ГЛАВА 1. ТЕОРИЯ ИНФОРМАЦИИ И
СИСТЕМА ИСКУССТВЕННОГО ИНТЕЛЛЕКТА «ЭЙДОС»
Пользуясь своим мозгом, как данным от господа Бога, математик мог не
интересоваться комбинаторными основами Его работы. Но искусственный интеллект
машин должен быть создан человеком, и человеку приходится погружаться в
неизбежную при этом комбинаторную математику. Пока еще рано делать окончательные
выводы о том, что это будет значить для общей архитектуры математики будущего.
А.Н. Колмогоров
Жизнь людей немыслима без источников информации в
форме, телефона, радио, телевидения, книг, газет и журналов. Люди постоянно
пополняют запас своих знаний, обмениваются ими с другими людьми, извлекают
новые знания из собственного и коллективного опыта. Между тем, математическая
теория, описывающая процессы передачи информации по каналам связи возникла
сравнительно недавно, в конце сороковых годов 20 века, благодаря трудам Фишера,
Хартли, Котельникова, Шеннона, Колмогорова, Хинчина и других (см. гл. 3
монографии [28]).
А.Н. Колмогоров [28-29] выделил три направления в развитии
теории информации в зависимости от трех подхода к определению понятия «количества
информации»:
чисто комбинаторный подход;
вероятностный подход;
алгоритмический подход.
Комбинаторный подход является наиболее естественным и
логически независимым от каких-либо вероятностных допущений. Он возник при
исследовании различных алфавитов и словарей. Пусть переменное x принимает
значения из множества X, состоящего из N элементов. Тогда энтропия переменного
x по определению равна (Хартли, 1928)
![]()
Энтропия характеризует неопределенность в положении
(состоянии) элемента множества. Задавая определенное значение ![]() , мы снимаем неопределенность,
сообщая информацию
, мы снимаем неопределенность,
сообщая информацию
![]()
Энтропия обладает свойством аддитивности: если имеется
несколько независимых переменных ![]() пробегающих множества, состоящие из
пробегающих множества, состоящие из ![]() элементов, то энтропия
элементов, то энтропия
![]()
Если переменные ![]() связаны таким образом, что при
связаны таким образом, что при ![]() число элементов множества
число элементов множества ![]() равно
равно ![]() , то условная энтропия
определяется равенством
, то условная энтропия
определяется равенством
![]()
Информацию в ![]() относительно
относительно ![]() можно определить по формуле
можно определить по формуле
![]()
Предположим, что имеется алфавит из s элементов, тогда
число слов, содержащих по ![]() вхождений i-ой буквы алфавита равно
вхождений i-ой буквы алфавита равно
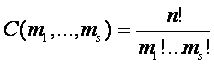
где ![]() . Количество информации этого
словаря составляет
. Количество информации этого
словаря составляет
![]() (1)
(1)
При ![]() справедлива асимптотическая формула
справедлива асимптотическая формула
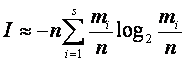
Следовательно, комбинаторный подход приводит к формуле
Шеннона для информации, которая при определенных ограничениях непосредственно
следует из (1):
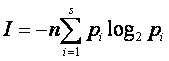 (2)
(2)
Здесь pi=mi/n
– частоты появления отдельных букв. Соответственно информация, приходящаяся на
один символ текста сообщения, составляет [30]:
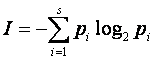 (3)
(3)
Это так называемая формула Шеннона для объема информации,
может быть легко обобщена на случай произвольного распределения вероятностей
случайного объекта ![]() (см. [28])
(см. [28])
![]() (4)
(4)
Мерой неопределенности распределения (4) является энтропия
(3), соответствующая количеству информации, которую надо сообщить, чтобы
устранить эту неопределенность.
В случае совместного распределения вероятностей двух
случайных объектов ![]()
![]()
при заданном значении ![]() находим условное распределение
находим условное распределение
![]()
Количество информации, которое необходимо для указания
точного значения ![]() равно, согласно (3)
равно, согласно (3)
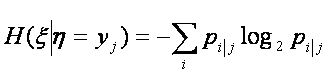
Вычисляя среднее значение этого выражения, находим
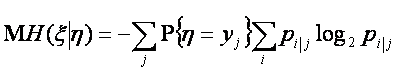
Величина информации относительно ![]() содержащаяся в задании
содержащаяся в задании ![]() определяется в виде
определяется в виде
![]()
Эту формулу можно записать в симметричном виде:
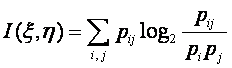 (5)
(5)
В таком виде формула для объема информации широко используется
в приложениях. В случае непрерывных распределений выражение (5) путем
предельного перехода приводится к виду [30]:
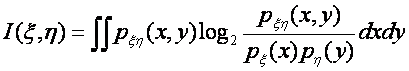 (6)
(6)
В случае передачи информации с частотой ![]() по зашумленному каналу скорость передачи
ограничена сверху согласно неравенству (Шеннон, 1948):
по зашумленному каналу скорость передачи
ограничена сверху согласно неравенству (Шеннон, 1948):
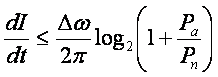 (7)
(7)
Здесь ![]() – мощность сигнала и шума соответственно.
– мощность сигнала и шума соответственно.
Вероятностный подход позволяет уточнить пределы применимости
полученных Шенноном выражений (3, 6, 7) и установить некоторые новые результаты
в теории информации [28].
При алгоритмическом подходе объем информации определяется
через сложность объекта, под которой понимается минимальная длина l(p) программы p, используя которую можно получить y из x. Согласно [28]
именно алгоритмический подход позволяет оценить количество наследственной
информации. Аналогичные идеи высказывали авторы [31], называя программу дублирования
наследственной информации правилами «игры жизни».
Как известно, жизнь является информационным процессом.
При этом все живое на нашей планете использует одну универсальную схему кодирования
и переноса информации, основанную на белках и нуклеиновых кислотах – ДНК и РНК.
В состав ДНК (РНК) входят четыре азотистых основания, образующих буквы
генетического алфавита – Аденин, Тимин (соответственно Урацил), Гуанин и
Цитозин. Четыре буквы комбинируются в трехбуквенные слова (кодоны), таким
образом, существует 43=64 различных кодонов. Система соответствий
кодон – аминокислота, т.е. генетический код, является универсальной, которую используют
как растения и животные, так и люди.
Молекула ДНК представляет собой двойную спираль с шагом
34 ангстрема и диаметром 20 ангстрем, которая соединяется парами четырех
указанных выше оснований с шагом 3,4 ангстрема. Соответствующая объемная
плотность генетической информации, вычисленная на основе комбинаторного
подхода, составляет около 1021 бит/см3, а полное
количество информации в молекуле ДНК человека около 108 бит.
Примерно 10% этого количества составляет план строения клетки и всего
организма. Копия этого плана передается из поколения в поколение. Игра жизни на
клеточном уровне сводится к дублированию наследственной информации. Отчасти
этот смысл жизни характерен и для отдельного организма, который стремится
воспроизвести себя половым или иным путем.
Заметим, что оценка объема наследственной информации не
может быть основана только на комбинаторике или теории вероятности, поскольку
условия ее воспроизведения подчиняются правилам, которые не меняются на
протяжении сотен миллионов лет. Эти правила, фактически, являются программами
высокого уровня, написанными для биологического компьютера. Кто написал эти
программы, остается под вопросом. Однако реально сделать оценку длины этих
программ пока не представляется возможным. Следует также отметить, что
дублирование наследственной информации осуществляется на молекулярных масштабах,
где велика роль квантовых эффектов. Системная (эмерджентная) теория информации
для квантовых состояний была развита в работе [32], в которой дано обобщение
формул Хартли (1) и Шеннона (5) на случай смешанных состояний.
В классической теории Шеннона [30] исследуется
передача символов по одному информационному каналу от одного источника к одному
приемнику. В общем случае можно поставить другую задачу: идентифицировать информационный
источник по сообщению от него [33].
Эта задача является своего рода обобщением метода идентификации
искусственного интеллекта, предложенного Аланом Тьюрингом и известной как «тест
Тьюринга» [34]. Тьюринг предлагал
использовать этот тест для того, чтобы эксперты-люди по сообщениям от системы
искусственного интеллекта и человека определили кто из них кто. А теперь
возникает вопрос о том, может ли искусственный интеллект по сообщениям, т.е. на
основании информации, полученной от объектов различной природы, в т.ч. людей,
идентифицировать их, т.е. отнести к тем или иным обобщенным категориям. Это
задача известна как задача «распознавания образов», к которой сводятся также
задачи идентификации и прогнозирования.
Для решения этой задачи метод Шеннона был обобщен путем
учета в математической модели возможности существования многих источников
информации, от которых по одному зашумленному каналу связи приходят к приемнику
не отдельные символы, а сообщения, состоящие из последовательностей символов
(признаков) любой длины.
Задача идентификации информационного источника по сообщению
от него, полученному приемником по зашумленному каналу может быть решена
методом, являющимся обобщением метода К. Шеннона [30]. Это позволяет применить
классическую теорию информации для построения моделей систем распознавания
образов и принятия решений [3, 33].
Для решения поставленной задачи необходимо вычислять
не средние информационные характеристики, как в теории Шеннона, а количество
информации, содержащееся в конкретном i–м
признаке (символе) о том, что он пришел от данного j–го источника информации. Это позволит определить суммарное количество
информации в сообщении о каждом информационном источнике, что дает интегральный
критерий для идентификации.
Логично предположить, что среднее количество информации,
содержащейся в системе признаков о системе классов (5) является усреднением
порций информации (слов или символов типа i),
приходящих от индивидуальных источников типа j:
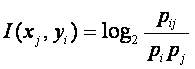 (8)
(8)
Если сообщение содержит М символов, то общее количество
информации, приходящей от источника типа j
определяется путем суммирования выражения (8):
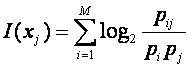 (9)
(9)
Если ранжировать классы в порядке убывания суммарного
количества информации о принадлежности к ним, содержащейся в данном сообщении
(т.е. описании объекта), и выбирать первый из них, т.е. тот, о котором в
сообщении содержится наибольшее суммарное количество информации, то мы получим
обоснованную статистическую процедуру, основанную на классической теории
информации, оптимальность которой доказывается в фундаментальной лемме Неймана
– Пирсона (см. [3]).
В семантической информационной модели при идентификации
и прогнозировании, по сути, осуществляется разложение векторов идентифицируемых
объектов по векторам классов распознавания, т.е. осуществляется «объектный
анализ» (по аналогии с спектральным, гармоническим или Фурье-анализом), что
позволяет рассматривать идентифицируемые объекты как суперпозицию обобщенных
образов классов различного типа с различными амплитудами.
При этом вектора обобщенных образов классов, с математической
точки зрения, представляют собой произвольные функции и не обязательно образуют
полную и не избыточную (ортонормированную) систему функций. Для любого объекта
всегда существует такая система базисных функций, что вектор объекта может быть
представлен в форме линейной суперпозиции (суммы) этих базисных функций с
различными амплитудами. Это утверждение, является одним из следствий
фундаментальной теоремы А.Н. Колмогорова, доказанной им в 1957 году [35].
Как известно, теорема Колмогорова является математической
основой для построения нейронных сетей, которые в свою очередь служат основой
для построения систем искусственного интеллекта. Теорема Колмогорова гласит,
что любая непрерывная функция от n
переменных F(x1, x2,
., xn) , определенная на n–мерном
единичном кубе, может быть представлена в виде суммы 2n+1 суперпозиций непрерывных и монотонных отображений единичных
отрезков:
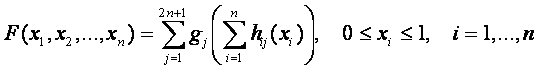
где gj
и hij – непрерывные
функции, причем hij не
зависят от функции F.
Эта теорема означает, что для реализации функций
многих переменных достаточно операций суммирования и композиции функций одной
переменной. Отметим, что в этом представлении лишь функции gj зависят от представляемой функции F, а функции hij универсальны. Вообще говоря, определение вида функций
hij и gj для данной функции F=F(x1, x2, ., xn) представляет
собой математическую проблему, для которой пока не найдено строгого решения. В
монографии [3] предлагается рассматривать семантическую информационную модель
как один из вариантов решения этой проблемы. В этом контексте функция F(x1, x2, ., xn)
интерпретируется как образ идентифицируемого объекта, функция hij – образ j-го класса, а функция gj – мера сходства образа
объекта с образом класса. Рассмотрим алгоритм нахождения этих функций путем применения
автоматизированного системно-когнитивного анализа (АСК-анализа).
АСК-анализ представляет собой непараметрический метод
искусственного интеллекта, основанный не на статистике, а на системном
обобщении теории информации, системном анализе и когнитивном моделировании [3].
Этот метод позволяет выделять полезный сигнал о связи признаков с обобщенными
категориями из шума путем обобщения (многоканальной или многопараметрической
типизации), осуществлять синтез информационным моделей больших размерностей, а
также использовать их для решения задач идентификации (прогнозирования),
поддержки принятия решений и просто исследования предметной области путем
исследования ее модели.
Метод и технология АСК-анализа включает:
– базовую когнитивную концепцию;
– математическую модель;
– методику численных расчетов;
– специальный программный инструментарий – универсальную
когнитивную аналитическую систему «Эйдос» [36].
Базовая когнитивная концепция АСК-анализа
рассматривает процесс познания, как многоуровневую иерархическую систему
обработки информации, причем когнитивные структуры каждого уровня являются
результатом интеграции структур предыдущего уровня.
На 1-м уровне этой системы находятся дискретные элементы
потока чувственного восприятия, которые на 2-м уровне интегрируются в
чувственный образ конкретного объекта. Те, в свою очередь, на 3-м уровне
интегрируются в обобщенные образы классов и факторов, образующие на 4-м уровне
кластеры, а на 5-м конструкты. Система конструктов на 6-м уровне образуют
текущую парадигму реальности (т.е. человек познает мир путем синтеза и
применения конструктов). На 7-м же уровне обнаруживается, что текущая парадигма
не единственно возможная, т.к. существуют другие формы сознания и реальности,
кроме известных до этого.
Ключевым для когнитивной концепции является понятие
факта, под которым понимается соответствие дискретного и интегрального
элементов познания (т.е. элементов разных уровней интеграции-иерархии),
обнаруженное на опыте. Факт рассматривается как квант смысла, что является
основой для его формализации. Мысль представляет собой действие над данными,
извлекающее из них смысл. Таким образом, происхождение смысла связывается со
своего рода «разностью потенциалов», существующей между смежными уровнями
интеграции-иерархии обработки информации в процессах познания. Между
когнитивными структурами разных уровней иерархии существует отношение «дискретное
– интегральное». Именно это служит основой формализации смысла. Из базовой
когнитивной концепции следует когнитивный конфигуратор, представляющий собой
минимальную полную систему когнитивных операций, названных «базовые когнитивные
операции системного анализа».
Всего выявлено 10 таких операций, каждая из которых оказалась
достаточно элементарной для формализации и программной реализации:
1)
присвоение имен;
2)
восприятие;
3)
обобщение
(синтез, индукция);
4)
абстрагирование;
5)
оценка
адекватности модели;
6)
сравнение,
идентификация и прогнозирование;
7)
дедукция и
абдукция;
8)
классификация и
генерация конструктов;
9)
содержательное
сравнение;
10)
планирование и
принятие решений об управлении.
Математическая модель АСК-анализа основана на системной
теории информации, которая создана в рамках реализации программной идеи
обобщения всех понятий математики, в частности теории информации, базирующихся
на теории множеств, путем тотальной замены понятия множества на более общее понятие
системы и тщательного отслеживания всех последствий этой замены. Благодаря
математической модели, положенной в основу АСК-анализа, этот метод является
непараметрическим и позволяет сопоставимо обрабатывать тысячи градаций факторов
(астропризнаков) и будущих состояний объекта управления (категорий) при
неполных (фрагментированных), зашумленных данных различной природы, т.е.
измеряемых в различных единицах измерения.
При этом на этапе синтеза модели осуществляется многокритериальная
типизация респондентов обучающей выборки по исследуемым категориям, т.е.
рассчитывается количество информации, которое содержится в фактах попадания
углов долготы в интервалы (рассматриваемые как критерии), о принадлежности респондента
к тем или иным категориям, а на этапе идентификации эта информация используется
для расчета степени сходства конкретных респондентов с обобщенными категориями.
Результат идентификации респондента, описанного данной
системой астропризнаков, представляет собой список обобщенных категорий
(классов), в котором они расположены в порядке убывания суммарного количества
информации о принадлежности респондента к каждому из них. Математическая модель
позволяет сформировать информационные портреты классов и астропризнаков, а
также осуществить их кластерный и конструктивный анализ.
Информационный портрет класса (обобщенной категории)
показывает какое количество информации содержит каждый астропризнак о
принадлежности респондента к данной категории.
Информационный (семантический) портрет астропризнака
является его развернутой смысловой количественной характеристикой, в которой
содержится информация о принадлежности респондента, обладающего данным
признаком, ко всем обобщенным категориям.
Кластеры классов представляют собой группы категорий,
сходных по характерным для них астропризнакам.
Кластеры астропризнаков представляют собой группы признаков,
сходных по их смыслу, т.е. по тому, какую информацию о принадлежности
респондентов, обладающих этими признаками к обобщенным категориям они содержат.
Под конструктом понимается система противоположных
(наиболее сильно отличающихся) кластеров, которые называются «полюсами»
конструкта, а также спектр промежуточных кластеров, к которым применима
количественная шкала измерения степени их сходства или различия.
Конструкты могут быть получены как результат кластерного
анализа кластеров категорий или астропризнаков, при этом конструкт
рассматривается как кластер с нечеткими границами, включающий в различной
степени, причем не только в положительной, но и в отрицательной, все классы или
астропризнаки.
Конструктивный анализ позволяет определить в принципе
совместимые и в принципе несовместимые по характерным для них астропризнакам
классы или обобщенные категории. Совместимыми называются классы, для которых
характерны сходные системы астропризнаков, а несовместимыми – для которых они
диаметрально противоположны и одновременно неосуществимы.
По результатам кластерно-конструктивного анализа строятся
диаграммы смыслового сходства-различия классов (признаков), соответствующие
определению семантических сетей и нечетких когнитивных схем, т.е.
представляющие собой ориентированные графы, в которых классы (признаки)
соединены линиями, толщина которых соответствует модулю, а цвет знаку их
сходства-различия.
Предложенная математическая модель в обобщенной постановке
обеспечивает содержательное сравнение классов друг с другом и астропризнаков
друг с другом, т.е. построение когнитивных диаграмм. Например, информационные
портреты классов содержат информацию о характерности признаков для классов.
Кластерно-конструктивный анализ обеспечивает сравнение классов друг с другом,
т.е. дает степень их сходства и различия. Но он не дает информации о том,
какими признаками эти классы похожи и какими отличаются, и какой вклад каждый
признак вносит в сходство или различие некоторых двух классов. Информация об
этом генерируется на основе анализа и сравнения двух информационных портретов,
что и осуществляется при содержательном сравнении классов. Каждая пара
признаков, принадлежащих сравниваемым классам, образует «смысловую связь»,
вносящую определенный вклад в сходство/различие между этими классами если эти
признаки тождественны друг другу или между ними имеется определенное
сходство/различие по смыслу. Список связей сортируется в порядке убывания
модуля силы связи, причем учитывается не более заданного их количества (это
связано с ограничениями при графическом отображении). Графической визуализацией
результатов содержательного сравнения классов являются когнитивные диаграммы с
многозначными связями. На когнитивной диаграмме классов отображены их
информационные портреты, в которых факторы расположены в порядке убывания их
характерности для этих классов, а линии, соединяющие астропризнаки, имеют
толщину и цвет, соответствующие модулю и знаку их вклада в сходство-различие
классов. Когнитивная диаграмма классов дает детальную расшифровку структуры конкретной
линии связи семантической сети. Кроме того, предложены и реализованы в модели
инвертированные когнитивные диаграммы, детально раскрывающие сходство-различие
двух астропризнаков по их влиянию на принадлежность респондента к различным
категориям, а также прямые и инвертированные диаграммы В.С. Мерлина (1986), в
которых показаны уровни и знаки связей между астропризнаками различных уровней
интегративности по их характерности для различных категорий. Предложены и
реализованы также классические и интегральные когнитивные карты, представляющие
собой диаграммы, объединяющие семантические сети классов и признаков и
нелокальные нейронные сети [34].
Методика численных расчетов АСК-анализа включает
структуры данных, способы представления и формализации (кодирования) входных,
промежуточных и выходных данных, а также алгоритмы реализации базовых
когнитивных операций системного анализа.
Специальный программный инструментарий АСК-анализа –
универсальная когнитивная аналитическая система «Эйдос» (см. таблицу 1)
обеспечивает:
– формализацию предметной области;
– подготовку обучающей выборки и управление ей, в т.ч.
взвешивание или «ремонт» данных;
– синтез семантической информационной модели предметной
области (обобщение или типизация);
– оптимизацию модели;
– проверку адекватности модели;
– идентификацию и прогнозирование;
– типологический анализ (включая решение обратной задачи
идентификации и прогнозирования, семантический информационный и
кластерно-конструктивный анализ классов и факторов);
– оригинальную графическую визуализацию результатов
анализа в форме когнитивной графики (простых и интегральных когнитивных карт,
семантических сетей и когнитивных диаграмм).
Общая структура системы «Эйдос» представлена в таблице A.
Таблица A. Общая структура универсальной когнитивной
аналитической системы «Эйдос»версии 12.5 (текущей на момент издания монографии)
|
Подсистема |
Режим |
Функция |
Операция |
|
|
1. Формализация ПО |
1. Классификационные шкалы и градации |
|||
|
2. Описательные шкалы (и градации) |
||||
|
3. Градации описательных шкал (признаки) |
||||
|
4. Иерархические уровни систем |
1. Уровни классов |
|||
|
2. Уровни признаков |
||||
|
5. Программные интерфейсы для импорта данных |
1. Импорт данных из TXT-фалов стандарта DOS-текст |
|||
|
2. Импорт данных из DBF-файлов стандарта проф.
А.Н.Лебедева |
||||
|
3. Импорт из транспонированных DBF-файлов проф.
А.Н.Лебедева |
||||
|
4. Генерация шкал и обучающей выборки RND-модели |
||||
|
5. Генерация шкал и обучающей выборки для
исследования чисел |
||||
|
6. Транспонирование DBF-матриц исходных данных |
||||
|
7. Импорт данных из DBF-файлов стандарта Евгения
Лебедева |
||||
|
8. Системно-когнитивный анализ стандартных
графических шрифтов |
||||
|
9. Микроструктура системы
как фактор управления ее макросвойствами |
||||
|
6. Почтовая служба по НСИ |
1. Обмен по классам |
|||
|
2. Обмен по обобщенным признакам |
||||
|
3. Обмен по первичным признакам |
||||
|
7. Печать анкеты |
||||
|
2. Синтез СИМ |
1. Ввод–корректировка обучающей выборки |
|||
|
2. Управление обучающей выборкой |
1. Параметрическое задание объектов для обработки |
|||
|
2. Статистическая характеристика, ручной ремонт |
||||
|
3. Автоматический ремонт обучающей выборки |
||||
|
3. Синтез семантической информационной модели СИМ |
1. Расчет матрицы абсолютных частот |
|||
|
2. Исключение артефактов (робастная процедура) |
||||
|
3. Расчет матрицы информативностей СИМ-1 и
сделать ее текущей |
||||
|
4. Расчет условных процентных распределений СИМ-1
и СИМ-2 |
||||
|
5. Автоматическое выполнение режимов 1–2–3–4 |
||||
|
6. Измерение сходимости и устойчивости модели |
1. Сходимость и устойчивость СИМ |
|||
|
2. Зависимость валидности модели от объема
обучающей выборки |
||||
|
7. Расчет матрицы информативностей СИМ-2 и
сделать ее текущей |
||||
|
8. Расчет стат. характеристик обучающей выборки |
||||
|
9. Рассчитать БД разн.факт.и теор.хи-квадрат СИМ-3
и сделать ее текущей |
||||
|
10. Рассчитать матрицу ROI СИМ-4 и сделать ее
текущей |
||||
|
11. Рассчитать
все модели: СИМ-1, СИМ-2, СИМ-3, СИМ-4 на основе Abs.dbf |
||||
|
4. Почтовая служба по обучающей информации |
||||
|
3. Оптимизация СИМ |
1. Формирование ортонормированного базиса классов |
|||
|
2. Исключение признаков с низкой селективной
силой |
||||
|
3. Удаление классов и признаков, по которым
недостаточно данных |
||||
|
4. Разделение классов на типичную и нетипичную
части |
||||
|
5. Генерация сочетанных признаков и
перекодирование обучающей выборки |
||||
|
6. Удаление малодостоверных данных в БД: ABS,
PER, INF по критерию хи-квадрат |
||||
|
4. Распознавание |
1. Ввод–корректировка распознаваемой выборки |
|||
|
2. Пакетное распознавание |
||||
|
3. Вывод результатов распознавания |
1. Разрез: один объект – много классов |
|||
|
2. Разрез: один класс – много объектов |
||||
|
4. Почтовая служба по распознаваемой выборке |
||||
|
5. Построение функций влияния |
||||
|
6. Докодирование сочетаний признаков в
распознаваемой выборке |
||||
|
7. Назначения объектов на классы (задача о назначениях) |
1. Задание ограничений на ресурсы по классам |
|||
|
2. Ввод затрат на объекты |
||||
|
3. Назначения объектов на классы (LC-алгоритм) |
||||
|
4. Сравнение эффективности LC и RND алгоритмов |
||||
|
8. Интерактивная идентификация - последовательный
анализ Вальда |
||||
|
9. Сортировка результатов пакетного распознавания |
||||
|
5. Типология |
1. Типологический анализ классов распознавания |
1. Информационные (ранговые) портреты (классов) |
||
|
2. Кластерный и конструктивный анализ классов |
1 Расчет матрицы сходства образов классов |
|||
|
2. Генерация кластеров и конструктов классов |
||||
|
3. Просмотр и печать кластеров и конструктов |
||||
|
4. Автоматическое выполнение режимов: 1,2,3 |
||||
|
5. Вывод 2d семантических сетей классов |
||||
|
6. Агломеративная древовидная кластеризация
классов |
||||
|
7. Вывод дерева классов |
||||
|
3. Когнитивные диаграммы классов |
||||
|
2. Типологический анализ первичных признаков |
1. Информационные (ранговые) портреты признаков |
|||
|
2. Кластерный и конструктивный анализ признаков |
1. Расчет матрицы сходства образов признаков |
|||
|
2. Генерация кластеров и конструктов признаков |
||||
|
3. Просмотр и печать кластеров и конструктов |
||||
|
4. Автоматическое выполнение режимов: 1,2,3 |
||||
|
5. Вывод 2d семантических сетей признаков |
||||
|
3. Когнитивные диаграммы признаков |
||||
|
3. Подготовка баз данных для визуализации
когнитивных функций в SigmaPlot и Excel |
||||
|
4. Визуализация прямых и обратных, позитивных и
негативных когнитивных функций |
||||
|
6. СК-анализ
СИМ |
1. Оценка достоверности заполнения объектов |
|||
|
2. Измерение адекватности семантической
информационной модели |
||||
|
3. Измерение независимости классов и признаков |
||||
|
4. Просмотр профилей классов и признаков |
||||
|
5. Графическое отображение нелокальных нейронов |
||||
|
6. Отображение Паретто-подмножеств нейронной сети |
||||
|
7. Классические и интегральные когнитивные карты |
||||
|
8. Восстановление |
1. Восстановление значений и визуализация
1d-функций |
|||
|
2. Восстановление значений и визуализация
2d-функций |
||||
|
3. Преобразование 2d-матрицы в 1d-таблицу с
признаками точек |
||||
|
4. Объединение многих БД: Inp_0001.dbf и т.д. в
Inp_data.dbf |
||||
|
5. Помощь по подсистеме (требования к исходным данным) |
||||
|
7. Сервис |
1. Генерация (сброс) БД |
1. Все базы данных |
||
|
2. НСИ |
1. Всех баз данных НСИ |
|||
|
2. БД классов |
||||
|
3. БД первичных признаков |
||||
|
4. БД обобщенных признаков |
||||
|
3. Обучающая выборка |
||||
|
4. Распознаваемая выборка |
||||
|
5. Базы данных статистики |
||||
|
2. Переиндексация всех баз данных |
||||
|
3. Печать БД абсолютных частот |
||||
|
4. Печать БД условных процентных распределений
СИМ-1 и СИМ-2 |
||||
|
5. Печать БД информативностей СИМ-1 и СИМ-2 |
||||
|
6. Интеллектуальная дескрипторная
информационно–поисковая система |
||||
|
7. Копирование основных баз данных СИМ |
||||
|
8. Сделать текущей матрицу информативностей СИМ-1 |
||||
|
9. Сделать текущей матрицу информативностей СИМ-2 |
||||
|
10. Конвертировать все PCX в GIF |
||||
|
11. Изменение структур БД к текущему стандарту |
||||
|
12. Сделать текущей матрицу информативностей
СИМ-3 |
||||
|
13. Сделать текущей матрицу информативностей
СИМ-4 |
||||
|
8. О системе |
1. Графическая заставка системы «Эйдос» |
|
||
|
2. Логотипы мультимоделей |
|
|||
В монографии [3] приведен перечень этапов системно-когнитивного
анализа, которые необходимо выполнить, чтобы осуществить синтез и исследование
модели объекта управления:
¾
Когнитивная
структуризация, а затем и формализация предметной области.
¾
Ввод
данных мониторинга в базу прецедентов (обучающую выборку).
¾
Синтез
семантической информационной модели (СИМ).
¾
Оптимизация
СИМ (в случае целесообразности).
¾
Проверка
адекватности СИМ (верификация модели, измерение внутренней и внешней,
дифференциальной и интегральной валидности).
¾
Решение задач идентификации состояний объекта
управления, прогнозирование и поддержка принятия управленческих решений по
управлению с применением СИМ.
¾
Системно-когнитивный
анализ СИМ.
Важной особенностью АСК-анализа является возможность
единообразной числовой обработки разнотипных числовых и не числовых данных. Это
обеспечивается тем, что не числовым величинам тем же методом, что и числовым,
приписываются сопоставимые в пространстве и времени, а также между собой, количественные
значения, позволяющие обрабатывать их как числовые:
¾
на
первых двух этапах АСК-анализа числовые величины сводятся к интервальным
оценкам, как и информация об объектах не числовой природы (фактах,
событиях) (этот этап реализуется и в методах интервальной статистики);
¾
на
третьем этапе АСК-анализа всем этим величинам по единой методике, основанной на
системном обобщении семантической теории информации [3], сопоставляются
количественные величины (имеющие смысл количества информации в признаке о
принадлежности объекта к классу), с которыми в дальнейшем и производятся все
операции моделирования (этот этап является уникальным для АСК-анализа).
Хотя
система искусственного интеллекта «Эйдос» [36] была создана специально для
решения задач распознавания в самом широком смысле, ее применение для
исследования проблем астросоциотипологии столкнулось с требованием
автоматизации расчетов при изменении числа секторов разбиения круга зодиака.
Поэтому была разработана специализированная система искусственного интеллекта «Эйдос-астра»
[7], позволяющая осуществлять пакетное распознавание категорий респондентов на
совокупности моделей с применением пяти алгоритмов «голосования» [4].