ГЛАВА 2. СИСТЕМА «ЭЙДОС-АСТРА»
В работе [1] был поставлен
вопрос: действительно ли существуют зависимости между астрономическими признаками респондентов
на момент рождения (астропризнаками) и обобщенными категориями, отражающими
социальный статус личности (т.к. астросоциотипами)?
По мнению авторов, на этот
вопрос, имеющий фундаментальное научное значение, был получен
убедительный положительный ответ, т. е. с применением автоматизированного системно-когнитивного
анализа (АСК-анализ) [3] – нового метода искусственного интеллекта и его
инструментария – системы «Эйдос» [36] были созданы модели, позволяющие
обоснованно утверждать, что эти зависимости существуют и их характер выявлен и
известен нам [2].
Необходимо отметить, что из
более 11000 категорий нами было выявлено всего лишь несколько десятков наиболее
статистически представленных категорий, для которых эти связи оказались
наиболее сильными [4].
В той же статье [1] был сформулирован
и второй вопрос, закономерно вытекающий из первого: возможно ли знание этих зависимостей между
астропризнаками и социальными типами использовать для идентификации
респондентов на практике?
Для положительного ответа на
второй вопрос необходимо не только выявить зависимости между астропризнаками и
социальным статусом респондентов, но и разработать такие модели и
технологии, которые бы обеспечили настолько высокий уровень достоверности
идентификации, чтобы это могло представлять уже не только научный, но и
прикладной интерес. В 2007 году нами были предприняты усилия по
созданию таких моделей и технологий.
В самом начале
исследований и разработок в области астросоциотипологии (такое название
получило новое научное направление, предложенное и развиваемое авторами в
рамках астросоциологии) были исследованы многочисленные модели, отличающиеся
наборами обобщенных категорий (классов), а также описательных шкал и градаций.
При этом созданные модели оценивались на достоверность методами бутстрепной
статистики, реализованными в системе «Эйдос» [36]. В результате была выбрана
модель, которая затем и была подробно исследована для получения ответа на
первый вопрос.
В работах [1-2, 4-6] было обнаружено
следующее:
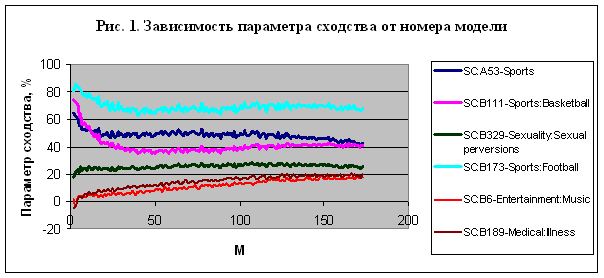
1.
Достоверность
идентификации одних и тех же классов в разных моделях различна, и для каждого класса всегда есть конкретная
частная модель, в которой он идентифицируется с наивысшей достоверностью – рис.
1.
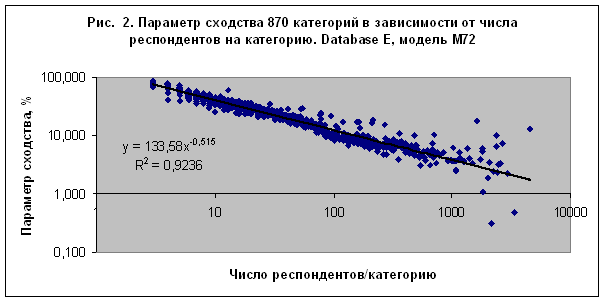
2.
Достоверность
идентификации по категориям обратно пропорционально зависит от количества
респондентов обучающей выборки, относящихся к этой категории – рис. 2.
Заметим, что во
всех расчетах, приведенных в данной монографии, параметр сходства,
характеризующий достоверность идентификации, определялся по формуле [4]:
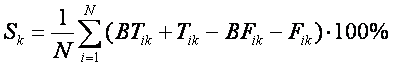 (10)
(10)
Sk
– достоверность идентификации «k-й» категории;
N
– количество респондентов в распознаваемой выборке;
BTik–
уровень сходства «i-го» респондента с «k-й» категорией, к которой он был
правильно отнесен системой;
Tik
– уровень сходства «i-го» респондента с «k-й» категорией, к которой он был
правильно не отнесен системой;
BFik
– уровень сходства «i-го» респондента с «k-й» категорией, к которой он был
ошибочно отнесен системой;
Fik
– уровень сходства «i-го» респондента с «k-й» категорией, к которой он был
ошибочно не отнесен системой.
Причины 1-й
закономерности мы видим в том, что чем больше респондентов обучающей выборки
приходится на категорию, тем выше вариабельность внутри нее по астропризнакам
и, соответственно, тем ниже уровень сходства каждого конкретного респондента с
обобщенным образом этой категории.
При небольшом
количестве респондентов на категорию задача идентификации с ней редуцируется в
задачу поиска, аналогичную тому, который осуществляется в
информационно-поисковых системах. Поиск осуществляется с высокой степенью
достоверности, но для нас он неинтересен, т.к. осуществляется не на основе
выявленных и действующих в предметной области (генеральной совокупности)
закономерностей, а по простому совпадению признаков. Из этого, казалось бы,
можно сделать вывод о том, что имеет смысл исследовать только те категории,
которые представлены очень большой статистикой. Например, в статье [4]
исследуются модели идентификации с 37 категориями, каждая из которых
представлена не менее 1000 респондентами. При этом «вес», т.е. вклад информации
о каждом конкретном респонденте в обобщенный образ категории становится
пренебрежимо малым, и поэтому достоверность модели можно проверять не на основе
респондентов, данные которых не использовались при ее синтезе, а на тех,
которые для этого использовались.
Закономерность на
рис. 2 интересна однако тем, что параметр сходства убывает, а не возрастает с
увеличением числа респондентов, приходящихся на категорию. Если бы
распознавание осуществлялось по схеме случайного угадывания, то параметр
сходства возрастал бы пропорционально числу респондентов, согласно уравнению
(1) и используемому методу АСК-анализа. Такое поведение параметра сходства
можно объяснить только наличием когерентности данных, что отражается при формировании
обобщенного портрета класса. Эта когерентность, по сути дела, является основным
фактором, связанным с влиянием небесных тел.
Само наличие
когерентности данных для большого числа категорий (870 категорий на рис. 2),
которые с большой степенью точности обобщаются степенной зависимостью, уже
свидетельствует о том, что задача распознавания категорий по астрономическим
параметрам небесных тел на момент рождения не сводится к тривиальному
угадыванию.
Об этом же
свидетельствует и наличие 2-й закономерности, отраженной на рис. 1. Если бы
распознавание сводилось к простому угадыванию, то этой закономерности вообще не
было, т.е. параметр сходства изменялся бы случайным образом при изменении
номера модели, который совпадает с числом секторов разбиения круга зодиака.
Здесь можно высказать два важных соображения:
¾
сам
факт наличия этой закономерности говорит о том, что, по-видимому, существует
много различных механизмов «детерминации» астропризнаками принадлежности
респондентов к социальным категориям, и для разных категорий этот механизм
различен, и поэтому одна модель более адекватно отражает один механизм, а
вторая другой;
¾
не
существует какой-то одной модели, обеспечивающей столь высокий уровень
идентификации респондентов по всем категориям, как наилучшая из частных моделей
по каждой из категорий.
Совместное
влияние двух факторов – числа секторов разбиения круга зодиака и числа
респондентов на категорию таково, что дисперсия данных на рис. 2 убывает с
увеличением числа секторов разбиения. Это находится в согласии с теорией информации
[3] и свидетельствует о том, что распознавание осуществляется именно по
астрономическим параметрам, точность представления которых возрастает (а
дисперсия убывает!) с ростом числа секторов разбиения.
Чтобы
использовать параметр сходства, полученный для различных разбиений круга
зодиака, для повышения уровня распознавания, у авторов в начале 2007 года
возник проект разработки специальной системы, которая реализовала бы «коллективы
решающих правил», т.е. была бы способна:
¾
автоматически
генерировать большое количество частных моделей, которые бы образовывали одну
целостную систему, которую мы назвали «мультимодель»;
¾
исследовать
частные модели на адекватность идентификации респондентов в них по различным
категориям;
¾
идентифицировать
респондентов в системе частных моделей, т.е. в каждой из них, в том числе с
учетом априорной информации о достоверности идентификации по различным
категориям в частных моделях («скоростное распознавание»);
¾
обобщать
результаты идентификации конкретных респондентов в разных частных моделях с
учетом информации о достоверности идентификации в них по разным категориям («голосование
моделей»).
Такая система была
разработана – это система «Эйдос-астра» [7], являющаяся 3-й системой окружения
универсальной когнитивной аналитической системы «Эйдос» [36].
Благодаря использованию
технологии голосования частных моделей или коллективов решающих правил в
системе «Эйдос-астра», достоверность идентификации респондентов по каждому из классов в
мультимодели не ниже, чем в частной модели, в которой он идентифицируется с
наивысшей достоверностью из всех созданных и исследованных
частных моделей. Это обеспечивается тем, что в каждой частной модели
идентификация проводится только по тем категориям, идентификация которых в
данной модели осуществляется с наивысшей достоверностью из всех частных моделей,
а также другими более сложными алгоритмами голосования и взвешивания решений,
которые кратко описаны ниже.
С помощью системы «Эйдос-астра»
в 2007 году были созданы и исследованы несколько мультимоделей, отличающихся
как набором социальных категорий, так и самих частных моделей. Например, в
статье [4] представлена одна из мультимоделей, включающая 37 социальных
категорий и 172 частные модели (каждая модель соответствует конкретному разбиению
круга зодиака). В этой мультимодели на каждую из категорий приходится не менее
1000 респондентов, а общий объем обучающей выборки составляет 20007
респондентов.
2.1. Описание системы «Эйдос-астра»
и алгоритмов голосования моделей
Система «Эйдос-астра»
предназначена для синтеза мультимодели и идентификации социального статуса
респондентов по астрономическим показателям на момент их рождения и применяется
с теми же целями, что и стандартные психологические и профориентационные тесты
(т.е. тесты на способность к определенным видам деятельности), обеспечивая
выполнение следующих функций:
¾ генерация исходных баз данных на основе времени и
координат рождения респондентов;
¾ генерация описательных шкал и градаций и обучающей
выборки для частных моделей с заданным числом разбиений описательных шкал;
¾ синтез мультимодели;
¾ измерение достоверности идентификации респондентов по
классам в частных моделях;
¾ идентификация респондентов распознаваемой выборки в
частных моделях;
¾ голосование результатов идентификации в частных моделях
и генерация баз данных для Универсальной когнитивной аналитической системы «ЭЙДОС»,
в которой проводится углубленное исследование созданной модели.
Текущая версия системы «Эйдос-астра»
состоит из набора отдельных сервисных программ и двух взаимосвязанных модулей,
первый из которых («Inpob_mm.exe») обеспечивает синтез мультимодели, а второй («Inprs_mm.exe»)
– ее тестирование на достоверность и применение для идентификации респондентов.
Эти модули разработаны на языке программирования CLIPPER 5.01+TOOLS II+BiGraph
3.01r1 и размещаются в головной директории для синтеза мультимодели, которую
определяет сам пользователь. Исходный текст этих
модулей 8-м шрифтом имеет размер: «Inpob_mm.exe» 63 листа, «Inprs_mm.exe» – 109
листов формата А4.
Перед запуском модуля синтеза мультимодели
(«Inpob_mm.exe») должны быть выполнены следующие шаги:
¾
база
данных с исходной информацией для синтеза мультимодели (база прецедентов)
должна быть записана в выработанном ранее совместно в В.Н. Шашиным /8/ стандарте
с именем «Abankall.dbf»;
¾
база
данных (БД), содержащая перечень социальных категорий, по которым будет
проводиться многопараметрическая типизация (обобщение), и идентификация должна
быть записана в стандарте с именем «Newpf.dbf» (файл формируется и записывается
в Excel в стандарте dbf 4 (dBASE IV) (*.dbf));
¾
в
диалоге пользователь задает перечень частных моделей (количество секторов в
описательных шкалах для создаваемых частных моделей).
Перечень
категорий и частотное распределение респондентов обучающей выборки по категориям,
а также объединенная база данных прецедентов формируются предварительно с помощью
специально для этого созданных сервисных программных модулей, входящих в состав
системы «Эйдос-астра».
При этом в
качестве исходной информации использовались Excel-файлы, содержащие для каждого
респондента информацию о категориях, к которым он относится, и полную
характеристику в форме астропризнаков. Основным источником астросоциотипологической
базы данных, подготовленной для системы ЭЙДОС, является AstroDatabank v. 4.00 [8].
Эта база содержит жизнеописание знаменитостей и простых людей, проживавших (или
проживающих) в США. Достоинством этой базы данных является то, что все события
жизни классифицированы, а все профессиональные и иные категории упорядочены.
При работе модуля
синтеза мультимодели он прогнозирует время завершения процесса и отображает его
стадию, а также сам ведет базу данных, содержащую протокол успешно завершенных
операций и позволяющую нормально продолжить и завершить процесс синтеза даже
после полного аварийного (т.е. в любой момент) выключения компьютера. Это
необходимо потому, что процесс синтеза мультимодели может быть довольно длительным:
от нескольких часов до нескольких суток и даже недель в зависимости от объема
обучающей выборки, количества и размерности частных моделей.
После завершения процесса
синтеза мультимодели запускается модуль «Inprs_mm.exe», обеспечивающий ее
использование для идентификации и прогнозирования. Этот модуль имеет следующие режимы:
1.
Измерение
внутренней дифференциальной валидности моделей, т.е. достоверности
идентификации классов в различных частных моделях [3].
2.
Генерация БД
Atest_mm.dbf для измерения достоверности идентификации в моделях.
3.
Скоростное
распознавание респондентов из Atest.dbf с использованием БД DostIden.dbf.
4.
Полное
распознавание респондентов из Atest.dbf во всех частных моделях.
5.
Голосование
моделей (с выбором одного из пяти алгоритмов).
6.
Голосование
моделей по всем ПЯТИ алгоритмам по очереди.
БД Atest_mm.dbf и Atest.dbf должны быть в том же
стандарте, что и БД Abankall.dbf.
Рассмотрим алгоритмы этих режимов.
2.2. Алгоритм измерения достоверности
идентификации классов в различных
частных моделях
1. Если БД достоверности идентификации классов
DostIden.dbf уже существует, то добавить или удалить в ней столбцы новых
частных моделей из БД Setup_mm.dbf, иначе – создавать эту БД заново (на шаге
4).
2. Если БД тестирующих выборок респондентов
TestResp.dbf уже существует, то спросить, переформировать ли ее заново (шаги 3,
6), иначе – использовать имеющуюся.
3. Если создание БД TestResp.dbf заново, то задать в
диалоге ее параметры.
4. ПОДГОТОВКА К ИСПОЛНЕНИЮ АЛГОРИТМА:
4.1. Выборка из БД Setup_mm.dbf массива видов моделей.
4.2. Запись строки описательных шкал для Logoastr_d.
4.3. Рекогносцировка.
5. Если не продолжение расчета БД DostIden.dbf, то
создать ее заново и заполнить нулями.
6. Если создание БД TestResp.dbf заново, то
6.1. Создать ее по заданным в п. 3 ее параметрам.
6.2. Заполнить кодами источников тестирующих респондентов.
7. Цикл по видам моделей из БД Setup_mm.dbf, начиная с
последней модели.
8. Создание БД результатов распознавания и
массива-локатора в директории частной модели.
9. Если продолжение расчета DostIden.dbf, то
пропустить уже просчитанные модели (где не нули).
10. Цикл по классам заданного диапазона.
11. Копирование тестирующей выборки ПО ЗАДАННОМУ
КЛАССУ В ТЕКУЩЕЙ МОДЕЛИ из обучающей в распознаваемую.
12. Если задано измерение внешней валидности –
удаление из обучающей выборки тестирующей и пересинтез модели, иначе п.13.
13. Идентификация тестирующей выборки ТОЛЬКО С ЕЕ
КЛАССОМ.
14. Конец цикла по классам заданного диапазона.
15. Расчет достоверности идентификации заданных
классов в данной модели.
16. Занесение информации о достоверности идентификации
в БД достоверности идентификации классов.
17. Если задано измерение внешней валидности – добавление
распознаваемой выборки к обучающей (ее восстановление), иначе п.18.
18. Конец цикла по видам моделей.
19. До расчет БД достоверности идентификации классов.
2.3. Алгоритм генерации БД «Atest_mm.dbf»
для измерения достоверности
идентификации в моделях
На первом этапе организуется
цикл по БД «TestResp.dbf», созданной в предыдущем режиме и содержащей коды (id)
респондентов для измерения достоверности идентификации по каждой категории. В
этом цикле формируется массив, содержащий коды респондентов и исключающий их
повторы в формируемой БД «Atest_mm.dbf».
На втором этапе из БД «Abankall.dbf»
выбираются записи по определенным на предыдущем этапе респондентам, и эти
записи добавляются в БД «Atest_mm.dbf».
В дальнейшем сформированная в
данном режиме база данных «Atest_mm.dbf» может быть использована для измерения
достоверности идентификации респондентов по категориям при полном
распознавании. Для этого ее надо предварительно переименовать в «Atest.dbf»,
т.к. на работу именно с этой базой рассчитан режим полного распознавания.
2.4. Алгоритм режима скоростного распознавания
респондентов из Atest.dbf с использованием априорной информации о достоверности
идентификации по категориям из БД DostIden.dbf
1. Сброс распознаваемой выборки во всех остальных частных
моделях.
2. Генерировать
распознаваемую выборку в тех частных моделях, которые оказались наиболее
достоверными по данным БД DostIden.dbf, причем в каждой частной модели
создавать ее только один раз. В каждой частной модели может наиболее достоверно
идентифицироваться НЕСКОЛЬКО классов. Поэтому нужно иметь БД с информацией об
этом и проводить распознавание в этой модели в ЦИКЛЕ по этим классам. Эта БД и
есть DostIden.dbf.
3. Сделать цикл по БД DostIden.dbf (по частным моделям
+ классам).
4. Идентифицировать ВСЕХ
респондентов из БД Atest.dbf в каждой частной модели ТОЛЬКО с теми классами,
которые идентифицируется в данной модели наиболее достоверно (по данным из
DostIden.dbf). Данный алгоритм основан на простой идее о том, что по каждой из
социальных категорий рационально идентифицировать респондентов только в той
частной модели, в которой эта категория (по данным предварительного
исследования частных моделей) идентифицируется с наивысшей достоверностью из
всех частных моделей. На описываемой мультимодели этот алгоритм осуществляет
идентификацию 370 респондентов за 40 минут вместо 2-х суток полной
идентификации.
2.5. Алгоритм полного распознавания
респондентов из Atest.dbf во всех
частных моделях
Существуют 3 варианта:
1-й: пакетного распознавания
респондентов из Atest.dbf не было выполнено ни в одной частной модели.
2-й: пакетное распознавания
респондентов из Atest.dbf было выполнено не во всех частных моделях.
3-й: пакетное распознавания
респондентов из Atest.dbf было выполнено во всех частных моделях.
Необходимо сообщить
пользователю, какой вариант имеет место – 2-й или 3-й, и предложить ему
закончить распознавание или начать заново:
¾
ЗАКОНЧИТЬ имеет
смысл с тем же файлом Atest.dbf;
¾
НАЧАТЬ ЗАНОВО
имеет смысл с новым файлом Atest.dbf;
¾
если
не было выполнено пакетного распознавания ни в одной частной модели, то просто
МОЛЧА начать его выполнять для тех моделей, для которых выполнен синтез модели.
Затем организуется цикл по частным моделям.
Распознавание выполняется только, если: синтез модели уже
выполнен, а распознавание еще нет.
Проводится запись исходных БД для генерации распознаваемой
выборки модели в поддиректорию с этой частной моделью.
Выполняется генерация исходных файлов распознаваемой выборки
частной модели из БД Atest.dbf.
Проводится пакетное распознавание как в базовой системе «Эйдос».
2.6.
Алгоритм голосования моделей
(с выбором одного из 5-и алгоритмов)
Пользователю
в диалоге предлагается задать один из режимов голосования моделей, когда в
итоговую карточку идентификации респондента берется:
1.
СУММАРНАЯ
ЧАСТОТА ИДЕНТИФИКАЦИИ респондента с каждым классом, рассчитанная по всем частным
моделям.
2.
СРЕДНЕЕ
уровней сходства с этим классом из всех карточек идентификации частных моделей.
3.
Уровень
сходства этого респондента с классом из той частной карточки идентификации, в
которой он МАКСИМАЛЬНЫЙ.
4.
Уровень
сходства из карточки идентификации той частной модели, которая показала
МАКСИМАЛЬНУЮ достоверность распознавания ДАННОГО КЛАССА из всех моделей.
5.
СРЕДНЕЕ
СУММЫ ПРОИЗВЕДЕНИЙ уровней сходства с данным классом на достоверность его
идентификации в частных моделях.
1-й алгоритм голосования
моделей.
В
данном алгоритме, который был предложен первым, определяется СУММАРНАЯ ЧАСТОТА
ИДЕНТИФИКАЦИИ респондента с каждым классом, рассчитанная по всем частным моделям.
Пользователю предлагается в диалоге ввести следующие
параметры:
¾
минимальный
учитываемый уровень сходства респондента с классом в %;
¾
частоту
идентификации респондента с классом в частных моделях в %.
Затем выполняются следующие шаги:
1.
Скопировать БД
Rasp.dbf из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид
модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать
так, чтобы записи с одинаковым результатом идентификации респондента с классом
оказались рядом.
4.
Создать новую БД
Rasp1.dbf, в которой сделать записи с суммарной частотой идентификации
респондента с каждым классом, рассчитанной по всем частным моделям.
5.
Физически
рассортировать объединенную БД так, как надо для отображения карточек
идентификации в базовой системе «Эйдос».
6.
Скопировать БД в
директорию ALL1 и переиндексировать.
2-й алгоритм голосования
моделей.
В
этом алгоритме определяется СРЕДНЕЕ уровней сходства с этим классом из всех
карточек идентификации частных моделей.
1.
Скопировать БД
Rasp.dbf из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид
модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать
так, чтобы записи с одинаковым результатом оказались рядом.
4.
Сделать новую БД
Rasp1.dbf, в которой объединить записи, просуммировав уровни сходства.
5.
Физически
рассортировать объединенную БД так, как надо для отображения карточек
идентификации в базовой системе «Эйдос».
6.
Скопировать
БД в директорию ALL2 и переиндексировать.
3-й алгоритм голосования моделей.
В данном алгоритме определяется
уровень сходства этого респондента с классом из той частной карточки
идентификации, в которой он МАКСИМАЛЬНЫЙ:
1.
Скопировать
БД Rasp.dbf из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид
модели.
2.
Объединить
их все в одну БД Rasp.dbf.
3.
Рассортировать
ее так, чтобы записи с одинаковым классом оказались рядом и ранжированы в
порядке убывания сходства.
4.
Сделать
новую БД Rasp1.dbf, в которой из предыдущей взять только записи с максимальным
уровнем сходства.
5.
Физически
рассортировать объединенную БД так, как надо для отображения карточек
идентификации в базовой системе «Эйдос».
6.
Скопировать
БД в директорию ALL3 и переиндексировать.
4-й алгоритм голосования моделей.
В данном алгоритме определяется
уровень сходства из карточки идентификации той частной модели, которая показала
МАКСИМАЛЬНУЮ достоверность распознавания ДАННОГО КЛАССА из всех моделей:
1.
Скопировать
БД Rasp.dbf из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид
модели.
2.
Объединить
их все в одну БД Rasp.dbf.
3.
Рассортировать ее
так, чтобы записи с одинаковым классом оказались рядом и ранжированы в порядке
убывания сходства.
4.
Сделать новую БД
Rasp1.dbf, в которую из предыдущей для каждого класса взять записи только из
тех частных моделей, в которых они идентифицируются с максимальной достоверностью.
5.
Физически
рассортировать объединенную БД так, как надо для отображения карточек
идентификации в базовой системе «Эйдос».
6.
Скопировать БД в
директорию ALL4 и переиндексировать.
5-й алгоритм голосования
моделей.
В данном
алгоритме определяется СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ уровней сходства с данным
классом на достоверность его идентификации в частных моделях:
1.
Скопировать БД Rasp.dbf из всех директорий
моделей с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все в одну БД Rasp.dbf.
3.
Рассортировать ее
так, чтобы записи с одинаковым классом оказались рядом и ранжированы в порядке
убывания сходства.
4.
Сделать новую БД
Rasp1.dbf, в которой из предыдущей взять СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ уровней
сходства с данным классом на достоверность его идентификации в частных моделях.
5.
Физически
рассортировать объединенную БД так, как надо для отображения карточек
идентификации в базовой системе «Эйдос».
6.
Скопировать БД в
директорию ALL5 и переиндексировать.
Алгоритм голосования моделей по всем ПЯТИ
алгоритмам по очереди.
Он представляет собой режим,
полностью аналогичный предыдущему, в котором все алгоритмы голосования запускаются
по очереди со значениями параметров по умолчанию.
2.7. «Эйдос-астра»
– интеллектуальная система научных исследований влияния космической среды на
поведение глобальных геосистем
Глобальные
геосистемы и теория управления
Актуальность исследования глобальных процессов, т.е.
процессов на Земле в целом (глобальных геосистем), сегодня уже ни у кого не
вызывает сомнения. Если раньше этот вопрос решался в основном в научной среде
на уровне несколько отвлеченного академического обсуждения, то теперь, в уже
наступившую эпоху глобальных катаклизмов природного и техногенного характера,
этот вопрос «неожиданно» приобрел печальную конкретику, т.к. непосредственно
коснулся многих миллионов или даже миллиардов людей.
Как известно из теории управления поведение любой системы
определяется состоянием самой системы (внутренними факторами и ее предысторией)
управляющими факторами, а также воздействием окружающей среды. Для глобальных
геосистем: ноосферы
(глобальных социальных и экономических процессов), биосферы, геосферы,
магнитосферы, атмосферы и других, внешней средой, с которой эти системы входят
в непосредственное взаимодействие, является ближайшее космическое окружение
нашей планеты, т.е. различные космические тела, входящие в состав Солнечной
системы.
В
работах [53-55, 58-59] авторы
рассмотрели различные аспекты влияния
космической среды на поведение ряда глобальных геосистем. При этом в основе
этих исследований лежит методология естественных
наук, т.к. они основаны на совместном изучении больших объемов
детализированной фактографической информации о динамике состояния этих
геосистем за длительные периоды времени, а с другой – астрономической
информации о параметрах тел Солнечной системы.
Естественные науки основаны на измерениях
и на интеллектуальном анализе результатов этих измерений. Само понятие «измерение»
в истории науки эволюционировало вместе с самой наукой. Можно выделить
следующие этапы эволюции понятия «измерение»:
– определение
наличия некоторого качества у объекта
измерения;
– получение
одного числа, количественно
характеризующего степень проявления некоторого качества объекта измерения;
– получение
одного числа, количественно характеризующего степень проявления некоторого
качества объекта измерения, а также получение погрешности определения этого числа, т.е. определение некоторого «доверительного
интервала», в который «истинное значение числа» попадает с определенной
заданной вероятностью;
– получение набора чисел с доверительными
интервалами для каждого из них, т.е. получение статистического распределения и изучение зависимости его параметров от
действующих на измеряемый объект факторов;
– получение
эмпирических законов, функциональных зависимостей и когнитивных функциональных
зависимостей.
Все научные
экспериментальные установки, по сути, являются информационно-измерительными системами (ИИС), т.е. позволяют
получить информацию об объекте исследования, т.е. его свойствах и состояниях. В
любой информационно-измерительной системе информация от объекта исследования к
системе обработки информации (входящей в состав ИИС) всегда передается по
некоторому каналу передачи информации.
В физических и астрономических исследованиях в качестве канала передачи информации
чаще всего выступают электромагнитные волны различных диапазонов: свет,
радиоволны и рентгеновское излучение.
Заметим, что на наш взгляд
отсутствие знаний о каналах передачи взаимодействия или недостаточное их
понимание не является фатальным препятствием на пути изучения свойств объектов
с помощью этого взаимодействия. Это означает, что возможно получение адекватной информации об исследуемом объекте по
слабо изученным каналам или каналам, природа которых вообще неизвестна. В процессах познания основное значение имеет
информация, получаемая об объекте познания по каналам взаимодействия с ним, а
не понимание природы этих каналов, которое не имеет принципиального значения на
первых этапах познания. Этот
подход будем называть информационным методом исследования. Он является аналогом
«черного ящика» в кибернетике. Информационный метод позволяет накапливать новую информацию об объектах познания, не зная
способа взаимодействия с ними, а также использовать эту информацию на практике,
что в последующем позволяет развить теоретически обоснованные представления о
природе, как самих исследуемых объектов, так и каналов взаимодействия с ними.
В этой связи необходимо
отметить, что эмпирический факт
(установленный в результате измерения) является первичным по отношению к
теории, т.е. для признания существования факта вообще нет необходимости в
какой-либо объясняющей его теории, хотя есть горькая поговорка о том, что «если
факт не вписывается в теорию, то тем хуже для факта». Дело же теории объяснять
уже известные факты и предсказывать новые, еще не обнаруженные
экспериментально.
Особенно ценным для развития
теории является достоверное обнаружение новых фактов, которые этой теорией не
объясняются, т.к. их теоретическое объяснение позволяет получить общую теорию,
для которой предыдущая теория является частным случаем. Поэтому теоретики
должны не отмахиваться от новых пока не объяснимых фактов или объявлять их
несуществующими лишь на том основании, что они не вписываются в их теории, а
наоборот, буквально охотится за подобными фактами.
Но что является
эмпирическим фактом в свете изложенных представлений о развитии понятия
измерения? Сегодня эмпирическим фактом можно считать обнаружение
причинно-следственных и функциональных зависимостей
в эмпирических данных, т.е. выявление новых знаний из данных, в частности выявление когнитивных
функциональных зависимостей в эмпирических данных.
Понятно, что
для достижения этой цели необходим адекватный инструмент и от функциональных
возможностей этого инструмента самым непосредственным образом зависит как сама
возможность выявления новых фактов и новых знаний из них, но также количество и
качество этих фактов и знаний.
При этом
вполне возможна ситуация, когда исследование с помощью современных
автоматизированных интеллектуальных технологий давно всем известных и
находящихся в общем доступе многолетних баз данных о фактических параметрах
геосистем и тел Солнечной системы позволит открыть в них как новые факты, так и
новые ранее неизвестные закономерности их взаимосвязи. Примерно так технологии
XXI века позволяют еще раз переработать отвалы золотой руды на шахтах конца XIX
– начала XX века и извлечь из них новые тонны золота, которые в свое время не
смогли извлечь с помощью существовавших тогда примитивных технологий.
В качестве современной
автоматизированной интеллектуальной технологии авторы применили
автоматизированный системно-когнитивный анализ (АСК-анализ) и его программный инструментарий
– универсальную когнитивную аналитическую систему «Эйдос» [36]. Эту систему
далее будем называть базовой системой «Эйдос». В состав этой системы входит
подсистема _152, содержащая ряд стандартных программных интерфейсов с внешними
источниками данных различных стандартов: текстовых, баз данных (БД) и
графических, расширяющих сферу ее применения. Некоторые из подобных интерфейсов
при своем развитии превратились в систему окружения «Эйдос-астра» [7].
Задачей данной монографии
является краткое описание системы «Эйдос-астра»
и опыта ее применения. Текущая версия данной системы состоит из двух основных
программных модулей, составляющих ядро системы, а также еще 25 взаимосвязанных
программных модулей, представляющих собой подсистемы, включающие режимы, а
также отдельных вспомогательных программных модулей (утилит) (см. диаграмму 1).
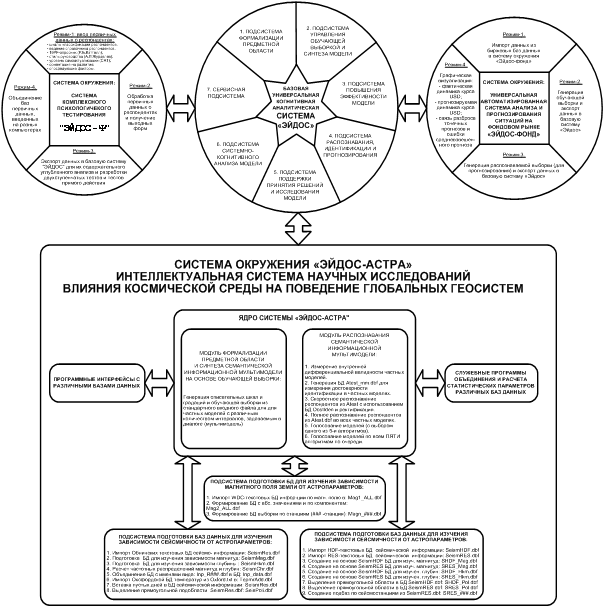
Диаграмма 1: базовая система «Эйдос» и системы
окружения
Первоначально система Эйдос-астра была предназначена
для исследований в области астросоциотипологии [2-6]. Первые исследования в
этом направлении проводились непосредственно с применением базовой системы «Эйдос»
[1]. Было создано и изучено на достоверность много различных моделей. При этом
оказалось, что одни модели показывают более высокую достоверность по одним
классам распознавания, тогда как другие – по другим. Со временем стало ясным,
что процесс создания и исследования различных частных моделей целесообразно
автоматизировать, с тем, чтобы создать мультимодель, позволяющую объединить их
достоинства частных моделей при этом преодолев их недостатки (принцип
коллектива решающих правил) [4]. Для этой цели и была создана система «Эйдос-астра»,
позволяющая автоматически генерировать
различные системы частных моделей (мультимодели), исследовать их на
достоверность в разрезе по классам и с учетом этой информации наиболее эффективно
использовать их для идентификации и прогнозирования. Но со временем
проблематика этих исследований расширилась и преобразовалась в целое новое
научное направление, которое можно было бы назвать: «Применение технологий искусственного интеллекта для исследования
влияния космической среды на поведение активных глобальных геосистем».
К подобным системам авторы относят: ноосферу (включая
глобальные социальные и экономические системы), биосферу, атмосферу,
гидросферу, геосферу и магнитосферу. По ряду из этих глобальных систем были
проведены исследования с применением системы «Эйдос-астра» и базовой системы «Эйдос»:
– ноосфера (включая глобальные социально-экономические
системы): исследование динамики фондового рынка и детерминации социального
статуса респондентов;
– геосфера: землетрясения, движение географического и
магнитного плюсов Земли;
– динамика магнитосферы Земли.
Оказалось, что система «Эйдос-астра» может сама рассматриваться
как универсальное интеллектуальное ядро, применимое для решения широкого класса
прямых и обратных интеллектуальных задач много параметрической типизации,
системной идентификации, прогнозирования и поддержки принятия решений и
научного исследования предметной области путем исследования ее семантической
информационной модели в самых различных предметных областях. При этом характерной
особенностью подобных задач является использование для исследований огромных по
объемам внешних баз данных, содержащих информацию о десятках и сотнях тысяч и
даже о миллионах событий. Эти базы данных размещены в Internet свободном
доступе [8, 44-46, 56-57, 60-63]. Для преобразования этих баз данных в форму,
удобную для исследования в системе «Эйдос-астра» и предварительной обработки
данная система была расширена путем
включения в ее состав ряда новых программных интерфейсов с внешними базами
исходных данных.
Технология моделирования социально-экономических и
природных процессов на основе системы искусственного интеллекта «Эйдос-астра»
Система искусственного интеллекта «Эйдос-астра» [7]
была создана на основе системы «Эйдос» [36]. Первоначально эта система
предназначалась для распознавания социальных категорий респондентов по
астрономическим данным на момент рождения [1-6] на основе теории сходства [2] с
использованием базы данных респондентов [8], содержащей более 26000 записей.
Однако, после того, как были установлены общие закономерности распознавания
социальных категорий и доказана основная теорема астросоциотипологии [9-16],
возникла идея применить систему «Эйдос-астра» для моделирования экономических
категорий, типа курсов валют. Было показано [18-19], что технология решения
задач распознавания экономических категорий практически не отличается от
технологии, развитой для социальных
категорий, ни по структуре используемых баз данных, ни по стадиям анализа.
Отличие же заключается только в нормировании входных астрономических
параметров, а также в использовании параметров расстояния от Земли до небесных
тел Солнечной Системы вместо угловых параметров т.н. домов Плацидуса,
используемых при распознавании социальных категорий.
Формирование исходной БД категорий валют происходит
автоматически на трех листах системы Excel, на первом из которых записываются
исходные данные, взятые с серверов
[44-46], на втором листе вычисляются
значения функции повышения (1)/снижения (0) курса, а на третьем
определяются категории курсов валют, которые объединяются в общий список – см.
таблицу 1. Отметим, что для удобства данные представлены на время,
соответствующее торгам на бирже в Нью-Йорке, США.
Астрономические параметры вычисляются на основе швейцарских
эфемерид (см. www.astro.com) в топоцентрической системе координат с началом в
точке (0 в.д.; 51.4833 с.ш.), что соответствует
координатам г. Гринвич, Великобритания. Эти параметры нормируются в процессе
обработки БД в системе «Эйдос-астра». Вычисления начинаются с синтеза моделей,
число и номер которых задается в диалоге
– рис. 3. Частные модели можно
создать сразу за одну сессию или добавлять последовательно. Их количество
определяется исследователем с учетом типа решаемых задач.
Таблица 1.
Формирование списка категорий валют
|
DATE |
EST |
USD/CAD Open |
USD/CAD High |
USD/CAD Low |
USD/CAD Close |
EUR/USD Open |
EUR/USD High |
EUR/USD Low |
EUR/USD Close |
|
2008.07.27 |
18:00 |
1.0191 |
1.0191 |
1.0186 |
1.0187 |
1.5697 |
1.5698 |
1.5685 |
1.5697 |
|
2008.07.27 |
19:00 |
1.0186 |
1.0198 |
1.0186 |
1.0195 |
1.5696 |
1.5697 |
1.5683 |
1.5692 |
|
2008.07.27 |
20:00 |
1.0196 |
1.0204 |
1.0195 |
1.0202 |
1.5693 |
1.5707 |
1.5684 |
1.5695 |
|
2008.07.27 |
21:00 |
1.0203 |
1.0203 |
1.0192 |
1.0194 |
1.5694 |
1.5704 |
1.5686 |
1.5696 |
|
Лист2 |
|
|
|
|
|
|
|
|
|
|
2008.07.27 |
19:00 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
2008.07.27 |
20:00 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
|
2008.07.27 |
21:00 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
|
Лист3 |
|
|
|
|
|
|
|
|
|
|
2008.07.27 |
19:00 |
A10 |
A21 |
A31 |
A41 |
A50 |
A60 |
A70 |
A80 |
|
2008.07.27 |
20:00 |
A11 |
A21 |
A31 |
A41 |
A50 |
A61 |
A71 |
A81 |
|
2008.07.27 |
21:00 |
A11 |
A20 |
A30 |
A40 |
A51 |
A60 |
A71 |
A81 |
|
Лист3 |
|
|
|
|
|
|
|
|
|
|
2008.07.27 |
19:00 |
A10:A21:A31:A41:A50:A60:A70:A80:A90:A100:A110:A120:A130:A141:A151:A161: |
|||||||
|
2008.07.27 |
20:00 |
A11:A21:A31:A41:A50:A61:A71:A81:A90:A101:A110:A121:A131:A141:A151:A161: |
|||||||
|
2008.07.27 |
21:00 |
A11:A20:A30:A40:A51:A60:A71:A81:A91:A101:A111:A121:A131:A140:A151:A160: |
|||||||
Синтез каждой модели включает семь стадий, начиная с
суммирования абсолютных частот признаков и, заканчивая, синтезом информационной
модели СИМ-1 или СИМ-2 (тип информационной модели задается в диалоге) – рис. 4.
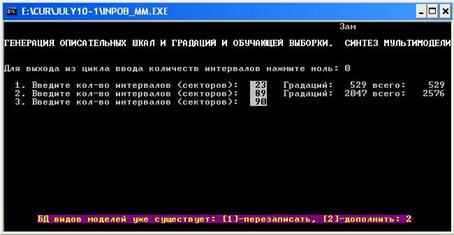
Рис. 3. Скриншот подсистемы синтеза мультимодели
(1-й подсистемы ядра системы «Эйдос-астра»)
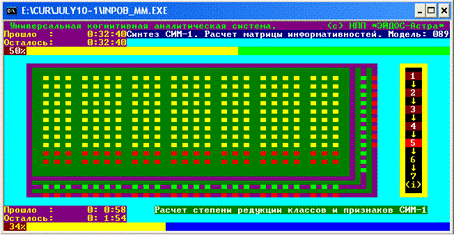
Рис. 4. Скриншот режима синтеза
информационной модели
После того, как
мультимодель создана, ее можно верифицировать, используя специальную программу
распознавания – рис. 5, в которой реализован алгоритм измерения внутренней дифференциальной
валидности частных моделей и мультимодели в целом. В режиме распознавания можно
задать в диалоге объем выборки, на которой производится измерение параметра
сходства – рис. 6. Для прогнозирования
курсов валют используется режим 4 программы распознавания. В этом режиме
обрабатываются астрономические данные на каждый день и час прогноза – рис. 7.
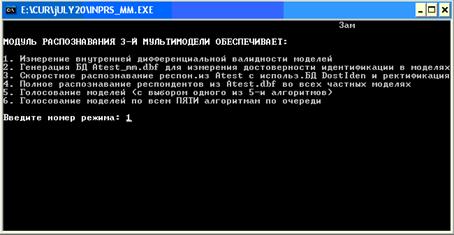
Рис. 5. Скриншот подсистемы
распознавания
(2-й подсистемы ядра системы «Эйдос-астра»)
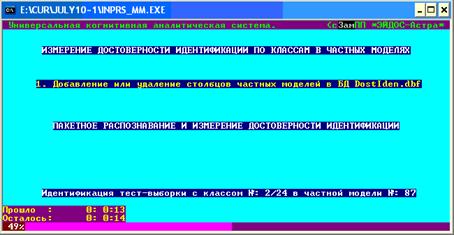
Рис. 6. Скриншот режима измерения
достоверности идентификации в разрезе по классам в частных моделях
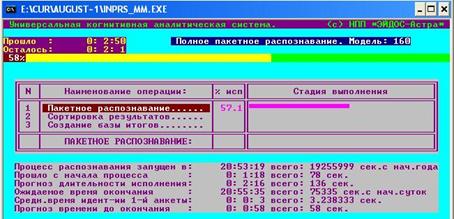
Рис. 7. Скриншот режима пакетного
распознавания
В результате
распознавания формируется таблица категорий
с указанием параметра сходства, которая используется для формирования итоговой
таблицы достоверности прогноза. Для обработки этих данных используется
специальный режим – рис. 8. В этом режиме каждой дате и времени прогноза
(например, 11 августа 18:00 на рис. 6) сопоставляется набор категорий с указанием
параметра сходства.
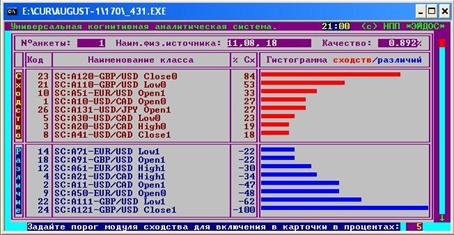
Рис. 8. Скриншот режима визуализации результатов
распознавания базовой системы «Эйдос»
Наконец, для стабилизации достоверности прогноза в системе
«Эйдос-астра» реализованы пять
алгоритмов голосования частных моделей описанные в работе [4]. Генерируя
несколько моделей, можно обобщить их прогнозы, используя один из пяти
алгоритмов /6/, когда в итоговый прогноз берется:
1) СУММАРНАЯ
ЧАСТОТА ИДЕНТИФИКАЦИИ, рассчитанная по всем частным моделям;
2) СРЕДНЕЕ
уровней сходства из всех прогнозов частных моделей;
3) Уровень
сходства из той частной модели, в которой он МАКСИМАЛЬНЫЙ;
4) Уровень
сходства из той частной модели, которая показала МАКСИМАЛЬНУЮ достоверность
распознавания ДАННОГО КЛАССА из всех моделей;
5) СРЕДНЕЕ
СУММЫ ПРОИЗВЕДЕНИЙ уровней сходства с данным классом на достоверность его
идентификации в частных моделях.
В результате численных экспериментов было установлено,
что при распознавании валют наиболее эффективным является третий алгоритм,
который позволяет повысить достоверность прогноза частных моделей.
Эффективность же самого эффективного третьего алгоритма в свою очередь зависит
от набора частных моделей. Из полученных данных следует, что максимальный
параметр сходства, используемый в прогнозе по третьему алгоритму, реализуется в
модели М27, которая соответствует циклу 2 недели. Этот цикл, видимо, является
наиболее значимым в валютных торгах, отраженных в используемых базах
данных.
Следующее интересное применение системы «Эйдос-астра»
связано с распознаванием сейсмических событий по астрономическим данным. В
работе [52] развита модель прогнозирования землетрясений на основе системы
искусственного интеллекта «Эйдос-астра». База данных землетрясений была
сформирована на основе оперативного сейсмологического каталога ГС РАН [56],
содержащего 65541 запись событий землетрясений, произошедших в различных
регионах мира в период с 1 января 1993 года по 20 ноября 2008 г. Моделирование
событий осуществлялось по параметру сходства, который является аналогом коэффициента корреляции в
статистике. Из исходной базы путем преобразования с помощью специальной
процедуры было образовано несколько различных БД для исследования влияния
астрономических параметров на магнитуду и глубину гипофокуса, на ежедневное
число землетрясений и на их локализацию.
Категория «Магнитуда» была получена из исходной базы
данных путем умножения параметра магнитуды MPSP на 10 и добавления символа А –
см. таблицу 2. Всего было образовано 47 категорий этого типа, которые
соответствуют изменению параметра MPSP от 3 до 7.5 с шагом 0.1 (46 категорий)
плюс одна категория А0, соответствующая тем случаям, когда по данным каталога
[56] параметр MPSP=0. Отметим, что магнитуда MPSP рассчитывается по
максимальной скорости смещения в объемных волнах [56].
ТАБЛИЦА.2. Фрагмент базы данных категории «Магнитуда»
|
ID |
NAME |
CATS1 |
SUNLON |
SUNDIST |
MOONLON |
MOONDIST |
|
1 |
01.01.1993
|
A54:A54:A56:A53: |
280.9686023746710 |
0.9832953224852 |
13.6193309143572 |
0.0026758287293 |
|
2 |
02.01.1993
|
A51:A49: |
281.9877769647200 |
0.9832827412929 |
25.8047627280948 |
0.0026514329751 |
|
3 |
03.01.1993
|
A60:A52:A46:A62:A53:A54: |
283.0068945266630 |
0.9832755597314 |
38.2524447909018 |
0.0026206202125 |
|
4 |
04.01.1993
|
A62:A53:A56:A60:A60: |
284.0259498778590 |
0.9832740284513 |
51.0313074310990 |
0.0025854001894 |
|
5 |
05.01.1993
|
A48: |
285.0449399774140 |
0.9832784151922 |
64.1942901475346 |
0.0025483733705 |
|
6 |
06.01.1993
|
A49:A58: |
286.0638619286330 |
0.9832889650152 |
77.7694840563520 |
0.0025125186647 |
|
7 |
07.01.1993
|
A61:A0:A57:A0: |
287.0827135891120 |
0.9833058932933 |
91.7514779908947 |
0.0024808734659 |
|
8 |
08.01.1993
|
A55:A55:A46: |
288.1014940625240 |
0.9833293611578 |
106.0953151556760 |
0.0024561346250 |
|
9 |
09.01.1993
|
A49:A56:A52:A47: |
289.1202049674210 |
0.9833594500691 |
120.7161775556960 |
0.0024402538842 |
|
10 |
10.01.1993
|
A66: |
290.1388517853630 |
0.9833961422425 |
135.4972701770000 |
0.0024341353125 |
Данные по глубине гипофокуса обрабатывались по формуле:
![]()
где
глубина выражена в километрах. Всего было выделено 54 категории,
соответствующие глубине гипофокуса от 0 до 812 км. В таблице 3 представлен
фрагмент базы данных категорий глубины гипофокуса.
ТАБЛИЦА. 3. Фрагмент базы данных
категории
«Глубина гипофокуса»
|
ID |
NAME |
CATS1 |
SUNLON |
SUNDIST |
MOONLON |
MOONDIST |
|
1 |
01.01.1993
|
B35:B35:B35:B53: |
280.9686023746710 |
0.9832953224852 |
13.6193309143572 |
0.0026758287293 |
|
2 |
02.01.1993
|
B35:B34: |
281.9877769647200 |
0.9832827412929 |
25.8047627280948 |
0.0026514329751 |
|
3 |
03.01.1993
|
B39:B11:B60:B41:B40:B40: |
283.0068945266630 |
0.9832755597314 |
38.2524447909018 |
0.0026206202125 |
|
4 |
04.01.1993
|
B42:B35:B43:B37:B35: |
284.0259498778590 |
0.9832740284513 |
51.0313074310990 |
0.0025854001894 |
|
5 |
05.01.1993
|
B36: |
285.0449399774140 |
0.9832784151922 |
64.1942901475346 |
0.0025483733705 |
|
6 |
06.01.1993
|
B35:B35: |
286.0638619286330 |
0.9832889650152 |
77.7694840563520 |
0.0025125186647 |
|
7 |
07.01.1993
|
B11:B23:B35:B35: |
287.0827135891120 |
0.9833058932933 |
91.7514779908947 |
0.0024808734659 |
|
8 |
08.01.1993
|
B11:B35:B63: |
288.1014940625240 |
0.9833293611578 |
106.0953151556760 |
0.0024561346250 |
|
9 |
09.01.1993
|
B35:B35:B35:B35: |
289.1202049674210 |
0.9833594500691 |
120.7161775556960 |
0.0024402538842 |
|
10 |
10.01.1993
|
B35: |
290.1388517853630 |
0.9833961422425 |
135.4972701770000 |
0.0024341353125 |
Была обнаружена зависимость параметра сходства от магнитуды,
глубины очага (гипофокуса) и числа землетрясений, происходящих ежедневно на
нашей планете, как в месячном, так и в 2-3 дневном прогнозе.
В работе [53] изучены вопросы прогнозирования параметров
сейсмической активности и климата по астрономическим данным на основе
семантических информационных моделей. Рассмотрено применение алгоритмов
повышения адекватности моделей и визуализации матрицы информативностей для установления
характера зависимости интенсивности сейсмических событий от гравитационных
потенциалов небесных тел.
В работе [54] представлены результаты прогнозирования
параметров сейсмической активности по астрономическим данным на основе
семантических информационных моделей с использованием всемирной базы
землетрясений [57], исследована совокупность 128320 событий землетрясений с
магнитудой ![]() , произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
Показано, что полученные результаты находятся в согласии с данными [52-53], что
позволяет расширить область применения развитых в этих работах моделей. Как было установлено, увеличение длины ряда
с 5082 до 16032 дней и числа событий с 65541 до 128320 позволяет существенно
поднять как среднее так максимальное значение параметра сходства категории
магнитуда.
, произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
Показано, что полученные результаты находятся в согласии с данными [52-53], что
позволяет расширить область применения развитых в этих работах моделей. Как было установлено, увеличение длины ряда
с 5082 до 16032 дней и числа событий с 65541 до 128320 позволяет существенно
поднять как среднее так максимальное значение параметра сходства категории
магнитуда.
В работе [55] исследованы семантические информационные
модели, содержащие данные о сейсмических событиях из всемирной базы [57],
астрономические параметры небесных тел, параметры смещения географического
полюса по данным [60], а также параметры магнитного поля земли из всемирной базы [61].
Установлено, что добавление в информационную модель данных по магнитному полю и
смещению географических полюсов позволяет увеличить достоверность прогноза
землетрясений, что указывает на существование глобальных общепланетарных механизмов
формирования сейсмических событий.
Исследуемая база данных сейсмических событий была
сформирована на основе базы данных Международного сейсмологического центра
(ISC) [57], содержащей 20489816 записей регистрации различными сейсмостанциями
событий землетрясений, произошедших на нашей планете в период с 1 января 1961
года по 31 декабря 2006 г.
Для решения
поставленных задач в состав системы «Эйдос-астра» были включены программные
интерфейсы, позволяющие объединять разрозненные данные [57] и [61] в единые
базы данных, выделять различные сегменты данных, производить необходимые
вычисления со всеми исследованными
базами исходных данных.
В базе данных [57] используется два формата записи -
HDF и RES с разбивкой файлов данных по станциям и по годам. Для каждого из этих
форматов была создана процедура перекодирования данных в формат DBF и
объединения разрозненных файлов в единые базы данных, с последующей
возможностью извлечения различных сегментов данных - рис. 9.
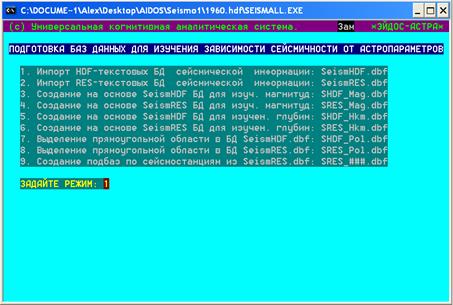
Рис. 9.1. Скриншот подсистемы обработки данных по
сейсмическим событиям в форматах HDF и RES [57]
В базе данных [61] используется специфический формат записи
параметров индукции магнитного поля WDC, который включает несколько разнородных
величин – D (склонение), F (амплитуда), H (горизонтальная составляющая
индукции), I (наклонение), X (меридиональная составляющая вектора индукции), Y
(азимутальная составляющая вектора индукции), Z (вертикальная составляющая
вектора индукции). При этом в зависимости от методики исследования на каждой из
240 станций в разные годы ведется запись от 3 до 7 параметров, что делает эту
базу крайне неудобной для исследования. Поэтому для обработки базы данных [61]
была создана программа, позволяющая делать выборку для каждого из 7 параметров
магнитного поля и для каждой станции наблюдения – рис. 9.2.
Наконец, в работе [64] исследованы семантические информационные
модели, содержащие данные о сейсмических событиях [57], астрономические
параметры небесных тел, параметры магнитного
поля Земли из всемирной базы [61], параметры смещения географического
полюса по данным [60], а также биржевой индекс S & P 500, по данным [63].
Установлено, что добавление в информационную модель данных по биржевому индексу
S & P 500 позволяет увеличить достоверность прогноза землетрясений, что
указывает на существование антропогенных механизмов влияния на сейсмическую активность.
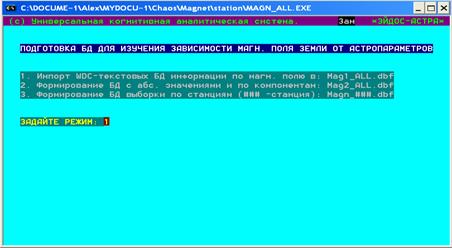
Рис. 9.2. Скриншот подсистемы обработки данных по магнитному
полю в формате WDC /26/
Обнаружена сильная взаимосвязь биржевого индекса S
& P 500 с данными по магнитной индукции, полученными на различных станциях.
С учетом этих данных построена корреляционная модель зависимости логарифма
объема продаж акций 500 крупнейших компаний США от дипольных моментов Урана и
Нептуна. Полученные результаты находятся в согласии с данными работы [65], в
которой была построена общая корреляционная модель зависимости котировок валют
на мировых валютных биржах от астрономических параметров.
Технология моделирования климата
Описанный метод распознавания категорий по астрономическим
данным можно применить для исследования любых природных процессов, например,
климата. Рассмотрим решение этой задачи для одного города (Оксфорда). В
качестве климатических категорий были выбраны усредненные за месяц данные по максимальной
температуре, осадкам и заморозкам, собранные в единую базу данных [62] на
станции наблюдения за погодой в Оксфорде за период с января 1853 г по сентябрь
2009 г – всего 1881 запись. Из данных [62] с помощью специальной программы –
рис. 9.3, было образовано 53 категории климатических параметров, в том числе:
22 категории температуры (градус С), 14 категорий осадков (мм) и 17 категорий
заморозка (дней в месяц).
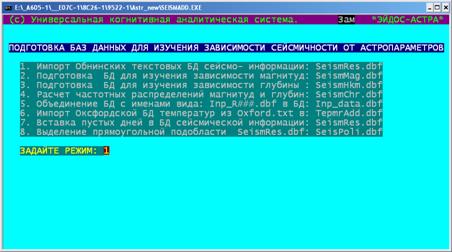
Рис. 9.3. Скриншот подсистемы обработки климатических
параметров и данных по сейсмическим событиям
Из этих категорий и из астрономических параметров, вычисленных
на середину каждого месяца, была образована БД, на основе которой были
синтезирована семантические информационные модели.
На рис. 10 представлен параметр сходства 53
климатических категорий в моделях М12 и М24.
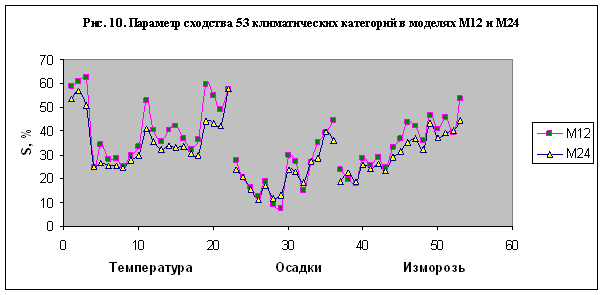
Отметим, что параметр
сходства является положительным для всех категорий, а его значение довольно
велико в исследованных моделях. Это означает, что климатические параметры зависят
от астрономических данных. Чтобы установить характер этой зависимости,
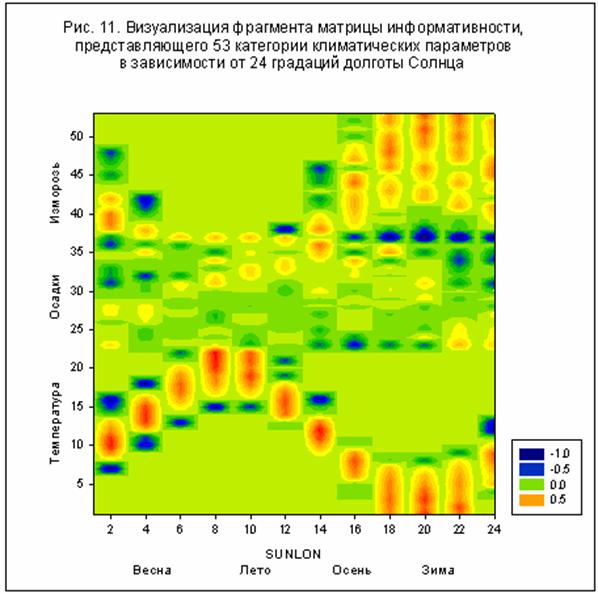
рассмотрим визуализацию фрагмента матрицы информативности модели М24 (для
наглядности), представляющего 53 климатические категории в зависимости от 24
градаций долготы Солнца – рис. 11.
В нижней части рис. 11
хорошо просматривается сезонный ход температуры воздуха в приземном слое
атмосферы, что обусловлено, главным образом, колебанием потока солнечной радиации,
связанным с движением нашей планеты вокруг Солнца (описывается долготой
Солнца).
Заметим, что данные [62]
являются ежемесячными, что хорошо отражено на рис. 11, где представлены 12
областей (окрашены в красный цвет), соответствующие максимальной температуре
воздуха. Данные по осадкам менее информативны в сравнении с температурой, а
данные по заморозкам (иней в воздухе), хотя и являются информативными,
неоднозначны, т.е. в разные годы число дней заморозка в данный месяц изменяется
в широких пределах.
Таким образом, метод
визуализации матрицы информативности позволяет установить наличие зависимости
категорий от астрономических параметров, хотя бы качественно. Например, по
данным на рис. 11 видно, что зимой заморозки более вероятны, нежели летом, а
осадки в Оксфорде более вероятны летом, нежели весной.
Таким
образом, система «Эйдос-астра»
является мощным инструментом для исследования социально-экономических и
природных процессов и систем в зависимости от астрономических параметров
небесных тел Солнечной системы. Предложенные математические модели, алгоритмы и
реализующие их программные средства (базовая система «Эйдос» и система окружения «Эйдос-астра» [7]), а
также технология и методика их применения обеспечили получение прикладных
результатов не только в области астросоциотипологии [2-6], но и в области
прогнозирования курсов валют [65], индекса S&P 500 [64], магнитного поля
Земли [59], сейсмических событий [54-55] и климата [53] по астрономическим
данным с использованием технологий искусственного интеллекта.
2.8. Развитие
интеллектуальной системы «Эйдос-астра», снимающее ограничения на размерность
баз знаний и разрешение когнитивных функций
Обзор информационных моделей и
исследований, выполненных на основе системы «Эйдос-астра»
Автоматизированный системно-когнитивный анализ [3] и
его инструментарий – базовая система «Эйдос» [7] получили широкое применение в
решении ряда задач, связанных выявлением знаний из эмпирических данных большой
размерности и решением на их основе задач идентификации, прогнозирования, принятия
решений и исследования предметной области. Как известно из теории управления
поведение любой системы определяется
состоянием самой системы (внутренними факторами и ее предысторией),
управляющими (технологическими) факторами, а также воздействием окружающей
среды. Не являются исключением и глобальные геосистемы: ноосфера (глобальные социально-экономические
процессы), биосфера, геосфера, магнитосфера, атмосфера и другие, для которых
внешней средой, с которой эти системы входят в непосредственное
взаимодействие, является ближайшее космическое окружение нашей планеты, т.е.
различные космические тела, входящие в состав Солнечной системы. Задачи
математического моделирования влияния небесных тел Солнечной системы на
глобальные геоситемы отличаются большой размерностью как по исходным базам
данных, так и по создаваемым в процессе моделирования информационным базам и
базам знаний..
Для решения этих задач была создана система «Эйдос-астра»
[7], позволяющая автоматически
генерировать различные системы частных моделей (мультимодели), исследовать их
на достоверность в разрезе по классам и с учетом этой информации наиболее
эффективно использовать их для идентификации и прогнозирования.
Первоначально исследования авторов были посвящены выявлению и исследованию
зависимости социального статуса респондентов (которых было коло 30 тысяч) от состояния
космической среды на момент их рождения [2-6]. Со временем проблематика
исследований расширилась и преобразовалась в целое новое научное направление: «Применение технологий искусственного
интеллекта для исследования влияния космической среды на поведение активных
глобальных геосистем».
В качестве современной автоматизированной интеллектуальной
технологии авторы применили автоматизированный системно-когнитивный анализ
(АСК-анализ) и его программный инструментарий – универсальную когнитивную
аналитическую систему «Эйдос» [3, 36]. В состав этой системы входит подсистема
_15, содержащая ряд стандартных программных интерфейсов с внешними источниками
данных различных стандартов: текстовых, баз данных (БД) и графических,
расширяющих сферу ее применения. Некоторые из подобных интерфейсов при своем
развитии преобразовались в системы окружения, которые выполняли больше функций,
чем программный интрефейс _152, но использовались совместно с базовой системой «Эйдос.
Первоначально авторами исследования проводились с применением именно этого
программного интерфейса с исходными базами данных и базовой системы «Эйдос».
При этом было разработано много программных интерфейсов с различными внешними
базами исходных данных, создано и исследовано большое количество различных
моделей. Со временем процесс генерации системы моделей, их исследования на
достоверность в разрезе по категориям, а также их использования для решения
задач идентификации, был автоматизирован, что и привело к созданию системы
окружения «Эйдос-астра» [7], которая включила в себя также все ранее
специализированные программные интерфейсы и специальный модуль визуализации
когнитивных функций.
В настоящее время система «Эйдос-астра» приобрела функциональную
полноту и превратилась в самостоятельный инструмент исследования, который может
применяться как совместно с базовой системой «Эйдос», так и независимо от нее.
Постановка проблемы
Базовая система «Эйдос» [3,36] была создана еще до создания операционной
системы Windows (в 1994 году на нее уже было получено 3 патента). В то время
трудно было себе представить, что когда-то в будущем может потребоваться более
4000 классов распознавания и 4000 признаков и были приняты технические решения,
связанные с повышением быстродействия путем организации внутреннего
кэширования, которые привели к соответствующему ограничению на размерности
создаваемых моделей. Когда создавалась система «Эйдос-астра», то при этом очень
широко использовались библиотеки процедур и функций системы «Эйдос» (и не очень
много внимания уделялось интерфейсу), что привело к наличию в системе «Эйдос-астра»
тех же ограничений на размерности моделей, что и в системе «Эйдос». Эти ограничения
создали определенные трудности в анализе задач большой размерности, связанных,
например, с анализом влияния небесных тел на сейсмические события, движение
полюса Земли и магнитное поле.
Справедливости ради необходимо отметить, что первоначально
система «Эйдос-астра» разрабатывалась как инструмент для проверки научных
гипотез о существовании зависимостей между параметрами космической среды и
глобальными процессами ноосфере Земли и этой цели она вполне соответствовала.
Кроме того указанные выше недостатки базовой системы «Эйдос» и системы «Эйдос-астра»
легко преодолеваются (без переписывания исходного текста) путем использования
новых версий языка программирования, на котором они были написаны (Alaska
xBase++, Arctica).
Идея и путь решения поставленной проблемы
Идея
решения сформулированной проблемы состоит в использовании новых перспективных
средств разработки новой версии системы «Эйдос-астра».
При этом использование различных инструментальных
средств имеет свои плюсы и минусы.
В частности использование Alaska xBase++ или Arctica позволяет
максимально использовать уже существующий исходный текст базовой системы «Эйдос»
и систем окружения и за счет этого существенно сократить трудоемкость и
длительность разработки, а это очень важно, т.к. распечатка этого исходного текста
6-м шрифтом составляет около 800 страниц. Отметим, что базовая система «Эйдос»
реализована в универсальной постановке,
не зависящей от предметной области, а ее привязка к конкретным областям
осуществляется на уровне адаптации и пересинтеза приложений, а также с
использованием полнофункционального набора программных интерфейсов с внешними
базами данных и различных систем окружения [7, 36, 66].
В качестве пути решения сформулированной
проблемы авторами принято решение о разработке новой версии системы «Эйдос-астра»
с использованием языка Java.
Java – это чрезвычайно перспективный язык программирования,
использование которого для данной цели вполне оправданно и обоснованно не
смотря на то, трудоемкость разработки выше, чем на Alaska xBase++ или Arctica,
т.к. приходится не переносить существующий исходный текст, а писать исходный
текст практически «с нуля».
Принято решение о реализации в новой версии данной системы
всех функций существующей версии, но без ограничений на размерность моделей и в
GUI, а затем о реализации в ней качественно новых возможностей, принципиально
не реализуемых с применением ранее использовавшегося инструментария. По сути,
идет речь не о переносе системы «Эйдос-астра» в существующей постановке, но с
преодолением ограничений на размерность моделей и недостатков интерфейса, а о разработке
качественно новой версии этой системы с сохранением всего лучшего, что было
достигнуто в предыдущих версиях.
Первые версии
системы «Эйдос-Java» уже созданы и тщательно протестированы на задачах, ранее решенных с помощью предыдущих
версий системы «Эйдос-астра». Было продемонстрировано полное тождество
полученных результатов, а также получены качественно новые результаты, ради
которых и создавалась система. В частности были сняты ограничения на размерность
модели с М173 до М36000 и по числу входных параметров с 23 до 253. Отметим, что
указанные новые ограничения параметров являются условными и определяются только
типом выбранных форматов файлов входных данных и оперативной памятью. Расширение системы выполнено в виде
отдельного приложения ViewVibe.jar [67], написанного на языке Java, снабженного
блоком графической визуализации расчетных матриц, включая матрицу
информативностей. Приложение ViewVibe.jar ориентировано на решение
естественно-научных, социально-экономических и психологических задач, связанных
с распознаванием событий по астрономическим данным, описанных в работах [1-6,
18-19, 52-55] и других.
Далее рассмотрим некоторые результаты исследований, проведенных с применением системы «Эйдос-Java».
Матрица информативностей в задаче о распознавании
категорий событий в поле центральных сил
Рассмотрим задачу распознавания категорий по астрономическим
данным [2, 10, 18]. Имеется множество событий Е, которому ставится в
соответствие множество категорий Кi. Событиями можно считать,
например, землетрясения, происходящие на нашей планете ежедневно, а категориями
– число одно- (А), двух- (В) или трехкратных событий (С), магнитуда которых
лежит в заданном интервале. Каждое такое событие характеризуется моментом
времени и географическими координатами места его происхождения. По этим данным
можно построить матрицу, содержащую координаты небесных тел, например углы
долготы, широты и расстояния. Будем
считать, что заданы частотные распределения Ni
– число событий, имеющих отношение к данной категории Кi.
Определим число случаев реализации данной категории, которое
приходится на заданный интервал изменения астрономических параметров, имеем в
дискретном случае:
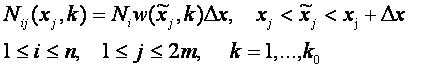 (11)
(11)
Здесь w –
плотность распределения событий вдоль нормированной координаты. Нормированная
переменная определяется через угловую и радиальную координаты следующим
образом:
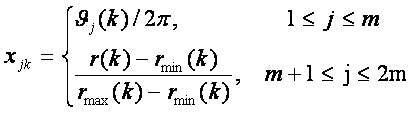
где
![]() - минимальное и максимальное удаление планеты
от центра масс системы, k0
– число небесных тел, используемых в задаче.
- минимальное и максимальное удаление планеты
от центра масс системы, k0
– число небесных тел, используемых в задаче.
Определим матрицу информативностей согласно
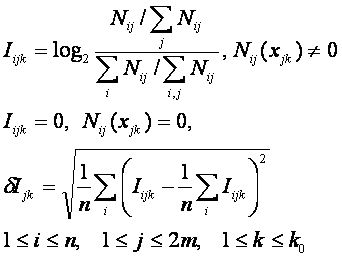 (12)
(12)
Первая величина (12) называется информативность признака,
а вторая величина является стандартным отклонением информативности или
интегральной информативностью (ИИ).
Рассмотрим связь информативности со статистикой
хи-вкадрат
Статистика c2 представляет
собой сумму вероятностей совместного наблюдения признаков и объектов по всей
корреляционной матрице или определенным ее подматрицам (т.е. сумму
относительных отклонений частот совместного наблюдения признаков и объектов от
среднего) [3, п.3.4]:
|
|
(13) |
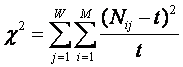
где:
– Nij
– фактическое количество встреч i-го
признака у объектов j-го класса;
– t –
теоретически ожидаемое количество встреч i-го признака у объектов j-го
класса.
|
|
(14) |
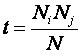
Нельзя не обратить
внимание на то, что статистика c2 математически простым образом связана с количеством информации в системе признаков о классе распознавания, в соответствии
с системным обобщением формулы Харкевича для плотности информации:
|
|
(15) |
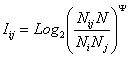
а именно из (14) и
(15) получаем:
|
|
(16) |
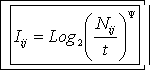
Выражение (16) для
количественной меры знаний, полученное в и используемое в автоматизированном
системно-когнитивном анализе (АСК-анализ), является чрезвычайно важным. По
сути, его смысл в том, что количественная мера знаний представляет собой
результат сравнения фактически наблюдаемой абсолютной частоты Nij встреч i-го признака у объектов j-го класса с теоретически ожидаемой
частотой его встреч t (4) в соответствии
с анализом хи-квадрат, которая и выступает в качестве нормы или базы сравнения.
Это сравнение в выражении (16) осуществляется путем вычисления отношения
фактически наблюдаемой абсолютной частоты Nij
встреч i-го признака у объектов j-го класса с теоретически ожидаемой
частотой его встреч t. Если при
использовании критерия хи-квадрат в качестве фильтра предлагается не
использовать для дальнейшего анализа фактически наблюдаемые частоты, меньшие
теоретически ожидаемых как недостоверные, то в АСК-анализе эти значения используются
и интерпретируются совершенно иначе: не как недостоверные, а как достоверно
отражающие отрицательную причинно-следственную
зависимость, т.к. дают, как легко
видеть из выражения (16) отрицательное количество информации: Iij < 0. Поэтому
применение фильтра хи-квадрат для отсеивания «недостоверной» информации эквивалентно
исключению отрицательных информативностей из базы знаний. Соответственно
исчезает возможность построения негативных когнитивных функций [69]. Фактически
применяемая в АСК-анлизе количественная мера знаний детально показывает как
образуется значение критерия хи-квадрат.
Из (16) очевидно:
|
|
(17) |
Сравнивая выражения
(13) и (17), видим, что числитель в выражении (13) под знаком суммы отличается
от выражения (17) только тем, что в выражении (17) вместо значений Nij и t взяты их логарифмы, т.е. по сути, отличаются только единицей измерения.
Поскольку логарифм является монотонно возрастающей функцией аргумента, то
введение логарифма не меняет общего характера поведения функции.
Фактически это
означает, что:
|
|
(18) |
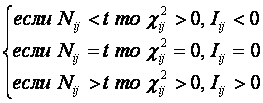
Если фактическая вероятность наблюдения i-го признака
при предъявлении объекта j-го класса равна теоретически ожидаемой (средней), то
наблюдение этого признака не несет никакой
информации о принадлежности объекта к данному классу. Если же она выше
средней – то это говорит в пользу того, что предъявлен объект данного класса,
если же ниже – то другого.
Поэтому наличие
статистической связи (информации) между признаками и классами
распознавания, т.е.
отличие вероятностей их совместных наблюдений от предсказываемого в соответствии
со случайным нормальным распределением, приводит к увеличению фактической
статистики c2 по сравнению с теоретической величиной.
Таким образом,
применяемая в автоматизированном системно-когнитивном анализе количественная
мера силы и направления причинно-следственной связи между факторами и поведением
объекта (его переходами в состояния, соответствующие классам), т.е.
информативность или количественная мера знаний (12) тесно связана с классическим
критерием наличия статистически
значимой связи хи-квадрат и можно обоснованно утверждать, что она не только не
противоречит ему, но и в определенной степени основана на нем и является его
развитием. Однако информативность представляется более развитым критерием, т.к.
отражает не только наличие и силу
связи, как хи-квадрат (18), но и ее знак, и главное – ее форму, т.е. сам вид
зависимости [69]. Кроме того, использование в качестве количественной
меры силы и направления связи количества информации позволяет привлечь хорошо развитые
представления теории информации для исследования причинно-следственных
зависимостей.
Связь между критерием хи-квадрат и когнитивными
функциями
Частично-редуцированные
когнитивные функции [69] строятся по максимуму информативности, т.е. по сути,
по наиболее достоверным данным, если для оценки их достоверности использовать
критерий хи-квадрат. Поэтому можно обоснованно ожидать, что использование
критерия хи-квадрат в качестве фильтра достоверных данных даст результаты,
сходные с результатами, приведенными в работе [69], однако приведет к потере
существенной информации об отрицательных причинно-следственных зависимостях,
визуализируемых в виде негативных когнитивных функций (уменьшится контрастность
их визуализации).
Из вышесказанного
следует возможность использования в качестве
количественной меры степени выраженности закономерностей в предметной области
использовать не матрицу абсолютных частот и меру c2, а новую меру, основанную на матрице информативностей и системном обобщении формулы Харкевича для
количества информации:
|
|
(19) |
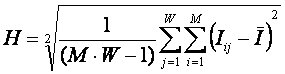
где:
|
|
– средняя
информативность признаков по матрице информативностей. |
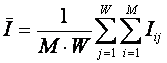
Значение данной
меры показывает среднее отличие количества информации в факторах о будущих
состояниях активного объекта управления от среднего количества информации в факторе
(которое при больших выборках близко к 0). По своей математической форме эта
мера сходна с мерами для значимости факторов и степени формирования образов
классов и коррелирует с объемом когнитивного пространства
классов и пространства атрибутов.
Описанная выше
математическая модель обеспечивает инвариантность результатов обучения Системы
относительно следующих параметров обучающей выборки:
1. Суммарное количество и порядок ввода анкет
обучающей выборки.
2. Количество анкет обучающей выборки
по каждому классу распознавания.
3. Суммарное количество признаков во всех анкетах
обучающей выборки.
4. Суммарное количество признаков по эталонным
описаниям различных классов распознавания.
5. Количество признаков и их порядок в отдельных
анкетах обучающей выборки.
Это обеспечивает
высокое качество решения задач системой распознавания на неполных и разнородных (в вышеперечисленных
аспектах) данных как обучающей,
так и распознаваемой выборки, т.е. при таких статистических характеристиках потоков
этих данных, которые чаще всего и встречается на практике и которыми невозможно
или очень сложно управлять.
Каждой категории можно сопоставить вектор информативности
астрономических параметров размерности 2mk0,
составленный из элементов матрицы информативности, путем последовательной
записи столбцов, соответствующих нормированной координате, в один столбец, т.е.
![]() (20)
(20)
С другой стороны, процесс идентификации, распознавания
и прогнозирования может рассматриваться как разложение вектора распознаваемого
объекта в ряд по векторам категорий (классов распознавания) [2]. Этот вектор,
состоящий из единиц и нулей, можно определить по координатам небесных тел,
соответствующих дате и месту происхождения события l в виде
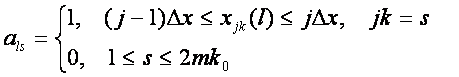 (21)
(21)
Таким образом, если нормированная координата небесного
тела из данных по объекту исследуемой выборки попадает в заданный интервал,
элементу вектора придается значение 1, а во всех остальных случаях – значение
0. Перечисление координат осуществляется последовательно, для каждого небесного
тела. В качестве астрономических параметров были использованы долгота, широта и
расстояние от Земли до десяти небесных тел – Солнца, Луны, Марса, Меркурия, Венеры,
Юпитера, Сатурна, Урана, Нептуна и Плутона, и долгота Северного Узла Луны.
В некоторых задачах возникает необходимость исследования
совместного влияния небесных тел и местных параметров, типа координат и угловой скорости движения полюса
Земли, индукции магнитного поля по измерениям на разных станциях, гравитационного
потенциала, числа пятен на Солнце и т.п. на сейсмические события [55,58-59].
В работах [70-71] была построена модель линейной регрессии,
описывающая движение полюса Земли, с использованием комбинаций астрономических
параметров, характеризующих влияние каждого небесного тела в виде:
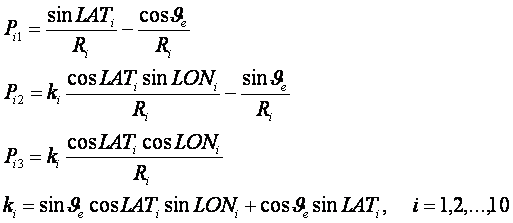 (22)
(22)
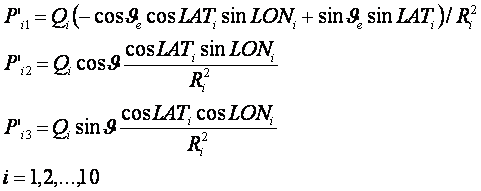 (23)
(23)
Здесь долгота (LON), широта (LAT) и расстояние (R) определяется
для каждого из 10 небесных тел, ![]() - угол наклона земной оси
относительно нормали к орбитальной плоскости, Qi – заряды небесных тел.
- угол наклона земной оси
относительно нормали к орбитальной плоскости, Qi – заряды небесных тел.
Отметим, что
данные для расстояний от Земли до небесных тел вычисляются в формулах (22-23) в
астрономических единицах. Параметры (22), (23) могут быть использованы наряду с
астрономическими параметрами.
При создании моделей были использованы данные ежедневного
числа солнечных пятен по наблюдениям американских астрономов [72] – параметр
RADAILY, данные по индукции магнитного поля Земли [61], данные по сейсмическим
событиям [57], а также координаты географического полюса – X, Y [60]. Данные по
индукции магнитного поля были взяты со следующих 23 станций (приведены только
IAGA коды): GNA, GUA, IRT, KAK, MMB, RES, THL, DRV, HER, FUG, ABG, HON, CLF,
LRV, SOD, AAE, AAA, TAN, SJG, AIA, TUC, BNG, MBO.
Решение прямой задачи включает в себя нормирование
входных параметров и приведение их к одному масштабу изменения в интервале
(0;360), разбиение интервалов на М частей, 2<M<36200, вычисление матрицы
абсолютных частот и информативности, в соответствии с формулами (11-12). Вопросы визуализации матрицы
информативностей и построение различных когнитивных функций рассмотрены в
работах [66, 73-74] и других.
Описание программы
Программа ViewVibe.jar написана на языке Java и может
быть использована на компьютерах с ОС типа Linux, Windows XP и выше. Скриншот основного меню программы приведен на рис. 12. Работа начинается с
загрузки данных (кнопка Load Data Table) из файла типа книги Excel с двумя
страницами. На первой странице файла данных перечислены имена категорий, а на
второй странице задаются номера и имена строк, категории и столбцы входных
параметров - рис. 13.
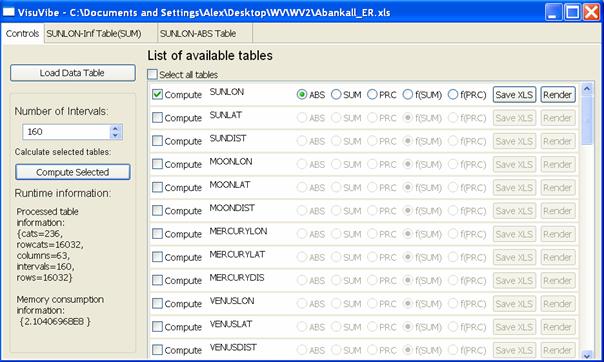
Рис. 12. Скриншот программы ViewVibe.jar

Рис. 13. Вид
первой и второй страниц файла загрузки
При загрузке данные
нормируются в соответствии с формулами (11) для приведения данных к одной
шкале. После этого программа готова к вычислениям. На этом этапе необходимо задать
число интервалов (номер модели) в окне Number of Intervals. По формулам (12)
вычисляется матрица частот и матрица информативности, а также служебные
матрицы, используемые в алгоритмах СИМ1 и СИМ2. Вычисления можно производить
для всех или только выбранных столбцов входных параметров путем пометки
соответствующего окна и запуска Compute Selected.
После вычислений
активируются окна основных и служебных матриц ABS, SUM, PRC, f(SUM), f(PRC).
Каждую из матриц можно сохранить в формате XLS, путем нажатия кнопки Save XLS,
а также создать на ее основе изображение процесса, путем нажатия кнопки
Render. Путь ко всем созданным
программой изображениям сохраняется на
верхней панели - рис. 12. Таким образом,
можно сравнивать изображения, полученные на основе различных матриц и в
различных моделях – рис. 14. При переходе по любому из путей открывается
изображение вместе с панелью редактирования и кнопкой возврата в основное меню
(Controls). На рис 14 представлен скриншот рабочего окна программы визуализации
матриц ABS, SUM, PRC, f(SUM), f(PRC). Окно содержит две полосы прокрутки для
просмотра изображений большого размера и кнопку изменения масштаба изображения
Zoom Image. Изображение можно раскрасить - кнопки Red, Green, Blue, Gray, сгладить –
кнопка Smooth, сделать правый и левый
поворот на 90 градусов - Rotate Left,
Rotate Right. Изображение сохраняется при нажатии кнопки Save Image по выбору в формате BMP,
JPG, PNG с исходным размером, который задается размером фрагмента матрицы
информативностей, т.е. размером=(число интервалов)×(число категорий)
пиксель.

Рис. 14. Два изображения координат и угловой скорости
движения полюса Земли в зависимости от долготы Солнца, созданных на основе
матриц информативностей в моделях М360 и
М160 и скриншот рабочего окна программы визуализации
Визуализация матриц семантических
информационных моделей движения полюса Земли
Для решения прикладных задач в АСК-анализе проводится
последовательное повышение степени формализации исходных данных до уровня,
обеспечивающего их обработку на компьютере в программной системе. После
выполнения когнитивной структуризации и формализации предметной области осуществляется
синтез модели. Он включает в себя расчет на основе эмпирических данных,
представленных в исследуемой выборке, следующих матриц:
– матрицы абсолютных частот ABS, которые используются
во многих статистических системах;
– матрицы условных и безусловных процентных распределений
PRC, которые используются в некоторых статистических системах;
– матрицы информативностей или матрицы знаний INF, которые
используются только в АСК-анализе.
Интересно сравнить изображения, полученные на основе
этих трех матриц в задаче о движении полюса Земли – рис. 15. В данной задаче
движение полюса характеризуется координатами X, Y и угловой скоростью X1, Y1 -
таблица 4. Как следует из данных, приведенных на рис. 15, при сравнении четырех
зависимостей Y(X), Y(Y), Y(X1), Y(Y1) на основе матрицы абсолютных частот
достаточно достоверно выявляется только линейная зависимость Y=Y. При
визуализации на основе матрицы процентных распределений выявляются все
зависимости, однако детали траектории движения полюса Y=Y(X), размыты из-за сильного контраста данных с
высокой и низкой частотой. И только при визуализации на основе матрицы
информативностей оказывается возможным проследить все детали движения полюса
– см. правый рис. 15 и рис. 14, на котором в увеличенном масштабе
представлены зависимости Х(X), Х(Y), Х(X1), Х(Y1).
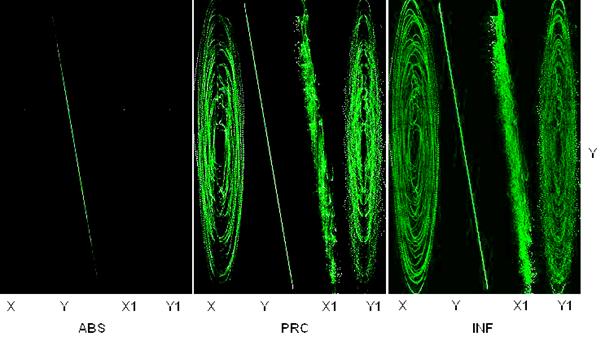
Рис. 15. Визуализация матрицы абсолютных частот (слева),
матрицы процентных распределений (в центре) и матрицы информативностей (справа)
Теоретическое объяснение целесообразности использования именно матрицы
информативностей (базы знаний) для визуализации когнитивных функций и решения
других задач (идентификации, прогнозирования, поддержки принятия решений и исследования
предметной области) состоит в следующем. На основе сравнения абсолютных частот
можно делать какие-либо выводы только в том случае, когда по разным классам
приведено одинаково количество примеров. В общем случае это количество примеров
по разным классам всегда разное,
поэтому матрица абсолютных частот сама по себе непригодна для решения вышеперечисленных
задач. Но на практике иногда встречается ситуация, когда это количество мало
отличается по разным классам и тогда использование этой матрицы не дает большой
ошибки и позволяет составить более-менее достоверное представление о предметной
области. Получить модель предметной области, инвариантную относительно
различий в количестве примеров по классам, можно перейдя от матрицы абсолютных
частот к матрице условных и безусловных процентных распределений. Использование
матрицы условных и безусловных процентных распределений позволяет получить
такой же уровень достоверности выводов о предметной области, какой матрица
абсолютных частот в случае равного
количества примеров по разным классам. Однако для того, чтобы получить эти
выводы необходимо сравнивать условные процентные распределения друг с другом.
При небольших размерностях моделей это сравнение может быть проведено вручную,
правда лишь на качественном уровне, однако при реальных встречающихся на
практике размерностях вручную это сделать не представляется возможным. Поэтому в АСК-анализе принято решение автоматизировать количественное
сравнение условных процентных распределений. При этом возник вопрос о том,
как именно их сравнивать: друг с другом или с какой-то базой сравнения. Если в
модели всего два класса, то приемлем вариант сравнения условных процентных
распределений по ним друг с другом. Но когда классов всего три, то уже не очень
понятно как это делать, если же их сотни, тысячи или десятки тысяч, то это
становится вообще непонятным. В АСК-анализе этот вопрос решен путем сравнения
условных процентных распределений по классам с безусловным процентным
распределением по всей выборке, которое и выступает базой (нормой) сравнения.
Это решение соответствует принятому в статистике методу средних и отклонений от
средних и представляет собой косвенное или опосредованное сравнение условных
процентных распределений друг с другом, т.к. база сравнения рассчитывается с их
использованием. Таким образом, матрица
информативностей представляет собой результат автоматизированного сравнения
условных процентных распределений признаков по классам с их безусловным
процентным распределением по всей выборке. По сути это результат нормировки
условных процентных распределений с использованием в качестве нормы
безусловного процентного распределения. Поэтому использование матрицы
информативностей освобождает исследователя-аналитика от необходимости
выполнения огромной рутинной работы (которую он как правило и не может
выполнить вручную, а когда может, то лишь на качественном, а не на
количественном уровне) по сравнению условных процентных распределений друг с
другом или с какой-либо базой сравнения и обеспечивает более высокий уровень
достоверности выводов, чем использование матрицы условных и безусловных
процентных распределений.
С увеличением количества интервалов оказывается возможным
установить такие закономерности движения полюса Земли, которые никак не
просматриваются при меньших разбиениях. На верхнем рис. 14 представлены
зависимости координат и угловой скорости полюса от долготы Солнца. На левом
рисунке, полученном в модели М360, на
данных для угловой скорости видны колебания, видимо, обусловленные влиянием
Луны, которые в модели М160 представляются как случайные выбросы.
На рис. 16 представлен фрагмент матрицы информативностей,
демонстрирующий зависимость координат (X,Y) и угловой скорости (X1, Y1)
движения полюса Земли – всего 244 категории, перечисленные в таблице 4, от
долготы Солнца в 1963-2006 годов по данным /26/. Как следует из данных,
приведенных на рис. 16, координаты полюса в зависимости от долготы Солнца
образуют жгуты, которые формируются из отдельных годичных движений на
протяжении многих лет. Отметим, что
категории угловой скорости не образуют достаточно четких нитевидных структур, подобных тем, что образуют категории координат.
Таблица 4 –
ЕЖЕДНЕВНАЯ ЧАСТОТА ПОЯВЛЕНИЯ КАТЕГОРИЙ КООРДИНАТ И УГЛОВОЙ СКОРОСТИ ДВИЖЕНИЯ ПОЛЮСА
ЗЕМЛИ В 1963-2006 ГОДАХ
|
Категория X |
ABS |
Категория Y |
ABS |
Категория X1 |
ABS |
Категория Y1 |
ABS |
|
A1-X=-0,29609 |
11 |
B1-Y=-0,01292 |
30 |
A1-X1=-0,006 |
1 |
B2-Y1=-0,00554 |
1 |
|
A2-X=-0,28609 |
8 |
B2-Y=-0,00292 |
55 |
A2-X1=-0,0058 |
2 |
B4-Y1=-0,00514 |
6 |
|
A3-X=-0,27609 |
8 |
B3-Y=0,00708 |
114 |
A3-X1=-0,0056 |
1 |
B5-Y1=-0,00494 |
4 |
|
A4-X=-0,26609 |
7 |
B4-Y=0,01708 |
139 |
A4-X1=-0,0054 |
5 |
B6-Y1=-0,00474 |
20 |
|
A5-X=-0,25609 |
17 |
B5-Y=0,02708 |
116 |
A5-X1=-0,0052 |
7 |
B7-Y1=-0,00454 |
42 |
|
A6-X=-0,24609 |
70 |
B6-Y=0,03708 |
95 |
A6-X1=-0,005 |
11 |
B8-Y1=-0,00434 |
46 |
|
A7-X=-0,23609 |
99 |
B7-Y=0,04708 |
104 |
A7-X1=-0,0048 |
23 |
B9-Y1=-0,00414 |
93 |
|
A8-X=-0,22609 |
140 |
B8-Y=0,05708 |
123 |
A8-X1=-0,0046 |
32 |
B10-Y1=-0,00394 |
130 |
|
A9-X=-0,21609 |
125 |
B9-Y=0,06708 |
217 |
A9-X1=-0,0044 |
47 |
B11-Y1=-0,00374 |
137 |
|
A10-X=-0,20609 |
194 |
B10-Y=0,07708 |
248 |
A10-X1=-0,0042 |
67 |
B12-Y1=-0,00354 |
169 |
|
A11-X=-0,19609 |
199 |
B11-Y=0,08708 |
253 |
A11-X1=-0,004 |
136 |
B13-Y1=-0,00334 |
204 |
|
A12-X=-0,18609 |
188 |
B12-Y=0,09708 |
207 |
A12-X1=-0,0038 |
150 |
B14-Y1=-0,00314 |
258 |
|
A13-X=-0,17609 |
173 |
B13-Y=0,10708 |
247 |
A13-X1=-0,0036 |
202 |
B15-Y1=-0,00294 |
345 |
|
A14-X=-0,16609 |
238 |
B14-Y=0,11708 |
274 |
A14-X1=-0,0034 |
265 |
B16-Y1=-0,00274 |
315 |
|
A15-X=-0,15609 |
378 |
B15-Y=0,12708 |
256 |
A15-X1=-0,0032 |
309 |
B17-Y1=-0,00254 |
390 |
|
A16-X=-0,14609 |
269 |
B16-Y=0,13708 |
314 |
A16-X1=-0,003 |
354 |
B18-Y1=-0,00234 |
434 |
|
A17-X=-0,13609 |
272 |
B17-Y=0,14708 |
317 |
A17-X1=-0,0028 |
356 |
B19-Y1=-0,00214 |
433 |
|
A18-X=-0,12609 |
269 |
B18-Y=0,15708 |
346 |
A18-X1=-0,0026 |
383 |
B20-Y1=-0,00194 |
446 |
|
A19-X=-0,11609 |
340 |
B19-Y=0,16708 |
375 |
A19-X1=-0,0024 |
335 |
B21-Y1=-0,00174 |
440 |
|
A20-X=-0,10609 |
354 |
B20-Y=0,17708 |
451 |
A20-X1=-0,0022 |
434 |
B22-Y1=-0,00154 |
449 |
|
A21-X=-0,09609 |
271 |
B21-Y=0,18708 |
427 |
A21-X1=-0,002 |
445 |
B23-Y1=-0,00134 |
473 |
|
A22-X=-0,08609 |
299 |
B22-Y=0,19708 |
432 |
A22-X1=-0,0018 |
412 |
B24-Y1=-0,00114 |
500 |
|
A23-X=-0,07609 |
302 |
B23-Y=0,20708 |
422 |
A23-X1=-0,0016 |
398 |
B25-Y1=-0,00094 |
586 |
|
A24-X=-0,06609 |
342 |
B24-Y=0,21708 |
341 |
A24-X1=-0,0014 |
422 |
B26-Y1=-0,00074 |
542 |
|
A25-X=-0,05609 |
385 |
B25-Y=0,22708 |
372 |
A25-X1=-0,0012 |
449 |
B27-Y1=-0,00054 |
581 |
|
A26-X=-0,04609 |
379 |
B26-Y=0,23708 |
478 |
A26-X1=-0,001 |
403 |
B28-Y1=-0,00034 |
515 |
|
A27-X=-0,03609 |
515 |
B27-Y=0,24708 |
417 |
A27-X1=-0,0008 |
510 |
B29-Y1=-0,00014 |
587 |
|
A28-X=-0,02609 |
406 |
B28-Y=0,25708 |
374 |
A28-X1=-0,0006 |
595 |
B30-Y1=0,00006 |
521 |
|
A29-X=-0,01609 |
460 |
B29-Y=0,26708 |
340 |
A29-X1=-0,0004 |
515 |
B31-Y1=0,00026 |
614 |
|
A30-X=-0,00609 |
421 |
B30-Y=0,27708 |
332 |
A30-X1=-0,0002 |
574 |
B32-Y1=0,00046 |
612 |
|
A31-X=0,00391 |
441 |
B31-Y=0,28708 |
333 |
A31-X1=0 |
656 |
B33-Y1=0,00066 |
575 |
|
A32-X=0,01391 |
336 |
B32-Y=0,29708 |
338 |
A32-X1=0,0002 |
554 |
B34-Y1=0,00086 |
468 |
|
A33-X=0,02391 |
347 |
B33-Y=0,30708 |
356 |
A33-X1=0,0004 |
575 |
B35-Y1=0,00106 |
427 |
|
A34-X=0,03391 |
347 |
B34-Y=0,31708 |
400 |
A34-X1=0,0006 |
546 |
B36-Y1=0,00126 |
403 |
|
A35-X=0,04391 |
369 |
B35-Y=0,32708 |
427 |
A35-X1=0,0008 |
458 |
B37-Y1=0,00146 |
503 |
|
A36-X=0,05391 |
419 |
B36-Y=0,33708 |
369 |
A36-X1=0,001 |
473 |
B38-Y1=0,00166 |
554 |
|
A37-X=0,06391 |
469 |
B37-Y=0,34708 |
370 |
A37-X1=0,0012 |
503 |
B39-Y1=0,00186 |
456 |
|
A38-X=0,07391 |
382 |
B38-Y=0,35708 |
341 |
A38-X1=0,0014 |
469 |
B40-Y1=0,00206 |
438 |
|
A39-X=0,08391 |
414 |
B39-Y=0,36708 |
379 |
A39-X1=0,0016 |
485 |
B41-Y1=0,00226 |
427 |
|
A40-X=0,09391 |
402 |
B40-Y=0,37708 |
450 |
A40-X1=0,0018 |
428 |
B42-Y1=0,00246 |
328 |
|
A41-X=0,10391 |
410 |
B41-Y=0,38708 |
372 |
A41-X1=0,002 |
338 |
B43-Y1=0,00266 |
271 |
|
A42-X=0,11391 |
350 |
B42-Y=0,39708 |
351 |
A42-X1=0,0022 |
343 |
B44-Y1=0,00286 |
306 |
|
A43-X=0,12391 |
371 |
B43-Y=0,40708 |
289 |
A43-X1=0,0024 |
344 |
B45-Y1=0,00306 |
246 |
|
A44-X=0,13391 |
416 |
B44-Y=0,41708 |
301 |
A44-X1=0,0026 |
353 |
B46-Y1=0,00326 |
197 |
|
A45-X=0,14391 |
267 |
B45-Y=0,42708 |
335 |
A45-X1=0,0028 |
257 |
B47-Y1=0,00346 |
170 |
|
A46-X=0,15391 |
280 |
B46-Y=0,43708 |
207 |
A46-X1=0,003 |
329 |
B48-Y1=0,00366 |
132 |
|
A47-X=0,16391 |
284 |
B47-Y=0,44708 |
214 |
A47-X1=0,0032 |
239 |
B49-Y1=0,00386 |
99 |
|
A48-X=0,17391 |
258 |
B48-Y=0,45708 |
241 |
A48-X1=0,0034 |
192 |
B50-Y1=0,00406 |
60 |
|
A49-X=0,18391 |
257 |
B49-Y=0,46708 |
229 |
A49-X1=0,0036 |
175 |
B51-Y1=0,00426 |
37 |
|
A50-X=0,19391 |
250 |
B50-Y=0,47708 |
282 |
A50-X1=0,0038 |
132 |
B52-Y1=0,00446 |
15 |
|
A51-X=0,20391 |
300 |
B51-Y=0,48708 |
181 |
A51-X1=0,004 |
106 |
B53-Y1=0,00466 |
5 |
|
A52-X=0,21391 |
256 |
B52-Y=0,49708 |
131 |
A52-X1=0,0042 |
83 |
B54-Y1=0,00486 |
8 |
|
A53-X=0,22391 |
294 |
B53-Y=0,50708 |
125 |
A53-X1=0,0044 |
65 |
B55-Y1=0,00506 |
3 |
|
A54-X=0,23391 |
181 |
B54-Y=0,51708 |
115 |
A54-X1=0,0046 |
41 |
B56-Y1=0,00526 |
4 |
|
A55-X=0,24391 |
170 |
B55-Y=0,52708 |
122 |
A55-X1=0,0048 |
15 |
B59-Y1=0,00586 |
2 |
|
A56-X=0,25391 |
190 |
B56-Y=0,53708 |
132 |
A56-X1=0,005 |
11 |
B62-Y1=0,00646 |
1 |
|
A57-X=0,26391 |
79 |
B57-Y=0,54708 |
147 |
A57-X1=0,0052 |
9 |
B64-Y1=0,00686 |
1 |
|
A58-X=0,27391 |
92 |
B58-Y=0,55708 |
103 |
A58-X1=0,0054 |
5 |
B65-Y1=0,00706 |
1 |
|
A59-X=0,28391 |
78 |
B59-Y=0,56708 |
68 |
A59-X1=0,0056 |
1 |
|
|
|
A60-X=0,29391 |
56 |
B60-Y=0,57708 |
14 |
A60-X1=0,0058 |
2 |
|
|
|
A61-X=0,30391 |
72 |
|
|
|
|
|
|
|
A62-X=0,31391 |
23 |
|
|
|
|
|
|

Рисунок 16. Зависимость
категорий координат и угловой скорости полюса Земли от долготы Солнца в модели
М480.
Согласно существующим представлениям, такое поведение
угловой скорости полюса в зависимости от долготы Солнца обусловлено наличием
случайной составляющей, связанной с движением атмосферы и океана относительно
земной коры.
Визуализация матриц семантических информационных моделей
сейсмических событий
Исследуемая база данных сейсмических событий была
сформирована на основе базы данных Международного сейсмологического центра –
ISC [57], содержащей 20489816 записей регистрации
различными сейсмостанциями событий землетрясений, произошедших на нашей планете
в период с 1 января 1961 года по 31 декабря 2006 г. Из исходной базы было
образовано несколько различных БД для исследования влияния астрономических
параметров на магнитуду и глубину гипофокуса, на ежедневное число землетрясений,
а также на средние параметры сейсмической активности. В работах [54-55,58]
исследована совокупность 128320 событий землетрясений с магнитудой ![]() , произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
, произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
В исходной БД сейсмические события характеризуются
магнитудой mb, которой можно сопоставить категорию магнитуды – таблица 5.
Поскольку события с одной и той же магнитудой могут повторяться в один день,
каждому значению магнитуды сопоставляется несколько типов категорий, а именно:
A – событие с магнитудой mb повторяется один раз;
B – событие с магнитудой mb повторяется два раза;
C – событие с
магнитудой mb повторяется три раза.
Кроме того, можно рассмотреть случай, когда, например, категория А усекается, путем отбрасывания
некоторых событий. Таким образом, были образованы категории А66, В59 и С53.
Таблица 5 – Частота
повторения категорий
сейсмической активности
|
Категория |
ABS |
Категория |
ABS |
Категория |
ABS |
|
A40-Mb=4,0 |
1362 |
B40-Mb=4,0 |
446 |
C40-Mb=4,0 |
130 |
|
A41-Mb=4,1 |
1580 |
B41-Mb=4,1 |
660 |
C41-Mb=4,1 |
259 |
|
A42-Mb=4,2 |
1796 |
B42-Mb=4,2 |
835 |
C42-Mb=4,2 |
362 |
|
A43-Mb=4,3 |
2224 |
B43-Mb=4,3 |
955 |
C43-Mb=4,3 |
436 |
|
A44-Mb=4,4 |
2744 |
B44-Mb=4,4 |
1099 |
C44-Mb=4,4 |
482 |
|
A45-Mb=4,5 |
3358 |
B45-Mb=4,5 |
1223 |
C45-Mb=4,5 |
468 |
|
A46-Mb=4,6 |
4119 |
B46-Mb=4,6 |
1455 |
C46-Mb=4,6 |
515 |
|
A47-Mb=4,7 |
4768 |
B47-Mb=4,7 |
1612 |
C47-Mb=4,7 |
501 |
|
A48-Mb=4,8 |
4954 |
B48-Mb=4,8 |
1817 |
C48-Mb=4,8 |
450 |
|
A49-Mb=4,9 |
5008 |
B49-Mb=4,9 |
1636 |
C49-Mb=4,9 |
447 |
|
A50-Mb=5 |
4904 |
B50-Mb=5 |
1428 |
C50-Mb=5 |
356 |
|
A51-Mb=5,1 |
4582 |
B51-Mb=5,1 |
1206 |
C51-Mb=5,1 |
293 |
|
A52-Mb=5,2 |
4134 |
B52-Mb=5,2 |
936 |
C52-Mb=5,2 |
166 |
|
A53-Mb=5,3 |
3563 |
B53-Mb=5,3 |
617 |
C53-Mb=5,3-6,0 |
105 |
|
A54-Mb=5,4 |
3010 |
B54-Mb=5,4 |
422 |
|
|
|
A55-Mb=5,5 |
2367 |
B55-Mb=5,5 |
261 |
|
|
|
A56-Mb=5,6 |
1940 |
B56-Mb=5,6 |
180 |
|
|
|
A57-Mb=5,7 |
1460 |
B57-Mb=5,7 |
93 |
|
|
|
A58-Mb=5,8 |
1179 |
B58-Mb=5,8 |
73 |
|
|
|
A59-Mb=5,9 |
864 |
B59-Mb=5,9-6,4 |
69 |
|
|
|
A60-Mb=6,0 |
656 |
|
|
|
|
|
A61-Mb=6,1 |
453 |
|
|
|
|
|
A62-Mb=6,2 |
319 |
|
|
|
|
|
A63-Mb=6,3 |
202 |
|
|
|
|
|
A64-Mb=6,4 |
137 |
|
|
|
|
|
A65-Mb=6,5 |
87 |
|
|
|
|
|
A66-Mb=6,6-7,0 |
68 |
|
|
|
|
На рис. 17 представлены
данные визуализации матрицы абсолютных частот в задаче распознавания
сейсмических событий по астрономическим данным, а также с учетом влияния магнитного
поля и движения полюса Земли в модели
М720. Анализируя данные, приведенные на рис. 17, можно сделать вывод о том, что
во всех рассмотренных случаях события группируются вблизи некоторых особых
точек отображения (11) – см. [18], образуя своеобразный линейчатый спектр.
Такое поведение обнаружено впервые, благодаря использованной технике
визуализации.
Другой эффект,
обнаруженный на моделях большой размерности, заключается в том, что отображение
сейсмических событий в зависимости от вертикальной компоненты индукции
магнитного поля имеет вид своеобразных «пальцев» или жезлов, которые по виду аналогичны
тем, что получаются при визуализации матрицы абсолютных частот сейсмических
событий в зависимости от расстояния до Урана – рис. 18.
Рисунок 17. Зависимость категорий
сейсмических событий А,В,С (в каждом рисунке категории отложены по вертикали
снизу вверх) от долготы Лунного Узла, Юпитера и Сатурна, и от вертикальной
компоненты индукции магнитного поля на станции GNA в модели М720. Для
визуализации использована матрица абсолютных частот и условных и безусловных
процентных распределений в случае магнитного поля
Рисунок 18. Зависимость категорий
сейсмических событий А,В,С (в каждом рисунке категории отложены по горизонтали
слева направо) от вертикальной компоненты индукции магнитного поля на станциях
AIA, GUA, HER, GNA, THL и от расстояния от Земли до Урана в модели М360. Для
визуализации использована матрица абсолютных частот.
Эта аналогия, впервые
обнаруженная в работе [55], послужила основой для создания моделей влияния
небесных тел на геомагнитное поле и на движение полюса Земли [58-59, 70-71].
Сравнивая картины
визуализации трех матриц в модели М360, описывающей зависимость категорий
сейсмических событий А,В,С от расстояния до Урана – рис. 19, находим, что матрица
информативностей наиболее точно отражает все детали этой зависимости. И хотя в этом случае корреляция событий
является весьма слабой, тем не менее, благодаря использованию АСК-анализа
удается выделить эту зависимость и найти комбинации астрономических параметров
в форме (22)-(23), которые в наибольшей степени влияют на сейсмические события,
движение полюса и магнитное поле Земли.

Рисунок
19. Визуализация матрицы информативностей (слева), матрицы процентных
распределений (в центре) и матрицы абсолютных частот (справа) в модели М360 демонстрирует зависимость
категорий сейсмических событий А,В,С (в каждом рисунке категории отложены по
горизонтали слева направо) от расстояния до Урана (вертикальная координата,
направленная сверху вниз).
Наконец, заметим, что исследованные в настоящей работе
зависимости относятся к классу когнитивных функций, визуализация которых
позволяет получить новые знания о поведении сложных систем, зависящих от
множества параметров большой размерности. Приведенные выше примеры показывают
существенное различие в стандартном классическом описании таких систем,
основанном на использовании матрицы абсолютных частот, и с использованием АСК-анализа.
Таким образом, можно сделать обоснованный вывод
о том, что сформулированная проблема
решена, т.е. создана новая версия системы искусственного интеллекта «Эйдос-астра» для решения прикладных
задач с эмпирическими данными большой
размерности. Приложение, написанное на языке JAVA, обеспечивает GUI и позволяет
подготовить и выполнить визуализацию матрицы
информативностей без ограничений, налагаемых реализацией предыдущих
версий системы «Эйдос-астра».
В качестве перспективы авторы рассматривают
реализацию в новой версии всех функций предыдущей версии, а также реализацию
качественно новых возможностей.
2.9. Метод
визуализации когнитивных функций – новый инструмент исследования эмпирических
данных большой размерности
Автоматизированный системно-когнитивный
анализ (АСК-анализ)
Проблема, решаемая практически во всех экспериментальных
исследованиях, состоит в выявлении причинно-следственных зависимостей из
эмпирических данных и формальном представлении этих зависимостей в
аналитической форме, т.е. в форме математических функций. Автоматизированный системно-когнитивный
анализ (АСК-анализ) предоставляет для этого ряд новых возможностей.
Информационные портреты градаций факторов (признаков)
были исторически первой формой выявления их влияния на принадлежность объекта к
классам, реализованной в системе «Эйдос» изначально, т.е. с самых первых версий
этой системы, так и в более поздних версиях. Аппарат визуализации полностью редуцированных
когнитивных функций средствами системы «Эйдос» был реализован в системе в
2004 [50]. В 2009-2010 годах началось широкое использование в научных
исследованиях [48-49, 53-55] нередуцированных
когнитивных функций, отображаемый внешними системами (например, SigmaPlot,
MS Excel) на основе баз данных, сформированных системой «Эйдос» (в режимах _53
и _683). В 2010 году авторами начали использоваться прямые и обратные,
редуцированные и нередуцированные когнитивные функции, отображаемые внешними
системами на основе баз данных, подготовленных системой «Эйдос». В начале 2011
года авторами был разработан специальный режим визуализации когнитивных функций
системы «Эйдос» [74], обеспечивающий визуализацию прямых и обратных, позитивных
и негативных, полностью и частично редуцированных когнитивных функций.
Автоматизированный системно-когнитивный анализ
(АСК-анализ) представляет собой новый
метод искусственного интеллекта, развитый это системный анализ, автоматизированный
путем структурирования по базовым когнитивным операциям системного анализа (БКОСА) и включающий: формализуемую
когнитивную концепцию, математическую модель, методику численных расчетов и
реализующий их программный инструментарий, в качестве которого в настоящее
время выступает универсальная когнитивная аналитическая система «Эйдос».
АСК-анализ был предложен в 2002 году одним из авторов [3].
Компоненты АСК-анализа:
– формализуемая
когнитивная концепция и следующий из нее когнитивный конфигуратор;
– теоретические
основы, методология, технология и методика АСК-анализа;
– математическая
модель АСК-анализа, основанная на системном обобщении семантической меры
целесообразности информации А. Харкевича;
– методика
численных расчетов, в универсальной форме реализующая математическую модель
СК-анализа, включающая иерархическую структуру данных и 24 детальных алгоритма
10 БКОСА;
– специальное
инструментальное программное обеспечение, реализующее математическую модель и
численный метод СК-анализа – Универсальная когнитивная аналитическая система «Эйдос»;
– методика,
технология и результаты синтеза рефлексивных АСУ активными объектами на основе
АСК-анализа.
Этапы АСК-анализа обеспечивают последовательное повышение
степени формализации знаний о предметной области до уровня, достаточного
для представления знаний в автоматизированной системе искусственного интеллекта
и решения в ней задач идентификации, прогнозирования и поддержки принятия решений (управления):
1) когнитивная
структуризация предметной области;
2) формализация
предметной области (конструирование классификационных и описательных шкал и
градаций);
3) подготовка
обучающей выборки (ввод данных мониторинга в базу прецедентов);
4) синтез
семантической информационной модели (СИМ);
5) повышение
эффективности СИМ;
6) проверка
адекватности СИМ (измерение внутренней и внешней, дифференциальной и
интегральной валидности);
7)
системно-когнитивный анализ СИМ, исследование моделируемого объекта путем
исследования его модели:
– решение задач
идентификации и прогнозирования;
– генерация
информационных портретов классов и факторов, т.е. решение обратной задачи
прогнозирования, поддержка принятия решений по управлению (результаты
отображаются в графической форме двухмерных и трехмерных профилей классов и
факторов);
–
кластерно-конструктивный анализ классов и факторов (результаты отображаются в
форме семантических сетей классов и факторов);
– содержательное
сравнение классов и факторов (результаты отображаются в форме когнитивных
диаграмм классов и факторов);
– изучение системы
детерминации состояний моделируемого объекта, нелокальные нейроны и
интерпретируемые нейронные сети;
– построение
классических когнитивных моделей (когнитивных карт).
– построение
интегральных когнитивных моделей (интегральных когнитивных карт).
Математическая модель АСК-анализа основана на системной теории информации (СТИ).
Системная теория информации (СТИ) – Отличия СТИ от классической теории информации
Больцмана-Найквиста-Хартли-Шеннона обусловлены отличиями понятия «система» от понятия «множество». СТИ рассматривает в качестве
элементов не только первичные элементы множества, но и элементы, представляющие
собой подсистемы различных уровней иерархии, образующиеся за счет взаимодействия первичных элементов, а
также учитывает понятие цели. В
рамках СТИ предложено системное обобщение семантической меры информации
Харкевича, которое удовлетворяет принципу соответствия с мерой Хартли в детерминистском
случае, как и мера Шеннона в случае равновероятных событий, чем преодолена
несогласованность семантической теории информации и классической теории
информации Шеннона. Так как данная мера учитывает понятие цели, то она является
количественной мерой знаний. В рамках СТИ предложены гипотезы «О возрастании
эмерджентности», следующие из нее: «О природе сложности системы», и «О видах
системной информации».
Формализуемая когнитивная концепция – когнитивная концепция, предложенная с целью
разработки СК-анализа. Из данной концепции выводятся структура когнитивного
конфигуратора, система базовых когнитивных операций и обобщенная схема
системного анализа, структурированного до уровня базовых когнитивных операций
(АСК-анализ).
Рассматривает
процесс познания, как многоуровневую иерархическую систему обработки
информации, в которой когнитивные структуры каждого уровня являются результатом
интеграции структур предыдущего уровня. На 1-м уровне этой системы находятся
дискретные элементы потока чувственного восприятия, которые на 2-м уровне
интегрируются в чувственный образ конкретного объекта. Те, в свою очередь, на
3-м уровне интегрируются в обобщенные образы классов и факторов, образующие на
4-м уровне кластеры, а на 5-м конструкты. Система конструктов на 6-м уровне
образуют текущую парадигму реальности (т.е. человек познает мир путем синтеза и
применения конструктов). На 7-м же уровне обнаруживается, что текущая парадигма
не единственно-возможная.
Ключевым для
когнитивной концепции является понятие факта,
под которым понимается соответствие дискретного и интегрального,
экстенсионального и интенсинального элементов познания (т.е. элементов разных
уровней интеграции-иерархии), обнаруженное на опыте. Факт рассматривается как квант смысла,
что является основой для его формализации. Таким образом, происхождение смысла
связывается со своего рода «разностью потенциалов», существующей между смежными
уровнями интеграции-иерархии обработки информации в процессах познания. Между
когнитивными структурами разных уровней иерархии существует отношение «дискретное
– интегральное». Объекты познания каждого уровня описываются как
экстенсионально, т.е. с использованием элементов более низкого иерархического
уровня познания, так и интенсионально, т.е. с использованием объекта более
высокого иерархического уровня познания. Например, каждый объект исследуемой
выборки экстенсионально описывается на языке признаков (градаций описательных шкал),
а интенсионально на языке обобщенных образов классов (градаций классификационных
шкал). Каждый класс экстенсионально описывается объектами, использованными для
синтеза его обобщенного образа, а интенсионально – принадлежностью данного
класса к некоторому кластеру. Кластеры экстенсионально описываются обобщенными
образами классов, которые в них входят, а интенсионально – конструктами,
представляющими собой оси координат в неортонормированном когнитивном
пространстве, отражающим парадигму реальности. Именно это служит основой
формализации смысла.
Когнитивный конфигуратор – минимальный полный набор познавательных
(когнитивных от: «cognition» – «познание»,
англ.) операций, к которым сводятся различные процессы познания, в т.ч.
системный анализ, как метод познания, достаточный для адекватного описания
данной предметной области. В формализуемой
когнитивной концепции выявлено 10 таких операций, каждая из которых
оказалась достаточно элементарной для формализации и программной реализации:
1) присвоение имен;
2) восприятие;
3) обобщение
(синтез, индукция);
4) абстрагирование;
5) оценка
адекватности модели;
6) сравнение,
идентификация и прогнозирование;
7) дедукция и
абдукция;
8) классификация и
генерация конструктов;
9) содержательное
сравнение;
10) планирование и
принятие решений об управлении.
Информационный портрет класса – это список факторов, ранжированных в порядке
убывания силы их влияния на переход объекта управления в состояние,
соответствующее данному классу. Информационный портрет класса отражает систему
его детерминации. Генерация информационного портрета класса представляет собой
решение обратной задачи прогнозирования, т.к. при прогнозировании по системе
факторов определяется спектр наиболее вероятных будущих состояний объекта
управления, в которые он может перейти под влиянием данной системы факторов, а
в информационном портрете мы, наоборот, по заданному будущему состоянию объекта
управления определяем систему факторов, детерминирующих это состояние, т.е.
вызывающих переход объекта управления в это состояние. В начале информационного
портрета класса идут факторы, оказывающие положительное влияние на переход
объекта управления в заданное состояние, затем факторы, не оказывающие на это
существенного влияния, и далее – факторы, препятствующие переходу объекта
управления в это состояние (в порядке возрастания силы препятствования).
Информационные портреты классов могут быть от отфильтрованы по диапазону факторов, т.е. мы можем отобразить
влияние на переход объекта управления в данное состояние не всех отраженных в
модели факторов, а только тех, коды которых попадают в определенный диапазон,
например, относящиеся к определенным описательным шкалам.
Информационный (семантический) портрет фактора – это список классов, ранжированный в порядке убывания
силы влияния данного фактора на переход объекта управления в состояния,
соответствующие данным классам. Информационный портрет фактора называется также
его семантическим портретом, т.к. в
соответствии с концепцией смысла системно-когнитивного анализа, являющейся
обобщением концепции смысла Шенка-Абельсона [50], смысл фактора состоит в том, какие будущие состояния объекта управления
он детерминирует. Сначала в этом списке идут состояния объекта управления,
на переход в которые данный фактор оказывает наибольшее влияние, затем
состояния, на которые данный фактор не оказывает существенного влияния, и далее
состояния – переходу в которые данный фактор препятствует. Информационные
портреты факторов могут быть от отфильтрованы
по диапазону классов, т.е. мы можем отобразить влияние данного фактора на
переход объекта управления не во все возможные будущие состояния, а только в
состояния, коды которых попадают в определенный диапазон, например, относящиеся
к определенным классификационным шкалам.
Когнитивная
функция представляет собой зависимость вероятностей перехода
объекта управления в будущие состояния, соответствующие классам, под влиянием
различных значений некоторого фактора.
Когнитивная функции
строится для подматриц матрицы информативностей (матрицы знаний) системы «Эйдос»,
образованных различными классификационными и описательными шкалами (одна из
подматриц выделена жирной линией и фоном) (таблица 6):
Таблица
6 – К ПОЯСНЕНИЮ ПОНЯТИЯ: «ПОДМАТРИЦЫ МАТРИЦЫ ЗНАНИЙ»
|
|
1-я |
2-я |
3-я |
|||||||
|
1-я градация |
2-я градация |
3-я градация |
1-я градация |
2-я градация |
3-я градация |
1-я градация |
2-я градация |
3-я градация |
||
|
1-я |
1-я градация |
|
|
|
|
|
|
|
|
|
|
2-я градация |
|
|
|
|
|
|
|
|
|
|
|
3-я градация |
|
|
|
|
|
|
|
|
|
|
|
2-я |
1-я градация |
|
|
|
|
|
|
|
|
|
|
2-я градация |
|
|
|
|
|
|
|
|
|
|
|
3-я градация |
|
|
|
|
|
|
|
|
|
|
|
3-я |
1-я градация |
|
|
|
|
|
|
|
|
|
|
2-я градация |
|
|
|
|
|
|
|
|
|
|
|
3-я градация |
|
|
|
|
|
|
|
|
|
|
Если взять
несколько информационных портретов факторов, соответствующих градациям одной
описательной шкалы, отфильтровать их по диапазону градаций некоторой
классификационной шкалы и взять из каждого информационного портрета по одному состоянию, на переход в
которое объекта управления данное значение фактора оказывает наибольшее
влияние, то мы и получим зависимость, отражающую вероятность перехода объекта
управления в будущие состояния под влиянием различных значений некоторого
фактора, т.е. полностью редуцированную когнитивную функцию.
Когнитивные функции
являются наиболее развитым средством изучения причинно-следственных
зависимостей в моделируемой предметной области, предоставляемым системой «Эйдос».
Необходимо отметить, что на вид функций влияния математической моделью
СК-анализа не накладывается никаких ограничений, в частности, они могут быть и нелинейные.
Введем
определение когнитивной функции:
когда функция используется для отображения причинно-следственной зависимости,
т.е. информации (согласно концепции Шенка-Абельсона [50]), или знаний, если эта информация полезна для
достижении целей, то будем называть такую функцию когнитивной функцией [50, 69], от англ. «cognition».
Смысл когнитивной
функциональной зависимости в том, что в значении аргумента содержится
определенное количество знаний о том, какое значение примет функция,
т.е. когнитивная функция отражает знания о полезных причинно-следственных
зависимостях, а не корреляцию.
Кратко рассмотрим выявление,
представление и использование знаний в
АСК-анализе и системе «Эйдос» и соотношение
смысла понятия «Когнитивная функция» с содержанием понятий: «Данные, информация
и знание», «эмпирическая закономерность, эмпирический закон и научный закон».
Для выявления знаний из эмпирических данных необходимо
осознанно и целенаправленно изменять форму их представления таким образом,
чтобы последовательно повышать степень их
формализации до уровня, который позволяет: а) ввести исходные данные в
интеллектуальные системы; б) преобразовать их в информацию и знания; в)
использовать знания для решения задач прогнозирования и принятия решений. Для
этого в АСК-анализе предусмотрены следующие этапы [3]:
1. Когнитивная структуризация предметной области, при
которой определяется, что мы хотим прогнозировать и на основе чего
(конструирование классификационных и описательных шкал).
2. Формализация предметной области, т.е. 1) разработка
градаций классификационных и описательных шкал номинального, порядкового и
числового типа; 2) использование разработанных на предыдущих этапах
классификационных и описательных шкал и градаций для формального описания
(кодирования) исследуемой выборки [75].
3. Синтез и верификация (оценка степени адекватности)
модели [76].
4. Если модель
адекватна, то использование ее для решения задач идентификации,
прогнозирования и принятия решений, а также для исследования моделируемой
предметной области.
Данные – это
информация, рассматриваемая безотносительно к ее смысловому содержанию,
находящаяся на носителях или в каналах связи и представленная в определенной
системе кодирования или на определенном языке (т.е. в формализованном виде).
Информация –
это осмысленные данные. Смысл, семантика, содержание (согласно концепции смысла
Шенка-Абельсона [50]) – это знание причинно-следственных зависимостей.
Знания – это
информация, полезная для достижения целей.
Процесс преобразования данных в информацию – это
анализ данных, т.е. 1) выявление в них событий;
2) выявление причинно-следственных связей (зависимостей) между этими событиями.
Факт наличия причинно-следственных зависимостей может
быть установлен методом хи-квадрат, а ее вид – многофакторным анализом. Однако факторный анализ позволяет
обрабатывать данные лишь очень небольших размерностей (по числу факторов) и
предъявляет чрезвычайно жесткие требования к наличию полных повторностей всех
вариантов сочетаний факторов в исходных данных (т.е. данные не должны быть
фрагментарными), что на практике выполнить удается крайне редко.
Поэтому большой интерес представляют другие подходы к
решению задачи выявления в эмпирических данных
причинно-следственных зависимостей и их вида, отражения выявленных зависимостей
в наглядной графической и аналитической форме.
Рассмотрим
вариант решения этой задачи, развиваемый в АСК-анализе и реализованный в
системе Эйдос».
Для этого сформулируем требования к форме представления данных,
информации и знаний, позволяющие оценить степень
их пригодности для решения задач прогнозирования и принятия решений, а
также исследования предметной области (например, кластерного анализа).
Прежде всего, результаты решения вышеперечисленных задач
должны быть инвариантны относительно:
– единиц
измерения градаций факторов (признаков);
– типов шкал,
используемых для формализации классов и факторов (номинальные, порядковые и
числовые);
– различных статистических
характеристик исходной выборки: частотных распределений объектов по классам
(обобщенным категориям), частотных распределений градаций факторов, различий в
количестве признаков в описаниях объектов исследуемой выборки, различий в
суммарном количестве признаков по классам.
Кроме того, форма представления должна обеспечивать решение
вышеперечисленных задач с минимальными дополнительными затратами ручного труда,
а это значит, что вся предварительная
обработка должна быть максимально автоматизирована.
Эти требования можно рассматривать и как критерии выбора наиболее подходящей для
решения вышеперечисленных задач формы представления данных, информации и
знаний.
Рассмотрим влияние
единиц измерения в исходной выборке на результаты решения задач прогнозирования
и принятия решений, а также исследования предметной области (например,
кластерного анализа).
Если в исходных данных какие-то значения выражены в
больших единицах измерения, то их числовые значения будут малыми, и наоборот,
если единицы измерения мелкие, то числовые значения – большие. Большие значения
оказывают большее влияние на результаты математической обработки, чем малые, и
это приводит к возникновению зависимости
результатов решения задач идентификации, прогнозирования и принятия решений, а
также кластерного анализа, от выбранных размерностей
исходных данных, что, на взгляд авторов, совершенно недопустимо и указывает на
то, что такое решение нельзя признать корректным и даже вообще решением. По
этой же причине некорректно совместно обрабатывать сами исходные данные, представленные
в различных
единицах измерения (натуральных или ценовых), например, складывать расстояния,
представленные в километрах и в метрах, а затем прибавлять к ним тонны и килограммы,
а затем еще и безразмерные величины, хотя, как ни удивительно, но как
показывает опыт на практике это довольно часто делается. Странно, что обычно на
это не обращают никакого внимания при
использовании исходных данных, представленных в различных единицах измерения.
Например, даже в таких популярных (причем, совершенно заслуженно) системах, как
SPSS, в подсистеме кластерного анализа приводятся примеры кластерного анализа
над исходными данными, представленными в различных единицах измерения.
Для решения поставленной задачи в АСК-анализе проводится
последовательное повышение степени формализации исходных данных до уровня, обеспечивающего
их обработку на компьютере в программной системе. После выполнения когнитивной
структуризации и формализации предметной области осуществляется синтез модели.
Он включает в себя расчет на основе эмпирических данных, представленных в
исследуемой выборке, следующих матриц:
– матрицы абсолютных частот (большинство статических
систем этим и ограничиваются);
– матрицы условных и безусловных процентных распределений
(в некоторых системах это также делается);
– матрицы информативностей или матрицы знаний (что
осуществляется только в АСК-анализе).
Рассмотрим,
используя вышеперечисленные критерии, в какой степени эти матрицы пригодны для решения задач прогнозирования
и принятия решений, а также исследования предметной области (например,
кластерного анализа) и какую работу необходимо выполнять вручную и
автоматизировать, чтобы повысить их пригодность для этого.
Матрица абсолютных частот отражает, сколько раз каждая градация факторов
встречается у объектов каждого класса.
Проблема
размерностей при расчете матрицы
абсолютных частот решается тем, что сами
размерные исходные данные с использованием шкал различных типов (номинальных,
порядковых и числовых) заменяются на факты их встречи, т.е. на частоты
встреч тех или иных их интервальных
значений [76] в различных группах, соответствующих классам. Фактом является
наблюдение определенного экстенсионального значения (признака, градации
фактора) у объекта исходной выборки, относящегося к некоторой интенсиональной
категории (классу).
Однако вышеперечисленные задачи решать на основе абсолютных
частот можно только в том случае, если по каждому классу в исходных данных было
приведено одинаковое количество
примеров, что на практике встречается крайне редко и является трудно достижимым
при сборе исходных данных, за исключением случая жестко спланированного
управляемого эксперимента (обычно очень небольшой размерности). Можно, конечно,
вручную учитывать это различие, однако реально это возможно сделать только на
моделях очень небольшой размерности и требует специальных усилий (работы).
Чтобы результаты решения вышеперечисленных задач не зависели от количества примеров по
разным классам (т.е. были инвариантны относительно формы
частотных распределений примеров по классам, частотного распределения признаков
и др.) можно перейти от матрицы абсолютных частот к матрице условных и
безусловных процентных распределений (матрице относительных частот или частостей).
При неограниченном увеличении объема выборки частости
стремятся (сходятся) к вероятностям, как своим пределам. Способ, которым
частости приближаются к вероятностям, называется сходимостью модели. В системе «Эйдос» реализован специальный режим,
позволяющий исследовать сходимость модели,
в том числе скорость сходимости и
погрешность различия частости и вероятности при различных объемах исследуемой
выборки. Учитывая все это при достаточно больших выборках, по мнению авторов,
допустимо вместо термина «частость» использовать термин «условная вероятность»,
тем более что в аналитических выражениях обычно оперируют именно вероятностями.
Однако и при решении вышеперечисленных задач на основе
матрицы условных и безусловных процентных распределений приходится вручную осуществлять сравнение условных
относительных частот, что реально возможно только на моделях очень малой
размерности и требует довольно больших специальных усилий. Поэтому есть смысл автоматизировать и это сравнение, так,
чтобы в нашем распоряжении была матрица, содержащая уже сами результаты
сравнения условных относительных частот в количественной форме.
Для того чтобы реализовать эту автоматизацию
необходимо выбрать базу сравнения и
способ сравнения, т.е. ответить на два вопроса:
– с чем
сравнивать условные относительные частоты: друг с другом или с безусловными
частотами;
– как сравнивать
условные относительные частоты: с помощью вычитания или с помощью деления.
Если в модели есть всего два класса, то можно
сравнивать условные относительные частоты как друг с другом, так и с безусловными
частотами, т.к. это одинаково как по трудоемкости (затрачиваемым вычислительным
ресурсам), так и по результатам сравнения. Если же в модели хотя бы три класса,
то уже возникают определенное затруднения в том, как сравнить условные
процентные распределения по ним, а если их сотни или тысячи, то это становится
даже в теоретическом плане непонятным. Поэтому в [3] предлагается использовать в качестве базы для сравнения (нормы) условных относительных частот их
взвешенное среднее по всей исследуемой выборке или безусловные частоты.
Что касается вопроса о том, вычитание или деление для
этого сравнения использовать, то этот вопрос не является принципиальным, т.к.
различие между вычитанием и делением сводится к выбору единиц измерения
результатов сравнения: если взять логарифм от отношения, то получится разность
логарифмов, которая ведет себя точно также, как разность логарифмируемых выражений.
Переход от матрицы абсолютных частот к матрице условных
и безусловных процентных распределений обеспечивает инвариантность результатов
решения вышеперечисленных задач от формы частотного распределения примеров по
классам, однако при этом никак не решается вопрос о зависимости этих результатов
от размерностей
различных градаций факторов (признаков) и типов шкал, используемых для
формализации факторов.
Проблему размерностей можно было бы решить, перейдя к стандартизированным величинам или
отношениям условных и безусловных вероятностей. Например, формулу Байеса можно рассматривать как дающую количественную оценку
степени влияния фактора на наступление некоторого события. Отношение условной
вероятности наблюдения некоторого значения фактора в группе (классе) к
безусловной вероятности его наблюдения по всей исследуемой выборке также можно
рассматривать как количественную меру силы и направления его влияния на переход
объекта в состояние, соответствующее классу, т.е. как количественную оценку
силы и направления причинно-следственной связи между ними.
Возникает вопрос о том, каким образом формально
описать влияние на объект не отельных значений факторов, а всей их системы. Для
того чтобы это сделать введем понятие частных критериев и интегрального
критерия.
Частным критерием будем называть выраженное в количественной форме влияние отдельного
значения фактора на переход объекта в различные состояния.
Это значит, что отношение условной вероятности наблюдения
некоторого значения фактора в группе (классе) к безусловной вероятности его
наблюдения по всей исследуемой выборке можно, рассматривать как частный
критерий.
Тогда, если значение фактора способствует переходу объекта
в некоторое состояние, то отношение условной вероятности наблюдения этого
значения фактора в группе (классе), соответствующей данному состоянию, будет больше
безусловной вероятности его наблюдения по всей исследуемой выборке и этот критерий
будет иметь значение больше 1.
Если значение фактора препятствует переходу
объекта в некоторое состояние, то отношение условной вероятности наблюдения
этого значения фактора в группе (классе), соответствующей данному состоянию,
будет меньше безусловной вероятности его наблюдения по всей
исследуемой выборке и этот критерий будет иметь значение меньше 1.
Если же значение фактора никак не влияет на
переход объекта в некоторое состояние, то отношение условной вероятности
наблюдения этого значения фактора в группе (классе), соответствующей данному
состоянию, будет равно безусловной вероятности его наблюдения по всей
исследуемой выборке и этот критерий будет иметь значение равное 1.
Интегральным критерием будем называть некоторое аналитическое выражение от
частных критериев, которое количественно отражает силу влияния системы факторов
на переход объекта в различные состояния.
Моделируемый объект является линейным, если результат совместного действия на него совокупности
факторов является суммой результатов
влияния на него каждого из этих факторов в отдельности, т.е. выполняется принцип суперпозиции факторов. Чем
меньше интенсивность взаимодействия между факторами в объекте, тем ближе система факторов к множеству
[77] и тем ближе объект к линейному. Таким образом, для линейных объектов можно
обоснованно считать, что взаимодействие между факторами в этих объектах
отсутствует, т.е. по сути можно считать, что на них действует не система
факторов, а множество факторов.
Для линейных
объектов интегральный критерий, отражающий совместное влияние факторов на
объект, можно представить в форме суммы
влияния каждого из этих факторов в отдельности, т.е. в форме суммы частных
критериев, т.е. для линейных объектов оправданно и обоснованно использовать аддитивный интегральный критерий.
Приведенные выше количественные меры силы и направления
причинно-следственных связей очень неудобны для использования подобных в
качестве частных критериев, в основном потому, что в случае отсутствия влияния фактора они равны 1.
В результате в аддитивном интегральном критерии будет присутствовать некое
слагаемое, равное количеству недействующих факторов, и для каждого класса это
слагаемое будет свое. В результате подобный интегральный критерий окажется
просто непригодным для оценки влияния совокупности факторов на поведение
объекта.
Поэтому эти частные критерии необходимо нормировать
так, чтобы в случае отсутствия влияния он принимали значение равное нулю, а не
единице. Есть много вариантов осуществить подобную нормировку, из которых
наиболее очевидными являются:
– вычесть 1 из отношения условной вероятности к безусловной;
– взять логарифм от отношения условной вероятности к
безусловной.
Первый вариант нормировки приводит к показателям типа
ROI (количественная оценка степени полезности инвестиций) и различным его
обобщениям. Второй вариант сразу приводит к семантической мере целесообразности
информации А.Харкевича. Из этих вариантов для количественной оценки степени
полезности информации для достижения целей предпочтительным является применение
меры А.Харкевича [69]. Это связано с тем, что использование логарифма в этой
мере позволяет привлечь огромный пласт понятий, связанных с данными,
информацией и знаниями, что является для нас очень ценным.
Очень важно,
что этот подход позволяет автоматически решить проблему сопоставимой обработки
многих факторов, измеряемых в различных единицах измерения, т.к. в этом подходе
рассматриваются не сами факторы, какой бы природы они не были и какими бы
шкалами не формализовались, а количество
информации, которое в них содержится о поведении моделируемого объекта [75-76].
Необходимо также отметить, что представление о полностью
линейных объектах (системах) является абстракцией и реально все объекты
являются принципиально нелинейными. Вместе с тем для большинства систем
нелинейные эффекты можно считать эффектами второго и более высоких порядков и
такие системы в первом приближении
можно считать линейными. Возможны различные модели взаимодействия факторов, в частности, развиваемые в форме
системного обобщения теории множеств [77]. Этот подход в перспективе может
стать одним из вариантов развития теории нелинейных систем.
Отметим, что математическая модель АСК-анализа (системная
теория информации) органично
учитывает принципиальную нелинейность всех объектов. Это проявляется в
нелокальности нейронной сети системы «Эйдос» [75], приводящей к зависимости всех
информативностей от любого изменения в исходных данных, а не как в методе обратного
распространения ошибки. В результате значения матрицы информативностей количественно
отражают факторы не как множество, а как систему.
Объект может перейти в некоторое будущее состояние под
действием различного количества факторов, но какая бы система факторов не
обусловливала (детерминировала) этот переход, в ней не может содержаться
информации больше, чем можно получить, точно узнав, что объект переходит в
данное состояние. Это количество информации в АСК-анализе называется «Теоретически
максимальное количество информации» и определяется только количеством классов
(будущих состояний объекта), которые в детерминистском случае равновероятны,
т.к. между классами и факторами выполняется взаимнооднозначное соответствие,
когда каждое будущее состояние однозначно определяется единственным фактором.
Формула А.Харкевича видоизменена в работе [3] таким образом, чтобы
удовлетворять принципу соответствия с формулой Р.Хартли в детерминистском
случае. Поэтому, чем меньше факторов, тем жестче ими детерминировано поведение
объекта, и наоборот, чем больше этих факторов, тем меньше влияние каждого из
них на поведение объекта. Например, если переход объекта в некоторое состояние
однозначно определяется единственным фактором, то добавление в модель еще
одного точно такого же фактора
приводит к тому, что в сумме эти два фактора будут оказывать тоже самое
влияние, которое делится между ними поровну.
Так в математической модели АСК-анализа учитывается взаимодействие факторов и отличие системы факторов от множества факторов [77], являющееся источником нелинейности
моделируемого объекта.
Итак, в матрице
информативнстей количественно отражены сила и направление влияния каждого
значения фактора на переход объекта в каждое из состояний, а также учтено, что
совокупность факторов является системой, а не множеством, т.е. учтены
взаимодействие факторов и нелинейность моделируемого объекта. Результаты
решения задач идентификации, прогнозирования, принятия решений и научного
исследования моделируемой предметной области (в частности
кластерно-конструктивного анализа), на основе матрицы информативностей инвариантны относительно формы
частотного распределения объектов исследуемой выборки по классам, единиц измерения
значений факторов и типа шкал, используемых для формализации факторов.
Это позволяет корректно использовать в АСК-анализе аддитивный
интегральный критерий в форме суммы
частных критериев не только для линейных, но и для нелинейных объектов.
Различие
между матрицей информативностей и матрицей знаний. Если в модели отражены лишь причинно-следственные
связи между факторами и будущими состояниями объекта, но не отражена степень
желательности ли нежелательности этих будущих состояний, то мы имеем дело с
матрицей информативностей. Если же некоторые из будущих событий
классифицируются как желательные, т.е. целевые, а другие как нежелательные, то
появляется возможность количественной оценки степени полезности информации о действии факторов для перевода объекта в
эти состояния, т.е. для преобразования информации в знания.
Процесс преобразования информации в знания – это процесс
оценки степени полезности информации для достижения желаемых будущих состояний,
т.е. целей.
Таким образом, матрица знаний количественно отражает
степень полезности (а также бесполезности и вредности) факторов для достижения
целей: она содержит знания в количественной форме о величине и направлении влияния каждого значения фактора на перевод
объекта в каждое из будущих состояний, как желаемое, так и нежелательное.
Факт – это
единство экстенсионального и интенсинального описания события, обнаруженного эмпирическим путем, т.е. по сути, факт это определение события. Пример
факта: «Кошка кормит котят молоком». Пример определения в науке: «Млекопитающее
– это животное (более общее, интенсиональное понятие), вскармливающее своих
детей молоком (экстенсиональный специфический признак)».
Закономерности
– это причинно-следственные зависимости, выявленные на исследуемой выборке и
распространяемые лишь на саму эту выборку.
Эмпирический закон – это причинно-следственные зависимости, выявленные на исследуемой
выборке и распространяемые на некоторую предметную область, более широкую, чем
исследуемая выборка, в которой действуют те
же причины действия причинно-следственных зависимостей, что и в исследуемой
выборке, на которой он обнаружены. Эта более широкая предметная область
называется генеральной совокупностью, по отношению к которой исследуемая
выборка репрезентативна. Эмпирический закон является феноменологическим, т.е.
внешним описанием зависимости последствий от причин, который не раскрывает механизма
или способа, которым реализуется эта зависимость.
Научный закон
– это содержательная интерпретация механизма действия эмпирического закона,
т.е. способа преобразования причин в
следствия. Научный закон является содержательным объяснением и интерпретацией эмпирического закона. Это объяснение,
когда оно разрабатывается, не сразу становится научным законом, а сначала имеет
статус научной гипотезы и приобретает статус научного закона лишь после того,
как на практике, т.е. эмпирически,
подтверждаются предсказания существования новых, ранее неизвестных явлений,
сделанные на основе научной гипотезы. Таким образом, научный закон – это
научная гипотеза, адекватность и прогностическая сила которой подтверждены
(верифицированы) эмпирически. Процесс преобразования научной гипотезы в научный
закон – это процесс подтверждения на практике адекватности этой научной
гипотезы.
Необходимо подчеркнуть, что существует принципиальная
возможность создания многих различных
моделей, одинаково адекватно отражающих одну и ту же предметную область. Иногда
такие модели и действительно созданы. Тогда возникает вопрос о критериях выбора одной модели, в
определенном смысле «наилучшей» из многих. Среди этих критериев следует
отметить адекватность, удовлетворение принципу соответствия и широту адекватно
отражаемой предметной области, а также ее простоту и красоту. Из многих моделей
предпочтительная та, которая более адекватна, та, которая адекватно отражает
более широкую предметную область и включает в себя на основе принципа соответствия
другие известные модели, а также более простая и красивая модель. Однако часто
бывает, что разработка многих моделей (научных теорий) весьма затруднительна и
есть или известна всего лишь одна-единственная модель. Тогда эта модель автоматически
становится наилучшей из всех известных.
Возникает соблазн неоправданно и необоснованно
считать, что реальность устроена именно таким образом, какой она отражается в
этой наилучшей по сформулированным выше критериям модели или научной теории,
т.е. необоснованно придать онтологический
статус абстрактной модели. В этом состоит широко распространенная
малозаметная ошибка познания, называемая «Гипостазирование». Однако эта ошибка
влечет за собой целый шлейф весьма заметных последствий, важнейшим из которых является
отрицание существования фактов, закономерностей и эмпирических законов, не
вписывающихся в те или иные научные теории, даже если эти факты в буквальном
смысле слова очевидны. Например,
апологеты воздухоплавания отрицали возможность летательных аппаратов тяжелее
воздуха, не смотря на птиц, которые садились и взлетали перед ними (или даже
смотря на них, но не осознавая, что они видят). При этом они исходили из того,
что принцип действия летальных аппаратов может быть основан только на законе
Архимеда, как это следовало из единственной известной им научной теории полета.
Однако существуют и другие принципы полета: в частности, баллистический, аэродинамический,
ракетный, электромагнитный, на которых может быть основан принцип действия
летательных аппаратов тяжелее воздуха, причем эти аппараты ни в коей мере не
нарушают закон Архимеда и полностью ему подчиняются.
Признание существования факта не зависит от обнаружения
закономерности. Признание существования закономерности не зависит от
обнаружения соответствующего эмпирического закона. Признание существования
эмпирических законов не зависит от наличия верифицированной содержательной
интерпретации или научного закона, а если она есть, то от того, является ли она
«правильной» или «неправильной» по тем или иным критериям или по чьему-то
мнению. Таким образом, признание
существования факта не зависит от наличия теории, которая его объясняет, и
отсутствие такой теории не является основанием для отрицания существования или
непризнания существования факта.
Когнитивные функции представляют собой новый перспективный
инструмент отражения и наглядной визуализации закономерностей и эмпирических
законов. Разработка содержательной
научной интерпретации когнитивных функций представляет собой способ познания
природы, общества и человека.
Когнитивные функции могут быть:
– прямые, отражающие зависимость классов от
признаков, обобщающие информационные портреты признаков;
– обратные, отражающие зависимость признаков от
классов, обобщающие информационные портреты классов;
– позитивные, показывающие чему способствуют
система детерминации;
– негативные, отражающие чему препятствуют
система детерминации;
– средневзвешенные, отражающие совокупное
влияние всех значений факторов на поведение объекта;
– с различной степенью редукции или степенью
детерминации, которая отражает в графической форме (в форме полосы) количество
знаний в аргументе о значении функции и является аналогом и обобщением
доверительного интервала.
Прямая и обратная, а также
позитивная и негативная когнитивные
функции полностью совпадают
(тождественны) друг с другом только
для жестко (т.е. полностью) детерминированных систем. Это связано с тем, что
матрица знаний, моделирующая полностью детерминированную систему, в которой
между значениями аргумента и значениями функции существует взаимно однозначное
соответствие, представляет собой диагональную матрицу [3]. Можно обоснованно
предположить, что степень совпадения прямой и обратной когнитивных функций
пропорциональна степени детерминированности моделируемой системы. Если интерпретировать значения факторов,
обусловливающих поведение системы, как ее экстенциональное описание,
относящееся к ее прошлому времени, а классы – как интенсиональное описание ее
будущих состояний, то можно сказать, что степень детерминации поведения системы
тем выше, чем более сходным являются влияние на нее прямой и обратной
причинности, т.е. если влияние прошлого на будущее совпадет с влиянием будущего
на прошлое. Чем сильнее влияние прошлого на будущее отличается от влияния
будущего на прошлое, тем слабее детерминированность в поведении системы, тем
ближе оно к случайному. При этом рассмотрение вопросов о физическом механизме
прямой и обратной причинности, как и самом существовании обратной причинности,
не входит в задачи данной работы.
Матрица информативности может быть использована для выявления и
визуализации когнитивных функциональных
зависимостей в фрагментированных и зашумленных данных большой размерности
[66]. Кратко поясним суть этого метода. Матрица информативностей рассчитывается
на основе системной теории информации [3] непосредственно на основе
эмпирических данных и представляет собой таблицу, в которой столбцы соответствуют
обобщенным образам классов, т.е.
будущим состояниям моделируемой системы, строки – значениям факторов, влияющих
на эту систему, а на пересечениях строк и столбцов находится количество
информации, которое содержится в факте действия значения фактора,
соответствующего строке, на переход системы в состояние, соответствующее
столбцу. Максимальное количество информации, которое может быть в значении
фактора, определяется числом будущих состояний моделируемой системы. Модуль
количества информации отражает силу влияния значения фактора, а знак –
направление этого влияния, т.е. то, способствует он или препятствует
наступлению данного состояния. Если последовательности классов и значений
факторов образуют порядковые шкалы или шкалы отношений, т.е. соответственно, на
них определены отношения «больше-меньше» или, кроме того, единица измерения,
начало отсчета и арифметические операции, то матрица информативностей допускает
наглядную графическую визуализацию, традиционного
для функций типа, когда значения факторов рассматриваются в качестве значений
аргумента, а классы, о наступлении которых в этих значениях факторов содержится
максимальное количество информации –
в качестве значений функции. Другие классы, менее обусловленные данным
значением фактора, а также те, наступлению которых это значение препятствует в
большей или меньшей степени, также могут отображаться соответствующими цветами,
и это также может представлять интерес, т.к. позволяет задействовать мощные способности
человека к анализу изображений. Когнитивные функции, представляемые в форме
матрицы информативностей, соответствуют очень общему виду функциональной
зависимости: многозначной функции многих
аргументов, т.к. каждое значение фактора влияет на все состояния
моделируемого объекта, и каждое его состояние обусловлено всеми значениями
факторов. Простой пример визуализации матрицы информативностей, полученной на
выборке, отражающей зависимость амплитуды затухающего гармонического колебания
от времени, приведен на нижеследующем рисунке 20, взятом
из работы [53], в котором степень детерминации
значения функции значением аргумента показана различными цветами: теплые цвета
– высокая степень детерминации, холодные – низкая.
Рисунок 1. Количество информации в значении
аргумента
о значении функции для нечеткой взаимно однозначной
когнитивной функции
Для визуализации матрицы
информативностей использовалась система SigmaPlot for Windows version 10.0. Для
преобразования матрицы информативностей в форму, удобную для использования в
системе SigmaPlot, применялся режим _683 системы «Эйдос».
Таким образом,
использование интервальных значений аргумента и функции позволяет с применением
теории информации непосредственно на основе эмпирических данных рассчитать, какое
количество информации содержится в
каждом значении аргумента о каждом значении функции. При этом получается, что
каждому значению аргумента соответствует не одно, а много значений функции, но
соответствуют в различной степени.
Заметим, что ход времени,
т.е. процесс преобразования неопределенного многовариантного будущего в
определенное безальтернативное настоящее, можно рассматривать как процесс редукции многозначных когнитивных
функций, отражающих будущее, в однозначные когнитивные функции, отражающие
настоящее. При преобразовании
неопределенного будущего в определенное настоящее происходит генерация информации, количество которой
соответствует степени уменьшения неопределенности, точно так же, как в процессе
измерения или познания. Поэтому можно обоснованно утверждать, что
многозначные когнитивные функции аналогичны по смыслу волновой функции (функция
плотности вероятности) квантовой механики (КМ) и квантовой теории поля (КТП), а
преобразование многозначной когнитивной функции в однозначную аналогично
процессу редукции волновой функции в
процессе измерения. Процесс редукции волновой функции и другие квантовые и
волновые явления тесно связаны с информацией и могут рассматриваться как информационные
процессы и явления [3]. Поэтому авторами вводятся понятия нередуцированной,
полностью и частично редуцированной когнитивной функции. Отметим, что понятие
частично-редуцированного состояния объекта (на примере электрона), по-видимому,
впервые введено Ричардом Фейнманом [78].
Для визуализации матрицы
информативностей (12) первоначально использовалась система SigmaPlot for
Windows version 10.0. Для преобразования матрицы информативностей в форму,
удобную для использования в системе SigmaPlot, применялись режимы _683 или _53
системы «Эйдос».
В дальнейшем была создана
подсистема визуализации когнитивных (каузальных) функций системы «Эйдос»
(Подсистема «Эйдос-VCF» или InfVisual) [79], вошедшая в состав базовой системы «Эйдос»
(режим _54) и в состав системы «Эйдос-астра» [80], позволяющая осуществлять
визуализацию, как всей матрицы информативностей, так и ее фрагментов, а также
строить прямые и обратные когнитивные функции различной степени редукции.
На рисунке
21, взятом из работы [53], представлены три нечеткие
многозначные функции, в которых каждому значению аргумента в различной
степени соответствует много различных значений функции. Рисунок 3 построен на основе
Оксфордской базы данных содержащей
среднемесячные метеорологические данные по температуре в приземном слое
воздуха, осадкам и заморозкам в период с января 1853 г по сентябрь 2009 г. (см.
http://www.metoffice.gov.uk/). Красный цвет на рисунке
соответствует максимальному
количеству информации в номере месяца о соответствующей среднемесячной
температуре, т.е. высокой степени
детерминации в отображаемой причинно-следственной зависимости.
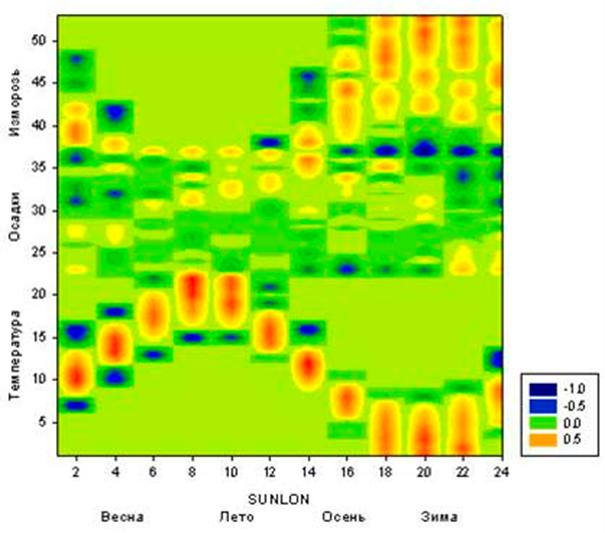
Рисунок 21.
Количество информации в значении аргумента
о значении функции для нечетких многозначных функций
Для визуализации матрицы
информативностей использовалась система SigmaPlot for Windows version 10.0. Для
преобразования матрицы информативностей в форму, удобную для использования в
системе SigmaPlot, применялся режим _683 системы «Эйдос».
Из этого рисунка видно
также, что зимой в Оксфорде заморозки более вероятны, чем летом, а осадки более
вероятны летом, чем весной. Данные по осадкам менее информативны в сравнении с
температурой, а данные по заморозкам (иней в воздухе), хотя и являются
информативными, но обладают более существенной неоднозначностью, т.к. в разные
годы число дней заморозков в данный месяц изменяется в более широких пределах,
чем температура.
В базовой системе «Эйдос»
реализован режим _53, обеспечивающий подготовку баз данных, содержащих выборки по подматрицам матрицы знаний в
форме, наиболее удобной для их визуализации во внешних системах SigmaPlot и MS
Excel. В данном режиме реализована возможность автоматического определения
классификационных шкал и градаций по заданному разделителю, а также задания их
вручную. Некоторые экранные формы этого режима приведены на рисунке 22,
результаты визуализации – на рисунках
23-25.
Рисунок 22. Экранные формы режима _53
базовой системы «Эйдос»

Рисунок 23.
Прямая нередуцированная когнитивная функция, построенная в MS Excel на основе базы знаний, сформированной по
Оксфордской базе данных
Рисунок 24.
Прямая полностью редуцированная когнитивная функция, построенная в MS Excel на
основе базы знаний, сформированной по Оксфордской базе данных.
Диаметр пузырьков на рисунках 23 и 24 пропорционален количеству информации в
значении аргумента о значении функции.
Важно, что на основе матриц, формируемых режимом _53
системы «Эйдос», используя стандартные возможности MS Excel, можно получить регрессии, аппроксимирующие найденные
зависимости.
При визуализации в системе SigmaPlot той же
подматрицы, что и на рисунках 23, 24, получим рисунок 25, а с применением
подсистемы «Эйдос-VCF» (или InfVisual) – рисунок 26:
Рисунок 25.
Прямая нередуцированная когнитивная функция, построенная в SigmaPlot на основе базы знаний, сформированной по
Оксфордской базе данных
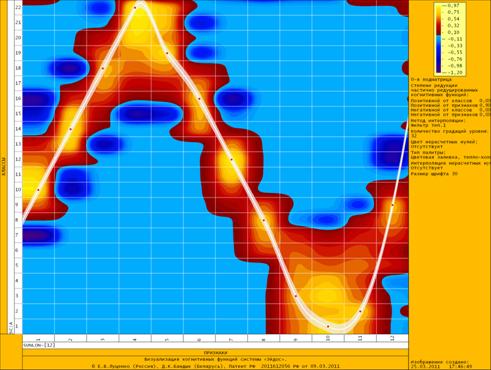
Рисунок 26.
Прямая частично редуцированная когнитивная функция, построенная в режиме _54
базовой системы «Эйдос» – подсистеме InfVisual (27) на основе базы знаний,
сформированной по Оксфордской базе данных
Подсистема «Эйдос-VCF» (или InfVisual) [79] предназначена для визуализации когнитивных
(каузальных) на основе матриц знаний базовой системы «Эйдос» и систем окружения
и может применяться в научных
организациях, применяющих системы искусственного интеллекта для решения задач
прогнозирования, поддержки принятия решений и научных исследований в различных
предметных областях. Она обеспечивает
выполнение следующих функций:
– импорт данных из универсальной когнитивной аналитической
системы «Эйдос», интеллектуальной системы научных исследований глобальных
геосистем «Эйдос-астра» и других систем окружения;
– задание в диалоге детальных параметров визуализации
когнитивных (каузальных) функций;
– визуализацию когнитивных (каузальных) функций: прямых
и обратных, позитивных и негативных, с заданной степенью редукции, а также
запись полученных изображений в виде файлов.
Для построения изолиний (линий уровня) трехмерных поверхностей
когнитивных функций в подсистеме используется триангуляция Делоне и авторские
методы сглаживания, разработанные Д.К.Бандык. Для интерполяции когнитивной
функции применен сплайн Акимы.
На рисунке 27 приведена главная экранная форма подсистемы
«Эйдос-VCF», а на рисунке 28 – экранная форма ее режима настроек:
Рисунок 27.
Главная экранная форма подсистемы «Эйдос-VCF»
Рисунок 28.
Экранная форма режима настроек подсистемы
«Эйдос-VCF» [79]
На рисунке 29 приведена экранная форма режима
ввода-корректировки наименований классификационных и описательных шкал и
градаций подсистемы «Эйдос-VCF», которая появляется при нажатии на клавишу «Определение
подматриц»:
Рисунок 29. Экранная
форма режима ввода-корректировки наименований классификационных и описательных
шкал и градаций подсистемы «Эйдос-VCF»
В подсистеме «Эйдос-VCF» имеется множество настроек каждого
параметра, показанного на окне настроек (рисунок 10) разворачивающимися списками,
которые в совокупности позволяют получить самые различные варианты изображений
когнитивных функций, из которых можно выбрать наиболее контрастно и удачно
отображающие их смысл. Например, параметр: «Тип палитры» может принимать
следующие варианты значений:

и при каждом из этих значений
когнитивная функция будет выглядеть по-разному. На рисунке 30 приведены
различные виды одной и той же
когнитивной функции, получающиеся при выборе различных значений параметра «Тип
палитры»:
|
|
|
|
|
|
|
|
|
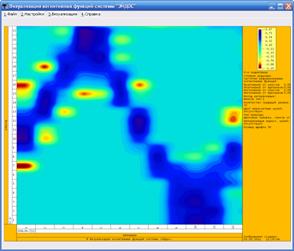
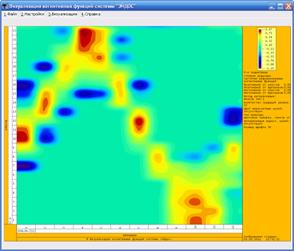
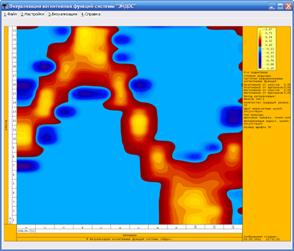

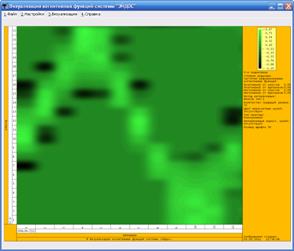
Рисунок 30. Изменение вида когнитивной функции при
выборе различных значений параметра «Тип палитры» в подсистеме «Эйдос-VCF»
В работах [58-59, 66, 73-74] и других рассмотрены многочисленные
примеры приложения АСК анализа и аппарата когнитивных функций в задачах
распознавания событий в поле центральных сил. К числу таких событий относятся,
в частности, ряды событий, происходящих на нашей планете, которая движется в
Солнечной системе в гравитационном поле Солнца. В качестве примера укажем ряды
сейсмических событий, исследованные в работах [52-55, 58-59], движение полюса
Земли [59, 66, 73-74], ряды социально-экономических событий [2, 64-65]. Ниже
дан краткий обзор перечисленных работ с акцентом на применение в них метода
визуализации когнитивных функций.
Обзор результатов распознавании категорий событий
в поле центральных сил
Рассмотрим задачу распознавания категорий по астрономическим
данным. Имеется множество событий A, которому ставится в соответствие множество
категорий Ci. Событиями можно считать, например, измерение координат
полюса Земли, а категориями – значение координат, лежащее в определенном
интервале. Каждое такое событие характеризуется моментом времени и географическими
координатами места его происхождения (которые в данной задаче фиксированы). По
этим данным можно построить матрицу, содержащую координаты небесных тел,
например астрономические углы долготы, широты и расстояния. Будем считать, что заданы частотные
распределения Ni – число
событий, имеющих отношение к данной категории Ci.
Определим число случаев реализации данной категории, которое
приходится на заданный интервал изменения астрономических параметров, матрицу
информативностей согласно (11)-(12).
Каждой категории можно сопоставить вектор информативности
астрономических параметров размерности 2mk0,
составленный из элементов матрицы информативности, путем последовательной
записи столбцов, соответствующих нормированной координате, в один столбец, т.е.
![]() (24)
(24)
С другой стороны, процесс
идентификации, распознавания и прогнозирования может рассматриваться как
разложение вектора распознаваемого объекта в ряд по векторам категорий (классов
распознавания) [3]. Этот вектор, состоящий из единиц и нулей, можно определить
по координатам небесных тел, соответствующих дате и месту происхождения
события l в виде
(25)
Таким образом, если
нормированная координата небесного тела из данных по объекту исследуемой
выборки попадает в заданный интервал, элементу вектора придается значение 1, а
во всех остальных случаях – значение 0. Перечисление координат осуществляется
последовательно, для каждого небесного тела.
В случае, когда система
векторов (24) является полной, можно точно любой вектор (25) представить в виде
линейной комбинации векторов системы (24). Коэффициенты этого разложения будут
соответствовать уровню сходства данного события с данной категорией. В случае
неполной системы векторов (24) точная процедура заменяется распознаванием или
разложением в ряд с некоторой погрешностью. При этом уровень сходства данных
события с той или иной категорией можно определить по величине скалярного
произведения вектора (24) на вектор (25), т.е. в координатной форме:
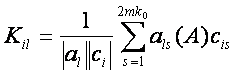 (26)
(26)
Отметим, что возможны
четыре исхода, при которых можно истинно или ложно отнести или не отнести
данное событие к данной категории. Для учета этих исходов распознавание категорий
в системе искусственного интеллекта «Эйдос-астра» [7] осуществляется по
параметру сходства, который определяется следующим образом [2]:
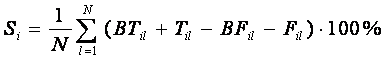 (27)
(27)
Si –
достоверность идентификации «i-й» категории;
N –
количество событий в распознаваемой выборке;
BTil – уровень сходства «l-го»
события с «i-й» категорией, к которой он был правильно отнесен системой;
Til – уровень сходства «l-го»
события с «i-й» категорией, к которой он был правильно не отнесен системой;
BFil – уровень сходства «l-го»
события с «i-й» категорией, к которой он был ошибочно отнесен системой;
Fil – уровень сходства «l-го»
события с «i-й» категорией, к которой он был ошибочно не отнесен системой.
При таком определении
параметр сходства изменяется в пределах от -100% до 100%, как обычный
коэффициент корреляции в статистике. При этом ошибки 1-го и 2-го рода (ошибки
ложной идентификации и ложной неидентификации) приводят к уменьшению параметра
сходства. Очевидно, что параметр сходства должен удовлетворять критерию простой
проверки
![]()
Было показано, что
процедура распознавания по параметру сходства (27), реализованная в системе
искусственного интеллекта «Эйдос-астра» [7],
является устойчивой как относительно объема выборки, так и относительно
числа ячеек модели. Математическое обоснование этой процедуры дано в монографии
[3].
На рис. 31 представлен
фрагмент матрицы информативностей, демонстрирующий зависимость координат (X,Y)
и угловой скорости (X1, Y1) движения полюса Земли – всего 244 категории,
перечисленные в таблице 4, от долготы Солнца в 1963-2006 годов по данным Earth
Orientation Centre [60]. Как следует из данных, приведенных на рис. 31,
координаты полюса в зависимости от долготы Солнца образуют жгуты, которые
формируются из отдельных годичных движений на протяжении многих лет. Отметим, что категории угловой скорости не
образуют достаточно четких нитевидных структур, подобных тем, что образуют категории координат.
Согласно существующим представлениям, такое поведение угловой скорости полюса в
зависимости от долготы Солнца обусловлено наличием случайной составляющей, связанной
с движением атмосферы и океана относительно земной коры.
Рисунок 31. Зависимость
категорий координат и угловой скорости полюса от долготы Солнца в модели М160
[13] (слева) и прямые позитивные (белая линия) и негативные (черная линия) когнитивные
функции координаты X (смещение вдоль меридиана Гринвич).
Прямая когнитивная функция, представленная на правом
рис. 31, белой/черной линией (позитивная/негатиная функция) характеризует
зависимость координаты Х смещения полюса вдоль меридиана Гринвич от долготы
Солнца. Позитивная функция показывает, что система детерминации способствует
увеличению амплитуды колебаний, а негативная функция, напротив, указывает на
стабилизацию относительно среднего значения.
Заметим, что просто графическое отображение матрицы
информативностей – это нередуцированная когнитивнвя функция (степень редукции
0). Кривая, соединяющая точки с максимальной информативностью для смежных
градаций описательной шкалы – это полностью редуцированная когнитивная функция
(степень редукции 1). Она показывает какое состояние объекта наиболее вероятно
для каждого значения аргумента, т.е. об осуществлении какого состояния в каждом
значении аргумента наибольшее количество информации.
В полностью редуцированной когнитивной функции из самого
вида ее графика не видно, в каком значении аргумента больше информации, а в
каком меньше в различных значениях аргумента. Эта информация есть в
нередуцированной когнитивной функции и отображается она в виде цвета. Но если
отображать ее на графике, то кажется удобным использовать для этого полосу
около графика полностью редуцированной когнитивной функции: чем эта полоса уже,
тем более определенным является ее значение, и чем шире – тем менее
определенным. Это соответствует понятию информации как количественной меры
снятия неопределенности: много информации в значении аргумента о значении
функции – неопределенность значения функции мала и полоса уже, мало информации
– неопределенность больше и полоса шире. Это напоминает и понятие доверительного
интервала.
Поскольку есть полностью нередуцированные и полностью
редуцированные функции, то вводится и понятие когнитивной функции с
промежуточной степенью редукции, т.е. частично редуцированные когнитивные
функции. Существует множество функций с различной степенью редукции. Степень
редукции задается в программе InfVisual в процессе построения изображения.
На рис. 32
представлен каталог данных визуализации матрицы информативностей в задаче
распознавания сейсмических событий по астрономическим данным с учетом влияния
магнитного поля и движения полюса Земли [74].
Исследуемая база данных сейсмических событий была
сформирована на основе базы данных Международного сейсмологического центра –
ISC [57], содержащей 20489816 записей регистрации
различными сейсмостанциями событий землетрясений, произошедших на нашей планете
в период с 1 января 1961 года по 31 декабря 2006 г. Из исходной базы было
образовано несколько различных БД для исследования влияния астрономических
параметров на магнитуду и глубину гипофокуса, на ежедневное число
землетрясений, а также на средние параметры сейсмической активности.
Исследована совокупность 128320 событий землетрясений с магнитудой ![]() , произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
, произошедших на нашей
планете в период с 9 февраля 1963 года по 31 декабря 2006 г (всего 16032 дня).
В исходной БД сейсмические события характеризуются
магнитудой mb, которой можно сопоставить категорию магнитуды – таблица 5.
Анализируя данные, приведенные на рис. 32, можно сделать вывод о том, что влияние
долготы Сатурна, Урана, Нептуна, Плутона и Северного узла Луны на сейсмические
события на Земле аналогично влиянию вертикальной компоненты индукции магнитного
поля Земли. Эта аналогия, впервые обнаруженная в работе [12], послужила основой
для создания моделей влияния небесных тел на геомагнитное поле и на движение
полюса Земли [12-13, 21-22].
На рис. 33 представлен каталог данных визуализации матрицы
информативностей в задаче распознавания социальных категорий респондентов по
астрономическим данным [1-6]. В этой задаче используется пространство данных
(1) различной размерности от 23х2=46 до
23х173=3979, в котором распознается вектор (5), состоящий из 870 [1] социальных
категорий. Выделяя среди этих категорий наиболее часто повторяющиеся, приходим
к задаче о распознавании 37 категорий [4] (отложены по вертикали на рис. 33) –
таблица 6, или только четырех [6].

Рисунок 32. Зависимость категорий сейсмических событий
А,В,С (в каждом рисунке категории отложены по вертикали снизу вверх) от долготы
небесных тел и от вертикальной компоненты индукции магнитного поля на 12
станциях
Из данных, приведенных на рис. 33, следует, что
подматрица информативностей является индивидуальной для каждого астрономического
параметра. Это позволяет осуществить процедуру распознавания по параметру
сходства (10) с относительно высокой вероятностью около 68,75% [4], что легло в
основу метода прогнозирования социальных категорий - астросоциотипологии [2].

Рисунок 33. Зависимость частоты социальных категорий
от угловых параметров небесных тел в модели М12 по данным [8].
Таблица 6 – Частота повторения социальных
категорий в БД [8]
|
NAME |
ABS |
NAME |
ABS |
|
SC:М- |
13892 |
SC:B45-Famous:Greatest hits |
1833 |
|
SC:Ж- |
5226 |
SC:A29-Parenting |
1812 |
|
SC:A53-Sports |
4608 |
SC:B173-Sports:Football |
1627 |
|
SC:A1-Book Collection |
4562 |
SC:B97-Occult Fields:Astrologer |
1509 |
|
SC:A15-Famous |
3456 |
SC:B21-Relationship:Number of marriages |
1461 |
|
SC:A42-Medical |
3037 |
SC:B2-Book Collection:Profiles Of Women |
1425 |
|
SC:A323-Sexuality |
2736 |
SC:A92-Birth |
1361 |
|
SC:A5-Entertainment |
2657 |
SC:B14-Entertainment:Actor/ Actress |
1296 |
|
SC:A9-Relationship |
2514 |
SC:?- |
1259 |
|
SC:A40-Occult Fields |
2430 |
SC:B49-Book Collection:American Book |
1204 |
|
SC:B111-Sports:Basketball |
2403 |
SC:B26-Personality:Body |
1206 |
|
SC:B329-Sexuality:Sexual perversions |
2415 |
SC:B189-Medical:Illness |
1236 |
|
SC:A55-Art |
2288 |
SC:B6-Entertainment:Music |
1124 |
|
SC:A19-Writers |
2281 |
SC:A99-Financial |
1102 |
|
SC:A129-Death |
2263 |
SC:B48-Famous:Top 5% of Profession |
1104 |
|
SC:A25-Personality |
2140 |
SC:A38-Politics |
1073 |
|
SC:A68-Childhood |
2069 |
SC:A23-Psychological |
1041 |
|
SC:A31-Business |
1858 |
SC:A108-Education |
1027 |
|
SC:C330-Sexuality:Sexual perversions: Homosexual m |
1858 |
|
|
Путем формальной замены социальных категорий на экономические,
был развит метод прогнозирования курсов валют по астрономическим данным [18-19]. В таблице 7 приведена ежедневная
частота повторения категорий повышения (1) и понижения (2) курсов валют в 2000-2009
гг, вычисленная по данным FOREX. На рис. 34 представлен каталог данных
визуализации матрицы информативностей категорий валют из таблицы 7 в зависимости
от долготы (LON) и расстояния (DIST) до небесных тел в модели М160.
Таблица 7 – Частота повторения категорий повышения (1)
и понижения (2) курсов валют в 2000-2009 годах [18-19].
|
NAME |
ABS |
NAME |
ABS |
|
A72-GBP/USD2 |
3624 |
A52-NZD/USD2 |
3444 |
|
A71-GBP/USD1 |
3582 |
A51-NZD/USD1 |
3762 |
|
A82-EUR/GBP2 |
3675 |
A112-EUR/CHF2 |
3558 |
|
A81-EUR/GBP1 |
3531 |
A111-EUR/CHF1 |
3648 |
|
A92-USD/CHF2 |
3672 |
A32-EUR/USD2 |
3549 |
|
A91-USD/CHF1 |
3534 |
A31-EUR/USD1 |
3657 |
|
A62-GBP/CHF2 |
3534 |
A22-USD/CAD2 |
3705 |
|
A61-GBP/CHF1 |
3672 |
A21-USD/CAD1 |
3501 |
|
A12-AUD/USD2 |
3462 |
A42-USD/JPY2 |
3627 |
|
A11-AUD/USD1 |
3744 |
A41-USD/JPY1 |
3579 |
|
A102-GBP/JPY2 |
3516 |
A121-EUR/JPY1 |
3768 |
|
A101-GBP/JPY1 |
3708 |
A122-EUR/JPY2 |
3438 |

Рисунок 34. Зависимость частоты категорий повышения/понижения
курсов валют от астрономических параметров небесных тел в модели М160 по
данным [44-46].
Из этих данных следует, что подматрицы
информативностей категорий курсов валют изменяются индивидуально в зависимости
от астрономических параметров небесных тел, что позволило создать метод
прогнозирования курсов валют [18-19, 47].
Полученные результаты позволяют предположить, что существует принцип
аналогии [58], объединяющий глобальные социальные, экономические и
природные процессы, происходящие на нашей планете, сформулировать теорему о распознавании
событий в поле центральных сил [10-18], а также создать метод исследования
указанных процессов на основе АСК-анализа и аппарата когнитивных функций [66, 73-74].
Развитый в автоматизированном системно-когнитивном
анализе аппарат выявления и визуализации причинно-следственных зависимостей в
форме когнитивных функций позволяет очень наглядно буквально увидеть такие
объективно существующие явления и закономерности, о самом существовании которых
еще недавно в науке вообще не было известно и которые весьма проблематично
обнаружить другими методами, в том числе аналитическими.
Здесь необходимо особо отметить, что данный подход предлагает такое распределение функций
по выявлению и анализу причинно-следственных зависимостей между человеком и
интеллектуальной системой, при котором на каждую из сторон возлагаются именно
те функции, которые в настоящее время (при современном уровне развития
технологии и сознания человека) ею выполняются лучше, чем другой стороной. В
частности, в настоящее время есть смысл использовать превосходные возможности
человека по выявлению закономерностей в изображениях. Но для этого необходимо
соответствующим образом подготовить и представить ему эти изображения, что
осознанно и целенаправленно реализовано авторами в методе визуализации
когнитивных функций.
Это позволяет обоснованно говорить о том, что
автоматизированный системно-когнитивный анализ и его программный инструментарий
– система «Эйдос-астра» и базовая система «Эйдос» представляют собой новый
инструмент исследования в астрономии и геофизике, своего рода «математический
телескоп», открывающий качественно новые, ранее недоступные возможности
исследования. История науки наглядно демонстрирует, что появление более
совершенных инструментов исследования, обеспечивающих качественно новые
возможности исследования, ранее всегда приводило к возникновению новых
направлений в науке. Так создание микроскопа позволило открыть целый мир
микроорганизмов и привело к возникновение микробиологии, создание оптического
телескопа позволило Галилео Галилею сразу же открыть спутники Юпитера и привело
к созданию оптической астрономии, создание радиотелескопа привело к возникновению
радиоастрономии, и.т.д. Авторы считают, что применение систем искусственного
интеллекта для анализа баз данных, содержащих информацию об огромном количестве
событий на Земле в различных глобальных системах, позволяет выявить в этих
данных влияние небесных тел Солнечной системы на эти события и, позволяет открыть существование новых, ранее
неизвестных объективно существующих явлений и закономерностей. По сути это
означает, что применение технологий искусственного интеллекта для исследования
влияния небесных тел Солнечной системы на глобальные геосистемы: ноосферу, биосферу,
атмосферу, магнитосферу, геосферу и другие, представляет собой новое
перспективное направление исследований и разработок в науке.
Выводы. Таким образом, когнитивные
функции являются адекватным математическим инструментом для формального
представления причинно-следственных зависимостей. Когнитивные функции
представляют собой многозначные интервальные функции многих аргументов, в
которых различные значения функции в различной степени соответствуют различным
значениям аргументов, причем количественной мерой этого соответствия выступает
знания, т.е. информация о причинно-следственных зависимостях в эмпирических
данных, полезная для достижения целей. Многочисленные исследования подтверждают, что предложенный авторами метод и программный инструментарий визуализации
когнитивных функций позволяют наглядно увидеть такие причинно-следственные
закономерности предметной области, которые другими методами выявить и описать
весьма проблематично.