ГЛАВА 2. СИСТЕМА
"ЭЙДОС-АСТРА"
В работе /8/ был поставлен
вопрос: действительно ли существуют зависимости между астрономическими признаками респондентов на
момент рождения (астропризнаками) и обобщенными категориями, отражающими социальный
статус личности (т.к. астросоциотипами)?
По мнению авторов, на этот
вопрос, имеющий фундаментальное научное значение, был получен убедительный
положительный ответ, т. е. с применением автоматизированного системно-когнитивного
анализа (АСК-анализ) /18–19/ – нового метода искусственного интеллекта и его инструментария
– системы "Эйдос" /2/ были созданы модели, позволяющие обоснованно утверждать,
что эти зависимости существуют и их характер выявлен и известен нам /6-17/.
Необходимо отметить, что
из более 11000 категорий нами было выявлено всего лишь несколько десятков наиболее
статистически представленных категорий, для которых эти связи оказались наиболее
сильными /15/.
В той же статье /8/ был
сформулирован и второй вопрос, закономерно вытекающий из первого: возможно ли знание
этих зависимостей между астропризнаками и социальными типами использовать для идентификации
респондентов на практике?
Для положительного ответа
на второй вопрос необходимо не только выявить зависимости между астропризнаками
и социальным статусом респондентов, но и разработать такие модели
и технологии, которые бы обеспечили настолько высокий уровень достоверности идентификации,
чтобы это могло представлять уже не только научный, но и прикладной интерес.
В 2007 году нами были предприняты усилия по созданию таких моделей и технологий.
В самом начале
исследований и разработок в области астросоциотипологии (такое название получило
новое научное направление, предложенное и развиваемое авторами в рамках астросоциологии)
были исследованы многочисленные модели, отличающиеся наборами обобщенных категорий
(классов), а также описательных шкал и градаций. При этом созданные модели оценивались
на достоверность методами бутстрепной статистики, реализованными в системе "Эйдос"
/2/. В результате была выбрана модель, которая затем и была подробно исследована
для получения ответа на первый вопрос.
В работах /6-17/
было обнаружено следующее:
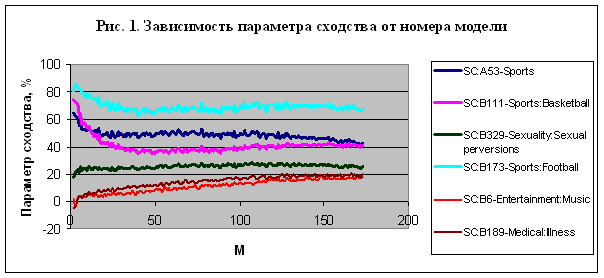
1.
Достоверность
идентификации одних и тех же классов в разных моделях различна, и для каждого класса всегда есть конкретная частная
модель, в которой он идентифицируется с наивысшей достоверностью – рис. 1.
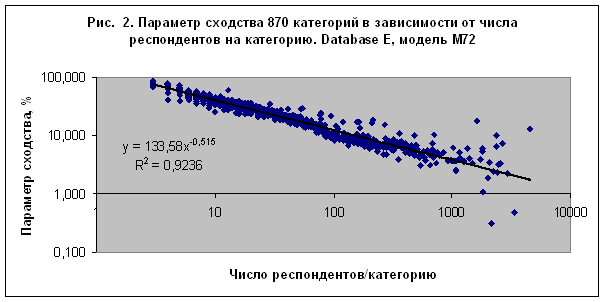
2.
Достоверность
идентификации по категориям обратно пропорционально зависит от количества
респондентов обучающей выборки, относящихся к этой категории – рис. 2.
Заметим, что
во всех расчетах, приведенных в данной монографии, параметр сходства, характеризующий
достоверность идентификации, определялся по формуле /15/:
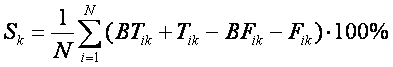 (10)
(10)
Sk –
достоверность идентификации "k-й" категории;
N –
количество респондентов в распознаваемой выборке;
BTik–
уровень сходства "i-го" респондента с "k-й" категорией, к которой
он был правильно отнесен системой;
Tik
– уровень сходства "i-го" респондента с "k-й" категорией, к
которой он был правильно не отнесен системой;
BFik
– уровень сходства "i-го" респондента с "k-й" категорией, к
которой он был ошибочно отнесен системой;
Fik
– уровень сходства "i-го" респондента с "k-й" категорией, к
которой он был ошибочно не отнесен системой.
Причины 1-й
закономерности мы видим в том, что чем больше респондентов обучающей выборки приходится
на категорию, тем выше вариабельность внутри нее по астропризнакам и, соответственно,
тем ниже уровень сходства каждого конкретного респондента с обобщенным образом этой
категории.
При небольшом
количестве респондентов на категорию задача идентификации с ней редуцируется в задачу
поиска, аналогичную тому, который осуществляется в информационно-поисковых системах.
Поиск осуществляется с высокой степенью достоверности, но для нас он неинтересен,
т.к. осуществляется не на основе выявленных и действующих в предметной области (генеральной
совокупности) закономерностей, а по простому совпадению признаков. Из этого, казалось
бы, можно сделать вывод о том, что имеет смысл исследовать только те категории,
которые представлены очень большой статистикой. Например, в статье /15/ исследуются
модели идентификации с 37 категориями, каждая из которых представлена не менее 1000
респондентами. При этом "вес", т.е. вклад информации о каждом конкретном
респонденте в обобщенный образ категории становится пренебрежимо малым, и поэтому
достоверность модели можно проверять не на основе респондентов, данные которых не
использовались при ее синтезе, а на тех, которые для этого использовались.
Закономерность
на рис. 2 интересна однако тем, что параметр сходства убывает, а не возрастает с
увеличением числа респондентов, приходящихся на категорию. Если бы распознавание
осуществлялось по схеме случайного угадывания, то параметр сходства возрастал бы
пропорционально числу респондентов, согласно уравнению (1) и используемому методу
АСК-анализа. Такое поведение параметра сходства можно объяснить только наличием
когерентности данных, что отражается при формировании обобщенного портрета класса.
Эта когерентность, по сути дела, является основным фактором, связанным с влиянием
небесных тел.
Само наличие
когерентности данных для большого числа категорий (870 категорий на рис. 2), которые
с большой степенью точности обобщаются степенной зависимостью, уже свидетельствует
о том, что задача распознавания категорий по астрономическим параметрам небесных
тел на момент рождения не сводится к тривиальному угадыванию.
Об этом же
свидетельствует и наличие 2-й закономерности, отраженной на рис. 1. Если бы распознавание
сводилось к простому угадыванию, то этой закономерности вообще не было, т.е. параметр
сходства изменялся бы случайным образом при изменении номера модели, который
совпадает с числом секторов разбиения круга зодиака. Здесь можно высказать два важных
соображения:
¾
сам факт
наличия этой закономерности говорит о том, что, по-видимому, существует много различных
механизмов "детерминации" астропризнаками принадлежности респондентов
к социальным категориям, и для разных категорий этот механизм различен, и
поэтому одна модель более адекватно отражает один механизм, а вторая другой;
¾
не существует
какой-то одной модели, обеспечивающей столь высокий уровень идентификации респондентов
по всем категориям, как наилучшая из частных моделей по каждой из категорий.
Совместное
влияние двух факторов – числа секторов разбиения круга зодиака и числа респондентов
на категорию таково, что дисперсия данных на рис. 2 убывает с увеличением числа
секторов разбиения. Это находится в согласии с теорией информации /1/ и свидетельствует
о том, что распознавание осуществляется именно по астрономическим параметрам, точность
представления которых возрастает (а дисперсия убывает!) с ростом числа секторов
разбиения.
Чтобы использовать
параметр сходства, полученный для различных разбиений круга зодиака, для повышения
уровня распознавания, у авторов в начале 2007 года возник проект разработки специальной
системы, которая реализовала бы "коллективы решающих правил",
т.е. была бы способна:
¾
автоматически
генерировать большое количество частных моделей, которые бы образовывали одну целостную
систему, которую мы назвали "мультимодель";
¾
исследовать
частные модели на адекватность идентификации респондентов в них по различным категориям;
¾
идентифицировать респондентов
в системе частных моделей, т.е. в каждой из них, в том числе с учетом априорной
информации о достоверности идентификации по различным категориям в частных моделях
("скоростное распознавание");
¾
обобщать результаты
идентификации конкретных респондентов в разных частных моделях с учетом информации
о достоверности идентификации в них по разным категориям ("голосование
моделей").
Такая система была разработана
– это система "Эйдос-астра" /3/, являющаяся 3-й системой окружения универсальной
когнитивной аналитической системы "Эйдос" /2/.
Благодаря использованию
технологии голосования частных моделей или коллективов решающих правил в системе
"Эйдос-астра", достоверность идентификации респондентов по каждому из классов в мультимодели
не ниже, чем в частной модели, в которой он идентифицируется с наивысшей достоверностью
из всех созданных и исследованных частных моделей. Это обеспечивается
тем, что в каждой частной модели идентификация проводится только по тем категориям,
идентификация которых в данной модели осуществляется с наивысшей достоверностью
из всех частных моделей, а также другими более сложными алгоритмами голосования
и взвешивания решений, которые кратко описаны ниже.
С помощью системы "Эйдос-астра"
в 2007 году были созданы и исследованы несколько мультимоделей, отличающихся как
набором социальных категорий, так и самих частных моделей. Например, в статье /15/
представлена одна из мультимоделей, включающая 37 социальных категорий и 172 частные
модели (каждая модель соответствует конкретному разбиению круга зодиака). В этой
мультимодели на каждую из категорий приходится не менее 1000 респондентов, а общий
объем обучающей выборки составляет 20007 респондентов.
2.1. Описание системы "Эйдос-астра"
и алгоритмов голосования моделей
Система "Эйдос-астра"
предназначена для синтеза мультимодели и идентификации социального статуса респондентов
по астрономическим показателям на момент их рождения и применяется с теми же целями,
что и стандартные психологические и профориентационные тесты (т.е. тесты на способность
к определенным видам деятельности), обеспечивая выполнение следующих функций:
¾ генерация исходных баз данных на основе времени и координат
рождения респондентов;
¾ генерация описательных шкал и градаций и обучающей выборки
для частных моделей с заданным числом разбиений описательных шкал;
¾ синтез мультимодели;
¾ измерение достоверности идентификации респондентов по классам
в частных моделях;
¾ идентификация респондентов распознаваемой выборки в частных
моделях;
¾ голосование результатов идентификации в частных моделях
и генерация баз данных для Универсальной когнитивной аналитической системы "ЭЙДОС",
в которой проводится углубленное исследование созданной модели.
Текущая версия системы
"Эйдос-астра" состоит из набора отдельных сервисных программ и двух взаимосвязанных
модулей, первый из которых ("Inpob_mm.exe") обеспечивает синтез мультимодели,
а второй ("Inprs_mm.exe") – ее тестирование на достоверность и применение
для идентификации респондентов. Эти модули разработаны на языке программирования
CLIPPER 5.01+TOOLS II+BiGraph 3.01r1 и размещаются в головной директории
для синтеза мультимодели, которую определяет сам пользователь.
Исходный текст этих модулей 8-м шрифтом имеет размер: "Inpob_mm.exe" 63
листа, "Inprs_mm.exe" – 109 листов формата А4.
Перед запуском модуля
синтеза мультимодели ("Inpob_mm.exe") должны быть выполнены следующие
шаги:
¾
база данных
с исходной информацией для синтеза мультимодели (база прецедентов) должна быть записана
в выработанном ранее совместно в В.Н. Шашиным /8/ стандарте с именем "Abankall.dbf";
¾
база данных
(БД), содержащая перечень социальных категорий, по которым будет проводиться многопараметрическая
типизация (обобщение), и идентификация должна быть записана в стандарте с именем
"Newpf.dbf" (файл формируется и записывается в Excel в стандарте dbf 4
(dBASE IV) (*.dbf));
¾
в диалоге
пользователь задает перечень частных моделей (количество секторов в описательных
шкалах для создаваемых частных моделей).
Перечень категорий
и частотное распределение респондентов обучающей выборки по категориям, а также
объединенная база данных прецедентов формируются предварительно с помощью специально
для этого созданных сервисных программных модулей, входящих в состав системы "Эйдос-астра".
При этом в
качестве исходной информации использовались Excel-файлы, содержащие для каждого
респондента информацию о категориях, к которым он относится, и полную характеристику
в форме астропризнаков. Основным источником астросоциотипологической базы данных,
подготовленной для системы ЭЙДОС, является AstroDatabank v. 4.00 /5/. Эта база содержит жизнеописание
знаменитостей и простых людей, проживавших (или проживающих) в США. Достоинством
этой базы данных является то, что все события жизни классифицированы, а все профессиональные
и иные категории упорядочены.
При работе
модуля синтеза мультимодели он прогнозирует время завершения процесса и отображает
его стадию, а также сам ведет базу данных, содержащую протокол успешно завершенных
операций и позволяющую нормально продолжить и завершить процесс синтеза даже после
полного аварийного (т.е. в любой момент) выключения компьютера. Это необходимо потому,
что процесс синтеза мультимодели может быть довольно длительным: от нескольких часов
до нескольких суток и даже недель в зависимости от объема обучающей выборки, количества
и размерности частных моделей.
После завершения процесса
синтеза мультимодели запускается модуль "Inprs_mm.exe", обеспечивающий
ее использование для идентификации и прогнозирования. Этот модуль имеет следующие
режимы:
1. Измерение внутренней дифференциальной валидности /19, 25/
моделей, т.е. достоверности идентификации классов в различных частных моделях.
2. Генерация БД Atest_mm.dbf для измерения достоверности идентификации
в моделях.
3. Скоростное распознавание респондентов из Atest.dbf с использованием
БД DostIden.dbf.
4. Полное распознавание респондентов из Atest.dbf во всех
частных моделях.
5. Голосование моделей (с выбором одного из пяти алгоритмов).
6. Голосование моделей по всем ПЯТИ алгоритмам по очереди.
БД Atest_mm.dbf и Atest.dbf
должны быть в том же стандарте, что и БД Abankall.dbf.
Рассмотрим алгоритмы этих режимов.
2.2. Алгоритм измерения достоверности
идентификации классов в различных
частных моделях
1. Если БД достоверности идентификации
классов DostIden.dbf уже существует, то добавить или удалить в ней столбцы новых
частных моделей из БД Setup_mm.dbf, иначе – создавать эту БД заново (на шаге 4).
2. Если БД тестирующих выборок
респондентов TestResp.dbf уже существует, то спросить, переформировать ли ее заново
(шаги 3, 6), иначе – использовать имеющуюся.
3. Если создание БД TestResp.dbf
заново, то задать в диалоге ее параметры.
4. ПОДГОТОВКА К ИСПОЛНЕНИЮ АЛГОРИТМА:
4.1. Выборка из БД Setup_mm.dbf
массива видов моделей.
4.2. Запись строки описательных
шкал для Logoastr_d.
4.3. Рекогносцировка.
5. Если не продолжение расчета
БД DostIden.dbf, то создать ее заново и заполнить нулями.
6. Если создание БД TestResp.dbf
заново, то
6.1. Создать ее по заданным
в п. 3 ее параметрам.
6.2. Заполнить кодами источников
тестирующих респондентов.
7. Цикл по видам моделей из
БД Setup_mm.dbf, начиная с последней модели.
8. Создание БД результатов распознавания
и массива-локатора в директории частной модели.
9. Если продолжение расчета
DostIden.dbf, то пропустить уже просчитанные модели (где не нули).
10. Цикл по классам заданного
диапазона.
11. Копирование тестирующей
выборки ПО ЗАДАННОМУ КЛАССУ В ТЕКУЩЕЙ МОДЕЛИ из обучающей в распознаваемую.
12. Если задано измерение внешней
валидности – удаление из обучающей выборки тестирующей и пересинтез модели, иначе
п.13.
13. Идентификация тестирующей
выборки ТОЛЬКО С ЕЕ КЛАССОМ.
14. Конец цикла по классам заданного
диапазона.
15. Расчет достоверности идентификации
заданных классов в данной модели.
16. Занесение информации о достоверности
идентификации в БД достоверности идентификации классов.
17. Если задано измерение внешней
валидности – добавление распознаваемой выборки к обучающей (ее восстановление),
иначе п.18.
18. Конец цикла по видам моделей.
19. Дорасчет БД достоверности
идентификации классов.
2.3. Алгоритм генерации БД "Atest_mm.dbf"
для измерения достоверности
идентификации в моделях
На первом этапе организуется
цикл по БД "TestResp.dbf", созданной в предыдущем режиме и содержащей
коды (id) респондентов для измерения достоверности идентификации по каждой категории.
В этом цикле формируется массив, содержащий коды респондентов и исключающий их повторы
в формируемой БД "Atest_mm.dbf".
На втором этапе из БД "Abankall.dbf"
выбираются записи по определенным на предыдущем этапе респондентам, и эти записи
добавляются в БД "Atest_mm.dbf".
В дальнейшем сформированная
в данном режиме база данных "Atest_mm.dbf" может быть использована для
измерения достоверности идентификации респондентов по категориям при полном распознавании.
Для этого ее надо предварительно переименовать в "Atest.dbf", т.к. на
работу именно с этой базой рассчитан режим полного распознавания.
2.4. Алгоритм режима скоростного распознавания респондентов из Atest.dbf
с использованием априорной информации о достоверности идентификации по категориям
из БД DostIden.dbf
1. Сброс распознаваемой выборки
во всех остальных частных моделях.
2. Сгенерировать распознаваемую
выборку в тех частных моделях, которые оказались наиболее достоверными по данным
БД DostIden.dbf, причем в каждой частной модели создавать ее только один раз. В
каждой частной модели может наиболее достоверно идентифицироваться НЕСКОЛЬКО классов.
Поэтому нужно иметь БД с информацией об этом и проводить распознавание в этой модели
в ЦИКЛЕ по этим классам. Эта БД и есть DostIden.dbf.
3. Сделать цикл по БД DostIden.dbf
(по частным моделям + классам).
4. Идентифицировать ВСЕХ
респондентов из БД Atest.dbf в каждой частной модели ТОЛЬКО с теми классами, которые
идентифицируется в данной модели наиболее достоверно (по данным из DostIden.dbf).
Данный алгоритм основан на простой идее о том, что по каждой из социальных категорий
рационально идентифицировать респондентов только в той частной модели, в которой
эта категория (по данным предварительного исследования частных моделей) идентифицируется
с наивысшей достоверностью из всех частных моделей. На описываемой мультимодели
этот алгоритм осуществляет идентификацию 370 респондентов за 40 минут вместо 2-х
суток полной идентификации.
2.5. Алгоритм полного распознавания
респондентов из Atest.dbf во всех
частных моделях
Существуют 3 варианта:
1-й: пакетного распознавания
респондентов из Atest.dbf не было выполнено ни в одной частной модели.
2-й: пакетное распознавания
респондентов из Atest.dbf было выполнено не во всех частных моделях.
3-й: пакетное распознавания
респондентов из Atest.dbf было выполнено во всех частных моделях.
Необходимо сообщить пользователю,
какой вариант имеет место – 2-й или 3-й, и предложить ему закончить распознавание
или начать заново:
¾
ЗАКОНЧИТЬ имеет смысл
с тем же файлом Atest.dbf;
¾
НАЧАТЬ ЗАНОВО имеет
смысл с новым файлом Atest.dbf;
¾
если не было выполнено
пакетного распознавания ни в одной частной модели, то просто МОЛЧА начать его выполнять
для тех моделей, для которых выполнен синтез модели.
Затем организуется цикл
по частным моделям.
Распознавание выполняется
только, если: синтез модели уже выполнен, а распознавание еще нет.
Проводится запись исходных
БД для генерации распознаваемой выборки модели в поддиректорию с этой частной моделью.
Выполняется генерация исходных
файлов распознаваемой выборки частной модели из БД Atest.dbf.
Проводится пакетное распознавание
как в базовой системе "Эйдос".
2.6. Алгоритм голосования моделей
(с выбором одного из 5-и алгоритмов)
Пользователю в диалоге предлагается
задать один из режимов голосования моделей, когда в итоговую карточку идентификации
респондента берется:
1.
СУММАРНАЯ ЧАСТОТА
ИДЕНТИФИКАЦИИ респондента с каждым классом, рассчитанная по всем частным моделям
/10-11/.
2.
СРЕДНЕЕ уровней сходства
с этим классом из всех карточек идентификации частных моделей.
3.
Уровень сходства этого
респондента с классом из той частной карточки идентификации, в которой он МАКСИМАЛЬНЫЙ.
4.
Уровень сходства из
карточки идентификации той частной модели, которая показала МАКСИМАЛЬНУЮ достоверность
распознавания ДАННОГО КЛАССА из всех моделей.
5.
СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ
уровней сходства с данным классом на достоверность его идентификации в частных моделях.
1-й алгоритм голосования моделей.
В данном алгоритме, который был предложен первым, определяется СУММАРНАЯ
ЧАСТОТА ИДЕНТИФИКАЦИИ респондента с каждым классом, рассчитанная по всем частным
моделям.
Пользователю предлагается в
диалоге ввести следующие параметры:
¾
минимальный учитываемый
уровень сходства респондента с классом в %;
¾
частоту идентификации
респондента с классом в частных моделях в %.
Затем выполняются следующие
шаги:
1.
Скопировать БД Rasp.dbf
из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать так,
чтобы записи с одинаковым результатом идентификации респондента с классом оказались
рядом.
4.
Создать новую БД Rasp1.dbf,
в которой сделать записи с суммарной частотой идентификации респондента с каждым
классом, рассчитанной по всем частным моделям.
5.
Физически рассортировать
объединенную БД так, как надо для отображения карточек идентификации в базовой системе
"Эйдос".
6.
Скопировать БД в директорию
ALL1 и переиндексировать.
2-й алгоритм голосования моделей.
В этом алгоритме определяется СРЕДНЕЕ уровней сходства с этим классом из
всех карточек идентификации частных моделей.
1.
Скопировать БД Rasp.dbf
из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать так,
чтобы записи с одинаковым результатом оказались рядом.
4.
Сделать новую БД Rasp1.dbf,
в которой объединить записи, просуммировав уровни сходства.
5.
Физически рассортировать
объединенную БД так, как надо для отображения карточек идентификации в базовой системе
"Эйдос".
6.
Скопировать БД в директорию
ALL2 и переиндексировать.
3-й алгоритм голосования моделей.
В данном алгоритме определяется уровень сходства этого респондента с классом
из той частной карточки идентификации, в которой он МАКСИМАЛЬНЫЙ:
1.
Скопировать БД Rasp.dbf
из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать ее
так, чтобы записи с одинаковым классом оказались рядом и ранжированы в порядке убывания
сходства.
4.
Сделать новую БД Rasp1.dbf,
в которой из предыдущей взять только записи с максимальным уровнем сходства.
5.
Физически рассортировать
объединенную БД так, как надо для отображения карточек идентификации в базовой системе
"Эйдос".
6.
Скопировать БД в директорию
ALL3 и переиндексировать.
4-й алгоритм голосования моделей.
В данном алгоритме определяется уровень сходства из карточки идентификации
той частной модели, которая показала МАКСИМАЛЬНУЮ достоверность распознавания ДАННОГО
КЛАССА из всех моделей:
1.
Скопировать БД Rasp.dbf
из всех директорий моделей с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все
в одну БД Rasp.dbf.
3.
Рассортировать ее
так, чтобы записи с одинаковым классом оказались рядом и ранжированы в порядке убывания
сходства.
4.
Сделать новую БД Rasp1.dbf,
в которую из предыдущей для каждого класса взять записи только из тех частных моделей,
в которых они идентифицируются с максимальной достоверностью.
5.
Физически рассортировать
объединенную БД так, как надо для отображения карточек идентификации в базовой системе
"Эйдос".
6.
Скопировать БД в директорию
ALL4 и переиндексировать.
5-й алгоритм голосования моделей.
В данном
алгоритме определяется СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ уровней сходства с данным классом
на достоверность его идентификации в частных моделях:
1.
Скопировать БД Rasp.dbf из всех директорий моделей
с именами: Rasp1###.dbf, где ### – вид модели.
2.
Объединить их все в одну БД Rasp.dbf.
3.
Рассортировать ее
так, чтобы записи с одинаковым классом оказались рядом и ранжированы в порядке убывания
сходства.
4.
Сделать новую БД Rasp1.dbf,
в которой из предыдущей взять СРЕДНЕЕ СУММЫ ПРОИЗВЕДЕНИЙ уровней сходства с данным
классом на достоверность его идентификации в частных моделях.
5.
Физически рассортировать
объединенную БД так, как надо для отображения карточек идентификации в базовой системе
"Эйдос".
6.
Скопировать БД в директорию
ALL5 и переиндексировать.
Алгоритм голосования моделей по всем ПЯТИ
алгоритмам по очереди.
Он представляет собой режим,
полностью аналогичный предыдущему, в котором все алгоритмы голосования запускаются
по очереди со значениями параметров по умолчанию.
Все частные и обобщающие
модели, созданные с помощью системы окружения "Эйдос-астра", полностью
совестимы с базовой универсальной когнитивной аналитической системой "Эйдос"
и могут быть просмотрены и исследованы в этой системе.