ГЛАВА 3 ТЕОРЕТИЧЕСКОЕ И МЕТОДОЛОГИЧЕСКОЕ ОПИСАНИЕ СК-АНАЛИЗА
3.1 Теоретическое описание СК-анализа
Для метода СК-анализа разработаны:
теоретические основы, включая базовую когнитивную концепцию; методика численных
расчетов; программный инструментарий; технология и методика их применения.
Системно-когнитивный анализ представляет
собой системный анализ, рассматриваемый как метод познания и структурированный по
базовым когнитивным (познавательным) операциям (БКОСА) [32].
Когнитивная концепция СК-анализа
разработана с учетом двух основных требований:
1. Адекватное отражение в когнитивной
концепции реальных процессов, реализуемых человеком в процессах познания.
2. Высокая степень приспособленности
когнитивной концепции для формализации в виде достаточно простых математических
и алгоритмических моделей, допускающих прозрачную программную реализацию в автоматизированной
системе.
Набор БКОСА следует из предложенной
в [32] формализуемой когнитивной концепции, рассматривающей процесс познания, как
многоуровневую иерархическую систему обработки информации в которой когнитивные
структуры каждого уровня являются результатом интеграции структур предыдущего уровня.
На 1-м уровне этой системы находятся дискретные
элементы потока чувственного восприятия, которые на 2-м уровне интегрируются в чувственный
образ конкретного объекта. Те, в свою очередь, на 3-м уровне интегрируются в обобщенные
образы классов и факторов, образующие на 4-м уровне кластеры, а на 5-м конструкты.
Система конструктов на 6-м уровне образуют текущую парадигму реальности (т.е. человек
познает мир путем синтеза и применения конструктов). На 7-м же уровне обнаруживается,
что текущая парадигма не единственно-возможная (рисунок 4).
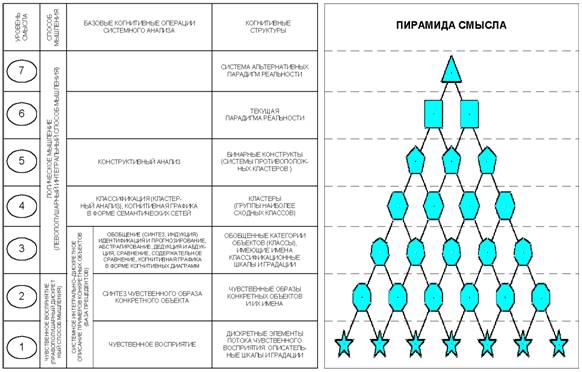
Рисунок 4 - Обобщенная схема формализуемой когнитивной
концепции иерархия базовых когнитивных операций
Ключевым для когнитивной концепции
является понятие факта, под которым понимается соответствие дискретного и интегрального
элементов познания (т.е. элементов разных уровней интеграции-иерархии), обнаруженное
на опыте. Факт рассматривается как квант смысла, что является основой для его формализации.
Таким образом, происхождение смысла
связывается со своего рода "разностью потенциалов", существующей между
смежными уровнями интеграции-иерархии обработки информации в процессах познания.
Из данной концепции выводятся структура
когнитивного конфигуратора, система базовых когнитивных операций и обобщенная схема
автоматизированного системного анализа, структурированного до уровня базовых когнитивных
операций (СК-анализ) (рисунок 5).
Между когнитивными структурами разных
уровней иерархии существует отношение "дискретное – интегральное". Именно
это служит основой формализации смысла.
Рисунок 5 – Обобщенная схема системно-когнитивного
анализа
Когнитивный конфигуратор, представляет
собой минимальную полную систему когнитивных операций, названных "базовые когнитивные
операции системного анализа"
Для решения задачи формализации
БКОСА необходимо решить следующие задачи:
1. Выбор единой интерпретируемой
численной меры для классов и атрибутов.
2. Выбор неметрической меры сходства
объектов в семантических пространствах.
4. Определение идентификационной
и прогностической ценности атрибутов.
5. Ортонормирование семантических
пространств классов и атрибутов (Парето-оптимизация).
При построении модели объекта управления
одной из принципиальных проблем является выбор формализованного представления для
индикаторов, критериев и факторов (далее: факторов). Эта проблема распадается на
две подпроблемы:
1. Выбор и обоснование смысла выбранной
численной меры.
2. Выбор математической формы и
способа определения (процедуры, алгоритма) количественного выражения для значений,
отражающих степень взаимосвязи факторов и будущих состояний активного объекта управления
(АОУ).
Рассмотрим требования к численной
мере, определяемые существом подпроблем. Эти требования вытекают из необходимости
совершать с численными значениями факторов математические операции (сложение, вычитание,
умножение и деление), что в свою очередь необходимо для построения полноценной математической
модели.
Требование 1: из формулировки 1-й
подпроблемы следует, что все факторы должны быть приведены к некоторой общей и универсальной
для всех факторов единице измерения, имеющей какой-то смысл, причем смысл, поддающийся
единой сопоставимой в пространстве и времени интерпретации.
Традиционно в специальной литературе
[57] рассматриваются следующие смысловые значения для факторов: стоимость (выигрыш-проигрыш
или прибыль-убытки); полезность; риск; корреляционная или причинно-следственная
взаимосвязь. Иногда предлагается использовать безразмерные меры для факторов, например
эластичность, однако, этот вариант не является вполне удовлетворительным, т.к. не
позволяет придать факторам содержательный и сопоставимый смысл и получить содержательную
интерпретацию выводов, полученных на основе математической модели.
Таким образом, возникает ключевая
при выборе численной меры проблема выбора смысла, т.е. по сути единиц измерения,
для индикаторов, критериев и факторов.
Требование 2: высокая степень адекватности
предметной области.
Требование 3: высокая скорость сходимости
при увеличении объема обучающей выборки.
Требование 4: высокая независимость
от артефактов.
Что касается конкретной математической
формы и процедуры определения числовых значений факторов в выбранных единицах измерения,
то обычно применяется метод взвешивания экспертных оценок, при котором эксперты
предлагают свои оценки, полученные как правило неформализованным путем. При этом
сами эксперты также обычно ранжированы по степени их компетентности. Фактически
при таком подходе числовые значения факторов является не определяемой, искомой,
а исходной величиной. Иначе обстоит дело в факторном анализе, но в этом методе,
опять же на основе экспертных оценок важности факторов, требуется предварительно,
т.е. перед проведением исследования, принять решение о том, какие факторы исследовать
(из-за жестких ограничений на размерность задачи в факторном анализе). Таким образом
оба эти подхода реализуемы при относительно небольших размерностях задачи, что с
точки зрения достижения целей настоящего исследования, является недостатком этих
подходов.
Поэтому самостоятельной и одной
из ключевых проблем является обоснованный и удачный выбор математической формы для
численной меры индикаторов и факторов.
Эта математическая форма с одной
стороны должна удовлетворять предыдущим требованиям, прежде всего требованию 1,
а также должна быть процедурно вычислимой, измеримой.
Существует большое количество мер
сходства, из которых можно было бы упомянуть скалярное произведение, ковариацию,
корреляцию, евклидово расстояние, расстояние Махалонобиса и др.
Проблема выбора меры сходства состоит
в том, что при выбранной численной мере для координат классов и факторов она должна
удовлетворять определенным критериям:
1. Обладать высокой степенью адекватности
предметной области, т.е. высокой валидностью, при различных объемах выборки, как
при очень малых, так и при средних и очень больших.
2. Иметь обоснованную, четкую, ясную
и интуитивно понятную интерпретацию.
3. Быть нетрудоемкой в вычислительном
отношении.
4. Обеспечивать корректное вычисление
меры сходства для пространств с неортонормированным базисом.
5. Обеспечивать высокую достоверность
и устойчивость идентификации при неполных (фрагментарных) и зашумленных данных.
Не все факторы имеют одинаковую ценность для решения
задач идентификации, прогнозирования и управления. Традиционно считается, что факторы
имеют одинаковую ценность только в тех случаях (обычно в психологии), когда определить
их действительную ценность не представляется возможным по каким-либо причинам.
Для достижения целей, поставленных
в данном исследовании, необходимо решить проблему определения ценности факторов,
т.е. разработать математическую модель и алгоритм, которые допускают программную
реализацию и обеспечивают на практике определение идентификационной и прогностической
ценности факторов.
Если не все факторы имеют одинаковую
ценность для решения задач идентификации, прогнозирования и управления, то возникает
проблема исключения из системы факторов тех из них, которые не представляют особой
ценности.
Удаление малоценных факторов вполне
оправданно и целесообразно, т.к. сбор и обработка информации по ним в среднем связана
с такими же затратами времени, вычислительных и информационных ресурсов, как и при
обработке ценных факторов. В этом состоит идея Парето-оптимизации.
Однако это удаление должно осуществляться
при вполне определенных граничных условиях, характеризующих результирующую систему:
– адекватность модели;
– количество признаков на класс;
– суммарное количество градаций
признаков в описательных шкалах.
В противном случае удаление факторов
может отрицательно сказываться на качестве решения задач. На практике проблема реализации
Парето-оптимизации состоит в том, что факторы вообще говоря коррелируют друг с другом
и поэтому их ценность может изменяться при удалении любого из них, в том числе и
наименее ценного. Поэтому просто взять и удалить наименее ценные факторы не представляется
возможным и необходимо разработать корректный итерационный вычислительный алгоритм
обеспечивающий решение этой проблемы при заданных граничных условиях.
Наличие инструментария АСК-анализа
(базовая система "Эйдос-Х++") [48] позволяет не только осуществить синтез
семантической информационной модели (СИМ), но и периодически проводить адаптацию
и синтез ее новых версий, обеспечивая тем самым ее локализацию для других мест применения
и отслеживание динамики предметной области, сохраняя тем самым высокую адекватность
модели в изменяющихся условиях. Важной особенностью АСК-анализа является возможность
единообразной числовой обработки разнотипных по смыслу и единицам измерения числовых
и нечисловых данных, в т.ч. текстовых и графических. Это обеспечивается тем, что
нечисловым величинам тем же методом, что и числовым, приписываются сопоставимые
в пространстве и времени, а также между собой, количественные значения, имеющие
смысл количества информации или знаний, что позволяет сопоставимо обрабатывать их
как числовые. При этом на первых двух этапах АСК-анализа числовые величины сводятся
к интервальным оценкам, как и информация об объектах нечисловой природы (фактах,
событиях, текстах) (этот этап реализуется и в методах интервальной статистики);
на третьем этапе АСК-анализа всем этим величинам по единой методике, основанной
на системном обобщении семантической теории информации А. Харкевича, сопоставляются
количественные величины (имеющие смысл количества информации или знаний в признаке
о принадлежности объекта к классу), с которыми в дальнейшем и производятся все операции
моделирования (этот этап является уникальным для АСК-анализа).
АСК-анализ обеспечивает:
– выявление знаний о поведении сложной
многопараметрической системы под действием большого количества факторов различной
природы (измеряемых в различных единицах измерения) из эмпирических данных;
– формализацию этих знаний в форме
баз знаний (с оценкой степени их адекватности);
– применение этих знаний для решения
задач прогнозирования и поддержки принятия решений, т.е. управления (рисунок 6).
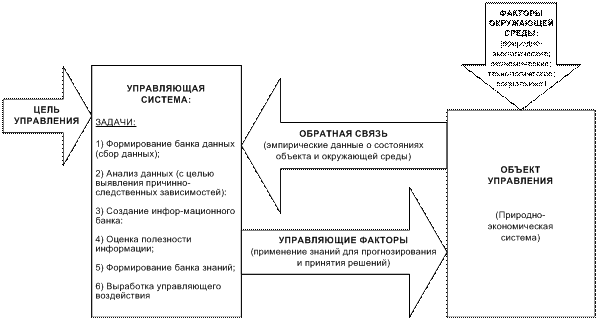
Рисунок 6- Цикл управления в АСК-анализе
Исходные данные об объекте управления
и прогнозирования обычно представлены в форме баз данных, чаще всего временных рядов,
т.е. данных, привязанных ко времени. Использовать для прогнозирования и принятия
решений непосредственно исходные данные не представляется возможным. Для этого необходимо
предварительно преобразовать данные в информацию и знания [34].
Информация есть осмысленные данные.
Смысл данных, в соответствии с концепцией смысл Шенка-Абельсона, состоит в том,
что известны причинно-следственные зависимости между событиями, которые описываются
этими данными. Таким образом, данные преобразуются в информацию в результате операции,
которая называется «Анализ данных» и состоит из двух этапов [34]:
1. Выявление событий в данных.
2. Выявление причинно-следственных
зависимостей между событиями.
Знания – это информация, полезная
для достижения целей.
Адекватным математическим инструментом
для формального представления причинно-следственных зависимостей являются когнитивные
функции. Когнитивные функции представляют собой многозначные интервальные функции
многих аргументов, в которых различные значения функции в различной степени соответствуют
различным значениям аргументов, причем количественной мерой этого соответствия выступает
знания, т.е. информация о причинно-следственных зависимостях в эмпирических данных,
полезная для достижения целей [34].
Математическая модель АСК-анализа
основана на системной теории информации, которая создана в рамках реализации программной
идеи обобщения всех понятий математики, в частности теории информации, базирующихся
на теории множеств, путем тотальной замены понятия множества на более общее понятие
системы и тщательного отслеживания всех последствий этой замены. Благодаря математической
модели, положенной в основу АСК-анализа, этот метод является непараметрическим и
позволяет сопоставимо обрабатывать тысячи градаций факторов (признаков) и будущих
состояний объекта управления (категорий) при неполных (фрагментированных), зашумленных
данных различной природы, т.е. измеряемых в различных единицах измерения.
При этом на этапе синтеза модели
осуществляется многокритериальная типизация респондентов обучающей выборки по исследуемым
категориям, т.е. рассчитывается количество информации, которое содержится в фактах
попадания углов долготы в интервалы (рассматриваемые как критерии), о принадлежности
респондента к тем или иным категориям, а на этапе идентификации эта информация используется
для расчета степени сходства конкретных респондентов с обобщенными категориями.
Результат идентификации респондента,
описанного данной системой признаков, представляет собой список обобщенных категорий
(классов), в котором они расположены в порядке убывания суммарного количества информации
о принадлежности респондента к каждому из них. Математическая модель позволяет сформировать
информационные портреты классов и признаков, а также осуществить их кластерный и
конструктивный анализ.
Информационный портрет класса (обобщенной
категории) показывает какое количество информации содержит каждый признак о принадлежности
респондента к данной категории.
Информационный (семантический) портрет
признака является его развернутой смысловой количественной характеристикой, в которой
содержится информация о принадлежности респондента, обладающего данным признаком,
ко всем обобщенным категориям.
Кластеры классов представляют собой
группы категорий, сходных по характерным для них признакам.
Кластеры признаков представляют
собой группы признаков, сходных по их смыслу, т.е. по тому, какую информацию о принадлежности
респондентов, обладающих этими признаками к обобщенным категориям они содержат.
Под конструктом понимается система
противоположных (наиболее сильно отличающихся) кластеров, которые называются «полюсами»
конструкта, а также спектр промежуточных кластеров, к которым применима количественная
шкала измерения степени их сходства или различия.
Конструкты могут быть получены как
результат кластерного анализа кластеров категорий или признаков, при этом конструкт
рассматривается как кластер с нечеткими границами, включающий в различной степени,
причем не только в положительной, но и в отрицательной, все классы или признаки.
Конструктивный анализ позволяет
определить в принципе совместимые и в принципе несовместимые по характерным для
них признакам классы или обобщенные категории. Совместимыми называются классы, для
которых характерны сходные системы признаков, а несовместимыми – для которых они
диаметрально противоположны и одновременно неосуществимы.
По результатам кластерно-конструктивного
анализа строятся диаграммы смыслового сходства-различия классов (признаков), соответствующие
определению семантических сетей и нечетких когнитивных схем, т.е. представляющие
собой ориентированные графы, в которых классы (признаки) соединены линиями, толщина
которых соответствует модулю, а цвет знаку их сходства-различия.
Предложенная математическая модель
в обобщенной постановке обеспечивает содержательное сравнение классов друг с другом
и признаков друг с другом, т.е. построение когнитивных диаграмм. Например, информационные
портреты классов содержат информацию о характерности признаков для классов.
Кластерно-конструктивный анализ
обеспечивает сравнение классов друг с другом, т.е. дает степень их сходства и различия.
Но он не дает информации о том, какими признаками эти классы похожи и какими отличаются,
и какой вклад каждый признак вносит в сходство или различие некоторых двух классов.
Информация об этом генерируется на основе анализа и сравнения двух информационных
портретов, что и осуществляется при содержательном сравнении классов. Каждая пара
признаков, принадлежащих сравниваемым классам, образует «смысловую связь», вносящую
определенный вклад в сходство/различие между этими классами если эти признаки тождественны
друг другу или между ними имеется определенное сходство/различие по смыслу. Список
связей сортируется в порядке убывания модуля силы связи, причем учитывается не более
заданного их количества (это связано с ограничениями при графическом отображении).
Графической визуализацией результатов содержательного
сравнения классов являются когнитивные диаграммы с многозначными связями. На когнитивной
диаграмме классов отображены их информационные портреты, в которых факторы расположены
в порядке убывания их характерности для этих классов, а линии, соединяющие признаки,
имеют толщину и цвет, соответствующие модулю и знаку их вклада в сходство-различие
классов. Когнитивная диаграмма классов дает детальную расшифровку структуры конкретной
линии связи семантической сети. Кроме того, предложены и реализованы в модели инвертированные
когнитивные диаграммы, детально раскрывающие сходство-различие двух признаков по
их влиянию на принадлежность респондента к различным категориям, а также прямые
и инвертированные диаграммы В.С. Мерлина (1986), в которых показаны уровни и знаки
связей между признаками различных уровней интегративности по их характерности для
различных категорий. Предложены и реализованы также классические и интегральные
когнитивные карты, представляющие собой диаграммы, объединяющие семантические сети
классов и признаков и нелокальные нейронные сети [33, 57].
3.2 Методика численных расчетов СК-анализа
Математическая модель СК-анализа
является реализацией в области теории информации программной идеи системного обобщения
математики.
Классическая формула Хартли имеет
вид:
![]() (1)
(1)
Найдем ее системное обобщение в
виде:
![]() (2)
(2)
Системное обобщение формулы Хартли
для равновероятностных состояний объекта управления имеет вид:
![]() (3)
(3)
где ![]() количество подсистем и m
элементов;
количество подсистем и m
элементов;
m – сложность подсистем;
M – максимальная сложность подсистем.
Так как ![]() , то при M=1 система переходит
в множество и выражение (3) приобретает вид (1), т.е. для него выполняется принцип
соответствия, являющийся обязательным для более общей теории.
, то при M=1 система переходит
в множество и выражение (3) приобретает вид (1), т.е. для него выполняется принцип
соответствия, являющийся обязательным для более общей теории.
Учитывая, что при
M=W:![]() (4)
(4)
Получается
![]() (5)
(5)
Выражение (5) дает приближенную
оценку максимального количества информации в элементе системы. Из выражения (5)
видно, что при увеличении числа элементов W количество информации I быстро стремится
к W (6) и уже при W>4 погрешность выражения (5) не превышает 1%:
При
![]() (6)
(6)
Приняв равные части выражений (2)
и (3) получим выражение для коэффициента эмерджентности Хартли:
![]() (7)
(7)
Необходимо отметить, что при M®1
когда система асимптотически переходит в множество j®1 и (2) ® (1), как и должно
быть согласно принципу соответствия.
С учетом (7) выражение (2) примет
вид:
![]() (8)
(8)
или при M=W и больших W, учитывая
(4 и 5):
![]() (9)
(9)
Выражение (8) и представляет собой
искомое системное обобщение классической формулы Хартли, а выражение (9) – его достаточно
хорошее приближение при большом количестве элементов в системе W.
Классическая формула А.Харкевича
имеет вид:
![]() (10)
(10)
где:![]() – условная вероятность перехода объекта в j-е состояние
при условии действия на него i-го значения фактора;
– условная вероятность перехода объекта в j-е состояние
при условии действия на него i-го значения фактора;
![]() – безусловная вероятность
перехода объекта в j-е состояние (вероятность самопроизвольного перехода или вероятность
перехода, посчитанная по всей выборке, т.е. при действии любого значения фактора).
– безусловная вероятность
перехода объекта в j-е состояние (вероятность самопроизвольного перехода или вероятность
перехода, посчитанная по всей выборке, т.е. при действии любого значения фактора).
Придадим выражению (10) следующий
эквивалентный вид при котором:
![]() (11)
(11)
где: i - признак (значение фактора):
1£ i £ M;
j - состояние объекта или класс:
1£ j £ W;
Pij – условная вероятность наблюдения
i-го значения фактора у объектов в j-го класса;
Pi – безусловная вероятность наблюдения
i-го значения фактора по всей выборке.
Из (11) видно, что формула Харкевича
для семантической меры информации по сути является логарифмом от формулы Байеса
для апостериорной вероятности (отношение условной вероятности к безусловной).
Известно, что классическая формула
Шеннона для количества информации для неравновероятных событий преобразуется в формулу
Хартли при условии, что события равновероятны, т.е. удовлетворяет фундаментальному
принципу соответствия. Поэтому теория информации Шеннона справедливо считается обобщением
теории Хартли для неравновероятных событий.
Однако, выражения (10) и (11) при
подстановке в них реальных численных значений вероятностей Pij, Pj и Pi не дает
количества информации в битах, т.е. для этого выражения не выполняется принцип соответствия,
обязательный для более общих теорий. Возможно, в этом состоит причина довольно сдержанного,
а иногда и скептического отношения специалистов по теории информации Шеннона к семантической
теории информации Харкевича.
Причину этого мы видим в том, что
в выражениях (10) и (11) отсутствуют глобальные параметры конкретной модели W и
M, т.е. в том, что А.Харкевич в своем выражении для количества информации не ввел
зависимости от мощности пространства будущих состояний объекта W и количества значений
факторов M, обуславливающих переход объекта в эти состояния.
Поставим задачу получить такое обобщение
формулы Харкевича, которое бы удовлетворяло тому же самому принципу соответствия,
что и формула Шеннона, т.е. преобразовывалось в формулу Хартли в предельном детерминистском
равновероятном случае, когда каждому классу (состоянию объекта) соответствует один
признак (значение фактора), и каждому признаку – один класс, и эти классы (а, значит
и признаки), равновероятны, и при этом каждый фактор однозначно, т.е. детерминистским
образом определяет переход объекта в определенное состояние, соответствующее классу.
Обобщение формулы (10) найдем в
виде:
![]() (12)
(12)
Найдем такое выражение для коэффициента
![]() , названого нами в честь
А.Харкевича "коэффициентом эмерджентности Харкевича", которое обеспечивает
выполнение для выражения (12) принципа соответствия с классической формулой Хартли
(1) и ее системным обобщением (2 и 3) в равновероятном детерминистском случае.
, названого нами в честь
А.Харкевича "коэффициентом эмерджентности Харкевича", которое обеспечивает
выполнение для выражения (12) принципа соответствия с классической формулой Хартли
(1) и ее системным обобщением (2 и 3) в равновероятном детерминистском случае.
Для этого нам потребуется выразить
вероятности Pij, Pj и Pi через частоты наблюдения признаков по классам (таблица
3). В таблице 1 рамкой обведена область значений, переменные определены ранее. Строки
соответствуют факторам, столбцы – будущим целевым и нежелательным состояниям объекта
управления, а на пересечении приведено количество наблюдений фактов.
Объекты обучающей выборки описываются
векторами (массивами) ![]() имеющихся у них признаков:
имеющихся у них признаков:
![]() (13)
(13)
Первоначально в матрице абсолютных
частот все значения равны нулю. Затем организуется цикл по объектам обучающей выборки.
Если предъявленного объекта относящегося к j-му классу есть i-й признак, то:
![]()
Таблица 3 – Матрица абсолютных частот
|
|
Классы |
Сумма |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Суммарное количество признаков |
|
|
|
|
|
|
|
|
Суммарное количество объектов обучающей выборки |
|
|
|
|
|
N |
|
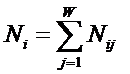
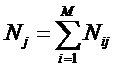
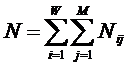
Здесь можно провести очень интересную
и важную аналогию между способом формирования матрицы абсолютных частот и работой
многоканальной системы выделения полезного сигнала из шума. Представим себе, что
все объекты, предъявляемые для формирования обобщенного образа некоторого класса
в действительности являются различными реализациями одного объекта – "Эйдоса"
(в смысле Платона), по-разному зашумленного
различными случайными обстоятельствами. И наша задача состоит в том, чтобы подавить
этот шум и выделить из него то общее и существенное, что отличает объекты данного
класса от объектов других классов. Учитывая, что шум чаще всего является "белым"
и имеет свойство при суммировании с самим собой стремиться к нулю, а сигнал при
этом наоборот возрастает пропорционально количеству слагаемых, то увеличение объема
обучающей выборки приводит ко все лучшему отношению сигнал/шум в матрице абсолютных
частот, т.е. к выделению полезной информации из шума. Примерно так мы начинаем постепенно
понимать смысл фразы, которую мы сразу не расслышали по телефону и несколько раз
переспрашивали. При этом в повторах шум не позволяет понять то одну, то другую часть
фразы, но в конце концов за счет использования памяти и интеллектуальной обработки
информации мы понимаем ее всю. Так и объекты, описанные признаками, можно рассматривать
как зашумленные фразы, несущие нам информацию об обобщенных образах классов: "Эйдосах"
[36, 37], к которым они относятся. И эту информацию мы выделяем из шума при синтезе
модели.
В результате формулы 10, 11 и 12
принимают вид:
![]() (14)
(14)
![]() (15)
(15)
![]() (16)
(16)
![]() (17)
(17)
![]() ,
, ![]() (18)
(18)
![]() =
=![]()
где: Nij – суммарное количество
наблюдений в исследуемой выборке факта: "действовало i-е значение фактора и
объект перешел в j-е состояние";
Nj – суммарное количество встреч
различных факторов у объектов, перешедших в j-е состояние;
Ni – суммарное количество встреч
i-го фактора у всех объектов исследуемой выборки;
N – суммарное количество встреч
различных факторов у всех объектов исследуемой выборки.
На основе анализа матрицы частот
классы можно сравнивать по наблюдаемым частотам признаков только в том случае, если
количество объектов по всем классам одинаково, как и суммарное количество признаков
по классам. Если же они отличаются, то корректно сравнивать классы можно только
по условным и безусловным вероятностям наблюдения признаков, посчитанных на основе
матрицы частот в соответствии с выражениями (14) и (15), в результате чего получается
матрица условных и безусловных вероятностей (процентных распределений) (таблица
4).
Таблица 4 – Матрица условных и безусловных процентных
распределений
|
|
Классы |
Безусловная вероятность признака |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Безусловная вероятность класса |
|
|
|
|
|
|
|
При расчете матрицы условных и безусловных
вероятностей Nj из таблицы 1 могут браться либо из предпоследней, либо из последней
строки. В 1-м случае Nj представляет собой "Суммарное количество признаков
у всех объектов, использованных для формирования обобщенного образа j-го класса",
а во 2-м случае, это "Суммарное количество объектов обучающей выборки, использованных
для формирования обобщенного образа j-го класса", соответственно получаем различные,
хотя и очень сходные семантические информационные модели, которые мы называем СИМ-1
и СИМ-2. Оба этих вида моделей поддерживаются системой "Эйдос".
Эквивалентность выражений (10) и
(11) устанавливается, если подставить в них выражения вероятности Pij, Pj и Pi через
частоты наблюдения признаков по классам из (14-18). В обоих случаях из выражений
(10) и (11) получается одно и тоже выражение (19):
![]() (19)
(19)
Формула (12) будет выглядеть как:
![]() (20)
(20)
При взаимно-однозначном соответствии
классов и признаков в равновероятном детерминистском случае матрица принимает вид
(таблица 3). К каждому классу относится один объект, имеющий единственный признак.
Получаем, что для всех i и j (21):
![]() (21)
(21)
Таким образом, обобщенная формула
А.Харкевича (20) с учетом (21) приобретает вид:
![]() (22)
(22)
В свою очередь:
![]() (23)
(23)
или, учитывая выражение для коэффициента
эмерджентности Хартли (7):
 (24)
(24)
Таблица 5 – Матрица частот в равновероятном
детерминистском случае
|
|
Классы |
Сумма |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения
факторов |
1 |
1 |
|
|
|
|
1 |
|
... |
|
1 |
|
|
|
1 |
|
|
i |
|
|
1 |
|
|
1 |
|
|
... |
|
|
|
1 |
|
1 |
|
|
M |
|
|
|
|
1 |
1 |
|
|
Сумма |
1 |
1 |
1 |
1 |
1 |
N |
|
Подставив коэффициент эмерджентности
А.Харкевича (21) в выражение (20), получим:
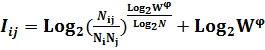 (25)
(25)
На практике для численных расчетов
удобнее использовать формулу (27), которая получается непосредственно из (20) после
подстановки в него выражения (26), когда система эквивалентна множеству (M=1), коэффициент
эмерджентности А.Харкевича приобретает вид:
![]() (26)
(26)
![]() (27)
(27)
В классическом анализе Шеннона идет
речь лишь о передаче символов по одному информационному каналу от одного источника
к одному приемнику. Его интересует, прежде всего, передача самого сообщения.
В данной работе ставится другая
задача: идентифицировать или распознать информационный источник по сообщению от
него. Поэтому метод Шеннона был обобщен путем учета в математической модели возможности
существования многих источников информации, о которых к приемнику по зашумленному
каналу связи приходят не отдельные символы-признаки, а сообщения, состоящие из последовательностей
символов (признаков) любой длины.
Следовательно, ставится задача идентификации
информационного источника по сообщению от него, полученному приемником по зашумленному
каналу. Метод, являющийся обобщением метода К.Шеннона, позволяет применить классическую
теорию информации для построения моделей систем распознавания образов и принятия
решений, ориентированных на применение для синтеза адаптивных АСУ сложными объектами.
Для решения поставленной задачи
необходимо вычислять не средние информационные характеристики, как в теории Шеннона,
а количество информации, содержащееся в конкретном i-м признаке (символе) о том,
что он пришел от данного j-го источника информации. Это позволит определить и суммарное
количество информации в сообщении о каждом информационном источнике, что дает интегральный
критерий для идентификации или прогнозирования состояния объекта.
Логично предположить, что среднее
количество информации, содержащейся в системе признаков о системе классов
![]() (28)
(28)
является ничем иным, как усреднением
(с учетом условной вероятности наблюдения) "индивидуальных количеств информации",
которые содержатся в конкретных признаках о конкретных классах (источниках), т.е.:
![]() (29)
(29)
Необходимо отметить, что применение
сложения в выражении (29) является вполне корректным и оправданным, так как информация
с самого начала вводилась как аддитивная величина, для которой операция сложения
является корректной.
Преобразуем выражение (29) к виду,
более удобному для применения на практике для численных расчетов. Для этого традиционным
для теории информации Шеннона способом выразим вероятности встреч признаков через
частоты их наблюдения:
![]() ,
, ![]() ,
, ![]() (30)
(30)
Подставив (30) в (29), получим:
![]() (31)
(31)
Если ранжировать классы в порядке
убывания суммарного количества информации о принадлежности к ним, содержащейся в
данном сообщении (т.е. описании объекта), и выбирать первый из них, т.е. тот, о
котором в сообщении содержится наибольшее количество информации, то мы получим обоснованную
статистическую процедуру, основанную на классической теории информации, оптимальность
которой доказывается в фундаментальной лемме Неймана-Пирсона [57].
Подставим значения вероятностей
из (30) в (28) и получим выражением для плотности информации Шеннона, выраженное
не через вероятности, а через частоты наблюдения символов, которые рассматриваются
как признаки объектов, т.е. количество информации, содержащееся в отдельном i-м
признаке о том, что другом конце канала связи находится j-й объект (32):
![]() (32)
(32)
Сравнивая выражения (25) и (32)
видим, что в системном обобщении формулы Харкевича 1-е слагаемое практически тождественно
выражению Шеннона для плотности информации, а 2-е слагаемое представляющем собой
плотность информации по Хартли.
Различия состоят в том, что в выражении (25) это
слагаемое возведено в степень, имеющую смысл коэффициента эмерджентности Харкевича.
Поэтому вполне оправданным называть это слагаемое не коэффициентом эмерджентности
Харкевича, а коэффициентом эмерджентности Шеннона-Харкевича. Необходимо отметить
также, что значения частот в этих формулах связаны с вероятностями несколько различным
образом (выражения 14-18 и 30).
Из этого следует также, что полученное
выражение (25) представляет собой нелинейную суперпозицию выражений для плотности
информации Шеннона и Хартли, и, таким образом, является обобщающим выражением для
плотности информации, которое при различных условиях асимптотически переходит в
классические выражения Хартли и Харкевича, а от выражения Шеннона отличается лишь
константой, т.е. 2-м слагаемым, характеризующим мощность множества состояний объекта
в модели.
Это позволяет нам обоснованно высказать
гипотезу о том, что системная теория информации (СТИ), базирующаяся на выражении
(25) для плотности информации, является более общей, чем теории Хартли, Шеннона
и Харкевича и асимптотически связана с ними через принцип соответствия (рисунок
7).
На основе анализа матрицы условных
и безусловных вероятностей (таблица 3) наблюдений признаков по классам и всей выборке
можно сравнивать признаки друг с другом по их роли для сравнения классов друг с
другом и конкретных объектов с обобщенными классами. При этом существует 3 основных
группы признаков:
1 - в одном классе встречаются,
а в других нет. Это детерминистские признаки, обнаружение такого признака у объекта
однозначно определяет его принадлежность к соответствующему классу;
2 - в одном классе встречаются чаще,
чем в других. Это статистические признаки, обнаружение такого признака у объекта
несет некоторую информацию о его принадлежности к соответствующему классу.
3 - в разных классах встречаются
одной и той же вероятностью. Это признаки, обнаружение которых у объекта не несет
никакой информации о его принадлежности к тем или иным классам.
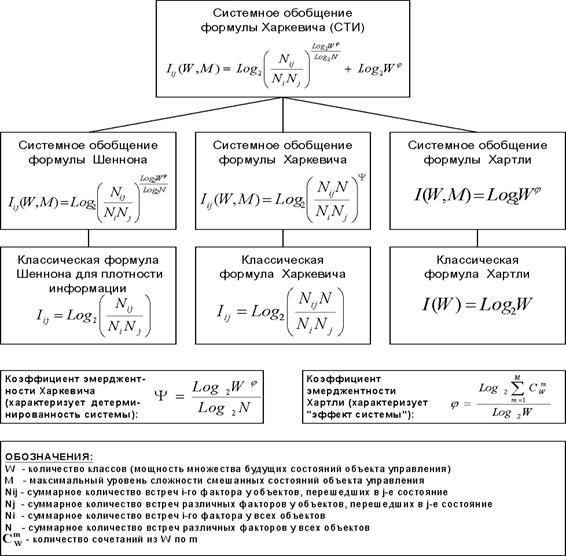
Рисунок 7 – Генезис системной (эмерджентной) теории
информации
Используя таблицу 4, проанализировав
условные вероятности (или процентные распределения) признаков по классам, можно
вынести правдоподобные суждения о принадлежности объектов, обладающих этими признакам
к тем или иным классам.
Но при этом существуют два недостатка:
1. Для того, чтобы отнести признак
к одной из вышеперечисленных групп необходимо сравнивать вероятности его наблюдения
по классам, т.е. каждый раз при таком сравнении выполнять соответствующую необходимую
для этого работу.
2. При отнесении признака ко 2-й
группе этого самого по себе еще недостаточно для его использования с целью идентификации
объекта, а необходимо еще оценить количество информации, которое содержится в факте
обнаружения у объекта этого признака о принадлежности этого объекта к каждому из
классов, а для этого необходим соответствующий математический и численный метод.
Что касается 1-го недостатка, то
о нем можно сказать, что для реальных задач большой размерности выполнение этого
сравнения вручную практически невозможно, а значит тем более невозможно и использование
результатов этого сравнения для решения задач идентификации, прогнозирования и поддержки
принятия решений, а тем более для исследования предметной области путем исследования
ее модели. Все это обусловлено тем, что результат сравнения вероятностей встречи
признака по классам не представляется при ручной обработке в количественной форме
некоторого одного числа: частного критерия, величина и знак которого отражали бы
результат такого сравнения.
2-й недостаток преодолевается методом,
который предложен А.Харкевичем в выражениях (10) и (11) и уточнен нами в системном
обобщении этих выражений (20). В этом методе предложено сравнивать не условные вероятности
наблюдения признаков по различным классам друг с другом, а условную вероятность
наблюдения признака по классу с безусловной вероятностью его наблюдения по всей
выборке.
Это предложение по своей сути полностью
соответствует известному статистическому методу отклонений от средних и нормативному
подходу, когда в качестве базы сравнения выбирается норма, т.е. среднее по всей
группе. На основе этого подхода формируются и критерии сравнения, т.е. можно сказать,
что критериальный подход изначально основан на нормативном.
Если такое сравнение провести по
всем признакам и классам, то получится матрица, снимающая оба указанных недостатка:
используя выражение (20) и данные таблицы 3 непосредственно прямым счетом получаем
матрицу знаний (таблица 6):
Таблица 6 – Матрица знаний информативностей
|
|
Классы |
Значимость фактора |
|||||
|
1 |
... |
j |
... |
W |
|||
|
Значения факторов |
1 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
Степень редукции класса |
s1 |
|
sj |
|
sW |
|
|
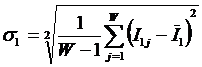
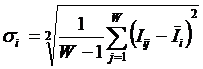
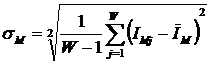
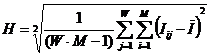
Среднее количество знаний в i-м
значении фактора (![]() ) определяется:
) определяется:
![]() (33)
(33)
При расчете матрицы знаний Nj из
таблицы 1 могут браться либо из предпоследней, либо из последней строки. В 1-м случае
Nj представляет собой "Суммарное количество признаков у всех объектов, использованных
для формирования обобщенного образа j-го класса", а во 2-м случае, это "Суммарное
количество объектов обучающей выборки, использованных для формирования обобщенного
образа j-го класса", соответственно получаем различные, хотя и очень сходные
семантические информационные модели, которые мы называем СИМ-1 и СИМ-2. Оба этих
вида моделей поддерживаются системой "Эйдос".
Количественные значения коэффициентов
![]() таблицы 4 являются знаниями о том, что "объект
перейдет в j-е состояние" если "на объект действует i-е значение фактора".
таблицы 4 являются знаниями о том, что "объект
перейдет в j-е состояние" если "на объект действует i-е значение фактора".
Принципиально важно, что эти весовые
коэффициенты не определяются экспертами на основе опыта интуитивным неформализуемым
способом, а рассчитываются непосредственно на основе эмпирических данных на основе
теоретически обоснованной модели, хорошо зарекомендовавшей себя на практике при
решении широкого круга задач в различных предметных областях.
Когда количество информации ![]() >0 – i–й фактор способствует
переходу объекта управления в j-е состояние, когда
>0 – i–й фактор способствует
переходу объекта управления в j-е состояние, когда ![]() <0 – препятствует этому
переходу, когда же
<0 – препятствует этому
переходу, когда же ![]() =0 – никак не влияет на это.
В векторе i-го фактора (строка матрицы информативностей) отображается, какое количество
информации о переходе объекта управления в каждое из будущих состояний содержится
в том факте, что данный фактор действует. В векторе j-го состояния класса (столбец
матрицы информативностей) отображается, какое количество информации о переходе объекта
управления в соответствующее состояние содержится в каждом из факторов.
=0 – никак не влияет на это.
В векторе i-го фактора (строка матрицы информативностей) отображается, какое количество
информации о переходе объекта управления в каждое из будущих состояний содержится
в том факте, что данный фактор действует. В векторе j-го состояния класса (столбец
матрицы информативностей) отображается, какое количество информации о переходе объекта
управления в соответствующее состояние содержится в каждом из факторов.
Таким образом, матрица знаний (информативностей)
(таблица 4) является обобщенной таблицей решений, в которой входы (факторы) и выходы
(будущие состояния объекта управления) связаны друг с другом не с помощью классических
(Аристотелевских) импликаций, принимающих только значения: "Истина" и
"Ложь", а различными значениями истинности, выраженными в битах и принимающими
значения от положительного теоретически-максимально-возможного ("Максимальная
степень истинности"), до теоретически неограниченного отрицательного ("Степень
ложности").
Фактически предложенная модель позволяет
осуществить синтез обобщенных таблиц решений для различных предметных областей непосредственно
на основе эмпирических исходных данных и продуцировать на их основе прямые и обратные
правдоподобные (нечеткие) логические рассуждения по неклассическим схемам с различными
расчетными значениями истинности, являющимся обобщением классических импликаций.
Таким образом, данная модель позволяет
рассчитать какое количество информации содержится в любом факте о наступлении любого
события в любой предметной области, причем для этого не требуется повторности этих
фактов и событий. Если же эти повторности осуществляются и при этом наблюдается
некоторая вариабельность значений факторов, обуславливающих наступление тех или
иных событий, то модель обеспечивает многопараметрическую типизацию, т.е. синтез
обобщенных образов классов или категорий наступающих событий с количественной оценкой
степени и знака влияния на их наступление различных значений факторов. Причем эти
значения факторов могут быть как количественными, так и качественными и измеряться
в любых единицах измерения, в любом случае в модели оценивается количество информации
которое в них содержится о наступлении событий, переходе объекта управления в определенные
состояния или просто о его принадлежности к тем или иным классам.
Кроме этого, данная модель позволяет
прогнозировать поведение объекта управления при воздействии на него не только одного,
но и целой системы факторов:
![]() (34)
(34)
В теории принятия решений скалярная
функция Ij векторного аргумента называется интегральным критерием. Основная проблема
состоит в выборе такого аналитического вида функции интегрального критерия, который
обеспечил бы эффективное решение сформулированной выше задачи АСУ.
Учитывая, что частные критерии (20)
имеют смысл количества информации, а информация по определению является аддитивной
функцией, предлагается ввести интегральный критерий, как аддитивную функцию от частных
критериев в виде:
![]() (35)
(35)
где ![]() – вектор j-го класса-состояния объекта управления;
– вектор j-го класса-состояния объекта управления;
![]() – вектор состояния предметной области, включающий
все виды факторов, характеризующих объект управления, возможные управляющие воздействия
и окружающую среду (массив-локатор), т.е.:
– вектор состояния предметной области, включающий
все виды факторов, характеризующих объект управления, возможные управляющие воздействия
и окружающую среду (массив-локатор), т.е.:
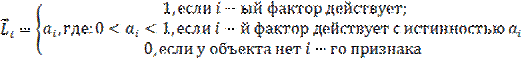 (36)
(36)
В реализованной модели значения
координат вектора состояния предметной области принимались равными либо 1 (фактор
действует), либо 0 (фактор не действует).
Таким образом, интегральный критерий
представляет собой суммарное количество информации, содержащееся в системе значений
факторов различной природы (т.е. факторах, характеризующих объект управления, управляющее
воздействие и окружающую среду) о переходе объекта управления в то или иное будущее
состояние.
В многокритериальной постановке
задача прогнозирования состояния объекта управления, при оказании на него заданного
многофакторного управляющего воздействия Ij, сводится к максимизации интегрального
критерия:
![]() (37)
(37)
Задача принятия решения о выборе
наиболее эффективного управляющего воздействия является обратной задачей по отношению
к задаче максимизации интегрального критерия (идентификации и прогнозирования),
т.е. вместо того, чтобы по набору факторов прогнозировать будущее состояние объекта,
наоборот, по заданному (целевому) состоянию объекта определяется такой набор факторов,
который с наибольшей эффективностью перевел бы объект управления в это состояние.
Предлагается еще одно обобщение
фундаментальной леммы Неймана-Пирсона, основанное на косвенном учете корреляций
между информативностями в векторе состояний при использовании средних по векторам.
Соответственно, вместо простой суммы количеств информации предлагается использовать
корреляцию между векторами состояния и объекта управления, которая количественно
измеряет степень сходства этих векторов:
![]() (38)
(38)
где: ![]() – средняя информативность по вектору класса;
– средняя информативность по вектору класса;
![]() – среднее по вектору идентифицируемой ситуации
(объекта).
– среднее по вектору идентифицируемой ситуации
(объекта).
![]() – среднеквадратичное отклонение информативностей
вектора класса;
– среднеквадратичное отклонение информативностей
вектора класса;
![]() – среднеквадратичное отклонение по вектору распознаваемого
объекта.
– среднеквадратичное отклонение по вектору распознаваемого
объекта.
Важно также отметить неметрическую
природу предложенного интегрального критерия сходства, благодаря чему его применение
является корректным и при неортонормированном семантическом информационном пространстве,
каким оно в подавляющем количестве случае и является, т.е. в общем случае.
Результат прогнозирования поведения
объекта управления, описанного данной системой факторов, представляет собой список
его возможных будущих состояний, в котором они расположены в порядке убывания суммарного
количества информации о переходе объекта управления в каждое из них.
Статистика ![]() представляет собой сумму вероятностей совместного
наблюдения признаков и объектов по всей корреляционной матрице или определенным
ее подматрицам (т.е. сумму относительных отклонений частот совместного наблюдения
признаков и объектов от среднего):
представляет собой сумму вероятностей совместного
наблюдения признаков и объектов по всей корреляционной матрице или определенным
ее подматрицам (т.е. сумму относительных отклонений частот совместного наблюдения
признаков и объектов от среднего):
![]() (39)
(39)
где ![]() – фактическое количество встреч i-го признака у
объектов j-го класса;
– фактическое количество встреч i-го признака у
объектов j-го класса;
t – ожидаемое количество встреч i-го признака у
объектов j-го класса.
при чем ![]() (40)
(40)
Статистика ![]() математически связана с количеством информации
в системе признаков о классе распознавания в соответствии с системным обобщением
формулы Харкевича для плотности информации (20) и формулы 40 получим:
математически связана с количеством информации
в системе признаков о классе распознавания в соответствии с системным обобщением
формулы Харкевича для плотности информации (20) и формулы 40 получим:
![]() (41)
(41)
или ![]() (42)
(42)
Сравнивая выражения (39) и (42),
видим, что числитель в выражении (39) под знаком суммы отличается от выражения (42)
только тем, что в выражении (37) вместо значений Nij и t взяты их логарифмы. Так
как логарифм является монотонно возрастающей функцией аргумента, то введение логарифма
не меняет общего характера поведения функции.
Фактически это означает, что:
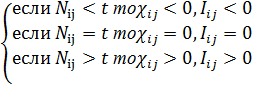 (43)
(43)
Из изложенного следует интерпретация
системной меры информации (41) с учетом статистики ![]() (39): если фактическая вероятность наблюдения i-го
признака при предъявлении объекта j-го класса равна ожидаемой (средней), то наблюдение
этого признака не несет никакой информации о принадлежности объекта к данному классу.
Если она выше средней, то это свидетельствует в пользу того, что предъявлен объект
данного класса, если ниже – то другого.
(39): если фактическая вероятность наблюдения i-го
признака при предъявлении объекта j-го класса равна ожидаемой (средней), то наблюдение
этого признака не несет никакой информации о принадлежности объекта к данному классу.
Если она выше средней, то это свидетельствует в пользу того, что предъявлен объект
данного класса, если ниже – то другого.
Поэтому наличие статистической связи (информации)
между признаками и классами распознавания, т.е. отличие вероятностей их совместных
наблюдений от предсказываемого в соответствии со случайным нормальным распределением,
приводит к увеличению фактической статистики ![]() по сравнению с теоретической величиной.
по сравнению с теоретической величиной.
Из этого следует возможность использования в качестве
количественной меры степени выраженности закономерностей в предметной области не
матрицы абсолютных частот и меры ![]() , а новой меры H, основанной
на матрице информативностей и системном обобщении формулы Харкевича для количества
информации:
, а новой меры H, основанной
на матрице информативностей и системном обобщении формулы Харкевича для количества
информации:
![]() (44)
(44)
Отсюда ![]() (45)
(45)
Меру H в выражении (45) предлагается назвать обобщенным
критерием степени сформированности модели Харкевича.
Значение данной меры показывает среднее отличие количества
информации в факторах о будущих состояниях активного объекта управления от среднего
количества информации в факторе (которое при больших выборках близко к 0). По своей
математической форме эта мера сходна с мерами для значимости (интегральной информативности)
факторов и степени сформированности образов классов и коррелирует с объемом неортонормированного
семантического информационного пространства классов и семантического информационного
пространства атрибутов.
Вышеописанная математическая модель обеспечивает
инвариантность результатов ее синтеза относительно следующих параметров обучающей
выборки: суммарное количество и порядок ввода анкет обучающей выборки; количество
анкет обучающей выборки по каждому классу распознавания; суммарное количество признаков
во всех анкетах обучающей выборки; суммарное количество признаков по классам распознавания;
количество признаков и их порядок в отдельных анкетах обучающей выборки. Это обеспечивает
высокую степень качества решения задач распознавания на неполных и разнородных (в
вышеперечисленных аспектах) данных как обучающей, так и распознаваемой выборки,
т.е. при таких статистических характеристиках потоков этих данных, которые чаще
всего и встречается на практике и которыми невозможно или очень сложно управлять.
Оценка адекватности семантической информационной
модели в СК-анализе и бутстрепные методы
Под адекватностью модели СК-анализа понимается ее
внутренняя и внешняя дифференциальная и интегральная валидность. Понятие валидности
является уточнением понятия адекватности, для которого определены процедуры количественного
измерения, т.е. валидность – это количественная адекватность. Это понятие количественно
отражает способность модели давать правильные результаты идентификации, прогнозирования
и способность вырабатывать правильные рекомендации по управлению.
Под внутренней валидностью понимается валидность
модели, измеренная после синтеза модели путем идентификации объектов обучающей выборки.
Под внешней валидностью понимается валидность модели,
измеренная после синтеза модели путем идентификации объектов, не входящих в обучающую
выборку.
Под дифференциальной валидностью модели понимается
достоверность идентификации объектов в разрезе по классам.
Под интегральной валидностью средневзвешенная дифференциальная
валидность.
Возможны все сочетания: внутренняя дифференциальная
валидность, внешняя интегральная валидность и т.д.
Основная идея бутстрепа по Б.Эфрону [57] состоит
в том, что методом Монте-Карло (статистических испытаний) многократно извлекаются
выборки из эмпирического распределения. Эти выборки, естественно, являются вариантами
исходной, напоминают ее.
Эта идея позволяет сконструировать алгоритм измерения
адекватности модели, состоящий из двух этапов:
1. Синтез модели на одном случайном подмножестве
обучающей выборки.
2. Измерение валидности модели на оставшемся подмножестве
обучающей выборки, не использованном для синтеза модели.
Поскольку оба случайных подмножества имеют переменный
состав по объектам обучающей выборки, то подобная процедура должна повторяться много
раз, после чего могут быть рассчитаны статистические характеристики адекватности
модели, например, такие как:
– средняя внешняя валидность;
– среднеквадратичное отклонение текущей внешней валидности
от средней и другие.
Достоинство бутстрепного подхода к оценке адекватности
модели состоит в том, что он позволяет измерить внешнюю валидность на уже имеющейся
выборке и изучить статистические характеристики, характеризующие адекватность модели
при изменении объема и состава выборки.
Предложенная семантическая информационная модель
является непараметрической, т.к. базируется на системной теории информации [32],
которая никоим образом не основана на предположениях о нормальности распределений
исследуемой выборки.
Под робастными понимаются процедуры,
обеспечивающие устойчивую работу модели на исходных данных, зашумленных артефактами,
т.е. данными, выпадающими из общих статистических закономерностей, которым подчиняется
исследуемая выборка.
Критерий выявления артефактов, реализованный
в СК-анализе, основан на том, что при увеличении объема статистики частоты значимых
атрибутов растут, как правило, пропорционально объему выборки, а частоты артефактов
так и остаются чрезвычайно малыми, близкими к единице. Таким образом, выявление
артефактов возможно только при достаточно большой статистике, т.к. в противном случае
недостаточно информации о поведении частот атрибутов с увеличением объема выборки.
В модели реализована такая процедура
удаления наиболее вероятных артефактов, и она, как показывает опыт, существенно
повышает качество (адекватность) модели.
3.3 Методика применения СК-анализа и программный
инструментарий системы «Эйдос – Х++»
Методика СК-анализа обеспечивает
повышение степени формализации знаний о предметной области до уровня, достаточного
для представления знаний в автоматизированной системе искусственного интеллекта
и решения в ней задач идентификации, прогнозирования и поддержки принятия решений
(управления), которая включает следующие этапы:
1) когнитивная структуризация предметной
области;
2) формализация предметной области
(определение классификационных и описательных шкал и градаций);
3) подготовка обучающей выборки
(ввод данных мониторинга в базу прецедентов);
4) синтез и верификация семантической
информационной модели (измерение внутренней и внешней, дифференциальной и интегральной
валидности);
7) системно-когнитивный анализ СИМ, исследование
моделируемого объекта с помощью:
– решения задач идентификации и прогнозирования;
– генерации информационных портретов классов и факторов
(решение обратной задачи прогнозирования, поддержка принятия решений по управлению);
– кластерно-конструктивный анализ классов и факторов
(результаты отображаются в форме семантических сетей классов и факторов);
– содержательное сравнение классов и факторов (результаты
отображаются в форме когнитивных диаграмм классов и факторов);
– изучение системы детерминации состояний моделируемого
объекта, нелокальные нейроны и интерпретируемые нейронные сети;
– изучение когнитивных функций (функции влияния);
– построение классических когнитивных моделей (когнитивных
карт).
– построение интегральных когнитивных моделей (интегральных
когнитивных карт).
Выполнение этих этапов обеспечивается с помощью специального
программного инструментария АСК-анализа – универсальной когнитивной аналитической
системы «Эйдос –Х++», которая является отечественным лицензионным программным продуктом
[54, 55], созданным исключительно с использованием официально приобретенного лицензионного
программного обеспечения.
Общая структура системы «Эйдос –Х++» представлена
в приложении 1.
Для разработки информационной модели предметной области
необходимо владеть основными принципами ее когнитивной структуризации и формализованного
описания. Преобразование эмпирических данных в информацию, а затем и знания в автоматизированном
системно-когнитивном анализе и его программном инструментарии – системе «Эйдос-Х++»
(рисунок 8).
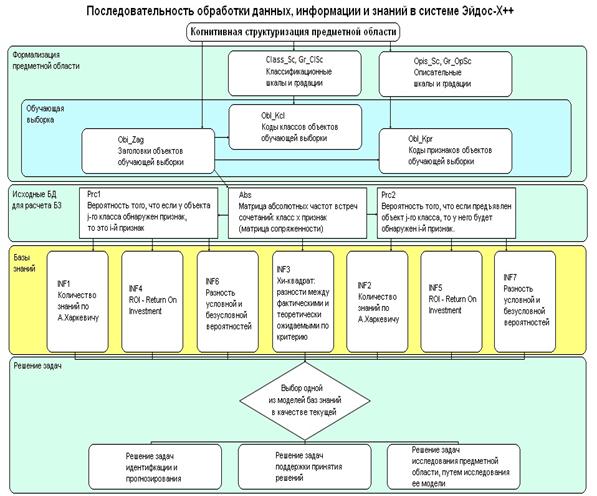
Рисунок 8
- Последовательность обработки данных, информации и знаний в системе «Эйдос-Х++»
Синтез содержательной информационной модели включает
следующие этапы:
1. Формализация (когнитивная структуризация предметной
области).
2. Формирование исследуемой выборки и управление
ею.
3. Синтез или адаптация модели.
4. Оптимизация модели.
5. Измерение адекватности модели (внутренней и внешней,
интегральной и дифференциальной валидности), ее скорости сходимости и семантической
устойчивости.
Идентификация и прогнозирование состояния объекта
управления, выработка управляющих воздействий включает:
1. Ввод распознаваемой выборки.
2. Пакетное распознавание.
3. Вывод результатов распознавания и их оценку.
Углубленный анализ содержательной информационной
модели предметной области выполняется в подсистеме "Типология" и включает:
1. Информационный и семантический анализ классов
и признаков.
2. Кластерно-конструктивный анализ классов распознавания
и признаков, включая визуализацию результатов анализа в оригинальной графической
форме когнитивной графики (семантические сети классов и признаков).
3. Когнитивный анализ классов и признаков (когнитивные
диаграммы и диаграммы Вольфа Мерлина).
Кроме этого система «Эйдос-X++» обеспечивает графическую
визуализацию результатов анализа в форме когнитивной графики (простых и интегральных
когнитивных карт, семантических сетей и когнитивных диаграмм).
В системе «Эйдос-X++» представлены семь моделей знаний,
частные критерии которых рассчитываются по (таблица 7): А. Харкевичу (два варианта
расчета); Хи-квадрат, ROI (два варианта расчета); коэффициент взаимосвязи, т.е.
разность условной и безусловной вероятностей (два варианта расчета).
Важной особенностью АСК-анализа является возможность
единообразной числовой обработки разнотипных числовых и нечисловых данных.
Это обеспечивается тем, что нечисловым величинам
тем же методом, что и числовым, приписываются сопоставимые в пространстве и времени,
а также между собой, количественные значения, позволяющие обрабатывать их как числовые:
Таблица 7 – Частные критерии знаний системы «Эйдос-Х++»
|
Наименование модели знаний |
Выражение через частоты |
|
|
относительные |
абсолютные |
|
|
INF1, частный критерий: количество знаний по А.Харкевичу,
1-й вариант расчета вероятностей: Nj – суммарное количество признаков по j-му
классу. Вероятность того, что если у объекта j-го класса обнаружен признак, то
это i-й признак |
|
|
|
INF2, частный критерий: количество знаний по А.Харкевичу,
2-й вариант расчета вероятностей: Nj – суммарное количество объектов по j-му классу.
Вероятность того, что если предъявлен объект j-го класса, то у него будет обнаружен
i-й признак. |
|
|
|
INF3, частный критерий: Хи-квадрат: разности между
фактическими и теоретически ожидаемыми абсолютными частотами |
- |
|
|
INF4, частный критерий: ROI - Return On Investment,
1-й вариант расчета вероятностей: |
|
|
|
INF5, частный критерий: ROI - Return On Investment,
2-й вариант расчета вероятностей: |
|
|
|
INF6, частный критерий: разность условной и безусловной
вероятностей, |
|
|
|
INF7, частный критерий: разность условной и безусловной
вероятностей, |
|
|
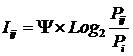
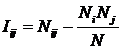
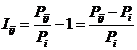
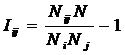
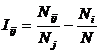
- на первых двух этапах
АСК-анализа числовые величины сводятся к интервальным оценкам, как и информация
об объектах нечисловой природы (фактах, событиях) (этот этап реализуется и в
методах интервальной статистики);
- на третьем этапе АСК-анализа
всем этим величинам по единой методике, основанной на системном обобщении семантической
теории информации [32], сопоставляются количественные величины (имеющие смысл
количества информации в признаке о принадлежности объекта к классу), с которыми
в дальнейшем и производятся все операции моделирования (этот этап является
уникальным для АСК-анализа).
Подводя итог, можно отметить, что
автоматизированный системно-когнитивный анализ является одним из современных
методов, оснащенный широко и успешно апробированным универсальным программным инструментарием
(система "Эйдос-Х++"), математическая модель которого, а также методика
численных расчетов (структуры данных и алгоритмы), технология их применения являются
адекватным инструментом для прогнозирования и поддержки принятия решений в зерновом
производстве по выбору агротехнологий.