РАЗДЕЛ 1.3.
ПРИНЦИПЫ ПОСТРОЕНИЯ ИНТЕЛЛЕКТУАЛЬНЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ
1.3.1. ЛЕКЦИЯ-7.
Системы с интеллектуальной
обратной связью и интеллектуальными интерфейсами
Учебные вопросы
1. Интеллектуальные интерфейсы. Использование биометрической информации о пользователе в управлении системами.
2. Системы с биологической обратной связью.
3. Системы с семантическим резонансом. Компьютерные (Y-технологии и интеллектуальный подсознательный интерфейс.
4. Системы виртуальной реальности и критерии реальности. Эффекты присутствия, деперсонализации и модификация сознания пользователя.
5. Системы с дистанционным телекинетическим интерфейсом.
1.3.1.1. Интеллектуальные интерфейсы. Использование биометрической информации о пользователе в управлении системами
1.3.1.1.1. Идентификация и аутентификация личности по почерку. Понятие клавиатурного почерка
Рассмотрим, в чем заключается различие между двумя формами представления одного и того же текста: рукописной и печатной. При этом могут исследоваться и сравниваться как сам процесс формирования текста, так и его результаты, т.е. уже сформированные тексты.
При исследовании уже сформированных текстов обнаруживается, что главное отличие рукописного текста от печатного состоит в значительно большей степени вариабельности начертаний одной и той же буквы разными людьми и одним и тем же человеком в различных состояниях, чем при воспроизведении тех же букв на различных пишущих машинках и принтерах.
Почерком будем называть систему индивидуальных особенностей начертания и
динамики воспроизведения букв, слов и предложений вручную различными
людьми или на различных устройствах печати.
В рукописной форме начертание букв является индивидуальным для каждого человека и зависит также от его состояния, хотя, конечно, в начертаниях каждой конкретной буквы всеми людьми безусловно есть и нечто общее, что и позволяет идентифицировать ее именно как данную букву при чтении.
К индивидуальным особенностям рукописного начертания букв в работе [125] отнесено 13 шкал с десятками градаций в каждой.
В печатной форме вариабельность начертания букв значительно меньше, чем в рукописной, но все же присутствует, особенно на печатных машинках, барабанных, знакосинтезирующих и литерных принтерах.
В СССР печатные машинки при продаже регистрировались и образец печати всех символов вместе с паспортными данными покупателя направлялся в "комптентные" органы. Это позволяло установить на какой машинке и кем напечатан тот или иной материал. Считается, что принтер тем лучше, чем меньше у него индивидуальных особенностей, т.е. чем ближе реально распечатываемые им тексты к некоторому идеалу – стандарту. Современные лазерные и струйные принтеры в исправном состоянии (новый барабан и картридж) практически не имеют индивидуальных особенностей.
На современных компьютерах основным устройством ввода текстовой информации является клавиатура. Результат ввода текста в компьютер с точки зрения начертания букв, слов и предложений не имеет особых индивидуальных особенностей (если не считать частот использования различных шрифтов, кеглей, жирностей, подчеркиваний и других эффектов, изменяющих вид текста). Поэтому необходимо ввести понятие клавиатурного почерка, под которым будем понимать систему индивидуальных особенностей начертаний и динамики воспроизведения букв, слов и предложений на клавиатуре.
1.3.1.1.2. Соотношение психографологии и атрибуции текстов
Таким образом, любой текст содержит не только ту информацию, для передачи которой его собственно и создавали, но и информацию о самом авторе этого текста и о технических средствах и технологии его создания.
Существует целая наука – "Психографология", которая ставит своей задачей получение максимального количества информации об авторах текстов на основе изучения индивидуальных особенностей их почерка [125].
В настоящее время в России действует институт графологии. На сайте этого института http://graphology.boom.ru можно познакомится с тем, что такое графология, с ее историей и задачами, которые она позволяет решать сегодня. Графологическое исследование имеет значительное преимущество перед простым тестированием или собеседованием, поскольку нет необходимости информировать человека, чей почерк подвергается изучению о производимых исследованиях.
Но текст представляет собой не просто совокупность букв, а сложную иерархическую структуру, в которой буквы образуют лишь фундамент пирамиды, а на более высоких ее уровнях находятся слова, предложения, и другие части текстов различных размеров, обладающие относительной целостностью и самостоятельностью (абзацы, параграфы, главы, части, книги).
Понятие почерка акцентирует внимание именно на начертании и динамике воспроизведения букв и слов. При этом в понятие почерка не входят индивидуальные особенности текстов, обнаруживаемые на более высоких уровнях иерархической организации текстов, например: частоты употребления тех или иных слов и словосочетаний, средние длины предложений и абзацев, и т.п. Но именно эти индивидуальные особенности текстов исследуются и используются при атрибуции анонимных и псевдонимных текстов (определении их вероятного авторства) и датировки.
Соответственно и текст может представлять для читателя интерес по крайней мере с трех точек зрения:
1. Как источник информации о том, о чем говорит автор, т.е. о предмете изложения.
2. Как источник информации о самом авторе.
3. Как источник информации о предмете изложения и об авторе.
В этом смысле читать Пушкина в рукописи может быть значительно интереснее, чем в взяв томик с полки. Это объясняется просто: в томике есть лишь сам результат работы поэта и выхолощена вся информация о процессе, т.е. о самом поэте, содержащаяся в почерке, способе размещения текста на листе, порядке и динамике его формирования, различных вариантах и ассоциациях, возникавших в процессе создания произведения.
Таким
образом, система, оснащенная интеллектуальным интерфейсом, может вести по-разному
в зависимости от результатов идентификации пользователя, его профессионального
уровня и текущего психофизиологического состояния.
1.3.1.1.3. Идентификация и аутентификация личности пользователя компьютера по клавиатурному почерку
Рассмотрим подробнее некоторые вопросы идентификации пользователей по клавиатурному почерку. При этом мы будем самым существенным образом основываться на работе: Завгородний В.В. и Мельников Ю.Н. Идентификация по клавиатурному почерку, "Банковские Технологии" №9, 1998 [37].
Проблемы идентификации и аутентификации пользователей компьютеров являются актуальными в связи с все большим распространением компьютерных преступлений. Использование для идентификации клавиатурного почерка является одним из направлений биометрических методов идентификации личности.
Подобные системы не обеспечивают такую же точность распознавания, как системы идентификации по отпечаткам пальцев или по рисунку радужной оболочки глаз, но имеют то преимущество, что система может быть полностью скрыта от пользователя, т. е. он может даже не подозревать о наличии такой системы контроля доступа.
Варианты постановки задачи распознавания клавиатурного почерка
Аутентификация – это проверка, действительно ли пользователь является тем, за кого себя выдает. При этом пользователь должен предварительно сообщить о себе идентификационную информацию: свое имя и пароль, соответствующий названному имени.
Идентификация – это установление его личности.
И идентификация, и аутентификация являются типичными задачами распознавания образов, которое может проводиться по заранее определенной или произвольной последовательности нажатий клавиш.
Характеристики клавиатурного почерка
При вводе информации пользователь последовательно нажимает и отпускает клавиши, соответствующие вводимому тексту. При этом для каждой нажимаемой клавиши можно фиксировать моменты нажатия и отпускания.
На IBM-совместимых персональных компьютерах на следующую клавишу можно нажимать до отпускания предыдущих, т.е. символ помещается в буфер клавиатуры только по нажатию клавиши, тогда как аппаратные прерывания от клавиатуры возникают и при нажатии, и при отпускании клавиши.
Основной характеристикой клавиатурного почерка следует считать временные интервалы между различными моментами ввода текста:
– между нажатиями клавиш;
– между отпусканиями клавиш;
– между нажатием и отпусканием одной клавиши;
– между отпусканием предыдущей и нажатием следующей клавиши.
Кроме того, могут учитываться производные от временных интервалов вторичные показатели, например такие как скорость и ускорение ввода.
Математические методы распознавания клавиатурного почерка
В литературе описано четыре математических подхода к решению задачи распознавания клавиатурного почерка пользователя ЭВМ:
– статистический;
– вероятностно-статистический;
– на базе теории распознавания образов и нечеткой логики;
– на основе нейросетевых алгоритмов.
За более подробным анализом подходов к использованию компьютерного почерка для идентификации и аутентификации пользователей компьютеров отсылаем к в вышеназванной статье.
1.3.1.1.4. Прогнозирование ошибок оператора по изменениям в его электроэнцефалограмме
В настоящее время в Институтом психологии РАН, Институтом Высшей Нервной Деятельности и Нейрофизиологии РАН, Высшей Школой Экономики и Кубанским государственном аграрным университетом (Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В.) проводятся исследования, продемонстрировавшие принципиальную возможность прогнозирования ошибок оператора при работе с клавиатурой, типа "ошибочное нажатие клавиши", "ошибочное ненажатие клавиши" и т.п. по изменениям в его электроэнцефалограмме (ЭЭГ). При этом для обработки информации успешно была применена система "Эйдос" [108, 224, 225, 226].
Эти работы в перспективе позволяют создать интеллектуальные высоконадежные интерфейсы, обеспечивающие решение этих и ряда других задач идентификации и прогнозирования состояния оператора в режиме реального времени непосредственно в процессе его работы с системой. При этом система в своей работе будет гибко учитывать текущее и прогнозируемое состояние оператора, что может проявляться в адаптации как алгоритмов работы, так и вида и содержания интерфейса.
Эти работы дополняют возможности заблаговременного отбора операторов, обладающих свойствами, необходимыми для высоко ответственных работ в экстремальных ситуациях [64, 67, 74, 77, 78, 85 – 88, 92, 104, 107, 111, 169].
1.3.1.2. Системы с биологической обратной связью
1.3.1.2.1. Общие положения
Системами с биологической обратной связью
(БОС) будем называть системы,
поведение которых зависит от психофизиологического (биологического) состояния
пользователя.
Это означает, что в состав систем с БОС в качестве подсистем входят информационно-измерительные системы и системы искусственного интеллекта.
Съем информации о состоянии пользователя осуществляется с помощью контактных и/или дистанционных датчиков в режиме реального времени с применением транспьютерных или обычных карт (плат) с аналого-цифровыми преобразователями (АЦП).
При этом информация может сниматься по большому количеству каналов – показателей (количество которых обычно кратно степеням двойки), подавляющее большинство которых обычно являются несознаваемыми для пользователя. Это является весьма существенным обстоятельством, т.к. означает, что системы БОС позволяют вывести на уровень сознания обычно ранее не осознаваемую информацию о состоянии своего организма, т.е. расширить область осознаваемого. А это значит, что у человека появляются условия, обеспечивающие возможность сознательного управления своими состояниями, ранее не управляемыми на сознательном уровне, что является важным эволюционным достижением технократической цивилизации.
Передача информации от блока съема информации к АЦП-карте может также осуществляться либо по проводной связи, либо дистанционно с использованием каналов инфракрасной или радиосвязи.
Приведем три примера применения подобных систем:
1. Мониторинг состояния сотрудников на конвейере с целью обеспечения высокого качества продукции.
2. Компьютерные тренажеры, основанные на БОС, для обучения больных с функциональными нарушениями управлению своим состоянием.
3. Компьютерные игры с БОС.
1.3.1.2.1. Мониторинг состояния сотрудников сборочного конвейера с целью обеспечения высокого качества продукции
Известно, что одной из основных причин производственного брака является ухудшение состояния сотрудников. Но сотрудники не всегда могут вовремя заметить это ухудшение, т.к. самооценка (самочувствие) обычно запаздывает по времени за моментом объективного ухудшения состояния. Поэтому является актуальным своевременное обнаружение объективного ухудшения параметров и адекватное реагирование на него.
С помощью систем БОС это достигается тем, что:
1. Каждому сотруднику одевается на руку браслет с компактным устройством диагностики ряда параметров, например таких, как:
– частота и наполнение пульса;
– кожно-гальваническая реакция;
– температура;
– давление;
– пототделение.
2. Это же устройство и периодически передает значения данных параметров на компьютер по радиоканалу.
3. Параметры от каждого сотрудника накапливаются в базе данных системы мониторинга на сервере, а также анализируются в режиме реального времени с учетом текущего состояния и динамики, в т.ч. вторичных (расчетных) показателей.
4. Когда параметры выходят за пределы коридора "нормы" или по их совокупности может быть поставлен диагноз, – сотрудник оперативно снимается с рабочего места и заменяется другим из резерва, а затем, при наличии показаний, направляется на лечение.
1.3.1.2.2. Компьютерные тренажеры, основанные на БОС, для обучения больных навыкам управления своим состоянием
Некоторыми процессами в своем организме мы не можем управлять не потому, что у нас нет рычагов управления, а лишь потому, что мы их не знаем, не имеем навыков их использования и не знаем результатов их применения. Но ключевой проблемой, без решения которой невозможно управление, является отсутствие быстрого и надежного, адекватного по содержанию канала обратной связи.
Все эти проблемы снимаются системами БОС:
– на экран компьютера в наглядной и легко интерпретируемой форме в режиме реального времени выводится информация о состоянии какой-либо подсистемы организма, например, об уровне pH (кислотности) в желудке;
– в качестве рычагов управления пациенту предлагается применить метод визуализации тех или иных образов, которые сообщаются врачом;
– когда пациент ярко зрительно представляет заданные образы, то при этом он обнаруживает, что кривая кислотности на экране начинает ползти вверх или вниз в прямом соответствии с тем, что именно он себе представляет.
Через пару недель подобных тренировок, проводимых по 15-20 минут через день пациент приобретает такой уровень навыков управления ранее не осознаваемыми процессами в своем организме, которых Хатха-йоги добиваются за многие годы упорных тренировок под руководством профессиональных опытных и ответственных наставников (Гуру). Причем скоро пациент начинает понимать, когда необходимо повысить или понизить кислотность и без компьютера с системой БОС и может делать это прямо в той обстановке, в которой возникла такая необходимость. Столь высокая эффективность метода БОС объясняется высокой скоростью, наглядностью и адекватностью обратной связи, что является одним из основных факторов, влияющих на эффективность формирования навыков управления своим состоянием.
Имеется информация, что такими методами могут лечиться или облегчаться многие заболевания, вплоть до диабета, причем не только на стадии функциональных нарушений, но даже и при наличии органических изменений.
1.3.1.2.3. Компьютерные игры с БОС
В последнее время появляется все больше компьютерных игр, включающих элементы БОС. При этом от психофизиологического состояния игрока может зависеть, например, и развитие сценария, и точность прицеливания при использовании оптического прицела.
В этих играх часто создаются ситуации, в которых человеку нужно быстро принимать и реализовать решения, при этом цена ошибки, а значит и психическая напряженность, и волнение игрока, постоянно увеличиваются. Этим самым создается экстремальная ситуация, напряженность которой все больше возрастает. В этих условиях лучших результатов достигает тот, у кого "крепче нервы", кто лучше может управлять собой в экстремальных ситуациях.
Поэтому игры с элементами БОС можно считать своего рода тренажерами по формированию и совершенствованию навыков адекватного поведения в экстремальных ситуациях.
Здесь необходимо отметить один очень существенный момент. В обычной реальности развитие событий зависит не непосредственно от нашего психофизиологического состояния, а лишь от того, как оно проявляется в наших действиях. В случае же виртуальной реальности развитие сценария игры может зависеть непосредственно от состояния игрока. Таким образом, в виртуальной реальности само сознательное (произвольное) или несознательное (непроизвольное) изменение нашего состояния по сути дела является действием. Аналогичная ситуация в обычной реальности может иметь место при высших формах сознания и проявлении сверхспособностей.
1.3.1.3. Системы с семантическим резонансом. Компьютерные Y-технологии и интеллектуальный подсознательный интерфейс
Системами с семантическим резонансом будем называть системы, поведение которых
зависит от состояния сознания пользователя и его психологической реакции на
смысловые стимулы.
Это означает, что в состав систем с семантическим резонансом, также как и систем с БОС, в качестве подсистем входят информационно-измерительные системы и системы искусственного интеллекта, аналогично осуществляется и съем информации о состоянии пользователя.
Различие между системами с БОС и с семантическим резонансом состоит в том, что в первом случае набор снимаемых параметров и методы их математической обработки определяются необходимостью идентификации биологического состояния пользователя, тогда как во втором – его реакции на смысловые стимулы (раздражители).
В частности, имеется возможность по наличию в электроэнцефалограмме так называемых вызванных потенциалов [221] установить реакцию человека на стимул: заинтересовался он или нет.
Здесь принципиально важно, что вызванные потенциалы после предъявления стимула по времени возникают гораздо раньше, чем его осознание.
Из этого следует ряд важных выводов:
1. Если
это осознание не наступает по каким-либо причинам, то вызванные потенциалы все
равно с очень высокой достоверностью позволяют прогнозировать ту реакцию,
которая была бы у человека, если бы информация о стимуле проникла в его
сознание (причинами, по которым зрительный образ стимула может не успеть
сформироваться и проникнуть в сознание пользователя, могут быть, например, его
очень сильную зашумленность, фрагментарность или слишком короткое время его
предъявления).
2. Реакция на стимул на уровне вызванных потенциалов не подвергается критическому анализу и корректировке на уровне сознания, т.е. является гораздо более "искренней" и "откровенной", адекватной и достоверной, чем сознательные ответы на опросник с тем же самым стимульным материалом (сознательные ответы зависят от мотивации, коньюктуры и массы других обстоятельств).
3. Для получения информации о подсознательной реакции пользователя на стимульный материал он может предъявляться в значительно более высоком темпе, чем при сознательном тестировании.
4. При подсознательном тестировании пользователь может даже не знать о том, что оно проводится.
Все это в совокупности означает, что системы с семантическим резонансом позволяют получить и вывести на уровень сознания обычно ранее не осознаваемую адекватную информацию о состоянии своего сознания, систем мотивации, целеполагания, ценностей и т.д., т.е. расширить область осознаваемого. Это позволяет создать качественно более благоприятные условия для управления состоянием сознания, чем ранее, что является важным эволюционным достижением технократической цивилизации.
Системы с семантическим резонансом могут эффективно использоваться в ряде направлений:
– психологическое и профессиональное тестирование, подбор персонала, в т.ч. для действий в специальных условиях и в измененных формах сознания;
– модификация сознания, систем мотиваций, целеполагания, ценностей и др. (компьютерное нейролингвистическое программирование: "компьютерные НЛП-технологии");
– компьютерные игры с системами семантической обратной связи.
1.3.1.4. Системы виртуальной реальности и критерии реальности. Эффекты присутствия, деперсонализации и модификация сознания пользователя
1.3.1.4.1. Классическое определение системы виртуальной реальности
ВИРТУАЛЬНАЯ
РЕАЛЬНОСТЬ (ВР) – модельная
трехмерная (3D) окружающая среда, создаваемая компьютерными средствами и
реалистично реагирующая на взаимодействие с пользователями
(http://dlc.miem.edu.ru/newsite.nsf/docs/CSD309).
Технической базой систем виртуальной реальности являются современные мощные персональные компьютеры и программное обеспечение высококачественной трехмерной визуализации и анимации. В качестве устройств ввода-вывода информации в системах ВР применяются виртуальные шлемы с дисплеями (HMD), в частности шлемы со стереоскопическими очками, и устройства 3D-ввода, например, мышь с пространственно управляемым курсором или "цифровые перчатки", которые обеспечивают тактильную обратную связь с пользователем.
Совершенствование систем виртуальной реальности
приводит ко все большей изоляции пользователя от обычной реальности, т.к. все
больше каналов взаимодействия
пользователя с окружающей средой замыкаются не на обычную, а на виртуальную
среду – виртуальную реальность, которая, при этом, становится все более и более
функционально-замкнутой и самодостаточной.
Создание систем ВР является закономерным следствием процесса совершенствования компьютерных систем отображения информации и интерфейса управления.
При обычной работе на компьютере монитор занимает не более 20% поля зрения пользователя. Системы ВР перекрывают все поле зрения.
Обычные мониторы не являются стереоскопическими, т.е. не создают объемного изображения. Правда, в последнее время появились разработки, которые, позволяют преодолеть это ограничение (достаточно сделать поиск в yandex.ru по запросу "Стереоскопический монитор"). Системы ВР изначально были стереоскопическими.
Звуковое сопровождение, в том числе со стерео и квадро-звуком, сегодня уже стали стандартом. В системах ВР человек не слышит ничего, кроме звуков этой виртуальной реальности.
В некоторых моделях систем виртуальной реальности пользователи имеют возможность восприятия изменяющейся перспективы и видят объекты с разных точек наблюдения, как если бы они сами находились и перемещались внутри модели.
Если пользователь располагает более развитыми (погруженными) устройствами ввода, например, такими, как цифровые перчатки и виртуальные шлемы, то модель может даже надлежащим образом реагировать на такие действия пользователя, как поворот головы или движение глаз.
Необходимо отметить, что в настоящее время системы виртуальной реальности развиваются очень быстрыми темпами и явно выражена тенденция проникновения технологий виртуальной реальности в стандартные компьютерные технологии широкого применения.
Развитие этих и других подобных средств привело к появлению качественно новых эффектов, которые ранее не наблюдались или наблюдались в очень малой степени:
– эффект присутствия пользователя в виртуальной реальности;
– эффект деперсонализации и модификации самосознания и сознания пользователя в виртуальной реальности.
1.3.1.4.2. "Эффект присутствия" в виртуальной реальности
Эффект
присутствия – это создаваемая для
пользователя иллюзия его присутствия
в смоделированной компьютером среде, при этом создается полное впечатление
"присутствия" в виртуальной среде, очень сходное с ощущением
присутствия в обычном "реальном" мире.
При этом виртуальная среда начинает осознаваться как реальная, а о реальной среде пользователь на время как бы совершенно или почти полностью "забывает". При этом технические особенности интерфейса также вытесняются из сознания, т.е. мы не замечаем этот интерфейс примерно так же, как собственное физическое тело или глаза, когда смотрим на захватывающий сюжет. Таким образом, реальная среда замещается виртуальной средой.
Исследования показывают, что для возникновения и силы эффекта присутствия определяющую роль играет реалистичность движения различных объектов в виртуальной реальности, а также убедительность реагирования объектов виртуальной реальности при взаимодействии с ними виртуального тела пользователя или других виртуальных объектов. В то же время, как это ни странно, естественность вида объектов виртуальной среды играет сравнительно меньшую роль.
1.3.1.4.3. Применения систем виртуальной реальности
Системы виртуальной реальности уже в настоящее время широко применяется во многих сферах жизни.
Одними из первых технологии виртуальной реальности были применены НАСА США для тренировки пилотов космических челноков и военных самолетов, при отработке приемов посадки, дозаправки в воздухе и т.п.
Самолет-невидика "Стелс" вообще управляется пилотом, практически находящемся в виртуальной реальности.
Из виртуальной реальности человек управляет роботом, выполняющим опасную или тонкую работу.
Технология Motion Capture, позволяет дистанционно "снять" движения с человека и присвоить их его трехмерной модели, что широко применяется для создания компьютерных игр и анимации рисованных персонажей в фильмах.
Особенно эффективно применение виртуальной реальности в рекламе, особенно в Интернет-рекламе на стадии информирования и убеждения.
С использованием виртуальной реальности можно показывать различные помещения, например, совершить виртуальную экскурсию по музею, учебному заведению, дому, коттеджу или местности (прогулка по Парижу от туристической фирмы).
Во всех этих приложениях важно, что в отличие от трехмерной графики, виртуальная реальность обеспечивает эффект присутствия и личного участия пользователя в наблюдаемых им событиях.
1.3.1.4.4. Модификация сознания и самосознания пользователя в виртуальной реальности
Сегодня уже для всех вполне очевидно, что виртуальная реальность может с успехом использоваться для развлечений, ведь она помогает представить себя в другой роли и в другом обличии. Однако в действительности этот эффект связан с модификацией "Образа Я", т.е. сознания и самосознания пользователя. Это значит, что последствия этого в действительности значительно серьезнее, чем обычно представляют, и далеко выходит за рамки собственно развлечений.
Как показано автором в ряде работ, приведенных на сайте http://Lc.kubagro.ru, форма сознания и самосознания человека определяются тем, как он осознает себя и окружающее, т.е. тем:
– что он осознает, как объективное, субъективное и несуществующее;
– с чем он отождествляет себя и что осознает как объекты окружающий среды.
Очевидно, что разработчики новейших компьютерных технологий совершенно неожиданно вторглись в абсолютно новую для себя сферу исследования измененных форм сознания, и далеко идущие системные последствия этого ими, как и вообще научным сообществом, пока еще очень мало осознаны.
Еще в 1079-1981 годах автором и Л.А.Бакурадзе были оформлены заявки на изобретение компьютерной системы, выполняющей все трудовые функции физического тела, обеспечивающую управление с использованием дистанционного мысленного воздействия, т.е. микротелекинеза. По мнению автора телекинез представляет собой управление физическими объектами путем воздействия на них непосредственно с высших планов без использования физического тела, т.е. тем же способом, с помощью которого любой человек, осознает он это или нет, управляет своим физическим телом. Были предложены технические и программные решения и инженерно – психологические методики. Система предлагалась адаптивной, т.е. автоматически настраивающейся на индивидуальные особенности, "почерк" оператора и его состояние сознания, с плавным переключением на дистанционные каналы при повышении их надежности (которая измерялась автоматически) и могла одновременно с выполнением основной работы выступать в качестве тренажера. Человек, начиная работу с системой в обычной форме сознания с использованием традиционных каналов (интерфейса), имея мгновенную адекватную по форме и содержанию обратную связь об эффективности своего телекинетического воздействия, должен быстро переходить в форму сознания, оптимальную для использования телекинеза в качестве управляющего воздействия.
1.3.1.4.5. Авторское определение системы виртуальной реальности
С учетом вышесказанного, предлагается следующее определение виртуальной реальности.
Система виртуальной реальности (ВР) – это система, обеспечивающая:
1. Генерацию полиперцептивной модели реальности в соответствии с математической моделью этой реальности, реализованной в программной системе.
2. Погружение пользователя в модель реальности путем подачи на все или основные его перцептивные каналы – органы восприятия, программно-управляемых по величине и содержанию воздействий: зрительного, слухового, тактильного, термического, вкусового и обонятельного и других.
3. Управление системой путем использования виртуального "образа Я" пользователя и виртуальных органов управления системой (интерфейса), на которые он воздействует, представляющие собой зависящую от пользователя часть модели реальности.
4. Реалистичную реакцию моделируемой реальности на виртуальное воздействие и управление со стороны пользователя.
5. Разрыв отождествления пользователя со своим "Образом Я" из обычной реальности (деперсонализация), и отождествление себя с "виртуальным образом Я", генерируемым системой виртуальной реальности (модификация сознания и самосознания пользователя).
6. Эффект присутствия пользователя в моделируемой реальности в своем "виртуальном образе Я", т.е. эффект личного участия пользователя в наблюдаемых виртуальных событиях.
7. Положительные
результаты применения критериев реальности, т.е. функциональную
замкнутость и самодостаточность виртуальной реальности, вследствие чего никакими действиями внутри виртуальной
реальности, осуществляемыми над ее объектами, в т.ч. объектами виртуального
интерфейса, с помощью своего виртуального тела, невозможно установить,
"истинная" эта реальность или виртуальная.
1.3.1.4.6. Критерии реальности при различных формах сознания и их применение в виртуальной реальности
В этой связи вспоминается ставший уже классическим первый фильм "Матрица", в котором Морфей, обращаясь к Нео, произносит свою знаменитую фразу: "Сейчас я покажу тебе, как выглядит окончательная истинная реальность". Эта фраза сразу вызвала у меня массу ассоциаций и вопросов, в частности:
1. А каковы критерии реальности?
2. А вдруг и эта реальность, которую Морфей назвал окончательной, истинной, в действительности является не более, чем симулятором следующего иерархического уровня, так сказать более фундаментальным симулятором?
Здесь возникает сложный мировоззренческий вопрос о том, возможно ли хотя бы в принципе находясь в виртуальной реальности не выходя за ее пределы установить, что ты находишься именно в виртуальной, а не истинной реальности, или это возможно сделать только задним числом, после выхода из виртуальной реальности и перехода в истинную реальность?
Итак, каковы же критерии реальности?
По нашему мнению, прежде всего это самосогласованность реальности, т.е. получение одной и той же информации качественно различными способами и по различным каналом связи (принцип наблюдаемости):
–
согласованность реальности самой с собой во времени;
– согласованность и взаимное
подтверждение информации от различных органов восприятия, которые обычно
реагируют на различные формы материи и часто являются парными (зрение, слух,
обоняние) и расположенными в различных точках пространства.
Например, мы не только что-то видим, но и
слышим, и осязаем, и можем попробовать его на вкус и ощутить запах и все эти
восприятия ОТ РАЗЛИЧНЫХ ОРГАНОВ ЧУВСТВ соответствуют друг другу и
означают, что перед нами некий определенный объект, а не галлюцинация или
визуализация. Согласованная и взаимно подтверждающая информация с различных
органов чувств, в соответствии с принципом наблюдаемости, также может рассматриваться
как повышающая достоверность и адекватность восприятия.
В современных компьютерных играх мы не
только видим довольно качественную визуализацию, но и соответствующее
реалистичное звуковое сопровождение. А в системах виртуальной реальности –
визуализация стереоскопическая (то, что мы видим РАЗНЫМИ глазами как бы с
разных точек в ПРОСТРАНСТВЕ также взаимно подтверждается), а также появляется
тактильный канал с обратной связью, который позволяет ощутить даже твердость,
вес и температуру моделируемого в виртуальной реальности объекта. Все это
вместе уже создает на столько высокую степень реалистичности, что может
возникнуть эффект присутствия в виртуальной реальности, деперсонализация и
отождествление с измененным образом Я, моделируемым в виртуальной реальности
(переход в измененную форму сознания).
Представим, что эти сформулированные критерии реальности не выполняются, т.е. нарушается ее самосогласованность. Как и в чем это может проявляться?
По-видимому, как своего рода "сбои" и различные "нарушения физических законов" и несогласованности в виртуальной реальности:
– "зацикливание" событий, как на заезженной пластинке, т.е. их многократное повторное осуществление без каких-либо изменений (пример: повторный проход черной кошки, с характерной остановкой и поворотом головы, в дверном проеме в "Матрице");
– прохождение сквозь стены;
– полеты и очень длинные прыжки, а также телепортация в своем "реальном" теле;
– действия в другом темпе времени, т.е. эффект замедления внешнего времени, соответствующий аналогичному ускорению внутреннего времени;
– действия в другом масштабе пространства, "увеличение" и "уменьшение" размеров, наблюдение мега и микроструктуры материи;
– видение сквозь стены, видение на больших расстояниях (в т.ч. с увеличением "как в телескоп"), видение прошлого и будущего;
– телекинез, пирокинез, психосинтез, левитация и т.п.;
– одновременное нахождение в нескольких местах.
Нетрудно заметить, что все эти проявления весьма напоминают так называемые "паранормальные явления", которые традиционно связывают с сверхвозможностями человека, т.е. с его возможностями при высших формах сознания.
Эти явления хотя и редко, но все же наблюдаются в нашем мире, что может указывать на то, что наша "истинная реальность" в определенной мере возможно является виртуальной, по крайней мере в большей степени, чем ранее предполагалось.
1.3.1.4.7. Принципы эквивалентности (относительности) Галилея и Эйнштейна и критерии виртуальной реальности
Вспомним известные в физике принципы относительности Галилея и Эйнштейна:
1. Никакими экспериментами внутри замкнутой системы невозможно отличить состояние покоя от состояния равномерного и прямолинейного движения (Галилей). Следовательно, покоящаяся система отсчета физически эквивалентна системе отсчета, движущейся равномерно и прямолинейно под действием сил инерции.
2. Никакими экспериментами внутри ограниченной по размерам замкнутой системы невозможно установить, движется она под действием сил гравитации или по инерции (Эйнштейн). Следовательно, система отсчета, движущаяся в поле сил тяготения физически эквивалентна системе отсчета, движущейся под действием сил инерции.
Легко заметить, что формулировка 7-го пункта в определении системы виртуальной реальности весьма сходна с формулировками принципов относительности Галилея и Эйнштейна: никакими действиями внутри виртуальной реальности, осуществляемыми над ее объектами, в т.ч. объектами виртуального интерфейса, с помощью своего виртуального тела, невозможно установить, "истинная" эта реальность или виртуальная.
Следовательно, виртуальная система отсчета, локализованная в полнофункциональной виртуальной реальности полностью физически эквивалентна физической системе отсчета, локализованной в "истинной реальности". Учитывая эту аналогию, принцип, предложенный автором, назовем принципом относительности или принципом эквивалентности виртуальной и истинной реальности.
1.3.1.5. Системы с дистанционным телекинетическим интерфейсом
В 1981 году Л.А.Бакурадзе и Е.В.Луценко были оформлены заявки на изобретение компьютерной системы, выполняющей все трудовые функции физического тела, обеспечивающую управление с использованием дистанционного мысленного воздействия, т.е. микротелекинеза.
По мнению автора телекинез представляет собой управление физическими объектами путем воздействия на них непосредственно с высших планов без использования физического тела, т.е. тем же способом, с помощью которого любой человек, осознает он это или нет, управляет своим физическим телом.
Были предложены технические и программные решения и инженерно – психологические методики. Система предлагалась адаптивной, т.е. автоматически настраивающейся на индивидуальные особенности, "почерк" оператора и его состояние сознания, с плавным переключением на дистанционные каналы при повышении их надежности (которая измерялась автоматически) и могла одновременно с выполнением основной работы выступать в качестве тренажера для овладения высшими формами сознания.
Человек, начиная работу с системой в обычной форме сознания с использованием традиционных каналов (интерфейса), имея мгновенную адекватную по форме и содержанию обратную связь об эффективности своего телекинетического воздействия, должен быстро переходить в одну из высших форм сознания, оптимальную для использования телекинеза в качестве управляющего воздействия.
Контрольные вопросы
1. Интеллектуальные интерфейсы. Использование биометрической информации о пользователе в управлении системами.
2. Идентификация и аутентификация личности по почерку. Понятие клавиатурного почерка.
3. Соотношение психографологии и атрибуции текстов.
4. Идентификация и аутентификация личности пользователя компьютера по клавиатурному почерку.
5. Прогнозирование ошибок оператора по изменениям в его электроэнцефалограмме.
6. Системы с биологической обратной связью (БОС).
7. Мониторинг состояния сотрудников сборочного конвейера с целью обеспечения высокого качества продукции.
8. Компьютерные тренажеры, основанные на БОС, для обучения больных навыкам управления своим состоянием.
9. Компьютерные игры с БОС.
10. Системы с семантическим резонансом. Компьютерные (Y-технологии и интеллектуальный подсознательный интерфейс.
11. Системы виртуальной реальности и критерии реальности. Эффекты присутствия, деперсонализации и модификация сознания пользователя.
12. Классическое определение системы виртуальной реальности.
13. "Эффект присутствия" в виртуальной реальности.
14. Применения систем виртуальной реальности.
15. Модификация сознания и самосознания пользователя в виртуальной реальности.
16. Авторское определение системы виртуальной реальности.
17. Критерии реальности при различных формах сознания и их применение в виртуальной реальности.
18. Принципы эквивалентности (относительности) Галилея и Эйнштейна и критерии виртуальной реальности.
19. Системы с дистанционным телекинетическим интерфейсом.
Рекомендуемая литература
1. Завгородний В.В., Мельников Ю.Н., Идентификация по клавиатурному почерку. "Банковские Технологии", №9, 1998.
2. Иванов А.И. Биометрическая идентификация личности по динамике подсознательных движений. Пенза. Издательство Пензенского государственного университета –2000, –188 с.
3. Луценко Е.В., Лаптев В.Н., Третьяк В.Г. Прогнозирование качества специальной деятельности методом подсознательного (подпорогового) тестирования на основе семантического резонанса. //В сб.: "Материалы II межвузовской научно-технической конференции". – Краснодар: КВИ, 2001. – С.127-128.
4. Луценко Е.В., Лебедев А.Н. Диагностика и прогнозирование профессиональных и творческих способностей методом АСК-анализа электроэнцефалограмм в системе "Эйдос". // Межвузовский сборник научных трудов, том 1. –Краснодар: КВИ. 2003.–С. 227-229.
5. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: постановка задачи. // Научный журнал КубГАУ. – 2004.– №4(6). – 9 с. http://ej.kubagro.ru.
6. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: описание эксперимента. // Научный журнал КубГАУ. – 2004.– №4(6). – 13 с. http://ej.kubagro.ru.
7. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: анализ результатов исследования. // Научный журнал КубГАУ. – 2004.– №4(6). – 17 с. http://ej.kubagro.ru.
8. Смирнов И., Безносюк Е., Журавлёв А. Психотехнологии: Компьютерный психосемантический анализ и психокоррекция на неосознаваемом уровне. - М.: Изд. группа Прогресс-Культура, 1995. - 416с.
9. Шагас Ч. Вызванные потенциалы мозга в норме и патологии. –М.: Мир, 1975. –314 с.
10. Сайт Луценко Е.В. http://Lc.kubagro.ru.
1.3.2. ЛЕКЦИЯ-8.
Автоматизированные системы
распознавания образов
Учебные вопросы
1. Основные понятия и определения, связанные с системами распознавания образов.
2. Проблема распознавания образов.
3. Классификация методов распознавания образов.
4. Применение распознавания образов для идентификации и прогнозирования. Сходство и различие в содержании понятий "идентификация" и "прогнозирование".
5. Роль и место распознавания образов в автоматизации управления сложными системами.
6. Методы кластерного анализа.
1.3.2.1. Основные понятия
Системой распознавания образов будем называть класс систем искусственного интеллекта, обеспечивающих:
– формирование конкретных образов объектов и обобщенных образов классов;
– обучение, т.е. формирование обобщенных образов классов на основе ряда примеров объектов, классифицированных (т.е. отнесенных к тем или иным категориям – классам) учителем и составляющих обучающую выборку;
– самообучение, т.е. формирование кластеров объектов на основе анализа неклассифицированной обучающей выборки;
– распознавание, т.е. идентификацию (и прогнозирование) состояний объектов, описанных признаками, друг с другом и с обобщенными образами классов;
– измерение степени адекватности модели;
– решение обратной задачи идентификации и прогнозирования (обеспечивается не всеми моделями).
1.3.2.1.1. Признаки и образы конкретных объектов, метафора фазового пространства
Признаками объектов будем называть конкретные результаты измерения значений их свойств.
Свойства объектов отличаются своим качеством и измеряются с помощью различных органов восприятия или измерительных приборов в различных единицах измерения.
Результатом измерения является снижение неопределенности в наших знаниях о значении свойств объекта. Значения свойств конкретизируются путем их сопоставления определенным градациям соответствующих измерительных шкал: номинальных, порядковых или отношений.
В номинальных шкалах отсутствуют отношения порядка, начало отсчета и единица измерения.
На порядковых шкалах определены отношения "больше – меньше", но отсутствуют начало отсчета и единица измерения.
На шкалах отношений определены отношения порядка, все арифметические операции, есть начало отсчета и единица измерения.
Можно представить себе, что шкалы образуют оси координат некоторого абстрактного многомерного пространства, которое будем называть "фазовым пространством".
В этом фазовом пространстве каждый конкретный объект представляется определенной точкой, имеющей координаты, соответствующие значениям его свойств по осям координат, т.е. градациям описательных шкал.
Оси координат фазового пространства в общем случае не являются взаимно-перпендикулярными шкалами отношений, т.е. в общем случае это пространство неортонормированное, более того – неметрическое. Следовательно, в нем в общем случае не применима Евклидова мера расстояний, т.е. не действует Евклидова метрика. Применение этой меры расстояний корректно, если одновременно выполняются два условия:
1. Все оси координат фазового пространства являются шкалами отношений.
2. Все оси координат взаимно-перпендикулярны или очень близки к этому.
1.3.2.1.2. Признаки и обобщенные образы классов
Обобщенный образ класса формируется из нескольких образов конкретных объектов, относящихся к данному классу, т.е. одной градации некоторой классификационной шкалы.
Обобщенные образы классов формализуются (кодируются) путем использования классификационных шкал и градаций, которые могут быть тех же типов, что и описательные, т.е. номинальные, порядковые и отношений.
Сама принадлежность конкретных объектов к данному классу определятся либо человеком-учителем, после чего фиксируется в обучающей выборке, либо самой системой автоматически на основе кластерного анализа конкретных объектов.
1.3.2.1.3. Обучающая выборка и ее репрезентативность по отношению к генеральной совокупности. Ремонт (взвешивание) данных
Рассмотрим, как зависит степень достоверности выводов о генеральной совокупности от объема обучающей выборки.
Если обучающая выборка включает все объекты генеральной совокупности, т.е. они совпадают, то достоверность выводов будет наиболее высокой (при всех прочих равных условиях).
Если же обучающая выборка очень мала, то вряд ли на ее основе могут быть сделаны достоверные выводы о генеральной совокупности, т.к. в этом случае в обучающую выборку могут даже не входить примеры объектов всех или подавляющего большинства классов.
Под репрезентативностью обучающей выборки будем понимать ее способность адекватно представлять генеральную совокупность, так что изучение самой генеральной совокупности можно корректно заменить исследованием обучающей выборки.
Но репрезентативность зависит не только от объема, но и от структуры обучающей выборки, т.е. от того, насколько полно представлены все категории объектов генеральной совокупности (классы) и от того, насколько полно они описаны признаками.
Взвешивание
данных или ремонт обучающей выборки – это операция, в результате которой частное распределение объектов по
классам в обучающей выборке максимально, на сколько это возможно, приближается
либо к частотному распределению генеральной совокупности (если оно известно из
независимых источников), либо к равномерному.
В системе "Эйдос" режим взвешивания данных реализован.
1.3.2.1.4. Основные операции: обобщение и распознавание
Сразу необходимо отметить, что операция обобщения реализуется далеко не во всех моделях систем распознавания (например, в методе k-ближайших соседей), а в тех, в которых оно реализуется, – это делается по-разному.
Обычно, пока не реализовано обобщение нет возможности определить ценность признаков для решения задачи идентификации.
Например, если у нас есть 10 конкретных мячей разного размера и цвета, состоящих из разных материалов и предназначенных для разных игр, и мы рассматриваем их как совершенно независимые друг от друга объекты, наряду с другими, то у нас нет возможности определить, какие признаки являются наиболее характерными для мячей и наиболее сильно отличают их от этих других объектов. Но как только мы сформируем обобщенные образы "мяч", "стул", и т.д., сразу выясниться, что цвет мяча и материал, из которого он сделан, не является жестко связанными с обобщенным образом класса "мяч", а наиболее существенно то, что он круглый и его можно бросать или бить во время игры.
Распознавание – это операция сравнения и определения
степени сходства образа данного конкретного объекта с образами других
конкретных объектов или с обобщенными образами классов, в результате которой
формируется рейтинг объектов или классов по убыванию сходства с распознаваемым
объектом.
Ключевым моментом при реализации операции распознавания в математической модели является выбор вида интегрального критерия или меры сходства, который бы на основе знания о признаках конкретного объекта позволил бы количественно определить степень его сходства с другими объектами или обобщенными образами классов.
В ортонормированном пространстве, осями которого являются шкалы отношений, вполне естественным является использовать в качестве такой меры сходства Евклидово расстояние. Однако, такие пространства на практике встречаются скорее как исключение из правила, а операция ортонормирования является довольно трудоемкой в вычислительном отношении и приводит к обеднению модели, а значит ее не всегда удобно и целесообразно осуществлять.
Поэтому актуальной является задача выбора или конструирования интегрального критерия сходства, применение которого было бы корректно и в неортонормированных пространствах. Кроме того, этот интегральный критерий должен быть устойчив к наличию шума, т.е. к неполноте и искажению как в исходных данных, так и самой численной модели.
Требование устойчивости к наличию шума математически означает, что результат применения интегрального критерия к сигналу, состоящему только из белого шума, должен быть равным нулю. Это значит, что в качестве интегрального критерия может быть применена функция, используемая при определении самого понятия "белый шум", т.е. свертка, скалярное произведение, корреляция.
Такой интегральный критерий предложен в математической модели системно-когнитивного анализа и реализован в системе "Эйдос".
1.3.2.1.5. Обучение с учителем (экспертом) и самообучение (кластерный анализ)
Причем, если описательные характеристики могут формироваться с помощью информационно-измерительной системы автоматически, то классификационные – представляют собой результат вообще говоря неформализуемого процесса оценки степени принадлежности данных объектов к различным классам, который осуществляется человеком-экспертом или, как традиционно говорят специалисты по распознаванию образов, "учителем". В этом случае не возникает вопроса о том, для формирования обобщенного образа каких классов использовать описание данного конкретного объекта.
Обучение
без учителя или самообучение –
это процесс формирования обобщенных образов классов, на основе обучающей
выборки, содержащей характеристики конкретных объектов, причем только в
описательных шкалах и градациях.
Поэтому этот процесс реализуется в три этапа:
1. Кластерный анализ объектов обучающей выборки, в результате которого определяются группы наиболее сходных их них по их признакам (кластеры).
2. Присвоение кластерам статуса обобщенных классов, для формирования обобщенных образов которых используются конкретные объекты, входящие именно в эти кластеры.
3. Формирование обобщенных образов классов, аналогично тому, как это делалось при обучении с учителем.
1.3.2.1.6. Верификация, адаптация и синтез модели
Как только произнесено или написано слово "модель", сразу неизбежно возникает вопрос о степени ее адекватности.
Верификация модели – это операция установления степени ее
адекватности (валидности) путем сравнения результатов идентификации конкретных
объектов с их фактической принадлежностью к обобщенным образам классов.
Различают внутреннюю и внешнюю, интегральную и дифференциальную валидность.
Внутренняя валидность – это способность модели верно идентифицировать объекты обучающей выборки.
Если модель имеет низкую внутреннюю валидность, то модель нельзя считать удачно сформированной.
Внешняя валидность – это способность модели верно идентифицировать объекты, не входящие в обучающую выборку.
Интегральная валидность – это средневзвешенная достоверность идентификации по всем классам и распознаваемым объектам.
Дифференциальная валидность – это способность модели верно идентифицировать объекты в разрезе по классам.
Адаптация модели – это учет в модели объектов, не входящих в обучающую выборку, но входящих в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна.
Если моделью верно идентифицируются объекты, не входящие в обучающую выборку, то это означает, что эти объекты входят в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна. Следовательно, на основе обучающей выборки удалось выявить закономерности взаимосвязей между признаками и принадлежностью объектов к классам, которые действуют не только в обучающей выборке, но имеют силу и для генеральной совокупности.
Адаптация модели не требует изменения классификационных и описательных шкал и градаций, а лишь объема обучающей выборки, и приводит к количественному изменению модели.
Синтез (или повторный синтез – пересинтез) модели – это учет в модели объектов, не входящих ни в обучающую выборку, ни в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна.
Это объекты с новыми, ранее неизвестными закономерностями взаимосвязей признаков с принадлежностью этих объектов к тем или иным классам. Причем и признаки, и классы, могут быть как те, которые уже были отражены в модели ранее, так и новые. Пересинтез модели приводит к ее качественному изменению.
1.3.2.2. Проблема распознавания образов
Проблема распознавания образов сводится к двум задачам: обучения и распознавания. Поэтому, прежде чем сформулировать задачу обучения распознаванию образов уточним, в чем смысл их распознавания.
Простейшим вариантом распознавания является строгий запрос на поиск объекта в базе данных по его признакам, который реализуется в информационно-поисковых системах. При этом каждому полю соответствует признак (описательная шкала), а значению поля – значение признака (градация описательной шкалы). Если в базе данных есть записи, все значения заданных полей которых точно совпадают со значениями, заданными в запросе на поиск, то эти записи извлекаются в отчет, иначе запись не извлекается.
Более сложными вариантами распознавания является нечеткий запрос с неполнотой информации, когда не все признаки искомых объектов задаются в запросе на поиск, т.к. не все они известны, и нечеткий запрос с шумом, когда не все признаки объекта известны, а некоторые считаются известными ошибочно. В этих случаях из базы данных извлекаются все объекты, у которых совпадает хотя бы один признак и в отчете объекты сортируются (ранжируются) в порядке убывания количества совпавших признаков. При этом при определении ранга объекта в отсортированном списке все признаки считаются имеющими одинаковый "вес" и учитывается только их количество.
Однако:
– во-первых, на самом деле признаки имеют разный вес, т.е. один и тот же признак в разной степени характерен для различных объектов;
– во-вторых, нас могут интересовать не столько сами объекты, извлекаемые из базы данных прецедентов по запросам, сколько классификация самого запроса, т.е. отнесение его к определенной категории, т.е. к тому или иному обобщенному образу класса.
Если реализация строгих и даже нечетких запросов не вызывает особых сложностей, то распознавание как идентификация с обобщенными образами классов, причем с учетом различия весов признаков представляет собой определенную проблему.
Обучение осуществляется путем предъявления системе отдельных объектов, описанных на языке признаков, с указанием их принадлежности тому или другому классу. При этом сама принадлежность к классам сообщается системе человеком – Учителем (экспертом).
В результате обучения распознающая система должна приобрести способность:
1. Относить объекты к классам, к которым они принадлежат (идентифицировать объекты верно).
2. Не относить объекты к классам, к которым они не принадлежат (неидентифицировать объекты ошибочно).
Эта и есть проблема обучения распознаванию образов, и состоит она в следующем:
1. В разработке математической модели, обеспечивающей: обобщение образов конкретных объектов и формирование обобщенных образов классов; расчет весов признаков; определение степени сходства конкретных объектов с классами и ранжирование классов по степени сходства с конкретным объектом, включая и положительное, и отрицательное сходство.
2. В наполнении этой модели конкретной информацией, характеризующей определенную предметную область.
1.3.2.3. Классификация методов распознавания образов
Распознаванием образов называются задачи установления отношений эквивалентности между конкретными и обобщенными образами-моделями объектов реального или идеального мира.
Отношения эквивалентности выражают принадлежность оцениваемых объектов к каким–либо классам, рассматриваемым как самостоятельные семантические единицы.
При построении алгоритмов распознавания классы эквивалентности могут задаваться исследователем, который пользуется собственными содержательными представлениями или использует внешнюю дополнительную информацию о сходстве и различии объектов в контексте решаемой задачи. Тогда говорят о "распознавании с учителем". В противном случае, т.е. когда автоматизированная система решает задачу классификации без привлечения внешней обучающей информации, говорят об автоматической классификации или "распознавании без учителя".
Большинство алгоритмов распознавания образов требует привлечения весьма значительных вычислительных мощностей, которые могут быть обеспечены только высокопроизводительной компьютерной техникой.
Различные авторы (Ю.Л. Барабаш, В.И. Васильев, А.Л. Горелик, В.А. Скрипкин, Р. Дуда, П. Харт, Л.Т.Кузин, Ф.И. Перегудов, Ф.П. Тарасенко, Темников Ф.Е., Афонин В.А., Дмитриев В.И., Дж. Ту, Р. Гонсалес, П. Уинстон, К. Фу, Я.З. Цыпкин и др.) дают различную типологию методов распознавания образов. Одни авторы различают параметрические, непараметрические и эвристические методы, другие – выделяют группы методов, исходя из исторически сложившихся школ и направлений в данной области.
Например, в работах В.А. Дюка [32, 33], в которых дан академический обзор методов распознавания, используется следующая типология методов распознавания образов:
– методы, основанные на принципе разделения;
– статистические методы;
– методы, построенные на основе "потенциальных функций";
– методы вычисления оценок (голосования);
– методы, основанные на исчислении высказываний, в частности на аппарате алгебры логики.
В основе данной классификации лежит различие в формальных методах распознавания образов и поэтому опущено рассмотрение эвристического подхода к распознаванию, получившего полное и адекватное развитие в экспертных системах.
Эвристический подход основан на трудно формализуемых знаниях и интуиции исследователя. При этом исследователь сам определяет, какую информацию и каким образом система должна использовать для достижения требуемого эффекта распознавания.
Подобная типология методов распознавания с той или иной степенью детализации встречается во многих работах по распознаванию. В то же время известные типологии не учитывают одну очень существенную характеристику, которая отражает специфику способа представления знаний о предметной области с помощью какого–либо формального алгоритма распознавания образов.
В.А. Дюка [32, 33] выделяет два основных способа представления знаний:
– интенсиональное, в виде схемы связей между атрибутами (признаками).
– экстенсиональное, с помощью конкретных фактов (объекты, примеры).
Интенсиональное представление фиксируют закономерности и связи, которыми объясняется структура данных. Применительно к диагностическим задачам такая фиксация заключается в определении операций над атрибутами (признаками) объектов, приводящих к требуемому диагностическому результату. Интенсиональные представления реализуются посредством операций над значениями атрибутов и не предполагают произведения операций над конкретными информационными фактами (объектами).
В свою очередь, экстенсиональные представления знаний связаны с описанием и фиксацией конкретных объектов из предметной области и реализуются в операциях, элементами которых служат объекты как целостные системы.
На наш
взгляд, можно провести глубокую и далеко идущую аналогию между интенсиональными и экстенсиональными представлениями знаний и механизмами, лежащими в основе деятельности левого
и правого полушарий головного мозга человека. Если для правого полушария
характерна целостная прототипная репрезентация окружающего мира, то левое полушарие оперирует закономерностями,
отражающими связи атрибутов этого мира.
Описанные выше два фундаментальных способа представления знаний позволяют предложить следующую классификацию методов распознавания образов:
– интенсиональные методы, основанные на операциях с признаками.
– экстенсиональные методы, основанные на операциях с объектами.
Необходимо
особо подчеркнуть, что существование именно этих двух (и только двух)
групп методов распознавания: оперирующих с признаками, и оперирующих с объектами, на наш взгляд,
глубоко закономерно. С этой точки зрения ни один из этих методов, взятый
отдельно от другого, не позволяет сформировать адекватное отражение предметной
области. Между этими методами существует отношение дополнительности в смысле Н.Бора, поэтому перспективные системы распознавания
должны обеспечивать реализацию обоих этих методов, а не только какого–либо
одного из них.
Таким образом, в основу классификации методов распознавания, предложенной В.А. Дюка [32, 33], положены фундаментальные закономерности, лежащие в основе человеческого способа познания вообще, что ставит ее в совершенно особое (привилегированное) положение по сравнению с другими классификациями, которые на этом фоне выглядят более легковесными и искусственными.
1.3.2.4. Применение распознавания образов для идентификации и прогнозирования. Сходство и различие в содержании понятий "идентификация" и "прогнозирование"
Термины "Распознавание образов" и "Идентификация" являются синонимами.
Идентификация и прогнозирование часто практически ничем друг от друга не отличаются по математическим моделям и алгоритмам. Основное различие между ними состоит в том, что при идентификации признаки и состояния объекта относятся к одному времени, тогда как при прогнозировании признаки (факторы) относятся к прошлому, а состояния объекта – к будущему.
Это означает, что системы распознавания образов с успехом могут применяться не только для решения задач идентификации, но и прогнозирования.
1.3.2.5. Роль и место распознавания образов в автоматизации управления сложными системами
1.3.2.5.1. Обобщенная структура системы управления
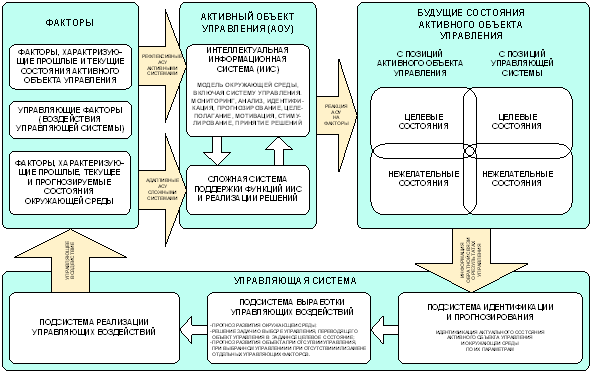
Автоматизированная система управления состоит из двух основных частей: объекта управления и управляющей системы (рисунок 71).
Управляющая система осуществляет следующие функции:
– идентификация состояния объекта управления;
– выработка управляющего воздействия исходя из целей управления с учетом состояния объекта управления и окружающей среды;
– оказание управляющего воздействия на объект управления.
|
|
|
Рисунок 71. Обобщенная схема рефлексивной
системы управления |
1.3.2.5.2. Место системы идентификации в системе управления
Распознавание образов есть не что иное, как идентификация состояния некоторого объекта. Автоматизированная система управления АСУ), построенная на традиционных принципах, может работать только на основе параметров, закономерности связей которых уже известны, изучены и отражены в математической модели. В итоге АСУ, основанные на традиционном подходе, практически не эффективны с активными многопараметрическими слабодетерминированными объектами управления, такими, например, как макро– и микро– социально-экономические системы в условиях динамичной экономики "переходного периода", иерархические элитные и этнические группы, социум и электорат, физиология и психика человека, природные и искусственные экосистемы и многие другие.
Поэтому,
в состав перспективных АСУ, обеспечивающих устойчивое управление активными
объектами в качестве существенных функциональных звеньев должны войти
подсистемы идентификации и прогнозирования состояний среды и объекта
управления, основанные на методах искусственного интеллекта (прежде всего
распознавания образов), методах поддержки принятия решений и теории информации.
1.3.2.5.3. Управление как задача, обратная идентификации и прогнозированию
Кратко рассмотрим вопрос о применении систем распознавания образов для принятия решений об управляющем воздействии. Очевидно, что применение систем распознавания для прогнозирования результатов управления при различных сочетаниях управляющих факторов позволяет рассмотреть и сравнить различные варианты управления и выбрать наилучшие из них по определенным критериям. Однако, этот подход на практике малоэффективен, особенно если факторов много, т.к. в этом случае количество сочетаний их значений может быть чрезвычайно большим.
Если в качестве классов распознавания взять целевые и иные будущие состояния объекта управления, а в качестве признаков – факторы, влияющие на него, то в модели распознавания образов может быть сформирована количественная мера причинно-следственной связи факторов и состояний.
Это позволяет по заданному целевому состоянию объекта управления получить информацию о силе и направлении влияния факторов, способствующих или препятствующих переходу объекта в это состояние, и, на этой основе, выработать решение об управляющем воздействии.
Задача выбора факторов по состоянию является обратной задачей прогнозирования, т.к. при прогнозировании, наоборот, определяется состояние по факторам.
Факторы могут быть разделены на следующие группы:
– характеризующие предысторию объекта управления и его актуальное состояние управления;
– технологические (управляющие) факторы;
– факторы окружающей среды;
Таким образом, системы распознавания образов могут быть применены в составе АСУ в подсистемах:
– идентификации состояния объекта управления;
– выработки управляющих воздействий.
Это целесообразно в случае, когда объект управления представляет собой сложную или активную систему.
1.3.2.6. Методы кластерного анализа
Термин "Кластерный анализ" впервые ввел Tryon в 1939.
Кластеризация – это операция автоматической классификации, в ходе которой объекты объединяются в группы (кластеры) таким образом, что внутри групп различия между объектами минимальны, а между группами – максимальны. При этом в ходе кластеризации не только определяется состав кластеров, но и сам их набор и границы.
Поэтому вполне обоснованно считается, что методы кластерного анализа используются в большинстве случаев тогда, когда нет каких-либо априорных гипотез относительно классов, т.е. исследование находится на первой эмпирической стадии: описательной.
Существует большое количество различных алгоритмов кластеризации, которые обычно связаны с полным перебором объектов и весьма трудоемки в вычислительном отношении, здесь же мы упомянем лишь о трех из них:
– объединение (древовидная кластеризация);
– двухвходовое объединение;
– метод K средних.
Рассмотрим кратко эти алгоритмы (описание взято с сайта http://StatSoft.ru).
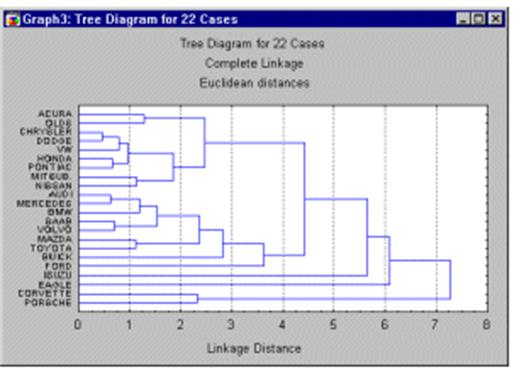
1.3.2.6.1. Древовидная кластеризация
Древовидная диаграмма (диаграмму (рисунок 72) начинается с конкретных объектов (в левой части диаграммы). Теперь представим себе, что постепенно (очень малыми шагами) вы "ослабляете" ваш критерий о том, какие объекты являются уникальными, а какие нет. Другими словами, вы понижаете порог, относящийся к решению об объединении двух или более объектов в один кластер.
В результате, вы связываете вместе всё большее и большее число объектов и агрегируете (объединяете) все больше и больше кластеров, состоящих из все сильнее различающихся элементов. Окончательно, на последнем шаге все объекты объединяются вместе.
|
|
|
Рисунок 72. Древовидная диаграмма последовательной кластеризации |
1.3.2.6.2. Двухвходовое объединение
Исследователь может кластеризовать конкретные образы наблюдаемых объектов для определения кластеров объектов со сходными признаками.
Он может также кластеризовать признаки для определения кластеров признаков, которые связаны со сходными конкретными объектами.
В двувходовом алгоритме эти процессы осуществляются одновременно.
1.3.2.6.3. Метод K средних
В этом методе принадлежность объектов к кластерам определяется таким образом, чтобы:
– минимизировать изменчивость (различия) объектов внутри кластеров;
– максимизировать изменчивость объектов между кластерами.
Контрольные вопросы
1. Основные понятия и определения, связанные с системами распознавания образов.
2. Признаки и образы конкретных объектов, метафора фазового пространства.
3. Признаки и обобщенные образы классов.
4. Обучающая выборка и ее репрезентативность по отношению к генеральной совокупности. Ремонт (взвешивание) данных.
5. Основные операции: обобщение и распознавание.
6. Обучение с учителем (экспертом) и самообучение (кластерный анализ).
7. Верификация, адаптация и синтез модели.
8. Проблема распознавания образов.
9. Классификация методов распознавания образов.
10. Применение распознавания образов для идентификации и прогнозирования. Сходство и различие в содержании понятий "идентификация" и "прогнозирование".
11. Роль и место распознавания образов в автоматизации управления сложными системами.
12. Обобщенная структура системы управления.
13. Место системы идентификации в системе управления.
14. Управление как задача, обратная идентификации и прогнозированию.
15. Методы кластерного анализа.
16. Метод кластеризации: "Древовидная кластеризация".
17. Метод кластеризации: "Двувходовое объединение".
18. Метод кластеризации: "Метод K средних".
Рекомендуемая литература
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1.3.3.
ЛЕКЦИЯ-9.
Математические методы
и автоматизированные системы
поддержки принятия решений
Учебные
вопросы
1. Многообразие задач принятия решений.
2. Языки описания методов принятия решений.
3. Выбор в условиях неопределенности.
4. Решение как компромисс и баланс различных интересов. О некоторых ограничениях оптимизационного подхода.
5. Экспертные методы выбора.
6. Юридическая ответственность за решения, принятые с применением систем поддержки принятия решений.
7. Условия корректности использования систем поддержки принятия решений.
8. Хранилища данных для принятия решений.
1.3.3.1. Многообразие задач принятия решений
1.3.3.1.1. Принятие решений, как реализация цели
Определение: принятие решения есть действие над
множеством альтернатив, в результате которого исходное множество альтернатив
сужается. Это действие называется "выбор".
Выбор является действием, придающим всей деятельности целенаправленность. Именно через акты выбора реализуется подчиненность всей деятельности определенной цели или совокупности взаимосвязанных целей.
Таким образом, для того, чтобы стал возможен акт выбора, необходимо следующее:
Порождение или обнаружение множества альтернатив, на котором предстоит совершить выбор.
Определение целей, ради достижения которых осуществляется выбор.
Разработка и применение способа сравнения альтернатив между собой, т.е. определение рейтинга предпочтения для каждой альтернативы, согласно определенным критериям, позволяющим косвенно оценивать, насколько каждая альтернатива соответствует цели.
Современные работы в области поддержки принятия решений выявили характерную ситуацию, которая состоит в том, что полная формализация нахождения наилучшего (в определенном смысле) решения возможна только для хорошо изученных, относительно простых задач, тогда как на практике чаще встречаются слабо структурированные задачи для которых полностью формализованных алгоритмов не разработано (если не считать полного перебора и метода проб и ошибок). Вместе с тем, опытные, компетентные и способные специалисты, часто делают выбор, который оказывается достаточно хорошим. Поэтому современная тенденция практики принятия решений в естественных ситуациях состоит в сочетании способности человека решать неформализованные задачи с возможностями формальных методов и компьютерного моделирования: диалоговые системы поддержки принятия решений, экспертные системы, адаптивные человеко-машинные автоматизированные системы управления, нейронные сети и когнитивные системы.
1.3.3.1.2. Принятие решений, как снятие неопределенности (информационный подход)
Процесс получения информации можно рассматривать как уменьшение неопределенности в результате приема сигнала, а количество информации, как количественную меру степени снятия неопределенности.
Но в результате выбора некоторого подмножества альтернатив из множества, т.е. в результате принятия решения, происходит тоже самое (уменьшение неопределенности).
Это значит, что каждый выбор, каждое решение порождает определенное количество информации, а значит может быть описано в терминах теории информации.
Простейшее понятие об информации (подход Хартли).
Будем считать, что если существует множество элементов и осуществляется выбор одного из них, то этим самым сообщается или генерируется определенное количество информации. Эта информация состоит в том, что если до выбора не было известно, какой элемент будет выбран, то после выбора это становится известным.
Найдем вид функции, связывающей количество информации, получаемой при выборе некоторого элемента из множества, с количеством элементов в этом множестве, т.е. с его мощностью.
Если множество элементов, из которых осуществляется выбор, состоит из одного-единственного элемента, то ясно, что его выбор предопределен, т.е. никакой неопределенности выбора нет. Таким образом, если мы узнаем, что выбран этот единственный элемент, то, очевидно, при этом мы не получаем никакой новой информации, т.е. получаем нулевое количество информации.
Если множество состоит из двух элементов, то неопределенность выбора минимальна. В этом случае минимально и количество информации, которое мы получаем, узнав, что совершен выбор одного из элементов. Минимальное количество информации получается при выборе одного из двух равновероятных вариантов. Это количество информации принято за единицу измерения и называется "бит".
Чем больше элементов в множестве, тем больше неопределенность выбора, тем больше информации мы получаем, узнав о том, какой выбран элемент.
Рассмотрим множество, состоящее из чисел в двоичной системе счисления длиной i двоичных разрядов. При этом каждый из разрядов может принимать значения только 0 и 1 (таблица 32).
Таблица 32 – К ЭВРИСТИЧЕСКОМУ ВЫВОДУ ФОРМУЛЫ КОЛИЧЕСТВА ИНФОРМАЦИИ
ПО ХАРТЛИ
|
Кол-во двоичных разрядов (i) |
Кол-во состояний N, которое можно
пронумеровать i-разрядными двоичными
числами |
Основание системы счисления |
||
|
10 |
16 |
2 |
||
|
1 |
2 |
0 1 |
0 1 |
0 1 |
|
2 |
4 |
0 1 2 3 |
0 1 2 3 |
00 01 10 11 |
|
3 |
8 |
0 1 2 3 4 5 6 7 |
0 1 2 3 4 5 6 7 |
000 001 010 011 100 101 110 111 |
|
4 |
16 |
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
0 1 2 3 4 5 6 7 8 9 A B C D E F |
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 |
|
*** |
*** |
|
|
|
|
i |
N=2i |
|
|
|
Из таблицы 32 очевидно, что количество этих чисел (элементов) в множестве равно:
|
|
|
Рассмотрим процесс выбора чисел из рассмотренного множества. До выбора вероятность выбрать любое число одинакова. Существует объективная неопределенность в вопросе о том, какое число будет выбрано. Эта неопределенность тем больше, чем больше N – количество чисел в множестве, а чисел тем больше – чем больше разрядность i этих чисел.
Примем, что выбор одного числа дает нам следующее количество информации:
|
|
|
Таким
образом, количество информации, содержащейся в двоичном числе, равно количеству
двоичных разрядов в этом числе. Это количество информации i мы получаем, когда
случайным равновероятным образом выпадает одно из двоичных чисел, записанных i
разрядами, или из некоторого множества выбирается объект произвольной природы,
пронумерованный этим числом (предполагается, что остальные объекты этого
множества пронумерованы остальными числами и этим они и отличаются).
Это выражение и представляет собой формулу Хартли для количества информации. Отметим, что оно полностью совпадает с выражением для энтропии (по Эшби), которая рассматривалась им как количественная мера степени неопределенности состояния системы.
Сам Хартли, возможно, пришел к своей мере на основе эвристических соображений, подобных только что изложенным, но в настоящее время строго доказано, что логарифмическая мера для количества информации однозначно следует из этих двух постулированных им условий.
Таким образом, информация по своей сущности
теснейшим и органичным образом связана с выбором и принятием решений.
Отсюда
следует простейшее на первый взгляд заключение: "Для принятия решений нужна информация, без информации принятие
решений невозможно, значение информации для принятия решений является определяющим,
процесс принятия решений генерирует информацию".
Мера Шеннона, как обобщение меры Хартли для неравновероятных событий.
Представим себе, что имеются объекты различных видов, причем:
– всего имеется M видов объектов;
– объектов каждого i-го вида имеется Ni.
Тогда по Хартли, если мы извлекаем один из объектов i-го вида, то получаем Ii бит информации
|
|
|
В
среднем по ![]() на один объект i-го
вида.
на один объект i-го
вида.
|
|
|
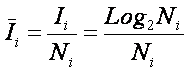
Сумма этих средних будет равна:
|
|
|
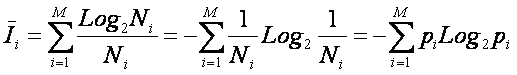
(где: pi=1/Ni, – вероятность встречи объектов i-го вида).
Последнее выражение – это и есть формула Шеннона, которая, таким образом, позволяет рассчитать средневзвешенное количество информации, приходящееся на один объект, получаемое при предъявлении объектов различных видов.
Отметим, что идентификация объектов, как относящихся к тому или иному виду (i-му виду) осуществляется на основе признаков этих объектов. В простейшем варианте это может быть и один признак, например номер вида на бильярдном шаре, но в реальных случаях признаков может быть очень много и их различные наборы сложным и неоднозначным образом могут быть связаны с принадлежностью объектов к тем или иным классам.
Но главный вывод от этого не изменяется: формула Шеннона дает средневзвешенное количество информации, приходящееся на один объект, получаемое при предъявлении объектов различных видов (классов), отличающихся своими наборами признаков. Мера Шеннона является обобщением меры Хартли для неравновероятных событий.
1.3.3.1.3. Связь принятия решений и распознавания образов
Распознавание образов есть решение задачи идентификации состояния объекта или системы, отнесение его к той или иной классификационной категории.
Распознавание образов и принятие решений тесно взаимосвязаны:
– само распознавание безусловно представляет собой принятие решения об отнесении состояния системы к той или иной категории;
– от того, к какой категории отнесено состояние системы самым непосредственным образом зависят и решения по управлению этой системой;
– математический аппарат распознавания образов и принятия решений имеет очень много аналогий, а иногда и просто является тождественным (например, сведение многокритериальной задачи к однокритериальной).
1.3.3.1.4. Классификация задач принятия решений
Множественность задач принятия решений связана с тем, что каждая компонента ситуации, в которой осуществляется принятие решений может реализовываться в качественно различных вариантах.
Вот только некоторые из этих вариантов:
Множество альтернатив с одной стороны может быть конечным, счетным или континуальным, а с другой – закрытым (т.е. известным полностью), или открытым (включающим неизвестные элементы).
Оценка альтернатив может осуществляться по одному или нескольким критериям, которые, в свою очередь, могут иметь количественный или качественный характер.
Режим выбора может быть однократным (разовым), или многократным, повторяющимся, включающим обратную связь по результатам выбора, т.е. допускающим обучение алгоритмов принятия решений с учетом последствий предыдущих выборов.
Последствия выбора каждой альтернативы могут быть точно известны заранее (выбор в условиях определенности), иметь вероятностный характер, когда известны вероятности возможных исходов после сделанного выбора (выбор в условиях риска), или иметь неоднозначный исход с неизвестными вероятностями (выбор в условиях неопределенности).
Ответственность за выбор может отсутствовать, быть индивидуальной или групповой.
Степень согласованности целей при групповом выборе может варьироваться от полного совпадения интересов сторон (кооперативный выбор), до их противоположности (выбор в конфликтной ситуации). Возможны также промежуточные варианты: компромисс, коалиция, нарастающий или затухающий конфликт.
Различные сочетания перечисленных вариантов и приводят к многочисленным задачам принятия решений, которые изучены в различной степени.
1.3.3.2. Языки описания методов принятия решений
Об одном и том же явлении можно говорить на различных языках различной степени общности адекватности. К настоящему времени сложилось три основных языка описания выбора.
Самым простым и наиболее развитым и наиболее популярным является критериальный язык.
1.3.3.2.1. Критериальный язык
Название этого языка связано с основным предположением, состоящим в том, что каждую отдельно взятую альтернативу можно оценить некоторым конкретным (одним) числом, после чего сравнение альтернатив сводится к сравнению соответствующих им чисел.
Пусть, например, {X} - множество альтернатив, а x – некоторая определенная альтернатива, принадлежащая этому множеству: xÌX. Тогда считается, что для всех x может быть задана функция: q(x), которая называется критерием (критерием качества, целевой функцией, функцией предпочтения, функцией полезности и т.п.), обладающая тем свойством, что если альтернатива x1 предпочтительнее x2: (обозначается: x1 > x2),
то:
q(x1) > q(x2).
При этом выбор сводится к отысканию альтернативы с наибольшим значением критериальной функции.
Однако, на практике использование лишь одного критерия для сравнения степени предпочтительности альтернатив оказывается неоправданным упрощением, т.к. более подробное рассмотрение альтернатив приводит к необходимости оценивать их не по одному, а по многим критериям, которые могут иметь различную природу и качественно отличаться друг от друга.
Например, при выборе наиболее приемлемого для пассажиров и эксплуатирующей организации типа самолета на определенных видах трасс сравнение идет одновременно по многим группам критериев: техническим, технологическим, экономическим, социальным, эргономическим и др.
Многокритериальные задачи не имеют однозначного общего решения. Поэтому предлагается много способов придать многокритериальной задаче частный вид, допускающий единственное общее решение. Естественно, что для разных способов эти решения являются в общем случае различными. Поэтому едва ли не главное в решении многокритериальной задачи - обоснование данного вида ее постановки.
Используются различные варианты упрощения многокритериальной задачи выбора. Перечислим некоторые из них.
1. Условная максимизация (находится не глобальный экстремум суперкритерия, или, как его еще называют, интегрального критерия, а локальный экстремум основного критерия).
2. Поиск альтернативы с заданными свойствами.
3. Нахождение множества Парето.
4. Сведение многокритериальной задачи к однокритериальной, путем ввода суперкритерия.
Рассмотрим подробнее формальную постановку метода сведения многокритериальной задачи к однокритериальной.
Введем суперкритерий q0(x), как скалярную функцию векторного аргумента:
q0(x)=
q0((q1(x), q2(x),..., qn(x)).
Суперкритерий позволяет упорядочить альтернативы по величине q0, выделив тем самым наилучшую (в смысле этого критерия). Вид функции q0 определяется тем, как конкретно мы представляем себе вклад каждого критерия в суперкритерий. Обычно используют аддитивные и мультипликативные функции:
Коэффициенты si обеспечивают:
1. Безразмерность или единую размерность числа aiqi/si (различные частные критерии могут иметь разную размерность, и тогда над ними нельзя производить арифметических операций и свести их в суперкритерий).
2. Нормировку, т.е. обеспечение условия: biqi/si<1.
Коэффициенты ai и bi отражают относительный вклад частных критериев qi в суперкритерий.
Итак, в многокритериальной постановке задача принятия решения о выборе одной из альтернатив сводится к максимизации суперкритерия.
Основная проблема в многокритериальной постановке задачи принятия решений состоит в том, что необходимо найти такой аналитический вид коэффициентов ai и bi, который бы обеспечил следующие свойства модели:
1. Высокую степень адекватности предметной области и точке зрения экспертов.
2. Минимальные вычислительные трудности максимизации суперкритерия, т.е. Его расчета для разных альтернатив.
3. Устойчивость результатов максимизации суперкритерия от малых возмущений исходных данных.
Устойчивость решения означает, что малое изменение исходных данных должно приводить к малому изменению величины суперкритерия, и, соответственно, к малому изменению принимаемого решения. То есть практически на тех же исходных данных должно приниматься или тоже самое, или очень близкое решение.
1.3.3.2.2. Язык последовательного бинарного выбора
Язык бинарных отношений является обобщением многокритериального языка и основан на учете того факта, что когда мы даем оценку некоторой альтернативе, то эта оценка всегда является относительной, т.е. явно или чаще неявно в качестве базы или системы отсчета для сравнения используются другие альтернативы из исследуемого множества или из генеральной совокупности. Мышление человека основано на поиске и анализе противоположностей (конструктов), поэтому, нам всегда проще выбрать один из двух противоположных вариантов, чем один вариант из большого и никак неупорядоченного их множества.
Таким образом, основные предположения этого языка сводятся к следующему:
1. Отдельная альтернатива не оценивается, т.е. критериальная функция не вводится.
2. Для каждой пары альтернатив некоторым образом можно установить, что одна из них предпочтительнее другой, либо они равноценны или несравнимы.
3. Отношение предпочтения в любой паре альтернатив не зависит от остальных альтернатив, предъявленных к выбору.
Существуют различные способы задания бинарных отношений: непосредственный, матричный, с использованием графов предпочтений, метод сечений и др.
Отношения между альтернативами одной пары выражают через понятия эквивалентности, порядка и доминирования.
1.3.3.2.3. Обобщенный язык функций выбора
Язык функций выбора основан на теории множеств и позволяет оперировать с отображениями множеств на свои подмножества, соответствующие различным вариантам выбора, без необходимости перечисления элементов. Этот язык является весьма общим и потенциально позволяет описывать любой выбор. Однако, математический аппарат обобщенных функций выбора в настоящее время еще только разрабатывается и проверяется в основном на задачах, которые уже решены с помощью критериального или бинарного подходов.
1.3.3.2.4. Групповой выбор
Пусть имеется группа лиц, имеющих право принимать участие в коллективном принятии решений. Предположим, что эта группа рассматривает некоторый набор альтернатив, и каждый член группы осуществляет свой выбор. Ставится задача о выработке решения, которое определенным образом согласует индивидуальные выборы и в каком-то смысле выражает "общее мнение" группы, т.е. принимается за групповой выбор.
Естественно, различным принципам согласования индивидуальных решений будут соответствовать различные групповые решения.
Правила согласования индивидуальных решений при групповом выборе называются правилами голосования. Наиболее распространенным является "правило большинства", при котором за групповое решение принимается альтернатива, получившая наибольшее число голосов.
Необходимо понимать, что такое решение отражает лишь распространенность различных точек зрения в группе, а не действительно оптимальный вариант, за который вообще никто может и не проголосовать. "Истина не определяется путем голосования", самой распространенной точкой зрения может быть и заблуждение.
Кроме того, существуют так называемые "парадоксы голосования", наиболее известный из которых парадокс Эрроу.
Эти парадоксы могут привести, и иногда действительно приводят, к очень неприятным особенностям процедуры голосования: например бывают случаи, когда группа вообще не может принять единственного решения (нет кворума или каждый голосует за свой уникальный вариант, и т.д.), а иногда (при многоступенчатом голосовании) меньшинство может навязать свою волю большинству, как это было на президентских выборах в США "Буш – Гор".
1.3.3.3. Выбор в условиях неопределенности
Выбор в условиях определенности – это частный случай выбора в условиях неопределенности (когда неопределенность близка к нулю).
Но неопределенность чего конкретно имеется в виду?
В современной теории выбора считается, что в задачах принятия решений существует три основных вида неопределенности:
1. Информационная (статистическая) неопределенность исходных данных для принятия решений.
2. Неопределенность последствий принятия решений (выбора).
3. Расплывчатость в описании компонент процесса принятия решений.
Рассмотрим их по порядку.
1.3.3.3.1. Информационная (статистическая) неопределенность в исходных данных
Данные, полученные о предметной области, не могут рассматриваться как абсолютно точные. Кроме того, очевидно, эти данные нас интересуют не сами по себе, а лишь в качестве сигналов, которые, возможно, несут определенную информацию о том, что нас в действительности интересует.
То есть, реалистичнее считать, что мы имеем дело с данными, не только зашумленными и неточными, но еще и косвенными, а возможно и не полными.
Кроме того эти данные касаются не всей исследуемой (генеральной) совокупности, а лишь определенного ее подмножества, о котором мы смогли фактически собрать данные, однако при этом мы хотим сделать выводы о всей совокупности, причем хотим еще и знать достоверность этих выводов.
В этих условиях используется теория статистических решений.
В этой теории существует два основных источника неопределенности. Во-первых, неизвестно, какому распределению подчиняются исходные данные. Во-вторых, неизвестно, какое распределение имеет то множество (генеральная совокупность), о котором мы хотим сделать выводы по его подмножеству, образующему исходные данные.
Статистические процедуры это и есть процедуры принятия решений, снимающих оба эти виды неопределенности.
Необходимо отметить, что существует ряд причин, которые приводят к некорректному применению статистических методов:
1. Статистические выводы, как и любые другие, всегда имеют некоторую определенную надежность или достоверность. Но, в отличие от многих других случаев, достоверность статистических выводов известна и определяется в ходе статистического исследования.
2. Качество решения, полученного в результате применения статистической процедуры зависит, от качества исходных данных.
3. Не следует подвергать статистической обработке данные, не имеющие статистической природы.
4. Необходимо использовать статистические процедуры, соответствующие уровню априорной информации об исследуемой совокупности (например, не следует применять методы дисперсионного анализа к негауссовым данным). Если распределение исходных данных неизвестно, то надо либо его установить, либо использовать несколько различных методов и сравнить результаты. Если они сильно отличаются - это говорит о неприменимости некоторых из использованных процедур.
1.3.3.3.2. Неопределенность последствий
Когда последствия выбора той или иной альтернативы однозначно определяются самой альтернативой, тогда можно не различать альтернативу и ее последствия, считая само собой разумеющимся, что выбирая альтернативу мы в действительности выбираем ее последствия.
Однако, в реальной практике нередко приходится иметь дело с более сложной ситуацией, когда выбор той или иной альтернативы неоднозначно определяет последствия сделанного выбора.
В случае дискретного набора альтернатив и исходов их выбора, при условии, что сам набор возможных исходов общий для всех альтернатив, можно считать, что различные альтернативы отличаются друг от друга распределением вероятностей исходов. Эти распределения вероятностей вообще говоря могут зависеть от результатов выбора альтернатив и реально наступивших в результате этого исходов. В простейшем случае исходы равновероятны. Сами исходы обычно имеют смысл выигрышей или потерь и выражаются количественно.
Если исходы равны для всех альтернатив, то выбирать нечего. Если же они различны, то можно сравнивать альтернативы, вводя для них те или иные количественные оценки. Разнообразие задач теории игр связано с различным выбором числовых характеристик потерь и выигрышей в результате выбора альтернатив, различными степенями конфликтности между сторонами, выбирающими альтернативы и т.д.
1.3.3.3.3. Расплывчатая неопределенность
Любая задача выбора является задачей целевого сужения множества альтернатив. Как формальное описание альтернатив (сам их перечень, перечень их признаков или параметров), так и описание правил их сравнения (критериев, отношений) всегда даются в терминах той или иной измерительной шкалы (даже тогда, когда тот, кто это делает, не знает об этом).
Известно, все шкалы размыты, но в разной степени. Под термином "размытие" понимается свойство шкал, состоящее в том, что всегда можно предъявить такие две альтернативы, которые различимы, т.е. различны в одной шкале и неразличимы, т.е. тождественны в другой - более размытой. Чем меньше градаций в некоторой шкале, тем более она размыта.
Таким образом, мы можем четко видеть альтернативы, и одновременно нечетко их классифицировать, т.е. иметь неопределенность в вопросе о том, к каким классам они относятся.
Уже в первой работе по принятию решений в расплывчатой ситуации Беллман и Заде выдвинули идею, состоящую в том, что и цели, и ограничения должны представляться как размытые (нечеткие) множества на множестве альтернатив.
1.3.3.4. Решение как компромисс и баланс различных интересов. О некоторых ограничениях оптимизационного подхода
Во всех рассмотренных выше задачах выбора и методах принятия решений проблема состояла в том, чтобы в исходном множестве найти наилучшие в заданных условиях, т.е. оптимальные в определенном смысле альтернативы.
Идея оптимальности является центральной идеей кибернетики и прочно вошла в практику проектирования и эксплуатации технических систем. Вместе с тем эта идея требует осторожного к себе отношения, когда мы пытаемся перенести ее в область управления сложными, большими и слабо детерминированными системами, такими, например, как социально-экономические системы.
Для этого заключения имеются достаточно веские основания. Рассмотрим некоторые из них.
1. Оптимальное решение нередко оказывается неустойчивым: т.е. незначительные изменения в условиях задачи, исходных данных или ограничениях могут привести к выбору существенно отличающихся альтернатив.
2. Оптимизационные модели разработаны лишь для узких классов достаточно простых задач, которые не всегда адекватно и системно отражают реальные объекты управления. Чаще всего оптимизационные методы позволяют оптимизировать лишь достаточно простые и хорошо формально описанные подсистемы некоторых больших и сложных систем, т.е. позволяют осуществить лишь локальную оптимизацию. Однако, если каждая подсистема некоторой большой системы будет работать оптимально, то это еще совершенно не означает, что оптимально будет работать и система в целом. То есть оптимизация подсистемы совсем не обязательно приводит к такому ее поведению, которое от нее требуется при оптимизации системы в целом. Более того, иногда локальная оптимизация может привести к негативным последствиям для системы в целом.
3. Часто максимизация критерия оптимизации согласно некоторой математической модели считается целью оптимизации, однако в действительностью целью является оптимизация объекта управления. Критерии оптимизации и математические модели всегда связаны с целью лишь косвенно, т.е. более или менее адекватно, но всегда приближенно.
Итак, идею оптимальности, чрезвычайно плодотворную для систем, поддающихся адекватной математической формализации, нельзя перенести на сложные системы. Конечно, математические модели, которые удается иногда предложить для таких систем, можно оптимизировать. Однако всегда следует учитывать сильную упрощенность этих моделей, а также то, что степень их адекватности фактически неизвестна. Поэтому не известно, какое чисто практическое значение имеет эта оптимизация. Высокая практичность оптимизации в технических системах не должна порождать иллюзий, что она будет настолько же эффективна при оптимизации сложных систем. Содержательное математическое моделирование сложных систем является весьма затруднительным, приблизительным и неточным. Чем сложнее система, тем осторожнее следует относится к идее ее оптимизации.
Поэтому, при разработке методов управления сложными, большими слабо детерминированными системами, основным является не оптимальность выбранного подхода с формальной математической точки зрения, а его адекватность поставленной цели и самому характеру объекта управления.
1.3.3.5. Экспертные методы выбора
При исследовании сложных систем часто возникают проблемы, которые по различным причинам не могут быть строго поставлены и решены с применением разработанного в настоящее время математического аппарата. В этих случаях прибегают к услугам экспертов (системных аналитиков), чей опыт и интуиция помогают уменьшить сложность проблемы.
Однако, необходимо учитывать, что эксперты сами представляют собой сверхсложные системы, и их деятельность сама зависит от многих внешних и внутренних условий. Поэтому в методиках организации экспертных оценок большое внимание уделяется созданию благоприятных внешних и психологических условий для работы экспертов.
На работу эксперта оказывают влияние следующие факторы:
– ответственность за использование результатов экспертизы;
– знание того, что привлекаются и другие эксперты;
– наличие информационного контакта между экспертами;
– межличностные отношения экспертов (если между ними есть информационный контакт);
– личная заинтересованность эксперта в результатах оценки;
– личностные качества экспертов (самолюбие, конформизм, воля и др.)
Взаимодействие между экспертами может как стимулировать, так и подавлять их деятельность. Поэтому в разных случаях используют различные методы экспертизы, отличающиеся характером взаимодействия экспертов друг с другом: анонимные и открытые опросы и анкетирования, совещания, дискуссии, деловые игры, мозговой штурм и т.д.
Существуют различные методы математической обработки мнений экспертов. Экспертам предлагают оценить различные альтернативы либо одним, либо системой показателей. Кроме того им предлагают оценить степень важности каждого показателя (его "вес" или "вклад"). Самим экспертам также приписывается уровень компетентности, соответствующий его вкладу в результирующее мнение группы.
Развитой методикой работы с экспертами является метод "Дельфи". Основная идея этого метода состоит в том, что критика и аргументация благотворно влияет на эксперта, если при этом не задевается его самолюбие и обеспечиваются условия, исключающие персональную конфронтацию.
Необходимо особо подчеркнуть, что существует принципиальное различие в характере использования экспертных методов в экспертных системах и в поддержке принятия решений. Если в первом случае от экспертов требуется формализация способов принятия решений, то во втором, лишь само решение, как таковое.
Поскольку эксперты привлекаются для реализации именно тех функций, которые в настоящее время или вообще не обеспечиваются автоматизированными системами, или выполняются ими хуже, чем человеком, то перспективным направлением развития автоматизированных систем является максимальная автоматизация этих функций.
1.3.3.6. Юридическая ответственность за решения, принятые с применением систем поддержки принятия решений
Необходимо отметить, что система поддержки принятия решений (СППР) не является физическим или юридическим лицом и не может нести ответственность за те или иные решения, которые принимаются с ее использованием.
Согласно действующему сейчас и в обозримой перспективе законодательству автоматизированную систему невозможно привлечь к административной или уголовной ответственности. Но это не означает, что в будущем подобные вопросы не возникнут по поводу созданных методами генной инженерии искусственных разумных биологических систем, которые автором совместно с Л.А.Бакурадзе в 1980 году были названы "квазибиологические роботы", или по поводу клонов, не ассоциированных в общечеловеческую социальную среду.
Ответственность за принятое решение всегда несет специалист, или, как говорят, "лицо, принимающее решения" (ЛПР).
Вместе с тем при выработке решения это лицо может обращаться к различной справочной информации, а также консультироваться со специалистами в различных предметных областях. При этом справочная информация может извлекаться по запросам из баз данных, а консультации могут происходить не с самими специалистами лично, а с автоматизированными системами поддержки принятия решений, в которых в формализованном и обобщенном виде содержаться знания многих специалистов.
Но в какой форме содержаться консультирующая информация и знания – это сути дела не меняет, т.е. ответственность за принятое решение все равно всегда лежит на лице, его приявшем, а не на консультирующих или поддерживающих решения системах. Поэтому эти системы и называются не "системы принятия решений", а лишь "системы поддержки принятия решений".
Особым случаем являются автоматизированные системы управления оружием, например, создаваемые в США в рамках программы "Стратегической оборонной инициативы" (СОИ). В этих системах человек может участвовать в процессе принятия решений лишь на этапах их создания, т.к. в на боевом дежурстве систем для участия человека просто не будет времени. И тем ни менее и эти системы принимают решения не самостоятельно, а на основе анализа фактической информации по тем критериям и алгоритмам, которые заложил в них человек. Таким образом, в подобных системах человек становится заложником своих же решений, принятых им ранее.
1.3.3.7. Условия корректности использования систем поддержки принятия решений
Этих условий три:
1. Само решение о выборе той или иной конкретной системы поддержки принятия решений должно приниматься лицом, принимающим решения, который и будет пользоваться ее рекомендациями, либо подчиненными ему компетентными специалистами по его личному поручению.
2. Сам выбор системы поддержки принятия решений должен осуществляться, как правило, не по их специальным, или, тем более, рекламным описаниям и литературным данным, а по результатам сравнительных испытаний на реальных примерах из практики работы организации.
3. Выбранная система должна быть официально принятой для решения тех задач, для решения которых она будет использоваться, т.е. должна быть сертифицирована.
Под сертификацией понимается:
– апробация системы поддержки принятия решений и оценка адекватности рекомендуемых ей решений на ряде реальных задач, которые возникали в прошлом или возникают в течение определенного периода экспериментальной эксплуатации;
– придание системе поддержки принятия решений юридического статуса, который предписывает и лицам принимающим решения "принимать к сведению" рекомендации системы.
Для сертификации системы создается соответствующая компетентная и полномочная комиссия, которая в течение определенного времени изучает систему и выдаваемые ею рекомендации на предмет адекватности складывающимся ситуациям. Результаты работы комиссии оформляются в форме юридического документа, имеющего силу в ведомстве или организации, в которых будет применяться система.
В этом документе описывается круг задач, для решения которых применяется система, инфраструктура и технология ее применения, а также определяются обязанности и персональная ответственность специалистов по эксплуатации системы.
Если система не сертифицирована, то ее применение некорректно с юридической точки зрения. На практике это происходит гораздо чаще, чем многие представляют, например, с системами бухгалтерского учета или психологическими тестами, которые распространяются на пиратских компакт-дисках, не локализованы для регионов и организаций применения, не адаптированы для решения задач, для решения которых они фактически применяются.
1.3.3.8. Хранилища данных для принятия решений
В разделе 4.2.5. данной работы мы рассматривали иерархическую систему обработки информации в которой на различных уровнях производятся различные операции по обработке данных, информации и знаний:
– на 1-м уровне накапливаются данные мониторинга;
– на 2-м уровне осуществляется анализ данных мониторинга с целью выявления в них зависимостей, что позволяет содержательно интерпретировать данные, т.е. генерировать информацию путем анализа данных;
– на 3-м уровне знание зависимостей в данных мониторинга используется для прогнозирования;
– на 4-м уровне возможности многовариантного прогнозирования и решения обратной задачи прогнозирования позволяют вырабатывать рекомендации и решения по достижению поставленных целей, т.е. генерировать и использовать знания путем системной обработки информации.
Выполнение операций каждого последующего уровня возможно только построения предыдущего уровня. Здесь уместно провести аналогию со строительством здания: пока не выполнен фундамент – не возводят стены, пока не возведены стены – не делают крышу, пока нет крыши – не проводят отделку и т.д. Аналогично, чтобы вытащить внутреннюю матрешку сначала надо раскрыть внешнюю. Могут существовать и более сложные алгоритмы, определяющие последовательность, например, типа используемых в игре "Ханойская башня".
Таким образом, фундаментом для генерации информации и знаний являются данные мониторинга.
Хранилище Данных (ХД или Data warehouses) – это база данных,
хранящая данные, агрегированные по многим измерениям. Данные из ХД никогда не
удаляются. Пополнение ХД происходит на периодической основе. При этом автоматически
формируются новые агрегаты данных, зависящие от старых. Доступ к ХД организован
особым образом на основе модели многомерного куба.
Итак, Хранилище Данных – это не автоматизированная система принятия решений, не экспертная система, не система логического вывода, а "всего лишь" оптимально организованная база данных, обеспечивающая максимально быстрый и комфортный доступ к информации, необходимой при принятии решений.
Принять любое управленческое решение, невозможно не обладая необходимой для этого информацией, обычно количественной. Для этого необходимо создание хранилищ данных (Data warehouses), то есть процесс сбора, отсеивания и предварительной обработки данных с целью предоставления результирующей информации пользователям для статистического анализа (а нередко и создания аналитических отчетов). Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных сформулировал основные требования к ним:
– поддержка высокой скорости получения данных из хранилища;
– поддержка внутренней непротиворечивости данных;
– возможность получения и сравнения так называемых срезов данных (slice and dice);
– наличие удобных утилит просмотра данных в хранилище;
– полнота и достоверность хранимых данных;
– поддержка качественного процесса пополнения данных.
Типичное хранилище данных, как правило, отличается от обычной реляционной базы данных.
Во-первых, обычные базы предназначены для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, - с помощью хранилища данных.
Во-вторых, обычные базы данных подвержены постоянным изменениям в процессе работы пользователей, а хранилище данных относительно стабильно: сведения в нем обычно обновляются согласно расписанию (например, еженедельно, ежедневно или ежечасно – в зависимости от потребностей). В идеале процесс пополнения представляет собой просто добавление новых данных за определенный период времени без изменения прежней информации, уже находящейся в хранилище.
В-третьих, обычные базы данных чаще всего являются источником данных, попадающих в хранилище. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Для более полного ознакомления с концепцией хранилищ данных рекомендуется обратиться к источникам [3, 4] списка рекомендуемой литературы.
Контрольные вопросы
1. Многообразие задач принятия решений.
2. Принятие решений, как реализация цели.
3. Принятие решений, как снятие неопределенности (информационный подход).
4. Связь принятия решений и распознавания образов.
5. Классификация задач принятия решений.
6. Языки описания методов принятия решений.
7. Критериальный язык.
8. Язык последовательного бинарного выбора.
9. Обобщенный язык функций выбора.
10. Групповой выбор.
11. Выбор в условиях неопределенности.
12. Информационная (статистическая) неопределенность в исходных данных.
13. Неопределенность последствий.
14. Расплывчатая неопределенность.
15. Решение как компромисс и баланс различных интересов. О некоторых ограничениях оптимизационного подхода.
16. Экспертные методы выбора.
17. Юридическая ответственность за решения, принятые с применением систем поддержки принятия решений.
18. Условия корректности использования систем поддержки принятия решений.
19. Хранилища данных для принятия решений.
Рекомендуемая литература
1. Перегудов Ф.И., Тарасенко Ф.П. Введение в системный анализ: Учебное пособие. – М.: Высшая школа, 1997. – 389с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
3. Бирюков А. Системы принятия решений и Хранилища Данных. //Системы управления базами данных #04/97. http://www.isuct.ru/~ivt/books/DBMS/DBMS7/dbms/1997/04/37.htm
4. Львов В. Создание систем поддержки принятия решений на основе
хранилищ данных. Ж-л "Системы управления базами данных", #03,
1.3.4. ЛЕКЦИЯ-10.
Экспертные системы
Учебные вопросы
1. Экспертные системы, базовые понятия.
2. Экспертные системы, методика построения.
3. Этап-1 синтеза ЭС: "Идентификация".
4. Этап-2 синтеза ЭС: "Концептуализация".
5. Этап-3 синтеза ЭС: "Формализация".
6. Этап-4 синтеза ЭС: "Разработка прототипа".
7. Этап-5 синтеза ЭС: "Экспериментальная эксплуатация".
8. Этап-6 синтеза ЭС: "Разработка продукта".
9. Этап-7 синтеза ЭС: "Промышленная эксплуатация".
Данный раздел основан на конспекте лекций по курсу "Основы проектирования систем искусственного интеллекта": Сотник С.Л. (1997-1998), который несложно найти Internet, например, по адресу: http://neuroschool.narod.ru/books/sotnik.html [191].
1.3.4.1. Экспертные системы, базовые понятия
Экспертная система (ЭС) – это программа, которая в определенных
отношениях заменяет эксперта или группу экспертов в той или иной предметной
области.
ЭС предназначены для решения практических задач, возникающих в слабо структурированных и трудно формализуемых предметных областях.
Исторически, ЭС были первыми системами искусственного интеллекта, которые привлекли внимание потребителей.
С ЭС связаны некоторые распространенные заблуждения.
Заблуждение первое: ЭС могут делать не более, а скорее даже менее того, чем эксперт, создавший данную систему.
Во-первых, существуют технологии синтеза самообучающихся ЭС, которые могут быть применены в предметной области, в которой вообще нет экспертов.
Во-вторых, технология ЭС позволяет объединить в одной системе знания нескольких экспертов, и, таким образом, в результате получить систему, которая может то, чего ни один из ее создателей не может.
Заблуждение второе: ЭС никогда не заменит человека-эксперта.
На практике часто ЭС могут создаваться и применяться для решения задач, в решении которых эксперты по ряду причин физического, юридического, финансового и организационного характера не могут принять личного участия, т.е. в точках, весьма удаленных от экспертов как в пространстве, так и во времени:
– знания могут извлекаться из научных работ или фактических данных, доступ к которым может обеспечиваться через Internet;
– доступ к ЭС и ее базе знаний также может быть получен через Internet.
1.3.4.2. Экспертные системы, методика построения
В настоящее время сложилась определенная технология разработки ЭС, которая включает следующие шесть этапов:
1. Идентификация.
2. Концептуализация.
3. Формализация.
4. Разработка прототипа.
5. Экспериментальная эксплуатация.
6. Разработка продукта.
7. Промышленная эксплуатация.
1.3.4.3. Этап-1: "Идентификация"
На этапе идентификации производится:
– неформальное осмысление задач, которые должна решать создаваемая ЭС;
– формирование требований к ЭС;
– определение ресурсов, необходимых для создания ЭС.
В результате идентификации функционально определяется что должна делать ЭС и что необходимо для ее создания.
Идентификация задачи заключается в составлении неформального (вербального, т.е. словесного) описания, в котором указываются:
– общие характеристики задачи;
– подзадачи, выделяемые внутри данной задачи;
– ключевые понятия (объекты), их входные и выходные данные;
– предположительный вид решения;
– знания, относящиеся к решаемой задаче.
В процессе идентификации задачи инженер по знаниям и эксперт работают в тесном контакте.
Начальное неформальное описание задачи, данное экспертом, затем используется инженером знаний для уточнения терминов и ключевых понятий.
Эксперт корректирует описание задачи, объясняет, как решать ее и какие рассуждения лежат в основе того или иного решения.
После нескольких циклов, уточняющих описание, эксперт и инженер по знаниям получают окончательное неформальное описание задачи.
При создании ЭС основными видами ресурсов являются:
– источники знаний (эксперты);
– инженеры знаний и программисты;
– инструментальные программные средства (экспертные оболочки);
– вычислительные средства;
– время разработки;
– объем финансирования.
1.3.4.4. Этап-2: "Концептуализация"
На данном этапе проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач.
Этот этап завершается созданием модели предметной области, включающей основные концепты и отношения между ними. На этапе концептуализации определяются следующие особенности задачи:
– типы доступных данных;
– исходные и выводимые данные,
– подзадачи общей задачи;
– используемые стратегии и гипотезы;
– виды взаимосвязей между объектами ПО, типы используемых отношений (иерархия, причина – следствие, часть – целое и т.п.);
– процессы, используемые в ходе решения;
– состав знаний, используемых при решении задачи;
– типы ограничений, накладываемых на процессы, используемые в ходе решения;
– состав знаний, используемых для обоснования решений.
Существует два подхода к процессу построения модели предметной области:
1. Атрибутивный подход (атрибутами называют существенные признаки) предполагает наличие полученной от экспертов информации в виде цепочек: "Класс (градация классификационной шкалы) – объект обучающей выборки – атрибут (описательная шкала) – значение атрибута (градация описательной шкалы)". Этот подход развивается в рамках направления, получившего название формирование знаний или "машинное обучение" (machine learning).
2. Структурный или когнитивный подход, основан на выделении элементов предметной области, их взаимосвязей и семантических (смысловых) отношений.
Атрибутивный подход требует полной информации о предметной области: об объектах, их атрибутах и о значениях атрибутов, а также дополнительной обучающей информации о принадлежности конкретных объектов к обобщенным классам, задаваемой экспертом. Отметим, что атрибутивный подход в экспертных системах имеет очень много общего с методами, применяемыми в распознавании образов.
Структурный подход к построению модели предметной области предполагает выделение следующих когнитивных элементов знаний:
1. Понятия.
2. Взаимосвязи.
3. Метапонятия.
4. Семантические отношения.
Выделяемые понятия предметной области должны образовывать систему, под которой понимается совокупность понятий, обладающая следующими свойствами:
– минимальностью (уникальностью, отсутствием избыточности);
– полнотой (достаточно полным описанием различных процессов, фактов, явлений предметной области);
– достоверностью (адекватностью, валидностью – соответствием выделенных единиц смысловой информации их реальным наименованиям).
Существует ряд методов выявления иерархической системы понятий и метапонятий (включая отношения между ними), позволяющей адекватно отразить предметную область:
1. Метод локального представления.
2. Метод вычисления коэффициента использования.
3. Метод формирования перечня понятий.
4. Ролевой метод.
5. Метода составления списка элементарных действий.
6. Методе составление оглавления учебника.
7. Текстологический метод.
8. Метод свободных ассоциаций для определения "смыслового расстояния" между понятиями.
9. Методе "сортировки карточек".
10. Метод обнаружения регулярностей.
11. Методы семантического дифференциала и репертуарных решеток.
Перечисленные методы применяются на этапе концептуализации при построении модели предметной области. Подробнее они описаны в упомянутой выше работе С.Л. Сотника.
1.3.4.5. Этап-3: "Формализация"
Этап формализации необходим для преобразования декларативных и процедурных знаний о предметной области, полученных на этапе концептуализации, в форму, пригодную для их обработки на компьютере.
На данном этапе:
– выбирается или разрабатывается формальный язык, обеспечивающий представление знаний и манипулирование ими;
– осуществляется формализация знаний, т.е. они преобразуются в форму, пригодную для обработки на компьютере.
Способы представления знаний: фреймы, сценарии, семантические сети, продукции.
Способы манипулирования знаниями: логический вывод, аналитическая модель, статистическая модель.
1.3.4.6. Этап-4: "Разработка прототипа"
Разработка прототипа включает три основных этапа:
1. Программная реализация системы, призванной обеспечить реальное решение поставленных задачи.
2. Наполнение базы знаний.
3. Тестирование (исследование) прототипа.
Исследование прототипа позволяет:
– оценить насколько реализованные в нем идеи, методы и способы представления знаний пригодны для решения поставленных задач;
– продемонстрировать тенденцию к повышению качества и эффективности решений для всех задач предметной области по мере увеличения объема знаний.
Положительные результаты тестирования прототипа являются основанием для его передачи в экспериментальную эксплуатацию.
1.3.4.7. Этап-5: "Экспериментальная эксплуатация"
На этапе экспериментальной эксплуатации прототипа экспертной системы с помощью нее решаются реальные задачи, однако, на практике результаты их решения не используются. При этом экспертной системой управляют представители разработчика и квалифицированные пользователи, прошедшие обучение у разработчика.
При этом круг предлагаемых для решения задач естественно расширяется, исправляются ошибки, собираются пожелания и замечания экспертов и пользователей, которые должны быть учтены в очередной версии экспертной системы.
В частности на этом этапе детализируются направления будущего развития экспертной системы путем добавления в нее:
– "дружественного" пользовательского интерфейса с системой контекстно-зависимых подсказок;
– развитых средств исследования и графического представления базы знаний и цепочек выводов, генерируемых системой;
– средств обеспечения адаптивности базы знаний;
– диспетчера задач, решаемых в системе и средств поддержки и использования архива уже созданных приложений.
1.3.4.8. Этап-6: "Разработка продукта"
На этом этапе программная реализация прототипа экспертной системы доводится до уровня программного продукта, который может успешно использоваться заказчиком без прямой помощи разработчиков.
При этом разрабатываются программные модули, поддерживающие возможности экспертной системы, определенные на предыдущем этапе, а также проводится:
– анализ функционирования системы при значительном расширении базы знаний;
– исследование возможностей системы в решении более широкого круга задач и принятие мер для обеспечения таких возможностей;
– анализ мнений пользователей о функционировании ЭС;
– разработка системы ввода-вывода, осуществляющей анализ или синтез предложений ограниченного естественного языка.
Пригодность ЭС для пользователя определяется удобством работы с ней и ее полезностью.
Полезность ЭС – это ее способность эффективно решать поставленные пользователем задачи.
Удобство работы с ЭС включает:
– естественность интерфейса (общение в привычном, не утомляющем пользователя виде);
– гибкость ЭС (способность системы настраиваться на различные задачи, а также учитывать изменения в квалификации пользователей);
– устойчивость системы к ошибкам (способность не выходить из строя при попадании неадекватных, т.е. неполных и зашумленных знаний в базу знаний, а также при ошибочных действиях пользователей).
1.3.4.9. Этап-7: "Промышленная эксплуатация"
После доведения экспертной системы до уровня программного продукта она передается в промышленную эксплуатацию. При этом задачи не только решаются экспертной системой, но и результаты решения используются на практике. Для этого при передаче системы в промышленную эксплуатацию она тестируется и сертифицируется заказчиком, как инструмент, пригодный для решения поставленных задач, т.е. экспертной системе и результатам ее работы присваивается соответствующий юридический статус. Экспертной системой управляют рядовые пользователи, прошедшие обучение у квалифицированных пользователей. При необходимости квалифицированным пользователям могут оказывать консультативную помощь представители разработчика.
Контрольные вопросы
1. Экспертные системы, базовые понятия.
2. Экспертные системы, методика построения.
3. Этап-1 синтеза ЭС: "Идентификация".
4. Этап-2 синтеза ЭС: "Концептуализация".
5. Этап-3 синтеза ЭС: "Формализация".
6. Этап-4 синтеза ЭС: "Разработка прототипа".
7. Этап-5 синтеза ЭС: "Экспериментальная эксплуатация".
8. Этап-6 синтеза ЭС: "Разработка продукта".
9. Этап-7 синтеза ЭС: "Промышленная эксплуатация".
Рекомендуемая литература
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1.3.5. ЛЕКЦИЯ-11.
Нейронные сети
Учебные вопросы
1. Биологический нейрон и формальная модель нейрона Маккалоки и Питтса.
2. Возможность решения простых задач классификации непосредственно одним нейроном.
3. Однослойная нейронная сеть и персептрон Розенблата.
4. Линейная разделимость и персептронная представляемость.
5. Многослойные нейронные сети.
6. Проблемы и перспективы нейронных сетей.
7. Модель нелокального нейрона и нелокальные интерпретируемые нейронные сети прямого счета.
В разделах 1.3.5.1 и 1.3.5.3 широко использованы материалы лекций по теории и приложениям искусственных нейронных сетей, размещенные в Internet Сергеем А. Тереховым, Лаборатория Искусственных Нейронных Сетей НТО-2, ВНИИТФ, Снежинск (http://alife.narod.ru/lectures/neural/Neu_index.htm) [197].
1.3.5.1. Биологический нейрон и формальная модель нейрона Маккалоки и Питтса
Биологический нейрон имеет вид, представленный на рисунке 73:
|
|
|
Рисунок 73. Структура биологического нейрона |
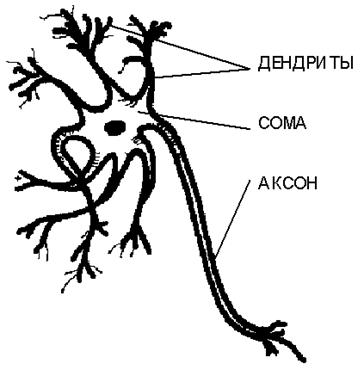
В 1943 году Дж. Маккалоки и У. Питт предложили формальную модель биологического нейрона как устройства, имеющего несколько входов (входные синапсы – дендриты), и один выход (выходной синапс – аксон) (рисунок 74).
|
|
|
Рисунок 74. Классическая модель нейрона Дж.
Маккалоки |
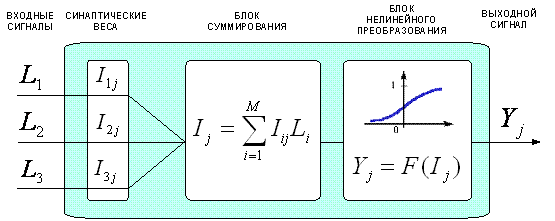
Дендриты получают информацию от источников информации (рецепторов) Li, в качестве которых могут выступать и нейроны. Набор входных сигналов {Li} характеризует объект, его состояние или ситуацию, обрабатываемую нейроном.
Каждому i-му входу j-го нейрона ставится в
соответствие некоторый весовой коэффициент Iij,
характеризующий степень влияния сигнала с
этого входа на аргумент передаточной (активационной) функции, определяющей сигнал Yj на выходе нейрона.
В нейроне происходит взвешенное суммирование
входных сигналов, и далее это значение используется как аргумент активационной (передаточной) функции нейрона. На рисунке
74 данная модель приведена в обозначениях,
принятых в настоящей работе.
1.3.5.2. Возможность решения простых задач классификации непосредственно одним нейроном
Представим себе, что необходимо решать задачу
определения
пола студентов по их внешне наблюдаемым признакам.
Есть, конечно, и более надежные способы, но мы их рассматривать не будем, т.к. они требуют дополнительных затрат для получения исходной информации и превращают задачу в тривиальную.
Поэтому будем рассматривать такие описательные шкалы и градации:
1. Длина волос: длинные, средние, короткие.
2. Наличие брюк: да, нет.
3. Использование духов или одеколона: да, нет.
Составим таблицу для определения весовых коэффициентов (таблица 33). Пусть столбцы этой таблицы соответствуют состояниям нейрона, а строки – дендритам, соединенным с соответствующими органами восприятия, которые способны устанавливать наличие или отсутствие соответствующего признака.
Тогда один из простейших способов определить значения весовых коэффициентов на дендритах будет заключаться в том, чтобы на пересечениях строк и столбцов просто проставить суммарное количество студентов в обучающей выборке, обладающих данным признаком.
Таблица 33 – ОПРЕДЕЛЕНИЕ ВЕСОВЫХ
КОЭФФИЦИЕНТОВ НЕЙРОНОВ НЕПОСРЕДСТВЕННО
НА ОСНОВЕ ЭМПИРИЧЕСКИХ ДАННЫХ
|
Описательные шкалы и градации |
Классификационные |
|
|
Юноши |
Девушки |
|
|
Длина волос: |
|
|
|
– длинные |
5 |
15 |
|
– средние |
10 |
10 |
|
– короткие |
15 |
5 |
|
Наличие брюк: |
|
|
|
– да; |
30 |
10 |
|
– нет |
0 |
20 |
|
Использование духов или
одеколона: |
|
|
|
– да; |
5 |
20 |
|
– нет |
25 |
10 |
Если нейрон должен выдавать высокий выходной сигнал, когда на входе ему предъявляется юноша и низкий – когда девушка, то весовые коэффициенты на дендритах берутся из столбца: "Юноши". И наоборот, если нейрон должен выдавать высокий выходной сигнал, когда на входе ему предъявляется девушка и низкий – когда юноша, то весовые коэффициенты на дендритах берутся из столбца: "Девушки".
Можно представить себе сеть из двух нейронов, в которой весовые коэффициенты на дендритах взяты из столбцов: "Юноши" и "Девушки".
Большее количество нейронов для решения данной задачи будет избыточным. Его имеет смысл использовать в том случае, когда мы хотим повысить надежность идентификации объектов нейронной сетью и различные сходные по смыслу нейроны будут использовать независимые друг от друга рецепторы.
Например, если мы не только видим идентифицируемый объект, но можем его и обонять, и ощупывать, то это повышает надежность его идентификации. В этом состоит общепринятый в физике критерий реальности – принцип наблюдаемости, согласно которому объективное существование установлено для тех объектов и явлений, существование которых установлено несколькими, по крайней мере, двумя, независимыми способами.
В общем
случае в нейронной сети каждому классу (градации классификационной шкалы) будет
соответствовать один нейрон и объект, признаки которого будут измерены
рецепторами на входе нейронной сети, будет идентифицирован сетью как класс,
соответствующий нейрону с максимальным уровнем сигнала на выходе.
Психологические тесты обычно позволяют тестировать респондента сразу по нескольким шкалам. Очевидно, нейронные сети, реализующие эти тесты, будут иметь как минимум столько нейронов, сколько шкал в психологическом тесте.
1.3.5.3. Однослойная нейронная сеть и персептрон Розенблата
Исторически первой искусственной нейронной сетью, способной к перцепции (восприятию) и формированию реакции на воспринятый стимул, явился Perceptron Розенблатта (F.Rosenblatt, 1957). Термин " Perceptron" происходит от латинского perceptio, что означает восприятие, познавание. Русским аналогом этого термина является "Персептрон". Его автором персептрон рассматривался не как конкретное техническое вычислительное устройство, а как модель работы мозга. Современные работы по искусственным нейронным сетям редко преследуют такую цель.
Простейший классический персептрон содержит элементы трех типов (рисунок 75), назначение которых в целом соответствует нейрону рефлекторной нейронной сети, рассмотренному выше.
|
|
|
Рисунок 75. Элементарный персептрон Розенблатта |
S-элементы – это сенсоры или рецепторы, принимающие двоичные сигналы от внешнего мира. Каждому S-элементу соответствует определенная градация некоторой описательной шкалы.
Далее сигналы поступают в слой ассоциативных или A-элементов (показана часть связей от S к A-элементам). Только ассоциативные элементы, представляющие собой формальные нейроны, выполняют совместную аддитивную обработку информации, поступающей от ряда S-элементов с учетом изменяемых весов связей (рисунок 75). Каждому A-элементу соответствует определенная градация некоторой классификационной шкалы.
R-элементы с фиксированными весами формируют сигнал реакции персептрона на входной стимул. R-элементы обобщают информацию о реакциях нейронов на входной объект, например могут выдавать сигнал об идентификации данного объекта, как относящегося к некоторому классу только в том случае, если все нейроны, соответствующие этому классу выдадут результат именно о такой идентификации объекта. Это означает, что в R-элементах может использоваться мультипликативная функция от выходных сигналов нейронов. R-элементы также, как и A-элементы, соответствует определенным градациям классификационных шкал.
Розенблатт считал такую нейронную сеть трехслойной, однако по современной терминологии, представленная сеть является однослойной, так как имеет только один слой нейропроцессорных элементов.
Если бы R-элементы были тождественными по функциям A-элементам, то нейронная сеть классического персептрона была бы двухслойной. Тогда бы A-элементы выступали для R-элементов в роли S-элементов.
Однослойный персептрон характеризуется матрицей синаптических связей ||W|| от S- к A-элементам. Элемент матрицы отвечает связи, ведущей от i-го S-элемента (строки) к j-му A-элементу (столбцы). Эта матрица очень напоминает матрицы абсолютных частот и информативностей, формируемые в семантической информационной модели, основанной на системной теории информации.
С точки зрения современной нейроинформатики однослойный персептрон представляет в основном чисто исторический интерес, вместе с тем на его примере могут быть изучены основные понятия и простые алгоритмы обучения нейронных сетей.
Обучение классической нейронной сети состоит в подстройке весовых коэффициентов каждого нейрона.
Пусть имеется набор пар векторов {xa, ya}, a = 1..p, называемый обучающей выборкой, состоящей из p объектов.
Вектор {xa} характеризует систему признаков конкретного объекта a обучающей выборки, зафиксированную S-элементами.
Вектор {ya} характеризует картину возбуждения нейронов при предъявлении нейронной сети конкретного объекта a обучающей выборки:
|
|

Будем называть нейронную сеть обученной на данной обучающей выборке, если при подаче на вход сети вектора {xa} на выходе всегда получается соответствующий вектор {ya}, т.е. каждому набору признаков соответствуют определенные классы.
Ф.Розенблаттом предложен итерационный алгоритм обучения из 4-х шагов, который состоит в подстройке матрицы весов, последовательно уменьшающей ошибку в выходных векторах:
|
Шаг
0: |
Начальные значения весов всех нейронов полагаются случайными. |
|
Шаг
1: |
Сети предъявляется входной образ xa, в результате формируется выходной образ. |
|
Шаг
2: |
Вычисляется вектор ошибки, делаемой сетью на выходе. |
|
Шаг
3: |
Вектора весовых коэффициентов корректируются таким образом, что величина корректировки пропорциональна ошибке на выходе и равна нулю если ошибка равна нулю: – модифицируются только компоненты матрицы весов, отвечающие ненулевым значениям входов; – знак приращения веса соответствует знаку ошибки, т.е. положительная ошибка (значение выхода меньше требуемого) проводит к усилению связи; – обучение каждого нейрона происходит независимо от обучения остальных нейронов, что соответствует важному с биологической точки зрения, принципу локальности обучения. |
|
Шаг
4: |
Шаги 1-3 повторяются для всех обучающих векторов. Один цикл последовательного предъявления всей выборки называется эпохой. Обучение завершается по истечении нескольких эпох, если выполняется по крайней мере одно из условий: – когда итерации сойдутся, т.е. вектор весов перестает изменяться; – когда полная просуммированная по всем векторам абсолютная ошибка станет меньше некоторого малого значения. |
Данный метод обучения был назван Ф.Розенблаттом "методом коррекции с обратной передачей сигнала ошибки". Имеется в виду передача сигнала ошибка от выхода сети на ее вход, где и определяются, и используются весовые коэффициенты. Позднее этот алгоритм назвали "d-правилом".
Данный алгоритм относится к широкому классу алгоритмов обучения с учителем, т.к. в нем считаются известными не только входные вектора, но и значения выходных векторов, т.е. имеется учитель, способный оценить правильность ответа ученика, причем в качестве последнего выступает нейронная сеть.
Розенблаттом доказана "Теорема о сходимости обучения" по d-правилу. Эта теорема говорит о том, что персептрон способен обучится любому обучающему набору, который он способен представить. Но она ничего не говорит о том, какие именно обучающие наборы он способен представить. Ответ на этот вопрос мы получим в следующем разделе.
1.3.5.4. Линейная разделимость и персептронная представляемость
При прямоугольной передаточной функции (1) каждый нейрон представляет собой пороговый элемент, который может находиться только в одном из двух состояний:
– возбужденном (активном), если взвешенная сумма входных сигналов больше некоторого порогового значения;
– заторможенном (пассивном), если взвешенная сумма входных сигналов меньше некоторого порогового значения.
|
|
( 1 ) |
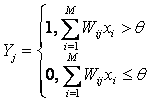
Следовательно, при заданных значениях весов и
порогов, каждый нейрон имеет единственное
определенное значение выходной активности для каждого возможного вектора
входов. При этих условиях множество
входных векторов, при которых нейрон активен (Y=1), отделено от множества
векторов, на которых нейрон пассивен (Y=0) гиперплоскостью
(2).
|
|
( 2 ) |
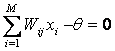
Следовательно, нейрон способен отделить только такие два множества векторов входов, для которых существует гиперплоскость, отделяющая одно множество от другого. Такие множества называют линейно разделимыми.
Необходимо отметить, что линейно-разделимые
множества являются составляют лишь очень незначительную часть всех множеств.
Поэтому данное ограничение персептрона является принципиальным. Оно было
преодолено лишь в 80-х годах путем введения нескольких слоев нейронов
в сетях Хопфилда и неокогнитроне Фукушимы.
В завершении остановимся на некоторых проблемах, которые остались нерешенными после работ Ф.Розенблатта:
1. Возможно ли обнаружить линейную разделимость классов до обучения сети?
2. Как определить скорость обучения, т.е. количество итераций, необходимых для достижения заданного качества обучения?
3. Как влияют на результаты обучения последовательность предъявления образов и их количество?
4. Имеет ли алгоритм обратного распространения ошибки преимущества перед простым перебором весов?
5. Каким будет качество обучения, если обучающая выборка содержит не все возможные на практике пары векторов и какими будут ответы персептрона на новые вектора, отсутствующие в обучающей выборке?
Особенно важным представляется последний вопрос, т.к. индивидуальный опыт принципиально всегда не является полным.
1.3.5.5. Многослойные нейронные сети
1.3.5.5.1. Многослойный персептрон
Каким же образом в многослойных (иерархических) нейронных сетях преодолевается принципиальное ограничение однослойных нейронных сетей, связанное с требованием линейной разделимости классов?
Часто то, что не удается сделать сразу, вполне возможно сделать по частям. Для этого изменяются задачи, решаемые слоями нейронной сети. Оказывается в 1-м слое не следует пытаться на основе первичных признаков, фиксируемых рецепторами, сразу идентифицировать классы, а нужно лишь сформировать линейно-разделимую систему вторичных признаков, которую уже во 2-м слое связать с классами (рисунок 76).
|
|
|
Рисунок 76. Двух-слойный персептрон [187] |
В многослойной сети выходные сигналы нейронов предыдущего слоя играют роль входных сигналов для нейронов последующего слоя, т.е. нейроны предыдущего слоя выступают в качестве рецепторов для нейронов последующего слоя.
Связи между смежными слоями нейронов будем называть непосредственными, а связи между слоями, разделенными N промежуточных слоев, будем называть связями N-го уровня опосредованности. Непосредственные связи – это связи 0-го уровня опосредованности. Промежуточные слои нейронов в многослойных сетях называют скрытыми.
Персептрон переводит входной образ, определяющий степени возбуждения рецепторов, в выходной образ, определяемый нейронами самого верхнего уровня, которых обычно, не очень много. Состояния возбуждения нейронов на верхнем уровне иерархии сети характеризуют принадлежность входного образа к тем или иным классам.
Таким образом, многослойный персептрон – это обучаемая распознающая система, реализующая корректируемое в процессе обучения линейное решающее правило в пространстве вторичных признаков, которые обычно являются фиксированными случайно выбранными линейными пороговыми функциями от первичных признаков.
При обучении на вход персептрона поочередно подаются сигналы из обучающей выборки, а также указания о классе, к которому следует отнести данный сигнал. Обучение перцептрона заключается в коррекции весов при каждой ошибке распознавания, т. е. при каждом случае несовпадения решения, выдаваемого персептроном, и истинного класса. Если персептрон ошибочно отнес сигнал, к некоторому классу, то веса функции, истинного класса увеличиваются, а ошибочного уменьшаются. В случае правильного решения все веса остаются неизменными.
Этот чрезвычайно простой алгоритм обучения обладает замечательным свойством: если существуют значения весов, при которых выборка может быть разделена безошибочно, то при определенных, легко выполнимых условиях эти значения будут найдены за конечное количество итераций.
При идентификации, распознавании, прогнозировании на вход многослойного персептрона поступает сигнал, представляющий собой набор первичных признаков, которые и фиксируются рецепторами. Сначала вычисляются вторичные признаки. Каждому такому вторичному признаку соответствует линейная от первичных признаков. Вторичный признак принимает значение 1, если соответствующая линейная функция превышает порог. В противном случае она принимает значение 0. Затем для каждого из классов вычисляется функция, линейная относительно вторичных признаков. Перцептрон вырабатывает решение о принадлежности входного сигнала к тому классу, которому соответствует функция от вторичных параметров, имеющая наибольшее значение.
Показано, что для представления произвольного нелинейного функционального отображения, задаваемого обучающей выборкой, достаточно всего двух слоев нейронов. Однако на практике, в случае сложных функций, использование более чем одного скрытого слоя может давать экономию полного числа нейронов.
1.3.5.5.2. Модель Хопфилда
В модели Хопфилда (J.J.Hopfield, 1982) впервые удалось установить связь между нелинейными динамическими системами и нейронными сетями.
Модель Хопфилда является обобщением модели многослойного персептрона путем добавления в нее следующих двух новых свойств:
1. В нейронной сети все нейроны непосредственно связаны друг с другом: силу связи i-го нейрона с j-м обозначим как Wij.
2. Связи между нейронами симметричны: Wij=Wji, сам с собой нейрон не связан Wii=0.
Каждый нейрон может принимать лишь два состояния, которые определяются по классической формуле (1). Изменение состояний возбуждения всех нейронов может происходить либо последовательно, либо одновременно (параллельно), но свойства сети Хопфилда не зависят от типа динамики.
Сеть Хопфилда способна распознавать объекты при неполных и зашумленных исходных данных, однако не может этого сделать, если изображение смещено или повернуто относительно его исходного состояния, представленного в обучающей выборке.
1.3.5.5.3. Когнитрон и неокогнитрон Фукушимы
В целом когнитрон (K.Fukushima, 1975) представляет собой иерархию слоев, последовательно связанных друг с другом, как в персептроне. Однако, при этом есть два существенных отличия:
1. Нейроны образуют не одномерную цепочку, а покрывают плоскость, аналогично слоистому строению зрительной коры человека.
2. Когнитрон состоит из иерархически связанных слоев нейронов двух типов – тормозящих и возбуждающих.
В когнитроне каждый слой реализует свой
уровень обобщения информации:
– входные слои чувствительны к отдельным элементарным структурам, например, линиям определенной ориентации или цвета;
– последующие слои реагируют уже на более сложные обобщенные образы;
– в слое наивысшего уровня иерархии активные нейроны определяют результат работы сети – узнавание определенного образа, при этом результатам распознавания соответствуют те нейроны, активность которых оказалась максимальной.
Однако добиться независимости (инвариантности) результатов распознавания от размеров и ориентации изображений удалось лишь в неокогнитроне, который был разработан Фукушимой в 1980 году и представляет собой как бы суперпозицию когнитронов, обученных распознаванию объектов различных типов, размеров и ориентации.
1.3.5.6. Проблемы и перспективы нейронных сетей
На наш взгляд к основным проблемам нейронных сетей можно отнести:
1. Сложность содержательной интерпретации смысла интенсивности входных сигналов и весовых коэффициентов ("проблема интерпретируемости весовых коэффициентов").
2. Сложность содержательной интерпретации и обоснования аддитивности аргумента и вида активационной (передаточной) функции нейрона ("проблема интерпретируемости передаточной функции").
3.
"Комбинаторный взрыв", возникающий при определении структуры связей
нейронов, подборе весовых коэффициентов и передаточных функций ("проблема размерности").
4. "Проблема линейной разделимости", возникающая потому, что возбуждение нейронов принимают лишь булевы значения 0 или 1.
Проблемы интерпретируемости приводят к снижению ценности полученных результатов работы сети, а проблема размерности – к очень жестким ограничениям на количество выходных нейронов в сети, на количество рецепторов и на сложность структуры взаимосвязей нейронов с сети. Достаточно сказать, что количество выходных нейронов в реальных нейронных сетях, реализуемых на базе известных программных пакетов, обычно не превышает несколько сотен, а чаще всего составляет единицы и десятки.
Проблема линейной разделимости приводит к необходимости применения многослойных нейронных сетей для реализации тех приложений, которые вполне могли бы поддерживаться сетями с значительно меньшим количеством слоев (вплоть до однослойных), если бы значения возбуждения нейронов были не дискретными булевыми значениями, а континуальными значениями, нормированными в определенном диапазоне.
Перечисленные проблемы предлагается решить путем использования модели нелокального нейрона, обеспечивающего построение нейронных сетей прямого счета.
1.3.5.7.
Модель нелокального нейрона и нелокальные интерпретируемые нейронные сети
прямого счета
1.3.5.7.1. Метафора нейросетевого представления семантической информационной модели
В данной работе предлагается представление, согласно которому каждый нейрон отражает определенное будущее состояние активного объекта управления, а нейронная сеть в целом – систему будущих состояний, как желательных (целевых), так и нежелательных. Весовые коэффициенты на дендритах нейронов имеют смысл силы и направления влияния факторов на переход активного объекта управления в то или иное будущее состояние. Таким образом, предложенная в данной работе семантическая информационная модель в принципе допускает представление в терминах и понятиях нейронных сетей. Однако при более детальном рассмотрении выясняется, что семантическая информационная модель является более общей, чем нейросетевая и для полного их соответствия необходимо внести в нейросетевую модель ряд дополнений.
1.3.5.7.2. Соответствие основных терминов и понятий
Предлагается следующая система соответствий, позволяющая рассматривать термины и понятия из теории нейронных сетей и предложенной семантической информационной модели практически как синонимы. Нейрон – вектор обобщенного образа класса в матрице информативностей. Входные сигналы – факторы (признаки). Весовой коэффициент – системная мера целесообразности информации. Обучение сети – адаптация модели, т.е. перерасчет значений весовых коэффициентов дендритов для каждого нейрона (матрицы информативностей) и изменение вида активационной функции. Самоорганизация сети – синтез модели, т.е. изменение количества нейронов и дендритов, изменение количества нейронных слоев и структуры связей между факторами и классами, а затем адаптация (перерасчет матрицы информативностей). Таким образом, адаптация – это обучение сети на уровне изменения информационных весовых коэффициентов и активационной функции, а синтез – на уровне изменения размерности и структуры связей нейронов сети. 1-й (входной) слой нейронной сети – формирование обобщенных образов классов. Сети Хопфилда и Хэмминга – обучение с учителем, сопоставление описательной и классификационной информации, идентификация и прогнозирование. 2-й слой, сети Хебба и Кохонена – самообучение, анализ структуры данных без априорной классификационной информации, формирование кластеров классов и факторов. 3-й слой – формирование конструктов (в традиционных нейронных сетях не реализовано). Необходимо отметить, что любой слой нейронной сети является в предлагаемой модели не только обрабатывающим, но и выходным, т.е. с одной стороны дает результаты обработки информации, имеющие самостоятельное значение, а с другой – поставляет информацию для последующих слоев нейронной сети, т.е. более высоких уровней иерархии информационной системы (в полном соответствии с формализуемой когнитивной концепцией).
1.3.5.7.3. Гипотеза о нелокальности нейрона и информационная нейросетевая парадигма
Модель нелокального нейрона: так как сигналы на дендритах различных нейронов вообще говоря коррелируют (или антикоррелируют) друг с другом, то, значения весовых коэффициентов, а значит и выходное значение на аксоне каждого конкретного нейрона вообще говоря не могут быть определены с использованием значений весовых коэффициентов на дендритах только данного конкретного нейрона, а должны учитывать интенсивности сигналов на всей системе дендритов нейронной сети в целом (рисунок 77).
|
|
|
Рисунок 77. Модель нелокального нейрона в обозначениях системной
теории информации |
За счет учета корреляций входных сигналов (если они фактически присутствуют в структуре данных), т.е. наличия общего самосогласованного информационного поля исходных данных всей нейронной сети (информационное пространство), нелокальные нейроны ведут себя так, как будто связаны с другими нейронами, хотя могут быть и не связаны с ними синаптически по входу и выходу ни прямо, ни опосредованно. Самосогласованность семантического информационного пространства [82] означает, что учет любого одного нового факта в информационной модели вообще говоря приводит к изменению всех весовых коэффициентов всех нейронов, а не только тех, на рецепторе которых обнаружен этот факт и тех, которые непосредственно или опосредованно синаптически с ним связаны.
В традиционной (т.е. локальной) модели нейрона весовые коэффициенты на его дендритах однозначно определяются заданным выходом на его аксоне и никак не зависят от параметров других нейронов, с которыми с нет прямой или опосредованной синаптической связи. Это связано с тем, что в общепринятой энергетической парадигме Хопфилда весовые коэффициенты дендритов имеют смысл интенсивностей входных воздействий. В методе "обратного распространения ошибки" процесс переобучения, т.е. интерактивного перерасчета весовых коэффициентов, начинается с нейрона, состояние которого оказалось ошибочным и захватывает только нейроны, ведущие от рецепторов к данному нейрону. Корреляции между локальными нейронами обусловлены сочетанием трех основных причин:
– наличием в исходных данных определенной структуры: корреляцией входных сигналов;
– синаптической связью локальных нейронов;
– избыточностью (дублированием) нейронной сети.
1.3.5.7.4. Решение проблемы интерпретируемости весовых коэффициентов (семантическая мера целесообразности информации и закон Фехнера)
В данной работе предлагается использовать такие весовые коэффициенты дендритов, чтобы активационная функция была линейной, т.е. по сути была равна своему аргументу: сумме. Этому условию удовлетворяют весовые коэффициенты, рассчитываемые с применением системного обобщения формулы Харкевича [64].
Очень важно, что данная мера, удовлетворяет известному эмпирическому закону Г.Фехнера (1860), согласно которому существует логарифмическая зависимость между интенсивностью фактора и величиной отклика на него биологической системы (в частности, величина ощущения прямо пропорциональна логарифму интенсивности раздражителя).
Предлагается информационный подход к нейронным сетям, по аналогии с энергетическим подходом Хопфилда (1980).
Суть этого подхода состоит в том, что интенсивности входных сигналов рассматриваются не сами по себе и не с точки зрения только их интенсивности, а как сообщения, несущие определенное количество информации или дезинформации о переходе нейрона и моделируемого им активного объекта управления в некоторое будущее состояние.
Под интенсивностью входного сигнала на
определенном дендрите мы будем понимать абсолютную частоту (количество) встреч фактора (признака),
соответствующего данному дендриту, при предъявлении нейронной сети объекта,
соответствующего определенному нейрону. Таким образом матрица абсолютных частот
рассматривается как способ накопления и первичного обобщения эмпирической
информации об интенсивностях входных сигналов на дендритах в разрезе по
нейронам.
Весовые коэффициенты, отражающие влияние каждого входного сигнала
на отклик каждого нейрона, т.е. величину его возбуждения или торможения,
представляют собой элементы матрицы информативностей, получающиеся из матрицы
абсолютных частот методом прямого счета с
использованием выражения для семантической меры целесообразности информации
[82].
При этом предложенная мера семантической целесообразности информации, как перекликается с нейронными сетями Кохонена, в которых также принято стандартизировать (нормализовать) входные сигналы, что позволяет в определенной мере уйти от многообразия передаточных функций.
Наличие ясной и обоснованной интерпретации весовых коэффициентов, как количества информации, позволяет предложить в качестве математической модели для их расчета системную теорию информации (СТИ).
1.3.5.7.5. Семантическая информационная модель, как нелокальная нейронная сеть
Учитывая большое количество содержательных параллелей между семантической информационной моделью и нейронными сетями предлагается рассматривать данную модель как нейросетевую модель, основанную на системной теории информации. В данной модели предлагается вариант решения важных нейросетевых проблем интерпретируемости и ограничения размерности за счет введения меры целесообразности информации (системное обобщение формулы Харкевича), обеспечивающей прямой расчет интерпретируемых весовых коэффициентов на основе непосредственно эмпирических данных. Итак, в данной работе предлагается новый класс нейронных сетей, основанных на семантической информационной модели и информационном подходе. Для этих сетей предлагается полное наименование: "Нелокальные интерпретируемые нейронные сети прямого счета" и сокращенное наименование: "Нелокальные нейронные сети".
Нелокальная нейронная сеть является системой нелокальных нейронов, обладающей качественно новыми (системными, эмерджентными) свойствами, не сводящимися к сумме свойств нейронов. В такой сети поведение нейронов определяется как их собственными свойствами и поступающими на них входными сигналами, так и свойствами нейронной сети в целом, т.е. поведение нейронов в нелокальной нейронной сети согласовано друг с другом не только за счет их прямого и опосредованного синаптического взаимодействия (как в традиционных нейронных сетях), но за счет общего информационного поля весовых коэффициентов всех нейронов данной сети.
1.3.5.7.6. Гипотеза о физической природе нелокального взаимодействия нейронов в нелокальной нейронной сети
В данной работе предлагается математическая модель, численный метод и программный инструментарий нелокальных нейронных сетей (универсальная когнитивная аналитическая система "Эйдос"), успешно апробированные в ряде предметных областей. Данная система обеспечивает неограниченное количество слоев ННС при максимальном количестве весовых коэффициентов в слое до 16 миллионов в версии 9.0 и до 4000 выходных нейронов, а в текущей версии 12.5 эти количества ограничены практически только емкостью диска. Но если рассматривать нелокальную нейронную сеть как модель реальных "биологических" нейронных сетей, то ясно, что формальной модели недостаточно и необходимо дополнить ее физической моделью о природе каналов нелокального взаимодействия нейронов в данной сети.
По мнению автора данный механизм основан на парадоксе Эйнштейна-Подольского Розена (ЭПР) [7, 165, 219]. По мнению автора, физическая реализация нелокальных нейронов может быть осуществлена за счет соединения как минимум одного дендрита каждого нейрона с датчиком микротелекинетического воздействия, на который человек может оказывать влияние дистанционно. Некоторые из подобных датчиков описаны в работе [165] и на сайте автора. По мнению автора, мозг может рассматриваться как оптимальная среда для редукции мыслей, в этом смысле квантовые компьютеры, основанные не на математических и программных моделях, а на физических нелокальных нейронах, могут оказаться во многих отношениях функционально эквивалентными физическому организму.
1.3.5.7.7. Решение проблемы интерпретируемости передаточной функции
Вопрос об интерпретируемости передаточной функции нейрона включает два основных аспекта:
1) об интерпретируемости аргумента передаточной функции;
2) об интерпретируемости вида передаточной функции.
1. Возникает естественный вопрос о том, чем обосновано включение в состав модели нейрона Дж. Маккалоки и У. Питтом именно аддитивного элемента, суммирующего входные сигналы, а не скажем мультипликативного или в виде какой-либо другой функции общего вида. По мнению автора такой выбор обоснован и имеет явную и убедительную интерпретацию именно в том случае, когда весовые коэффициенты имеют смысл количества информации, т.к. в этом случае данная мера представляет собой неметрический критерий сходства, основанный на лемме Неймана-Пирсона [148]. Сумма весовых коэффициентов, соответствующих набору действующих факторов (входных сигналов) дает величину выходного сигнала на аксоне каждого нейрона.
2. Вид передаточной функции содержательно в теории нейронных сетей явно не обосновывается. Предлагается гипотеза, что на практике вид передаточной функции подбирается таким образом, чтобы соответствовать смыслу подобранных в данном конкретном случае весовых коэффициентов. Так как при применении в различных предметных областях смысл весовых коэффициентов в явном виде не контролируется и может отличаться, то выбор вида передаточной функции позволяет частично компенсировать эти различия.
Предлагаемый интерпретируемый вид весовых коэффициентов обеспечивает единую и стандартную интерпретацию аргумента и значения передаточной функции независимо от предметной области. Поэтому в нелокальной нейронной модели передаточная функция нейрона всегда линейна (аргумент равен функции). Следовательно в модели нелокального нейрона блок суммирования по сути дела объединен с блоком нелинейного преобразования (точнее, второй отсутствует, а его роль выполняет блок суммирования), в отличие от стандартных передаточных функций локальных нейронов: логистической, гиперболического тангенса, пороговой линейной, экспоненциально распределенной, полиномиальной и импульсно-кодовой.
Нелокальные нейроны как бы "резонируют" на ансамбли входных сигналов, причем этот резонанс может быть обоснованно назван семантическим (смысловым), т.к. весовые коэффициенты рассчитаны на основе предложенной семантической меры целесообразности информации. Таким образом, разложение вектора идентифицируемого объекта в ряд по векторам обобщенных образов классов осуществляется на основе семантического резонанса нейронов выходного слоя на ансамбль входных сигналов (признаков, факторов).
1.3.5.7.8. Решение проблемы размерности
Вместо итерационного подбора весовых коэффициентов путем полного перебора вариантов их значений при малых вариациях (методы обратного распространения ошибки и градиентного спуска к локальному экстремуму) предлагается прямой расчет этих коэффициентов на основе процедуры и выражений, обоснованных в предложенных системной теории информации и семантической информационной модели. Выигрыш во времени и используемых вычислительных ресурсах, получаемый за счет этого, быстро возрастает при увеличении размерности нейронной сети.
1.3.5.7.9. Решение проблемы линейной разделимости
Вводятся промежуточные линейно-разделимые классы распознавания, которые рассматриваются как вторичные признаки при идентификации объектов с ранее не разделимыми классами. Это решение соответствует введению дополнительных слоев нейронной сети.
В системе "Эйдос" функция представления нейронов предыдущего слоя в качестве рецепторов последующего слоя автоматизирована, что в случае необходимости позволяет в полуавтоматическом режиме преобразовать однослойную сеть с линейно-неразделимыми классами в иерархическую нейронную сеть в которой эти классы линейно-разделены относительно вторичных признаков в слоях более высоких уровней иерархии.
1.3.5.7.10. Моделирование причинно-следственных цепочек в нейронных сетях и семантической информационной модели
Факторы описывают причины, а классы – следствия. Но и следствия в свою очередь являются причинами более отдаленных последствий. Предлагаемая семантическая информационная модель позволяет рассматривать события, обнаружение которых осуществляется в режиме идентификации, как причины последующих событий, т.е. как факторы, их вызывающие. При этом факт наступления этих событий моделируется путем включения в модель факторов, соответствующих классам (событиям). В нейронных сетях этот процесс моделируется путем включения в сеть дополнительных нейронных слоев и создания обратных связей между слоями, обеспечивающих передачу в предыдущие слои результатов работы последующих слоев.
1.3.5.7.11. Моделирование иерархических структур обработки информации
Рассмотрим иерархическую структуру информации на примере использования психологического теста для оценки психологических качеств сотрудников и влияния этих качеств на эффективность работы фирмы. В нейронной сети иерархическим уровням обработки информации соответствуют слои, поэтому далее будем использовать термины "слой нейронной сети" и "иерархический уровень обработки информации" как синонимы. Рецепторы дают информацию по ответам сотрудника на опросник, нейроны 1-го слоя дают оценку психологических качеств и сигнал с их аксонов является входным для нейронов 2-го слоя, дающих оценку качества работы фирмы. В семантической информационной модели существует три варианта моделирования подобных иерархических структур обработки информации:
1. Заменить все слои одним слоем и выявлять зависимости непосредственно между исходными данными с первичных рецепторов и интересующими итоговыми оценками, например, ответами сотрудников на вопросы и результатами работы фирмы. Этот подход эффективен с прагматической точки зрения, но дает мало информации для теоретических обобщений.
2. Каждый слой моделируется отдельной семантической информационной моделью, включающей свои классификационные и описательные шкалы и градации, обучающую выборку, матрицы абсолютных частот и информативностей. Вся система иерархической обработки информации моделируется системой этих моделей, взаимосвязанных друг с другом по входу-выходу: результаты классификации объектов обучающей выборки 1-й моделью рассматриваются как свойства этих объектов во 2-й модели, в которой они используются для классификации 2-го уровня. Например, психологические качества сотрудников, установленные в результате психологического тестирования, рассматриваются как свойства сотрудников, влияющие на эффективность работы фирмы. Данный подход эффективен и с прагматической, и с теоретической точек зрения, но является громоздким в программной реализации.
3. Моделирование каждого слоя соответствующими подматрицами матриц абсолютных частот и информативностей (таблица 34).
Примечание: в таблице 34 представлена именно логическая структура данных, т.е. в реальных базах данных нет записей, содержащих информацию о влиянии рецепторов n-го слоя на нейроны слоев, номера которых не равны n.
Этот вариант обладает преимуществами первых двух и преодолевает их недостатки. В нем применяется следующий итерационный алгоритм послойного расчета, где n={1, 2, …, N}, N – количество слоев нейронной сети:
Шаг n: расчет весовых коэффициентов n-го слоя, идентификация объектов обучающей выборки в нейронах n-го слоя, если слой (n+1) существует, то занесение в обучающую выборку в качестве свойств объектов (n+1)-го слоя результатов их идентификации в нейронах n-го слоя.
Таблица 34 – ЛОГИЧЕСКАЯ СТРУКТУРА ДАННЫХ, СООТВЕТСТВУЮЩАЯ ТРЕХСЛОЙНОЙ НЕЛОКАЛЬНОЙ НЕЙРОННОЙ СЕТИ
|
Рецепторы – факторы, влияющие на поведение объекта управления |
Нейроны - будущие состояния
объекта управления |
Дифференцирующая способность входного сигнала |
||
|
Нейроны 1-го слоя: психологические качества сотрудников |
Нейроны 2-го слоя: успешность деятельности сотрудника |
Нейроны 3-го слоя: успешность деятельности фирмы |
||
|
Рецепторы 1-го слоя: ответы сотрудников на вопросы анкеты |
Весовые коэффициенты 1-го слоя |
– – – |
– – – |
|
|
Рецепторы 2-го слоя: психологические качества сотрудников |
– – – |
Весовые коэффициенты 2-го слоя |
– – – |
|
|
Рецепторы 3-го слоя: успешность деятельности сотрудника |
– – – |
– – – |
Весовые коэффициенты 3-го слоя |
|
|
Степень обученности нейрона |
|
|
|
Степень обученности нейронной сети |
1.3.5.7.12. Нейронные сети и СК-анализ
Известные в литературе нейронные сети, в отличие от предлагаемой семантической информационной модели и нелокальных нейронных сетей, не обеспечивают реализацию всех базовых когнитивных операций, входящих в когнитивный конфигуратор. В частности, традиционные нейронные сети решают лишь задачу идентификации (прогнозирования) и не обеспечивают решение обратной задачи (дедукции), необходимой для принятия решения о выборе многофакторного управляющего воздействия. Кроме того не решается вопрос об уменьшении размерности нейронной сети без ущерба для ее адекватности (абстрагирование).
Результаты численного моделирования и исследования свойств нейронных сетей этого класса при управлении в АПК и других предметных областях позволяют предположить, в качестве модели реальных когнитивных процессов они обладает более высокой адекватностью, чем нейронные сети других типов.
1.3.5.7.13. Графическое отображение нейронов, Паррето-подмножеств нелокальной нейронной сети, семантических сетей, когнитивных карт и диаграмм в системе "Эйдос"
Для каждого технологического фактора в соответствии с предложенной моделью определяется величина и направление его влиянии на осуществление всех желаемых и не желаемых хозяйственных ситуаций. Для каждой ситуации эта информация отображается в различных текстовых и графических формах, в частности в форме нелокального нейрона (рисунок 78).
На данной и последующих графических диаграммах цвет линии означает знак связи (красный – положительная, синий – отрицательная), а толщина – ее модуль.
Паретто-подмножеством нелокальной нейронной сети будем называть ее подмножество, включающее наиболее значимые связи. Пример графического отображения такого подмножества приведен в таблицах 35 – 37.
Факторы (сигналы с рецепторов) в модели нелокального нейрона взаимосвязаны друг с другом. Эти связи графически отображаются в форме семантической сети (рисунок 78).
|
|
|
Рисунок 78. Отображение результатов кластерно-конструктивного анализа факторов в форме семантической сети (когнитивной карты) в системе "Эйдос" |
Структуру любой линии связи семантической сети можно детально изучить в когнитивной диаграмме (рисунок 79).
Дополнение модели нейрона связями факторов позволяет построить классическую когнитивную карту ситуации (будущего состояния АОУ). Необходимо отметить, что все указанные графические формы генерируются системой "Эйдос" автоматически в соответствии с созданной моделью.
Нелокальный нейрон представляет собой будущее состояние объекта управления с изображением наиболее сильно влияющих на него факторов с указанием силы и направления (способствует-препятствует) их влияния (рисунок 80).
|
|
|
|
Рисунок 79. Когнитивная диаграмма кластера
факторов: "Глубина и способ обработки почвы: вспашка на 20- |
|
|
|
||
|
Рисунок 80. Примеры нелокальных нейронов, отражающих влияние инвестиций на уровень качества жизни в регионе (система "Эйдос") |
||
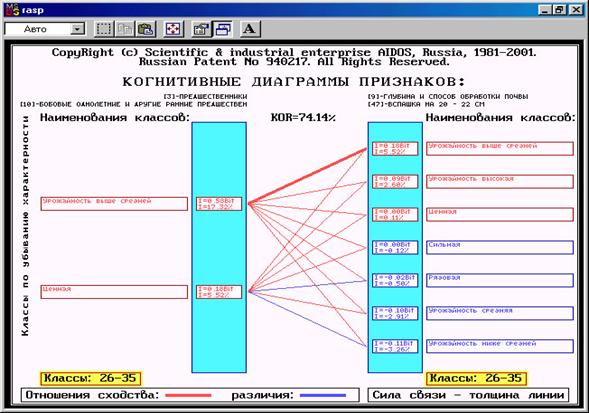
Нейронная сеть представляет собой совокупность взаимосвязанных нейронов. В классических нейронных сетях связь между нейронами осуществляется по входным и выходным сигналам, а в нелокальных нейронных сетях [82] – на основе общего информационного поля.
В таблице 35 приводится классификация причинно-следственных связей по рангам. Эта классификация использована для отображения параметров заданий на генерацию и соответствующих фрагментов нейронных сетей (таблица 36). Фрагменты нейронной сети со связями 0-го уровня опосредованности, т.е. соответствующие смежным слоям многослойной сети, показаны на голубом фоне. В пустых клетках таблицы 35 могут быть отображены фрагменты нейронной сети, аналогичные показанным. Однако новой информации, по сравнению с уже показанными, они не содержат, т.к. практически они образуются из них путем перемены местами нейронов и рецепторов (инвертирования – отражения относительно горизонтальной оси). Сгенерированные по этим заданиям фрагменты нейронной сети приведены в форме, позволяющей составить из них многослойную нейронную сеть (таблицы 36 и 37). "ти таблицы взяты из работы [202].
Система "Эйдос" обеспечивает построение любого подмножества многослойной нейронной сети с заданными или выбираемыми по заданным критериям рецепторами и нейронами, связанными друг с другом связями любого уровня опосредованности.
Таблица 35 – ВИДЫ КАУЗАЛЬНЫХ СВЯЗЕЙ МЕЖДУ ОБЪЕКТАМИ РАЗЛИЧНЫХ УРОВНЕЙ ИЕРАРХИЧЕСКОЙ МОДЕЛИ И СООТВЕТСТВУЮЩИЕ ФРАГМЕНТЫ НЕЙРОННОЙ СЕТИ
|
Факторы (наименования,
коды) |
Классы
(наименования, коды) |
|||
|
Уровень качества
жизни |
Годы |
Частные критерии уровня качества
жизни |
||
|
Наименования |
Коды |
99-103 |
86-98 |
1-85 |
|
Годы |
626-638 |
|
|
|
|
Частные критерии качества
жизни |
541-625 |
|
|
|
|
Первичные факторы (инвестиции) |
1-85 |
|
|
|






Таблица 36 – ФРАГМЕНТЫ МНОГОУРОВНЕВОЙ
СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ И НЕЙРОННОЙ СЕТИ
С НЕПОСРЕДСТВЕННЫМИ СВЯЗЯМИ
|
Уровень |
Нейронная
сеть |
|
|
№ |
Наимено- вание |
|
|
4 3 |
Уровни качества Жизни (значения
Интегрального критерия уровня качества жизни) Годы |
|
|
3 2 |
Годы Вторичные факторы (частные критерии
уровня качества жизни) |
|
|
2 1 |
Вторичные факторы (частные критерии
уровня качества жизни) Первичные факторы |
|

Таблица 37 – ФРАГМЕНТЫ МНОГОУРОВНЕВОЙ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ И МНОГОСЛОЙНОЙ НЕЙРОННОЙ СЕТИ СО СВЯЗЯМИ РАЗЛИЧНОЙ СТЕПЕНИ ОПОСРЕДОВАННОСТИ
|
Уровень |
Нейронная
сеть |
||||
|
№ |
Наимено- вание |
Слои со
связями 0-го уровня опосредованности |
Слои со
связями 1-го уровня опосредованности |
Слои со
связями 1-го уровня опосредованности |
Слои со
связями 2-го уровня опосредованности |
|
4 3 |
Уровни качества Жизни (значения
Интегрального критерия уровня качества жизни) Годы |
|
|
|
|
|
3 2 |
Годы Вторичные факторы (частные критерии
уровня качества жизни) |
|
|
||
|
2 1 |
Вторичные факторы (частные критерии
уровня качества жизни) Первичные факторы |
|
|
||






Обучение нелокальной нейронной сети
В классических нейронных сетях обучение состоит в таком подборе весовых коэффициентов на дендритах, что минимизируется ошибка выходного сигнала сети по сравнению с эталонным. Этот вид обучения аналогичен обучению человека с уже сформированным мозгом, т.е. в достаточно зрелом возрасте, когда структура нейронной сети уже сформирована и фиксирована.
Однако в раннем возрасте и до наступления зрелости может быть основную роль играет другой вид обучения, который состоит в том, что формируется и перестраивается сама структура нейронной сети. Этот процесс включает:
– формирование новых связей между уже существующими нейронами;
– формирование новых нейронов;
– формирование связей между уже существующими и новыми нейронами;
– формирование связей между новыми нейронами;
– формирование новых нейронных систем (ансамблей) и слоев.
В классической нейронной сети обучение в каждом конкретном случае затрагивает лишь те нейроны, которые физически связаны с входными рецепторами и конкретными выходными аксонами.
В нелокальной нейронной сети могут возникать и новые связи между рецепторами и аксонами (адаптивность СИМ и ННС), а также добавляться новые рецепторы и нейроны (пересинтез СИМ и ННС).
Классические когнитивные карты
Классическая когнитивная карта представляет собой нейрон, соответствующий некоторому состоянию объекта управления с рецепторами, каждый из которых соответствует фактору в определенной степени способствующему или препятствующему переходу объекта в это состояние. Рецепторы соединены связями как с нейроном, так и друг с другом. Связи рецепторов с нейроном отражают силу и направление влияния факторов, а связи рецепторов друг с другом, отображаемые в форме семантической сети факторов, – сходство и различие между рецепторами по характеру их влияния на объект управления. Таким образом, классическая когнитивная карта представляет собой нейрон с семантической сетью факторов, изображенные на одной диаграмме (рисунок 81).
|
|
|
|
|
|
|
Рисунок 81. Примеры классических когнитивных
карт, отражающих влияние |
|
Обобщенные когнитивные карты
Если объединить несколько классических когнитивных карт на одной диаграмме и изобразить на ней также связи между нейронами в форме семантической сети классов, то получим обобщенную (интегральную) когнитивную карту. На рисунке 82 приведена обобщенная когнитивная карта, отражающая результаты идентификации лет с помощью интегрального критерия уровня качества жизни, на рисунке 83 – влияние инвестиций на уровень качества жизни.
|
|
|
Рисунок 82. Результаты оценки лет с 1991 по
2003 |
|
|
|
Рисунок 83. Обобщенная (интегральная)
когнитивная карта, |
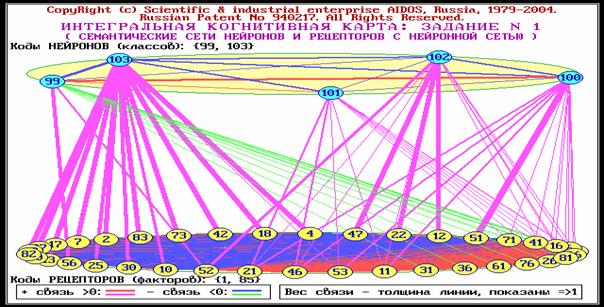
Система "Эйдос" обеспечивает построение любого подмножества многоуровневой семантической информационной модели с заданными или выбираемыми по заданным критериям рецепторами и нейронами, связанными друг с другом связями любого уровня опосредованности в форме классических и обобщенных когнитивных карт. В частности, в системе полуавтоматически формируется задание на генерацию подмножеств обобщенной когнитивной карты, показанных на рисунках 84.
|
|
|
|
Рисунок 84. Примеры подмножеств интегральной
когнитивной карты, |
|
Резюме
Предлагается модель нелокального нейрона, являющаяся обобщением классической модели Дж. Маккалоки и У. Питтса. Суть нелокальности данной модели состоит в том, что весовые коэффициенты каждого нейрона зависят не только от нейронов, прямо или косвенно соединенных с ним синаптически, но и от всех остальных нейронов сети, не затрагиваемых при обратном распространении ошибки от данного нейрона. Предлагается новый класс нейронных сетей: "Нелокальные интерпретируемые нейронные сети прямого счета" (нелокальные нейронные сети – ННС). Организация ННС обеспечивает один из вариантов решения традиционных для нейронных сетей проблем:
– содержательной интерпретации смысла
интенсивности входных сигналов и весовых коэффициентов ("проблема интерпретируемости весовых коэффициентов");
– содержательной
интерпретации и обоснования аддитивности аргумента и вида активационной
(передаточной) функции нейрона ("проблема
интерпретируемости передаточной функции");
– "Комбинаторного
взрыва" при определении структуры связей нейронов, подборе весовых
коэффициентов и передаточных функций ("проблема
размерности");
– "проблема линейной разделимости классов" в случае отсутствия вариабельности весовых коэффициентов нейронов, соответствующих тем или иным классам.
Математическая модель ННС основана на предложенной автором системной теории информации и семантической информационной модели автоматизированного системно-когнитивного анализа (АСК-анализ), и в отличие от известных нейронных сетей, обеспечивают автоматизацию всех 10 базовых когнитивных операций, образующих "когнитивный конфигуратор". Предложены не только математическая модель, но также и соответствующий численный метод (включая алгоритмы и структуры данных), а также программный инструментарий нелокальных нейронных сетей (универсальная когнитивная аналитическая система "Эйдос" версии 12.5), успешно апробированные в ряде предметных областей. Данная система обеспечивает неограниченное количество слоев ННС при максимальном количестве весовых коэффициентов в слое до 16 миллионов (в текущей версии), до 4000 выходных нейронов, а также автоматическую визуализацию и запись в виде графических файлов сформированных моделей нелокальных нейронов и Паретто-подмножеств нелокальной нейронной сети.
Контрольные вопросы
1. Биологический нейрон и формальная модель нейрона Маккалоки и Питтса.
2. Возможность решения простых задач классификации непосредственно одним нейроном.
3. Однослойная нейронная сеть и персептрон Розенблата.
4. Линейная разделимость и персептронная представляемость.
5. Многослойные нейронные сети.
6. Многослойный персептрон.
7. Модель Хопфилда.
8. Когнитрон и неокогнитрон Фукушимы.
9. Проблемы и перспективы нейронных сетей.
10. Модель нелокального нейрона и нелокальные интерпретируемые нейронные сети прямого счета.
11. Метафора нейросетевого представления семантической информационной модели.
12. Соответствие основных терминов и понятий.
13. Гипотеза о нелокальности нейрона и информационная нейросетевая парадигма.
14. Решение проблемы интерпретируемости весовых коэффициентов (семантическая мера целесообразности информации и закон Фехнера).
15. Семантическая информационная модель, как нелокальная нейронная сеть.
16. Гипотеза о физической природе нелокального взаимодействия нейронов в нелокальной нейронной сети.
17. Решение проблемы интерпретируемости передаточной функции.
18. Решение проблемы размерности.
19. Решение проблемы линейной разделимости.
20. Моделирование причинно-следственных цепочек в нейронных сетях и семантической информационной модели.
21. Моделирование иерархических структур обработки информации.
22. Нейронные сети и СК-анализ.
23. Графическое отображение нейронов, Паррето-подмножеств нелокальной нейронной сети, семантических сетей, когнитивных карт и диаграмм в системе "Эйдос".
Рекомендуемая литература
1. Lutsenko E.V. Conceptual principles of the system (emergent) information theory & its application for the cognitive modelling of the active objects (entities) //2002 IEEE International Conference on Artificial Intelligence System (ICAIS 2002). –Computer society, IEEE, Los Alamos, California, Washington-Brussels-Tokyo, p. 268-269.
2. Бранский В.П. Философские основания проблемы синтеза релятивистских и квантовых принципов. –Л: ЛГУ, 1973. –175с.
3. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
4. Луценко Е.В. Интерференция последствий выбора в результате одновременного выбора альтернатив и необходимость разработки эмерджентной теории информации. //В сб.: "Материалы III всероссийской межвузовской научно-технической конференции". – Краснодар: КВИ, 2002. – С.24-30.
5. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
6. Роберт Г.Джан, Бренда Дж.Данн. Границы реальности. (Роль сознания в физическом мире). /Пер. с англ. - М.: Объединенный институт высоких температур РАН, 1995. - 287с.
7. Цехмистро И.З. Поиски квантовой концепции физических оснований сознания. –Харьков: ХГУ, 1981. - 275с.
8. Терехов С.А. Лекции по теории и приложениям искусственных нейронных сетей. Лаборатория Искусственных Нейронных Сетей НТО-2, ВНИИТФ, Снежинск, http://alife.narod.ru/lectures/neural/Neu_index.htm.
9. Ткачев А.Н., Луценко Е.В. Формальная постановка задачи и синтез многоуровневой семантической информационной модели влияния инвестиций на уровень качества жизни населения региона // Научный журнал КубГАУ. – 2004.– №4(6). –22 с. http://ej.kubagro.ru
10. Ткачев А.Н., Луценко Е.В. Исследование многоуровневой семантической информационной модели влияния инвестиций на уровень качества жизни населения региона // Научный журнал КубГАУ. – 2004.– №4(6). –28 с. http://ej.kubagro.ru
11. Сайт "Курс статистики", раздел "Нейронные сети": http://www.statsoft.ru/home/textbook/modules/stneunet.html.
1.3.6.
ЛЕКЦИЯ-12.
Генетические алгоритмы
и моделирование биологической эволюции
Учебные вопросы
1. Основные понятия, принципы и предпосылки генетических алгоритмов.
2. Пример работы простого генетического алгоритма.
3. Достоинства и недостатки генетических алгоритмов.
4. Примеры применения генетических алгоритмов.
1.1.6.1. Основные понятия, принципы и предпосылки генетических алгоритмов
Генетические Алгоритмы (ГА) – это адаптивные методы функциональной
оптимизации, основанные на компьютерном имитационном
моделировании биологической эволюции. Основные принципы ГА были
сформулированы Голландом (Holland, 1975), и хорошо описаны во многих работах и
на ряде сайтов в Internet.
В настоящее время существует ряд теорий биологической эволюции (Ж.-Б.Ламарка, П.Тейяра де Шардена, К.Э.Бэра, Л.С.Берга, А.А.Любищева, С.В.Мейена и др.), однако, ни одна из них не считается общепризнанной. Наиболее известной и популярной, конечно, является теория Чарльза Дарвина, которую он представил в работе "Происхождение Видов" в 1859 году.
Эта теория, как и другие, содержит довольно много нерешенных проблем, глубокое рассмотрение которых далеко выходит за рамки данной работы. Здесь мы можем отметить лишь некоторые наиболее известные из них. Как это ни парадоксально, но несмотря на то, что сам Чарльз Дарвин назвал свою работу "Происхождение Видов" но как раз именно происхождения видов она и не объясняет. Дело в том, что возникновение нового вида "по алгоритму Дарвина" является крайне маловероятным событием, т.к. для этого требуется случайное возникновение в одной точке пространства и времени сразу не менее 100 особей нового вида, т.е. особей, которые могли бы иметь плодовитое потомство. При меньшем количестве особей вид обречен на вымирание. Поэтому процесс видообразования на основе случайных мутаций должен был бы занять несуразно много времени (по некоторым оценкам даже в намного раз больше, чем время существования Вселенной). Кроме того, "алгоритм Дарвина" не объясняет явной системности в многообразии возникающих форм, типа закона гомологичных рядов Н.И. Вавилова. Поэтому Л.С. Берг предложил очень интересную концепцию номогенеза – закономерной или направленной эволюции живого. В этой концепции предполагается, что филогенез имеет определенное направление и смена форма является не случайной, а задается некоторым вектором, природа которого не ясна. Идеи номогенеза глубоко разработал и развил А.А. Любищев, высказавший гипотезу о математических закономерностях, которые определяют многообразие живых форм. Кроме того, Дарвин не смог показать механизм наследования, при котором поддерживается и закрепляется изменчивость. Это было на пятьдесят лет до того, как генетическая теория наследственности начала распространяться по миру, и за тридцать лет до того, как "эволюционный синтез" укрепил связь между теорией эволюции и молодой генетикой.
Тем ни менее и не смотря на свои недостатки, именно теория Дарвина традиционно и моделируется в ГА, хотя, конечно, это не исключает возможности моделирования и других теорий эволюции в ГА. Более того, возможно именно такое компьютерное моделирование и сравнение его результатов с картиной реальной эволюции жизни на Земле может быть и сыграет положительную роль в дальнейшей разработке наиболее адекватной теории биологической эволюции.
Теория Дарвина применима не к отдельным особям, а к популяциям – большому количеству особей одного вида, т.е. способных давать плодовитое потомство, находящейся в определенной статичной или динамичной внешней среде.
В основе модели эволюции Дарвина лежат случайные изменения отдельных материальных элементов живого организма при переходе от поколения к поколению. Целесообразные изменения, которые облегчают выживание и производство потомков в данной конкретной внешней среде, сохраняются и передаются потомству, т.е. наследуются. Особи, не имеющие соответствующих приспособлений, погибают, не оставив потомства или оставив его меньше, чем приспособленные (считается, что количество потомства пропорционально степени приспособленности). Поэтому в результате естественного отбора возникает популяция из наиболее приспособленных особей, которая может стать основой нового вида.
Естественный отбор происходит в условиях конкуренции особей популяции, а иногда и различных видов, друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют за привлечение брачного партнера. Те особи, которые наиболее приспособлены к окружающим условиям, будут иметь относительно больше шансов воспроизвести потомков. Слабо приспособленные особи либо совсем не произведут потомства, либо их потомство будет очень немногочисленным. Это означает, что гены от высоко адаптированных или приспособленных особей будут распространятся в увеличивающемся количестве потомков на каждом последующем поколении.
Таким образом, по сути дела каждый конкретный генетический алгоритм представляют имитационную модель некоторой определенной теории биологической эволюции или ее варианта. Вместе с тем необходимо отметить, что сами исследователи биологической эволюции пока еще не до конца определились с критериями и методами определения степени существенности для поддерживаемой ими теории эволюции тех или иных биологических процессов, которые собственно и моделируются в генетических алгоритмах.
1.1.6.2. Пример работы простого генетического алгоритма
На рисунке 85 приведен пример простого генетического алгоритма.
|
|
|
Рисунок 85. Простой генетический алгоритм |
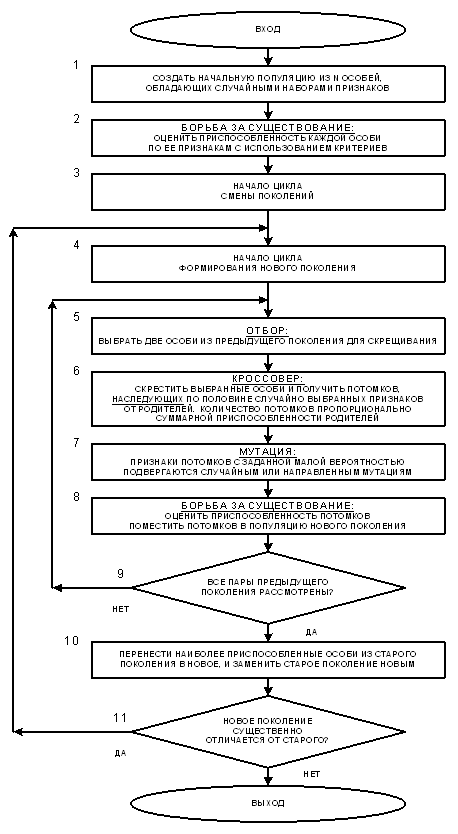
Работа ГА представляет собой итерационный процесс, который продолжается до тех пор, пока поколения не перестанут существенно отличаться друг от друга, или не пройдет заданное количество поколений или заданное время. Для каждого поколения реализуются отбор, кроссовер (скрещивание) и мутация. Рассмотрим этот алгоритм.
Шаг 1: генерируется начальная популяция, состоящая из N особей со случайными наборами признаков.
Шаг 2 (борьба за существование): вычисляется абсолютная приспособленность каждой особи популяции к условиям среды f(i) и суммарная приспособленность особей популяции, характеризующая приспособленность всей популяции. Затем при пропорциональном отборе для каждой особи вычисляется ее относительный вклад в суммарную приспособленность популяции Ps(i), т.е. отношение ее абсолютной приспособленности f(i) к суммарной приспособленности всех особей популяции (3):
|
|
( 3 ) |
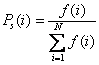
В выражении (3) сразу обращает на себя внимание возможность сравнения абсолютной приспособленности i-й особи f(i) не с суммарной приспособленностью всех особей популяции, а со средней абсолютной приспособленностью особи популяции (4):
|
|
( 4 ) |
Тогда получим (5):
|
|
( 5 ) |

Если взять логарифм по основанию 2 от выражения (5), то получим количество информации, содержащееся в признаках особи о том, что она выживет и даст потомство (6).
|
|
( 6 ) |
Необходимо отметить, что эта формула
совпадает с формулой для семантического количества информации Харкевича, если
целью считать индивидуальное выживание и продолжение рода. Это значит,
что даже чисто формально приспособленность особи представляет
собой количество информации, содержащееся в ее фенотипе о продолжении ее
генотипа в последующих поколениях.
Поскольку количество потомства особи пропорционально ее приспособленности, то естественно считать, что если это количество информации:
– положительно, то данная особь выживает и дает потомство, численность которого пропорциональна этому количеству информации;
– равно нулю, то особь доживает до половозрелого возраста, но потомства не дает (его численность равна нулю);
– меньше нуля, то особь погибает до достижения половозрелого возраста.
Таким образом, можно сделать фундаментальный
вывод, имеющий даже мировоззренческое звучание, о том, что естественный отбор представляет
собой процесс генерации и накопления информации о выживании и продолжении рода
в ряде поколений популяции, как системы.
Это накопление информации происходит на различных уровнях иерархии популяции, как системы, включающей:
– элементы системы: отдельные особи;
– взаимосвязи между элементами: отношения между особями в популяции, обеспечивающие передачу последующим поколениям максимального количества информации об их выживании и продолжении рода (путем скрещивания наиболее приспособленных особей и наследования рациональных приобретений);
– цель системы: сохранение и развитие популяции, реализуется через цели особей: индивидуальное выживание и продолжение рода.
Фенотип соответствует генотипу и представляет собой его внешнее проявление в признаках особи. Особь взаимодействует с окружающей средой и другими особями в соответствии со своим фенотипом. В случае, если это взаимодействие удачно, то особь передает генетическую информацию, определяющую фенотип, последующим поколениям.
Шаг 3: начало цикла смены поколений.
Шаг 4: начало цикла формирования нового поколения.
Шаг 5 (отбор): осуществляется пропорциональный отбор особей, которые могут участвовать в продолжении рода. Отбираются только те особи популяции, у которых количество информации в фенотипе и генотипе о выживании и продолжении рода положительно, причем вероятность выбора пропорциональна этому количеству информации.
Шаг 6 (кроссовер): отобранные для продолжения рода на предыдущем шаге особи с заданной вероятностью Pc подвергаются скрещиванию или кроссоверу (рекомбинации).
Если кроссовер происходит, то потомки получают по половине случайным образом определенных признаков от каждого из родителей. Численность потомства пропорциональна суммарной приспособленности родителей. В некоторых вариантах ГА потомки после своего появления заменяют собой родителей и переходят к мутации.
Если кроссовер не происходит, то исходные особи – несостоявшиеся родители, переходят на стадию мутации.
Шаг 7 (мутация): выполняются операторы мутации. При этом признаки потомков с вероятностью Pm случайным образом изменяются на другие. Отметим, что использование механизма случайных мутаций роднит генетические алгоритмы с таким широко известным методом имитационного моделирования, как метод Монте-Карло.
Шаг 8 (борьба за существование): оценивается приспособленность потомков (по тому же алгоритму, что и на шаге 2).
Шаг 9: проверяется, все ли отобранные особи дали потомство.
Если нет, то происходит переход на шаг 5 и продолжается формирование нового поколения, иначе – переход на следующий шаг 10.
Шаг 10: происходит смена поколений:
– потомки помещаются в новое поколение;
– наиболее приспособленные особи из старого поколения переносятся в новое, причем для каждой из них это возможно не более заданного количества раз;
– полученная новая популяция замещает собой старую.
Шаг 11: проверяется выполнение условия останова генетического алгоритма. Выход из генетического алгоритма происходит либо тогда, когда новые поколения перестают существенно отличаться от предыдущих, т.е., как говорят, "алгоритм сходится", либо когда пройдено заданное количество поколений или заданное время работы алгоритма (чтобы не было "зацикливания" и динамического зависания в случае, когда решение не может быть найдено в заданное время ).
Если ГА сошелся, то это означает, что решение найдено, т.е. получено поколение, идеально приспособленное к условиям данной фиксированной среды обитания.
Иначе – переход на шаг 4 – начало формирования нового поколения.
В реальной биологической эволюции этим дело не ограничивается, т.к. любая популяция кроме освоения некоторой экологической ниши пытается также выйти за ее пределы освоить и другие ниши, как правило "смежные". Именно за счет этих процессов жизнь вышла из моря на сушу, проникла в воздушное пространство и поверхностный слой почвы, а сейчас осваивает космическое пространство.
Конечно, реальные генетические алгоритмы, на которых проводятся научные исследования, чаще всего мало похожи на приведенный пример. Исследователи экспериментируют с различными параметрами генетических алгоритмов, например: способами отбора особей для скрещивания; критериями приспособленности и жесткостью влияния факторов среды; способами выбора признаков, передающихся от родителей потомкам (рецессивные и не рецессивные гены и т.д.); интенсивностью, видом случайного распределения и направленностью мутаций; различными подходами к воспроизводству и отбору.
Поэтому под термином "генетические алгоритмы" по сути дела надо понимать не одну модель, а довольно широкий класс алгоритмов, подчас мало похожих друг на друга.
В настоящее время рассматривается много различных операторов отбора, кроссовера и мутации: турнирный отбор (Brindle, 1981; Goldberg и Deb, 1991), реализует n турниров, чтобы выбрать n особей, при этом каждый турнир построен на выборке k элементов из популяции, и выбора лучшей особи среди них (наиболее распространен турнирный отбор с k=2); элитный отбор (De Jong, 1975) гарантируют, что при отборе обязательно будут выживать лучший или лучшие члены популяции совокупности (наиболее распространена процедура обязательного сохранения только одной лучшей особи, если она не прошла как другие через процесс отбора, кроссовера и мутации); двухточечный кроссовер (Cavicchio, 1970; Goldberg, 1989c) и равномерный кроссовер (Syswerda, 1989) отличаются способами наследования потомками признаков родителей.
Не смотря на то, что модели биологической эволюции, реализуемые в ГА, обычно сильно упрощены по сравнению с природным оригиналом, тем ни менее ГА являются мощным средством, которое может с успехом применяться для решения широкого класса прикладных задач, включая те, которые трудно, а иногда и вовсе невозможно, решить другими методами.
1.1.6.3. Достоинства и недостатки генетических алгоритмов
Однако, ГА не гарантирует обнаружения глобального решения за приемлемое время. ГА не гарантируют и того, что найденное решение будет оптимальным решением. Тем ни менее они применимы для поиска "достаточно хорошего" решения задачи за "достаточно короткое время". ГА представляют собой разновидность алгоритмов поиска и имеют преимущества перед другими алгоритмами при очень больших размерностях задач и отсутствия упорядоченности в исходных данных, когда альтернативой им является метод полного перебора вариантов.
В случаях, когда задача может быть решена специально разработанным для нее методом, практически всегда такие методы будут эффективнее ГА как по быстродействию, так и по точности найденных решений.
Главным же достоинством ГА является то, что они могут применяться для решения сложных неформализованных задач, для которых не разработано специальных методов, т.е. ГА обеспечивают решение проблем. Но даже в тех случаях, для которых хорошо работают существующие методики, можно достигнуть интересных результатов сочетая их с ГА.
1.1.6.4. Примеры применения генетических алгоритмов
Данный раздел основан на статье Алексея Андреева "Электродарвин" (http://www.fuga.ru/articles/2004/03/genetic-pro.htm), к которой мы и отсылаем за очень интересными подробностями.
В 1994 году Эндрю Кин из университета Саутгемптона использовал генетический алгоритм в дизайне космических кораблей. За основу была взята модель опоры космической станции, спроектированной в NASA из которой после смены 15 поколений, включавших 4.500 вариантов дизайна, получилась модель, превосходящая по тестам тот вариант, что разработали люди.
Аналогичный генетический алгоритм был использован NASA при разработке антенны для спутника.
Джон Коза из Стэнфорда разработал технологию генетического программирования, в которой результатом эволюции становятся не отдельные числовые параметры "особей", а целые имитационные программы, которые являются виртуальными аналогами реальных устройств. Эта технология позволила компании Genetic Programming повторить 15 человеческих изобретений, 6 из которых были запатентованы после 2000 года, то есть представляют собой самые передовые достижения, а один из контроллеров, "выведенных" в GP, даже превосходит аналогичную человеческую разработку.
Сейчас плоды электронной эволюции можно найти в самых разных сферах: от двигателя самолета Boeing 777 до новых антибиотиков.
Генетические алгоритмы представляют собой компьютерное моделирование эволюции. Материальное воплощение сконструированных таким образом систем до сих пор была невозможна без участия человека. Однако интенсивно ведутся работы, результатом которых является уменьшение зависимости машинной эволюции от человека. Эти работы ведутся по двум основным направлениям:
1. Естественный отбор, моделируемый ГА, переносится из виртуального мира в реальный, например, проводятся эксперименты по реальным битвам роботов на выживание.
2. Интеллектуальные системы, основанные на ГА, конструируют роботов, которые в принципе могут быть изготовлены на автоматизированных заводах без участия человека.
Пример воплощения ГА в реальной битве роботов на выживание: в 2002 году в британском центре Magna открылся павильон Live Robots, где боролись за выживание 12 роботов двух видов: "гелиофаги", способные добывать электроэнергию с использованием солнечных батарей; "хищники", которые могли получать электроэнергию только от гелиофагов. Выжившие роботы загружали свои "гены" в погибших и, таким образом, образовывали новые поколения. Те хищники, которые забирали всю энергию у гелиофагов, теряли источник питания и погибали, не передавая свою тактику потомкам, поступавшие же "более разумно" продолжили свой род. В результате возникла равновесная сбалансированная искусственная экосистема с двумя популяциями.
Пример конструирования роботов роботами: в Brandeis University была создана программа Golem, которая сама конструировала роботов. В программу была база деталей, а также механизм мутаций и функция пригодности для "отсеивания" неудачников – тех, кто не научился двигаться. После 600 поколений за несколько дней программа получила модели трех ползающих роботов. Показательно, что роботы оказались симметричными, хотя симметрия никак не была явно прописана в правилах эволюции и исходных данных. Это означает, что она появилась в ходе моделирования машинной эволюции как полезная черта, позволяющая двигаться прямолинейно.
Контрольные вопросы
1. Основные понятия, принципы и предпосылки генетических алгоритмов.
2. Пример работы простого генетического алгоритма.
3. Достоинства и недостатки генетических алгоритмов.
4. Примеры применения генетических алгоритмов.
Рекомендуемая литература
1. Исаев С. Популярно о генетических алгоритмах. http://home.od.ua/~relayer/algo/neuro/ga-pop/
2. Алексей Андреев. Электродарвин. http://www.fuga.ru/articles/2004/03/genetic-pro.htm
3. Сотник С.Л. Конспект лекций по курсу "Основы проектирования систем искусственного интеллекта": (1997-1998), http://neuroschool.narod.ru/books/sotnik.html.
1.3.7.
ЛЕКЦИЯ-13.
Когнитивное моделирование
Учебные вопросы:
1. Определение основных понятий: "Когнитивное моделирование" и "Классическая когнитивная карта", их связь с когнитивной психологией и гносеологией.
2. Когнитивная (познавательно-целевая) структуризация знаний об исследуемом объекте и внешней для него среды на основе PEST-анализа и SWOT-анализа.
3. Разработка программы реализации стратегии развития исследуемого объекта на основе динамического имитационного моделирования (при поддержке программного пакета Ithink).
1.3.7.1. Определение основных понятий: "Когнитивное моделирование" и "Классическая когнитивная карта", их связь с когнитивной психологией и гносеологией
Термин: "Когнитивный" происходит от "cognition" – "познание" (англ.) и используется для обозначения нового перспективного направления психологии (когнитивная психология), а также направления развития систем искусственного интеллекта (когнитивное моделирование и системно-когнитивный анализ), в которых ставится и решается задача автоматизации некоторых функций, реализуемых человеком, в процессе познания.
Исторически процессы познания первоначально изучались философами. В философии теория познания (сознания) называется гносеологией, от греч. gnosis, – знание, учение, познание, в отличие от онтологии – учения о бытие.
Однако, философский анализ процессов познания не касается исследования естественно-научными методами конкретных форм сознания и характерных для них методов познания, а также конкретных способов их достижения и реализации.
Когнитивная психология – это область психологии, непосредственно
теоретически и экспериментально изучающая процессы познания у конкретных людей,
различного пола, возраста, социального статуса и т.д.
Когнитивное моделирование – это способ анализа, обеспечивающий определение
силы и направления влияния факторов на перевод объекта управления в целевое
состояние с учетом сходства и различия в влиянии различных факторов на объект
управления.
Классическая когнитивная карта – это ориентированный граф, в котором
привилегированной вершиной является некоторое будущее (как правило, целевое)
состояние объекта управления, остальные вершины соответствуют факторам, дуги,
соединяющие факторы с вершиной состояния имеют толщину и знак, соответствующий
силе и направлению влияния данного фактора на переход объекта управления в
данное состояние, а дуги, соединяющие факторы показывают сходство и различие в
влиянии этих факторов на объект управления.
Ведущей научной организацией России, занимающейся разработкой и применением технологии когнитивного анализа, является Институт проблем управления РАН, подразделение: Сектор-51, ученые Максимов В.И., Корноушенко Е.К., Качаев С.В., Григорян А.К. и другие. На их научных трудах в области когнитивного анализа и основывается данная лекция.
В основе технологии когнитивного анализа и моделирования (рисунок 86) лежит когнитивная (познавательно-целевая) структуризация знаний об объекте и внешней для него среды.
|
|
|
Рисунок 86. Технология когнитивного анализа и моделирования |
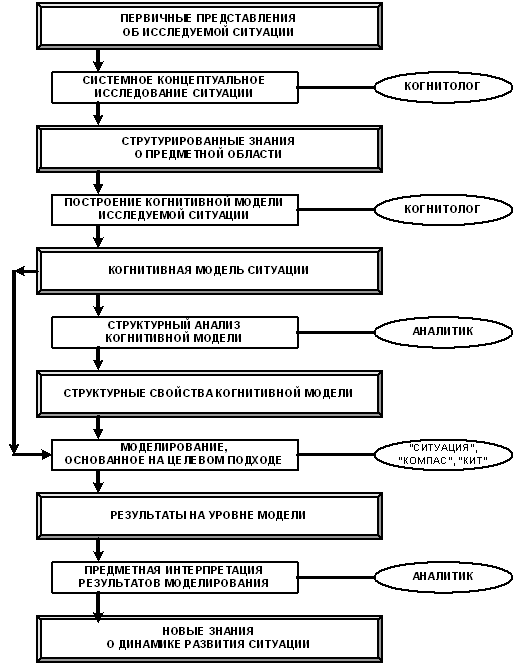
Когнитивная структуризация предметной
области – это выявление будущих
целевых и нежелательных состояний объекта управления и наиболее существенных
(базисных) факторов управления и внешней среды, влияющих на переход объекта в
эти состояния, а также установление на качественном уровне
причинно-следственных связей между ними, с учетом взаимовлияния факторов друг на
друга.
Результаты когнитивной структуризации отображаются с помощью когнитивной карты (модели).
1.3.7.2. Когнитивная (познавательно-целевая) структуризация знаний об исследуемом объекте и внешней для него среды на основе PEST-анализа и SWOT-анализа
Отбор базисных факторов проводится путем
применения PEST-анализа, выделяющего четыре основные группы факторов
(аспекта), определяющих поведение исследуемого объекта (рисунок 87):
– Policy – политика;
– Economy – экономика;
– Society – общество (социокультурный аспект);
– Technology – технология.
|
|
|
Рисунок 87. Факторы PEST-анализа |
Для каждого конкретного сложного объекта существует свой особый набор наиболее существенных факторов, определяющих его поведение и развитие.
PEST-анализ можно рассматривать как вариант системного анализа, т.к. факторы, относящиеся к перечисленным четырем аспектам, в общем случае тесно взаимосвязаны и характеризуют различные иерархические уровни общества, как системы.
В этой системе есть детерминирующие связи, направленные с нижних уровней иерархии системы к верхним (наука и технология влияет на экономику, экономика влияет на политику), а также обратные и межуровневые связи. Изменение любого из факторов через эту систему связей может влиять на все остальные.
Эти изменения могут представлять угрозу развитию объекта, или, наоборот, предоставлять новые возможности для его успешного развития.
Следующий шаг – ситуационный анализ проблем, SWOT-анализ
(рисунок 88):
– Strengths – сильные стороны;
– Weaknesses – недостатки, слабые стороны;
– Opportunities – возможности;
– Threats – угрозы.
|
|
|
Рисунок 88. Факторы SWOT-анализа |
Он включает анализ сильных и слабых сторон развития исследуемого объекта в их взаимодействии с угрозами и возможностями и позволяет определить актуальные проблемные области, узкие места, шансы и опасности, с учетом факторов внешней среды.
Возможности определяются как обстоятельства, способствующее благоприятному развитию объекта.
Угрозы – это ситуации, в которых может быть нанесен ущерб объекту, например может быть нарушено его функционирование или он может лишится имеющихся преимуществ.
На основании анализа различных возможных сочетаний сильных и слабых сторон с угрозами и возможностями формируется проблемное поле исследуемого объекта.
Проблемное поле – это совокупность проблем, существующих в моделируемом объекте и окружающей среде, в их взаимосвязи друг с другом.
Наличие такой информации – основа для определения целей (направлений) развития и путей их достижения, выработки стратегии развития.
Когнитивное моделирование на основе проведенного ситуационного анализа позволяет подготовить альтернативные варианты решений по снижению степени риска в выделенных проблемных зонах, прогнозировать возможные события, которые могут тяжелее всего отразиться на положении моделируемого объекта.
Этапы когнитивной технологии и их результаты, представленные на рисунке 86, конкретизированы в таблице 38:
Таблица 38 – ЭТАПЫ КОГНИТИВНОЙ ТЕХНОЛОГИИ
И РЕЗУЛЬТАТЫ ЕЕ ПРИМЕНЕНИЯ
|
Наименование этапа |
Форма представления результата |
|
1. Когнитивная (познавательно-целевая)
структуризация знаний об исследуемом объекте и внешней для него среды на основе
PEST-анализа и SWOT-анализа: 1.2. Выявление факторов, характеризующих возможности и угрозы со стороны внешней среды объекта 1.3. Построение проблемного поля исследуемого объекта |
Отчет о системном концептуальном исследовании объекта и его проблемной области |
|
2. Построение когнитивной модели
развития объекта – формализация знаний, полученных на этапе когнитивной
структуризации 2.2. Установление и обоснование взаимосвязей между факторами 2.3. Построение графовой модели |
Компьютерная когнитивная модель объекта в виде ориентированного графа (и матрицы взаимосвязей факторов) |
Продолжение таблицы 38
|
Наименование этапа |
Форма представления результата |
|
3. Сценарное исследование тенденций
развития ситуации вокруг исследуемого объекта (при поддержке программных
комплексов "СИТУАЦИЯ", "КОМПАС", "КИТ") 3.2. Задание сценариев исследования и их моделирование 3.3.
Выявление тенденций развития объекта в его макроокружении |
Отчет о сценарном исследовании ситуации, с интерпретацией и выводами |
|
4. Разработка стратегий управления ситуацией вокруг исследуемого объекта 4.1.
Определение и обоснование цели управления |
Отчет о разработке стратегий управления с обоснованием стратегий по разным критериям качества управления |
|
5. Поиск и обоснование стратегий
достижения цели в стабильных или изменяющихся ситуациях |
Отчет о разработке стратегий достижения цели в стабильных или изменяющихся ситуациях |
|
6.
Разработка программы реализации стратегии развития исследуемого объекта на
основе динамического имитационного моделирования (при поддержке программного
пакета Ithink) 6.2. Координация 6.3. Контроль за исполнением |
Программа реализации стратегии развития объекта. Компьютерная имитационная модель развития объекта |
1.3.7.3. Разработка программы реализации стратегии развития исследуемого объекта на основе динамического имитационного моделирования (при поддержке программного пакета Ithink)
Технология когнитивного анализа и моделирования поддерживается программными комплексами "Ситуация", "Компас", "КИТ" (рисунок 86), созданными в ИПУ РАН, которые позволяют в сложных и неопределенных ситуациях быстро, комплексно и системно охарактеризовать и обосновать сложившуюся ситуацию и на качественном уровне предложить пути решения проблемы в этой ситуации с учетом факторов внешней среды.
Применение когнитивных технологий открывает новые возможности прогнозирования и управления в различных областях:
– в экономической сфере это позволяет в сжатые сроки разработать и обосновать стратегию экономического развития предприятия, банка, региона или даже целого государства с учетом влияния изменений во внешней среде;
– в сфере финансов и фондового рынка – учесть ожидания участников рынка;
– в военной области и области информационной безопасности – противостоять стратегическому информационному оружию, заблаговременно распознавая конфликтные структуры и вырабатывая адекватные меры реагирования на угрозы.
Когнитивные технологии автоматизируют часть функций процессов познания, поэтому они с успехом могут применяться во всех областях, в которых востребовано само познание. Вот лишь некоторые из этих областей:
1. Модели и методы интеллектуальных информационных технологий и систем для создания геополитических, национальных и региональных стратегий социально-экономического развития.
2. Модели выживания "мягких" систем в изменяющихся средах при дефиците ресурсов.
3. Ситуационный анализ и управление развитием событий в кризисных средах и ситуациях.
4. Информационный мониторинг социально-политических, социально-экономических и военно-политических ситуаций.
5. Разработка принципов и методологии проведения компьютерного анализа проблемных ситуаций.
6. Выработка аналитических сценариев развития проблемных ситуаций и управления ими.
7. Подготовка рекомендаций по решению первоочередных стратегических проблем на основе компьютерной системы анализа проблемных ситуаций.
8. Мониторинг проблем в социально-экономическом развитии корпорации, региона, города, государства.
9. Технология когнитивного моделирования целенаправленного развития региона РФ.
10. Анализ развития региона и мониторинг проблемных ситуаций при целенаправленном развитии региона.
11. Модели для формирования государственного регулирования и саморегулирования потребительского рынка.
12. Анализ и управление развитием ситуации на потребительском рынке.
Технология когнитивного моделирования может быть широко использована для уникальных проектов развития регионов, банков, корпораций (и др. объектов) в кризисных условиях после соответствующего обучения.
Контрольные вопросы
1. Определение основных понятий: "Когнитивное моделирование" и "Классическая когнитивная карта", их связь с когнитивной психологией и гносеологией.
2. Когнитивная (познавательно-целевая) структуризация знаний об исследуемом объекте и внешней для него среды на основе PEST-анализа и SWOT-анализа.
3. Разработка программы реализации стратегии развития исследуемого объекта на основе динамического имитационного моделирования (при поддержке программного пакета Ithink).
Рекомендуемая литература
1. Сайт: ИПУ РАН, Сектор-51 сектор "Когнитивный анализ и моделирование ситуаций": http://www.ipu.ru/labs/lab51/projects.htm.
2. Максимов В.И.,
Корноушенко Е.К. Знание – основа анализа. Банковские технологии, № 4, 1997.
3. Корноушенко
Е.К., Максимов В.И. Управление процессами в слабоформализованных средах при
стабилизации графовых моделей среды. Труды ИПУ, вып.2, 1998.
4. Максимов В.И.,
Корноушенко Е.К. Аналитические основы применения когнитивного подхода при
решении слабоструктурированных задач. Труды ИПУ, вып.2, 1998.
5. Максимов В.И.,
Качаев С.В., Корноушенко Е.К. Концептуальное моделирование и мониторинг
проблемных и конфликтных ситуаций при целенаправленном развитии региона. В сб.
"Современные технологии управления для администраций городов и
регионов". Фонд "Проблемы управления", М. 1998.
6. Максимов В.И.,
Корноушенко Е.К., Качаев С.В. Анализ ситуации и компенсация теневых аспектов в
свободной торговле. В сб. "Современные технологии управления для
администраций городов и регионов". Фонд "Проблемы управления",
М. 1998.
7. Максимов В.И.,
Корноушенко Е.К., Качаев С.В., Григорян А.К. Когнитивный подход к анализу
проблемы демонополизации в транспортном комплексе. Труды ИПУ, вып.2, 1998.
8. Райков А.Н. Аналитическим службам - информационные технологии. /Ваш выбор. 1994. № 4. - С.28-29.
9. Райков А.Н. Гносеологическая декомпозиция процессов рефлексивного управления. /"Рефлексивное управление". Тезисы международного симпозиума (17-19.10.2000). – М.: Ин-т психол. РАН, 2000. – С.89-90.
10. Райков А.Н. Интеллектуальные информационные технологии и системы. В 2-х частях. – М.: МИРЭА, 1998. – 213с.
11. Райков А.Н. Интеллектуальные информационные технологии: Учебное пособие. – М.: МГИРЭА(ТУ), 2000. - 96с.
1.3.8.
ЛЕКЦИЯ-14.
Выявление знаний из опыта
(эмпирических фактов) и интеллектуальный
анализ данных (data mining)
Учебные вопросы
1. Интеллектуальный анализ данных (data mining)
2. Типы выявляемых закономерностей data mining.
3. Математический аппарат data mining.
4. Области применения технологий интеллектуального анализа данных.
5. Автоматизированные системы для интеллектуального анализа данных.
Данная лекция основана на работе В. Дюк, А.
Самойленко. Data Mining: учебный курс (+ CD-ROM).
1.3.8.1. Интеллектуальный анализ данных
Интеллектуальный анализ данных (ИАД или data mining) – это процесс обнаружения в "сырых" данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Обзор материалов Internet, посвященных ИАД показывает, что данное определение является классическим. Тем ни менее, на наш взгляд, оно содержит несколько неточностей:
– в определение этого понятия входят слова "анализ" и "знания", тогда как знания нужны для управления, т.е. достижения цели;
– для интерпретации доступны не только знания, но уже и информация (см. раздел 1.1.2.1. данной работы);
– термин "ИАД" не подразумевает какого-либо одного метода анализа данных, но является собирательным и объединяет многие направления исследований и разработок в области СИИ.
Поэтому предлагается другое, более точное определение понятия.
Интеллектуальный анализ данных (ИАД или data
mining) – это совокупность математических моделей, численных методов,
программных средств и информационных технологий, обеспечивающих обнаружение
в эмпирических данных доступной для
интерпретации информации и синтез на основе этой информации ранее
неизвестных, нетривиальных и практически полезных для достижения определенных целей знаний.
Технологии data mining являются наиболее совершенным инструментом для решения сложных аналитических задач. Они основаны на мощном математическом и статистическом аппарате, корректное применение которого позволяет достичь высоких результатов.
Все большим количеством компаний предлагаются услуги в области интеллектуального анализа данных, что предполагает проведение следующих работ:
– проведение исследования накопленной статистики;
– выявление закономерностей;
– создание моделей данных;
– верификация и апробация моделей данных;
– внедрение модели в практику.
1.3.8.2. Типы выявляемых закономерностей
Успех применения систем data mining основан на том, что эти технологии обеспечивают исследование эмпирических данных и выявление в них скрытых закономерностей различных видов.
Ассоциация (идентификация). Если некоторый факт-1 является частью определенного события, то с расчетной вероятностью и другой факт-2, связанный с первым, будет частью того же события.
Последовательность (прогнозирование). Если свершилось некоторое событие-1, то с расчетной вероятностью через определенный период времени свершится другое событие-2, связанное с первым.
Классификация. На основании информации о свойствах объекта ему присваивается определенное дискретное значение показателя, по которому проводится классификация (идентификатор).
Кластеризация. Наиболее сходные по своим признакам объекты объединяются в группы (кластеры) таким образом, что в разных кластерах оказываются наиболее сильно отличающиеся друг от друга объекты. Кластеризация аналогична классификации, но в отличие от последней классы – кластеры объектов заранее не известны, а формируются в процессе кластеризации.
Прогнозирование. Прошлые фактические значения величин используются для прогнозирования будущих значений тех же или других величин на основании на основании знания зависимостей между ними, трендов и статистики.
1.3.8.2.1. Ассоциация
Ассоциация используется для определения закономерностей в событиях или процессах. Ассоциации связывают различные факты одного события. В качестве примера может служить выявленная закономерность, что мужчины, предпочитающие элитные сорта кофе в три раза чаще покупают импортные сигареты, чем мужчины, покупающие обычный кофе.
Результатом ассоциативного анализа являются правила вида: Если факт А является частью события, то с вероятностью Х факт B будет частью того же события.
Например:
Если покупатель берет чипсы, то существует 85-ти процентная вероятность, что он приобретет еще легкие алкогольные напитки или пиво.
Если человек едет в отпуск и покупает авиабилеты на всю семью, то с вероятностью 95 процентов они снимут машину в месте отдыха на весь период.
Имея историю продаж в розничном магазине, можно разработать шаблоны покупок (стандартные наборы), например для продуктового отдела. Из-за широкого применения в торговле ассоциативный анализ часто называют анализом рыночной корзины.
1.3.8.2.2. Последовательность
Последовательные шаблоны аналогичны ассоциациям с той лишь разницей, что связывают события, разнесенные во времени. Например, последовательный шаблон может предсказывать, что человек, купивший посудомоечную машину с вероятностью 0.7 купит сушилку для одежды в течение следующих шести месяцев. Для увеличения этой вероятности магазин может предложить ему скидку в 10% на покупку сушильного аппарата в течение трех или четырех месяцев после покупки посудомоечной машины.
1.3.8.2.3. Классификация
Классификация – наиболее часто используемый метод интеллектуального анализа. Данный метод сосредотачивает внимание на поведении и атрибутах уже существующих групп. Группы могут включать людей, которые часто летают, много тратят, лояльных клиентов, людей, которые откликаются на компании прямой рассылки и т.д. С помощью алгоритмов классификации можно классифицировать объекты по заранее известным характеристикам. В классификации часто используются индукционные алгоритмы, которые позволяют по небольшому массиву данных, отнесенных к известным классам, определять дополнительные классы. Примером использования классификации может служить определение характеристик клиентов, которые вероятно захотят/не захотят приобрести определенный продукт или услугу. Имея такую группировку клиентов, мы можем значительно сократить расходы на акциях продвижения товара или прямой рассылки.
1.3.8.2.4. Кластеризация
Кластеризация используется для обнаружения классов схожих объектов в имеющемся наборе данных. Кластеризация аналогична классификации, но в отличие от последней классы объектов заранее не известны. Методы кластеризации широко используют алгоритмы нейронных сетей и статистическую обработку. В процессе кластеризации средство интеллектуального анализа определяет схожие характеристики объектов и на их основе объединяет объекты в классы. Качество процесса кластеризации определяется схожестью объектов внутри класса и степенью отличия разных классов между собой. Кластеризация обычно применяется для решения таких задач, как определение производственного брака или выявления групп услуг по кредитным карточкам предпочтительных для разных групп клиентов.
1.3.8.2.5. Прогнозирование
Регрессия – один из двух методов прогнозирования. Данный метод использует имеющиеся фактические значения величин для прогнозирования будущих на основании трендов и имеющейся статистики. Например, объем продаж аксессуаров для спортивных машин можно спрогнозировать по количеству проданных спортивных машин в прошлом месяце.
Различие между регрессией и временными рядами состоит в том, что временные ряды предсказывают значения переменных, зависящих от времени. Например, с их помощью можно прогнозировать количество несчастных случаев во время каникул на основе аналогичных данных за прошлый период. Время в данном случае может содержать иерархии (рабочая неделя, календарная неделя, период) праздники, сезоны, интервалы дат.
1.3.8.3. Математический аппарат
Основой систем data mining является выявление различных закономерностей в данных. При этом применяются следующие методы:
– деревья решений;
– алгоритмы кластеризации;
– регрессионный анализ;
– нейронные сети;
– временные ряды.
1.3.8.3.1. Деревья решений
Деревья решения являются одним из наиболее популярных подходов к решению задач data mining. Они создают иерархическую структуру классифицирующих правил типа «ЕСЛИ... ТО...», имеющую вид дерева. Для того чтобы решить, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид «значение параметра A больше x». Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный – то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
Популярность подхода связана с наглядностью и понятностью. Но очень остро для деревьев решений стоит проблема значимости. Дело в том, что отдельным узлам на каждом новом построенном уровне дерева соответствует все меньшее и меньшее число записей данных – дерево дробит данные на большое количество частных случаев. Чем больше этих частных случаев, чем меньше обучающих примеров попадает в каждый такой частный случай, тем менее уверенной становится их классификация. Если построенное дерево слишком «кустистое» – состоит из неоправданно большого числа мелких веточек – оно не будет давать статистически обоснованных ответов. Как показывает практика, в большинстве систем, использующих деревья решений, эта проблема не находит удовлетворительного решения. Кроме того, общеизвестно, и это легко показать, что деревья решений дают полезные результаты только в случае независимых признаков. В противном случае они лишь создают иллюзию логического вывода.
Область применения деревьев решений в настоящее время широка, но все задачи, решаемые этим аппаратом, могут быть объединены в следующие три класса:
Описание данных. Деревья решений позволяют хранить информацию о данных в компактной форме, вместо них мы можем хранить дерево решений, которое содержит точное описание объектов.
Классификация. Деревья решений отлично справляются с задачами классификации, т.е. отнесения объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения.
Регрессия. Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых (входных) переменных. Например, к этому классу относятся задачи численного прогнозирования (предсказания значений целевой переменной).
1.3.8.3.2. Регрессионный анализ
Регрессионный анализ позволяет исследовать формы связи, устанавливающие количественные соотношения между случайными величинами изучаемого процесса.
Регрессия наиболее часто используется для построения прогнозных моделей.
1.3.8.3.3. Нейронные сети
Нейронные представляют собой большой класс систем, архитектура которых пытается имитировать построение нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном персептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д.
Эти значения рассматриваются как сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ, реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо «натренировать» на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
1.3.8.3.4. Временные ряды
Временной ряд – это расположение во времени статистических показателей, которые в
своих последовательных изменениях отражают ход развития изучаемых процессов.
Временные ряды исследуются с различными целями. В одном ряде случаях бывает достаточно получить описание характерных особенностей ряда, а в другом ряде случаев требуется не только предсказывать будущие значения временного ряда, но и управлять его поведением. Метод анализа временного ряда определяется, с одной стороны, целями анализа, а с другой стороны, вероятностной природой формирования его значений.
Спектральный анализ. Позволяет находить периодические составляющие временного ряда
Корреляционный анализ. Позволяет находить существенные периодические зависимости и соответствующие им задержки (лаги) как внутри одного ряда (автокорреляция), так и между несколькими рядами. (кросскорреляция)
Модели авторегрессии и скользящего среднего. Модели ориентированы на описание процессов, проявляющих однородные колебания, возбуждаемые случайными воздействиями. Позволяют предсказывать будущие значения ряда.
1.3.8.4. Области применения технологий интеллектуального анализа данных
Системы, основанные на технологиях интеллектуального анализа данных, используются в компаниях различного профиля. Однако существует целый ряд областей, для которых накоплен богатый и очень успешный опыт применения подобных систем.
Торговля. Анализ потребительской корзины, исследование временных шаблонов, создание прогнозирующих моделей, оптимизация складских запасов.
Банковское дело. Сегментация клиентов, выявление мошенничества с кредитными картами, прогнозирование изменения клиентуры, анализ финансовых рисков.
Страховой бизнес. Сегментация клиентов, выявление фактов мошенничества, анализ страховых рисков, разработка новых продуктов, расчет страховых премий.
Телекоммуникации. Анализ лояльности клиентов, сегментирование клиентской базы и услуг, анализ внешних факторов на отказы оборудования, выявление случаев несанкционированного доступа к сети.
Производственные предприятия. Оптимизация закупок, диагностика брака на ранних стадиях, диагностика оборудования, маркетинг.
Нефтегазовая отрасль. Диагностика оборудования и нефте-газопроводов, прогнозирование цен, разведка месторождений, анализ влияния внешних и внутренних факторов на объемы продаж.
1.3.8.4.1. Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью технологий data mining в сфере розничной торговли:
Анализ покупательской корзины предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
Исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа «Если сегодня покупатель приобрел видеокамеру, то, через какое время он вероятнее всего купит новые батарейки и пленку?»
Создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
1.3.8.4.2. Банковская деятельность
Достижения технологии data mining используются в банковском деле для решения проблем Телекоммуникации.
В области телекоммуникаций характерен растущий уровень конкуренции. Здесь методы data mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удержать существующих клиентов и привлечь новых. В число типичных мероприятий входят:
– анализ записей о подробных характеристиках вызовов;
– выявление степени лояльности клиентов.
Анализ записей о подробных характеристиках вызовов. Назначение такого анализа – выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг.
Выявление степени лояльности клиентов. Некоторые клиенты все время меняют провайдеров, пользуясь программами новых компаний, стимулирующими появление новых клиентов. Data mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными. В итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше всего
Технологии data mining активно применяются в центрах обработки вызовов телекоммуникационных компаний.
1.3.8.4.3. Страховой бизнес
Страховые компании накапливают значительные объемы подробнейшей информации о клиентах, используемых ими услугах, страховых премиях и выплатах. Технологии data mining позволяют использовать накопившиеся данные для решения следующих задач:
Классификация и кластеризация клиентов. Система интеллектуального анализа данных позволяет страховой компании проводить эффективную тарифную политику, основанную на индивидуальных предпочтениях различных категорий клиентов.
Разработка нового товара. Технологии data mining являются инструментом, с помощью которого можно спрогнозировать спрос на услугу, оценить страховые выплаты и сформировать политику в отношении взимаемых страховых премий.
1.3.8.4.4. Производство
Большинство производственных компаний используют системы интеллектуального анализа данных для решения следующих задач.
Оптимизации логистических цепочек. Data mining позволяет снизить затраты на логистику за счет эффективного прогнозирования продаж товаров и закупок сырья/комплектующих.
Проведение маркетинговых исследований. Накопленные данные о сбыте продукции могут быть использованы при разработке новых продуктов или для повышения эффективности рекламных кампаний.
Диагностика брака на ранних стадиях. Анализ зависимостей позволяет оценить степень риска изготовления бракованного изделия на ранних стадиях производства. Очевидно, что это позволяет сэкономить существенные средства.
1.3.8.5. Автоматизированные системы для интеллектуального анализа данных
Эта тема рекомендуется для самостоятельного изучения и написания реферата, с демонстрацией презентации или демо-версии.
Резюме
Интеллектуальный
анализ данных
Интеллектуальный анализ данных (data mining) – это процесс обнаружения в
"сырых" данных ранее неизвестных, нетривиальных, практически полезных
и доступных интерпретации знаний, необходимых для принятия решений в различных
сферах человеческой деятельности.
Технологии интеллектуального анализа данных на сегодняшний день являются наиболее совершенным инструментом для решения сложных аналитических задач. Необходимо отметить, что технологии data mining не имеют собственного уникального математического аппарата и программного инструментария, а объединяют различные математические методы и системы искусственного интеллекта.
Системы интеллектуального анализа данных основаны на мощном математическом и статистическом аппарате, грамотное применение которого позволяет достичь высоких результатов в бизнесе.
Компания BI Partner предлагает реализацию полного спектра услуг в области интеллектуального анализа данных, что подразумевает проведение исследования накопленной статистики, выявление закономерностей, создание модели данных, ее апробация и внедрение в бизнес-процессы предприятия. ПО, которое мы используем в своих решениях, успешно используется во многих Российских компаниях.
Области
применения технологий интеллектуального анализа данных.
Торговля. Анализ потребительской корзины, исследование временных шаблонов, создание прогнозирующих моделей, оптимизация складских запасов.
Банковское дело. Сегментация клиентов, выявление мошенничества с кредитными картами, прогнозирование изменения клиентуры, анализ финансовых рисков.
Страховой бизнес. Сегментация клиентов, выявление фактов мошенничества, анализ страховых рисков, разработка новых продуктов, расчет страховых премий.
Телекоммуникации. Анализ лояльности клиентов, сегментирование клиентской базы и услуг, анализ внешних факторов на отказы оборудования, выявление случаев несанкционированного доступа к сети.
Производственные предприятия. Оптимизация закупок, диагностика брака на ранних стадиях, диагностика оборудования, маркетинг.
Нефтегазовая отрасль. Диагностика оборудования и нефте/газопроводов, прогнозирование цен, разведка месторождений, анализ влияния внешних и внутренних факторов на объемы продаж.
Типы
выявляемых закономерностей
Основой систем data mining является выявление различных закономерностей в данных.
Ассоциация. Если факт А является частью события, то с вероятностью Х% факт B будет частью того же события.
Последовательность. Если свершилось событие А, то с вероятностью Х% через период времени Т свершится событие B.
Классификация. На основании информации о свойствах объекта присвоение ему того или иного дискретного значения показателя, по которому проводится классификация.
Кластеризация. Кластеризация аналогична классификации, но в отличие от последней классы объектов заранее не известны.
Прогнозирование. Использование имеющиеся фактических значений величин для прогнозирования будущих на основании трендов и имеющейся статистики.
Математический
аппарат
Основой систем data mining является выявление различных закономерностей в данных: деревья решений; алгоритмы кластеризации; регрессионный анализ; нейронные сети; временные ряды.
Контрольные вопросы
1. Интеллектуальный анализ данных (data mining).
2. Типы выявляемых закономерностей data mining: ассоциация, последовательность, классификация, кластеризация, прогнозирование.
3. Математический аппарат data mining: деревья решений, регрессионный анализ, нейронные сети, временные ряды.
4. Области применения технологий интеллектуального анализа данных: розничная торговля, банковская деятельность, страховой бизнес, производство, автоматизированные системы для интеллектуального анализа данных.
Рекомендуемая литература
1. Дюк В., Самойленко А. Data Mining: учебный
курс (+ CD-ROM).
2. Сайт компании BI Partner: http://www.bipartner.ru/services/dm.html.
3. Шапот М., Рощупкина В. Интеллектуальный анализ данных и управление процессами. // Открытые системы. –№ 4-5, 1998. –С. 29.
4.
Шапот М. Интеллектуальный анализ данных в системах поддержки принятия решений. Журнал "Открытые
системы", #01, 1998 год //
Издательство "Открытые системы" (www.osp.ru),
адрес статьи: http://www.osp.ru/os/1998/01/30.htm.