Однако распространенные
в настоящее время статистические программные продукты отстают от современного уровня
научных исследований примерно на 30 лет. Весьма актуальна задача разработки статистических
пакетов нового поколения, соответствующих современному научному уровню и одновременно
обеспечивающих удобства пользователей, достигнутые в популярных ныне пакетах. Эта
задача должна решаться одновременно с созданием систем обучения, сопровождения и
внедрения пакетов нового поколения, в частности, в соответствии с технологиями типа
«Шесть сигм».
3.4. Основы статистики интервальных данных
Как установлено в разделе 2.3, одной
из точек роста статистических методов и математических методов экономики в целом
является статистика интервальных данных. В настоящем разделе рассмотрим основные
идеи асимптотической математической статистики интервальных данных, в которой элементы
выборки – не числа, а интервалы.
Алгоритмы и выводы статистики интервальных данных принципиально
отличаются от алгоритмов и выводов классической математической статистики. Приведем
базовые результаты, связанные с основополагающими понятиями нотны и рационального
объема выборки. Статистика интервальных данных является составной частью системной
нечеткой интервальной математики [32, 33].
3.4.1. О развитии статистики интервальных
данных
Перспективная и быстро развивающаяся
область статистических исследований последних десятилетий – математическая статистика
интервальных данных. Речь идет о развитии методов прикладной математической статистики
в ситуации, когда статистические данные – не числа, а интервалы, в частности, порожденные
наложением ошибок измерения на значения случайных величин. Полученные результаты
были отражены, в частности, в выступлениях на проведенной в «Заводской лаборатории»
дискуссии [234] и в докладах Международной
конференции по интервальным и стохастическим методам в науке и технике ИНТЕРВАЛ-92
[235]. Приведем основные идеи весьма перспективного для вероятностно-статистических
методов и моделей принятия решений асимптотического направления в статистике интервальных
данных.
В настоящее время признается необходимым
изучение устойчивости (робастности) оценок параметров к малым отклонениям исходных
данных и предпосылок модели (см. раздел 3.2 настоящей монографии). Однако популярная
среди теоретиков модель засорения (модель Тьюки-Хьюбера) во многих прикладных постановках
представляется не вполне адекватной. Эта модель нацелена на изучение влияния больших
«выбросов». Поскольку любые реальные измерения лежат в некотором фиксированном диапазоне,
а именно, заданном в техническом паспорте средства измерения, то зачастую выбросы
не могут быть слишком большими. Поэтому представляются полезными иные, более общие
схемы устойчивости, впервые введенные в монографии [73], в которых, например, учитываются
возможные отклонения распределений результатов наблюдений от предположений модели.
В одной из таких схем изучается
влияние интервальности исходных данных на статистические выводы. Необходимость такого
изучения стала очевидной следующим образом. В государственных стандартах СССР по
прикладной статистике в обязательном порядке давалось справочное приложение «Примеры
применения правил стандарта». При подготовке ГОСТ 11.011-83 [133] разработчикам
стандарта были переданы для анализа реальные данные о наработке резцов до предельного
состояния (в часах). Оказалось, что все эти данные представляли собой либо целые
числа, либо полуцелые (т.е. после умножения на 2 становящиеся целыми). Ясно, что
исходная длительность наработок искажена. Необходимо учесть в статистических процедурах
наличие такого искажения исходных данных. Как это сделать?
Первое, что приходит в голову –
модель группировки данных [236], согласно которой для истинного значения Х проводится замена на ближайшее число из
множества {0,5n, n = 1, 2, 3, ...}. Однако эту модель целесообразно подвергнуть сомнению,
а также рассмотреть иные модели. Так, возможно, что Х надо приводить к ближайшему сверху элементу указанного множества –
если проверка качества поставленных на испытание резцов проводилась раз в полчаса.
Другой вариант: если расстояния от Х до
двух ближайших элементов множества {0,5n,
n = 1, 2, 3, ...} примерно равны, то естественно
ввести рандомизацию при выборе заменяющего числа, и т.д.
Целесообразно построить принципиально
новую математико-статистическую модель, согласно которой результаты наблюдений – не числа, а интервалы. Например, если в таблице
исходных данных приведено значение 53,5, то это значит, что реальное значение –
какое-то число от 53,0 до 54,0, т.е. какое-то число в интервале [53,5 – 0,5; 53,5
+ 0,5], где 0,5 – максимально возможная погрешность. Принимая эту модель, мы попадаем
в новую научную область – статистику интервальных данных [237, 238]. Статистика
интервальных данных идейно связана с интервальной математикой, в которой в роли
чисел выступают интервалы (см., например, монографию [239]). Это направление математики
является дальнейшим развитием хорошо известных правил приближенных вычислений, посвященных
выражению погрешностей суммы, разности, произведения, частного через погрешности
тех чисел, над которыми осуществляются перечисленные операции.
В интервальной математике сумма
двух интервальных чисел [a, b] и [c, d] имеет вид [a, b]
+ [c, d] = [a + c, b + d],
а разность определяется по формуле [a, b]
– [c, d] = [a – d, b – c]. Для положительных
a, b, c, d произведение определяется
формулой [a, b] × [c, d] = [ac, bd],
а частное имеет вид [a, b]/[c, d] = = [a/d, b/c]. Эти формулы получены при решении соответствующих оптимизационных
задач. Пусть х лежит в отрезке [a, b],
а у – в отрезке [c, d]. Каково минимальное
и максимальное значение для х + у? Очевидно,
a + c и b + d соответственно. Минимальные и максимальные
значения для х – у, ху, х/у указывают
нижние и верхние границы для интервальных чисел, задающих результаты арифметических
операций. А от арифметических операций можно перейти ко всем остальным математическим
алгоритмам. Так строится интервальная математика.
Как видно из сборника трудов Международной
конференции [235], исследователям удалось решить ряд задач теории интервальных дифференциальных
уравнений, в которых коэффициенты, начальные условия и решения описываются с помощью
интервалов. По мнению некоторых специалистов, статистика интервальных данных является
частью интервальной математики [239]. Впрочем, распространена и другая точка зрения,
согласно которой такое включение нецелесообразно, поскольку статистика интервальных
данных использует несколько иные подходы к алгоритмам анализа реальных данных, чем
сложившиеся в интервальной математике (подробнее см. ниже).
В настоящем разделе рассматриваем
асимптотические методы статистического анализа интервальных данных при больших объемах
выборок и малых погрешностях измерений. В отличие от классической математической
статистики, сначала устремляется к бесконечности объем выборки и только потом –
уменьшаются до нуля погрешности (в классической математической статистике предельные
переходы осуществляются в обратном порядке – сначала уменьшаются до нуля погрешности
измерений, и только затем - устремляется к бесконечности объем выборки). В частности,
еще в начале 1980-х годов с помощью такой асимптотики сформулированы правила выбора
метода оценивания в ГОСТ 11.011-83 [133].
Нами разработана [240] общая схема
исследования, включающая расчет нотны (максимально возможного отклонения статистики,
вызванного интервальностью исходных данных) и рационального объема выборки (превышение
которого не дает существенного повышения точности оценивания). Она применена к оцениванию
математического ожидания и дисперсии [234], медианы и коэффициента вариации [241],
параметров гамма-распределения [133, 242] и характеристик аддитивных статистик [240],
при проверке гипотез о параметрах нормального распределения, в т.ч. с помощью критерия
Стьюдента, а также гипотезы однородности с помощью критерия Смирнова [241]. Изучено
асимптотическое поведение оценок метода моментов и оценок максимального правдоподобия
(а также более общих – оценок минимального контраста), проведено асимптотическое
сравнение этих методов в случае интервальных данных, найдены общие условия, при
которых, в отличие от классической математической статистики, метод моментов дает
более точные оценки, чем метод максимального правдоподобия [243].
Разработаны подходы к рассмотрению
интервальных данных в основных постановках регрессионного, дискриминантного и кластерного
анализов [244]. Изучено влияние погрешностей измерений и наблюдений на свойства
алгоритмов регрессионного анализа, разработаны способы расчета нотн и рациональных
объемов выборок, введены и исследованы новые понятия многомерных и асимптотических
нотн, доказаны соответствующие предельные теоремы [244, 245]. Проведена первоначальная
разработка интервального дискриминантного анализа, рассмотрено влияние интервальности
данных на показатель качества классификации [244, 246]. Основные идеи и результаты
рассматриваемого направления в статистике интервальных данных приведены в публикациях
обзорного характера [237, 238].
Как показала Международная конференция
ИНТЕРВАЛ-92, в области асимптотической математической статистики интервальных данных
мы имеем мировой приоритет. По нашему мнению, со временем во все виды статистического
программного обеспечения должны быть включены алгоритмы интервальной статистики,
«параллельные» обычно используемым алгоритмам прикладной математической статистики.
Это позволит в явном виде учесть наличие погрешностей у результатов наблюдений,
сблизить позиции метрологов и статистиков.
Многие из утверждений статистики
интервальных данных весьма отличаются от аналогов из классической математической
статистики. В частности, не существует состоятельных оценок; средний квадрат ошибки
оценки, как правило, асимптотически равен сумме дисперсии оценки, рассчитанной согласно
классической теории, и некоторого положительного числа (равного квадрату т.н. нотны
– максимально возможного отклонения значения статистики из-за погрешностей исходных
данных) – в результате, метод моментов оказывается иногда точнее метода максимального
правдоподобия [243]; нецелесообразно увеличивать объем выборки сверх некоторого
предела (называемого рациональным объемом выборки) – вопреки классической теории,
согласно которой чем больше объем выборки, тем точнее выводы.
В стандарт [133] включен раздел
5, посвященный выбору метода оценивания при неизвестных параметрах формы и масштаба
и известном параметре сдвига и основанный на концепциях статистики интервальных
данных. Теоретическое обоснование этого раздела стандарта опубликовано лишь через
5 лет в статье [242].
В
Вторая ведущая научная школа в
области статистики интервальных данных – это школа проф. А.П. Вощинина (1937 - 2008),
активно работающая с конца 70-х годов. Полученные результаты отражены в ряде монографий
(см., прежде всего, [248, 249, 250]), статей [234, 251, 252], докладов, в частности,
в трудах [235] Международной конференции ИНТЕРВАЛ-92, диссертациях [253, 254]. Изучены
проблемы регрессионного анализа, планирования эксперимента, сравнения альтернатив
и принятия решений в условиях интервальной неопределенности.
Рассматриваемое ниже наше научное
направление отличается нацеленностью на асимптотические результаты, полученные при
больших объемах выборок и малых погрешностях измерений, поэтому его полное название
таково: асимптотическая математическая статистика интервальных данных.
3.4.2. Основные идеи статистики
интервальных данных
Сформулируем сначала основные идеи
асимптотической математической статистики интервальных данных, а затем рассмотрим
реализацию этих идей на простых примерах, отослав по поводу многочисленных конкретных
результатов к имеющимся публикациям. Основные идеи достаточно просты, в то время
как их проработка в конкретных ситуациях зачастую оказывается достаточно трудоемкой.
Пусть существо реального явления
описывается выборкой x1, x2, ..., xn. В вероятностной
теории математической статистики, из которой мы исходим (см. справочник [60]), выборка
– это набор независимых в совокупности одинаково распределенных случайных величин.
Однако беспристрастный и тщательный анализ подавляющего большинства реальных задач
показывает, что статистику известна отнюдь не выборка x1, x2, ..., xn, а другие (искаженные) величины
yj = xj + ej, j = 1, 2, ...,
n,
где e1, e2, …, en – некоторые погрешности измерений, наблюдений, анализов,
опытов, испытаний, исследований (например, инструментальные ошибки).
Одна из причин появления погрешностей
– запись результатов наблюдений с конечным числом значащих цифр. Дело в том, что
для случайных величин с непрерывными функциями распределения событие, состоящее
в попадании хотя бы одного элемента выборки в множество рациональных чисел, согласно
правилам теории вероятностей имеет вероятность 0, а такими событиями в теории вероятностей
принято пренебрегать. Поэтому при рассуждениях о выборках из тех или иных непрерывных
распределений из параметрических семейств - нормального, логарифмически нормального,
экспоненциального, равномерного, гамма-распределений, распределения Вейбулла-Гнеденко
и др. - приходится принимать, что эти распределения имеют элементы исходной выборки
x1, x2, ..., xn,
в то время как статистической обработке доступны лишь искаженные значения yj = xj + ej, записываемые конечным
(и небольшим) числом значащих цифр, а потому входящие в множество рациональных чисел.
Введем обозначения
x = (x1, x2,
..., xn), y = (y1,
y2, ..., yn), e = (e1 + e2 + … + en).
Пусть статистические выводы основываются
на статистике f : Rn ® R1,
используемой для оценивания параметров и характеристик распределения, проверки гипотез
и решения иных статистических задач. Принципиально важная для статистики интервальных
данных идея такова:
СТАТИСТИК ЗНАЕТ ТОЛЬКО f(y), НО НЕ f(x).
Очевидно, в статистических выводах
необходимо отразить различие между f(y) и f(x). Одним из двух основных понятий статистики
интервальных данных является понятие нотны.
Определение. Величину
максимально возможного (по абсолютной величине) отклонения, вызванного погрешностями
наблюдений e, известного статистику значения
f(y) от истинного значения f(x),
т.е.
Nf(x) = sup | f(y) – f(x)
|,
где супремум берется по множеству
возможных значений вектора погрешностей e (см. ниже), будем называть НОТНОЙ.
Если функция f имеет частные производные второго порядка,
а ограничения на погрешности имеют вид
| ei | £ D, i = 1, 2, …, n, (1)
причем D мало, то приращение функции f с точностью до бесконечно малых более высокого порядка описывается
главным линейным членом, т.е.
![]()
Чтобы получить асимптотическое
(при D ® 0) выражение для нотны, достаточно найти максимум и минимум
линейной функции (главного линейного члена) на кубе, заданном неравенствами (1).
Легко видеть, что максимум достигается, если положить
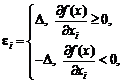
а минимум, отличающийся от максимума
только знаком, достигается при ![]() = –ei. Следовательно, нотна
с точностью до бесконечно малых более высокого порядка имеет вид
= –ei. Следовательно, нотна
с точностью до бесконечно малых более высокого порядка имеет вид
![]()
Это выражение назовем асимптотической нотной.
Условие (1) означает, что исходные
данные представляются статистику в виде интервалов [yi – D; yi + D], i = 1, 2,
…, n (отсюда и название этого научного
направления). Ограничения на погрешности могут задаваться разными способами – кроме
абсолютных ошибок используются относительные или иные показатели различия между
x и y.
Если задана не предельная абсолютная
погрешность D, а предельная относительная
погрешность d, т.е. ограничения на погрешности
вошедших в выборку результатов измерений имеют вид
| ei | £ d | xi |, i = 1, 2, …, n,
то аналогичным образом получаем,
что нотна с точностью до бесконечно малых более высокого порядка, т.е. асимптотическая
нотна, имеет вид
![]()
При практическом использовании
рассматриваемой концепции необходимо провести тотальную замену символов x на символы y. В каждом конкретном случае удается показать, что в силу малости погрешностей
разность Nf(y) – Nf(x) является бесконечно малой более высокого
порядка сравнительно с Nf(x) или Nf(y).
3.4.3. Основные результаты в вероятностной
модели
В классической вероятностной модели
элементы исходной выборки x1, x2, ..., xn
рассматриваются как независимые одинаково распределенные случайные величины. Как
правило, существует некоторая константа C
> 0 такая, что в смысле сходимости по вероятности
![]() (2)
(2)
Соотношение (2) доказывается отдельно
для каждой конкретной задачи.
При использовании классических
статистических методов в большинстве случаев используемая статистика f(x)
является асимптотически нормальной. Это означает, что существуют константы а и s2 такие, что
![]()
где F(x) – функция
стандартного нормального распределения с математическим ожиданием 0 и дисперсией
1. При этом обычно оказывается, что
![]() ,
,
![]()
а потому в классической математической
статистике средний квадрат ошибки статистической оценки равен
![]()
с точностью до членов более высокого
порядка.
В статистике интервальных данных
ситуация совсем иная – обычно можно доказать, что средний квадрат ошибки равен
![]() (3)
(3)
Из соотношения (3) вытекает ряд
важных следствий. Правая часть этого равенства, в отличие от правой части соответствующего
классического равенства, не стремится к 0 при безграничном возрастании объема выборки.
Она остается больше некоторого положительного числа, а именно, квадрата нотны. Следовательно,
статистика f(x) не является состоятельной оценкой параметра
a. Более того, состоятельных оценок вообще не существует.
Пусть доверительным интервалом
для параметра a, соответствующим заданной
доверительной вероятности g, в классической математической статистике является интервал (cn(g); dn(g)). В статистике интервальных данных аналогичный доверительный
интервал является более широким. Он имеет вид (cn(g) – Nf(y); dn(g) + Nf(y)). Таким образом, его длина увеличивается
на две нотны. Следовательно, при увеличении объема выборки длина доверительного
интервала не может стать меньше, чем
В статистике интервальных данных
методы оценивания параметров имеют другие свойства по сравнению с классической математической
статистикой. Так, при больших объемах выборок метод моментов может быть заметно
лучше, чем метод максимального правдоподобия (т.е. иметь меньший средний квадрат
ошибки – см. формулу (3)), в то время как в классической математической статистике
второй из названных методов всегда не хуже первого.
3.4.4. Рациональный объем выборки
Анализ формулы (3) показывает,
что в отличие от классической математической статистики нецелесообразно безгранично
увеличивать объем выборки, поскольку средний квадрат ошибки остается всегда большим
квадрата нотны. Поэтому представляется полезным ввести понятие «рационального объема
выборки» nrat, при
достижении которого продолжать наблюдения нецелесообразно.
Как установить «рациональный объем
выборки»? Можно воспользоваться идеей применения «принципа уравнивания погрешностей»,
выдвинутой в монографии [7]. Речь идет о том, что вклад погрешностей различной природы
в общую погрешность должен быть примерно одинаков. Этот принцип дает возможность
выбирать необходимую точность оценивания тех или иных характеристик в тех случаях,
когда это зависит от исследователя. В статистике интервальных данных в соответствии
с «принципом уравнивания погрешностей» предлагается определять рациональный объем
выборки nrat из
условия равенства двух величин – метрологической составляющей, связанной с нотной,
и статистической составляющей – в среднем квадрате ошибки (3), т.е. из условия
![]()
Для практического использования
выражения для рационального объема выборки неизвестные теоретические характеристики
необходимо заменить их оценками. Это делается в каждой конкретной задаче по-своему.
Исследовательскую программу в области
статистики интервальных данных можно «в двух словах» сформулировать так: для любого
алгоритма анализа данных (алгоритма прикладной статистики) необходимо вычислить
нотну и рациональный объем выборки. Или иные величины из того же понятийного ряда,
возникающие в многомерном случае, при наличии нескольких выборок и при иных обобщениях
описываемой здесь простейшей схемы. Затем проследить влияние погрешностей исходных
данных на точность оценивания, доверительные интервалы, значения статистик критериев
при проверке гипотез, уровни значимости и другие характеристики статистических выводов.
Очевидно, классическая математическая статистика является (предельной) частью статистики
интервальных данных, выделяемой условием D = 0.
Поясним теоретические концепции
статистики интервальных данных на простых примерах оценивания математического ожидания
и дисперсии.
3.4.5. Оценивание математического
ожидания
Пусть необходимо оценить математическое
ожидание случайной величины с помощью обычной оценки – среднего арифметического
результатов наблюдений, т.е.
![]()
Тогда при справедливости ограничений
(1) на абсолютные погрешности имеем Nf(x) = D. Таким образом, нотна полностью известна и не зависит
от многомерной точки, в которой берется. Это утверждение вполне естественно: если
каждый результат наблюдения известен с точностью до D, то и среднее арифметическое известно с той же точностью.
Ведь возможна систематическая ошибка – если к каждому результату наблюдения добавить
D, то и среднее арифметическое
увеличится на D.
Поскольку
![]()
то в ранее введенных обозначениях
s2 = D(x1).
Следовательно, рациональный объем
выборки равен
![]()
Для практического использования
полученной формулы надо оценить дисперсию результатов наблюдений. Можно доказать,
что, поскольку D мало, это можно сделать обычным способом, например, с помощью несмещенной
выборочной оценки дисперсии
![]()
Здесь и далее рассуждения часто
идут на двух уровнях. Первый – это уровень «истинных» случайных величин, обозначаемых
в настоящем разделе «х», описывающих реальность, но неизвестных специалисту
по анализу данных. Второй – уровень известных этому специалисту величин «у», отличающихся погрешностями от истинных.
Погрешности малы, поэтому функции от х
отличаются от функций от у на некоторые
бесконечно малые величины. Эти соображения и позволяют использовать s2(y) как оценку D(x1).
Итак, выборочной оценкой рационального
объема выборки является
![]()
Уже на этом первом рассматриваемом
примере видим, что рациональный объем выборки находится не где-то вдали, "в
районе бесконечности", а непосредственно рядом с теми объемами, с которыми
имеет дело любой практически работающий статистик. Например, если статистик знает,
что
![]()
то nrat = 36. А именно такова погрешность контрольных шаблонов
во многих технологических процессах! Поэтому, занимаясь управлением качеством, необходимо
обращать внимание на действующую на предприятии систему измерений.
По сравнению с классической математической
статистикой доверительный интервал для математического
ожидания (для заданной доверительной вероятности g) имеет другой вид, а именно:
![]() (4)
(4)
где u(g) – квантиль порядка (1 + g)/2 стандартного нормального распределения с математическим
ожиданием 0 и дисперсией 1.
По поводу формулы (4) была довольно
жаркая дискуссия среди специалистов. Отмечалось, что она получена на основе Центральной
предельной теоремы теории вероятностей и может быть использована при любом распределении
результатов наблюдений (с конечной дисперсией). Если же имеется дополнительная информация,
то, по мнению отдельных специалистов, формула (4) может быть уточнена. Например,
если известно, что распределение xi
является нормальным, в качестве u(g) целесообразно использовать квантиль распределения Стьюдента.
К этому надо добавить, что по небольшому числу наблюдений нельзя надежно установить
нормальность, а при росте объема выборки квантили распределения Стьюдента приближаются
к квантилям нормального распределения.
Вопрос о том, часто ли результаты
наблюдений имеют нормальное распределение, подробно обсуждался среди специалистов.
Выяснилось, что распределения встречающихся в практических задачах результатов измерений
почти всегда отличны от нормальных [121]. А также и от распределений из иных параметрических
семейств, описываемых в учебниках по теории вероятностей и математической статистике.
Применительно к оцениванию математического ожидания (но не к оцениванию
других характеристик или параметров распределения) факт существования границы возможной
точности, определяемой точностью исходных данных, неоднократно отмечался в литературе
([192, с. 230–234], [255, с. 121] и др.).
3.4.6. Оценивание дисперсии
Для статистики f(y) = s2(y), где s2(y) – выборочная дисперсия (несмещенная оценка
теоретической дисперсии), при справедливости ограничений (1) на абсолютные погрешности
имеем
![]()
Можно показать, что нотна Nf(y) сходится к константе
2DM | x1
– M(x1) |
по вероятности с точностью до o(D), когда n стремится
к бесконечности. Это же предельное соотношение верно и для нотны Nf(х), вычисленной для исходных данных. Таким
образом, в данном случае справедлива формула (2) с
C = 2M | x1 – M(x1)
|.
Известно (см., например, [256]),
что случайная величина
![]()
является асимптотически нормальной
с математическим ожиданием 0 и дисперсией ![]()
Из сказанного вытекает: в статистике интервальных данных асимптотический
доверительный интервал для дисперсии s2 (соответствующий
доверительной вероятности g) имеет вид
(s2(y) – A; s2
+ A),
где
здесь u(g) обозначает тот же самый квантиль стандартного нормального распределения,
что и выше в случае оценивания математического ожидания.
Рациональный объем выборки при
оценивании дисперсии равен
![]()
а выборочную оценку рационального
объема выборки nsample–rat
можно вычислить, заменяя теоретические моменты на соответствующие выборочные и используя
доступные статистику результаты наблюдений, содержащие погрешности.
Что можно сказать о численной величине
рационального объема выборки? Как и в случае оценивания математического ожидания,
она отнюдь не выходит за пределы обычно используемых объемов выборок. Так, если
принять, что распределение результатов наблюдений xi является нормальным с математическим ожиданием 0 и дисперсией
s2, то в результате вычисления моментов случайных величин
в предыдущей формуле получаем, что
![]()
где p – отношение длины окружности к диаметру, p = = 3,141592… Например, если D = s/6, то nrat = 11. Это
меньше, чем при оценивании математического ожидания в предыдущем примере.
3.4.7. Статистика интервальных данных
в прикладной статистике
Кратко рассмотрим положение статистики интервальных данных (СИД) среди
других методов математического описания неопределенностей и анализа данных.
Нечеткость и СИД. С формальной точки зрения описание нечеткости интервалом
– это частный случай описания ее нечетким множеством. В СИД функция принадлежности
нечеткого множества имеет специфический вид – она равна 1 в некотором интервале
и 0 вне его. Такая функция принадлежности описывается всего двумя параметрами (границами
интервала). Эта простота описания делает математический аппарат СИД гораздо более
прозрачным, чем аппарат теории нечеткости в общем случае (однако при этом надо иметь
в виду, что, вопреки основополагающей идее Л.А. Заде, переход от "принадлежности
к множеству" к "непринадлежности" является скачкообразным, а не непрерывным).
Это, в свою очередь, позволяет исследователю продвинуться дальше, чем при использовании
функций принадлежности произвольного вида.
Интервальная математика и СИД. Можно было бы сказать, что СИД – часть интервальной математики,
что СИД так соотносится с прикладной математической статистикой, как интервальная
математика – с математикой в целом. Однако исторически сложилось так, что интервальная
математика занимается прежде всего вычислительным погрешностями. С точки зрения
интервальной математики две известные формулы для выборочной дисперсии, а именно
![]() ,
,
имеют разные погрешности. А с точки
зрения СИД эти две формулы задают одну и ту же функцию, и поэтому им соответствуют
совпадающие нотны и рациональные объемы выборок. Интервальная математика прослеживает
процесс вычислений, СИД этим не занимается. Необходимо отметить, что типовые постановки
СИД могут быть перенесены в другие области математики, и, наоборот, вычислительные
алгоритмы прикладной математической статистики и СИД заслуживают изучения в духе
интервальной математики. Однако и то, и другое – скорее дело будущего, а не нынешнего
уровня научных исследований в рассматриваемой области. Из уже сделанного отметим
применение методов СИД при анализе такой основополагающей характеристики финансовых
потоков инвестиционных проектов, как NPV
– чистая текущая стоимость [16, гл.9].
Математическая статистика и СИД. Математическая статистика и СИД отличаются тем, в каком
порядке делаются предельные переходы n
® ¥ и D ®0. При этом СИД переходит
в математическую статистику при D = 0. Правда, тогда исчезают основные особенности СИД:
нотна становится равной 0, а рациональный объем выборки – бесконечности. Рассмотренные
выше методы СИД разработаны в предположении, что погрешности малы (но не исчезают),
а объем выборки велик. СИД расширяет классическую математическую статистику тем,
что в исходных статистических данных каждое число заменяет интервалом. С другой
стороны, можно считать СИД новым этапом развития математической статистики.
Статистика объектов нечисловой природы и
СИД. Статистика объектов нечисловой природы (СОНП) (см. [82] и следующий
раздел настоящей монографии) расширяет область применения классической математической
статистики путем включения в нее новых видов статистических данных. Естественно,
при этом появляются новые виды алгоритмов анализа статистических данных и новый
математический аппарат (в частности, происходит переход от методов суммирования
к методам оптимизации). С точки зрения СОНП частному виду новых статистических данных
– интервальным данным – соответствует СИД. Напомним, что одно из двух основных понятий
СИД – нотна – определяется как решение оптимизационной задачи. Однако СИД, изучая
классические методы прикладной статистики применительно к интервальным данным, по
математическому аппарату ближе к классической математической статистике, чем другие
части СОНП, например, статистика бинарных отношений.
Робастные методы статистики и СИД. Если понимать робастность согласно монографии [7] как
теорию устойчивости статистических методов по отношению к допустимым отклонениям
исходных данных и предпосылок модели, то в СИД рассматривается одна из естественных
постановок робастности. Однако в массовом сознании специалистов термин «робастность»
закрепился за моделью засорения выборки большими выбросами (модель Тьюки-Хубера),
хотя эта модель не имеет большого практического значения [5]. К этой модели СИД
не имеет отношения.
Теория устойчивости и СИД. Общей схеме устойчивости (см. [7, 123, 257] и раздел 3.2
настоящей монографии) математических моделей социально-экономических явлений и процессов
по отношению к допустимым отклонениям исходных данных и предпосылок моделей СИД
полностью соответствует. Она посвящена математико-статистическим моделям, используемым
при анализе статистических данных, а допустимые отклонения – это интервалы, заданные
ограничениями на погрешности. СИД можно рассматривать как пример теории, в которой
учет устойчивости позволил сделать нетривиальные выводы. Отметим, что с точки зрения
общей схемы устойчивости [7] устойчивость по Ляпунову в теории дифференциальных
уравнений – весьма частный случай, в котором из-за его конкретности удалось весьма
далеко продвинуться.
Минимаксные методы, типовые отклонения и
СИД. Постановки СИД относятся к минимаксным.
За основу берется максимально возможное отклонение. Это – «подход пессимиста», применяемый,
например, в теории антагонистических игр. Использование минимаксного подхода позволяет
подозревать СИД в завышении роли погрешностей измерения. Однако примеры изучения
вероятностно-статистических моделей погрешностей, проведенные, в частности, при
разработке методов оценивания параметров гамма-распределения [133, 242], показали,
что это подозрение не подтверждается. Влияние погрешностей измерений по порядку
такое же, только вместо максимально возможного отклонения (нотны) приходится рассматривать
математическое ожидание соответствующего отклонения. Подчеркнем, что применение
в СИД вероятностно-статистических моделей погрешностей не менее перспективно, чем
минимаксных.
Подход научной школы А.П. Вощинина и СИД. Если в математической статистике неопределенность только
статистическая, то в научной школе А.П. Вощинина – только интервальная. Можно сказать,
что СИД лежит между классической прикладной математической статистикой и областью
исследований научной школы А.П. Вощинина. Другое отличие состоит в том, что в этой
школе разрабатывают новые методы анализа интервальных данных, а в СИД в настоящее
время изучается устойчивость классических статистических методов по отношению к
малым погрешностям. Подход СИД оправдывается распространенностью этих методов, однако
в дальнейшем следует переходить к разработке новых методов, специально предназначенных
для анализа интервальных данных.
Анализ чувствительности и СИД. При анализе чувствительности, как и в СИД, рассчитывают
производные по используемым переменным, или непосредственно находят изменения при
отклонении переменной на, например, ±10% от базового значения. Однако этот анализ делают по
каждой переменной отдельно. В СИД все переменные рассматриваются совместно, и находится
максимально возможное отклонение (нотна). При малых погрешностях удается на основе
главного члена разложения функции в многомерный ряд Тейлора получить удобную формулу
для нотны. Можно сказать, что СИД – это многомерный анализ чувствительности.
* * *
Асимптотической математической
статистике интервальных данных посвящены обширные главы в монографиях [5, 33, 36,
54]. Продолжают интенсивно развиваться научные исследования как в научной школе
А.П. Вощинина [258, 259], так и в СИД [83, 260, 261, 262].
По нашему мнению, во все виды статистического
программного обеспечения должны быть включены алгоритмы интервальной статистики,
«параллельные» обычно используемым в настоящее время алгоритмам прикладной математической
статистики. Это позволит в явном виде учесть наличие погрешностей у результатов
наблюдений (измерений, испытаний, анализов, опытов).
Статистика интервальных данных
является составной частью системной нечеткой интервальной математики [32, 33, 263]
– перспективного направления теоретической и вычислительной математики.
3.5. О развитии статистики нечисловых данных
Около тридцати пяти лет назад статистика нечисловых данных
(синонимы - статистика объектов нечисловой природы, нечисловая статистика) была
выделена как самостоятельная область математической статистики. Как показано в разделе
2.3.5, статистика нечисловых данных является
центральной частью прикладной математической статистики. В настоящем разделе проанализируем
разработку основных идей в этой области на фоне развития прикладной статистики
в целом и в связи с формированием нового перспективного направления теоретической
и прикладной математики - системной нечеткой интервальной математики [32, 33].
Термин "статистика объектов нечисловой природы"
впервые появился в
3.5.1. Послевоенное развитие отечественной
статистики
К 60-м годам ХХ в. в нашей стране (как и во всем мире)
сформировалась научно-практическая дисциплина, которую называем классической математической
статистикой. Статистики учились теории по книге Г. Крамера [265], написанной в военные
годы и впервые изданной в нашей стране в
Затем внимание многих специалистов сосредоточилось на изучении
математических конструкций, используемых в статистике. Примером таких работ является
монография [267]. В ней получены продвинутые математические результаты, но трудно
(видимо - вообще невозможно) выделить рекомендации для статистика, анализирующего
конкретные данные.
Как реакция на уход теоретиков-статистиков в математику
выделилась новая научная дисциплина - прикладная статистика. В учебнике [5] в качестве
рубежа, когда это стало очевидным, мы указали
Вполне естественно, что в прикладной статистике стали развиваться
математические методы и модели. Необходимость их развития вытекает из потребностей
конкретных прикладных исследований. Это математизированное ядро прикладной статистики
хочется назвать теоретической статистикой. Тогда под собственно прикладной статистикой
следует понимать обширную промежуточную область между теоретической статистикой
и применением статистических методов в конкретных областях. В нее входят, в частности,
вопросы формирования вероятностно-статистических моделей и выбора конкретных методов
анализа данных (т.е. методология прикладной статистики и других статистических методов),
проблемы разработки и применения информационных статистических технологий, организации
сбора и анализа данных, т.е. разработки статистических технологий.
Таким образом, общая схема современной статистической науки
выглядит следующим образом (от абстрактного к конкретному):
1. Математическая статистика – часть математики, изучающая
статистические структуры. Сама по себе не дает рецептов анализа статистических данных,
однако разрабатывает методы, полезные для использования в теоретической статистике.
Можно вслед за Г. Крамером [265] в качестве названия этой области статистической
науки использовать термин "Математические методы статистики".
2. Теоретическая статистика – наука, посвященная моделям
и методам анализа конкретных статистических данных.
3. Прикладная статистика (в узком смысле) занимается статистическими
технологиями сбора и обработки данных. Она включает в себя методологию статистических
методов, вопросы организации выборочных исследований, разработки статистических
технологий, создания и использования статистических программных продуктов.
4. Применение статистических методов в конкретных областях.
Соответствующие области научно-прикладных исследований иногда имеют собственные
названия (в экономике и менеджменте – эконометрика, в биологии – биометрика, в химии
– хемометрия, в технических исследованиях – технометрика), а иногда специальных
названий пока нет или они не устоялись (применения статистических методов в геологии,
демографии, социологии, медицине, истории, и т.д.). Термин "социометрика"
имеет более узкий смысл, чем можно было бы ожидать - под ним понимают не статистические
методы в социологии, а всего лишь статистические методы изучения малых групп. Для
обозначения математических и статистических метолов в истории иногда используют
термин "клиометрика", но при этом не рассматривают основное достижение
в этой области - новую статистическую хронологию [199]. И т.д., и т.п.
Часто позиции 2 и 3 вместе называют прикладной статистикой
(как мы это сделали в учебнике [5], написанном в
Примечание. Здесь
мы уточнили схему внутреннего деления статистической теории, предложенную в [152].
Естественный смысл приобрели термины «теоретическая статистика» и «прикладная статистика»
(в узком смысле). Однако необходимо иметь в виду, что в сравнительно недавнем учебнике
[5] прикладная статистика понимается в широком смысле, т.е. как объединение позиций
2 и 3.
К сожалению, в настоящее время невозможно отождествить
теоретическую статистику с математической, поскольку последняя (как часть математики
- научной специальности «теория вероятностей и математическая статистика») заметно
оторвалась от задач практики. Однако начинают проявляться любопытные тенденции.
Дело в том, что в нашей стране математическая статистика "вымирает". Исследователи
в этой области с возрастом снижают активность, новые не появляются, число работ
уменьшается, особенно диссертационных. В то же время прикладная статистика активно
развивается. Можно предсказать, что в ближайшие десятилетия прикладная статистика
полностью "поглотит" математическую, вместе с названием. Так завершится
"раскол 1981 года". И снова будет единая "математическая статистика".
Как известно, издавна идут споры о том, существует ли прикладная
математика. В частности, уиверждают, что вся математика является прикладной, а лишь
математики делятся на тех, для кого теоремы важнее ("чистые"), и тех,
для кого важнее приложения ("прикладные"). Аналогичные споры имели место
и в статистической науке. Замечательный советский статистик член-корреспондент АН
СССР Л.Н. Большев, один из авторов лучшего на русском языке сборника статистических
таблиц [69], в конце 1970-х гг. в беседе с А.И. Орловым активно возражал против
термина "прикладная статистика", поскольку, по его словам, "вся статистика
является прикладной". При этом он отметил, что этот термин - реакция на развитие
"аналитической статистики" (работы типа [267]), которая занимается внутриматематическими
вопросами [268, с.7]. Прошло несколько десятилетий, и стало ясно, что Л.Н. Большев
был прав - "вся статистика является прикладной", и имя ей - "математическая
статистика", а внутриматематическая "аналитическая статистика" была
модным увлечением математиков и ушла в прошлое.
Отметим, что математическая статистика, как и теоретическая
с прикладной, заметно отличается от ведомственной науки органов официальной государственной
статистики. ЦСУ, Госкомстат, Росстат применяли и применяют лишь проверенные временем
приемы позапрошлого (девятнадцатого) века. Возможно, следовало бы от этого ведомства
полностью отмежеваться и сменить название научной области, например, на «Анализ
данных». В настоящее время компромиссным самоназванием нашей научно-практической
дисциплины является термин «статистические методы».
Как уже говорилось, во второй половине 80-х годов развернулось
общественное движение, имеющее целью создание профессионального объединения статистиков.
Аналогами являются британское Королевское статистическое общество (основано в
В ходе создания ВСА было проанализировано состояние и перспективы
развития теоретической и прикладной статистики. В частности, выделены пять актуальных
направлений, в которых развивается современная прикладная статистика, т.е. пять
«точек роста» статистической науки: непараметрика, робастность, бутстреп, интервальная
статистика, статистика объектов нечисловой природы. Первые четыре из этих направлений
достаточно подробно рассмотрены выше в настоящей монографии в разделах 3.1 - 3.4
соответственно.
3.5.2. Краткая история статистики объектов
нечисловой природы
Перейдем к сути статистики объектов нечисловой природы
(она же - статистика нечисловых данных, или нечисловая статистика). Типичный исходный
объект в прикладной статистике - это выборка, т.е. совокупность независимых одинаково
распределенных случайных элементов. Какова природа этих элементов? В классической
математической статистике элементы выборки - это числа. В многомерном статистическом
анализе - вектора. А в нечисловой статистике элементы выборки - это объекты нечисловой
природы, которые нельзя складывать и умножать на числа. Другими словами, объекты
нечисловой природы лежат в пространствах, не имеющих векторной структуры.
Примерами объектов нечисловой природы являются:
- значения качественных признаков, в том числе результаты
кодировки объектов с помощью заданного перечня категорий (градаций);
- упорядочения (ранжировки) экспертами образцов продукции
(при оценке её технического уровня, качества и конкурентоспособности)) или заявок
на проведение научных работ (при проведении конкурсов на выделение грантов);
- классификации, т.е. разбиения объектов на группы сходных
между собой (кластеры);
- толерантности, т.е. бинарные отношения, описывающие сходство
объектов между собой, например, сходства тематики научных работ, оцениваемого экспертами
с целью рационального формирования экспертных советов внутри определенной области
науки;
- другие виды отношений на конечных множествах (унарных,
бинарных, тернарных и др.);
- результаты парных сравнений или контроля качества продукции
по альтернативному признаку («годен» - «брак»), т.е. последовательности из 0 и 1;
- множества (обычные или нечеткие), например, зоны, пораженные
коррозией, или перечни возможных причин аварии, составленные экспертами независимо
друг от друга;
- слова, предложения, тексты;
- вектора, координаты которых - совокупность значений разнотипных
признаков, например, результат составления статистического отчета о научно-технической
деятельности организации или анкета эксперта, в которой ответы на часть вопросов
носят качественный характер, а на часть - количественный;
- ответы на вопросы экспертной, медицинской, маркетинговой
или социологической анкеты, часть из которых носит количественный характер (возможно,
интервальный), часть сводится к выбору одной из нескольких подсказок, а часть представляет
собой тексты;
- графы;
- ориентированные графы;
- блок-схемы;
- кривые,
- фигуры;
- тела в пространстве;
- рисунки (образы, сцены);
- звуки (фонемы);
- алгоритмы;
- модели различных явлений и процессов;
- отношения в малой группе;
- предметы одежды;
- песни;
- цирковые номера;
- поэтические произведения;
- элементы метрического пространства;
- элементы произвольного пространства, и т.д.
Список можно продолжать сколь угодно долго, поскольку окружающие
нас явления и процессы лишь в редких случаях можно адекватно описать с помощью чисел.
(Хотя стоит напомнить, что любые символы кодируются в памяти компьютера с помощью
последовательностей 0 и 1.)
Рассмотренные выше интервальные данные тоже можно рассматривать
как пример объектов нечисловой природы, а именно, как частный случай нечетких множеств.
Если характеристическая функция нечеткого множества равна 1 на некотором интервале
и равна 0 вне этого интервала, то задание такого нечеткого множества эквивалентно
заданию интервала. С методологической точки зрения важно, что теория нечетких
множеств в определенном смысле сводится к теории случайных множеств. Цикл соответствующих
теорем приведен в монографиях [7, 33], а также в учебниках [5, 16, 36, 54].
С 70-х годов в основном в ответ на запросы теории экспертных
оценок (а также технических исследований, экономики, социологии и медицины) развивались
различные направления статистики объектов нечисловой природы. Были установлены основные
связи между конкретными видами таких объектов, разработаны для них базовые вероятностные
модели. Сводка была дана в монографии [7], препринте [144].
Следующий этап (80-е годы) - выделение статистики объектов
нечисловой природы в качестве самостоятельной дисциплины в рамках прикладной статистики
(шире, математических методов исследования), ядром которого являются методы статистического
анализа данных произвольной природы. Для работ этого периода характерна сосредоточенность
на внутренних проблемах нечисловой статистики. Проводились всесоюзные конференции
[269, 270], выпускались монографии [271 - 276], сборники трудов [277 - 279], защищались
диссертации [280 - 286]. Наиболее представительным является сборник [87], подготовленный
совместно комиссией «Статистика объектов нечисловой природы» Научного Совета АН
СССР по комплексной проблеме «Кибернетика» и Институтом социологических исследований
АН СССР.
К 90-м годам статистика объектов нечисловой природы с теоретической
точки зрения была достаточно хорошо развита, основные идеи, подходы и методы были
разработаны и изучены математически, в частности, доказано достаточно много теорем.
Однако она оставалась недостаточно апробированной на практике. И в 90-е годы наступило
время перейти от теоретико-статистических исследований к применению полученных результатов
на практике и включить их в учебный процесс, что и было сделано (см., например,
учебники [5, 16, 36, 54], написанные несколько позже, в первое десятилетие XXI в.).
В 90-е годы опубликованы обзоры [287 - 289] по статистике объектов нечисловой природы
и многочисленные конкретные исследования, к рассмотрению которых и переходим.
3.5.3. Основные идеи и направления статистики
объектов нечисловой природы
В чем принципиальная новизна нечисловой статистики? Для
классической математической статистики характерна операция сложения. При расчете
выборочных характеристик распределения (выборочное среднее арифметическое, выборочная
дисперсия и др.), в регрессионном анализе и других областях этой научной дисциплины
постоянно используются суммы. Математический аппарат - законы больших чисел, Центральная
предельная теорема и другие теоремы - нацелены на изучение сумм. В нечисловой же
статистике нельзя использовать операцию сложения, поскольку элементы выборки лежат
в пространствах, где нет операции сложения. Методы обработки нечисловых данных основаны
на принципиально ином математическом аппарате - на применении различных расстояний
в пространствах объектов нечисловой природы.
Следует отметить, что в статистике объектов нечисловой
природы одна и та же математическая схема может с успехом применяться во многих
прикладных областях, для анализа данных различных типов, а потому ее целесообразно
формулировать и изучать в наиболее общем виде, для объектов произвольной природы.
Кратко рассмотрим несколько идей, развиваемых в статистике
объектов нечисловой природы для данных, лежащих в пространствах произвольного вида.
Они нацелены на решение классических задач описания данных, оценивания, проверки
гипотез - но для неклассических данных, а потому неклассическими методами.
Первой обсудим проблему определения средних величин. В
рамках теории измерений удается указать вид средних величин, соответствующих тем
или иным шкалам измерения. Теория измерений [7, 136, 137], в середине ХХ в. рассматривавшаяся
как часть математического обеспечения психологии, к настоящему времени признана
общенаучной дисциплиной. Современные достижения рассмотрены в статьях [198, 290
-292].
В классической математической статистике средние величины
вводят с помощью операций сложения (выборочное среднее арифметическое, математическое
ожидание) или упорядочения (выборочная и теоретическая медианы). В пространствах
произвольной природы средние значения нельзя определить с помощью операций сложения
или упорядочения. Теоретические и эмпирические средние приходится вводить как решения
экстремальных задач. Теоретическое среднее определяется как решение задачи минимизации
математического ожидания (в классическом смысле) расстояния от случайного элемента
со значениями в рассматриваемом пространстве до фиксированной точки этого пространства
(минимизируется указанная функция от этой точки). Для получения эмпирического среднего
математическое ожидание берется по эмпирическому распределению, т.е. берется сумма
расстояний от некоторой точки до элементов выборки и затем минимизируется по этой
точке (примером является медиана Кемени [143]). При этом как эмпирическое, так и
теоретическое средние как решения экстремальных задач могут быть не единственными
элементами рассматриваемого пространства, а являться некоторыми множествами таких
элементов, которые могут оказаться и пустыми. Тем не менее удалось сформулировать
и доказать законы больших чисел для средних величин, определенных указанным образом,
т.е. установить сходимость (в специально определенном смысле) эмпирических средних
к теоретическим [5, 16, 293 - 295].
Оказалось, что методы доказательства законов больших чисел
допускают существенно более широкую область применения, чем та, для которой они
были разработаны. А именно, удалось изучить асимптотику решений экстремальных статистических
задач, к которым, как известно, сводится большинство постановок прикладной статистики.
В частности, кроме законов больших чисел установлена и состоятельность оценок минимального
контраста, в том числе оценок максимального правдоподобия и робастных оценок. К
настоящему времени подобные оценки изучены также и в интервальной статистике. Полученные
результаты относительно асимптотики решений экстремальных статистических задач применяются
в работах [296 - 300].
В статистике в пространствах произвольной природы большую
роль играют непараметрические оценки плотности, используемые, в частности, в различных
алгоритмах регрессионного, дискриминантного, кластерного анализов. В нечисловой
статистике предложен и изучен ряд типов непараметрических оценок плотности в пространствах
произвольной природы, в том числе в дискретных пространствах [175, 301 - 306]. В
частности, доказана их состоятельность, изучена скорость сходимости и установлен
(для ядерных оценок плотности) примечательный факт совпадения наилучшей скорости
сходимости в произвольном пространстве с той, которая имеет быть в классической
теории для числовых случайных величин [125].
Дискриминантный, кластерный, регрессионный анализы в пространствах
произвольной природы основаны либо на параметрической теории - и тогда применяется
подход, связанный с асимптотикой решения экстремальных статистических задач - либо
на непараметрической теории - и тогда используются алгоритмы на основе непараметрических
оценок плотности [36].
Для анализа нечисловых, в частности, экспертных данных
весьма важны методы классификации [307 - 313]. Обзоры таких методов и наши научные
результаты даны в работах [65, 120, 134, 176, 180, 314 - 320]. Интересно движение
мысли в другом направлении в рамках новой парадигмы (см. разд. 2.1 настоящей монографии),
согласно которой наиболее естественно ставить и решать задачи классификации, основанные
на использовании расстояний или показателей различия, именно в рамках статистики
объектов нечисловой природы (а не, скажем, многомерного статистического анализа).
Это касается как распознавания образов с учителем (другими словами, дискриминантного
анализа), так и распознавания образов без учителя (т.е. кластерного анализа). Аналогичным
образом задачи многомерного шкалирования, т.е. визуализации данных [141, 142, 321],
также естественно отнести к статистике объектов нечисловой природы.
Для проверки гипотез в пространствах нечисловой природы
могут быть использованы статистики интегрального типа, в частности, типа омега-квадрат
[71, 75, 161, 146, 173, 322]. Любопытно, что предельная теория таких статистик,
построенная первоначально в классической постановке [323], приобрела естественный
(завершенный, изящный) вид именно для пространств произвольного вида [149, 324],
поскольку при этом удалось провести рассуждения, опираясь на базовые математические
соотношения, а не на те частные (с общей точки зрения), что были связаны с конечномерным
пространством.
Представляют практический интерес результаты, связанные
с конкретными областями статистики объектов нечисловой природы, в частности, со
статистикой нечетких множеств [85] и со статистикой случайных множеств (напомним,
что теория нечетких множеств в определенном смысле сводится к теории случайных множеств),
с непараметрической теорией парных сравнений и люсианов (бернуллиевских бинарных
векторов), с аксиоматическим введением метрик в конкретных пространствах объектов
нечисловой природы, а также с рядом других конкретных постановок. Отметим бурный
рост интереса со стороны прикладников к математическому аппарату теории нечеткости
[138, 325 - 328].
Результаты контроля штучной продукции по альтернативному
(бинарному, дихотомическому) признаку представляют собой последовательности из 0
и 1 – объекты нечисловой природы, а потому теорию статистического контроля относят
к нечисловой статистике [163, 287]. В рамках новой парадигмы статистических методов,
шире, математических методов экономики постоянно публикуются работы по этой тематике,
предназначенные для специалистов по статистическим методам управления качеством
продукции [159, 160, 224, 329 - 332]. Для служб контроллинга особенно важны методы
статистического контроля процессов, предназначенные для выявления отклонений методом
контрольных карт [97, 158, 177, 333].
При статистическом анализе нечисловых данных возникает
необходимость оценивать параметры модели. Вместо метода максимального правдоподобия
целесообразно применять метод одношаговых оценок [334 - 337].
Интенсивно ведется разработка новых методов анализа конкретных
видов нечисловых данных. Так, С.А. Смоляк рассматривает проблему восстановления
функции многих переменных по ее точным или приближенным значениям в отдельных точках.
Для функций числовых переменных – это обычная задача интерполяции, однако он решает
задачу восстановления функции от номинальных или порядковых переменных и предлагает
эвристические методы, основанные на формализации дискретного аналога понятия «гладкости»
функции [338, 339]. А.Н. Горбач и Н.А. Цейтлин на основе практических потребностей
(прежде всего, потребностей маркетинга) обосновывают необходимость построения статистической
теории спонтанных последовательностей, вводят расстояния между ними [340] и разрабатывают
методы анализа этого нового вида объектов нечисловой природы [341]. Бурно развивается
раздел нечисловой статистики, посвященный организационным структурам [9, 56, 342
- 347].
Статистика объектов нечисловой природы порождена потребностями
практики, прежде всего в области экспертных оценок. Вполне естественно, что названия
сборников трудов неформального научного коллектива, развивающего нечисловую статистику,
начинались со слов «Экспертные оценки» [348 - 351]. Различным вопросам теории и
практики экспертных оценок посвящен ряд монографий, подготовленных членами нашего
научного коллектива [52, 54, 55, 59, 145, 352 - 355]. Научные результаты последних
лет постоянно публикуются в журналах «Заводская лаборатория» [356 - 365], «Автоматика
и телемеханика» [202, 366 - 368], "Научном журнале КубГАУ" [135, 369,
370] и других [371, 372].
Экспертные методы, как и статистические, активно используются
при прогнозировании. Тематике прогнозирования наш «незримый коллектив» уделяет значительное
место [169, 170, 373 - 375]. Отметим цикл исследований по разработке научных основ
создания автоматизированной системы прогнозирования и предотвращения авиационных
происшествий [376 - 380].
Как показано в разд. 3.1, одна из основных областей непараметрической
статистики – это ранговая статистика, т.е. основанная на рангах – номерах элементов
выборок в вариационных рядах. Ранги измерены в порядковых шкалах, а значения ранговых
статистик инвариантны относительно любых строго возрастающих преобразований - допустимых
преобразований в таких шкалах. Это означает, что существенную часть непараметрической
статистики [69, 380, 381] можно включить в нечисловую статистику. Тем более это
касается статистики интервальных данных, изучающей методы анализа нечисловых данных
конкретного вида – интервалов. Так, в учебнике [36] статистика интервальных данных
включена в нечисловую статистику. Однако в настоящей монографии мы предпочли рассмотреть
непараметрику, статистику интервальных данных и нечисловую статистику по отдельности.
В частности, потому, что статистика в пространствах произвольной природы является
центральной областью только для последнего из трех рассмотренных здесь направлений
прикладной статистики.
Вопросы внедрения математических методов исследования всегда
были в центре внимания нашего творческого сообщества, а потому и нашего раздела
«Математические методы исследования» журнала «Заводская лаборатория» [224, 230,
382]. Подчеркивалось большое теоретическое и прикладное значение статистики объектов
нечисловой природы [155], необходимость перехода от отдельных методов анализа данных
к разработке высоких статистических технологий [51] и использования современных
систем внедрения математических методов, таких как система «Шесть сигм» и ее аналоги
[233]. Обсуждались проблемы программного обеспечения [223, 227, 228]. Однако приходится
констатировать, что создание линейки современных программных продуктов по нечисловой
статистике – пока дело будущего.
3.5.4. О некоторых нерешенных проблемах
нечисловой статистики
За каждым новым научным результатом открывается многообразие
неизвестного. Рассмотрим несколько конкретных постановок.
В статистике в пространствах общей природы получены аналоги
классического закона больших чисел. Но нет аналога центральной предельной теоремы.
Какова скорость сходимости эмпирических средних к теоретическим? Как сравнить различные
способы усреднения? В частности, что лучше применять для усреднения упорядочений
– медиану Кемени или среднее по Кемени (среднее отличается от медианы тем, что в
качестве показателя различия берется не расстояние Кемени, а его квадрат)? Какие
конкретные представители различных классов непараметрических оценок плотности достойны
рекомендации для использования в нацеленных на практическое применение алгоритмах
и программных продуктах анализа нечисловых данных?
До сих пор не проведена полная классификация классических
статистических методов с точки зрения теории измерений. Законченные результаты получены
только для теории средних [5, 7, 16, 54, 200]. А именно, доказано, что для измерений
в порядковой шкале в качестве средних можно использовать только порядковые статистики,
например, медиану (при нечетном объеме выборки). Среднее арифметическое применять
нельзя. Однако многочисленные эксперименты показывают, что упорядочения объектов
по средним арифметическим рангов и по медианам рангов в подавляющем большинстве
случаев совпадают или близки. Нужна теория, объясняющая этот экспериментальный факт.
Ряд вопросов поставлен в статье [383].
Все более широкое распространение получает теория нечеткости.
Давно установлено, что она в определенном смысле сводится к теории случайных множеств
[33, 85]. Требуется на основе предложенного (или иного, если будет найден) метода
сведения проанализировать различные теоретические и прикладные постановки теории
нечеткости и рассмотреть их в рамках вероятностно-статистических методов и моделей.
Представляет интерес оба направления движения - от нечетких множеств к случайным
и, в обратном направлении, от случайных множеств к нечетким.
Перейдем к классическим областям статистики. Начнем с обсуждения
влияния отклонений от традиционных предпосылок (ср. раздел 3.2 настоящей монографии).
В вероятностной теории статистических методов выборка обычно моделируется как конечная
последовательность независимых одинаково распределенных случайных величин или векторов.
В парадигме середины ХХ в. часто предполагают, что эти величины (вектора) имеют
нормальное распределение.
При внимательном взгляде совершенно ясна нереалистичность
приведенных классических предпосылок. Независимость результатов измерений обычно
принимается «из общих предположений», между тем во многих случаях очевидна их коррелированность.
Одинаковая распределенность также вызывает сомнения из-за изменения во времени свойств
измеряемых образцов, средств измерения и психофизического состояния специалистов,
проводящих измерения (испытания, анализы, опыты). Даже обоснованность самого применения
вероятностных моделей иногда вызывает сомнения, например, при моделировании уникальных
измерений (согласно классическим воззрениям, теорию вероятностей обычно привлекают
при изучении массовых явлений). И уж совсем редко распределения результатов измерений
можно считать нормальными [5, 16].
Итак, методы классической математической статистики обычно
используют вне сферы их обоснованной применимости. Какова влияние отклонений от
традиционных предпосылок на статистические выводы? В настоящее время об этом имеются
лишь отрывочные сведения. Приведем три примера.
Пример 1. Построение доверительного интервала
для математического ожидания обычно проводят с использованием распределения Стьюдента
(при справедливости гипотезы нормальности). Как следует их Центральной предельной
теоремы (ЦПТ) теории вероятностей, в асимптотике (при большом объеме выборки) такие
расчетные методы дают правильные результаты (из ЦПТ вытекает использование квантилей
нормального распределения, а из классической теории - квантилей распределения Стьюдента,
но при росте объема выборки квантили распределения Стьюдента стремятся к соответствующим
квантилям нормального распределения). Подробнее об этом см. в статье [165].
Пример 2. Для проверки однородности двух
независимых выборок (на самом деле, как показано в разд. 3.1.1 настоящей монографии,
- для проверки равенства математических ожиданий) обычно рекомендуют использовать
двухвыборочный критерий Стьюдента. Предпосылки его использования – это нормальность
распределений, соответствующих выборкам, и равенство их дисперсий. Что будет при
отклонении от нормальности распределений, из которых взяты выборки, от нормальности?
Если объемы выборок равны или если дисперсии совпадают, то в асимптотике (когда
объемы выборок безгранично возрастают) классический метод является корректным. Если
же объемы выборок существенно отличаются или дисперсии различны, то критерий Стьюдента
проверки гипотезы однородности применять нельзя, поскольку распределение двухвыборочной
статистики Стьюдента будет существенно отличаться от классического. Поскольку проверка
равенства дисперсий - более сложная задача, чем проверка равенства математических
ожиданий, то для выборок разного объема использовать двухвыборочную статистику Стьюдента
не следует, целесообразно применять критерий Крамера-Уэлча [5, 16, 71].
Пример 3. В задаче отбраковки (исключения)
резко выделяющихся наблюдений (выбросов) расчетные методы, основанные на нормальности,
являются крайне неустойчивыми по отношению к отклонениям от нормальности, что полностью
лишает эти методы научной обоснованности [5, 16, 156].
Примеры 1 - 3 показывают весь спектр возможных свойств
классических расчетных методов в случае отклонения от нормальности. Методы примера
1 оказываются вполне пригодными при таких отклонениях, примера 2 - пригодными в
некоторых случаях, примера 3 - полностью непригодными.
Итак, имеется необходимость изучения свойств расчетных
методов классической математической статистики, опирающихся на предположение нормальности,
в ситуациях, когда это предположение не выполнено. Аппаратом для такого
изучения наряду с методом Монте-Карло могут послужить предельные теоремы теории
вероятностей, прежде всего Центральная Предельная Теорема, поскольку интересующие
нас расчетные методы обычно используют разнообразные суммы. Пока подобное изучение
не проведено, остается неясной научная ценность, например, применения основанного
на предположении многомерной нормальности технологии факторного анализа к векторам
из переменных, принимающих небольшое число градаций и к тому же измеренных в порядковой
шкале. Очевиден выход за пределы предположений, в рамках которых разработана и обоснована
технология факторного анализа. Неясно, какими свойствами обладают результаты расчетов
вне области применимости этих расчетов.
Почему в современных условиях прежде всего необходимо изучение
классических алгоритмов, а не построение новых, специально предназначенных для работы
в условиях отклонения от классических предпосылок?
Во-первых, потому, что классические алгоритмы в настоящее
время наиболее распространены (прежде всего из-за пороков сложившейся системы образования
как прикладников, так и теоретиков). Например, для проверки однородности двух независимых
выборок традиционно используют критерий Стьюдента, при этом условия его применимости
не проверяют. Насколько обоснованными являются выводы? Как следует из примера 2,
во многих случаях выводы нет оснований подвергать сомнению, хотя они получены с
помощью некорректной процедуры.
Во-вторых, более новые подходы зачастую методологически
уязвимы. Так, известная робастная модель засорения Тьюки-Хубера нацелена на борьбу
с большими выбросами, которые зачастую физически невозможны из-за ограниченности
интервала значений измеряемой характеристики, в котором работает конкретное средство
измерения. Следовательно, модель Тьюки-Хубера-Хампеля [195, 196] имеет скорее теоретическое
значение, чем практическое. Сказанное, конечно, не обозначает, что следует прекратить
разработку, изучение и внедрение непараметрических и устойчивых методов, выделенных
выше как «точки роста» современной прикладной статистики.
Нерешенным проблемам статистики посвящены статьи [157,
384]. Одна из важных проблем - использование асимптотических результатов при конечных
объемах выборок. Конечно, естественно изучить свойства алгоритма с помощью метода
Монте-Карло. Однако из какого конкретного распределения брать выборки при моделировании?
От выбора распределения зависит результат. Кроме того, датчики псевдослучайных чисел
лишь имитируют случайность. До сих пор неизвестно, каким датчиком целесообразно
пользоваться в случае возможного безграничного роста размерности пространства (см.
развернутое обсуждение затронутых проблем в разделе 3.3. настоящей монографии).
Другая проблема – обоснование выбора одного из многих критериев
для проверки конкретной гипотезы. Например, для проверки однородности двух независимых
выборок можно предложить критерии Стьюдента, Крамера-Уэлча, Лорда, хи-квадрат, Вилкоксона
(Манна-Уитни), Ван-дер-Вардена, Сэвиджа, Н.В. Смирнова, типа омега-квадрат (Лемана-Розенблатта),
Реньи, Г.В. Мартынова и др. [71, 174]. Какой выбрать?
Критерии однородности проанализированы в монографии [385].
Естественных подходов к сравнению критериев несколько - на основе асимптотической
относительной эффективности по Бахадуру, Ходжесу-Леману, Питмену. И каждый критерий
является оптимальным при соответствующей альтернативе или подходящем распределении
на множестве альтернатив. При этом математические выкладки обычно используют альтернативу
сдвига, сравнительно редко встречающуюся в практике анализа реальных статистических
данных. Итог печален - блестящая математическая техника, продемонстрированная в
[385], не позволяет дать рекомендации для выбора критерия проверки однородности
при анализе реальных данных.
Проблемы разработки высоких статистических технологий поставлены
в программной статье [51] (см. также сайт "Высокие статистические технологии"
http://orlovs.pp.ru).
Используемые при обработке реальных данных статистические технологии состоят из
последовательности операций, каждая из которых, как правило, хорошо изучена, поскольку
сводится к оцениванию (параметров, характеристик, распределений) или проверке той
или иной гипотезы. Однако статистические свойства результатов обработки, полученных
в результате последовательного применения таких операций, мало изучены. Необходима
теория, позволяющая изучать свойства статистических технологий и так их конструировать,
чтобы обеспечить высокое качество обработки данных.
В заключение отметим, что развернутое описание статистики
нечисловых данных дано в монографиях [5, 7, 16, 36, 54]. При дальнейшем развитии
исследований важно опираться на современную методологию [50]. Работы в области статистики
объектов нечисловой природы активно продолжаются (см., например, [190, 295]). Эта
область, как видно из проведенного выше анализа, имеет много общего с системной
нечеткой интервальной математикой [32, 33, 263]. Статистика объектов нечисловой
природы соответствует новой парадигме математической статистики, разобранной, например,
в статье [63], более того, именно развитие этой научно-практической области стимулировало
появление новой парадигмы математической статистики, прикладной статистики, математических
методов экономики, шире - математических методов исследования (подробнее см. раздел
2.1 настоящей монографии, полностью посвященный новой парадигме математических методов экономики).