ЧАСТЬ 1-Я:
НЕЧЕТКОЕ
ИНТЕРВАЛЬНОЕ
ОБОБЩЕНИЕ
МАТЕМАТИКИ
ГЛАВА 1. ЧИСЛА И МНОЖЕСТВА – ОСНОВА СОВРЕМЕННОЙ МАТЕМАТИКИ
Математика – язык науки [1, с.18]. С появлением
новых объектов обсуждения язык развивается. «Между математикой и практикой
всегда существует двусторонняя связь; математика предлагает практике понятия и
методы исследования, которыми она уже располагает, а практика постоянно
сообщает математике, что ей необходимо» [1, c.53].
В настоящей работе мы рассматриваем
необходимость расширения математического аппарата с целью учета присущих реальности
нечеткости, интервальности, системности, а также основы соответствующего
предлагаемого нами нового перспективного направления теоретической и
вычислительной математики – системной нечеткой интервальной математики (СНИМ).
1.1.
Числа и множества
Анализируя, следуя А.Н. Колмогорову [2],
математику в ее историческом развитии, констатируем, что ее основой являются
действительные числа и множества. С прикладной точки зрения проанализируем эти
понятия, обсудим необходимость обобщений и наметим пути таких обобщений.
Несколько слов о том, что известно всем
специалистам, занимающимся разработкой и применением математических методов
исследования.
Натуральные, рациональные, действительные числа
используются в различных расчетах, основанных на математических моделях.
Глубокое изучение натуральных числе было осуществлено уже в Древней Греции. В
частности, была установлена бесконечность ряда натуральных чисел. Однако
строгая теория действительных чисел была построена только во второй половине
XIX в.
Тогда же была разработана
теория множеств, оказавшаяся весьма удобной для определения понятий и
построения математических моделей.
1.2. Функции
Кратко рассмотрим классическое
понятие функциональной зависимости или функции в математике.
Под функциональной зависимостью
(функцией) понимается закон или правило, по которому осуществляется отображение
множества числовых значений аргумента (область определения) на множество
числовых значений функции (область значений). В более общем определении область
определения и область значений могут быть произвольными множествами, не
обязательно числовыми.
Чтобы ввести функцию, задают
два множества А и В – область определения и область значений соответственно,
а функцию f описывают как отображение из А в В, т.е. как
множество всех пар (x, f(x), где х – элемент
множества А, а f(x) – соответствующий элемент множества В.
Второй пример – чтобы сформулировать вероятностно-статистическую модель какого-либо
реального явления, необходимо начать с пространства (множества) элементарных
событий и случайных величин – функций, для которых это пространство является
областью определения. Практика показывает, что игнорирование этих начальных определений
приводит к недоразумениям и ошибкам.
В математике для классических
функций обычно вводится большое количество различных ограничений, накладывающих
соответствующие ограничения на возможности их практического применения,
но позволяющих использовать и развивать математические конструкции, основанные
на описанном выше понятии функции в математике. К этим ограничениям, прежде
всего, относятся то, что множества значений аргумента и значений функции
являются числовыми, чаще всего континуальными (интервал, луч прямая), и между
ними существует взаимно-однозначное соответствие, т.е. функция является
биективной. Обычно предполагается также, что эти множества или не обладают
никакой структурой, или имеют алгебраическую структуру группы, кольца, поля или
аналогичную.
Вместе с тем при определении и
использовании функций необходимо различать математические, прагматические и
компьютерные числа, учитывать, что множества могут быть нечеткими или
случайными, элементами множеств могут быть не только числа, но и
лингвистические переменные, а также результаты измерений в различных шкалах, в
частности, в порядковых, кроме того множества могут образовывать системы. Всем
этим обусловлены существенные ограничения, которые накладываются на возможности
применения классического математического понятия функции для моделирования
социально-экономических объектов. Как следствие, возникает необходимость
разработки математического аппарата, снимающего эти ограничения. Кратко рассмотрим
совокупность поставленных вопросов вопросы ниже.
1.3. Парадоксы теории множеств
Практически сразу же после
появления теории множеств в ней были обнаружены противоречия (парадоксы). Один
из них – парадокс Бертрана Рассела, открытый им в
Пусть К— множество всех
множеств, которые не содержат себя в качестве своего элемента. Содержит ли К
само себя в качестве элемента? Если предположить, что содержит, то мы получаем
противоречие с «не содержат себя в качестве своего элемента». Если
предположить, что К не содержит себя, как элемент, то вновь возникает
противоречие, ведь К — множество всех множеств, которые не
содержат себя в качестве своего элемента, а значит, должно содержать все такие
множества, включая и себя.
Конечно, парадокс Рассела можно
сформулировать без употребления термина «множество». Пусть по определению брадобрей
- это тот, кто бреет тех¸ кто сам не бреется. Должен ли брадобрей брить
самого себя? Ответ «да» противоречит определению брадобрея. Ответ «нет» относит
брадобрея к тем, кто сам не бреется, следовательно, он себя сам должен брить.
Противоречие в парадоксе
Рассела возникает из-за использования в рассуждении внутренне противоречивого
понятия «множества всех множеств» и представления о возможности неограниченного
применения законов классической логики при работе с множествами [3, с.17-18].
Для преодоления этого парадокса было предложено несколько путей. Наиболее
известный состоит в построении для теории множеств непротиворечивой аксиоматической
теории, по отношению к которой являлись бы допустимыми все «действительно
нужные» (в некотором смысле) способы оперирования с множествами.
Было предложено несколько
возможных аксиоматических теорий, однако ни для одной из них до настоящего
момента не найдено доказательства непротиворечивости. Более того, как показал
К. Гёдель, доказав ряд теорем о неполноте, такого доказательства не может
существовать (в строго определенном смысле). Отметим, что парадоксы ставят под
сомнение не только теорию множеств и построенный на ее основе математический
инструментарий, но и схемы логических рассуждений. Приходится констатировать,
что здание современной математики и логики не имеет законченного обоснования,
построено на песке.
Самое интересное состоит в том,
что реально работающие математики, разрабатывающие теории и доказывающие теоремы,
решающие прикладные задачи, обычно совсем не обеспокоены существованием
парадокса Рассела и аналогичных ему. Они спокойно используют «наивную» теорию
множеств, не обращая внимание на возможность парадоксов и не обращаясь к той
или иной аксиоматической теории множеств. Заниматься такими теориями – удел
специалистов по математической логике.
Однако само наличие парадокса
Рассела и ему аналогичных показывает, что развитие математики не закончено.
Требуется развитие новых концепций. О некоторых из них пойдет речь ниже в настоящей
книге.
1.4. Основные понятия математики
Функции обычно определяются с
помощью множеств (области определения, области значений и подмножества
декартова произведения этих областей, задающего отображение области определения
на область значений. Число же является основным понятием математики с
древнейших времен, и стержнем развития математики вплоть до XIX в. является
развитие понятия числа. Еще один символ математики – фигуры и тела. Им
посвящена элементарная геометрия. Однако развитие этой области математики
прекратилось в начале ХХ в. Сейчас элементарная геометрия – предмет изучения в
средней школе, новые научные результаты в ней не появляются. Ее наследники -
современные геометрические дисциплины, такие, как проективная геометрия, дифференциальная
геометрия, общая топология, алгебраическая топология и др. – далеки от
реального мира. Их чисто теоретические результаты практически не используются
при решении прикладных задач.
Поэтому сосредоточимся на
рассмотрении только двух понятий - числа и множества.
ГЛАВА 2.
МАТЕМАТИЧЕСКИЕ, ПРАГМАТИЧЕСКИЕ
И КОМПЬЮТЕРНЫЕ ЧИСЛА
Обсудим базовое для математики понятие числа.
Будем считать, что читателю знакомы математические числа, о которых
рассказывают в средней и высшей школе - натуральные числа, дроби, действительные
(вещественные) числа. Комплексные числа и кватернионы не потребуют специального
обсуждения..
2.1. Реально используем не математические числа
Констатируем, что реально используемые – назовем
их прагматическими - числа зачастую не являются математическими. Так,
результаты измерений обычно задаются небольшим количеством значащих цифр (от 1
до 5).
Например, записывать численность жителей страны
с точностью до одного человека бессмысленно, поскольку указанная численность
весьма быстро меняется. Так, для России
начала текущего тысячелетия каждые пятнадцать секунд умирал человек, каждые
двадцать секунд появлялся новорожденный, следовательно, каждую минуту
численность населения уменьшалась на одного человека, а потому любое конкретное
значение этой численности с точностью до одного человека могло соответствовать
действительности в течение лишь одной минуты.
Экономические величины порядка миллиардов рублей
бессмысленно записывать с точностью до копеек. Надо – с точностью до миллионов.
Расчеты обычно ведем, используя десятичную
запись чисел. Напомним, что многие математические числа требуют для своей
записи бесконечно много десятичных знаков. Например, длина диагонали квадрата
со сторонами единичной длины не может быть выражена конечным числом десятичных знаков.
Как и длина окружности единичного диаметра и основание натуральных логарифмов.
И даже запись результата деления 1 на 3 состоит – в математике – из
бесконечного числа десятичных знаков: 0,3333333... Десятичная запись - это
декларативная форма представления числа, при которой число непосредственно
готово для использования в вычислениях, а представление чисел в виде формул -
это процедурная форма представления числа, подобная алгебраической, при которой
перед использованием числа для вычислений необходимо предварительно еще
вычислить его. Проблема в том, что это надо делать, но это не всегда
возможно, даже в принципе (например в случае иррациональных чисел).
На практике мы используем числа в десятичной
записи, иногда дроби. Так, результаты измерений обычно задаются небольшим
количеством значащих цифр (от 1 до 5). Т.е. пользуемся множеством чисел из
конечного числа элементов. Даже если обобщить арифметическую практику, принять,
что могут использоваться любые дроби (записываемые конечным количеством цифр), то
множество возможных числе оказывается счетным. А множество действительных чисел
имеет мощность континуума. Это означает, что почти все действительные числа
«существуют» только в теории, не встречаются при вычислениях. Хорошо известны
примеры таких чисел – длина диагонали квадрата с единичной стороной, площадь
круга радиуса 1, основание натуральных логарифмов. Их обозначают специальными
значками, а при вычислениях вынуждены использовать лишь приближенные значения.
Среди реально используемых чисел выделим два
класса – прагматические и компьютерные.
2.2. Прагматические числа
Прагматические числа – это результаты измерений,
прямых иди косвенных (рассчитанных по результатам прямых измерений), с помощью
средств измерений или экспертных. Инженеры хорошо знают, что результат
измерения всегда имеет погрешность, и указывают оценку погрешности (например,
вносят ее в технический паспорт средства измерения). Экономисты также понимают
принципиальную неточность своих расчетов, однако погрешность указывают не
всегда, хотя ясно, что при рассмотрении экономической величины порядка
нескольких миллиардов рублей нет смысла принимать во внимание копейки (а также
и сотни тысяч рублей).
Итак, при решении реальных задач мы вынуждены
пользоваться не математическими числами, а прагматическими. В результате
тождества чистой математики не всегда выполняются при анализе данных,
выраженных прагматическими числами.
Например, для выборочной дисперсии, рассчитанной
по выборке x1, x2, …, xn,
с точки зрения чистой математики справедливо тождество, которое проверяется с
помощью равносильных преобразований:
![]() .
.
Однако
расчеты по левой и правой частям этой формулы могут дать весьма различающиеся
значения. Например, рассмотрим ситуацию, когда xi = 109
+ yi, i = 1, 2, …, n, где yi –
величины порядка 1 (для определенности, от (-3) до 3). Тогда в левой части формулы
усредняются величины порядка 1 (числа от 0 до 9). А вот в правой из числа
порядка 1018 вычитается число также порядка 1018, т.е.
каждое из них имеет 18 знаков до запятой, и первые 17 из них должны совпасть.
Ясно, что из-за погрешностей вычислений такое совпадение будет не всегда.
Вычисления по правой части формулы для выборочной дисперсии могут число,
заметно отличающееся от результата расчета по левой части. Например, может
получиться отрицательное число. Приходилось видеть весьма недоумевающие лица
прикладников, у которых дисперсия получилась отрицательной.
2.3. Компьютерные числа
Компьютерные числа - результаты компьютерных
расчетов. Они могут быть получены не при анализе прагматических числе, а при
расчетах на условных примерах. Принципиальным является понятие машинного нуля.
Все математические числа, меньшие (по абсолютной величине) некоторой границы,
компьютер воспринимает как 0.
Как следствие существования «машинного нуля»,
некоторые результаты чистой математики неверны для расчетов на компьютерах.
Например, с точки зрения чистой математики сумма
![]()
при
росте числа слагаемых n стремится к
бесконечности (известно, что это сумма растет как lnn – натуральный
логарифм числа слагаемых). При расчетах на компьютере при росте числа слагаемых
наступит момент, когда очередное слагаемое станет меньше «машинного нуля»,
компьютер его (и все дальнейшие) воспримет как 0, сумма перестанет меняться,
останется конечной. Компьютер выдаст в качестве суммы ряда некоторое число (а
отнюдь не бесконечность. (Для конкретного случая можно разрабатывать специально
для него приспособленные алгоритмы расчетов. Но это не меняет общего вывода об
отличии компьютерных числе от математических.)
Констатируем, что реально используемые числа
зачастую не являются математическими. Из сказанного вытекает необходимость
модернизации основ математики. Нужен математический аппарат, позволяющий
оперировать с прагматическими и компьютерными числами.
Принципиальное различие математических,
прагматических и компьютерных чисел подробно обсуждает Е.М. Левич [4].
2.4. Два парадокса, связанные с числами
Приведем еще два парадокса, основанных на этом
различии [5].
Как уже отмечалось, все реальные результаты
наблюдений записываются рациональными числами (обычно десятичными числами с
небольшим - от 2 до 5 - числом значащих цифр). Как известно, множество
рациональных чисел счетно, а потому вероятность попадания значения непрерывной
случайной величины в него равно 0. Следовательно, все рассуждения, связанные с
моделированием непрерывными случайными величинами реальных результатов
наблюдений - это рассуждения о том, что происходит внутри множества меры 0.
Первый парадокс состоит в том, что множествами меры 0 в теории вероятностей
принято пренебрегать. Другими словами, с точки зрения теории вероятностей всеми
реальными данными можно пренебречь, поскольку они входят в одно фиксированное
множество меры 0. Т.е. реальный мир не существует с точки зрения математика.
Глубже проанализируем ситуацию. Сколько всего
чисел используется для записи реальных результатов наблюдений? Речь идет о
типовых результатах наблюдений, измерений, испытаний, опытов, анализов в
технических, естественнонаучных, экономических, социологических, медицинских и
иных исследованиях. Если эти числа в десятичной записи имеют вид (a,bcde)10k,
где a принимает значения от 1 до 9, а стоящие после запятой b, c, d,
e - от 0 до 9, в то время как показатель степени k меняется от
(-100) до +100, то общее количество возможных чисел равно 9х104х201=18 090 000,
т.е. меньше 20 миллионов. А с учетом знака – 40 миллионов. Второй парадокс,
усиливающий первый, состоит в том, что для описания реальных результатов
наблюдений вполне достаточно 40 миллионов отдельных символов. Бесконечность
натурального ряда и континуум числовой прямой - это математические абстракции,
надстроенные над дискретной и состоящей из конечного числа элементов
совокупностью прагматических чисел, отражающих результаты реальных измерений.
(При изменении числа значащих цифр принципиальный вывод не меняется.) Таким
образом, реальные данные лежат не только во множестве меры 0, но и в конечном
множестве, причем число элементов в этом множестве вполне обозримо.
Из сказанного вытекает необходимость модернизации
основ математики. Нужен математический аппарат, позволяющий оперировать с
прагматическими и компьютерными числами.
ГЛАВА 3. ОТ ОБЫЧНЫХ МНОЖЕСТВ – К НЕЧЕТКИМ
В теории множеств переход от принадлежности
элемента множеству к непринадлежности происходит скачком, что не всегда
соответствует представлениям о свойствах реальных совокупностей. Следовательно,
теорию множеств также необходимо модернизировать. Основное направление при этом
– использование множеств с размытыми границами.
В
За прошедшие десятилетия «пушистой» тематике
посвящены тысячи статей и книг. Появилось новое направление в вычислительной
математике и математической кибернетике – теория нечеткости. Выходят
международные научные журналы, проводятся конференции, в том числе и в нашей
стране. Обсудим, почему необходимо учитывать нечеткость при описании мышления и
восприятия человека.
3.1. Что такое «Куча»?
Знаменитый софизм «Куча» обсуждали еще
древнегреческие философы. Вот как можно его изложить: «Одно зерно не составляет
кучу. Если к тому, что не оставляет кучи, добавить одно зерно, то куча не
получится. Следовательно, никакое количество зерен не составляет кучу».
Рассуждение соответствует известному принципу
математической индукции. База индукции – это утверждение: «Одно зерно не
составляет кучу». Индуктивный переход: «Если к тому, что не оставляет кучи,
добавить одно зерно, то куча не получится». И заключение: «Совокупность n
зерен не составляет кучу при любом n». Другими словами: «Никакое
количество зерен не составляет кучу».
Полученное утверждение явно нелепо: каждый
согласится, что 100 миллионов зерен пшеницы – довольно большая куча (объемом
около 6 кубометров). Как же возникает столь абсурдный вывод?
О чем говорит этот софизм? В нем обсуждаются два
понятия – «несколько зерен» и «куча» - и показывается, что граница между ними в
мышлении людей и в отражающем это мышление естественном языке (русском,
английском, китайском, любом другом) нечетка, размыта.
В самом деле, разве можно указать такое число N,
что совокупность из N зерен – уже куча, а из (N-1) зерна – еще
нет? Можно ли допустить, например, что 325 647 зерен не образуют кучу, а
325 648 – образуют? Конечно, указание точной границы здесь бессмысленно.
Ни один человек не сможет различить эти две совокупности зерен.
Представим теперь, что проводится специальная
серия опытов: большому числу людей предлагают наборы из n зерен и
спрашивают: «Это куча?» И пусть никто не уклоняется от ответа.
Что будет происходить? При малом n все
единодушны: «Нет, это не куча, это всего лишь несколько зерен». При многих миллионах
зерен все тоже будут едины в своем мнении: «Это куча». А при промежуточных
значениях n мнения могут разделиться – одни выскажутся за «кучу», другие
против.
Результаты описанного эксперимент допускает
плодотворную интерпретацию: каждому числу зерен n можно сопоставить
число pn – долю опрошенных, которые считают n зерен
кучей. С такой точки зрения понятие «куча» описывается не одним числом –
границей между «несколькими зернами» и «кучей», а последовательностью pn,
n = 1, 2, …, члены которой равны нулю при малых n и единице – при
больших.
3.2. Обсуждение понятия «нечеткость» Борелем и Пуанкаре
Софизм «Куча» в начале ХХ в. обсуждал
французский математик Эмиль Борель. Он предложил описывать понятие «куча»
последовательностью pn, n = 1, 2, …, и указал способ
получения этой последовательности с помощью массового опроса. Исходил Э. Борель
из глубокого анализа понятия физической непрерывности, выполненного великим
математиком и физиком Анри Пуанкаре. В частности, Пуанкаре писал:
«… Непосредственные результаты опыта могут быть
выражены следующими соотношениями:
А = В, В = С, A < C,
которые можно рассматривать как формулу физической
непрерывности. Эта формула заключает в себе недопустимое разногласие с законом
противоречия; необходимость избежать его и заставила нас изобрести идею
математической непрерывности» [7, с.28].
Поясним мысль Пуанкаре. Пусть A(n)
– гиря весом в n граммов. Пусть эксперт сравнивает две гири «вручную»,
т.е. не используя весов. Очевидно, эксперт не в состоянии уловить разницу в
А(1000) = А(1001), А(1001) = А(1002),
…, А(1999) = А(2000).
Вместе с тем гири весом в
А(1000) < A(2000).
Очевидно, два заключения одного и того же
эксперта противоречат друг другу. В выводах эксперта нарушается транзитивность.
Наблюдаем парадокс того же типа, что и софизм «Куча». Сказанное показывает, что
процесс математического моделирования процессов измерений, в том числе
получения экспертных мнений, нетривиален.
Понятие «куча» размыто не только для
совокупности людей, но и для отдельно взятого человека. Представьте себе, что
вам предъявляют один за другим наборы зерен, спрашивая: «Это куча?» Что вы
будете отвечать? При малом числе зерен – «нет», при большом – «да», а при
промежуточном станете колебаться. Если экспериментатор настойчив, он вытянет у
вас ответ типа: «Это скорее куча, чем несколько зерен». А если он убедительно
потребует от вас оценить числом степень вашей уверенности, то добьется
чего-нибудь вроде: «Семьдесят пять шансов из ста за то, что это куча». В итоге
ваше личное мнение будет выражено последовательностью pn, n
= 1, 2, …, того же типа, что и мнение большой совокупности экспертов.
3.3. Человек мыслит нечетко
Понятия, используемые людьми, отнюдь не всегда
легко выразить числами. Например, что такое «оранжевый цвет»? Казалось бы,
ответить на этот вопрос нетрудно – достаточно указать на шкале электромагнитных
волн границы, между которыми лежит оранжевый цвет. В «Малой Советской
Энциклопедии» (
Но подумайте: неужели вы сможете ощутить разницу
в цвете при переходе на 1 микрометр – от 655,5 мкм (оранжевый цвет) к 656,5 мкм
(красный). Конечно, нет.
Размыты не только представления о цветах.
Представьте себе, например, множество петухов. Представили? А теперь скажите:
относится ли к нему леденцовый петушок на деревянной палочке? Задумались, не
так ли? Вот и здесь расплывчатость…
Описанные ситуации типичны. Понятия
естественного языка, с помощью которого мы общаемся друг с другом, как правило,
размыты.
Нечеткость свойственна не только естественному
языку, но и диалектам науки. Возьмем для примера физику. Зададимся вопросом:
можно ли указать длину предмета (для определенности в метрах) с точностью до
тридцатого знака после запятой? Вещество состоит из атомов, атомы из
электронов, протонов и нейтронов. Можно ли указать абсолютно точно положение
электрона? В квантовой механике получен принцип неопределенности: произведение
неопределенности в определении импульса частицы на неопределенность в
определении ее положения всегда больше вполне определенной величины –
постоянной Планка. Импульс электрона в атоме не может достигать сколь угодно
высоких значений (импульс – это произведение скорости на массу; скорость не
превосходит скорости света, масса электрона известна). Таким образом,
неопределенность импульса ограничена. Стало быть, неопределенность в положении
электрона всегда больше некоторой величины – согласно расчетам, примерно 10-
Бытует мнение, что непогрешимой четкостью
отличается язык математики. Однако это не так. Например, мы уже не раз
употребляли слово «множество». Повторим еще раз, это фундаментальное понятие
лежит в основе современной математики. Существует математическая теория
множеств. Как и во всякой математической теории, все ее положения базируются на
системе аксиом. Эту систему можно строить по-разному. Выражаясь языком
специалистов, теория множеств может быть аксиоматизирована различными
способами. В получающихся при этом разновидностях теории множеств некоторые
выводы оказываются прямо противоположными. Возьмем для примера так называемую
континуум-гипотезу. При одних аксиоматизациях она верна, при других – верно ее
отрицание.
Что же говорить о других менее точных науках?
Одному из авторов настоящей книги в свое время пришлось столкнуться с таким
любопытным фактом: по определению одной группы медиков «затяжное течение острой
пневмонии» имеет место в шести случаях из ста, по мнению другой – в
шестидесяти. Различие в 10 раз!
В подобных ситуациях возникает естественное
желание навести четкость в понятиях и представлениях. Однако часто разные
группы и даже отдельные лица понимают термины по-своему, например, как в только
что приведенном примере с термином «затяжное течение острой пневмонии». Удастся
ли договориться? Кроме того, в наведении четкости есть своя мера и своя опасная
грань, за которой излишняя четкость становится вредной.
3.4. Когда вредна излишняя четкость?
Например, при проведении некоторых
социологических и экспертных исследований интересуются мнениями опрашиваемых,
не учитывая, что эти мнения весьма нечетки или еще не сформировались. Вот
вопросы одной, взятой наугад, анкеты: «Что прежде всего необходимо вам для
счастья? Иметь интересную работу? Пользоваться уважением окружающих? Любить и
быть любимым? Иметь много денег? Приносить пользу людям?» Сумеете ли вы с
абсолютной уверенностью выбрать одну и только одну позицию из перечня? Ведь
организаторы опроса настаивают на четкости. С расчетом на нее обычно и
составляются анкеты. (Вспомним – ведь и мы, проводя мысленный опрос по поводу
софизма «Куча», запрещали уклоняться от ответа на вопрос: «Это куча?» - и
требовали отвечать либо «да», либо «нет».) И опрашивающие сами уже стараются сформулировать
свое мнение поотчетливее. Однако эти мнения зачастую имеют довольно слабую
связь с реальными представлениями людей, что порою приводит к существенным
ошибкам в прогнозировании на основе подобных социологических или экспертных
данных.
Разумно ли в таких ситуациях добиваться
предельной четкости? Взвешивая этот вопрос, обратимся еще раз к математике. Как
мы видели, даже в ней нет окончательной ясности с некоторыми важными понятиями.
Между тем математики в массе своей применяют эти понятия весьма широко и обычно
довольно успешно – эффективность математических методов в самых различных
сферах знания и практической деятельности общеизвестна. Точно также
естественный язык используется без особых затруднений, несмотря на свою
нечеткость.
Идеалом математических теорий считают
аксиоматические, в которых заданы исходные постулаты (аксиомы) и правила вывода
следствий из них. Однако сами математики аксиоматическими теориями почти
никогла не пользуются, поскольку с их помощью мозг человека не может ни получить
новое знание сам, ни осознать полученное другими. Так, группа французских
математиков, работавших под псевдонимом «Н. Бурбаки», решила вывести определение
натуральному числу 1 (единица) с помощью аксиоматической теории, относящейся к
математической логике. Они это сделали, но для строгого определения
понадобилась толстая книга. Другой пример – элементарная геометрия. Широко
известна ее система аксиом. Однако при решении задач, при преподавании ею не
пользуются, поскольку невозможна для воприятия цепочка рассуждений от аксиом
до, например, теоремы Пифагора.
Итак, мы мыслим нечетко, и это нам не мешает.
Более того, именно нечеткость мыслей и слов позволяет нам понимать друг друга,
приходить к соглашению и действовать совместно. Только представьте, что было
бы, если бы постоянно приходилось уточнять используемые в разговоре слова!
Иногда приходится это делать – и тогда появляются огромные тексты договоров и
инструкций. Стандартная инструкция к мобильному телефону занимает больше 200
страниц – кто же ее полностью прочитает, прежде чем сделает звонок…
Мы убедились, что, во-первых, мышлению человека
органически присуща нечеткость, а во-вторых, эта нечеткость ничуть не зазорна:
она естественна. Значит, при разработке математических моделей мышления и
поведения человека надо учитывать эту нечеткость – игнорировать ее нельзя!
Необходим соответствующий математический аппарат, моделирующий нечеткость
восприятия, познания и принятия решений.
Но какие математические понятия следует при этом
применять?
В основании современной математики лежит понятие
множества. Чтобы задать то или иное конкретное множество предметов (объектов,
элементов), надо относительно каждого предмета уметь ответить на вопрос:
«Принадлежит данный предмет данному множеству или не принадлежит?» Но мы уже
видели, что границы понятий, как правило, размыты, так что четкий ответ на
подобный вопрос возможен далеко не всегда. Значит, для описания нечеткости надо
взять за основу понятие множества, несколько отличающееся от привычного, более
широкое, чем оно.
ГЛАВА 4. ТЕОРИЯ
НЕЧЕТКИХ МНОЖЕСТВ
И «НЕЧЕТКОЕ УДВОЕНИЕ» МАТЕМАТИКИ
Чтобы определить нечеткое множество, надо
сначала задать совокупность всех тех элементов, для которых имеет смысл говорить
о мере их принадлежности рассматриваемому нечеткому множеству. Эта совокупность
называется универсальным множеством. Например, для «кучи» - это множество
натуральных чисел, для описания цветов – отрезок шкалы электромагнитных волн,
соответствующий видимому свету.
4.1. Функции принадлежности
Пусть A - некоторое универсальное
множество. Подмножество B множества A характеризуется своей
характеристической функцией
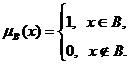 (1)
(1)
Что такое нечеткое множество? Обычно говорят,
что нечеткое подмножество C множества A характеризуется своей
функцией принадлежности ![]() . Значение функции принадлежности в точке х показывает
степень принадлежности этой точки нечеткому множеству. Нечеткое множество
описывает неопределенность, соответствующую точке х – она одновременно и
входит, и не входит в нечеткое множество С. За вхождение -
. Значение функции принадлежности в точке х показывает
степень принадлежности этой точки нечеткому множеству. Нечеткое множество
описывает неопределенность, соответствующую точке х – она одновременно и
входит, и не входит в нечеткое множество С. За вхождение - ![]() шансов, за второе –
(1-
шансов, за второе –
(1- ![]() ) шансов.
) шансов.
Если функция принадлежности ![]() имеет вид (1) при некотором
B, то C есть обычное (четкое) подмножество A. Таким образом,
теория нечетких множество является не менее общей математической дисциплиной,
чем обычная теория множеств, поскольку обычные множества – частный случай
нечетких. Соответственно можно ожидать, что теория нечеткости как целое
обобщает классическую математику. Однако позже мы увидим, что теория нечеткости
в определенном смысле сводится к теории случайных множеств и тем самым является
частью классической математики. Другими словами, по степени общности обычная
математика и нечеткая математика эквивалентны. Однако для практического
применения в теории принятия решений описание и анализ неопределенностей с
помощью теории нечетких множеств весьма плодотворны.
имеет вид (1) при некотором
B, то C есть обычное (четкое) подмножество A. Таким образом,
теория нечетких множество является не менее общей математической дисциплиной,
чем обычная теория множеств, поскольку обычные множества – частный случай
нечетких. Соответственно можно ожидать, что теория нечеткости как целое
обобщает классическую математику. Однако позже мы увидим, что теория нечеткости
в определенном смысле сводится к теории случайных множеств и тем самым является
частью классической математики. Другими словами, по степени общности обычная
математика и нечеткая математика эквивалентны. Однако для практического
применения в теории принятия решений описание и анализ неопределенностей с
помощью теории нечетких множеств весьма плодотворны.
Обычное подмножество можно было бы отождествить
с его характеристической функцией. Этого математики не делают, поскольку для
задания функции (в ныне принятом подходе) необходимо сначала задать множество.
Нечеткое же подмножество с формальной точки зрения можно отождествить с его
функцией принадлежности. Однако термин «нечеткое подмножество» предпочтительнее
при построении математических моделей реальных явлений.
Теория нечеткости является обобщением
интервальной математики (о ней подробнее ниже), в которой для описания реальных
объектов вместо чисел используются интервалы. Действительно, функция
принадлежности
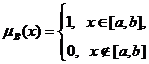 (2)
(2)
задает
интервальную неопределенность – про рассматриваемую величину известно лишь, что
она лежит в заданном интервале [a,b]. Тем самым описание
неопределенностей с помощью нечетких множеств является более общим, чем с
помощью интервалов.
4.2. Современная теория нечетких множеств
Начало современной теории нечеткости положено
работой
За десятилетия, прошедшие с появления работы Л.А.
Заде [6], «пушистой» тематике посвящены тысячи статей и книг. Выполнено
достаточно много как теоретических, так и прикладных работ. Появилось новое
направление в прикладной математике – теория нечеткости. Выходят международные
научные журналы, проводятся конференции. В нашей стране концепция Заде активно
обсуждалась еще в 60-е и 70-е гг. (см. обзор в [8]), однако первая книга
российского автора по теории нечеткости вышла лишь в
Л.А. Заде рассматривал теорию нечетких множеств
как аппарат анализа и моделирования гуманистических систем, т.е. систем, в
которых участвует человек. Его подход опирается на предпосылку о том, что
элементами мышления человека являются не числа, а элементы некоторых нечетких
множеств или классов объектов, для которых переход от «принадлежности» к «непринадлежности»
не скачкообразен, а непрерывен. В настоящее время методы теории нечеткости
используются почти во всех прикладных областях, в том числе при управлении
предприятием, качеством продукции и технологическими процессами. Нет необходимости
связывать теорию нечеткости только с гуманистическими системами.
Л.А. Заде использовал термины «теория нечетких
множеств» и «нечеткая логика». Мы предпочитаем говорить о теории нечеткости.
Термин «нечеткая логика» не является синонимом к термину «теория нечеткости»,
поскольку логика – это наука о мышлении человека, а теория нечеткости
применяется не только для моделирования мышления. Нечеткая логика – это часть
теории нечеткости.
Аппарат теории нечеткости довольно громоздок. В
качестве примера дадим определения теоретико-множественных операций над
нечеткими множествами. Пусть C и D –
два нечетких подмножества универсального множества A с функциями принадлежности
![]() и
и ![]() соответственно. Пересечением
соответственно. Пересечением ![]() , произведением CD, объединением
, произведением CD, объединением ![]() , отрицанием
, отрицанием ![]() , суммой C+D
называются нечеткие подмножества A с функциями принадлежности
, суммой C+D
называются нечеткие подмножества A с функциями принадлежности
![]()
![]()
![]()
соответственно.
Для демонстрации специфики нечетких множеств
рассмотрим некоторые их свойства.
В дальнейшем считаем, что все рассматриваемые
нечеткие множества являются подмножествами одного и того же множества Y.
4.3. Законы де Моргана для нечетких множеств
Как известно, законами де Моргана называются
следующие тождества алгебры множеств
![]() (2)
(2)
Теорема
1. Для нечетких множеств справедливы тождества
![]() (3)
(3)
![]() (4)
(4)
Доказательство теоремы 1 состоит в
непосредственной проверке (как это сделано ниже при доказательстве теоремы 2)
справедливости соотношений (3) и (4) путем вычисления значений функций
принадлежности участвующих в этих соотношениях нечетких множеств на основе
определений, данных выше.
Тождества (3) и (4) назовем законами де
Моргана для нечетких множеств. В отличие от классического случая
соотношений (2), они состоят из четырех тождеств, одна пара которых относится к
операциям объединения и пересечения, а вторая - к операциям произведения и
суммы. Как и соотношение (2) в алгебре множеств, законы де Моргана в алгебре
нечетких множеств позволяют преобразовывать выражения и формулы, в состав которых
входят операции отрицания.
4.4. Дистрибутивный закон для нечетких множеств
Некоторые свойства операций над множествами не
выполнены для нечетких множеств. Так, ![]() за исключением случая,
когда А - «четкое» множество (т.е. функция принадлежности принимает
только значения 0 и 1).
за исключением случая,
когда А - «четкое» множество (т.е. функция принадлежности принимает
только значения 0 и 1).
Верен ли дистрибутивный закон для нечетких
множеств? В литературе иногда расплывчато утверждается, что «не всегда». Внесем
полную ясность.
Теорема 2. Для любых нечетких
множеств А, В и С
![]() (5)
(5)
В то же время равенство
![]() (6)
(6)
справедливо тогда и только тогда, когда при всех
![]()
![]()
Доказательство. Фиксируем произвольный элемент ![]() . Для сокращения записи обозначим
. Для сокращения записи обозначим ![]() Для доказательства
тождества (5) необходимо показать, что
Для доказательства
тождества (5) необходимо показать, что
![]() (7)
(7)
Рассмотрим различные упорядочения трех чисел a,
b, c. Пусть сначала ![]() Тогда левая часть
соотношения (7) есть
Тогда левая часть
соотношения (7) есть ![]() а правая
а правая ![]() т.е. равенство (7)
справедливо.
т.е. равенство (7)
справедливо.
Пусть ![]() Тогда в соотношении
(7) слева стоит
Тогда в соотношении
(7) слева стоит ![]() а справа
а справа ![]() т.е. соотношение (7)
опять является равенством.
т.е. соотношение (7)
опять является равенством.
Если ![]() то в соотношении (7)
слева стоит
то в соотношении (7)
слева стоит ![]() а справа
а справа ![]() т.е. обе части снова
совпадают.
т.е. обе части снова
совпадают.
Три остальные упорядочения чисел a, b, c разбирать
нет необходимости, поскольку в соотношение (6) числа b и c входят
симметрично. Тождество (5) доказано.
Второе утверждение теоремы 2 вытекает из того,
что в соответствии с определениями операций над нечеткими множествами
![]()
и
![]()
Эти два выражения совпадают тогда и только
тогда, когда, когда ![]() что и требовалось
доказать.
что и требовалось
доказать.
Определение 1. Носителем нечеткого
множества А называется совокупность всех точек ![]() , для которых
, для которых ![]()
Следствие теоремы 2. Если носители нечетких
множеств В и С совпадают с У, то равенство (6) имеет место
тогда и только тогда, когда А - «четкое» (т.е. обычное, классическое, не
нечеткое) множество.
Доказательство. По условию ![]() при всех
при всех ![]() . Тогда из теоремы 2 следует, что
. Тогда из теоремы 2 следует, что ![]() т.е.
т.е. ![]() или
или ![]() , что и означает, что А - четкое множество.
, что и означает, что А - четкое множество.
4.5. Нечеткое удвоение математики
Поскольку теория множеств – основа современной
математики, понятие нечеткости позволяет «удвоить математику»: заменяя обычные
множества нечеткими, мы можем каждому математическому объекту (понятию,
термину) поставить в соответствие его нечеткий аналог. Рассматривают, например,
нечеткие классификации, упорядочения, логики, теоремы, алгоритмы, правила принятия
решений и т.д., и т.п. Чтобы это перечисление не выглядело для неискушенного
читателя просто набором слов, разберем несколько примеров.
Первым в нашем списке упомянуты классификации.
Под классификацией имеется в виду разбиение совокупности элементов на классы –
группы сходных между собой элементов [10]. В четкой классификации каждый
элемент относится к одному определенному классу. А в размытой – задается
функция принадлежности элемента различным классам. Расплывчатая классификация
обычно больше соответствует реальности, чем строгая.
Представьте себе – идет вам навстречу человек.
Лишь в редких случаях вы с уверенностью скажете: «Это блондин». Чаще о цвете
волос придется высказаться уклончиво: «Скорее шатен, чем брюнет». Так что,
признайтесь, классификация встречных по цвету волос у вас нечеткая. Поэтому
пушистые классификации надо изучать – этим и занимается соответствующая часть
туманной математики.
Пример нечеткого упорядочения нетрудно найти в магазине,
присмотревшись к поведению нерешительного покупателя. Надо приобрести часы, да
вот какие? И «Слава» нравится, и «Ракета» современна. Другими словами, и
«Слава» на сколько-то процентов привлекательна, и «Ракета» - тут и появляются
функции принадлежности марок часов к множеству привлекательных. А ведь
сравнивать можно по многим критериям – по внешнему виду, по цене, по надежности
и т.д. Для каждого критерия – своя туманность, нужно эти расплывчатости сводить
вместе, чтобы принять решение – покупать или не покупать… А для описания всего
этого надо развивать математическую теорию нечетких упорядочений, принятия
расплывчатых решений…
А что такое нечеткая логика? С позиций обычной
логики утверждения бывают либо истинные, либо ложные. А в размытой логике –
утверждения в какой-то степени истинны, а в какой-то – ложны. Присмотритесь к
себе – очень многое, что вы говорите и думаете, имеет лишь относительную
истинность. Например, вы сказали: «Вчера я хорошо поработал». Сразу возникают
вопросы: «А разве нельзя было поработать еще лучше? Что значит – хорошо?»
Согласитесь: ваши слова истинны не на сто процентов. И подобное можно сказать
не только по части житейских высказываний, но и относительно утверждений науки.
Вот, скажем, как выглядит нечеткий аналог теоремы
о том, что три медианы треугольника пересекаются в одной точке:
«Пусть АВ, ВС и СА – примерно прямые линии,
которые образуют примерно треугольник с вершинами А, В и С. Пусть М1,
М2, М3 – примерно середины сторон ВС, СА и АВ соответственно.
Тогда примерно прямые линии АМ1, ВМ2 и СМ3
образуют примерно треугольник Т1Т2Т3, который
более или менее мал относительно треугольника АВС» [11, с.137-138].
Конечно, эта формулировка становится разумной
только после того, как будет точно определен смысл слов «примерно» и «более или
менее мал». Вот как, скажем, можно уточнить понятие «примерно отрезок АВ»: под
ним будем понимать любую кривую, проходящую через точки А и В, такую, что
расстояние (в обычном смысле) от любой точки кривой до отрезка АВ мало по
отношению к длине АВ. Остается выяснить, что значит «мало». Ответ может
даваться нечетким множеством со своей функцией принадлежности.
Нечеткие алгоритмы – тоже не экзотика. Многие
инструкции в какой-то мере расплывчаты. Беря поваренную книгу, любая хозяйка
знает: чтобы блюдо удалось, к печатным рецептам надо добавить свою
интерпретацию, а также смекалку и удачу. Если же поручить роботу готовить суп,
то придется нечеткие слова естественного языка определять с помощью функций
принадлежности. Например, определить понятие «варить до готовности». Значит,
нужна соответствующая математическая теория – теория нечетких алгоритмов.
Продолжать можно без конца. «Удвоение
математики» - настоятельная необходимость. Однако «скоро сказка сказывается, да
нескоро дело делается». Теория нечеткости молода. Всего лишь почти пятьдесят
лет! Миг по сравнению с двадцатью пятью веками геометрии!
4.6. Польза нечеткости
Несмотря на свою молодость, нечеткая математика
находит успешные приложения. Примеры описания неопределенностей с помощью
нечетких множеств часто приводятся в литературе. Например, в [12] приведено
описание понятия «богатый человек», разобрана разработка методики
ценообразования на основе теории нечетких множеств.
Поскольку размытость свойственна самому
восприятию и мышлению человека, теория нечеткости используется прежде всего в
науках, изучающих эти стороны человеческой натуры: в психологии, в социологии,
в исследовании операций… Зачастую в ходе социологических и экспертных опросов
человеку легче сформулировать свое мнение расплывчато, а не предельно четко, и
размытый ответ является к тому же более адекватным. Поэтому создаются методы
сбора и анализа нечеткой информации.
Пример – система управления рыбным промыслом.
Исходная информация – сообщения с судов и мнения экспертов. Они нечетки: в
таком-то квадрате количество рыбы оценивается величиной между таким-то нижним и
таким-то верхним пределами, суда стоит направить туда-то, и т.д. По этим данным
согласно алгоритмам нечеткой математики производится оптимизация в расплывчатых
условиях. И затем выдается четкий приказ: каким судам куда идти. (Результат его
выполнения – количество выловленной рыбы – разумеется, нельзя предсказать
точно: нечеткость исходной информации не устраняется четкостью приказа.)
Аппарат теории нечеткости оказался полезным в
самых разных прикладных областях – в химической технологии и в медицине, при
управлении движением автотранспорта и в экономической географии, в теории
надежности и при контроле качества продукции.
Группа химиков во главе с академиком В.В. Кафаровым
изучала процессы, протекающие в ванне стекловаренной печи при производстве
листового стекла. Основное при этом – исследовать распределение поля температур
в бассейне ванны. Можно это делать в классическом стиле, рассматривая
дифференциальное уравнение в частных производных, которому удовлетворяет поле
температур. Уравнение это можно решить хорошо известным среди специалистов
методом Фурье. Но пушистые химики предлагают другой подход. В соответствии с
ним приращение температуры при переходе от одной точки бассейна печи к другой является
нечетким. Химики рассчитали поле температур размытым методом и сравнили свои
результаты с числами, полученными по методу Фурье. Относительное расхождение не
превышало 6%, что считается пренебрежимо малым в этой области. Но компьютерные
расчеты заняли в 5-6 раз меньше машинного времени. В этом и состояла польза
применения методлов теории нечеткости.
4.7. Парадокс теории нечеткости
В концепции размытости есть свой подход к
познанию мира, к построению математических моделей реальных явлений. Хочется во
всем увидеть нечеткость и смоделировать эту нечеткость подходящим расплывчатым
объектов.
Мы уже рассмотрели много примеров, когда такой
подход разумен и полезен. Возникает искушение провозгласить тезис: «Все в мире
нечетко». Он выглядит особенно привлекательно в связи с большой вредностью
излишней, обманчивой четкости. Но можно ли этот тезис провести последовательно?
Нечеткое множество задается функцией
принадлежности. Обратим внимание на аргумент и на значение этой функции. Четкие
это объекты или размытые? Тезис «все в мире нечетко» наталкивает на мысль, что
они расплывчаты.
Действительно, вспомним примеры – скажем, софизм
«Куча». Сначала поговорим про аргумент функции, т.е. про число зерен,
относительно которых решается вопрос: «Куча это или не куча?» Число зерен в
достаточно большой совокупности – разве может оно быть известно абсолютно
точно? Как ни считай зерна – вручную, на вес, автоматически – всегда возможны
ошибки (человек может ошибиться, автоматические весы измеряют с погрешностями
(описаны в паспорте средства измерения), и даже – могут сломаться…). Или
пройдемся по остальным примерам – всюду то же самое.
А теперь – о значении функции принадлежности.
Оно уж тем более нечетко! Мнение человека – разве имеет смысл выражать его хотя
бы с тремя значащими цифрами? В социологии общепринято, что человек в словесных
оценках обычно не может различить больше трех, в лучшем случае – шести градаций
(эти величины вытекают и из математической модели, разработанной в [13]).
Отсюда можно вывести с помощью соответствующего расчета, что функция
принадлежности, отражающее мнение одного человека, может быть определена лишь с
точностью 0,17 – 0,33. Так что мнение отдельного лица следовало бы выразить не
тонкой кривой – графиком функции, а довольно широкой полосой. Если же функция
принадлежности строится как среднее (среднее арифметическое или медиана)
индивидуальных мнений, то и тогда ее значения известны отнюдь не абсолютно
точно из-за того, что опрашиваемая совокупность людей обычно не включает и
малой доли тех, кого можно было опросить. И только если значения функции
принадлежности определяются по аналитическим формулам, они известны абсолютно
точно. Но тогда возникает законный вопрос: насколько обоснованы сами эти
формулы? Обычно оказывается, что обоснование у них довольно слабое…
Каков итог? И аргумент, и значение функции
принадлежности, как правило, необходимо считать нечеткими.
Что же из этого следует? Начнем опять с
аргумента. Он сам является не строго определенной величиной, а некоторым нечетким
множеством величин, значит, описывается некоторой функцией принадлежности –
задается каким-то своим аргументом. А этот новый аргумент – он ведь тоже
нечеток! Опять появляется функция принадлежности – с каким-то третьим
аргументом. И так далее.
Остановимся ли мы когда-либо на этом пути? Если
остановимся, то должны будем использовать четкие значения аргумента – а это
противоречит тезису «все в мире нечетко». В соответствии с эти тезисом четкие
значения фиктивны, им ничто в мире не соответствует. Если же не остановимся, то
получим бесконечную последовательность нечетких моделей, в которой из каждого
размытого множества, как из матрешки, вылезает новая расплывчатость. Возможны
ли при этом обоснованные расчеты?
Далее, значение функции принадлежности также
необходимо считать нечетким. Л.А. Заде разработал аппарат пушистых множеств с
размытыми функциями принадлежности, благоразумно не вдаваясь при этом в
рассуждения о том, на каком же шагу считать функции принадлежности четкой.
Итак, основной парадокс теории нечеткости
состоит в том, что привлекательный тезис «все в мире нечетко» невозможно последовательно
раскрыть в рамках математических моделей. Конечно, описанный парадокс не мешает
успешно использовать расплывчатую математику в конкретных приложениях. Из него
вытекает лишь необходимость указывать и обсуждать границы ее применимости.
4.8. Примеры
описания неопределенностей
с помощью нечетких множеств
Один пример подробно обсуждался выше – понятие
«Куча». Второй пример – понятие «богатый». Оно часто используется при
обсуждении социально-экономических проблем, в том числе и в связи с подготовкой
и принятием решений. Однако очевидно, что разные лица вкладывают в это понятие
различное содержание. Сотрудники Института высоких статистических технологий и эконометрики
МГТУ им. Н.Э. Баумана провели (в
Мини-анкета
опроса выглядела так:
1.
При каком месячном доходе (в млн. руб. на одного человека) Вы считали бы себя
богатым человеком?
2.
Оценив свой сегодняшний доход, к какой из категорий Вы себя относите:
а)
богатые;
б)
достаток выше среднего;
в)
достаток ниже среднего;
г)
бедные;
д)
за чертой бедности?
(В дальнейшем вместо полного наименования
категорий будем оперировать буквами, например «в» - категория, «б» - категория и т.д.)
3.
Ваша профессия, специальность.
Всего
опрошено 74 человека, из них 40 - научные работники и преподаватели, 34
человека - не занятых в сфере науки и образования, в том числе 5 рабочих и 5
пенсионеров. Из всех опрошенных только один (!) считает себя богатым. Несколько
типичных ответов научных работников и преподавателей приведено в табл. 1, а
аналогичные сведения для работников коммерческой сферы – в табл. 2.
Таблица 1
Типичные ответы научных работников и
преподавателей
|
Ответы на вопрос 3 |
Ответы на вопрос 1, млн. руб./чел. |
Ответы на вопрос 2 |
Пол |
|
Кандидат
наук |
1 |
д |
ж |
|
Преподаватель |
1 |
в |
ж |
|
Доцент |
1 |
б |
ж |
|
Учитель |
10 |
в |
м |
|
Старший
научный сотрудник |
10 |
д |
м |
|
Инженер-физик |
24 |
д |
ж |
|
Программист |
25 |
г |
м |
|
Научный
работник |
45 |
г |
м |
Таблица 2
Типичные ответы
работников коммерческой сферы.
|
Ответы
на вопрос 3 |
Ответы |
Ответы |
Пол |
|
Вице-президент
банка |
100 |
а |
ж |
|
Зам.
директора банка |
50 |
б |
ж |
|
Начальник.
кредитного отдела |
50 |
б |
м |
|
Начальник
отдела ценных бумаг |
10 |
б |
м |
|
Главный
бухгалтер |
20 |
д |
ж |
|
Бухгалтер |
15 |
в |
ж |
|
Менеджер
банка |
11 |
б |
м |
|
Начальник
отдела проектирования |
10 |
в |
ж |
Разброс ответов на первый вопрос – от 1
до 100 млн. руб. в месяц на человека. Результаты опроса показывают, что
критерий богатства у финансовых работников в целом несколько выше, чем у
научных (см. гистограммы на рис. 1 и рис. 2 ниже).
Опрос показал, что выявить какое-нибудь
конкретное значение суммы, которая необходима «для полного счастья», пусть даже
с небольшим разбросом, нельзя, что вполне естественно. Как видно из таблиц 1 и
2, денежный эквивалент богатства колеблется от 1 до 100 миллионов рублей в
месяц. Подтвердилось мнение, что работники сферы образования в подавляющем большинстве
причисляют свой достаток к категории «в» и ниже (81% опрошенных), в том числе к
категории «д» отнесли свой достаток 57%.
Со служащими коммерческих структур и
бюджетных организаций иная картина: «г» - категория 1 человек (4%), «д» - категория
4 человека (17%), «б» - категория - 46% и 1 человек «а» - категория.
Пенсионеры, что не вызывает удивления,
отнесли свой доход к категории «д» (4 человека), и лишь один человек указал «г»
- категорию. Рабочие же ответили так: 4 человека - «в», и один человек - «б».
Для представления общей картины в табл.
3 приведены данные об ответах работников других профессий.
Таблица 3
Типичные ответы
работников различных профессий.
|
Ответы
на вопрос 3 |
Ответы на
вопрос 1 |
Ответы на вопрос
2 |
Пол |
|
Работник
торговли |
1 |
б |
ж |
|
Дворник |
2 |
в |
ж |
|
Водитель |
10 |
в |
м |
|
Военнослужащий |
10 |
в |
м |
|
Владелец
бензоколонки |
20 |
б |
ж |
|
Пенсионер |
6 |
д |
ж |
|
Начальник
фабрики |
20 |
б |
м |
|
Хирург |
5 |
в |
м |
|
Домохозяйка |
10 |
в |
ж |
|
Слесарь-механик |
25 |
в |
м |
|
Юрист |
10 |
б |
м |
|
Оператор
ЭВМ |
20 |
д |
м |
|
Работник
собеса |
3 |
д |
ж |
|
Архитектор |
25 |
б |
ж |
Прослеживается интересное явление: чем
выше планка богатства для человека, тем к более низкой категории относительно
этой планки он себя относит.
Для сводки данных естественно
использовать гистограммы. Для этого необходимо сгруппировать ответы.
Использовались 7 классов (интервалов):
1 – до 5 миллионов рублей в месяц на
человека (включительно);
2 – от 5 до 10 миллионов;
3- от 10 до 15 миллионов;
4 – от 15 до 20 миллионов;
5 – от 20 до 25 миллионов;
6 – от 25 до 30 миллионов;
7 – более 30 миллионов.
(Во
всех интервалах левая граница исключена, а правая, наоборот – включена.)
Сводная информация представлена на рис.
1 (для научных работников и преподавателей) и рис. 2 (для всех остальных, т.е.
для лиц, не занятых в сфере науки и образования - служащих иных бюджетных
организаций, коммерческих структур, рабочих, пенсионеров).
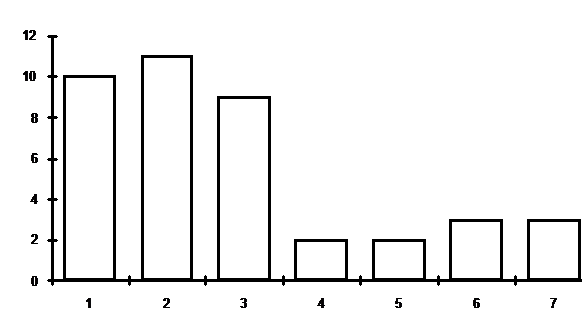
Рис. 1. Гистограмма ответов на вопрос 1
для научных работников и преподавателей (40 человек)
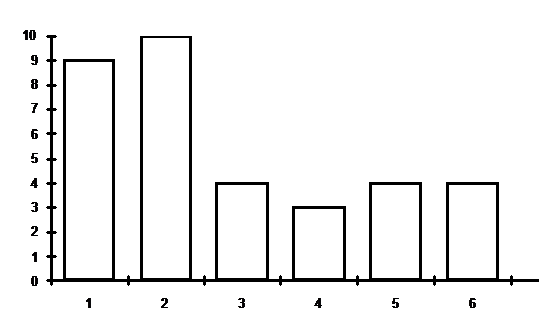
Рис.
2. Гистограмма ответов на вопрос 1 для лиц, не занятых в сфере науки и
образования (34 человека)
Для двух выделенных групп, а также для
некоторых подгрупп второй группы рассчитаны сводные средние характеристики –
выборочные средние арифметические, медианы, моды. При этом медиана группы -
количество млн. руб., названное центральным по порядковому номеру опрашиваемым
в возрастающем ряду ответов на вопрос 1, а мода группы - интервал, на котором
столбик гистограммы - самый высокий,
т.е. в него «попало» максимальное количество опрашиваемых. Результаты приведены
в табл. 4.
Таблица 4
Сводные средние
характеристики ответов на вопрос 1
для различных групп (в
млн. руб. в мес. на чел.).
|
Группа
опрошенных |
Среднее арифметическое |
медиана |
мода |
|
Научные
работники и преподаватели |
11,66 |
7,25 |
(5; 10) |
|
Лиц, не
занятых в сфере науки и образования |
14,4 |
10 |
(5; 10) |
|
Служащие
коммерческих структур и бюджетных организаций |
17,91 |
10 |
(5; 10) |
|
Рабочие |
15 |
13 |
- |
|
Пенсионеры |
10,3 |
10 |
- |
Построим нечеткое множество,
описывающее понятие «богатый человек» в соответствии с представлениями
опрошенных. Для этого составим табл. 5 на основе рис. 1 и рис. 2 с учетом размаха
ответов на первый вопрос.
Таблица 5
Характеристики ответов,
попавших в интервалы
|
№ |
Номер интервала |
0 |
1 |
2 |
3 |
4 |
|
1 |
Интервал, млн. руб. в месяц |
(0;1) |
[1;5] |
(5;10] |
(10;15] |
(15;20] |
|
2 |
Число ответов в интервале |
0 |
19 |
21 |
13 |
5 |
|
3 |
Доля ответов в интервале |
0 |
0,257 |
0,284 |
0,176 |
0,068 |
|
4 |
Накопленное число ответов |
0 |
19 |
40 |
53 |
58 |
|
5 |
Накопленная доля ответов |
0 |
0,257 |
0,541 |
0,716 |
0,784 |
Продолжение таблицы 5
|
№ |
Номер интервала |
5 |
6 |
7 |
8 |
|
1 |
Интервал, млн. руб. в месяц |
(20;25] |
(25;30] |
(30;100) |
[100;+∞) |
|
2 |
Число ответов в интервале |
6 |
7 |
2 |
1 |
|
3 |
Доля ответов в интервале |
0,081 |
0,095 |
0,027 |
0,013 |
|
4 |
Накопленное число ответов |
64 |
71 |
73 |
74 |
|
5 |
Накопленная доля ответов |
0,865 |
0,960 |
0,987 |
1,000 |
Пятая строка табл. 5 задает функцию
принадлежности нечеткого множества, выражающего понятие «богатый человек» в
терминах его ежемесячного дохода. Это нечеткое множество является подмножеством
множества из 9 интервалов, заданных в строке 2 табл. 5. Или множества из 9
условных номеров {0, 1, 2, …, 8}. Эмпирическая функция распределения,
построенная по выборке из ответов 74 опрошенных на первый вопрос мини-анкеты,
описывает понятие «богатый человек» как нечеткое подмножество положительной
полуоси.
О разработке методики ценообразования
на основе теории нечетких множеств. Для оценки значений показателей, не имеющих
количественной оценки, можно использовать методы нечетких множеств. Например,
П.В. Битюков применял нечеткие множества при моделировании задач
ценообразования на электронные обучающие курсы, используемые при дистанционном
обучении (см. [12, гл.8]). Им проведено исследование значений фактора «Уровень
качества курса» с использованием нечетких множеств. В ходе практического
использования предложенной П.В. Битюковым методики ценообразования значения
ряда других факторов могут также определяться с использованием теории нечетких
множеств. Например, ее можно использовать для определения прогноза рейтинга
специальности в вузе с помощью экспертов, а также значений других факторов,
относящихся к группе «Особенности курса». Опишем подход П.В. Битюкова как
пример практического использования теории нечетких множеств.
Значение оценки, присваиваемой каждому
интервалу для фактора «Уровень качества курса», определяется на универсальной
шкале [0,1], где необходимо разместить значения лингвистической переменной
«Уровень качества курса»: НИЗКИЙ, СРЕДНИЙ, ВЫСОКИЙ. Степень принадлежности
некоторого значения вычисляется как отношение числа ответов, в которых оно
встречалось в определенном интервале шкалы, к максимальному (для этого
значения) числу ответов по всем интервалам.
В ходе работы над диссертацией проведен
опрос экспертов о степени влияния уровня качества электронных курсов на их потребительную
ценность. Каждому эксперту в процессе опроса предлагалось оценить с позиции
потребителя ценность того или иного класса курсов в зависимости от уровня
качества. Эксперты давали свою оценку для каждого класса курсов по 10-ти
балльной шкале (где 1 - min, 10 - max). Для перехода к универсальной шкале
[0,1], все значения 10-ти балльной шкалы оценки ценности были разделены на
максимальную оценку 10.
Используя свойства функции
принадлежности, необходимо предварительно обработать данные с тем, чтобы
уменьшить искажения, вносимые опросом. Естественными свойствами функций
принадлежности являются наличие одного максимума и гладкие, затухающие до нуля
фронты. Для обработки статистических данных можно воспользоваться так
называемой матрицей подсказок. Предварительно удаляются явно ошибочные элементы.
Критерием удаления служит наличие нескольких нулей в строке вокруг этого
элемента.
Элементы матрицы подсказок вычисляются
по формуле:
![]() ,
,
где
![]() - элемент таблицы с результатами
анкетирования, сгруппированными по интервалам.
- элемент таблицы с результатами
анкетирования, сгруппированными по интервалам.
Матрица подсказок представляет собой
строку, в которой выбирается максимальный элемент: ![]() , и далее все
ее элементы преобразуются по формуле:
, и далее все
ее элементы преобразуются по формуле:
![]() .
.
Для столбцов, где ![]() , применяется
линейная аппроксимация:
, применяется
линейная аппроксимация:
![]() .
.
Результаты расчетов сводятся в таблицу,
на основании которой строятся функции принадлежности. Для этого находятся
максимальные элементы по строкам:
![]() .
.
Функция
принадлежности вычисляется по формуле:
![]() .
.
Результаты расчетов приведены в табл.
6.
Таблица 6
Значения функции
принадлежности лингвистической переменной
|
μi |
Интервал
на универсальной шкале |
|||||||||
|
0,1 |
0,2 |
0,3 |
0,4 |
0,5 |
0,6 |
0,7 |
0,8 |
0,9 |
1,0 |
|
|
μ1 |
0 |
0,2 |
1 |
1 |
0,89 |
0,67 |
0 |
0 |
0 |
0 |
|
μ2 |
0 |
0 |
0 |
0 |
0 |
0,33 |
1 |
1 |
0 |
0 |
|
μ3 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
На рис. 3 сплошными линиями показаны
функции принадлежности значений лингвистической переменной «Уровень качества
курса» после обработки таблицы, содержащей результаты опроса. Как видно из
графика, функции принадлежности удовлетворяют описанным выше свойствам. Для
сравнения пунктирной линией, выделенной крестиками, показана функция принадлежности
лингвистической переменной для значения НИЗКИЙ* без обработки данных.
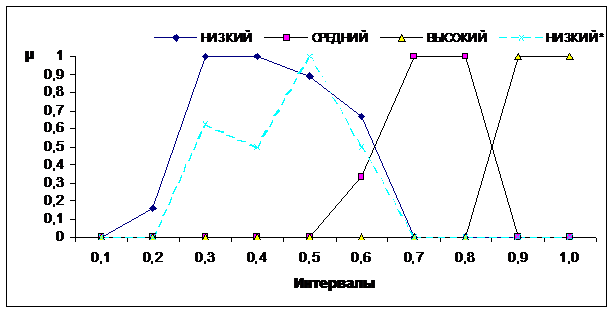 Рис. 3. График функций
принадлежности значений лингвистической переменной «Уровень качества курса».
Рис. 3. График функций
принадлежности значений лингвистической переменной «Уровень качества курса».
Сбор и описание нечетких данных.
Разработано большое количество процедур описания нечеткости. Так, согласно Э. Борелю
понятие «Куча» описывается с помощью функции распределения – при каждом
конкретном х значение функции принадлежности – это доля людей, считающих
совокупность из х зерен кучей. Результат подобного опроса может дать и кривую
иного вида, например, по поводу понятия «молодой» (слева будут отделены «дети»,
а справа – «люди зрелого и пожилого возраста»). Нечеткая толерантность может
оцениваться с помощью случайных толерантностей (см. [12, разд. 7.2]).
Целесообразно попытаться выделить
наиболее практически полезные простые формы функций принадлежности. Видимо,
наиболее простой является «ступенька» - внутри некоторого интервала функция
принадлежности равна 1, а вне этого интервала равна 0. Это – простейший способ
«размывания» числа путем замены его интервалом. Нечеткое множество описывается
двумя числами – концами интервала. Оценки этих чисел можно получить с помощью экспертов.
Статистическая теория подобных нечетких множеств, т.е. статистика интервальных
данных, рассмотрена ниже. Связь с практикой очевидна – при прогнозировании
погоды температура обычно описывается интервалами.
Тремя числами a < b < c
описывается функция принадлежности типа треугольника. При этом левее числа а и
правее числа с функция принадлежности равна 0. В точке b функция принадлежности
принимает значение 1. На отрезке [a; b] функция принадлежности линейно растет
от 0 до 1, а на отрезке [b;c] – линейно убывает от 1 до 0. Оценки трех чисел a
< b < c получают при опросе экспертов.
Следующий по сложности вид функции
принадлежности – типа трапеции – описывается четырьмя числами a < b < c
< d. Левее a и правее d функция принадлежности равна 0. На отрезке [a; b]
она линейно возрастает от 0 до 1, на отрезке [b; c] во всех точках равна 1, а
на отрезке [c; d] линейно убывает от 1 до 0. Для оценивания четверки чисел a
< b < c < d используют экспертов.
Ряд результатов статистики нечетких
данных приведен в первой монографии российского автора по нечетким множествам
[9] и во многих дальнейших публикациях, в том числе в [8, 12, 88].
Вторая часть настоящей книги посвящена
системному обобщению математики. В частности, глава 11 посвящена когнитивным
функциям – обобщению классического понятия функциональной зависимости на основе
теории информации. Когнитивную функцию можно рассматривать как вариант нечеткой
функциональной зависимости, для которой значение функции принадлежности,
соответствующей конкретному значению зависимой переменной, определяется с
помощью количества информации об этом значении в значении аргумента. Очень
важно, что это количество информации рассчитывается на основе теоретически
обоснованной модели непосредственно на основе эмпирических данных. Ценность
такого подхода определяется тем, что специалисты по математическому
моделированию, разрабатывая модели на основе теории нечетких множеств, зачастую
не рассматривают вопрос о том, откуда брать функции принадлежности, другими
словами, начинают рассмотрение с различных весьма произвольных гипотез о том,
что эти функции имеют тот или иной вид. Здесь же, в теории когнитивных функций
(см. главу 11), предлагается простой и понятный способ, как обоснованно
рассчитывать функции принадлежности.
4.9. О статистике
нечетких множеств
Обсудим некоторые вопросы статистического
анализа нечетких данных. Нечеткие множества – частный вид объектов нечисловой
природы. Поэтому при обработке выборки, элементами которой являются нечеткие
множества, могут быть использованы различные методы анализа статистических
данных произвольной природы - расчет средних, непараметрических оценок
плотности, построение диагностических правил и т.д. [81].
Среднее значение нечеткого множества.
Однако иногда используются методы, учитывающие специфику нечетких множеств.
Например, пусть универсальным множеством для рассматриваемого нечеткого
множества является конечная совокупность действительных чисел {x1, x2, ...,
xn}. Тогда под средним значением нечеткого множества иногда понимают число. А
именно, среднее значение нечеткого множества определяют по формуле:
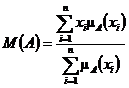 ,
,
где
![]() - функция принадлежности нечеткого множества
A. Если знаменатель равен 1, то эта формула определяет математическое ожидание
случайной величины, для которой вероятность попасть в точку xi равна
- функция принадлежности нечеткого множества
A. Если знаменатель равен 1, то эта формула определяет математическое ожидание
случайной величины, для которой вероятность попасть в точку xi равна ![]() . Такое
определение наиболее естественно, когда нечеткое множество A интерпретируется
как нечеткое число.
. Такое
определение наиболее естественно, когда нечеткое множество A интерпретируется
как нечеткое число.
Очевидно, наряду с М(А) может оказаться
полезным использование эмпирических средних, определяемых (согласно статистике
в пространствах произвольной природы как части нечисловой статистики [8]) путем
решения соответствующих оптимизационных задач. Для конкретных расчетов
необходимо ввести то или иное расстояние между нечеткими множествами.
Расстояния в пространствах нечетких
множеств. Как известно, многие методы статистики нечисловых данных базируются
на использовании расстояний (или показателей различия) в соответствующих
пространствах нечисловой природы. Расстояние между нечеткими подмножествами А и
В множества Х = {x1, x2, …, xk} можно определить как
![]()
где
![]() - функция
принадлежности нечеткого множества A, а
- функция
принадлежности нечеткого множества A, а ![]() - функция
принадлежности нечеткого множества B. Может использоваться и другое расстояние:
- функция
принадлежности нечеткого множества B. Может использоваться и другое расстояние:
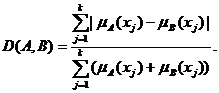
(Примем
это расстояние равным 0, если функции принадлежности тождественно равны 0.)
В соответствии с аксиоматическим
подходом к выбору расстояний (метрик) в пространствах нечисловой природы разработан
обширный набор систем аксиом, из которых выводится тот или иной вид расстояний
(метрик) в конкретных пространствах, в том числе в пространствах нечетких
множеств (см. [8, 81]). При использовании вероятностных моделей расстояние
между случайными нечеткими множествами (т.е. между случайными элементами со
значениями в пространстве нечетких множеств) само является случайной величиной,
имеющей в ряде постановок асимптотически нормальное распределение.
Проверка гипотез о нечетких множествах.
Пусть ответ эксперта – нечеткое множество. Естественно считать, что его ответ,
как показание любого средства измерения, содержит погрешности. Если есть
несколько экспертов, то в качестве единой оценки (группового мнения)
естественно взять эмпирическое среднее их ответов. Но возникает естественный
вопрос: действительно ли все эксперты измеряют одно и то же? Может быть, глядя
на реальный объект, они оценивают его с разных сторон? Например, на научную
статью можно смотреть как с теоретической точки зрения, как и с прикладной, и
соответствующие оценки будут, скорее всего, различны (если они совпадают, то
работа либо никуда не годится, либо является выдающейся).
Итак, возник вопрос: как проверить
согласованность мнений экспертов? Надо сначала определить понятие
согласованности. Пусть А – нечеткий ответ эксперта. Будем считать, что соответствующая
функция принадлежности есть сумма двух слагаемых:
![]() ,
,
где
N(A) – «истинное» нечеткое множество, а ξA(u) – «погрешность» эксперта как
прибора. Естественно рассмотреть две постановки.
Мнения экспертов А(1), А(2), …, А(m)
будем считать согласованными, если
N(А(1))
= N(А(2)) = …, N(А(m)).
Рассмотрим две группы экспертов. В
первой у всех «истинное» мнение N(A), а во второй у всех - N(В). Две группы
будем считать согласованными по мнениям, если
N(A)
= N(В).
Согласованность определена. Как же ее
проверить? Если экспертов достаточно много, то эти гипотезы можно проверять
отдельно для каждого элемента множества – общего носителя нечетких ответов.
Проверка последней гипотезы переходит в проверку однородности двух независимых
выборок [81]. Здесь ограничимся приведенными выше постановками основных
гипотез.
Восстановление зависимости между
нечеткими переменными. Рассмотрим две нечеткие переменные А и В. Пусть каждый
из n испытуемых выдает в ответ на вопрос два нечетких множества Ai и Bi, i = 1,
2, …, n. Необходимо восстановить зависимость В от А, другими словами, наилучшим
образом приблизить В с помощью А.
Для иллюстрации основной идеи
ограничимся парной линейной регрессией нечетких множеств. Нечеткое множество С
назовем линейной функцией от нечеткого множества А, если для любого х из
носителя А функции принадлежности множеств А и С таковы, что µС(х) = µА(у) при
х = αу + β. Другими словами,
µС(х)
= µА((х - β)/α)
для
любого х из носителя А. В таком случае естественно писать
С
= αА +β.
Однако нечеткие переменные, как и привычные
для статистиков числовые переменные, обычно несколько отклоняются от линейной
связи. Наилучшее линейное приближение нечеткой переменной В с помощью линейной
функции от нечеткой переменной А естественно искать, решая задачу минимизации
по α, β расстояния от В до С. Пусть
ρ(В,
α0А + β0) = min ρ(B, αA + β),
где
ρ – некоторое расстояние между нечеткими множествами, а минимизация
проводится по всем возможным значениям α и β. Тогда наилучшей
линейной аппроксимацией В является α0А + β0. Если рассматриваемый
минимум равен 0, то имеет место точная линейная зависимость.
Для восстановления зависимости по
выборочным парам нечетких переменных естественно воспользоваться подходом, развитым
в статистике в пространствах произвольной природы для параметрической регрессии
(аппроксимации). В соответствии с методами статистики нечисловых данных [8] в
качестве наилучших оценок параметров линейной зависимости следует рассматривать
![]() .
.
Тогда
наилучшим линейным приближением В является С* = α*А + β*.
Вероятностно-статистическая теория
регрессионного анализа нечетких переменных строится как частный случай аналогичной
теории для переменных произвольной природы [8, 81]. В частности, при обычных
предположениях оценки α*, β* являются состоятельными, т.е. α*
→ α0 и β* → β0 при n → ∞.
Кластер-анализ нечетких переменных.
Строить группы сходных между собой нечетких переменных (кластеры) можно многими
способами. Опишем два семейства алгоритмов.
Пусть на пространстве, в котором лежат
результаты наблюдений, т.е. на пространстве нечетких множеств, заданы две меры
близости ρ и τ (например, это могут быть введенные выше расстояния d
и D). Берется один из результатов наблюдений (нечеткое множество) и вокруг него
описывается шар радиуса R, определяемый мерой близости ρ. (Напомним, что
шаром с центром в х относительно ρ называется множество всех элементов у
рассматриваемого пространства таких, что ρ(х, у) < R.) Берутся результаты
наблюдений (элементы выборки), попавшие в этот шар, и находится их эмпирическое
среднее относительно второй меры близости τ. Оно берется за новый центр,
вокруг которого снова описывается шар радиуса R относительно ρ, и
процедура повторяется. (Чтобы алгоритм был полностью определен, необходимо
сформулировать правило выбора элемента эмпирического среднего в качестве нового
центра, если эмпирическое среднее состоит более чем из одного элемента.)
Когда центр шара зафиксируется
(перестанет меняться), попавшие в этот шар элементы объявляются первым
кластером и исключаются из дальнейшего рассмотрения. Алгоритм применяется к совокупности
оставшихся результатов наблюдений, выделяет из нее второй кластер и т.д.
Всегда ли центр шара остановится? При
реальных расчетах в течение многих лет так было всегда. Соответствующая теория
построена лишь в
Обширное семейство образуют алгоритмы
кластер-анализа типа «Дендрограмма», известные также под названием «агломеративные
иерархические алгоритмы средней связи». На первом шаге алгоритма из этого
семейства каждый результат наблюдения рассматривается как отдельный кластер.
Далее на каждом шагу происходит объединение двух самых близких кластеров.
Название «Дендрограмма» объясняется тем, что результат работы алгоритма обычно
представляется в виде дерева. Каждая его ветвь соответствует кластеру,
появляющемуся на каком-либо шагу работы алгоритма. Слияние ветвей соответствует
объединению кластеров, а ствол – заключительному шагу, когда все наблюдения
оказываются объединенными в один кластер.
Для работы алгоритмов кластер-анализа
типа «Дендрограмма» необходимо определить расстояние между кластерами. Естественно
использовать ассоциативные средние, которыми, как известно, являются средние по
Колмогорову всевозможных попарных расстояний между элементами двух
рассматриваемых кластеров. Итак, расстояние между кластерами K и L, состоящими
из n1 и n2 элементов соответственно, определяется по формуле:
 ,
,
где
ρ – некоторое расстояние между нечеткими множествами;
F
– строго монотонная функция (строго возрастающая или строго убывающая).
Соображения теории измерений позволяют
ограничить круг возможных алгоритмов типа «Дендрограмма». Естественно принять,
что единица измерения расстояния выбрана произвольно. Тогда измерения
проводятся в шкале отношений, и согласно результатам теории измерений [8] из
всех средних по Колмогорову годятся только степенные средние, т.е.
F(z)
= zλ при λ ≠ 0 или F(z) = ln(z).
Чтобы получить разбиение на кластеры,
надо «разрезать» дерево на определенной высоте, т.е. объединять кластеры лишь
до тех пор, пока расстояние между ними меньше заранее выбранной константы. При
альтернативном подходе заранее фиксируется число кластеров. Рассматривают и
двухкритериальную постановку, когда минимизируют сумму (или максимум) внутрикластерных
разбросов и число кластеров. Для решения задачи двухкритериальной минимизации
либо один из критериев заменяют ограничением, либо два критерия «свертывают» в
один, либо применяют иные подходы (последовательная оптимизация, построение
поверхности Парето и др.).
При классификации нечетких множеств
полезны все подходы теории классификации [10], основанные только на использовании
расстояний.
ГЛАВА 5. О СВЕДЕНИИ ТЕОРИИ НЕЧЕТКИХ МНОЖЕСТВ К ТЕОРИИ СЛУЧАЙНЫХ МНОЖЕСТВ
5.1. Нечеткость и случайность
С самого начала появления современной теории
нечеткости в 1960-е годы началось обсуждение ее взаимоотношений с теорией
вероятностей. Дело в том, что функция принадлежности нечеткого множества
напоминает плотность распределения вероятностей. Отличие только в том, что
сумма вероятностей по всем возможным значениям случайной величины (или
интеграл, если множество возможных значений несчетно) всегда равна 1, а сумма S
значений функции принадлежности (в непрерывном случае — интеграл от
функции принадлежности) может быть любым неотрицательным числом. Возникает
искушение пронормировать функцию принадлежности, т.е. разделить все ее значения
на S (при S ![]() 0), чтобы
свести ее к распределению вероятностей (или к плотности вероятности). Однако
специалисты по нечеткости справедливо возражают против такого «примитивного»
сведения, поскольку оно проводится отдельно для каждой размытости (нечеткого
множества), и определения обычных операций над нечеткими множествами
согласовать с ним нельзя. Последнее утверждение означает следующее. Пусть
указанным образом преобразованы функции принадлежности нечетких множеств А
и В. Как при этом преобразуются функции принадлежности АÇВ, АÈВ, А + В, АВ?
Установить это невозможно в принципе. Последнее утверждение становится
совершенно ясным после рассмотрения нескольких примеров пар нечетких множеств с
одними и теми же суммами значений функций принадлежности, но различными результатами
теоретико-множественных операций над ними. Причем и суммы значений
соответствующих функций принадлежности для этих результатов
теоретико-множественных операций, например, для пересечений множеств, также
различны.
0), чтобы
свести ее к распределению вероятностей (или к плотности вероятности). Однако
специалисты по нечеткости справедливо возражают против такого «примитивного»
сведения, поскольку оно проводится отдельно для каждой размытости (нечеткого
множества), и определения обычных операций над нечеткими множествами
согласовать с ним нельзя. Последнее утверждение означает следующее. Пусть
указанным образом преобразованы функции принадлежности нечетких множеств А
и В. Как при этом преобразуются функции принадлежности АÇВ, АÈВ, А + В, АВ?
Установить это невозможно в принципе. Последнее утверждение становится
совершенно ясным после рассмотрения нескольких примеров пар нечетких множеств с
одними и теми же суммами значений функций принадлежности, но различными результатами
теоретико-множественных операций над ними. Причем и суммы значений
соответствующих функций принадлежности для этих результатов
теоретико-множественных операций, например, для пересечений множеств, также
различны.
В работах по нечетким множествам время
от времени утверждается, что теория нечеткости самостоятельный раздел прикладной
математики и не имеет отношения к теории вероятностей ((см., например, обзор
литературы в монографиях [9, 13]). Некоторые авторы, обсуждавшие
взаимоотношения теории нечеткости и теории вероятностей, подчеркивали различие
между этими областями теоретических и прикладных исследований. Обычно
сопоставляют аксиоматику и сравнивают области приложений.
Аргументы при втором типе сравнений не
имеют доказательной силы, поскольку по поводу границ применимости даже такой
давно выделившейся научной области, как вероятностно-статистические методы,
имеются различные мнения. Более того, нет единства мнений об арифметике. Итог
рассуждений одного из наиболее известных французских математиков Анри Лебега по
поводу границ применимости арифметики таков: «Арифметика применима тогда, когда
она применима» (см. его монографию [17, с.21-22]).
При сравнении различных аксиоматик
теории нечеткости и теории вероятностей нетрудно увидеть, что списки аксиом
различаются. Из этого, однако, отнюдь не следует, что между указанными теориями
нельзя установить связь, типа известного сведения евклидовой геометрии на
плоскости к арифметике (точнее к теории числовой системы R2 -
см., например, монографию [18]). Эти две аксиоматики — евклидовой
геометрии и арифметики — на первый взгляд весьма сильно различаются.
Можно понять желание энтузиастов теории
нечеткости подчеркнуть принципиальную новизну своего научного аппарата. Однако
не менее важно установить связи этого подхода с ранее известными.
Как оказалось, теория
нечетких множеств тесно связана с теорией случайных множеств.
5.2. Случайные множества
Что такое случайное множество? Начнем с понятия
случайной величины. Это величина, зависящая от случая, т.е. функция от
элементарного исхода (события). Скажем, результат наблюдения, зависящий от
случайных привходящих факторов. А случайное множество – это множество,
зависящее от случая. Другими словами, функция, область определения которой –
пространство элементарных событий, а область значений – совокупность множеств,
например, совокупность всех подмножеств некоторого конкретного множества.
Случайные множества используются во
многих прикладных задачах [13]. В монографиях [14, 15] случайные множества использовались
для моделирования распространения лесных пожаров. Пусть пожар начался с
загорания в определенной точке. В следующий момент времени загорятся некоторые
из соседних точек. А некоторые не загорятся. Через час огнем будет охвачено
некоторое множество. Форма пожара будет описываться случайным множеством,
зависящим от времени.
От чего зависит форма пожара? Конечно,
от того, как «устроен» лес – какие в нем породы деревьев, сколько сухостоя,
есть ли естественные преграды для огня (ручьи, овраги), а также от метеорологических
условий – куда дует ветер, сколько осадков выпало за последнее время, какова
температура воздуха… Все эти условия неизвестны в точности наблюдателю на
самолете. Поэтому для него вполне естественно моделировать распространение
пожара с помощью теории вероятностей. Эти модели, разработанные на основе
теории случайных множеств, находят применение в лесном хозяйстве [14, 15].
Теория нечетких множеств сводится к
теории случайных множеств с помощью понятия «проекция случайного множества». С
каждым случайным множеством можно связать некоторую функцию – вероятность того,
что элемент принадлежит множеству. Эта функция обладает всеми свойствами
функции принадлежности нечеткого множества. Соответствующее нечеткое множество
и называют проекцией исходного случайного множества. Оказывается, верно и
обратное – для любого размытого множества можно подобрать случайное множество
так, что вероятность принадлежности элемента случайному множеству всюду совпадает
с функцией принадлежности заданного размытого множества. Подобное соответствие
можно установить так, что результаты операций над множествами тоже будут
соответствовать друг другу.
Есть все основания полагать, что связь
между размытостью и вероятностью позволит применить в теории нечеткости методы
и результаты, накопленные в теории случайных множеств. И наоборот, даст
возможность перенести понятия и постановки задач из первой теории во вторую,
что послужит прогрессу в обеих.
Почему же специалисты по нечетким
множествам порою «открещиваются» от теории вероятностей? Одна из причин – устаревшее
на три четверти века представление о математике случая, согласно которой она
рассматривается как «наука о массовых явлениях»: вероятность мыслится как
предел частоты, а случайное событие – как то, которое может произойти, а
может не произойти. Всё это – отголоски
далекого прошлого, когда теория вероятностей недостаточно отделялась от ее
приложений. Ныне она опирается на четкую систему аксиом, обычно – на аксиоматику
А.Н. Колмогорова. В
Разберем подробнее связи между теорией
нечеткости и теорией случайных множеств.
5.3. Нечеткие множества как проекции случайных множеств.
Рассмотрим метод сведения теории нечетких
множеств к теории случайных множеств.
Определение 2. Пусть ![]() - случайное
подмножество конечного множества У. Нечеткое множество В, определенное
на У, называется проекцией А и обозначается Proj A, если
- случайное
подмножество конечного множества У. Нечеткое множество В, определенное
на У, называется проекцией А и обозначается Proj A, если
![]() (8)
(8)
при
всех ![]()
Очевидно, каждому случайному множеству А
можно поставить в соответствие с помощью формулы (8) нечеткое множество В =
Proj A. Оказывается, верно и обратное.
Теорема 3. Для любого
нечеткого подмножества В конечного множества У существует
случайное подмножество А множества У такое, что В = Proj A.
Доказательство. Достаточно
задать распределение случайного множества А. Пусть У1
- носитель В (см. определение 1 выше).
Без ограничения общности можно считать, что ![]() при некотором m
и элементы У1 занумерованы в таком порядке, что
при некотором m
и элементы У1 занумерованы в таком порядке, что
![]()
Введем
множества
![]()
Положим
![]()
![]()
![]()
Для
всех остальных подмножеств Х множества У положим Р(А=Х)=0.
Поскольку элемент yt входит во множества Y(1),
Y(2),…, Y(t) и не входит во множества Y(t+1),…, Y(m), то
из приведенных выше формул следует, что![]() Если
Если ![]() то, очевидно,
то, очевидно, ![]() Теорема 3 доказана.
Теорема 3 доказана.
Распределение случайного множества с
независимыми элементами, как следует из [8], полностью определяется его проекцией.
Для конечного случайного множества общего вида это не так. Для уточнения
сказанного понадобится следующая теорема.
Теорема 4. Для случайного
подмножества А множества У из конечного числа элементов наборы
чисел
![]() и
и ![]()
выражаются
один через другой.
Доказательство. Второй набор
выражается через первый следующим образом:
![]()
Элементы
первого набора выразить через второй можно с помощью формулы включений и
исключений из формальной логики, в соответствии с которой
![]()
В
этой формуле в первой сумме у пробегает все элементы множества Y\X,
во второй сумме переменные суммирования у1 и у2
не совпадают и также пробегают это множество, и т.д. Ссылка на формулу
включений и исключений завершает доказательство теоремы 4.
В соответствии с теоремой 4 случайное
множество А можно характеризовать не только распределением, но и набором
чисел ![]() В этом наборе
В этом наборе ![]() а других связей типа равенств
нет. В этот набор входят числа
а других связей типа равенств
нет. В этот набор входят числа ![]() следовательно,
фиксация проекции случайного множества эквивалентна фиксации k = Card(Y)
параметров из (2k-1) параметров, задающих
распределение случайного множества А в общем случае. (Здесь символом Card(Y)
обозначено число элементов множества Y.)
следовательно,
фиксация проекции случайного множества эквивалентна фиксации k = Card(Y)
параметров из (2k-1) параметров, задающих
распределение случайного множества А в общем случае. (Здесь символом Card(Y)
обозначено число элементов множества Y.)
Будет полезна следующая теорема.
Теорема 5. Если Proj A = B,
то Proj![]()
Для доказательства достаточно
воспользоваться тождеством из теории случайных множеств ![]() формулой для
вероятности накрытия
формулой для
вероятности накрытия ![]()
![]() , определением отрицания нечеткого множества и тем, что сумма
всех P(A=X) равна 1. Под формулой для вероятности накрытия
имеется в виду следующее утверждение: чтобы найти вероятность накрытия
фиксированного элемента q случайным подмножеством
S конечного множества Q, достаточно вычислить
, определением отрицания нечеткого множества и тем, что сумма
всех P(A=X) равна 1. Под формулой для вероятности накрытия
имеется в виду следующее утверждение: чтобы найти вероятность накрытия
фиксированного элемента q случайным подмножеством
S конечного множества Q, достаточно вычислить
![]()
где
суммирование идет по всем подмножествам A множества Q,
содержащим q.
5.4. Пересечения и произведения
нечетких
и случайных множеств
Выясним, как операции над случайными множествами
соотносятся с операциями над их проекциями. В силу законов де Моргана (теорема
1) и теоремы 5 достаточно рассмотреть операцию пересечения случайных множеств.
Теорема 6. Если случайные
подмножества А1 и А2 конечного
множества У независимы, то нечеткое множество ![]() является произведением
нечетких множеств Proj A1 и Proj A2.
является произведением
нечетких множеств Proj A1 и Proj A2.
Доказательство. Надо показать,
что для любого ![]()
![]() (9)
(9)
По
формуле для вероятности накрытия точки случайным множеством (см. выше)
![]() (10)
(10)
Легко
проверить, что распределение пересечения случайных множеств ![]() можно выразить через
их совместное распределение следующим образом:
можно выразить через
их совместное распределение следующим образом:
![]() (11)
(11)
Из
соотношений (10) и (11) следует, что вероятность накрытия для пересечения
случайных множеств можно представить в виде двойной суммы
![]() (12)
(12)
Заметим
теперь, что правую часть формулы (12) можно переписать следующим образом:
![]() (13)
(13)
Действительно,
формула (12) отличается от формулы (13) лишь тем, что в ней сгруппированы
члены, в которых пересечение переменных суммирования ![]() принимает постоянное
значение. Воспользовавшись определением независимости случайных множеств и
правилом перемножения сумм, получаем, что из (12) и (13) вытекает равенство
принимает постоянное
значение. Воспользовавшись определением независимости случайных множеств и
правилом перемножения сумм, получаем, что из (12) и (13) вытекает равенство
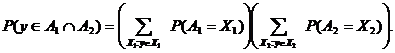
Для
завершения доказательства теоремы 6 достаточно еще раз сослаться на формулу для
вероятности накрытия точки случайным множеством.
Определение 3. Носителем
случайного множества С называется совокупность всех тех элементов ![]() для которых
для которых ![]()
Теорема 7. Равенство
Proj![]() = (Proj
= (Proj![]() Proj A2)
Proj A2)
верно
тогда и только тогда, когда пересечение носителей случайных множеств ![]() и
и ![]() пусто.
пусто.
Доказательство. Необходимо
выяснить условия, при которых
![]() (14)
(14)
Положим
![]()
Тогда
равенство (14) сводится к условию
![]() (15)
(15)
Ясно,
что соотношение (15) выполнено тогда и только тогда, когда р2р3=0
при всех ![]() т.е. не существует ни одного элемента
т.е. не существует ни одного элемента ![]() такого, что
одновременно
такого, что
одновременно ![]() и
и ![]() , а это эквивалентно пустоте пересечения носителей случайных
множеств
, а это эквивалентно пустоте пересечения носителей случайных
множеств ![]() и
и ![]() . Теорема 7 доказана.
. Теорема 7 доказана.
5.5. Сведение последовательности
операций над нечеткими
множествами к последовательности
операций
над случайными множествами
Выше получены некоторые связи между нечеткими и
случайными множествами. Изучение этих связей [9, 13] началось с введения
случайных множеств с целью развития и обобщения аппарата нечетких множеств Л.А.
Заде. Дело в том, что математический аппарат нечетких множеств не позволяет в
должной мере учитывать различные варианты зависимости между понятиями
(объектами), моделируемыми с его помощью, не является достаточно гибким. Так,
для описания «общей части» двух нечетких множеств есть лишь две операции -
произведение и пересечение. Если применяется первая из них, то фактически
предполагается, что множества ведут себя как проекции независимых случайных
множеств (см. выше теорему 6). Операция пересечения также накладывает вполне
определенные ограничения на вид зависимости между множествами (см. выше теорему
7), причем в этом случае найдены даже необходимые и достаточные условия.
Желательно иметь более широкие возможности для моделирования зависимости между
множествами (понятиями, объектами). Использование математического аппарата
случайных множеств предоставляет такие возможности.
Цель сведения теории нечетких множеств
к теории случайных множеств - за любой конструкцией из нечетких множеств
увидеть конструкцию из случайных множеств, определяющую свойства первой,
аналогично тому, как за плотностью распределения вероятностей мы видим
случайную величину. Приведем результаты по сведению алгебры нечетких множеств к
алгебре случайных множеств.
Определение 4. Вероятностное
пространство {Ω, G, P} назовем делимым, если для любого
измеримого множества Х![]() G и любого положительного числа
G и любого положительного числа ![]() , меньшего Р(Х), можно указать измеримое множество
, меньшего Р(Х), можно указать измеримое множество
![]() такое, что
такое, что ![]()
Пример. Пусть ![]() - единичный куб
конечномерного линейного пространства, G есть сигма-алгебра борелевских
множеств, а P - мера Лебега. Тогда {Ω, G, P} -
делимое вероятностное пространство.
- единичный куб
конечномерного линейного пространства, G есть сигма-алгебра борелевских
множеств, а P - мера Лебега. Тогда {Ω, G, P} -
делимое вероятностное пространство.
Таким образом, делимое вероятностное
пространство - это не экзотика. Обычный куб является примером такого пространства.
Доказательство сформулированного в
примере утверждения проводится стандартными математическими приемами. Они основаны
на том, что измеримое множество можно сколь угодно точно приблизить открытыми
множествами, последние представляются в виде суммы не более чем счетного числа
открытых шаров, а для шаров делимость проверяется непосредственно (от шара Х
тело объема ![]() отделяется
соответствующей плоскостью).
отделяется
соответствующей плоскостью).
Теорема 8. Пусть даны
случайное множество А на делимом вероятностном пространстве {Ω,
G, P} со значениями во множестве всех подмножеств множества Y из
конечного числа элементов, и нечеткое множество D на Y.
Тогда
существуют случайные множества С1, С2, С3,
С4 на
том же вероятностном пространстве такие, что
Proj![]() Proj
Proj![]() Proj
Proj![]()
Proj![]() Proj
Proj![]()
где
B = Proj A.
Доказательство. В силу справедливости
законов де Моргана для нечетких (см. теорему 1 выше) и для случайных множеств,
а также теоремы 5 выше (об отрицаниях) достаточно доказать существование
случайных множеств С1 и С2.
Рассмотрим распределение вероятностей
во множестве всех подмножеств множества Y, соответствующее
случайному множеству С такому, что Proj C = D (оно существует в
силу теоремы 3). Построим случайное множество С2 с указанным
распределением, независимое от А. Тогда ![]() по теореме 6.
по теореме 6.
Перейдем к построению случайного
множества С1. По теореме 7 необходимо и достаточно определить
случайное множество ![]() так, чтобы ProjC1
= D и пересечение носителей случайных множеств
так, чтобы ProjC1
= D и пересечение носителей случайных множеств ![]() и
и ![]() было пусто, т.е.
было пусто, т.е.
![]()
для
![]() и
и
![]()
для
![]() .
.
Построим ![]() , исходя из заданного случайного множества
, исходя из заданного случайного множества ![]() Пусть
Пусть ![]() Исключим элемент у1
из
Исключим элемент у1
из ![]() для стольких элементарных событий
для стольких элементарных событий ![]() , чтобы для полученного случайного множества
, чтобы для полученного случайного множества ![]() было справедливо
равенство
было справедливо
равенство
![]()
(именно
здесь используется делимость вероятностного пространства, на котором задано
случайное множество ![]() ). Для
). Для ![]() , очевидно,
, очевидно,
![]()
Аналогичным
образом последовательно исключаем у из ![]() для всех
для всех ![]() и добавляем у в
и добавляем у в
![]() для всех
для всех ![]() , меняя на каждом шагу
, меняя на каждом шагу ![]() только для
только для ![]() так, чтобы
так, чтобы
![]()
(ясно,
что при рассмотрении ![]() случайное множество
случайное множество ![]() не меняется). Перебрав
все элементы Y, получим случайное множество
не меняется). Перебрав
все элементы Y, получим случайное множество ![]() , для которого выполнено требуемое. Теорема 8 доказана.
, для которого выполнено требуемое. Теорема 8 доказана.
Основной результат о сведении теории
нечетких множеств к теории случайных множеств дается следующей теоремой.
Теорема 9. Пусть ![]() - некоторые нечеткие
подмножества множества Y из конечного числа
элементов. Рассмотрим результаты последовательного выполнения
теоретико-множественных операций
- некоторые нечеткие
подмножества множества Y из конечного числа
элементов. Рассмотрим результаты последовательного выполнения
теоретико-множественных операций
![]()
где
![]() - символ одной из
следующих теоретико-множественных операций над нечеткими множествами:
пересечение, произведение, объединение, сумма (на разных местах могут стоять
разные символы). Тогда существуют случайные подмножества
- символ одной из
следующих теоретико-множественных операций над нечеткими множествами:
пересечение, произведение, объединение, сумма (на разных местах могут стоять
разные символы). Тогда существуют случайные подмножества ![]() того же множества Y такие,
что
того же множества Y такие,
что
Proj![]()
и,
кроме того, результаты теоретико-множественных операций связаны аналогичными
соотношениями
Proj![]()
где
знак ![]() означает, что на рассматриваемом
месте стоит символ пересечения
означает, что на рассматриваемом
месте стоит символ пересечения ![]() случайных множеств,
если в определении Bm стоит символ пересечения или символ
произведения нечетких множеств, и соответственно символ объединения
случайных множеств,
если в определении Bm стоит символ пересечения или символ
произведения нечетких множеств, и соответственно символ объединения ![]() случайных множеств,
если в Bm стоит символ объединения или символ суммы нечетких
множеств.
случайных множеств,
если в Bm стоит символ объединения или символ суммы нечетких
множеств.
Комментарий. Поясним содержание
теоремы. Например, если
![]()
то
![]()
Как
совместить справедливость дистрибутивного закона для случайных множеств
(вытекающего из его справедливости для обычных множеств) с теоремой 2 выше, в
которой показано, что для нечетких множеств, вообще говоря, ![]() ? Дело в том, что хотя в соответствии с теоремой 9 для любых
трех нечетких множеств В1, В2 и В3
можно указать три случайных множества А1, А2
и А3 такие, что
? Дело в том, что хотя в соответствии с теоремой 9 для любых
трех нечетких множеств В1, В2 и В3
можно указать три случайных множества А1, А2
и А3 такие, что
Proj![]() Proj
Proj![]() Proj
Proj![]() ,
,
где
![]()
но
при этом, вообще говоря,
Proj![]()
и,
кроме случаев, указанных в теореме 2,
Proj![]()
Доказательство теоремы 9
проводится по индукции. При t = 1 распределение случайного множества
строится с помощью теоремы 3. Затем конструируется само случайное множество А1,
определенное на делимом вероятностном пространстве (нетрудно проверить, что на
делимом вероятностном пространстве можно построить случайное подмножество
конечного множества с любым заданным распределением именно в силу делимости пространства).
Далее случайные множества А2, А3, …, At
строим по индукции с помощью теоремы Теорема 9 доказана.
Замечание. Проведенное
доказательство теоремы 9 проходит и в случае, когда при определении Bm используются
отрицания, точнее, кроме Bm ранее введенного вида
используются также последовательности результатов теоретико-множественных операций,
очередной шаг в которых имеет вид
![]()
А
именно, сначала при помощи законов де Моргана (теорема 1 выше) проводится
преобразование, в результате которого в последовательности Bm остаются
только отрицания отдельных подмножеств из совокупности ![]() , а затем с помощью теоремы 5 вообще удается избавиться от
отрицаний и вернуться к условиям теоремы 9.
, а затем с помощью теоремы 5 вообще удается избавиться от
отрицаний и вернуться к условиям теоремы 9.
Итак, в настоящей главе описаны связи
между такими объектами нечисловой природы, как нечеткие и случайные множества,
установленные в нашей стране в первой половине 70-х годов, начиная с работы
[19]. Через несколько лет, а именно, в начале 80-х годов, близкие подходы стали
развиваться и за рубежом. Одна из работ [20] носит примечательное название
«Нечеткие множества как классы эквивалентности случайных множеств».
В эконометрике и прикладной статистике
разработан ряд методов статистического анализа нечетких данных, в том числе
методы классификации, регрессии, проверки гипотез о совпадении функций
принадлежности по опытным данным и т.д., при этом оказались полезными общие
подходы статистики объектов нечисловой природы [8]. Методологические и
прикладные вопросы теории нечеткости широко обсуждаются в литературе. Приведем
пример.
5.6. Нечеткий экспертный выбор в контроллинге инноваций
Обсудим одно применение экспертных технологий,
разработанных на основе теории нечеткости.
В настоящее время активно
разрабатывается подход к управлению инновационными проектами, основанный на методологии
контроллинга. Одной из главных причин возникновения и внедрения концепции
контроллинга для разработки инноваций на промышленных предприятиях стала
необходимость в системной интеграции различных аспектов управления инновационными
проектами. Контроллинг обеспечивает методическую и инструментальную базу для
поддержки основных функций менеджмента: планирования, учета, контроля и
анализа, а также оценки ситуаций для принятия управленческих решений [21].
Этапы контроллинга инноваций.
Согласно [22], контроллинг инноваций включает в себя:
- оценку реализуемости проекта;
- информационную поддержку планирования
разработки инновационного проекта;
- информационную поддержку контроля над
осуществлением инновационного проекта;
- информационную поддержку функции
анализа.
На
первом этапе контроллеру проекта необходимо ответить на вопрос: достигнет ли
предприятие поставленных перед ним целей, если приступит к реализации проекта.
Цели проекта - как и цели самого предприятия, должны иметь ясный смысл, результаты,
полученные при достижении цели, должны быть измеримы, а заданные ограничения
(по времени, рамкам бюджета, выделенным ресурсам и качеству получаемых
результатов) выполнимы. Если при реализации проекта общефирменные цели не
достигаются, то подразделение контроллинга вырабатывает предложения об
альтернативных вариантах реализации проекта, способных удовлетворить
поставленные цели.
На этом этапе возникает задача выбора
варианта реализации проекта, позволяющего достичь общефирменные цели.
Для решения этой задачи можно
воспользоваться эконометрическими методами. Эконометрика - это наука, изучающая
конкретные количественные и качественные взаимосвязи экономических объектов и
процессов с помощью математических и статистических методов и моделей, поэтому
именно в эконометрике следует искать методы для решения поставленной задачи.
Каждый предложенный вариант реализации
проекта имеет свои преимущества и недостатки. Он может характеризоваться как
количественными экономическими показателями, такими, как затраты, поступления и
др., техническими показателями, описывающими характеристики качества
разрабатываемого продукта, так и качественными показателями, выраженными в виде
терминов, например, крошечный, маленький, средний.
Целесообразно выделить эталонный
вариант реализации проекта и его характеристики. Характеристики подбираются таким
образом, чтобы проект был оптимальным с точки зрения предъявляемых к нему
требований. Чтобы сравнить варианты реализации проекта с эталонным вариантом и
выбрать из них лучший, можно применить эконометрические методы, основанные на
алгоритмах анализа качественных и количественных данных. Такие методы подробнее
рассматриваются ниже.
На втором этапе осуществляется
разработка планово-организационных мероприятий. Подразделение контроллинга
разрабатывает методики и инструменты планирования, наилучшим образом подходящие
в данных условиях и обеспечивающие наиболее точные результаты. Подготовленный
план проверяется на реализуемость, затем решаются вопросы, связанные с координацией
участников проекта, с организацией информационного потока, с организацией работ
и назначением ответственных.
На третьем этапе устанавливается время
проведения контрольных мероприятий, связанное с выполнением определенных блоков
работ. Выбираются подконтрольные показатели, характеризующие финансовое и
организационное состояние проекта. Устанавливаются допустимые отклонения
выбранных показателей, превышение которых может привести к негативным последствиям.
Проводится учет показателей, фиксация отклонений. Выявляются причины и
виновники отклонений.
На заключительном четвертом этапе
подразделение контроллинга оценивает влияние выявленных отклонений на дальнейшие
шаги реализации проекта. Выясняет, как выявленные отклонения повлияли на
основные управляемые параметры проекта.
По окончанию цикла контроллер проекта
подготавливает отчет с предложением вариантов решения возникших проблем и
изменением плановых величин на следующий период.
Эконометрические методы сравнения и
выбора. На первом этапе контроллинга инноваций необходимо решить задачу
выбора варианта реализации проекта. Выбор между вариантами очевиден, если один
из вариантов лучше другого по всем рассматриваемым показателям. В реальных
ситуациях выбора варианты обычно несравнимы - первый лучше по одним
показателям, второй - по другим. Для сравнения вариантов целесообразно прибегать
к экспертным технологиям [12].
Одна группа экспертных технологий
нацелена на выявление объективного упорядочения вариантов в результате
усреднения мнений экспертов. Используют различные способы расчета на основе
средних рангов (прежде всего средних арифметических и медиан). Для
моделирования результатов парных сравнений применяют теорию люсианов. Для
экспертных оценок находят медиану Кемени, и т.д.
Другая группа экспертных технологий
нацелена на получение коэффициентов весомости (важности, значимости) отдельных
показателей. Итоговая оценка варианта реализации проекта получается в
результате суммирования произведений значений показателей на соответствующие
коэффициенты весомости. Иногда эти коэффициенты оцениваются экспертами на
основе иерархической системы показателей. Более обоснованным является
экспертно-статистический метод, согласно которому на основе обучающей выборки
восстанавливается зависимость между показателями варианта реализации
инновационного проекта и его итоговой оценкой.
Использование теории нечеткости.
Для сравнения вариантов реализации инновационного проекта и выбора из них лучшего
можно использовать подход, основанный на описании качественных характеристик
нечеткими множествами. Опишем его [22].
Пусть S = {Si, i = 1, 2, …, n}
– множество, состоящее из n вариантов реализации
инновационного проекта. Для каждого варианта Si определено m
характеристик Qij, j
= 1, 2, …, m. В зависимости от конкретных условий набор характеристик
может меняться.
Необходимо выделить эталонный вариант
реализации проекта So и его характеристики Q0j.
Характеристики подбираются таким образом, чтобы проект был оптимальным с точки
зрения предъявляемых к нему требований.
Требуется проранжировать имеющиеся
варианты S реализации инновационного проекта по заданным m
характеристикам на соответствие эталону.
Для каждой характеристики Qij,
согласно рассматриваемой методике, строится нечеткое множество ![]() . Для этого сначала определяются возможные значения
переменной xj, удовлетворяющие характеристике Qij.
Предполагается, что они составляют отрезок Xij. Определяется середина qij
и полуширина (радиус)
. Для этого сначала определяются возможные значения
переменной xj, удовлетворяющие характеристике Qij.
Предполагается, что они составляют отрезок Xij. Определяется середина qij
и полуширина (радиус) ![]() отрезка Xij:
Таким образом,
отрезка Xij:
Таким образом,
![]() .
.
Для описания критерия Qij
могут применяться различные функции принадлежности. В соответствии с [22] используем
функцию принадлежности следующего вида:
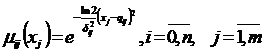 .
.
Исходя
из построения множества Xij, в точке qij функция имеет максимум, в пределах множества Xij
функция принадлежности принимает значения больше 0,5, а вне Xij – меньше:
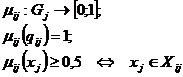
В
результате получаем нечеткие множества
![]() ,
,
описывающие
критерии Qij.
Чтобы определить, в какой мере
характеристика варианта si близка характеристике
эталонного варианта so, вычисляют степень
равенства vij соответствующих нечетких множеств:
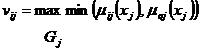 .
.
Значение
максимина достигается в точке пересечения функций принадлежности:
![]() ,
,
где
![]() .
.
Произведя взвешенное голосование,
получают интегральную оценку vi соответствия
совокупности характеристик варианта реализации проекта si
совокупности характеристик эталонного варианта s0:
![]() ,
,
где
![]() .
.
Здесь
![]() является весом j-го
критерия и показывает уровень его важности.
является весом j-го
критерия и показывает уровень его важности.
При обсуждении различных подходов к
выбору наилучшего варианта реализации инновационного проекта иногда противопоставляют
вероятностно-статистические модели и методы теории нечеткости. С обоснованной
выше методологической точки зрения весьма важно, что такое противопоставление
лишено оснований.
ГЛАВА 6. ИНТЕРВАЛЬНЫЕ ЧИСЛА КАК ЧАСТНЫЙ СЛУЧАЙ НЕЧЕТКИХ МНОЖЕСТВ
6.1. Интервальные числа и операции над ними
Интервальное число – это
нечеткое множество с функцией принадлежности, равной 1 на отрезке [a, b] и
равной 0 вне этого отрезка. Проще говоря, интервальное число – это (замкнутый)
интервал [a, b]. Интервальное число – самый простой частный случай нечеткого
множества. Хотя для интервальных чисел не выполняется одно из важных свойств
нечетких множеств – непрерывность перехода от «непринадлежности к множеству» к
«принадлежности», это математическое понятие позволяет успешно моделировать
разброс результатов косвенных измерений и погрешности других расчетов в
прикладных научных исследованиях.
Интервальные числа часто
используются для описания результатов измерений, поскольку измерение всегда
проводится с некоторой неопределенностью. Прогноз погоды, как и другие
прогнозы, дается в виде интервала, например: «Температура завтра днем будет 15
– 17 градусов Цельсия».
Арифметические операции над интервальными
числами [a, b] и [c, d] определяются следующим
образом:
[a, b]
+ [c, d] = [a + c, b + d], [a, b] – [c,
d] = [a – d+ c, b – c],
[a, b]
[c, d] = [ac, bd], [a,
b] / [c, d] = [a/d, b/c]
(формулы для умножения и
деления приведены в случае положительных чисел a, b, c, d). Эти формулы
получены при решении соответствующих оптимизационных задач. Пусть х
лежит в отрезке [a, b], а у — в отрезке [c, d]. Каково минимальное и максимальное
значение для х + у? Очевидно, a + c и b + d соответственно. Минимальные и максимальные
значения для х – у, ху, х/у указывают нижние и верхние границы для
интервальных чисел, задающих результаты арифметических операций. А от арифметических
операций можно перейти ко всем остальным математическим алгоритмам. Так
строится интервальная математика: определив арифметические операции, можем по
аналогии с обычной математикой проводить различные расчеты, поскольку алгоритмы
расчетов представляют собой последовательности арифметических действий.
6.2. «Интервальное удвоение» математики
Первая монография по
интервальной математике была опубликована Р.Е. Муром [23] в
Любую математическую
конструкцию, использующую числа, можно обобщить, заменив обычные числа на
интервальные. Таким образом, применение интервальных чисел позволяет произвести
«интервальное удвоение» математики. Открывается большое поле для теоретических
исследований, имеющих непосредственный практический интерес. Вначале основные
применения были связаны с автоматическим контролем ошибок округления при
вычислениях на ЭВМ. Затем начали учитывать ошибки дискретизации численных
методов и ошибки в начальных данных. Статистика интервальных данных исходит из
модели, согласно которой элементы выборки известны лишь с точностью до
«плюс-минус дельта», т.е. выборка состоит из интервалов фиксированной длины со
случайными концами.
«Интервальное удвоение»
математики состоит в том, что всюду, где используются действительные числа, их
можно заменить интервалами (интервальными числами). Например, можно решать
системы линейных алгебраических уравнений с интервальными коэффициентами или
системы линейных дифференциальных уравнений с интервальными коэффициентами и
интервальными граничными условиями. В статистике интервальных данных элементы
выборки – не числа, а интервалы. В этом разделе прикладной статистики
разработаны принципиально новые (по сравнению с классической математической
статистикой) подходы, основанные на понятиях нотны и рационального объемы выборки
(см. следующую главу).
Констатируем необходимость
расширения математического аппарата с целью учета присущих реальности
нечеткости и интервальности. Такая необходимость отмечалась в ряде публикаций
[25-27], но пока еще не стала общепризнанной. На описании неопределенностей с
помощью вероятностных моделей не останавливаемся, поскольку такому подходу
посвящено множество работ.
Рассмотрим подробнее статистику
интервальных данных.
ГЛАВА 7. СТАТИСТИКА ИНТЕРВАЛЬНЫХ ДАННЫХ
В статистике интервальных данных
элементы выборки — не числа, а интервалы. Это приводит к алгоритмам и выводам,
принципиально отличающимся от классических. Настоящая работа посвящена основным
идеям и подходам асимптотической статистики интервальных данных. Приведены
результаты, связанные с основополагающими в рассматриваемой области прикладной
математической статистики понятиями нотны и рационального объема выборки.
7.1. Развитие статистики интервальных данных
Перспективная и быстро развивающаяся область
статистических исследований последних десятилетий — математическая статистика
интервальных данных. Речь идет о развитии методов прикладной математической
статистики в ситуации, когда статистические данные — не числа, а интервалы, в
частности, порожденные наложением ошибок измерения на значения случайных величин.
Полученные результаты отражены в выступлениях на проведенной в журнале
«Заводская лаборатория» дискуссии [28] и в докладах Международной конференции
ИНТЕРВАЛ-92 [29]. Приведем основные идеи весьма перспективного для вероятностно-статистических
и интервальных методов и моделей принятия решений асимптотического направления
в статистике интервальных данных, в котором синтезируются идеи интервальной математики
и математической статистики.
В настоящее время признается
необходимым изучение устойчивости (робастности) оценок параметров к малым
отклонениям исходных данных и предпосылок модели. Однако популярная среди
теоретиков модель засорения (Тьюки-Хьюбера) представляется не вполне
адекватной. Эта модель нацелена на изучение влияния больших «выбросов».
Поскольку любые реальные измерения лежат в некотором фиксированном диапазоне, а
именно, заданном в техническом паспорте средства измерения, то зачастую выбросы
не могут быть слишком большими. Поэтому представляются полезными иные, более
общие схемы устойчивости, введенные в монографии [13], в которых, например,
учитываются отклонения распределений результатов наблюдений от предположений
модели.
В одной из таких схем изучается влияние
интервальности исходных данных на статистические выводы. Необходимость такого
изучения стала очевидной следующим образом. В государственных стандартах СССР
по прикладной статистике в обязательном порядке давалось справочное приложение
«Примеры применения правил стандарта». При подготовке ГОСТ 11.011-83 [30]
разработчикам стандарта были переданы для анализа реальные данные о наработке
резцов до предельного состояния (в часах). Оказалось, что все эти данные
представляли собой либо целые числа, либо полуцелые (т.е. после умножения на 2
становящиеся целыми). Ясно, что исходная длительность наработок искажена.
Необходимо учесть в статистических процедурах наличие такого искажения исходных
данных. Как это сделать?
Первое, что приходит в голову — модель
группировки данных, согласно которой для истинного значения Х проводится
замена на ближайшее число из множества {0,5n, n = 1, 2, 3, ...}.
Однако эту модель целесообразно подвергнуть сомнению, а также рассмотреть иные
модели. Так, возможно, что Х надо приводить к ближайшему сверху элементу
указанного множества — если проверка качества поставленных на испытание резцов
проводилась раз в полчаса. Другой вариант: если расстояния от Х до двух
ближайших элементов множества {0,5n, n = 1, 2, 3, ...} примерно
равны, то естественно ввести рандомизацию при выборе заменяющего числа, и т.д.
Целесообразно построить новую
математико-статистическую модель, согласно которой результаты наблюдений —
не числа, а интервалы. Например, если в таблице приведено значение 53,5, то
это значит, что реальное значение — какое-то число от 53,0 до 54,0, т.е.
какое-то число в интервале [53,5 – 0,5; 53,5 + 0,5], где 0,5 — максимально
возможная погрешность. Принимая эту модель, мы попадаем в новую научную
область — статистику интервальных данных [31, 32]. Статистика интервальных
данных идейно связана с интервальной математикой, в которой в роли чисел
выступают интервалы (см., например, монографию [24]). Это направление
математики является дальнейшим развитием всем известных правил приближенных
вычислений, посвященных выражению погрешностей суммы, разности, произведения,
частного через погрешности тех чисел, над которыми осуществляются перечисленные
операции.
Как видно из сборника трудов
Международной конференции [29], исследователям удалось решить ряд задач теории
интервальных дифференциальных уравнений, в которых коэффициенты, начальные
условия и решения описываются с помощью интервалов. По мнению ряда
специалистов, статистика интервальных данных является частью интервальной
математики [24]. Впрочем, распространена и другая точка зрения, согласно которой
такое включение нецелесообразно, поскольку статистика интервальных данных
использует несколько иные подходы к алгоритмам анализа реальных данных, чем
сложившиеся в интервальной математике (подробнее см. ниже).
В настоящей главе развиваем
асимптотические методы статистического анализа интервальных данных при больших
объемах выборок и малых погрешностях измерений. В отличие от классической
математической статистики, сначала устремляется к бесконечности объем выборки и
только потом — уменьшаются до нуля погрешности (в классической математической
статистике предельные переходы осуществляются в обратном порядке – сначала
уменьшаются до нуля погрешности измерений, и только затем - устремляется к
бесконечности объем выборки). В частности, еще в начале 1980-х годов с помощью
такой асимптотики сформулированы правила выбора метода оценивания в ГОСТ
11.011-83 [30].
Нами разработана [33] общая схема
исследования, включающая расчет нотны (максимально возможного отклонения статистики,
вызванного интервальностью исходных данных) и рационального объема выборки
(превышение которого не дает существенного повышения точности оценивания). Она
применена к оцениванию математического ожидания и дисперсии [28], медианы и
коэффициента вариации [34], параметров гамма-распределения [30, 35] и
характеристик аддитивных статистик [33], при проверке гипотез о параметрах
нормального распределения, в т.ч. с помощью критерия Стьюдента, а также
гипотезы однородности с помощью критерия Смирнова [34]. Изучено асимптотическое
поведение оценок метода моментов и оценок максимального правдоподобия (а также
более общих — оценок минимального контраста), проведено асимптотическое
сравнение этих методов в случае интервальных данных, найдены общие условия, при
которых, в отличие от классической математической статистики, метод моментов
дает более точные оценки, чем метод максимального правдоподобия [36].
Разработаны подходы к рассмотрению
интервальных данных в основных постановках регрессионного, дискриминантного и
кластерного анализов [37]. Изучено влияние погрешностей измерений и наблюдений
на свойства алгоритмов регрессионного анализа, разработаны способы расчета нотн
и рациональных объемов выборок, введены и исследованы новые понятия многомерных
и асимптотических нотн, доказаны соответствующие предельные теоремы [37, 38].
Проведена первоначальная разработка интервального дискриминантного анализа,
рассмотрено влияние интервальности данных на показатель качества классификации
[37, 39]. Основные идеи и результаты рассматриваемого направления в статистике
интервальных данных приведены в публикациях обзорного характера [31, 32].
Как показала Международная конференция
ИНТЕРВАЛ-92, в области асимптотической математической статистики интервальных
данных мы имеем мировой приоритет. По нашему мнению, со временем во все виды
статистического программного обеспечения должны быть включены алгоритмы
интервальной статистики, «параллельные» обычно используемым алгоритмам прикладной
математической статистики. Это позволит в явном виде учесть наличие
погрешностей у результатов наблюдений, сблизить позиции метрологов и
статистиков.
Многие из утверждений статистики интервальных
данных весьма отличаются от аналогов из классической математической статистики.
В частности, не существует состоятельных оценок; средний квадрат ошибки оценки,
как правило, асимптотически равен сумме дисперсии оценки, рассчитанной согласно
классической теории, и некоторого положительного числа (равного квадрату т.н.
нотны — максимально возможного отклонения значения статистики из-за
погрешностей исходных данных) — в результате, метод моментов оказывается иногда
точнее метода максимального правдоподобия [36]; нецелесообразно увеличивать объем
выборки сверх некоторого предела (называемого рациональным объемом выборки) —
вопреки классической теории, согласно которой чем больше объем выборки, тем
точнее выводы.
В стандарт [30] включен раздел 5, посвященный
выбору
метода оценивания при неизвестных параметрах формы и масштаба и известном
параметре сдвига и основанный на концепциях статистики интервальных данных.
Теоретическое обоснование этого раздела стандарта опубликовано лишь через 5 лет
в работе [35].
В
Вторая (наряду с научной школой проф.
А.И. Орлова) ведущая научная школа в области статистики интервальных данных —
это школа проф. А.П. Вощинина (1937 - 2008), активно работающая с конца 70-х
годов. Полученные результаты отражены в ряде монографий (см., прежде всего,
[42, 43, 44]), статей [28, 45, 46, 47, 48], докладов, в частности, в трудах
[29] Международной конференции ИНТЕРВАЛ-92, диссертациях [49, 50]. Изучены
проблемы регрессионного анализа, планирования эксперимента, сравнения
альтернатив и принятия решений в условиях интервальной неопределенности.
Рассматриваемое ниже наше научное
направление отличается нацеленностью на асимптотические результаты, полученные
при больших объемах выборок и малых погрешностях измерений, поэтому его полное
название таково: асимптотическая математическая статистика интервальных данных.
7.2. Основные идеи и результаты
статистики интервальных данных
Сформулируем
сначала основные идеи асимптотической математической статистики интервальных
данных, а затем рассмотрим реализацию этих идей на перечисленных выше примерах.
Основные идеи достаточно просты, в то время как их проработка в конкретных
ситуациях зачастую оказывается достаточно трудоемкой.
Пусть существо реального явления
описывается выборкой x1, x2, ...,
xn. В вероятностной теории математической статистики, из которой
мы исходим (см. справочник [51]), выборка — это набор независимых в
совокупности одинаково распределенных случайных величин. Однако беспристрастный
и тщательный анализ подавляющего большинства реальных задач показывает, что
статистику известна отнюдь не выборка x1, x2,
..., xn, а величины
yj = xj
+ ej,
j = 1, 2, ..., n,
где
e1, e2, …, en
— некоторые погрешности измерений,
наблюдений, анализов, опытов, исследований (например, инструментальные ошибки).
Одна из причин появления погрешностей —
запись результатов наблюдений с конечным числом значащих цифр. Дело в том, что
для случайных величин с непрерывными функциями распределения событие, состоящее
в попадании хотя бы одного элемента выборки в множество рациональных чисел,
согласно правилам теории вероятностей имеет вероятность 0, а такими событиями в
теории вероятностей принято пренебрегать. Поэтому при рассуждениях о выборках
из нормального, логарифмически нормального, экспоненциального, равномерного,
гамма-распределений, распределения Вейбулла-Гнеденко и др. приходится
принимать, что эти распределения имеют элементы исходной выборки x1,
x2, ..., xn, в то время как статистической
обработке доступны лишь искаженные значения yj = xj + ej.
Введем обозначения
x = (x1, x2, ..., xn),
y = (y1, y2, ..., yn),
e = (e1 + e2 + … + en).
Пусть
статистические выводы основываются на статистике f : Rn ® R1, используемой для
оценивания параметров и характеристик распределения, проверки гипотез и решения
иных статистических задач. Принципиально важная для статистики интервальных
данных идея такова: СТАТИСТИК ЗНАЕТ ТОЛЬКО f(y), НО НЕ f(x).
Очевидно, в статистических выводах
необходимо отразить различие между f(y) и f(x).
Одним из двух основных понятий статистики интервальных данных является понятие
нотны.
Определение. Величину
максимально возможного (по абсолютной величине) отклонения, вызванного
погрешностями наблюдений e, известного статистику значения f(y)
от истинного значения f(x), т.е.
Nf(x) = sup | f(y) – f(x) |,
где
супремум берется по множеству возможных значений вектора погрешностей e (см. ниже), будем
называть НОТНОЙ.
Если функция f имеет частные
производные второго порядка, а ограничения на погрешности имеют вид[1]
| ei
| £ D, i
= 1, 2, …, n, (1)
причем
D
мало, то приращение функции f с точностью до бесконечно малых более
высокого порядка описывается главным линейным членом, т.е.
![]()
Чтобы
получить асимптотическое (при D ® 0) выражение для нотны,
достаточно найти максимум и минимум линейной функции (главного линейного члена)
на кубе, заданном неравенствами (1). Легко видеть, что максимум достигается,
если положить
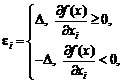
а
минимум, отличающийся от максимума только знаком, достигается при ![]() = –ei.
Следовательно, нотна с точностью до бесконечно малых более высокого
порядка имеет вид
= –ei.
Следовательно, нотна с точностью до бесконечно малых более высокого
порядка имеет вид
![]()
Это
выражение назовем асимптотической нотной.
Условие (1) означает, что исходные
данные представляются статистику в виде интервалов [yi – D; yi
+ D], i
= 1, 2, …, n (отсюда и название этого научного направления). Ограничения
на погрешности могут задаваться разными способами — кроме абсолютных ошибок
используются относительные или иные показатели различия между x и y.
Если задана не предельная абсолютная
погрешность D,
а предельная относительная погрешность d, т.е. ограничения на погрешности
вошедших в выборку результатов измерений имеют вид
| ei | £ d | xi |, i = 1, 2, …, n,
то
аналогичным образом получаем, что нотна с точностью до бесконечно малых более
высокого порядка, т.е. асимптотическая нотна, имеет вид
![]()
При
практическом использовании рассматриваемой концепции необходимо провести
тотальную замену символов x на символы y.
В каждом конкретном случае удается показать, что в силу малости погрешностей
разность Nf(y) – Nf(x)
является бесконечно малой более высокого порядка сравнительно с Nf(x)
или Nf(y).
Основные результаты в вероятностной
модели. В классической вероятностной
модели элементы исходной выборки x1, x2,
..., xn рассматриваются как независимые одинаково распределенные
случайные величины. Как правило, существует некоторая константа C > 0
такая, что в смысле сходимости по вероятности
![]() (2)
(2)
Соотношение
(2) доказывается отдельно для каждой конкретной задачи.
При использовании классических
статистических методов в большинстве случаев используемая статистика f(x)
является асимптотически нормальной. Это означает, что существуют константы а
и s2 такие, что
![]()
где
F(x)
— функция стандартного нормального распределения с математическим ожиданием 0 и
дисперсией 1. При этом обычно оказывается, что
![]() и
и ![]()
а
потому в классической математической статистике средний квадрат ошибки статистической
оценки равен
![]()
с
точностью до членов более высокого порядка.
В статистике интервальных данных
ситуация совсем иная — обычно можно доказать, что средний квадрат ошибки
равен
![]() (3)
(3)
Из соотношения (3) вытекает ряд важных
следствий. Правая часть этого равенства, в отличие от правой части соответствующего
классического равенства, не стремится к 0 при безграничном возрастании объема
выборки. Она остается больше некоторого положительного числа, а именно,
квадрата нотны. Следовательно, статистика f(x) не является
состоятельной оценкой параметра a. Более того, состоятельных оценок
вообще не существует.
Пусть доверительным интервалом для
параметра a, соответствующим заданной доверительной вероятности g, в классической
математической статистике является интервал (cn(g); dn(g)). В статистике
интервальных данных аналогичный доверительный интервал является более широким.
Он имеет вид (cn(g) – Nf(y);
dn(g) + Nf(y)).
Таким образом, его длина увеличивается на две нотны. Следовательно, при
увеличении объема выборки длина доверительного интервала не может стать меньше,
чем
В статистике интервальных данных методы
оценивания параметров имеют другие свойства по сравнению с классической
математической статистикой. Так, при больших объемах выборок метод моментов
может быть заметно лучше, чем метод максимального правдоподобия (т.е. иметь
меньший средний квадрат ошибки — см. формулу (3)), в то время как в
классической математической статистике второй из названных методов всегда не
хуже первого.
Рациональный объем выборки. Анализ
формулы (3) показывает, что в отличие от классической математической статистики
нецелесообразно безгранично увеличивать объем выборки, поскольку средний
квадрат ошибки остается всегда большим квадрата нотны. Поэтому представляется
полезным ввести понятие «рационального объема выборки» nrat, при достижении которого
продолжать наблюдения нецелесообразно.
Как установить «рациональный объем
выборки»? Можно воспользоваться идеей «принципа уравнивания погрешностей»,
выдвинутой в монографии [13]. Речь идет о том, что вклад погрешностей различной
природы в общую погрешность должен быть примерно одинаков. Этот принцип дает
возможность выбирать необходимую точность оценивания тех или иных характеристик
в тех случаях, когда это зависит от исследователя. В статистике интервальных
данных в соответствии с «принципом уравнивания погрешностей» предлагается
определять рациональный объем выборки nrat
из условия равенства двух величин — метрологической составляющей, связанной с
нотной, и статистической составляющей — в среднем квадрате ошибки (3),
т.е. из условия
![]()
Для
практического использования выражения для рационального объема выборки
неизвестные теоретические характеристики необходимо заменить их оценками. Это
делается в каждой конкретной задаче по-своему.
Исследовательскую программу в области
статистики интервальных данных можно «в двух словах» сформулировать так: для
любого алгоритма анализа данных (алгоритма прикладной статистики) необходимо
вычислить нотну и рациональный объем выборки. Или иные величины из того же
понятийного ряда, возникающие в многомерном случае, при наличии нескольких
выборок и при иных обобщениях описываемой здесь простейшей схемы. Затем
проследить влияние погрешностей исходных данных на точность оценивания,
доверительные интервалы, значения статистик критериев при проверке гипотез,
уровни значимости и другие характеристики статистических выводов. Очевидно,
классическая математическая статистика является частью статистики интервальных
данных, выделяемой условием D = 0.
Поясним теоретические концепции
статистики интервальных данных на простых примерах.
7.3. Оценивание математического ожидания и дисперсии
Пусть
необходимо оценить математическое ожидание случайной величины с помощью обычной
оценки — среднего арифметического результатов наблюдений, т.е.
![]()
Тогда
при справедливости ограничений (1) на абсолютные погрешности имеем Nf(x)
= D. Таким образом, нотна
полностью известна и не зависит от многомерной точки, в которой берется. Вполне
естественно: если каждый результат наблюдения известен с точностью до D, то и среднее
арифметическое известно с той же точностью. Ведь возможна систематическая
ошибка — если к каждому результату наблюдения добавить D, то и среднее
арифметическое увеличится на D.
Поскольку
![]()
то
в ранее введенных обозначениях
s2 = D(x1).
Следовательно,
рациональный объем выборки равен
![]()
Для практического использования
полученной формулы надо оценить дисперсию результатов наблюдений. Можно
доказать, что, поскольку D мало, это можно сделать обычным способом,
например, с помощью несмещенной выборочной оценки дисперсии
![]()
Здесь и далее рассуждения часто идут на
двух уровнях. Первый — это уровень «истинных» случайных величин, обозначаемых «х»,
описывающих реальность, но неизвестных специалисту по анализу данных.
Второй — уровень известных этому специалисту величин «у», отличающихся
погрешностями от истинных. Погрешности малы, поэтому функции от х
отличаются от функций от у на некоторые бесконечно малые величины. Эти
соображения и позволяют использовать s2(y)
как оценку D(x1).
Итак, выборочной оценкой рационального
объема выборки является
![]()
Уже на этом первом рассматриваемом
примере видим, что рациональный объем выборки находится не где-то вдали, а непосредственно
рядом с теми объемами, с которыми имеет дело любой практически работающий
статистик. Например, если статистик знает, что
![]()
то
nrat = 36. А именно такова
погрешность контрольных шаблонов во многих технологических процессах! Поэтому,
занимаясь управлением качеством, необходимо обращать внимание на действующую на
предприятии систему измерений.
По сравнению с классической
математической статистикой доверительный
интервал для математического ожидания (для заданной доверительной вероятности g) имеет другой вид:
![]() (4)
(4)
где
u(g) — квантиль порядка (1
+ g)/2 стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1.
По поводу формулы (4) была довольно
жаркая дискуссия среди специалистов. Отмечалось, что она получена на основе
Центральной предельной теоремы теории вероятностей и может быть использована
при любом распределении результатов наблюдений (с конечной дисперсией). Если же
имеется дополнительная информация, то, по мнению отдельных специалистов,
формула (4) может быть уточнена. Например, если известно, что распределение xi
является нормальным, в качестве u(g) целесообразно
использовать квантиль распределения Стьюдента. К этому надо добавить, что по
небольшому числу наблюдений нельзя надежно установить нормальность, а при росте
объема выборки квантили распределения Стьюдента приближаются к квантилям
нормального распределения.
Вопрос о том, часто ли результаты
наблюдений имеют нормальное распределение, подробно обсуждался среди специалистов.
Выяснилось, что распределения встречающихся в практических задачах результатов
измерений почти всегда отличны от нормальных [52]. А также и от распределений
из иных параметрических семейств, описываемых в учебниках.
Применительно к оцениванию
математического ожидания (но не к оцениванию других характеристик или
параметров распределения) факт существования границы возможной точности,
определяемой точностью исходных данных, неоднократно отмечался в литературе
([53, с. 230–234], [54, с. 121] и др.).
Оценивание дисперсии. Для статистики f(y)
= s2(y), где s2(y)
— выборочная дисперсия (несмещенная оценка теоретической дисперсии), при
справедливости ограничений (1) на абсолютные погрешности имеем
![]()
Можно
показать, что нотна Nf(y) сходится к
2DM | x1 – M(x1) |
по
вероятности с точностью до o(D), когда n
стремится к бесконечности. Это же предельное соотношение верно и для нотны Nf(х),
вычисленной для исходных данных. Таким образом, в данном случае справедлива
формула (2) с
C = 2M
| x1 – M(x1) |.
Известно [55], что случайная величина
![]()
является
асимптотически нормальной с математическим ожиданием 0 и дисперсией ![]()
Из сказанного вытекает: в статистике
интервальных данных асимптотический доверительный интервал для дисперсии s2 (соответствующий
доверительной вероятности g) имеет вид
(s2(y)
– A; s2 + A),
где
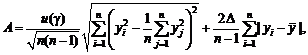
здесь
u(g) обозначает тот же
самый квантиль стандартного нормального распределения, что и выше в случае
оценивания математического ожидания.
Рациональный объем выборки при
оценивании дисперсии равен
![]()
а
выборочную оценку рационального объема выборки nsample–rat
можно вычислить, заменяя теоретические моменты на соответствующие выборочные и
используя доступные статистику результаты наблюдений, содержащие погрешности.
Что можно сказать о численной величине
рационального объема выборки? Как и в случае оценивания математического
ожидания, она отнюдь не выходит за пределы обычно используемых объемов выборок.
Так, если распределение результатов наблюдений xi является нормальным с
математическим ожиданием 0 и дисперсией s2, то в результате
вычисления моментов случайных величин в предыдущей формуле получаем, что
![]()
где
p
— отношение длины окружности к диаметру, p = = 3,141592…
Например, если D = s/6, то nrat = 11. Это меньше, чем при оценивании математического
ожидания в предыдущем примере.
7.4. Интервальные данные в задачах оценивания
Поясним
теоретические концепции статистики интервальных данных на нескольких простых
примерах.
Пример 1. Аддитивные
статистики. Пусть
g : R1 ® R1 — некоторая непрерывная
функция. Аддитивные статистики имеют вид
![]()
Тогда
![]()
![]()
по
вероятности при n ® ¥, если математические
ожидания в правых частях двух последних соотношений существуют. Применяя
рассмотренные выше общие соображения, получаем, что при малых фиксированных D и d и достаточно больших n
значения f(y) могут принимать любые
величины из разрешенных (например, записываемых заданным числом значащих цифр)
в замкнутом интервале
![]() (5)
(5)
при
ограничениях (1) на абсолютные ошибки и в замкнутом интервале
![]() (6)
(6)
при
ограничениях на относительные погрешности результатов наблюдений. Обратим
внимание, что длины этих интервалов независимы от объема выборки, в частности,
не стремятся к 0 при его росте.
К каким последствиям это
отсутствие стремления к 0 приводит в задачах статистического оценивания?
Поскольку для статистик аддитивного типа
![]() (7)
(7)
по
вероятности при n ® ¥, если математическое
ожидание в правой части формулы (7) существует, то аддитивную статистику f(x)
естественно рассматривать как непараметрическую оценку этого математического
ожидания. Термин «непараметрическая» означает, что не делается предположений о
принадлежности функции распределения выборки к тому или иному параметрическому
семейству распределения. Распределение статистики f(x)
зависит от распределения результатов наблюдений. Однако для любого
распределения результатов наблюдений с конечной дисперсией статистика f(x)
является состоятельной и асимптотически нормальной оценкой для
математического ожидания, указанного в правой части формулы (7).
Как известно, в рамках
классической математической статистики в предположении существования ненулевой
дисперсии Dg(x1) в силу асимптотической
нормальности аддитивной статистики f(x)
асимптотический доверительный интервал, соответствующий доверительной
вероятности g,
имеет вид
![]()
где
s(g(x))
— выборочное среднее квадратическое отклонение, построенное по g(x1), g(x2),…, g(xn),
а ![]() — квантиль стандартного нормального
распределения порядка
— квантиль стандартного нормального
распределения порядка ![]()
В рассматриваемой модели
порождения интервальных данных вместо f(x)
необходимо использовать f(y),
а вместо g(xi) — соответственно, g(yi),
i = 1, 2, …, n. При этом доверительный
интервал необходимо расширить с учетом формул (5) и (6).
В соответствии с
проведенными рассуждениями для аддитивных статистик асимптотическая нотна имеет
вид
![]()
при
ограничениях (1) на абсолютную погрешность и
![]()
при
ограничениях на относительную погрешность. В первом случае нотна является
обобщением понятия предельной абсолютной систематической ошибки, во втором —
предельной относительной систематической ошибки. Отметим, что, как и в примерах
1 и 2, асимптотическая нотна не зависит от точки, в которой вычисляется. Таким
образом, она является константой для конкретного метода статистического анализа
данных.
Поскольку n
велико, а D
и d
малы, можно пренебречь отличием выборочного среднего квадратического отклонения
s(g(y)),
вычисленного по выборке преобразованных значений g(y1), g(y2), …, g(yn),
от выборочного среднего квадратического отклонения s(g(x)),
построенного по выборке g(x1), g(x2), …, g(xn).
Разность этих двух величин является бесконечно малой, они приближаются к одной
и той же положительной константе.
В статистике
интервальных данных выборочный доверительный интервал для Mg(x1) имеет вид
В асимптотике его длина
такова:
![]() (8)
(8)
где
s2 — дисперсия g(x1), в то время как в
классической теории математической статистики имеется только второе слагаемое.
Соотношение (8) — аналог суммарной ошибки у метрологов [53]. Поскольку первое
слагаемое положительно, то оценивание Mg(x1) с помощью f(y)
не является состоятельным.
Для аддитивных статистик
при больших n максимум (по возможным
погрешностям) среднего квадрата отклонения оценки имеет вид
![]() (9)
(9)
с
точностью до членов более высокого порядка. Исходя из принципа уравнивания
погрешностей в общей схеме устойчивости [13], нецелесообразно второе слагаемое
в (9) делать меньше первого за счет увеличения объема выборки n.
Рациональный
объем выборки, т.е. тот объем, при котором равны погрешности оценивания (или
проверки гипотез), вызванные погрешностями исходных данных, и статистические
погрешности, рассчитанные по обычным правилам математической статистики (при ei º 0), для аддитивных
статистик согласно (9) имеет вид
![]() (10)
(10)
В качестве примера
рассмотрим экспоненциально распределенные результаты наблюдений xiс M(x1) = D(x1) = 1. Оцениваем
математическое ожидание с помощью выборочного среднего арифметического при
ограничениях на относительную погрешность. Тогда согласно формуле (10)
![]()
В частности, если
относительная погрешность измерений d = 10%, то рациональный
объем выборки равен 100. Формуле (10) соответствует также рассмотренный выше
пример 1.
Пример 2. Оценивание
медианы распределения с помощью выборочной медианы. Хотя нельзя выделить
главный линейный член из-за недифференцируемости функции f(x),
выражающей выборочную медиану через элементы выборки, непосредственно из
определения нотны следует, что при ограничениях на абсолютные погрешности
![]()
а
при ограничениях на относительные погрешности
![]()
с
точностью до бесконечно малых более высокого порядка, где xmed — теоретическая медиана. Доверительный интервал для медианы
имеет вид
![]()
где [a1(x);
a2(x)] — доверительный
интервал для медианы, вычисленный по классическим правилам непараметрической статистики
[56]. Для нахождения рационального объема выборки можно использовать
асимптотическую дисперсию выборочной медианы. Она, как известно (см., например,
[57, с. 178]), равна
![]()
где
p(xmed) — плотность
распределения результатов измерений в точке xmed. Следовательно,
рациональный объем выборки имеет вид
![]()
при
ограничениях на абсолютные и относительные погрешности результатов измерений
соответственно. Для практического использования этих формул следует оценить
плотность распределения результатов измерений в одной точке — теоретической медиане.
Это можно сделать с помощью тех или иных непараметрических оценок плотности
[56].
Если результаты
наблюдений имеют стандартное нормальное распределение с математическим
ожиданием 0 и дисперсией 1, то
![]()
В этом случае
рациональный объем выборки в p/2 раз больше, чем для оценивания
математического ожидания (см. выше). Однако для других распределений
рассматриваемое соотношение объемов может быть иным, в частности, меньше 1. Как
вытекает из работы А.Н. Колмогорова
Пример 3. Оценивание
коэффициента вариации. Рассмотрим выборочный коэффициент вариации
Как нетрудно подсчитать,
![]()
В случае ограничений на
относительную погрешность
![]()
На основе этого
предельного соотношения и формулы для асимптотической дисперсии выборочного
коэффициента вариации, приведенной в [56], могут быть найдены по описанной выше
схеме доверительные границы для теоретического коэффициента вариации и
рациональный объем выборки.
Замечание. Формулы для
рационального объема выборки получены на основе асимптотической теории, а
применяются для получения конечных объемов — 36 и 100 в рассмотренных ранее
примерах. Как всегда при использовании асимптотических результатов
математической статистики, необходимы дополнительные исследования для изучения
точности асимптотических формул при конечных объемах выборок.
Перейдем от отдельных
примеров к более общей ситуации. Рассмотрим классическую в прикладной
математической статистике параметрическую задачу оценивания. Исходные данные —
выборка x1, x2, …, xn,
состоящая из n действительных чисел. В вероятностной
модели простой случайной выборки ее элементы x1, x2,
…, xn считаются набором
реализаций n независимых одинаково распределенных случайных
величин. Будем считать, что эти величины имеют плотность f(x).
В параметрической статистической теории предполагается, что плотность f(x)
известна с точностью до конечномерного параметра, т.е., f(x)
= f(x, q0) при некотором q0 Î Q Í Rk.
Это, конечно, весьма сильное предположение, которое требует обоснования и
проверки; однако в настоящее время параметрическая теория оценивания широко
используется в различных прикладных областях.
Все результаты
наблюдений определяются с некоторой точностью, в частности, записываются с
помощью конечного числа значащих цифр (обычно 2–5). Следовательно, все реальные
распределения результатов наблюдений дискретны. Обычно считают, что эти
дискретные распределения достаточно хорошо приближаются непрерывными. Уточняя
это утверждение, приходим к уже рассматривавшейся модели, согласно которой
статистику доступны лишь величины
yj
= xj + ej,
j = 1, 2, …, n,
где
xi — «истинные» значения, e1, e2, …, en
— погрешности наблюдений (включая погрешности дискретизации). В вероятностной
модели принимаем, что n пар
(x1, e1), (x2, e2), …, (xn,
en)
образуют
простую случайную выборку из некоторого двумерного распределения, причем x1,
x2, ..., xn — выборка из
распределения с плотностью f(x)
= f(x, q0). Необходимо учитывать,
что xi и ei
— реализации зависимых случайных величин (если считать их независимыми, то
распределение yi будет непрерывным, а не
дискретным). Поскольку систематическую ошибку, как правило, нельзя полностью
исключить [53, с. 141], то необходимо рассматривать случай Mei ¹ 0. Нет оснований
априори принимать и нормальность распределения погрешностей (согласно сводкам
экспериментальных данных о разнообразии форм распределения погрешностей
измерений, приведенным в [53, с. 148] и [56, с. 71–77], в подавляющем
большинстве случаев гипотеза о нормальном распределении погрешностей оказалась
неприемлемой для средств измерений различных типов). Таким образом, все три
распространенных представления о свойствах погрешностей не адекватны
реальности. Влияние погрешностей наблюдений на свойства статистических моделей
необходимо изучать на основе иных моделей, а именно, моделей интервальной
статистики.
Пусть e — характеристика
величины погрешности, например, средняя квадратическая ошибка ![]() В классической математической статистике e считается пренебрежимо
малой (e ® 0) при фиксированном
объеме выборки n. Общие результаты доказываются в
асимптотике n ® ¥. Таким образом, в
классической математической статистике сначала делается предельный переход e ® 0, а затем предельный
переход n ® ¥. В статистике интервальных
данных принимаем, что объем выборки достаточно велик (n
® ¥), но всем измерениям
соответствует одна и та же характеристика погрешности e ¹ 0. Полезные для анализа
реальных данных предельные теоремы получаем при e ® 0. В статистике
интервальных данных сначала делается предельный переход n
®
¥,
а затем предельный переход e ® 0. Итак, в обеих теориях используются одни и те
же два предельных перехода: n ® ¥ и e ® 0, но в разном порядке.
Утверждения обеих теорий принципиально различны.
В классической математической статистике e считается пренебрежимо
малой (e ® 0) при фиксированном
объеме выборки n. Общие результаты доказываются в
асимптотике n ® ¥. Таким образом, в
классической математической статистике сначала делается предельный переход e ® 0, а затем предельный
переход n ® ¥. В статистике интервальных
данных принимаем, что объем выборки достаточно велик (n
® ¥), но всем измерениям
соответствует одна и та же характеристика погрешности e ¹ 0. Полезные для анализа
реальных данных предельные теоремы получаем при e ® 0. В статистике
интервальных данных сначала делается предельный переход n
®
¥,
а затем предельный переход e ® 0. Итак, в обеих теориях используются одни и те
же два предельных перехода: n ® ¥ и e ® 0, но в разном порядке.
Утверждения обеих теорий принципиально различны.
В дальнейшем изложение
идет на примере оценивания параметров гамма-распределения, хотя аналогичные
результаты можно получить и для других параметрических семейств, а также
для задач проверки гипотез (см. ниже) и т.д. Наша цель — продемонстрировать
основные черты подхода статистики интервальных данных. Его разработка была
стимулирована подготовкой ГОСТ 11.011-83 [30].
Отметим, что постановки
статистики объектов нечисловой природы соответствуют подходу, принятому в общей
теории устойчивости [13, 56]. В соответствии с этим подходом выборке x
= (x1,
x2, ..., xn) ставится в
соответствие множество допустимых отклонений G(x),
т.е. множество возможных значений вектора результатов наблюдений y
= (y1, y2, ..., yn).
Если известно, что абсолютная погрешность результатов измерений не превосходит D, то множество
допустимых отклонений имеет вид
G(x,
D) = {y :|
yi – xi | £ D, i
= 1, 2, …, n}.
Если известно, что
относительная погрешность не превосходит d, то множество
допустимых отклонений имеет вид
![]()
Теория устойчивости
позволяет учесть «наихудшие» отклонения, т.е. приводит к выводам типа
минимаксных, в то время как конкретные модели погрешностей позволяют делать
заключения о поведении статистик «в среднем».
Оценки параметров
гамма-распределения. Как
известно, случайная величина Х имеет гамма-распределение, если ее плотность
такова [30]:
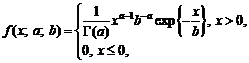
где
a — параметр формы, b — параметр масштаба, G(a)
— гамма-функция. Отметим, что есть и иные способы параметризации семейства
гамма-распределений [59].
Поскольку M(X)
= ab, D(X)
= ab2, то оценки метода имеют вид
![]()
где
![]() — выборочное среднее арифметическое, а s2 — выборочная дисперсия.
Можно показать, что при больших n
— выборочное среднее арифметическое, а s2 — выборочная дисперсия.
Можно показать, что при больших n
![]() (11)
(11)
с
точностью до бесконечно малых более высокого порядка.
Оценка максимального
правдоподобия a* имеет вид [30]:
![]() (12)
(12)
где
![]() — функция, обратная к функции
— функция, обратная к функции
![]()
При больших n
с точностью до бесконечно малых более высокого порядка
![]()
Как и для оценок метода
моментов, оценка максимального правдоподобия b* параметра масштаба
имеет вид
b* = ![]() /a*.
/a*.
При больших n
с точностью до бесконечно малых более высокого порядка
![]()
Используя свойства
гамма-функции, можно показать [30], что при больших а
![]()
с
точностью до бесконечно малых более высокого порядка. Сравнивая с формулами
(11), убеждаемся в том, что средние квадраты ошибок для оценок метода моментов
больше соответствующих средних квадратов ошибок для оценок максимального
правдоподобия. Таким образом, с точки зрения классической математической
статистики оценки максимального правдоподобия имеют преимущество по сравнению с
оценками метода моментов.
Необходимость учета
погрешностей измерений. Положим
![]()
Из свойств функции ![]() следует [30, с. 14], что при малых v
следует [30, с. 14], что при малых v
a*~ 1/(2n). (13)
В силу состоятельности
оценки максимального правдоподобия a* из формулы (13) следует,
что n
® 0 по вероятности при a
® ¥.
Согласно модели
статистики интервальных данных результатами наблюдений являются не xi, а yi, вместо v
по реальным данным рассчитывают
![]()
Имеем
![]() (14)
(14)
В силу Закона больших
чисел при достаточно малой погрешности e, обеспечивающей
возможность приближения
ln(1 + a) ~ a для слагаемых в формуле
(14), или, что эквивалентно, при достаточно малых предельной абсолютной
погрешности D
в формуле (1) или достаточно малой предельной относительной погрешности d имеем при n
® ¥
![]()
по
вероятности (в предположении, что все погрешности одинаково распределены).
Таким образом, наличие погрешностей вносит сдвиг, вообще говоря, не исчезающий
при росте объема выборки. Следовательно, если c ¹ 0, то оценка
максимального правдоподобия не является состоятельной. Имеем
![]()
где величина a*(y) определена по формуле (12) с заменой xi на yi, i = 1, 2,
…, n. Из
формулы (13) следует [30], что
a*(y) – a » –2(a*)2c, (15)
т.е. влияние погрешностей измерений
увеличивается по мере роста а.
Из
формул для v и w следует, что с точностью до бесконечно
малых более высокого порядка
![]() (16)
(16)
С целью
нахождения асимптотического распределения w выделим, используя формулу (16) и формулу
для v,
главные члены в соответствующих слагаемых
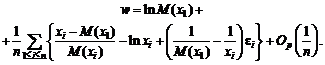 (17)
(17)
Таким
образом, величина w
представлена в виде суммы независимых одинаково распределенных случайных
величин (с точностью до зависящего от случая остаточного члена порядка 1/n). В каждом слагаемом выделяются две части
— одна, соответствующая v, и
вторая, в которую входят ei. На основе представления (17)
можно показать, что при n
®
¥, e ® 0 распределения случайных величин v и w асимптотически нормальны, причем
M(w) » M(v) + c, D(w) » D(v).
Из
асимптотического совпадения дисперсий v и w, вида параметров асимптотического
распределения (при a
®
¥)
оценки максимального правдоподобия a* и
формулы (15) вытекает одно из основных соотношений статистики интервальных
данных
![]() (18)
(18)
Соотношение
(18) уточняет утверждение о несостоятельности a*. Из
него следует также, что не имеет смысла безгранично увеличивать объем выборки n с целью повышения точности оценивания
параметра а, поскольку при этом уменьшается только второе слагаемое в
(18), а первое остается постоянным.
В
соответствии с общим подходом статистики интервальных данных в стандарте [30]
предлагается определять рациональный объем выборки nrat из условия «уравнивания
погрешностей» (это условие было впервые предложено в монографии [13]) различных
видов в формуле (18), т.е. из условия
![]()
Упрощая
это уравнение в предположении a
®
¥,
получаем, что
![]()
Согласно
сказанному выше, целесообразно использовать лишь выборки с объемами n £ nrat. Превышение рационального
объема выборки nrat не
дает существенного повышения точности оценивания.
Применение
методов теории устойчивости. Найдем асимптотическую нотну.
Как следует из вида главного линейного члена в формуле (17), решение
оптимизационной задачи
w – v ®
max, |ei| £
D,
соответствующей ограничениям на абсолютные
погрешности, имеет вид
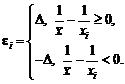
Однако
при этом пары (xi, ei) не образуют простую случайную
выборку, т.к. в выражения для ei входит ![]() . Однако при n ®
¥ можно
заменить
. Однако при n ®
¥ можно
заменить ![]() на М(х1). Тогда
получаем, что
на М(х1). Тогда
получаем, что
w – v
» AD
при a > 1, где
![]()
Таким
образом, с точностью до бесконечно малых более высокого порядка нотна имеет вид
Na*(y) = 2(a*)2c, c = AD.
Применим
полученные результаты к построению доверительных интервалов. В постановке
классической математической статистики (т.е. при e = 0)
доверительный интервал для параметра формы а, соответствующий
доверительной вероятности g, имеет
вид [30]
![]()
где ![]() — квантиль порядка
— квантиль порядка ![]() стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1,
стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1,
![]()
В
постановке статистики интервальных данных (т.е. при e ¹ 0)
следует рассматривать доверительный интервал
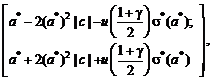
где
![]()
в вероятностной постановке (пары (xi, ei) образуют простую случайную
выборку) и c = AD в оптимизационной постановке.
Как в вероятностной, так и в оптимизационной постановках длина доверительного
интервала не стремится к 0 при n
®
¥.
Если
ограничения наложены на предельную относительную погрешность, задана величина d, то значение с можно найти с помощью
следующих правил приближенных вычислений [60, с. 142].
(I). Относительная погрешность суммы
заключена между наибольшей и наименьшей из относительных погрешностей слагаемых.
(II). Относительная погрешность произведения и
частного равна сумме относительных погрешностей сомножителей или,
соответственно, делимого и делителя.
Можно
показать, что в рамках статистики интервальных данных с ограничениями на
относительную погрешность правила (I) и (II) являются строгими утверждениями при d ® 0.
Обозначим
относительную погрешность некоторой величины t через ОП(t), абсолютную погрешность — через АП(t).
Из
правила (I)
следует, что ОП(![]() ) = d, а из правила (II) — что
) = d, а из правила (II) — что
![]()
Поскольку
рассмотрения ведутся при a
®
¥, то в
силу неравенства Чебышева
![]() (19)
(19)
по вероятности при a ®
¥,
поскольку и числитель, и знаменатель в (19) с близкой к 1 вероятностью лежат в
промежутке ![]() где константа d может быть определена с помощью
упомянутого неравенства Чебышева.
где константа d может быть определена с помощью
упомянутого неравенства Чебышева.
Поскольку
при справедливости (19) с точностью до бесконечно малых более высокого порядка
![]()
то с помощью трех последних соотношений имеем
![]() (20)
(20)
Применим еще одно правило
приближенных вычислений [60, с. 142].
(III). Предельная абсолютная погрешность суммы
равна сумме предельных абсолютных погрешностей слагаемых.
Из (20)
и правила (III)
следует, что
АП(v) = 2d.
Из
этого соотношения и (15) вытекает [30, с. 44, ф-ла (18)], что
АП(a*) = 4a2d,
откуда в соответствии с ранее полученной
формулой для рационального объема выборки с заменой c = 2d
получаем, что
![]()
В
частности, при a =
5,00; d = 0,01 получаем nrat = 50, т.е. в ситуации, в
которой были получены данные о наработке резцов до предельного состояния (см.
табл. 1,
составленную согласно [30, с. 29]),
проводить более 50 наблюдений нерационально.
Таблица 1
Наработка резцов до
предельного состояния, ч
|
№ п/п |
Наработка, ч |
№ п/п |
Наработка, ч |
№ п/п |
Наработка, ч |
|
1 |
9 |
18 |
47,5 |
35 |
63 |
|
2 |
17,5 |
19 |
48 |
36 |
64,5 |
|
3 |
21 |
20 |
50 |
37 |
65 |
|
4 |
26,5 |
21 |
51 |
38 |
67,5 |
|
5 |
27,5 |
22 |
53,5 |
39 |
68,5 |
|
6 |
31 |
23 |
55 |
40 |
70 |
|
7 |
32,5 |
24 |
56 |
41 |
72,5 |
|
8 |
34 |
25 |
56 |
42 |
77,5 |
|
9 |
36 |
26 |
56,5 |
43 |
81 |
|
10 |
36,5 |
27 |
57,5 |
44 |
82,5 |
|
11 |
39 |
28 |
58 |
45 |
90 |
|
12 |
40 |
29 |
59 |
46 |
96 |
|
13 |
41 |
30 |
59 |
47 |
101,5 |
|
14 |
42,5 |
31 |
60 |
48 |
117,5 |
|
15 |
43 |
32 |
61 |
49 |
127,5 |
|
16 |
45 |
33 |
61,5 |
50 |
130 |
|
17 |
46 |
34 |
62 |
|
|
В соответствии с ранее
проведенными рассмотрениями асимптотический доверительный интервал для a,
соответствующий доверительной вероятности g = 0,95, имеет вид
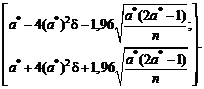
В частности, при a* = 5,00, d = 0,01, n
= 50 имеем асимптотический доверительный интервал [2,12; 7,86] вместо [3,14;
6,86] при d
= 0.
При больших а в
силу соображений, приведенных при выводе формулы (19), можно связать между
собой относительную и абсолютную погрешности результатов наблюдений xi:
![]() (21)
(21)
Следовательно, при
больших а имеем
![]()
Таким образом,
проведенные рассуждения дали возможность вычислить асимптотику интеграла,
задающего величину А.
Сравнение методов
оценивания. Изучим
влияние погрешностей измерений (с ограничениями на абсолютную погрешность) на
оценку ![]() метода моментов. Имеем
метода моментов. Имеем
![]()
Погрешность s2 зависит от способа
вычисления s2. Если используется формула
![]() (22)
(22)
то
необходимо использовать соотношения
АП(xi
– ![]() ) = 2D, АП[(xi
–
) = 2D, АП[(xi
– ![]() )2] » 2|xi
–
)2] » 2|xi
– ![]() | D.
| D.
По сравнению с анализом
влияния погрешностей на оценку a* здесь возникает новый
момент — необходимость учета погрешностей в случайной составляющей отклонения
оценки ![]() от оцениваемого параметра, в то время как при
рассмотрении оценки максимального правдоподобия погрешности давали лишь
смещение. Примем в соответствии с неравенством Чебышева
от оцениваемого параметра, в то время как при
рассмотрении оценки максимального правдоподобия погрешности давали лишь
смещение. Примем в соответствии с неравенством Чебышева
![]() (23)
(23)
тогда
![]()
Замечание.( Если вычислять s2 по формуле
![]() (24)
(24)
то
аналогичные вычисления дают, что
АП(s2) » 4abD,
т.е.
погрешность при больших а существенно больше. Хотя правые части формул
(22) и (24) тождественно равны, но погрешности вычислений по этим формулам
весьма отличаются. Связано это с тем, что в формуле (24) последняя операция —
нахождение разности двух больших чисел, примерно равных по величине (для
выборки из гамма-распределения при большом значении параметра формы).)
Из полученных
результатов следует, что
![]()
При выводе этой формулы
использована линеаризация влияния погрешностей (выделение главного линейного
члена). Используя связь (21) между абсолютной и относительной погрешностями,
можно записать
![]()
Эта формула отличается
от приведенной в [30, с. 44, формула (19)]
![]()
поскольку
в [30] вместо (23) использовалась оценка
![]()
Используя соотношение
(23), мы характеризуем влияние погрешностей «в среднем».
Доверительный интервал,
соответствующий доверительной вероятности 0,95, имеет вид
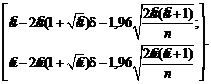
Если ![]() = 5,00; d = 0,01; n = 50, то получаем
доверительный интервал [2,54; 7,46] вместо [2,86; 7,14] при d = 0. Хотя при d = 0 доверительный
интервал для a при использовании оценки метода моментов
= 5,00; d = 0,01; n = 50, то получаем
доверительный интервал [2,54; 7,46] вместо [2,86; 7,14] при d = 0. Хотя при d = 0 доверительный
интервал для a при использовании оценки метода моментов
![]() шире, чем при использовании оценки максимального
правдоподобия а*, при d = 0,01 результат
сравнения длин интервалов противоположен.
шире, чем при использовании оценки максимального
правдоподобия а*, при d = 0,01 результат
сравнения длин интервалов противоположен.
Необходимо выбрать
способ сравнения двух методов оценивания параметра а, поскольку в длины
доверительных интервалов входят две составляющие — зависящая от доверительной
вероятности и не зависящая от нее. Выберем d =
0,68, т.е. ![]() . Тогда
оценке максимального правдоподобия а* соответствует полудлина
доверительного интервала
. Тогда
оценке максимального правдоподобия а* соответствует полудлина
доверительного интервала
![]() (25)
(25)
а
оценке ![]() метода моментов соответствует полудлина доверительного
интервала
метода моментов соответствует полудлина доверительного
интервала
![]() (26)
(26)
Ясно, что больших а
или больших n справедливо неравенство n(a*) > n(![]() ), т.е. метод
моментов лучше метода максимального правдоподобия, вопреки классическим
результатам Р. Фишера при d = 0 [61, с. 99].
), т.е. метод
моментов лучше метода максимального правдоподобия, вопреки классическим
результатам Р. Фишера при d = 0 [61, с. 99].
Из (25) и (26)
элементарными преобразованиями получаем следующее правило принятия решений.
Если
![]()
то
n(a*) ³ n(![]() ) и следует
использовать
) и следует
использовать ![]() ; а если
; а если ![]() то n(a*) < n(
то n(a*) < n(![]() ) и надо
применять а*. Для выбора метода оценивания при обработке
реальных данных целесообразно использовать B(
) и надо
применять а*. Для выбора метода оценивания при обработке
реальных данных целесообразно использовать B(![]() ) (см. раздел
5 в ГОСТ 11.011-83 [30, с. 10–11]).
) (см. раздел
5 в ГОСТ 11.011-83 [30, с. 10–11]).
Пример анализа реальных
данных опубликован в [30].
На основе рассмотрения
проблем оценивания параметров гамма-распределения можно сделать некоторые общие
выводы. Если в классической теории математической статистики:
а) существуют
состоятельные оценки an параметра а,
![]()
б) для повышения
точности оценивания объем выборки целесообразно безгранично увеличивать;
в) оценки максимального
правдоподобия лучше оценок метода моментов,
то в статистике
интервальных данных, учитывающей погрешности измерений, соответственно:
а) не существует
состоятельных оценок: для любой оценки an существует константа
с такая, что
![]()
б) не имеет смысла
рассматривать объемы выборок, большие «рационального объема выборки» nrat;
в) оценки метода
моментов в обширной области параметров (a, n,
d) лучше оценок
максимального правдоподобия, в частности, при a ® ¥ и при n
®¥.
Ясно, что приведенные
выше результаты справедливы не только для рассмотренной задачи оценивания
параметров гамма-распределения, но и для многих других постановок прикладной
математической статистики.
Метрологические,
методические, статистические и вычислительные погрешности. Целесообразно выделить
ряд видов погрешностей статистических данных. Погрешности, вызванные
неточностью измерения исходных данных, называем метрологическими. Их
максимальное значение можно оценить с помощью нотны. Впрочем, выше на примере
оценивания параметров гамма-распределения показано, что переход от максимального
отклонения к реально имеющемуся в вероятностно-статистической модели не меняет
выводы (с точностью до умножения предельных значений погрешностей D или d на константы). Как
правило, метрологические погрешности не убывают с ростом объема выборки.
Методические погрешности вызваны
неадекватностью вероятностно-статистической модели, отклонением реальности от
ее предпосылок. Неадекватность обычно не исчезает при росте объема выборки. Методические
погрешности целесообразно изучать с помощью «общей схемы устойчивости» [13,
56], обобщающей популярную в теории робастных статистических процедур модель
засорения большими выбросами. В настоящей главе методические погрешности не
рассматриваются.
Статистическая погрешность — это та
погрешность, которая традиционно рассматривается в математической статистике.
Ее характеристики — дисперсия оценки, дополнение до 1 мощности критерия при
фиксированной альтернативе и т.д. Как правило, статистическая погрешность
стремится к 0 при росте объема выборки.
Вычислительная погрешность
определяется алгоритмами расчета, в частности, правилами округления. На уровне
чистой математики справедливо тождество правых частей формул (22) и (24),
задающих выборочную дисперсию s2, а на уровне вычислительной
математики формула (22) дает при определенных условиях существенно больше
верных значащих цифр, чем вторая [62, с. 51–52].
Выше на примере задачи
оценивания параметров гамма-распределения рассмотрено совместное действие метрологических
и вычислительных погрешностей, причем погрешности вычислений оценивались по
классическим правилам для ручного счета [60]. Оказалось, что при таком подходе
оценки метода моментов имеют преимущество перед оценками максимального
правдоподобия в обширной области изменения параметров. Однако, если учитывать
только метрологические погрешности, как это делалось выше в примерах 1–3, то с
помощью аналогичных выкладок можно показать, что оценки этих двух типов имеют
(при достаточно больших n) одинаковую
погрешность.
Вычислительную
погрешность здесь подробно не рассматриваем. Ряд интересных результатов о ее
роли в статистике получили Н.Н. Ляшенко и М.С. Никулин [63].
Проведем сравнение
методов оценивания параметров в более общей постановке.
В теории оценивания
параметров классической математической статистики установлено, что метод
максимального правдоподобия, как правило, лучше (в смысле асимптотической дисперсии
и асимптотического среднего квадрата ошибки), чем метод моментов. Однако в
интервальной статистике это, вообще говоря, не так, что продемонстрировано выше
на примере оценивания параметров гамма-распределения. Сравним эти два метода оценивания
в случае интервальных данных в общей постановке. Поскольку метод максимального
правдоподобия — частный случай метода минимального контраста, начнем с разбора
этого несколько более общего метода.
Оценки минимального
контраста. Пусть
Х — пространство, в котором лежат независимые одинаково распределенные
случайные элементы x1, x2, …, xn,
… Будем оценивать элемент пространства параметров Q с помощью функции
контраста f : X ´ Q ® R1. Оценкой минимального
контраста называется
![]()
Если множество qn
состоит из более чем одного элемента, то оценкой минимального контраста
называют также любой элемент qn.
Оценками минимального
контраста являются многие робастные статистики [13, 64]. Эти оценки широко
используются в статистике объектов нечисловой природы [3, 56], поскольку при X
= Q
переходят в эмпирические средние, а если X = Q — пространство бинарных
отношений — в медиану Кемени.
Пусть в Х имеется
мера m
(заданная на той же s-алгебре, что участвует в определении
случайных элементов xi), и p(x;
q)
— плотность распределения xi по мере m. Если
f(x;
q) = –ln
p(x; q),
то
оценка минимального контраста переходит в оценку максимального правдоподобия.
Асимптотическое
поведение оценок минимального контраста в случае пространств Х и Q общего вида хорошо
изучено [65], в частности, известны условия состоятельности оценок. Здесь ограничимся
случаем X = R1, но при этом введя
погрешности измерений ei. Примем также, что Q = (qmin,
qmax)
Í
R1.
В рассматриваемой
математической модели предполагается, что статистику известны лишь искаженные
значения yi = xi + ei,
i = 1, 2, …, n. Поэтому вместо qn
он вычисляет
![]()
Будем изучать величину ![]() – qn
в предположении, что погрешности измерений ei
малы. Цель этого изучения — продемонстрировать идеи статистики интервальных
данных при достаточно простых предположениях. Поэтому естественно следовать условиям
и ходу рассуждений, которые обычно принимаются при изучении оценок
максимального правдоподобия [66, п. 33.3].
– qn
в предположении, что погрешности измерений ei
малы. Цель этого изучения — продемонстрировать идеи статистики интервальных
данных при достаточно простых предположениях. Поэтому естественно следовать условиям
и ходу рассуждений, которые обычно принимаются при изучении оценок
максимального правдоподобия [66, п. 33.3].
Пусть q0 — истинное значение
параметра, функция f(x;
q) трижды дифференцируема
по q,
причем
![]()
при
всех x, q. Тогда
 (27)
(27)
где
|a(x)|
< 1.
Используя обозначения
векторов x = (x1, x2, ..., xn),
y =
= (y1, y2, ..., yn),
введем суммы
![]()
![]()
![]()
Аналогичным образом
введем функции B0(y),
B1(y), R(y),
в которых вместо xi стоят yi,
i = 1, 2, …, n.
Поскольку в соответствии
с теоремой Ферма оценка минимального контраста qт удовлетворяет уравнению
![]() (28)
(28)
то,
подставляя в (27) xi вместо x и
суммируя по i = 1, 2, …, n,
получаем, что
![]() (29)
(29)
откуда
 (30)
(30)
Решения уравнения (28)
будем также называть оценками минимального контраста. Хотя уравнение (28) —
лишь необходимое условие минимума, такое словоупотребление не будет вызывать
трудностей.
Теорема 1[2]. Пусть для любого x выполнено
соотношение (27). Пусть для случайной величины х1 с
распределением, соответствующим значению параметра q = q0, существуют математические
ожидания
![]() (31)
(31)
Тогда существуют оценки
минимального контраста qn такие, что qn ® q0 при n
® ¥ (в смысле сходимости по
вероятности).
Доказательство. Возьмем e > 0 и d > 0. В силу Закона
больших чисел (теорема Хинчина) существует n(e, d) такое, что для любого n
> n(e, d) справедливы
неравенства
P{|B0| ³ d2} < e/3, P{|B1| < |A|/2}
< e/3, P{R(x)
> 2M} < e/3.
Тогда с вероятностью не
менее 1 – e одновременно выполняются
соотношения
|B0| £ d2, |B1| ³ |A|/2,
R(x) £ 2M. (32)
При q Î [q0 – d; q0 + d] рассмотрим многочлен
второй степени
![]()
(см.
формулу (29)). С вероятностью не менее 1 – e выполнены соотношения
![]()
Если 0 < 2(M
+ 1)d < |A|,
то знак y(q) в точках q1 = q0 – d и q2 = q0 + d определяется знаком
линейного члена B1(qi
– q0), i = 1,
2, следовательно, знаки y(q1) и y(q2) различны, а потому
существует qn Î [q0 – d; q0 + d] такое, что y(qn)
= 0, что и требовалось доказать.
Теорема 2. Пусть выполнены условия
теоремы 1 и, кроме того, для случайной величины х1,
распределение которой соответствует значению параметра q = q0, существует
математическое ожидание
![]()
Тогда оценка
минимального контраста имеет асимптотически нормальное распределение:
![]() (33)
(33)
для
любого х, где Ф(x) — функция стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1.
Доказательство. Из Центральной
предельной теоремы вытекает, что числитель в правой части формулы (30)
асимптотически нормален с математическим ожиданием 0 и дисперсией s2. Первое слагаемое в
знаменателе формулы (30) в силу условий (31) и Закона больших чисел сходится по
вероятности к A ¹ 0, а второе слагаемое
по тем же основаниям и с учетом теоремы 1 — к 0. Итак, знаменатель сходится по
вероятности к A ¹ 0. Доказательство
теоремы 2 завершает ссылка на теорему о наследовании сходимости [8, Приложение
1].
Нотна оценки
минимального контраста. Аналогично (30) нетрудно получить, что
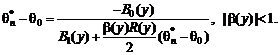 (34)
(34)
Следовательно, ![]() есть разность правых частей формул (30) и
(34). Найдем максимально возможное значение (т.е. нотну) величины
есть разность правых частей формул (30) и
(34). Найдем максимально возможное значение (т.е. нотну) величины ![]() при ограничениях (1) на абсолютные погрешности
результатов измерений.
при ограничениях (1) на абсолютные погрешности
результатов измерений.
Покажем, что при D ® 0 для некоторого C >
0 нотна имеет вид
![]()
![]() (35)
(35)
Поскольку ![]() то из (33) и (35) следует, что
то из (33) и (35) следует, что
![]() (36)
(36)
Можно сказать, что
наличие погрешностей ei приводит к появлению
систематической ошибки (смещения) у оценки метода максимального правдоподобия,
и нотна является максимально возможным значением этой систематической ошибки.
В правой части (36)
первое слагаемое — квадрат асимптотической нотны, второе соответствует
статистической ошибке. Приравнивая их, получаем рациональный объем выборки
![]()
Остается доказать
соотношение (35) и вычислить С. Укажем сначала условия, при которых ![]() (по вероятности) при n
® ¥ одновременно с D ® 0.
(по вероятности) при n
® ¥ одновременно с D ® 0.
Теорема 3. Пусть существуют
константа D0 и функции g1(x),
g2(x), g3(x)
такие, что при 0 £ D £ D0 и –1 £ g £ 1 выполнены неравенства
(ср. формулу (27))
![]()
![]() (37)
(37)
![]()
при
всех x. Пусть для случайной величины х1,
распределение которой соответствует q = q0, существуют m1 = Mg1(x1), m2 = Mg2(x1) и m3 = Mg3(x1). Пусть
выполнены условия теоремы 1. Тогда ![]() (по вероятности) при D ® 0, n
® ¥.
(по вероятности) при D ® 0, n
® ¥.
Доказательство. Проведем по схеме доказательства
теоремы 1. Из неравенств (37) вытекает, что
![]()
![]() (38)
(38)
![]() .
.
Возьмем e > 0 и d > 0. В силу Закона
больших чисел (теорема Хинчина) существует n(e, d) такое, что для любого n
>
> n(e, d) справедливы
неравенства
![]()
![]()
Тогда с вероятностью не
менее 1 – e одновременно выполняются
соотношения
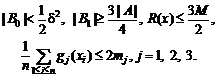
В силу (38) при этом
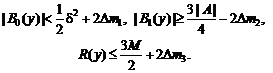
Пусть
![]()
Тогда с вероятностью не
менее 1 – e одновременно выполняются
соотношения (ср. (32))
![]()
Завершается
доказательство дословным повторением такового в теореме 1, с единственным
отличием — заменой в обозначениях x на y.
Теорема 4. Пусть выполнены условия
теоремы 3 и, кроме того, существуют математические ожидания (при q = q0)
![]() (39)
(39)
Тогда выполнено
соотношение (35) с
![]() (40)
(40)
Доказательство. Воспользуемся следующим
элементарным соотношением. Пусть a и b
— бесконечно
малые по сравнению с Z и B
соответственно. Тогда с точностью до бесконечно малых более высокого порядка
![]()
Чтобы применить это
соотношение к анализу ![]() – qn
в соответствии с (30), (34) и теоремой 2, положим
– qn
в соответствии с (30), (34) и теоремой 2, положим
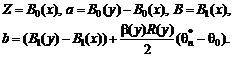
В силу условий теоремы 4
при малых ei с точностью до членов
более высокого порядка
![]()
![]()
![]() .
.
При D ® 0 эти величины
бесконечно малы, а потому с учетом сходимости B1(x)
к А и теоремы 3
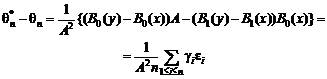
с
точностью до бесконечно малых более высокого порядка, где
![]()
Ясно, что задача
оптимизации
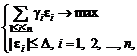 (41)
(41)
имеет
решение
![]()
при
этом максимальное значение линейной формы есть ![]() . Поэтому
. Поэтому
 (42)
(42)
С целью упрощения правой
части (42) воспользуемся тем, что
![]() (43)
(43)
где
|a|
£ 1. Поскольку при n
® ¥
![]()
по
вероятности, то второе слагаемое в (43) сходится к 0, а первое в силу закона
больших чисел с учетом (39) сходится к СА2, где С
определено в (40). Теорема 4 доказана.
Оценки метода моментов. Пусть g
: Rk ® R1, hj
: R1 ® R1, j
= 1, 2, …, k, — некоторые функции. Рассмотрим аналоги выборочных
моментов
![]()
Оценки метода моментов
имеют вид
![]() (x)
= g(m1, m2, …, mk)
(x)
= g(m1, m2, …, mk)
(функции
g и hj должны удовлетворять
некоторым дополнительным условиям [55, с. 80], которые здесь не приводим).
Очевидно, что
![]()
![]() (44)
(44)
с
точностью до бесконечно малых более высокого порядка, а потому с той же
точностью
![]() (45)
(45)
Теорема 5. Пусть при q = q0 существуют
математические ожидания
![]()
функция
g дважды непрерывно дифференцируема в некоторой окрестности
точки (M1, M2, …, Mk).
Пусть существует функция t : R1 ® R1 такая, что
 (46)
(46)
причем
Mt(x1) существует. Тогда
![]()
с
точностью до бесконечно малых более высокого порядка, причем
![]()
Доказательство теоремы 5 сводится к
обоснованию проведенных ранее рассуждений, позволивших получить формулу (45). В
условиях теоремы 5 собраны предположения, достаточные для такого обоснования.
Так, условие (46) дает возможность обосновать соотношения (44); существование ![]() обеспечивает существование С1,
и т.д. Завершает доказательство ссылка на решение задачи оптимизации (41) и
применение Закона больших чисел.
обеспечивает существование С1,
и т.д. Завершает доказательство ссылка на решение задачи оптимизации (41) и
применение Закона больших чисел.
Полученные в теоремах 4
и 5 нотны оценок минимального контраста и метода моментов, асимптотические
дисперсии этих оценок (см. теорему 2 и [67] соответственно) позволяют находить
рациональные объемы выборок, строить доверительные интервалы с учетом
погрешностей измерений, а также сравнивать оценки по среднему квадрату ошибки
(36). Подобное сравнение проведено для оценок максимального правдоподобия и
метода моментов параметров гамма-распределения. Установлено, что классический
вывод о преимуществе оценок максимального правдоподобия [61, с. 99–100]
неверен в случае D > 0.
7.5. Интервальные данные в задачах проверки гипотез
С позиций статистики
интервальных данных целесообразно изучить все практически используемые
процедуры прикладной математической статистики, установить соответствующие
нотны и рациональные объемы выборок. Это позволит устранить разрыв между
математическими схемами прикладной статистики и реальностью влияния
погрешностей наблюдений на свойства статистических процедур. Статистика
интервальных данных — часть теории устойчивых статистических процедур, развитой
в монографии [13]. Часть, более адекватная реальной статистической практике,
чем некоторые другие постановки, например, с засорением нормального
распределения большими выбросами.
Рассмотрим подходы
статистики интервальных данных в задачах проверки статистических гипотез. Пусть
принятие решения основано на сравнении рассчитанного по выборке значения
статистики критерия f = f(y1, y2, …, yn)
с граничным значением С: если f > C,
то гипотеза отвергается, если же f £ C,
то принимается. С учетом погрешностей измерений выборочное значение статистики
критерия может принимать любое значение в интервале [f(y) –
Nf(y); f(y)
+ Nf(y)]. Это означает, что
«истинное» значение порога, соответствующее реально используемому критерию, находится
между C – Nf(y)
и C + Nf(y),
а потому уровень значимости описанного правила (критерия) лежит между 1 – P(C
+ Nf(y)) и 1 – P(C
– Nf(y)), где P(Z)
= P(f < Z).
Пример 1[3]. Пусть x1, x2, …, xn
— выборка из нормального распределения с математическим ожиданием а и единичной
дисперсией. Необходимо проверить гипотезу H0: a =
0 при альтернативе H1 : a
¹
0.
Как известно из любого
учебного курса математической статистики, следует использовать статистику f =
![]() и порог C = F(1 – a/2), где a — уровень значимости,
Ф(×)
— функция стандартного нормального распределения с математическим ожиданием 0 и
дисперсией 1. В частности, С = 1,96 при a = 0,05.
и порог C = F(1 – a/2), где a — уровень значимости,
Ф(×)
— функция стандартного нормального распределения с математическим ожиданием 0 и
дисперсией 1. В частности, С = 1,96 при a = 0,05.
При ограничениях (1) на
абсолютную погрешность Nf(y)
= ![]() D. Например, если D = 0,1, а n
= 100, то Nf(y) = 1,0. Это означает,
что истинное значение порога лежит между 0,96 и 2,96, а истинный уровень
значимости — между 0,003 и 0,34. Можно сделать и другой вывод: нулевую гипотезу
H0 допустимо отклонить на уровне значимости 0,05
лишь тогда, когда
D. Например, если D = 0,1, а n
= 100, то Nf(y) = 1,0. Это означает,
что истинное значение порога лежит между 0,96 и 2,96, а истинный уровень
значимости — между 0,003 и 0,34. Можно сделать и другой вывод: нулевую гипотезу
H0 допустимо отклонить на уровне значимости 0,05
лишь тогда, когда
f > 2,96.
Если же n
= 400 при D
= 0,1, то Nf(y) = 2,0 и C
– Nf(y) =
= –0,04, в то время как C + Nf(y)
= 3,96. Таким образом, даже в случае x = 0 гипотеза H0 может быть отвергнута
только из-за погрешностей измерений результатов наблюдений.
Вернемся к общему случаю
проверки гипотез. С учетом погрешностей измерений граничное значение Ca в статистике интервальных
данных целесообразно заменить на Ca + Nf(y).
Такая замена дает гарантию, что вероятность отклонения нулевой гипотезы H0, когда она верна, не
более a. При проверке гипотез
аналогом статистической погрешности, рассмотренной выше в задачах оценивания,
является Cα. Суммарная погрешность
имеет вид Ca + Nf(y).
Исходя из принципа уравнивания погрешностей [13], целесообразно определять
рациональный объем выборки из условия
Cα = Nf(y).
Если f
= |f1|, где f1 при справедливости H0 имеет асимптотически
нормальное распределение с математическим ожиданием 0 и дисперсией s2 / n,
то
![]() (47)
(47)
при
больших n, где u(1 – a/2) — квантиль порядка 1
– a/2 стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1. Из (47)
вытекает, что в рассматриваемом случае
![]()
В условиях примера 1 f1 = ![]() и
и
![]()
Пример 2. Рассмотрим статистику
одновыборочного критерия Стьюдента
![]()
где
n
— выборочный коэффициент вариации. Тогда с точностью до бесконечно малых более
высокого порядка нотна для t имеет вид
![]()
где
Nn(y)
— рассмотренная ранее нотна для выборочного коэффициента вариации. Поскольку
распределение статистики Стьюдента t сходится к стандартному
нормальному, то небольшое изменение предыдущих рассуждений дает
![]()
Пример 3. Рассмотрим
двухвыборочный критерий Смирнова, предназначенный для проверки однородности
(совпадения) функций распределения двух независимых выборок [68]. Статистика
этого критерия имеет вид
![]()
где
Fm(x) — эмпирическая функция
распределения, построенная по первой выборке объема m, извлеченной из
генеральной совокупности с функцией распределения F(x),
а Gn(x) — эмпирическая функция
распределения, построенная по второй выборке объема n, извлеченной из
генеральной совокупности с функцией распределения G(x).
Нулевая гипотеза имеет вид H0 : F(x)
º
G(x), альтернативная
состоит в ее отрицании: H1 : F(x)
¹
G(x) при некотором x.
Значение статистики сравнивают с порогом D(a, m,
n). зависящим от уровня значимости a и объемов выборок m и n.
Если значение статистики не превосходит порога, то принимают нулевую гипотезу,
если больше порога — альтернативную. Пороговые значения D(a, m,
n) берут из таблиц [69]. Описанный критерий иногда
неправильно называют критерием Колмогорова-Смирнова. История вопроса описана в
[70].
При ограничениях (1) на
абсолютные погрешности и справедливости нулевой гипотезы H0 : F(x)
º
G(x) нотна имеет вид (при
больших объемах выборок)
![]()
Если F(x)
= G(x) = x при
0 £
x £ 1, то ND
= 2D. С помощью условия Ca = Nf(y)
при уровне значимости a = 0,05 и достаточно
больших объемах выборок (т.е. используя асимптотическое выражение для порога
согласно [68, 69]) получаем, что выборки имеет смысл увеличивать, если
![]()
Правая часть этой
формулы при D
= 0,1 равна 46. Если m = n,
то последнее неравенство переходит в n £ 92.
Теоретические результаты
в области статистических методов входят в практику через алгоритмы расчетов,
воплощенные в программные средства (пакеты программ, диалоговые системы). Ввод
данных в современной статистической программной системе должен содержать
запросы о погрешностях результатов измерений. На основе ответов на эти запросы
вычисляются нотны рассматриваемых статистик, а затем — доверительные интервалы
при оценивании, разброс уровней значимости при проверке гипотез, рациональные
объемы выборок. Необходимо использовать систему алгоритмов и программ
статистики интервальных данных, «параллельную» подобным системам для
классической математической статистики.
7.6. Линейный регрессионный анализ интервальных данных
Перейдем к многомерному статистическому анализу. Сначала с
позиций асимптотической математической статистики интервальных данных
рассмотрим оценки метода наименьших квадратов (МНК).
Статистическое
исследование зависимостей — одна из наиболее важных задач, которые возникают в
различных областях науки и техники. Под словами «исследование зависимостей»
имеется в виду выявление и описание существующей связи между исследуемыми
переменными на основании результатов статистических наблюдений. К методам
исследования зависимостей относятся: регрессионный анализ, многомерное
шкалирование, идентификация параметров динамических объектов, факторный анализ,
дисперсионный анализ, корреляционный анализ и др. Однако многие реальные
ситуации характеризуются наличием данных интервального типа, причем известны
допустимые границы погрешностей (например, из технических паспортов средств измерения).
Если какая-либо группа
объектов характеризуется переменными Х1, Х2,
..., Хm и проведен эксперимент, состоящий из n опытов,
где в каждом опыте эти переменные измеряются один раз, то экспериментатор
получает набор чисел: Х1j, Х2j,
..., Хmj (j = 1,
…, n).
Однако процесс
измерения, какой бы физической природы он ни был, обычно не дает однозначный
результат. Реально результатом измерения какой-либо величины Х являются
два числа: ХH — нижняя граница и ХB —
верхняя граница. Причем ХИСТ Î [ХH, ХB],
где ХИСТ — истинное значение измеряемой величины. Результат
измерения можно записать как X: [ХH, ХB].
Интервальное число X может быть представлено другим способом, а именно, X:
[Хm, Dx], где ХH
= Хm — Dx, ХH = Хm
+ Dx. Здесь Хm
— центр интервала (как правило, не совпадающий с ХИСТ), а Dx — максимально возможная
погрешность измерения.
Метод наименьших
квадратов для интервальных данных. Пусть математическая модель задана следующим образом:
у = Q(x, b)
+ e,
где
х = (х1, х2, ..., хm)
— вектор влияющих переменных (факторов), поддающихся измерению; b = (b1,
b2, ..., br) — вектор оцениваемых
параметров модели; у — отклик модели (скаляр); Q(x, b)
— скалярная функция векторов х и b; наконец, e — случайная ошибка
(невязка, погрешность).
Пусть проведено n
опытов, причем в каждом опыте измерены (один раз) значения отклика (у) и
вектора факторов (х). Результаты измерений могут быть представлены в
следующем виде:
Х = {хij;
i = 1, …, n; j = 1, …, m}, Y = (y1,
y2, …, yn ), Е = (e1, e2, …, en),
где
Х — матрица значений измеренного вектора (х) в n опытах; Y
— вектор значений измеренного отклика в n опытах; Е — вектор
случайных ошибок. Тогда выполняется матричное соотношение:
Y
= Q(X, b)
+ Е,
где
Q(X, b) = (Q(x1, b), Q(x2,
b), ..., Q(xn, b))T,
причем x1, x2, ..., xn —
m-мерные вектора, которые составляют матрицу Х = (x1,
x2, ..., xn)T.
Введем меру близости d(Y,
Q) между векторами Y и Q. В МНК в качестве d(Y,
Q) берется квадратичная форма взвешенных квадратов ![]() невязок ei = yi – Q(xi,
b), т.е.
невязок ei = yi – Q(xi,
b), т.е.
d(Y, Q) = [Y – Q(X, b)]T
W[Y – Q(X, b)],
где
W = {wij, i, j = 1, …, n} —
матрица весов, не зависящая от b. Тогда в качестве оценки b можно
выбрать такое b*, при котором мера близости d(Y,
Q) принимает минимальное значение, т.е.
b* = {b
: d(Y, Q)
® ![]()
В общем случае решение
этой экстремальной задачи может быть не единственным. Поэтому в дальнейшем
будем иметь в виду одно из этих решений. Оно может быть выражено в виде некоторой
вектор-функции b* = f(X, Y), где f(X,
Y) = (f1(X, Y), f2(X,
Y), ..., fr(Х, У))T,
причем действительнозначные функции fi(X, Y) непрерывны
и дифференцируемы по (X, Y) Î Z, где Z
— область определения функции f(X, Y). Эти свойства
функции f(X, Y) дают возможность использовать
подходы статистики интервальных данных.
Преимущество метода
наименьших квадратов заключается в сравнительной простоте и универсальности
вычислительных процедур. Однако не всегда оценка МНК является состоятельной
(при функции Q(X, b), не являющейся линейной по векторному
параметру b), что ограничивает его применение на практике.
Важным частным случаем
является линейный МНК, когда Q(x, b) есть линейная функция
от b:
у = boxo
+ b1x1 + ... + bmxm
+ e
= bхT + e,
где,
возможно, xo = 1, а bo — свободный член
линейной комбинации. Как известно, в этом случае МНК-оценка имеет вид:
b* = (XTWX)–1XTWY.
Если матрица XTWX
не вырождена, то эта оценка является единственной. Если матрица весов W
единичная, то
b* = (XTX)–1XTY.
Пусть выполняются
следующие предположения относительно распределения ошибок ei :
– ошибки ei имеют нулевые
математические ожидания М{ei} =
0;
– результаты наблюдений имеют одинаковую дисперсию D{ei}
= σ2;
– ошибки наблюдений некоррелированы, т.е. cov{ei, ej} = 0.
Тогда, как известно,
оценки МНК являются наилучшими линейными оценками, т.е. состоятельными и
несмещенными оценками, которые представляют собой линейные функции результатов
наблюдений и обладают минимальными дисперсиями среди множества всех линейных
несмещенных оценок. Далее именно этот наиболее практически важный частный
случай рассмотрим более подробно.
Как и в других
постановках асимптотической математической статистики интервальных данных, при
использовании МНК измеренные величины отличаются от истинных значений из-за
наличия погрешностей измерения. Запишем истинные данные в следующей форме:
![]()
где
R — индекс, указывающий на то, что значение истинное. Истинные и
измеренные данные связаны следующим образом:
X
= XR + DX,
Y = YR + DY,
где
![]()
Предположим, что
погрешности измерения отвечают граничным условиям
![]() (48)
(48)
аналогичным
ограничениям (1).
Пусть множество W возможных
значений (XR, YR) входит в Z —
область определения функции f(X, Y). Рассмотрим b*R
— оценку МНК, рассчитанную по истинным значениям факторов и отклика,
и b* — оценку МНК, найденную по искаженным погрешностями
данным. Тогда
![]()
Ввести понятие нотны
придется несколько иначе, чем это было сделано выше, поскольку оценивается не
одномерный параметр, а вектор. Положим:
![]()
Будем называть n(1)
нижней нотной, а n(2) верхней нотной. Предположим, что при
безграничном возрастании числа измерений n, т.е. при n →
∞, вектора n(1), n(2) стремятся к постоянным значениям N(1),
N(2) соответственно. Тогда N(1) будем называть нижней
асимптотической нотной, а N(2) — верхней асимптотической нотной.
Рассмотрим доверительное
множество Ba=Ba(n, b*R)
для вектора параметров b, т.е. замкнутое связное множество точек в r-мерном
евклидовом пространстве такое, что P(b
Î
Ba) = a, где a — доверительная
вероятность, соответствующая Ba (a ≈ 1). Другими
словами, Ba(n, b*R)
есть область рассеивания (аналог эллипсоида рассеивания) случайного вектора b*R
с доверительной вероятностью a и числом опытов n.
Из определения верхней и
нижней нотн следует, что всегда b*R Î [b* – n(1);
b* + n(2)] (т.е. по каждой
координате выполнено соответствующее неравенство). В соответствии с
определением нижней асимптотической нотны и верхней асимптотической нотны можно
считать, что b*R Î [b* – N(1);
b* + N(2)] при достаточно
большом числе наблюдений n. Этот многомерный интервал описывает r-мерный
гиперпараллелепипед P.
Каким-либо образом
разобьем P на L гиперпараллелепипедов. Пусть bk
— внутренняя точка k-го гиперпараллелепипеда. Учитывая свойства
доверительного множества и устремляя L к бесконечности, можно
утверждать, что P(b Î C)
³
a, где
![]()
Таким образом, множество
C характеризует неопределенность при оценивании вектора параметров b.
Его можно назвать доверительным множеством в статистике интервальных данных.
Введем некоторую меру М(X),
характеризующую «величину» множества X Í Rr.
По определению меры она удовлетворяет условию: если ![]() и
и ![]() то M(X) =
то M(X) =
= M(Z) + M(Y).
Примерами такой меры являются площадь для r = 2 и объем для r =
3. Тогда:
М(C) = М(P)
+ М(F), (49)
где
F = C\P. Здесь М(F) характеризует меру статистической неопределенности,
в большинстве случаев она убывает при увеличении числа опытов n. В то же
время М(P) характеризует меру интервальной (метрологической)
неопределенности, и, как правило, М(P) стремится к некоторой
постоянной величине при увеличении числа опытов n. Пусть теперь
требуется найти то число опытов, при котором статистическая неопределенность
составляет d-ю часть общей
неопределенности, т.е.
М(F) = dМ(C), (50)
где
d
< 1.
Тогда, подставив соотношение (50) в равенство (49) и решив уравнение
относительно n, получим искомое число опытов. В асимптотической
математической статистике интервальных данных оно называется «рациональным
объемом выборки». При этом d есть «степень малости» статистической
неопределенности М(P) относительно всей неопределенности. Она
выбирается из практических соображений. При использовании «принципа уравнивания
погрешностей» согласно [13] имеем d = 1/2.
Метод
наименьших квадратов для линейной модели.
Рассмотрим наиболее важный для практики частный случай МНК, когда модель
описывается линейным уравнением (см. выше).
Для простоты описания преобразований пронормируем переменные
хij, уi следующим образом:
![]()
где
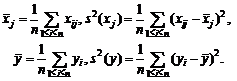
Тогда
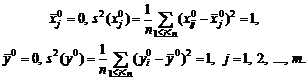
В дальнейшем изложении будем считать, что рассматриваемые
переменные пронормированы описанным образом, и верхние индексы 0
опустим. Для облегчения демонстрации основных идей примем достаточно
естественные предположения.
1. Для рассматриваемых переменных существуют следующие
пределы:
![]()
2. Количество опытов n таково, что можно пользоваться
асимптотическими результатами, полученными при n ® ¥.
3. Погрешности измерения удовлетворяют одному из следующих
типов ограничений.
Тип 1. Абсолютные погрешности
измерения ограничены согласно (48).
Тип 2. Относительные
погрешности измерения ограничены:
![]()
Тип 3. Ограничения наложены на
сумму погрешностей:
(Поскольку все
переменные пронормированы, т.е. представляют собой относительные величины, то
различие в размерностях исходных переменных не влияет на возможность сложения погрешностей.)
Перейдем к вычислению
нотны оценки МНК. Справедливо равенство:
Воспользуемся следующей
теоремой из теории матриц [71].
Теорема. Если функция f(l) разлагается в
степенной ряд в круге сходимости |l – l0| < r, т.е.
![]()
то
это разложение сохраняет силу, если скалярный аргумент заменить любой матрицей А,
характеристические числа которой lk, k = 1, …, n,
лежат внутри круга сходимости.
Из этой теоремы
вытекает, что
![]()
если
![]()
Легко убедиться, что:
![]()
где
![]()
Это вытекает из
последовательности равенств:
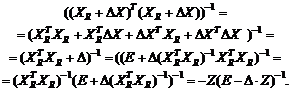
Применим приведенную
выше теорему из теории матриц, полагая А = DZ и принимая, что
собственные числа этой матрицы удовлетворяют неравенству |lk| < 1. Тогда получим:
Подставив последнее
соотношение в заключение упомянутой теоремы, получим:
Для дальнейшего анализа
понадобится вспомогательное утверждение. Исходя из предположений 1–3, докажем,
что:
![]()
Доказательство. Справедливо равенство
где
![]() — состоятельные и несмещенные оценки дисперсий
и коэффициентов ковариации, т.е.
— состоятельные и несмещенные оценки дисперсий
и коэффициентов ковариации, т.е.
![]()
тогда
![]()
где
![]()
Другими словами, каждый
элемент матрицы, обозначенной как о(1/n), есть бесконечно малая
величина порядка 1/n. Для рассматриваемого случая cov(x) = E,
поэтому
![]()
Предположим, что n
достаточно велико и можно считать, что собственные числа матрицы О(1/n)
меньше единицы по модулю, тогда
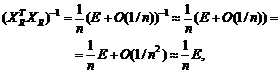
что
и требовалось доказать.
Подставим доказанное
асимптотическое соотношение в формулу для приращения b*, получим
Выразим Db* относительно приращений
DХ, DY до 2-ro порядка
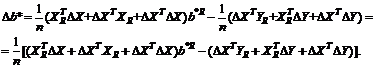
Перейдем от матричной к
скалярной форме, опуская индекс (R):
![]()
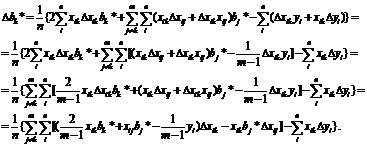
Будем искать max(|Dbk*|) по Dxij и Dyi (i = 1, …, п;
j = 1, …, m). Для этого рассмотрим все три ранее введенных типа
ограничений на ошибки измерения.
Тип 1 (абсолютные погрешности
измерения ограничены). Тогда:
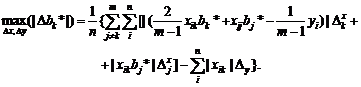
Тип 2 (относительные
погрешности измерения ограничены). Аналогично получим:
![]()
Тип З (ограничения наложены
на сумму погрешностей). Предположим, что ![]() достигает максимального значения при таких
значениях погрешностей Dxij и Dyi, которые мы обозначим
как:
достигает максимального значения при таких
значениях погрешностей Dxij и Dyi, которые мы обозначим
как:
![]()
Тогда:
![]()
Ввиду линейности
последнего выражения и выполнения ограничения типа 3:
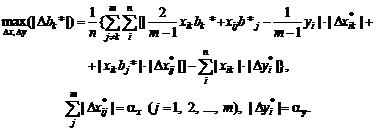
Для простоты записей
выкладок сделаем следующие замены:
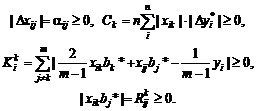
Теперь для достижения
поставленной цели можно сформулировать следующую задачу, которая разделяется на
m типовых задач оптимизации:
![]()
где
![]()
при
ограничениях
![]()
Перепишем минимизируемые
функции в следующем виде:
![]()
Очевидно, что fik
> 0.
Легко видеть, что
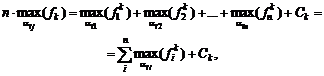
где
![]()
Следовательно,
необходимо решить nm задач
![]()
при
ограничениях «типа равенства»:
![]()
где
![]()
причем
![]()
Сформулирована типовая
задача поиска экстремума функции. Она легко решается. Поскольку
![]()
то
максимальное отклонение МНК-оценки k-ого параметра равно
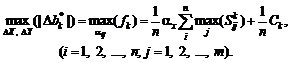
Кроме рассмотренных выше
трех видов ограничений на погрешности могут представлять интерес и другие, но
для демонстрации типовых результатов ограничимся только этими тремя видами.
Оценивание линейной регрессионной связи. В качестве примера
рассмотрим оценивание линейной регрессионной связи случайных величин у и
х1, х2, ..., хm с
нулевыми математическими ожиданиями. Пусть эта связь описывается соотношением:
![]()
где
b1, b2, ..., bm —
постоянные, а случайная величина е некоррелирована с х1,
х2, ..., хm. Допустим,
необходимо оценить неизвестные параметры b1, b2,
..., bm по серии независимых испытаний:
![]()
Здесь при каждом i
= 1, 2, …, n имеем новую независимую реализацию рассматриваемых
случайных величин. В этой частной схеме оценки наименьших квадратов ![]()
![]() , …,
, …, ![]() параметров b1, b2,
..., bm являются, как известно, состоятельными [72].
параметров b1, b2,
..., bm являются, как известно, состоятельными [72].
Пусть величины х1,
х2, ..., хm в дополнение к попарной
независимости имеют единичные дисперсии. Тогда из Закона больших чисел [72]
следует существование следующих пределов (см. предположение 1 выше):
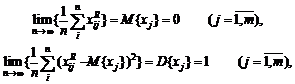
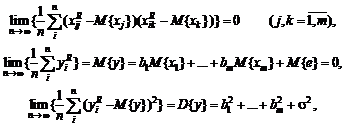
где
s
— среднее
квадратическое отклонение случайной величины е.
Пусть измерения
производятся с погрешностями, удовлетворяющими ограничениям типа 1, тогда
максимальное приращение величины ![]() как показано выше, равно:
как показано выше, равно:
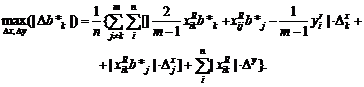
Перейдем к предельному
случаю и выпишем выражение для нотны:
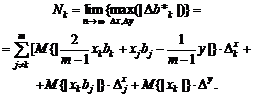
В качестве примера
рассмотрим случай m = 2. Тогда
![]()
Приведенное выше
выражение для максимального приращения метрологической погрешности не может
быть использовано в случае m = 1. Для m = 1 выведем выражение для
нотны, исходя из соотношения:
![]()
Подставив m = 1,
получим:
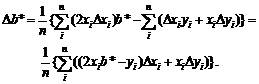
Следовательно, нотна
выглядит так:
Nf
= M{|2xb* – y|}Dx + M{|x|}Dy.
Для нахождения
рационального объема выборки необходимо сделать следующее.
Этап 1. Выразить зависимость
размеров и меры области рассеивания Ba(n, b) от
числа опытов n (см. выше).
Этап 2. Ввести меру
неопределенности и записать соотношение между статистической и интервальной
неопределенностями.
Этап 3. По результатам этапов 1
и 2 получить выражение для рационального объема выборки.
Для выполнения этапа 1
определим область рассеивания следующим образом. Пусть доверительным множеством
Ba(n, b)
является m-мерный куб со сторонами длиною 2k, для которого
P(b
Î Ba(n,
b*R)) = a.
Исследуем случайный
вектор b* и
![]()
Как известно, если
элементы матрицы А = {аij} —случайные, т.е. А —
случайная матрица, то ее математическим ожиданием является матрица,
составленная из математических ожиданий ее элементов, т.е. М{А} =
{М{аij}}.
Утверждение 1. Пусть А = {аij}
и В = {bij} — случайные матрицы порядка (m х n)
и (n х r) соответственно, причем любая пара их элементов (аij,
bkl) состоит из независимых случайных величин. Тогда
математическое ожидание произведения матриц равно произведению математических
ожиданий сомножителей, т.е. M{AB} = M{A} M{B}.
Доказательство. На основании определения
математического ожидания матрицы заключаем, что
![]()
но
так как случайные величины аik, bkj
независимы, то
![]()
что
и требовалось доказать.
Утверждение 2. Пусть А = {аij}
и В = {bij} — случайные матрицы порядка (m ´ n) и (n ´ r)
соответственно. Тогда математическое ожидание суммы матриц равно сумме
математических ожиданий слагаемых, т.е. М{А + В} = М{А}
+ М{В}.
Доказательство. На основании определения
математического ожидания матрицы заключаем, что
M{А + В} =
{М{аij + bij}} = {М{аij}
+ М{bij}} = M{A} + M{B},
что
и требовалось доказать.
Найдем математическое
ожидание и ковариационную матрицу вектора b* с помощью
утверждений 1, 2 и выражения для b*R,
приведенного выше. Имеем
![]()
Но так как M{e}
= 0, то M{b*R} = b. Это
означает, что оценка МНК является несмещенной.
Найдем ковариационную
матрицу:
![]()
Можно доказать, что
![]()
Но M{e×eT}
= D{e} = s2E,
поэтому
![]()
Как выяснено ранее, для
достаточно большого количества опытов n выполняется приближенное
равенство
![]() (51)
(51)
тогда
при больших n
![]()
Осталось определить вид
распределения вектора b*R. Из выражения для b*R,
приведенного выше, и асимптотического соотношения (51) следует, что
![]()
Можно показать, что
вектор b*R имеет асимптотически нормальное распределение,
т.е.
![]()
Тогда совместная функция
плотности распределения вероятностей случайных величин ![]() ,
, ![]() , …,
, …, ![]() будет иметь в асимптотике вид:
будет иметь в асимптотике вид:
![]() (52)
(52)
где
![]()
Тогда справедливы
соотношения
![]()
Подставим в формулу
(52), получим
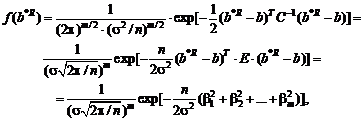
где
![]()
Вычислим асимптотическую
вероятность попадания описывающего реальность вектора параметров b в m-мерный
куб с длиной стороны, равной 2k, и с центром b*R.
![]()
![]()
![]()
Сделаем замену
![]()
Тогда
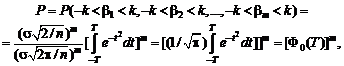
где
Т = (n/2)1/2(k/s), а F0(Т) — интеграл
Лапласа,
![]()
где
![]() — функция стандартного нормального
распределения с математическим ожиданием 0 и дисперсией 1. Из последнего соотношения
получаем
— функция стандартного нормального
распределения с математическим ожиданием 0 и дисперсией 1. Из последнего соотношения
получаем
Т = ![]() (P1/m),
(P1/m),
где
Ф–1(Р) — обратная функция Лапласа. Отсюда следует, что
k = s (2/n)1/2
Ф0–1 (Р1/m). (53)
Напомним, что
доверительная область Ba(n, b) —
это
m-мерный куб, длина стороны которого равна К, т.е.
P(b Î
Ba(n, b)) = P (–K < b1 < K, –K < b2 < K, …, –K < bm < K) = a.
Подставляя P = a в формулу (53), получим
К = k = s (2/n)1/2Ф0–1(a 1/m). (54)
Соотношение (54)
выражает зависимость размеров доверительной области (т.е. длины ребра куба К)
от числа опытов n, среднего квадратического отклонения s ошибки е и
доверительной вероятности a. Это соотношение понадобится для определения
рационального объема выборки.
Переходим к этапу 2.
Необходимо ввести меру разброса (неопределенности) и установить соотношение
между статистической и интервальной (метрологической) неопределенностями с
соответствии с ранее сформулированным общим подходом.
Пусть A —
некоторое измеримое множество точек в m-мерном евклидовом пространстве,
характеризующее неопределенность задания вектора а Î A. Тогда необходимо ввести
некую меру М(А), измеряющую степень неопределенности. Такой мерой
может служить m-мерный объем V(A) множества А (т.е.
его мера Лебега или Жордана), М(А) = V(A).
Пусть P — m-мерный
параллелепипед, характеризующий интервальную неопределенность. Длины его сторон
равны значениям нотн 2N1, 2N2, …, 2Nm,
а центр а (точка пересечений диагоналей параллелепипеда)
находится в точке b*R. Пусть C — измеримое
множество точек, характеризующее общую неопределенность. В рассматриваемом
случае это m-мерный параллелепипед, длины сторон которого равны 2(N1
+ K), 2(N2 + K), …, 2(Nm
+ K), а центр находится в точке b*R.
Тогда
M(P) = V(P) = 2mN1N2…Nm, (55)
M(C) = V(C) = 2m
(N1 + K)(N2 + K)…(Nm
+ K). (56)
Справедливо соотношение
(49), согласно которому М(C) = М(P)
+ М(F), где множество F = C\P характеризует
статистическую неопределенность.
На этапе 3 получаем по
результатам этапов 1 и 2 выражение для рационального объема выборки. Найдем то
число опытов, при котором статистическая неопределенность составит d 100% от общей неопределенности,
т.е. согласно правилу (50)
M(F)
= М(C) – М(P) = dM(C) (57)
где
0 < d
< 1.
Подставив (55) и (56) в (57), получим
![]()
Следовательно,
![]()
Преобразуем эту формулу:
![]()
откуда
![]()
Если статистическая
погрешность мала относительно метрологической, т.е. величины K/Ni
малы, то
![]()
При m = 1 эта
формула является точной. Из нее следует, что для дальнейших расчетов можно
использовать соотношение
![]()
Отсюда нетрудно найти К:
![]() (58)
(58)
Подставив в формулу (58)
зависимость K = K(n),
полученную в формуле (54), находим приближенное (асимптотическое) выражение для
рационального объема выборки:
![]()
При m = 1 эта
формула также справедлива, более того, является точной.
Переход от произведения
к сумме является обоснованным при достаточно малом d, т.е. при достаточно
малой статистической неопределенности по сравнению с метрологической.
В общем случае можно находить К и затем рациональный объем выборки тем
или иным численным методом.
Пример 1. Представляет интерес
определение nрац для случая, когда m = 2, поскольку
простейшая линейная регрессия с m = 2 широко применяется. В этом случае
базовое соотношение имеет вид
(1 + К/N1)(1
+ К/N2) = 1/(1 – d).
Решая это уравнение
относительно К, получаем
К = 0,5{ –(N1
+ N2) + [(N1 + N2)2
+ 4N1N2 (d/(1 –d)]1/2}.
Далее, подставив в
формулу (54), получим уравнение для рационального объема выборки в случае m =
2:
s(2/n)1/2Ф–1(a1/2) = 0,5{–(N1
+ N2) + [(N1 + N2)2+4N1N2(d/(1 – d)]1/2}.
Следовательно,
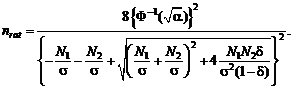
При использовании
«принципа уравнивания погрешностей» согласно [3] d = 1/2. При
доверительной вероятности ![]() имеем
имеем ![]() и согласно [42]
и согласно [42] ![]() Для этих численных значений
Для этих численных значений
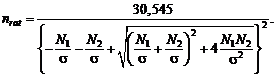
Если ![]() то
то ![]() Если же
Если же ![]()
![]() то
то ![]() Если первое из этих чисел превышает обычно
используемые объемы выборок, то второе находится в «рабочей зоне» регрессионного
анализа.
Если первое из этих чисел превышает обычно
используемые объемы выборок, то второе находится в «рабочей зоне» регрессионного
анализа.
Парная регрессия. Наиболее простой и
одновременно наиболее широко применяемый частный случай парной регрессии
рассмотрим подробнее. Модель имеет вид
![]()
Здесь xi
— значения фактора (независимой переменной), yi — значения отклика
(зависимой переменной), ei — статистические
погрешности, a, b
— неизвестные параметры, оцениваемые методом наименьших квадратов. Она
переходит в модель (используем альтернативную запись линейной модели)
![]()
если
положить
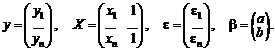
Естественно принять, что
погрешности факторов описываются матрицей
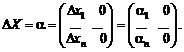
В рассматриваемой модели
интервального метода наименьших квадратов
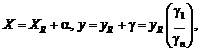
где
X, y — наблюдаемые (т.е.
известные статистику) значения фактора и отклика; XR, yR — истинные значения переменных;
a, g — погрешности измерений
переменных. Пусть b* — оценка метода
наименьших квадратов, вычисленная по наблюдаемым значениям переменных; ![]() — аналогичная оценка, найденная по истинным
значениям. В соответствии с ранее проведенными рассуждениями
— аналогичная оценка, найденная по истинным
значениям. В соответствии с ранее проведенными рассуждениями
![]() (59)
(59)
с
точностью до бесконечно малых более высокого порядка по |a| и |g|. В формуле (59)
использовано обозначение ![]() Вычислим правую часть в (59), выделим главный
линейный член и найдем нотну.
Вычислим правую часть в (59), выделим главный
линейный член и найдем нотну.
Легко видеть, что
![]() (60)
(60)
где
суммирование проводится от 1 до n. Для упрощения обозначений
в дальнейшем до конца настоящего пункта не будем указывать эти пределы
суммирования. Из (60) вытекает, что
![]() (61)
(61)
Легко подсчитать, что
![]() (62)
(62)
Положим
![]()
Тогда знаменатель в (61)
равен ![]() Из (61) и (62) следует, что
Из (61) и (62) следует, что
![]() (63)
(63)
Здесь и далее опустим
индекс i, по которому проводится суммирование.
Это не может привести к недоразумению, поскольку всюду суммирование проводится
по индексу i в интервале от 1 до n. Из (61) и (63)
следует, что
![]() (64)
(64)
где
![]()
![]()
![]()
Наконец, вычисляем
основной множитель в (59)
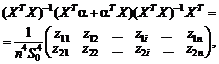 (65)
(65)
где
![]()
Перейдем к вычислению
второго члена с ![]() в (59). Имеем
в (59). Имеем
![]() (67)
(67)
где
![]()
Складывая правые части
(65) и (67) и умножая на у, получим окончательный вид члена с a в (59):
![]() (68)
(68)
где
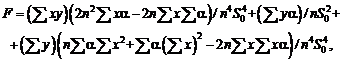 (69)
(69)
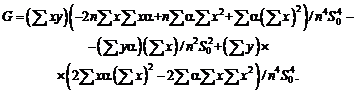
Для вычисления нотны
выделим главный линейный член. Сначала найдем частные производные. Имеем
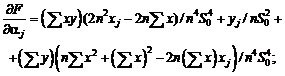 (70)
(70)
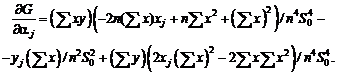
Если ограничения имеют
вид
![]()
то
максимально возможное отклонение оценки а* параметра а
из-за погрешностей aj
таково:
![]()
где
производные заданы формулой (70).
Пример 2. Пусть вектор (х,
y) имеет двумерное нормальное распределение с нулевыми
математическими ожиданиями, единичными дисперсиями и коэффициентом корреляции r. Тогда
![]() (71)
(71)
При этом
![]()
следовательно,
максимально возможному изменению параметра b* соответствует сдвиг всех
xi в одну сторону, т.е. наличие систематической
ошибки при определении х-ов. В то же время согласно (71) значения в
асимптотике выбираются по правилу
![]()
Таким образом,
максимальному изменению а* соответствуют не те aj,
что максимальному изменению b*. В этом состоит новое
по сравнению с одномерным случаем. В зависимости от вида ограничений на
возможные отклонения, в частности, от вида метрики в пространстве параметров,
будут «согласовываться» отклонения по отдельным параметрам. Ситуация аналогична
той, что возникает в классической математической статистике в связи с
оптимальным оцениванием параметров. Если параметр одномерен, то ситуация с
оцениванием достаточно прозрачна — есть понятие эффективных оценок, показателем
качества оценки является средний квадрат ошибки, а при ее несмещенности — дисперсия.
В случае нескольких параметров возникает необходимость соизмерить точность
оценивания по разным параметрам. Есть много критериев оптимальности (см.,
например, [73]), но нет признанных правил выбора среди них.
Вернемся к формуле (59).
Интересно, что отклонения вектора параметров, вызванные отклонениями значений
факторов a и отклика g, входят в (59)
аддитивно. Хотя
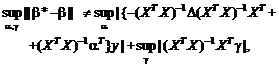
но
для отдельных компонент (не векторов!) имеет место равенство.
В случае парной
регрессии
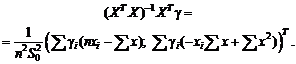 (72)
(72)
Из формул (68), (69) и
(72) следует, что
![]()
где
F и G определены в (69), а
![]()
![]()
Итак, продемонстрирована
возможность применения основных подходов статистики интервальных данных в
регрессионном анализе.
Пример использования
интервального регрессионного анализа. Методы статистики интервальных данных наряду с
классическими методами оказываются полезными не только в традиционных
статистических задачах, но и во многих других областях, в частности, в
экономике и управлении промышленными предприятиями [56, 74]. Пример
использования статистики интервальных данных в инвестиционном менеджменте
подробно описан в [56] (см. также соответствующий раздел ниже). Перспективы
применения статистики интервальных данных в контроллинге рассмотрены в [75].
Компьютерный анализ данных и использование статистических методов в
информационных системах управления предприятием при решении задач контроллинга
рассмотрены в [76]. Рассмотрим практический пример применения интервального
регрессионного анализа при анализе и прогнозировании затрат предприятия [77].[4]
Выпуск продукции y
зависит от величины суммарных переменных затрат х. Условные исходные
данные для предприятия «Омега» приведены в табл. 1. Необходимо построить
уравнение регрессии и найти нотну. В данном случае n
= 12, k = 2. Зависимость ищется в виде y
= ax + b.
Таблица 1
Исходные данные для
предприятия «Омега», тыс. руб.
|
№
п/п |
х |
y |
№
п/п |
х |
y |
|
1 |
15,1 |
89,0 |
7 |
44,3 |
145,9 |
|
2 |
16,8 |
110,8 |
8 |
46,0 |
151,8 |
|
3 |
25,0 |
104,4 |
9 |
46,8 |
153,7 |
|
4 |
30,7 |
116,1 |
10 |
53,4 |
161,8 |
|
5 |
33,2 |
127,8 |
11 |
56,5 |
175,8 |
|
6 |
44,2 |
143,3 |
12 |
65,4 |
193,4 |
Пусть как для х,
так и для y максимально возможная погрешность l = 10. Можно доказать
[37], что указанное значение l допустимо считать малым, поскольку под
«малостью» следует понимать малость относительно типовых значений х и y.
Построим уравнение регрессии согласно методу наименьших квадратов:
![]()
Оценим максимально
возможное изменение (приращение) вектора (a*, b*) оценок параметров
линейной зависимости методом наименьших квадратов при изменении исходных
данных, когда a и g малы (см. формулу (59)
выше). Для этого найдем нотны — максимально возможные изменения координат этого
вектора в предположении ![]() и
и ![]()
Na*(x, y)
= 0,87; Nb*(x,
y) = 32,98.
Найдем доверительные
интервалы для параметров a и b
согласно [56, п. 5.1] при доверительной вероятности 0,95. Для параметра a
(т.е. для переменных затрат на единицу выпуска) нижняя доверительная граница ![]() а верхняя —
а верхняя — ![]() Доверительный интервал для параметра a
с учетом нотны равен [1,595 – 0,87; 2,233 + 0,87] или [0,73; 3,1]. Ширина
«классического» доверительного интервала d1 = aB(0,95)
– aH(0,95) равна 0,63, что несколько меньше, чем нотна 0,87.
Доверительный интервал для параметра a
с учетом нотны равен [1,595 – 0,87; 2,233 + 0,87] или [0,73; 3,1]. Ширина
«классического» доверительного интервала d1 = aB(0,95)
– aH(0,95) равна 0,63, что несколько меньше, чем нотна 0,87.
Для параметра b (т.е.
для постоянных затрат) нижняя доверительная граница ![]() а верхняя — bB(0,95) = 68,13. Ширина
«классического» доверительного интервала для параметра b* равна 9,63, т.е. почти
в 3 раза меньше, чем нотна 32,98. Доверительный интервал для параметра b
с учетом нотны равен [58,51 – 32,98; 68,13 + 32,98] или [25,53; 101,12].
а верхняя — bB(0,95) = 68,13. Ширина
«классического» доверительного интервала для параметра b* равна 9,63, т.е. почти
в 3 раза меньше, чем нотна 32,98. Доверительный интервал для параметра b
с учетом нотны равен [58,51 – 32,98; 68,13 + 32,98] или [25,53; 101,12].
Итак, восстановленная
зависимость с учетом метрологических и статистических погрешностей имеет вид
![]()
Исходя из погрешностей
коэффициентов линейной зависимости, можно указать нижнюю и верхнюю
доверительные границы для функции
![]()
![]()
Более точно
доверительные границы для значения функции в определенной точке можно указать,
если найти нотну и статистическую погрешность не для коэффициентов, а
непосредственно для значения функции [56, п. 5.1].
Полученные результаты
дают возможность оценивать точность прогнозирования с помощью восстановленной
зависимости, рассчитывая нижние и верхние границы для значения зависимой
переменной. Например, при х = 100 нижняя и верхняя границы интервала
равны
yн
(100)
= (1,914 — 1,187)100 + 63,32 – 37,79 = 98,23;
yв
(100)
= (1,914 + 1,187)100 + 63,32 + 37,79 = 411,21.
Некоторые замечания. На основе использования
вероятностных моделей регрессионного анализа [56, гл. 5.1] удается построить
доверительные границы для восстановленной зависимости. Однако при практическом
применении вероятностных моделей не всегда легко обосновать предположения,
наложенные на вектор невязок e (независимость и одинаковую распределенность
его координат). Кроме того, при моделировании экономических явлений и процессов
обычно нет оснований использовать нормально распределенные случайные величины
[56, гл. 4.1], следовательно, нельзя применять методы регрессионного анализа, основанные
на нормальном распределении погрешностей. При этом объем данных обычно таков,
что применение асимптотических формул непараметрического регрессионного анализа
[56, гл. 5] не вполне оправдано. Поэтому описанный выше подход интервального
регрессионного анализа представляется не менее оправданным, чем подход на
основе вероятностных моделей. В этом мы согласны с А.П. Вощининым [46].
Представляется необходимым использование интервального регрессионного анализа в
различных областях научных и прикладных исследований, прежде всего, в
технических, экономических, управленческих разработках.
7.7. Интервальный дискриминантный анализ
Перейдем к задачам
классификации в статистике интервальных данных. Как известно [78], важная их
часть — задачи дискриминации (диагностики, распознавания образов с учителем). В
этих задачах заданы классы (полностью или частично, с помощью обучающих
выборок), и необходимо принять решение — к какому из этих классов отнести вновь
поступающий объект.
В линейном
дискриминантном анализе правило принятия решений основано на линейной функции f(x)
от распознаваемого вектора ![]() Рассмотрим для простоты случай двух классов.
Правило принятия решений определяется константой С — при f(x)
> C распознаваемый объект относится к первому классу, при f(x)
£
C — ко второму.
Рассмотрим для простоты случай двух классов.
Правило принятия решений определяется константой С — при f(x)
> C распознаваемый объект относится к первому классу, при f(x)
£
C — ко второму.
В первоначальной
вероятностной модели Р. Фишера предполагается, что классы заданы обучающими
выборками объемов N1 и N2, соответственно, из
многомерных нормальных распределений с разными математическими ожиданиями, но
одинаковыми ковариационными матрицами. В соответствии с леммой Неймана-Пирсона,
дающей правило принятия решений при проверке статистических гипотез,
дискриминантная функция является линейной. Для ее практического использования
теоретические характеристики распределения необходимо заменить на выборочные.
Тогда дискриминантная функция приобретает следующий вид
![]()
Здесь ![]() — выборочное среднее арифметическое по первой
выборке
— выборочное среднее арифметическое по первой
выборке ![]() а
а ![]() — выборочное среднее арифметическое по второй
выборке
— выборочное среднее арифметическое по второй
выборке ![]()
![]() В роли S может выступать любая
состоятельная оценка общей для выборок ковариационной матрицы. Обычно
используют следующую оценку, естественным образом сконструированную на основе
выборочных ковариационных матриц:
В роли S может выступать любая
состоятельная оценка общей для выборок ковариационной матрицы. Обычно
используют следующую оценку, естественным образом сконструированную на основе
выборочных ковариационных матриц:
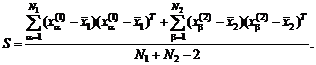
В соответствии с
подходом статистики интервальных данных считаем, что специалисту по анализу
данных известны лишь значения с погрешностями
![]()
Таким образом, вместо f(x)
статистик делает выводы на основе искаженной линейной дискриминантной функции f1(x),
в которой коэффициенты рассчитаны не по исходным данным ![]() а по искаженным погрешностями значениям
а по искаженным погрешностями значениям ![]()
![]()
Это модель с искаженными
параметрами дискриминантной функции. Следующая модель — такая, в которой
распознаваемый вектор x также известен с
ошибкой. Далее, константа С может появляться в модели различными
способами. Она может задаваться априори абсолютно точно. Может задаваться с
какой-то ошибкой, не связанной с ошибками, вызванными конечностью обучающих
выборок. Может рассчитываться по обучающим выборкам, например, с целью уравнять
ошибки классификации, т.е. провести плоскость дискриминации через середину
отрезка, соединяющего центры классов. Итак, целый спектр моделей ошибок.
На какие статистические
процедуры влияют ошибки в исходных данных? Здесь тоже много постановок. Можно
изучать влияние погрешностей измерений на значения дискриминантной функции f,
например, в той точке, куда попадает вновь поступающий объект х.
Очевидно, случайная величина f(x)
имеет некоторое распределение, определяемое распределениями обучающих выборок.
Выше описана модель Р. Фишера с нормально распределенными совокупностями.
Однако реальные данные, как правило, не подчиняются нормальному распределению
[56]. Тем не менее линейный статистический анализ имеет смысл и для распределений,
не являющихся нормальными (при этом вместо свойств многомерного нормального
распределения приходится опираться на многомерную центральную предельную
теорему и теорему о наследовании сходимости [13]). В частности, приравняв
метрологическую ошибку, вызванную погрешностями исходных данных, и
статистическую ошибку, получим условие, определяющее рациональность объемов
выборок. Здесь два объема выборок, а не один, как в большинстве рассмотренных
постановок статистики интервальных данных. С подобным мы сталкивались ранее при
рассмотрении двухвыборочного критерия Смирнова.
Естественно изучать
влияние погрешностей исходных данных не при конкретном х, а для правила
принятия решений в целом. Может представлять интерес изучение характеристик
этого правила по всем х или по какому-либо отрезку. Более интересно
рассмотреть показатель качества классификации, связанный с пересчетом на модель
линейного дискриминантного анализа [56, 79].
Математический аппарат
изучения перечисленных моделей развит выше в предыдущих разделах настоящей
главы. Некоторые результаты приведены в [39]. Из-за большого объема выкладок
ограничимся приведенными здесь замечаниями.
7.8. Интервальный кластер-анализ
Кластер-анализ, как известно
[78], имеет целью разбиение совокупности объектов на группы сходных между
собой. Многие методы кластер-анализа основаны на использовании расстояний между
объектами. (Степень близости между объектами может измеряться также с помощью
мер близости и показателей различия, для которых неравенство треугольника
выполнено не всегда.) Рассмотрим влияние погрешностей измерения на расстояния
между объектами и на результаты работы алгоритмов кластер-анализа.
С ростом размерности р
евклидова пространства диагональ единичного куба растет как ![]() А какова погрешность определения евклидова
расстояния? Пусть двум рассматриваемым объектам соответствуют
А какова погрешность определения евклидова
расстояния? Пусть двум рассматриваемым объектам соответствуют ![]() и
и ![]() — вектора размерности р. Они известны с
погрешностями
— вектора размерности р. Они известны с
погрешностями ![]() и
и ![]() , т.е.
статистику доступны лишь вектора
, т.е.
статистику доступны лишь вектора ![]() Легко видеть, что
Легко видеть, что
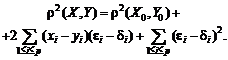 (73)
(73)
Пусть ограничения на
абсолютные погрешности имеют вид
![]()
Такая запись ограничений
предполагает, что все переменные имеют примерно одинаковый разброс. Трудно
ожидать этого, если переменные имеют различные размерности. Однако рассматриваемые
ограничения на погрешности естественны, если переменные предварительно
стандартизованы, т.е. центрированы и пронормированы (т.е. из каждого значения
вычтено среднее арифметическое, а разность поделена на выборочное среднее
квадратическое отклонение).
Пусть ![]() Тогда последнее слагаемое в (73) не превосходит
Тогда последнее слагаемое в (73) не превосходит
![]() поэтому им можно пренебречь. Тогда из (73)
следует, что нотна евклидова расстояния имеет вид
поэтому им можно пренебречь. Тогда из (73)
следует, что нотна евклидова расстояния имеет вид
![]()
с точностью до
бесконечно малых более высокого порядка. Если случайные величины ![]() имеют одинаковые математические ожидания и для
них справедлив закон больших чисел (эти предположения естественны, если
переменные перед применением кластер-анализа стандартизованы), то существует
константа С такая, что
имеют одинаковые математические ожидания и для
них справедлив закон больших чисел (эти предположения естественны, если
переменные перед применением кластер-анализа стандартизованы), то существует
константа С такая, что
![]()
с
точностью до бесконечно малых более высокого порядка при малых D, больших р и pD2 ® 0.
Из рассмотрений
настоящего пункта вытекает, что
![]() (74)
(74)
при
некотором q
таком, что |q| < 1.
Какое минимальное
расстояние является различимым? По аналогии с определением рационального объема
выборки при проверке гипотез предлагается уравнять слагаемые в (74), т.е. определять
минимально различимое расстояние rmin
из условия
![]() . (75)
. (75)
Естественно принять, что
расстояния, меньшие rmin, не отличаются от 0,
т.е. точки, лежащие на расстоянии r £ rmin,
не различаются между собой.
Каков порядок величины С?
Если xi и yi независимы и имеют
стандартное нормальное распределение с математическим ожиданием 0 и дисперсией
1, то, как легко подсчитать, ![]() и соответственно С = 4,51.
Следовательно, в этой модели
и соответственно С = 4,51.
Следовательно, в этой модели
![]()
Формула (75) показывает,
что хотя с ростом размерности пространства р растет диаметр (длина
диагонали) единичного куба — естественной области расположения значений
переменных, с той же скоростью растет и естественное квантование расстояния с
помощью порога неразличимости rmin, т.е. увеличение размерности
(вовлечение новых переменных), вообще говоря, не улучшает возможности
кластер-анализа.
Можно сделать выводы и
для конкретных алгоритмов. В дендрограммах (например, результатах работы
иерархических агломеративных алгоритмах ближнего соседа, дальнего соседа,
средней связи) можно порекомендовать склеивать (т.е. объединять) уровни,
отличающиеся менее чем на rmin. Если все уровни
склеятся, то можно сделать вывод, что у данных нет кластерной структуры, они
однородны. В алгоритмах типа «Форель» центр тяжести текущего кластера
определяется с точностью ±D по каждой координате, а
порог для включения точки в кластер (радиус шара R) из-за погрешностей
исходных данных может измениться согласно (74) на
![]()
Поэтому кроме расчетов с
R рекомендуется провести также расчеты с радиусами R1 и R2, где
![]() ,
,
и
сравнить полученные разбиения. Быть адекватными реальности могут только выводы,
общие для всех трех расчетов. Эти рекомендации развивают общую идею [3] о
целесообразности проведения расчетов при различных значениях параметров алгоритмов
с целью выделения выводов, инвариантных по отношению к выбору конкретного
алгоритма.
7.9. Интервальные данные в инвестиционном менеджменте
Методы статистики
интервальных данных оказываются полезными не только в традиционных технических
и эконометрических задачах, но и во многих других областях, например, в инвестиционном
менеджменте.
Основная идея
формулируется так. Все знают, что любое инженерное измерение проводится с
некоторой погрешностью. Эту погрешность обычно приводят в документации и
учитывают при принятии решений. Ясно, что и любое экономическое измерение также
проводится с погрешностью. А вот какова она? Необходимо уметь ее оценивать,
поскольку ошибки при принятии экономических решений обходятся дорого.
Например, как принимать
решение о выгодности или невыгодности инвестиционного проекта? Как сравнивать
инвестиционные проекты между собой? Как известно, для решения этих задач
используют такие экономические характеристики, как NPV (Net Present Value)
— чистая текущая стоимость (этот термин переводится с английского также
как чистый дисконтированный доход, чистое приведенное значение и др.),
внутренняя норма доходности, срок окупаемости, показатели рентабельности и др.
С экономической точки
зрения инвестиционные проекты описываются финансовыми потоками, т.е. функциями
от времени, значениями которых являются платежи (и тогда значения этих функций
отрицательны) и поступления (значения функций положительны). Сравнение
инвестиционных проектов — это сравнение функций от времени с учетом внешней
среды, проявляющейся в виде дисконт-функции (как результата воздействия
социальных, технологических, экологических, экономических и политических
факторов), и представлений законодателя или инвестора — обычно ограничений на
финансовые потоки платежей и на горизонт планирования. Основная проблема при
сравнении инвестиционных проектов такова: что лучше — меньше, но сейчас, или
больше, но потом? Как правило, чем больше вкладываем сейчас, тем больше
получаем в более или менее отдаленном будущем. Вопрос в том, достаточны ли
будущие поступления, чтобы покрыть нынешние платежи и дать приемлемую для
инвестора прибыль?
В настоящее время широко
используются различные теоретические подходы к сравнению инвестиционных
проектов и облегчающие расчеты компьютерные системы, в частности, ТЭО-ИНВЕСТ, Project
Expert, COMFAR, PROPSIN, Альт-Инвест. Однако ряд важных моментов в них не
учтен.
Введем основные понятия.
Дисконт-функция как
функция от времени показывает, сколько стоит для фирмы 1 руб. в заданный момент
времени, если его привести к начальному моменту. Если дисконт-функция —
константа для разных отраслей, товаров и проектов, то эта константа называется
дисконт-фактором, или просто дисконтом. Дисконт-функция определяется совместным
действием различных факторов, в частности, реальной процентной ставки и индекса
инфляции. Реальная процентная ставка описывает «нормальный» рост экономики
(т.е. без инфляции). В стабильной ситуации доходность от вложения средств в
различные отрасли, в частности, в банковские депозиты, примерно одинакова.
Сейчас она, по оценке ряда экспертов, около 12%. Итак, нынешний 1 руб. превращается
в 1,12 руб. через год, а потому 1 руб. через год соответствует 1/1,12 = 0,89
руб. сейчас — это и есть максимум дисконта.
Обозначим дисконт буквой
С. Если q — банковский процент (плата за депозит), т.е. вложив в
начале года в банк 1 руб., в конце года получим (1 + q) руб., то дисконт
определяется по формуле С = 1/(1 + q). При таком подходе
полагают, что банковские проценты одинаковы во всех банках. Более правильно
было бы считать q, а потому и С, нечисловыми величинами, а
именно, интервалами [q1; q2] и [С1;
С2]. Следовательно, экономические выводы должны быть исследованы
на устойчивость (применяют и термин «чувствительность») по
отношению к возможным отклонениям.
Как функцию времени t
дисконт-функцию обозначим C(t). При постоянстве
дисконт-фактора имеем C(t) = Сt.
Если q = 0,12, С = 0,89, то 1 руб. за 2 года превращается в 1,122
= 1,2544, через 3 — в 1,4049. Итак, 1 руб., получаемый через 2 года, соответствует
1/1,2544 = 0,7972 руб., т.е. 79,72 коп. сейчас, а 1 руб., обещанный через 3
года, соответствует 0,71 руб. сейчас. Другими словами, С(2) = 0,80, а С(3)
= 0,71. Если дисконт-фактор зависит от времени, в первый год равен С1,
во второй — С2, в третий — С3, ..., в t-ый
год — Сt, то C(t)=
С1, С2, С3, ..., Сt.
Рассмотрим
характеристики потоков платежей. Срок окупаемости — тот срок, за который доходы
покроют расходы. Обычно предполагается, что после этого проект приносит только
прибыль. Это верно не всегда. Простейший вариант, для которого не возникает
никаких парадоксов, состоит в том, что все инвестиции (капиталовложения)
делаются сразу, в начале, а затем инвестор получает только доход. Сложности
возникают, если проект состоит из нескольких очередей, вложения распределены во
времени.
Примитивный способ
расчета срока окупаемости состоит в делении объема вложений А на
ожидаемый ежегодный доход В. Тогда срок окупаемости равен А/В.
Этот способ некорректен. Если дисконт-фактор равен С, то максимально
возможный суммарный доход равен
ВС + ВС2 +
ВС3 + ВС4 + ВС5 + ... = ВС
(1 + С + С2 + С3 + С4
+ ...) = ВС/(1 – С).
Если А/В меньше С/(1
– С), то можно рассчитать срок окупаемости проекта, но он будет больше,
чем А/В. Если же А/В больше или равно С/(1 – С),
то проект не окупится никогда. Поскольку максимум С равен 0,89, то
проект не окупится никогда, если А/В не меньше 8,09.
Пусть вложения равны 1
млн. руб., ежегодная прибыль составляет 500 тыс., т.е. А/В = 2,
дисконт-фактор С = 0.8. При примитивном подходе (при С = 1) срок
окупаемости равен 2 годам. А на самом деле? За k лет будет возвращено
ВС (1 + С + С2
+ С3 + С4 + ... + Ck)
= ВС(1 – Сk+1) / (1 – С).
Срок окупаемости k
получаем из уравнения 1=0,5´0,8(1 – 0,8k +
1)/(1 – 0,8), откуда k = 2,11. Он оказался равным 2,11 лет, т.е.
увеличился примерно на 6 недель. Это немного. Однако если В = 0,2, то
имеем уравнение 1 = 0,2´0,8(1 – 0,8k +
1) / (1 – 0,8). У этого уравнения нет корней, поскольку А/В = 5
> С/(1 – С) = 0.8/(1 – 0,8) = 4. Проект не окупится
никогда. Прибыль можно ожидать лишь при А/В < 4. Рассмотрим
промежуточный случай, В = 0,33, с «примитивным» сроком окупаемости 3
года. Тогда имеем уравнение 1 = 0,33 ´ 0,8 (1 – 0,8k +
1)/ (1 – 0,8), откуда k = 5,40.
Рассмотрим финансовый
поток a(0), a(1), a(2), a(3), ..., a(t),
... . (для простоты примем, что платежи или поступления происходят раз
в год). Выше рассмотрен поток с одним платежом a(0) = (–А) и
дальнейшими поступлениями a(1) = a(2) = a(3) = ... = a(t)
= .... = В. Чистая текущая стоимость (Net Present Value, сокращенно
NPV) рассчитывается для финансового потока путем приведения затрат и
поступлений к начальному моменту времени:
NPV = a(0) + a(1)С(1) + a(2)С(2) + a(3)С(3) + ... + a(t)С(t)
+ ...,
где
С(t) — дисконт-функция. В простейшем случае, когда дисконт-фактор
не меняется год от года и имеет вид С = = 1/(1 + q), формула
для NPV конкретизируется:
NPV = NPV(q) = a(0)
+ a(1)/(1 + q) + a(2)/(1 +
q)2 +
+ a(3)/(1 + q)3 + ... +a(t)/(1 + q)t
+ ...
Пусть, например, a(0) = –10, a(1) =
NPV(0,12) = –10 + 3 ´ 0,89 + 4 ´ 0.80 + 5 ´ 0,71 =
= –10 + 2,67 + 3,20 + 3,55 = –0,58.
Итак, проект невыгоден
для вложения капитала, поскольку NPV(0,12) отрицательна. При отсутствии
дисконтирования (при С = 1, q = 0) вывод иной:
NPV(0) = –10 + 3 + 4 + 5 =
2,
проект
выгоден.
Срок окупаемости и сам
вывод о прибыльности проекта зависят от неизвестного дисконт-фактора С
или даже от неизвестной дисконт-функции — ибо какие у нас основания считать будущую
дисконт-функцию постоянной? Экономическая история России последних лет
показывает, что банки часто меняют проценты платы за депозит. Часто предлагают
использовать норму дисконта, равную приемлемой для инвестора норме дохода на
капитал. Это значит, что экономисты явным образом обращаются к инвестору
как к эксперту, который должен назвать им некоторое число исходя из своего
опыта и интуиции (т.е. экономисты перекладывают свою работу на инвестора).
Кроме того, при этом игнорируется изменение указанной нормы во времени,
Приведем пример
исследования NPV на устойчивость (чувствительность) к малым отклонениям
значений дисконт-функции. Для этого надо найти максимально возможное отклонение
NPV при допустимых отклонениях значений дисконт-функции (или, если
угодно, значений банковских процентов). В качестве примера рассмотрим
NPV
= NPV (a(0), a(1),
С(1), a(2), С(2), a(3),
С(3)) = a(0) + a(1)С(1)
+ a(2)С(2) + a(3)С(3).
Предположим, что
изучается устойчивость (чувствительность) для ранее рассмотренных значений
a(0)
= (–10), a(1) =
Пусть максимально
возможные отклонения С(1), С(2), С(3) равны ±0,05. Тогда
максимум значений NPV равен
NPVmax = (–10) + 3 ´ 0,94 + 4 ´ 0.85 + 5 ´ 0,76 = (–10) + 2,82 +
3,40 + 3,80 = 0,02,
в
то время как минимум значений NPV есть
NPVmin = (–10) + 3 ´ 0,84 + 4 ´ 0.75 + 5 ´ 0,66 = (–10) + 2,52 +
3,00 + 3,30 = –1,18.
Для NPV получаем
интервал от (–1,18) до (+0,02). В нем есть и положительные, и отрицательные
значения. Следовательно, нет однозначного заключения — проект убыточен или выгоден.
Для принятия решения не обойтись без экспертов.
Для иных характеристик,
например, внутренней нормы доходности, выводы аналогичны. Дополнительные
проблемы вносит неопределенность горизонта планирования, а также будущая
инфляция. Если считать, что финансовый поток должен учитывать инфляцию, то это
означает, что до принятия решений об инвестициях необходимо на годы вперед
спрогнозировать рост цен, а это до сих пор еще не удавалось ни одной
государственной или частной исследовательской структуре. Если же рост цен не учитывать,
то отдаленные во времени доходы могут «растаять» в огне инфляции. На практике
риски учитывают, увеличивая q на десяток-другой
процентов.
7.10. Статистика интервальных
данных
в прикладной статистике
Кратко рассмотрим положение статистики интервальных данных (СИД) среди других методов описания
неопределенностей и анализа данных [80]. Проще говоря, положение СИД в
прикладной статистике [81].
Нечеткость и СИД. С формальной точки
зрения описание нечеткости интервалом — это частный случай описания ее нечетким
множеством. В СИД функция принадлежности нечеткого множества имеет
специфический вид — она равна 1 в некотором интервале и 0 вне его. Такая
функция принадлежности описывается всего двумя параметрами (границами
интервала). Эта простота описания делает математический аппарат СИД гораздо более
прозрачным, чем аппарат теории нечеткости в общем случае. Это, в свою очередь,
позволяет исследователю продвинуться дальше, чем при использовании функций
принадлежности произвольного вида.
Интервальная
математика и СИД. Можно
было бы сказать, что СИД — часть интервальной математики, что СИД так
соотносится с прикладной математической статистикой, как интервальная
математика — с математикой в целом. Однако исторически сложилось так, что
интервальная математика занимается прежде всего вычислительным погрешностями. С
точки зрения интервальной математики две известные формулы для выборочной
дисперсии, а именно
![]() ,
,
имеют разные погрешности. А с точки зрения СИД
эти две формулы задают одну и ту же функцию, и поэтому им соответствуют
совпадающие нотны и рациональные объемы выборок. Интервальная математика
прослеживает процесс вычислений, СИД этим не занимается. Необходимо отметить,
что типовые постановки СИД могут быть перенесены в другие области математики,
и, наоборот, вычислительные алгоритмы прикладной математической статистики и
СИД заслуживают изучения. Однако и то, и другое — скорее дело будущего. Из уже
сделанного отметим применение методов СИД при анализе такой характеристики финансовых
потоков, как NPV — чистая текущая
стоимость [56, гл.9].
Математическая статистика и СИД. Математическая
статистика и СИД отличаются тем, в каком порядке делаются предельные переходы n ® ¥ и D ®0. При этом СИД
переходит в математическую статистику при D = 0. Правда, тогда
исчезают основные особенности СИД: нотна становится равной 0, а рациональный
объем выборки — бесконечности. Рассмотренные выше методы СИД разработаны в
предположении, что погрешности малы (но не исчезают), а объем выборки велик. СИД
расширяет классическую математическую статистику тем, что в исходных
статистических данных каждое число заменяет интервалом. С другой стороны, можно
считать СИД новым этапом развития математической статистики, соответствующим ее
новой парадигме [83, 84, 85].
Статистика объектов нечисловой природы и СИД. Статистика объектов нечисловой природы (СОНП) [85] (другие названия
– статистика нечисловых данных, нечисловая статистика [8]) - расширяет область
применения классической математической статистики путем включения в нее новых
видов статистических данных. Естественно, при этом появляются новые виды
алгоритмов анализа статистических данных и новый математический аппарат (в
частности, происходит переход от методов суммирования к методам оптимизации). С
точки зрения СОНП частному виду новых статистических данных — интервальным данным
— соответствует СИД. Напомним, что одно из двух основных понятий СИД — нотна —
определяется как решение оптимизационной задачи. Однако СИД, изучая
классические методы прикладной статистики применительно к интервальным данным,
по математическому аппарату ближе к классической математической статистике, чем
другие части СОНП, например, статистика бинарных отношений.
Робастные методы статистики и СИД.
Если понимать робастность согласно [13] как теорию устойчивости статистических
методов по отношению к допустимым отклонениям исходных данных и предпосылок
модели, то в СИД рассматривается одна из естественных постановок робастности.
Однако в массовом сознании специалистов термин «робастность» закрепился за
моделью засорения выборки большими выбросами (модель Тьюки-Хубера), хотя эта
модель не имеет большого практического значения [81]. К этой модели СИД не
имеет отношения.
Теория
устойчивости и СИД.
Общей схеме устойчивости [13, 86, 87] математических моделей
социально-экономических явлений и процессов по отношению к допустимым
отклонениям исходных данных и предпосылок моделей СИД полностью соответствует.
Она посвящена математико-статистическим моделям, используемым при анализе
статистических данных, а допустимые отклонения — это интервалы, заданные
ограничениями на погрешности. СИД можно рассматривать как пример теории, в которой
учет устойчивости позволил сделать нетривиальные выводы. Отметим, что с точки
зрения общей схемы устойчивости [13] устойчивость по Ляпунову в теории
дифференциальных уравнений — весьма частный случай общей теории устойчивости, в
котором из-за его конкретности удалось весьма далеко продвинуться.
Минимаксные методы, типовые отклонения и СИД. Постановки СИД
относятся к минимаксным. За основу берется максимально возможное отклонение.
Это — «подход пессимиста», применяемый, например, в теории антагонистических
игр. Использование минимаксного подхода позволяет подозревать СИД в завышении
роли погрешностей измерения. Однако примеры изучения
вероятностно-статистических моделей погрешностей, проведенные, в частности, при
разработке методов оценивания параметров гамма-распределения [30, 35],
показали, что это подозрение не подтверждается. Влияние погрешностей измерений
по порядку такое же, только вместо максимально возможного отклонения (нотны)
приходится рассматривать математическое ожидание соответствующего отклонения.
Подчеркнем, что применение в СИД вероятностно-статистических моделей погрешностей
не менее перспективно, чем минимаксных.
Подход научной школы А.П. Вощинина и СИД. Если
в математической статистике неопределенность только статистическая, то в
научной школе А.П. Вощинина — только интервальная. Можно сказать, что СИД лежит
между классической прикладной математической статистикой и областью
исследований научной школы А.П. Вощинина. Другое отличие состоит в том, что в
этой школе разрабатывают новые методы анализа интервальных данных, а в СИД в
настоящее время изучается устойчивость классических статистических методов по
отношению к малым погрешностям. Подход СИД оправдывается распространенностью
этих методов, однако в дальнейшем следует переходить к разработке новых
методов, специально предназначенных для анализа интервальных данных.
Анализ чувствительности и СИД. При анализе чувствительности,
как и в СИД, рассчитывают производные по используемым переменным, или
непосредственно находят изменения при отклонении переменной на ±10% от базового
значения. Однако этот анализ делают по каждой переменной отдельно. В СИД все
переменные рассматриваются совместно, и находится максимально возможное
отклонение (нотна). При малых погрешностях удается на основе главного члена
разложения функции в многомерный ряд Тейлора получить удобную формулу для
нотны. Можно сказать, что СИД — это многомерный анализ чувствительности.
Заключительные замечания. Асимптотической математической
статистике интервальных данных посвящены главы в учебниках [81, 88, 89].
Развиваются научные исследования как в научной школе А.П. Вощинина [47, 48],
так и в СИД [59, 77, 90].
По нашему мнению, во все виды статистического программного
обеспечения должны быть включены алгоритмы интервальной статистики,
«параллельные» обычно используемым в настоящее время алгоритмам прикладной
математической статистики. Это позволит в явном виде учесть наличие
погрешностей у результатов наблюдений (измерений, испытаний, анализов, опытов).
Статистика интервальных данных является
составной частью системной нечеткой интервальной математики [91, 92] –
перспективного направления теоретической и вычислительной математики.