ГЛАВА 8. СИСТЕМА КАК ОБОБЩЕНИЕ МНОЖЕСТВА. СИСТЕМНОЕ ОБОБЩЕНИЕ МАТЕМАТИКИ И ЗАДАЧИ, ВОЗНИКАЮЩИЕ ПРИ ЭТОМ
В науке принято два основных принципа
определения понятий:
– через подведение определяемого понятия под более общее понятие и выделение из него
определяемого понятия путем указания одного или нескольких его специфических признаков (например,
млекопитающие – это животные, выкармливающие своих детенышей молоком);
– процедурное определение, которое определяет
понятие путем указания пути к нему
или способа его достижения (магнитный северный полюс – это точка, в которую
попадешь, если все время двигаться на север, определяя направление движения с помощью
магнитного компаса).
Как это ни парадоксально, но понятия системы и
множества могут быть определены друг через друга, т.е. трудно сказать, какое из
этих понятие является более общим.
Определение системы через множество.
Система
есть множество элементов, взаимосвязанных друг с другом, что дает системе новые
качества, которых не было у элементов. Эти новые системные свойства еще называются
эмерджентными, т.к. не очень просто понять, откуда они берутся. Чем больше сила
взаимодействия элементов, тем сильнее свойства системы отличаются от свойств
множества и тем выше уровень системности и синергетический эффект. Получается,
что система – это множество элементов, но не всякое множество, а только такое,
в котором элементы взаимосвязаны (это и есть специфический признак, выделяющий
системы в множестве), т.е. множество – это более общее понятие.
Определение множества через систему.
Но можно рассуждать и иначе, считая более общим
понятием систему, т.е. мы ведь можем определить понятие множества через понятие
системы. Множество – это система, в которой
сила взаимодействия между элементами равна нулю (это и есть отличительный
признак, выделяющий множества среди систем). Тогда более общим понятием
является система, а множества – это просто системы с нулевым уровнем системности.
Вторая точка зрения объективно является
предпочтительной, т.к. совершенно очевидно, что понятие множества является предельной абстракцией от понятия системы и
реально в мире существуют только системы, а множеств в чистом виде не существует,
как не существует математической точки. Точнее сказать, что множества,
конечно, существуют, но всегда исключительно и только в составе систем как их
базовый уровень иерархии, на котором они основаны.
Из этого вытекает очень важный вывод: все понятия и теории, основанные
на понятии множества, допускают обобщение путем замены понятия множества на
понятие системы и тщательного прослеживания всех последствий этой замены.
При этом более общие теории будут удовлетворять принципу соответствия,
обязательному для более общих теорий, т.е. в асимптотическом случае, когда сила взаимосвязи элементов систем
будет стремиться к нулю, системы будут все меньше отличаться от множеств и
системное обобщение теории перейдет к классическому варианту, основанному на
понятии множества. В предельном
случае, когда сила взаимосвязи точно
равна нулю, системная теория будет давать точно
такие же результаты, как основанная на понятии множества.
Этот вывод верен для всех теорий, но в данной работе
для авторов наиболее интересным и важным является то, что очень многие, если не
практически все понятия современной математики
основаны на понятии множества, в частности на математической теории множеств. К
таким понятиям относятся понятия:
– математической операции: преобразования одного
или нескольких исходных множеств в одно или несколько результирующих;
– функциональной зависимости: отображение
множества значений аргумента на множество значений функции для однозначной
функции одного аргумента или отображение множеств значений аргументов на
множества значений функций для многозначной функции многих аргументов;
– «количество информации»: функция от свойств
множества.
В монографии [99] впервые
сформулирована, а в работе [186] подробно обоснована программная идея
системного обобщения математики, суть которой состоит в тотальной замене понятия
"множество" на более общее понятие "система" и прослеживании
всех последствий этого. При этом обеспечивается соблюдение принципа
соответствия, обязательного для более общей теории, т.к. при понижении уровня
системности система по своим свойствам становится все ближе к множеству и
система с нулевым уровнем системности и есть множество. Приводится развернутый
пример реализации этой программной идеи в области теории информации, в качестве
которого выступает предложенная в 2002 году системная теория информации [97],
являющаяся системным обобщением теории информации Найквиста – Больцмана – Хартли
– Шеннона и семантической теории информации Харкевича. Основа этой теории
состоит в обобщении комбинаторного понятия информации Хартли I = Log2N на основе идеи о
том, что количество информации определяется не мощностью множества N, а мощностью системы, под которой
предлагается понимать суммарное
количество подсистем различного уровня иерархии в системе, начиная с базовых
элементов исходного множества и заканчивая системой в целом. При этом в 2002
году, когда было предложено системное обобщение формулы Хартли, число подсистем
в системе, т.е. мощность системы Ns,
предлагалось рассчитывать по формуле:
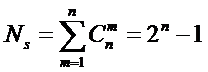 .
.
Соответственно,
системное обобщение формулы Хартли для количества информации в системе из n элементов предлагалось в виде:
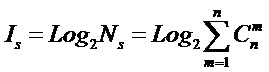
В работе [270] дано системное обобщение формулы Хартли для количества
информации для квантовых систем, подчиняющиеся статистике как Ферми-Дирака, так
и Бозе-Эйнштейна, и стало ясно, что предложенные в 2002 году в работе [97] вышеприведенные
выражения имеют силу только для систем, подчиняющихся статистике Ферми-Дирака.
В работе [188]
кратко описывается семантическая информационная модель системно-когнитивного
анализа (СК-анализ), вводится универсальная информационная мера силы и направления
влияния значений факторов (независимая от их природы и единиц измерения) на
поведение объекта управления (основанная на лемме Неймана – Пирсона), а также
неметрический интегральный критерий сходства между образами конкретных объектов
и обобщенными образами классов, образами классов и образами значений факторов.
Идентификация и прогнозирование рассматривается как разложение образа конкретного объекта в ряд по обобщенным образам
классов (объектный анализ), что предлагается рассматривать как возможный
вариант решения на практике 13-й
проблемы Гильберта.
В статьях [189, 191] обоснована идея системного
обобщения математики и сделан первый шаг по ее реализации: предложен вариант
системной теории информации [97, 201]. В данной работе осуществлена попытка
сделать второй шаг в этом же направлении: на концептуальном уровне
рассматривается один из возможных подходов к системному обобщению
математического понятия множества, а именно – подход, основанный на системной
теории информации. Предполагается, что этот подход может стать основой для
системного обобщения теории множеств и создания математической теории систем.
Сформулированы задачи, возникающие на пути достижения этой цели (разработки
системного обобщения математики) и предложены или намечены пути их решения:
Задача 1: найти способ представления системы как совокупности
взаимосвязанных множеств.
Задача 2: сформулировать, чем отличаются друг от друга различные
системы, состоящие из одних и тех же базисных элементов.
Задача 3: обосновать принципы геометрической интерпретации
понятий: "элемент системы" и "система".
Задача 4: предложить способы аналитического описания (задания)
подсистем как элементов системы.
Задача 5: описать системное семантическое пространство
для отображения систем в форме эйдосов (эйдос-пространство).
Задача 6: описать принцип формирования эйдосов (включая
зеркальные части).
Задача 7: показать, что базовая когнитивная концепция [97]
формализуется многослойной системой эйдос-пространств (термин автора) различных
размерностей.
Задача 8: показать, что системная теория информации позволяет
непосредственно на основе эмпирических данных определять вид функций
принадлежности, т.е. решать одну из основных задач теории нечетких множеств.
Задача 9: сформулировать перспективы: разработка операций
с системами: объединение (сложение), пересечение (умножение), вычитание.
Привести предварительные соображения по сложению систем.
Далее рассмотрим более подробно некоторые
основные результаты перечисленных выше работ и некоторых других без дополнительных
специальных ссылок на них, т.к. они уже даны.
8.1. Программная идея системного обобщения
математики
и ее применение для создания системной теории информации
Фундаментом,
находящимся в самом основании грандиозного здания современной математики,
являются понятие множества и теория множеств. Теория множеств лежит в
основе самого глубокого в настоящее время обоснования таких базовых
математических понятий, как "число" и "функция". Определенное
время этот фундамент казался незыблемым. Однако вскоре в работах выдающихся
ученых XX века, прежде всего, Давида Гильберта, Бертрана Рассела и Курта
Геделя, со всей очевидностью было обнажены фундаментальные логические и
лингвистические проблемы, в частности, проявляющиеся в форме парадоксов теории множеств. Это, в свою
очередь, привело к появлению ряда развернутых предложений по пересмотру самых
глубоких оснований математики. В задачи данной работы не входит рассмотрение
этой интереснейшей проблематики, а также истории возникновения и развития
понятий числа и функции.
Однако очевиден тот факт, что Вселенная состоит из систем различных уровней иерархии.
Система представляет собой множество
элементов, объединенных в целое за счет взаимодействия элементов
друг с другом, т.е. за счет отношений между ними, и обеспечивает преимущества
в достижении целей.
Преимущества в достижении целей обеспечиваются
за счет системного эффекта.
Системный эффект состоит в том, что свойства
системы не сводятся к сумме свойств ее элементов, т.е. система, как
целое, обладает рядом новых,
т.е. эмерджентных свойств,
которых не было у ее элементов, взятых по отдельности [97].
Уровень системности тем выше, чем выше интенсивность
взаимодействия элементов системы и сильнее отличаются свойства системы от
свойств входящих в нее элементов, т.е. чем выше системный эффект, чем значительнее отличается система от множества
[189].
Таким образом, система
обеспечивает тем большие преимущества в достижении целей, чем выше ее уровень
системности [189].
В частности, система с нулевым уровнем системности
вообще ничем не отличается от множества образующих ее элементов, т.е.
тождественна этому множеству и никаких преимуществ в достижении целей не
обеспечивает. Этим самым
достигается выполнение принципа соответствия между понятиями системы и
множества, обязательного для более общей теории. Из соблюдения этого
принципа для понятий множества и системы следует его соблюдение для математических
понятий, в частности, понятий системной теории информации [253], основанных на
теории множеств и их системных обобщений.
Поэтому проблема, решаемая в данной работе, состоит в
явном несоответствии между системным
характером объекта познания и несистемным характером современной математики,
как средства познания. Он заключается
в том, что, с одной стороны, мир, как объект познания, представляет
собой совокупность систем различных уровней иерархии, а с другой – математика,
как наиболее мощное средство познания и моделирования этого мира, основана не
на теории систем, а на теории множеств.
Общеизвестна
эффективность математики, которая тем более удивительна, если учесть, что она
достигается уже фактически в нулевом приближении, т.е. при рассмотрении систем
как множеств. Так, как может возрасти адекватность математики и ее мощь, как
средства познания и универсального языка моделирования реальности, если удастся
получить ее системное обобщение! Поэтому, на взгляд автора, актуальность разработки системного
обобщения математики совершенно очевидна.
Предлагается
следующая программная идея системного
обобщения математики: обобщить все понятия математики,
базирующиеся на теории множеств, путем тотальной замены понятия множества на
понятие системы и тщательного отслеживания всех последствий этой замены.
Реализация данной
программной идеи потребует, прежде всего, системное обобщение самой теории
множеств и преобразование ее в "Математическую
теорию систем", которая, согласно
принципу соответствия, будет плавно переходить в современную классическую
теорию множеств при уровне системности, стремящемся к нулю. При этом необходимо
заметить, что существующая в настоящее время наука под названием "Теория
систем" (а также: системный анализ, системный подход, информационная
теория систем и т.п.) ни в коей мере не является обобщением математической
теории множеств, и ее не следует путать с предлагаемой "Математической теорией систем". На наш взгляд,
существуют некоторые возможности обобщения ряда понятий математики и без
разработки математической теории систем. К таким понятиям относятся, прежде
всего, "информация" и "функция".
Системному
обобщению понятия информации и применениею этого понятия посвящены работы [93-279]
и др. На основе предложенной системной теории информации (СТИ) были разработаны
математическая модель и методика численных расчетов (структуры данных и
алгоритмы), а также специальный программный инструментарий (система
"Эйдос") автоматизированного системно-когнитивного анализа
(АСК-анализ), который представляет собой системный анализ, автоматизированный путем
его рассмотрения как метода познания и структурирования по базовым когнитивным
операциям.
В АСК-анализе
теоретически обоснована и реализована на практике в форме конкретной
информационной методики и технологии процедура установления новой
универсальной, сопоставимой в пространстве и времени, ранее не используемой
количественной, т.е. выражаемой числами, меры соответствия между событиями или
явлениями любого рода, получившей название "системная мера
целесообразности информации", которая, по сути, является количественной мерой
знаний [170]. Это является достаточным основанием для того, чтобы назвать эти
числа "когнитивными" от английского слова "cognition" –
"познание".
В настоящее время
под функцией понимается соответствие друг другу нескольких множеств чисел.
Поэтому виды функций можно классифицировать, по крайней мере, в зависимости от:
– природы этих
чисел (натуральные, целые, дробные, действительные, комплексные и т.п.);
– количества и вида
множеств чисел, связанных друг с другом в функции (функции одного, нескольких,
многих, счетного или континуального количества аргументов, однозначные и многозначные
функции, дискретные или континуальные функции);
– степени жесткости
и меры силы связи между множествами чисел (детерминистские функции, функции, в
которых в качестве меры связи используется вероятность, корреляция и другие меры);
– степени
расплывчатости чисел в множествах и самой формы функции (четкие и нечеткие
функции, использование различных видов шкал, в частности, интервальных оценок).
Так как функции,
выявляемые модели предметной области методом АСК-анализа, связывают друг с
другом множества когнитивных чисел, то предлагается называть их
"когнитивными функциями" [280].
Учитывая перечисленные возможности классификации функций, когнитивные функции можно
считать нечеткими интервальными недетерминистскими многозначными функциями
многих аргументов, в которых в качестве меры силы связи между множествами значений
аргумента и значений функции используется количество информации или знаний.
Отметим, что детерминистские однозначные функции нескольких аргументов могут
рассматриваться как частный случай когнитивных функций, к которому они сводятся
при анализе жестко детерминированной предметной области, скажем
макроскопических механических явлений, описываемых классической физикой.
Автором
предлагается программная идея системного обобщения понятий математики, в
частности теории информации, основанных на теории множеств, путем замены
понятия множества на более содержательное понятие системы. Частично эта идея
была реализована автором при разработке автоматизированного
системно-когнитивного анализа (АСК-анализа), математическая модель которого
основана на системном обобщении формул для количества информации Хартли и
Харкевича. Реализация следующего шага – системное обобщение понятия функциональной
зависимости рассматривается в работе [280], в ней же вводятся новые научные
понятия и соответствующие термины "когнитивные функции" и
"когнитивные числа". На численных примерах показано, что АСК-анализ
обеспечивает выявление когнитивных функциональных зависимостей в многомерных
зашумленных фрагментированных данных.
Вывод. Формулируется и обосновывается программная
идея системного обобщения математики, суть которой состоит в тотальной замене
понятия "множество" на более общее понятие "система" и
прослеживание всех последствий этого. При этом обеспечивается соблюдение
принципа соответствия, обязательного для более общей теории, т.к. система с
нулевым уровнем системности есть множество. Приводится развернутый пример
реализации этой программной идеи, в качестве которого выступает предложенная
автором [97]
системная теория информации, являющаяся
системным обобщением теории информации Найквиста – Больцмана – Хартли – Шеннона
и семантической теории информации Харкевича.
Необходимо
отметить, что сходные идеи независимо развиваются В.Б.
Вяткиным в ряде интересных работ[1],
посвященных созданию синергетической теории информации (считаю это название
очень удачным). Видимо, подобные идеи буквально "витают в воздухе".
8.2. Неформальная постановка и обсуждение
задач,
возникающих при системном обобщении теории множеств
Данный раздел основан на работе [189]. Впервые программная
идея системного обобщения математики и явной форме была сформулирована автором
в 2005 году в работе [166], а системная теория
информации (СТИ), явлюящяся ее реализацией в области теории информации,
предложена в 2002 году [97], сами же идеи и
математические модели развивались и ранее, фактически с 1979 года[2].
В работе поставлена цель – сделать второй шаг в том же направлении: на
концептуальном уровне рассмотреть один из возможных подходов к
системному обобщению математического понятия множества, а именно – подход,
основанный на системной теории информации. Предполагается, что этот или
подобный подход может способствовать созданию
математической теории систем как системного обобщения теории множеств, что
является весьма актуальным как для самой математики, так и для наук,
использующих математику.
Для достижения данной цели осуществим ее
декомпозицию в последовательность задач, являющихся этапами ее
достижения:
Задача 1: найти способ представления системы как совокупности
взаимосвязанных множеств.
Задача 2: сформулировать, чем отличаются друг от друга
различные системы, состоящие из одних и тех же базисных элементов.
Задача 3: обосновать принципы геометрической интерпретации
понятий: "элемент системы" и "система".
Задача 4: предложить способы аналитического описания
(задания) подсистем как элементов системы.
Задача 5: описать системное семантическое пространство
для отображения систем в форме эйдосов (эйдос-пространство).
Задача 6: описать принцип формирования эйдосов (включая
зеркальные части).
Задача 7: показать, что базовая когнитивная концепция
формализуется многослойной системой эйдос-пространство (термин автора)
различных размерностей.
Задача 8: показать, что системная теория информации позволяет
непосредственно на основе эмпирических данных определять вид функций
принадлежности, т.е. решать одну из основных задач теории нечетких множеств.
Задача 9: сформулировать перспективы: разработка операций
с системами: объединение (сложение), пересечение (умножение), вычитание.
Привести предварительные соображения по сложению систем.
Кратко, на
концептуальном уровне, т.е. на уровне идей, без разработки соответствующего
математического формализма рассмотрим предлагаемый вариант решения этих задач.
Задача
1: найти способ представления системы как совокупности
взаимосвязанных множеств.
Для того чтобы получить системное обобщение
теории множеств, необходимо найти способ представления системы как совокупности
взаимосвязанных множеств. Ожидается, что это позволит с минимальными
доработками применить прекрасно разработанный аппарат теории множеств для описания систем.
Определение 1:
1. Система есть иерархическая структура подсистем.
2. В
каждой системе существует нулевой наиболее фундаментальный уровень иерархии,
представляющий собой классическое множество базисных элементов, не имеющих
никаких свойств.
3. Каждая
подсистема относится к определенному уровню иерархии системы, который
определяется только количеством базисных элементов в данной подсистеме.
4.
Элементами подсистем каждого уровня иерархии являются как подсистемы предыдущих
более фундаментальных уровней иерархии, так и базисные элементы.
Таким образом, будем считать, что система
отличается от множества базисных элементов, из которых она состоит, тем, что
эти элементы образуют подсистемы
различной структуры и сложности (рисунок 1).
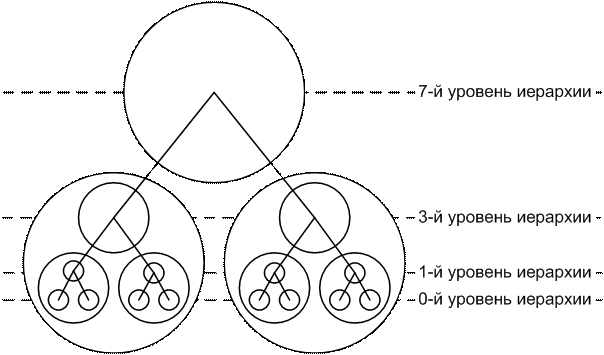
Рисунок 1 – Элементы-подсистемы различных
уровней иерархии
В простейшем
случае можно считать, что элементы системы (подсистемы) не имеют внутренней
структуры, т.е. не включают в себя подсистемы, а являются подмножествами базисного множества, состоящими непосредственно
из базисных элементов. Но вообще говоря это не так[3].
На рисунке 2 показаны как элементы-подмножества
базисного уровня (23, 456 78910: отмечены зеленым цветом), так и
элементы-подсистемы, включающие не только непосредственно элементы базисного
уровня, но и их подмножества или подсистемы (123, 23456, 45678910: отмечены
желтым цветом).
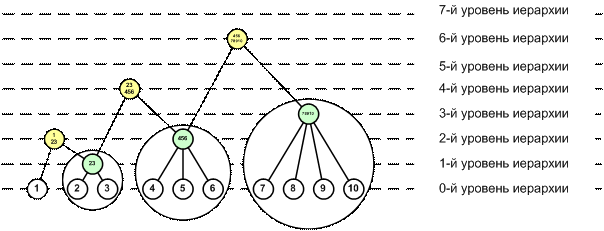
Рисунок 2 – Элементы-подмножества и
элементы-подсистемы
различных уровней иерархии системы
Из рисунка 2 также видно, что различие между
элементами-подмножествами и элементами-подсистемами возникает только для
элементов, начиная со 2-го уровня иерархии, т.к. только для этих элементов
возможен уровень сложности,
достаточный для существования этого различия [170]. Например, видно, что элемент-подсистема
123 отличается от элемента-подмножества
456 наличием внутренней структуры, т.е. тем, что включает не только базисный
элемент 1, но и подсистему 23, при этом и оба элемента: и 123, и 456 относятся
ко 2-му уровню иерархии системы.
Таким образом, можно сделать вывод о том, что два элемента тождественны, если они
состоят из одних и тех же базисных элементов и у них тождественна структура. Отметим,
что поскольку у множеств нет структуры, то для тождества множеств достаточно тождества входящих в них
элементов.
Для системы, состоящей из элементов-множеств,
можно применять термин "аморфная система" (например: газ или жидкость),
а из элементов-систем – "структурированная система" (например:
кристалл). Аморфные и структурированные системы, состоящие из одних и тех же
базисных элементов, можно считать различными фазовыми состояниями одной
системы, отличающимися уровнем
системности.
Задача 2: сформулировать, чем отличаются друг от друга различные
системы, состоящие из одних и тех же базисных элементов.
Для того чтобы решить эту задачу, сформулируем
несколько определений.
Определение 2: Полной или максимальной системой будем называть
такую систему, в которой реализуются все формально возможные сочетания базисных
элементов.
Таким образом, если в системе имеется n базисных элементов, то полная система
включает ![]() подсистем,
представляющих собой сочетания базисных элементов по m, где m={1, 2, 3, ..., n}. Подсистемы полной системы можно
классифицировать различными способами, но одним из наиболее простых и
естественных является классификация по их мощности
(в смысле теории множеств), т.е. по количеству
входящих
в них базисных элементов.
подсистем,
представляющих собой сочетания базисных элементов по m, где m={1, 2, 3, ..., n}. Подсистемы полной системы можно
классифицировать различными способами, но одним из наиболее простых и
естественных является классификация по их мощности
(в смысле теории множеств), т.е. по количеству
входящих
в них базисных элементов.
Определение 3: Мощностью подсистемы будем называть количество
входящих в нее базисных элементов.
Определение 4: k-й уровень иерархии системы состоит из всех ее
подсистем мощности (k+1).
Из определений 3 и 4 следует, что:
0-й уровень иерархии системы состоит из
подсистем, включающих 1 базисный элемент, это базисный уровень иерархии, на
котором система не отличается от множества;
1-й уровень иерархии системы состоит из
подсистем, включающих 2 базисных элемента;
2-й уровень иерархии системы состоит из
подсистем, включающих 3 базисных элемента;
.......................
k-й уровень иерархии
системы состоит из подсистем, включающих (k+1)
базисных элемента.
Из этих определений следует также, что базисный
уровень является 0-м (нулевым) уровнем иерархии системы и состоит из подсистем
мощности 1. Это означает, что сами базисные элементы можно рассматривать как подсистемы, имеющие мощность, равную 1,
т.е. в определенном смысле можно считать, что базисный элемент состоит из
самого себя, в отличие от элементов других иерархических уровней системы,
которые включают базисные элементы, но сами себя не включают. Необходимо
отметить, что если бы элементы различных иерархических уровней системы включали
не только базисные элементы, но и самих себя, то мощность подсистем различных
уровней изменялась бы следующим образом:
– элементы 0-го уровня
иерархии, т.е. базисные элементы: мощность 1;
– элементы 1-го уровня иерархии: мощность 3 (2
базисных элемента + 1, т.к. элемент включает сам себя);
– элементы 2-го уровня иерархии: мощность 4 (3
базисных элемента + 1, т.к. элемент включает сам себя);
.........................
– элементы k-го
уровня иерархии: мощность (k+2) ((k+1) базисных элемента + 1, т.к. элемент
включает сам себя), что, как мы считаем, неприемлемо,
т.к. нарушает простую и очевидную логическую последовательность между 0-м и 1-м
уровнями иерархии.
Определение 5: Реальной системой будем называть систему, в которой
реализуются не все формально-возможные сочетания базисных элементов, а лишь некоторые
из них.
В этом случае возникает естественный и
закономерный вопрос: "По какой причине
получается так, что в реальной системе реализуются не все, а лишь некоторые
сочетания базисных элементов?" Для ответа на этот вопрос введем понятие
"правила запрета".
Определение 6: Правилами запрета будем называть механизм или
способ, с помощью которого обеспечивается формирование различной структуры
систем, состоящих из одних и тех же базисных элементов.
Таким образом, правила запрета являются средством
получения конкретных реальных систем из максимальной, включающей все возможные сочетания
базисных элементов. Например, в квантовой механике существует Принцип запрета
Паули для квнтовых систем, подчиняющихся квантовой статистике Ферми-Дирака.
Определение 7: n-тождественными системами (т.е. системами,
тождественными на n-м уровне иерархии) будем называть системы, состоящие из одних
и тех же элементов на n-м уровне иерархии. Два элемента-подсистемы тождественны,
если они состоят из одних и тех же базисных элементов и у них тождественна структура,
т.е. связи между базисными элементами.
В
частности, 0-тождественными являются системы, состоящие из одних и тех же
базисных элементов, независимо от того, отличаются ли они друг от друга связями
между этими элементами, т.е. своей структурой.
Из определений 2 и 7 следует, что:
– реальные 0-тождественные
системы являются подмножествами одной
и той же полной системы;
– полная система является объединением всех возможных 0-тождественных реальных
систем.
Отметим, что поскольку у
множеств нет структуры, то для тождества множеств достаточно тождества входящих
в них элементов.
Задача
3: обосновать принципы
геометрической интерпретации понятий "элемент системы" и
"система".
Основываясь на аналогии между
базисными элементами и геометрическими точками (и первые и вторые не имеют
никаких свойств, кроме свойства отличаться друг от друга), припишем базисным элементам
смысл, аналогичный смыслу геометрической точки. Тогда
элементы-подмножества различных иерархических уровней системы, отличающиеся
друг от друга количеством базисных элементов, можно представить в виде систем
из соответствующего количества точек. Однако как геометрически интерпретировать
эти системы?
Для того чтобы ответить на этот
вопрос, обратим внимание на то, что:
– пространство 0-й размерности
есть одна точка 0-й размерности, т.е. классическая точка, известная в
математике (в частности, в геометрии, дифференциальном и интегральном исчислении),
а также в основанной на них физике;
– пространство 1-й размерности
– это прямая линия, однозначно определяется системой из двух
точек 0-й размерности;
– пространство 2-й размерности
– это плоскость, однозначно определяется системой из трех
точек 0-й размерности;
– пространство 3-й размерности
– это пространство, однозначно определяется системой из четырех
точек 0-й размерности;
......................
– пространство i-й размерности однозначно определяется
системой из (i+1) точек 0-й размерности.
Однако различным количеством
точек однозначно определяется не только положение пространства или гиперплоскости
соответствующей размерности в многомерном пространстве, но и определенный тип геометрической фигуры:
– одна точка 0-й размерности
задает точку;
– система из двух
точек 0-й размерности задает отрезок прямой линии;
– система из трех
точек 0-й размерности задает треугольник;
– система из четырех
точек 0-й размерности задает тетраэдр (один из пяти 3-мерных
многогранников Платона);
............................
– система из i
точек 0-й размерности задает многомерную фигуру, называемую i-мерный
симплекс.
В этой связи возникает один
очень существенный вопрос: "Каким образом получается так, что
геометрические фигуры, образованные из точек нулевой размерности, вдруг
приобретают новое качество, а именно ненулевую размерность, которого ни в какой
форме не было у базисных элементов, из которых они состоят?"
По мнению автора, ответ на это
вопрос самым непосредственным образом связан с понятием системных или
эмерджентных свойств, т.е. с тем, что система
имеет качественно новые системные или эмерджентные свойства, которых не было у
ее элементов (не сводящиеся к сумме свойств ее элементов). Кроме системного
анализа, проблемами изучения системных свойств занимаются многие науки, в
частности: химия, биология, физика,
синергетика и математика, особенно теория фракталов.
Возникает известная
"проблема кучи зерен", которую можно проиллюстрировать следующим
образом: "Одно зерно – это явно не куча, два – тоже, и три, и четыре и
пять – тоже, а вот 10 – это уже вроде как маленькая кучка, а вот
"куча" – это, наверное, где-то от 1531 до 73568 зерен и более".
В контексте данной работы и решаемой задачи "проблему кучи" можно
переформулировать следующим образом: "Какой
минимальный элемент пространства или геометрической фигуры некоторой
размерности можно считать обладающим той же размерностью, что и само пространство
или фигура?"
В химии аналогичный вопрос
звучит примерно так: "Какой минимальный объем вещества обладает теми же
химическими свойствами, что и макроколичество этого вещества". В химии ответ
известен: это молекула данного вещества.
Если молекулу любого вещества расщепить на элементы (атомы), перечисленные в
таблице Д.И. Менделеева, из которых она состоит, то свойства этого вещества
исчезнут, хотя элементы останутся.
Однако что же при этом исчезает такое, что приводит к исчезновению
свойств вещества? Ответ вполне очевиден: при расщеплении молекулы исчезают взаимосвязи между элементами (атомами),
благодаря которым они и образовывали минимальную систему данного вещества,
обладающую его химическим свойствами, т.е. его молекулу. Необходимо отметить,
что приведенный пример имеет несколько упрощенный характер, т.к. элементы
таблицы Д.И. Менделеева также образуют вещества, т.е. простейшей молекулой
является сам элемент. С другой стороны, макрообъект не всегда состоит из
молекул, он может быть, например, ионным кристаллом как NaCl (поваренная соль).
В информационной теории систем
(ИТС), идеи которой мы пытаемся развивать в данной работе, предлагается
считать, что минимальным элементом пространства или геометрической фигуры некоторой
размерности, обладающим той же размерностью, что и само пространство или
фигура, является точка этого пространства".
Получается, что пространства и геометрические фигуры различной размерности состоят из различных
точек, т.е. точек также различной размерности. Поэтому геометрические
фигуры можно рассматривать как системы, состоящие из точек различной
размерности и имеющие различную структуру взаимосвязей между этими точками.
Таким образом, геометрическим аналогом системы в рамках информационной теории систем
является
многомерная геометрическая фигура, состоящая из точек различной размерности и
структуры, взаимосвязанных между собой в определенную структуру.
Отметим, что в рамках данной работы
мы не рассматриваем вопросы топологической целостности (связности) элементов фигур
и наличия у них некоторой сплошной гиперповерхности, ограничивающей некоторый
гиперобъем. Вопрос, связанный с метрикой пространства, будет конкретизирован
при рассмотрении следующих задач. Отметим, что вообще понятие "геометрическая
фигура" связано с понятиями "топологическое пространство" и
"геометрическое место точек", кроме того, фигура может быть
определена операционально, например, в форме некоторой начальной фигуры и
алгоритма ее преобразования для получения элементов фигуры, как это делается в
теории фракталов.
Итак, системы можно представить
как многомерные геометрические фигуры, состоящие из точек различной размерности
и структуры, взаимосвязанных между собой в определенную структуру. При этом i-мерные точки, как системы, имеют эмерджентные
свойства (i-гиперобъем), которых не было у точек меньших размерностей, из
которых они состоят:
– 0-мерная точка не имеет
никаких качеств (9-мера: S0);
– 1-мерная точка имеет длину
(1-мера: S1);
– 2-мерная точка имеет площадь
(2-мера: S2);
– 3-мерная точка имеет объем
(3-мера: S3);
...........................
– i-мерная точка имеет i-гиперобъем
(i-мера: Si).
Смысл размерности пространства
состоит в том, что она количественно показывает, на сколько быстро возрастает
"содержимое" тела при увеличении его линейных размеров или при
уменьшении линейных размеров объектов, "заполняющих" это тело.
Одним из наиболее
распространенных и общепринятых способов определения размерности многомерной
геометрической фигуры является применение известной формулы Хаусдорфа:
|
|
(1) |
где
D
– размерность
многомерной геометрической фигуры;
S
–
обобщенный объем многомерной
геометрической фигуры: S1
– длина, S2 – площадь, S3 – объем, ..., Si – i-гиперобъем;
L –
линейный размер многомерной геометрической фигуры.
В соответствии с выражением
(1), получаем:
|
– для линии (S1): |
|
|
– для плоскости (S2): |
|
|
– для объема (S3): |
|
Обращает на себя внимание
следующая закономерность:
– при увеличении линейных
размеров геометрической фигуры в 2 раза ее i-гиперобъем
возрастает в 2i раз;
– при размерности
пространства, равной i, минимальное количество
i-мерных шаров, заполняющих i-мерный куб, равно N=2i
(рисунок 3).
Эта
закономерность формально точно
совпадает с комбинаторной мерой Хартли для количества информации:
|
|
(2) |
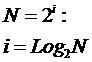 ,
,где
i –
количество информации (в битах);
N –
количество элементов в множестве.
В
соответствии с представлением о кубической размерности фракталов (box dimension)[4], будем
оценивать размерность "i"
пространства по тому, как быстро возрастает количество i-мерных объектов, помещающихся в какое-либо i-мерное тело при увеличении его размеров или при уменьшении
размеров объектов. Примем, в качестве множества "А" i-мерный
куб (i-куб), а в качестве элементов
множества – i-мерные шары (i-шар). Пусть N(r) – минимальное количество i-шаров
радиуса r, заполняющих (покрывающих)
"A" в i-мерной кубической
укладке.
Если i-шары
имеют очень большой диаметр, сопоставимый с длиной ребра i-куба, то ясно, что в i-кубе
всегда, независимо от размерности пространства, будет помещаться только один i-шар. Поэтому диаметр i-шара нужно взять таким, чтобы в i-кубе поместилось несколько i-шаров. Например, достаточно взять начальный диаметр в два раза меньше длины ребра. Тогда
при уменьшении диаметра i-шаров их
будет помещаться в i-кубе все больше
и больше, и мы все точнее сможем определить размерность пространства, которая,
как ясно из вышесказанного, является пределом D:
|
|
(3) |

при r, стремящемся к нулю. Этот
предел, если он существует, и
называется кубической размерностью пространства. Известно, что Хаусдорфова
размерность не превосходит кубическую,
а для самоподобных фракталов (определение фракталов, как самоподобных множеств, дано Дж.
Хатчинсоном) они совпадают. Самоподобным
называется множество, части которого образованы из целого множества путем таких
его преобразований, как масштабирование, отражение, перенос и поворот.
Таким
образом, размерность пространства можно
рассматривать или интерпретировать как количество осей координат, которых
необходимо и достаточно для однозначного определения положения объектов в
этом пространстве.
Казалось
бы, в этом утверждении нет ничего нового. Однако не будем спешить с выводами.
Дело в
том, что каждое значение координат несет некоторое количество информации,
необходимой для идентификации i-объекта,
путем определения его положения в i-пространстве,
причем это количество информации тем
больше, чем выше размерность i-пространства.
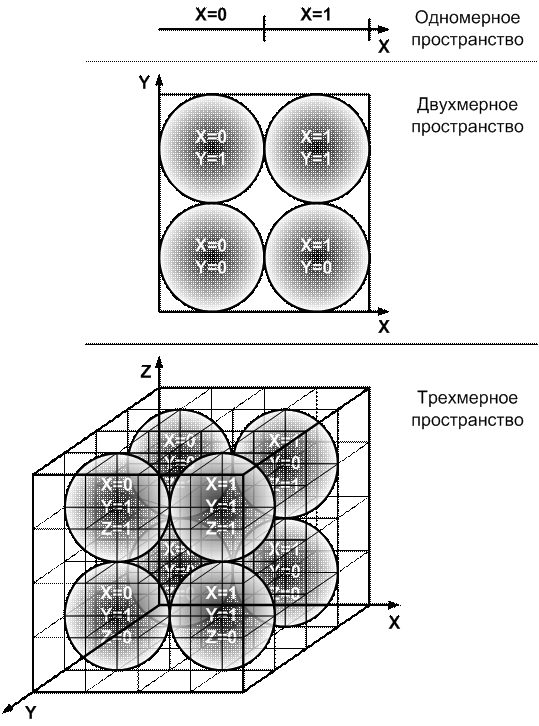
Рисунок 1 – Примеры плотной упаковки шаров в
кубе, сторона
которого в два раза превышает диаметр шара, при различных
размерностях пространства и шаров (размерности: 1, 2 и 3)
Таким образом,
координаты i-объекта в i-пространстве вполне обоснованно можно
рассматривать как признаки этого объекта, с помощью которых он идентифицируется,
т.е. отличается от остальных объектов. Причем эти признаки можно рассматривать
как градации описательных шкал, в
качестве которых выступают оси координат, а сами шкалы могут быть номинальные,
порядковые (интервальные) или числовые (шкалы отношений). По эти признакам
необходимо идентифицировать объект. Это уже формулировка задачи идентификации
или распознавания, которую можно решать, в том числе с применением теории
информации. Таким образом, появляется возможность исследования
информационных свойств не только геометрического, но и физического пространства
(если учесть, что общая теория относительности ОТО, т.е. теория гравитации
Альберта Эйнштейна описывает гравитацию как искривление пространства).
Таким образом, мы видим
важную аналогию между понятиями геометрии и теории информации, представленную в
таблице.
Аналогия между геометрией и теорией информации
|
№ |
Геометрия |
Теория информации |
||
|
Si – i-гиперобъем |
i – размерность пространства |
N –
количество элементов в множестве |
i –
количество информации (по Хартли) |
|
|
1 |
2 |
1 |
2 |
1 |
|
2 |
4 |
2 |
4 |
2 |
|
3 |
8 |
3 |
8 |
3 |
|
4 |
16 |
4 |
16 |
4 |
|
5 |
32 |
5 |
32 |
5 |
|
6 |
64 |
6 |
64 |
6 |
|
7 |
128 |
7 |
128 |
7 |
|
8 |
256 |
8 |
256 |
8 |
|
... |
... |
... |
... |
... |
|
i |
|
|
|
|
Отметим также, что известна [21, 22] так
называемая "фрактальная размерность" d1 (4), которую часто называют информационной размерностью, т.к. она показывает, какое количество информации необходимо для определения местоположения
точки в многомерном пространстве.
|
|
(4) |
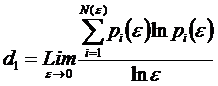 .
.В выражении (4) обозначено:
![]() – сторона
гиперкубической ячейки i-пространства
объемом:
– сторона
гиперкубической ячейки i-пространства
объемом: ![]() ;
;
![]() –
количество занятых ячеек, в которых содержится хотя бы одна точка;
–
количество занятых ячеек, в которых содержится хотя бы одна точка;
![]() – вероятность того,
что некоторая точка содержится в i-й
ячейке, при этом:
– вероятность того,
что некоторая точка содержится в i-й
ячейке, при этом: ![]() ;
;
![]() – количество точек в i-й ячейке.
– количество точек в i-й ячейке.
Из данных таблицы,
выражения (4) видно, что Хаусдорфа
размерность пространства и информационная размерность соотносятся как
комбинаторная мера Хартли для количества информации и статистическая мера
информации Шеннона для неравновероятных событий.
Основываясь на этой
существенной аналогии, можно сделать некоторые выводы и предположения, в том числе об информационных свойствах
пространства и перемещающихся в них объектах:
1. Размерность пространства можно
определить как его информационную емкость.
2. Поскольку информация связана с энтропией:
численно равна ей, но имеет противоположный знак, то можно предположить, что чем
выше размерность пространства, тем выше его антиэнтропийные свойства.
3. Энтропия связана с энергией:
– при сообщении энергии
системе ее энтропия повышается, и уровень системности (организованности)
уменьшается (вплоть до распада структуры системы), а при передаче энергии от
системы (охлаждение) ее энтропия уменьшается, и уровень системности
(организованности) возрастает;
– в замкнутых системах
вектор потока энергии всегда направлен в сторону уменьшения ее плотности (закон
возрастания энтропии);
– физические объекты
представляют собой сложные системы,
различные структурные уровни организации которых локализуются в пространствах
различных размерностей: более глубокие (высокие) и фундаментальные (сущностные)
структурные уровни локализуются в пространствах больших размерностей, а менее
фундаментальные, внешние уровни (форма) – в пространствах меньших размерностей;
– объекты представляют
собой каналы информационного и энергетического взаимодействия тех структурных
уровней организации материи, на которых они локализованы (отличаются от
окружающей среды), при этом при передаче информации осуществляется
преобразование языковой формы ее представления;
– поток информации в
объектах направлен из пространств высшей размерности в пространства низшей
размерности, от сущности к форме, что придает антиэнтропийные свойства форме и
позволяет ей сохранять устойчивость во внешней среде;
– одни объекты
взаимодействуют с помощью других объектов (подобъектов), при этом подобъекты
являются квантами поля, с помощью которого осуществляется взаимодействие объектов,
а объекты – источниками этого поля (зарядами); заряды всегда локализуются в
пространстве с меньшей размерностью, чем порождаемое ими поле, с помощью
которого они взаимодействуют.
Любой объект, в т.ч.
человек, является системой, которую можно представить себе в качестве i-точки некоторого i-пространства, причем не только абстрактного (фазового, семантического
или иного), но и вполне "физического", в смысле реально "объективно"
существующего.
Развитие любого объекта,
в т. ч. человека, можно представить себе как движение в некотором пространстве,
которое осуществляется путем чередования состояний двух типов: локализованного
в пространстве, но с неопределенным направлением перемещения (бифуркационное
состояние), и с определенным направлением перемещения, но с неопределенной
локализацией (детерминистское состояние).
Для особого класса геометрических фигур-фракталов
получаются не только целые, но и дробные
значения размерности, причем обычно превосходящие
размерность элементов, из которых строится фрактал. Это означает, что фрактал обладает качественно новыми
эмерджентными, системными свойствами по сравнению со своими элементами, т.е.
свойствами, которыми эти элементы не обладали, и, таким образом, является системой составляющих его элементов.
На этом даже может быть основано одно из
определений фракталов: фракталом называется геометрическая фигура,
размерность которой превосходит размерность геометрических объектов, из
которых он состоит. На основании этого определения и вышесказанного мы
можем высказать гипотезу о том, что все
геометрические фигуры являются фракталами, а классические фигуры, для
которых ранее считалось, что они не фракталы, также являются особым видом и частным случаем фракталов.
По аналогии с введенным автором понятием
"антисистемы" [166], можно предложить и определение
"антифрактала": это геометрическая фигура, размерность
которой меньше размерности геометрических объектов, из которых он состоит.
Остается лишь добавить, что, по-видимому,
классическая геометрия от Евклида до Римана изучает геометрические фигуры,
размерность которых строго равна
размерности геометрических объектов, из которых они состоят, т.е. фигуры,
являющиеся не системами, а множествами. Однако множество является частным
случаем системы [166]. Это означает, что в рамках классической
геометрии все виды i-мерных точек
"по умолчанию" ошибочно
считались 0-точками, т.е. точками нулевой размерности, но обнаружить это
возможно только в рамках более общей системной
геометрии, являющейся системным обобщением классической геометрии. Это
наводит на мысль о том, что, по-видимому, фрактальная геометрия является одним из
первых разработанных разделов системной геометрии. В этой связи
можно высказать геометрическую гипотезу о том, что геометрические фигуры
классической геометрии являются фракталами с одним уровнем самоподобия,
состоящими из системных точек, подобных фигуре в целом и той же размерности:
"точка" – "фигура-в-целом" (по Дж. Хатчинсону). Это определение
по смыслу совпадает с определением так называемой "истинной
бесконечности" Г.В.Ф. Гегеля, согласно которому истинно бесконечной является
система, подобная каждой своей части. Подобные системы, по Шеннону,
обладают максимальной взаимной информацией и минимальной энтропией, к подобным
системам относятся и фракталы (Дж. Хатчинсон), и живые организмы, состоящие из клеток, в каждой
из которых находится полный геном, содержащий информацию о всем организме.
Возможно, даже во Вселенной нет ни одного объекта, не являющегося истинно-бесконечным
и не содержащего в своей сущности полной информации о всей Вселенной.
Поэтому древние утверждали равенство или
даже тождество "микро- и макрокосма".
Бенуа Мандельброт в своей основополагающей
работе[5]
пишет, что "размерность есть локальное свойство пространства", т.е.
иначе говоря, она может изменяться от точки к точке, как квривзна. В связи с
этим возникает физическая гипотеза о том,
что, возможно, наше физическое пространство имеет размерность, не точно равную 3, а просто очень
близкую к 3, причем эта размерность (и статистическое
распределение i-мерных точек – систем разного типа) в принципе может
изменяться с течением времени в разных областях пространства в зависимости от
тех или иных физических условий, и совершенно не обязательно связанных только с
гравитацией и гравитационной массой (вдруг, например, окажется, что размерность
пространства изменяется во время ударов молний, землетрясений, ядерных взрывов,
вблизи торнадо, а также в аномальных зонах). В этой связи возникает идея
о разработке метода и прецизионной мобильной технологии измерения текущей фактической размерности пространства
в различных его точках, и, если такая технология будет создана, то, возможно,
также и о создании службы мониторинга и прогнозирования динамики размерности
пространства. Соответсвенно можно ввести понятие «Поле размерности» и попытаться понять от чего зависит локальная
размерность реального физического пространства. Мы уже не говорим о том, какие
возможные перспективы открываются, если удастся теоретически найти и
практически реализовать способы управления размерностью пространства.
Выше уже отмечалось, что смысл
размерности пространства состоит в том, что она количественно показывает на
сколько быстро возрастает "содержимое" тела при увеличении его
линейных размеров или при уменьшении линейных размеров объектов, "заполняющих"
тело. В рамках системной теории информации автором получены выражения для
коэффициентов эмерджентности Хартли и Харкевича [1, 1–20], названные так автором в честь этих выдающихся ученых:
|
|
(5) |
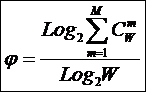 ,
,где
W – количество чистых (классических)
состояний системы, т.е. количество базисных элементов;
j – коэффициент
эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых состояний).
Непосредственно из вида
выражения для коэффициента эмерджентности Хартли (5) ясно, что он представляет
собой относительное превышение количества информации в системе при учете
системных эффектов (смешанных состояний, иерархической структуры ее подсистем и
т.п.) над количеством информации без учета системности, т.е. этот коэффициент отражает уровень системности объекта.
Таким образом, коэффициент
эмерджентности Хартли отражает уровень системности объекта и изменяется
от 1 (системность минимальна, т.е. отсутствует) до W/Log2W
(системность максимальна). Очевидно, для каждого количества
базисных элементов системы существует свой максимальный уровень
системности, который никогда реально не достигается из-за действия правил
запрета на реализацию в системе ряда подсистем различных уровней
иерархии. Таким образом, коэффициент эмерджентности Хартли дает верхнюю оценку
уровня системности i-точки из W базисных элементов.
Из сравнения коэффициент
эмерджентности Хартли (5) с мерой Хаусдорфа (1) и кубической
размерностью (3)
видно, что коэффициент эмерджентности Хартли, отражающий "уровень
системности", можно интерпретировать как своего рода размерность
системы, т.е. скорость возрастания ее системных (эмерджентных) свойств
при количественном увеличении мощности базисного множества системы.
Упрощенно можно считать, что:
– пространство 0-й размерности
есть одна точка 0-й размерности, т.е. классическая точка, известная в
математике (в частности в геометрии, дифференциальном и интегральном исчислении),
а также в основанной на них физике;
– пространство 1-й размерности
– это прямая линия, состоит из точек 1-й размерности, представляющих собой
системы из 2-х точек 0-й размерности, т.е. отрезков, имеющих бесконечно малую
длину (не нулевую);
– пространство 2-й размерности
– это плоскость, состоит из точек 2-й
размерности, представляющих собой системы из 3-х точек 0-й размерности, или
точки 1-й размерности и точки 0-й размерности, т.е. треугольников, имеющих
бесконечно малую площадь (не нулевую);
– пространство 3-й размерности
– это пространство, состоит из точек 3-й размерности, представляющих собой
системы из 4-х точек 0-й размерности, или точки 3-й размерности и точки 0-й
размерности т.е. тетраэдров, имеющих бесконечно малый объем (не нулевой);
.....
– пространство i-й размерности состоит из точек i-й размерности, представляющих собой системы из (i+1)-х точек 0-й размерности, или точки i-й размерности и точки 0-й размерности,
т.е. i-мерных симплексов, имеющих
бесконечно малый i-гиперобъем (i-мера: Si) (не нулевую).
В
заключение хотелось бы подчеркнуть, что все предложенные в данной
работе мысли и положения высказываются исключительно
в порядке обсуждения и ни в коей мере не претендуют на какую-либо полноту и завершенность.
Дальнейшее изложение основано
на рабате [191],
нумерация формул, рисунков и таблиц сохранены.
Задача
4: предложить способы
аналитического описания (задания) подсистем, как элементов системы.
Для решения данной задачи
необходимо найти способ представления в виде аналитической функции системы из
(i+1) 0-мерных точек, произвольным
образом расположенных в i-мерном пространстве. Предлагается представить эту
систему точек в виде пространственных аппроксимирующих функций, вейвлетов и/или сплайнов в многомерном пространстве.
В геометрии существует один
принципиальный вопрос, который, насколько известно, в явной форме не задавался:
"Каким
образом получается так, что из точек нулевой размерности, не обладающих
никакими свойствами, образуются геометрические объекты, обладающие целым
набором геометрических (и даже физических, как в теории гравитации А. Эйнштейна)
свойств, таких как размерность, длина, площадь, объем, кривизна, кручение и
т.д.?"
Предлагается следующий ответ на
этот вопрос, основанный на программной идее системного обобщения математики: необходимо
ввести понятие геометрической системы и признать, что новые свойства
геометрических систем, отсутствующие у элементов, из которых они состоят,
являются системными или эмерджентными свойствами, которые образуются за счет
взаимосвязей между элементами этих систем. Фактически все исследуемые в
геометрии объекты, называемые по-разному: "геометрическим местом
точек", "многообразием" и т.д., в действительности являются
геометрическими системами.
По
мере усложнения кривых у них, соответственно, повышается уровень системности и появляются все новые и новые системные (эмерджентные) свойства: если прямая
линия обладает только одним новым свойством: размерностью, которого не было у составляющих ее точек 0-вой
размерности, то плоская кривая, т.е.
кривая, полностью лежащая в плоскости, кроме того, обладает и кривизной, а пространственные кривые обладают еще и кручением.
Аналитически подобные кривые
описываются и исследуются в дифференциальной геометрии и топологии с помощью векторного
и тензорного анализа. Это описание может быть довольно сложным, поэтому в
данной работе предлагается использовать параметрическое
задание пространственных кривых через их проекции
на координатные плоскости многомерного пространства. При обсуждении данной
задачи для простоты будем предполагать, что это ортонормированное пространство с евклидовой метрикой. В общем случае если кривая однозначно задается
системой из (i+1) 0-мерных точек, произвольным
образом расположенных в i-мерном пространстве, для ее однозначного представления
требуется i взаимно-ортогональных (координатных) плоскостей, на которые она
проектируется. Сами же эти плоские проекции пространственной кривой можно
аппроксимировать различными функциями, но мы предлагаем использовать для этого степенные
полиномы различных степеней.
Для нас именно этот вариант
аппроксимирующих функций наиболее удобен и интересен, т.к. известно, что полином i-й степени однозначно определяется
(i+1) точками на плоскости и гарантировано проходит через них, т.е. не
только однозначно определяется ими, но и сам однозначно определяет их.
В частности:
– полином 1-й степени
однозначно определяется 2-мя точками 0-й размерности, гарантировано проходит через них и однозначно определяет
аналитически точку пространства 1-й размерности, т.е. прямой линии;
– полином 2-й степени
однозначно определяется 3-мя точками 0-й размерности, гарантировано проходит через них и однозначно определяет
аналитически точку пространства 2-й размерности, т.е. плоскости;
– полином 3-й степени
однозначно определяется 4-мя точками 0-й размерности, гарантировано проходит через них и однозначно определяет
аналитически точку пространства 3-й размерности, т.е. трехмерного пространства;
.................................................................................................
– полином i-й степени
однозначно определяется (i+1)-мя точками 0-й размерности, гарантировано проходит через них и однозначно определяет
аналитически точку пространства i-й размерности.
Это и означает, что аппроксимация проекций пространственных кривых, задаваемых системой точек в
многомерном пространстве степенными полиномами, является взаимно-однозначным (т.е. полностью адекватным) способом аналитического
представления этой системы точек. Таким образом, системе из (i+1) 0-мерных точек
в i-мерном пространстве аналитически соответствует система из i степенных полиномов
i-й степени. Это утверждение и предлагается считать одним из вариантов
решения задачи 4.
Приведем простой и наглядный пример, иллюстрирующий сформулированные
выше положения. В качестве систем
0-мерных точек рассмотрим обобщенные образы классов, полученные путем обобщения
конкретных образов железнодорожных составов, идущих на запад и на восток
(рисунок 1). Этот пример приведен в учебном пособии [98, 101] в качестве
лабораторной работы №1, описание этой работы находится в свободном общем
доступе (http://lc.kubagro.ru/aidos/aidos06_lab/lab_01.htm),
поэтому здесь подробно на нем останавливаться не будем.
|
|
Используя технологию и методику применения автоматизированного
системно-когнитивного анализа (АСК-анализ) [97], построим семантическую информационную
модель (СИМ), позволяющую определить направление движения состава по его
признакам. Формализация предметной области включает разработку
классификационных и описательных шкал и градаций (таблица 1) и обучающей
выборки (таблица 2). |
|
Рисунок 1 – Примеры поездов, идущих на запад и на восток |
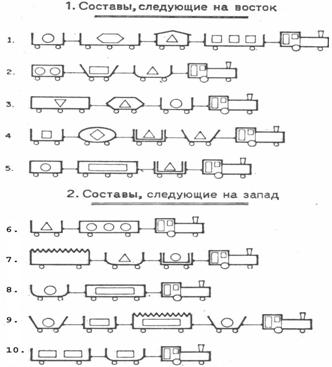
Классификационные шкалы и
градации:
1. Состав следует на восток.
2. Состав следует на запад.
Таблица 1 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
|
Наименование описательной шкалы |
Градация описательной шкалы |
Кол-во |
|
|
Наименование |
Код |
||
|
Количество
вагонов в составе: |
2 |
1 |
3 |
|
3 |
2 |
4 |
|
|
4 |
3 |
3 |
|
|
Форма вагона: |
V-образная. |
4 |
3 |
|
Прямоугольная |
5 |
10 |
|
|
Ромбовидная |
6 |
1 |
|
|
U-образная. |
7 |
4 |
|
|
Эллипсоидная. |
8 |
1 |
|
|
Длина вагона: |
Короткий. |
9 |
10 |
|
Длинный |
10 |
8 |
|
|
Количество осей
вагона: |
2 |
11 |
9 |
|
3 |
12 |
4 |
|
|
Вид стенок
вагона: |
Одинарные |
13 |
10 |
|
Двойные |
14 |
3 |
|
|
Вид крыши
вагона: |
Отсутствует |
15 |
10 |
|
Гофрированная |
16 |
2 |
|
|
Двухскатная |
17 |
1 |
|
|
Прямая
(эллипсоидная) |
18 |
6 |
|
|
Груз
(количество и вид): |
1 большой круг. |
19 |
7 |
|
2 маленьких
круга |
20 |
1 |
|
|
3 маленьких
круга |
21 |
1 |
|
|
1 квадрат |
22 |
1 |
|
|
3 квадрата. |
23 |
1 |
|
|
1 короткий
прямоугольник. |
24 |
3 |
|
|
2 коротких
прямоугольника |
25 |
1 |
|
|
1 длинный
прямоугольник |
26 |
3 |
|
|
1 треугольник |
27 |
7 |
|
|
1 перевернутый
треугольник. |
28 |
1 |
|
|
1 ромб. |
29 |
2 |
|
|
1 шестиугольник |
30 |
|
|
|
Груза нет |
31 |
1 |
|
Таблица 2 – ОБУЧАЮЩАЯ ВЫБОРКА
|
№ |
Наименование
состава |
Коды класса |
Коды признаков |
||||||||||
|
1 |
Состав-1 |
1 |
3 |
5 |
5 |
5 |
5 |
9 |
9 |
10 |
10 |
11 |
11 |
|
11 |
12 |
13 |
13 |
13 |
13 |
15 |
15 |
15 |
17 |
19 |
|||
|
29 |
27 |
23 |
|
|
|
|
|
|
|
|
|||
|
2 |
Состав-2 |
1 |
2 |
5 |
4 |
7 |
9 |
9 |
9 |
2 |
2 |
2 |
13 |
|
13 |
13 |
15 |
15 |
18 |
20 |
24 |
27 |
|
|
|
|||
|
3 |
Состав-3 |
1 |
2 |
5 |
6 |
5 |
10 |
9 |
9 |
12 |
11 |
11 |
13 |
|
13 |
13 |
18 |
18 |
15 |
28 |
27 |
19 |
|
|
|
|||
|
4 |
Состав-4 |
1 |
3 |
5 |
8 |
5 |
4 |
9 |
9 |
9 |
9 |
13 |
13 |
|
13 |
14 |
15 |
15 |
15 |
18 |
22 |
29 |
27 |
27 |
11 |
|||
|
11 |
11 |
11 |
|
|
|
|
|
|
|
|
|||
|
5 |
Состав-5 |
1 |
2 |
5 |
5 |
5 |
9 |
9 |
10 |
11 |
11 |
12 |
13 |
|
13 |
14 |
18 |
18 |
15 |
19 |
26 |
27 |
|
|
|
|||
|
6 |
Состав-6 |
2 |
1 |
5 |
5 |
9 |
10 |
11 |
11 |
13 |
13 |
15 |
18 |
|
27 |
21 |
|
|
|
|
|
|
|
|
|
|||
|
7 |
Состав-7 |
2 |
2 |
5 |
5 |
7 |
10 |
9 |
9 |
11 |
11 |
11 |
13 |
|
13 |
14 |
16 |
15 |
15 |
31 |
27 |
19 |
|
|
|
|||
|
8 |
Состав-8 |
2 |
1 |
7 |
5 |
9 |
10 |
11 |
12 |
19 |
26 |
15 |
18 |
|
13 |
13 |
|
|
|
|
|
|
|
|
|
|||
|
9 |
Состав-9 |
2 |
3 |
4 |
4 |
5 |
5 |
9 |
9 |
9 |
10 |
11 |
11 |
|
11 |
11 |
13 |
13 |
13 |
13 |
15 |
15 |
15 |
16 |
19 |
|||
|
24 |
26 |
19 |
|
|
|
|
|
|
|
|
|||
|
10 |
Состав-10 |
2 |
1 |
5 |
7 |
9 |
10 |
11 |
11 |
13 |
13 |
15 |
15 |
|
25 |
24 |
|
|
|
|
|
|
|
|
|
|||
После ввода классификационных и
описательных шкал и градаций, а также обучающей выборки в универсальную когнитивную
аналитическую систему "Эйдос" (являющуюся программным инструментарием
АСК-анализа), в результате синтеза СИМ была получена следующая матрица
абсолютных частот (таблица 3).
Таблица
3 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ
|
Наименование описательной шкалы |
Градация описательной шкалы |
Наименования и
коды классов (градаций
классификационных шкал) |
Кол-во |
||
|
Наименование |
Код |
Состав следует на
восток |
Состав следует на
запад |
||
|
Количество
вагонов в составе: |
2 |
1 |
0 |
3 |
3 |
|
3 |
2 |
3 |
1 |
4 |
|
|
4 |
3 |
2 |
1 |
3 |
|
|
Форма
вагона: |
V-образная. |
4 |
2 |
1 |
3 |
|
Прямоугольная |
5 |
5 |
5 |
10 |
|
|
Ромбовидная |
6 |
1 |
0 |
1 |
|
|
U-образная. |
7 |
1 |
3 |
4 |
|
|
Эллипсоидная. |
8 |
1 |
0 |
1 |
|
|
Длина
вагона: |
Короткий. |
9 |
5 |
5 |
10 |
|
Длинный |
10 |
3 |
5 |
8 |
|
|
Количество
осей вагона: |
2 |
11 |
4 |
5 |
9 |
|
3 |
12 |
3 |
1 |
4 |
|
|
Вид
стенок вагона: |
Одинарные |
13 |
5 |
5 |
10 |
|
Двойные |
14 |
2 |
1 |
3 |
|
|
Вид
крыши вагона: |
Отсутствует |
15 |
5 |
5 |
10 |
|
Гофрированная |
16 |
0 |
2 |
2 |
|
|
Двухскатная |
17 |
1 |
0 |
1 |
|
|
Прямая
(эллипсоидная) |
18 |
4 |
2 |
6 |
|
|
Груз
(количество и вид): |
1
большой круг. |
19 |
3 |
4 |
7 |
|
2
маленьких круга |
20 |
1 |
0 |
1 |
|
|
3
маленьких круга |
21 |
0 |
1 |
1 |
|
|
1
квадрат |
22 |
1 |
0 |
1 |
|
|
3
квадрата. |
23 |
1 |
0 |
1 |
|
|
1
короткий прямоугольник. |
24 |
1 |
2 |
3 |
|
|
2
коротких прямоугольника |
25 |
0 |
1 |
1 |
|
|
1
длинный прямоугольник |
26 |
1 |
2 |
3 |
|
|
1
треугольник |
27 |
5 |
2 |
7 |
|
|
1
перевернутый треугольник. |
28 |
1 |
0 |
1 |
|
|
1
ромб. |
29 |
2 |
0 |
2 |
|
|
1
шестиугольник |
30 |
0 |
0 |
0 |
|
|
Груза
нет |
31 |
0 |
1 |
1 |
|
Напомним, что мы предлагаем рассматривать описательные
шкалы как оси координат в многомерном неортонормированном пространстве, а
градации описательных шкал – как интервальные значения, т.е. координаты на этих
осях (признаки). Для того чтобы построить в многомерном пространстве
кривую, соответствующую некоторому заданному классу, в качестве значений по каждой координате будем рассматривать суммарное
количество встреч данного признака у объектов этого класса.
Используя графическую систему
SigmaPlot for Windows Version 10.0 фирмы Systat Software Inc., построим
трехмерные образы исследуемых нами классов, выбрав три описательные шкалы,
отмеченные светло-зеленым цветом, и предполагая, что пространство является
ортонормированным. Последнее предположение в общем случае не выполняется (как и
нашем примере), но этим обстоятельством на данном этапе мы вынуждены пренебречь,
т.к. нам неизвестны системы, позволяющие строить по координатам точек в
криволинейных или косоугольных координатах многомерные объекты и проектировать
их в евклидово трехмерное или двумерное пространство.
Для построения графиков в
системе SigmaPlot выполним подготовку исходных данных, выполнив следующие
операции:
1. Выберем 3 описательные
шкалы: форма вагона; вид крыши вагона и груз (количество и вид), в каждой из
которых не менее 4-х градаций, что достаточно для получения наглядной кривой.
2. Система SigmaPlot
предъявляет требование, чтобы по всем осям было равное количество
координат, т.к. точка в многомерном пространстве задается координатами по всем
осям. Однако в наших данных это требование не выполняется. Всего существует два
варианта решить эту проблему: дополнить нулями недостающие координаты,
ограничиться по всем осям тем количеством координат, которое в оси с
минимальным их количеством. Мы выбираем второй вариант и оставляем по каждой из
осей по 4 координаты, как в оси "Вид крыши вагона", в которой их
минимальное количество.
3. Для большей наглядности перед
построением графиков градации по каждой шкале рассортируем в порядке возрастания их значений для одного из
классов (по каждой оси координат они могут быть оставлены в исходном порядке
либо рассортированы в порядке возрастания или убывания).
В результате получим исходную
таблицу данных для построения графиков в системе SigmaPlot (таблица 4) и сами
графики (рисунок 2).
Таблица 4 – ДАННЫЕ ИЗ
МАТРИЦЫ АБСОЛЮТНЫХ ЧАСТОТ
ДЛЯ ПОСТРОЕНИЯ ГРАФИКОВ В СИСТЕМЕ SIGMAPLOT
|
Ось |
Наименование описательной шкалы |
Градация описательной шкалы |
Наименования и коды классов (градаций классификационных шкал) |
Кол-во |
||
|
Наименование |
Код |
Состав следует на восток |
Состав следует на запад |
|||
|
X |
Форма вагона |
U-образная. |
7 |
1 |
3 |
4 |
|
Эллипсоидная. |
8 |
1 |
0 |
1 |
||
|
V-образная. |
4 |
2 |
1 |
3 |
||
|
Прямоугольная |
5 |
5 |
5 |
10 |
||
|
Y |
Вид крыши
вагона |
Гофрированная |
16 |
0 |
2 |
2 |
|
Двухскатная |
17 |
1 |
0 |
1 |
||
|
Прямая
(эллипсоидная) |
18 |
4 |
2 |
6 |
||
|
Отсутствует |
15 |
5 |
5 |
10 |
||
|
Z |
Груз
(количество и вид) |
1 перевернутый
треугольник. |
28 |
1 |
0 |
1 |
|
1 ромб. |
29 |
2 |
0 |
2 |
||
|
1 большой круг. |
19 |
3 |
4 |
7 |
||
|
1 треугольник |
27 |
5 |
2 |
7 |
||
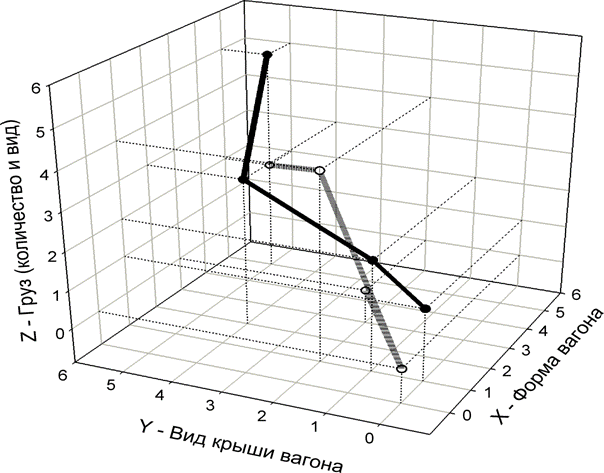
Рисунок 2 – Отображение фрагмента семантического пространства
с образами составов, следующих на восток (сплошная линия) и на запад (пунктир).
Единица измерения по шкалам – количество встреч признака
Рассмотрим проекции этих пространственных кривых
на координатные плоскости и аппроксимации этих проекций степенными полиномами.
На основе данных таблицы 4 получим сочетания координат для точек проекций
кривых, соответствующих поездам, следующим на восток и на запад, на
координатные плоскости XY, XZ и YZ (таблица 5), а затем построим график
проекции YZ и его аппроксимацию полиномом 3-й степени (рисунок 3).
Для примера выбрана именно данная проекция пространственной кривой класса "Поезда, следующие на восток",
т.к. при выбранном способе сортировки координат по возрастанию значений она
оказалась монотонно-возрастающей по обеим
координатам, что является необходимым и достаточным условием для
возможности аппроксимации кривой именно степенным полином.
Таблица 5 –
СОЧЕТАНИЯ КООРДИНАТ ДЛЯ ТОЧЕК ПРОЕКЦИЙ КРИВЫХ НА КООРДИНАТНЫЕ ПЛОСКОСТИ XY, XZ
И YZ
|
|
|
Восток |
Запад |
|
Восток |
|
Запад |
||
|
X |
|
|
|
|
XY |
|
|
XY |
|
|
Форма вагона |
U-образная. |
1 |
3 |
|
1 |
0 |
|
3 |
2 |
|
Эллипсоидная. |
1 |
0 |
|
1 |
1 |
|
0 |
0 |
|
|
V-образная. |
2 |
1 |
|
2 |
4 |
|
1 |
2 |
|
|
Прямоугольная |
5 |
5 |
|
5 |
5 |
|
5 |
5 |
|
|
Y |
|
|
|
|
XZ |
|
|
XZ |
|
|
Вид крыши
вагона |
Гофрированная |
0 |
2 |
|
1 |
1 |
|
3 |
0 |
|
Двухскатная |
1 |
0 |
|
1 |
2 |
|
0 |
0 |
|
|
Прямая
(эллипсоидная) |
4 |
2 |
|
2 |
3 |
|
1 |
4 |
|
|
Отсутствует |
5 |
5 |
|
5 |
5 |
|
5 |
2 |
|
|
Z |
|
|
|
|
YZ |
|
|
YZ |
|
|
Груз
(количество и вид) |
1 перевернутый
треугольник. |
1 |
0 |
|
0 |
1 |
|
2 |
0 |
|
1 ромб. |
2 |
0 |
|
1 |
2 |
|
0 |
0 |
|
|
1 большой круг. |
3 |
4 |
|
4 |
3 |
|
2 |
4 |
|
|
1 треугольник |
5 |
2 |
|
5 |
5 |
|
5 |
2 |
|
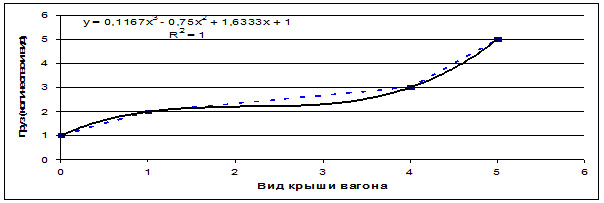
Рисунок 3 – Проекция пространственной кривой класса: "Поезда, следующие
на восток" на координатную плоскость "YZ" (синий пунктир) и
аппроксимация этой проекции полиномом
3-й степени (черная сплошная линия)
Задача
5: описать системное семантическое
пространство для отображения систем в форме эйдосов (эйдос-пространство).
Прежде всего, отметим, что нас не устраивает
в классическом семантическом пространстве,
рассмотренном при обсуждении возможных подходов к решению предыдущей задачи.
Напомним, что в этом пространстве в качестве осей координат рассматривались
описательные шкалы, в качестве координат на этих осях – градации описательных
шкал (интервальные значения, признаки), а в качестве значений по каждой координате
– суммарное количество встреч данного признака у объектов этого класса. При
этом классическое семантическое пространство, вообще говоря (т.е. в общем
случае), является многомерным неортонормированным пространством, т.к. углы
между осями координат не являются прямыми, а единицы измерения по различным
осям различны. Более того, это пространство может быть
искривлено, скручено и т.п., не говоря уже о том, что его локальная фрактальная
размерность может изменяться от точки к точке.
В качестве меры расстояния в этом пространстве
обычно используют евклидову метрику (многомерный аналог теоремы Пифагора), как
правило совершенно забывая при этом, что для корректного применения
этой метрики необходимо, чтобы пространство было ортонормированным, и по всем осям использовалась бы одна
и та же единица измерения, либо они все были безразмерными. Эти условия
являются совершенно необходимыми и обязательными. Если для неортонормированного
пространства существует обобщение теоремы Пифагора, и оно просто по неизвестным
причинам не используется (правда более-менее простой аналитический вид это
выражение имеет только для плоскости и трехмерного пространства), то вопрос о
единицах измерения по осям просто
игнорируется, т.е. не ставится и не осбуждается. Мы же напротив, обращаем
на это внимание, как принципиальный вопрос [277], т.к. получается, что выбор
единиц измерения сильно сказывается на результатах исследования, что некорректно.
Об этом вопросе упоминается в работе
отечественных классиков системного анализа Ф.И. Перегудова и Ф.П. Тарасенко[6]
(при рассмотрении многокритериального метода приятия решений и формировании
интегрального критерия из частных критериев). Между тем, широко известно, что с размерностями в математических выражениях,
в которые входят различные по смыслу величины, измеряемые в различных единицах
измерения, нужно обращаться очень аккуратно.
Даже на уроке физики в средней школе обязательно проверяют размерности
получаемых в результате решения задач величин, и если они не соответствуют
смыслу этих величин и принятым для них размерностям, то это является явным признаком ошибки
в решении. Однако в статистических системах, системах анализа данных и
системах искусственного интеллекта (кроме системы "Эйдос"), почему-то
совершенно не задумываясь, спокойно совершают операции сложения, вычитания и
другие более сложные математические операции с величинами, имеющими качественно различающийся смысл и,
соответственно, измеряемыми в совершенно различных единицах измерения.
Удивительно, но такой подход на
практике традиционен и в нем нет ничего необычного. Например, в известной
статистической системе SPSS в разделе по изучению кластерного анализа приведены
обучающие примеры, в которых между собой сравниваются различные модели
автомобилей. При этом признаками для сравнения этих моделей являются:
количество ведущих мостов, количество цилиндров, мощность двигателя, расход
топлива и т.п. параметры, измеряемые количественно,
естественно, в различных единицах
измерения. Затем с использованием евклидовой
меры сходства (корректность использования которой также еще нужно
обосновать) вычисляется параметр сходства
между этими моделями, строится матрица сходства, на основе которой и
проводится кластерный анализ. Ясно, что это некорректно, т.к., например, 4
ведущих колеса или 4 цилиндра будут иметь одинаковый вес при определении
сходства моделей, а мощность
Конечно, это совершенно не
означает, что режим кластерного анализа системы SPSS невозможно использовать
корректно. Для этого достаточно в матрицу исходных данных кластерного анализа
ввести либо безразмерные (например, стандартизированные)
величины, либо величины, приведенные к одной размерности, например, можно
вычислить, как влияет тот или иной размерный параметр модели автомобиля на его
цену, и вводить не сам этот параметр, а
его влияние на цену автомобиля (например, в какой-либо валюте в индексированных
ценах). Аналогично можно изучать влияние различных факторов на продолжительность
жизни, вводя для исследования не сами значения этих факторов, а их влияние на эту продолжительность
(например, в годах). При этом сами параметры или факторы могут измеряться в
самых различных единицах измерения, например, количество сигарет, выкуренных за
день, количество метров, пройденных пешком, количество минут, потраченных на
утреннюю зарядку и т.п., но все это, в каких бы единицах измерения оно не измерялось,
прибавляет или отнимает какие-то минуты
нашей жизни. Проблема только в том, что это нужно понимать и делать самому, а
система своими странными примерами правоцирует пользователей на некорректное
применение.
Таким образом, мы считаем
необходимым использовать для моделирования реальности не классическое
семантическое пространство, а другое пространство (назовем его системным
семантическим пространством или кратко эйдос-пространством),
которое характеризуется следующими свойствами:
1. В качестве осей координат
используются конструкты, т.е. понятия, имеющие смысловые полюса и спектр
промежуточных смысловых значений с количественной или порядковой шкалой
смыслового сходства и различия между ними. По
всем осям координат используется одна и
та же единица измерения.
2. Величины или значения
координат выражаются количественными величинами, имеющими один и тот же смысл
не только для одной оси, но и для всех осей координат, т.е. всего эйдос-пространства.
3. Значения координат несут
информацию не только о положении точки в этом пространстве, но и о степени
принадлежности этой точки к многомерному объекту, соответствующему
обобщенному образу класса (будем называть этот образ "эйдос" (от
греч. εἶδος – вид, образ)
– идея,
понятие, образ). Координаты образов классов в
эйдос-пространстве – информативности, рассчитываемые согласно системной теории
информации [97, 93-280]. Более того, эти значения координат являются
величинами, учитывающими системный эффект
взаимодействия всех классов в
эйдос-пространстве со всеми
градациями описательных шкал (поэтому для математической модели системы
"Эйдос" и был предложен термин "нелокальная нейронная сеть"
[138]), в отличие от классических нейронных сетей с обратным распространением
ошибки. Предлагается считать координаты точек в эйдос-пространстве компонентами
i-мерных когнитивных чисел [166], по аналогии с действительными числами
(1-мерными), комплексными числами (2-мерными), кватернионами (3-мерными).
4. Интегральный критерий
сходства образа конкретного объекта с классом, классов друг с другом, значений
факторов друг с другом, т.е. метрика или "информационное расстояние"
– свертка или скалярное произведение векторов классов или объекта и класса
[1–20, 9, 10], величина, которую корректно использовать в случае неортонормированного
пространства (в общем случае эйдос-пространство неортонормированно), так как:
а) сами величины
информативностей (см. п. 3) учитывают углы
между описательными шкалами (если угол между двумя описательными шкалами равен
0, то информативности градаций этих шкал уменьшаются в два раза),
б) свертка в координатной форме, по сути, является просто суммой информативностей тех признаков,
которые есть у конкретного объекта, и математически никак не связана с предположением об ортонормированности или неортономированности
эйдос-пространства.
5. Это эйдос-пространство
является, вообще говоря, многомерным неортонормированным пространством с
неевклидовой метрикой.
Мы осознаем мир, используя
эйдос-пространство, а детально исследуем модели объектов внутреннего и внешнего
мира, сформированные в этом пространстве, изучая их проекции на координатные
плоскости, а чаще на оси координат, т.е. конструкты. Так, что мы действительно
осознаем не сам мир, а лишь проекции его объектов, подобные теням на стенах пещеры
Платона, причем в действительности эти тени даже не от самих объектов,
а лишь от их моделей в нашем сознании (т.к. мы осознаем не непосредственно
сами объекты "какие они есть на самом деле, т.е. сами по себе" (еще
вопрос, возможно ли это хотя бы в принципе), а лишь отражения этих объектов в
нашем сознании).
Продолжим изучение примера,
который мы рассматривали при обсуждении предыдущей задачи. В таблице 6
приведено количество информации, рассчитанное согласно системной теории
информации [97], которое содержится в градациях описательных шкал (признаках) о
принадлежности конкретных объектов, обладающих этими признаками, к обобщенным
классам: "Состав, следующий на восток", "Состав, следующий на запад".
Таблица 6 – МАТРИЦА
ИНФОРМАТИВНОСТЕЙ (БИТ)
|
Наименование описательной шкалы |
Градация описательной шкалы |
Наименования и коды классов (градаций классификационных шкал) |
||
|
Наименование |
Код |
Состав следует на восток |
Состав следует на запад |
|
|
Количество
вагонов в составе: |
2 |
1 |
0,00000000 |
0,15333187 |
|
3 |
2 |
0,07610294 |
-0,13573296 |
|
|
4 |
3 |
0,05154327 |
-0,07574658 |
|
|
Форма вагона: |
V-образная. |
4 |
0,05154327 |
-0,07574658 |
|
Прямоугольная |
5 |
-0,00844310 |
0,00879946 |
|
|
Ромбовидная |
6 |
0,13608931 |
0,00000000 |
|
|
U-образная. |
7 |
-0,15297552 |
0,09334550 |
|
|
Эллипсоидная. |
8 |
0,13608931 |
0,00000000 |
|
|
Длина вагона: |
Короткий. |
9 |
-0,00844310 |
0,00879946 |
|
Длинный |
10 |
-0,06842948 |
0,05532850 |
|
|
Количество осей
вагона: |
2 |
11 |
-0,03300278 |
0,03076883 |
|
3 |
12 |
0,07610294 |
-0,13573296 |
|
|
Вид стенок
вагона: |
Одинарные |
13 |
-0,00844310 |
0,00879946 |
|
Двойные |
14 |
0,05154327 |
-0,07574658 |
|
|
Вид крыши
вагона: |
Отсутствует |
15 |
-0,00844310 |
0,00879946 |
|
Гофрированная |
16 |
0,00000000 |
0,15333187 |
|
|
Двухскатная |
17 |
0,13608931 |
0,00000000 |
|
|
Прямая
(эллипсоидная) |
18 |
0,05154327 |
-0,07574658 |
|
|
Груз (количество
и вид): |
1 большой круг. |
19 |
-0,04058602 |
0,03664292 |
|
2 маленьких
круга |
20 |
0,13608931 |
0,00000000 |
|
|
3 маленьких
круга |
21 |
0,00000000 |
0,15333187 |
|
|
1 квадрат |
22 |
0,13608931 |
0,00000000 |
|
|
3 квадрата. |
23 |
0,13608931 |
0,00000000 |
|
|
1 короткий
прямоугольник. |
24 |
-0,09298915 |
0,06878583 |
|
|
2 коротких
прямоугольника |
25 |
0,00000000 |
0,15333187 |
|
|
1 длинный
прямоугольник |
26 |
-0,09298915 |
0,06878583 |
|
|
1 треугольник |
27 |
0,06592940 |
-0,10788950 |
|
|
1 перевернутый
треугольник. |
28 |
0,13608931 |
0,00000000 |
|
|
1 ромб. |
29 |
0,13608931 |
0,00000000 |
|
|
1 шестиугольник |
30 |
0,00000000 |
0,00000000 |
|
|
Груза нет |
31 |
0,00000000 |
0,15333187 |
|
Далее выберем из таблицы 6 только те
информативности, которые соответствуют градациям описательных шкал, рассмотренных
в предыдущей задаче (для обеспечения сопоставимости), и в результате получим
таблицу 7 и ее графическое отображение на рисунке 4.
Таблица 7 – ДАННЫЕ ИЗ
МАТРИЦЫ ИНФОРМАТИВНОСТЕЙ
ДЛЯ ПОСТРОЕНИЯ ГРАФИКОВ В СИСТЕМЕ SIGMAPLOT
|
Ось |
Наименование описательной шкалы |
Градация описательной шкалы |
Наименования и коды классов (градаций классификационных шкал) |
||
|
Наименование |
Код |
Состав следует на восток |
Состав следует на запад |
||
|
X |
Форма вагона |
U-образная. |
7 |
-0,15297552 |
0,09334550 |
|
Прямоугольная |
5 |
-0,00844310 |
0,00879946 |
||
|
V-образная. |
4 |
0,05154327 |
-0,07574658 |
||
|
Эллипсоидная. |
8 |
0,13608931 |
0,00000000 |
||
|
Y |
Вид крыши
вагона |
Отсутствует |
15 |
-0,00844310 |
0,00879946 |
|
Гофрированная |
16 |
0,00000000 |
0,15333187 |
||
|
Прямая
(эллипсоидная) |
18 |
0,05154327 |
-0,07574658 |
||
|
Двухскатная |
17 |
0,13608931 |
0,00000000 |
||
|
Z |
Груз
(количество и вид) |
1 большой круг. |
19 |
-0,04058602 |
0,03664292 |
|
1 треугольник |
27 |
0,06592940 |
-0,10788950 |
||
|
1 перевернутый
треугольник. |
28 |
0,13608931 |
0,00000000 |
||
|
1 ромб. |
29 |
0,13608931 |
0,00000000 |
||
Рисунок 4 – Отображение фрагмента системного семантического
пространства (эйдос-пространства) с образами составов, следующих
на восток (сплошная линия) и на запад
(пунктир). Единица измерения
по шкалам – биты
Рассмотрим проекции
этих пространственных кривых на координатные плоскости и аппроксимации этих
проекций степенными полиномами. На основе таблицы 7 получим сочетания координат
для точек проекций кривых, соответствующих поездам, следующим на восток и на
запад, на координатные плоскости XY, XZ и YZ (таблица 8), а затем построим
график проекции XY и его аппроксимацию полиномом 3-й степени (рисунки 5 и 6). В
таблице 8 области данных, отображенные на рисунках 5 и 6, обведены жирной
рамкой.
Таблица 8 – СОЧЕТАНИЯ КООРДИНАТ ДЛЯ ПРОЕКЦИЙ КРИВЫХ ИЗ
ЭЙДОС-ПРОСТРАНСТВА НА КООРДИНАТНЫЕ ПЛОСКОСТИ XY, XZ И YZ
|
|
|
Восток |
Запад |
|
Восток |
|
|
Запад |
|
|
X |
|
|
|
|
XY |
|
|
XY |
|
|
Форма вагона |
U-образная. |
-0,153 |
0,093 |
|
-0,153 |
-0,008 |
|
0,093 |
0,009 |
|
Прямоугольная |
-0,008 |
0,009 |
|
-0,008 |
0,000 |
|
0,009 |
0,153 |
|
|
V-образная. |
0,052 |
-0,076 |
|
0,052 |
0,052 |
|
-0,076 |
-0,076 |
|
|
Эллипсоидная. |
0,136 |
0,000 |
|
0,136 |
0,136 |
|
0,000 |
0,000 |
|
|
Y |
|
|
|
|
XZ |
|
|
XZ |
|
|
Вид крыши
вагона |
Отсутствует |
-0,008 |
0,009 |
|
-0,153 |
-0,041 |
|
0,093 |
0,037 |
|
Гофрированная |
0,000 |
0,153 |
|
-0,008 |
0,066 |
|
0,009 |
-0,108 |
|
|
Прямая
(эллипсоидная) |
0,052 |
-0,076 |
|
0,052 |
0,136 |
|
-0,076 |
0,000 |
|
|
Двухскатная |
0,136 |
0,000 |
|
0,136 |
0,136 |
|
0,000 |
0,000 |
|
|
Z |
|
|
|
|
YZ |
|
|
YZ |
|
|
Груз
(количество и вид) |
1 большой круг. |
-0,041 |
0,037 |
|
-0,008 |
-0,041 |
|
0,009 |
0,037 |
|
1 треугольник |
0,066 |
-0,108 |
|
0,000 |
0,066 |
|
0,153 |
-0,108 |
|
|
1 перевернутый
треугольник. |
0,136 |
0,000 |
|
0,052 |
0,136 |
|
-0,076 |
0,000 |
|
|
1 ромб. |
0,136 |
0,000 |
|
0,136 |
0,136 |
|
0,000 |
0,000 |
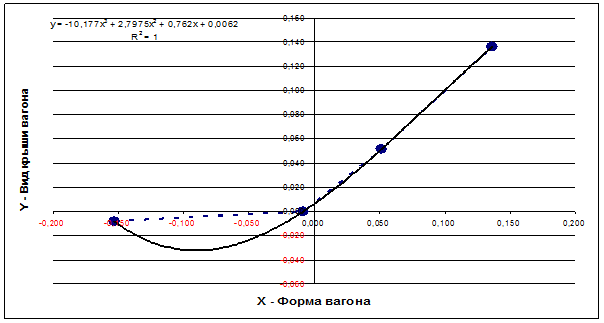
Рисунок 5 – Проекция эйдоса (класса): "Поезда, следующие на
восток"
на координатную плоскость "XY" (синий пунктир) и
аппроксимация этой
проекции полиномом 3-й степени (черная сплошная линия)
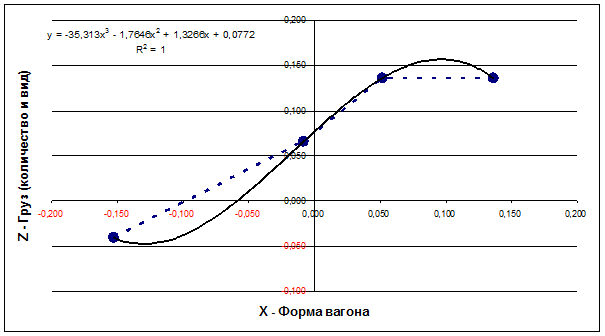
Рисунок 6 – Проекция эйдоса (класса): "Поезда, следующие на
восток"
на координатную плоскость "XZ" (синий пунктир) и
аппроксимация этой
проекции полиномом 3-й степени (черная сплошная линия)
Для примера выбраны именно проекции
пространственной кривой (эйдоса) класса "Поезда,
следующие на восток", т.к. при выбранном способе сортировки координат
по возрастанию значений они оказались монотонно-возрастающими
по обеим координатам, что является необходимым и достаточным условием для
возможности аппроксимации кривой степенным полином. Отметим, что для аппроксимации
всех проекций эйдосов на координатные
плоскости с коэффциентом детерминации R2=1 (т.е. с нулевой
погрешностью) оказалось достточно полиномов 3-й степени.
Задача
6: описать принцип формирования эйдосов
(включая зеркальные части).
Автоматизированный
системно-когнитивный анализ (АСК-анализ) [97] представляет собой метод,
технологию и методику формирования эйдосов и включает следующие этапы:
1. Когнитивная структуризация,
а затем и формализация предметной области.
2. Ввод данных
мониторинга в базу прецедентов (обучающую выборку) за период, в течение
которого имеется необходимая информация в электронной форме.
3. Синтез
семантической информационной модели (СИМ).
4. Оптимизация СИМ.
5. Проверка
адекватности СИМ (измерение внутренней и внешней, дифференциальной и
интегральной валидности).
6. Анализ СИМ.
7. Решение задач
идентификации состояний объекта управления, прогнозирования и поддержки
принятия управленческих решений по управлению с применением СИМ.
На первых двух
этапах АСК-анализа, детально рассмотренных в работах [9, 10], числовые величины
сводятся к интервальным оценкам, как и информация об объектах нечисловой природы
(фактах, событиях). Этот этап реализуется и в методах интервальной статистики.
На третьем этапе
СК-анализа всем этим величинам (по единой методике, основанной на системном
обобщении семантической теории информации А. Харкевича) сопоставляются количественные
величины, с которыми в дальнейшем и производятся все операции моделирования.
Обобщенный образ класса (эйдос) представляет
собой элемент определенного уровня иерархии системы, т.е. множество, в котором
в качестве элементов-признаков выступают элементы предыдущего уровня иерархии
системы.
Информационный портрет класса представляет собой
список признаков этого класса, ранжированный в порядке убывания количества
информации, содержащейся в этих признаках о принадлежности к данному классу.
Этот информационный портрет может быть разделен на две части: позитивную: с
положительными информативностями (эйдос), и негативную: с отрицательными
информативностями (антиэйдос). Эйдос и антиэйдос представляют собой как бы зеркальные части информационного портрета.
Значения координат точки, входящей в эйдос, равны
количеству информации в соответствующем признаке (градации описательной шкалы)
о принадлежности конкретного обладающего этим признаком объекта к обобщенному
образу класса (градации классификационной шкалы).
Если классические координаты
точки в семантическом пространстве несут информацию только о положении точки в
пространстве и все, то системные координаты точки в эйдос-пространстве, кроме
этого, несут также и информацию о принадлежности объекта, в который входит
данная точка, к эйдосу (обобщенному образу класса), т.е. к системе точек.
Подробнее задачу № 6
рассматривать в данной работе нецелесообразно, т.к. она неоднократно
реализовалась в ряде приложений и исследований, проведенных по технологии
АСК-анализа, о которых имеются многочисленные общедоступные публикации, в
частности, размещенные по Internet-адресам:
– http://ej.kubagro.ru/a/viewaut.asp?id=11;
– http://lc.kubagro.ru/aidos/Eidos.htm.
Задача
7: показать, что базовая
когнитивная концепция [97] формализуется многослойной системой эйдос-пространств.
Из базовой когнитивной
концепции, предложенной в работе [97], следует иерархическая структура процесса
познания (таблица 9).
Таблица 9 – ИЕРАРХИЧЕСКАЯ СТРУКТУРА
ПРОЦЕССА ПОЗНАНИЯ
|
Уровень иерархии процесса познания |
Элемент |
Действие с элементами |
Система |
|
1 |
признаки |
синтез |
образы
конкретных объектов |
|
2 |
признаки,
образы конкретных объектов |
обобщение,
многопараметрическая типизация |
обобщенные
образы классов |
|
3 |
классы |
нахождение
наиболее сходных, обобщение |
кластеры |
|
4 |
кластеры |
нахождение
наиболее отличающихся |
конструкты |
|
5 |
конструкты |
синтез |
действующая
парадигма предметной области |
При этом на разных уровнях
иерархии системы познания элементами являются: признаки, а системами – образы
конкретных объектов, описанные системами признаков по 2, 3 и т.д., а на других
элементами выступают уже конкретные образы, а системами – обобщенные образы
классов, которые, в свою очередь, являются элементами систем-кластеров, а они –
элементами систем-конструктов, система конструктов образует парадигму. В 1996
году в работе [94], а затем в работе [138] автором была
предложена идея создания подобных многоуровневых моделей в АСК-анализе. В
последующем в ряде работ автора с соавторами [102, 154, 99] и других были созданы и
исследованы подобные многоуровневые модели, каждый из уровней которых формализуется
эйдос-пространством определенной размерности.
Таким образом, можно сделать
вывод о том, что базовая когнитивная концепция и реализующий ее АСК-анализ
формализуются многослойной системой взаимосвязанных
эйдос-пространств. Если на 2-м уровне иерархии оси координат представляют собой
описательные шкалы, градациями которых являются признаки, а обобщенные образы
классов (градации классификационных шкал) представляются пространственными кривыми
в эйдос-пространстве, то на 3-м уровне иерархии градациями описательных шкал
являются классы, а пространственные кривые – эйдосы отображают уже кластеры.
Задача
8: показать, что системная
теория информации позволяет непосредственно
на основе эмпирических данных определять вид функций принадлежности, т.е. решать одну из основных задач теории
нечетких множеств.
В теории нечетких множеств,
предложенной в 1965 году Лотфи А. Заде, понятие
множества было обобщено, путем задания функции
принадлежности элемента множеству, количественно задающей степень принадлежности элемента
множеству (в классическом множестве элемент мог либо принадлежать, либо не
принадлежать множеству). Было предложено
несколько различных аналитических видов функций принадлежности и разработаны
операции с нечеткими множествами, зависящие от вида этих априорно заданных
функций.
Таким образом, в теории
нечетких множеств математическое понятие
множества было обогащено свойствами,
и это несколько приблизило его к понятию "система" и позволило получить
более общую теорию, чем классическая теория множеств.
Однако мы считаем, что теория
нечетких множеств является лишь первым шагом и в этом направлении еще много
работы. Например, ясно, что для реальных объектов, моделируемых множествами,
фактический вид функции принадлежности может отличаться от ранее априорно
определенных и затем аксиоматически постулированных и аналитически
исследованных. Между тем именно фактический вид функции принадлежности
характеризует специфику конкретного объекта исследования, и поэтому ее знание
обуславливает адекватность моделирования этого объекта с помощью аппарата
нечетких множеств. Поэтому возникает проблема
определения вида функции принадлежности
непосредственно на основе эмпирических данных и все значения и
актуальность решения этой проблемы общим
универсальным методом трудно переоценить. В настоящее время имеется ряд попыток
найти подобный универсальный метод и
разработать технологию и методику его применения на практике. В разделе 4.8 данной монографии приведен
пример подхода, позволяющего решить эту проблему. Одной из таких попыток
является интеграция теории нечетких множеств и нейронных сетей: так называемые
нечеткие нейронные сети[7].
С применением системной теории
информации (СТИ) также непосредственно на
основе эмпирических данных определяется функция принадлежности элемента
множеству, в частности:
– в информационном портрете
определяется степень принадлежности признака классу;
– при идентификации объекта
определяется степень его сходства с классами;
– при проведении кластерного
анализа определяется степень сходства классов с кластерами.
На рисунке 7 в качестве примера
приведена экранная форма системы "Эйдос", в которой показана степень принадлежности конкретных
образов составов, описанных в обучающей выборке, к обобщенному образу класса:
"Состав, следующий на запад". Таким образом, можно считать, что
данный класс представляет собой нечеткое множество, включающее все составы, следующие
на запад, но в разной степени. Состав-10 наиболее похож на обобщенный образ
данного класса, т.е. является наиболее типичным для него, а состав-3 наименее
типичным. Для составов 1, 2, 3, 4 и 5 степень принадлежности к классу
"Состав, следующий на запад" отрицательна, т.е. они не относятся к
этому классу в соответствии с созданной моделью.
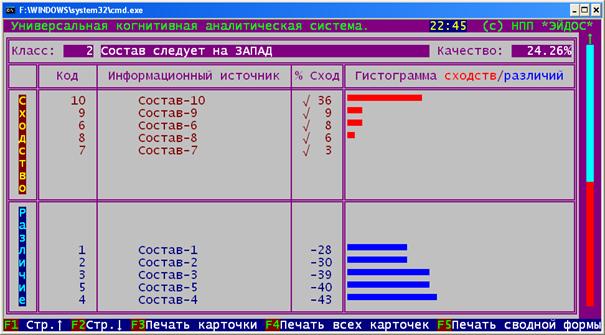
Рисунок 7 – Функция принадлежности конкретных образов
составов обучающей выборки к обобщенному образу класса:
"Состав, следующий на запад"
В таблице 10 приведен
информационный портрет обобщенного образа класса: "Состав, следующий на
запад", включая позитивную и негативную части, т.е. эйдос и антиэйдос.
Таблица 10 – ИНФОРМАЦИОННЫЙ ПОРТРЕТ КЛАССА
РАСПОЗНАВАНИЯ:
Код: 2
Наименование: Состав следует на ЗАПАД
Позитивный и негативный портрет (эйдос и антиэйдос).
Фильтрации по кодам признаков нет.
Фильтрации по модулю информативности нет.
|
Код признака |
Наименования описательных шкал и градаций |
Информативность |
||
|
Бит |
% от теоретически максимально возможной информативности |
Сумма нарастающим итогом, % |
||
|
1 |
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ: |
|
|
|
|
1 |
2 |
0.153 |
15.33 |
15.3 |
|
6 |
ВИД КРЫШИ
ВАГОНА: |
|
|
|
|
16 |
Гофрированная |
0.153 |
15.33 |
30.7 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
21 |
3 маленьких
круга |
0.153 |
15.33 |
46.0 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
25 |
2 коротких
прямоугольника |
0.153 |
15.33 |
61.3 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
31 |
Груза нет |
0.153 |
15.33 |
76.7 |
|
2 |
ФОРМА ВАГОНА: |
|
|
|
|
7 |
U-образная. |
0.093 |
9.33 |
86.0 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
24 |
1 короткий
прямоугольник. |
0.069 |
6.88 |
92.9 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
26 |
1 длинный прямоугольник |
0.069 |
6.88 |
99.7 |
|
3 |
ДЛИНА ВАГОНА: |
|
|
|
|
10 |
Длинный |
0.055 |
5.53 |
105.3 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
19 |
1 большой
круг. |
0.037 |
3.66 |
108.9 |
|
4 |
КОЛИЧЕСТВО
ОСЕЙ ВАГОНА: |
|
|
|
|
11 |
2 |
0.031 |
3.08 |
112.0 |
|
2 |
ФОРМА ВАГОНА: |
|
|
|
|
5 |
Прямоугольная |
0.009 |
0.88 |
112.9 |
|
3 |
ДЛИНА ВАГОНА: |
|
|
|
|
9 |
Короткий. |
0.009 |
0.88 |
113.8 |
|
5 |
ВИД СТЕНОК
ВАГОНА: |
|
|
|
|
13 |
Одинарные |
0.009 |
0.88 |
114.7 |
|
6 |
ВИД КРЫШИ
ВАГОНА: |
|
|
|
|
15 |
Отсутствует |
0.009 |
0.88 |
115.5 |
|
1 |
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ: |
|
|
|
|
3 |
4 |
-0.076 |
-7.57 |
123.1 |
|
2 |
ФОРМА ВАГОНА: |
|
|
|
|
4 |
V-образная. |
-0.076 |
-7.57 |
130.7 |
|
5 |
ВИД СТЕНОК
ВАГОНА: |
|
|
|
|
14 |
Двойные |
-0.076 |
-7.57 |
138.2 |
|
6 |
ВИД КРЫШИ
ВАГОНА: |
|
|
|
|
18 |
Прямая
(эллипсоидная) |
-0.076 |
-7.57 |
145.8 |
|
7 |
ГРУЗ
(КОЛИЧЕСТВО И ВИД): |
|
|
|
|
27 |
1 треугольник |
-0.108 |
-10.79 |
156.6 |
|
1 |
КОЛИЧЕСТВО
ВАГОНОВ В СОСТАВЕ: |
|
|
|
|
2 |
3 |
-0.136 |
-13.57 |
170.2 |
|
4 |
КОЛИЧЕСТВО
ОСЕЙ ВАГОНА: |
|
|
|
|
12 |
3 |
-0.136 |
-13.57 |
183.7 |
Фоном светло-желтого цвета в
информационном портрете выделены положительные информативности, а
светло-зеленого – отрицательные, соответствующие эйдосу и антиэйдосу или эйдосу
и его зеркальной части.
Информативность
в битах – это количество информации, которое мы получаем о принадлежности некоторого объекта к данному классу, если узнаем,
что он обладает этим признаком. Как показано в базовой
когнитивной концепции [97], если мы анализируем только образы конкретных
объектов и никак не обобщаем их, относя к
каким-то классам и называя их обобщенными именами, то не можем
определить, какие признаки этих объектов являются характерными для них, а какие
случайными. Например, если маленький ребенок видит различные мячи впервые и не
знает, что это все мячи, то такие признаки мячей, как круглый и пустой будут
для него столь же важны, как цвет и рисунок на мяче. Однако при обобщении
появляется возможность определить, какие признаки являются более характерными
для того или иного обобщенного класса, какие менее, а какие – вообще
случайными. Это и делается в АСК-анализе
на основе системной теории информации: степень
характерности признака для класса измеряется количеством информации, которое мы получаем из факта наблюдения этого признака о принадлежности к классу. Таким образом, характерные признаки в большей степени принадлежат классу,
нехарактерные – менее, а случайные и принадлежащие другим классам, несходным с
данным, вообще не принадлежат. Это и означает, что системная теория информации и АСК-анализ тесно связаны с теорией нечетких
множеств и даже позволяют решать некоторые важные для этой теории задачи,
такие, например, как определение вида функции принадлежности непосредственно на
основе эмпирических данных и использование знания вида этой функции для решения
задач идентификации, прогнозирования и поддержки принятия решений.
Процент от теоретически
максимально возможной информативности –
это процент, который составляет информативность в битах от теоретически
максимально возможной информативности.
Теоретически-максимальная
возможная информативность полностью определяется суммарным количеством градаций
классификационных шкал, т.е. классов и равна количеству информации, которое мы
получаем, когда достоверно узнаем, что некоторый объект принадлежит к
определенному классу: это количество информации в битах равно двоичному
логарифму от количества классов в семантической информационной модели (мера
Хартли).
Суммарная информативность
нарастающим итогом в процентах – это накопительная сумма от столбца:
"Процент от теоретически максимально возможной информативности". Она
показывает, насколько полно описан информационный потрет класса и есть ли в нем
какая-либо избыточность описания. Если избыточность есть, т.е. суммарное
количество информации в признаках, описывающих потрет, больше 100 %, то это
означает, что существуют корреляции между признаками, т.е. пространство
неортонормированное, если же описание неполное, то это означает, что для
обеспечения полноты описания данного класса в модели необходимо увеличить
размерность эйдос-пространства путем добавления в него новых, желательно,
максимально независимых от уже имеющихся описательных шкал и градаций.
Во всех этих случаях
определена, т.е. имеет смысл, не только положительная принадлежность, но и
отрицательная. Например, отрицательная информативность признака несет информацию
о непринадлежности конкретного
объекта, обладающего этим признаком, к данному классу. Примеры определения конкретного
вида функций принадлежности непосредственно на основе эмпирических данных и
применения этих функций для идентификации и прогнозирования объектов в
различных предметных областях можно обнаружить в работах автора по применению
АСК-анализа: http://ej.kubagro.ru/a/viewaut.asp?id=11.
Правда, во всех этих случаях
функция принадлежности в системе "Эйдос" (являющейся инструментарием
АСК-анализа) задана таблично, но это не является особым ограничением, т.к.
таблично-заданные функции всегда можно аппроксимировать наиболее подходящей в
каком-то смысле аналитической зависимостью, например, степенными полиномами,
полиномами Чебышева или Лагранжа, рядами функций различного вида, Фурье,
степенными, показательными, рядами спецфункций или функций общего вида, как это
принято в АСК-анализе.
Задача
9: сформулировать
перспективы: разработка операций с системами: объединение (сложение),
пересечение (умножение), вычитание. Привести предварительные соображения по
сложению систем.
В качестве перспективы мы
рассматриваем разработку математического формализма, обеспечивающего операции
с системами: объединение (сложение), пересечение (умножение), вычитание.
В предварительном плане мы
приведем здесь некоторые соображения по операции сложения систем. В
отличие от сложения множеств, при сложении систем у системы-суммы появляются
новые эмерджентные свойства, которых не было у систем-слагаемых. Именно эту
особенность сложения систем отражает системная теория информации [97].
Элементы-подмножества системы
отличаются не только количеством базисных элементов, но и тем, какие именно
конкретно это базисные элементы, т.е. элементы, состоящие из одинакового количества базисных
элементов, различаются, если различается, по крайней мере, один из этих
базисных элементов.
Элементы-подсистемы, состоящие
из одних и тех же базисных элементов (0-тождественные элементы), тождественны,
если тождественна их структура, и
отличаются друг от друга, если отличается их структура.
Приведем
примеры.
Лингвистические
системы, в том числе естественный язык (вербализация), являются одним из
наиболее мощных, точных и удачных из всех выработанных человечеством средств
моделирования реальности и отражения ее в сознании. Язык имеет многие системные
свойства реальности, благодаря чему он и является достаточно адекватным для
физического сознания средством ее отражения.
Поэтому в 1-м примере
рассмотрим два предложения, естественно,
состоящие из слов, написанных с помощью букв. Каждое предложение будем рассматривать как систему, состоящую на
базисном уровне из букв, а на 1-м уровне иерархии – из слов. На 0-м уровне
у них будет пересечение, состоящее из общих букв, а 1-м уровне – пересечение,
состоящее из общих слов. Естественно, результаты пересечения систем на 1-м
уровне будут различаться, если считать тождественными только те слова, которые
полностью тождественны по всем буквам, или слова, являющиеся словоформами от одного слова. Рассмотрим
два предложения (таблица 11).
Таблица 11 – ПЕРЕСЕЧЕНИЕ ЛИНГВИСТИЧЕСКИХ
СИСТЕМ
НА 0-М И 1-М ИЕРАРХИЧЕСКИХ УРОВНЯХ ИХ
СТРУКТУРЫ (ПРОЗА)
|
№ |
Система |
0-й
уровень иерархии (буквы) |
1-й
уровень иерархии (слова) |
|
1 |
У лукоморья
дуб зеленый |
бдезйклмно р уыья |
зеленый |
|
2 |
Под дубом
рос зеленый лук |
бдезйклмнопрсуы |
зеленый |
Жирным шрифтом выделены буквы, общие в обоих предложениях. Видно, что
13 букв из 17, которые используются в этих предложениях, общие для обоих
предложений, тогда как из 9 слов общее (тождественно) только одно. Таким
образом, пересечение этих предложений как систем на базисном уровне составляет:
13/17´100=76,47
%, а на 1-м иерархическом уровне – 1/9´100=11,11 %.
Рассмотрим более сложный 2-й
пример со стихами и былинами. При этом, так же как и в 1-м примере, будем считать каждое предложение системой,
состоящей на базисном уровне из букв, а на 1-м уровне иерархии – из слов и
рифм. Однако в отличие от 1-го примера, будем считать тождественными словоформы одного слова, кроме того,
будем учитывать рифму, которую также
отнесем к 1-му уровню иерархии.
Выделим одинаковым цветом
тождественные слова и рифмы:
У
лукоморья дуб зеленый,
Златая
цепь на дубе том:
И
днем, и ночью кот ученый
Все
ходит по цепи кругом
(А.С. Пушкин
"Руслан и Людмила")
Представим результаты анализа
пересечений предложений в виде таблиц 12–15.
Таблица 12 – ПЕРЕСЕЧЕНИЕ
ЛИНГВИСТИЧЕСКИХ СИСТЕМ
НА 0-М УРОВНЕ ИЕРАРХИИ В СИМВОЛАХ
(СТИХИ)
|
PREDL |
P01 |
P02 |
P03 |
P04 |
|
|
P01 |
У
лукоморья дуб зелен-ый |
-бдезйклмноруыь |
-бдезлмноуья |
-дейкмноуыь |
-декмору |
|
P02 |
Златая
цепь на дубе т-ом |
-бдезлмноуья |
-абдезлмноптуць |
-демнотуь |
-демоптуц |
|
P03 |
И
днем, и ночью кот учен-ый |
-дейкмноуыь |
-демнотуь |
,-деийкмнотучыь |
-деикмоту |
|
P04 |
Все
ходит по цепи круг-ом |
-декмору |
-демоптуц |
-деикмоту |
-вгдеикмопрстух |
Таблица 13 – ПЕРЕСЕЧЕНИЕ
ЛИНГВИСТИЧЕСКИХ СИСТЕМ
НА 0-М УРОВНЕ ИЕРАРХИИ В ПРОЦЕНТАХ
(СТИХИ)
|
KOD |
PREDL |
P01 |
P02 |
P03 |
P04 |
|
P01 |
У
лукоморья дуб зелен-ый |
100,000 |
70,588 |
75,000 |
56,250 |
|
P02 |
Златая
цепь на дубе т-ом |
70,588 |
100,000 |
62,500 |
62,500 |
|
P03 |
И
днем, и ночью кот учен-ый |
75,000 |
62,500 |
100,000 |
62,500 |
|
P04 |
Все
ходит по цепи круг-ом |
56,250 |
62,500 |
62,500 |
100,000 |
Таблица 14 – ПЕРЕСЕЧЕНИЕ
ЛИНГВИСТИЧЕСКИХ СИСТЕМ
НА 1-М УРОВНЕ ИЕРАРХИИ В СЛОВОФОРМАХ
(СТИХИ)
|
Код |
PREDL |
P01 |
P02 |
P03 |
P04 |
|
P01 |
У
лукоморья дуб зелен-ый |
дуб
зелен лукоморья ый |
дуб |
ый |
|
|
P02 |
Златая
цепь на дубе т-ом |
дуб |
дубе
златая на ом цепь |
|
ом
цепи |
|
P03 |
И
днем, и ночью кот учен-ый |
ый |
|
днем
кот ночью учен ый |
|
|
P04 |
Все
ходит по цепи круг-ом |
|
ом
цепи |
|
все
круг ом по ходит цепи |
Примечание: в
таблицах 12–15 использован следующий технический
прием: чтобы программа выделила рифмы, как структурные элементы 1-го уровня иерархии,
они отделены знаком тире, используемым в качестве разделителя.
Таблица 15 – ПЕРЕСЕЧЕНИЕ
ЛИНГВИСТИЧЕСКИХ СИСТЕМ
НА 1-М УРОВНЕ ИЕРАРХИИ В ПРОЦЕНТАХ
(СТИХИ)
|
KOD |
PREDL |
P01 |
P02 |
P03 |
P04 |
|
P01 |
У
лукоморья дуб зелен-ый |
100,000 |
25,000 |
25,000 |
0,000 |
|
P02 |
Златая
цепь на дубе т-ом |
25,000 |
100,000 |
0,000 |
40,000 |
|
P03 |
И
днем, и ночью кот учен-ый |
25,000 |
0,000 |
100,000 |
0,000 |
|
P04 |
Все
ходит по цепи круг-ом |
0,000 |
40,000 |
0,000 |
100,000 |
Рассмотрим былинный текст:
У ласкова у
князя у Владимира
Было
пированице, почестен пир,
Для многих
князей, для бояр,
Для русских
могучих богатырей;
Красное
солнышко к вечеру -
Почестный
пир идет на веселие,
Все на пиру
пьяны - веселы,
Все на пиру
порасхвастались:
Богатый
хвастает золотой казной,
Глупый
хвастает молодой женой,
Умный
хвастает старой матерью,
Сильный
хвастает своей силою -
Силою,
ухваткою богатырскою;
За тем за
столом за дубовым
Сидит один
богатырь -
Ничем-то он
молодец не хвастает
(Русская былина
"Сухман".
Владимиро-Суздальский
период.
Cер. XII - конец XIII
века)
Результаты анализа пересечений
предложений из этого текста представлены в таблицах 16–19.



Тождественные или сходные слова, производные от
одного слова (словоформы), рифмы и повторы, особенно широко использовавшиеся в
русских былинах, повышают степень пересечения предложений текста на различных
иерархических уровнях его организации и, тем самым, помогают организовать между
ними смысловую связь, служат смысловыми маркерами, повышают количество связей в
лингвистической системе, а значит повыщают ее уровень системности и легкость
восприятия смысла, а также заряд нетождественности в тексте, т.е. его
невербальную смысловую нагрузку. Таким образом, можно сделать вывод о том, что рифмы
и повторы словоформ повышают уровень системности теста, вследствие чего стихи и
былины можно считать более высокоорганизованной формой текста, чем проза.
Эти результаты получены с помощью программы,
исходный текст которой приведен ниже, разработанной автором при подготовке
данной работы специально с целью исследования пересечений лингвистических
систем на 0-м и 1-м уровнях иерархии языка программирования (xBase++ или
CLIPPER 5.01+TOOLS II):
********************************************************
*** ЛУЦЕНКО Е.В. 04/13/08 10:11am ***
*** Исследование пересечений лингвистических
систем ***
*** на 0-м и 1-м уровнях иерархии (буквы, слова) ***
********************************************************
G_buf=SAVESCREEN(0,0,24,79)
FOR j=0 TO 24
@j,0 SAY
REPLICATE("█",80) COLOR "n/n"
NEXT
***** Если БД исходных предложений нет, то создать ее и
выйти
IF .NOT. FILE("LingvSys.dbf")
CLOSE ALL
CREATE Struc
APPEND BLANK
REPLACE
Field_name WITH "Kod",;
Field_type WITH "C",;
Field_len WITH 5,;
Field_dec WITH 0
APPEND BLANK
REPLACE Field_name WITH "Predl",;
Field_type WITH "C",;
Field_len WITH 65,;
Field_dec WITH 0
APPEND BLANK
REPLACE
Field_name WITH "ListChar",;
Field_type WITH "C",;
Field_len WITH 65,;
Field_dec WITH 0
APPEND BLANK
REPLACE
Field_name WITH "ListWord",;
Field_type WITH "C",;
Field_len WITH 65,;
Field_dec WITH 0
CREATE
LingvSys FROM Struc
Mess =
"Необходимо ввести предложения в БД *LingvSys* и запустить программу
!!!"
@20,
40-LEN(Mess)/2 SAY Mess COLOR "w+/n"
INKEY(0)
INKEY(0)
RESTSCREEN(0,0,24,79,G_buf)
QUIT
ENDIF
********************************************************************
***** 0-й УРОВЕНЬ ИЕРАРХИИ (БУКВЫ)
*********************************
********************************************************************
***** Составить отсортированный список уникальных
символов, входящих в предложения
***** Определить максимальную длину предложения и листа
уникальных символов
CLOSE ALL
USE LingvSys EXCLUSIVE NEW // Открыть БД с предложениями
N_Predl = RECCOUNT() // Кол-во предложений в БД
Max_Pred = -999
Max_List = -999
DBGOTOP()
DO WHILE .NOT. EOF()
REPLACE
ListChar WITH CHARSORT(CHARLIST(LOWER(Predl)))
// Сформировать отсортированный список уникальных букв предложения
Max_Pred =
MAX(Max_Pred, LEN(ALLTRIM(Predl)))
Max_List =
MAX(Max_List, LEN(ALLTRIM(ListChar)))
DBSKIP(1)
ENDDO
***** Создать БД совпадения символов в предложениях
CLOSE ALL
CREATE Struc
APPEND BLANK
REPLACE Field_name WITH "Kod",;
Field_type WITH "C",;
Field_len WITH 5,;
Field_dec WITH 0
APPEND BLANK
REPLACE Field_name WITH "Predl",;
Field_type WITH "C",;
Field_len WITH Max_Pred,;
Field_dec WITH 0
FOR i = 1 TO N_Predl
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Field_name WITH Fn,;
Field_type WITH "C",;
Field_len WITH
Max_List,;
Field_dec WITH 0
NEXT
CREATE SovList0 FROM Struc
***** Создать БД % совпадения символов в предложениях
CLOSE ALL
CREATE Struc
APPEND BLANK
REPLACE Field_name WITH "Kod",;
Field_type WITH "C",;
Field_len WITH 5,;
Field_dec WITH 0
APPEND BLANK
REPLACE Field_name WITH "Predl",;
Field_type WITH "C",;
Field_len WITH Max_Pred,;
Field_dec WITH 0
FOR i = 1 TO N_Predl
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Field_name WITH Fn,;
Field_type WITH "N",;
Field_len WITH 7,;
Field_dec WITH 3
NEXT
CREATE SovPerc0 FROM Struc
***** Заполнить БД совпадения символов в предложениях
***** и БД % совпадений пустыми записями
CLOSE ALL
USE SovPerc0 EXCLUSIVE NEW // Открыть БД совпадения предложений
в %
USE SovList0 EXCLUSIVE NEW // Открыть БД совпадения символов в предложениях
USE LingvSys EXCLUSIVE NEW // Открыть БД с предложениями
FOR i = 1 TO N_Predl
SELECT
LingvSys
DBGOTO(i)
M_Predl =
Predl
SELECT
SovList0
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Kod WITH Fn
REPLACE Predl
WITH M_Predl
SELECT
SovPerc0
APPEND BLANK
REPLACE
Kod WITH Fn
REPLACE Predl
WITH M_Predl
NEXT
****** Построение БД пересечений предложений на уровне
букв
SELECT LingvSys
FOR i=1 TO N_Predl // Цикл по предложениям
DBGOTO(i)
// Переход на запись с 1-м предложением
Ar_List1 =
ListChar
// Присвоить переменной значение 1-го предложения
FOR j=1 TO
N_Predl
// Цикл по предложениям
DBGOTO(j) //
Переход на запись со 2-м предложением
Ar_List2
= ListChar
// Присвоить переменной значение 2-го предложения
M12 =
CHARONE(CHARSORT(CHARONLY(Ar_List1,Ar_List2))) // Получить символы, общие для
обоих предложений (убрав повторы) и отсортировать их
IF
LEN(M12) > 0 // Если
были общие символы
SELECT
SovList0
DBGOTO(i);FIELDPUT(2+j, M12) // Записать пересечение
DBGOTO(j);FIELDPUT(2+i, M12)
SELECT
Lingvsys
// Сделать текущей БД исходных предложений
ENDIF
NEXT
NEXT
****** Расчет % сходства предложений на уровне букв: (%
совпадающих букв
****** от суммарного количества уникальных букв обоих
предложений)
SELECT SovList0
FOR i=1 TO N_Predl // Цикл по строкам предложениям
DBGOTO(i)
Ar_List1 =
FIELDGET(2+i) // Присвоить
переменной значение листа символов 1-го предложения
FOR j=i TO
N_Predl // Цикл по столбцам
предложениям
Ar_List2
= FIELDGET(2+j) // Присвоить переменной
значение листа символов 2-го предложения
Ar_m12 :=
{} // Массив совпадающих символов
обоих предложений
Ar_sum :=
{} // Массив всех уникальных символов
обоих предложений
FOR k=1
TO LEN(Ar_List1)
L =
SUBSTR(Ar_List1, k, 1) // k-й символ
1-го предложения
IF
AT(L, Ar_List2) > 0
IF
ASCAN(Ar_m12, L) = 0
AADD(Ar_m12, L)
ENDIF
ENDIF
IF
ASCAN(Ar_sum, L) = 0
AADD(Ar_sum, L)
ENDIF
NEXT
FOR k=1
TO LEN(Ar_List2)
L =
SUBSTR(Ar_List2, k, 1) // k-й символ
2-го предложения
IF
ASCAN(Ar_sum, L) = 0
AADD(Ar_sum, L)
ENDIF
NEXT
IF
LEN(Ar_sum) > 0
SELECT
SovPerc0
DBGOTO(i);FIELDPUT(2+j, LEN(Ar_m12)/LEN(Ar_sum)*100)
DBGOTO(j);FIELDPUT(2+i, LEN(Ar_m12)/LEN(Ar_sum)*100)
SELECT
SovList0
ENDIF
NEXT
NEXT
********************************************************************
***** 1-й УРОВЕНЬ ИЕРАРХИИ (СЛОВА)
*********************************
********************************************************************
***** Составить отсортированный список уникальных слов,
входящих в предложения
***** Определить максимальную длину предложения и листа
уникальных слов
CLOSE ALL
USE LingvSys EXCLUSIVE NEW // Открыть БД с предложениями
N_Predl = RECCOUNT() // Кол-во предложений в БД
Max_Pred = -999
Max_List = -999
DBGOTOP()
DO WHILE .NOT. EOF()
*** Сформировать
отсортированный список уникальных слов предложения
Ar_word := {}
M_Predl =
Predl
FOR w=1 TO
NUMTOKEN(M_Predl)
M_Word =
ALLTRIM(LOWER(TOKEN(M_Predl, w)))
IF
LEN(M_Word) > 1 //
Исключение предлогов
IF ASCAN(Ar_word, M_Word) = 0 // Исключение повторов слов
AADD(Ar_word, M_Word)
// Добавление слова в массив
ENDIF
ENDIF
NEXT
ASORT(Ar_word)
M_ListWord =
""
FOR w=1 TO
LEN(Ar_word)
M_ListWord
= M_ListWord + Ar_word[w] + " "
NEXT
REPLACE
ListWord WITH ALLTRIM(M_ListWord)
Max_Pred =
MAX(Max_Pred, LEN(ALLTRIM(M_Predl)))
Max_List =
MAX(Max_List, LEN(ALLTRIM(M_ListWord)))
DBSKIP(1)
ENDDO
***** Создать БД совпадения слов в предложениях
CLOSE ALL
CREATE Struc
APPEND BLANK
REPLACE Field_name WITH "Kod",;
Field_type WITH "C",;
Field_len WITH 5,;
Field_dec WITH 0
APPEND BLANK
REPLACE Field_name WITH "Predl",;
Field_type WITH "C",;
Field_len WITH
Max_Pred,;
Field_dec WITH 0
FOR i = 1 TO N_Predl
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Field_name WITH Fn,;
Field_type WITH "C",;
Field_len WITH Max_List,;
Field_dec WITH 0
NEXT
CREATE SovList1 FROM Struc
***** Создать БД % совпадения слов в предложениях
CLOSE ALL
CREATE Struc
APPEND BLANK
REPLACE Field_name WITH "Kod",;
Field_type WITH "C",;
Field_len WITH 5,;
Field_dec WITH 0
APPEND BLANK
REPLACE Field_name WITH "Predl",;
Field_type WITH "C",;
Field_len WITH Max_Pred,;
Field_dec WITH 0
FOR i = 1 TO N_Predl
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Field_name WITH Fn,;
Field_type WITH "N",;
Field_len WITH 7,;
Field_dec WITH 3
NEXT
CREATE SovPerc1 FROM Struc
ERASE("Struc.dbf")
***** Заполнить БД совпадения слов в предложениях
***** и БД % совпадений пустыми записями
CLOSE ALL
USE SovPerc1 EXCLUSIVE NEW // Открыть БД совпадения предложений
в %
USE SovList1 EXCLUSIVE NEW // Открыть БД совпадения сслов в предложениях
USE LingvSys EXCLUSIVE NEW // Открыть БД с предложениями
FOR i = 1 TO N_Predl
SELECT
LingvSys
DBGOTO(i)
M_Predl =
Predl
SELECT
SovList1
APPEND BLANK
Fn =
"P"+STRTRAN(STR(i,2)," ","0")
REPLACE
Kod WITH Fn
REPLACE Predl
WITH M_Predl
SELECT
SovPerc1
APPEND BLANK
REPLACE
Kod WITH Fn
REPLACE Predl
WITH M_Predl
NEXT
*** Построение БД пересечений предложений на уровне
слов
FOR i=1 TO N_Predl // Цикл по
предложениям
SELECT
LingvSys
DBGOTO(i) // Переход
на запись с 1-м предложением
*******
Занести в массив значения слов 1-го предложения
Ar_List1 :=
{}
M_ListWord =
LOWER(ListWord)
FOR w=1 TO
NUMTOKEN(M_ListWord)
M_Word =
ALLTRIM(TOKEN(M_ListWord, w))
IF
ASCAN(Ar_List1, M_Word) = 0 //
Исключение повторов слов
AADD(Ar_List1, M_Word)
// Добваление слова в массив
ENDIF
NEXT
FOR j=1 TO
N_Predl // Цикл по предложениям
DBGOTO(j)
// Переход на запись со 2-м предложением
*******
Занести в массив значения слов 2-го предложения
Ar_List2
:= {}
M_ListWord = LOWER(ListWord)
FOR w=1
TO NUMTOKEN(M_ListWord)
M_Word = TOKEN(M_ListWord, w)
IF
ASCAN(Ar_List2, M_Word) = 0 //
Исключение повторов слов
AADD(Ar_List2, M_Word)
// Добваление слова в массив
ENDIF
NEXT
***
Получить слова и словоформы, ОБЩИЕ для обоих предложений
***
(убрав повторы) и отсортировать их
***
Определить словоформы с использованием расстояния Левенштейна
Krs = 3 // Критерий
сходства словоформ
Ar_m12 :=
{} // Массив
общих словоформ
FOR w1=1
TO LEN(Ar_List1)
FOR
w2=1 TO LEN(Ar_List2)
*** Сравнение сходства двух слов или словоформ
*** с использованием расстояния Левенштейна
IF STRDIFF(Ar_List1[w1], Ar_List2[w2]) <= Krs
Flag_ins = .F.
** Исключение тождественных повторов
IF ASCAN(Ar_m12, Ar_List1[w1]) = 0
Flag_ins = .T.
ENDIF
IF Flag_ins = .F.
*** Исключение повторов словоформ
*** т.е. сходных слов в массиве еще нет
LEN_Ar_m12 = LEN(Ar_m12)
n = 0
FOR k=1 TO LEN_Ar_m12
IF STRDIFF(Ar_m12[k],
Ar_List1[w1]) > Krs
++n
ENDIF
NEXT
IF n = LEN_Ar_m12 // Все
имеющиеся в массиве слова не похожи
Flag_ins = .T.
ENDIF
ENDIF
IF Flag_ins
AADD(Ar_m12, Ar_List1[w1])
// Добавление слова в массив
ENDIF
ENDIF
NEXT
NEXT
*****
Сформировать переменную для записи в БД сходства слов
M_m12 =
""
FOR w=1
TO LEN(Ar_m12)
M_m12
= M_m12 + Ar_m12[w] + " "
NEXT
IF
LEN(Ar_m12) > 0 // Если были
общие слова
SELECT
SovList1
DBGOTO(i);FIELDPUT(2+j, ALLTRIM(M_m12)) // Записать общие слова в БД совпадений
DBGOTO(j);FIELDPUT(2+i, ALLTRIM(M_m12)) // Записать общие слова в БД совпадений
SELECT
Lingvsys
// Сделать текущей БД исходных предложений
ENDIF
NEXT
NEXT
****** Расчет % сходства предложений на уровне слов: (%
совпадающих слов
****** от суммарного количества уникальных слов обоих
предложений)
SELECT SovList1
FOR i=1 TO N_Predl // Цикл по
строкам предложениям
DBGOTO(i)
********
Занести в массив значения слов 1-го предложения
Ar_List1 := {}
M_ListWord =
FIELDGET(2+i)
FOR w=1 TO
NUMTOKEN(M_ListWord)
M_Word =
TOKEN(M_ListWord, w)
AADD(Ar_List1, M_Word)
// Добавление слова в массив
NEXT
FOR j=i TO
N_Predl // Цикл по
столбцам предложениям
********
Занести в массив значения слов 2-го предложения
Ar_List2
:= {}
M_ListWord = FIELDGET(2+j)
FOR w=1
TO NUMTOKEN(M_ListWord)
M_Word = TOKEN(M_ListWord, w)
AADD(Ar_List2, M_Word)
// Добавление слова в массив
NEXT
***
Получить слова, ОБЩИЕ для обоих предложений
***
(убрав повторы) и отсортировать их
***
Определить словоформы с использованием расстояния Левенштейна
Krs = 3
// Критерий сходства словоформ
Ar_m12 :=
{} // Массив совпадающих словоформ
обоих предложений
FOR w1=1
TO LEN(Ar_List1)
FOR
w2=1 TO LEN(Ar_List2)
*** Сравнение сходства двух слов или словоформ
*** с использованием расстояния
Левенштейна
IF STRDIFF(Ar_List1[w1], Ar_List2[w2]) <= Krs
*** Исключение повторов словоформ, т.е. добавлять
*** только если сходных слов в массиве еще нет
LEN_Ar_m12 = LEN(Ar_m12)
n = 0
IF LEN_Ar_m12 > 0
FOR k=1 TO LEN_Ar_m12
IF STRDIFF(Ar_m12[k],
Ar_List1[w1]) > Krs
++n
ENDIF
NEXT
ENDIF
IF n = LEN_Ar_m12 // Все
имеющиеся в массиве слова не похожи
AADD(Ar_m12, Ar_List1[w1]) //
Добавление слова в массив
ENDIF
ENDIF
NEXT
NEXT
****** Формирование
массива уникальных слов
****** и
словоформ, входящих в 1-е, 2-е или в оба предложения
Ar_sum :=
{} // Массив всех уникальных
словоформ обоих предложений
FOR i1=1
TO LEN(Ar_List1)
AADD(Ar_sum, Ar_List1[i1])
// Добавление слова в массив
NEXT
FOR i1=1
TO LEN(Ar_sum)
FOR
j1=1 TO LEN(Ar_List2)
*** Сравнение сходства двух слов или словоформ
*** с использованием расстояния Левенштейна
IF STRDIFF(Ar_sum[i1],
Ar_List2[j1]) <= Krs
*** Исключение повторов словоформ, т.е. добавлять слово
*** только если сходных слов в массиве еще нет
LEN_Ar_sum = LEN(Ar_sum)
n = 0
IF LEN_Ar_sum > 0
FOR k=1 TO LEN_Ar_sum
IF STRDIFF(Ar_sum[k],
Ar_List2[j1]) > Krs
++n
ENDIF
NEXT
ENDIF
IF n = LEN_Ar_sum // Все
имеющиеся в массиве слова не похожи
AADD(Ar_sum, Ar_List2[j1]) //
Добавление слова в массив
ENDIF
ENDIF
NEXT
NEXT
** Занесение
информации в БД % сходства предложений на уровне слов
IF
LEN(Ar_sum) > 0
SELECT
SovPerc1
DBGOTO(i);FIELDPUT(2+j, LEN(Ar_m12)/LEN(Ar_sum)*100)
DBGOTO(j);FIELDPUT(2+i, LEN(Ar_m12)/LEN(Ar_sum)*100)
SELECT
SovList1
ENDIF
NEXT
NEXT
Mess = "Исследование пересечений лингвистических
систем успешно завершено !!!"
@20, 40-LEN(Mess)/2 SAY Mess COLOR "w+/n"
INKEY(0)
INKEY(0)
RESTSCREEN(0,0,24,79,G_buf)
QUIT
Более развитие подходы, основанные на АСК-анализе,
в которых символы имеют различный вес
для идентификации слов (в различной степени характерны для слов или принадлежат
словам), а слова – различный вес для идентификации текстов (в различной степени
характерны для текстов или принадлежат текстам), и эти веса вычисляются на основе примеров (и
эти функции принадлежности вычисляются непосредственно на основе эмпирических
данных), были апробированы автором при решении задач идентификации слов по
входящим в них буквам [147] и атрибуции анонимных и псевдонимных текстов [150].
Итак, сделаем некоторые обобщения.
Две системы тождественны, если тождественны все
их элементы на всех уровнях иерархии, а также тождества их структура, т.е.
взмиосвязи между элементами. В теории множеств о структуре речи не было.
Если есть две системы, то в них могут входить
различные 0-тождественные
элементы-подсистемы. Это означает, что на 0-м уровне иерархии эти системы могут
иметь пересечение в смысле теории
множеств, а на последующих уровнях иерархии его может и не быть.
Определение 10: пересечением двух систем является система, состоящая из
элементов, являющихся пересечением на каждом из имеющихся иерархических уровней
этих систем.
Выводы
Ранее автором была обоснована программная идея
системного обобщения математики и сделан первый шаг по ее реализации: предложен
вариант системной теории информации (СТИ).
В данной работе осуществлена попытка – сделать второй шаг в том же направлении:
рассматривается один из возможных подходов к системному обобщению
математического понятия множества, а
именно – подход, основанный на системной теории информации. Предполагается, что
этот подход может стать основой для системного обобщения теории множеств и
создания математической теории систем.
По ходу обсуждения сформулированных задач и
подходов к их решению было выяснено, что в современной науке уже
созданы научные теории
(более того, они общепризнанны), которые хорошо вписываются в предложенную
программную идею системного обобщения математики как элементы мозаики в общую картину,
контуры которой мы и пытались нащупать. В дальнейшем при реализации
предложенной программной идеи системного обобщения математики эта мозаика будет
дополняться новыми элементами и, в конце
концов, мы увидим всю картину в целом.
Так что
же это за теории?
Прежде всего, это общая теория относительности
(ОТО) Альберта Эйнштейна, основанная на общей идее о том, что физические явления можно
описывать свойствами пространства –
времени, например, гравитацию можно рассматривать как
искривление пространства. В последующем эта идея получила развитие в
работах по геометродинамике Дж. Уиллера, однако, описать другие физические
явления с помощью геометрии оказалось на данном этапе затруднительным, что, по
мнению автора, обусловлено, в том числе, недостаточной развитостью самой
геометрии, в частности бедностью набора свойств геометрических объектов. Будем надеяться, что
разработка системного обобщения геометрии
позволит кардинально преодолеть эту проблему и описать свойства физических
(да и других) объектов и явлений как эмерджентные свойства геометрических
систем, лежащих в их основе и этими свойствами не обладающих. Если эту
идею довести до логического конца, то будет стерта непреодолимая граница между
математикой и физикой, математикой и другими науками. С учетом того, что
системная геометрия и системная теория информации оказываются тесно
взаимосвязанными, можно высказать следующую гипотезу, которая кажется вполне
обоснованной: любые процессы и явления внутреннего и внешнего мира независимо от их
природы можно рассматривать как информационные процессы, в которых
объекты информационно взаимодействуют друг с другом с помощью каналов связи с
определенными характеристиками, и при этом, соответственно, выделяется или
поглощается энергия, изменяется уровень организации, уровень системности
взаимодействующих объектов, изменяется их структура и функции (свойства). Для
целенаправленного изменения структуры и функций объектов и явлений любой
природы, в т.ч. квантовых, можно использовать методы и средства теории
автоматизированного управления, применяя при этом для воздействия на объекты с
целью управления ими информационные, по своей природе, управляющие факторы
(отметим, что эта идея в развитой форме была высказана и реализована еще в 1984
году[8]).
Таким образом, теория информации, ее идеи и методы могут проникнуть во все области науки и
практики, т.к. информация – это предельно общая категория, даже более общая,
чем категории "бытие и небытие", "материя и сознание", так
как что бы мы не говорили об этих или других категориях, мы,
прежде всего, обмениваемся
информацией об их содержании и строим их информационные модели.
Это и фрактальная геометрия Бенуа Мандельброта, в которой, пожалуй,
впервые в геометрии со времен Евклида коренным образом изменено представление о
геометрических объектах в бесконечно-малом, обобщено представление о
размерности пространства, стали систематически рассматриваться эмерджентные
свойства геометрических систем.
Это и теория нечетких множеств Лотфи Заде, в которой может быть
еще не вполне осознанно и целенаправленно, но были обогащены свойства математических множеств, в результате чего, по
сути, нечетким множествам были приписаны отдельные свойства систем.
Все это вселяет надежду, что программная идея
системного обобщения математики является вполне оправданной и обоснованной, и у
нее есть перспективы применения и развития, т.е. действительно может
быть получено системное обобщение любого математического понятия, основанного
на понятии множества, любой области математики, основанной на теории множеств,
путем тотальной замены понятия "множество" на более общее понятие
"система" и прослеживания всех последствий этого. То, что эта
надежда не беспочвенна, подтверждается не только существованием уже
перечисленных выше общепринятых теорий, но и появлением целого ряда новаторских
работ, подобных работам [30, 31, 32], демонстрирующим качественно новый уровень
понимания проблем, связанных с системами и информацией.
Замечание
по вопросу о названии "Системного обобщения теории множеств",
возможность которого мы обсуждали в данном разделе. Для этого обобщения были бы
очень удачны термины: "Математическая теория систем" или
"Информационная теория систем", однако эти термины уже есть в
арсенале науки [24, 25], и при этом в них
вкладывается иное смысловое
содержание. Поэтому, видимо, придется либо несколько переосмыслить это содержание (что кажется более рациональным, т.к.
в науке постоянно происходит процесс переосмысления ее содержания), либо
научное направление, к которому относится данная работа, так и называть: "Системное
обобщение теории множеств".
В заключение
хотелось бы отметить, что авторы полностью осознают весьма спорный характер высказанных в данной работе мыслей и положений, но
все же изложили их потому, что считают их интересными,
поэтому все эти мысли и положения высказываются здесь исключительно в порядке научного обсуждения и ни в коей мере не
претендуют на какую-либо полноту и завершенность.