ЛР-6:
"Атрибуция анонимных
и псевдонимных текстов"
Краткая теория
Данная лабораторная работа является продолжением предыдущей, поэтому внимательно прочитайте теорию по предыдущей лабораторной работе. В этой работе исследуется возможность атрибуции текстов с применением технологии и инструментария системно-когнитивного анализа. Приведен подробный численный пример реализации всех этапов СК-анализа при атрибуции текстов, т.е. когнитивной структуризации и формализации предметной области; формирования обучающей выборки; синтеза семантической информационной модели; ее оптимизации и измерения адекватности; адаптации и пересинтеза; а также типологического и кластерно-конструктивного анализа.
Под атрибуцией анонимных и
псевдонимных текстов понимается установление их вероятного авторства
([1-5] рекомендуемой литературы).
Анонимные тексты – это тексты вообще без подписи автора, а псевдонимные – подписанные не фамилией автора, а псевдонимом.
Задача идентификации текстов на основе анализа предложений является тривиальной из-за практически абсолютной уникальности предложений. Поэтому больший интерес представляет задача идентификация текстов на основе анализа слов, т.е. задача атрибуции текстов, имеющая очень большое научное и практическое значение. К этой задаче сводится определение вероятного авторства текстов в случае, когда автор не указан (анонимный текст) или указан его псевдоним (псевдонимный текст), а также датировка текста.
Но самое главное, что к задаче атрибуции текстов сводятся задачи идентификации, прогнозирования, сравнения и классификации объектов, описанных на естественном языке (причем не важно, на каком именно).
С ней связаны также задачи автоматического выделения дескрипторов и задачи нечеткого поиска и идентификации.
Все эти задачи имеют практическое значение для специалистов по прикладной информатики в экономике и юриспруденции, которых готовит Кубанский государственный аграрный университет.
Одному из вариантов рения этих задач с применением интеллектуальной технологии "Эйдос" и посвящена данная лабораторная работа.
Задания
Следуя логике Системно-когнитивного анализа выполнить следующие работы.
1. Осуществить когнитивную структуризацию предметной области.
2. Выполнить формализацию предметной области.
3. Сформировать обучающую выборку.
4. Осуществить синтез семантической информационной модели.
5. Оптимизировать семантическую информационную модель.
6. Проверить семантическую информационную модель на адекватность, измерить внутреннюю и внешнюю, дифференциальную и интегральную валидность.
7. Выполнить адаптацию модели и измерить, как изменилась ее адекватность.
8. Осуществить пересинтез модели и измерить, как изменилась ее адекватность.
9. Вывести информационные портреты текстов и дать их интерпретацию.
10. Выполнить кластерно-конструктивный анализ модели.
Пример решения
1. Осуществить когнитивную структуризацию предметной области.
Под когнитивной структуризацией в СК-анализе понимается определение причин и следствий, факторов и состояний объекта управления, исходной информации и того, на что она влияет.
В данной лабораторной работе необходимо решить задачу идентификации текстов по входящим в них словам. Следовательно, необходимо будет сформировать обобщенные образы текстов, соответствующих определенной тематике или автору (будем считать, что сочинение принадлежит тому писателю, творчеству которого оно посвящено). Для этого в качестве объектов обучающей выборки использоваться фрагменты текстов школьных сочинений, взятые из Internet, а в качестве признаков текстов будут использоваться входящие в них слова.
Каждое сочинение разобьем случайным образом на примерно равные по размеру небольшие фрагменты, которые используем в качестве объектов обучающей выборки.
2. Выполнить формализацию предметной области.
Под формализацией предметной области понимается разработка классификационных и описательных шкал и градаций и ввод их в программную систему "Эйдос", являющуюся инструментарием СК-анализа.
2.1. Формирование классификационных
шкал и градаций
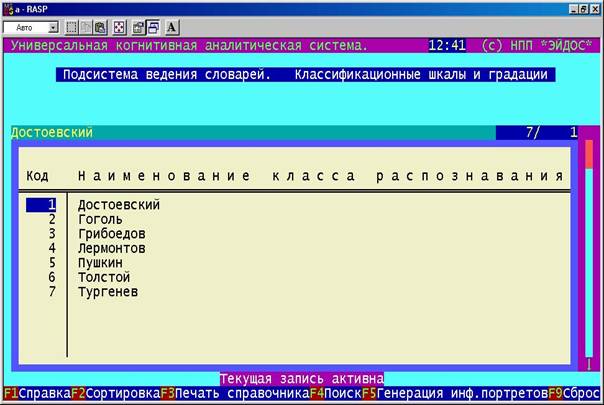
В подсистеме "Классификационные шкалы и градации" введем классы, соответствующие следующим писателям: Ф.М. Достоевский; Н.В. Гоголь; А.С. Грибоедов; М.Ю. Лермонтов; А.С. Пушкин; Л.Н. Толстой; И.С. Тургенев (рисунок 152).
|
|
|
Рисунок 152. Ввод классов |
2.1. Формирование описательных
шкал и градаций
Для этого исходные файлы для формирования объекты обучающей выборки должны быть средствами Word представлены в виде текстовых файлов, стандарта "Текст DOS" (без разбиения на строки).
Затем каждый из этих файлов разбивается на столько файлов, сколько в нем строк, причем имена этих файлов должны иметь вид: ####SUBSTR(File_name,4).TXT, где #### – сквозной номер файлов, соответствующий будущему номеру анкеты обучающей выборки, SUBSTR(File_name,4) – первые 4 символа имени исходного файла.
Полученные файлы должны быть помещены в поддиректорию DOB системы "Эйдос", а исходные – удалены из нее.
Это осуществляется одним из трех способов:
1. Вручную.
2. С использованием специальной программы, текст которой приводится ниже (язык программирования xBase).
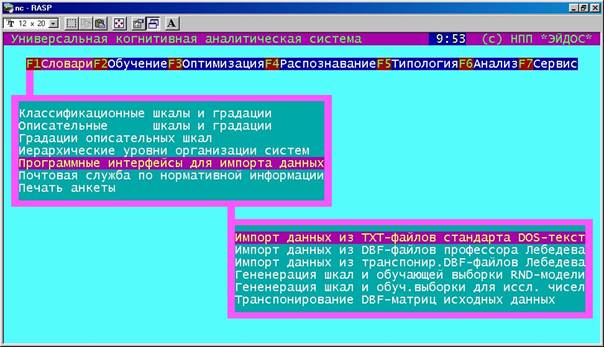
3. В режиме: "Словари
– Программные интерфейсы для импорта данных – Импорт данных из TXT-файлов
стандарта "Текст DOS", формируем описательные шкалы и градации
(рисунок 153), причем в качестве признаков выбираем слова.
Исходный
текст программы записи TXT-файлов с данными по строкам
**************************************************************************
********** Разбиение текстовых файлов DOS на нумерованные файлы по
строкам
********** Луценко Е.В., 03/31/04 04:24pm
**************************************************************************
scr_start=SAVESCREEN(0,0,24,79)
SHOWTIME(0,58,.T.,"rb/n")
FOR j=0 TO 24
@j,0 SAY SPACE(80) COLOR
"n/n"
NEXT
********** Удаление TXT-файлов, имена которых начинаются на 0
FILEDELETE("0*.TXT")
***** РЕКОГНОСЦИРОВКА
Count = ADIR("*.TXT") && Кол-во TXT-файлов
IF Count = 0
Mess = "В текущей
директории TXT-файлов не обнаружено !!!"
@15,40-LEN(Mess)/2 SAY Mess
COLOR "gr+/n"
INKEY(0)
RESTSCREEN(0,0,24,79,scr_start)
SHOWTIME()
QUIT
ENDIF
PRIVATE Name[Count],Size[Count]
&& Имена и размеры файлов
Count = ADIR("*.txt",Name,Size)
SortData(Name,Size,LEN(Name),1)
&& Сортировка файлов по алфавиту
CrLf = CHR(13)+CHR(10)
&& Конец строки (абзаца) (CrLf)
*** Загрузка TXT-файлов
Num_pp = 0
&& Номера выходных файлов
FOR f = 1 TO Count
&& Начало цикла по TXT-файлам
****** Загрузка файла
Buffer = FILESTR(Name[f],.T.)
Buffer = CHARONE("
",Buffer) && Удаление
повторяющихся пробелов
Buffer = Buffer + CrLf
Len = AT(CrLf,Buffer)
DO WHILE Len > 0 .AND.
LASTKEY() <> 27 && Цикл
по строкам
Len = AT(CrLf,Buffer)
IF Len > 0
****** Запись фрагмента
файла
Str_pr =
ALLTRIM(SUBSTR(Buffer,1,Len-1))
Fn_out =
STRTRAN(STR(++Num_pp,4),"
","0")+SUBSTR(Name[f],1,4)+".TXT"
STRFILE(Str_pr,Fn_out)
****** Исключение из
буфера записанной строки
Buffer =
ALLTRIM(SUBSTR(Buffer,Len+1))
ENDIF
ENDDO
NEXT
*** Удаление исходных TXT-файлов
FOR f=1 TO Count
FILEDELETE(Name[f])
NEXT
RESTSCREEN(0,0,24,79,scr_start)
SHOWTIME()
QUIT
|
|
|
Рисунок 153. Выход на режим генерации
справочников |
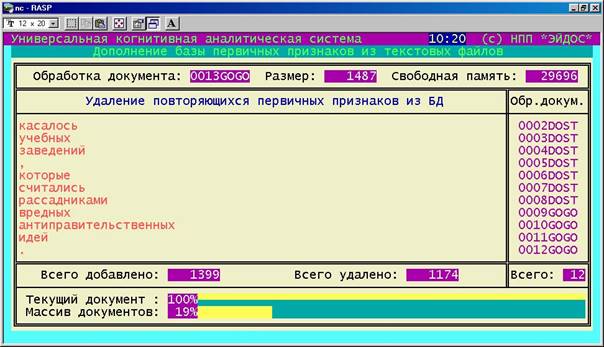
На рисунке 154 приведена экранная форма, отображающая ход процесса генерации описательных шкал и градаций и TXT-файлов, содержащих примеры текстов с разбиением по строкам.
|
|
|
Рисунок 154. Генерация описательных шкал и
градаций |
В результате получаем классификационные и описательные шкалы и градации, приведенные в таблицах 79 и 80.
Таблица 79 – КЛАССИФИКАЦИОННЫЕ
ШКАЛЫ И ГРАДАЦИИ
|
Код |
Наименование |
|
1 |
Достоевский |
|
2 |
Гоголь |
|
3 |
Грибоедов |
|
4 |
Лермонтов |
|
5 |
Пушкин |
|
6 |
Толстой |
|
7 |
Тургенев |
Таблица 80 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ (фрагмент)
|
Код |
Наименование |
Код |
Наименование |
Код |
Наименование |
|
1 |
! |
41 |
Бедные |
81 |
Все |
|
2 |
( |
42 |
Без |
82 |
Вспомним |
|
3 |
(основной |
43 |
Бездушных |
83 |
Встреча |
|
4 |
) |
44 |
Безумным |
84 |
Всюду |
|
5 |
, |
45 |
Безумных |
85 |
Вы |
|
6 |
- |
46 |
Безухов |
86 |
Вызывают |
|
7 |
. |
47 |
Безухову |
87 |
Высокие |
|
8 |
1812 |
48 |
Белинский |
88 |
Высокопарные |
|
9 |
20- |
49 |
Бессильной |
89 |
Г |
|
10 |
30-е |
50 |
Бог |
90 |
Герой |
|
11 |
30-х |
51 |
Боже |
91 |
Главная |
|
12 |
60-х |
52 |
Болконский |
92 |
Глухость |
|
13 |
: |
53 |
Болконскому |
93 |
Говоря |
|
14 |
; |
54 |
Бордо |
94 |
Гоголь |
|
15 |
? |
55 |
Борис |
95 |
Гоголя |
|
16 |
Bcтает |
56 |
Бориса |
96 |
Годунов |
|
17 |
XIX |
57 |
Бородинским |
97 |
Горе |
|
18 |
А |
58 |
Бородинского |
98 |
Гости |
|
19 |
Автор |
59 |
Буянов |
99 |
Грибоедов |
|
20 |
Авторский |
60 |
Была |
100 |
Грибоедова |
|
21 |
Агрессивная |
61 |
В |
101 |
Гулливера |
|
22 |
Адама |
62 |
Ведь |
102 |
Да |
|
23 |
Александр |
63 |
Везде |
103 |
Даже |
|
24 |
Александра |
64 |
Век |
104 |
Дворянин-аристократ |
|
25 |
Алексевна |
65 |
Великий |
105 |
Действительно |
|
26 |
Алексеевна |
66 |
Великолепная |
106 |
Дельвигу |
|
27 |
Аммоса |
67 |
Вернулся |
107 |
Денисова |
|
28 |
Андреевич |
68 |
Взволнованный |
108 |
Дидло |
|
29 |
Андрей |
69 |
Взгляды |
109 |
Для |
|
30 |
Андрею |
70 |
Власы |
110 |
Дмитриевна |
|
31 |
Анной |
71 |
Вместе |
111 |
Добролюбова |
|
32 |
Архивам |
72 |
Внешней |
112 |
Достоевского |
|
33 |
Афанасьевича |
73 |
Внешние |
113 |
Драматична |
|
34 |
Ах |
74 |
Воды |
114 |
Друбецкого |
|
35 |
Базаров |
75 |
Возникает |
115 |
Другое |
|
36 |
Базарова |
76 |
Война |
116 |
Думы |
|
37 |
Базаровым |
77 |
Вообще |
117 |
Дуни |
|
38 |
Балы |
78 |
Вопрос |
118 |
Дуня |
|
39 |
Бегущим |
79 |
Вот |
119 |
Душа |
|
40 |
Бедность |
80 |
Время |
120 |
Евгений |
Приводится лишь фрагмент описательных шкал и градаций, т.к. размерность справочника составляет 3522 градации (т.е. слова).
3. Сформировать обучающую выборку
Обучающая выборка представляет собой фрагменты текстов различных авторов, используемые в качестве примеров для формирования семантической информационной модели. На основе анализа этих примеров выявляются взаимосвязи между теми или иными словами и принадлежностью текстов разным авторам.
Для генерации обучающей выборки используется 1-й режим 2-й подсистемы, функция F7InpTXT – F6Ввод из всех файлов. При этом в качестве признаков, также как при формировании описательных шкал и градаций, выбираются слова (рисунок 155).
|
|
|
Рисунок 155. Генерация обучающей выборки из TXT-файлов |
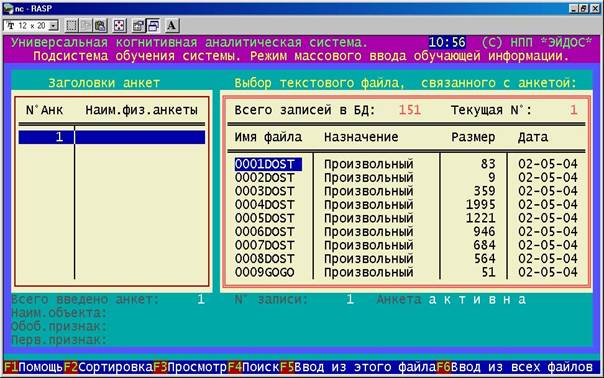
В результате формируется обучающая выборка, состоящая из 151 примера фрагментов текстов различных авторов. Остается лишь проставить в каждом примере (анкете) код писателя, о котором данный текст, т.е. код класса (в левом окне).
4. Осуществить синтез семантической информационной модели
Синтез модели осуществляется во 2-й подсистеме, 4-м режиме, 5-й функции (рисунок 156).
|
|
|
Рисунок 156. Запуск режима: |
Стадия процесса синтеза отображается в ряде экранных форм, одна из которых приводится на рисунке 157.
|
|
|
Рисунок 157. Экранная форма, отображающая одну из стадий процесса синтеза семантической информационной модели |
5. Оптимизировать
семантическую информационную модель
Оптимизация модели представляет собой исключение из нее малозначащих признаков без потери адекватности модели. Эта операция осуществляется во 2-м режиме 3-й подсистемы (рисунок 158).
|
|
|
Рисунок 158. Выход на режимы оптимизации модели |
При том имеется возможность вывести график ценности признаков "нарастающим итогом", т.е. Паретто-диаграмму признаков (рисунок 159).
|
|
|
Рисунок 159. Паретто-диаграмма признаков |
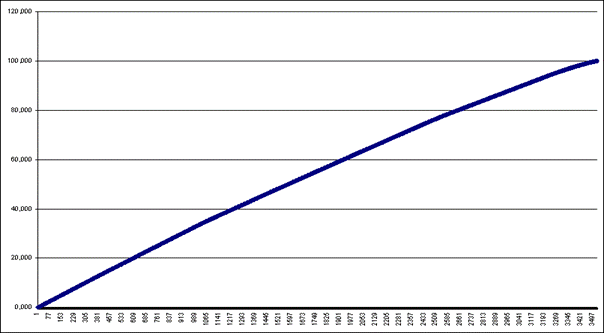
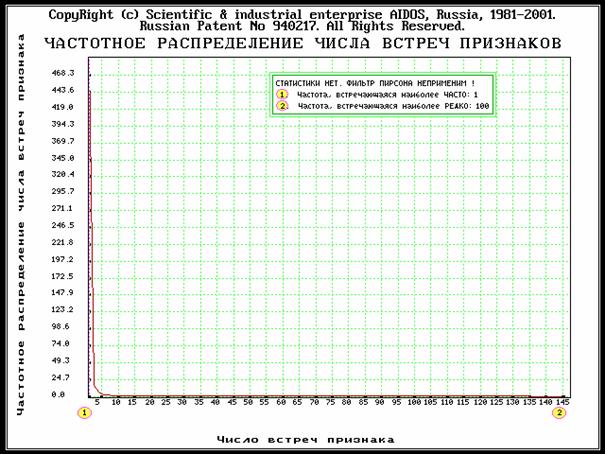
Видно, что в системе признаков нет имеющих очень малую или нулевую ценность. Это связано с тем, что все слова являются практически уникальными для фрагментов текстов, т.е. встречаются во всех текстах в основном от 1 до 5 раз (рисунок 160).
|
|
|
Рисунок 160. Частотное распределение частот признаков |
6. Проверить
семантическую информационную модель на адекватность, измерить внутреннюю и
внешнюю, дифференциальную и интегральную валидность
6.1. Внутренняя дифференциальная и интегральная валидность
Под внутренней валидностью понимается способность модели верно идентифицировать объекты, входящие в обучающую выборку.
Для измерения адекватности модели необходимо выполнить следующие действия:
1. Скопировать обучающую выборку в распознаваемую (во 1-м режиме 2-й подсистемы нажав клавишу F5).
2. Выполнить пакетное распознавание (во 2-м режиме 4-й подсистемы, задав 1-й критерий сходства) (рисунок 161).
3. Измерить адекватность модели (во 2-м режиме 6-й подсистемы) (рисунки 162 и 163).
|
|
|
Рисунок 161. Выход на режим пакетного распознавания |
|
|
|
Рисунок 162. Выход на режим измерения адекватности модели |
|
|
|
Рисунок 163. Экранная форма управления измерением адекватности модели и отображения результатов |
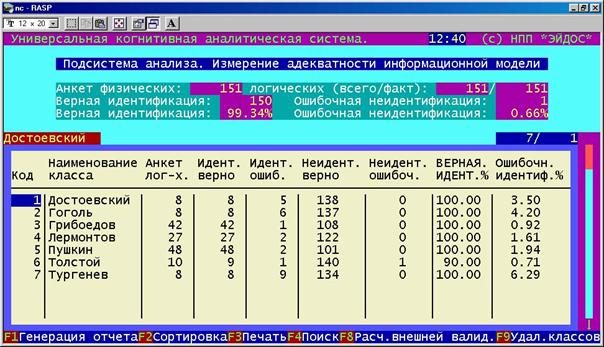
Эта форма может прокучиваться вправо-влево. В верхней части формы приведены показатели интегральной валидности (средневзвешенные по всей обучающей выборке), а в самой таблице – дифференциальной валидности, т.е. в разрезе по классам.
Кроме того, результаты измерения адекватности модели выводятся в форме файлов с именами ValidSys.txt (рисунок 164) и ValAnkSt.txt (рисунок 165) стандарта "TXT-текст DOS" в поддиректории TXT. Первый файл имеет вид:
|
|
|
Рисунок 164. Выходная форма ValidSys.txt с
результатами измерения |
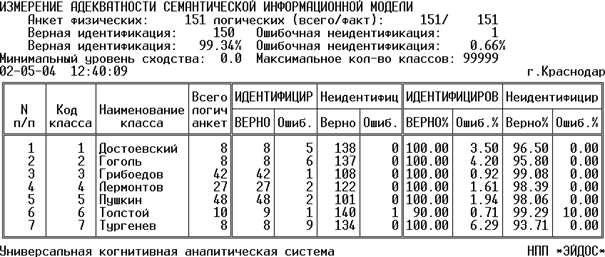
Рассмотрим, что означают графы этой выходной формы.
"Всего логических анкет" – это количество анкет (примеров текстов) в обучающей выборке, на основе которых формировался образ данного класса.
"Идентифицировано верно" – это количество анкет обучающей выборки, которые идентифицированы как классы, к которым они действительно относятся.
"Идентифицировано ошибочно" – это количество анкет обучающей выборки, которые идентифицированы как классы, к которым они в действительности не относятся (ошибка идентификации).
"Неидентифицировано верно" – это количество анкет обучающей выборки, которые неидентифицированы как классы, к которым они действительно не относятся.
"Неидентифицировано ошибочно" – это количество анкет обучающей выборки, которые неидентифицированы как классы, к которым они в действительности относятся (ошибка неидентфикации).
В правой части формы приведены те же показатели, но в процентом выражении:
– для анкет, идентифицированных верно и неидентифицированных ошибочно за 100% принимается количество логических анкет обучающей выборки по данному классу;
– для анкет, идентифицированных ошибочно и неидентифицированных верно за 100% принимается суммарное количество логических анкет обучающей выборки за вычетом логических анкет по данному классу.
|
|
|
Рисунок 165. Фрагмент выходной формы ValAnkSt.txt с результатами измерения адекватности модели и отображения результатов |

В данной форме приведены коды анкет обучающей выборки, которые были учтены в каждой графе предыдущей формы по каждому классу.
6.2. Внешняя дифференциальная и интегральная валидность
Под внешней валидностью понимается способность модели верно идентифицировать объекты, не входящие в обучающую выборку, но относящиеся к генеральной совокупности, по отношению к которой она репрезентативна.
Для измерения внешней валидности необходимо выполнить следующие действия:
1. В режиме измерения адекватности модели запустить режим измерения внешней валидности (нажав F8 Измерение внешней валидности) (рисунок 166).
2. Выбрать один из режимов удаления объектов обучающей выборки, приведенный на экранной форме (рисунок 167).
|
|
|
Рисунок 166. Режим переноса анкет обучающей
выборки |
Результат выполнения всех указанных на рисунке 166 действий приведен на рисунке 167.
|
|
|
Рисунок 167. Выходная форма с результатами
измерения |
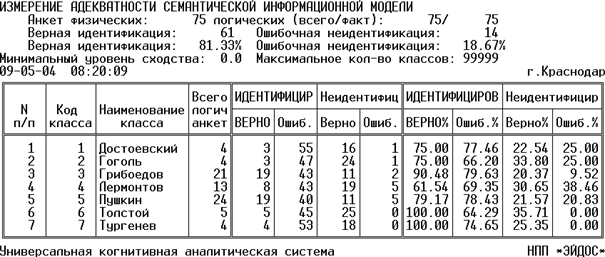
При этом исходная выборка была разделена на две:
– в обучающей выборке остались только нечетные анкеты;
– в распознаваемую выборку были включены только четные анкеты;
– при распознавании был использован 2-й интегральный критерий: сумма количества информации.
Анализ отчета по внешней валидности, приведенного на рисунке 167, позволяет сделать вывод о высокой степени адекватности семантической информационной модели. Это значит, что взаимосвязи между словами, использованными в текстах, и принадлежностью этих текстов различным авторам, выявленные по примерам обучающей выборки, оказались имеющими силу и для других фрагментов текстов, приведенных в распознаваемой выборке. Это означает, что они относятся к генеральной совокупности, по отношению к которой обучающая выборка репрезентативна.
7. Выполнить
адаптацию модели и измерить, как изменилась ее адекватность
Под адаптацией модели понимается ее количественная модификация, осуществляемая путем включения в обучающую выборку дополнительных примеров реализации объектов, относящихся к тем же самым классам и описанным в той же системе признаков.
На первом этапе, для изучения адаптивности модели осуществим ее синтез на основе обучающей выборки, состоящей из нечетных анкет, которая использовалась в примере для измерения внешней валидности. Но в отличие от этого примера эту же выборку используем и как распознаваемую.
На втором этапе осуществим синтез модели на основе полной обучающей выборки, включающей как четные, так и нечетные анкеты.
Адаптация модели повышает точность идентификации объектов той же самой генеральной совокупности.
8. Осуществить
пересинтез модели и измерить, как изменилась ее адекватность
Под повторным синтезом (пересинтезом) модели понимается ее качественная модификация, осуществляемая путем включения в модель новых дополнительных классификационных и описательных шкал и градаций, представленных примерами в обучающей выборке.
Пересинтез модели обеспечивает возможность ее применения для идентификации объектов расширенной или новой генеральной совокупности.
Приведем пример синтеза новой модели, обобщающей предыдущую.
В модель добавлены новые классы распознавания (таблица 81).
Таблица 81 – КЛАССИФИКАЦИОННЫЕ ШКАЛЫ
|
№ |
Наименования классов распознавания |
|
1 |
Загадки
о животных |
|
2 |
А.П.Чехов
"Вишневый сад" |
|
3 |
Ф.М.Достоевский
"Преступление и наказание" |
|
4 |
Н.В.Гоголь
"Ревизор" |
|
5 |
А.С.Грибоедов
"Горе от ума" |
|
6 |
И.А.Крылов |
|
7 |
М.Ю.Лермонтов
"Мцыри" |
|
8 |
Фольклорные
загадки о природе |
|
9 |
Некрасов
"Кому на Руси жить хорошо" |
|
10 |
Пословицы |
Продолжение таблицы 81
|
№ |
Наименования классов распознавания |
|
11 |
А.С.Пушкин
"Евгений Онегин" |
|
12 |
Загадки
о саде и огороде |
|
13 |
В.Шекспир |
|
14 |
М.А.Шолохов
"Тихий Дон" |
|
15 |
Скороговорки |
|
16 |
Л.Н.Толстой
"Война и мир" |
|
17 |
И.С.Тургенев
"Отцы и дети" |
Описательные шкалы и градации не приводятся, т.к. размерность составляет 6974 градации. Необходимо отметить, что текущая версия 12.5 системы "Эйдос" не имеет принципиальных ограничений на суммарное количество градаций классификационных и описательных шкал при синтезе модели и решении задач идентификации и прогнозирования, а также количество объектов обучающей выборки. Реально решались задачи с объемом обучающей выборки до 25000 объектов с 1500 классами и 7000 признаками. При этом был осуществлен синтез и исследование моделей, содержащих до 25 миллионов фактов.
В программном интерфейсе импорта данных из 17 исходных текстовых файлов, посвященных различным темам (см. таблицу 81) было сформировано 592 фрагмента, которые стали основой обучающей выборки.
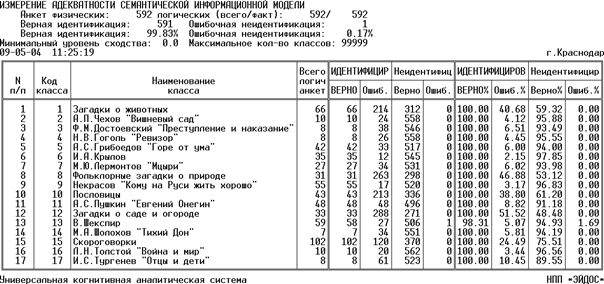
После синтеза модели измеряется ее адекватность. Для этого обучающая выборка копируется в распознаваемую, после чего проводится распознавание и измерение валидности (рисунок 168). Продемонстрирована очень высокая внутренняя валидность новой модели.
|
|
|
Рисунок 168. Выходная форма с результатами
измерения |
9. Вывести
информационные портреты текстов и дать их интерпретацию
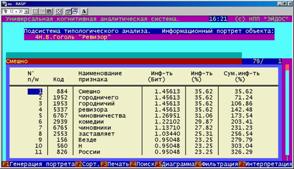
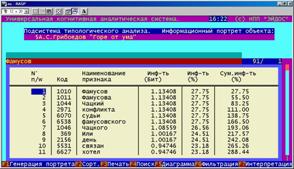
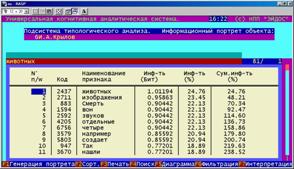
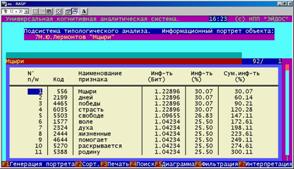
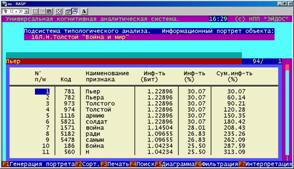
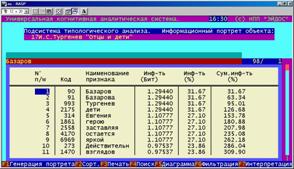
Информационный портрет класса представляет собой список признаков в порядке убывания количества информации, содержащегося в этих признаках о принадлежности к данному классу.
Генерируются они 1-м режиме 5-й подсистемы "Типология" (рисунок 169). Информационные портреты классов отображаются системой "Эйдос" в виде экранных форм, круговых диаграмм и гистограмм, а также в распечатываются в форме таблиц в поддиректории TXT. Графические формы записываются в поддиректории PCX.
|
|
|
|
|
|
|
|
|
|
|
|
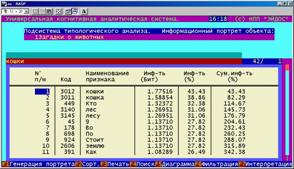
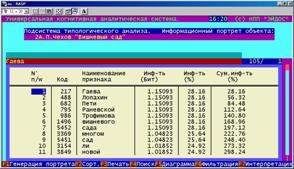
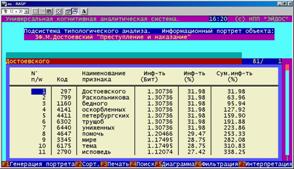
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рисунок 169. Информационные портреты классов |
|
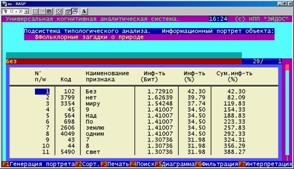
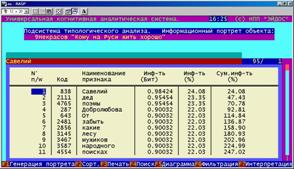
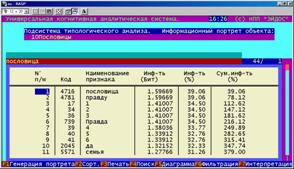
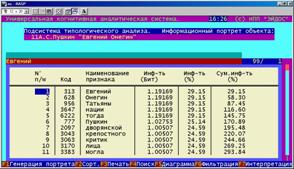
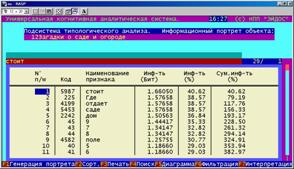
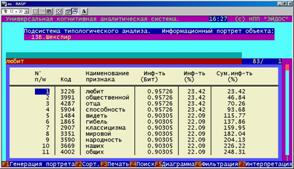
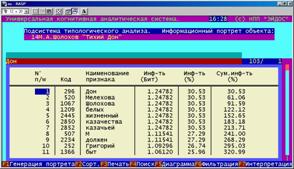
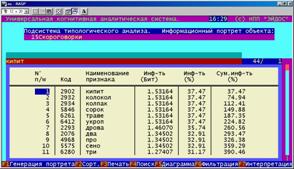
10. Выполнить
кластерно-конструктивный анализ модели
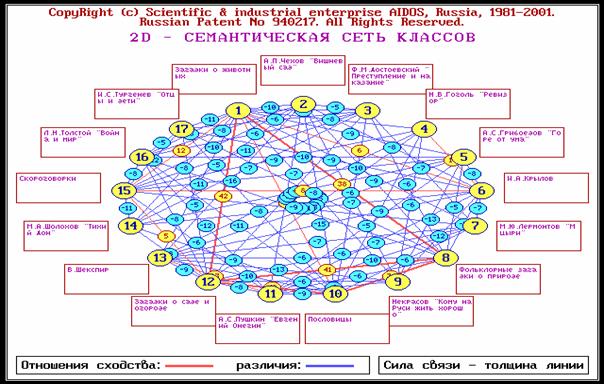
Кластерно-конструктивный анализ классов и признаков реализуется в 5-й подсистеме "Типология". В результате рассчитываются матрицы сходства классов и признаков, на основе которых генерируется и выводится ряд текстовых и графических форм. В данной работе мы приведем для примера лишь матрицу сходства классов (таблица 82 и отображающую ее в графической форме семантическую сеть классов (рисунок 170).
Таблица 82 – МАТРИЦА СХОДСТВА КЛАССОВ
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
|
1 |
100,0
|
-9,55
|
-8,94
|
-8,16
|
-9,46
|
6,32
|
-10,08
|
38,11
|
-6,24
|
33,86
|
-4,34
|
41,96
|
-11,12
|
-8,17
|
11,70
|
-8,00
|
-11,05
|
|
2 |
-9,55
|
100,0
|
-5,11
|
-0,35
|
-2,47
|
-7,84
|
-2,95
|
-9,07
|
-5,50
|
-5,44
|
-6,47
|
1,20
|
-16,31
|
-5,43
|
-10,08
|
-8,26
|
2,04
|
|
3 |
-8,94
|
-5,11
|
100,0
|
-2,39
|
1,12
|
-3,97
|
-6,81
|
-5,61
|
-0,10
|
-6,56
|
-3,05
|
-10,13
|
-0,41
|
-7,36
|
-11,47
|
-6,04
|
-6,32
|
|
4 |
-8,16
|
-0,35
|
-2,39
|
100,0
|
2,52
|
9,73
|
1,33
|
-4,36
|
-6,23
|
-9,19
|
-4,94
|
-8,33
|
-9,55
|
-1,41
|
-9,14
|
-1,91
|
3,14
|
|
5 |
-9,46
|
-2,47
|
1,12
|
2,52
|
100,0
|
-8,31
|
-1,87
|
-5,24
|
-12,74
|
-1,25
|
-5,30
|
-4,55
|
-12,89
|
-8,85
|
-6,73
|
-9,59
|
-3,52
|
|
6 |
6,32
|
-7,84
|
-3,97
|
9,73
|
-8,31
|
100,0
|
-6,55
|
-5,05
|
-12,06
|
0,49
|
-7,34
|
-2,99
|
-15,19
|
-11,13
|
8,18
|
-3,10
|
-8,75
|
|
7 |
-10,08
|
-2,95
|
-6,81
|
1,33
|
-1,87
|
-6,55
|
100,0
|
-4,35
|
-1,04
|
-6,10
|
-10,14
|
-5,71
|
-7,09
|
-0,21
|
-9,40
|
-3,97
|
3,67
|
|
8 |
38,11
|
-9,07
|
-5,61
|
-4,36
|
-5,24
|
-5,05
|
-4,35
|
100,0
|
-2,38
|
34,04
|
-6,03
|
41,21
|
-6,48
|
-4,72
|
0,87
|
-8,50
|
-8,17
|
|
9 |
-6,24
|
-5,50
|
-0,10
|
-6,23
|
-12,74
|
-12,06
|
-1,04
|
-2,38
|
100,0
|
-1,85
|
-8,20
|
-6,28
|
-12,89
|
-1,18
|
-2,41
|
0,73
|
-3,53
|
|
10 |
33,86
|
-5,44
|
-6,56
|
-9,19
|
-1,25
|
0,49
|
-6,10
|
34,04
|
-1,85
|
100,0
|
-8,76
|
39,59
|
-9,83
|
-9,07
|
-1,63
|
-11,22
|
-7,73
|
|
11 |
-4,34
|
-6,47
|
-3,05
|
-4,94
|
-5,30
|
-7,34
|
-10,14
|
-6,03
|
-8,20
|
-8,76
|
100,0
|
-7,79
|
13,47
|
-3,96
|
-5,98
|
-11,77
|
-2,47
|
|
12 |
41,96
|
1,20
|
-10,13
|
-8,33
|
-4,55
|
-2,99
|
-5,71
|
41,21
|
-6,28
|
39,59
|
-7,79
|
100,0
|
-8,80
|
-8,13
|
5,09
|
-8,29
|
-5,24
|
|
13 |
-11,12
|
-16,31
|
-0,41
|
-9,55
|
-12,89
|
-15,19
|
-7,09
|
-6,48
|
-12,89
|
-9,83
|
13,47
|
-8,80
|
100,0
|
-3,67
|
-3,20
|
-1,92
|
1,77
|
|
14 |
-8,17
|
-5,43
|
-7,36
|
-1,41
|
-8,85
|
-11,13
|
-0,21
|
-4,72
|
-1,18
|
-9,07
|
-3,96
|
-8,13
|
-3,67
|
100,0
|
-11,07
|
-0,69
|
-3,25
|
|
15 |
11,70
|
-10,08
|
-11,47
|
-9,14
|
-6,73
|
8,18
|
-9,40
|
0,87
|
-2,41
|
-1,63
|
-5,98
|
5,09
|
-3,20
|
-11,07
|
100,0
|
-8,44
|
-12,23
|
|
16 |
-8,00
|
-8,26
|
-6,04
|
-1,91
|
-9,59
|
-3,10
|
-3,97
|
-8,50
|
0,73
|
-11,22
|
-11,77
|
-8,29
|
-1,92
|
-0,69
|
-8,44
|
100,0
|
-5,50
|
|
17 |
-11,05
|
2,04
|
-6,32
|
3,14
|
-3,52
|
-8,75
|
3,67
|
-8,17
|
-3,53
|
-7,73
|
-2,47
|
-5,24
|
1,77
|
-3,25
|
-12,23
|
-5,50
|
100,0
|
|
|
|
Рисунок 170. Отображение матрицы сходства классов в графической форме семантической сети классов (отображены связи значимостью более 5%) |
Выводы
Продемонстрирована возможность и эффективность применения технологии и инструментария системно-когнитивного анализа для решения ряда задач атрибуции текстов.
Приведен подробный численный пример (с большим количеством конкретных иллюстративных материалов) реализации всех этапов СК-анализа при атрибуции текстов: когнитивной структуризации и формализации предметной области; формирования обучающей выборки; синтеза семантической информационной модели; оптимизации и измерения адекватности модели; адаптации и пересинтеза модели; типологического и кластерно-конструктивного анализа модели.
Контрольные вопросы
1. Что такое атрибуция текстов?
2. Каким образом выполняется когнитивная структуризация предметной области?
3. В чем состоит формализацию предметной области и как ее осуществить в системе "Эйдос"?
4. Какие средства формирования обучающей выборки используются в системе "Эйдос" при решении задач атрибуции текстов?
5. В какой подсистеме и в каком режиме системы "Эйдос" осуществляется синтез семантической информационной модели и в чем он состоит?
6. В чем заключается оптимизация семантической информационной модели и как она осуществляется в системе "Эйдос"?
7. Как семантическая информационная модель проверяется на адекватность?
8. Как связана адекватность модели с внутренней и внешней, дифференциальной и интегральной валидностью?
9. Каким образом можно в системе "Эйдос" выполнить адаптацию модели и измерить, как изменилась ее адекватность?
10. Как в системе "Эйдос" осуществить пересинтез модели и измерить, как изменилась ее адекватность?
11. Чем отличается адаптация модели от пересинтеза в системе "Эйдос"?
12. В каких подсистемах и режимах системы "Эйдос" можно вывести информационные портреты?
13. В каких подсистемах и режимах системы "Эйдос" можно выполнить кластерно-конструктивный анализ модели?
Литература по лабораторной работе
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный
системно-когнитивный анализ в управлении активными объектами (системная теория
информации и ее применение в исследовании экономических,
социально-психологических, технологических и организационно-технических систем):
Монография (научное издание). – Краснодар:
КубГАУ. 2002. – 605 с.