ГЛАВА-2. ПРОГНОЗИРОВАНИЕ РЕЗУЛЬТАТОВ ВЫРАЩИВАНИЯ СЕЛЬСКОХОЗЯЙСТВЕННЫХ
КУЛЬТУР И ПОДДЕРЖКА ПРИНЯТИЯ РЕШЕНИЙ ПО РАЦИОНАЛЬНОМУ ВЫБОРУ АГРОТЕХНОЛОГИЙ
2.1.
Решение задач прогнозирования и поддержки
приянтия решений в растениводстве с применением
системы "ЭЙДОС" в 1993-1996 годах
Исследование
проведено совместно с д.б.н., к.т.н., профессором О.А.Засухиной на базе
Кубанского государственного аграрного университета в 1993-1996 годах [27], ей
принадлежала и идея этого исследования. Методологической и инструментально-технологической
основой данного исследования являлись системно-когнитивный анализ (СК-анализ) и
система "Эйдос" [27], ранее использовавшиеся для решения математически-подобных
задач в других предметных областях.
С помощью
сформированной содержательной информационной модели прогнозировались результаты
выращивания сельскохозяйственных культур и вырабатывались научно-обоснованных
рекомендации по управлению урожайностью и качеством сельскохозяйственной продукции.
Созданная
модель включала:
– объект
управления (сельскохозяйственную культуру: зерновые колосовые);
– классы
(будущие состояния объекта управления, т.е. количественные и качественные
результаты выращивания);
– факторы
управляющей системы (агротехнологии, т.е. нормы высева, виды и нормы внесения
удобрений, методы вспашки, ротация севооборота и т.п.);
– факторы
окружающей среды (вид почв, культуры–предшественники по предшествующим годам и
др.).
Размерность модели составила: 35
прогнозируемых результатов выращивания, 188 градаций факторов, 217 прецедентов
в обучающей выборке, 18594 факта.
На основе предложенной технологии СК-анализа в среде системы "Эйдос"
разработано конкретное приложение, обеспечивающее управление продуктивностью
(урожайностью) и качеством сельскохозяйственных культур путем выбора и
применения оптимальной агротехнологии в зависимости от таких факторов, как:
– поставленная цель (максимальное количество или максимальное качество
продукции);
– вид почв;
– метод вспашки;
– культура-предшественник;
– нормы высева;
– виды и нормы внесения удобрений;
– ротация севооборота;
а также ряда других параметров объекта управления и окружающей среды.
1.
Формулировка целей методики и в соответствии с ними разработка перечня
прогнозируемых хозяйственных ситуаций, т.е. результатов выращивания (например,
для классификации будущих состояний, в том числе целевых, могут быть
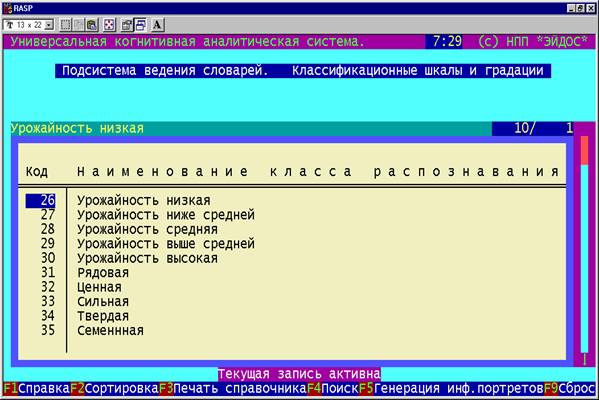
использованы "шкала качества" и "шкала количества", рисунок 7):
|
|
|
Рисунок 7. Будущие состояния объекта управления: количественные и
качественные результаты выращивания сельхозкультуры (зерновые колосовые) |
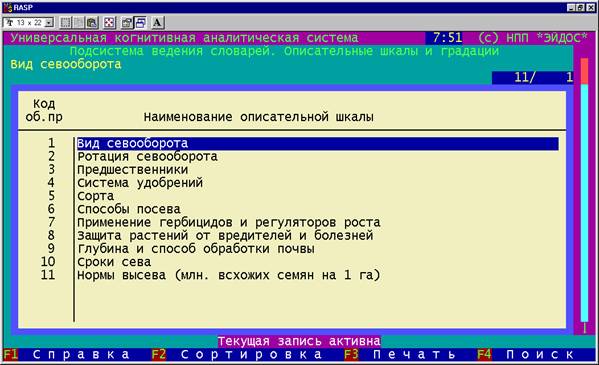
2. Разработка формализованного паспорта результатов выращивания
сельхозкультур, позволяющего описать в пригодной для компьютерной обработки
форме результаты выращивания конкретной сельхозкультуры на конкретном поле и по
конкретной технологии.
Формализованный
паспорт состоит из трех частей:
– первая
включает целевые и нежелательные будущие состояния объекта управления;
– вторая
содержит описательные шкалы и градации, описывающие не зависящие от воли
человека факторы окружающей среды;
– третья –
зависящие от человека, т.е. технологические факторы, которые можно
рассматривать как средство достижения желаемых хозяйственных результатов (рисунок
8).
|
|
|
Рисунок 8. Видеограмма с фрагментом справочника |
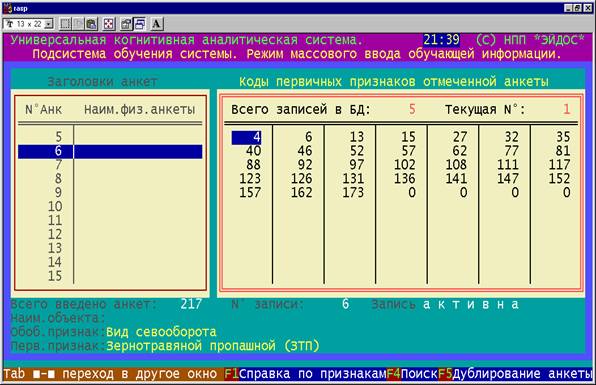
3. Использование бумажного архива по выращиванию сельхозкультур для
заполнения формализованных паспортов и ввода
в программную инструментальную систему "Эйдос" в качестве примеров
выращивания (обучающей выборки) (рисунок
9).
|
|
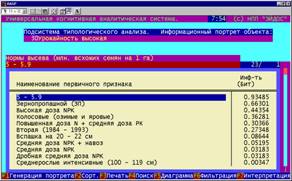
4. Выявление (на основе предъявленных реальных примеров выращивания
сельхозкультур) взаимосвязей между применяемыми технологиями и полученными
результатами и формирование информационных портретов по каждому возможному
результату выращивания.
Информационный портрет хозяйственной ситуации представляет собой
перечень технологических факторов с количественным указанием того, какое
влияние оказывает каждый из них на осуществление данной ситуации (рисунок 10):
|
|
|
|
|
|
|
Рисунок 10. Примеры информационных портретов |
|
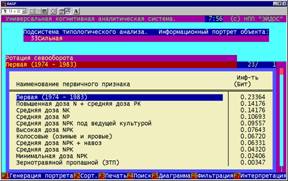
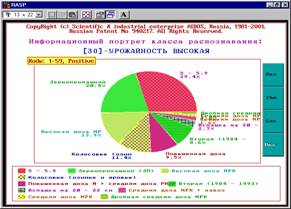
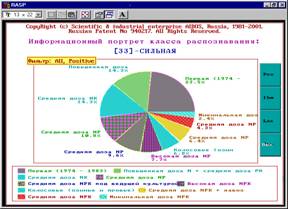
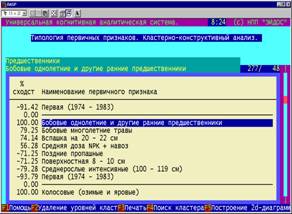
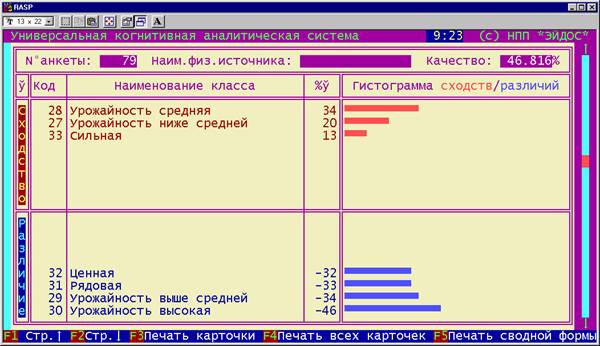
5. Каждый из технологических факторов на основе приведенных примеров
характеризуется тем, какое влияние он оказывает на осуществление каждой
(целевой или нежелательной) хозяйственной ситуации (рисунок 11):
|
|
|
|
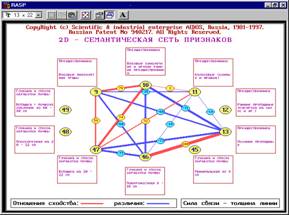
Рисунок 11. Семантический портрет признака: |
|
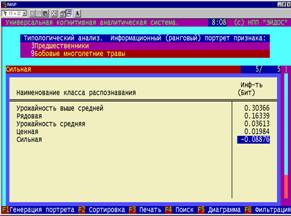
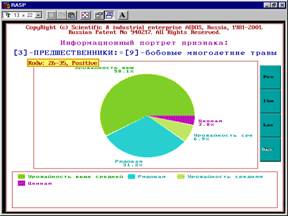
6. Сравнение различных хозяйственных ситуаций и формирование групп
наиболее сходных из них (кластеров), а также определение кластеров, наиболее
сильно отличаются друг от друга (конструктов). При этом на экспериментальной
базе данных был выявлен конструкт "качество-оличество", означающий,
что для получения высокого качества и большого количества необходимы совершенно
противоположные и несовместимые (т.е. невозможные одновременно) почвы:
предшественники и агротехнологические приемы (рисунок 12):
|
|
|
|
Рисунок 12. Конструкт классов: "Качество – количество" и
семантическая сеть классов по шкалам: "Качество – количество" |
|
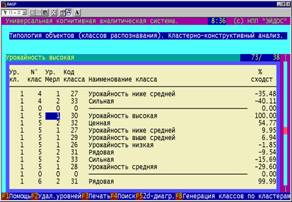
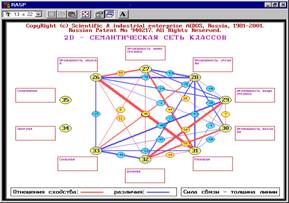
7. Группировка технологических факторов в кластеры и конструкты. Кластерно-конструктивный анализ факторов
показал, что некоторые различные по своей
природе факторы имеют сходное влияние на хозяйственные результаты. Эти
факторы предложено использовать для замены
друг друга в случае необходимости (рисунок 13):
|
|
|
|
Рисунок 13. Конструкт факторов: "Предшественники бобовые … –
Ротация первая…" и
семантической сети факторов: "Предшественники – Глубина обработки почвы" |
|
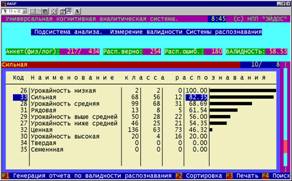
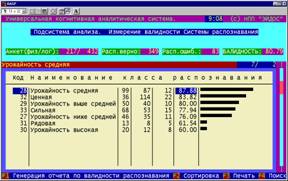
8. Проверка способности созданного приложения правильно прогнозировать
хозяйственные результаты на массиве уже введенных формализованных паспортов
показала, что валидность оказалась недостаточно высокой для практического
применения: на уровне 58%. Причиной
этого являются артефакты, из-за которых некоторые хозяйственные ситуации
оказались слабо детерминированными (рисунок 14). Удаление артефактов привело к повышению интегральной валидности до
80%, что достаточно для практического использования методики (рисунок 15)
|
|
|
|
Рисунок 14. Интегральная и дифференциальная
валидность методики до исключения артефактов |
Рисунок 15. Интегральная и дифференциальная
валидность методики после исключения артефактов |
Таким образом, решены две основные задачи:
1. Прогнозирование того, какие хозяйственные результаты наиболее
вероятны (а какие практически невозможны) на данном виде почв и с данными
предшественниками, а также при условии применения имеющихся в распоряжении
агротехнологий (рисунок 16). Указана мера сходства прогнозируемой ситуации
с каждым будущим состоянием.
|
|
|
Рисунок 16. Пример карточки прогнозирования для конкретных условий
выращивания |
2. Поодержка принятия решений по выбору управляющих
воздействий, т.е. консультирование по вопросам о том, какие виды почв,
предшественники и агротехнологии должны быть, чтобы можно было рассчитывать с
определенной уверенностью на заданный хозяйственный результат. Для этого
достаточно вывести информационный портрет заданного целевого состояния.
Система "Эйдос" позволяет оценивать степень достоверности
своих прогнозов и рекомендаций по управлению, т.е. она не просто дает рекомендацию,
но и количественно оценивает степень ее надежности. Кроме того, система дает
характеристику влияния каждого технологического приема и рекомендации по замене
желательных, но очень дорогих или не имеющихся в наличии технологических
приемов, другими, более дешевыми и доступными, и, при этом, имеющими сходное
влияние на хозяйственные результаты.
Таким образом, данная методика позволяет "просматривать" различные
варианты технологии, прогнозировать последствия применения различных
технологических приемов, и на этой основе вырабатывать научно обоснованные
рекомендации по выбору возделываемой культуры и оптимальной для поставленных
целей агротехнологии.
В данном
исследовании в количественной форме
были обнаружены как уже известные закономерности по влиянию предшественников,
почв, удобрений, способов вспашки и т.д. на результаты выращивания
сельхозкультур, так и новые, ранее неизвестные.
2.2.
Постановка задачи, синтез и исследование модели
прогнозирования урожайности зерновых колосовых
и поддержки принятия решений
по рациональному выбору агротехнологий
2.2.1. Проблематика работы
В
растениеводстве, в частности науке и практике возделывания зерновых колосовых,
известно большое количество технологических схем (карт), разработанных за
многие годы труда агрономов, в основном еще в период плановой, затратной экономики,
когда никого особо не интересовало какой ценой дается урожай. В наше время
такой подход уже устраивает, т.к. обязательным условием хозяйствования в современных
условиях является рентабельность производства.
Поэтому
учеными ведется интенсивная работа по созданию новых экономически эффективных сортов и агротехнологических приемов, в
частности таких как: подготовка почвы, удобрения и средства защиты растений, и
эта работа ведется успешно. Однако сразу после создания широко применять эти новые сорта и агротехнологии неразумно, т.к.
вообще говоря неизвестно, какие это даст результаты в наших конкретных условиях. Для прогнозирования результатов и научно-обоснованного выбора рациональных
агротехнологий, обеспечивающих желаемый результат, все эти новые сорта и агротехнологии предварительно должны быть изучены, причем
обязательно в условиях региона выращивания, т.е. в конкретных
агрометеорологических условиях Краснодарского края.
Таким
образом, проблема, решаемая
в работе, состоит в том, что с одной стороны появляются новые сорта и агротехнологии,
позиционируемые на рынке как экономически эффективные, а с другой стороны в
конкретных условиях Краснодарского края последствия их применения изучены
недостаточно, что усложняет принятие решений по их применению.
Практическая значимость решения этой проблемы для хозяйств очевидна,
т.к. достоверное прогнозирование результатов применения и научно-обоснованные
рекомендации по рациональному выбору агротехнологий позволят повысить экономическую
эффективность хозяйствования.
Научная
новизна решения данной проблемы состоит в том, что в данной работе
впервые предлагается и апробируется вариант ее решения на основе применения
современных информационных технологий путем интеллектуальной обработки ретроспективных данных, отражающих фактический опыт выращивания исследуемых
сортов, т.е. без специального планирования и проведения длительных и
дорогостоящих полевых испытаний сортов в условиях применения различных
агротехнологий.
Актуальность исследования обусловлена ее практической
значимостью и научной новиной.
Объектом исследования является технология выращивания зерновых
колосовых, а предметом исследования:
изучение влияния различных агротехнологий на урожайность пшеницы сортов и
ячменя в конкретных агрометеорологических условиях Краснодарского края.
Поэтому целью исследования является
разработка технологии и методики прогнозирования
хозяйственных результатов применения тех или иных агротехнологий, а также
поддержки принятия решений по выбору таких сортов и рациональных агротехнологий
для выращивания, которые бы с высокой вероятностью дали бы заранее заданный
желаемый хозяйственный результат.
Задачи исследования вытекают и его цели путем ее декомпозиции и являются этапами ее достижения:
Задача 1. Обосновать требования к методу решения задачи и определить степень
соответствия известных методов обоснованным требованиям.
Задача 2. Выбрать наиболее подходящий по обоснованным критериям метод решения проблемы.
Задача 3. Кратко описать суть выбранного метода.
Задача 4. Описать методику применения выбранного метода для решения поставленной
проблемы.
Задача 5. Описать результаты применения методики (эффективность, научные
результаты и выводы, практические рекомендации).
Задача 6. Рассмотреть ограничения метода и методики его применения, перспективы
их развития и применения.
Кратко, на
сколько это возможно в рамках работы, рассмотрим решение поставленных задач.
2.2.2. Задача 1.
Обосновать требования к методу решения задачи
и определить степень соответствия известных методов
обоснованным требованиям.
Возникает
вопрос о том, каким образом в современных условиях можно было бы наиболее
рационально и эффективно решить поставленную проблему и достичь цели исследования.
Традиционные технологии разработки технологических карт требуют многолетних целенаправленных тщательно
заранее спланированных исследований и связаны с проведением экспериментов по
выращиванию в условиях применения различных агротехнологий возделывания. Все
это требует очень и очень значительных временных и финансовых затрат, а также
других видов ресурсов.
Поэтому
ученые-агрономы постоянно ищут новые возможности выявления и исследования
зависимостей в эмпирических данных. Все чаще для этих целей применяются
современные информационные технологии, в частности статистические методы и
реализующие их программных системы. Однако и на этом пути возникают свои
специфические проблемы.
В частности
наиболее распространенный метод выявления зависимостей: многофакторный анализ по ряду причин не позволяет исследовать всю систему факторов, действующих в реальных
агросистемах. К этим причинам относятся прежде всего следующие:
1. Большое
количество реально действующих факторов: не 2-7, а десятки, сотни и даже тысячи.
2.
Значительная зашумленность (или низкая точность и достоверность) исходных
данных.
3.
Требование к нормальному характеру распределения исходных данных (т.к. метод
параметрический).
4. Наличие
доступного программного инструментария, реализующего метод.
5.
Требование к полноте исходных данных, т.е. к наличию в них всех сочетаний значений исследуемых факторов.
6.
Возможность разумной содержательной интерпретации результатов применения
метода.
На практике
выполнение всех этих условий нереально даже при нескольких факторах, либо, как
уже говорилось, требует очень значительных затрат времени и других ресурсов.
Рассмотрим,
например 4-е требование. Довольно типичной является ситуация, когда какой-то
подходящий по литературному описанию для решения поставленной проблемы
математический метод на практике применить не удается, так как не разработана
соответствующая методика численных расчетов и отсутствует или недоступен
реализующий их программный инструментарий. Например, подобная ситуация сложилась
с многокритериальным методом поддержки принятия решений, описанным в классической
работе [91] или теорией информационного поля [4].
Попытка
выполнить 5-е требование всего при 3-х факторах с 10-ю значениями каждого
порождает необходимость исследования 1000 результатов выращивания. Конечно же
на практике это нереально, не говоря уже о десятках, сотнях или тысячах факторов.
Необходимо отметить, что на практике подобных данных взять просто негде, т.к. в
реальных данных обычно наблюдаются лишь очень
небольшие подматрицы без пропусков, т.е. со всеми сочетаниями значений
факторов. Заполнять же пропуски путем интерполяции обычно некорректно (хотя это
и делается), т.к. это возможно только если в строке и столбце, на пересечениях
которых находится клетка с пропуском больше нет пропусков. Если же они есть то
заполнение пропущенной клетки вообще говоря приведет к изменению остальных
незаполненных значений, что фактически делает их вообще неопределенными.
Считается,
что 6-е требование в случае многофакторного анализа трудно выполнимо уже при 5
факторах и более.
На практике
все эти причины в совокупности (а ведь действует еще и субъективный фактор)
приводят к весьма ограниченному
применению математических методов при решении поставленной проблемы, по
крайней мере если судить по защищаемым в области агрономии диссертациям, как
правило дело сводится к исследованию влияния одного фактора на значения какого либо одного же результирующего параметра, например глубины вспашки на
содержание клейковины для какого-либо конкретного сорта пшеницы при всех прочих равных условиях.
Поэтому к
методу исследования предъявляются следующие требования,
т.е. метод должен:
–
обеспечивать выявление силы и направления влияния сотен или даже тысяч
факторов;
– быть
непараметрическим, чтобы не требовалось доказательство гипотез о нормальности
исследуемой выборки;
– корректно
обрабатывать неполные (фрагментированные) данные, т.е. данные, в которых
встречаются не все сочетания значений исследуемых факторов;
– эффективно
подавлять шум в данных и выявлять закономерности на фоне шума, значительно
превосходящего сигнал по амплитуде (при достаточно большой выборке);
– имеет
доступный программный инструментарий, реализующий метод;
–
обеспечивать возможность разумной содержательной интерпретации результатов
применения метода.
2.2.3. Задача 2.
Выбрать наиболее подходящий
по обоснованным критериям
метод решения проблемы.
Для решения
поставленной проблемы предлагается применить новый математический метод системно-когнитивного анализа
(СК-анализ), который: обеспечивает выявление силы и направления влияния сотен
или даже тысяч факторов; является непараметрическим; позволяет корректно
обрабатывать неполные (фрагментированные) данные; эффективно подавлять шум в данных
и выявлять закономерности на фоне шума; имеет доступный программный
инструментарий, реализующий метод (универсальная когнитивная аналитическая
система "Эйдос"); обеспечивает возможность разумной содержательной
интерпретации результатов применения метода [27].
2.2.4. Задача 3.
Кратко описать суть выбранного метода.
Системно-когнитивный
анализ представляет собой системный анализ, рассматриваемый как метод познания
и структурированный по базовым когнитивным (познавательным) операциям (БКОСА) [27].
СК-анализ
включает:
–
теоретические основы, включая базовую когнитивную концепцию;
–
математическую модель (системную теорию информации);
– методику
численных расчетов (структуры данных и алгоритмы их обработки);
–
специальный программный инструментарий, реализующий математическую модель и
методику численных расчетов СК-анализа (универсальная когнитивная аналитическая
система "Эйдос").
2.2.4.1. Теоретические основы СК-анализа (включая базовую когнитивную концепцию).
Сам набор
БКОСА следует из предложенной в [27] формализуемой когнитивной концепции,
рассматривающей процесс познания, как многоуровневую иерархическую систему
обработки информации в которой когнитивные
структуры каждого уровня являются результатом интеграции структур предыдущего
уровня.
На 1-м
уровне этой системы находятся дискретные элементы потока чувственного
восприятия, которые на 2-м уровне интегрируются в чувственный образ конкретного
объекта. Те, в свою очередь, на 3-м уровне интегрируются в обобщенные образы
классов и факторов, образующие на 4-м уровне кластеры, а на 5-м конструкты.
Система конструктов на 6-м уровне образуют текущую парадигму реальности (т.е. человек
познает мир путем синтеза и применения конструктов). На 7-м же уровне обнаруживается,
что текущая парадигма не единственно-возможная (рисунок 17).
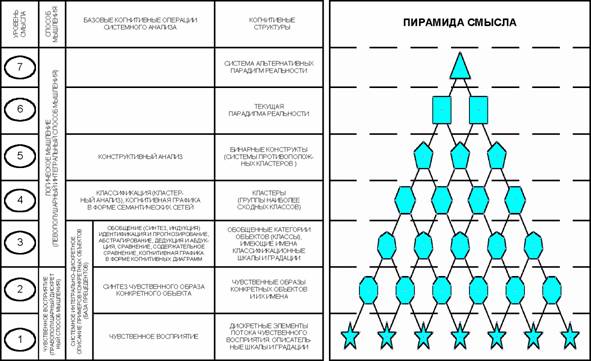
Рисунок 17. Обобщенная схема формализуемой когнитивной концепции (иерархия
базовых когнитивных операций)
Ключевым для
когнитивной концепции является понятие факта, под которым понимается
соответствие дискретного и интегрального элементов познания (т.е. элементов
разных уровней интеграции-иерархии), обнаруженное на опыте. Факт рассматривается
как квант смысла, что является основой для его формализации.
Из данной концепции
выводятся структура когнитивного конфигуратора, система базовых когнитивных
операций и обобщенная схема автоматизированного системного анализа, структурированного
до уровня базовых когнитивных операций (СК-анализ).
Между
когнитивными структурами разных уровней иерархии существует отношение
"дискретное – интегральное". Именно это служит основой формализации
смысла.
Когнитивный
конфигуратор, представляет собой минимальную полную систему когнитивных
операций, названных "базовые когнитивные операции системного анализа"
(БКОСА). Всего выявлено 10 таких операций, каждая из которых достаточно элементарна
для формализации и программной реализации:
1)
присвоение имен;
2)
восприятие;
3) обобщение
(синтез, индукция, многопараметрическая типизация);
4) абстрагирование;
5) оценка
адекватности модели;
6)
сравнение, идентификация и прогнозирование;
7) дедукция
и абдукция;
8)
классификация и генерация конструктов;
9)
содержательное сравнение;
10)
планирование и принятие решений об управлении.
В работе [27]
предложены математическая модель, методика счисленных расчетов, включающая
структуры данных и алгоритмы реализации БКОСА, а также программный инструментарий
СК-анализа – универсальная когнитивная аналитическая система "Эйдос"
[27].
2.2.4.2. Математическая модель (системная теория информации) и методика численных расчетов СК-анализа (структуры данных и алгоритмы их обработки).
Математическая
модель и методика численных расчетов СК-анализа предложены и подробно описаны в
работах [27], и здесь их приводить нецелесообразно. Отметим лишь, что модель обеспечивает выявление знаний [56] непосредственно из эмпирических
фактов, при этом для каждой группы
объектов, по которой проводится многопараметрическая типизация (обобщение), в
качестве контрольной группы (нормы)
выступает вся исследуемая выборка
(теоретически вся генеральная совокупность, которую эта выборка представляет). О
математической модели СК-анализа, т.е. системной теории информации (СТИ), необходимо
еще сказать, что она является одним из возможных вариантов реализации в области
теории информации программной идеи системного обобщения математики,
предложенной автором [29, 48, 49, 50].
2.2.4.3. Специальный программный инструментарий СК-анализа, реализующий математическую модель и методику численных расчетов (универсальная когнитивная аналитическая система "Эйдос").
2.2.4.3.1. Основные функции системы "Эйдос"
Универсальная
когнитивная аналитическая система "Эйдос" является отечественным
лицензионным программным продуктом на который имеется ряд свидетельств
РосПатента РФ[1], созданным исключительно с
использованием официально приобретенного лицензионного программного
обеспечения. По системе "Эйдос" и различным аспектам ее применения
имеется более 150 публикаций ряда авторов.
Система
"Эйдос" является одним из элементов предлагаемого
решения проблемы и достижения цели данной работы, т.к. она обеспечивает решение
следующих задач:
1. Синтез и
адаптация семантической информационной модели предметной области, включая
объект активный управления и окружающую среду.
2.
Идентификация и прогнозирование состояния активного объекта управления, а также
разработка управляющих воздействий для его перевода в заданные целевые состояния.
3.
Углубленный анализ семантической информационной модели предметной области.
Таким
образом, система "Эйдос" является инструментарием, решающим проблему
данной работы.
2.2.4.3.5.
Синтез содержательной информационной модели
предметной области
Для
разработки информационной модели предметной области необходимо владеть
основными принципами ее когнитивной структуризации и формализованного описания.
Синтез содержательной информационной модели включает следующие этапы:
1. Когнитивная структуризация и формализация предметной области.
2. Формирование исследуемой выборки и управление ею.
3. Синтез или адаптация модели.
4. Оптимизация модели.
5. Измерение адекватности модели (внутренней и внешней, интегральной и
дифференциальной валидности), ее
скорости сходимости и семантической устойчивости.
2.2.4.3.6.
Идентификация и прогнозирование состояния
объекта управления, выработка управляющих воздействий
Данный вид
работ включает:
1. Ввод
распознаваемой выборки.
2. Пакетное распознавание.
3. Вывод
результатов распознавания и их оценку.
2.2.4.3.7.
Углубленный анализ содержательной информационной
модели предметной области
Углубленный
анализ выполняется в подсистеме "Типология" и включает:
1.
Информационный и семантический анализ классов и признаков.
2.
Кластерно-конструктивный анализ классов распознавания и признаков, включая
визуализацию результатов анализа в оригинальной графической форме когнитивной
графики (семантические сети классов и признаков).
3.
Когнитивный анализ классов и признаков (когнитивные диаграммы и диаграммы
Вольфа Мерлина, нейросетевой анализ, классические и интегральные когнитивные
карты).
2.2.4.3.8. Обобщенная структура системы "Эйдос"
Данной
обобщенной структуре соответствуют и структура управления и дерево диалога
системы (таблица 5):
Подробнее
подсистемы, режимы, функции и операции, реализуемые системой "Эйдос",
описаны в работе [27].
Таблица 5 – ОБОБЩЕННАЯ СТРУКТУРА СИСТЕМЫ "ЭЙДОС"
(текущей версии 12.5 от
20.04.2008)
|
Подсистема |
Режим |
Функция |
Операция |
|
|
1. Формализация ПО |
1. Классификационные шкалы и градации |
|||
|
2. Описательные шкалы (и градации) |
||||
|
3. Градации описательных шкал
(признаки) |
||||
|
4. Иерархические уровни систем |
1. Уровни классов |
|||
|
2. Уровни признаков |
||||
|
5. Программные интерфейсы для импорта
данных |
1. Импорт данных из TXT-фалов
стандарта DOS-текст |
|||
|
2. Импорт данных из DBF-файлов
стандарта проф. А.Н.Лебедева |
||||
|
3. Импорт из транспонированных
DBF-файлов проф. А.Н.Лебедева |
||||
|
4. Генерация шкал и обучающей выборки
RND-модели |
||||
|
5. Генерация шкал и обучающей выборки
для исследования чисел |
||||
|
6. Транспонирование DBF-матриц
исходных данных |
||||
|
7. Импорт данных из DBF-файлов
стандарта Евгения Лебедева |
||||
|
6. Почтовая служба по НСИ |
1. Обмен по классам |
|||
|
2. Обмен по обобщенным признакам |
||||
|
3. Обмен по первичным признакам |
||||
|
7. Печать анкеты |
||||
|
2. Синтез СИМ |
1. Ввод–корректировка обучающей
выборки |
|||
|
2. Управление обучающей выборкой |
1. Параметрическое задание объектов
для обработки |
|||
|
2. Статистическая характеристика,
ручной ремонт |
||||
|
3. Автоматический ремонт обучающей
выборки |
||||
|
3. Синтез семантической информационной
модели СИМ |
1. Расчет матрицы абсолютных частот |
|||
|
2. Исключение артефактов (робастная
процедура) |
||||
|
3. Расчет матрицы информативностей
СИМ-1 и сделать ее текущей |
||||
|
4. Расчет условных процентных
распределений СИМ-1 и СИМ-2 |
||||
|
5. Автоматическое выполнение режимов
1–2–3–4 |
||||
|
6. Измерение сходимости и устойчивости
модели |
1. Сходимость и устойчивость СИМ |
|||
|
2. Зависимость валидности модели от
объема обучающей выборки |
||||
|
7. Расчет матрицы информативностей
СИМ-2 и сделать ее текущей |
||||
|
4. Почтовая служба по обучающей
информации |
||||
|
3. Оптимизация СИМ |
1. Формирование ортонормированного
базиса классов |
|||
|
2. Исключение признаков с низкой
селективной силой |
||||
|
3. Удаление классов и признаков, по
которым недостаточно данных |
||||
|
4. Разделение классов на типичную и
нетипичную части |
||||
|
5. Генерация сочетанных признаков и
перекодирование обучающей выборки |
||||
|
4. Распознавание |
1. Ввод–корректировка распознаваемой
выборки |
|||
|
2. Пакетное распознавание |
||||
|
3. Вывод результатов распознавания |
1. Разрез: один объект – много
классов |
|||
|
2. Разрез: один класс – много
объектов |
||||
|
4. Почтовая служба по распознаваемой
выборке |
||||
|
5. Построение функций влияния |
||||
|
6. Докодирование сочетаний признаков
в распознаваемой выборке |
||||
|
5. Типология |
1. Типологический анализ классов
распознавания |
1. Информационные (ранговые) портреты
(классов) |
||
|
2. Кластерный и конструктивный анализ
классов |
1 Расчет матрицы сходства образов классов |
|||
|
2. Генерация кластеров и конструктов
классов |
||||
|
3. Просмотр и печать кластеров и конструктов |
||||
|
4. Автоматическое выполнение режимов:
1,2,3 |
||||
|
5. Вывод 2d семантических сетей
классов |
||||
|
3. Когнитивные диаграммы классов |
||||
|
2. Типологический анализ первичных
признаков |
1. Информационные (ранговые) портреты
признаков |
|||
|
2. Кластерный и конструктивный анализ
признаков |
1. Расчет матрицы сходства образов признаков |
|||
|
2. Генерация кластеров и конструктов
признаков |
||||
|
3. Просмотр и печать кластеров и конструктов |
||||
|
4. Автоматическое выполнение режимов:
1,2,3 |
||||
|
5. Вывод 2d семантических сетей признаков |
||||
|
3. Когнитивные диаграммы признаков |
||||
|
6. СК-анализ СИМ |
1. Оценка достоверности заполнения
объектов |
|||
|
2. Измерение адекватности
семантической информационной модели |
||||
|
3. Измерение независимости классов и
признаков |
||||
|
4. Просмотр профилей классов и
признаков |
||||
|
5. Графическое отображение нелокальных
нейронов |
||||
|
6. Отображение Паретто-подмножеств
нейронной сети |
||||
|
7. Классические и интегральные
когнитивные карты |
||||
|
7. Сервис |
1. Генерация (сброс) БД |
1. Все базы данных |
||
|
2. НСИ |
1. Всех баз данных НСИ |
|||
|
2. БД классов |
||||
|
3. БД первичных признаков |
||||
|
4. БД обобщенных признаков |
||||
|
3. Обучающая выборка |
||||
|
4. Распознаваемая выборка |
||||
|
5. Базы данных статистики |
||||
|
2. Переиндексация всех баз данных |
||||
|
3. Печать БД абсолютных частот |
||||
|
4. Печать БД условных процентных
распределений СИМ-1 и СИМ-2 |
||||
|
5. Печать БД информативностей СИМ-1 и
СИМ-2 |
||||
|
6. Интеллектуальная дескрипторная
информационно–поисковая система |
||||
|
7. Копирование основных баз данных
СИМ |
||||
|
8. Сделать текущей матрицу
информативностей СИМ-1 |
||||
|
9. Сделать текущей матрицу
информативностей СИМ-1 |
||||
Метод СК-анализа
был успешно применен для решения ряда задач, сходных с решаемыми в данной работе
[23-111 и др][2].
2.2.5. Задача 4.
Описать методику применения выбранного метода
для решения поставленной проблемы.
СК-анализ
представляет собой метод решения поставленной проблемы, включающий теорию и математическую
модель.. Для того, чтобы это метод, как
впрочем и любой другой, стало возможным применить на практике его нужно оснастить
методикой, т.е. необходимо разработать методику численных расчетов, реализующую счисленную
модель, а также программный инструментарий, реализующий эту в общем виде эту
методику численных расчетов. Рассмотрим подробнее применение этой методики
для решения проблемы, сформулированной в данном разделе.
2.2.5.1. Основные этапы методики применения автоматизированного системно-когнитивного анализа
Автоматизированный
системно-когнитивный анализ (АСК-анализ) [27, 35, 36] представляет собой метод
СК-анализа, технологию, основанную на применении инструментария СК-анализа –
системы "Эйдос" и методику применения этой системы для формирования
семантической информационной модели предметной области (СИМ) и включает
следующие этапы:
1.
Когнитивная структуризация, а затем и формализация предметной области.
2. Ввод
данных мониторинга в базу прецедентов (обучающую выборку) за период, в течение
которого имеется необходимая информация в электронной форме.
3. Синтез
семантической информационной модели (СИМ).
4.
Оптимизация СИМ.
5. Проверка
адекватности СИМ (измерение внутренней и внешней, дифференциальной и интегральной
валидности).
6. Решение
задач идентификации состояний объекта управления, прогнозирования и поддержки
принятия управленческих решений по управлению с применением СИМ.
7.
Системно-когнитивный и кластерно-конструктивный анализ СИМ.
На первых
двух этапах АСК-анализа, детально рассмотренных в работах [27, 35, 36],
числовые величины сводятся к интервальным оценкам, как и информация об объектах
нечисловой природы (фактах, событиях). Этот этап реализуется и в методах
интервальной статистики.
На третьем
этапе СК-анализа всем этим величинам по единой методике, основанной на
системном обобщении семантической теории информации А.Харкевича, сопоставляются
количественные величины, с которыми в дальнейшем и производятся все операции
моделирования.
Последовательное
выполнение всех этих этапов и представляет собой решение сформулированной в
данной работе проблемы.
Рассмотрим
эти этапы.
2.2.5.2. Когнитивная
структуризация, а затем и формализация предметной области.
Подробно
типовая методика когнитивной структуризации и формализации предметной области
приведена в работе [60], поэтому здесь мы не будем давать определения этих
понятий и приводить теоретическую часть, а сразу опишем результаты применения
этой методики при решении проблемы, сформулированной в данной работе.
На этапе когнитивной структуризации
предметной области в
качестве классификационных шкал выберем результирующие состояния объекта управления:
1.
Культура
2.
Сорт
3.
Урожайность (точн.знач)
4.
Урожайность (инт.оценка)
5.
Качество
6.
Культура + сорт + урожайность
7.
Культура + сорт + качество
8.
Культура + урожайность (округленная)
9.
Культура + качество
В качестве факторов
(т.е. описательных шкал), обуславливающих переход объекта управления в эти
результирующие состояния, выберем следующие:
1.
Предшественники
2.
Уровень плодородия
3.
Обработка почвы
4.
Удобрение
5.
Защита растений
На этапе формализации предметной области конкретизируем градации
классификационных и описательных шкал (таблицы 6 и 7).
Таблица 6 – КЛАССИФИКАЦИОННЫЕ ШКАЛЫ И ГРАДАЦИИ
|
Наименование
классификационных шкал и градаций |
|
|
1 |
1.
КУЛЬТУРА-Озимая пшеница |
|
2 |
1.
КУЛЬТУРА-Озимый Ячмень |
|
3 |
1.
КУЛЬТУРА-Яровой ячмень |
|
4 |
2.
СОРТ- |
|
5 |
2.
СОРТ-Батько |
|
6 |
2.
СОРТ-Победа-50 |
|
7 |
2.
СОРТ-Руфа |
|
8 |
2.
СОРТ-Юна |
|
9 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {0.00, 7.90} |
|
10 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {7.90, 15.80} |
|
11 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {15.80, 23.70} |
|
12 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {23.70, 31.60} |
|
13 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {31.60, 39.50} |
|
14 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {39.50, 47.40} |
|
15 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {47.40, 55.30} |
|
16 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {55.30, 63.20} |
|
17 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {63.20, 71.10} |
|
18 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {71.10, 79.00} |
|
19 |
3.
УРОЖАЙНОСТЬ (ТОЧН.ЗНАЧ.): {79.00, 86.90} |
|
20 |
4.
УРОЖАЙНОСТЬ (ИНТ.ОЦЕНКА)-{00,0-17,5} |
|
21 |
4.
УРОЖАЙНОСТЬ (ИНТ.ОЦЕНКА)-{17,5-34,9} |
|
22 |
4.
УРОЖАЙНОСТЬ (ИНТ.ОЦЕНКА)-{34,9-52,4} |
|
23 |
4.
УРОЖАЙНОСТЬ (ИНТ.ОЦЕНКА)-{52,4-69,8} |
|
24 |
4.
УРОЖАЙНОСТЬ (ИНТ.ОЦЕНКА)-{69,8-87,3} |
|
25 |
5.
КАЧЕСТВО- |
|
26 |
5.
КАЧЕСТВО-Ценная |
|
27 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Батько+{00,0-17,5} |
|
28 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Батько+{52,4-69,8} |
|
29 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Батько+{69,8-87,3} |
|
30 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Победа-50+{00,0-17,5} |
|
31 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Победа-50+{34,9-52,4} |
|
32 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Победа-50+{52,4-69,8} |
|
33 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Победа-50+{69,8-87,3} |
|
34 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Руфа+{00,0-17,5} |
|
35 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Руфа+{34,9-52,4} |
|
36 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Руфа+{52,4-69,8} |
|
37 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Руфа+{69,8-87,3} |
|
38 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Юна+{00,0-17,5} |
|
39 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Юна+{34,9-52,4} |
|
40 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Юна+{52,4-69,8} |
|
41 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимая пшеница+Юна+{69,8-87,3} |
|
42 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимый Ячмень++{00,0-17,5} |
|
43 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимый Ячмень++{34,9-52,4} |
|
44 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимый Ячмень++{52,4-69,8} |
|
45 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Озимый Ячмень++{69,8-87,3} |
|
46 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Яровой ячмень++{00,0-17,5} |
|
47 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Яровой ячмень++{17,5-34,9} |
|
48 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Яровой ячмень++{34,9-52,4} |
|
49 |
6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ-Яровой ячмень++{52,4-69,8} |
|
Код |
Наименование
классификационных шкал и градаций |
|
50 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Озимая пшеница+Батько+Ценная |
|
51 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Озимая пшеница+Победа-50+Ценная |
|
52 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Озимая пшеница+Руфа+Ценная |
|
53 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Озимая пшеница+Юна+Ценная |
|
54 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Озимый Ячмень++ |
|
55 |
7.
КУЛЬТУРА+СОРТ+КАЧЕСТВО-Яровой ячмень++ |
|
56 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимая пшеница+{00,0-17,5} |
|
57 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимая пшеница+{34,9-52,4} |
|
58 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимая пшеница+{52,4-69,8} |
|
59 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимая пшеница+{69,8-87,3} |
|
60 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимый Ячмень+{00,0-17,5} |
|
61 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимый Ячмень+{34,9-52,4} |
|
62 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимый Ячмень+{52,4-69,8} |
|
63 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Озимый Ячмень+{69,8-87,3} |
|
64 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Яровой ячмень+{00,0-17,5} |
|
65 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Яровой ячмень+{17,5-34,9} |
|
66 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Яровой ячмень+{34,9-52,4} |
|
67 |
8.
КУЛЬТУРА+УРОЖАЙНОСТЬ-Яровой ячмень+{52,4-69,8} |
|
68 |
9.
КУЛЬТУРА+КАЧЕСТВО-Озимая пшеница+Ценная |
|
69 |
9.
КУЛЬТУРА+КАЧЕСТВО-Озимый Ячмень+ |
|
70 |
9.
КУЛЬТУРА+КАЧЕСТВО-Яровой ячмень+ |
Таблица 7 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
|
Код |
Наименование описательных
шкал и градаций |
|
[ 1] |
10. ПРЕДШЕСТВЕННИКИ
|
|
1 |
10.
ПРЕДШЕСТВЕННИКИ-. |
|
2 |
10.
ПРЕДШЕСТВЕННИКИ-Кукуруза. |
|
3 |
10.
ПРЕДШЕСТВЕННИКИ-Многолетние травы |
|
4 |
10.
ПРЕДШЕСТВЕННИКИ-Сахарная свекла |
|
[ 2] |
11. УРОВЕНЬ ПЛОДОРОДИЯ |
|
5 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Высокий. |
|
6 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Низкий |
|
7 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Средний. |
|
[ 3] |
12. ОБРАБОТКА ПОЧВЫ
|
|
8 |
12.
ОБРАБОТКА ПОЧВЫ-Безотвальная. |
|
9 |
12.
ОБРАБОТКА ПОЧВЫ-Отвальная |
|
10 |
12.
ОБРАБОТКА ПОЧВЫ-Поверхностная |
|
[ 4] |
13. УДОБРЕНИЕ |
|
11 |
13.
УДОБРЕНИЕ-Минеральная система |
|
12 |
13.
УДОБРЕНИЕ-Органическая система. |
|
13 |
13.
УДОБРЕНИЕ-Органическо-минеральная |
|
14 |
13.
УДОБРЕНИЕ-Отсутствует |
|
[ 5] |
14. ЗАЩИТА РАСТЕНИЙ
|
|
15 |
14.
ЗАЩИТА РАСТЕНИЙ- Бактороденцид 3 кг/га :
Фосфид цинка т.п. (5%) 4 кг/га |
2.2.5.3. Ввод данных мониторинга в базу прецедентов
(обучающую выборку) за период, в течение которого имеется необходимая
информация в электронной форме.
Этот ввод
осуществлялся с помощью специально предназначенного для подобных случаев
универсального программного интерфейса между внешними базами данных и системой
"Эйдос" (рисунок 18).
|
|
|
Рисунок 18. Экранная форма универсального программного интерфейса между
внешними базами данных и системой "Эйдос" |
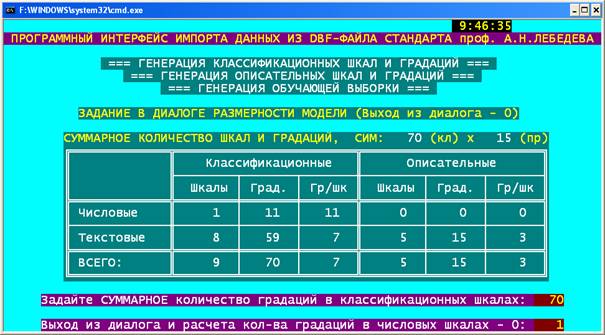
Данный программный интерфейс обеспечивает
автоматическое формирование классификационных и описательных шкал и градаций и
обучающей выборки на основе DBF-файла с сходными данными приведенного ниже стандарта.
Этот DBF-файл должен иметь имя: Inp_data.dbf
и может быть получен в Excel, если выбрать "Сохранить как" и задать
тип файла: DBF 4, dBASE IV. Каждая строка файла содержит данные об одном
объекте обучающей выборки. Все столбцы этого файла могут быть как текстового,
так и числового типа
1-й столбец содержит наименование источника
данных длиной < 16 символов.
Столбцы со 2-го по N-й являются
классификационными шкалами и содержат информацию о классах, к которым принадлежат
объекты обучающей выборки.
Столбцы с N+1 по последний являются
описательными шкалами и содержат информацию о признаках, характеризующих эти
объекты.
Русские наименования классификационных и
описательных шкал должны быть строками в файле с именем Inp_name.txt стандарта:
MS DOS (кириллица).
Система автоматически находит минимальное и
максимальное числовые значения в каждом столбце классов или признаков и
формирует заданное в диалоге количество ОДИНАКОВЫХ для каждой шкалы числовых
интервалов. Затем числовые значения заменяются их интервальными значениями. Каждое
УНИКАЛЬНОЕ текстовое или интервальное значение считается градацией
классификационной или описательной шкалы, характеризующей объект.
Затем с использованием этой информации
генерируется обучающая выборка, в которой каждой строке DBF-файла исходных
данных соответствует одна физическая анкета, содержащая столько логических
анкет, сколько уникальных классов в диапазоне столбцов классов, и коды
признаков, которые соответствуют попаданиям числовых значений признаков в
интервалы.
В таблице 8 представлен
фрагмент
исходного Excel-файла. Файл Inp_data.dbf по структуре не отличается от
экселевского за исключением того, что наименования полей в нем вида: N1,
N2,..., N15. Из-за того, что таблица не помещается в стандартный лист по лирине
она показана по частям (вправо). Для того, чтобы исключить длинные текстовые
кириллические наименования полей из экселевского файла нужно перед записью
выделить блоком часть таблицы с латинскими наименованиями полей и нужными
данными. Интервальные значения и сочетания классов в Excel-файле образованы
средствами Excel.
В результате
работы данного программного интерфейса (рисунок 18) на основе файлов
Inp_data.dbf и Inp_name.txt автоматически
формируются классификационные и описательные шкалы и градации (таблицы 6 и 7),
обучающая выборка (таблица 9).
Таблица 8 – EXCEL-ФАЙЛ С ИСХОДНЫМИ ДАННЫМИ (ФРАГМЕНТ)
|
№ |
Культура |
Сорт |
Урожайность |
|
|
|
(точн. знач) |
(инт. оценка) |
Качество |
|||
|
N1 |
N2 |
N3 |
N4 |
N5 |
N6 |
|
1 |
Озимая пшеница |
Победа-50 |
49,5 |
{34,9-52,4} |
Ценная |
|
2 |
Озимая пшеница |
Победа-50 |
48,4 |
{34,9-52,4} |
Ценная |
|
3 |
Озимая пшеница |
Победа-50 |
45,4 |
{34,9-52,4} |
Ценная |
|
4 |
Озимая пшеница |
Победа-50 |
65,0 |
{52,4-69,8} |
Ценная |
|
5 |
Озимая пшеница |
Победа-50 |
65,8 |
{52,4-69,8} |
Ценная |
|
6 |
Озимая пшеница |
Победа-50 |
60,1 |
{52,4-69,8} |
Ценная |
|
7 |
Озимая пшеница |
Победа-50 |
62,3 |
{52,4-69,8} |
Ценная |
|
8 |
Озимая пшеница |
Победа-50 |
60,6 |
{52,4-69,8} |
Ценная |
|
9 |
Озимая пшеница |
Победа-50 |
58,3 |
{52,4-69,8} |
Ценная |
|
10 |
Озимая пшеница |
Победа-50 |
0,0 |
{00,0-17,5} |
Ценная |
|
11 |
Озимая пшеница |
Победа-50 |
0,0 |
{00,0-17,5} |
Ценная |
|
12 |
Озимая пшеница |
Победа-50 |
0,0 |
{00,0-17,5} |
Ценная |
|
13 |
Озимая пшеница |
Победа-50 |
46,8 |
{34,9-52,4} |
Ценная |
|
14 |
Озимая пшеница |
Победа-50 |
48,9 |
{34,9-52,4} |
Ценная |
|
15 |
Озимая пшеница |
Победа-50 |
42,4 |
{34,9-52,4} |
Ценная |
|
16 |
Озимая пшеница |
Победа-50 |
64,3 |
{52,4-69,8} |
Ценная |
|
17 |
Озимая пшеница |
Победа-50 |
63,7 |
{52,4-69,8} |
Ценная |
|
18 |
Озимая пшеница |
Победа-50 |
62,1 |
{52,4-69,8} |
Ценная |
|
19 |
Озимая пшеница |
Победа-50 |
68,8 |
{52,4-69,8} |
Ценная |
|
20 |
Озимая пшеница |
Победа-50 |
65,9 |
{52,4-69,8} |
Ценная |
|
21 |
Озимая пшеница |
Победа-50 |
63,8 |
{52,4-69,8} |
Ценная |
Продолжение
таблицы 8
|
№ |
Культура + сорт +
урожайность |
Культура + сорт + качество |
|
|
N1 |
N7 |
N8 |
|
|
1 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая
пшеница+Победа-50+Ценная |
|
|
2 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая пшеница+Победа-50+Ценная |
|
|
3 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая
пшеница+Победа-50+Ценная |
|
|
4 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
5 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
6 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
7 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
8 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
9 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
10 |
Озимая
пшеница+Победа-50+{00,0-17,5} |
Озимая
пшеница+Победа-50+Ценная |
|
|
11 |
Озимая
пшеница+Победа-50+{00,0-17,5} |
Озимая
пшеница+Победа-50+Ценная |
|
|
12 |
Озимая
пшеница+Победа-50+{00,0-17,5} |
Озимая
пшеница+Победа-50+Ценная |
|
|
13 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая
пшеница+Победа-50+Ценная |
|
|
14 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая
пшеница+Победа-50+Ценная |
|
|
15 |
Озимая
пшеница+Победа-50+{34,9-52,4} |
Озимая
пшеница+Победа-50+Ценная |
|
|
16 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
17 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
18 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
19 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
20 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
|
21 |
Озимая
пшеница+Победа-50+{52,4-69,8} |
Озимая
пшеница+Победа-50+Ценная |
|
Продолжение
таблицы 8
|
№ |
Культура + урожайность
(округленная) |
Культура + качество |
Предшественники |
Уровень плодо-родия |
|
|
N1 |
N9 |
N10 |
N11 |
N12 |
|
|
1 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
2 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
3 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
4 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
5 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
6 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
7 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
8 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
9 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
10 |
Озимая пшеница+{00,0-17,5} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
11 |
Озимая пшеница+{00,0-17,5} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
12 |
Озимая пшеница+{00,0-17,5} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
13 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
14 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
15 |
Озимая пшеница+{34,9-52,4} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
16 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
17 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
18 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
|
19 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Низкий |
|
|
20 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Средний |
|
|
21 |
Озимая пшеница+{52,4-69,8} |
Озимая пшеница+Ценная |
Многолетние травы |
Высокий |
|
Продолжение
таблицы 8
|
№ |
Обработка почвы |
Удобрение |
Защита растений |
|
|
N1 |
N13 |
N14 |
N15 |
|
|
1 |
Отвальная |
Отсутствует |
Бактороденцид 3 кг/га : Фосфид цинка т.п. (5%) 4
кг/га |
|
|
2 |
Безотвальная |
Отсутствует |
Тоже самое |
|
|
3 |
Поверхностная |
Отсутствует |
Тоже самое |
|
|
4 |
Отвальная |
Минеральная система |
Тоже самое |
|
|
5 |
Безотвальная |
Минеральная система |
Тоже самое |
|
|
6 |
Поверхностная |
Минеральная система |
Тоже самое |
|
|
7 |
Отвальная |
Органическая система |
Тоже самое |
|
|
8 |
Безотвальная |
Органическая система |
Тоже самое |
|
|
9 |
Поверхностная |
Органическая система |
Тоже самое |
|
|
10 |
Отвальная |
Органическо-минеральная |
Тоже самое |
|
|
11 |
Безотвальная |
Органическо-минеральная |
Тоже самое |
|
|
12 |
Поверхностная |
Органическо-минеральная |
Тоже самое |
|
|
13 |
Отвальная |
Отсутствует |
Тоже самое |
|
|
14 |
Безотвальная |
Отсутствует |
Тоже самое |
|
|
15 |
Поверхностная |
Отсутствует |
Тоже самое |
|
|
16 |
Отвальная |
Минеральная система |
Тоже самое |
|
|
17 |
Безотвальная |
Минеральная система |
Тоже самое |
|
|
18 |
Поверхностная |
Минеральная система |
Тоже самое |
|
|
19 |
Отвальная |
Органическая система |
Тоже самое |
|
|
20 |
Безотвальная |
Органическая система |
Тоже самое |
|
|
21 |
Поверхностная |
Органическая система |
Тоже самое |
|
Таблица 9 – ОБУЧАЮЩАЯ ВЫБОРКА (ФРАГМЕНТ)
|
Код |
Наиме- нование |
Классы |
Признаки |
||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
2 |
3 |
4 |
5 |
||
|
1 |
1 |
1 |
6 |
15 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
6 |
9 |
14 |
15 |
|
2 |
2 |
1 |
6 |
15 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
7 |
8 |
14 |
15 |
|
3 |
3 |
1 |
6 |
14 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
5 |
10 |
14 |
15 |
|
4 |
4 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
6 |
9 |
11 |
15 |
|
5 |
5 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
11 |
15 |
|
6 |
6 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
11 |
15 |
|
7 |
7 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
6 |
9 |
12 |
15 |
|
8 |
8 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
12 |
15 |
|
9 |
9 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
12 |
15 |
|
10 |
10 |
1 |
6 |
9 |
20 |
26 |
30 |
51 |
56 |
68 |
3 |
6 |
9 |
13 |
15 |
|
11 |
11 |
1 |
6 |
9 |
20 |
26 |
30 |
51 |
56 |
68 |
3 |
7 |
8 |
13 |
15 |
|
12 |
12 |
1 |
6 |
9 |
20 |
26 |
30 |
51 |
56 |
68 |
3 |
5 |
10 |
13 |
15 |
|
13 |
13 |
1 |
6 |
14 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
6 |
9 |
14 |
15 |
|
14 |
14 |
1 |
6 |
15 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
7 |
8 |
14 |
15 |
|
15 |
15 |
1 |
6 |
14 |
22 |
26 |
31 |
51 |
57 |
68 |
3 |
5 |
10 |
14 |
15 |
|
16 |
16 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
6 |
9 |
11 |
15 |
|
17 |
17 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
11 |
15 |
|
18 |
18 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
11 |
15 |
|
19 |
19 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
6 |
9 |
12 |
15 |
|
20 |
20 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
12 |
15 |
|
21 |
21 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
12 |
15 |
|
22 |
22 |
1 |
6 |
18 |
24 |
26 |
33 |
51 |
59 |
68 |
3 |
6 |
9 |
13 |
15 |
|
23 |
23 |
1 |
6 |
17 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
13 |
15 |
|
24 |
24 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
13 |
15 |
|
25 |
25 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
6 |
9 |
14 |
15 |
|
26 |
26 |
1 |
6 |
16 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
7 |
8 |
14 |
15 |
|
27 |
27 |
1 |
6 |
15 |
23 |
26 |
32 |
51 |
58 |
68 |
3 |
5 |
10 |
14 |
15 |
|
28 |
28 |
1 |
6 |
19 |
24 |
26 |
33 |
51 |
59 |
68 |
3 |
6 |
9 |
11 |
15 |
|
29 |
29 |
1 |
6 |
19 |
24 |
26 |
33 |
51 |
59 |
68 |
3 |
7 |
8 |
11 |
15 |
|
30 |
30 |
1 |
6 |
18 |
24 |
26 |
33 |
51 |
59 |
68 |
3 |
5 |
10 |
11 |
15 |
Всего
обучающая выборка включает описания 308 случаев выращивания озимой пшеницы
нескольких сортов, озимого и ярового ячменя и здесь не приводится из-за
большого объема.
2.2.5.4. Синтез семантической информационной модели (СИМ).
Стандартными
средствами системы "Эйдос" (режим: _235) был выполнен синтез
семантической информационной модели (СИМ).
2.2.5.5. Оптимизация СИМ.
В системе
"Эйдос" реализовано несколько различных методов оптимизации (в смысле
улучшения адекватности) модели: это и
исключение из модели статистически малопредставленных классов и факторов
(артефактов), и исключение незначимых факторов, и ремонт (взвешивание) данных,
что обеспечивает не только классическую, но и структурную репрезентативность исследуемой
выборки по отношению к генеральной совокупности, и итерационное разделение
классов на типичную и нетипичную части, и генерация моделей больших
размерностей с сочетанными признаками.
Однако
проведенные численные эксперименты с применением этих методов оптимизации
модели показали, что их применение нецелесообразно по двум причинам:
1.
Полученная исходная модель и так обладает достаточно хорошими характеристиками
адекватности.
2.
Применение методов улучшения адекватности модели не дает ощутимых результатов.
Пункт 2
можно объяснить тем, что когда модель хорошая, то дальше ее улучшать сложнее,
чем модель с низкой адекватностью.
2.2.5.6. Проверка адекватности СИМ (измерение внутренней и внешней,
дифференциальной и интегральной валидности).
Контрольное
измерение адекватности СИМ было проведено на исходной выборке, включающей 308
случаев, т.е. физических анкет, состоящих из 2774 логических анкет Каждый
случай выращивания описан в одной физической анкете (строке Excel-файла), но
используется для формирования нескольких классов, в среднем 9, т.е. каждая
физическая анкета включает в среднем 9 логических анкет.
При этом
были получены результаты, представленные в таблице 10.
Итоговые
средневзвешенные показатели адекватности модели приведены ниже:
11. Среднее
количество и % логических анкет, правильно отнесенных к классу: 81.547, т.е. 85.306%
12. Среднее
количество и % логических анкет, ошибочно не отнесенных к классу: 14.047, т.е. 14.694%
13. Среднее
количество и % логических анкет, ошибочно отнесенных к классу: 60.461, т.е. 28.465%
14. Среднее
количество и % логических анкет, правильно не отнесенных к классу: 151.945, т.е. 71.535%
15.
Средневзвешенная вероятность случайного угадывания принадлежности объекта к
классу: 31.037%.
16.
Средневзвешенная эффективность применения модели по сравнению со случайным
угадыванием: 7.095 раз.
Например,
класс: "1. КУЛЬТУРА-Озимый Ячмень" в исследуемой выборке встретился
48 раз, значит вероятность случайного угадывания того, что случай выращивания
относится именно к данному классу составляет: 48/308*100=15,584(%), с использованием
же модели к этому классу были отнесены все
случаи, в действительности к нему относящиеся, т.е. 100%, что в 6.417 раз выше
вероятности случайного угадывания. Напомним, что уже при вероятности правильной
идентификации в 2.5 раз выше, чем вероятность случайного угадывания, считается,
что с достоверностью 95% в модели обнаружена закономерность.
В общем эти
показатели адекватности модели можно считать достаточными для решения проблемы,
сформулированной в данной работе, т.е. для решения задач прогнозирования и поддержки
принятия решений. Кроме того, поскольку модель адекватна, т.е. верно отражает
предметную область, то исследование модели можно считать исследованием самой
предметной области.
Таблица 10 – ИЗМЕРЕНИЕ АДЕКВАТНОСТИ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ
МОДЕЛИ
Всего физических анкет: 308 (100% для п.15)
Всего логических анкет: 2774
4. Средняя достоверность идентификации
логических анкет с учетом сходства : 13.388%
5. Среднее сходство логических анкет,
правильно отнесенных к классу : 6.643%
6. Среднее сходство логических анкет,
ошибочно не отнесенных к классу : 1.679%
7. Среднее сходство логических анкет,
ошибочно отнесенных к классу : 5.507%
8. Среднее сходство логических анкет,
правильно не отнесенных к классу :
13.932%
9. Средняя достоверность идентификации
логических анкет с учетом кол-ва :
51.618%
10. Среднее
количество физич-х анкет, действительно
относящихся к классу: 95.594 (100% для п.11 и п.12)
Среднее количество физич-х анкет,
действительно не относящихся к классу: 212.406 (100% для п.13 и п.14)
Всего физических анкет: 308.000 (100% для п.15)
11. Среднее
количество и % лог-их анкет, правильно
отнесенных к классу: 81.547, т.е.
85.306%
12. Среднее
количество и % лог-их анкет, ошибочно
не отнесенных к классу: 14.047,
т.е. 14.694%
13. Среднее
количество и % лог-их анкет, ошибочно
отнесенных к классу: 60.461, т.е.
28.465%
14. Среднее
количество и % лог-их анкет, правильно
не отнесенных к классу: 151.945,
т.е. 71.535%
15. Средневзвешенная
вероятность случайного угадывания принадлежности объекта к классу ( % ): 31.037
16. Средневзвешенная
эффективность применения модели по сравнению со случ. угадыванием (раз): 7.095
|
№ |
Наименование класса |
Достов. идентиф. лог.анк. с уч.ко- личества эвр.крит |
Кол-во лог.анк. дейст-но относя- щихся к классу |
Количество логических анкет правильно или ошибочно отнесенных или не отнесенных к
классу |
Вероятн. случай- ного угадыва- ния (%) =NLA/NFA |
Эффектив модели по срав. со случ. угадыв. (раз) |
|||
|
Правиль. отнесен. |
Ошибочно не отнес |
Ощибочно отнесен. |
Правиль. не отнес |
||||||
|
1 |
3 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
|
1 |
1. КУЛЬТУРА-Озимая пшеница |
70,8 |
212 |
167 |
45 |
0 |
96 |
68,8 |
1,1 |
|
2 |
1. КУЛЬТУРА-Озимый Ячмень |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
|
3 |
1. КУЛЬТУРА-Яровой ячмень |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
|
4 |
2. СОРТ- |
70,8 |
96 |
96 |
0 |
45 |
167 |
31,2 |
3,2 |
|
5 |
2. СОРТ-Батько |
37,7 |
45 |
45 |
0 |
96 |
167 |
14,6 |
6,8 |
|
6 |
2. СОРТ-Победа-50 |
76,6 |
72 |
36 |
36 |
0 |
236 |
23,4 |
2,1 |
|
7 |
2. СОРТ-Руфа |
76,6 |
47 |
47 |
0 |
36 |
225 |
15,3 |
6,6 |
|
8 |
2. СОРТ-Юна |
100,0 |
48 |
48 |
0 |
0 |
260 |
15,6 |
6,4 |
|
9 |
3. УРОЖАЙНОСТЬ: {0.00, 7.90} |
54,5 |
137 |
136 |
1 |
69 |
102 |
44,5 |
2,2 |
|
12 |
3. УРОЖАЙНОСТЬ: {23.70, 31.60} |
3,2 |
2 |
2 |
0 |
149 |
157 |
0,6 |
154,1 |
|
13 |
3. УРОЖАЙНОСТЬ: {31.60, 39.50} |
7,1 |
7 |
6 |
1 |
142 |
159 |
2,3 |
37,7 |
|
14 |
3. УРОЖАЙНОСТЬ: {39.50, 47.40} |
7,8 |
14 |
14 |
0 |
142 |
152 |
4,5 |
22,0 |
|
15 |
3. УРОЖАЙНОСТЬ: {47.40, 55.30} |
14,9 |
26 |
25 |
1 |
130 |
152 |
8,4 |
11,4 |
|
16 |
3. УРОЖАЙНОСТЬ: {55.30, 63.20} |
21,4 |
26 |
22 |
4 |
117 |
165 |
8,4 |
10,0 |
|
17 |
3. УРОЖАЙНОСТЬ: {63.20, 71.10} |
28,6 |
41 |
32 |
9 |
101 |
166 |
13,3 |
5,9 |
|
18 |
3. УРОЖАЙНОСТЬ: {71.10, 79.00} |
32,5 |
38 |
29 |
9 |
95 |
175 |
12,3 |
6,2 |
|
19 |
3. УРОЖАЙНОСТЬ: {79.00, 86.90} |
38,3 |
19 |
18 |
1 |
94 |
195 |
6,2 |
15,4 |
|
20 |
4. УРОЖАЙНОСТЬ-{00,0-17,5} |
54,5 |
137 |
136 |
1 |
69 |
102 |
44,5 |
2,2 |
|
21 |
4. УРОЖАЙНОСТЬ-{17,5-34,9} |
4,5 |
4 |
4 |
0 |
147 |
157 |
1,3 |
77,0 |
|
22 |
4. УРОЖАЙНОСТЬ-{34,9-52,4} |
33,8 |
33 |
33 |
0 |
102 |
173 |
10,7 |
9,3 |
|
23 |
4. УРОЖАЙНОСТЬ-{52,4-69,8} |
39,6 |
73 |
51 |
22 |
71 |
164 |
23,7 |
2,9 |
|
24 |
4. УРОЖАЙНОСТЬ-{69,8-87,3} |
40,9 |
61 |
52 |
9 |
82 |
165 |
19,8 |
4,3 |
|
25 |
5. КАЧЕСТВО- |
70,8 |
96 |
96 |
0 |
45 |
167 |
31,2 |
3,2 |
|
26 |
5. КАЧЕСТВО- Ценная |
70,8 |
212 |
167 |
45 |
0 |
96 |
68,8 |
1,1 |
|
27 |
6. Озимая пшеница+Батько+{00,0-17,5} |
-19,5 |
30 |
30 |
0 |
184 |
94 |
9,7 |
10,3 |
|
28 |
6. Озимая пшеница+Батько+{52,4-69,8} |
21,4 |
6 |
6 |
0 |
121 |
181 |
1,9 |
51,3 |
|
29 |
6. Озимая пшеница+Батько+{69,8-87,3} |
23,4 |
9 |
9 |
0 |
118 |
181 |
2,9 |
34,2 |
|
30 |
6. Озимая пшеница+Победа-50+{00,0-17,5} |
36,4 |
3 |
3 |
0 |
98 |
207 |
1,0 |
102,7 |
|
31 |
6. Озимая пшеница+Победа-50+{34,9-52,4} |
46,8 |
11 |
11 |
0 |
82 |
215 |
3,6 |
28,0 |
|
32 |
6. Озимая пшеница+Победа-50+{52,4-69,8} |
66,2 |
30 |
23 |
7 |
45 |
233 |
9,7 |
7,9 |
|
33 |
6. Озимая пшеница+Победа-50+{69,8-87,3} |
56,5 |
28 |
22 |
6 |
61 |
219 |
9,1 |
8,6 |
|
34 |
6. Озимая пшеница+Руфа+{00,0-17,5} |
34,4 |
20 |
20 |
0 |
101 |
187 |
6,5 |
15,4 |
|
35 |
6. Озимая пшеница+Руфа+{34,9-52,4} |
27,9 |
6 |
6 |
0 |
111 |
191 |
1,9 |
51,3 |
|
36 |
6. Озимая пшеница+Руфа+{52,4-69,8} |
24,0 |
18 |
16 |
2 |
115 |
175 |
5,8 |
15,2 |
|
37 |
6. Озимая пшеница+Руфа+{69,8-87,3} |
17,5 |
3 |
3 |
0 |
127 |
178 |
1,0 |
102,7 |
|
38 |
6. Озимая пшеница+Юна+{00,0-17,5} |
53,2 |
20 |
20 |
0 |
72 |
216 |
6,5 |
15,4 |
|
39 |
6. Озимая пшеница+Юна+{34,9-52,4} |
13,6 |
2 |
2 |
0 |
133 |
173 |
0,6 |
154,1 |
|
40 |
6. Озимая пшеница+Юна+{52,4-69,8} |
27,3 |
9 |
8 |
1 |
111 |
188 |
2,9 |
30,4 |
|
41 |
6. Озимая пшеница+Юна+{69,8-87,3} |
51,9 |
17 |
17 |
0 |
74 |
217 |
5,5 |
18,1 |
|
42 |
6. Озимый Ячмень++{00,0-17,5} |
7,8 |
32 |
32 |
0 |
142 |
134 |
10,4 |
9,6 |
|
43 |
6. Озимый Ячмень++{34,9-52,4} |
35,1 |
3 |
3 |
0 |
100 |
205 |
1,0 |
102,7 |
|
44 |
6. Озимый Ячмень++{52,4-69,8} |
7,8 |
9 |
9 |
0 |
142 |
157 |
2,9 |
34,2 |
|
45 |
6. Озимый Ячмень++{69,8-87,3} |
21,4 |
4 |
4 |
0 |
121 |
183 |
1,3 |
77,0 |
|
46 |
6. Яровой ячмень++{00,0-17,5} |
7,8 |
32 |
32 |
0 |
142 |
134 |
10,4 |
9,6 |
|
47 |
6. Яровой ячмень++{17,5-34,9} |
4,5 |
4 |
4 |
0 |
147 |
157 |
1,3 |
77,0 |
|
48 |
6. Яровой ячмень++{34,9-52,4} |
24,7 |
11 |
11 |
0 |
116 |
181 |
3,6 |
28,0 |
|
49 |
6. Яровой ячмень++{52,4-69,8} |
19,5 |
1 |
1 |
0 |
124 |
183 |
0,3 |
307,7 |
|
№ |
Наименование класса |
Достов. идентиф. лог.анк. с уч.ко- личества эвр.крит |
Кол-во лог.анк. дейст-но относя- щихся к классу |
Количество логических анкет правильно или ошибочно отнесенных или не отнесенных к
классу |
Вероятн. случай- ного угадыва- ния (%) =NLA/NFA |
Эффектив модели по срав. со случ. угадыв. (раз) |
|||
|
Правиль. отнесен. |
Ошибочно не отнес |
Ощибочно отнесен. |
Правиль. не отнес |
||||||
|
50 |
7. Озимая пшеница+Батько+Ценная |
37,7 |
45 |
45 |
0 |
96 |
167 |
14,6 |
6,8 |
|
51 |
7. Озимая пшеница+Победа-50+Ценная |
76,6 |
72 |
36 |
36 |
0 |
236 |
23,4 |
2,1 |
|
52 |
7. Озимая пшеница+Руфа+Ценная |
76,6 |
47 |
47 |
0 |
36 |
225 |
15,3 |
6,6 |
|
53 |
7. Озимая пшеница+Юна+Ценная |
100,0 |
48 |
48 |
0 |
0 |
260 |
15,6 |
6,4 |
|
54 |
7. Озимый Ячмень++ |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
|
55 |
7. Яровой ячмень++ |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
|
56 |
8. Озимая пшеница+{00,0-17,5} |
13,0 |
73 |
72 |
1 |
133 |
102 |
23,7 |
4,2 |
|
57 |
8. Озимая пшеница+{34,9-52,4} |
27,3 |
19 |
17 |
2 |
110 |
179 |
6,2 |
14,5 |
|
58 |
8. Озимая пшеница+{52,4-69,8} |
46,8 |
63 |
50 |
13 |
69 |
176 |
20,5 |
3,9 |
|
59 |
8. Озимая пшеница+{69,8-87,3} |
38,3 |
57 |
48 |
9 |
86 |
165 |
18,5 |
4,6 |
|
60 |
8. Озимый Ячмень+{00,0-17,5} |
7,8 |
32 |
32 |
0 |
142 |
134 |
10,4 |
9,6 |
|
61 |
8. Озимый Ячмень+{34,9-52,4} |
35,1 |
3 |
3 |
0 |
100 |
205 |
1,0 |
102,7 |
|
62 |
8. Озимый Ячмень+{52,4-69,8} |
7,8 |
9 |
9 |
0 |
142 |
157 |
2,9 |
34,2 |
|
63 |
8. Озимый Ячмень+{69,8-87,3} |
21,4 |
4 |
4 |
0 |
121 |
183 |
1,3 |
77,0 |
|
64 |
8. Яровой ячмень+{00,0-17,5} |
7,8 |
32 |
32 |
0 |
142 |
134 |
10,4 |
9,6 |
|
65 |
8. Яровой ячмень+{17,5-34,9} |
4,5 |
4 |
4 |
0 |
147 |
157 |
1,3 |
77,0 |
|
66 |
8. Яровой ячмень+{34,9-52,4} |
24,7 |
11 |
11 |
0 |
116 |
181 |
3,6 |
28,0 |
|
67 |
8. Яровой ячмень+{52,4-69,8} |
19,5 |
1 |
1 |
0 |
124 |
183 |
0,3 |
307,7 |
|
68 |
9. Озимая пшеница+Ценная |
70,8 |
212 |
167 |
45 |
0 |
96 |
68,8 |
1,1 |
|
69 |
9. Озимый Ячмень+ |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
|
70 |
9. Яровой ячмень+ |
39,6 |
48 |
48 |
0 |
93 |
167 |
15,6 |
6,4 |
Универсальная когнитивная
аналитическая система НПП *ЭЙДОС*
ФОРМУЛЫ РАСЧЕТА ПОКАЗАТЕЛЕЙ
ДИФФЕРЕНЦИАЛЬНОЙ ВАЛИДНОСТИ (ПО КЛАССАМ):
C04[k] = C05[k] - C06[k] - C07[k] + C08[k]
C09[k] = ( C11[k] -
C12[k] - C13[k] + C14[k] ) / ( C11[k] + C12[k] + C13[k] + C14[k] ) * 100
C10[k] = C11[k] + C12[k]
C15[k] = C10[k] / NFiz * 100
C16[k] = C09[k] / C15[k]
где k - класс (соответствует строке)
где NFiz - суммарное
количество физических анкет (объектов) в распознаваемой выборке
ФОРМУЛЫ РАСЧЕТА
ПОКАЗАТЕЛЕЙ ИНТЕГРАЛЬНОЙ ВАЛИДНОСТИ (СРЕДНЕВЗВЕШЕННОЕ ПО ВСЕМ КЛАССАМ):
Ci = СУММА_по_k(
Ci[k] * C10[k] ) / NLog
где i = { 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16 }
где NLog =
СУММА_по_k(C10[k]) - суммарное количество логических анкет в распознаваемой
выборке
ПРИМЕЧАНИЕ: учтены
только результаты идентификации с модулем сходства не менее: 0
1. Как видно из приведенной в таблице 10
информации, созданная семантическая информационная модель обладает довольно
высокой степенью достоверности, т.е. достаточно адекватно отражает исследуемую
предметную область.
2. Это означает, что эту модель можно корректно
использовать для:
– решения задачи прогнозирования
урожайности озимой пшеницы исследованных сортов и озимого ячменя;
– для решения задач поддержки принятия
решений по рациональному выбору агротехнологий, с наиболее высокой вероятностью
приводящих к заранее заданному желаемому хозяйственному и экономическому результату;
– исследование данной модели корректно
считать исследованием самой моделируемой (отраженной в модели) предметной
области.
2.2.5.7. Решение задач идентификации состояний объекта управления,
прогнозирования и поддержки принятия решений по управлению с применением СИМ.
2.2.5.7.1. Задача прогнозирования
Отметим, что
задачи идентификации (распознавания) и
прогнозирования в СК-анализе математически ничем не отличаются кроме того, что в задаче идентификации признаки
объекта и принадлежность его состояния к определенному классу практически
одновременны (или очень незначительно отстоят друг от друга во времени), тогда
как при прогнозировании признаки состояния или детерминирующие его значения
факторов (градации описательных шкал) относятся к прошлому или настоящему, а
состояния объекта – к будущему.
В нашем
случае задача прогнозирования состоит в том, чтобы по планируемым к применению или
уже применяемым агротехнологиям спрогнозировать наиболее вероятные хозяйственные
результаты.
Для решения
задачи прогнозирования информация о планируемых к применению агротехнологиях
заносится в систему "Эйдос" в режиме ввода анкет распознаваемой
выборки. Например, в анкете №2 введена информация о применении следующих агротехнологий
(таблица 11):
Таблица 11 – АНКЕТА
РАСПОЗНАВАЕМОЙ ВЫБОРКИ №2
23-04-08 12:11:22
г.Краснодар
|
Код |
Наименование описательных
шкал и градаций |
|
3 |
10.
ПРЕДШЕСТВЕННИКИ-Многолетние травы |
|
7 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Средний. |
|
8 |
12.
ОБРАБОТКА ПОЧВЫ-Безотвальная. |
|
14 |
13.
УДОБРЕНИЕ-Отсутствует |
|
15 |
14.
ЗАЩИТА РАСТЕНИЙ- Бактороденцид 3 кг/га :
Фосфид цинка т.п. (5%) 4 кг/га |
Универсальная когнитивная
аналитическая система НПП *ЭЙДОС*
Результаты
сравнения конкретного образа, описанного данными значениями факторов, приведены
в экранной форме на рисунке 19.
|
|
|
Рисунок 19. Экранная форма с результатами прогнозирования |
В экранной
форме наименования классов видны не полностью и показаны только те классы, с
которыми данная конкретная ситуация наиболее сходна или наиболее различна.
Полная информация о результатах прогнозирования представлена в распечатке
(таблица 12).
Классы, к
которым объект (ситуация) действительно относится, отмечены символом: "√".
Важно, что
инструментарий СК-анализа система
"Эйдос" не только обеспечивает прогнозирование, но и оценивает достоверность этого
прогнозирования. Это делается на нескольких уровнях:
1. На
рисунке 19 и в таблице 12 в карточке идентификации есть параметр: "% Сх", обозначающий процент
сходства конкретного образа объекта и обобщенного образа класса.
2. В таблице
10 есть информация о степени достоверности идентификации, посчитанный для
каждого класса по всем объектам,
действительно относящимся к нему, а также с учетом ошибочно к нему отнесенных.
3. В
карточке идентификации рисунке 19 и в таблице 12 есть параметр: "Качество результата
распознавания:" (в примере он равен 16.184%).
Таблица 12 – РЕЗУЛЬТАТ ПРОГНОЗИРОВАНИЯ РЕЗУЛЬТАТОВ ВЫРАЩИВАНИЯ В
УСЛОВИЯХ ПРИМЕНЕНИЯ НАБОРА АГРОТЕХНОЛОГИЙ ИЗ ТАБЛИЦЫ №11
1-й и 2-й
параметры используются совместно: если мы знаем что по данному классу
результаты идентификации в данной модели обычно недостоверны, то не следует
доверять такому результату, даже если этот класс первый в карточке
идентификации и с ним высокий уровень сходства. 3-й параметр представляет собой
эвристический критерий, сходный по форме со средне-квадратичным отклонением, но
с весовым коэффициентом, увеличивающим роль первых строк гистограммы и отражает
результаты идентификации по всей карточке
в целом: он увеличивается при увеличении уровня сходства с классами в
начале гистограммы и увеличением разницы в уровне сходства между разными классами.
2.2.5.7.2. Задача поддержки принятия решений
Задача поддержки принятия решений является обратной
по отношению к задаче прогнозирования: если в задаче прогнозирования требуется
по значениям факторов определить в какие состояния может под их влиянием
перейти объект управления, то в задаче поддержки принятия решений наоборот, по заданному будущему
состоянию объекта управления (обычно целевому) определить значения факторов,
которые с наибольшей вероятностью переведут объект управления в это состояние.
Примечание: мы называем задачу выработки
научно-обоснованных рекомендаций по выбору агротехнологий задачей поддержки
принятия решений, а не задачей приятия решений, т.к. считаем, что в нашем
случае компьютер и интеллектуальная система не принимают решений, что является
прерогативой специалиста, а лишь консультируют
специалиста о наиболее вероятных последствиях тех или иных решений. Таким
образом, компьютер и интеллектуальная система являются лишь инструментом, помогающим специалисту
выполнять работу, за результаты которой именно он и несет ответственность.
Предположим
нас, как руководителя или специалиста хозяйства, интересует вопрос о том, какие
необходимо применить агротехнологии, чтобы получить очень высокую урожайность
озимой пшеницы сорта Пебеда-50.
Для ответа
на это вопрос необходимо в системе "Эйдос" войти в подсистему
"Типология" и выбрав режим: _511 "Информационные портреты
классов", а затем в нем выбрать класс, система детерминации которого нас
интересует, в данном случае класс с кодом 33. Послед нажатия клавиши Enter
появится экранная форма, приведенная на рисунке 20.
|
|
|
Рисунок 20. Экранная форма, отображающая |
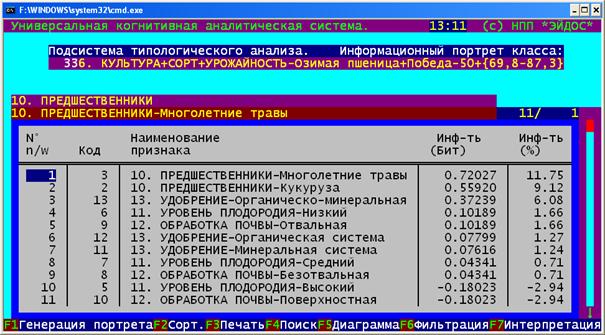
Распечатка
информационного портрета данного класса (с более подробной и полной
информацией) приведена в таблице 13.
Таблица 13 – ИНФОРМАЦИОННЫЙ ПОРТРЕТ КЛАССА
Код класса: 33
Классификационная шкала: 6.
КУЛЬТУРА+СОРТ+УРОЖАЙНОСТЬ
Градация классификационной шкалы: -Озимая пшеница+Победа-50+{69,8-87,3}
|
№ |
Код |
Наименование фактора и его
значения |
Количество информации |
|
|
Бит |
% от теоретически максимально возможного |
|||
|
1 |
3 |
10.
ПРЕДШЕСТВЕННИКИ-Многолетние травы |
0,72027 |
11,75 |
|
2 |
2 |
10.
ПРЕДШЕСТВЕННИКИ-Кукуруза |
0,55920 |
9,12 |
|
3 |
13 |
13.
УДОБРЕНИЕ-Органическо-минеральная |
0,37239 |
6,08 |
|
4 |
6 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Низкий |
0,10189 |
1,66 |
|
5 |
9 |
12.
ОБРАБОТКА ПОЧВЫ-Отвальная |
0,10189 |
1,66 |
|
6 |
12 |
13.
УДОБРЕНИЕ-Органическая система |
0,07799 |
1,27 |
|
7 |
11 |
13.
УДОБРЕНИЕ-Минеральная система |
0,07616 |
1,24 |
|
8 |
7 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Средний |
0,04341 |
0,71 |
|
9 |
8 |
12.
ОБРАБОТКА ПОЧВЫ-Безотвальная |
0,04341 |
0,71 |
|
10 |
5 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ-Высокий |
-0,18023 |
-2,94 |
|
11 |
10 |
12.
ОБРАБОТКА ПОЧВЫ-Поверхностная |
-0,18023 |
-2,94 |
Теоретически максимально возможная информативность –
это количество информации, которое мы в принципе можем получить из факта
действия некоторого значения фактора, который однозначно переводит
объект управления в заранее заданное состояние. Это количество информации
определяется только количеством классов (градаций классификационных шкал) по
формуле: Imax=Log2(70) и в нашем случае, когда у нас в
модели 70 классов (см. таблицу 6) равно: 6,129
бита.
Данные таблицы 13 средствами системы "Эйдос"
могут быть представлены в форме круговой диаграммы и нелокального нейрона (рисунки
21 и 22).
Из информационного портрета, приведенного в на
рисунках 21 и 22, а также в таблице 13, видно, что более 3/4 суммарного влияния на получение хозяйственного
результата: "Озимая пшеница+Победа-50+{69,8-87,3}" обеспечивается
системным (т.к. СИМ учитывает взаимодействие
факторов) действием всего трех факторов: предшественники многолетние травы
и кукуруза и органическо-минеральная система удобрений. При этом обработка
почвы не играет особой роли, но желательна отвальная, а не поверхностная
(которая препятствует этому результату). Возможно это несколько парадоксально,
но данный хозяйственный результат получается на почвах низкого или среднего
плодородия, а не на плодородных почвах, как можно было бы ожидать. По-видимому,
это связано с тем, что на плодородных почвах не применяются интенсивные
технологии, в основном обуславливающие этот результат.
|
|
|
Рисунок 21. Круговая диаграмма информационного портрета класса: "Озимая
пшеница+Победа-50+{69,8-87,3}" |
|
|
|
Рисунок 22. Нелокальный нейрон класса: "Озимая
пшеница+Победа-50+{69,8-87,3}" |
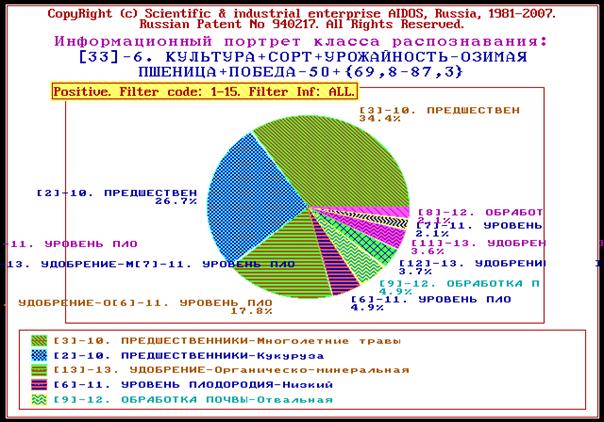
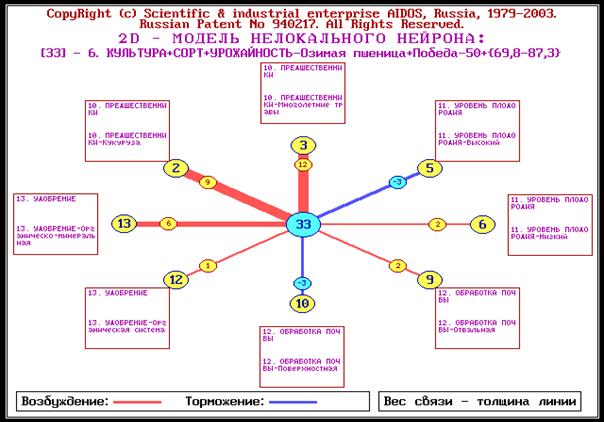
2.2.5.8. Системно-когнитивный и кластерно-конструктивный анализ СИМ.
Необходимо
отметить, что система "Эйдос" возможности исследования СИМ в системе
"Эйдос" весьма разнообразны: достаточно сказать, что система генерирует
50 видов текстовых форм (отформатированных для MS Word и MS Excel), и 52 вида
графических форм, подавляющее большинство которых не имеет аналога в Excel и
других системах обработки данных и предложена автором [27]. В данном разделе мы
рассмотрим лишь некоторые из них, чтобы не перегружать работу излишними деталями.
2.2.5.8.1. Задача выявления силы и направления влияния факторов
Прежде всего
обратим внимание на то, что, значения разных агротехнологических факторов имеют
разные силу и направление влияния на различные хозяйственный результаты.
Информацию об этом можно получить из матрицы информативностей, приведенной в
таблице 14.
Таблица 14 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ (ФРАГМЕНТ, Бит ´ 100)
|
|
Код |
Коды классов |
|||||||||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
||
|
Коды признаков |
1 |
-49 |
50 |
50 |
50 |
50 |
0 |
0 |
0 |
26 |
0 |
0 |
50 |
14 |
6 |
-26 |
-34 |
-73 |
-19 |
-139 |
26 |
|
2 |
24 |
0 |
0 |
0 |
0 |
40 |
84 |
0 |
-39 |
0 |
0 |
0 |
30 |
-15 |
35 |
16 |
35 |
20 |
-34 |
-39 |
|
|
3 |
24 |
0 |
0 |
0 |
0 |
94 |
0 |
0 |
-107 |
0 |
0 |
0 |
0 |
39 |
18 |
62 |
33 |
-25 |
64 |
-107 |
|
|
4 |
24 |
0 |
0 |
0 |
0 |
0 |
0 |
119 |
-4 |
0 |
0 |
0 |
0 |
-50 |
-46 |
-46 |
14 |
19 |
71 |
-4 |
|
|
5 |
-0 |
0 |
0 |
0 |
0 |
0 |
-2 |
0 |
26 |
0 |
0 |
0 |
0 |
-9 |
-49 |
-13 |
-43 |
-29 |
-29 |
26 |
|
|
6 |
-0 |
-0 |
-0 |
-0 |
-0 |
-0 |
1 |
-0 |
-246 |
0 |
0 |
70 |
60 |
49 |
43 |
30 |
33 |
43 |
15 |
-246 |
|
|
7 |
0 |
-0 |
-0 |
-0 |
-0 |
-0 |
1 |
-0 |
25 |
0 |
0 |
0 |
-55 |
0 |
-35 |
-35 |
-14 |
-60 |
6 |
25 |
|
|
8 |
0 |
-0 |
-0 |
-0 |
-0 |
-0 |
1 |
-0 |
25 |
0 |
0 |
0 |
-55 |
0 |
-35 |
-35 |
-14 |
-60 |
6 |
25 |
|
|
9 |
-0 |
-0 |
-0 |
-0 |
-0 |
-0 |
1 |
-0 |
-246 |
0 |
0 |
70 |
60 |
49 |
43 |
30 |
33 |
43 |
15 |
-246 |
|
|
10 |
-0 |
0 |
0 |
0 |
0 |
0 |
-2 |
0 |
26 |
0 |
0 |
0 |
0 |
-9 |
-49 |
-13 |
-43 |
-29 |
-29 |
26 |
|
|
11 |
0 |
-1 |
-1 |
-1 |
3 |
-1 |
0 |
-1 |
-5 |
0 |
0 |
44 |
34 |
-81 |
-77 |
-18 |
19 |
28 |
24 |
-5 |
|
|
12 |
0 |
-1 |
-1 |
-1 |
3 |
-1 |
1 |
-1 |
9 |
0 |
0 |
0 |
0 |
-11 |
20 |
13 |
-2 |
-30 |
-56 |
9 |
|
|
13 |
-1 |
3 |
3 |
3 |
-12 |
3 |
-2 |
3 |
0 |
0 |
0 |
0 |
0 |
-33 |
-73 |
-73 |
13 |
23 |
50 |
0 |
|
|
14 |
0 |
-1 |
-1 |
-1 |
3 |
-1 |
1 |
-1 |
-5 |
0 |
0 |
44 |
52 |
52 |
44 |
33 |
-47 |
-56 |
0 |
-5 |
|
|
15 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Каждое
значение фактора имеет некоторую вариабельность в матрице информативностей, количественное
значение которой (среднеквадратичное отклонение) и принято в СК-анализе за
ценность этого признака для решения задач прогнозирования и поддержки принятия
решений. На рисунке 23 приведена Паррето-кривая
(накопительная) ценности градаций факторов:
|
Рисунок 23. Паррето-кривая
ценности градаций факторов |
Но есть в
СК-анализе и характеристика силы влияния описательной шкалы (фактора) в целом: это среднее от силы влияния
всех градаций этой описательной шкалы. В таблице 15 приведены описательные
шкалы с количественной оценкой силы их влияния.
Таблица 15 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ
С КОЛИЧЕСТВЕННОЙ ОЦЕНКОЙ СИЛЫ ИХ ВЛИЯНИЯ
|
N° п/п |
Код шкалы |
Наименования описательных шкал |
Значимость шкалы |
Коды градаций |
|||
|
1 |
2 |
3 |
4 |
||||
|
1 |
1 |
10.
ПРЕДШЕСТВЕННИКИ |
0.36735 |
1 |
2 |
3 |
4 |
|
2 |
2 |
11.
УРОВЕНЬ ПЛОДОРОДИЯ. |
0.33853 |
5 |
6 |
7 |
|
|
3 |
3 |
12.
ОБРАБОТКА ПОЧВЫ |
0.33853 |
8 |
9 |
10 |
|
|
4 |
4 |
13.
УДОБРЕНИЕ |
0.26107 |
11 |
12 |
13 |
14 |
|
5 |
5 |
14.
ЗАЩИТА РАСТЕНИЙ |
0.00000 |
15 |
|
|
|
Из таблицы
11 мы видим, что наибольшее влияние на результат имеют предшественники и
уровень плодородия почвы.
2.2.5.8.2. СК-анализ, как метод вариабельных контрольных групп
Возникает
закономерный вопрос о том, почему фактор: "14. ЗАЩИТА РАСТЕНИЙ" имеет
нулевое влияние. Ответ на этот вопрос
прост: "Потому, что у него одна-единственная градация и она есть во всех приведенных примерах выращивания,
т.е. по
градациям этой шкалы нулевая вариабельность".
Если бы в
обучающей выборке были указаны разные варианты защиты растений, т.е. были
бы контрольные группы по этому параметру, как они есть по остальным[3], то тогда появилась
бы возможность определить, каким образом каждый из этих вариантов защиты
растений влияет на хозяйственные результаты, т.е. определить силу
и направление влияния значений этого фактора на все, исследуемые в
модели результаты применения агротехнологий.
Аналогично,
если посчитать влияние на урожайность зерновых колосовых фактора "Наличие солнечного освещения", то получится
тоже ноль, если не сравнить
результаты с контрольной группой, выращиваемых в условиях абсолютной темноты, например
в какой-нибудь пещере, причем не обязательно при всех прочих равных условиях.
Отметим, что
если бы в исходных данных была вариабельность по качеству пшеницы (в исследованных данных была только ценная пшеница), то модель позволила бы определить сиу и
направление влияния технологических факторов и на этот показатель, а если бы в исходных данных были указаны
предшественники не только прошлого года, как сейчас, но и позапрошлого, и 3, 4,
5, 6, 7, 8, 9, 10 и более лет назад, то семантическая информационная модель
позволила бы исследовать их влияние на количество и качество урожая зерновых
колосовых, а также количественно
выявить и использовать для автоматизированного
прогнозирования и поддержки принятия решений в растениеводстве законы севооборота.
2.2.5.8.3. Семантические сети классов и факторов.
Система
"Эйдос" в режимах кластерно-конструктивного анализа позволяет
исследовать классы по сходству их системы детерминации и факторы по их влиянию
на поведение объекта управления.
Состояния
объекта управления, соответствующие классам, сходным по их системам
детерминации могут быть достигнуты
одновременно, а различные (образующие полюса конструкта) являются альтернативными
и одновременно получены быть не могут.
Значения
факторов, сходные по их влиянию на поведение объекта управления могут быть
использованы в качестве замены друг друга, если они имеют
разную стоимость или какой-то из них нет возможности или нерационально использовать,
а другой есть возможность или более рационально.
По этим
причинам результаты кластерно-конструктивного анализа модели представляют не
только научный, но и вполне прагматический интерес.
В таблицах 16
и 17 приведены фрагменты матриц сходства классов и значений факторов, а на
рисунках 8 и 9 фрагменты соответствующих, т.е. отображающих эти матрицы,
семантических сетей классов и факторов.
Таблица 16 – МАТРИЦА СХОДСТВА КЛАССОВ (ФРАГМЕНТ, %)
|
Код |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
|
1 |
100 |
-82 |
-82 |
-82 |
-78 |
49 |
36 |
36 |
-19 |
0 |
0 |
-43 |
-2 |
-9 |
17 |
31 |
68 |
16 |
|
2 |
-82 |
100 |
100 |
100 |
95 |
-9 |
-7 |
-7 |
19 |
0 |
0 |
29 |
2 |
4 |
-11 |
-25 |
-56 |
-7 |
|
3 |
-82 |
100 |
100 |
100 |
95 |
-9 |
-7 |
-7 |
19 |
0 |
0 |
29 |
2 |
4 |
-11 |
-25 |
-56 |
-7 |
|
4 |
-82 |
100 |
100 |
100 |
95 |
-9 |
-7 |
-7 |
19 |
0 |
0 |
29 |
2 |
4 |
-11 |
-25 |
-56 |
-7 |
|
5 |
-78 |
95 |
95 |
95 |
100 |
-10 |
-6 |
-7 |
18 |
0 |
0 |
35 |
8 |
8 |
1 |
-8 |
-59 |
-15 |
|
6 |
49 |
-9 |
-9 |
-9 |
-10 |
100 |
33 |
-10 |
-21 |
0 |
0 |
-26 |
-1 |
23 |
29 |
54 |
40 |
-2 |
|
7 |
36 |
-7 |
-7 |
-7 |
-6 |
33 |
100 |
-7 |
-3 |
0 |
0 |
-16 |
17 |
-8 |
33 |
18 |
33 |
22 |
|
8 |
36 |
-7 |
-7 |
-7 |
-7 |
-10 |
-7 |
100 |
9 |
0 |
0 |
-19 |
-8 |
-37 |
-22 |
-32 |
14 |
21 |
|
9 |
-19 |
19 |
19 |
19 |
18 |
-21 |
-3 |
9 |
100 |
0 |
0 |
-66 |
-64 |
-58 |
-63 |
-60 |
-62 |
-62 |
|
10 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
11 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
12 |
-43 |
29 |
29 |
29 |
35 |
-26 |
-16 |
-19 |
-66 |
0 |
0 |
100 |
76 |
41 |
40 |
33 |
6 |
44 |
|
13 |
-2 |
2 |
2 |
2 |
8 |
-1 |
17 |
-8 |
-64 |
0 |
0 |
76 |
100 |
31 |
53 |
53 |
25 |
64 |
|
14 |
-9 |
4 |
4 |
4 |
8 |
23 |
-8 |
-37 |
-58 |
0 |
0 |
41 |
31 |
100 |
79 |
67 |
-4 |
-18 |
|
15 |
17 |
-11 |
-11 |
-11 |
1 |
29 |
33 |
-22 |
-63 |
0 |
0 |
40 |
53 |
79 |
100 |
83 |
28 |
10 |
|
16 |
31 |
-25 |
-25 |
-25 |
-8 |
54 |
18 |
-32 |
-60 |
0 |
0 |
33 |
53 |
67 |
83 |
100 |
31 |
6 |
|
17 |
68 |
-56 |
-56 |
-56 |
-59 |
40 |
33 |
14 |
-62 |
0 |
0 |
6 |
25 |
-4 |
28 |
31 |
100 |
66 |
|
18 |
16 |
-7 |
-7 |
-7 |
-15 |
-2 |
22 |
21 |
-62 |
0 |
0 |
44 |
64 |
-18 |
10 |
6 |
66 |
100 |
Таблица 17 – МАТРИЦА СХОДСТВА
СМЫСЛОВЫХ ЗНАЧЕНИЙ ФАКТОРОВ (%)
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
1 |
100 |
-31 |
-38 |
-23 |
43 |
9 |
33 |
33 |
9 |
43 |
3 |
30 |
9 |
18 |
0 |
|
2 |
-31 |
100 |
32 |
-17 |
-24 |
18 |
-33 |
-33 |
18 |
-24 |
-2 |
-14 |
-12 |
6 |
0 |
|
3 |
-38 |
32 |
100 |
-12 |
-23 |
40 |
-26 |
-26 |
40 |
-23 |
-7 |
-19 |
-0 |
18 |
0 |
|
4 |
-23 |
-17 |
-12 |
100 |
-3 |
-4 |
13 |
13 |
-4 |
-3 |
25 |
4 |
27 |
-25 |
0 |
|
5 |
43 |
-24 |
-23 |
-3 |
100 |
-39 |
72 |
72 |
-39 |
100 |
16 |
21 |
7 |
-2 |
0 |
|
6 |
9 |
18 |
40 |
-4 |
-39 |
100 |
-41 |
-41 |
100 |
-39 |
11 |
-3 |
10 |
20 |
0 |
|
7 |
33 |
-33 |
-26 |
13 |
72 |
-41 |
100 |
100 |
-41 |
72 |
9 |
32 |
18 |
-25 |
0 |
|
8 |
33 |
-33 |
-26 |
13 |
72 |
-41 |
100 |
100 |
-41 |
72 |
9 |
32 |
18 |
-25 |
0 |
|
9 |
9 |
18 |
40 |
-4 |
-39 |
100 |
-41 |
-41 |
100 |
-39 |
11 |
-3 |
10 |
20 |
0 |
|
10 |
43 |
-24 |
-23 |
-3 |
100 |
-39 |
72 |
72 |
-39 |
100 |
16 |
21 |
7 |
-2 |
0 |
|
11 |
3 |
-2 |
-7 |
25 |
16 |
11 |
9 |
9 |
11 |
16 |
100 |
-3 |
39 |
-21 |
0 |
|
12 |
30 |
-14 |
-19 |
4 |
21 |
-3 |
32 |
32 |
-3 |
21 |
-3 |
100 |
-24 |
-6 |
0 |
|
13 |
9 |
-12 |
-0 |
27 |
7 |
10 |
18 |
18 |
10 |
7 |
39 |
-24 |
100 |
-35 |
0 |
|
14 |
18 |
6 |
18 |
-25 |
-2 |
20 |
-25 |
-25 |
20 |
-2 |
-21 |
-6 |
-35 |
100 |
0 |
|
15 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
На рисунке 24 приведена семантическая сеть,
показывающая степень сходства различных классов по системе детерминирующих их
значений агротехнологических факторов.
На рисунке 25 приведена семантическая сеть
значений факторов, показывающая их сходство и различие по силе и направлению
влияния на поведение объекта управления, т.е. получение хозяйственных результатов
|
|
|
Рисунок 24. Семантическая сеть классов, соответствующих различным
урожайностям исследуемых сортов озимой пшеницы: Батько, Победа-50, Руфа и
Юна. |
|
|
|
Рисунок 25. Семантическая сеть значений агротехнологических
факторов, показывающая их сходство и различие по силе и направлению влияния
на поведение объекта управления, т.е. получение хозяйственных результатов |
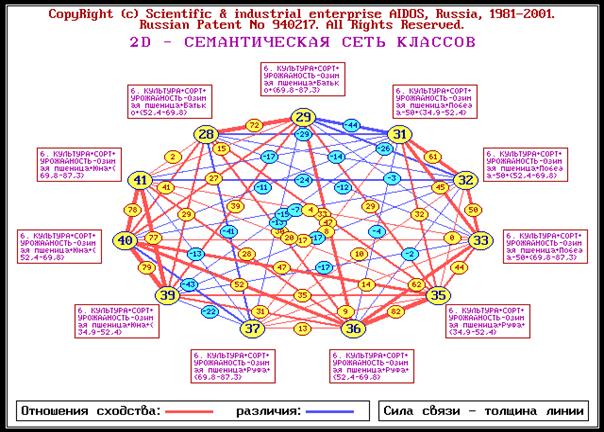
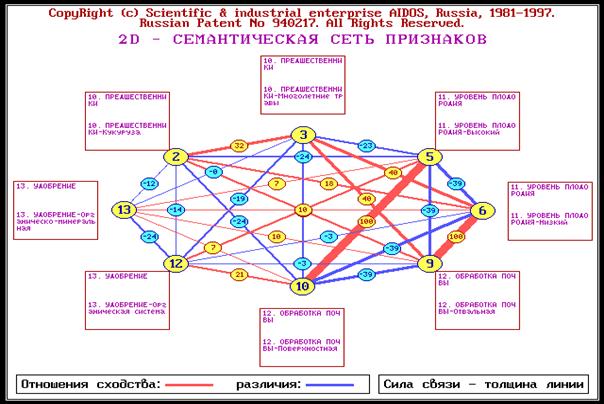
На рисунках 24 и
25 цветом показан знак отношения (связи): красными линиями показаны отношения
сходства, а синими – различия, толщина линий отражает силу связи по модулю.
2.2.5.8.4. Когнитивные диаграммы классов и факторов.
Если семантические сети классов показывают сходство и
различие многих классов между собой по системе детерминирующих их значений
факторов, но при этом структура каждой связи содержательно не раскрывается,
т.е. на сети не показано, какие значения какой вклад вносят в сходство-различие
классов, то на когнитивной диаграмме мы содержательно и на сколько возможно
детально видим именно структуру связи, но только между двумя выбранными классами.
Когнитивная диаграмма имеет следующую структуру:
– справа и слева мы видим информационные портреты выбранных
классов;
– в каждом информационном портрете в верхней
части красным
цветом изображены значения факторов, способствующих переходу объекта управления в
состояние, соответствующее данному классу; в нижней части синим цветом изображены значения
факторов, препятствующих
переходу объекта управления в это состояние;
– линии красного
цвета показывают вклад в сходство двух классов, а синие – вносящие вклад в
различие, толщина линий отражает силу их вклада в сходство-различие по модулю.
Рассмотрим
когнитивную диаграмму на рисунке 26.
|
|
|
Рисунок 26. Когнитивная диаграмма двух классов: Озимая
пшеница+Победа-50+{34,9-52,4} Озимая
пшеница+Победа-50+{69,8-87,3} |
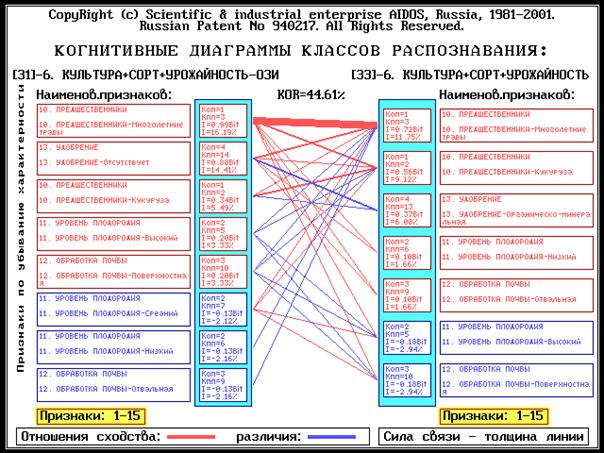
Эта когнитивная диаграмма содержательно отражает в наглядной графической форме сходство и
различие систем детерминации состояний, соответствующих высокой и низкой урожайности
озимой пшеницы сорта Победа-50. Основной вклад в сходство этих двух состояний
вносит то, что для них обоих характерны предшественники-многолетние травы.
Однако на этом сходство заканчивается: если для высокой урожайности характерно
применение органическо-минерального удобрения и отвальная обработка почвы, то
при низкой урожайности удобрения не применяются и почва обрабатывается
поверхностно. Видимо это различие в агротехнологиях и обуславливает различие в
хозяйственном результате выращивания, в данном случае в урожайности озимой
пшеницы сорта Победа-50 по этим агротехнологиям.
Если семантические сети значений факторов показывают
сходство и различие многих значений факторов между собой по тому, какие классы
они детерминируют, но при этом структура каждой связи содержательно не
раскрывается, т.е. на сети не показано, какие значения какой вклад вносят в
сходство-различие значений факторов, то на инвертированной когнитивной диаграмме
мы содержательно и на сколько возможно детально видим именно структуру связи,
но только между двумя выбранными значениями факторов.
Инвертированная когнитивная диаграмма имеет следующую
структуру:
– справа и слева мы видим семантические информационные
портреты выбранных значений факторов;
– в каждом информационном портрете в верхней
части красным
цветом изображены классы, переходу в которые данное значение фактора способствует;
в нижней
части синим
цветом изображены классы, переходу в которые данное значение фактора препятствует;
– линии красного
цвета показывают вклад в сходство двух значений факторов, а синие – вносящие
вклад в различие, толщина линий отражает силу их вклада в сходство-различие по
модулю.
Рассмотрим инвертированную
когнитивную диаграмму на рисунке 27.
|
|
|
Рисунок 27. Содержательное сравнение силы и направления влияния |
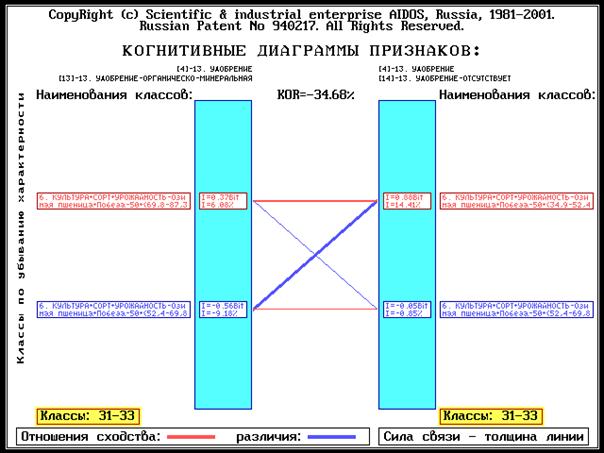
Эта
инвертированная когнитивная диаграмма содержательно
отражает в наглядной графической форме сходство и различие двух значений
факторов, по тому, какую урожайность озимой пшеницы сорта Победа-50 они
детерминируют. Из этой диаграммы видно, что применение органическо-минерального
удобрения детерминирует получение очень высокой урожайности, тогда как
отсутствие удобрений наоборот, детерминирует очень низкую урожайность.
2.2.5.8.5. Когнитивные карты (классические и интегральные).
Если объединить нелокальный нейрон (рисунок 22)
семантической сетью значений факторов (рисунок 25), то получим классическую или
простую когнитивную карту (рисунок 28).
|
|
|
Рисунок 28. Классическая когнитивная карта, отражающая систему
детерминации класса: "Озимая пшеница+Победа-50+{69,8-87,3}" с учетом
сходства и различия силы и направления влияния значений факторов на это состояние |
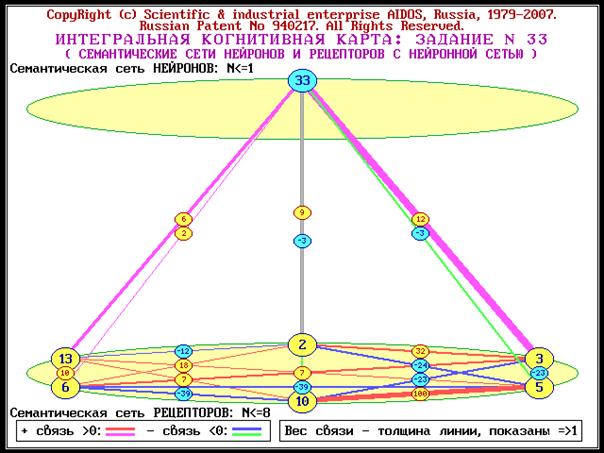
Данная
когнитивная карта отображает в наглядной графической форме систему детерминации
состояния с объекта управления, т.е. класса с кодом 33: "Озимая
пшеница+Победа-50+{69,8-87,3}" (очень высокая урожайность). В нижней части
карты указаны коды значений технологических факторов, расшифровка смысла
которых дана в таблице 7. Красные и синие линии, соединяющие значения факторов,
отражают соответственно их сходство и различие по влиянию на поведение объекта
управления, т.е. его переход во все состояния, соответствующие всем классам
(таблица 6) а толщина этих линий отражает величину этого сходства или различия.
Вертикальные линии отражают силу и направление влияния значений факторов на
переход объекта управления в состояние с кодом 33: сиреневые линии обозначают
способствующие этому факторы, а зелеными – препятствующие, толщина линий
обозначает силу влияния.
Приведем
пример интегральной когнитивной
карты, представляющей собой небольшой фрагмент системно-когнитивной модели
предметной области (рисунок 29). Не смотря на то, что эта модель
сформирована в системе "Эйдос" отобразить ее целиком не представляется
возможным по чисто техническим причинам из-за ее большой размерности.
|
|
|
Рисунок 29. Пример интегральной когнитивной карты |
Интегральная
когнитивная карта представляет собой систему из семантических сетей классов и
значений факторов, при этом каждый класс соединен как нелокальный нейрон
линиями детерминации с системой детерминирующих его значений факторов.
Интегральная
когнитивная карта представляет собой суперпозицию нескольких простых
когнитивных карт, каждая из которых устроена так, как описано в пояснении к
рисунку 28.
В верхней
части карты указаны коды классов, соответствующих будущим состояниям объекта
управления, расшифровка смысла которых дана в таблице 6. Красные и синие линии,
соединяющие классы, отражают соответственно их сходство и различие по системе
их детерминации, т.е. значениям факторов, обуславливающих переход объекта
управления во все состояния, соответствующие всем классам (таблица 6), а
толщина этих линий отражает величину этого сходства или различия.
2.2.6. Задача 5.
Описать результаты применения методики (эффективность, научные результаты и
выводы,
практические рекомендации).
Ученые-агрономы,
увидев какие знания мы выявили с применением СК-анализа из эмпирических данных
могу возразить: "Но ведь это же все давно известно!"
Что на это можно ответить?
1-е: едва ли эти закономерности были известны в количественной форме да еще
с такой точностью.
2-е: в научной литературе и учебных пособиях эти знания содержаться в текстовой форме, не позволяющей непосредственно использовать их для
решения задач прогнозирования и поддержки принятия решений.
3-е: форма, в которой в системе "Эйдос" содержаться эти знания непосредственно позволяет решать задачи
прогнозирования и поддержки принятия решений, в т.ч. в перспективе и в режиме
on-line доступа к серверу через Internet (для этого необходима программная разработка).
4-е: это хорошо, что знания, выявленные нами с применением технологии
СК-анализа непосредственно из
эмпирических данных, совпали с точкой зрения специалистов и экспертов в данной
предметной области. Это подтверждает работоспособность метода СК-анализа и
позволяет предположить и надеяться, что те знания, которые с помощью этого
метода можно выявить в других предметных областях, в которых еще нет экспертов,
также будут адекватны в смысле соответствия действительности, а это означает,
что у нас в распоряжении новый инструмент научного познания с уникальными
возможностями.
5-е: наличие технологии СК-анализа позволяет в принципе уточнять эти
знания, как в явной, так и в неявной форме внося в них учет локальных (местных)
особенностей как регионов, так и районов и даже отдельных хозяйств, а также
учитывать изменения, происходящие с течением времени (динамику). Ожидается, что
эти уточненные, "локализованные", "адаптированные" знания
будут более адекватны, а значит и более эффективны на практике, чем знания, не
учитывающие местную специфику, взятые из общероссийских или иностранных научных
работ и учебников.
6-е: интеллектуальные системы, подобные системе "Эйдос", способны
накапливать огромные базы эмпирических
данных, эквивалентные опыту многих тысяч специалистов, посвятивших
возделыванию данной культуры всю свою жизнь, и не просто накапливать, но и выявлять знания непосредственно из этих эмпирических данных, и обрабатывать эти знания и использовать их для прогнозирования,
поддержки принятия решений и исследования предметной области. Авторы
выражают уверенность, что применение подобных систем и баз знаний на практике
может предостеречь молодых специалистов, а в некоторых случаев даже и более
опытных, от просчетов и ошибок в планировании технологических процессов, повысить
качество их работы.
7-е: основной научный вывод, который можно сделать
из проделанной работы, состоит в том, что существует, более того, находятся в
нашем распоряжении, работоспособные интеллектуальные технологии, обеспечивающие
выявление знаний непосредственно из эмпирических данных, и эти технологии позволяют
использовать эти знания для решения задач прогнозирования результатов
применения тех или иных агротехнологий в растениеводстве, а также для поддержки
принятия решений по выбору рациональных агротехнологий, с наивысшей вероятностью
обуславливающих заранее заданный хозяйственный и экономический результат.
8-е: на основе вышеизложенного можно обоснованно дать практическую
рекомендацию применять подобные интеллектуальные технологии на уровне КубГАУ и
департамента сельского хозяйства для чего необходимо создать соответствующую
инфраструктуру (подразделение, типа аналитического и консалтингового центра).
9-е: материал данной работы может стать основой полноценной лекции и
лабораторной работы по дисциплине "Интеллектуальные информационные
системы" для факультета прикладной информатики, а также спецкурса по
применению современных информационных технологий для студентов и специалистов
агрономических специальностей и курсов повышения квалификации.
2.2.7. Задача 6.
Рассмотреть ограничения метода
и методики его применения,
перспективы их развития и использования.
Рассмотренный
в данной работевариант решения проблемы ограничен как по самому набору
агротехнологических факторов, так и их по вариабельности и объему исследуемой
выборки.
Набор
агротехнологических факторов ограничен в связи со сложностью и ограничениями
доступа к первичной фактографической информации, содержащейся в журналах
агрономов. Этой же причиной обусловлен и довольно ограниченный объем исследуемой
выборки: всего 3-9 случаев выращивания. Вариабельность исследуемых факторов
ограничена в связи с тем, что информация, которую удалось получить и обработать
и описать это в данной работесоответствует применению стандартных технологических
карт, которым обязаны следовать агрономы в соответствии с условиями договоров
на научное обслуживание хозяйств.
Конечно
такая исходная база данных далека от желаемой. Ограниченностью исходной
информации обусловлена относительная скромность результатов, которые удалось
продемонстрировать. По этой причине авторы предлагают рассматривать данную работулишь
в качестве примера, демонстрирующего принципиальные
возможности предлагаемой технологии и показывающей какие задачи и как можно
было бы решать, если бы исследователям и разработчикам был обеспечен доступ к
реальной исходной информации по истории выращивания тех или иных культур в хозяйствах
за длительный период времени.
Заключение
В заключение хотелось бы выразить
благодарность доктору сельскохозяйственных наук, профессору Малюге Николаю Григорьевичу за
предоставленную исходную информацию, также выразить надежду, что данная работа
будет продолжена.