ГЛАВА
4. ИССЛЕДОВАНИЕ АСТРОСОЦИОТИПОВ
С ПРИМЕНЕНИЕМ СЕМАНТИЧЕСКИХ
ИНФОРМАЦИОННЫХ МУЛЬТИМОДЕЛЕЙ
В данной главе дан обзор работ /15-16/, в которых приводятся
основные научные результаты по семантической информационной мультимодели, обеспечивающей
как выявление зависимостей между астропризнаками и принадлежностью респондентов
к обобщенным социальным категориям, так и использование знания этих зависимостей
для идентификации респондентов по этим категориям. Исследованная в /15/ мультимодель
включает 172 частные модели на 37 обобщенных категорий, причем каждая из категорий
представлена не менее чем 1000 респондентов при общем объеме выборки 20007 респондентов.
Основным источником данных, подготовленной
для системы "Эйдос", является AstroDatabank (www.astrodatabank.com). Использованная
нами четвертая версия этого банка данных содержит 31012 записей, из которых 23217 составляют
карты рождения известных личностей с описанием их биографии, 6643 карты рождения
людей без имени, отнесенных к определенной категории и 1152 карты мунданных событий,
типа землятресения, авиационных катастроф и т.п. Общий объем банка данных составляет
около 300 Мб. В нем содержатся астрономические параметры в 4 системах домов, поэтому
в данной версии можно экспортировать в использованный нами DBF4 формат астрономические
параметры, включая долготу и склонение планет, а также положение углов домов. Достоинством этого банка данных является то, что,
все события жизни классифицированы, а все профессиональные и иные категории упорядочены.
В результате сортировки исходных данных были получены астрономические и биографические
данные для 20007 уникальных персон и 16360 записей событий, происходивших с ними.
Для них всех были вычислены координаты небесных тел. Для записей с точным временем
вычислялись куспиды домов в системе Плацидуса. В анализе были использованы эфемериды
следующих небесных тел: Солнца, Луны, Меркурия, Венеры, Марса, Юпитера, Сатурна,
Урана, Нептуна и Плутона.
Однако в процессе исследований выяснилось, что данная база
данных обладает рядом недостатков, среди которых хотелось бы отметить крайне неравномерное
распределение респондентов по категориям: из 11000 категорий, к которым относятся
респонденты этой базы лишь 37 представлены 1000 респондентов и более. Поэтому выводы,
полученные различным категориям, обладают разной степенью статистической достоверности:
по хорошо представленным категориям можно
говорить о надежно выявленных эмпирических
законах, а по малопредставленным – об исследовании неких зависимостей, которые
нет возможности классифицировать как случайные или закономерные.
Дело в том, что чем меньше респондентов относится к категории,
тем меньше вариабельность параметров респондентов, отнесенных к категории. В предельном
случае, когда образ категории сформирован на примере одного респондента, вариабельность
полностью отсутствует. В этом случае, по сути, задача распознавания вырождается
(редуцируется) до задачи информационного поиска, т.е. становится тривиальной. Поэтому
достоверность решения этой задачи максимальна и практически равна 100 %. Чем больше
респондентов относится к некоторой категории, тем выше вариабельность параметров
респондентов (астропризнаков) внутри категории, тем сложнее получить обобщенный
образ этой категории и тем сложнее достоверно осуществить идентификацию конкретного
респондента с этим образом. Однако именно это, т.е. определение уровня сходства
конкретного респондента с обобщенным образом, сформированным на основе большого
количества респондентов, относящихся к данной категории, и представляет и научный,
и прагматический интерес.
Таким образом возникает проблема, состоящая в том, что
для повышения статистической достоверности выводов необходимо увеличивать количество
респондентов, относящихся к обобщенным категориям, однако это приводит к понижению
достоверности идентификации респондентов с этими категориями из-за возрастания вариабельности
внутри категорий.
В астросоциологии данная проблема ставится впервые, и в
этом состоит ее научная новизна. Решение данной проблемы позволяет одновременно
повысить и адекватность, и статистическую достоверность идентификации респондентов
с астросоциотипами, что имеет высокую практическую значимость для служб, связанных
с управлением персоналом. В этом и состоит актуальность решения данной проблемы.
Одним из эффективных методов повышения адекватности модели
является сортировка исходных записей базы данных и удаление из нее нетипичных представителей
данных категорий /16/. Рассмотрим этот метод более подробно на одном примере.
Объектом исследования являются модели, отражающие взаимосвязи
между астропризнаками респондентов и принадлежностью этих респондентов к астросоциотипам,
а предметом исследования – частные информационные
семантические модели с 2, 3, 12 и 128 секторами.
Выбор именно этих частных моделей для исследования был
обусловлен тем, что они представляют три группы частных моделей: с малым (2, 3),
средним (12) и большим (128) количеством секторов, что позволяет оценить зависимость
эффективности метода, применяемого для решения проблемы, от количества секторов
в частной модели.
Целью исследования является повышение адекватности идентификации респондентов
в частных моделях по хорошо статистически представленным астросоциотипам.
Данную цель предполагается достичь путем ее декомпозиции в следующую последовательность
задач, являющихся этапами ее достижения:
1.
Разработка дерева
обобщенных категорий, к которым относятся респонденты, представленные в исходной
базе данных.
2.
Расчет распределения
респондентов по категориям.
3.
Удаление из списка
категорий всех, к которым относится менее 1000 респондентов.
4.
Синтез частных моделей
для наиболее представленных социальных категорий с различным количеством секторов.
5.
Выбор метода повышения
адекватности и исследование частных моделей с малым (2, 3), средним (12) и большим
(128) количеством секторов выбранным методом.
Решение задач 1-4 приведено в работе /15/, а решение 5-й
задачи в работе /16/.
Обоснование требований
к методу решения проблемы. Метод должен
обеспечивать возможность работы с частными моделями, созданными в системе "Эйдос-астра"
/3/ и при этом повышать адекватность отдельной заданной модели, т.е. не использовать алгоритмы голосования (коллективы
решающих правил), которые уже были исследованы в /15/.
На сколько можно судить по литературным данным сформулированным
требованиям в принципе удовлетворяют две системы: это SPSS и система "Эйдос".
В системе SPSS можно методами кластерного анализа исследовать
матрицу информативностей и построить дерево классов, отражающее их сходство и различие.
Ясно, что сходство классов тем выше, чем больше респондентов относится одновременно
к обоим этим классам, т.е. чем больше их пересечение по исходным данным, чем выше
корреляция между ними. На основе этого можно попытаться сконструировать такую систему
классов, которые бы имели минимальное пересечение по исходным данным, т.е. провести
ортонормирование системы классов. При этом из системы классов будут удалены те из
них, которые наиболее сильно коррелируют друг с другом. Это теоретически возможно,
но практически осуществимо лишь для очень небольших обучающих выборок и небольших
наборов классов, т.к. после изменения набора классов необходимо соответственно перекодировать
обучающую выборку, и провести пересинтез модели. Для исследуемых нами баз данных
с помощью системы SPSS это практически неосуществимо. Кроме того система SPSS вообще
не обеспечивает многопараметрическую типизацию (обобщение, формирование обобщенных
образов категорий) на основе описаний респондентов.
В системе "Эйдос" /2/ реализованы режимы ортонормирования
семантического пространства классов и семантического пространства атрибутов, а также
режим разделения классов на типичную и нетипичную части, автоматизирующие все необходимые
для этого функции, причем в процессе выполнения этих режимов создаются различные
частные модели и при этом используется многопараметрическая типизация.
По этим причинам для решения сформулированной проблемы
авторами принято решение применить метод разделения классов на типичную и нетипичную
части, реализованный в системе "Эйдос". Необходимо отметить, что этот
метод уже апробирован для решения подобных задач в других предметных областях и
при этом продемонстрировал очень высокую эффективность, но для решения поставленной
проблемы применяется впервые.
Описание метода.
Данный метод представляет собой итерационный
процесс синтеза частных моделей, отличающихся наборами классов (обобщенных категорий).
Цикл итераций начинается с копирования исходной модели в директорию для первой итерации.
В последующих итерациях частная модель копируется из директории с текущей итерацией
в директорию с последующей итерацией. Выход из цикла итераций происходит при достижении
заданной достоверности идентификации или 100% достоверности, заданного количества
итераций или при стабилизации достоверности (ее неизменности в двух итерациях).
В каждой итерации проводится синтез модели и идентификация
респондентов обучающей выборки с обобщенными категориями. Если
респондент не отнесен системой к обобщенной категории, хотя в действительности по
данным обучающей выборки относится к ней, то это означает, что он является нетипичным для этой категории, в которой,
видимо, очень высока вариабельность параметров, и это означает, что надо разделить
эту категорию на несколько таким образом, чтобы вариабельность параметров внутри
каждой из них была минимальной и достаточной для наиболее достоверной идентификации
респондентов. При этом формируется дерево разделения категорий, похожее на формирующееся
при древовидной кластеризации, причем на каждой итерации каждая обобщенная категория
разделяется не более, чем на две категории.
Описание методики
(технологии) применения метода на практике. На практике для применения данного режима системы "Эйдос" (_35)
были выполнены следующие работы:
¾
создана директория Razd_kl для исследования моделей
методом разделения классов на типичную и нетипичную части;
¾
внутри этой директории созданы директории Razd_002,
Razd_003, Razd_012, Razd_128 для исследования частных моделей с 2, 3, 12 и 128 секторами
соответственно;
¾
в каждую из этих директорий скопированы папки с
исходной частной моделью (из директории с мультимоделью, содержащей 172 ранее созданные
частные модели) и папка с системой "Эйдос";
¾
для каждой частной модели: все файлы из директории
с исходной моделью скопированы в директорию с системой "Эйдос";
¾
для каждой частной модели: система "Эйдос"
запускается на исполнение и затем запускается режим _35: "Разделение классов
на типичную и нетипичную части" (при этом задается 7 итераций);
¾
данный режим исполняется и формирует директории
с именами вида: Razd_kl\razd_002\ITER_##, где ## – номер итерации;
¾
в поддиректории TXT каждой директории с итерацией
содержится файл: Razd_kl\razd_002\ITER_02\TXT\NCD_TREE.TXT, содержащий в псевдографическом виде дерево классов для
данной итерации;
¾
в базах данных DOSTITER.DBF содержится информация
о достоверности идентификации по всей обучающей выборке, достигнутая в текущей итерации.
В таблице 16 и на рисунке 31 приведены сводные данные по
достоверности идентификации всех 20007 респондентов обучающей выборки в частных
моделях, полученных из исходных частных моделей с 2, 3, 12 и 128 секторами на различных
итерациях.
Таблица 16. Достоверность идентификации
20007 респондентов на различных итерациях
|
Номер итерации |
Количество секторов в частной модели |
|||
|
2 |
3 |
12 |
128 |
|
|
1 |
66,311 |
72,562 |
72,374 |
73,923 |
|
2 |
82,678 |
80,240 |
81,702 |
80,022 |
|
3 |
83,829 |
79,802 |
82,348 |
81,599 |
|
4 |
82,974 |
79,840 |
82,480 |
82,171 |
|
5 |
82,515 |
79,927 |
82,474 |
82,528 |
|
6 |
82,460 |
80,043 |
82,556 |
82,756 |
|
7 |
82,472 |
80,182 |
82,622 |
82,922 |
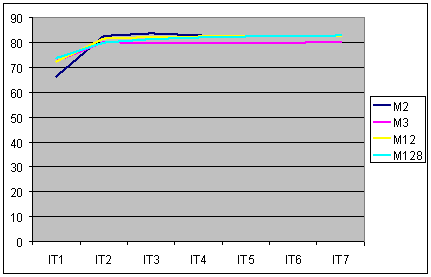
Рис. 31. Достоверность идентификации на различных
итерациях в моделях М2, М3, М12 и М128
Из приведенных таблицы и рисунка следует вывод о высокой
эффективности применения выбранного метода разделения классов на типичную и нетипичную
части, который обеспечил уже на 1-й итерации достоверность идентификации обучающей
выборки, включающей 20007 респондентов, 65-75%, а уже на 2-й и 3-й итерациях эта
достоверность достигает 82-83%. Видно также, что наибольший эффект дают уже первые
три итерации, а последующие мало что меняют в эффективности частных моделей.
Главный научный вывод, который можно
обоснованно сделать на основе проведенного исследования состоит в том, что метод разделения классов на типичную и нетипичную части
позволяет получить семантические информационные модели с очень высокой достоверностью
идентификации респондентов, достигающей 83% на огромной тестирующей выборке из 20007
респондентов.
Второй вывод состоит в том, что для получения модели с
высокой достоверностью не играет особой роли количество секторов в исходной модели,
т.е. эффективность метода практически не зависит
от количества секторов в частных моделях.
В работе /16/ приводится дерево категорий
для частной модели с 2 секторами, полученное на 7-й итерации. Из этого дерева категорий можно сделать вывод о том, что
одни категории обладают более высокой внутренней вариабельностью и разделяются в
процессе итераций на большее количество классов, чем другие, которые идентифицируются
с большей достоверностью. Ярким примером категории 2-го типа является SC:A53-Sports.
Примененный метод разделения классов на типичную и нетипичную
части продемонстрировал свою высокую эффективность. Полученные в результате применения
данного метода семантические информационные модели имеют достоверность идентификации
достаточно высокую для того, чтобы применять эти модели на практике в консультирующих
системах.
Необходимо отметить очень высокие затраты машинного времени
и других вычислительных ресурсов на расчеты, связанные с получением новых более
достоверных частных моделей. Этим и объясняется выбор для данного исследования всего
4-х частных моделей, а не всех 172-х, полученных ранее, а также то обстоятельство,
что количество итераций было ограничено 7-ю. В вычислительных экспериментах на моделях
меньшей размерности в других предметных областях и при большем количестве итераций
этим же методом были получены модели со 100% достоверностью /26/.
В работе /15/ была изучена эффективность пяти алгоритмов
голосования по сравнению со случайным угадыванием – таблица 17. Сравнивались
алгоритмы распознавания в мультимоделях, когда за параметр сходства принимается:
А1. СУММАРНАЯ ЧАСТОТА ИДЕНТИФИКАЦИИ
респондента с каждым классом, рассчитанная по всем частным моделям /10-11/.
А2. СРЕДНЕЕ уровней сходства
с этим классом из всех карточек идентификации частных моделей.
А3. Уровень сходства этого
респондента с классом из той частной карточки идентификации, в которой он МАКСИМАЛЬНЫЙ.
А4. Уровень сходства из
карточки идентификации той частной модели, которая показала МАКСИМАЛЬНУЮ достоверность
распознавания ДАННОГО КЛАССА из всех моделей.
А5. СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ
уровней сходства с данным классом на достоверность его идентификации в частных моделях.
Таблица 17. Эффективность алгоритмов голосования
по сравнению со случайным угадыванием
|
Имя категории |
А1 |
А2 |
А3 |
А4 |
А5 |
|
SC:М- |
5,781 |
9,25 |
3,262 |
2,323 |
10,947 |
|
SC:A323-Sexuality |
8,409 |
6,167 |
18,271 |
7,645 |
7,708 |
|
SC:B329-Sexual perversions |
8,81 |
8,222 |
10,883 |
1,996 |
5,389 |
|
SC:C330- Homosexual m |
10,277 |
15,418 |
6,159 |
9,136 |
9,679 |
|
SC:B189-Medical:Illness |
11,936 |
6,379 |
8,968 |
10,242 |
3,85 |
|
SC:A53-Sports |
12,333 |
36,996 |
6,371 |
4,068 |
7,113 |
|
SC:A42-Medical |
12,758 |
9,25 |
5,139 |
12,432 |
3,997 |
|
SC:A5-Entertainment |
13,704 |
11,212 |
4,791 |
12,589 |
12,432 |
|
SC:A9-Relationship |
14,231 |
6,981 |
3,482 |
0,961 |
3,557 |
|
SC:A29-Parenting |
16,088 |
4,302 |
4,567 |
3,61 |
0,903 |
|
SC:B21- Number of marriages |
16,088 |
20,555 |
6,491 |
5,609 |
7,175 |
|
SC:A31-Business |
16,088 |
18,501 |
10,242 |
8,712 |
3,263 |
|
SC:B26-Personality:Body |
16,088 |
6,981 |
7,255 |
8,094 |
7,631 |
|
SC:A23-Psychological |
17,618 |
9,487 |
21,763 |
20,483 |
3,652 |
|
SC:A25-Personality |
19,474 |
16,088 |
9,992 |
3,7 |
5,668 |
|
SC:A19-Writers |
21,763 |
11,212 |
3,706 |
6,662 |
11,419 |
|
SC:A129-Death |
21,763 |
8,409 |
2,868 |
5,073 |
7,645 |
|
SC:A1-Book Collection |
23,127 |
8,604 |
6,049 |
4,509 |
9,922 |
|
SC:B111-Sports:Basketball |
23,127 |
24,667 |
10,883 |
9,024 |
8,804 |
|
SC:B14-Entertainment:Actor/ Actress |
24,667 |
16,088 |
8,222 |
6,395 |
9,282 |
|
SC:A15-Famous |
26,427 |
2,782 |
1,393 |
2,847 |
22,652 |
|
SC:A55-Art |
28,458 |
8,409 |
8,409 |
10,999 |
4,441 |
|
SC:B49-Book Collection:Am. Book |
28,458 |
7,551 |
9,024 |
7,604 |
7,604 |
|
SC:A38-Politics |
30,836 |
7,872 |
11,551 |
3,807 |
6,662 |
|
SC:B173-Sports:Football |
30,836 |
10,277 |
12,318 |
7,113 |
7,362 |
|
SC:A99-Financial |
30,836 |
15,418 |
8,604 |
5,867 |
3,034 |
|
SC:B48-:Top 5% of Profession |
33,636 |
9,737 |
14,799 |
6,483 |
11,674 |
|
SC:B6-Entertainment:Music |
33,636 |
12,333 |
9,737 |
2,43 |
1,858 |
|
SC:A68-Childhood |
36,996 |
11,936 |
13,683 |
2,337 |
6,605 |
|
SC:Ж- |
36,996 |
16,818 |
6,727 |
5,011 |
4,365 |
|
SC:A108-Education |
41,118 |
11,212 |
13,704 |
9,282 |
17,922 |
|
SC:B45-Famous:Greatest hits |
46,253 |
17,618 |
3,362 |
10,781 |
9,626 |
|
SC:B2-Book Collection:Profiles Of W |
46,253 |
6,852 |
4,556 |
7,362 |
6,578 |
|
SC:A92-Birth |
52,854 |
10 |
6,066 |
13,703 |
3,584 |
|
SC:?- |
52,854 |
23,127 |
20,555 |
20,555 |
18,271 |
|
SC:A40-Occult Fields |
74,019 |
13,214 |
26,427 |
26,427 |
2,368 |
|
SC:B97-Occult Fields:Astrologer |
92,507 |
28,458 |
9,25 |
12,182 |
2,575 |
|
Среднее значение |
19,336 |
9,668 |
6,364 |
5,396 |
5,147 |
Из анализа данных, приведенных в таблице 17,
видно, что использование мультимодели и алгоритмов голосования дает результаты идентификации
(по большинству категорий), существенно отличающиеся от случайного угадывания (в
лучшую сторону). Из статистики известно, что если достоверность идентификации
выше вероятности случайного угадывания в 2.5 раза, то вывод о том, что
существует закономерность имеет достоверность 95%. Из этого можно сделать три важных
вывода:
1. В обучающей выборке выявлены взаимосвязи
между астрономическими признаками респондентов на момент рождения (астропризнаками)
и обобщенными социальными категориями (астросоциотипами), показывающие, что эта
выборка существенно отличается от случайной.
2. Знание этих выявленных закономерностей позволяет
относить респондентов к обобщенным социальным категориям с достоверностью, значительно
превосходящей вероятность случайного угадывания.
3. Достоверность предыдущих двух выводов, как
статистических высказываний, составляет значительно более 95 %.
Итак, в мультимодели, основанной на солидной
базе прецедентов (20007 респондентов) с огромной статистической представительностью
категорий (не менее 1000 респондентов на категорию), получены результаты идентификации
респондентов тестирующей выборки из 370 респондентов, подобранных таким образом,
чтобы их было не менее 10 на категорию.
Полученные результаты идентификации подтверждают:
1. В созданной с помощью системы "Эйдос-астра"
мультимодели выявлены зависимости между астропризнаками респондентов на момент их
рождения и принадлежностью этих респондентов к обобщенным социальным категориям
(типам).
2. Эти зависимости имеют такую силу, что их
знание, по-видимому, может быть успешно использовано для идентификации респондентов
по категориям.
3. Методы голосования моделей (коллективы решающих
правил) позволяют повысить достоверность полученных результатов идентификации до
21 %, по сравнению с наихудшими частными моделями, поэтому это может представлять
не только чисто научный, но, по-видимому, и практический интерес. Полученные результаты
показывают, что достоверность идентификации с помощью мультимодели часто в 2,5 раза,
а иногда – и в десятки раз превышает вероятность случайного угадывания, значит,
их достоверность, как статистических высказываний, в этих случаях выше 95 %.
4. Выявлены категории, по которым уровень достоверности
идентификации особенно высок или очень низкий. С учетом этого, предлагается при
отнесении респондента системой к категориям второго типа не принимать эти результаты
слишком серьезно.
5. Результаты экспериментального тестирования
показали,
что научные разработки, описанные выше, представляют не только научный, но и практический
интерес, т.к. совпадение прогноза с фактом является довольно высоким и вполне очевидным
как для консультанта, так и для его клиентов.
Рассмотрим, каким образом полученные результаты
могут быть использованы в социологии.