РАЗДЕЛ
1.2.
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ И ПРИМЕНЕНИЕ
УНИВЕРСАЛЬНОЙ КОГНИТИВНОЙ
АНАЛИТИЧЕСКОЙ СИСТЕМЫ "ЭЙДОС"
1.2.1. ЛЕКЦИЯ-3.
Теоретические основы системно-когнитивного анализа
Учебные вопросы:
1. Системный анализ, как метод познания.
2. Когнитивная концепция и синтез когнитивного конфигуратора.
3. СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных операций.
4. Место и роль СК-анализа в структуре управления.
1.2.1.1. Системный анализ, как метод познания
1.2.1.1.1. Принципы системного анализа
Анализ (дедукция) представляет собой метод познания "от общего к частному", "от целого к частям". Абдукция представляет собой обобщение дедукции на основе нечеткой логики. При анализе существует опасность за исследованием частей упустить из рассмотрения их взаимодействие, то общее, что их объединяет в целое (т.е. взаимодействие частей для достижения общей цели). Такой подход был характерен для метафизического (не диалектичного) стиля мышления. Системный анализ лишен этого недостатка, поэтому многие совершенно справедливо считают системный анализ "современным воплощением прикладной диалектики" [148].
В этом контексте развиваемая в данной работе модель развитии активных систем путем чередования детерминистских и бифуркационных состояний представляет собой ничто иное, как естественнонаучное трактовку закона диалектики "Перехода количественных изменений в качественные". Иначе говоря, детерминистские этапы – это этапы количественного, эволюционного изменения объекта управления, а бифуркационные – этапы его качественного, революционного преобразования. Поэтому системный анализ рассматривается в данной работе как теоретический метод познания детерминистско-бифуркационной динамики систем. Таким образом, логически системный анализ можно считать результатом выполнения программы естественнонаучного развития диалектики, хотя исторически он и возник иначе. Саму когнитивную психологию также в определенной мере можно рассматривать как результат выполнения программы естественнонаучного развития гносеологии.
"Системный анализ" – это такой анализ систем, при котором за исследованием частей не только теряется целое, но и весь процесс исследования структуры системы и взаимосвязей ее элементов осуществляется под углом зрения целей и функций системы (авт.).
Система – это совокупность элементов (частей), взаимодействующих друг с другом для достижения некоторой общей цели. Система обеспечивает преимущество в достижении цели, т.е. достижение цели разрозненными элементами вне системы менее вероятно или вообще невозможно.
Система – это всегда нечто большее, чем просто сумма частей, т.е. она обладает качественно новыми (эмерджентными) свойствами, которые отсутствуют у ее частей. По мнению автора, в конечном счете все свойства имеют эмерджентную природу, т.е. любое качество основано на уровне Реальности этим качеством не обладающим. Термин "Реальность" включает и бытие, и небытие.
Например, качество "быть соленым " основано на свойствах Na и Cl, этим качеством ни в коей мере не обладающими. Движение с различными скоростями в метрическом пространстве основано на нелокальном уровне Реальности, в котором нет локализации объектов в физическом пространстве-времени. Об этом догадался еще Зенон и отразил логически в своих знаменитых апориях из которых следует не невозможность движения, как некоторые почему-то думают, а лишь невозможность адекватного отражения движения средствами формальной логики.
Системный анализ используется в тех случаях,
когда стремятся исследовать объект с разных сторон, комплексно. Термин
"системный анализ" впервые появился в
Во многих работах системный анализ развивается применительно к программно-целевому планированию и управлению. Однако, при этом получили развитие формализованные методики анализа систем (декомпозиции). В работах ведущих ученых по программированию урожая: Денисова Е.П., Ермохина Ю.И., Каюмова М. К., Мухортова С.Я., Неклюдова А.Ф., Филина В.И., Царева А.П., связанных с проблематикой данного исследования, в явной форме не используется автоматизированный системный анализ. Это, по-видимому, обусловлено тем, что формализованные средства системного анализа, обеспечивающие декомпозицию с сохранением целостности практически отсутствуют.
Системный анализ основывается на следующих принципах: единства – совместное рассмотрение системы как единого целого и как совокупности частей; развития – учет изменяемости системы, ее способности к развитию, накапливанию информации с учетом динамики окружающей среды; глобальной цели – ответственность за выбор глобальной цели (оптимум для подсистем вообще говоря не является оптимумом для всей системы); функциональности – совместное рассмотрение структуры системы и функций с приоритетом функций над структурой; децентрализации – сочетание децентрализации и централизации; иерархии – учет соподчинения и ранжирования частей; неопределенности – учет вероятностного наступления события; организованности – степень выполнения решений и выводов.
Сущность системного подхода формулировалась многими авторами. В развернутом виде она сформулирована Афанасьевым В.Н., Колмановским В.Б. и Носовым В.Р., определившими ряд взаимосвязанных аспектов, которые в совокупности и единстве составляют системный подход: системно-элементный, отвечающий на вопрос, из чего (каких компонентов) образована система; системно-структурный, раскрывающий внутреннюю организацию системы, способ взаимодействия образующих ее компонентов; системно-функциональный, показывающий, какие функции выполняет система и образующие ее компоненты; системно-коммуникационный, раскрывающий взаимосвязь данной системы с другими как по горизонтали, так и по вертикали; системно-интегративный, показывающий механизмы, факторы сохранения, совершенствования и развития системы; системно-исторический, отвечающий на вопрос, как, каким образом возникла система, какие этапы в своем развитии проходила, каковы ее исторические перспективы.
Системный анализ используется для того, чтобы организовать процесс принятия решения в сложных проблемных ситуациях. При этом основным требованием системного анализа является полнота и всесторонность рассмотрения проблемы. Основной особенностью системного анализа является сочетание формальных методов и неформализованного (экспертного) знания. Последнее помогает неформализованным путем найти новые пути решения проблемы, не содержащиеся в формальной модели, а затем учесть последствия решений в модели, т.е. формализовать их, за счет чего непрерывно развивать модель и методы поддержки принятия решений.
С учетом вышесказанного в определении системного анализа нужно подчеркнуть, что системный анализ:
– применяется для решения таких проблем, которые не могут быть поставлены и решены отдельными методами математики, т.е. проблем с неопределенностью ситуации принятия решения, когда используют не только формальные методы, но и методы качественного анализа ("формализованный здравый смысл"), интуицию и опыт лиц, принимающих решения;
– объединяет разные методы на основе единой методики;
– опирается на научное мировоззрение;
– объединяет знания, суждения и интуицию специалистов различных областей знаний и обязывает их к определенной дисциплине мышления;
– уделяет основное внимание целям и целеобразованию.
В частности, основными специфическими особенностями системного анализа, отличающими его от других системных направлений, являются:
1. Наличие в системном анализе средств для организации процессов целеобразования, структуризации и анализа целей (другие системные направления ставят задачу достижения целей, разработки вариантов пути их достижения и выбора наилучшего из этих вариантов, а системный анализ рассматривает объекты как активные системы, способные к целеобразованию и принятию решений, а затем уже и к достижению сформированных целей путем реализации принятых решений).
2. Разработка и использование методики, в которой определены этапы, подэтапы системного анализа и методы их выполнения, причем в методике сочетаются как формальные методы и модели, так и методы, основанные на интуиции специалистов, помогающие использовать их знания, что обусловливает особую привлекательность системного анализа для решения экономических проблем, в том числе в такой сложно формализуемой области как АПК.
1.2.1.1.2. Методы и этапы системного анализа
Основные методы, направленные на использование интуиции и опыта специалистов, а также методы формализованного представления систем, т.е. методы системного анализа, рассмотрены в работах [148]: метод "мозговой атаки"; метод экспертных оценок; метод "Делъфи"; метод "дерева целей"; морфологические методы.
Ведущие зарубежные Акофф Р., Бир С., Винер Р., Месарович М., Мако Д., Такахара И., Оптнер С.Л., Черчмен У., Эшби У.Р., Янг С., и отечественные ученые в области системного анализа Ф.И.Перегудов, Ф.П.Тарасенко [148], В.С.Симанков, Э.Х.Лийв [59], В.Н.Спицнадель, предлагают несколько отличающиеся друг от друга схемы основных этапов системного анализа.
Отечественные классики в области системного анализа Ф.И.Перегудов и Ф.П.Тарасенко считают [148], что системный анализ не может быть полностью формализован. Ими предложена следующая схема неформализованных этапов системного анализа (рисунок 8):
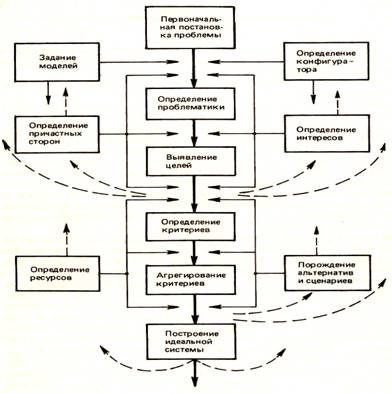
1. Определение конфигуратора.
2. Постановка проблемы – отправной момент исследования. В исследовании системы ему предшествует работа по структурированию проблемы.
3. Расширение проблемы до проблематики, т.е. нахождение системы проблем или задач, существенно связанных с исследуемой проблемой, без учета которых она не может быть решена.
4. Выявление целей: цели указывают направление, в котором надо двигаться, чтобы поэтапно решить проблему.
5. Формирование критериев. Критерий – это количественное отражение степени достижения системой поставленных перед ней целей. Критерий –это правило выбора предпочтительного варианта решения из ряда альтернативных. Критериев может быть несколько. Многокритериальность является способом повышения адекватности описания цели. Критерии должны описать по возможности все важные аспекты цели, но при этом необходимо минимизировать число необходимых критериев.
6. Агрегирование критериев. Выявленные критерии могут быть объединены либо в группы, либо заменены обобщающим критерием.
7. Генерирование альтернатив и выбор с использованием критериев наилучшей из них. Формирование множества альтернатив является творческим этапом системного анализа.
8. Исследование ресурсных возможностей, включая информационные потоки и ресурсы.
9. Выбор формализации (построение и использование моделей и ограничений) для решения проблемы.
10. Оптимизация (для простых систем).
11. Декомпозиция.
12. Наблюдение и эксперименты над исследуемой системой.
13. Построение системы.
14. Использование результатов проведенного системного исследования.
Однако в утверждении этих авторов есть некоторый смысловой парадокс, состоящий в том, что предложенная ими схема сама может рассматриваться как первый шаг на пути формализации представленных на ней этапов системного анализа в форме алгоритма.
Как уже отмечалось, специфической особенностью системного анализа является сочетание качественных и формальных методов. Такое сочетание составляет основу любой используемой методики. Различные схемы системного анализа, предлагаемые ведущими учеными в этой области (Оптнер С.Л., Янг С., Федоренко Н.П., Никаноров С.П., Черняк Ю.И., Перегудов Ф.И., Тарасенко Ф.П., Симанков В.С., Казиев В.М., Лийв Э.Х.) сведены в таблице 3.
Наиболее детализированная на данный момент многоуровневая иерархическая структуризация системного анализа в виде IDEF0-диаграмм, насколько известно автору, предложена в докторской диссертации В.С.Симанкова (в данной работе не приводится из-за ее ограниченного объема, но она приведена в работе [64]).
Работы по детализации системного анализа вдохновлялись надеждой на то, что более мелкие этапы легче автоматизировать. Этой надежде суждено было сбыться лишь частично. Но парадокс этого пути автоматизации системного анализа, который оправданно было бы назвать путем "максимальной детализации" состоит в том, что на пути "максимальной детализации" сама автоматизация системного анализа велась не системно: т.е. различные мелкие этапы СА автоматизировались различными не связанными друг с другом группами ученых и разработчиков, которые исходили при этом из своих целей, научных интересов и возможностей.
В результате на данный момент сложилась следующая картина:
– не все этапы системного анализа автоматизированы;
– для автоматизации различных этапов системного анализа применяются различные математические модели и теории;
– эти модели реализуются с применением различных программных систем, не связанных друг с другом и не образующие единого инструментального комплекса;
– эти программные системы созданы с использованием различных инструментальных средств, на различных платформах и языках программирования;
– как правило, эти программные системы имеют специализированный характер, т.е. автоматизируют отдельные этапы системного анализа не в универсальной форме, а лишь в одной конкретной предметной области.
Поэтому автор считает, что
"максимальная детализация системного анализа" – не самоцель, т.е.
бессмысленна "детализация ради детализации". Безусловно, данное
направление представляет интерес в научном плане, однако, по-видимому, оно не
перспективно как путь автоматизации системного анализа, т.к. опыт показывает,
что будучи изначально предназначено для облегчения процесса автоматизации на
деле оно лишь фактически усложнило решение этой задачи.
Анализ приведенных детализированных схем этапов и процедур системного анализа показывает, что на всех этапах широко используются когнитивные операции, т.е. операции, связанные с познанием предметной области и объекта управления и с созданием их идеальной модели.
Поэтому в данной работе предлагается иной путь автоматизации системного анализа, основанный не на его максимальной детализации, а на интеграции с когнитивными технологиями путем структурирования по когнитивным операциям.
1.2.1.1.3. Этапы когнитивного анализа
Рассмотрим этапы когнитивного анализа в варианте, предлагаемом ведущими отечественными учеными в этой области Максимов В.И., Корноушенко Е.К., Гребенюк Е.А., Григорян А.К. (рисунок 9). В этой связи необходимо также отметить работы Казиева В.М., С.В.Качаева, А.А.Кулинич, А.Н.Райкова, Д.И.Макаренко, С.В.Ковриги, Е.А.Гребенюка, А.К.Григоряна в области когнитивного анализа [52, 114 – 118, 160 – 163].
|
|
|
Рисунок 9. Этапы когнитивного анализа по В.И.Максимову и Е.К.Корноушенко |

Если проанализировать перечисленные методы системного анализа, то можно сделать основополагающий для данного исследования вывод о том, что все они самым существенным образом так или иначе основаны на процессах познания предметной области.
Поэтому как одно из важных и перспективных направлений автоматизации системного анализа предлагается рассматривать автоматизацию когнитивных операций системного анализа. Чтобы выявить эти операции и определить их место и роль в процессах познания, рассмотрим базовую когнитивную концепцию.
1.2.1.1.4. Предлагаемая обобщенная схема системного анализа, ориентированного на интеграцию с когнитивными технологиями
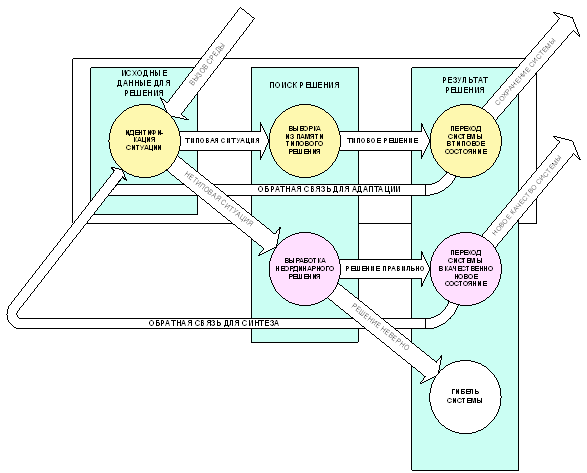
Сопоставительный анализ приведенных в таблице 3 и рисунке 9 схем системного и когнитивного анализа, показывает, что они во многом взаимно дополняют друг друга. Это говорит о возможности объединения различных схем системного анализа и когнитивного анализа в одной схеме " системного анализа, ориентированного на интеграцию с когнитивными технологиями". Предполагается, что это целесообразно, т.к. полученная схема системного анализа более пригодна для формализации и автоматизации, чем приведенные схемы детализированного системного анализа. С учетом этого, а также модели реагирования открытых систем на вызовы среды, предложенной в 1984 В.Н. Лаптевым (рисунок 10), нами предложена схема системного анализа, ориентированного на интеграцию с когнитивными технологиями, представленная на рисунке 11.
|
|
|
Рисунок 10. Схема реагирования открытой
системы |
|
|
|
|
Рисунок
11. Схема системного анализа, ориентированного |
|
1.2.1.2. Когнитивная концепция и синтез когнитивного конфигуратора
В данном разделе приводится когнитивная концепция, разработанная автором исследования в 1998 году [105], с учетом двух основных требований:
1. Адекватное отражение в когнитивной концепции реальных процессов, реализуемых человеком в процессах познания.
2. Высокая степень приспособленности
когнитивной концепции для формализации в виде достаточно простых математических
и алгоритмических моделей, допускающих прозрачную программную реализацию в
автоматизированной системе.
1.2.1.2.1. Понятие когнитивного конфигуратора и необходимость естественнонаучной (формализуемой) когнитивной концепции
1.2.1.2.1.1. Определение понятия конфигуратора
Понятие
конфигуратора, по-видимому, впервые предложено В.А.Лефевром [148], хотя
безусловно это понятие использовалось и раньше, но, во-первых, оно не получало
самостоятельного названия, а, во-вторых, использовалось в частных случаях и не
получало обобщения. Под конфигуратором
В.А.Лефевр понимал минимальный полный набор понятийных шкал или конструктов,
достаточный для адекватного описания предметной области. Примеры
конфигураторов приведены в [148].
1.2.1.2.1.2. Понятие когнитивного конфигуратора
В исследованиях по когнитивной психологии
изучается значительное количество различных операций, связанных с процессом
познания. Однако, насколько известно из литературы, психологами не ставился
вопрос о выделении из всего множества когнитивных операций такого минимального
(базового) набора наиболее элементарных из них, из которых как составные могли
бы строится другие операции. Ясно, что для выделения таких базовых когнитивных
операций (БКО) необходимо построить их иерархическую систему, в фундаменте
которой будут находится наиболее элементарные из них, на втором уровне –
производные от них, обладающие более высоким уровнем интегративности, и т.д.
Таким
образом, под когнитивным конфигуратором будем понимать минимальный полный набор
базовых когнитивных операций, достаточный для представления различных процессов
познания.
1.2.1.2.1.3. Когнитивные концепции и операции
Проведенный анализ когнитивных концепций показал, что они разрабатывались ведущими психологами (Пиаже, Солсо, Найсер) без учета требований, связанных с их дальнейшей формализацией и автоматизацией. Поэтому имеющиеся концепции когнитивной психологии слабо подходят для этой цели; в когнитивной психологии не ставилась и не решалась задача конструирования когнитивного конфигуратора и, соответственно, не сформулировано понятие базовой когнитивной операции.
1.2.1.2.2. Предлагаемая когнитивная концепция
Автоматизировать процесс познания в целом безусловно значительно сложнее, чем отдельные операции процесса познания. Но для этого прежде всего необходимо выявить эти операции и найти место каждой из них в системе или последовательности процесса познания.
Сделать это предлагается в форме когнитивной концепции, которая должна удовлетворять следующим требованиям:
– адекватность, т.е. точное отражение сущности процессов познания, характерных для человека, в частности описание процессов вербализации, семантической адаптации и семантического синтеза (уточнения смысла слов и понятий и включения в словарь новых слов и понятий);
– высокая степень детализации и структурированности до уровня достаточно простых базовых когнитивных операций;
– возможность математического описания, формализации и автоматизации.
Однако приходится констатировать, что даже концепции когнитивной психологии, значительно более конкретные, чем гносеологические, разрабатывались без учета необходимости построения реализующих их математических и алгоритмических моделей и программных систем. Более того, в когнитивной психологии из всего многообразия различных исследуемых когнитивных операций не выделены базовые, к суперпозиции и различным вариантам сочетаний которых сводятся различные процессы познания. Поэтому для достижения целей данного исследования концепции когнитивной психологии мало применимы.
В связи с этим в данном исследовании предлагается когнитивная концепция, удовлетворяющая сформулированным выше требованиям. Эта концепция достаточно проста, иначе было бы невозможно ее формализовать, многие ее положения интуитивно очевидны или хорошо известны, тем ни менее в целостном виде она сформулирована лишь в работе [64]. Положения когнитивной концепции приведены в определенном порядке, соответствующем реальному ходу процесса познания "от конкретных эмпирических исходных данных к содержательным информационным моделям, а затем к их верификации, адаптации и, в случае необходимости, к пересинтезу".
На базе выше сформулированных положений автором предложена целостная система взглядов на процесс познания, т.е. когнитивная концепция [64] (рисунок 12).
|
|
|
Рисунок 12. Обобщенная схема предлагаемой когнитивной концепции |
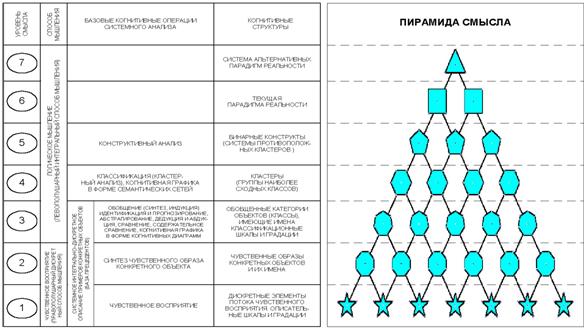
Суть предложенной когнитивной концепции состоит в том, что процесс познания рассматривается как многоуровневая иерархическая система обработки информации, в которой каждый последующий уровень является результатом интеграции элементов предыдущего уровня. На 1-м уровне этой системы находятся дискретные элементы потока чувственного восприятия, которые на 2-м уровне интегрируются в чувственный образ конкретного объекта. Те, в свою очередь, на 3-м уровне интегрируются в обобщенные образы классов и факторов, образующие на 4-м уровне кластеры, а на 5-м конструкты. Система конструктов на 6-м уровне образуют текущую парадигму реальности (т.е. человек познает мир путем синтеза и применения конструктов). На 7-м же уровне обнаруживается, что текущая парадигма не является единственно-возможной.
Ключевым для когнитивной концепции является понятие факта, под которым понимается соответствие дискретного и интегрального элементов познания (т.е. элементов разных уровней интеграции-иерархии), обнаруженное на опыте. Факт рассматривается как квант смысла, что является основой для его формализации. Таким образом, происхождение смысла связывается со своего рода "разностью потенциалов", существующей между смежными уровнями интеграции-иерархии обработки информации в процессах познания.
1. Процесс познания начинается с чувственного восприятия. Различные органы восприятия дают качественно-различную чувственную информацию в форме дискретного потока элементов восприятия. Эти элементы формализуются с помощью описательных шкал и градаций.
2. В процессе накопления опыта выявляются взаимосвязи между элементами чувственного восприятия: одни элементы часто наблюдаются с другими (имеет место их пространственно-временная корреляция), другие же вместе встречаются достаточно редко. Существование устойчивых связей между элементами восприятия говорит о том, что они отражают некую реальность, интегральную по отношению к этим элементам. Эту реальность будем называть объектами восприятия. Рассматриваемые в единстве с объектами элементы восприятия будем называть признаками объектов. Таким образом, органы восприятия дают чувственную информацию о признаках наблюдаемых объектов, процессов и явлений окружающего мира (объектов). Чувственный образ конкретного объекта представляет собой систему, возникающую как результат процесса синтеза признаков этого объекта. В условиях усложненного восприятия синтез чувственного образа объекта может быть существенно замедленным и даже не завершаться в реальном времени.
3. Человек присваивает конкретным объектам названия (имена) и сравнивает объекты друг с другом. При сравнении выясняется, что одни объекты в различных степенях сходны по их признакам, а другие отличаются. Сходные объекты объединяются в обобщенные категории (классы), которым присваиваются имена, производные от имен входящих в категорию конкретных объектов. Классы формализуются с помощью классификационных шкал и градаций и обеспечивают интегральный способ описания действительности. Путем обобщения (синтеза, индукции) информации о признаках конкретных объектов, входящих в те или иные классы, формируются обобщенные образы классов. Накопление опыта и сравнение обобщенных образов классов друг с другом позволяет определить степень характерности признаков для классов, смысл признаков и ценность каждого признака для идентификации конкретных объектов с классами и сравнения классов, а также исключить наименее ценные признаки из дальнейшего анализа без существенного сокращения количества полезной информации о предметной области (абстрагирование). Абстрагирование позволяет существенно сократить затраты внутренних ресурсов системы на анализ информации. Идентификация представляет собой процесс узнавания, т.е. установление соответствия между чувственным описанием объекта, как совокупности дискретных признаков, и неделимым (целостным) именем класса, которое ассоциируется с местом и ролью воспринимаемого объекта в природе и обществе. Дискретное и целостное восприятие действительности поддерживаются как правило различными полушариями мозга: соответственно, правым и левым (доминантность полушарий). Таким образом именно системное взаимодействие интегрального (целостного) и дискретного способов восприятия обеспечивает возможность установление содержательного смысла событий. При выполнении когнитивной операции "содержательное сравнение" двух классов определяется вклад каждого признака в их сходство или различие.
4. После идентификации уникальных объектов с классами возможна их классификация и присвоение обобщающих имен группам похожих классов. Для обозначения группы похожих классов используем понятие "кластер". Но и сами кластеры в результате выполнения когнитивной операции "генерация конструктов" могут быть классифицированы по степени сходства друг с другом. Для обозначения системы двух противоположных кластеров, с "спектром" промежуточных кластеров между ними, будем использовать термин "бинарный конструкт", при этом сами противоположные кластеры будем называть "полюса бинарного конструкта". Бинарные конструкты классов и атрибутов, т.е. конструкты с двумя полюсами, наиболее типичны для человека и представляет собой когнитивные структуры, играющие огромную роль в процессах познания. Достаточно сказать, что познание можно рассматривать как процесс генерации, совершенствования и применения конструктов. Качество конструкта тем выше, чем сильнее отличаются его полюса, т.е. чем больше диапазон его смысла.
Результаты идентификации и прогнозирования, осуществленные с помощью модели, путем выполнения когнитивной операции "верификация" сопоставляются с опытом, после чего определяется целесообразность выполнения когнитивной операции "обучение". При этом может возникнуть три основных варианта, которые на рисунке 13 обозначены цифрами:
|
|
|
Рисунок 13. К пояснению смысла понятий: |
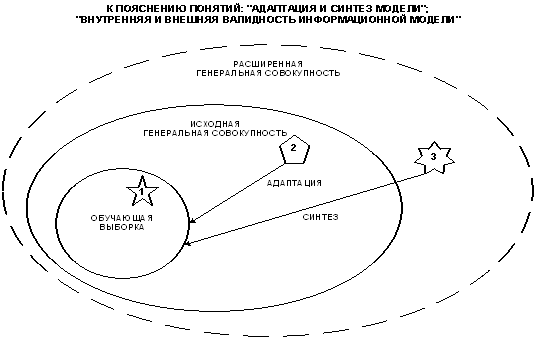
1. Объект, входит в обучающую выборку и достоверно идентифицируется (внутренняя валидность, в адаптации нет необходимости).
2. Объект, не входит в обучающую выборку, но входит в исходную генеральную совокупность, по отношению к которой эта выборка репрезентативна, и достоверно идентифицируется (внешняя валидность, добавление объекта к обучающей выборке и адаптация модели приводит к количественному уточнению смысла признаков и образов классов).
3. Объект не входит в исходную генеральную совокупность и идентифицируется недостоверно (внешняя валидность, добавление объекта к обучающей выборке и синтез модели приводит к качественному уточнению смысла признаков и образов классов, исходная генеральная совокупность расширяется).
1.2.1.2.3. Когнитивный конфигуратор и базовые когнитивные операции системного анализа
Таким образом из предложенной когнитивной
концепции вытекает существование по крайней мере 10 базовых когнитивных
операций системного анализа (БКОСА) (таблица 4):
|
Таблица 4 – ОБОБЩЕННЫЙ СПИСОК
БКОСА |
|
|
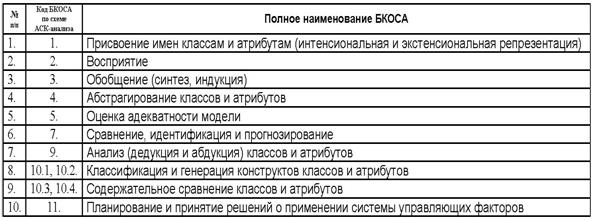
Необходимо отметить, что классификация операций системного анализа по В.М.Казиеву [64] ближе всего к позиции, излагаемой в данной работе, т.к. этим автором названы 6 из 10 базовых когнитивных операций системного анализа: формализация; синтез (индукция); абстрагирование; анализ (дедукция); распознавание, и идентификация образов; классификация. Вместе с тем им не приводятся математическая модель, алгоритмы и инструментарий реализации этих операций и не ставится задача их разработки, кроме того некоторые из них приведены дважды под разными названиями, например: анализ и синтез это тоже самое, что дедукция и индукция (таблица 4).
Необходимо также отметить, что по-видимому, впервые идея сведения мышления и процессов познания к когнитивным операциям была четко и осознанно письменно сформулирована в V веке до н.э.: "Сущность интеллекта проявляется в способностях обобщения, абстрагирования, сравнения и классификации" (цит.по пам., Патанжали, Йога-Сутра, авт.).
Познание предметной области с одной стороны безусловно является фундаментом, на котором строится все грандиозное здание системного анализа, а с другой стороны, процессы познания являются связующим звеном, органично объединяющим "блоки" принципов и методов системного анализа в стройное здание. Более того, процессы познания буквально пронизывают все методы и принципы системного анализа, входя в них как один из самых существенных элементов.
Однако, на этом основании неверным будет
представлять, что когнитивные операции являются подмножеством понятия
"системный анализ", скорее наоборот: системный анализ представляет
собой один из теоретических методов познания, представимый в форме определенной
последовательности когнитивных операций, тогда как другие последовательности этих операций позволяют образовать
другие формы теоретического познания.
1.2.1.2.4. Задачи формализации базовых когнитивных операций системного анализа
Для решения задачи формализации БКОСА необходимо решить следующие задачи:
1. Выбор единой интерпретируемой численной меры для классов и атрибутов.
2. Выбор неметрической меры сходства объектов в семантических пространствах.
4. Определение идентификационной и прогностической ценности атрибутов.
5. Ортонормирование семантических пространств классов и атрибутов (Парето-оптимизация).
Выбор единой интерпретируемой численной меры для классов и атрибутов
При построении модели объекта управления одной из принципиальных проблем является выбор формализованного представления для индикаторов, критериев и факторов (далее: факторов). Эта проблема распадается на две подпроблемы:
1. Выбор и обоснование смысла выбранной численной меры.
2. Выбор математической формы и способа определения (процедуры, алгоритма) количественного выражения для значений, отражающих степень взаимосвязи факторов и будущих состояний АОУ.
Рассмотрим требования к численной мере, определяемые существом подпроблем. Эти требования вытекают из необходимости совершать с численными значениями факторов математические операции (сложение, вычитание, умножение и деление), что в свою очередь необходимо для построения полноценной математической модели.
Требование 1: из формулировки 1-й подпроблемы следует, что все факторы должны быть приведены к некоторой общей и универсальной для всех факторов единице измерения, имеющей какой-то смысл, причем смысл, поддающийся единой сопоставимой в пространстве и времени интерпретации.
Традиционно в специальной литературе [10] рассматриваются следующие смысловые значения для факторов: стоимость (выигрыш-проигрыш или прибыль-убытки); полезность; риск; корреляционная или причинно-следственная взаимосвязь. Иногда предлагается использовать безразмерные меры для факторов, например эластичность, однако, этот вариант не является вполне удовлетворительным, т.к. не позволяет придать факторам содержательный и сопоставимый смысл и получить содержательную интерпретацию выводов, полученных на основе математической модели.
Таким
образом, возникает ключевая при выборе численной меры проблема выбора смысла,
т.е. по сути единиц измерения, для индикаторов, критериев и факторов.
Требование 2: высокая степень адекватности предметной области.
Требование 3: высокая скорость сходимости при увеличении объема обучающей выборки.
Требование 4: высокая независимость от артефактов.
Что касается конкретной математической формы и процедуры определения числовых значений факторов в выбранных единицах измерения, то обычно применяется метод взвешивания экспертных оценок, при котором эксперты предлагают свои оценки, полученные как правило неформализованным путем. При этом сами эксперты также обычно ранжированы по степени их компетентности. Фактически при таком подходе числовые значения факторов является не определяемой, искомой, а исходной величиной. Иначе обстоит дело в факторном анализе, но в этом методе, опять же на основе экспертных оценок важности факторов, требуется предварительно, т.е. перед проведением исследования, принять решение о том, какие факторы исследовать (из-за жестких ограничений на размерность задачи в факторном анализе). Таким образом оба эти подхода реализуемы при относительно небольших размерностях задачи, что с точки зрения достижения целей настоящего исследования, является недостатком этих подходов.
Поэтому
самостоятельной и одной из ключевых проблем является обоснованный и удачный
выбор математической формы для численной меры индикаторов и факторов.
Эта математическая форма с одной стороны должна удовлетворять предыдущим требованиям, прежде всего требованию 1, а также должна быть процедурно вычислимой, измеримой.
Выбор неметрической меры сходства объектов в семантических пространствах
Существует большое количество мер сходства, из которых можно было бы упомянуть скалярное произведение, ковариацию, корреляцию, евклидово расстояние, расстояние Махалонобиса и др.
Проблема выбора меры сходства состоит в том, что при выбранной численной мере для координат классов и факторов она должна удовлетворять определенным критериям:
1. Обладать высокой степенью адекватности предметной области, т.е. высокой валидностью, при различных объемах выборки, как при очень малых, так и при средних и очень больших.
2. Иметь обоснованную, четкую, ясную и интуитивно понятную интерпретацию.
3. Быть нетрудоемкой в вычислительном отношении.
4. Обеспечивать корректное вычисление меры сходства для пространств с неортонормированным базисом.
Определение идентификационной и прогностической ценности атрибутов
Не все факторы имеют одинаковую ценность для решения задач идентификации, прогнозирования и управления. Традиционно считается, что факторы имеют одинаковую ценность только в тех случаях (обычно в психологии), когда определить их действительную ценность не представляется возможным по каким-либо причинам.
Для достижения целей, поставленных в данном исследовании, необходимо решить проблему определения ценности факторов, т.е. разработать математическую модель и алгоритм, которые допускают программную реализацию и обеспечивают на практике определение идентификационной и прогностической ценности факторов.
Ортонормирование семантических пространств классов и атрибутов (Парето-оптимизация)
Если не все факторы имеют одинаковую ценность для решения задач идентификации, прогнозирования и управления, то возникает проблема исключения из системы факторов тех из них, которые не представляют особой ценности. Удаление малоценных факторов вполне оправданно и целесообразно, т.к. сбор и обработка информации по ним в среднем связана с такими же затратами времени, вычислительных и информационных ресурсов, как и при обработке ценных факторов. В этом состоит идея Парето-оптимизации. Однако это удаление должно осуществляться при вполне определенных граничных условиях, характеризующих результирующую систему: адекватность модели; количество признаков на класс; суммарное количество градаций признаков в описательных шкалах. В противном случае удаление факторов может отрицательно сказываться на качестве решения задач. На практике проблема реализации Парето-оптимизации состоит в том, что факторы вообще говоря коррелируют друг с другом и поэтому их ценность может изменяться при удалении любого из них, в том числе и наименее ценного. Поэтому просто взять и удалить наименее ценные факторы не представляется возможным и необходимо разработать корректный итерационный вычислительный алгоритм обеспечивающий решение этой проблемы при заданных граничных условиях.
1.2.1.3. СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных операций
В предложенной схеме системного анализа (рисунок 11) наглядно прослеживается сходство с когнитивным анализом (рисунок 9). Это естественно, т.к. системный анализ рассматриваться многими авторами, как одна из форм теоретического познания. Учитывая это и с целью создания благоприятных условий для дальнейшей декомпозиции системного анализа до уровня, достаточного для разработки алгоритмов и программной реализации, предлагается структурировать системный анализ до уровня базовых когнитивных операций. Предлагается рассматривать системный анализ, структурированный до уровня базовых когнитивных операций, как системно-когнитивный анализ (СК-анализ). Насколько известно впервые понятие "СК-анализ" предложено в 1995 году А.Е.Кибрик и Е.А.Богдановой. Однако этими авторами данное понятие было введено в другой предметной области, ими не ставилась и не решалась задача автоматизации СК-анализа.
В связи с тем, что СК-анализ структурируется нами до уровня БКОСА, его алгоритмизация и последующая автоматизация становится практически решаемой задачей, в отличие от автоматизация непосредственно системного анализа или детализированного системного анализа.
Отсюда
органично вытекает возможность структурирования системного анализа до
уровня базовых когнитивных (познавательных) операций.
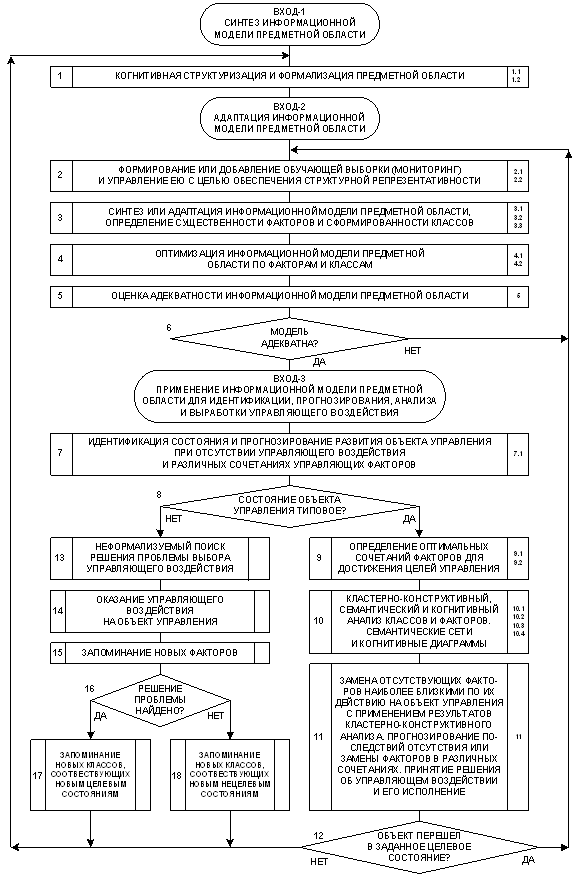
Учитывая структуру когнитивного конфигуратора (таблица 4) конкретизируем обобщенную схему этапов системного анализа, ориентированного на интеграцию с когнитивными технологиями (рисунок 11), в результате чего получим обобщенную схему этапов СК-анализа (рисунок 14).
|
|
|
Рисунок 14. Обобщенная схема этапов СК-анализа |

Предложенная схема представляет собой схему системного анализа, структурированного до уровня базовых когнитивных операций, который предлагается называть "Системно-когнитивным анализом (СК-анализ). Нумерация блоков на рисунке 14 соответствует этапам СА на рисунке 11.
Схема, СК-анализа,
представленная на рисунке 14, определяет место каждой базовой когнитивной операции в системном анализе.
1.2.1.4. Место и роль СК-анализа в структуре управления
Управление в АПК рассматривается в данной работе в контексте использования автоматизированных систем управления в этой области. Поэтому в данном разделе предложена классификация функционально-структурных типов АСУ и показано место адаптивных АСУ сложными системами и рефлексивных АСУ активными объектами в этой классификации; показаны место и роль СК-анализа в рефлексивных АСУ активными объектами [64].
1.2.1.4.1. Структура типовой АСУ
Цель применения АСУ обычно можно представить в виде некоторой суперпозиции трех подцелей:
1) стабилизация состояния объекта управления в динамичной или агрессивной внешней среде;
2) перевод объекта в некоторое конечное (целевое) состояние, в котором он приобретает определенные заранее заданные свойства;
3) повышение качества функционирования АСУ (синтез новых моделей и их адаптация).
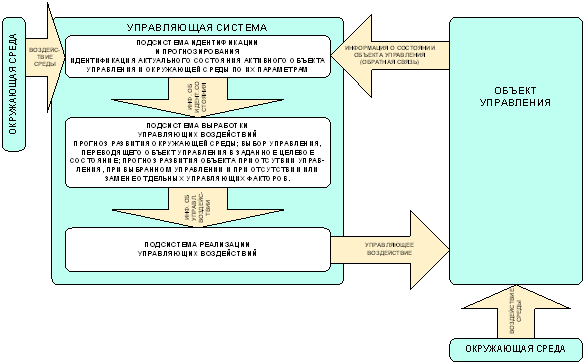
Обычно АСУ рассматривается как система, состоящая из двух основных подсистем: управляющей и управляемой, т.е. из субъекта и объекта управления (рисунок 15).
Как правило, АСУ действует в определенной окружающей среде, которая является общей и для субъекта, и для объекта управления.
Граница между тем, что считается окружающей средой, и тем, что считается объектом управления относительна и определяется возможностью управляющей системы оказывать на них воздействие: на объект управления управляющее воздействие может быть оказано, а на среду нет.
|
|
1.2.1.4.2. Параметрическая модель адаптивной АСУ сложными системами
Конкретизируем типовую структуру АСУ (рисунок 15), используя классификацию входных и выходных параметров объекта управления. В результате получим параметрическую модель адаптивной АСУ сложными системами (рисунок 16).
|
|
|
Рисунок 16. Параметрическая модель адаптивной АСУ сложными системами |
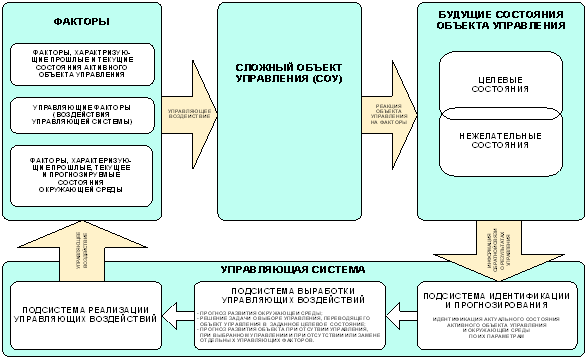
Входные параметры (факторы) делятся на три группы: характеризующие предысторию и текущее состояние объекта управления, управляющие (технологические) факторы и факторы окружающей среды.
Выходные параметры – это свойства объекта управления, зависящие от входных параметров (в т.ч. параметров, характеризующих среду). В автоматизированных системах параметрического управления целью управления является получение определенных значений выходных параметров объекта управления, т.е. перевод объекта управления в заданное целевое состояние.
Однако, в случае сложного объекта управления
(СОУ) его выходные параметры связаны с состоянием сложным и неоднозначным
(нечетким) способом. Поэтому возможность параметрического управления сложными
объектами является проблематичной и вводится более общее понятие
"управление по состоянию СОУ".
Для ААСУ СС выполняется принцип соответствия, т.е. в предельном случае, когда связь выходных параметров и состояний объекта управления имеет однозначный и детерминистский характер, управление по состояниям сводится к управлению по параметрам и функции ААСУ СС сводится к их подмножеству: т.е. к функциям типовой АСУ. Однако, когда состояние объекта управления связано с его параметрами сложным и неоднозначным образом, возникает задача идентификации состояния СОУ по его выходным параметрам, которая решается подсистемой идентификации управляющей подсистемы, работающей на принципах адаптивного распознавания образов. При этом классами распознавания являются текущие состояния сложного объекта управления, а признаками – его выходные параметры.
Подсистема выработки управляющих воздействий, также основанная на алгоритмах распознавания образов, решает следующие задачи: прогноз развития окружающей среды; прогноз развития объекта управления в условиях отсутствия управляющих воздействий ("движение по инерции"); выбор управления, переводящего объект управления в целевое состояние.
Подсистема реализации управляющих воздействий осуществляет выбранное технологическое воздействие на объект управления.
1.2.1.4.3. Модель рефлексивной АСУ активными объектами и понятие мета-управления
АСУ активными объектами (объектами) (РАСУ АО), является обобщением ААСУ СС на случай, когда сложная система является активной, т.е. имеет собственные цели, которые в общем случае не совпадают с целями управляющей системы. Из этого обстоятельства следует, что активный объект управления (АОУ) имеет собственную модель себя и своей окружающей среды, включая и управляющую систему, как один из ее элементов.
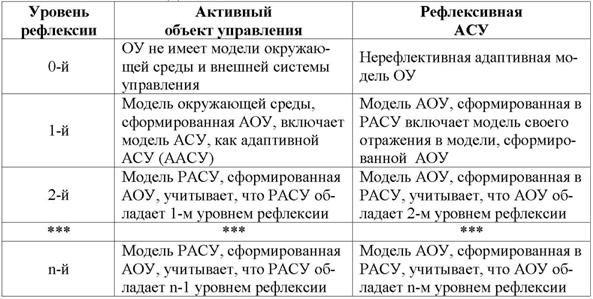
Классификация различных уровней рефлексивности приведена в таблице 5.
|
Таблица 5 – УРОВНИ РЕФЛЕКСИВНОСТИ |
|
|
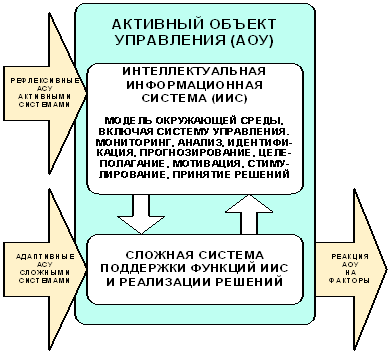
Простейшая модель АОУ включает два уровня (рисунок 17) и предполагает возможность оказания управляющих воздействий на различных уровнях АОУ:
– уровне воздействия на систему поддержки системы управления;
– уровне системы управления.
|
|
|
Рисунок 17. Двухуровневая модель активной
системы |
Различия между ААСУ СС и РАСУ АО приведены в таблице 6:
Таблица 6 – РАЗЛИЧИЯ МЕЖДУ ААСУ СС И РАСУ АО
|
|
ААСУ СС |
РАСУ АО |
|
Модель объекта управления |
Объект управления рассматривается
как физическая система, пассивно воспринимающая управляющая воздействия |
Объект управления
рассматривается как субъект, имеющий системы: целеполагания; моделирования
себя (рефлективность) и окружающей среды (включая управляющую систему);
принятия и реализации решений |
|
Характер управляющего воздействия |
Энергетическое (физическое) воздействие |
Информационное
воздействие, мета-управление |
Конечно, РАСУ АО не исключает возможности энергетического воздействия на физическую структуру АОУ, как в ААСУ СС, но это также может осуществляться с учетом характеристик его интеллектуальной информационной системы. Таким образом, в РАСУ АО управление АОУ осуществляется путем управления его системой управления, т.е. путем мета-управления: согласования целей системы управления и активного объекта управления; создания у активного объекта управления благоприятного для достижения целей управления и восприятия управляющих воздействий образа управляющей системы; создания у активного объекта управления мотивации, ориентирующей его на достижение целей управления. Таким образом, мета-управление представляет собой управление теми условиями, на основе которых активный объект управления формирует цели и принимает решения. Учитывая сказанное, получим структуру РАСУ АО как обобщение структуры ААСУ СС на случай активного объекта управления (рисунок 18).
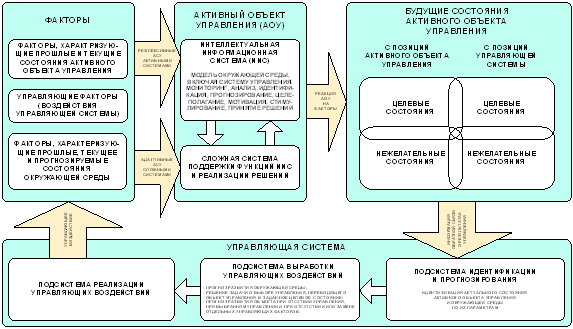
1.2.1.4.4. Двухконтурная модель РАСУ в АПК
Концепция рефлексивной АСУ в АПК и технология QFD (технология развертывания функций качества)
Чтобы сформулировать концепцию управления В РАСУ АПК рассмотрим упрощенную формальную модель. Процесс управления состоит из последовательных циклов управления, каждый из которых включают следующие этапы: количественное сопоставимое измерение параметров и идентификация состояния объекта управления; оценка эффективности (качества) предыдущего управляющего воздействия; если предыдущее управляющее воздействие не обеспечило приближения цели, то выработка новых или корректировка (адаптация) имеющихся методов принятия решений; иначе – выработка нового управляющего воздействия на основе имеющихся методов принятия решений; реализация управляющего воздействия.
При этом объектами управления, в соответствии с технологией QFD (развертывания функций качества) на различных уровнях являются потребительские свойства продукта, свойства его компонент, технологический процесс и его элементы (операции) (рисунок 19) [64].
|
|
|
Рисунок 19. Обобщенная схема QFD-технологии |
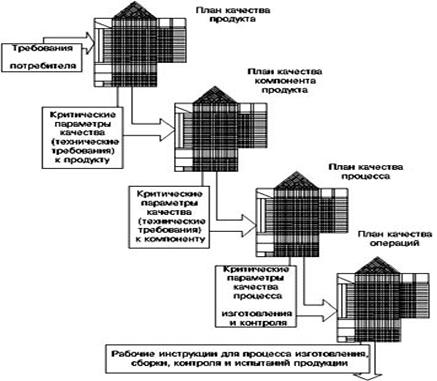
Рефлексивная АСУ АПК группы Б: 1-й контур: "Агротехнологии – конечный продукт"
Конкретизируем общие положения QFD-технологии (развертывание функций качества) для случая РАСУ АПК. Из этой технологии следует, что в этой РАСУ должно быть по крайней мере два уровня:
1-й уровень – управление производством конечной продукции;
2-й уровень – управление качеством технологии производства конечной продукции.
Такие АСУ, которые управляют производством конечного продукта, будем называть АСУ группы "Б" (АСУ средств потребления). Применительно к РАСУ АПК, АСУ группы "Б" – это АСУ управления производством сельхозпродукции с помощью агротехнологий (рисунок 20).
|
|
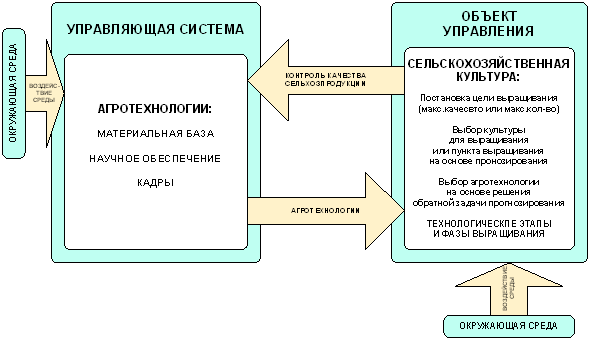
Обычно считается известным влияние тех или иных традиционных агротехнологий на потребительские свойства конечного продукта и его цену. Это положение не подвергается в данной работе сомнению, однако необходимо отметить, что само понятие "известно" существенно отличается в гуманитарной и технических областях, т.е. в этих областях приняты различные критерии для классификации исследуемых закономерностей на "известные" и "неизвестные". Это приводит к тому, что в ряде случаев то, что "гуманитарии" считают для себя известным не является таковым для "естественников", т.е. они, конечно, имеют эти знания, но они их не устраивают. Как правило гуманитариев устраивает качественная оценка связи, в результате они часто оперируют нечеткими высказываниями типа: "Бобовые предшественники приводят к повышению урожая зерновых колосовых". И это для них приемлемо. Однако для создания АСУ знаний выраженных в такой форме недостаточно, требуется количественная формулировка, значит специалист по созданию АСУ будет ставить вопрос о проведении специальных исследований для выявления и количественного измерения силы и направления влияния подобных связей.
Поэтому при создании РАСУ АПК возникают проблемы: количественного измерения различных параметров агротехнологических процессов и окружающей среды и выявления количественных зависимостей между этими параметрами и количественными и качественными характеристиками конечной продукции. Причем характеристики конечной продукции могут быть выражены в интервальных величинах в натуральном или в ценовом выражении.
Во всех случаях внедрение АСУ означает прежде всего изменение (совершенствование) технологии воздействия на объект управления (рисунок 21).
|
|
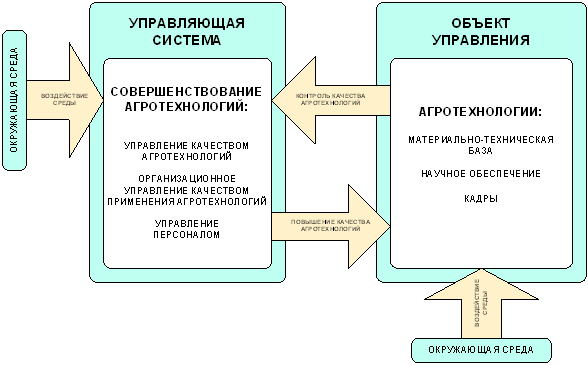
Таким образом, сам процесс внедрения АСУ можно рассматривать как процесс управления совершенствованием технологии производства конечного продукта.
Рефлексивная АСУ АПК группы А: 2-й контур:
"Руководство – агротехнологический процесс"
АСУ, в которых сама агротехнология является объектом управления, мы отнесем к группе "А" (таблица 7):
Таблица 7 – КОМПОНЕНТЫ АСУ АГРОТЕХНОЛОГИЯМИ
|
№ |
Элементы АСУ |
РАСУ АПК |
|
1 |
Сырье |
Агротехнологии и кадры до
внедрения РАСУ АПК |
|
2 |
Объект управления |
Агротехнологический
процесс и руководящие кадры |
|
3 |
Управляющие факторы |
Материально-техническое и
научно-методическое обеспечение агротехнологического процесса, повышение
квалификации руководящих кадров |
|
4 |
Конечный продукт |
Агротехнологии и
руководящие кадры после внедрения РАСУ АПК |
|
5 |
Потребитель |
Производители
сельскохозяйственной продукции |
|
6 |
Окружающая среда |
Рынок труда и
агротехнологий |
Технические АСУ группы "А" являются чем-то экзотическим, т.к. объект управления, как правило, представляет собой систему с медленноменяющимися параметрами. В этих областях АСУ после внедрения работают достаточно длительное время без существенных изменений.
В РАСУ АПК ситуация иная: и сам объект управления (сельхозкультуры и агротехнологии), и условия окружающей среды (природной, экономической, социальной), являются весьма динамичными, из чего с необходимостью следует и высокая динамичность агротехнологий. Следовательно РАСУ АПК группы "Б" фактически не только не может быть внедрена, но даже и разработана без одновременной разработки и внедрения РАСУ АПК группы "А", которая бы обеспечила ей высокий уровень адаптивности, достаточный для обеспечения поддержки адекватности модели как при количественных, так и при качественных изменениях предметной области. Обобщенная схема РАСУ АПК группы "А" приведена на рисунке 18.
Двухконтурная модель и обобщенная схема рефлексивной АСУ качеством подготовки специалистов
Объединение РАСУ АПК групп "А" и "Б" приводит к схеме двухуровневой РАСУ АПК, в которой первый контур управления включает управление сельхозкультурой, а второй контур управления обеспечивает управление самой агротехнологией. На уровне "А" РАСУ АПК осуществляется разработка и совершенствование агротехнологий, а на уровне "Б" – выбор и использование оптимальной агротехнологии для получения заданных количественных и качественных параметров конечного продукта.
Отметим, что в данной работе рассмотрение ведется на примере плодоводства и растениеводства, но это не является ограничением и легко обобщается на отрасли птицеводства, животноводства, рыбоводства и др.
Но и управление агротехнологиями будет беспредметным без обратной связи, содержащей информацию об эффективности как традиционных агротехнологических методов, так и инноваций, т.е. без учета их влияния на качество хозяйственных результатов.
Кроме того РАСУ АПК включает ряд обеспечивающих систем, работа которых направлена на создание наиболее благоприятных условий для выполнения основной функции РАСУ АПК, т.е. обеспечение максимальной прибыли путем производства и реализации заданного количества и качества наиболее рентабельной продукции. Это так называемые обеспечивающие подсистемы: стратегическое управление (включая совершенствование организационной структуры управления); управление инновационной деятельностью (НИР, ОКР, внедрение); управление информационными ресурсами (локальные и корпоративные сети, Internet); управление планово-экономической, финансовой и хозяйственной деятельностью, и др. Необходимо также отметить, что РАСУ АПК работает в определенной окружающей среде, которая, в частности, включает: социально-экономическую среду; рынок труда; рынок агротехнологий; рынок наукоемкой продукции.
Учитывая вышесказанное, предлагается следующая двухуровневая обобщенная модель РАСУ АПК, включающую в качестве базовых подсистем РАСУ АПК групп "А" и "Б", а также обеспечивающие подсистемы (рисунок 22).
|
|
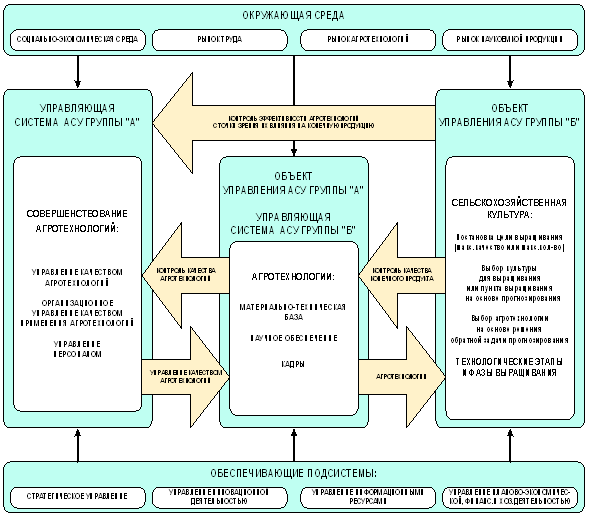
Необходимо отметить, что двухуровневая схема АСУ АПК является обобщением структуры типовой АСУ, а не обобщением структуры РАСУ АО. Чтобы рассматривать ее именно как рефлексивную АСУ необходимо иметь в виду, что и агротехнологии, и объект управления в АПК, являются активными системами и управляющие воздействия на них имеют информационный характер, т.е. являются метауправляющими. Безусловно, что информационные потоки обуславливают соответствующие финансовые, энергетические и вещественные потоки, изучаемые логистически.
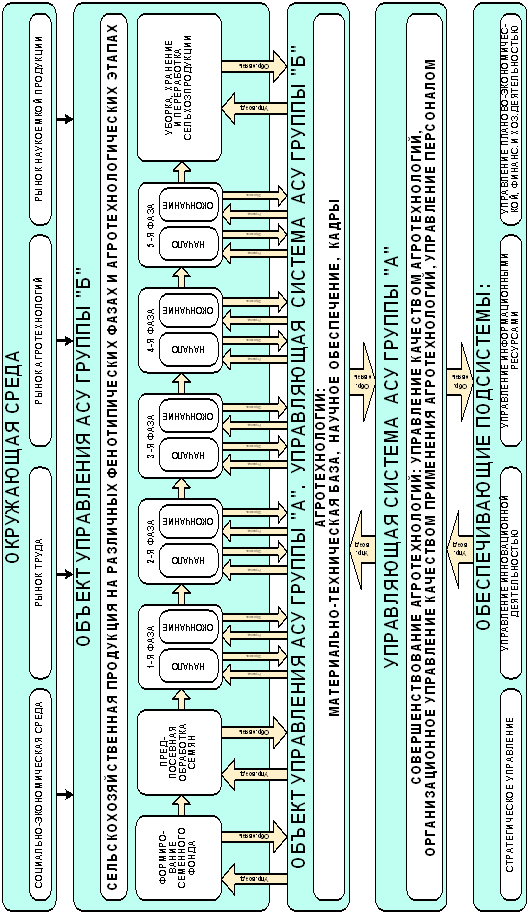
На рисунке 23 представлен вариант двухуровневой АСУ АПК, в котором показаны фазы развития сельскохозяйственной культуры и соответствующие агротехнологические этапы.
|
|
Рисунок
23. Детализированная схема РАСУ АПК, |
Резюме
1. С целью поиска путей автоматизации системного анализа проанализированы различные его варианты, предложенные ведущими учеными в этой области. Показана несостоятельность мнения о том, что автоматизацию системного анализа осуществить тем проще, чем более он детализирован. Отмечена не системность самой этой идеи, противоречащая духу системного анализа.
2. Предложена альтернативная идея поиска путей автоматизации системного анализа на пути его интеграции с когнитивными технологиями. В рамках этой идеи предложено структурировать системный анализ до уровня базовых когнитивных операций, достаточно элементарных, чтобы их было возможно автоматизировать при современном уровне развития науки и техники.
3. Для выявления базовых когнитивных операций разработана формализуемая когнитивная концепция. В ней процесс познания рассматривается как многоуровневая иерархическая система обработки информации, в которой когнитивные структуры каждого последующий уровня является результатом интеграции структур предыдущего уровня:
на 1-м уровне этой системы находятся дискретные элементы потока чувственного восприятия, которые получаются непосредственно от органов чувств и рассматриваются как исходная информация о реальности;
на 2-м уровне дискретные элементы потока чувственного восприятия интегрируются в чувственные образы конкретных объектов и факторов, которым присваиваются конкретные имена;
на 3-м уровне конкретные чувственные образы объектов и факторов интегрируются в обобщенные образы классов и факторов, которым присваиваются обобщенные и символические имена (обобщение и абстрагирование);
на 4-м уровне обобщенные образы классов и факторов сравниваются друг с другом и классифицируются в кластеры;
на 5-м уровне кластеры классов и факторов сравниваются друг с другом и образуют бинарные и многополюсные конструкты;
на 6-м уровне конструкты классов и факторов образуют текущую парадигму реальности, формулируется гипотеза о том, что человек познает мир путем синтеза и применения конструктов;
на 7-м уровне сравниваются текущие парадигмы конкретных людей и их групп, в результате чего обнаруживается, что текущая парадигма не единственно-возможная.
Предложенная когнитивная концепция включает периодическое подтверждение на практике адекватности или неадекватности сформированной модели предметной области, а также ее количественное уточнение с учетом новых достоверных данных (адаптация) или ее качественное переформирование (синтез) в случае необходимости.
4. Понятие факта является ключевым для когнитивной концепции. Под фактом понимается соответствие дискретного и интегрального элементов познания (т.е. элементов разных, как правило смежных, уровней интеграции-иерархии), обнаруженное на опыте. Факт рассматривается как квант смысла, что является основой для математической модели смысла в предложенной семантической информационной модели. Таким образом, происхождение смысла связывается со своего рода "разностью потенциалов", существующей между смежными уровнями интеграции-иерархии обработки информации в процессах познания.
5. В рамках когнитивной концепции сконструирован когнитивный конфигуратор (тер. авт.). Он представляющий собой минимальную полную систему когнитивных операций, названных "базовые когнитивные операции системного анализа" (БКОСА). Выявлено следующих десять БКОСА: 1) присвоение имен; 2) восприятие; 3) обобщение (синтез, индукция); 4) абстрагирование; 5) оценка адекватности модели; 6) сравнение, идентификация и прогнозирование; 7) дедукция и абдукция; 8) классификация и генерация конструктов; 9) содержательное сравнение; 10) планирование и принятие решений об управлении.
Таким образом, на основе предложенной когнитивной концепции выводятся структура когнитивного конфигуратора, система базовых когнитивных операций и обобщенная схема автоматизированного СА, структурированного до уровня базовых когнитивных операций, получившего в данном исследовании название "СК-анализ".
6. Предложена структура рефлексивной АСУ активными объектами, включающая двухуровневую модель активного объекта управления, классификацию факторов и будущих состояний объекта управления.
Двухуровневая модель активного объекта управления предполагает два типа управляющих воздействий: информационное (мета-управляющее) воздействие на интеллектуальную информационную систему активного объекта управления; энергетическое (силовое) воздействие на сложную систему поддержки функций интеллектуальной информационной системы активного объекта управления.
Классификация факторов, включает: факторы, характеризующие активный объект управления в его прошлых и текущем состояниях, в том числе факторы, характеризующие его как активную, рефлексивную систему; управляющие факторы; факторы окружающей среды.
Будущие состояния активного объекта управления, классифицируются как целевые и нежелательные с позиций управляющей системы и самого активного объекта управления. В общем случае эти классификации не совпадают.
7. Разработаны классификация функционально-структурных типов АСУ и показано место адаптивных АСУ сложными системами и рефлексивных АСУ активными объектами в этой классификации; показаны роль и место СК-анализа в РАСУ АО.
Рассмотрена типовая структура АСУ, предложена параметрическая модель адаптивной АСУ сложными системами (ААСУ СС) и, на основе конкретизации технологии QFD (развертывания функций качества), предложена двухуровневая модель РАСУ АО, являющаяся обобщением ААСУ СС на случай активных объектов управления:
1-й уровень обеспечивает управление АОУ;
2-й уровень – управление технологией воздействия на АОУ.
Проведенное сравнение ААСУ СС и РАСУ АО АПК по способу управляющего воздействия на объект управления, степени управляемости на детерминистских и бифуркационных этапах развития объекта управления и уровню адаптивности позволяет сделать вывод о предпочтительности эксплуатационных характеристик РАСУ АО при управлении активными объектами. Это обусловлено двумя основными обстоятельствами: в ААСУ СС обеспечивается лишь количественная адаптация модели АОУ, что не обеспечивает сохранение ее адекватности после прохождения объектом управления точки бифуркации, т.е. его качественной трансформации, тогда как в РАСУ АО в этом случае осуществляется повторный синтез модели АОУ; в ААСУ СС рефлексивность и активный характер объекта управления не учитываются и управляющее воздействие на него имеет энергетический (силовой) характер, тогда как в РАСУ АО – это прежде всего воздействие на информационный уровень объекта управления, т.е. мета-управление (коррекция его целей, модели себя и окружающей среды, мотиваций способов принятия и реализации решений в направлении их сближения и согласования с целями управляющей системы). Показано, что в рефлексивных АСУ активными объектами информационное мета-управление активным объектом состоит в коррекции его целей и мотиваций в направлении сближения его целей с целями управляющей системы.
Контрольные вопросы
1. Системный анализ, как метод познания.
2. Принципы системного анализа.
3. Методы и этапы системного анализа.
4. Этапы когнитивного анализа.
5. Обобщенная схема системного анализа, ориентированного на интеграцию с когнитивными технологиями.
6. Когнитивная концепция и синтез когнитивного конфигуратора.
7. Понятие когнитивного конфигуратора и необходимость естественно-научной (формализуемой) когнитивной концепции.
8. Формализуемая когнитивная концепция
9. Когнитивный конфигуратор и БКОСА.
10. Задачи формализации базовых когнитивных операций системного анализа.
11. СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных операций.
12. Место и роль СК-анализа в структуре управления.
13. Структура типовой АСУ.
14. Параметрическая модель адаптивной АСУ сложными системами.
15. Модель рефлексивной АСУ активными объектами и мета-управление.
16. Двухконтурная модель РАСУ в АПК.
Рекомендуемая литература
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1.2.2.
ЛЕКЦИЯ-4.
Системная теория информации
и семантическая информационная модель
Учебные вопросы
1. Теоретические основы системной теории информации.
2. Семантическая информационная модель СК-анализа.
3. Некоторые свойства математической модели (сходимость, адекватность, устойчивость и др.).
4. Взаимосвязь математической модели СК-анализа с другими моделями.
1.2.2.1. Теоретические основы системной теории информации
1.2.2.1.1. Требования к математической модели и численной мере
Для практической реализации идеи решения проблемы необходимо сформулировать требования к математической модели и численной мере, вытекающие из когнитивной концепции и специфических свойств активного объекта управления в АПК (слабодетерминированность, многофакторность, активность).
Требования к математической модели предусматривают: содержательную интерпретируемость; эффективную вычислимость на основе непосредственно эмпирических данных (наличие эффективного численного метода); универсальность; адекватность; сходимость; семантическую устойчивость; сопоставимость результатов моделирования в пространстве и времени; непараметричность; формализацию базовых когнитивных операций системного анализа (прежде всего таких, как обобщение, абстрагирование, сравнение, классификация и др.); корректность работы на фрагментарных, неточных и зашумленных данных; возможность обработки данных очень больших размерностей (тысячи факторов и будущих состояний объекта управления); математическую и алгоритмическую ясность и простоту, эффективность программной реализации.
Требования к численной мере. Ключевым при построении математических моделей является выбор количественной меры, обеспечивающей учет степени причинно-следственной взаимосвязи исследуемых параметров. Эта мера должна удовлетворять следующим требованиям: 1) обеспечивать эффективную вычислимость на основе эмпирических данных, полученных непосредственно из опыта; 2) обладать универсальностью, т.е. независимостью от предметной области; 3) подчиняться единому для различных предметных областей принципу содержательной интерпретации; 4) количественно измеряться в единых единицах измерения а количественной шкале (шкала с естественным нулем, максимумом или минимумом); 5) учитывать понятия: "цели объекта управления", "цели управления"; "мощность множества будущих состояний объекта управления"; уровень системности объекта управления; степень детерминированности объекта управления; 6) обладать сопоставимостью в пространстве и во времени; 7) обеспечивать возможность введения метрики или неметрической функции принадлежности на базе выбранной количественной меры.
Для того, чтобы выбрать тип (класс) модели, удовлетворяющей сформулированным требованиям, необходимо решить на какой форме информации эта модель будет основана: абсолютной, относительной или аналитической.
1.2.2.1.2. Выбор базовой численной меры
Абсолютная, относительная и аналитическая информация.
Широко известны абсолютная и относительная формы информации. Абсолютная форма – это просто количество, частота. Относительная форма – это доли, проценты, относительные частоты и вероятности.
Менее знакомы специалисты с аналитической формой информации, примером которой является условные вероятности, стандартизированные статистические значения, эластичность и количество информации.
Очевидно, что и из относительной информации, взятой изолированно, вырванной из контекста, делать какие-либо обоснованные выводы не представляется возможным. Для того, чтобы о чем-то судить по процентам, нужен их сопоставительный анализ, т.е. анализ всего процентного распределения. Обычно для используется "база оценки", в качестве которой используется среднего по всей совокупности или "скользящее среднее" (нормативный подход: норма – среднее).
Аналитическая (сопоставительная) информация – это информация, содержащаяся в отношении вероятности (или процента) к некоторой базовой величине, например к средней вероятности по всей выборке. Аналитическими являются также стандартизированные величины в статистике и количество информации в теории информации.
Очевидно, именно аналитическая информация является наиболее кондиционной для употребления с той точки зрения, что позволяет непосредственно делать содержательные выводы об исследуемой предметной области (точнее будет сказать, что она сама и является выводом), тогда как для того, чтобы сделать аналогичные выводы на основе относительной, и особенно абсолютной информации требуется ее значительная предварительная обработка.
Выбор в качестве базовой численной меры количества информации
Как было показано в лекции 2, системный
анализ представляет собой теоретический метод познания, т.е. информационный
процесс, в котором поток информации направлен от познаваемого объекта к
познающему субъекту. Процесс труда, напротив, представляет собой процесс, в котором поток информации направлен
от субъекта к объекту. При этом информация передается по каналу связи,
представляющему собой средства труда, и записывается в носитель информации
(предмет труда), который в ходе этого процесса преобразуется в заранее заданную
форму, т.е. в продукт труда. Таким образом, процесс труда по сути дела представляет собой
информационный процесс, обратный по направлению потока информации
процессу познания. Управление представляет собой процесс, на различных этапах
которого выполняются функции, сходные с процессами труда (управляющее
воздействие) и познания (обратная связь). По мнению автора, информационный
подход к управлению является наиболее общим. Поэтому
в качестве количественной меры взаимосвязи факторов и будущих состояний АОУ
целесообразно использовать количество информации. Более подробное
обоснование целесообразности выбора в качестве численной меры количества
информации приведено в работе автора [64].
Однако, известно много различных информационных мер и, следовательно, возникает задача выбора одной из них, оптимальной по выбранным критериям. Различные выражения классической теории информации для количества информации: Хартли, Шеннона, Харкевича и др., учитывают различные аспекты информационного моделирования объектов (таблице 8):
|
Таблица 8 – СООТВЕТСТВИЕ
ТРЕБОВАНИЯМ |
|
|
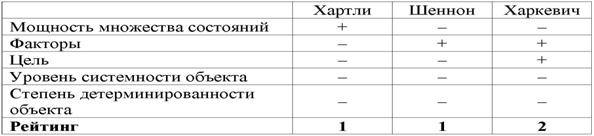
– формула Хартли учитывает количество классов (мощность множества состояний объекта управления) но никак не учитывает их признаков или факторов, переводящих объект в эти состояния, т.е. содержит интегральное описание объектов;
– формула Шеннона основывается на учете признаков, т.е. основывается на дискретном описании объектов;
– формула Харкевича учитывает понятие цели и также как формула Шеннона основана на статистике признаков, но не учитывает мощности множества будущих состояний объекта управления, включающего целевые и другие будущие состояния объекта управления и также как формула Шеннона основывается на дискретном описании объектов.
Как видно из таблицы 8, классическая формула Харкевича по учитываемым критериям имеет преимущества перед классическими формулами Хартли и Шеннона, т.к. учитывает как факторы, так и понятие цели, ключевое для системного анализа, теории и практики управления (в т.ч. АСУ). Поэтому именно выражение для семантической целесообразности информации Харкевича взято за основу при выводе обобщающего выражения, удовлетворяющего всем предъявляемым требованиям.
1.2.2.1.3. Конструирование системной численной меры на основе базовой
Системное обобщение формулы Хартли для количества информации
Классическая формула Хартли имеет вид:
|
|
Будем искать ее системное обобщение в виде:
|
|
где:
W – количество чистых (классических) состояний системы.
j – коэффициент эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых состояний);
Учитывая, что возможны смешанные состояния, являющиеся нелинейной суперпозицией или
одновременной реализацией чистых (классических) состояний "из W по
m", всего возможно ![]() состояний системы, являющихся сочетаниями классических
состояний. Таким образом, примем за аксиому, что системное
обобщение формулы Хартли имеет вид [64]:
состояний системы, являющихся сочетаниями классических
состояний. Таким образом, примем за аксиому, что системное
обобщение формулы Хартли имеет вид [64]:
|
|
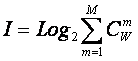
где: W – количество элементов в системе альтернативных будущих состояний АОУ (количество чистых состояний); m – сложность смешанных состояний АОУ; M – максимальная сложность смешанных состояний АОУ.
Выражение (1) дает количество информации в
активной системе, в которой чистые и смешанные состояния равновероятны.
Смешанные состояния активных систем, возникающие под действием системы нелинейно-взаимодействующих
факторов, считаются такими же измеримыми, как и чистые альтернативные
состояния, возникающие под действием детерминистских факторов. Так как ![]() , то при M=1 выражение (3.3) приобретает вид (3.1), т.е.
выполняется принцип соответствия,
являющийся обязательным для более общей теории.
, то при M=1 выражение (3.3) приобретает вид (3.1), т.е.
выполняется принцип соответствия,
являющийся обязательным для более общей теории.
Рассмотрим подробнее смысл выражения (3.3), представив сумму в виде ряда слагаемых:
|
|
Первое слагаемое в (3.4) дает количество информации по классической формуле Хартли, а остальные слагаемые – дополнительное количество информации, получаемое за счет системного эффекта, т.е. за счет наличия у системы иерархической структуры или смешанных состояний. По сути дела эта дополнительная информация является информацией об иерархической структуре системы, как состоящей из ряда подсистем различных уровней сложности.
Например, пусть система состоит из W пронумерованных элементов 1-го уровня иерархии. Тогда на 2-м уровне иерархии элементы соединены в подсистемы из 2 элементов 1-го уровня, на 3-м – из 3, и т.д. Если выборка любого элемента равновероятна, то из факта выбора n-го элемента по классической формуле Хартли мы получаем количество информации согласно (3.1). Если же при этом известно, что данный элемент входит в определенную подсистему 2-го уровня, то это дает дополнительное количество информации, за счет учета второго слагаемого, поэтому общее количество получаемой при этом информации будет определяться выражением (3.4) уже с двумя слагаемыми (M=2). Если элемент одновременно входит в M подсистем разных уровней, то количество информации, получаемое о системе и ее подсистемах при выборке этого элемента определяется выражением (3.4). Так, если мы вытаскиваем кирпич из неструктурированной кучи, состоящей из 32 кирпичей, то получаем 5 бит информации, если же из этих кирпичей сложен дом, то при аналогичном действии мы получаем дополнительное количество информации о том, из каких части дома (подсистем различного уровня иерархии) вытащен этот кирпич. Действия каменщика, укладывающего кирпич на место, предусмотренное проектом, значительно выше по целесообразности, чем у грузчика, складывающего кирпичи в кучу. Учитывая, что при M=W:
|
|
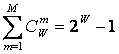
в этом случае получаем:
|
|
Выражение (3.5) дает оценку максимального количества информации, которое может содержаться в элементе системы с учетом его вхождения в различные подсистемы ее иерархической структуры.
Однако реально в любой системе осуществляются не все формально возможные сочетания элементов 1-го уровня иерархии, т.к. существуют различные правила запрета, различные для разных систем. Это означает, что возможно множество различных систем, состоящих из одинакового количества тождественных элементов, и отличающихся своей структурой, т.е. строением подсистем различных иерархических уровней. Эти различия систем как раз и возникают благодаря различию действующих для них этих правил запрета. По этой причине систему правил запрета предлагается назвать информационным проектом системы. Различные системы, состоящие из равного количества одинаковых элементов (например, дома, состоящие из 20000 кирпичей), отличаются друг от друга именно по причине различия своих информационных проектов.
Из выражения (3.5) очевидно, что I быстро стремится к W:
|
|
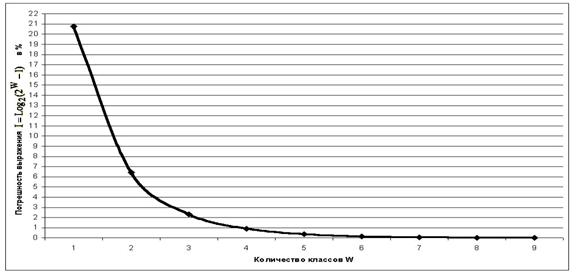
В действительности уже при W>4 погрешность выражения (3.5) не превышает 1% (таблица 9):
|
Таблица 9 – ЗАВИСИМОСТЬ ПОГРЕШНОСТИ |
|
|

График зависимости погрешности выражения (3.5) от количества классов W приведен на рисунке 24.
|
|
|
Рисунок 24. Зависимость погрешности приближенного выражения системного обобщения формулы Хартли от количества классов W |
Приравняв правые части выражений (3.2) и (3.3):
|
|
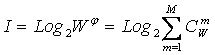
получим выражение для коэффициента эмерджентности Хартли (терм. авт.):
|
|
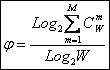
Непосредственно
из вида выражения для коэффициента эмерджентности Хартли (3.9) ясно, что он
представляет собой относительное превышение количества информации о системе при
учете системных эффектов (смешанных состояний, иерархической структуры ее
подсистем и т.п.) над количеством информации без учета системности, т.е. этот коэффициент отражает уровень
системности объекта.
С учетом выражения (3.9) выражение (3.2) примет вид:
|
|
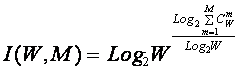
или при M=W и больших W, учитывая (3.4 – 3.6):
|
|
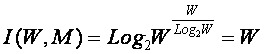
Выражение (3.10) и представляет собой искомое системное обобщение классической формулы Хартли, а выражение (3.11) – его достаточно хорошее приближение при большом количестве элементов или состояний системы (W).
Коэффициент эмерджентности Хартли представляет собой относительное превышение количества информации о системе при учете системных эффектов (смешанных состояний, иерархической структуры ее подсистем и т.п.) над количеством информации без учета системности, т.е. этот коэффициент является аналитическим выражением для уровня системности объекта. Таким образом, коэффициент эмерджентности Хартли отражает уровень системности объекта и изменяется от 1 (системность минимальна, т.е. отсутствует) до W/Log2W (системность максимальна). Очевидно, для каждого количества элементов системы существует свой максимальный уровень системности, который никогда реально не достигается из-за действия правил запрета на реализацию в системе ряда подсистем различных уровней иерархии.
Например: из 32 букв русского
алфавита может быть образовано не ![]() осмысленных
6-буквенных слов, а значительно меньше. Если мы услышим одно из этих в принципе
возможных слов, то получим не 5´6=30
информации, содержащейся непосредственно в буквах (в одной букве содержится Log232=5
бит), а 30+19,79=49,79 бит, т.е. в 1.66 раз больше. Это и есть уровень системности иерархического уровня 6-буквенных
слов русского языка. Уровень системности русского языка, как системы, состоящей из слов длиной от одной до 6 букв, согласно
выражения (3.9) с учетом (3.5), равен примерно 6,4. Но при этом еще не была
учтена информация, содержащаяся в последовательности слов, в последовательности
предложений и т.д.
осмысленных
6-буквенных слов, а значительно меньше. Если мы услышим одно из этих в принципе
возможных слов, то получим не 5´6=30
информации, содержащейся непосредственно в буквах (в одной букве содержится Log232=5
бит), а 30+19,79=49,79 бит, т.е. в 1.66 раз больше. Это и есть уровень системности иерархического уровня 6-буквенных
слов русского языка. Уровень системности русского языка, как системы, состоящей из слов длиной от одной до 6 букв, согласно
выражения (3.9) с учетом (3.5), равен примерно 6,4. Но при этом еще не была
учтена информация, содержащаяся в последовательности слов, в последовательности
предложений и т.д.
Итак, в предложении сдержится значительно больше информации, чем в буквах, с помощью которых оно написано, т.к. кроме букв информацию содержат слова, сочетания слов, последовательность предложений и т.д.. Буквы образуют 1-й иерархический уровень языка, слова – 2-й, предложения – 3-й, абзацы – 4-й, параграфы – 5-й, главы – 6-й, произведения – 7-й. Теория Шеннона концентрирует основное внимание на рассмотрении 1-го уровня, т.е. рассматривает тексты, прежде всего, как последовательность символов. Но именно иерархическая организация, не учитываемая в теории Шеннона и отраженная в системной теории информации, обеспечивает языку его удивительную мощь, как средства отражения и моделирования реальности.
Аналогично и в генах, этих своеобразных "символах генома", содержится значительно больше информации о фенотипе, чем предполагается в классической генетике Менделя, т.к. гены образуют ансамбли различных уровней иерархии в зависимости от влияния среды и технологий управления (явление адаптивности системы "генотип-среда", Драгавцев В.А., 1993). Если ген уподобить букве алфавита, а смысл фразы – фенотипическому признаку, то можно сказать, что возможно очень большое количество фраз с одним и тем же смысловым содержанием (тогда как в классической генетике считалось, что признак соответствует гену, хотя есть и такие). После расшифровки генома человека мы настолько же приблизились к его пониманию, как изучивший русскую или немецкую азбуку англичанин, не знающий этих языков, приблизился к чтению в оригинале и пониманию содержания "Войны и Мира" Льва Толстого или "Феноменологии Духа" Георга В.Ф.Гегеля.
На уровне слов верхняя оценка уровня системности русского языка с учетом (3.5) составляет огромную величину: 2616,48 (предполагается, что в русском языке 40000 слов и предложения могут иметь любую длину). Необходимо отметить, что правила запрета на порядок слов в русском языке значительно слабее, чем, например в английском, поэтому в русском языке возможно гораздо больше грамматически правильных и несущих различную информацию предложений из одних и тех же слов, чем в английском. Это значит, что уровень системности русского языка на уровне предложений, по-видимому, значительно превосходит уровень системности английского языка. При длине предложения до 2-х слов системность русского языка на уровне предложений согласно (3.9) составляет: 52330916.
Анализ выражения (3.9) показывает, что при М=1 оно преобразуется в (3.1), т.е. выполняется принцип соответствия. При М>1 количество информации в соответствии с системной теорией информации (СТИ) (3.9) будет превосходить количество информации, рассчитанное по классической теории информации (КТИ) (3.1). Непосредственно из выражения (3.2) получаем:
|
|
Первое слагаемое в выражении (3.12) отражает количество информации, согласно КТИ, а второе – СТИ, т.е. доля системной информации.
Представляет несомненный интерес исследование закономерностей изменения доли системной информации в поведении элемента системы в зависимости от количества классов W и сложности смешанных состояний M.
В таблице 10 приведены результаты численных расчетов в соответствии с выражением (3.9). Сводные данные из таблицы 10 приведены в таблице 11, а в графическом виде они представлены на рисунке 25.
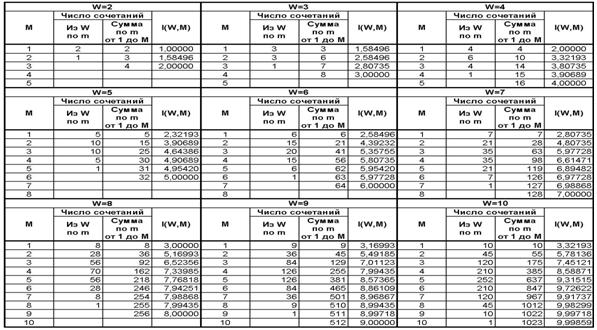
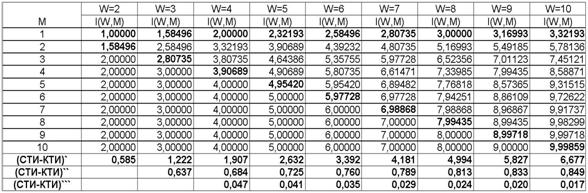
|
|
|
Рисунок 25. Зависимость количества информации
I(W,M) |
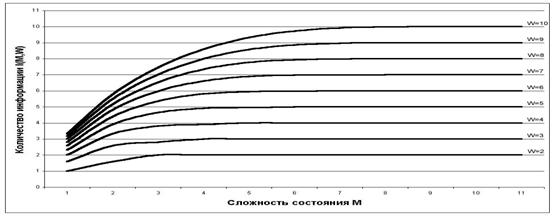
Рост количества информации в СТИ по сравнению с КТИ обусловлен системным эффектом (эмерджентностью), который связан с учетом смешанных состояний, возникающих путем одновременной реализации (суперпозиции) нескольких чистых (классических) состояний под действием системы нелинейно-взаимодействующих недетерминистских факторов. Выражение (3.9) дает максимальную возможную оценку количества информации, т.к. могут существовать различные правила запрета на реализацию тех или иных смешанных состояний.
Фактически это означает, что в СТИ множество
возможных состояний объекта рассматривается не как совокупность несвязанных
друг с другом состояний, как в КТИ, а как система,
уровень системности которой как раз и определяется коэффициентом эмерджентности
Хартли j
(3.9), являющегося монотонно возрастающей функцией сложности смешанных
состояний M. Следовательно, дополнительная
информация, которую мы получаем из поведения объекта в СТИ, по сути дела
является информацией о системе всех возможных состояний объекта,
элементом которой является объект в некотором данном состоянии.
Гипотеза о законе возрастания эмерджентности и следствия из него
Численные расчеты и аналитические выкладки в
соответствии с СТИ показывают, что при возрастании количества элементов в
системе доля системной информации в поведении ее элементов возрастает. Это
обнаруженное нами новое фундаментальное свойство систем предлагается назвать
законом возрастания эмерджентности.
Закон возрастания эмерджентности: "Чем больше элементов в системе, тем большую долю содержащейся в ней информации составляет информация, содержащаяся во взаимосвязях ее элементов".
На рисунках 26 и 27 приведены графики скорости и ускорения возрастания эмерджентности в зависимости от количества элементов W в системе.
|
|
|
|
Рисунок 26. Возрастание доли системной информации в поведении элемента системы при увеличении количества элементов W |
Рисунок 27. Ускорение возрастания доли системной информации в поведении элемента системы от количества элементов W |
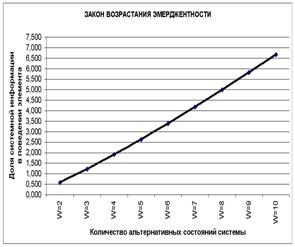
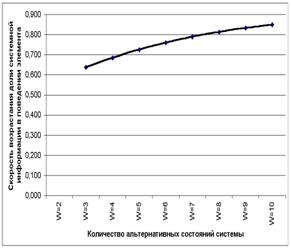
Более детальный анализ предполагаемого закона возрастания эмерджентности с использованием конечных разностей первого и второго порядка (таблица 11) показывает, что при увеличении количества элементов в системе доля системной информации в ней возрастает с ускорением, которое постепенно уменьшается. Это утверждение будем называть леммой 1.
Продолжим анализ закона возрастания эмерджентности. Учитывая, что:
|
|
|
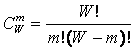
выражение (3.3) принимает вид:
|
|
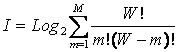
где: 1<=М<=W.
|
|
|
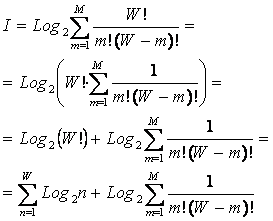
и учитывая, что Log21=0, выражение (3.13) приобретает вид:
|
|
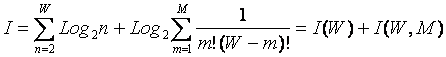
Где введены обозначения:
|
|
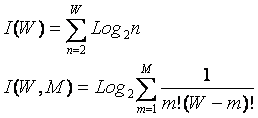
С учетом (3.14) выражение (3.9) для коэффициента эмерджентности Хартли приобретает вид:
|
|
|

Заменяя в (3.13) факториал на Гамма-функцию, получаем обобщение выражения (3.3) на непрерывный случай:
|
|
|
Или окончательно:
|
|
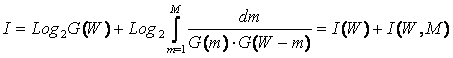
Для непрерывного случая обозначения (3.15) принимают вид:
|
|
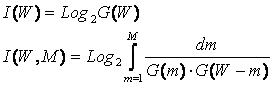
Учитывая выражения (3.9) и (3.16) получим выражение для коэффициента эмерджентности Хартли для непрерывного случая:
|
|
|
И окончательно для непрерывного случая:
|
|
(3. 18) |
Анализируя выражения (3.14) и (3.16) видим, что количество информации, получаемое при выборке из системы некоторого ее элемента, состоит из двух слагаемых:
1) I(W), зависящего только от количества элементов в системе W (первое слагаемое);
2) I(W, M), зависящего как от количества элементов в системе W, так и от максимальной сложности, т.е. связности элементов подсистем M между собой (второе слагаемое).
Этот результат позволяет высказать гипотезы "О природе сложности системы"
и "О видах системной информации":
– сложность системы определяется количеством
содержащейся в ней информации;
– системная информация включает две
составляющих: зависящее от количества элементов системы и зависящее также от
характера взаимосвязей между элементами.
Изучим какой относительный вклад вносит каждое слагаемое в общее количество информации системы в зависимости от числа элементов в системе W и сложности подсистем M. Результаты численных расчетов показывают, что чем выше уровень системности, тем большая доля информации системы содержится во взаимосвязях ее элементов, и чем меньше элементов с системе, тем быстрее возрастает доля информации, содержащейся во взаимосвязях элементов при возрастании уровня системности. Эти утверждения будем рассматривать как леммы 2 и 3. Таким образом полная формулировка гипотезы о законе возрастания эмерджентности с гипотезой о видах информации в системе и тремя леммами приобретает вид:
ГИПОТЕЗА
О ЗАКОНЕ ВОЗРАСТАНИЯ ЭМЕРДЖЕНОСТИ: "Чем больше элементов в системе, тем большую долю содержащейся в
ней информации составляет информация, содержащаяся во взаимосвязях ее
элементов" (рисунок 28).
|
|
|
Рисунок
28. Закон
возрастания эмерджентности |
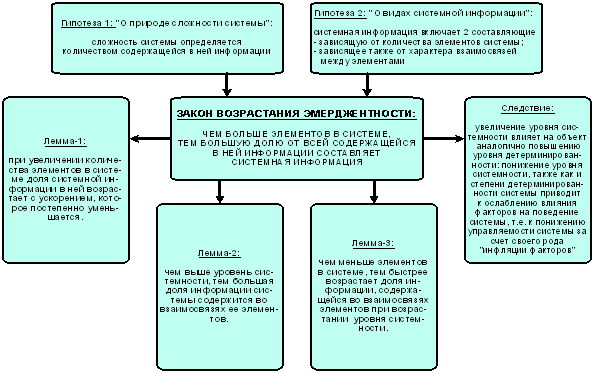
Гипотеза
1: "О природе сложности системы": сложность системы определяется количеством содержащейся в ней
информации.
Гипотеза
2: "О видах системной информации": системная информация включает две составляющие:
– зависящую от количества элементов системы;
– зависящую как от количества элементов
системы, так и от сложности взаимосвязей между ними.
Лемма-1: при увеличении количества элементов в системе
доля системной информации в ней возрастает с ускорением, которое постепенно
уменьшается.
Лемма-2: чем выше уровень системности, тем большая
доля информации системы содержится во взаимосвязях ее элементов.
Лемма-3: чем меньше элементов в системе, тем быстрее
возрастает доля информации, содержащейся во взаимосвязях элементов при
возрастании уровня системности.
Системное обобщение классической формулы Харкевича, как количественная мера знаний
Это обобщение представляет большой интерес,
в связи с тем, что А.Харкевич впервые
ввел в теорию информации понятие цели. Он считал, что количество
информации, сообщенное объекту, можно измерять по изменению вероятности
достижения цели этим объектом за счет использования им этой информации.
Рассмотрим таблицу 12, в которой столбцы соответствуют будущим состояниям АОУ (целевым и нежелательным), а строки факторам, характеризующим объект управления, управляющую систему и окружающую среду.
|
|
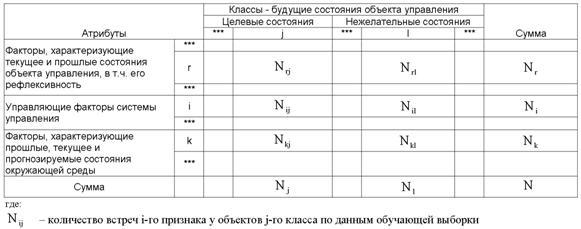
Классическая формула А.Харкевича имеет вид:
|
|
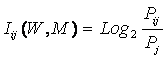
где:
– W – количество классов (мощность множества будущих состояний объекта управления)
– M – максимальный уровень сложности смешанных состояний объекта управления;
– индекс i обозначает фактор: 1£
i £
M;
– индекс j обозначает класс: 1£
j £
W;
– Pij – вероятность достижения объектом управления j-й цели при условии сообщения ему i-й информации;
– Pj – вероятность самопроизвольного достижения объектом управления j-й цели.
Ниже глобальные параметры модели W и M в выражениях для I опускаются, т.к. они являются константами для конкретной математической модели СК-анализа.
Однако: А.Харкевич в своем выражении для количества информации не ввел зависимости количества информации, от мощности пространства будущих состояний объекта управления, в т.ч. от количества его целевых состояний. Вместе с тем, один из возможных вариантов учета количества будущих состояний объекта управления обеспечивается классической и системной формулами Хартли (3.1) и (3.9); выражение (3.19) при подстановке в него реальных численных значений вероятностей Pij и Pj не дает количества информации в битах; для выражения (3.19) не выполняется принцип соответствия, считающийся обязательным для обобщающих теорий. Возможно, в этом состоит одна из причин слабого взаимодействия между классической теорией информации Шеннона и семантической теорией информации.
Чтобы снять эти вопросы, приближенно выразим вероятности Pij, Pi и Pj через частоты:
|
|

В (3.20) использованы обозначения:
Nij – суммарное количество наблюдений факта: "действовал i-й фактор и объект перешел в j-е состояние";
Nj – суммарное количество встреч различных факторов у объектов, перешедших в j-е состояние;
Ni – суммарное количество встреч i-го фактора у всех объектов;
N – суммарное количество встреч различных факторов у всех объектов.
Подставим в выражение (3.19) значения для Pij и Pj из (3.20):
|
|
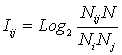
Введем коэффициент эмерджентности Y в модифицированную формулу А.Харкевича:
|
|
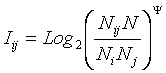
где: Y – коэффициент эмерджентности Харкевича (как будет показано выше, он определяет степень детерминированности объекта с уровнем системной организации j, имеющего W чистых состояний, на переходы в которые оказывают влияние M факторов, о чем в модели накоплено N фактов).
Известно, что классическая формула Шеннона
для количества информации для неравновероятных событий преобразуется в формулу
Хартли при условии, что события равновероятны, т.е. удовлетворяет
фундаментальному принципу соответствия [64].
Естественно
потребовать, чтобы и обобщенная формула Харкевича также удовлетворяла
аналогичному принципу соответствия, т.е. преобразовывалась в формулу Хартли в
предельном случае, когда каждому классу (состоянию объекта) соответствует один
признак (фактор), и каждому признаку – один класс, и эти классы (а, значит и
признаки), равновероятны. Иначе говоря факторов столько же, сколько и
будущих состояний объекта управления, все факторы детерминистские, а состояния
объекта управления – альтернативные, т.е. каждый фактор однозначно определяет
переход объекта управления в определенное состояние.
В этом предельном случае отпадает необходимость двухвекторного описания объектов, при котором 1-й вектор (классификационный) содержит интегральное описание объекта, как принадлежащего к определенным классам, а 2-й вектор (описательный) – дискретное его описание, как имеющего определенные атрибуты. Соответственно, двухвекторная модель, предложенная в данной работе, преобразуется в "вырожденный" частный случай – стандартную статистическую модель. В этом случае количество информации, содержащейся в признаке о принадлежности объекта к классу является максимальным и равным количеству информации, вычисляемому по системной формуле Хартли (3.9).
Таким образом при взаимно-однозначном соответствии классов и признаков:
|
|
формула А.Харкевича (3.13) приобретает вид:
|
|
откуда:
|
|
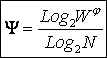
или, учитывая выражение для коэффициента эмерджентности Хартли (3.8):
|
|

Смысл коэффициента эмерджентности Харкевича (3.25) проясняется, если учесть, что при количестве состояний системы W равном количеству фактов N о действии на эту систему различных факторов он равен 1. В этом случае факторы однозначно определяют состояния объекта управления, т.е. являются детерминистскими. Если же количество фактов N о действии на эту систему различных факторов превосходит количество ее состояний W, что является гораздо более типичным случаем, то этот коэффициент меньше 1. По-видимому, это означает, что в этом случае факторы как правило не однозначно (и не так жестко как детерминистские) определяют поведение объекта управления, т.е. являются статистическими.
Таким образом, коэффициент эмерджентности
Харкевича Y
изменяется от 0 до 1 и определяет степень детерминированности системы:
– Y=1
соответствует полностью детерминированной системе, поведение которой однозначно
определяется действием минимального количества факторов, которых столько же,
сколько состояний системы;
– Y=0
соответствует полностью случайной системе, поведение которой никак не зависит
действия факторов независимо от их количества;
– 0<Y<1
соответствуют большинству реальных систем поведение которых зависит от многих
факторов, число которых превосходит количество состояний системы, причем ни
одно из состояний не определяется однозначно никакими сочетаниями действующих
факторов (рисунок 29):
|
|
|
Рисунок 29. Интерпретация коэффициентов
эмерджентности СТИ |
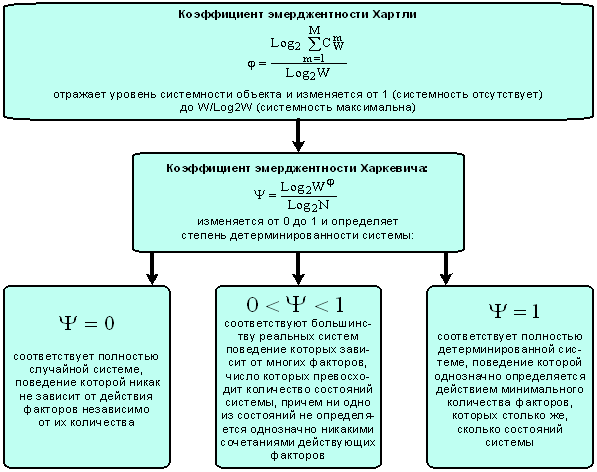
Из выражения (3.25) видно, что в частном случае, когда реализуются только чистые состояния объекта управления, т.е. M=1, коэффициент эмерджентности А.Харкевича приобретает вид:
|
|
Подставив коэффициент эмерджентности А.Харкевича (3.25) в выражение (3.22), получим:
|
|
|

или окончательно:
|
|
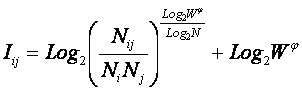
Из вида выражения (3.25) для Y очевидно, что увеличение уровня системности влияет на семантическую информационную модель (3.28) аналогично повышению уровня детерминированности системы: понижение уровня системности, также как и степени детерминированности системы приводит к ослаблению влияния факторов на поведение системы, т.е. к понижению управляемости системы за счет своего рода "инфляции факторов".
Например: управлять толпой из 1000 человек значительно сложнее, чем воздушно-десантным полком той же численности. Процесс превращения 1000 новобранцев в воздушно-десантный полк это и есть процесс повышения уровня системности и степени детерминированности системы. Этот процесс включает процесс иерархического структурирования (на отделения, взвода, роты, батальоны), а также процесс повышения степени детерминированности команд, путем повышения "степени беспрекословности" их исполнения. Оркестр, настраивающий инструменты, также весьма существенно отличается от оркестра, исполняющего произведение под управлением дирижера.
Необходимо отметить, что при повторном использовании той же самой обучающей выборки степень детерминированности модели уменьшается. Очевидно, с формальной математической точки зрения этого явления можно избежать, если перед расчетом информативностей признаков делить абсолютные частоты на количество объектов обучающей выборки.
С использованием выражения (3.28) непосредственно из матрицы абсолютных частот (таблица 12) рассчитывается матрица информативностей (таблица 13), содержащая связи между факторами и будущими состояниями АОУ и имеющая много различных интерпретаций и играющая основополагающую роль в данном исследовании.
|
|
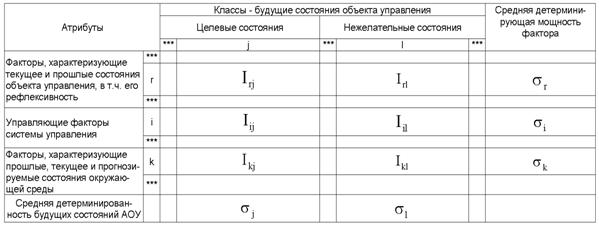
Из рассмотрения основополагающего выражения (3.28) видно, что:
1. При выполнении условий взаимно-однозначного соответствия классов и признаков (3.23) первое слагаемое в выражении (3.28) обращается в ноль и при всех реальных значениях входящих в него переменных оно отрицательно.
2. Выражение (3.28) является нелинейной суперпозицией двух выражений: системного общения формулы Хартли (второе слагаемое), и первого слагаемого, которое имеет вид формулы Шеннона для плотности информации и отличается от него тем, что выражение под логарифмом находится в степени, которая совпадает с коэффициентом эмерджентности Харкевича, а также способом взаимосвязи входящих в него абсолютных частот с вероятностями.
Это
дает основание предположить, что первое слагаемое в выражении (3.28) является
одной из форм системного обобщения выражения Шеннона для плотности информации:
|
|
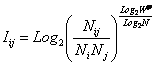
Поэтому вполне оправданным будет назвать степень в (3.29) коэффициентом эмерджентности Шеннона-Харкевича.
Генезис системной (эмерджентной) теории информации
Полученное
системное обобщение формулы Харкевича (3.28) учитывает как взаимосвязь между
признаками (факторами) и будущими, в т.ч. целевыми состояниями объекта
управления, так и мощность множества будущих состояний объекта управления.
Кроме того она объединяет возможности интегрального и дискретного описания
объектов, учитывает уровень системности и степень детерминированности
описываемой системы (таблица 14):
|
|

При этом факторами являются управляющие
факторы, т.е. управления со стороны системы управления, факторы окружающей
среды, а также факторы, характеризующие текущее и прошлые состояния объекта
управления. Все это делает полученное выражение (3.28) оптимальным по
сформулированным критериям для целей построения содержательных информационных
моделей активных объектов управления и для применения для синтеза адаптивных
систем управления (см. диаграмму: "Генезис системного обобщения формулы
Харкевича для количества информации", рисунок 30).
|
|
|
Рисунок 30. Генезис системной (эмерджентной) теории информации |
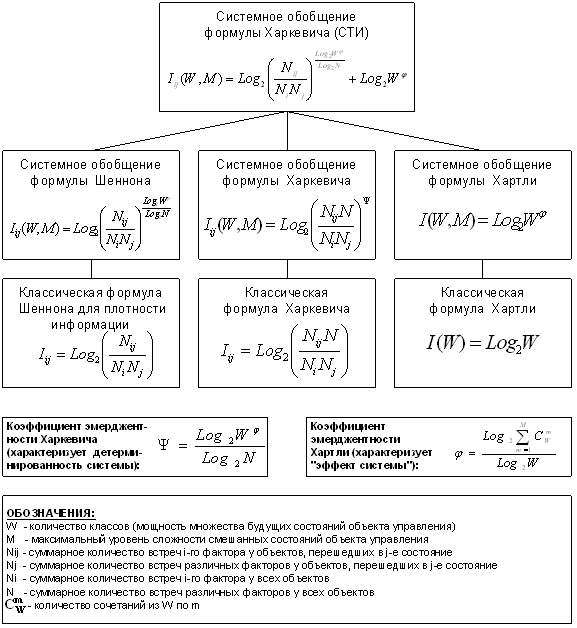
Итак, различные выражения классической теории информации для количества информации: Хартли, Шеннона и Харкевича учитывают различные аспекты информационного моделирования объектов.
Полученное
системное обобщение формулы А.Харкевича (3.28) учитывает как взаимосвязь между
признаками (факторами) и будущими, в т.ч. целевыми состояниями объекта
управления, так и мощность множества будущих состояний. Кроме того она
объединяет возможности интегрального и дискретного описания объектов, учитывает
уровень системности и степень детерминированности системы.
Различие между классическим понятием
информации и его предложенным системным обобщением определяется различием между
понятиями множества и системы, на основе которых они сформированы. Система при
этом рассматривается как множество элементов, объединенных определенными видами
взаимодействия ради достижения некоторой общей цели.
Все
это делает полученное выражение (3.28) оптимальным по сформулированным
критериям для целей построения содержательных информационных моделей активных
объектов управления и для применения для синтеза рефлексивных АСУ активными
объектами.
1.2.2.2. Семантическая информационная модель СК-анализа
Основная проблема, решаемая в аналитической модели: выбор способа вычисления весовых коэффициентов, отражающих степень и характер влияния факторов на переход активного объекта управления в различные состояния.
Основное отличие предлагаемого подхода от методов обобщения экспертных оценок состоит в том, что в предлагаемом подходе от экспертов требуется лишь само решение, а весовые коэффициенты автоматически подбираются в соответствии с моделью таким образом, что в сходных случаях будут приниматься решения, аналогичные предлагаемым экспертами. В традиционных подходах от экспертов требуют либо самих весовых коэффициентов, либо правил принятия решения (продукций).
1.2.2.2.1. Формализм динамики взаимодействующих семантических информационных пространств. Двухвекторное представление данных.
Не всегда и не все классы являются атрибутами, также не всегда и не все атрибуты являются классами по смыслу (в данной модели это может быть так в многослойной нейронной сети) Поэтому традиционное представление данных в форме одной матрицы с одинаковыми строками и столбцами представляется нецелесообразным и предлагается более общее – двухвекторное представление. В предлагаемой математической модели формальное описание объекта представляет собой совокупность его интенсионального и экстенсионального описаний.
Интенсиональное (дискретное) описание – это последовательность информативностей (но не кодов) тех и только тех признаков, которые реально фактически встретились у данного конкретного объекта.
Экстенсиональное (континуальное) описание состоит из информативностей (но не кодов) тех классов распознавания, для формирования образов которых по мнению экспертов целесообразно использовать интенсиональное описание данного конкретного объекта.
Именно
взаимодействие и взаимная дополнительность этих двух взаимоисключающих видов
описания объектов формирует то, что психологи, логики и философы называют
"смысл".
Таким образом, формальное описание объекта в предлагаемой модели состоит из двух векторов. Первый вектор описывает к каким обобщенным категориям (классам распознавания) относится объект с точки зрения экспертов (вектор субъективной, смысловой, человеческой оценки). Второй же вектор содержит информацию о том, какими признаками обладает данный объект (вектор объективных характеристик). Необходимо особо подчеркнуть, что связь этих двух векторов друг с другом имеет вообще говоря не детерминистский, а вероятностный, статистический характер.
Если объект описан обоими векторами, то это описание можно использовать для формирования обобщенных образов классов распознавания, а также для проверки степени успешности выполнения этой задачи.
Если объект описан только вторым вектором –
вектором признаков, то его можно использовать только для решения задачи
распознавания (идентификации), которую можно рассматривать как задачу
восстановления вектора классов данного объекта по его известному вектору признаков.
Предлагаемая модель удовлетворяет принципу соответствия, т.е. в ней одновекторный вариант описания предметной области получается как некоторое подмножество из возможных в ней вариантов, определяемое двумя ограничениями:
– справочник классов распознавания тождественно совпадает со справочником признаков;
– наличие какого-либо признака у объекта обучающей выборки однозначно (детерминистским образом) определяет принадлежность этого объекта к соответствующему классу распознавания (взаимно-однозначное соответствие классов и признаков).
Очевидно, эти ограничения приводят и к соответствующим ограничениям, накладываемым в свою очередь на варианты обработки информации и анализа данных в подобных системах.
Если говорить конкретнее, такая модель данных стирает различие между атрибутами и классами и не позволяет решать ряд задач, в которых эта абстракция является недопустимым упрощением. Эти задачи будут подробнее рассмотрены ниже.
Семантические пространства классов и атрибутов
Наглядно модель данных целесообразно представить себе в виде двух взаимосвязанных фазовых (т.е. абстрактных) пространств, в первом из которых осями координат служат шкалы атрибутов (пространство атрибутов), а во втором – шкалы классов (пространство классов).
В пространстве атрибутов векторами являются объекты обучающей выборки и обобщенные образы классов. Вектор класса представляет собой массив координат в фазовом пространстве, каждый элемент массива, т.е. координата, соответствует определенному атрибуту, а значение этой координаты – весовому коэффициенту, отражающему количество информации, содержащееся в факте наблюдения данного атрибута у объекта о принадлежности этого объекта к данному классу.
В пространстве классов векторами являются атрибуты. Вектор атрибута представляет собой массив координат в фазовом пространстве, каждый элемент массива, т.е. координата, соответствует определенному классу, а значение этой координаты – весовому коэффициенту, отражающему количество информации, содержащееся в факте наблюдения объекта данного класса о том, что у этого объекта будет определенный атрибут.
Таким образом, выбор смысла и математической формы значений весовых коэффициентов в виде количества информации вводит метрику в этих фазовых пространствах. Поэтому данные пространства являются нелинейными самосогласованными пространствами. Ясно, что линейная разделяющая функция в нелинейном пространстве является нелинейной функцией в линейном пространстве. Самосогласованность семантических пространств означает, что любое изменение одной координаты в общем случае связано с изменением всех остальных. Нелинейность и самосогласованность самым существенным образом отличает предложенные семантические информационные пространства классов и атрибутов от линейного семантического пространства, используемого в основном в психодиагностике [32], в котором осями являются признаки (шкалы), а значениями координат по осям являются непосредственно градации признаков.
Однако этого недостаточно. Чтобы над векторами в фазовых пространствах можно было корректно выполнять стандартные операции сложения, вычитания, скалярного и векторного умножения, выполнять преобразования системы координат, переход от одной системы координат к другой, и вообще применять аппарат линейной алгебры и аналитической геометрии, что представляет большой научный и практический интерес и является очень актуальным, необходимо корректно ввести в этих пространствах системы координат т.е. системы отсчета, удовлетворяющие определенным требованиям.
Требования к системам координат, свойства векторов классов и атрибутов, решение проблемы снижения размерности описания и ортонормирования
В качестве осей координат пространства атрибутов целесообразно выбрать вектора атрибутов, обладающие следующими свойствами:
1. Их должно быть минимальное количество, достаточное для полного описания предметной области.
2. Эти вектора должны пересекаться в одной точке.
3. Значения координат вектора должны измеряться в одной единице измерения, т.е. должны быть сопоставимы.
Для выполнения первого требования необходимо, чтобы математическая форма и смысл весовых коэффициентов были выбраны таким образом, чтобы модули векторов атрибутов в пространстве классов были пропорциональны их значимости для решения задач идентификации, прогнозирования и управления. Причем наиболее значимые вектора атрибутов не должны коррелировать друг с другом, т.е. должны быть ортонормированны. В этом случае при удалении векторов с минимальными модулями автоматически останутся наиболее значимые практически ортонормированные вектора, которые можно принять за базисные, т.е. в качестве осей системы координат.
Второе требование означает, что минимальное расстояние между этими векторами в пространстве классов должно быть равно нулю.
Третье требование предполагает соответствующий выбор математической формы для значений координат.
Эти идеальные требования практически никогда не будут соблюдаться на практике с абсолютной точностью. Однако этого и не требуется. Достаточно, чтобы реально выбранные в качестве базисных атрибуты отображались в пространстве классов векторами, для которых эти требования выполняются с точностью, достаточной для применения соответствующих математических моделей и математического аппарата на практике.
Аналогично обстоит дело и с минимизацией размерности пространства классов. В качестве базисных могут выбраны вектора классов, имеющие максимальную длину и взаимно (попарно) ортонормированные.
Очевидно, задача выбора базисных векторов имеет не единственное решение, т.е. может существовать несколько систем таких векторов, которые можно рассматривать как результат действия преобразований системы координат, состоящих из смещений и поворотов.
1.2.2.2.2. Применение классической теории информации К.Шеннона для расчета весовых коэффициентов и мер сходства
Формально, распознавание есть не что иное, как принятие решения о принадлежности распознаваемого объекта или его состояния к определенному классу (классам) [9, 92]. Из этого следует внутренняя и органичная связь методов распознавания образов и принятия решений. Аналитический обзор позволяет сделать вывод, что наиболее глубокая основа этой связи состоит в том, что и распознавание образов, и принятие решений есть прежде всего снятие неопределенности. Распознавание снимает неопределенность в вопросе о том, к какому классу относится распознаваемый объект. Если до распознавания существовала неопределенность в вопросе о том, к какому классу относится распознаваемый объект или его состояние, то в результате распознавания эта неопределенность уменьшается, причем возможно и до нуля (когда объект идентифицируется однозначно). Принятие решения (выбор) также снимает неопределенность в вопросе о том, какое из возможных решений будет принято, если существовало несколько альтернативных вариантов решений и принимается одно из них.
Для строгого исследования процессов снятия неопределенности оптимальным является применение аппарата теории информации, которая как бы специально создана для этой цели. Из этого непосредственно следует возможность применения методов теории информации для решения задач распознавания и принятия решений в АСУ. Таким образом, теория информации может рассматриваться как единая основа методов распознавания образов и принятия решений.
Формальная постановка задачи
В рефлексивных АСУ активными объектами модели распознавания образов и принятия решений применимы в подсистемах идентификации состояния АОУ и выработки управляющего воздействия: идентификация состояния АОУ представляет собой принятие решения о принадлежности этого состояния к определенной классификационной категории (задача распознавания); выбор многофакторного управляющего воздействия из множества возможных вариантов представляет собой принятие решения (обратная задача распознавания).
Распознавание образов есть принятие решения о принадлежности объекта или его состояния к определенному классу. Если до распознавания существовала неопределенность в вопросе о том, к какому классу относится распознаваемый объект или его состояние, то в результате распознавания эта неопределенность уменьшается, в том числе может быть и до нуля (когда объект идентифицируется однозначно). Из данной постановки непосредственно следует возможность применения методов теории информации для решения задач распознавания образов и принятия решений в АСУ.
Информация как мера снятия неопределенности
Как было показано выше, теория информация применима в АСУ для решения задач идентификации состояния сложного объекта управления (задача распознавания) и принятия решения о выборе многофакторного управляющего воздействия (обратная задача распознавания).
Так в результате процесса познания
уменьшается неопределенность в наших знаниях о состоянии объекта познания, а в
результате процесса труда (по сути управления) – уменьшается неопределенность
поведения продукта труда (или объекта управления). В любом случае количество
переданной информации представляет собой количественную меру степени снятия
неопределенности.
Процесс получения информации можно интерпретировать как изменение неопределенности в вопросе о том, от какого источника отправлено сообщение в результате приема сигнала по каналу связи. Подробно данная модель приведена в работе [64].
Количество информации в индивидуальных событиях и лемма Неймана–Пирсона
В классическом анализе Шеннона идет речь лишь о передаче символов по одному информационному каналу от одного источника к одному приемнику. Его интересует прежде всего передача самого сообщения.
В данном исследовании ставится другая задача: идентифицировать информационный источник по сообщению от него. Поэтому метод Шеннона был обобщен путем учета в математической модели возможности существования многих источников информации, о которых к приемнику по зашумленному каналу связи приходят не отдельные символы–признаки, а сообщения, состоящие из последовательностей символов (признаков) любой длины.
Следовательно, ставится задача идентификации информационного источника по сообщению от него, полученному приемником по зашумленному каналу. Метод, являющийся обобщением метода К.Шеннона, позволяет применить классическую теорию информации для построения моделей систем распознавания образов и принятия решений, ориентированных на применение для синтеза адаптивных АСУ сложными объектами.
Для решения поставленной задачи необходимо
вычислять не средние информационные характеристики, как в теории Шеннона, а
количество информации, содержащееся в конкретном i–м признаке (символе) о том,
что он пришел от данного j–го источника информации. Это позволит определить и
суммарное количество информации в сообщении о каждом информационном источнике,
что дает интегральный критерий для идентификации или прогнозирования состояния
АОУ.
Логично предположить, что среднее количество информации, содержащейся в системе признаков о системе классов
|
|
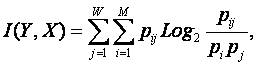
является ничем иным, как усреднением (с учетом условной вероятности наблюдения) "индивидуальных количеств информации", которые содержатся в конкретных признаках о конкретных классах (источниках), т.е.:
|
|
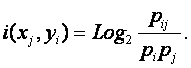
Это выражение определяет так называемую "плотность информации", т.е. количество информации, которое содержится в одном отдельно взятом факте наблюдения i–го символа (признака) на приемнике о том, что этот символ (признак) послан j–м источником.
Если в сообщении содержится M символов, то суммарное количество информации о принадлежности данного сообщения j–му информационному источнику (классу) составляет:
|
|
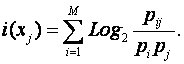
Необходимо отметить, что применение сложения в выражении (3.43) является вполне корректным и оправданным, так как информация с самого начала вводилась как аддитивная величина, для которой операция сложения является корректной.
Преобразуем выражение (3.50) к виду, более удобному для практического применения (численных расчетов). Для этого выразим вероятности встреч признаков через частоты их наблюдения:
|
|
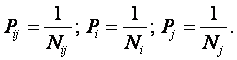
Подставив (3.44) в (3.25), получим:
|
|
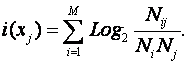
Если ранжировать классы в порядке убывания суммарного количества информации о принадлежности к ним, содержащейся в данном сообщении (т.е. описании объекта), и выбирать первый из них, т.е. тот, о котором в сообщении содержится наибольшее количество информации, то мы получим обоснованную статистическую процедуру, основанную на классической теории информации, оптимальность которой доказывается в фундаментальной лемме Неймана–Пирсона [148].
Сравнивая выражения (3.34) и (3.28) видим, что в системное обобщенное формулы Харкевича входит слагаемое, сходное с выражением Шеннона для плотности информации. Различия состоят в том, что в выражении (3.28) это слагаемое возведено в степень, имеющую смысл коэффициента эмерджентности Харкевича. Необходимо отметить, что значения частот в этих формулах связаны с вероятностями несколько различным образом (выражения 3.20 и 3.33).
Если ранжировать классы в порядке убывания суммарного количества информации о принадлежности к ним, содержащейся в данном сообщении (т.е. описании объекта), и выбирать первый из них, т.е. тот, о котором в сообщении содержится наибольшее количество информации, то мы получим обоснованную статистическую процедуру, основанную на классической теории информации, оптимальность которой доказывается в фундаментальной лемме Неймана–Пирсона [148].
Таким образом, распознавание образов есть принятие решения о принадлежности объекта или его состояния к определенному классу. Если до распознавания существовала неопределенность в вопросе о том, к какому классу относится распознаваемый объект или его состояние, то в результате распознавания эта неопределенность уменьшается, в том числе может быть и до нуля. Понятие информации может быть определено следующим образом: "Информация есть количественная мера степени снятия неопределенности". Количество информации является мерой соответствия распознаваемого объекта (его состояния) обобщенному образу класса.
Количество информации имеет ряд вполне определенных свойств. Эти свойства позволяют ввести понятие "количество информации в индивидуальных событиях", которое является весьма перспективным для применения в системах распознавания образов и поддержки принятия решений.
1.2.2.2.3. Математическая модель метода распознавания образов и принятия решений, основанного на системной теории информации
Формальная постановка основной задачи рефлексивной АСУ активными объектами и ее декомпозиция
Рассмотрим некоторые основные понятия, необходимые для дальнейшего изложения. При этом будут использованы как литературные данные, так и результаты, полученные в предыдущих главах данной работы.
Принятие решения в АСУ – это выбор некоторого наиболее предпочтительного управляющего воздействия из исходного множества всех возможных управляющих воздействий, обеспечивающего наиболее эффективное достижение целей управления. В результате выбора неопределенность исходного множества уменьшается на величину информации, которая порождается самим актом выбора [64]. Следовательно, теория информации может быть применена как для идентификации состояний объекта управления, так и для принятия решений об управляющих воздействиях в АСУ.
Модель АСУ включает в себя: модель объекта управления, модель управляющей подсистемы, а также модель внешней среды. Управляющая подсистема реализует следующие функции: идентификация состояния объекта управления, выработка управляющего воздействия, реализация управляющего воздействия.
С позиций теории информации сложный объект
управления (АОУ) может рассматриваться как шумящий (определенным образом)
информационный канал, на вход которого подаются входные параметры ![]() , представляющие собой управляющие воздействия, а также
факторы предыстории и среды, а на выходе фиксируются выходные параметры
, представляющие собой управляющие воздействия, а также
факторы предыстории и среды, а на выходе фиксируются выходные параметры ![]() , связанные как с входными параметрами, так и с целевыми и
иными состояниями объекта управления.
, связанные как с входными параметрами, так и с целевыми и
иными состояниями объекта управления.
Одной из основных задач АСУ является задача
принятия решения о наиболее эффективном управляющем воздействии. В терминах
теории информации эта задача формулируется следующим образом: зная целевое состояние объекта управления, на
основе его информационной модели определить такие входные параметры ![]() , которые с учетом предыстории и актуального состояния объекта
управления, а также влияния среды с наибольшей эффективностью переведут его в
целевое состояние, характеризующееся выходными параметрами
, которые с учетом предыстории и актуального состояния объекта
управления, а также влияния среды с наибольшей эффективностью переведут его в
целевое состояние, характеризующееся выходными параметрами ![]() .
.
С решением этой задачи тесно связана задача декодирования теории информации: "По полученному в условиях помех сообщению определить, какое сообщение было передано" [176]. Для решения данной задачи используются коды, корректирующие ошибки, а в более общем случае, - различные методы распознавания образов.
Учитывая вышесказанное, предлагается рассматривать принятие решения об управляющем воздействии в АСУ как решение обратной задачи декодирования, которая формулируется следующим образом: "Какое сообщение необходимо подать на вход зашумленного канала связи, чтобы на его выходе получить заранее заданное сообщение". Данная задача решается на основе математической модели канала связи.
Декомпозиция основной задачи в ряд частных подзадач
Построение аналитической модели АОУ затруднено из-за отсутствия или недостатка априорной информации об объекте управления, а также из-за ограниченности и сложности используемого математического аппарата. В связи с этим предлагается путь решения данной проблемы, состоящий в поэтапном решении следующих задач:
1–я задача: разработать абстрактную модель более общего класса (содержательную информационную);
2–я задача: обучить абстрактную информационную модель путем учета информации о реальном поведении АОУ, поступающей в процессе экспериментальной эксплуатации АСУ; на этом этапе адаптируется и конкретизируется абстрактная модель АОУ, т.е. в ней все более точно отражаются взаимосвязи между входными параметрами и состояниями АОУ;
3–я задача: на основе конкретной содержательной информационной модели разработать алгоритмы решения следующих задач АСУ:
3.1. Расчет влияния факторов на переход АОУ в различные возможные состояния (обучение, адаптация).
3.2. Прогнозирование поведения АОУ при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (основная задача АСУ).
3.3. Выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; контролируемое удаление второстепенных факторов с низкой дифференцирующей способностью, т.е. снижение размерности модели при заданных ограничениях.
3.4. Сравнение влияния факторов. Сравнение состояний АОУ.
Сформулируем предлагаемую абстрактную модель АОУ, опишем способ ее конкретизации и приведем алгоритмы решения задач адаптивных АСУ АОУ на основе данной модели.
Решение задачи 1: "Синтез семантической информационной модели активного объекта управления"
Исходные данные для выявления взаимосвязей между факторами и состояниями объекта управления предлагается представить в виде корреляционной матрицы – матрицы абсолютных частот (таблица 15):
|
Таблица 15 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ |
|
|
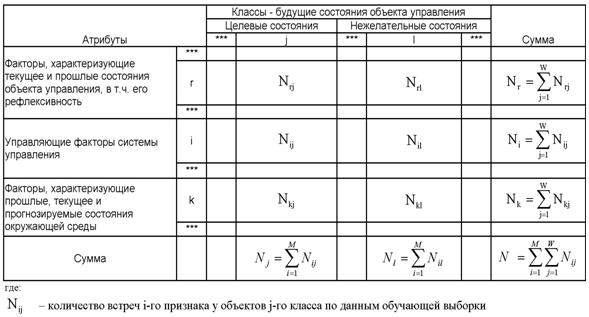
В этой матрице в качестве классов (столбцов) приняты будущие состояния объекта управления, как целевые, так и нежелательные, а в качестве атрибутов (строк) – факторы, которые разделены на три основных группы, математически обрабатываемые единообразно: факторы, характеризующие текущее и прошлые состояния объекта управления; управляющие факторы системы управления; факторы, характеризующие прошлые, текущее и прогнозируемые состояния окружающей среды. Отметим, что форма таблицы 15 является универсальной формой представления и обобщения фактов – эмпирических данных в единстве их дискретного и интегрального представления (причины – следствия, факторы – результирующие состояния, признаки – обобщенные образы классов, образное – логическое и т.п.).
Управляющие факторы объединяются в группы, внутри каждой из которых они альтернативны (несовместны), а между которыми - нет (совместны). В этом случае внутри каждой группы выбирают одно из доступных управляющих воздействий с максимальным влиянием. Варианты содержательной информационной модели без учета прошлых состояний объекта управления и с их учетом, аналогичны, соответственно, простым и составным цепям Маркова, автоматам без памяти и с памятью.
В качестве количественной меры влияния факторов, предложено использовать обобщенную формулу А.Харкевича (3.28), полученную на основе предложенной эмерджентной теории информации. При этом по формуле (3.28) непосредственно из матрицы абсолютных частот (таблица 15) рассчитывается матрица информативностей (таблица 16), которая и представляет собой основу содержательной информационной модели предметной области.
|
Таблица 16 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ |
|
|
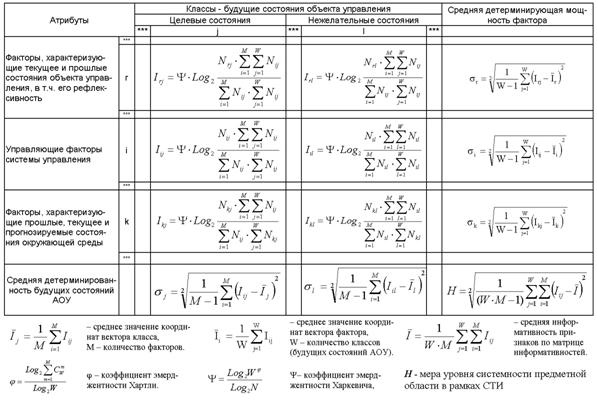
Весовые коэффициенты таблицы 3.28
непосредственно определяют, какое количество информации Iij система
управления получает о наступлении события: "активный объект управления
перейдет в j–е состояние", из сообщения: "на активный объект
управления действует i–й фактор".
Принципиально важно, что эти весовые коэффициенты не определяются экспертами неформализуемым способом, а рассчитываются непосредственно на основе эмпирических данных и удовлетворяют всем ранее сформулированным требованиям, т.е. являются сопоставимыми, содержательно интерпретируемыми, отражают понятия "достижение цели управления" и "мощность множества будущих состояний объекта управления" и т.д.
В данном исследовании обосновано, что предложенная информационная мера обеспечивает сопоставимость индивидуальных количеств информации, содержащейся в факторах о классах, а также сопоставимость интегральных критериев, рассчитанных для одного объекта и разных классов, для разных объектов и разных классов.
Когда количество информации Iij>0 – i–й фактор способствует переходу объекта управления в j–е состояние, когда Iij<0 – препятствует этому переходу, когда же Iij=0 – никак не влияет на это. В векторе i–го фактора (строка матрицы информативностей) отображается, какое количество информации о переходе объекта управления в каждое из будущих состояний содержится в том факте, что данный фактор действует. В векторе j–го состояния класса (столбец матрицы информативностей) отображается, какое количество информации о переходе объекта управления в соответствующее состояние содержится в каждом из факторов.
Таким
образом, матрица информативностей (таблица 16) является обобщенной таблицей
решений, в которой входы (факторы) и выходы (будущие состояния АОУ) связаны
друг с другом не с помощью классических (Аристотелевских) импликаций,
принимающих только значения: "Истина" и "Ложь", а различными значениями истинности,
выраженными в битах и принимающими значения от положительного
теоретически-максимально-возможного ("Максимальная степень
истинности"), до теоретически неограниченного отрицательного
("Степень ложности").
Фактически предложенная модель позволяет осуществить синтез обобщенных таблиц решений для различных предметных областей непосредственно на основе эмпирических исходных данных и продуцировать на их основе прямые и обратные правдоподобные (нечеткие) логические рассуждения по неклассическим схемам с различными расчетными значениями истинности, являющимся обобщением классических импликаций (таблица 17).
|
Таблица 17 – ПРЯМЫЕ И ОБРАТНЫЕ ПРАВДОПОДОБНЫЕ ЛОГИЧЕСКИЕ ВЫСКАЗЫВАНИЯ С РАСЧЕТНОЙ (В СООТВЕТСТВИИ С СТИ) СТЕПЕНЬЮ ИСТИННОСТИ ИМПЛИКАЦИЙ |
|
|
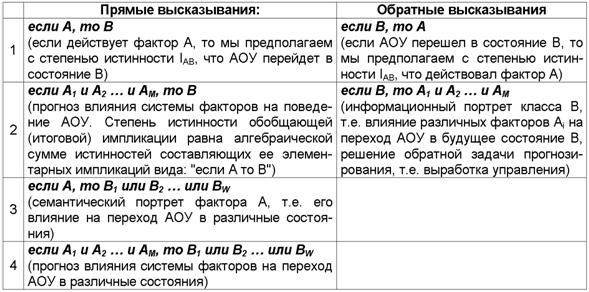
Приведем пример более сложного высказывания, которое может быть рассчитано непосредственно на основе матрицы информативностей – обобщенной таблицы решений (таблица 16):
Если A, со степенью истинности a(A,B)
детерминирует B, и если С, со степенью истинности a(C,D)
детерминирует D, и A совпадает по смыслу с C со степенью истинности a(A,C),
то это вносит вклад в совпадение B с D, равный степени истинности a(B,D).
При этом в прямых рассуждениях как предпосылки рассматриваются факторы, а как заключение – будущие состояния АОУ, а в обратных – наоборот: как предпосылки – будущие состояния АОУ, а как заключение – факторы. Степень истинности i-й предпосылки – это просто количество информации Iij, содержащейся в ней о наступлении j-го будущего состояния АОУ. Если предпосылок несколько, то степень истинности наступления j-го состояния АОУ равна суммарному количеству информации, содержащемуся в них об этом. Количество информации в i-м факторе о наступлении j-го состояния АОУ, рассчитывается в соответствии с выражением (3.28) СТИ.
Прямые правдоподобные логические рассуждения позволяют прогнозировать степень достоверности наступления события по действующим факторам, а обратные – по заданному состоянию восстановить степень необходимости и степень нежелательности каждого фактора для наступления этого состояния, т.е. принимать решение по выбору управляющих воздействий на АОУ, оптимальных для перевода его в заданное целевое состояние.
Необходимо отметить, что предложенная модель, основывающаяся на теории информации, обеспечивает автоматизированное формирования системы нечетких правил по содержимому входных данных, как и комбинация нечеткой логики Заде-Коско с нейронными сетями Кохонена. Принципиально важно, что качественное изменение модели путем добавления в нее новых классов не уменьшает достоверности распознавания уже сформированных классов. Кроме того, при сравнении распознаваемого объекта с каждым классом учитываются не только признаки, имеющиеся у объекта, но и отсутствующие у него, поэтому предложенной моделью правильно идентифицируются объекты, признаки которых образуют множества, одно из которых является подмножеством другого (как и в Неокогнитроне К.Фукушимы) [197].
Данная модель позволяет прогнозировать поведение АОУ при воздействии на него не только одного, но и целой системы факторов:
|
|
В теории принятия решений скалярная функция Ij векторного аргумента называется интегральным критерием. Основная проблема состоит в выборе такого аналитического вида функции интегрального критерия, который обеспечил бы эффективное решение сформулированной выше задачи АСУ.
Учитывая, что частные критерии (3.28) имеют смысл количества информации, а информация по определению является аддитивной функцией, предлагается ввести интегральный критерий, как аддитивную функцию от частных критериев в виде:
|
|
В выражении (3.54) круглыми скобками обозначено скалярное произведение. В координатной форме это выражение имеет вид:
|
|
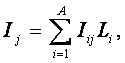 ,
,где:
![]() – вектор j–го состояния объекта управления;
– вектор j–го состояния объекта управления;
![]() – вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
– вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:

В реализованной модели значения координат вектора состояния ПО принимались равными либо 1 (фактор действует), либо 0 (фактор не действует).
Таким образом, интегральный критерий представляет собой суммарное количество информации, содержащееся в системе факторов различной природы (т.е. факторах, характеризующих объект управления, управляющее воздействие и окружающую среду) о переходе активного объекта управления в будущее (в т.ч. целевое или нежелательное) состояние.
В многокритериальной постановке задача прогнозирования состояния объекта управления, при оказании на него заданного многофакторного управляющего воздействия Ij, сводится к максимизации интегрального критерия:
|
|
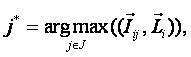
т.е. к выбору такого состояния объекта управления, для которого
интегральный критерий максимален.
Задача принятия решения о выборе наиболее эффективного управляющего воздействия является обратной задачей по отношению к задаче максимизации интегрального критерия (идентификации и прогнозирования), т.е. вместо того, чтобы по набору факторов прогнозировать будущее состояние АОУ, наоборот, по заданному (целевому) состоянию АОУ определяется такой набор факторов, который с наибольшей эффективностью перевел бы объект управления в это состояние.
Предлагается еще одно обобщение этой фундаментальной леммы, основанное на косвенном учете корреляций между информативностями в векторе состояний при использовании средних по векторам. Соответственно, вместо простой суммы количеств информации предлагается использовать корреляцию между векторами состояния и объекта управления, которая количественно измеряет степень сходства этих векторов:
|
|
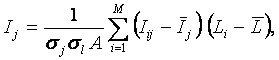
где:
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по
вектору идентифицируемой ситуации (объекта).
– среднее по
вектору идентифицируемой ситуации (объекта).
![]() –
среднеквадратичное отклонение информативностей вектора класса;
–
среднеквадратичное отклонение информативностей вектора класса;
![]() –
среднеквадратичное отклонение по вектору распознаваемого объекта.
–
среднеквадратичное отклонение по вектору распознаваемого объекта.
Выражение (3.39) получается непосредственно из (3.37) после замены координат перемножаемых векторов их стандартизированными значениями:

Результат
прогнозирования поведения объекта управления, описанного данной системой
факторов, представляет собой список его возможных будущих состояний, в котором
они расположены в порядке убывания суммарного количества информации о переходе
объекта управления в каждое из них.
Сравнения результатов идентификации и прогнозирования с опытными данными, с использованием выражений (3.37) и (3.39), показали, что при малых выборках они практически не отличаются, но при увеличении объема выборки до 400 и более (независимо от предметной области) выражение (3.39) дает погрешность идентификации (прогнозирования) на 5% – 7% меньше, чем (3.37). Поэтому в предлагаемой модели фактически используется не метрическая мера сходства (3.39).
В связи с тем, что в дальнейшем изложении широко применяются понятия теории АСУ, теории информации (связи), теории распознавания образов и методов принятия решений, приведем таблицу соответствия наиболее часто используемых нами терминов из этих научных направлений, имеющих сходный смысл (таблица 18):
|
Таблица 18 – СООТВЕТСТВИЕ ТЕРМИНОВ |
|
|
Вывод системного обобщения формулы Харкевича (3.28) приведен в разделе 3.1 данной работы. Чрезвычайно важное для данного исследования выражение (3.28) заслуживает специального комментария. Прежде всего нельзя не обратить внимания на то, что оно по своей математической форме, т.е. формально, ничем не отличается от выражения для превышения сигнала над помехой для информационного канала [196]. Из этого, на первый взгляд, внешнего совпадения следует интересная интерпретация выражения (3.28). А именно: можно считать, что обнаружив некоторый i–й признак у объекта, предъявленного на распознавание, мы тем самым получаем сигнал, содержащий некоторое количество информации
![]()
о том, что этот объект принадлежит к j–му классу. По–видимому, это так и есть, однако чтобы оценить насколько много или мало этой информации нами получено, ее необходимо с чем–то сравнить, т.е. необходимо иметь точку отсчета или базу для сравнения. В качестве такой базы естественно принять среднее по всем признакам количество информации, которое мы получаем, обнаружив этот j–й класс:
![]()
Иначе говоря, если при предъявлении какого–либо объекта на распознавание у него обнаружен i–й признак, то для того, чтобы сделать из этого факта обоснованный вывод о принадлежности этого объекта к тому или иному классу, необходимо знать и учесть, насколько часто вообще (т.е. в среднем) обнаруживается этот признак при предъявлении объектов данного класса.
Фактически это среднее количество информации можно рассматривать как некоторый "информационный шум", который имеется в данном признаке и не несет никакой полезной информации о принадлежности объектов к тем или иным классам. Полезной же информацией является степень отличия от этого шума. Таким образом классическому выражению Харкевича (3.12) для семантической целесообразности информации может быть придан более привычный для теории связи вид:
![]()
который интерпретируется как вычитание шума из полезного сигнала. Эта операция является совершенно стандартной в системах шумоподавления.
Если
полезный сигнал выше уровня шума, то его обнаружение несет информацию в пользу
принадлежности объекта к данному классу, если нет – то, наоборот, в пользу не
принадлежности.
Возвращаясь к выражению (3.12), необходимо
отметить, что сам А.А.Харкевич рассматривал ![]() как вероятность достижения цели, при условии, что
система получила информацию
как вероятность достижения цели, при условии, что
система получила информацию ![]() , а
, а ![]() – как вероятность ее достижения при условии, что
система этой информации не получала. Очевидно, что фактически
– как вероятность ее достижения при условии, что
система этой информации не получала. Очевидно, что фактически ![]() соответствует вероятности случайного угадывания
объектом управления правильного пути к цели, или, что тоже самое, вероятности
самопроизвольного, т.е. без оказания управляющих воздействий, достижения АОУ
целевого заданного состояния.
соответствует вероятности случайного угадывания
объектом управления правильного пути к цели, или, что тоже самое, вероятности
самопроизвольного, т.е. без оказания управляющих воздействий, достижения АОУ
целевого заданного состояния.
Необходимо отметить также, что каждый признак объекта управления как канала связи может быть охарактеризован динамическим диапазоном, равным разности максимально возможного (допустимого) уровня сигнала в канале и уровня помех в логарифмическом масштабе:
![]()
Максимальное количество информации, которое может содержаться в признаке, полностью определяется количеством классов распознавания W и равно количеству информации по Хартли: I=Log2W.
Динамический диапазон признака является количественной мерой его полезности (ценности) для распознавания, но все же предпочтительней для этой цели является среднее количество полезной для классификации информации в признаке, т.е. исправленное выборочное среднеквадратичное отклонение информативностей:
|
|
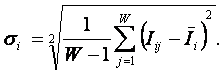
Очевидна близость этой меры к длине вектора признака в семантическом пространстве атрибутов:
|
|
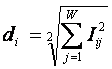
В сущности выражение (3.40) просто представляет собой нормированный вариант (3.41).
Решение задачи 2: "Адаптация модели объекта управления"
На основе обучающей выборки, содержащей информацию о том, какие факторы действовали, когда АОУ переходил в те или иные состояния, методом прямого счета формируется матрица абсолютных частот, имеющая вид, представленный в таблице 15. Необходимо отметить, что в случае АОУ в большинстве случаев нет возможности провести полный факторный эксперимент для заполнения матрицы абсолютных частот. В данной работе предполагается, что это и не обязательно, т.е. на практике достаточно воспользоваться естественной вариабельностью факторов и состояний АОУ, представленных в обучающей выборке. С увеличением объема обучающей выборки в ней со временем будут представлены все практически встречающиеся варианты сочетаний факторов и состояний АОУ.
В соответствии с выражением (3.28),
непосредственно на основе матрицы абсолютных частот ||![]() || (таблица 15) рассчитывается матрица информативностей
факторов ||
|| (таблица 15) рассчитывается матрица информативностей
факторов ||![]() || (таблица 16).
|| (таблица 16).
Количество
информации в i–м факторе о наступлении j–го состояния АОУ является
статистической мерой их связи и количественной мерой влияния данного фактора на
переход АОУ в данное состояние.
Решение задачи 3: "Разработка алгоритмов решения основных задач АСУ"
Как было показано в разделе 3.2, решение задачи 3 предполагает решение следующих подзадач.
Решение подзадачи 3.1: "Расчет влияния факторов на переход объекта управления в различные состояния (обучение, адаптация)"
При изменении объема обучающей выборки или
изменении экспертных оценок прежде всего пересчитывается матрица абсолютных
частот, а затем, на ее основании и в соответствии с выражением (3.28), -
матрица информативностей. Таким образом, предложенная
модель обеспечивает отображение динамических взаимосвязей, с одной стороны,
между входными и выходными параметрами, а с другой, - между параметрами и состояниями объекта управления.
Конкретно, это отображение осуществляется в форме так называемых векторов
факторов и состояний.
В профиле (векторе) i–го фактора (строка матрицы информативностей) отображается, какое количество информации о переходе АОУ в каждое из возможных состояний содержится в том факте, что данный фактор действует.
В профиле (векторе) j–го состояния АОУ (столбец матрицы информативностей) отображается, какое количество информации о переходе АОУ в данное состояние содержится в каждом из факторов.
Решение подзадачи 3.2: "Прогнозирование поведения объекта управления при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (обратная задача прогнозирования)"
Прогнозирование состояния АОУ осуществляется следующим образом:
1. Собирается информация о действующих факторах, характеризующих состояние предметной области (активный объект управления описывается факторами, характеризующими его текущее и прошлые состояния; управляющая система характеризуется технологическими факторами, с помощью которых она оказывает управляющее воздействие на активный объект управления; окружающая среда характеризуется прошлыми, текущими и прогнозируемыми факторами, которые также оказывают воздействие на активный объект управления).
2. Для каждого возможного будущего состояния АОУ подсчитывается суммарное количество информации, содержащееся во всей системе факторов (согласно п.1), о наступлении этого состояния.
3. Все будущие состояния АОУ ранжируются в порядке убывания количества информации об их осуществлении.
Этот ранжированный список будущих состояний АОУ и представляет собой первичный результат прогнозирования.
Если задано некоторое определенное целевое состояние, то выбор управляющих воздействий для фактического применения производится из списка, в котором все возможные управляющие воздействия расположены в порядке убывания их влияния на перевод АОУ в данное целевое состояние. Такой список называется информационным портретом состояния АОУ [64].
Управляющие воздействия могут быть объединены в группы, внутри каждой из которых они альтернативны (несовместны), а между которыми - нет (совместны). В этом случае внутри каждой группы выбирают одно из фактически доступных управляющих воздействий с максимальным влиянием на достижение заданного целевого состояния АОУ.
Однако выбор многофакторного управляющего воздействия нельзя считать завершенным без прогнозирования результатов его применения. Описание АОУ в актуальном состоянии состоит из списка факторов окружающей среды, предыстории АОУ, описания его актуального (исходного) состояния, а также выбранных управляющих воздействий. Имея эту информацию по каждому из факторов в соответствии с выражением (3.39), нетрудно подсчитать, какое количество информации о переходе в каждое из состояний содержится суммарно во всей системе факторов. Данный метод соответствует фундаментальной лемме Неймана–Пирсона, содержащей доказательство оптимальности метода выбора той из двух статистических гипотез, о которой в системе факторов содержится больше информации. В то же время он является обобщением леммы Неймана–Пирсона, так как вместо информационной меры Шеннона используется системное обобщение семантической меры целесообразности информации Харкевича.
Предлагается еще одно обобщение этой
фундаментальной леммы, основанное на косвенном учете корреляций между
информативностями в профиле состояния при использовании среднего по профилю.
Соответственно, вместо простой суммы количеств информации предлагается использовать
ковариацию между векторами состояния и АОУ, которая количественно измеряет
степень сходства формы этих векторов.
Результат
прогнозирования поведения АОУ, описанного данной системой факторов,
представляет собой список состояний, в котором они расположены в порядке
убывания суммарного количества информации о переходе АОУ в каждое из них.
Решение подзадачи 3.3: "Выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; снижение размерности модели при заданных ограничениях"
Естественно считать, что некоторый фактор является тем более ценным, чем больше среднее количество информации, содержащееся в этом факторе о поведении АОУ [64]. Но так как в предложенной модели количество информации может быть и отрицательным (если фактор уменьшает вероятность перехода АОУ в некоторое состояние), то простое среднее арифметическое информативностей может быть близко к нулю. При этом среднее будет равно нулю и в случае, когда все информативности равны нулю, и тогда, когда они будут велики по модулю, но с разными знаками. Следовательно, более адекватной оценкой полезности фактора является среднее модулей или, что наиболее точно, исправленное (несмещенное) среднеквадратичное отклонение информативностей по профилю признака.
Ценность фактора по сути дела определяется его полезностью для различения состояний АОУ, т.е. является его дифференцирующей способностью или селективностью.
Необходимо также отметить, что различные состояния АОУ обладают различной степенью обусловленности, т.е. в различной степени детерминированы факторами: некоторые слабо зависят от учтенных факторов, тогда как другие определяются ими практически однозначно. Количественно детерминируемость состояния АОУ предлагается оценивать стандартным отклонением информативностей вектора обобщенного образа данного состояния.
Предложено и реализовано несколько
итерационных алгоритмов корректного удаления малозначимых факторов и
слабодетерминированных состояний АОУ при заданных граничных условиях [64]. Решение задачи снижения размерности модели
АОУ при заданных граничных условиях позволяет снизить эксплуатационные затраты
и повысить эффективность РАСУ АО.
Решение подзадачи 3.4: "Сравнение влияния факторов. Сравнение состояний объекта управления"
Факторы могут сравниваться друг с другом по тому влиянию, которое они оказывают на поведение АОУ. Сами состояния могут сравниваться друг с другом по тем факторам, которые способствуют или препятствуют переходу АОУ в эти состояния. Это сравнение может содержать лишь результат, т.е. различные степени сходства/различия (в кластерном анализе), или содержать также причины этого сходства/различия (в когнитивных диаграммах).
Эти задачи играют важную роль в теории и практике РАСУ АО при необходимости замены одних управляющих воздействий другими, но аналогичными по эффекту, а также при изучении вопросов семантической устойчивости управления (различимости состояний АОУ по детерминирующим их факторам).
Этот анализ проводится над классами распознавания и над признаками. Он включает: информационный (ранговый) анализ; кластерный и конструктивный анализ, семантические сети; содержательное сравнение информационных портретов, когнитивные диаграммы.
Семантический информационный анализ
Предложенная математическая модель позволяет сформировать информационные портреты обобщенных эталонных образов классов распознавания и признаков.
Портреты классов распознавания представляют собой списки признаков в порядке убывания содержащегося в них количества информации о принадлежности к этим классам.
Информационный портрет класса распознавания показывает нам, каков информационный вклад каждого признака в общий объем информации, содержащейся в обобщенном образе этого класса.
В подходе к решению задач рефлексивных АСУ АО, основанном на применении методов распознавания образов, классам распознавания соответствуют, во–первых, исходные, а во–вторых, результирующие, в том числе целевые состояния объекта управления. Это значит, что в первом случае портреты классов используются для идентификации исходного состояния АОУ, потому что именно с ними сравнивается состояние объекта управления, а во втором – для выработки управляющего воздействия, так как его выбирают в форме суперпозиции неальтернативных факторов из информационного портрета целевого состояния, оказывающих наибольшее влияние на перевод АОУ в это состояние.
Портреты признаков представляют собой списки классов распознавания в порядке убывания количества информации о них, которое содержит данный признак. По своей сути информационный портрет признака раскрывает нам смысл данного признака, т.е. его семантическую нагрузку. В теории и практике рефлексивных АСУ АО информационный портрет фактора является развернутой количественной характеристикой, содержащей информацию о силе и характере его влияния на перевод АОУ в каждое из возможных результирующих состояний, в том числе в целевые. Информационные портреты классов и признаков допускают наглядную графическую интерпретацию в виде двухмерных (2d) и трехмерных (3d) диаграмм.
Кластерно-конструктивный анализ и семантические сети
Кластеры представляют собой такие группы классов распознавания (или признаков), внутри которых эти классы наиболее схожи друг с другом, а между которыми наиболее различны [64]. В данной работе, в качестве классов распознавания рассматриваются как исходные, так и результирующие, в том числе целевые состояния объекта управления, а в качестве признаков – факторы, влияющие на переход АОУ в результирующие состояния.
Исходные состояния АОУ, объединенные в кластер, характеризуются общими или сходными методами перевода в целевые состояния. Результирующие состояния АОУ, объединенные в кластер, являются слаборазличимыми по факторам, детерминирующим перевод АОУ в эти состояния. Это означает, что одно и то же управляющее воздействие при одних и тех же предпосылках (исходном состоянии и предыстории объекта управления и среды) могут привести к переводу АОУ в одно из результирующих состояний, относящихся к одному кластеру. Поэтому кластерный анализ результирующих состояний АОУ является инструментом, позволяющим изучать вопросы устойчивости управления сложными объектами.
При выборе управляющего воздействия как суперпозиции неальтернативных факторов часто возникает вопрос о замене одних управляющих факторов другими, имеющими сходное влияние на перевод АОУ из данного текущего состояния в заданное целевое состояние. Кластерный анализ факторов как раз и позволяет решить эту задачу: при невозможности применить некоторый управляющий фактор его можно заменить другим фактором из того же кластера.
При формировании кластеров используются матрицы сходства объектов и признаков, формируемые на основе матрицы информативностей.
В соответствии с предлагаемой математической моделью могут быть сформированы кластеры для заданного диапазона кодов классов распознавания (признаков) или заданных диапазонов уровней системной организации с различными критериями включения объекта (признака) в кластер.
Эти критерии могут быть сформированы автоматически либо заданы непосредственно. В последнем уровне кластеризации, в частности при задании одного уровня, в кластеры включаются не только похожие, но и все непохожие объекты (признаки), и, таким образом, формируются конструкты классов распознавания и признаков.
В данной работе под конструктом понимается система противоположных (наиболее сильно отличающихся) кластеров, которые называются "полюсами" конструкта, а также спектр промежуточных кластеров, к которым применима количественная шкала измерения степени их сходства или различия [64].
Понятия "кластер" и "конструкт" тесно взаимосвязаны:
– так как положительный и отрицательный полюса конструкта представляют собой кластеры, в наибольшей степени отличающиеся друг от друга, то конструкты могут быть получены как результат кластерного анализа кластеров;
– конструкт может рассматриваться как кластер с нечеткими границами, включающий в различной степени, причем не только в положительной, но и отрицательной, все классы (признаки).
В теории рефлексивных АСУ АО, конструктивный анализ позволяет решить такие задачи, как:
1. Определение в принципе совместимых и в принципе несовместимых целевых состояний АОУ. Совместимыми называются целевые состояния, для достижения которых необходимы сходные предпосылки и управляющие воздействия, а несовместимыми – для которых они должны быть диаметрально противоположными. Например, обычно сложно совмещаются такие целевые состояния, как очень высокое качество продукции и очень большое ее количество.
2. Определение факторов, имеющих не только сходное (это возможно и на уровне кластерного анализа), но и совершенно противоположное влияние на поведение сложного объекта управления.
Современный интеллект имеет дуальную структуру и, по сути дела, мыслит в системе кластеров и конструктов. Поэтому инструмент автоматизированного кластерно–конструктивного анализа может быть успешно применен для рефлексивного управления активными объектами.
Необходимо отметить, что формирование кластеров затруднено из-за проблемы комбинаторного взрыва, так как требует полного перебора и проверки "из n по m" сочетаний элементов (классов или признаков) в кластеры. Конструкты же формируются непосредственно из матрицы сходства прямой выборкой и сортировкой, что значительно проще в вычислительном отношении, так как конструктов значительно меньше, чем кластеров (всего n2). Поэтому учитывая, что при формировании конструктов автоматически формируются и их полюса, т.е. кластеры, в предложенной математической модели реализован не кластерный анализ, а сразу конструктивный (как более простой в вычислительном отношении и более ценный по получаемым результатам).
Диаграммы смыслового сходства–различия классов (признаков) соответствуют определению семантических сетей [64], т.е. представляют собой ориентированные графы, в которых признаки соединены линиями, соответствующими их смысловому сходству–различию.
Когнитивные диаграммы классов и признаков
В предложенной в настоящем исследовании математической модели в обобщенной постановке реализована возможность содержательного сравнения обобщенных образов классов распознавания и признаков, т.е. построения когнитивных диаграмм [64].
В информационных портретах классов
распознавания мы видим, какое
количество информации о принадлежности (или не принадлежности) к данному классу
мы получаем, обнаружив у некоторого объекта признаки, содержащиеся в
информационном портрете. В кластерно-конструктивном анализе
мы получаем результаты сравнения классов распознавания друг с другом, т.е. мы
видим, насколько они сходны и насколько отличаются. Но мы не видим, какими признаками они похожи и какими
отличаются, и какой вклад каждый признак вносит в сходство или различие
некоторых двух классов.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили два информационных портрета. Эту работу и осуществляет режим содержательного сравнения классов распознавания.
Аналогично, в информационных портретах
признаков мы видим, какое количество информации о принадлежности (или не
принадлежности) к различным классам распознавания мы получаем, обнаружив
у некоторого объекта данный признак. В кластерно-конструктивном анализе
мы получаем результаты сравнения признаков друг с другом, т.е. мы видим,
насколько они сходны и насколько отличаются. Но мы не видим, какими классами они похожи и какими отличаются,
и какой вклад каждый класс вносит в смысловое сходство или различие
некоторых двух признаков.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили информационные портреты двух признаков. Эту работу и осуществляет режим содержательного (смыслового) сравнения признаков.
Содержательное (смысловое) сравнение классов
Обобщим математическую модель, предложенную и развиваемую в данной главе, на случай содержательного сравнения двух классов распознавания: J–го и L–го.
Признаки, которые есть по крайней мере в одном из классов, будем называть связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие по смыслу, они вносят определенный вклад в отношения сходства/различия между классами.
Список выявленных связей сортируется в порядке убывания модуля силы связи, причем учитывается не более заданного количества связей.
Пусть, например:
у J–го класса обнаружен i–й признак,
у L–го класса обнаружен k–й признак.
Используем те же обозначения, что и в разделе 3.1.
На основе обучающей выборки системой рассчитывается матрица абсолютных частот встреч признаков по классам (таблица 15).
В разделе 3.1. получено выражение (3.28) для расчета количества информации в i–м признаке о принадлежности некоторого конкретного объекта к j–му классу (плотность информации), которое имеет вид:
|
|
(3.28) |
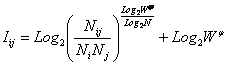
Аналогично, формула для количества информации в k–м признаке о принадлежности к L–му классу имеет вид:
|
|
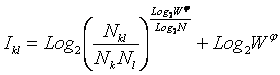
Вклад некоторого признака i в сходство/различие двух классов j и l равен соответствующему слагаемому корреляции образов этих классов, т.е. просто произведению информативностей
|
|
Классический коэффициент корреляции Пирсона, количественно определяющий степень сходства векторов двух классов: j и l, на основе учета вклада каждой связи, образованной i–м признаком, рассчитывается по формуле
|
|
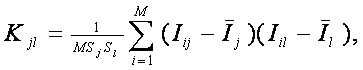
где:
|
|
– средняя информативность признаков j–го класса; |
|
|
– средняя информативность признаков L–го класса; |
|
|
– среднеквадратичное отклонение информативностей признаков j–го класса; |
|
|
– среднеквадратичное отклонение информативностей признаков L–го класса. |
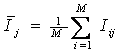
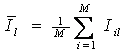
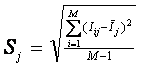
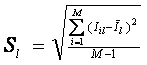
Проанализируем, насколько классический
коэффициент корреляции Пирсона (3.62) пригоден для решения важных задач:
– содержательного сравнения классов;
– изучения внутренней многоуровневой структуры класса.
Упростим анализ, считая, что средние информативности признаков по обоим классам близки к нулю, что при достаточно больших выборках (более 400 примеров в обучающей выборке) практически близко к истине.
Каждое слагаемое (3.43) суммы (3.44) отражает связь между классами, образованную одним i–м признаком. I–я связь существует в том и только в том случае, если i–й признак есть у обоих классов. Поэтому эти связи уместно называть одно–однозначными.
Этот подход можно назвать классическим для когнитивного анализа. Рассмотрим когнитивную диаграмму, приведенную на стр. 222 работы основной работы классика когнитивной психологии Р.Солсо (Когнитивная психология. /Пер. с англ. - М.: Тривола, 1996. - 600с.) (рисунок 31).
|
|
|
Рисунок 31. Когнитивная диаграмма |

В приведенной когнитивной диаграмме наглядно в графической форме показано сравнение классов (обобщенных образов) "Малиновка" и "Птица" разных уровней общности по их атрибутам (признакам). Как видно из диаграммы, в ней:
1. Все атрибуты имеют одинаковый вес, т.е. не учитывается, что некоторые атрибуты более важны для идентификации класса, чем другие. Это соответствует предположению, что этот вес равен по модулю 1 для всех атрибутов.
2. Все признаки имеют одинаковый знак, т.е. они все характерны для классов и нет атрибутов нехарактерных. Это соответствует предположению, что вес всех признаков положительный, т.е. все признаки вносят вклад в сходство и нет признаков, вносящих вклад в различие.
3. Классы сравниваются только по тем атрибутам, которые есть одновременно у них обоих, т.е. признаки, имеющиеся у обоих классов вносят вклад в сходство классов, а признаки, которые есть только у одного из классов не вносят никакого вклада ни в сходство классов, ни в различие. Это соответствует предположению, что атрибуты ортонормированы, т.е. корреляция их друг с другом равна 0 (атрибуты семантически не связаны).
Каждое из этих трех допущений является довольно сильным и желательно их снять и, тем самым, обобщить принцип построения когнитивных диаграмм, приведенный в данном примере.
Но это означает, что данный подход не позволяет сравнивать классы, описанные различными, т.е. непересекающимися наборами признаков. Но даже если общие признаки и есть, то невозможность учета вклада остальных признаков является недостатком классического подхода, так как из содержательного анализа связей неконтролируемо исключается потенциально существенная информация. Таким образом, классический подход имеет ограниченную применимость при решении задачи №1. Для решения задачи №2 подход, основанный на формуле (3.44), вообще не применим, так как различные уровни системной организации классов образованы различными признаками и, следовательно, между уровнями не будет ни одной одно–однозначной связи.
Основываясь на этих соображениях,
предлагается в общем случае учитывать вклад в сходство/различие двух классов,
который вносят не только общие, но и остальные признаки. Логично предположить,
что этот вклад (при прочих равных условиях) будет тем меньше, чем меньше корреляция
между этими признаками.
Следовательно, для обобщения выражения для
силы связи (3.43) необходимо умножить произведение информативностей признаков
на коэффициент корреляции между ними, отражающий
степень сходства или различия признаков по смыслу.
Таким образом, будем считать, что любые два признака (i,k) вносят определенный вклад в сходство/различие двух классов (j,l), определяемый сходством/различием признаков и количеством информации о принадлежности к этим классам, которое содержится в данных признаках:
|
|
где: ![]() – классический коэффициент корреляции Пирсона, количественно
определяющий степень сходства по смыслу двух признаков: i и k, на основе учета
вклада каждой связи, образованной содержащейся в них информацией о
принадлежности к j–му классу
– классический коэффициент корреляции Пирсона, количественно
определяющий степень сходства по смыслу двух признаков: i и k, на основе учета
вклада каждой связи, образованной содержащейся в них информацией о
принадлежности к j–му классу
|
|
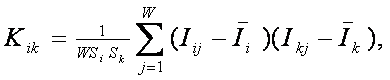
где
|
|
– средняя информативность координат вектора i–го признака; |
|
|
– средняя информативность координат вектора k–го признака; |
|
|
– среднеквадратичное отклонение координат вектора i–го признака; |
|
|
– среднеквадратичное отклонение координат вектора k–го признака. |
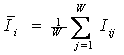
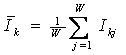
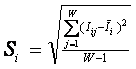
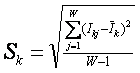
Коэффициент корреляции между признаками
(3.46) рассчитывается на основе всей обучающей
выборки, а не только объектов двух сравниваемых классов. Так как коэффициент
корреляции между признаками (3.46) практически всегда не равен нулю, то каждый признак i образует связи со всеми
признаками k, где k={1,...,A}, а каждый признак k в свою очередь связан со
всеми остальными признаками. Это означает, что выражение (3.45) является обобщением (3.43) с учетом много-многозначных
связей.
На основе этих представлений сформулируем выражение для обобщенного коэффициента корреляции Пирсона между двумя классами: j и l, учитывающего вклад в их сходство/различие не только одно–однозначных, но и много–многозначных связей, образуемых коррелирующими признаками. Когнитивные диаграммы с много–многозначными связями предлагается называть обобщенными когнитивными диаграммами.
|
|
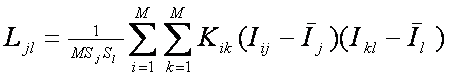
где Kik определяется выражением (3.46).
Сравним классический (3.44) и обобщенный (3.47) коэффициенты корреляции Пирсона друг с другом. Очевидно, при i=k (3.47) преобразуется в (3.44), т.е. соблюдается принцип соответствия. Отметим, что модель позволяет задавать минимальный коэффициент корреляции (порог) между признаками, образующими учитываемые связи. При пороге 100% отображаются только одно–однозначные связи, учитываемые в классическом коэффициенте корреляции (3.44). Из выражений (3.47) и (3.44) видно, что
|
|
так как в обобщенном коэффициенте корреляции учитываются связи между классами, образованные за счет учета корреляций между различными признаками. Ясно, что отношение
|
|
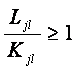
отражает степень избыточности описания классов. В модели имеется возможность исключения из системы признаков наименее ценных из них для идентификации классов. При этом в первую очередь удаляются сильно коррелирующие друг с другом признаки. В результате степень избыточности системы признаков уменьшается, и она становится ближе к ортонормированной.
Рассмотрим вопрос о единицах измерения, в которых количественно выражаются связи между классами.
Сходство двух признаков ![]() выражается величиной
от – 1 до +1.
выражается величиной
от – 1 до +1.
Максимальная теоретически возможная информативность признака в Bit выражается формулой
|
|
Таким образом, учитывая выражения (3.45) и (3.50) получаем, что максимальная теоретически возможная сила связи Rmax равна
|
|
В разработанном инструментарии СК-анализа, реализующем данную модель (описанном в лекции 6), реализован режим отображения когнитивной графики, где фактическая сила связи (3.45) в когнитивных диаграммах выражается в процентах от максимальной теоретически возможной силы связи (3.50). На графической диаграмме (рисунок 32) отображается 8 наиболее сильных по модулю связей, рассчитанных согласно формулы (3.47), причем знак связи изображается цветом (красный +, синий – ), а величина – толщиной линии.
|
|
|
Рисунок 32. Когнитивная диаграмма |
Имеется возможность выводить диаграммы только с положительными или только с отрицательными связями (для не цветных принтеров).
Частным случаем предложенных в данной работе обобщенных когнитивных диаграмм являются известные диаграммы В.С.Мерлина (Очерк интегрального исследования индивидуальности. - М., 1986. - 187с.). Эти диаграммы представляют обобщенные когнитивные диаграммы, формируемые в соответствии с предложенной моделью при следующих граничных условиях:
1. Класс сравнивается сам с собой.
2. Фильтрация левого и правого информационных портретов выбрана по уровням системной организации признаков (в данном случае – уровням Мерлина, терм. авт.).
3. Левый класс отображается с фильтрацией по одному уровню системной организации, а правый – по другому.
4. Диалог задания вида диаграмм предоставляет пользователю возможность задать следующие параметры:
– способ нормирования толщины линий, отображающих связи: нормирование по текущей диаграмме или по всем диаграммам;
– способ фильтрации признаков в информационных портретах диаграммы: по диапазону признаков или по диапазону уровней системной организации (уровням Мерлина);
– сами диапазоны признаков или уровней для левого и правого информационных портретов;
– максимальное количество связей, отображаемых на диаграмме;
– уровень сходства признаков, образующих одну связь, отображаемую на диаграмме: от 0 до 100%. При уровне сходства 100% в диаграммах отображаются только связи, образованные теми признаками, которые есть в обоих портретах одновременно, т.е. взаимно–однозначные связи. При уровне сходства менее 100% вообще говоря связи становятся много–многозначными, так как каждый признак корреляционно связан со всеми остальными;
– уровень сходства классов, отображаемых на диаграмме.
Таким образом, в предлагаемой математической модели в общем виде реализована возможность содержательного сравнения обобщенных образов состояний АОУ и факторов, т.е. построения когнитивных диаграмм [64], веса атрибутов определяются автоматически на основе исходных данных в соответствии с математической моделью и могут принимать различные по величине положительные и отрицательные значения. Кроме того на основе кластерного анализа атрибутов определяются корреляции между ними, которые учитываются при определении вклада атрибутов в сходство или различие классов. Поэтому отношения между атрибутами разных классов в когнитивной диаграмме не "один к одному", как в диаграмме на рисунке 31, а "многие ко многим" (рисунок 32).
В информационном портрете состояния АОУ показано, какое количество информации о принадлежности (не принадлежности) АОУ к данному состоянию, а также о переходе (не переходе) АОУ в данное состояние содержится в том факте, что на АОУ действуют факторы, содержащиеся в данном информационном портрете.
Кластерно-конструктивный анализ дает результат сравнения состояний АОУ друг с другом, т.е. показывает, насколько эти состояния сходны друг с другом и насколько отличаются друг от друга. Но он не показывает, какими факторами эти состояния АОУ похожи и какими отличаются, и какой вклад каждый фактор вносит в сходство или различие каждых двух состояний. Чтобы получить эту информацию, необходимо проанализировать два информационных портрета, что и делается при содержательном сравнении состояний АОУ .
Смысл
и значение диаграмм Мерлина применительно к проблематике АСУ состоит в том, что
они наглядно представляют внутреннюю структуру детерминации состояний АОУ,
т.е. показывают, каким образом связаны друг с другом факторы и будущие состояния
АОУ.
Таким образом:
– для моделирования процессов принятия решений в рефлесивных АСУ активными системами целесообразно применение многокритериального подхода с аддитивным интегральным критерием, в котором в качестве частных критериев используется семантическая мера целесообразности информации (Харкевич, 1960);
– предложенная математическая модель обеспечивает эффективное решение следующих задач, возникающих при синтезе адаптивных АСУ АОУ: разработка абстрактной информационной модели АОУ; адаптация и конкретизация абстрактной модели на основе апостериорной информации о реальном поведении АОУ; расчет влияния факторов на переход АОУ в различные возможные состояния; прогнозирование поведения АОУ при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (основная задача АСУ); выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; контролируемое удаление второстепенных факторов с низкой дифференцирующей способностью, т.е. снижение размерности модели при заданных ограничениях; сравнение влияния факторов, сравнение целевых и других состояний АОУ.
Предложенная методология, основанная на теории информации, обеспечивает эффективное моделирование задач принятия решений в адаптивных АСУ сложными системами.
Содержательное (смысловое) сравнение признаков
Предложенная математическая модель позволяет осуществить содержательное сравнение информационных портретов двух признаков.
Выявляются классы, которые есть по крайней мере в одном из векторов. Такие классы называются связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие, они вносят определенный вклад в отношения сходства/различия между признаками по смыслу.
Все связи между признаками сортируются в порядке убывания модуля, в соответствии с определенными ограничениями, связанными с тем, что нет необходимости учитывать очень слабые связи.
Для каждого класса известно, какое количество информации о принадлежности к нему содержит данный признак – это информативность. Здесь необходимо уточнить, что информативность признака – это не только количество информации в признаке о принадлежности к данному классу, но и количество информации в классе о том, что при нем наблюдается данный признак, т.е. это взаимная информация класса и признака.
Если бы классы были тождественны друг другу, т.е. это был бы один класс, то его вклад в сходство/различие двух признаков был бы просто равен соответствующему данному классу слагаемому корреляции этих признаков, т.е. просто произведению информативностей.
Но поскольку это в общем случае это могут быть различные классы, то, очевидно, необходимо умножить произведение информативностей на коэффициент корреляции между классами.
Таким образом, будем считать, что любые два класса (j,l) вносят определенный вклад в сходство/различие двух признаков (i,k), определяемый сходством/различием этих классов и количеством информации о принадлежности к ним, которое содержится в данных признаках
|
|
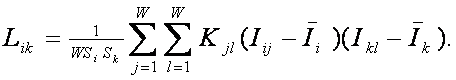
Вывод формулы (3.52) обобщенного коэффициента корреляции Пирсона для двух признаков совершенно аналогичен выводу формулы (3.47), поэтому он здесь не приводится. Формулы для всех входящих в (3.52) величин приведены выше в предыдущем разделе.
Так же, как и в режиме содержательного сравнения классов, в данном режиме сила связи выражается в процентах от максимальной теоретически–возможной силы связи. На диаграммах отображается 16 наиболее значимых связей, рассчитанных согласно этой формуле, причем знак связи изображается цветом (красный +, синий –), а величина – толщиной линии. Имеется возможность вывода диаграмм только с положительными или только с отрицательными связями.
Математическая модель позволяет получить обобщенные инвертированные когнитивные диаграммы для любых двух заданных признаков, для пар наиболее похожих и непохожих признаков, для всех их возможных сочетаний, а также инвертированные диаграммы Мерлина.
Необходимо отметить, что понятия, соответствующие по смыслу терминам "обобщенная инвертированная когнитивная диаграмма" и "инвертированная диаграмма Мерлина" не упоминаются даже в фундаментальных руководствах по когнитивной психологии и впервые предложены в [92]. Эти диаграммы представляют собой частный случай обобщенных когнитивных диаграмм признаков, формируемых в соответствии с предложенной математической моделью при следующих ограничениях:
1. Признак сравнивается сам с собой.
2. Выбрана фильтрация левого и правого вектора по уровням системной организации классов (аналог уровней Мерлина для свойств).
3. Левый вектор отображается с фильтрацией по одному уровню системной организации классов, а правый – по другому.
Обоснование сопоставимости частных критериев Iij
Применение этого метода корректно, если можно
сравнивать суммарное количество информации о переходе АОУ в различные
состояния, рассчитанное в соответствии с выражением (3.44), т.е. если они
сопоставимы друг с другом.
Будем считать, что величины сопоставимы тогда и только тогда, когда одновременно выполняются следующие три условия:
1. Сопоставимы индивидуальные количества информации, содержащейся в признаках о принадлежности к классам.
2. Сопоставимы величины, рассчитанные для одного объекта и разных классов.
3. Сопоставимы величины, рассчитанные для разных объектов и разных классов.
Очевидно, для решения всех этих вопросов необходимо дать точное и полное определение самого термина "сопоставимость".
Считается,
что величины сопоставимы, если существует некоторая количественная шкала для
измерения этих величин.
Таким образом, в нашем случае сопоставимость обеспечивается, если на шкале определены направление и единица измерения, а также есть абсолютный минимум (ноль) или максимум.
Докажем теоремы о выполнении условий сопоставимости для упрощенной и полной информационных моделей объектов и классов распознавания. Для этого рассмотрим вышеперечисленные необходимые и достаточные условия сопоставимости для упрощенной и полной информационных моделей.
Теорема-1: Индивидуальные количества информации, содержащейся в признаках объекта о принадлежности к классам, сопоставимы между собой.
В упрощенной информационной модели класса и информационной модели объекта принято, что все признаки имеют одинаковый вес, который равен 1, если признак есть у класса, и 0, если его нет. Уже одним этим обеспечивается сопоставимость индивидуальных количеств информации в упрощенной модели.
В полной модели количество информации рассчитывается в соответствии с модифицированной формулой Харкевича (3.28). Таким образом, в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов распознавания. Следовательно, для полной информационной модели сопоставимость индивидуальных количеств информации также обеспечивается, так как для них применима шкала отношений.
Это
означает, что индивидуальные количества информации можно суммировать и ввести
интегральный критерий как аддитивную меру от индивидуальных количеств
информации, что и требовалось доказать.
Теорема-2: Величины суммарной информации, рассчитанные для одного объекта и разных классов, сопоставимы друг с другом.
В упрощенной информационной модели вариант расстояния Хэмминга Hj, в котором учитываются только совпадения единиц (т.е. существующих признаков), для кодовых слов объекта и класса равно:
|
|
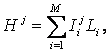
где ![]() – кодовое слово (профиль, массив–локатор) j–го класса;
– кодовое слово (профиль, массив–локатор) j–го класса;
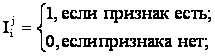
Li – кодовое слово (профиль, массив–локатор) объекта.
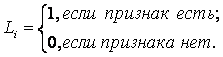
Пусть длина кодового слова (количество признаков) равна А. Длины кодовых слов объекта и классов одинаковы. Признаки могут принимать значения {0,1}. Тогда из этих условий и выражения (3.53) следует:
|
|
Но
выражение (3.54) является математическим определением шкалы отношений,
что означает полную сопоставимость предложенной меры сходства для упрощенной
информационной модели одного объекта и многих классов. Для обобщенной
информационной модели этот вывод сохраняет силу, т.к. в этой модели информация
в соответствии с выражением (3.28) измеряется в единицах измерения – битах,
определенных на шкале измерения информации, и на этой шкале имеется 0 и
теоретический максимум, определяемый в соответствии с выражением Хартли. В
полной информационной модели мера сходства объекта с классом ![]() имеет вид, определяемый выражением (3.39).
имеет вид, определяемый выражением (3.39).
Очевидно, величина ![]() нормирована:
нормирована:
|
|
что и доказывает применимость шкалы отношений и полную сопоставимость меры сходства для полной информационной модели одного объекта и многих классов.
Это
значит, что можно сравнивать меры сходства данного объекта с каждым из классов
и ранжировать классы в порядке убывания сходства с данным объектом , что и
требовалось доказать.
Теорема-3: Величины суммарной информации, рассчитанные для разных объектов и разных классов, а также классов и классов, признаков и признаков, взаимно-сопоставимы.
Очевидно, величина ![]() , рассчитанная по формуле (3.39) для различных объектов и
классов нормирована:
, рассчитанная по формуле (3.39) для различных объектов и
классов нормирована:
|
|
что и доказывает применимость шкалы отношений и полную сопоставимость мер сходства для полной информационной модели многих объектов и многих классов.
Это значит, что можно сравнивать меры сходства различных объектов с классами распознавания и делать выводы о том, что одни объекты распознаются лучше, а другие хуже на данном наборе классов и признаков, что и т.д.
Аналогичные
рассуждения верны и для сравнения векторов классов друг с другом, а также
векторов признаков друг с другом, что позволяет применить модели
кластерно-конструктивного анализа и алгоритмы построения семантических сетей,
что и требовалось доказать.
Теорема-4: Неметрический интегральный критерий сходства, основанный на модифицированной формуле А.Харкевича и обобщенной лемме Неймана-Пирсона, аддитивен.
Рассмотрим информационные модели распознаваемого объекта и классов распознавания, т.е. модели, основанные на теории кодирования – декодирования и расстоянии Хэмминга (кодовое расстояние) в качестве критерия сходства. Эта модель является упрощенной, но достаточно адекватной для решения вопроса об аддитивности меры сходства объектов и классов.
Информационная модель распознаваемого объекта представляет собой двоичное слово, каждый разряд которого соответствует определенному признаку. Если признак есть у распознаваемого объекта, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам распознаваемого объекта, называется его кодовым словом.
Упрощенная информационная модель класса распознавания есть двоичное слово, каждый разряд которого соответствует определенному признаку. Соответствие между двоичными разрядами и признаками для классов то же самое, что и для распознаваемых объектов. Если признак есть у класса, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам класса, называется его кодовым словом.
Такая модель класса является упрощенной, так как в ней принято, что все признаки имеют одинаковый вес равный 1, если он есть у класса, и 0, если его нет, тогда как в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов.
Таким образом, в упрощенной информационной модели различные классы распознавания отличаются друг от друга только наборами признаков, которые им соответствуют.
При использовании этих упрощенных моделей задача распознавания объекта сводится к задаче декодирования, т.е. кодовые слова объектов рассматриваются как искаженные зашумленным каналом связи кодовые слова классов. Распознавание состоит в том, что по кодовому слову объекта определяется наиболее близкое ему в определенном смысле кодовое слово класса. При этом естественной и наиболее простой мерой сходства между распознаваемым объектом и классом является расстояние Хэмминга между их кодовыми словами, т.е. количество разрядов, которыми они отличаются друг от друга.
Рассмотрим теперь вопрос об аддитивности количества информации как частного критерия в интегральном критерии.
Известно [148], что существует всего два варианта формирования интегрального критерия из частных критериев: аддитивный и мультипликативный, поэтому задача сводится к выбору одного из этих вариантов.
Рассмотрим эти варианты. Пусть кодовое слово объекта состоит из N разрядов. Тогда добавление еще одного разряда, отображающего имеющийся (1) или отсутствующий (0) признак, приведет к различным результатам в случаях, когда интегральный критерий есть аддитивная и мультипликативная функция индивидуальных количеств информации в признаках (таблица 19).
|
Таблица 19 – СРАВНЕНИЕ АДДИТИВНОГО И
МУЛЬТИПЛИКАТИВНОГО ВАРИАНТОВ ИНТЕГРАЛЬНОГО КРИТЕРИЯ |
||
|
Дополнительный |
Аддитивная
|
Мультипликативная
|
|
Есть (1) |
|
|
|
Нет (0) |
|
|
Здесь предполагается, что: I=f(n), f(1)=1, f(0)=0.
Итак, если функция аддитивна – добавление еще одного разряда увеличит количество информации в кодовом слове на 1 бит, если соответствующий признак есть, и не изменит этого количества, если его нет; если же функция мультипликативна, – то это не изменит количества информации в кодовом слове, если соответствующий признак есть, и сделает его равным нулю, если его нет.
Очевидно, мультипликативный вариант интегрального критерия не соответствует классическим представлениям о природе информации, тогда как аддитивный вариант полностью им соответствует: требование аддитивности самой меры информации было впервые обосновано Хартли в 1928 году, подтверждено Шенноном в 1948 году, и в последующем развитии теории информации никогда не подвергалось сомнению. На аддитивности частных критериев, имеющих смысл количества информации, основана известная лемма Неймана-Пирсона [148, стр.152].
Пусть по выборке (т.е. совокупности факторов) {x=x1,…, xN} требуется отдать предпочтение одной из конкурирующих гипотез (H1 или H0), т.е. определить в какое будущее состояние перейдет объект управления, если известны распределения наблюдений при каждой из них (по данным обучающей выборки), т.е. р(х|H0) и р(х|H1). Как обработать предпочтительную гипотезу? Из теории информации известно, что никакая обработка не может увеличить количества информации, содержащегося в выборке {х}. Следовательно, выборке {х} нужно поставить в соответствие число, содержащее всю полезную информацию, т.е. обработать выборку без потерь. Возникает мысль о у том, чтобы вычислить индивидуальные количества информации в выборке {х} о каждой из гипотез и сравнить их:
|
|
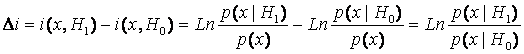
Какой из гипотез отдать предпочтение, зависит
теперь от величины Di и
от того, какой порог сравнения мы назначим. Оптимальность данной статистической
процедуры специально доказывается в математической статистике, – именно к этому
сводится содержание фундаментальной Леммы Неймана-Пирсона, которая утверждает,
что предпочтение следует отдавать той
статистической гипотезе, о которой в выборке содержится больше информации.
Согласно описанной выше процедуре предполагается, что объект управления перейдет в то будущее состояние, о переходе в которое в системе факторов содержится большее суммарное количество информации.
Таким образом, аддитивность интегрального критерия, основанного на
частных критериях, имеющих смысл количества информации, можно считать
обоснованной, что и требовалось доказать.
Обобщение интегральной модели путем учета значений выходных параметров объекта управления
Выходные параметры![]() – это свойства объекта управления, зависят от входных
параметров (в том числе параметров, характеризующих среду) и связанны с его
целевым состоянием сложным и неоднозначным способом:
– это свойства объекта управления, зависят от входных
параметров (в том числе параметров, характеризующих среду) и связанны с его
целевым состоянием сложным и неоднозначным способом:
![]()
Задача идентификации состояния АОУ по его выходным параметрам решается подсистемой идентификации управляющей подсистемы, работающей на принципах системы распознавания образов. При этом классами распознавания являются выходные состояния АОУ, а признаками – его выходные параметры.
Подсистема выработки
управляющих воздействий, также основанная на алгоритмах распознавания образов,
обеспечивает выбор управления ![]() , переводящего объект управления в целевое состояние
, переводящего объект управления в целевое состояние ![]() .
.
При этом
последовательно решаются следующие две обратные задачи распознавания:
во–первых, по
заданному целевому состоянию ![]() определяются
наиболее характерные для данного состояния выходные параметры объекта
управления:
определяются
наиболее характерные для данного состояния выходные параметры объекта
управления:
![]()
во–вторых, по
определенному на предыдущем шаге набору выходных параметров ![]() определяются входные параметры
определяются входные параметры ![]() , с наибольшей эффективностью переводящие объект
управления в данное целевое состояние с этими выходными параметрами:
, с наибольшей эффективностью переводящие объект
управления в данное целевое состояние с этими выходными параметрами:
![]()
1. Таким образом, определенная ограниченность подхода Шеннона, рассмотренная в данной главе, преодолевается в семантической информационной математической модели СК-анализа, основанной на СТИ. В рамках СТИ установлено, что одной из наиболее перспективных конкретизаций апостериорного подхода, является подход, предложенный в 1960 году А.А.Харкевичем [196]. Для моделирования процессов принятия решений в рефлексивных АСУ активными объектами предложено применить многокритериальный подхода с аддитивным интегральным критерием, в котором в качестве частных критериев используется системная мера семантической целесообразности информации. При этом количество информации оценивается косвенно: по изменению степени целесообразности поведения системы, получившей эту информацию. В результате получения информации поведение системы улучшается (растет выигрыш), а в результате получения дезинформации – ухудшается (растет проигрыш). Известны и более развитые семантические меры информации [148], основанные на интересных и правдоподобных идеях, однако они наталкиваются на значительные математические трудности и сложности в программной реализации, поэтому их рассмотрение в данном исследовании признано нецелесообразным.
2. Предложенная математическая модель обеспечивает эффективное решение следующих задач, возникающих в рефлексивных АСУ АО:
– разработка абстрактной информационной модели АОУ;
– адаптация и конкретизация абстрактной модели на основе информации о реальном поведении АОУ;
– расчет влияния факторов на переход АОУ в различные возможные состояния;
– прогнозирование поведения АОУ при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (основная задача АСУ);
– выявление факторов, вносящих основной вклад в детерминацию состояния АОУ;
– корректное удаление второстепенных факторов с низкой дифференцирующей способностью, т.е. снижение размерности модели при заданных граничных условиях;
– сравнение влияния факторов, сравнение целевых и других состояний АОУ.
3. Показано, что предложенная методология, основанная на системном обобщении теории информации, обеспечивает эффективное моделирование задач принятия решений в РАСУ АОУ.
4. Доказана возможность сведения многокритериальной задачи принятия решений к однокритериальной, показана глубокая внутренняя взаимосвязь данной модели с математической моделью распознавания образов. На этой основе введено понятие "интегрального метода" распознавания и принятия решений и, после анализа и переосмысления основных понятий теории информации, предложена базовая математическая модель "интегрального метода", основанная на системной теории информации. Показано, что теория информации может рассматриваться как единая математическая и методологическая основа методов распознавания образов и теории принятия решений. При этом распознавание образов рассматривается как принятие решения о принадлежности объекта к определенному классу распознавания, прогнозирование – как распознавание будущих состояний, а принятие решения об управляющем воздействии на объект управления в АСУ как решение обратной задачи прогнозирования (распознавания).
5. Проведено исследование базовой математической модели на примере решения основной задачи АСУ – задачи принятия решения о наиболее эффективном управляющем воздействии. Осуществлена декомпозиция основной задачи в последовательность частных задач для каждой из которых найдено решение, показана взаимосвязь основной задачи АСУ с задачей декодирования теории информации.
1.2.2.3. Некоторые свойства математической модели (сходимость, адекватность, устойчивость и др.)
Под сходимостью семантической информационной модели в данной работе понимается:
а) зависимость информативностей факторов (в матрице информативностей) от объема обучающей выборки;
б) зависимость адекватности модели (интегральной и дифференциальной валидности) от объема обучающей выборки.
Для измерения сходимости в смыслах "а" и "б" в инструментарии СК-анализа – системе "Эйдос" реализован специальный исследовательский режим.
Под адекватностью модели понимается ее внутренняя и внешняя дифференциальная и интегральная валидность. Понятие валидности является уточнением понятия адекватности, для которого определены процедуры количественного измерения, т.е. валидность – это количественная адекватность. Это понятие количественно отражает способность модели давать правильные результаты идентификации, прогнозирования и способность вырабатывать правильные рекомендации по управлению. Под внутренней валидностью понимается валидность модели, измеренная после синтеза модели путем идентификации объектов обучающей выборки. Под внешней валидностью понимается валидность модели, измеренная после синтеза модели путем идентификации объектов, не входящих в обучающую выборку. Под дифференциальной валидностью модели понимается достоверность идентификации объектов в разрезе по классам. Под интегральной валидностью средневзвешенная дифференциальная валидность. Возможны все сочетания: внутренняя дифференциальная валидность, внешняя интегральная валидность и т.д. (таблица 20).
Таблица 20 – К ОПРЕДЕЛЕНИЮ ПОНЯТИЯ ВАЛИДНОСТИ |
||
|
|
Внутренняя валидность |
Внешняя валидность |
|
Дифференциальная
валидность |
Валидность
модели, измеренная после синтеза модели путем идентификации объектов
обучающей выборки в разрезе по классам |
Валидность модели, измеренная после синтеза модели
путем идентификации объектов, не входящих в обучающую выборку в разрезе по
классам |
|
Интегральная
валидность |
Средневзвешенная по всем классам достоверность
идентификации объектов обучающей выборки |
Средневзвешенная по всем классам достоверность
идентификации объектов, не входящих в обучающую выборку |
Под устойчивостью модели понимается ее способность давать незначительные различия в прогнозах и рекомендациях по управлению при незначительных различиях в исходных данных для решения этих задач.
1.2.2.3.1. Непараметричность модели. Робастные процедуры и фильтры для исключения артефактов
Предложенная семантическая информационная модель является непараметрической, т.к. не основана на предположениях о нормальности распределений исследуемой выборки. Под робастными понимаются процедуры, обеспечивающие устойчивую работу модели на исходных данных, зашумленных артефактами, т.е. данными, выпадающими из общих статистических закономерностей, которым подчиняется исследуемая выборка. Выявление артефактов возможно только при большой статистике, т.к. при малой статистике все частоты атрибутов малы и невозможно отличить артефакт от значимого атрибута. Критерий выявления артефактов основан на том, что при увеличении объема статистики частоты значимых атрибутов растут, как правило, пропорционально объему выборки, а частоты артефактов так и остаются чрезвычайно малыми, близкими к единице. В модели реализована такая процедура удаления наиболее вероятных артефактов, и она, как показывает опыт, существенно повышает качество (адекватность) модели.
1.2.2.3.2. Зависимость информативностей факторов от объема обучающей выборки
При учете в модели апостериорной информации, содержащейся в очередном объекте обучающей выборки, осуществляется перерасчет значений информативностей всех атрибутов. При этом изменяется количество информации, содержащейся в факте обнаружения у объекта данного атрибута о принадлежности объекта к определенному классу.
В этом процессе пересчета информативностей атрибута их значения "сходятся" к некоторому пределу в соответствии с двумя "сценариями":
1) процесс "последовательных приближений", напоминающего по своей форме "затухающие колебания" (рисунок 33);
2) относительно "плавное" возрастание или убывание с небольшими временными отклонениями от этой тенденции (рисунок 34).
|
|
|
Рисунок 33. Зависимость количества информации,
содержащегося |
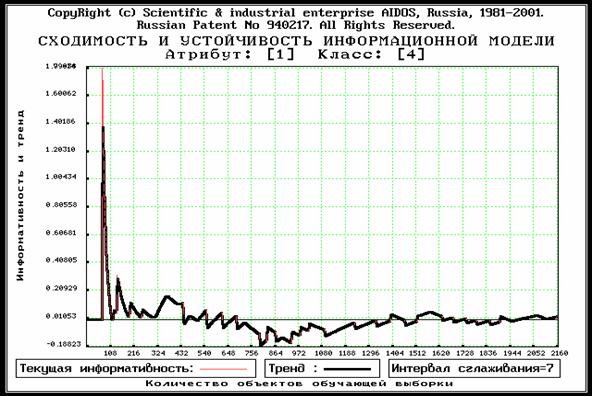
|
|
|
Рисунок 34. Зависимость количества информации, содержащегося в атрибуте №1 о принадлежности идентифицируемого объекта (обладающего этим атрибутом) к классу №10 от объема обучающей выборки |
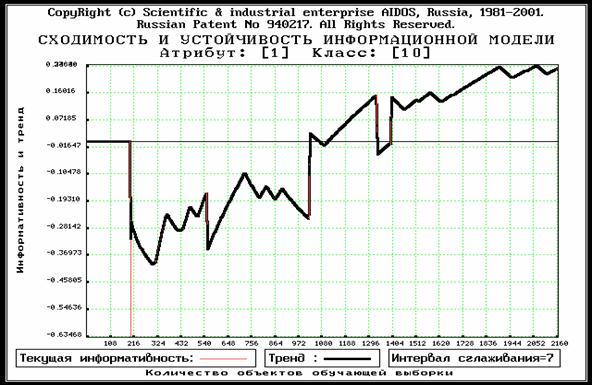
Как показали численные эксперименты и специально проведенные исследования, других сценариев на практике не наблюдается.
В любом случае при накоплении достаточно
большой статистики и сохранении закономерностей предметной области, отражаемых
обучающей выборкой, модель стабилизируется
в том смысле, что значения информативностей атрибутов перестают существенно
изменяться.
Это дает основание утверждать, что при достижении этого состояния добавление новых примеров из обучающей выборки не вносит в модель ничего нового в модель и процесс обучения продолжать нецелесообразно. Это и является одним из критериев для принятия решения об остановке процесса обучения.
1.2.2.3.3. Зависимость адекватности семантической информационной модели от объема обучающей выборки (адекватность при малых и больших выборках)
При экспериментальном исследовании свойств предлагаемой математической модели было установлено следующее (рисунок 35).
|
|
|
Рисунок 35. Зависимость адекватности модели от объема обучающей выборки |
1. При малых выборках адекватность модели (внутренняя интегральная и дифференциальная валидность) равна 100% (рисунок 35, диапазон "А"). Это можно объяснить тем, что при малых объемах выборки все выявленные закономерности имеют детерминистский характер.
2. При увеличении объема исследуемой выборки происходит понижение адекватности модели (переход: А®В) и стабилизация ее адекватности на некотором уровне около 95-98% (рисунок 35, диапазон "В").
3. Учет в модели объектов обучающей выборки, отражающих закономерности, качественно отличающиеся от ранее выявленных, приводит к понижению адекватности модели (переход: В®С) и ее стабилизации на уровне от 80 до 90% (рисунок 35, диапазон "С").
4. Внутри диапазона "В" вариабельность объектов обучающей выборки по закономерностям "атрибут®класс" меньше, чем в диапазоне "С", т.е. объекты обучающей выборки диапазона "В" более однородны, чем "С".
Выявленные в модели причинно-следственные закономерности имеют силу для определенного подмножества обучающей выборки, например, отражающих определенный период времени, который соответствует детерминистскому периоду развития предметной области. При качественном изменении закономерностей устаревшие данные могут даже на некоторое время (пока модель не сойдется к новым закономерностям) нарушать ее адекватность.
В многочисленных проведенных практических исследованных модель показала высокую скорость сходимости и высокую адекватность на малых выборках. На больших выборках (т.е. охватывающих несколько детерминистских и бифуркационных состояний предметной области) закономерности с коротким периодом "причина-следствие" переформировываются заново, а с длительным (охватывающим несколько детерминистских и бифуркационных состояний) – автоматически становятся незначимыми и не ухудшают адекватность модели, если процесс апериодический, или сохраняют силу, если они имеют фундаментальный характер.
Выявленные закономерности сходимости модели позволяют сформулировать следующий критерий остановки процесса обучения: если в модели ничего существенно не меняется при добавлении в обучающую выборку все новых и новых данных, то это означает, что модель адекватно отображает генеральную совокупность, к которой относятся эти данные, и продолжать процесс обучения нецелесообразно.
Здесь уместно рассмотреть ответ на следующий вопрос. Если для формирования образов классов распознавания предъявлено настолько малое количество обучающих объектов, что говорить об обобщении и статистике не приходится, то как это может повлиять на качество формирования модели и ее адекватность? При большой статистике, как показывает опыт, около 95% объектов, формирующих образ некоторого класса оказывается типичными для него, а остальные не типичными. Следовательно, если этот образ формируется на основе буквально одного - двух объектов, то вероятнее всего (т.е. с вероятностью около 95%) они являются типичными, и, следовательно, образ будет сформирован практически таким же, как и при большой статистике, т.е. правильным. При увеличении статистики в этом случае информативности признаков, составляющих образ практически не меняются). Но есть некоторая, сравнительно незначительная вероятность (около 5%), что попадется нетипичная анкета. Тогда при увеличении статистики образ быстро качественно изменится и "быстро сойдется" к адекватному, "нетипичная" анкета будет идентифицирована и ее данные либо будут удалены из модели, либо для нее специально будет создан свой класс.
При незначительной статистике относительный вклад каждого объекта в обобщенный образ некоторого класса, сформированный с его применением, будет достаточно велик. Поэтому в этом случае при распознавании модель уверенно относит объект к этому классу. При большой статистике модель также уверенно относит типичные объекты к классам, сформированным с их применением. Незначительное количество нетипичных объектов могут быть распознаны ошибочно, т.е. не отнесены моделью к тем классам, к которым их отнесли эксперты.
Наличие в системе очень сходных классов также может формально уменьшать валидность модели. Однако фактически эти очень сходные классы целесообразно объединить в один, т.к. по-видимому, их разделение объективно ничем не оправдано, т.е. не соответствует действительности. Для осуществления данной операции в математической модели целесообразно использовать режим: "Получение статистической характеристики обучающей выборки и объединение классов (ручной ремонт обучающей выборки)".
1.2.2.3.4. Семантическая устойчивость модели
Под семантической устойчивостью модели [64] нами понимается ее свойство давать малое различие в прогнозе при замене одних факторов, другими, мало отличающимися по смыслу (т.е. сходными по их влиянию на поведение АОУ). Проведенные автором исследования численные эксперименты в течение 1987 – 2003 годов показали, что разработанная математическая модель обладает очень высокой семантической устойчивостью.
1.2.2.3.5. Зависимость некоторых параметров модели от ее ортонормированности
Изучим зависимость уровня системности, степени детерминированности и адекватности модели от ее ортонормированности. В связи с тем, что соответствующий научно-исследовательский режим, позволяющий изучить эти зависимости методом численного эксперимента, на момент написания данной работы находится в стадии разработки, получим интересующие нас зависимости путем анализа выражений (3.9) и (3.25).
При этом будем различать ортонормированность модели по классам и ортонормированность по атрибутам.
Зависимость адекватности модели от ее ортонормированности
Модель изучалась методом численного эксперимента. При этом были получены следующие результаты.
На 1-м этапе ортонормирования адекватность модели (ее внутренняя дифференциальная и интегральная валидность) возрастает. Это можно объяснить тем, что, во-первых, уменьшается количество ошибок идентификации с близкими, т.е. коррелирующими классами, и, во-вторых, удаление из модели малоинформативных признаков по сути улучшает отношение "сигнал/шум" модели, т.е. качество идентификации.
На 2-м этапе ортонормирования адекватность модели стабилизируется и незначительно колеблется около максимума. Это объясняется тем, что атрибуты, удаляемые на этом этапе, не являются критическим для адекватности модели.
На 3-м этапе ортонормирования адекватность модели начинает уменьшаться, т.к. дальнейшее удаление атрибутов не позволяет адекватно описать предметную область.
При приближении процесса ортонормирования к 3-му этапу или его наступлении этот процесс должен быть остановлен.
Зависимость уровня системности модели от ее ортонормированности
Рассмотрим выражение (3.9):
|
|
(3.9) |
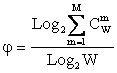
При выполнении операции ортонормирования по
классам из модели последовательно удаляются те из них, которые наиболее сильно
корреляционно связаны друг с другом. В результате в модели остаются классы
практически не коррелирующие, т.е. ортонормированные. Поэтому можно
предположить, что в результате
ортонормирования правила запрета на образование подсистем классов становятся
более жесткими, и уровень системности модели уменьшается.
Зависимость степени детерминированности модели от ее ортонормированности
Рассмотрим выражение (3.25):
|
|
(3.25) |
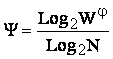
Так как каждый класс как правило описан более чем одним признаком, то при ортонормировании классов и удалении некоторых из них из модели суммарное количество признаков N будет уменьшаться быстрее, чем количество классов W, поэтому степень детерминированности будет возрастать.
При ортонормировании атрибутов числитель
выражения (3.25) не изменяется, а знаменатель уменьшается, поэтому и в этом
случае степень детерминированности
возрастает.
Таким
образом, ортонормирование модели
приводит к увеличению степени ее детерминированности.
По этой причине предлагается считать "детерменированностью" и "системностью" модели не их значения в текущем состоянии модели, а тот предел, к которому стремятся эти величины при корректном ортонормировании модели при достижении ею точки максимума адекватности.
1.2.2.4. Взаимосвязь математической модели СК-анализа с другими моделями
1.2.2.4.1. Взаимосвязь системной меры целесообразности информации со статистикой c2 и новая мера уровня системности предметной области
Статистика c2 представляет собой сумму вероятностей совместного наблюдения признаков и объектов по всей корреляционной матрице или определенным ее подматрицам (т.е. сумму относительных отклонений частот совместного наблюдения признаков и объектов от среднего):
|
|
где:
– Nij – фактическое количество встреч i-го признака у объектов j-го класса;
– t – ожидаемое количество встреч i-го признака у объектов j-го класса.
|
|

Отметим, что статистика c2 математически связана с количеством информации в системе признаков о классе распознавания, в соответствии с системным обобщением формулы Харкевича для плотности информации (3.28)
|
|
а именно из (3.58) и (3.59) получаем:
|
|
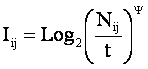
Из (3.60) очевидно:
|
|
Сравнивая выражения (3.57) и (3.61), видим, что числитель в выражении (3.57) под знаком суммы отличается от выражения (3.61) только тем, что в выражении (3.61) вместо значений Nij и t взяты их логарифмы. Так как логарифм является монотонно возрастающей функцией аргумента, то введение логарифма не меняет общего характера поведения функции.
Фактически это означает, что:
|
|
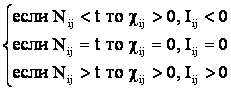
Если фактическая вероятность наблюдения i–го признака при предъявлении объекта j–го класса равна ожидаемой (средней), то наблюдение этого признака не несет никакой информации о принадлежности объекта к данному классу. Если же она выше средней – то это говорит в пользу того, что предъявлен объект данного класса, если же ниже – то другого.
Поэтому наличие статистической связи (информации) между признаками и классами распознавания, т.е. отличие вероятностей их совместных наблюдений от предсказываемого в соответствии со случайным нормальным распределением, приводит к увеличению фактической статистики c2 по сравнению с теоретической величиной.
Из этого следует возможность использования в качестве количественной меры степени выраженности закономерностей в предметной области не матрицы абсолютных частот и меры c2, а новой меры H, основанной на матрице информативностей и системном обобщении формулы Харкевича для количества информации:
|
|
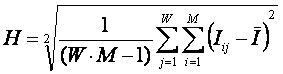
где:
|
|
– средняя информативность признаков по матрице информативностей. |
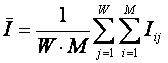
Меру H в выражении (3.63) предлагается назвать обобщенным критерием сформированности модели Харкевича.
Значение данной меры показывает среднее отличие количества информации в факторах о будущих состояниях активного объекта управления от среднего количества информации в факторе (которое при больших выборках близко к 0). По своей математической форме эта мера сходна с мерами для значимости факторов и степени сформированности образов классов и коррелирует с объемом пространства классов и пространства атрибутов.
Описанная выше
математическая модель обеспечивает инвариантность результатов ее синтеза
относительно следующих параметров обучающей выборки: суммарное количество и порядок ввода анкет
обучающей выборки; количество анкет обучающей выборки по каждому
классу распознавания; суммарное количество
признаков во всех анкетах обучающей выборки; суммарное
количество признаков по эталонным описаниям различных классов распознавания; количество признаков
и их порядок в отдельных анкетах обучающей выборки.
Это обеспечивает высокое качество решения задач системой распознавания на неполных и разнородных (в вышеперечисленных аспектах) данных как обучающей, так и распознаваемой выборки, т.е. при таких статистических характеристиках потоков этих данных, которые чаще всего и встречается на практике и которыми невозможно или очень сложно управлять.
1.2.2.4.2. Сравнение, идентификация и прогнозирование как разложение векторов объектов в ряд по векторам классов (объектный анализ)
В разделе 3.2.3 были введены неметрические интегральные критерии сходства объекта, описанного массивом-локатором Li с обобщенными образами классов Iij (выражения 3.35 – 3.37)
В выражении (3.64) круглыми скобками обозначено скалярное произведение. В координатной форме это выражение имеет вид:
|
|
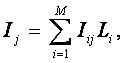 ,
,где:
![]() – вектор j–го
состояния объекта управления;
– вектор j–го
состояния объекта управления;
![]() – вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
– вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:

Для непрерывного случая выражение (3.65) принимает вид:
|
|
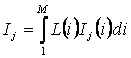
Таким образом, выражение (3.66) представляет собой вариант выражения (3.65) интегрального критерия сходства объекта и класса для непрерывного случая в координатной форме.
Интересно и очень важно отметить, что коэффициенты ряда Фурье по своей
математической форме и смыслу сходны с ненормированными коэффициентами
корреляции, т.е. по сути скалярными произведениями для непрерывных функций в
координатной форме: выражение (3.66), между разлагаемой в ряд кривой f(x) и
функциями Sin и Сos различных частот и амплитуд на отрезке [–L, L] [3]:
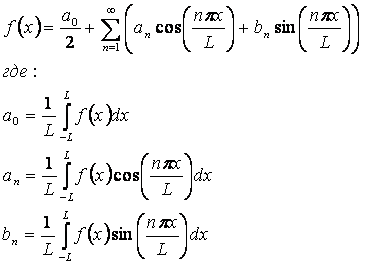
где: n={1, 2, 3,…} – натуральное число.
Из сравнения выражений (3.66) и (3.67) следует вывод, что процесс идентификации и прогнозирования (распознавания), реализованный в предложенной математической модели, может рассматриваться как разложение вектора-локатора распознаваемого объекта в ряд по векторам информативностей классов распознавания (которые представляют собой произвольные функции, сформированные при синтезе модели на основе эмпирических данных).
Например, при результатах идентификации, представленных на рисунке 36.
|
|
|
Рисунок 36. Пример разложения профиля курсанта усл.№69 |
Продолжая развивать аналогию с разложением в ряд, данный результат идентификации можно представить в векторной аналитической форме:
|
|
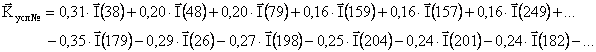
Или в координатной форме, более удобной для численных расчетов:
|
|
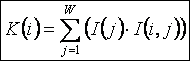
где:
I(j) – интегральный критерий сходства массива-локатора, описывающего состояние объекта, и j-го класса, рассчитываемый согласно выражения (3.39):
|
|
(3.39) |
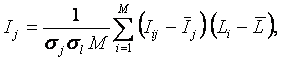
I(i,j) – вектор обобщенного образа j-го класса, координаты которого рассчитываются в соответствии с системным обобщением формулы Харкевича (3.28):
|
|
(3.28) |

Примечание: обозначения I(i,j) и Iij, и т.п. эквивалентны. Смысл всех переменных, входящих в выражения (3.28) и (3.39) раскрыт в разделе 3.1.3 данной работы.
При дальнейшем развитии данной аналогии естественно возникают вопросы: о полноте, избыточности и ортонормированности системы векторов классов как функций, по которым будет вестись разложение вектора объекта; о сходимости, т.е. вообще возможности и корректности такого разложения.
В общем случае вектор объекта совершенно не обязательно должен разлагаться в ряд по векторам классов таким образом, что сумма ряда во всех точках точно совпадала со значениям исходной функции. Это означает, что система векторов классов может быть неполна по отношению к профилю распознаваемого объекта, и, тем более, всех возможных объектов.
Предлагается
считать не разлагаемые в ряд, т.е. плохо распознаваемые объекты, суперпозицией хорошо распознаваемых объектов ("похожих" на те, которые
использовались для формирования обобщенных образов классов), и объектов,
которые и не должны распознаваться, так как объекты этого типа не встречались в обучающей выборке и не
использовались для формирования обобщенных образов классов, а также не
относятся к представляемой обучающей выборкой генеральной совокупности.
Нераспознаваемую компоненту можно рассматривать либо как шум, либо считать ее полезным сигналом, несущим ценную информацию о еще не исследованных объектах интересующей нас предметной области (в зависимости от целей и тезауруса исследователей). Первый вариант не приводит к осложнениям, так как примененный в математической модели алгоритм сравнения векторов объектов и классов, основанный на вычислении нормированной корреляции Пирсона (сумма произведений), является весьма устойчивым к наличию белого шума в идентифицируемом сигнале. Во втором варианте необходимо дообучить систему распознаванию объектов, несущих такую компоненту (в этой возможности и заключается адаптивность модели). Технически этот вопрос решается просто копированием описаний плохо распознавшихся объектов из распознаваемой выборки в обучающую, их идентификацией экспертами и дообучением системы. Кроме того, может быть целесообразным расширить справочник классов распознавания новыми классами, соответствующими этим объектам.
Но на практике гораздо чаще наблюдается противоположная ситуация (можно даже сказать, что она типична), когда система векторов избыточна, т.е. в системе классов распознавания есть очень похожие классы (между которыми имеет место высокая корреляция, наблюдаемая в режиме: "кластерно-конструктивный анализ"). Практически это означает, что в системе сформировано несколько практически одинаковых образов с разными наименованиями. Для исследователя это само по себе является очень ценной информацией. Однако, если исходить только из потребности разложения распознаваемого объекта в ряд по векторам классов (чтобы определить суперпозицией каких образов он является, т.е. "разложить его на компоненты"), то наличие сильно коррелирующих друг с другом векторов представляется неоправданным, так как просто увеличивает размерности данных, внося в них мало нового по существу. Поэтому возникает задача исключения избыточности системы классов распознавания, т.е. выбора из всей системы классов распознавания такого минимального их набора, в котором профили классов минимально коррелируют друг с другом, т.е. ортогональны в фазовом пространстве признаков. Это условие в теории рядов называется "ортонормируемостью" системы базовых функций, а в факторном анализе связано с идеей выделения "главных компонент".
В предлагаемой математической модели релизованы два варианта выхода из данной ситуации:
1) исключение неформирующихся, расплывчатых классов;
2) объединение почти идентичных по содержанию (дублирующих друг друга) классов.
Но выбрать нужный вариант и реализовать его, используя соответствующие режимы, пользователь технологии АСК-анализа должен сам. Вся необходимая и достаточная информация для принятия соответствующих решений предоставляется пользователю инструментария АСК-анализа.
Если считать, что функции образов составляют формально–логическую систему, к которой применима теорема Геделя, то можно сформулировать эту теорему для данного случая следующим образом: "Для любой системы базисных функций в принципе всегда может существовать по крайней мере одна такая функция, что она не может быть разложена в ряд по данной системе базисных функций, т.е. функция, которая является ортонормированной ко всей системе базисных функций в целом".
Очевидно, не взаимосвязанными друг с другом могут быть только четко оформленные, детерминистские образы, т.е. образы с высокой степенью редукции ("степень сформированности конструкта"). Поэтому в процессе выявления взаимно–ортогональных базисных образов в первую очередь будут выброшены аморфные "расплывчатые" образы, которые связаны практически со всеми остальными образами.
В некоторых случаях результат такого процесса представляет интерес и это делает оправданным его реализацию. Однако можно предположить, что и наличие расплывчатых образов в системе является оправданным, так как в этом случае система образов не будет формальной и подчиняющейся теореме Геделя, следовательно, система распознавания будет более полна в том смысле, что повысится вероятность идентификации любого объекта, предъявленного ей на распознавание. Конечно, уровень сходства с аморфным образом не может быть столь же высоким, как с четко оформленным, поэтому в этом случае может быть более уместно применить термин "ассоциация" или нечеткая, расплывчатая идентификация, чем "однозначная идентификация".
Итак, можно сделать следующий вывод:
допустимость в математической модели СК-анализа не только четко оформленных (детерминистских)
образов, но и образов аморфных, нечетких, расплывчатых является важным достоинством
данной модели. Это обусловлено тем, что данная модель обеспечивает корректные
результаты анализа, идентификации и прогнозирования даже в тех случаях, когда
модели идентификации и информационно–поисковые системы детерминистского типа
традиционных АСУ практически неработоспособны. В этих условиях данная модель
СК-анализа работает как система ассоциативной (нечеткой) идентификации.
Таким
образом, в предложенной семантической информационной модели при идентификации и
прогнозировании по сути дела осуществляется разложение векторов
идентифицируемых объектов по векторам классов распознавания, т.е. осуществляется "объектный анализ" (по аналогии с спектральным, гармоническим или Фурье–анализом), что позволяет рассматривать идентифицируемые объекты как суперпозицию обобщенных образов классов
различного типа с различными амплитудами (3.68). При этом вектора обобщенных образов
классов с математической точки зрения представляют собой произвольные функции,
и не обязательно образуют полную и не избыточную (ортонормированную) систему
функций.
Для любого объекта всегда существует такая система базисных функций, что вектор объекта может быть представлен в форме линейной суперпозиции (суммы) этих базисных функций с различными амплитудами. Это утверждение, по-видимому, является одним из следствий фундаментальной теоремы А.Н.Колмогорова, доказанной им в 1957 году (О представлении непрерывных функций нескольких переменных в виде суперпозиций непрерывных функций одного переменного и сложения // Докл. АН СССР, том 114, с. 953-956, 1957).
Теорема Колмогорова: Любая непрерывная функция от n переменных F(x1, x2, ..., xn) может быть представлена в виде:
|
|
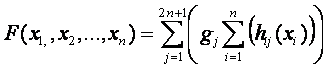
где gj и hij – непрерывные функции, причем hij не зависят от функции F.
Эта теорема означает, что для реализации функций многих переменных достаточно операций суммирования и композиции функций одной переменной. Удивительно, что в этом представлении лишь функции gj зависят от представляемой функции F, а функции hij универсальны. Необходимо отметить, что терема Колмогорова является обобщением теоремы В.И.Арнольда (1957), которая дает решение 13-й проблемы Гильберта.
К сожалению определение вида функций hij и gj для данной функции F представляет собой математическую проблему, для которой пока не найдено общего строгого решения.
В данной работе предлагается рассматривать предлагаемую
семантическую информационную модель как один из вариантов решения этой
проблемы. В этом контексте функция F интерпретируется как образ
идентифицируемого объекта, функция hij – как образ j-го класса, а
функция gj – как мера сходства образа объекта с образом класса.
1.2.2.4.3. Системно-когнитивный и факторный анализ. СК-анализ, как метод вариабельных контрольных групп
В науке широко известен "метод контрольных групп" (терм. авт.), позволяющий оценить влияние некоторого фактора на исследуемую группу по сравнению с контрольной, на которую он не влияет.
Обобщением метода контрольных групп является полный и дробный факторный анализ, при котором исследуется не одна контрольная группа, а столько, сколько факторов. При этом в каждой группе исследуется влияние одного фактора при остальных фиксированных. Таким образом факторный анализ можно было бы назвать "методом фиксированных контрольных групп". Факторный анализ требует проведения специально организованных экспериментов, что представляет собой проблему даже при нескольких факторах при большой длительности цикла управления (которая в АПК может составлять до десяти лет и более).
Например, для сбора исходных данных в факторном эксперименте при 3 факторах с 10 градациями каждый необходимо провести 103=1000 экспериментов. На практике это редко осуществимо.
Поэтому перед проведением факторного эксперимента обычно выбирают небольшое количество наиболее значимых или интересных факторов для исследования. Вопрос о том, какие факторы исследовать, решается самим исследователем на основе неформальных методов.
СК-анализ является обобщением метода факторного анализа в том смысле, что контрольные группы отличаются не значениями одного фактора при остальных фиксированных, а в общем случае различными комбинациями значений действующих факторов. СК-анализ позволяет выявлять и корректно исследовать влияние тысяч факторов на объект управления на основе непосредственно эмпирических данных, причем неполных и неупорядоченных, как в факторном эксперименте. При этом определяется и значимость факторов, что позволяет обоснованно выбрать из них небольшое количество наиболее значимых для последующего более детального исследования методом факторного анализа. Необходимо отметить, что СК-анализ является непараметрическим методом, в отличие от факторного анализа.
1.2.2.4.4. Семантическая мера целесообразности информации и эластичность
Эластичность в непрерывном случае
Рассмотрим связь эластичности и семантической меры целесообразности информации, опираясь на результаты работы автора [64, 98]. Пусть численное значение некоторого параметра экономической системы описывается переменной y, зависящей от фактора x и эта зависимость описывается функцией y=f(x). Тогда степень и направление влияния фактора x на параметр y можно численно измерить производной (3.69), представляющей собой предел отношения абсолютных изменений величин y и x:
|
|
(3. 69) |
Однако применение производной не очень удобно, т.к. она зависит от размерности величин y и x и, по этой причине, обладает недостаточной сопоставимостью в пространстве и времени. Кроме того, сама по себе скорость абсолютного изменения некоторого параметра объекта безотносительно к средней величине этого параметра, содержит недостаточно информации об этом объекте. Например, если на очередных выборах за некоторого кандидата отдано на 500 голосов больше, чем на предыдущих, то важно знать, а на сколько это процентов больше. Поэтому в экономике введено понятие эластичности Ex(y) функции y=f(x), которое определяется как предел отношения не абсолютных, а относительных изменений значений переменных y и x:
|
|
(3. 70) |

Так как ![]() , и
, и ![]() , то эластичность можно представить в виде логарифмической
производной:
, то эластичность можно представить в виде логарифмической
производной:
|
|
(3. 71) |
Эластичность в дискретном случае
Для численных расчетов необходимо перейти к дискретному случаю, в частности для численного взятия производных используем метод конечных разностей. В конечных разностях выражение (3) принимает вид:
|
|
(3. 72) |
Свойства эластичности
Рассмотрим некоторые свойства эластичности, которые, как мы заметили, удивительным образом полностью или частично совпадают со свойствами логарифма (таблица 21).
Таблица 21 – СВОЙСТВА ЭЛАСТИЧНОСТИ И ЛОГАРИФМА
|
№ |
ЭЛАСТИЧНОСТЬ |
ЛОГАРИФМ |
Примечание |
|
1 |
Эластичность
взаимно-обратной функции взаимно-обратна:
|
Логарифм взаимно-обратной
функции равен той же функции с обратным знаком:
|
Совпадает по модулю (с
точностью до знака) |
|
2 |
Эластичность произведения
двух функций одного аргумента равна сумме эластичностей функций:
|
Логарифм произведения двух
функций одного аргумента равна сумме логарифмов функций:
|
Полностью совпадает |
|
3 |
Эластичность частного двух
функций одного аргумента равна разности эластичностей функций:
|
Логарифм частного двух
функций одного аргумента равна разности логарифмов функций:
|
Полностью совпадает |
|
4 |
Эластичность показательной
функции
|
Логарифм показательной
функции
|
Полностью совпадает |
|
5 |
Область значений эластичности:
|
Область значений логарифма:
|
Полностью совпадает |
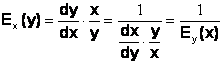
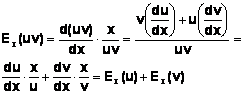
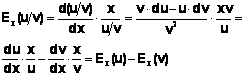
Необходимо отметить, что ряд других свойств эластичности, таких как эластичность суммы функций, эластичность линейной функции и др., не совпадают со свойствами логарифма. Итак, учитывая свойства эластичности 2-5 (таблица 21) мы видим, что большинство свойств эластичности совпадают со свойствами логарифмической функции. Это позволяет высказать гипотезу, что свойства эластичности Ex(y) схожи со свойствами количества информации I, т.к. во все выражения для количества информации Хартли-Найквиста-Больцмана, Шеннона и Харкевича входит логарифмическая функция.
Какая же из этих мер информации в наибольшей степени соответствует понятию эластичности? Ключевым в решении этого вопроса является свойство 5 (таблица 21):
– область значений мер Хартли-Найквиста-Больцмана
и Шеннона изменяется от 0 до ![]() ;
;
– область значений меры Харкевича, как и
эластичности, изменяется от ![]() до
до ![]() , как и эластичности.
, как и эластичности.
Однако классическая мера семантической целесообразности информации мера Харкевича не удовлетворяет принципу соответствия с мерой Хартли в детерминистском случае, поэтому автором данной работы в [64] предложена системная мера целесообразности информации (СМЦИ) – Iij(W,M). В отличие от эластичности Ex(y), которая определена для однозначной функции одного аргумента, Iij(W,M) определена для многозначной функции многих аргументов.
Таким образом, системная мера целесообразности информации, предложенная в настоящем исследовании, имеет математические свойства сходные со свойствами эластичности многозначной функции многих аргументов.
1.2.2.4.5. Связь семантической информационной модели с нейронными сетями
В 1943 году Дж. Маккалоки и У. Питт
предложили формальную модель биологического нейрона как устройства, имеющего
несколько входов (входные синапсы – дендриты), и один выход (выходной синапс –
аксон). Дендриты получают информацию от источников информации (рецепторов) Li, в качестве которых могут
выступать и нейроны. Набор входных сигналов {Li} характеризует объект или ситуацию, обрабатываемую
нейроном. Каждому i-му входу j-го нейрона ставится в соответствие некоторый
весовой коэффициент Iij,
характеризующий степень влияния сигнала с этого входа на аргумент передаточной
(активационной) функции, определяющей сигнал Yj на выходе нейрона. В нейроне происходит взвешенное суммирование входных сигналов, и далее
это значение используется как аргумент
активационной (передаточной) функции нейрона. На рисунке 37 данная модель
приведена в обозначениях, принятых в настоящей
работе.
|
|
|
Рисунок 37. Классическая модель нейрона Дж. Маккалоки и У. Питта (1943) в обозначениях системной теории информации |
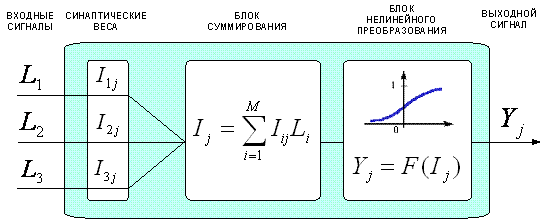
Метафора нейросетевого представления семантической информационной модели
В данной работе предлагается представление, согласно которому каждый нейрон отражает определенное будущее состояние активного объекта управления, а нейронная сеть в целом – систему будущих состояний, как желательных (целевых), так и нежелательных. Весовые коэффициенты на дендридах нейронов имеют смысл силы и направления влияния факторов на переход активного объекта управления в то или иное будущее состояние. Таким образом, предложенная в данной работе семантическая информационная модель в принципе допускает представление в терминах и понятиях нейронных сетей. Однако при более детальном рассмотрении выясняется, что семантическая информационная модель является более общей, чем нейросетевая и для полного их соответствия необходимо внести в нейросетевую модель ряд дополнений.
Соответствие основных терминов и понятий
Предлагается следующая система соответствий, позволяющая рассматривать термины и понятия из теории нейронных сетей и предложенной семантической информационной модели практически как синонимы. Нейрон – вектор обобщенного образа класса в матрице информативностей. Входные сигналы – факторы (признаки). Весовой коэффициент – системная мера целесообразности информации. Обучение сети – адаптация модели, т.е. перерасчет значений весовых коэффициентов дендридов для каждого нейрона (матрицы информативностей) и изменение вида активационной функции. Самоорганизация сети – синтез модели, т.е. изменение количества нейронов и дендридов, изменение количества нейронных слоев и структуры связей между факторами и классами, а затем адаптация (перерасчет матрицы информативностей). Таким образом, адаптация – это обучение сети на уровне изменения информационных весовых коэффициентов и активационной функции, а синтез – на уровне изменения размерности и структуры связей нейронов сети. 1-й (входной) слой нейронной сети – формирование обобщенных образов классов. Сети Хопфилда и Хэмминга – обучение с учителем, сопоставление описательной и классификационной информации, идентификация и прогнозирование. 2-й слой, сети Хебба и Кохонена – самообучение, анализ структуры данных без априорной классификационной информации, формирование кластеров классов и факторов. 3-й слой – формирование конструктов (в традиционных нейронных сетях не реализовано). Необходимо отметить, что любой слой нейронной сети является в предлагаемой модели не только обрабатывающим, но и выходным, т.е. с одной стороны дает результаты обработки информации, имеющие самостоятельное значение, а с другой – поставляет информацию для последующих слоев нейронной сети, т.е. более высоких уровней иерархии информационной системы (в полном соответствии с формализуемой когнитивной концепцией).
Недостатки нейронных сетей и пути их преодоления в семантической информационной модели
К основным недостаткам нейронных сетей можно отнести:
1. Сложность содержательной интерпретации смысла интенсивности входных сигналов и весовых коэффициентов ("проблема интерпретируемости весовых коэффициентов").
2. Сложность содержательной интерпретации и обоснования аддитивности аргумента и вида активационной (передаточной) функции нейрона ("проблема интерпретируемости передаточной функции").
3. "Комбинаторный взрыв",
возникающий при определении структуры связей нейронов, подборе весовых
коэффициентов и передаточных функций ("проблема
размерности").
Проблемы интерпретируемости приводят к снижению ценности полученных результатов работы сети, а проблема размерности – к очень жестким ограничениям на количество выходных нейронов в сети, на количество рецепторов и на сложность структуры взаимосвязей нейронов с сети. Достаточно сказать, что количество выходных нейронов в реальных нейронных сетях, реализуемых на базе известных программных пакетов, обычно не превышает несколько сотен, а чаще всего составляет единицы и десятки.
Гипотеза о нелокальности нейрона и информационная нейросетевая парадигма
Модель нелокального нейрона: так как сигналы на дендридах различных нейронов вообще говоря коррелируют (или антикоррелируют) друг с другом, то, значения весовых коэффициентов, а значит и выходное значение на аксоне каждого конкретного нейрона вообще говоря не могут быть определены с использованием значений весовых коэффициентов на дендридах только данного конкретного нейрона, а должны учитывать интенсивности сигналов на всей системе дендридов нейронной сети в целом (рисунок 38).
|
|
|
Рисунок 38. Модель нелокального нейрона в обозначениях системной теории информации |
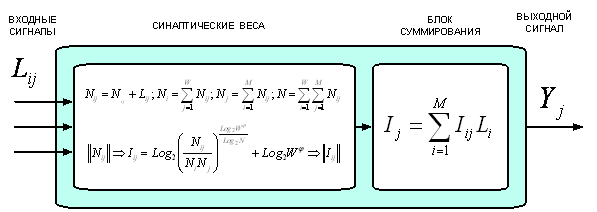
За счет учета корреляций входных сигналов (если они фактически присутствуют в структуре данных), т.е. наличия общего самосогласованного информационного поля исходных данных всей нейронной сети (информационное пространство), нелокальные нейроны ведут себя так, как будто связаны с другими нейронами, хотя могут быть и не связаны с ними синаптически по входу и выходу ни прямо, ни опосредованно. Самосогласованность семантического информационного пространства означает, что учет любого одного нового факта в информационной модели вообще говоря приводит к изменению всех весовых коэффициентов всех нейронов, а не только тех, на рецепторе которых обнаружен этот факт и тех, которые непосредственно или опосредованно синаптически с ним связаны.
В традиционной (т.е. локальной) модели нейрона весовые коэффициенты на его дендридах однозначно определяются заданным выходом на его аксоне и никак не зависят от параметров других нейронов, с которыми с нет прямой или опосредованной синаптической связи. Это связано с тем, что в общепринятой энергетической парадигме Хопфилда весовые коэффициенты дендридов имеют смысл интенсивностей входных воздействий. В методе "обратного распространения ошибки" процесс переобучения, т.е. интерактивного перерасчета весовых коэффициентов, начинается с нейрона, состояние которого оказалось ошибочным и захватывает только нейроны, ведущие от рецепторов к данному нейрону. Корреляции между локальными нейронами обусловлены сочетанием трех основных причин:
– наличием в исходных данных определенной структуры: корреляцией входных сигналов;
– синаптической связью локальных нейронов;
– избыточностью (дублированием) нейронной сети.
Решение проблемы интерпретируемости весовых коэффициентов (семантическая мера целесообразности информации и закон Фехнера)
В данной работе предлагается использовать такие весовые коэффициенты дендридов, чтобы активационная функция была линейной, т.е. по сути была равна своему аргументу: сумме. Этому условию удовлетворяют весовые коэффициенты, рассчитываемые с применением системного обобщения формулы Харкевича (3.28).
Очень важно, что данная мера, удовлетворяет известному эмпирическому закону Г.Фехнера (1860), согласно которому существует логарифмическая зависимость между интенсивностью фактора и величиной отклика на него биологической системы (в частности, величина ощущения прямо пропорциональна логарифму интенсивности раздражителя).
Предлагается информационный подход к нейронным сетям, по аналогии с энергетическим подходом Хопфилда (1980).
Суть этого подхода состоит в том, что интенсивности входных сигналов рассматриваются не сами по себе и не с точки зрения только их интенсивности, а как сообщения, несущие определенное количество информации или дезинформации о переходе нейрона и моделируемого им активного объекта управления в некоторое будущее состояние.
Под интенсивностью входного сигнала на
определенном дендриде мы будем понимать абсолютную частоту (количество) встреч фактора (признака),
соответствующего данному дендриду, при предъявлении нейронной сети объекта,
соответствующего определенному нейрону. Таким образом матрица абсолютных частот
рассматривается как способ накопления и первичного обобщения эмпирической
информации об интенсивностях входных сигналов на дендридах в разрезе по нейронам.
Весовые коэффициенты, отражающие влияние каждого входного сигнала
на отклик каждого нейрона, т.е. величину его возбуждения или торможения,
представляют собой элементы матрицы информативностей, получающиеся из матрицы
абсолютных частот методом прямого счета с
использованием выражения для семантической меры целесообразности информации
(3.28).
При этом предложенная мера семантической целесообразности информации, как перекликается с нейронными сетями Кохонена, в которых также принято стандартизировать (нормализовать) входные сигналы, что позволяет в определенной мере уйти от многообразия передаточных функций.
Наличие ясной и обоснованной интерпретации весовых коэффициентов, как количества информации, позволяет предложить в качестве математической модели для их расчета системную теорию информации (СТИ).
Семантическая информационная модель, как нелокальная нейронная сеть
Учитывая большое количество содержательных параллелей между семантической информационной моделью и нейронными сетями предлагается рассматривать данную модель как нейросетевую модель, основанную на системной теории информации. В данной модели предлагается вариант решения важных нейросетевых проблем интерпретируемости и ограничения размерности за счет введения меры целесообразности информации (системное обобщение формулы Харкевича), обеспечивающей прямой расчет интерпретируемых весовых коэффициентов на основе непосредственно эмпирических данных. Итак, в данной работе предлагается новый класс нейронных сетей, основанных на семантической информационной модели и информационном подходе. Для этих сетей предлагается полное наименование: "Нелокальные интерпретируемые нейронные сети прямого счета" и сокращенное наименование: "Нелокальные нейронные сети".
Нелокальная нейронная сеть является системой нелокальных нейронов, обладающей качественно новыми (системными, эмерджентными) свойствами, не сводящимися к сумме свойств нейронов. В такой сети поведение нейронов определяется как их собственными свойствами и поступающими на них входными сигналами, так и свойствами нейронной сети в целом, т.е. поведение нейронов в нелокальной нейронной сети согласовано друг с другом не только за счет их прямого и опосредованного синаптического взаимодействия (как в традиционных нейронных сетях), но за счет общего информационного поля весовых коэффициентов всех нейронов данной сети.
Гипотеза о физической природе нелокального взаимодействия нейронов в нелокальной нейронной сети
В данной работе предлагается математическая модель, численный метод и программный инструментарий нелокальных нейронных сетей (универсальная когнитивная аналитическая система "Эйдос"), успешно апробированные в ряде предметных областей. Данная система обеспечивает неограниченное количество слоев ННС при максимальном количестве весовых коэффициентов в слое до 16 миллионов (в текущей версии 9.0) и до 4000 выходных нейронов. Но если рассматривать нелокальную нейронную сеть как модель реальных "биологических" нейронных сетей, то ясно, что формальной модели недостаточно и необходимо дополнить ее физической моделью о природе каналов нелокального взаимодействия нейронов в данной сети. По мнению автора данный механизм основан на парадоксе Эйнштейна-Подольского Розена (ЭПР) [165, 219]. По мнению автора, физическая реализация нелокальных нейронов может быть осуществлена за счет соединения как минимум одного дендрида каждого нейрона с датчиком микротелекинетического воздействия, на который человек может оказывать влияние дистанционно. Некоторые из подобных датчиков описаны в работе [165]. По мнению автора, квантовые компьютеры, основанные не на математических и программных моделях, а на физических нелокальных нейронах, могут оказаться во многих отношениях функционально эквивалентными физическому организму.
Решение проблемы интерпретируемости передаточной функции
Вопрос об интерпретируемости передаточной функции нейрона включает два основных аспекта:
– об интерпретируемости аргумента передаточной функции;
– об интерпретируемости вида передаточной функции.
1. Возникает естественный вопрос о том, чем обосновано включение в состав модели нейрона Дж. Маккалоки и У. Питтом именно аддитивного элемента, суммирующего входные сигналы, а не скажем мультипликативного или в виде функции общего вида. По мнению автора такой выбор обоснован и имеет явную и убедительную интерпретацию именно в том случае, когда весовые коэффициенты имеют смысл количества информации, т.к. в этом случае данная мера представляет собой неметрический критерий сходства (3.37), основанный на лемме Неймана-Пирсона. Сумма весовых коэффициентов, соответствующих набору действующих факторов (входных сигналов) дает величину выходного сигнала на аксоне каждого нейрона.
2. Вид передаточной функции содержательно в теории нейронных сетей явно не обосновывается. Предлагается гипотеза, что на практике вид передаточной функции подбирается таким образом, чтобы соответствовать смыслу подобранных в данном конкретном случае весовых коэффициентов. Так как при применении в различных предметных областях смысл весовых коэффициентов в явном виде не контролируется и может отличаться, то выбор вида передаточной функции позволяет частично компенсировать эти различия.
Предлагаемый интерпретируемый вид весовых коэффициентов обеспечивает единую и стандартную интерпретацию аргумента и значения передаточной функции независимо от предметной области. Поэтому в нелокальной нейронной модели передаточная функция нейрона всегда линейна (аргумент равен функции). Следовательно в модели нелокального нейрона блок суммирования по сути дела объединен с блоком нелинейного преобразования (точнее, второй отсутствует, а его роль выполняет блок суммирования), в отличие от стандартных передаточных функций локальных нейронов: логистической, гиперболического тангенса, пороговой линейной, экспоненциально распределенной, полиномиальной и импульсно-кодовой.
Нелокальные нейроны как бы "резонируют" на ансамбли входных сигналов, причем этот резонанс может быть обоснованно назван семантическим (смысловым), т.к. весовые коэффициенты рассчитаны на основе предложенной семантической меры целесообразности информации. Таким образом, разложение вектора идентифицируемого объекта в ряд по векторам обобщенных образов классов осуществляется на основе семантического резонанса нейронов выходного слоя на ансамбль входных сигналов (признаков, факторов).
Решение проблемы размерности
Вместо итерационного подбора весовых коэффициентов путем полного перебора вариантов их значений при малых вариациях (методы обратного распространения ошибки и градиентного спуска к локальному экстремуму) предлагается прямой расчет этих коэффициентов на основе процедуры и выражений, обоснованных в предложенных системной теории информации и семантической информационной модели. Выигрыш во времени и используемых вычислительных ресурсах, получаемый за счет этого, быстро возрастает при увеличении размерности нейронной сети.
Моделирование причинно-следственных цепочек в нейронных сетях и семантической информационной модели
Факторы описывают причины, а классы – следствия. Но и следствия в свою очередь являются причинами более отдаленных последствий. Предлагаемая семантическая информационная модель позволяет рассматривать события, обнаружение которых осуществляется в режиме идентификации, как причины последующих событий, т.е. как факторы, их вызывающие. При этом факт наступления этих событий моделируется путем включения в модель факторов, соответствующих классам (событиям). В нейронных сетях этот процесс моделируется путем включения в сеть дополнительных нейронных слоев и создания обратных связей между слоями, обеспечивающих передачу в предыдущие слои результатов работы последующих слоев.
Моделирование иерархических структур обработки информации
Рассмотрим иерархическую структуру информации на примере использования психологического теста для оценки психологических качеств сотрудников и влияния этих качеств на эффективность работы фирмы. В нейронной сети иерархическим уровням обработки информации соответствуют слои, поэтому далее будем использовать термины "слой нейронной сети" и "иерархический уровень обработки информации" как синонимы. Рецепторы дают информацию по ответам сотрудника на опросник, нейроны 1-го слоя дают оценку психологических качеств и сигнал с их аксонов является входным для нейронов 2-го слоя, дающих оценку качества работы фирмы. В семантической информационной модели существует три варианта моделирования подобных иерархических структур обработки информации:
1. Заменить все слои одним слоем и выявлять зависимости непосредственно между исходными данными с первичных рецепторов и интересующими итоговыми оценками, например, ответами сотрудников на вопросы и результатами работы фирмы. Этот подход эффективен с прагматической точки зрения, но дает мало информации для теоретических обобщений.
2. Каждый слой моделируется отдельной семантической информационной моделью, включающей свои классификационные и описательные шкалы и градации, обучающую выборку, матрицы абсолютных частот и информативностей. Вся система иерархической обработки информации моделируется системой этих моделей, взаимосвязанных друг с другом по входу-выходу: результаты классификации объектов обучающей выборки 1-й моделью рассматриваются как свойства этих объектов во 2-й модели, в которой они используются для классификации 2-го уровня. Например, психологические качества сотрудников, установленные в результате психологического тестирования, рассматриваются как свойства сотрудников, влияющие на эффективность работы фирмы. Данный подход эффективен и с прагматической, и с теоретической точек зрения, но является громоздким в программной реализации.
3. Моделирование каждого слоя соответствующими подматрицами матриц абсолютных частот и информативностей (таблица 22).
Таблица 22 – ЛОГИЧЕСКАЯ МОДЕЛЬ СТРУКТУРЫ ДАННЫХ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ, СООТВЕТСТВУЮЩАЯ ТРЕХСЛОЙНОЙ НЕЛОКАЛЬНОЙ НЕЙРОННОЙ СЕТИ
|
Рецепторы – факторы, влияющие на поведение объекта управления |
Нейроны - будущие состояния
объекта управления |
Дифференцирующая способность входного сигнала |
||
|
Нейроны 1-го слоя: психологические качества сотрудников |
Нейроны 2-го слоя: успешность деятельности сотрудника |
Нейроны 3-го слоя: успешность деятельности фирмы |
||
|
Рецепторы 1-го слоя: ответы сотрудников на вопросы анкеты |
Весовые коэффициенты 1-го слоя |
– – – |
– – – |
|
|
Рецепторы 2-го слоя: психологические качества сотрудников |
– – – |
Весовые коэффициенты 2-го слоя |
– – – |
|
|
Рецепторы 3-го слоя: успешность деятельности сотрудника |
– – – |
– – – |
Весовые коэффициенты 3-го слоя |
|
|
Степень обученности нейрона |
|
|
|
Степень обученности нейронной сети |
Этот вариант обладает преимуществами первых двух и преодолевает их недостатки. В нем применяется следующий итерационный алгоритм послойного расчета, где n={1, 2, …, N}, N – количество слоев нейронной сети:
Шаг n: расчет весовых коэффициентов n-го слоя, идентификация объектов обучающей выборки в нейронах n-го слоя, если слой (n+1) существует, то занесение в обучающую выборку в качестве свойств объектов (n+1)-го слоя результатов их идентификации в нейронах n-го слоя.
Примечание: в таблице 22 представлена именно логическая структура данных, т.е. в реальных базах данных нет записей, содержащих информацию о влиянии рецепторов n-го слоя на нейроны слоев, номера которых не равны n.
Нейронные сети и СК-анализ
Известные в литературе нейронные сети, в отличие от предлагаемой семантической информационной модели и нелокальных нейронных сетей, не обеспечивают реализацию всех базовых когнитивных операций, входящих в когнитивный конфигуратор. В частности, традиционные нейронные сети решают лишь задачу идентификации (прогнозирования) и не обеспечивают решение обратной задачи (дедукции), необходимой для принятия решения о выборе многофакторного управляющего воздействия. Кроме того не решается вопрос об уменьшении размерности нейронной сети без ущерба для ее адекватности (абстрагирование).
Результаты численного моделирования и исследования свойств нейронных сетей этого класса при управлении в АПК и других предметных областях позволяют предположить, в качестве модели реальных когнитивных процессов они обладает более высокой адекватностью, чем нейронные сети других типов.
Графическое
отображение нейронов и Паррето-подмножеств нелокальной нейронной сети
Ниже приводятся примеры графического отображения нелокального нейрона и Паретто-подмножества (нейронов с наиболее значимыми связями) нелокальной нейронной сети в системе "Эйдос" (рисунки 39 и 40).
|
|
|
Рисунок 39. Графическое отображение нелокального нейрона в системе "Эйдос" |
|
|
|
Рисунок 40. Графическое отображение нелокальной нейронной сети в системе "Эйдос" |
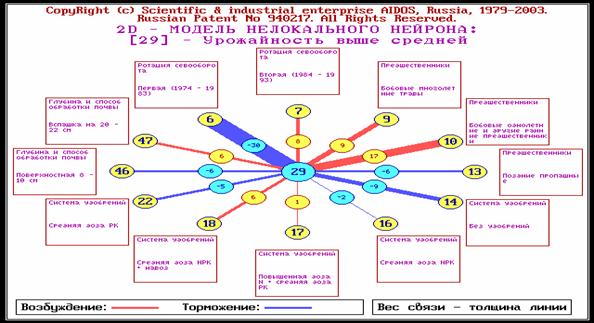
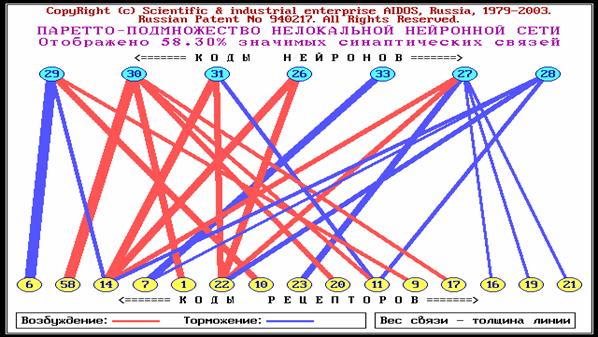
1.2.2.4.6. Математический метод СК-анализа в свете идей интервальной бутстрепной робастной статистики объектов нечисловой природы
Постановка проблемы
Современный этап развития информационных технологий характеризуется быстрым ростом производительности компьютеров облегчением доступа к ним. С этим связан возрастающий интерес к использованию компьютерных технологий для организации мониторинга различных объектов, анализа данных, прогнозирования и управления в различных предметных областях. И у исследователей, и у руководителей, имеются определенные ожидания и надежды на повышение эффективности применения компьютерных технологий.
Однако на пути реализации этих ожиданий имеются определенные сложности, связанные с относительным отставанием в развитии математических методов и реализующего их программного инструментария.
И анализ, и прогнозирование, и управление самым непосредственным образом основываются на математическом моделировании объектов. Математическое моделирование в свою очередь предполагают возможность выполнения всех арифметических операций (сложение, вычитание, умножение и деление) над отображениями объектов в моделях и над их элементами.
В практике интеллектуального анализа данных в экономике, социологии, психологии, педагогике и других предметных областях все чаще встречаются ситуации, когда необходимо в рамках единой математической модели совместно обрабатывать числовые и нечисловые данные.
В свою очередь числовые данные могут быть различной природы и, соответственно, измеряться в самых различных единицах измерения. Ясно, что арифметические операции можно выполнять только над числовыми данными, измеряемыми в одних единицах измерения.
Данные нечисловой природы, т.е. различные факты и события, характеризуются тем, что с ними вообще нельзя выполнять арифметические операции.
Соответственно,
возникает потребность в математических
методах и программном инструментарии, обеспечивающих совместную сопоставимую
обработку разнородных числовых данных и данных нечисловой природы.
Традиционные пути решения проблемы
Традиционно при необходимости проведения подобных исследований реализуется один из двух вариантов, т.е. либо изучается подмножество однородных по своей природе данных, измеряемых в одних единицах измерения; либо перед исследованием данные приводятся к сопоставимому виду, например, широко используются процентные или другие относительные величины, реже – стандартизированные значения.
Ясно, что первый вариант является не решением проблемы, а лишь ее вынужденным обходом, обусловленным ограничениями реально имеющегося в распоряжении исследователей инструментария.
Второй вариант лишь частично решает проблему, т.к. хотя и снимает различие в единицах измерения, но не преодолевает принципиального различия между количественными и качественными (нечисловыми) величинами и не позволяет обрабатывать их совместно в рамках единой модели.
В последние годы развивается ряд новых методов статистики, полный обзор которых дан в работах А. И. Орлова [http://antorlov.chat.ru]. Прежде всего, это интервальная статистика, статистика объектов нечисловой природы, робастные, бутстрепные и непараметрические методы.
В частности методы интервальной статистики, позволяют сводить числовые величины к фактам попадания их значений в определенные интервалы, т.е. к событиям. При этом преодолевается проблема различия в размерности числовых величин. Это обеспечивает также обработку числовых величин, как событий совместно с информацией о других событиях, связанных с объектами нечисловой природы. Таким образом, интервальные методы сводят обработку числовых величин к методам обработки нечисловой информации и позволяет обрабатывать их единообразно по одной методике. И это является очень важным достижением.
Идея решения проблемы
Это, в общем-то, вполне очевидный и естественный ход. Однако достигается этот результат дорогой ценой, т.е. путем сведения числовых величин к нечисловым, т.е. путем сведения их к "низменному типу", что приводит к утрате ряда возможностей обработки. Это происходит потому, что для числовых величин существует гораздо больше методов и возможностей обработки, чем для нечисловых.
По нашему мнению более предпочтительным является противоположный подход, основанный на введении некоторой количественной меры, позволяющей единым и сопоставимым образом описывать как числовые данные различной природы, так и нечисловые величины с использованием всего арсенала возможностей, имеющегося при обработке числовых данных.
Аналогично, если у нас есть документы стандартов "Документ Word" и "Текст-DOS" и мы хотели бы обрабатывать их все в одном редакторе, то это можно сделать либо преобразовав все документы Word в "низменный стандарт" "Текст-DOS", либо наоборот, преобразовав "досовские" документы в формат Word.
В 1979 году автором разработана [80], а в 1981 году впервые применена [66] математическая модель, обеспечивающая реализацию этой идеи. В последующем этот математический аппарат был развит в ряде работ, основной из которых является [5], был разработана соответствующая ему методика численных расчетов, включающая структуры данных и алгоритмы базовых когнитивных операций, а также создана программная система "Эйдос", реализующая математическую модель и методику численных расчетов [141, 142, 144, 145, 146].
Предложенный
метод получил название "Системно-когнитивный анализ" (СК-анализ)
[64]. В СК-анализе нечисловым величинам
тем же методом, что и числовым, приписываются сопоставимые в пространстве и
времени, а также между собой, количественные значения, позволяющие обрабатывать
их как числовые.
СК-анализ включает следующие этапы:
1. Когнитивная структуризация, а затем и формализация предметной области.
2. Ввод данных мониторинга в базу прецедентов за период, в течение которого имеется необходимая информация в электронной форме.
3. Синтез семантической информационной модели (СИМ).
4. Оптимизация СИМ.
5. Проверка адекватности СИМ (измерение внутренней и внешней, дифференциальной и интегральной валидности).
6. Анализ СИМ.
7. Решение задач идентификации состояний объекта управления, прогнозирование и поддержка принятия управленческих решений по управлению с применением СИМ.
На
первых двух этапах СК-анализа, детально рассмотренных в работе [64], числовые
величины сводятся к интервальным оценкам, как и информация об объектах
нечисловой природы (фактах, событиях). Этот этап реализуется и в методах интервальной
статистики.
На
третьем этапе СК-анализа всем этим величинам по единой методике, основанной на
системном обобщении семантической теории информации А.Харкевича, сопоставляются
количественные величины, с которыми в дальнейшем и производятся все операции
моделирования.
Математическая модель СК-анализа
Системное обобщение формулы Хартли
В выражении (3) приведено системное обобщение формулы Хартли для равновероятных состояний объекта управления.
|
|
(1) |
|
(4) |
|
|
(2) |
|
(5) |
|
|
(3) |
|
(6) |
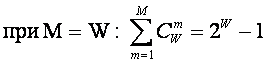
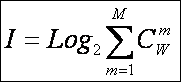
W – количество чистых (классических) состояний системы.
j – коэффициент эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых состояний).
Гипотеза о Законе возрастания эмерджентности
Исследование математических выражений системной теории информации (7 – 12) позволило сформулировать гипотезу о существовании "Закона возрастания эмерджентности". Суть этой гипотезы в том, что в самих элементах системы содержится сравнительно небольшая доля всей содержащейся в ней информации, а основной ее объем составляет системная информация, содержащаяся в подсистемах различного уровня иерархии.
Различие между классическим и предложенным
системным понятиями информации соответствует различию между понятиями МНОЖЕСТВА
И СИСТЕМЫ, на основе которых они сформированы.
|
|
(7) |
|
(8) |
|
(9) |
|
(10) |
|
|
|
(12) |
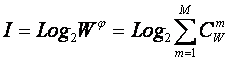
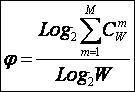
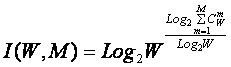
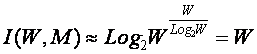
|
|
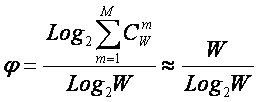
|
|

Системное обобщение формулы Харкевича
Ниже приведен вывод системного обобщения формулы Харкевича, а именно:
– классическая формула Харкевича через вероятности перехода системы в целевое состояние при условии сообщения ей определенной информации и самопроизвольно (13);
– выражение классической формулы Харкевича через частоты (14, 15);
– вывод коэффициента эмерджентности Харкевича на основе принципа соответствия с выражением Хартли в детерминистском случае (16 –19);
– вывод системного обобщения формулы Харкевича;
– окончательное выражение для системного обобщения формулы Харкевича (21).
Классическая формула Харкевича
|
|
(13) |
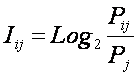
Pij – вероятность перехода объекта управления в j-е состояние в условиях действия i-го фактора;
Pj – вероятность самопроизвольного перехода объекта управления в j-е состояние, т.е. в условиях отсутствия действия i-го фактора или всреднем.
Известно, что корреляция не является мерой причинно-следственных связей. Если корреляция между действием некоторого фактора и переходом объекта управления в определенное состояние высока, то это еще не значит, что данный фактор является причиной этого перехода. Для того чтобы по корреляции можно было судить о наличии причинно-следственной связи необходимо сравнить исследуемую группу с контрольной группой, т.е. с группой, в которой данный фактор не действовал.
Также и высокая вероятность перехода объекта управления в определенное состояние в условиях действия некоторого фактора сама по себе не говорит о наличии причинно-следственной связи между ними, т.е. о том, что данный фактор обусловил переход объекта в это состояние. Это связано с тем, что вероятность перехода объекта в это состояние может быть вообще очень высокой независимо от действия фактора. Поэтому в качестве меры силы причинной обусловленности определенного состояния объекта действием некоторого фактора Харкевич предложил логарифм отношения вероятностей перехода в объекта в это состояние в условиях действия фактора и при его отсутствии или в среднем (13).
Таким
образом семантическая мера информации Харкевича является мерой наличия
причинно-следственных связей между факторами и состояниями объекта управления.
Выражение классической формулы Харкевича через частоты фактов
|
|
(14) |
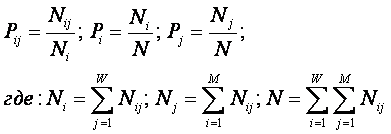
|
|
(15) |
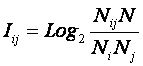
Вывод коэффициента эмерджентности Харкевича на основе принципа соответствия с выражением Хартли в детерминистском случае
Однако мера Харкевича (13) не удовлетворяет принципу соответствия мерой Хартли как мера Шеннона, т.е. не переходит в меру Хартли в детерминистском случае, т.е. когда каждому будущему состоянию объекта управления соответствует единственный уникальный фактор и между факторами и состояниями имеется взаимно однозначное соответствие (17).
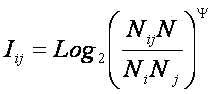
Откуда:
|
|
(18) |
|
(19) |
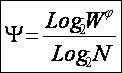
Вывод системного обобщения формулы Харкевича
|
|
(20) |
|
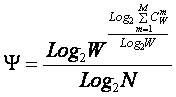

Окончательное выражение для системного обобщения формулы Харкевича
|
|
(21) |
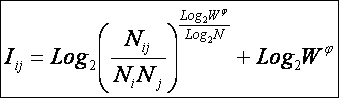
Связь системной теории информации (СТИ) с теорией Хартли-Найквиста-Больцмана и теорией Шеннона
Связь между выражениями для плотности информации в теориях Хартли, Шеннона и СТИ приведена на рисунке 41.
|
|
|
Рисунок 41. Связь между выражениями для
плотности информации |
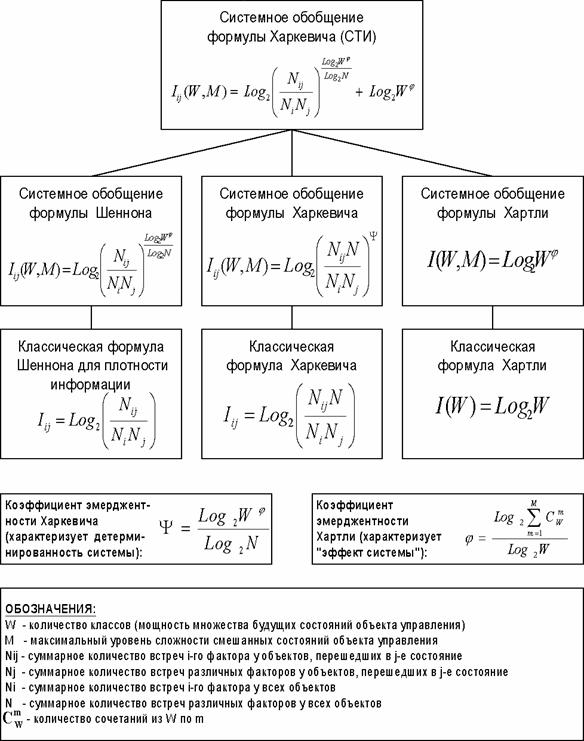
Интерпретация коэффициентов эмерджентности СТИ
Интерпретация коэффициентов эмерджентности, предложенных в рамках системной теории информации, приведена на рисунке 42.
|
|
|
Рисунок 42. Интерпретация коэффициентов эмерджентности СТИ |

Коэффициент эмерджентности Хартли j (4) представляет собой относительное превышение количества информации о системе при учете системных эффектов (смешанных состояний, иерархической структуры ее подсистем и т.п.) над количеством информации без учета системности, т.е. этот коэффициент является аналитическим выражением для уровня системности объекта.
Коэффициент эмерджентности Харкевича Y, изменяется от 0 до 1 и определяет степень детерминированности системы.
Таким образом, в предложенном системном обобщении формулы Харкевича (21) впервые непосредственно в аналитическом выражении для самого понятия "Информация" отражены такие фундаментальные свойства систем, как "Уровень системности" и "Степень детерминированности" системы.
Основной формой первичного обобщения эмпирической информации в модели является матрица абсолютных частот (таблица 23). В этой матрице строки соответствуют факторам, столбцы – будущим целевым и нежелательным состояниям объекта управления, а на их пересечении приведено количество наблюдения фактов (по данным обучающей выборки), когда действовал некоторый i-й фактор и объект управления перешел в некоторое j-е состояние.
Таблица 23 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ
|
|
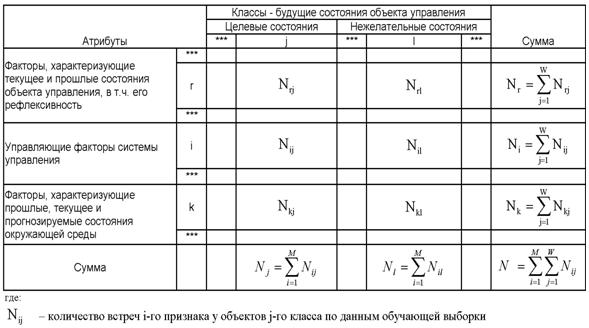
Непосредственно на основе матрицы абсолютных частот с использованием системного обобщения формулы Харкевича (21) рассчитывается матрица информативностей (таблица 24).
Таблица 24 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ
|
|
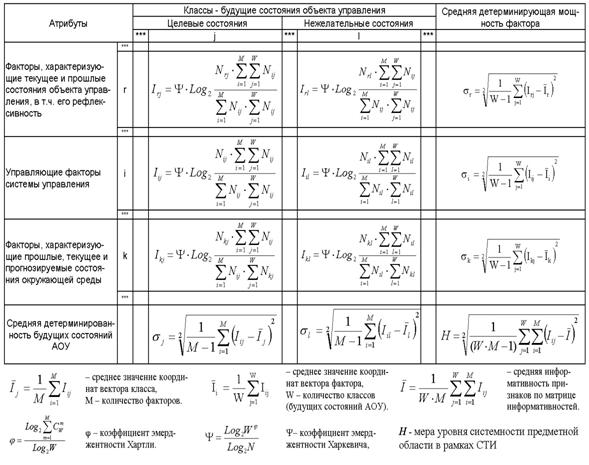
Матрица информативностей является универсальной формой представления смысла эмпирических данных в единстве их дискретного и интегрального представления (причины – последствия, факторы – результирующие состояния, признаки – обобщенные образы классов, образное – логическое, дискретное – интегральное).
Весовые коэффициенты матрицы информативностей непосредственно определяют, какое количество информации Iij система управления получает о наступлении события: "объект управления перейдет в j–е состояние", из сообщения: "на объект управления действует i–й фактор".
Когда количество информации Iij>0 – i–й фактор способствует переходу объекта управления в j–е состояние, когда Iij<0 – препятствует этому переходу, когда же Iij=0 – никак не влияет на это.
Таким
образом, предлагаемая семантическая информационная модель позволяет непосредственно
на основе эмпирических данных и независимо от предметной области рассчитать, какие количество информации
содержится в любом событии о любом другом событии.
Этот вывод является ключевым для данной работы, т.к. конкретно показывает возможность числовой обработки в СК-анализе как числовой, так и нечисловой информации.
Матрица информативностей является также обобщенной (неклассической) таблицей решений, в которой входы (факторы) и выходы (будущие состояния объекта управления) связаны друг с другом не с помощью классических (Аристотелевских) импликаций, принимающих только значения: "Истина" и "Ложь", а различными значениями истинности, выраженными в битах и принимающими значения от положительного теоретически-максимально-возможного, до теоретически неограниченного отрицательного. Некоторые неклассические высказывания, генерируемые на основе матрицы информативности, приведены на плакате.
Неметрический интегральный критерий сходства, основанный на лемме Неймана-Пирсона
В выражениях (22 – 24) приведен неметрический интегральный критерий сходства, основанный на фундаментальной лемме Неймана-Пирсона, обеспечивающий идентификацию и прогнозирование в предложенных неортонормированных семантических пространствах с финитной метрикой, в которых в качестве координат векторов будущих состояний объекта управления и факторов выступает количество информации, рассчитанное в соответствии с системной теорией информации (21), а не Булевы координаты или частоты, как обычно.
|
|
(22) |
|
(23) |
Или в координатной форме:
|
|
(24) |
|
(25) |
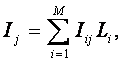
![]() – вектор j–го состояния объекта управления;
– вектор j–го состояния объекта управления;
![]() – вектор
состояния предметной области, включающий все виды факторов, характеризующих объект
управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
– вектор
состояния предметной области, включающий все виды факторов, характеризующих объект
управления, возможные управляющие воздействия и окружающую среду
(массив–локатор), т.е.:
|
|

|
|
(26) |
|
(27) |
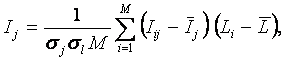
![]() – средняя
информативность по вектору класса;
– средняя
информативность по вектору класса;
![]() – среднее по
вектору идентифицируемой ситуации (объекта).
– среднее по
вектору идентифицируемой ситуации (объекта).
![]() –
среднеквадратичное отклонение информативностей вектора класса;
–
среднеквадратичное отклонение информативностей вектора класса;
![]() –
среднеквадратичное отклонение по вектору распознаваемого объекта.
–
среднеквадратичное отклонение по вектору распознаваемого объекта.
Связь системной меры целесообразности информации с критерием c2
В (28 – 33) показана связь системной меры целесообразности информации с известным критерием c2, а также предложен новый критерий уровня системности предметной области, являющийся нормированным объемом семантического пространства (34, 35).
|
|
(28) |
|
(29) |
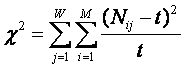
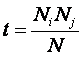
– Nij – фактическое количество встреч i-го признака у объектов j-го класса;
– t – ожидаемое количество встреч i-го признака у объектов j-го класса.
|
|
(30) |
|
(31) |
||
|
|
(32) |
|
(33) |
||
|
|
(34) |
|
(35) |
||
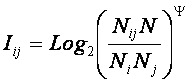
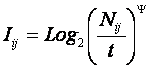
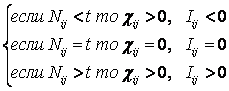
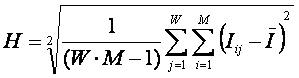
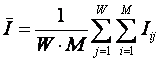
Предлагается более точный критерий уровня системности модели является объем неортонормированного семантического пространства, рассчитанный как объем многомерного параллелепипеда, ребрами которого являются оси семантического пространства. Однако для этой меры сложнее в общем виде записать аналитическое выражение и для ее вычисления могут быть использованы численные методы с использованием многомерного обобщения смешанного произведения векторов.
Абстрагирование
(ортонормирование) существенно уменьшает размерность семантического
пространства без существенного уменьшения его объема.
Оценка адекватности семантической информационной модели в СК-анализе и бутстрепные методы
Под адекватностью модели СК-анализа понимается ее внутренняя и внешняя дифференциальная и интегральная валидность. Понятие валидности является уточнением понятия адекватности, для которого определены процедуры количественного измерения, т.е. валидность – это количественная адекватность. Это понятие количественно отражает способность модели давать правильные результаты идентификации, прогнозирования и способность вырабатывать правильные рекомендации по управлению.
Под внутренней валидностью понимается валидность модели, измеренная после синтеза модели путем идентификации объектов обучающей выборки.
Под внешней валидностью понимается валидность модели, измеренная после синтеза модели путем идентификации объектов, не входящих в обучающую выборку.
Под дифференциальной валидностью модели понимается достоверность идентификации объектов в разрезе по классам.
Под интегральной валидностью средневзвешенная дифференциальная валидность.
Возможны все сочетания: внутренняя дифференциальная валидность, внешняя интегральная валидность и т.д.
Основная идея бутстрепа по Б.Эфрону [110] состоит в том, что методом Монте-Карло (статистических испытаний) многократно извлекаются выборки из эмпирического распределения. Эти выборки, естественно, являются вариантами исходной, напоминают ее.
Эта идея позволяет сконструировать алгоритм измерения адекватности модели, состоящий из двух этапов:
1. Синтез модели на одном случайном подмножестве обучающей выборки.
2. Измерение валидности модели на оставшемся подмножестве обучающей выборки, не использованном для синтеза модели.
Поскольку оба случайных подмножества имеют переменный состав по объектам обучающей выборки, то подобная процедура должна повторяться много раз, после чего могут быть рассчитаны статистические характеристики адекватности модели, например, такие как:
– средняя внешняя валидность;
– среднеквадратичное отклонение текущей внешней валидности от средней и другие.
Достоинство бутстрепного подхода к оценке адекватности модели состоит в том, что он позволяет измерить внешнюю валидность на уже имеющейся выборке и изучить статистические характеристики, характеризующие адекватность модели при изменении объема и состава выборки.
Непараметричность модели. Робастные процедуры и фильтры для исключения артефактов
Предложенная семантическая информационная модель является непараметрической, т.к. базируется на системной теории информации [64], которая никоим образом не основана на предположениях о нормальности распределений исследуемой выборки.
Под робастными понимаются процедуры, обеспечивающие устойчивую работу модели на исходных данных, зашумленных артефактами, т.е. данными, выпадающими из общих статистических закономерностей, которым подчиняется исследуемая выборка.
Критерий выявления артефактов, реализованный в СК-анализе, основан на том, что при увеличении объема статистики частоты значимых атрибутов растут, как правило, пропорционально объему выборки, а частоты артефактов так и остаются чрезвычайно малыми, близкими к единице. Таким образом, выявление артефактов возможно только при достаточно большой статистике, т.к. в противном случае недостаточно информации о поведении частот атрибутов с увеличением объема выборки.
В модели реализована такая процедура удаления наиболее вероятных артефактов, и она, как показывает опыт, существенно повышает качество (адекватность) модели.
Методика численных расчетов СК-анализа
Детальный список БКОСА и их алгоритмов
В таблице 25 приведен детальный список базовых когнитивных операций системного анализа, которым соответствует 24 алгоритма, которые здесь привести нет возможности из-за их объемности. Но они все приведены в полном виде в работе [64].
Таблица
25 – ДЕТАЛЬНЫЙ СПИСОК
БАЗОВЫХ КОГНИТИВНЫХ ОПЕРАЦИЙ СИСТЕМНОГО АНАЛИЗА (БКОСА)
|
№ алгоритма |
Код БКОСА по схеме СК-анализа |
№ БКОСА |
Наименование БКОСА |
Полное наименование базовых
когнитивных операций системного анализа (БКОСА) |
|
|
1.1 |
1 |
Присвоение |
Присвоение
имен классам |
|
|
1.2 |
Присвоение
имен атрибутам |
||
|
1 |
2.1. |
2 |
Восприятие |
Восприятие и
запоминание исходной обучающей |
|
2 |
2.2. |
Репрезентация.
Сопоставление индивидуального |
Продолжение таблицы 25
|
№ алгоритма |
Код БКОСА по схеме СК-анализа |
№ БКОСА |
Наименование БКОСА |
Полное наименование базовых
когнитивных операций системного анализа (БКОСА) |
|
3 |
3.1.1. |
3 |
Обобщение (синтез, |
Накопление
первичных данных |
|
4 |
3.1.2. |
Исключение
артефактов |
||
|
5 |
3.1.3. |
Расчет
истинности смысловых связей между |
||
|
6 |
3.2. |
Определение
значимости шкал и градаций факторов, уровней Мерлина |
||
|
7 |
3.3. |
Определение
значимости шкал и градаций классов, уровней Мерлина |
||
|
8 |
4.1. |
4 |
Абстраги- рование |
Абстрагирование
факторов (снижение размерности семантического пространства факторов) |
|
9 |
4.2. |
Абстрагирование
классов (снижение размерности семантического пространства классов) |
||
|
10 |
5. |
5 |
Оценка |
Оценка
адекватности информационной модели |
|
11 |
7. |
6 |
Сравнение,
идентификация и прогнозирование |
Сравнение,
идентификация и прогнозирование. Распознавание состояний конкретных объектов
(объектный анализ) |
|
12 |
9.1. |
7 |
Анализ, дедукция |
Анализ,
дедукция и абдукция классов (семантический анализ обобщенных образов классов,
решение |
|
13 |
9.2. |
Анализ,
дедукция и абдукция факторов |
||
|
14 |
10.1.1. |
8 |
Классификация конструктов |
Классификация
обобщенных образов классов |
|
15 |
10.1.2. |
Формирование
бинарных конструктов классов |
||
|
16 |
10.1.3. |
Визуализация
семантических сетей классов |
||
|
17 |
10.2.1. |
Классификация
факторов |
||
|
18 |
10.2.2. |
Формирование
бинарных конструктов факторов |
||
|
19 |
10.2.3. |
Визуализация
семантических сетей факторов |
||
|
20 |
10.3.1. |
9 |
Содержательное |
Содержательное
сравнение классов |
|
21 |
10.3.2. |
Расчет и
отображение многомногозначных когнитивных диаграмм, в т.ч. диаграмм Мерлина |
||
|
22 |
10.4.1. |
Содержательное
сравнение факторов |
||
|
23 |
10.4.2. |
Расчет и
отображение многомногозначных когнитивных диаграмм, в т.ч. инвертированных
диаграмм Мерлина |
||
|
24 |
11. |
10 |
Планирование и управление |
Многовариантное
планирование и принятие решения о применении системы управляющих факторов |
Иерархическая структура данных семантической информационной модели СК-анализа
На рисунке 43 приведена в обобщенном виде иерархическая структура баз данных семантической информационной модели системно-когнитивного анализа. На этой схеме базы данных обозначены прямоугольниками, а базовые когнитивные операции системного анализа, преобразующие одну базу в другую – стрелками с надписями. Имеются также базовые когнитивные операции, формирующие выходные графические формы. Из этой схемы видно, что одни базовые когнитивные операции готовят данные для других операций, относящихся к более высоким уровням иерархии системы процессов познания. Этим определяется возможная последовательность выполнения базовых когнитивных операций.
|
|
|
Рисунок 43. Иерархическая структура баз данных семантической информационной модели системно-когнитивного анализа |
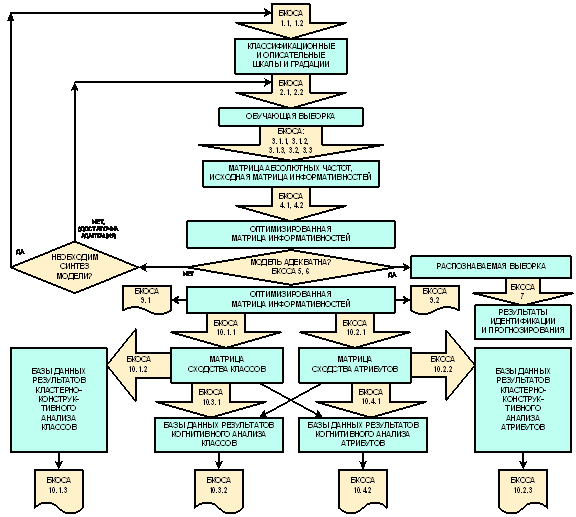
Специальный программный инструментарий СК-анализа – система "Эйдос"
На таблице 26 показана обобщенная схема когнитивной аналитической системы "Эйдос", которая реализует математическую модель и численный метод системно-когнитивного анализа и, таким образом, является его инструментарием.
В состав данной системы входит 7 подсистем.
Первые 3 подсистемы являются инструментальными, т.е. позволяют осуществлять синтез и адаптацию модели.
Остальные 4 подсистемы обеспечивают идентификацию, прогнозирование и кластерно-конструктивный анализ модели, в т.ч. верификацию модели и выработку управляющих воздействий.
Система "Эйдос" является довольно большой системой: распечатка ее исходных текстов 6-м шрифтом составляет около 800 листов, она генерирует 54 графических формы (двумерные и трехмерные) и 50 текстовых форм. На данную систему и системы окружения получено 8 свидетельств РосПатента РФ.
Таблица
26 – ОБОБЩЕННАЯ СТРУКТУРА УНИВЕРСАЛЬНОЙ
КОГНИТИВНОЙ АНАЛИТИЧЕСКОЙ СИСТЕМЫ "ЭЙДОС"
|
Подсистема |
Режим |
Функция |
Операция |
|
1. Словари |
1. Классификационные шкалы и градации |
||
|
2. Описательные шкалы (и градации) |
|||
|
3. Градации описательных шкал
(признаки) |
|||
|
4. Иерархические уровни систем |
1. Уровни классов |
||
|
2. Уровни признаков |
|||
|
5. Программные интерфейсы для импорта
данных |
1. Импорт данных из TXT-фалов
стандарта DOS-текст |
||
|
2. Импорт данных из DBF-файлов
стандарта проф. А.Н.Лебедева |
|||
|
3. Импорт из транспонированных
DBF-файлов проф. А.Н.Лебедева |
|||
|
4. Генерация шкал и обучающей выборки
RND-модели |
|||
|
5. Генерация шкал и обучающей выборки
для исследования чисел |
|||
|
6. Транспонирование DBF-матриц
исходных данных |
|||
|
6. Почтовая служба по НСИ |
1. Обмен по классам |
||
|
2. Обмен по обобщенным признакам |
|||
|
3. Обмен по первичным признакам |
|||
|
7. Печать анкеты |
|||
|
2. Обучение |
1. Ввод–корректировка обучающей
выборки |
||
|
2. Управление обучающей выборкой |
1. Параметрическое задание объектов
для обработки |
||
|
2. Статистическая характеристика,
ручной ремонт |
|||
|
3. Автоматический ремонт обучающей
выборки |
|||
|
3. Пакетное обучение системы распознавания |
1. Накопление абсолютных частот |
||
|
2. Исключение артефактов (робастная
процедура) |
|||
|
3. Расчет информативностей признаков |
|||
|
4. Расчет условных процентных
распределений |
|||
|
5. Автоматическое выполнение режимов
1–2–3–4 |
|||
|
6. Измерение сходимости и устойчивости
модели |
1. Сходимость и устойчивость СИМ |
||
|
2. Зависимость валидности модели от
объема обучающей выборки |
|||
|
4. Почтовая служба по обучающей информации |
|||
|
3. Оптимизация |
1. Формирование ортонормированного
базиса классов |
||
|
2. Исключение признаков с низкой
селективной силой |
|||
|
3. Удаление классов и признаков, по
которым недостаточно данных |
|||
|
4. Распознавание |
1. Ввод–корректировка распознаваемой
выборки |
||
|
2. Пакетное распознавание |
|||
|
3. Вывод результатов распознавания |
1. Разрез: один объект – много
классов |
||
|
2. Разрез: один класс – много
объектов |
|||
|
4. Почтовая служба по распознаваемой
выборке |
|||
|
5. Типология |
1. Типологический анализ классов распознавания |
1. Информационные (ранговые) портреты
(классов) |
|
|
2. Кластерный и конструктивный анализ
классов |
1 Расчет матрицы сходства образов
классов |
||
|
2. Генерация кластеров и конструктов
классов |
|||
|
3. Просмотр и печать кластеров и
конструктов |
|||
|
4. Автоматическое выполнение режимов:
1,2,3 |
|||
|
5. Вывод 2d семантических сетей
классов |
|||
|
3. Когнитивные диаграммы классов |
|||
|
2. Типологический анализ первичных
признаков |
1. Информационные (ранговые) портреты
признаков |
||
|
2. Кластерный и конструктивный анализ
признаков |
1. Расчет матрицы сходства образов
признаков |
||
|
2. Генерация кластеров и конструктов
признаков |
|||
|
3. Просмотр и печать кластеров и
конструктов |
|||
|
4. Автоматическое выполнение режимов:
1,2,3 |
|||
|
5. Вывод 2d семантических сетей
признаков |
|||
|
3. Когнитивные диаграммы признаков |
|||
|
6. Анализ |
1. Оценка достоверности заполнения
объектов |
||
|
2. Измерение адекватности
семантической информационной модели |
|||
|
3. Измерение независимости классов и
признаков |
|||
|
4. Просмотр профилей классов и
признаков |
|||
|
5. Графическое отображение нелокальных
нейронов |
|||
|
6. Отображение Паретто-подмножеств
нейронной сети |
|||
|
7. Классические и интегральные
когнитивные карты |
|||
Продолжение таблицы 26
|
Подсистема |
Режим |
Функция |
Операция |
|
7. Сервис |
1. Генерация (сброс) БД |
1. Все базы данных |
|
|
2. НСИ |
1. Всех баз данных |
||
|
2. БД классов |
|||
|
3. БД первичных признаков |
|||
|
4. БД обобщенных признаков |
|||
|
3. Обучающая выборка |
|||
|
4. Распознаваемая выборка |
|||
|
5. Базы данных статистики |
|||
|
2. Переиндексация всех баз данных |
|||
|
3. Печать БД абсолютных частот |
|||
|
4. Печать БД условных процентных
распределений |
|||
|
5. Печать БД информативностей |
|||
|
6. Интеллектуальная дескрипторная
информационно–поисковая система |
|||
Выводы
Интервальные оценки сводят анализ чисел к анализу фактов и позволяют обрабатывать количественные величины как нечисловые данные. Это ограничивает возможности обработки количественных величин методами обработки нечисловых данных. В математической модели СК-анализа, основанной на системной теории информации, наоборот, качественным, нечисловым данным, сопоставляются количественные величины. Это позволяет использовать все возможности количественных методов для исследования нечисловых данных.
Таким образом, в СК-анализе числовые и нечисловые данные обрабатываются единообразно на основе единой математической модели как числовые данные.
Рассматривается связь метода измерения адекватности модели в СК-анализе с бутстрепными методами.
Описывается робастная процедура выявления и устранения артефактов в СК-анализе.
Резюме
1. Сформулированы требования к математической модели и к численной мере. Затем на их основе обоснован выбор базовой численной меры. Для этого рассмотрены три вида информации: абсолютная, относительная и аналитическая информация. Предпочтение отдано аналитической форме информации, к которой принадлежат относительные вероятности, относительные проценты и количество информации. Вместо традиционных мер, основанных на понятии "стоимости" и "полезности" предложено использовать информационную меру. Рассмотрены различные аспекты применения теории информации для анализа процесса труда и средств труда как информационных систем. Показано, что принятие решения об управляющем воздействии есть обратный процесс по отношению к идентификации и прогнозированию, т.е. познанию. Установлена связь количества (синтаксиса) и качества (содержания, семантики) информации, записываемой в структуре предмета труда, с меновой и потребительной стоимостью. Сформулирована информационная теория стоимости, в которой информация рассматривается как сущность стоимости и как "первичный" и по сути единственный товар. Рассмотрены вопросы определения стоимости и амортизация интеллектуальных систем и баз знаний. Показано, что их стоимость как генераторов информации возрастает в процессе эксплуатации. С позиций теории информации раскрыт фундаментальный источник экономической эффективности АСУ и систем интеллектуальной обработки данных: понижение энтропии объекта управления как приемника сообщений в результате получения управляющей информации. Сделан вывод о целесообразности выбора в качестве базовой численной меры количества информации. Поставлена задача выбора или конструирования конкретной численной меры, основанной на понятии информации.
2. В классической теории информации Шеннона, созданной на основе
обобщения результатов Больцмана, Найквиста и Хартли, само понятие информации
определяется на основе теоретико-множественных и комбинаторных представлений
путем анализа поведения классического макрообъекта, который может переходить
только в четко фиксированные альтернативные редуцированные состояния. Однако,
квантовые объекты и сложные активные рефлексивные системы могут оказываться
одновременно в двух и более альтернативных для классических объектов
состояниях. Такие состояния названы смешанными. Таким образом в реальности наблюдается
картина последствий, не сводящаяся к простой сумме последствий альтернативных
вариантов. Она больше напоминает квантовое физическое явление, которое
называется интерференцией плотности вероятности. Это явление, безусловно
имеющее системный характер, предлагается называть "интерференция
последствий выбора".
3. Предлагается обобщение классической теория информации Хартли-Шеннона
путем рассмотрения активных объектов в качестве объектов, на основе анализа
которых формируется само основополагающее понятие информации. Обобщенную таким
образом теорию информации предлагается называть системной или эмерджентной
теорией информации (СТИ). Основным отличием эмерджентной теории информации от
классической является учет свойства системности, как фундаментального и
универсального свойства всех объектов, на уровне самого понятия информации, а
не только в последующем изложении, как в классической теории.
4. Предложена системная модификация формулы Хартли для количества
информации:
|
|
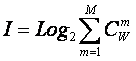
где:
W – количество чистых (классических) состояний системы;
![]() – сочетания "по m" классических состояний.
– сочетания "по m" классических состояний.
Так как ![]() , то при M=1 выполняется принцип соответствия, являющийся
обязательным для более общей теории. Данная формула дает верхнюю оценку
возможного количества информации
состоянии системы, т.к. возможны различные правила запрета и реальное
количество возможных состояний системы будет меньшим, чем
, то при M=1 выполняется принцип соответствия, являющийся
обязательным для более общей теории. Данная формула дает верхнюю оценку
возможного количества информации
состоянии системы, т.к. возможны различные правила запрета и реальное
количество возможных состояний системы будет меньшим, чем ![]() .
.
Предложено приближенное выражение для системной модификации формулы
Хартли (при M=W):
|
|
При W>4 погрешность данного выражения не превышает 1%.
Дополнительная информация, которую мы получаем из поведения объекта в
СТИ, по сути дела является информацией о множестве всех его возможных
состояний, как системы, элементом которой является объект в некотором данном
состоянии.
5. Численные расчеты и аналитические выкладки согласно СТИ показывают,
что при возрастании количества элементов в системе доля системной информации в
поведении ее элементов возрастает, причем возрастает ускоренно. Это
установленное нами свойство систем названо "Законом возрастания эмерджентности".
6. Предложена системная модификация классической формулы А.Харкевича,
являющееся нелинейной суперпозицией классических выражением для плотности
информации Шеннона и количества информации Хартли.
|
|
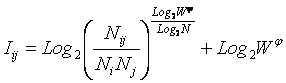
где: j – коэффициент
эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых
состояний):
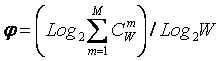
Установлено, что полученное выражение учитывает как взаимосвязь между
признаками (факторами) и будущими, в т.ч. целевыми состояниями объекта
управления, так и мощность множества будущих состояний. Эта мера отражает
уровень системности и степень детерминированности объекта, объединяет
возможности их интегрального и дискретного описания, что является основой формализации смысла, а также удовлетворяет
принципу соответствия, т.е. преобразуется в формулу Хартли в предельном случае,
когда каждому классу (состоянию объекта) соответствует один признак (фактор), и
каждому признаку – один класс, и эти классы, а значит и признаки, равновероятны.
7. Все это делает семантическую меру целесообразности информации
оптимальной по сформулированным критериям для целей построения семантической
информационной модели активных объектов управления и для применения при синтезе
рефлексивных АСУ активными системами.
8. В разработанной семантической информационной модели генерируется
обобщенная таблица решений, в которой входы (факторы) и выходы будущие
состояния активного объекта управления (АОУ) связаны друг с другом не с помощью
классических (Аристотелевских) импликаций, принимающих только значения:
"Истина" и "Ложь", а различными значениями истинности,
выраженными в битах и принимающими значения от положительного
теоретически-максимально-возможного ("Максимальная степень
истинности"), до теоретически неограниченного отрицательного
("Степень ложности"). Синтез обобщенных таблиц решений для различных
предметных областей осуществляется непосредственно на основе эмпирических
исходных данных. На основе этих таблиц продуцируются прямые и обратные
правдоподобные (нечеткие) логические рассуждения по неклассическим схемам с
различными расчетными значениями истинности, являющимся обобщением классических
импликаций. При этом в прямых рассуждениях как предпосылки рассматриваются
факторы, а как заключения – будущие состояния АОУ, а в обратных – наоборот.
Степень истинности i-й предпосылки – это количество информации Iij,
содержащейся в предпосылке о наступлении j-го будущего состояния активного
объекта управления.
9. В качестве меры сходства объекта с классом, класса с классом и
атрибута с атрибутом предложено использовать неметрический интегральный
критерий, основанный на лемме Неймана-Пирсона, – суммарное количество
информации. Если предпосылок несколько, то степень истинности наступления j-го
состояния АОУ равна суммарному количеству информации, содержащемуся в них об
этом:
|
|
Или в координатной форме:
|
|
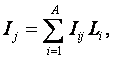 ,
,где: ![]() – вектор j–го
состояния объекта управления, координаты которого в информационном
семантическом пространстве рассчитываются согласно системного обобщения формулы
Харкевича, приведенной в п.6;
– вектор j–го
состояния объекта управления, координаты которого в информационном
семантическом пространстве рассчитываются согласно системного обобщения формулы
Харкевича, приведенной в п.6; ![]() – булев вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор). Обоснована замена значений координат этих векторов их
стандартизированными значениями.
– булев вектор
состояния предметной области, включающий все виды факторов, характеризующих
объект управления, возможные управляющие воздействия и окружающую среду
(массив–локатор). Обоснована замена значений координат этих векторов их
стандартизированными значениями.
10. Предложенная семантическая информационная модель позволяет решать задачи идентификации и прогнозирования развития активных систем (разложение вектора объекта по векторам классов – "Объектный анализ"), а также вырабатывать эффективные управляющие воздействия путем решения обратной задачи прогнозирования и применения элементов нетрадиционной логики и правдоподобных (нечетких) рассуждений. В ней объединены преимущества содержательных и статистических моделей, созданы предпосылки для реализации СК-анализа.
11. Исследована взаимосвязь примененной в модели семантической меры Харкевича со статистикой c2, и, на этой основе, предложена новая статистическая мера наличия причинно-следственных связей в предметной области H, основанная на модифицированной формуле Харкевича:
|
|
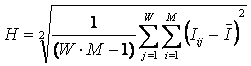
где:
|
|
– средняя информативность признаков по матрице информативностей. |
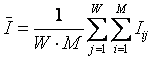
Обоснована устойчивость модели при малых и больших выборках, дано обоснование сопоставимости частных критериев, разработана интерпретация распознавания как объектного анализа (разложение вектора объекта в ряд по векторам классов), предложены робастные процедуры, а также процедуры обеспечения структурной репрезентативности выборки.
12. Предлагается модель нелокального нейрона, являющаяся обобщением классической модели Дж. Маккалоки и У. Питта. Суть нелокальности данной модели состоит в том, что весовые коэффициенты каждого нейрона зависят не только от нейронов, прямо или косвенно соединенных с ним синаптически, но и от всех остальных нейронов сети, не затрагиваемых при обратном распространении ошибки от данного нейрона. Предлагается новый класс нейронных сетей: "Нелокальные интерпретируемые нейронные сети прямого счета" (нелокальные нейронные сети – ННС). Организация ННС обеспечивает один из вариантов решения традиционных для нейронных сетей проблем: содержательной интерпретации смысла интенсивности входных сигналов и весовых коэффициентов ("проблема интерпретируемости весовых коэффициентов"); содержательной интерпретации и обоснования аддитивности аргумента и вида активационной (передаточной) функции нейрона ("проблема интерпретируемости передаточной функции"); "Комбинаторного взрыва" при определении структуры связей нейронов, подборе весовых коэффициентов и передаточных функций ("проблема размерности"). Математическая модель ННС основана на предложенной автором системной теории информации и семантической информационной модели автоматизированного системно-когнитивного анализа (АСК-анализ), и в отличие от известных нейронных сетей, обеспечивают автоматизацию всех 10 базовых когнитивных операций, образующих "когнитивный конфигуратор". Предложены не только математическая модель, но также и соответствующий численный метод (включая алгоритмы и структуры данных), а также программный инструментарий нелокальных нейронных сетей (универсальная когнитивная аналитическая система "Эйдос" версии 12.5), успешно апробированные в ряде предметных областей. Данная система обеспечивает практически неограниченное количество слоев ННС, рецепторов, выходных нейронов и связывающих их весовых коэффициентов (десятки миллионов), а также автоматическую визуализацию и запись в виде графических файлов сформированных моделей нелокальных нейронов и Паретто-подмножеств нелокальной нейронной сети.
13. Введено в научный оборот новое понятие: коэффициент эмерджентности Хартли j, который представляет собой относительное превышение количества информации о системе при учете системных эффектов (смешанных состояний, иерархической структуры ее подсистем и т.п.) над количеством информации без учета системности, т.е. этот коэффициент отражает уровень системности объекта. Этот уровень системности объекта изменяется от 1 (системность минимальна, т.е. отсутствует) до W/Log2W (системность максимальна). Для каждого количества элементов системы существует свой максимальный уровень системности, который никогда реально не достигается из-за действия правил запрета на реализацию в системе ряда подсистем различных уровней иерархии.
Введено в научный оборот новое понятие: коэффициент эмерджентности Харкевича Y, который изменяется от 0 до 1 и определяет степень детерминированности системы: Y=1 соответствует полностью детерминированной системе, поведение которой однозначно определяется действием минимальным количеством факторов, которых столько же, сколько состояний системы; Y=0 соответствует полностью случайной системе, поведение которой никак не зависит действия факторов независимо от их количества; 0<Y<1 соответствуют большинству реальных систем, поведение которых зависит от многих факторов, число которых превосходит количество состояний системы, причем ни одно из состояний не определяется однозначно никакими сочетаниями действующих факторов. Увеличение уровня системности влияет на семантическую информационную модель аналогично повышению уровня детерминированности. Понижение уровня системности, также как и степени детерминированности системы приводит к ослаблению влияния факторов на поведение системы, т.е. к своего рода "инфляции факторов".
Основной вывод:
В предложенном системном обобщении формулы Харкевича впервые непосредственно в аналитическом выражении для самого понятия "Информация" отражены такие фундаментальные свойства систем, как "Уровень системности" и "Степень детерминированности" системы, кроме того это выражение (как и формула Шеннона) удовлетворяет принципу соответствия с выражением Хартли в детерминистском случае, учитывает понятие цели и мощность множества будущих состояний объекта управления, объединяет возможности интегрального и дискретного описания объектов. По этим причинам полученное выражение является оптимальным и его целесообразно использовать в качестве основы для построения математической модели рефлексивных АСУ активными объектами.
Контрольные вопросы
1. Теоретические основы системной теории информации.
2. Требования к математической модели и численной мере СТИ.
3. Выбор базовой численной меры СТИ.
4. Конструирование системной численной меры на основе базовой в СТИ.
5. Семантическая информационная модель СК-анализа.
6. Формализм динамики взаимодействующих семантических информационных пространств. Двухвекторное представление данных.
7. Применение классической теории информации К.Шеннона для расчета весовых коэффициентов и мер сходства.
8. Математическая модель метода распознавания образов и принятия решений, основанного на системной теории информации.
9. Некоторые свойства математической модели СК-анализа (сходимость, адекватность, устойчивость и др.).
10. Непараметричность модели. Робастные процедуры и фильтры для исключения артефактов в математической модели СК-анализа.
11. Зависимость информативностей факторов от объема обучающей выборки.
12. Зависимость адекватности семантической информационной модели от объема обучающей выборки (адекватность при малых и больших выборках).
13. Семантическая устойчивость модели СК-анализа.
14. Зависимость параметров модели СК-анализа от ее ортонормированности.
15. Взаимосвязь математической модели СК-анализа с другими моделями.
16. Взаимосвязь системной меры целесообразности информации со статистикой Х2 и новая мера уровня системности предметной области.
17. Сравнение, идентификация и прогнозирование как разложение векторов объектов в ряд по векторам классов (объектный анализ).
18. Системно-когнитивный и факторный анализ. СК-анализ, как метод вариабельных контрольных групп.
19. Семантическая мера целесообразности информации и эластичность.
20. Связь семантической информационной модели с нейронными сетями.
21. Математический метод СК-анализа в свете идей интервальной бутстрепной робастной статистики объектов нечисловой природы.
Рекомендуемая литература
1.
Орлов А.И. "Высокие статистические
технологии": http://antorlov.chat.ru.
2. Луценко Е.В. Автоматизированная система распознавания образов: математическая модель и опыт применения. //В сб.: "В.И. Вернадский и современность (к 130-летию со дня рождения)". - Краснодар: КНА, 1993. - С.37-42.
3. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). – Краснодар: КЮИ МВД РФ, 1996. – 280с.
4. Луценко Е.В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). –Краснодар: КубГАУ. 2002. –605 с.
5. Пат. № 940217. РФ. Универсальная автоматизированная система распознавания образов "ЭЙДОС". /Е.В.Луценко (Россия); Заяв. № 940103. Опубл. 11.05.94. – 50с.
6. Пат. № 2003610986 РФ. Универсальная когнитивная аналитическая система "ЭЙДОС" / Е.В.Луценко (Россия); Заяв. № 2003610510 РФ. Опубл. от 22.04.2003. – 50с.
7. Луценко Е.В. Типовая методика и инструментарий когнитивной структуризации и формализации задач в СК-анализе. // Научный журнал КубГАУ. – 2004.– № 1 (3). –18 с. http://ej.kubagro.ru
8. Эфрон Б. Нетрадиционные методы многомерного статистического анализа. - М.: Финансы и статистика, 1988. – 263 с.
1.2.3.
ЛЕКЦИЯ-5.
Методика численных расчетов
(алгоритмы и структуры данных)
Учебные вопросы
1. Принципы формализации предметной области и подготовки эмпирических данных.
2. Иерархическая структура данных и последовательность численных расчетов в СК-анализе.
3. Обобщенное описание алгоритмов СК-анализа.
4. Детальные алгоритмы СК-анализа.
1.2.3.1. Принципы формализации предметной области и подготовки эмпирических данных
Понятие шкалы и градации. Типы шкал
Формализация предметной области это процесс, состоящий из двух основных этапов:
1. Конструирование шкал и градаций для описания и кодирования состояний объекта управления и факторов, влияющих на его поведение.
2. Отнесение состояний объекта управления и факторов к определенным градациям соответствующих шкал.
В данной работе предлагается следующие определения.
Шкала – это способ
классификации объектов по наименованиям или степени выраженности некоторого
свойства.
Градация – это положение
на шкале (или интервал, диапазон), соответствующее наименованию или
определенной степени выраженности свойства.
Понятие шкалы тесно связано с ключевым понятием когнитивной психологии: понятием конструкта, более того, практически является синонимом или формальным аналогом этого понятия.
Конструктом называется понятие, имеющее полюса, противоположные по смыслу, и ряд промежуточных градаций, отражающих различную степень выраженности некоторого качества. Познание состоит в создании (генерировании) новых конструктов и их использовании для ориентации в предметной области. Таким образом, формализация предметной области по сути дела представляет собой ее познание, т.е. когнитивную структуризацию. В приведенной таблице 27 дана характеристика измерительных шкал согласно [64]. Конечно, наименования могут быть присвоены градациям всех видов измерительных шкал.
|
|
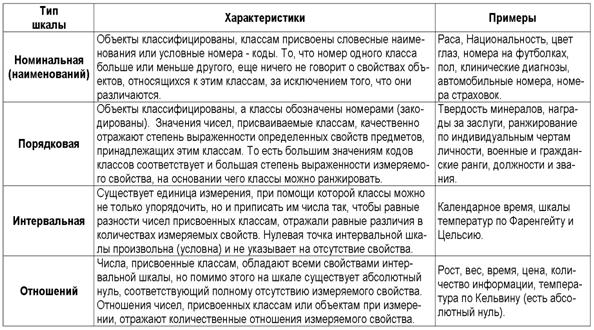
Шкалы классов (классификационные шкалы)
Плодотворным является представление классов, как некоторых областей в фазовом пространстве, в котором в качестве осей координат выступают некоторые шкалы классов меньшего уровня общности или признаков. Классы распознавания могут рассматриваться, также, как градации (конкретные значения, заданные с некоторой точностью, или диапазоны – зоны), заданные на этих шкалах. Количество шкал, тип шкал и количество градаций на них в предлагаемой модели задает сам пользователь.
Если представить эти шкалы как оси координат, то, очевидно, наиболее обобщенным классам распознавания соответствуют зоны на самих осях. Кроме того возможны варианты сочетаний по 2 оси, соответствующие областям на координатных плоскостях. Существуют также области в фазовом пространстве, образованные сочетаниями градаций сразу n-го количества шкал, где n <= N, где N - размерность фазового пространства. Естественно, пользователь может исследовать только те классы, которые его интересуют, сознательно принимая решение не рассматривать остальных. Но он должен знать, что и остальные классы также могут быть сформированы и исследованы, а для этого нужно иметь их классификацию, принцип разработки которой мы только что рассмотрели.
Конкретными реализациями обобщенных категорий могут быть объекты, их состояния или ситуации (но применять мы, как правило, будем термин "объекты", всегда имея в виду и остальные возможные варианты). Синонимами понятия "класс" являются применяющиеся в специальной литературе термины "объекты", "категории", "образы", "эталоны", "типы", "профили", "вектора". В данной работе объекты рассматриваются как конкретные реализации классов, а классы – как обобщенные образы объектов определенной категории.
Когда классы распознавания сформированы с ними могут осуществляться три основные операции: сравнение конкретных объектов, их состояний или ситуаций с классами; сравнение классов друг с другом; вывод информации о содержании обобщенного образа класса в форме таблиц или графических диаграмм.
Шкалы атрибутов (описательные шкалы)
Конкретные объекты, предъявляемые на входе модели в качестве примеров или реализаций некоторых обобщенных классов (прецедентов), описываются на языке атрибутов, т.е. признаков.
Признаки могут иметь любую природу, в частности: объективную - физическую, химическую и др. (вес, температура, рост); социально-экономическую (меновую и потребительную стоимость, степень амортизации, процент дивидендов); эмоционально-психологическую (привлекательный, предупредительный, исполнительный, конфликтный и т.п.).
Система признаков двухуровневая, что позволяет формализовать (шкалировать) не только качественные (да/нет), но и количественные (числовые) признаки, а также позволяет обрабатывать вопросы со многими, в том числе и неальтернативными вариантами ответов. Вопрос с вариантами ответов можно рассматривать как шкалу с градациями. Такое понимание позволяет "ввести в оборот" хорошо разработанную теорию шкалирования, что является весьма ценным. В предлагаемой модели нет ограничений на тип и количество шкал, а также на количество градаций в них (за исключением суммарного общего количества градаций. Нет в предлагаемой модели и таких искусственных ограничений, как, например, необходимость одинакового количества градаций во всех шкалах, или необходимость использовать только шкалы только одного какого-либо типа, и т.п., которые, как правило, встречаются в других системах.
В принципе могут быть сконструированы системы признаков, представляемые деревьями трех и более уровней, однако программно реализовывать их нецелесообразно, т.к. они все сводятся к двухуровневым деревьям (вопросы с вариантами ответов).
1.2.3.2. Иерархическая структура данных и последовательность численных расчетов в СК-анализе
Рассмотрим 6 уровней базовых когнитивных операций системного анализа и 5-ти уровневую иерархическую структуру данных (рисунок 44), на базе которой и реализуются эти операции.
На 1-м уровне непосредственно на основе исходной информации, путем применения БКОСА 2.1 и 2.2 формируется матрица абсолютных частот.
На 2-м уровне на основе матрицы абсолютных частот путем применения БКОСА 3.1.1, 3.1.2, 3.1.3, 3.2, 3.3 формируется матрица информативностей, являющаяся основой для выполнения последующих БКОСА и обеспечивающая независимость времени их выполнения от объема обучающей выборки.
На 3-м уровне путем выполнения БКОСА 4.1 и 4.2 формируется оптимизированная матрица информативностей. Оптимизация обеспечивает экономию труда, времени и других затрат на эксплуатацию содержательной информационной модели.
На 4-м уровне с использованием оптимизированной матрицы информативностей выполняются БКОСА 9.1, 9.2, а также 10.1.1 и 10.2.1. Две последние операции обеспечивают (соответственно) создание матриц сходства классов и атрибутов, являющихся, в свою очередь, основой для реализации последующих БКОСА.
На 5-м уровне на основе матриц сходства путем выполнения БКОСА 10.1.2, 10.2.2, 10.3.1 и 10.4.1 рассчитываются базы данных, когнитивного и кластерно-конструктивного анализа.
На 6-м уровне, с использованием баз данных, созданных на 5-м уровне, реализуются БКОСА 10.1.3, 10.3.2, 10.4.2 и 10.2.3.
|
|
|
Рисунок 44. Иерархическая структура данных |
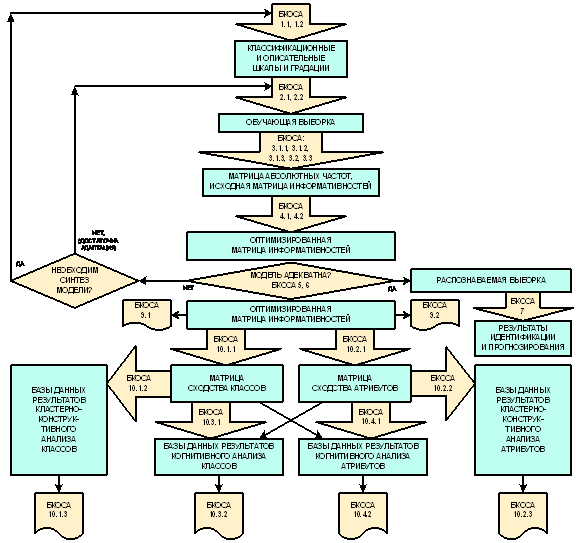
1.2.3.3. Обобщенное описание алгоритмов СК-анализа
В данном разделе приведены 24 детальных алгоритма всех 10 базовых когнитивных операций системного анализа (таблица 28), коды которых полностью соответствуют обобщенной схеме СК-анализа (рисунок 44).
|
Таблица 28 – БАЗОВЫЕ КОГНИТИВНЫЕ ОПЕРАЦИИ |
|
|
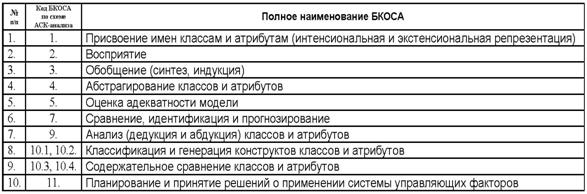
В таблице 29 приведена структура каждой базовой когнитивной операции, дана их нумерация в соответствии с обобщенной схемой СК-анализа и нумерация реализующих их алгоритмов.
|
Таблица 29 – ДЕТАЛЬНЫЙ СПИСОК БКОСА И ИХ АЛГОРИТМОВ |
|
|
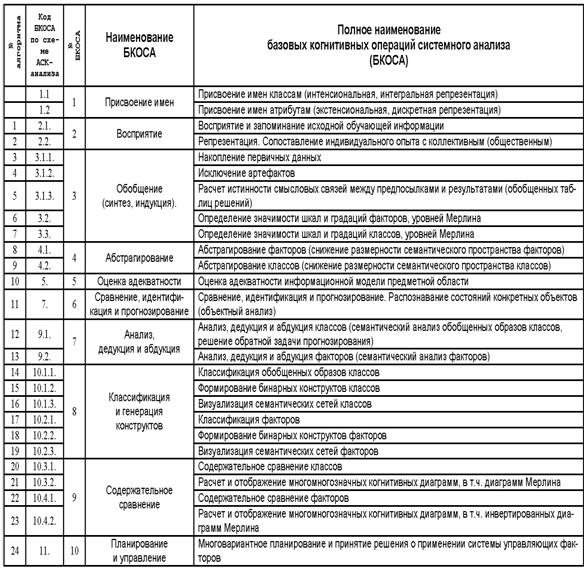
Описания базовых когнитивных операций системного анализа и их реальные детализированные алгоритмы приведены ниже (рисунки 45 – 68).
БКОСА-2.1. "Восприятие и запоминание исходной обучающей информации"
В базы данных вводятся двухвекторные (дискретно-интегральные) описания объектов, включающие как их описание на языке признаков, так и принадлежность к определенным классификационным категориям – классам.
БКОСА-2.2. "Репрезентация. Сопоставление индивидуального опыта с коллективным (общественным)"
В ряде случаев, особенно при проведении политологических исследований, необходимо, чтобы исследуемая выборка корректно представляла генеральную совокупность не только в смысле традиционно понимаемой репрезентативности, но и по распределению респондентов по категориям (т.е. структурно) соответствовала ей. Добиться этого путем подбора объектов для исследования затруднительно, т.к. каждый объект может относиться одновременно ко многим классификационным категориям. Данный алгоритм обеспечивает выборку из исследуемого множества объектов последовательных подмножеств, наиболее близких по частотному распределению объектов по категориям к заданному распределению. Данная операция называется также "взвешивание или ремонт данных".
БКОСА-3.1.1. "Обобщение (синтез, индукция). Накопление первичных данных"
На основе анализа обучающей выборки обеспечивается накопление в базах данных первичных элементов смысла, т.е. фактов, состоящих в том, что определенный признак встретился у объекта определенного класса.
БКОСА-3.1.2. "Обобщение (синтез, индукция). Исключение артефактов"
При отсутствии статистики невозможно отличить закономерные факты от не вписывающихся в общую складывающуюся картину и искажающих ее, т.е. артефактов. При накоплении же достаточной статистики это возможно и данный алгоритм позволяет выявить и исключить из дальнейшего анализа артефакты. Необходимо отметить, что в результате действия данного алгоритма существенно повышается качество содержательной модели предметной области, в частности ее валидность.
БКОСА-3.1.3. "Обобщение (синтез, индукция). Расчет степени истинности содержательных смысловых связей между предпосылками и результатами (обобщенных таблиц решений)"
Непосредственно на основе матрицы абсолютных частот позволяет вычислить количество информации, содержащейся в факте наблюдения у некоторого объекта определенного признака о том, что данный объект принадлежит к определенной классификационной категории.
БКОСА-3.2. "Определение значимости шкал и градаций факторов, уровней Мерлина"
Рассчитывается среднее количество информации, которое система управления получает о поведении АОУ из фактов о действии тех или иных факторов и их значений. Кроме того, если факторы классифицированы независимым способом по уровням Мерлина, то определяется и значимость этих уровней.
БКОСА-3.3. "Определение значимости шкал и градаций классов, уровней Мерлина"
Рассчитывается среднее количество информации, которое система управления получает из одного признака, если известен класс. Если классы относятся к уровням Мерлина, то определяется и их значимость.
БКОСА-4.1. "Абстрагирование факторов (снижение размерности семантического пространства факторов)"
С помощью метода последовательных приближений (итерационный алгоритм) при заданных граничных условиях снижается размерность пространства атрибутов без существенного уменьшения его объема и адекватности модели. Критерий остановки итерационного процесса – достижение одного из граничных условий.
БКОСА-4.2. "Абстрагирование классов (снижение размерности семантического пространства классов)"
С помощью метода последовательных приближений (итерационный алгоритм) при заданных граничных условиях снижается размерность пространства классов без существенного уменьшения его и адекватности объема. Критерий остановки итерационного процесса – достижение одного из граничных условий.
БКОСА-5. "Оценка адекватности информационной модели предметной области"
Осуществляется идентификация объектов обучающей выборки (классификационный вектор которых уже известен) и затем рассчитывается средневзвешенная погрешность идентификации (интегральная валидность), а также погрешность идентификации с каждым классом (дифференциальная валидность). Если модель имеет приемлемый уровень адекватности, то принимается решение о возможности ее использования в адаптивном режиме на объектах, не входящих в обучающую выборку, но относящихся к генеральной совокупности, по отношению к которой эта выборка репрезентативна. Если же модель недостаточно адекватна, то продолжаются работы по синтезу адекватной модели путем увеличения количества классов и факторов, а также корректировки описаний объектов обучающей выборки и увеличения их количества.
БКОСА-7. "Сравнение, идентификация и прогнозирование. Распознавание состояний конкретных объектов (объектный анализ)"
Рассчитывается количество информации, содержащееся в описании идентифицируемого объекта о его принадлежности к каждому из классов. Все классы ранжируются в порядке убывания количества информации о принадлежности к ним в описании данного объекта. Таким образом, вектор объекта разлагается в ряд по векторам классов. Кроме того, все объекты ранжируются в порядке убывания сходства с каждым классом. Таким образом, вектор класса разлагается в ряд по векторам объектов.
БКОСА-9.1. "Дедукция и абдукция классов (семантический анализ обобщенных образов классов, решение обратной задачи прогнозирования)"
Координаты вектора класса (т.е. факторы) ранжируются в порядке убывания их значений. Таким образом, в начале списка оказываются факторы, оказывающие наиболее сильное влияние на переход АОУ в состояние, соответствующее данному классу, а в конце списка – препятствующие этому. Это позволяет выбрать факторы для управляющего воздействия, целью которого является перевод АОУ в состояние, соответствующее данному классу. Механизм фильтрации позволяет "изолированно" рассматривать влияние различных групп факторов: например, факторов, характеризующих объект управления, управляющую систему или окружающую среду. Абдукция представляет собой обобщение дедукции на основе нечеткой логики. В данном случае это означает, что фактор связан с классом не детерминистским образом, а через количество информации, которое в нем содержится о данном класса.
БКОСА-9.2. "Дедукция и абдукция факторов (семантический анализ факторов)"
Классы ранжируются в порядке убывания влияния данного фактора на переход АОУ в состояния, соответствующие этим классам. В начале списка оказываются состояния, на переход в которые данный фактор оказывает наибольшее влияние, а в конце – на переход в которые данный фактор препятствует. Этот список является развернутой характеристикой смысла фактора.
БКОСА-10.1.1. "Классификация обобщенных образов классов"
Сравниваются вектора классов и формируется диагональная матрица сходства классов, в которой по обоим осям расположены коды классов а в клетках находятся нормированные коэффициенты, численно отражающие степень сходства или различия векторов соответствующих классов.
БКОСА-10.1.2. "Формирование бинарных конструктов классов"
На основе матрицы сходства классов для каждого из них формируется ранжированный список остальных, в котором они расположены в порядке убывания сходства с данным классом. Такие списки представляют собой бинарные конструкты, а их полюса соответствуют кластерам.
БКОСА-10.1.3. "Визуализация семантических сетей классов"
На основе матрицы сходства классов визуализируются ориентированные графы, вершинам которых соответствуют классы, а ребрам – степени их сходства или различия. Знак связи обозначается цветом: красный цвет – сходство, синий – различие, толщина линии соответствует модулю (силе) связи. Необходимо отметить, что для подобных графов в литературе пока нет устоявшегося общепринятого названия: в данном исследовании, как и в предшествующих работах автора, они называются семантическими сетями, в литературе по когнитивному анализу их называют когнитивными картами, а в литературе по когнитивному анализу – когнитивными картами или схемами [114 – 118].
БКОСА-10.2.1. "Классификация факторов"
Сравниваются вектора факторов и формируется диагональная матрица сходства факторов, в которой по обоим осям расположены коды факторов, а в клетках находятся нормированные коэффициенты, численно отражающие степень сходства или различия векторов соответствующих факторов.
БКОСА-10.2.2. "Формирование бинарных конструктов факторов"
На основе матрицы сходства факторов для каждого из них формируется ранжированный список остальных, в котором они расположены в порядке убывания сходства с данным фактором. Такие списки представляют собой бинарные конструкты, а их полюса соответствуют кластерам.
БКОСА-10.2.3. "Визуализация семантических сетей факторов"
На основе матрицы сходства факторов визуализируются ориентированные графы, вершинам которых соответствуют заданные факторы, а ребрам – степени их сходства или различия. Знак связи обозначается цветом: красный цвет – сходство, синий – различие, толщина линии соответствует модулю (силе) связи.
БКОСА-10.3.1. "Содержательное сравнение классов"
Каждая связь между классами в семантической сети, отражающая степень их сходства или различия, имеет определенную структуру, описанную в разделе 3.2.3 исследования. Эта структура включает ряд элементов, каждый из которых соответствует одному слагаемому обобщенной меры сходства векторов классов.
БКОСА-10.3.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. диаграмм Вольфа Мерлина"
Из всех составляющих связи между классами выбираются 8 наиболее сильных и отображаются в форме линий, цвет которых означает знак, а толщина – модуль силы связи. Классы изображаются в форме наиболее значимых фрагментов их информационных портретов. При этом учитываются корреляции между факторами.
БКОСА-10.4.1. "Содержательное сравнение факторов"
Каждая связь между факторами в семантической сети, отражающая степень их сходства или различия, имеет определенную структуру, описанную в разделе 3.2.3 исследования. Эта структура включает ряд элементов, каждый из которых соответствует одному слагаемому обобщенной меры сходства векторов факторов.
БКОСА-10.4.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. инвертированных диаграмм Мерлина"
Из всех составляющих связи между факторами выбираются 16 наиболее сильных и отображаются в форме линий, цвет которых означает знак, а толщина – модуль силы связи. Факторы отображаются в форме наиболее значимых фрагментов их семантических портретов. При этом учитываются корреляции между классами.
БКОСА-11. "Многовариантное планирование и принятие решения о применении системы управляющих факторов"
Выполняется в несколько этапов:
1) выполняется прогноз развития АОУ в условиях отсутствия управляющих воздействий, т.е. реализуется БКОСА-7 ("движение по инерции");
2) если в соответствии с прогнозом по п.1 АОУ достигает заданного целевого состояния (т.е. прогноз "удовлетворительный"), то планирование прекращается (переход на п.6); иначе – выполняется п.3;
3) путем решения обратной задачи прогнозирования (БКОСА-9.1) определяется набор факторов, оптимальный для перевода АОУ в заданное целевое состояние;
4) если все эти факторы есть возможность использовать для управления, то на этом планирование прекращается (переход п.6); иначе переход на п.5;
5) используя результаты кластерно-конструктивного анализа факторов (БКОСА 10.2.1, 10.2.2, 10.2.3) последовательно ищется замена для факторов, которые нет возможности использовать и после каждой замены выполняется прогнозирование (БКОСА-7); если результаты прогнозирования удовлетворительные – окончание планирования (переход на п.6); иначе принятие решения о невозможности выработки корректного управляющего воздействия;
6) окончание планирования.
Информационный портрет представляет собой детализацию вершин семантической сети. Когнитивные диаграммы детально раскрывают структуру связи между двумя вершинами семантической сети, представленными в форме информационных портретов. Поэтому для расшифровки структуры вершин семантической сети и связей между ними, предлагается ввести новое понятие "Семантическая когнитивная сеть", которая представляет собой систему когнитивных диаграмм, объединенных в макроструктуру, соответствующую структуре семантической сети.
1.2.3.4. Детальные алгоритмы СК-анализа
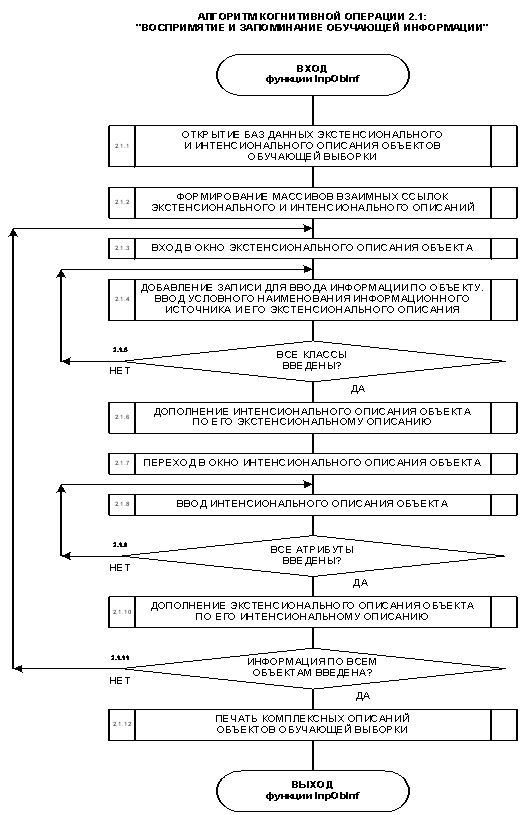

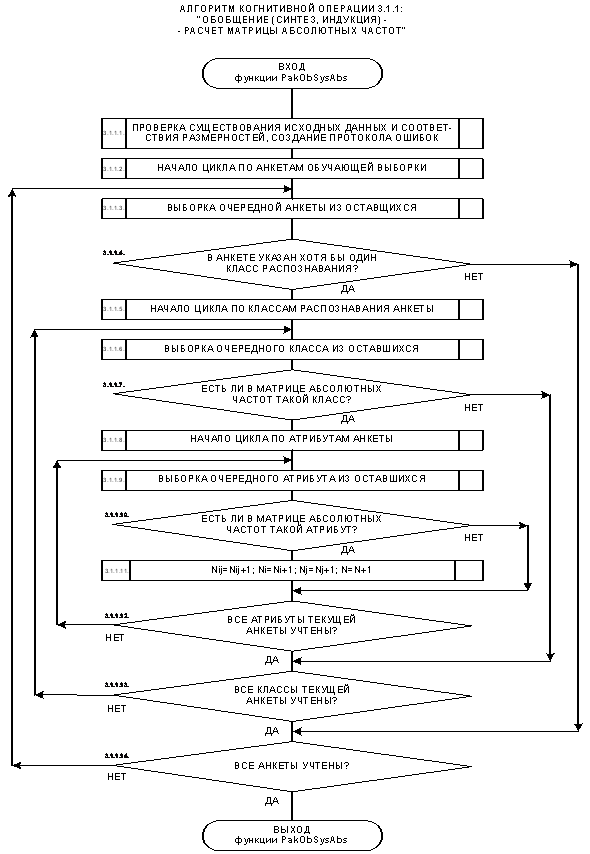
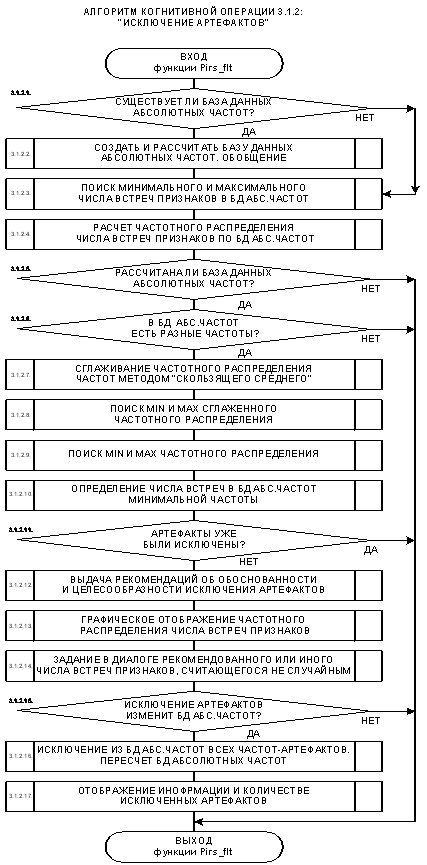
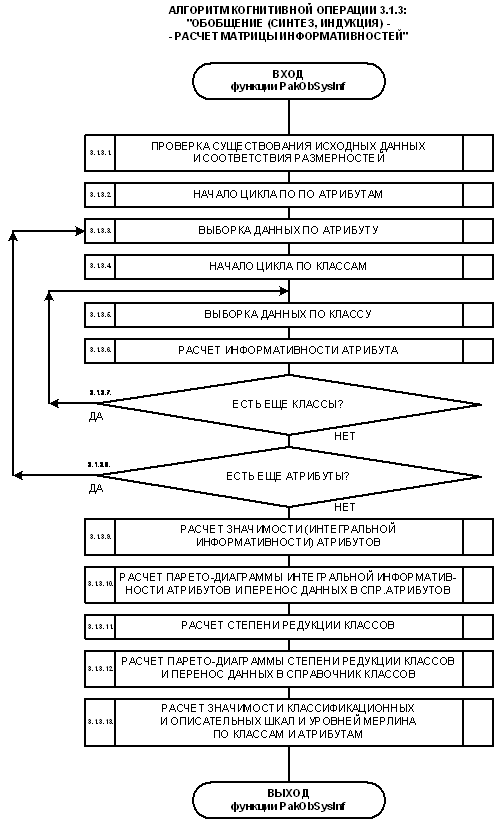
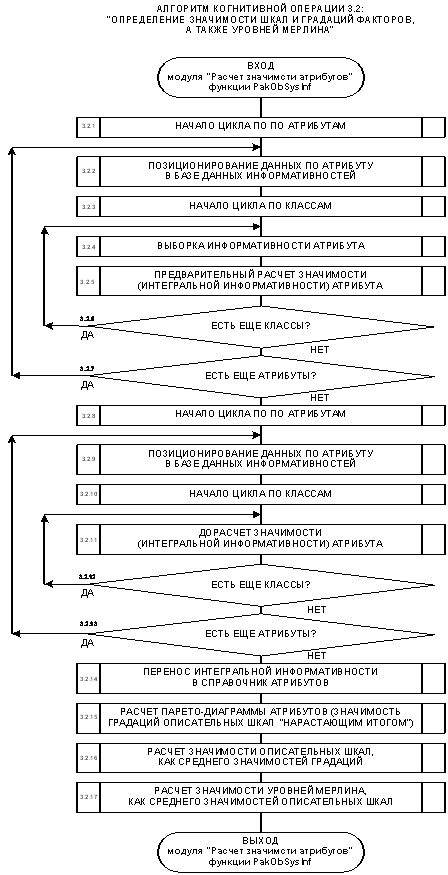
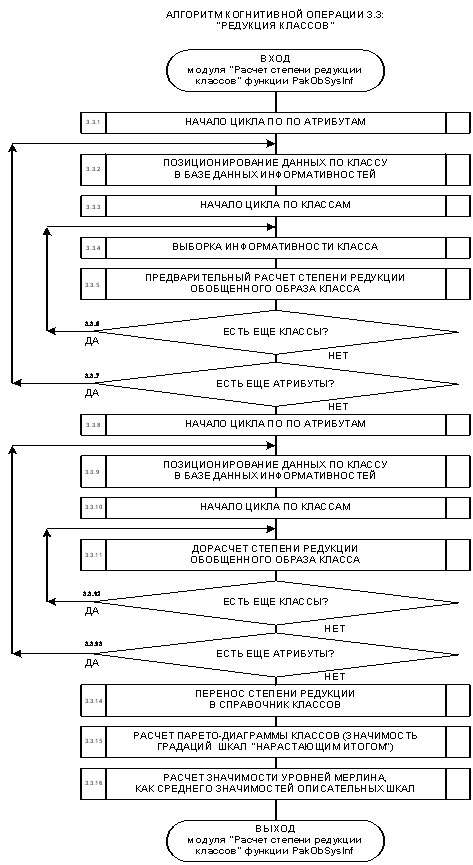
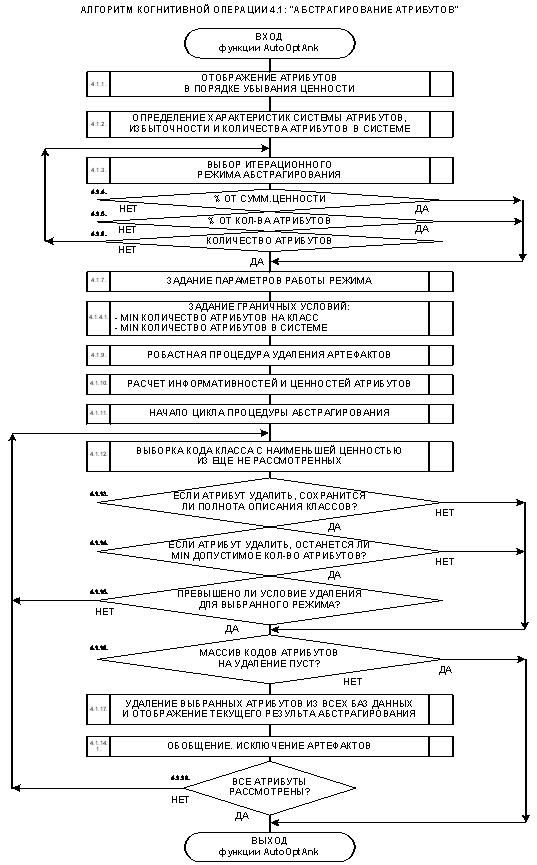
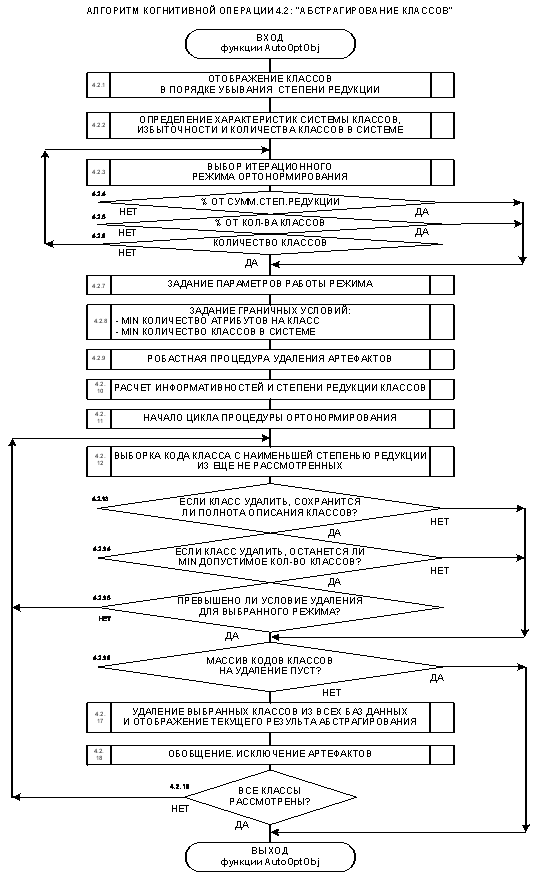
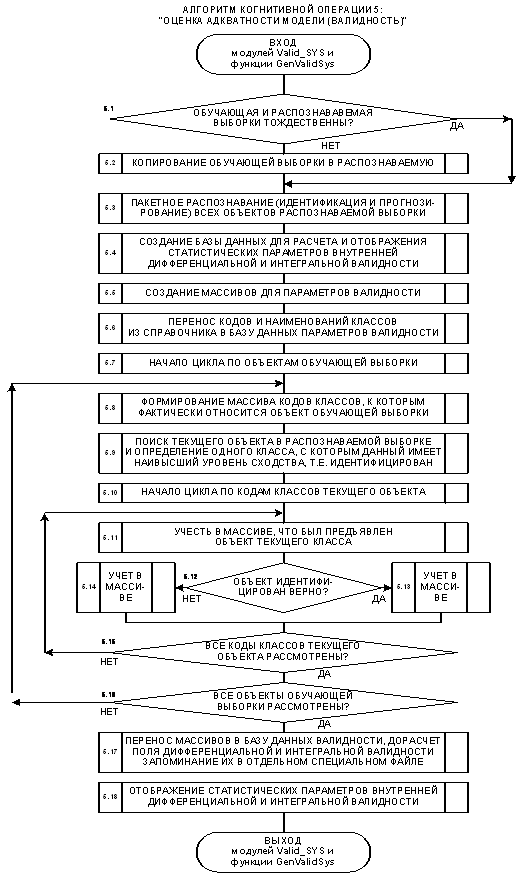


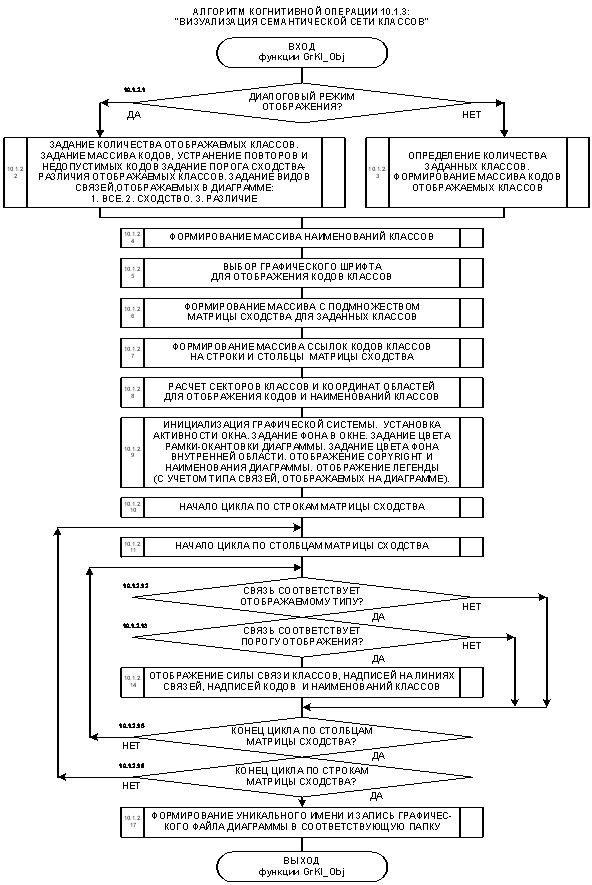


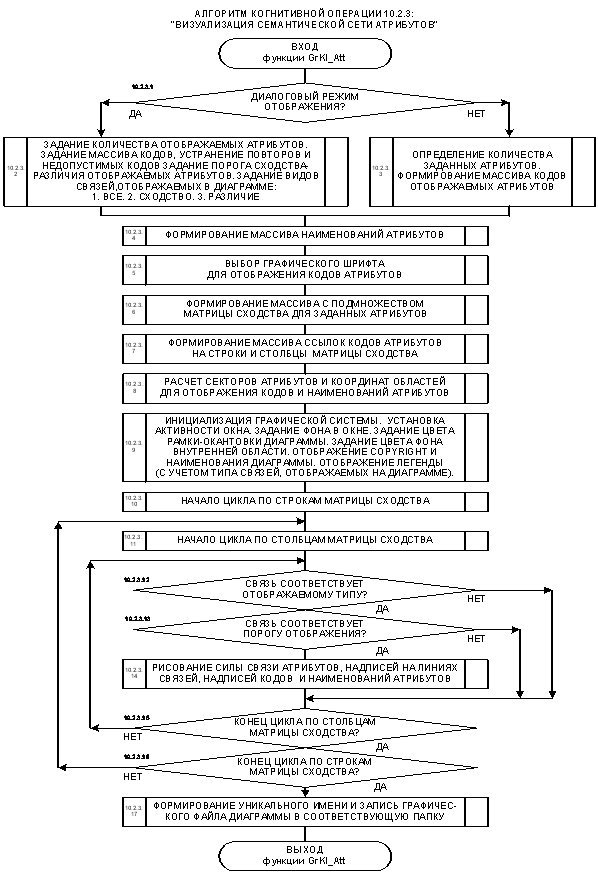

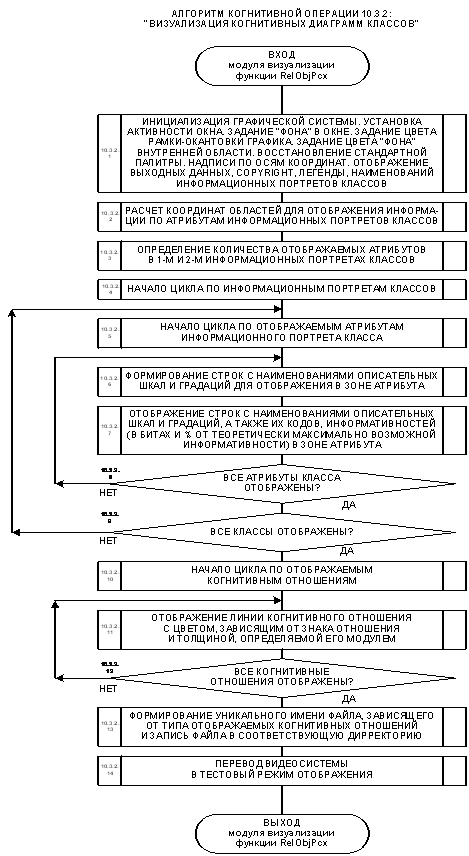

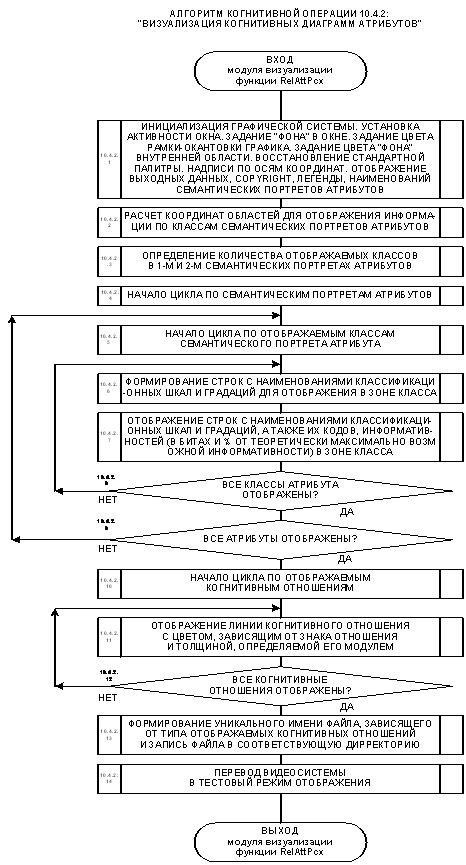
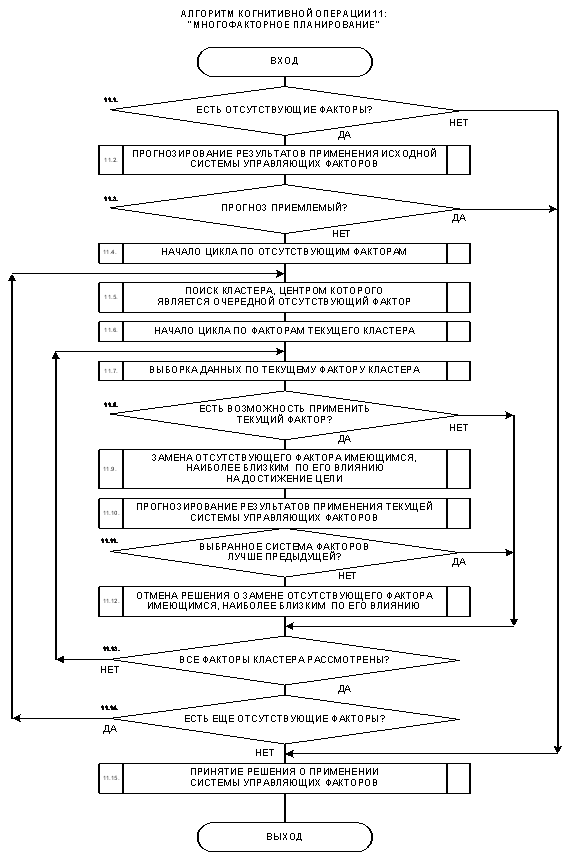
Резюме
1.
Разработан численный метод СК-анализа, включающий:
–
иерархическую структуру данных семантической информационной модели;
– 24
детальных алгоритма 10 базовых когнитивных операций системного анализа,
алгоритмы кластерно-конструктивного и когнитивного анализа, нечеткой логики и
когнитивной графики, обеспечивающие оригинальную визуализацию результатов интеллектуального
анализа данных (нечеткие графы).
2. Предложенный численный метод СК-анализа обеспечил конкретизацию моделей БКОСА, достаточную для их реализации в одной программной системе.
Контрольные вопросы
1. Принципы формализации предметной области и подготовки эмпирических данных.
2. Иерархическая структура данных и последовательность численных расчетов в СК-анализе
3. Обобщенное описание алгоритмов СК-анализа
4. БКОСА-2.1. "Восприятие и запоминание исходной обучающей информации".
5. БКОСА-2.2. "Репрезентация. Сопоставление индивидуального опыта с коллективным (общественным)".
6. БКОСА-3.1.1. "Обобщение (синтез, индукция). Накопление первичных данных".
7. БКОСА-3.1.2. "Обобщение (синтез, индукция). Исключение артефактов".
8. БКОСА-3.1.3. "Обобщение (синтез, индукция). Расчет степени истинности содержательных смысловых связей между предпосылками и результатами (обобщенных таблиц решений)".
9. БКОСА-3.2. "Определение значимости шкал и градаций факторов, уровней Мерлина".
10. БКОСА-3.3. "Определение значимости шкал и градаций классов, уровней Мерлина".
11. БКОСА-4.1. "Абстрагирование факторов (снижение размерности семантического пространства факторов)".
12. БКОСА-4.2. "Абстрагирование классов (снижение размерности семантического пространства классов)".
13. БКОСА-5. "Оценка адекватности информационной модели предметной области".
14. БКОСА-7. "Сравнение, идентификация и прогнозирование. Распознавание состояний конкретных объектов (объектный анализ)".
15. БКОСА-9.1. "Дедукция и абдукция классов (семантический анализ обобщенных образов классов, решение обратной задачи прогнозирования)".
16. БКОСА-9.2. "Дедукция и абдукция факторов (семантический анализ факторов)".
17. БКОСА-10.1.1. "Классификация обобщенных образов классов".
18. БКОСА-10.1.2. "Формирование бинарных конструктов классов".
19. БКОСА-10.1.3. "Визуализация семантических сетей классов".
20. БКОСА-10.2.1. "Классификация факторов".
21. БКОСА-10.2.2. "Формирование бинарных конструктов факторов".
22. БКОСА-10.2.3. "Визуализация семантических сетей факторов".
23. БКОСА-10.3.1. "Содержательное сравнение классов".
25. БКОСА-10.3.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. диаграмм Вольфа Мерлина".
26. БКОСА-10.4.1. "Содержательное сравнение факторов".
27. БКОСА-10.4.2. "Расчет и отображение многомногозначных когнитивных диаграмм, в т.ч. инвертированных диаграмм Мерлина".
28. БКОСА-11. "Многовариантное планирование и принятие решения о применении системы управляющих факторов".
29. Детальные алгоритмы СК-анализа.
Рекомендуемая литература
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1.2.4.
ЛЕКЦИЯ-6.
Технология синтеза
и эксплуатации приложений в системе "Эйдос"
Учебные вопросы
1. Назначение и состав системы "ЭЙДОС".
2. Пользовательский интерфейс, технология разработки и эксплуатации приложений в системе "ЭЙДОС".
3. Технические характеристики и обеспечение эксплуатации системы "ЭЙДОС" (версии 12.5).
4. АСК-анализ, как технология синтеза и эксплуатации рефлексивных АСУ активными объектами.
В данной лекции рассматривается инструментарий
автоматизации СК-анализа в качестве которого выступает универсальная
когнитивная аналитическая система "Эйдос". Данная система является одним
из вариантов программной реализации предложенной математической модели
и численного метода СК-анализа. Наличие данного инструментария,
автоматизирующего СК-анализ, позволяет ввести в новый термин: автоматизированный системно-когнитивный
анализ (АСК-анализ), под которым понимается СК-анализ, оснащенный математическим
методом, методикой численных расчетов и реализующим их программным инструментарием.
1.2.4.1. Назначение и состав системы "ЭЙДОС"
1.2.4.1.1. Цели и основные функции системы "Эйдос"
Универсальная когнитивная аналитическая система "Эйдос" является отечественным лицензионным программным продуктом [139 – 146], созданным с использованием официально приобретенного лицензионного программного обеспечения. По системе "Эйдос" и различным аспектам ее практического применения имеется более 80 публикаций автора с соавторами [29, 30, 34, 62, 64 – 111, 139 – 146, 169, 172 – 185, 201 – 206, 212, 214, 224 – 226], в т.ч. 5 монографий. Система "Эйдос" является программным инструментарием, реализующим математическую модель и методику численных расчетов СК-анализа. Она обеспечивает реализацию следующих функций:
1. Синтез и адаптация семантической информационной модели предметной области, включая активный объект управления и окружающую среду.
2. Идентификация и прогнозирование состояния активного объекта управления, а также разработка управляющих воздействий для его перевода в заданные целевые состояния.
3. Углубленный анализ семантической информационной модели предметной области.
Система "Эйдос" является специальным программным инструментарием, реализующим предложенные математическую модель и численный метод (структуры данных и алгоритмы) и решающим проблему данной работы.
Синтез содержательной информационной модели предметной области
Синтез модели в СК-анализе осуществляется с применением подсистем: "Словари", "Обучение", "Оптимизация", "Распознавание" и "Анализ". Он включает следующие этапы:
1) формализация (когнитивная структуризация
предметной области);
2) формирование исследуемой выборки и управление
ею;
3) синтез или адаптация модели;
4) оптимизация модели;
5) измерение адекватности модели (внутренней и внешней, интегральной и дифференциальной валидности), ее скорости сходимости и семантической устойчивости.
Идентификация и прогнозирование состояния объекта управления, выработка управляющих воздействий
Данный вид работ осуществляется с помощью подсистем "Распознавание" и "Анализ". Эти подсистемы обеспечивают: ввод распознаваемой выборки; пакетное распознавание; вывод результатов распознавания и их оценку, в т.ч. с использованием данных по дифференциальной валидности модели.
Углубленный анализ содержательной информационной модели предметной области
Этот анализ выполняется в подсистеме "Типология", которая включает:
1. Информационный и семантический анализ классов и признаков.
2. Кластерно-конструктивный анализ классов распознавания и признаков, включая визуализацию результатов анализа в оригинальной графической форме когнитивной графики (семантические сети классов и признаков).
3. Когнитивный анализ классов и признаков (когнитивные диаграммы и диаграммы Вольфа Мерлина).
1.2.4.1.2. Обобщенная структура системы "Эйдос"
Система "Эйдос" включает семь подсистем: "Словари", "Обучение", "Оптимизация", "Распознавание", "Типология", "Анализ", "Сервис" (таблица 30).
Таблица 30 – ОБОБЩЕННАЯ СТРУКТУРА СИСТЕМЫ "ЭЙДОС" (версии 12.5)
|
Подсистема |
Режим |
Функция |
Операция |
|
1. Словари |
1.
Классификационные шкалы и градации |
||
|
2.
Описательные шкалы (и градации) |
|||
|
3. Градации
описательных шкал (признаки) |
|||
|
4. Иерархические
уровни систем |
1. Уровни
классов |
||
|
2. Уровни
признаков |
|||
|
5. Программные
интерфейсы для импорта данных |
1. Импорт
данных из TXT-фалов стандарта DOS-текст |
||
|
2. Импорт
данных из DBF-файлов стандарта проф. А.Н.Лебедева |
|||
|
3. Импорт из
транспонированных DBF-файлов проф. А.Н.Лебедева |
|||
|
4. Генерация
шкал и обучающей выборки RND-модели |
|||
|
5. Генерация
шкал и обучающей выборки для исследования чисел |
|||
|
6.
Транспонирование DBF-матриц исходных данных |
|||
|
6. Почтовая
служба по НСИ |
1. Обмен по
классам |
||
|
2. Обмен по
обобщенным признакам |
|||
|
3. Обмен по
первичным признакам |
|||
|
7. Печать
анкеты |
|||
Продолжение таблицы 30
|
Подсистема |
Режим |
Функция |
Операция |
|
2. Обучение |
1.
Ввод–корректировка обучающей выборки |
||
|
2.
Управление обучающей выборкой |
1.
Параметрическое задание объектов для обработки |
||
|
2.
Статистическая характеристика, ручной ремонт |
|||
|
3.
Автоматический ремонт обучающей выборки |
|||
|
3. Пакетное
обучение системы распознавания |
1.
Накопление абсолютных частот |
||
|
2.
Исключение артефактов (робастная процедура) |
|||
|
3. Расчет
информативностей признаков |
|||
|
4. Расчет
условных процентных распределений |
|||
|
5.
Автоматическое выполнение режимов 1–2–3–4 |
|||
|
6. Измерение
сходимости и устойчивости модели |
1.
Сходимость и устойчивость СИМ |
||
|
2.
Зависимость валидности модели от объема обучающей выборки |
|||
|
4. Почтовая
служба по обучающей информации |
|||
|
3. Оптимизация |
1.
Формирование ортонормированного базиса классов |
||
|
2.
Исключение признаков с низкой селективной силой |
|||
|
3. Удаление
классов и признаков, по которым недостаточно данных |
|||
|
4. Распознавание |
1.
Ввод–корректировка распознаваемой выборки |
||
|
2. Пакетное
распознавание |
|||
|
3. Вывод результатов
распознавания |
1. Разрез:
один объект – много классов |
||
|
2. Разрез:
один класс – много объектов |
|||
|
4. Почтовая
служба по распознаваемой выборке |
|||
|
5. Типология |
1. Типологический
анализ классов распознавания |
1.
Информационные (ранговые) портреты (классов) |
|
|
2.
Кластерный и конструктивный анализ классов |
1 Расчет
матрицы сходства образов классов |
||
|
2. Генерация
кластеров и конструктов классов |
|||
|
3. Просмотр
и печать кластеров и конструктов |
|||
|
4. Автоматическое
выполнение режимов: 1,2,3 |
|||
|
5. Вывод 2d
семантических сетей классов |
|||
|
3.
Когнитивные диаграммы классов |
|||
|
2. Типологический
анализ первичных признаков |
1.
Информационные (ранговые) портреты признаков |
||
|
2.
Кластерный и конструктивный анализ признаков |
1. Расчет
матрицы сходства образов признаков |
||
|
2. Генерация
кластеров и конструктов признаков |
|||
|
3. Просмотр
и печать кластеров и конструктов |
|||
|
4.
Автоматическое выполнение режимов: 1,2,3 |
|||
|
5. Вывод 2d
семантических сетей признаков |
|||
|
3. Когнитивные
диаграммы признаков |
|||
|
6. Анализ |
1. Оценка
достоверности заполнения объектов |
||
|
2. Измерение
адекватности семантической информационной модели |
|||
|
3. Измерение
независимости классов и признаков |
|||
|
4. Просмотр
профилей классов и признаков |
|||
|
5. Графическое
отображение нелокальных нейронов |
|||
|
6.
Отображение Паретто-подмножеств нейронной сети |
|||
|
7.
Классические и интегральные когнитивные карты |
|||
|
7. Сервис |
1. Генерация
(сброс) БД |
1. Все базы
данных |
|
|
2. НСИ |
1. Всех баз
данных |
||
|
2. БД
классов |
|||
|
3. БД первичных
признаков |
|||
|
4. БД
обобщенных признаков |
|||
|
3. Обучающая
выборка |
|||
|
4.
Распознаваемая выборка |
|||
|
5. Базы
данных статистики |
|||
|
2.
Переиндексация всех баз данных |
|||
|
3. Печать БД
абсолютных частот |
|||
|
4. Печать БД
условных процентных распределений |
|||
|
5. Печать БД
информативностей |
|||
|
6.
Интеллектуальная дескрипторная информационно–поисковая система |
|||
Структура и взаимодействие этих подсистем позволяют полностью реализовать все аспекты СК-анализа в удобной для пользователя форме. Обобщенной структуре соответствуют и структура управления и дерево диалога системы. Подробнее подсистемы, режимы, функции и операции, реализуемые системой "Эйдос", описаны в работах [64, 92].
1.2.4.2. Пользовательский интерфейс, технология разработки и эксплуатации приложений в системе "ЭЙДОС"
Не смотря на то, что данный раздел посвящен интерфейсу системы "Эйдос", видеограммы и экранные формы в нем не приводятся, т.к. они есть в описаниях лабораторных работ. В наименованиях разделов с описаниями подсистем и режимов системы "Эйдос" указаны коды реализуемых ими базовых когнитивных операций системного анализа в соответствии с обобщенной схемой СК-анализа (рисунок 14).
1.2.4.2.1. Начальный этап синтеза модели: когнитивная структуризация и формализация предметной области, подготовка исходных данных (подсистема "Словари") (БКОСА-1, БКОСА-2)
Подсистема "Словари" обеспечивает формализацию предметной области. Она реализует следующие режимы: классификационные шкалы и градации; описательные шкалы и градации; градации описательных шкал; иерархические уровни организации систем; автоматический ввод первичных признаков из текстовых файлов; почтовая служба по нормативно-справочной информации; печать анкеты.
Классификационные шкалы и градации (БКОСА-1.1)
Классификационные шкалы и градации предназначены для ввода справочника будущих состояний активного объекта управления – классов. Режим: "Классификационные шкалы и градации" обеспечивает ведение базы данных классификационных шкал и градаций классов: ввод; корректировку; удаление; распечатку (в текстовый файл); сортировку; поиск по базе данных.
Описательные шкалы и градации (БКОСА-1.2)
Описательные шкалы и градации предназначены для ввода справочников факторов, влияющих на поведение активного объекта управления – признаков. В этом режиме обеспечивается ввод, удаление, корректировка, копирование наименований описательных шкал и связанных с ними градаций. Характерной особенностью системы "Эйдос" является возможность использования неальтернативных градаций, которых может быть различное количество по различным шкалам (в широких пределах). Справочник позволяет работать непосредственно с градациями (с учетом связей со шкалами), видеть их общее количество, а также просматривать и распечатывать процентное распределение ответов респондентов по.
Уровни организации систем (уровни Вольфа Мерлина) являются независимым способом классификации классов и факторов, что позволяет легко создавать и анализировать различные их подмножества как сами по себе, так и в сопоставлении друг с другом. В.С.Мерлин предложил интегральную концепцию индивидуальности, в которой рассматривал взаимодействие и взаимообусловленность различных уровней свойств личности: от генетически предопределенных, до социально-обусловленных и отражающих сиюминутное состояние. В системе "Эйдос" предусмотрен аппарат, позволяющий классифицировать факторы таким образом, что становится возможным исследовать различные уровни их организации и взаимообусловленности. Уровни организации классов предназначены для классификации будущих состояний активного объекта управления, как целевых и нежелательных с точки зрения самого объекта управления и управляющей системы, а также различных вариантов сочетаний этих вариантов. Возможны и другие виды классификации.
Система "Эйдос" обеспечивает решение задач атрибуции анонимных и псевдонимных текстов (установления вероятного авторства), датировки текстов, определения их принадлежности к определенным традициям, школам или течениям мысли [72, 73]. При этом различные структуры, из которых состоят тексты, рассматриваются как их атрибуты. В системе "Эйдос" реализован специальный режим, обеспечивающий автоматическое выявление и ввод этих атрибутов текстов непосредственно из текстовых файлов.
Технология работы в системе "Эйдос" не предусматривает одновременной работы многих пользователей с одними и теми же базами данных в режиме корректировки записей. Поэтому возможна эффективная организация распределенной работы по многомашинной технологии без использования ЛВС. Для обеспечения необходимой тождественности справочников на различных компьютерах служит режим "Почтовая служба по НСИ".
Классификационные шкалы и градации в экономических, социально-психологических и политологических исследованиях часто представляют собой опросники (анкеты). Для их распечатки в файл (в поддиректорию "TXT") служит режим: "Печать анкеты". В системе "Эйдос" все текстовые и графические входные и выходные формы автоматически сохраняются в виде файлов, удобных для использования в различных приложениях под Windows.
Ввод-корректировка обучающей информации (БКОСА-2.1)
Данная подсистема обеспечивает ввод и корректировку обучающей выборки, управление ею, синтез и адаптацию модели на основе данных обучающей выборки, экспорт и импорт данных с других компьютеров.
Для ввода-корректировки обучающей выборки служит соответствующий режим, имеющий двухоконный интерфейс, позволяющий ввести в обучающую выборку двухвекторные описания объектов. Левое окно служит для ввода классификационной характеристики объекта. В этом окне каждому объекту соответствует одна строка с прокруткой. В правом окне вводится описательная характеристика объекта на языке признаков. Каждому объекту соответствует окно с прокруткой. Переход между окнами осуществляется по нажатию клавиши "TAB". Количество объектов в обучающей выборке не ограничено. Имеется практический опыт проведения расчетов с объемами обучающей выборки до 7000 объектов, суммарным количеством градаций описательных шкал до 3900 и количеством классов до 1500. Реализована также возможность автоматического формирования объектов обучающей выборки путем кодирования текстовых файлов.
В системе реализован ряд программных интерфейсов, обеспечивающих автоматическое формирование классификационных и описательных шкал и градаций, а также обучающей выборки:
– импорт данных из файлов стандарта "Текст DOS";
– импорт данных из DBF-файлов, стандарта проф. А.Н.Лебедева;
– импорт данных из транспонированных DBF-файлов, стандарта профессора А.Н.Лебедева;
– генерация случайной модели;
– генерация учебной модели для исследования свойств натуральных чисел.
Управление составом обучающей информации (БКОСА-2.2)
Данный режим предназначен для управления обучающей выборкой путем параметрического задания подмножеств анкет для обработки, объединения классов, автоматического ремонта обучающей выборки ("ремонт или взвешивание данных"). Параметрическое выделение подмножества анкет для обработки может осуществляться логически и физически (рекомендуется 2-й вариант), это осуществляется путем сравнения с анкетой-маской. В ней задаются коды тех классов и признаков, которые обязательно должны присутствовать во всех анкетах обрабатываемого подмножества. Режим: "Статистическая характеристика обучающей выборки. Ручной ремонт" предназначен для выявления слабо представленных классов (по которым недостаточно данных) и объединения нескольких классов в один. При этом производится переформирование справочника классов и автоматическое перекодирование анкет обучающей выборки. В режиме "Автоматический ремонт обучающей выборки (ремонт или взвешивание данных)" реализуется БКОСА-2.2: задается частотное распределение объектов по категориям, характерное для генеральной совокупности (или другое), затем автоматически осуществляется формирование последовательных подмножеств анкет обучающей выборки (с увеличивающимся числом анкет), на каждом этапе максимально соответствующих заданному частотному распределению генеральной совокупности. При этом используется метод последовательных приближений по минимаксному критерию: максимизация корреляции и минимизация максимального отклонения. Соответствующие графики представлены на рисунке 69.
Система рекомендует оптимальное (по этим двум критериям) подмножество и позволяет исключить остальные анкеты из рассмотрения. На рисунке 70 приведены графики частотных распределений объектов генеральной совокупности и выбранного подмножества обучающей выборки по категориям (классам), а также отклонение между этими распределениями.
|
|
|
Рисунок 69. Автоматический ремонт обучающей выборки (диагр.1) (БКОСА-2.2) |
|
|
|
Рисунок 70. Автоматический ремонт обучающей выборки (диагр.2) (БКОСА-2.2) |
При достижении минимакса можно говорить об обеспечении структурной репрезентативности [64].
1.2.4.2.2. Синтез модели: пакетное обучение системы распознавания (подсистема "Обучение") (БКОСА-3)
Данный режим обеспечивает: расчет матрицы абсолютных частот, поиск и исключение из дальнейшего анализа артефактов, расчет матрицы информативностей, расчет матрицы условных процентных распределений, пакетный режим автоматического выполнения вышеперечисленных 4-х режимов, а также исследовательский режим, обеспечивающий измерение скорости сходимости и семантической устойчивости сформированной содержательной информационной модели.
Расчет матрицы абсолютных частот (БКОСА-3.1.1)
В данном режиме осуществляется последовательное считывание всех анкет обучающей выборки и использование описаний объектов для формирования статистики встреч признаков в разрезе по классам. На экране в наглядной форме отображается стадия этого процесса, который может занимать значительное время при больших размерностях задачи и объеме обучающей выборки. Кроме того на качественном уровне красным отображается заполнение матрицы абсолютных частот данными: классы соответствуют столбцам, а признаки – строкам. Поэтому значительная фрагментарность данных легко обнаруживается еще на этой стадии. Данный режим обеспечивает полную "развязку по данным" и независимость времени исполнения процессов синтеза модели и ее анализа от объема обучающей выборки. Кроме того в данном режиме выявляются 4 типа формально-обнаружимых ошибок в исходных данных и по ним формируется файл отчета.
Исключение артефактов (робастная процедура) (БКОСА-3.1.2)
В данном режиме на основе исследования частотного распределения частот встреч признаков в матрице абсолютных частот, делаются выводы:
– об отсутствии статистики и невозможности обнаружения и исключения артефактов;
– о наличии статистики и возможности выявления артефактов (если частоты встреч признаков растут пропорционально объему обучающей выборки, то это нормально, артефактами считаются признаки, по которым эта закономерность нарушается).
На основе этих выводов рекомендуется частота, которая признается незначимой и характерной для артефактов и осуществляется переформирование баз данных с исключенными артефактами.
Расчет матриц информативностей (БКОСА-3.1.3, 3.2, 3.3)
В этом режиме непосредственно на основе матрицы абсолютных частот с применением системного обобщения формулы Харкевича, предложенного автором в рамках СТИ (3.28), рассчитывается матрица информативностей, определяются значимость признаков, степень сформированности обобщенных образов классов, а также обобщенный критерий сформированности модели Харкевича (3.63) для всей матрицы информативностей в целом. На экране монитора наглядно отображается стадия выполнения процесса и структура заполнения матрицы информативностей значимыми данными (на качественном уровне). На основе матрицы абсолютных частот рассчитывается и матрица условных процентных распределений.
Автоматическое выполнение режимов 1-2-3-4. В данном пакетном режиме последовательно выполняются ранее перечисленные режимы обучения системы (кроме режима исключения артефактов).
Измерение сходимости и устойчивости модели
Для измерения сходимости и устойчивости модели СК-анализа задаются параметры, определяющие исследование скорости сходимости:
– порядок выборки анкет (физический, случайный, в порядке возрастания соответствия генеральной совокупности, в порядке убывания степени многообразия, вносимого анкетой в модель);
– количество и коды признаков, по которым исследуется сходимость модели;
– интервал сглаживания для расчета скользящей погрешности.
В данном режиме организован цикл по объектам обучающей выборки, в котором после учета каждой анкеты в матрице абсолютных частот перерассчитывается матрица информативностей и в отдельной базе данных запоминаются информативности для заданных признаков. Это позволяет измерять и графически отображать скорость сходимости и семантическую устойчивость модели. В работах [64, 76], на примере прогнозирования фондового рынка, подробно рассматриваются вопросы сходимости и семантической устойчивости содержательной информационной модели.
Почтовая служба по обучающей информации обеспечивает экспорт и импорт баз данных обучающей выборки при решении задач в системе "Эйдос" по многомашинной технологии.
1.2.4.2.3. Оптимизация модели (подсистема "Оптимизация") (БКОСА-4)
В данной подсистеме различными способами корректно реализуется контролируемое существенное снижение размерности семантических пространств классов и атрибутов при несущественном уменьшении их объема.
Формирование ортонормированного базиса классов (БКОСА-4.2)
Формирование ортонормированного базиса классов реализуется с применением одного из трех итерационных алгоритмов оптимизации, относящиеся к методу последовательных приближений:
1) исключение из модели заданного количества наименее сформированных классов;
2) исключение заданного процента количества классов от оставшихся (адаптивный шаг);
3) исключение классов, вносящих заданный процент степени сформированности от оставшегося суммарного (адаптивный шаг).
Критерий остановки процесса последовательных приближений – срабатывание хотя бы одного из заданных ограничений:
а) достигнуто заданное минимальное количество классов в модели;
б) достигнута заданная полнота описания признака.
Прокрутка окна вправо позволяет просмотреть дополнительные характеристики, позволяющие оценить степень сформированности образов классов и ортонормированность пространства классов.
Исключение признаков с низкой селективной силой (БКОСА-4.1)
С этой целью реализовано три итерационных алгоритма оптимизации, относящиеся к методу последовательных приближений:
– путем исключения из модели заданного количества наименее значимых признаков;
– путем исключения заданного процента количества признаков от оставшихся (адаптивный шаг);
– путем исключения признаков, вносящих заданный процент значимости от оставшейся суммарной (адаптивный шаг).
Критерий остановки процесса исключения признаков с низкой селективной силой – срабатывание одного из заданных ограничений:
а) достигнуто заданное минимальное количество признаков в модели;
б) достигнуто заданное минимальное количество признаков на класс (полнота описания класса).
Удаление классов и признаков, по которым недостаточно данных
В данном режиме реализована возможность удаления из модели всех классов и признаков, по которым или вообще нет данных, или их недостаточно в соответствии с заданным критерием. Этот режим сходен с режимом выявления и исключения артефактов.
1.2.4.2.4. Верификация модели (оценка ее адекватности) (БКОСА-5)
Данный режим исполняется после синтеза модели. Верификация модели осуществляется путем копирования обучающей выборки в распознаваемую, пакетного распознавания и последующего анализа в режиме "Измерение валидности системы распознавания" подсистемы "Анализ". Он показывает средневзвешенную погрешность идентификации (интегральная валидность) и погрешность идентификации в разрезе по классам. При этом объект считается отнесенным к классу, с которым у него наибольшее сходство. Необходимо отметить, что остальные классы, находящиеся по уровню сходства на второй и последующих позициях не учитываются. Это обусловлено тем, что их учет привел бы к завышению оценки валидности модели.
Классы, по которым дифференциальная валидность неприемлемо низка считаются не сформированными. Причинами этого может быть очень высокая вариабельность объектов, отнесенных к данным классам (тогда имеет смысл разделить их на несколько), а также недостаток достоверной классификационной и описательной информации по этим классам (некорректная работа экспертов).
1.2.4.2.5. Эксплуатация приложения в режиме адаптации и периодического синтеза модели (БКОСА-7, БКОСА-9, БКОСА-10)
Идентификация и прогнозирование (подсистема "Распознавание") (БКОСА-7)
Данная подсистема реализует режимы ввода и корректировки распознаваемой выборки; пакетного распознавания; вывода результатов и межмашинного обмена данными. Ввод-корректировка распознаваемых анкет осуществляется в двухоконном интерфейсе: в левом окне показаны заголовки идентифицируемых объектов, в которых отображаются их коды и условные наименования, а в правом окне – описания объектов на языке признаков. В левом окне каждому объекту соответствует строка, а в правом – окно с прокруткой. Переход между окнами происходит по нажатию клавиши "TAB". В данном режиме каждая анкета распознаваемой выборки последовательно идентифицируется с каждым классом. Вывод результатов распознавания (идентификации и прогнозирования) возможен в двух разрезах:
а) информация о сходстве каждого объекта со всеми классами;
б) информация о сходстве каждого класса со всеми объектами.
Система генерирует обобщающий отчет по итогам идентификации, в котором в каждой строке дана информация о классе, с которым распознаваемый объект имеет наивысший уровень сходства (в процентах). Качество результата идентификации – это эвристическая оценка качества, учитывающая максимальную величину сходства, различие между первым и вторым классами по уровню сходства и в (меньшей степени) общий вид распределения классов по уровням сходства с данным объектом. Каждой строке обобщающего отчета соответствует карточка результатов идентификации (прогнозирования), которая по сути дела представляет собой результат разложения вектора объекта в ряд по векторам классов. Эти карточки распечатываются в файл с полными наименованиями классов и содержат классы, с уровнем сходства выше заданного.
Почтовая служба по распознаваемым анкетам обеспечивает запись на дискету распознаваемой выборки и считывание распознаваемой выборки с дискеты с добавлением к имеющейся на текущем компьютере. Этот режим служит для объединения информации по идентифицируемым объектам, введенной на различных компьютерах.
Подсистема "Типология" обеспечивает типологический анализ классов и признаков.
Типологический анализ классов включает: информационные (ранговые) портреты; кластерно-конструктивный и когнитивный анализ классов.
Информационные портреты классов (БКОСА-9.1)
Информационный портрет класса представляет собой список признаков в порядке убывания количества информации о принадлежности к данному классу. Такой список представляет собой результат решения обратной задачи идентификации (прогнозирования). Фильтрация (F6) позволяет выделить из информационного портрета класса диапазон признаков (по кодам или уровням Мерлина) и, таким образом, исследовать влияние заданных признаков на переход активного объекта управления в состояние, соответствующее данному классу.
Кластерный и конструктивный анализ классов обеспечивает: расчет матрицы сходства классов; генерацию кластеров и конструктов; просмотр и печать кластеров и конструктов; пакетный режим, обеспечивающий автоматическое выполнение первых трех режимов при установках параметров "по умолчанию"; визуализацию результатов кластерно-конструктивного анализа в форме семантических сетей и когнитивных диаграмм.
Расчет матрицы сходства эталонов классов (БКОСА-10.1.1)
В данном режиме непосредственно на основе оптимизированной матрицы информативностей рассчитывается матрица сходства классов. На экране в наглядной форме отображается информация о текущей стадии выполнения этого процесса.
Генерация кластеров и конструктов классов (БКОСА-10.1.2)
В данном режиме пользователем задаются параметры для генерации кластеров и конструктов классов, позволяющие исключить из форм центральную часть конструктов (оставить только полюса), а также сформировать кластеры и конструкты для заданных (кодами или уровнями Мерлина) подматриц. В данном режиме обеспечивается отображение отчета по конструктам и вывод его в виде текстового файла. Реализован режим быстрого поиска заданного конструкта и быстрый выход на него по заданному классу.
Автоматическое выполнение режимов 1-2-3
В данном пакетном режиме автоматически выполняются вышеперечисленные 3 режима с параметрами "по умолчанию". Выполнение пакетного режима целесообразно в самом начале проведения типологического анализа для общей оценки его результатов. Более детальные результаты получаются при выполнении отдельных режимов с конкретными значениями параметров.
Вывод 2d-семантических сетей классов (БКОСА-10.1.3)
В данном режиме пользователем в диалоге с системой "Эйдос" задаются коды от 3 до 12 классов (ограничение связано с тем, что больше классов не помещается на мониторе при используемом разрешении), а затем на основе данных матрицы сходства классов отображается ориентированный граф, в вершинах которого находятся классы, а ребра соответствуют знаку (красный – "+", синий – "-") и величине (толщина линии) сходства/различия между ними. Посередине каждой линии уровень сходства/различия соответствующих классов отображается в числовой форме (в процентах). Такие графы в данной работе называются 2d-семантическими сетями классов (2d означает "двухмерные").
Когнитивные диаграммы классов (БКОСА-10.3.1, 10.3.2)
В системе "Эйдос" реализован двухоконный интерфейс ввода задания на формирование когнитивных диаграмм и пример такой диаграммы. Переход между окнами осуществляется по клавише "ТАВ", выбор класса для когнитивной диаграммы – по нажатию клавиши "Enter". В верхней левой части верхнего окна отображаются коды выбранных классов. Генерация и вывод когнитивной диаграммы для заданных классов выполняется по нажатию клавиши F5. Отображаемые диаграммы всегда записываются в виде графических файлов в соответствующие поддиректории. Имеются также пакетные режимы генерации диаграмм: генерацию когнитивных диаграмм для полюсов конструктов (F6), генерация всех возможных когнитивных диаграмм (F7), а также генерация диаграмм Вольфа Мерлина (F8). При задании всех этих режимов имеется возможность задания большого количества параметров, определяющих вид диаграмм и содержание отображаемой на них информации.
Типологический анализ атрибутов обеспечивает: формирование и отображение семантических портретов атрибутов (признаков), а также кластерно-конструктивный и когнитивный анализ атрибутов.
Семантические портреты атрибутов (БКОСА-9.2)
В данном режиме обеспечивается формирование семантического портрета заданного признака и его отображение в текстовой и графической формах. Окно для просмотра текстового отчета имеет прокрутку вправо, что позволяет отобразить количественные характеристики. Графическая диаграмма выводится по нажатию клавиши F5, и может быть непосредственно распечатана или записана в виде графического файла в соответствующую поддиректорию.
Кластерный и конструктивный анализ атрибутов обеспечивает: расчет матрицы сходства признаков; генерация кластеров и конструктов признаков: просмотр и печать результатов кластерно-конструктивного анализа; автоматическое выполнение перечисленных режимов; отображение результатов кластерно-конструктивного анализа в форме семантических сетей и когнитивных диаграмм.
Расчет матрицы сходства атрибутов (БКОСА-10.2.1)
Стадия выполнения расчета матрицы сходства признаков наглядно отображается на мониторе.
Генерация кластеров и конструктов атрибутов (БКОСА-10.2.2)
В данном режиме имеется возможность задания ряда параметров, детально определяющих обрабатываемые данные и форму вывода результатов анализа и отображаются результаты кластерно-конструктивного анализа. Имеются также многочисленные возможности манипулирования данными (различные варианты поиска, сортировки и фильтрации).
Автоматическое выполнение режимов 1-2-3. Автоматически реализуются три вышеперечисленные режима.
Вывод 2d-семантических сетей атрибутов (БКОСА-10.2.3)
Результаты кластерно-конструктивного анализа признаков отображаются для заданных признаков в наглядной графической форме семантических сетей.
Когнитивные диаграммы атрибутов (БКОСА-10.4.1, 10.4.2)
Это новый вид когнитивных диаграмм, не встречающийся в литературе. Частным случаем этих диаграмм являются инвертированные диаграммы Вольфа Мерлина (терм. авт.). При их генерации имеется возможность задания ряда параметров, определяющих обрабатываемые данные и форму отображения результатов.
В подсистеме "Анализ" реализованы режимы:
– оценки анкет по шкале лживости;
– измерения внутренней интегральной и дифференциальной валидности модели;
– измерения независимости классов и признаков (стандартный анализ c2);
– генерации большого количества разнообразных 2d & 3d графических форм на основе данных матриц абсолютных частот, условных процентных распределений и информативностей (2d & 3d означает: "двухмерные и трехмерные");
– генерации и графического отображения нелокальных нейронов, нейронных сетей, классических и интегральных когнитивных карт.
Оценка достоверности заполнения анкет
В данном режиме исследуются корреляции между ответами в каждой анкете, эти корреляции сравниваются с выявленными на основе всей обучающей выборки и все анкеты ранжируются в порядке уменьшения типичности обнаруженных в них корреляций. Считается, что если корреляции в анкете соответствуют "среднестатистическим", которые принимаются за "норму", то анкета отражает обнаруженные макрозакономерности, если же нет, то возникает подозрение в том, что она заполнена некорректно.
В режиме "Измерение независимости объектов и признаков" реализован стандартный анализ c2, а также рассчитываются коэффициенты Пирсона, Чупрова и Крамера, популярные в экономических, социологических и политологических исследованиях. В системе задание на расчет матриц сопряженности вводится в специальный бланк, который служит также для отображения обобщающих результатов расчетов. На основе этого задания рассчитываются и записываются в форме текстовых файлов одномерные и двумерные матрицы сопряженности для заданных подматриц.
В отличие от матриц сопряженности, выводимых в известной системе SPSS, здесь они выводятся с текстовыми пояснениями на том языке, на котором сформированы классификационные и описательные шкалы, с констатацией того, обнаружена ли статистически-значимая связь на заданном уровне значимости. Необходимо также отметить, что в системе "Эйдос" не используются табулированные теоретические значения критерия c2 для различных степеней свободы, а необходимые теоретические значения непосредственно рассчитываются системой, причем со значительно большей точностью, чем они приведены в таблицах (при этом численно берется обратный интеграл вероятностей).
Режим "Просмотр профилей классов и признаков". Система "Эйдос" текущей версии 12.5 позволяет генерировать и выводить более 54 различных видов 2d & 3d графических форм, каждая из которых выводится в форме, определяемой задаваемыми в диалоге параметрами.
Подсистема "Сервис". Реальная эксплуатация ни одной программной системы невозможна либо без тщательного сопровождения эксплуатации и без наличия в системе развитых средств обеспечения надежности эксплуатации. В системе "Эйдос" для этого служит подсистема "Сервис" в которой:
– автоматически ведется архивирование баз данных;
– создаются отсутствующие базы данных и индексные массивы;
– распечатываются в текстовые файлы служебные формы, являющиеся основой содержательной информационной модели (базы абсолютных частот, условных процентных распределений и информативностей).
В подсистему "Сервис" входит также интеллектуальная дескрипторная информационно-поисковая система, автоматически генерирующая нечеткие дескрипторы и имеющая интерфейс нечетких запросов на любом естественном языке, использующем кириллицу или латиницу (т.е. не только русском). Отчет по результатам запроса содержит информационные объекты базы данных системы, ранжированные в порядке уменьшения степени соответствия запросу.
1.2.4.3. Технические характеристики и обеспечение эксплуатации системы "ЭЙДОС" (версии 12.5)
1.2.4.3.1. Состав системы "Эйдос": базовая система, системы окружения и программные интерфейсы импорта данных
Система "Эйдос" (текущей версии 12.5) включает базовую систему (система "Эйдос" в узком смысле слова), а также две системы окружения:
– систему комплексного психологического тестирования "Эйдос-Y", разработанную совместно с С.Д.Некрасовым [142, 169];
– систему анализа и прогнозирования ситуация на фондовом рынке "Эйдос-фонд", разработанную совместно с Б.Х.Шульман [146].
Данные системы окружения представляют собой программные интерфейсы базовой системы "Эйдос" с базами данных психологических тестов и биржевыми базами данных соответственно, а также выполняют ряд самостоятельных функций по предварительной обработке информации.
1.2.4.3.2. Отличия системы "Эйдос" от аналогов: экспертных и статистических систем
От экспертных систем система "Эйдос" отличается тем, что для ее обучения от экспертов требуется лишь само их решение о принадлежности того или иного объекта или его состояния к определенному классу, а не формулирование правил (продукций) или весовых коэффициентов, позволяющих прийти к такому решению (система генерирует их сама, т.е. автоматически). Дело в том, что часто эксперт не может или не хочет вербализовать, тем более формализовать свои способы принятия решений. Система "Эйдос" генерирует обобщенную таблицу решений непосредственно на основе эмпирических данных и их оценки экспертами.
От систем статистической обработки информации система "Эйдос" отличается прежде всего своими целями, которые состоят в следующем: формирование обобщенных образов исследуемых классов распознавания и признаков по данным обучающей выборки (т.е. обучение); исключение из системы признаков тех из них, которые оказались наименее ценными для решения задач системы; вывод информации по обобщенным образам классов распознавания и признаков в удобной для восприятия и анализа текстовой и графической форме (информационные или ранговые портреты); сравнение распознаваемых формальных описаний объектов с обобщенными образами классов распознавания (распознавание); сравнение обобщенных образов классов распознавания и признаков друг с другом (кластерно-конструктивный анализ); расчет частотных распределений классов распознавания и признаков, а также двумерных матриц сопряженности на основе критерия c2 и коэффициентов Пирсона, Чупрова и Крамера; результаты кластерно-конструктивного и информационного анализа выводятся в форме семантических сетей и когнитивных диаграмм. Система "Эйдос" в универсальной форме автоматизирует базовые когнитивные операции системного анализа, т.е. является инструментарием СК-анализа. Таким образом, система "Эйдос" выполняет за исследователя-аналитика ту работу, которую при использовании систем статистической обработки ему приходится выполнять вручную, что чаще всего просто невозможно при реальных размерностях данных. Поэтому система "Эйдос" и называется универсальной когнитивной аналитической системой.
1.2.4.3.3. Некоторые количественные характеристики системы "Эйдос"
Система "Эйдос" обеспечивает генерацию и запись в виде файлов более 54 видов 2d & 3d графических форм и 50 видов текстовых форм, перечень которых приведен в таблице 31.
При применении системы в самых различных предметных областях обеспечивается достоверность распознавания обучающей выборки: на уровне 90% (интегральная валидность), которая существенно повышается после Парето-оптимизации системы признаков (т.е. после исключения признаков с низкой селективной силой), удаления из модели артефактов, а также классов и признаков, по которым недостаточно данных. Система "Эйдос" версии 12.5 обеспечивает синтез модели, включающей десятки тысяч классов и признаков при неограниченном объеме обучающей выборки, причем признаки могут быть не только качественные (да/нет), но и количественные, т.е. числовые. В некоторых режимах анализа модели имеются ограничения на ее размерность, которые на данном этапе преодолеваются путем оптимизации модели. Реализована возможность разработки супертестов, в том числе интеграции стандартных тестов в свою среду, (при этом не играет роли известны ли методики интерпретации, т.е. "ключи" этих тестов). В системе имеется научная графика, обеспечивающая высокую степень наглядности, а также естественный словесный интерфейс при обучении Системы и запросах на распознавание.
Исходные тексты системы "Эйдос" и систем окружения "Эйдос-Y" и "Эйдос-фонд" в формате "Текст-DOS" имеют объем около 2.5 Мб; их распечатка 6-м шрифтом составляет около 800 страниц.
|
|
1.2.4.3.4. Обеспечение эксплуатации системы "Эйдос"
Универсальная когнитивная аналитическая система "Эйдос" представляет собой программную систему, и для ее эксплуатации, как и для эксплуатации любой программной системы, необходима определенная инфраструктура. Без инфраструктуры эксплуатации любая программная система остается лишь файлом, записанным на винчестере. В зависимости от масштабности решаемых задач управления и специфики предметной области данная структура может быть как довольно малочисленной, так и более развитой. Однако в любом случае ее основные функциональные и структурные характеристики остаются примерно одними и теми же. Кратко рассмотрим эту инфраструктуру на примере гипотетической организации, производящей определенные виды продукции.
Основная цель: обеспечивать информационную и аналитическую поддержку деятельности организации, направленную на производство запланированного объема продукции заданного качества, достижение высокой эффективности управления и устойчивого поступательного развития.
Данная основная цель предполагает выполнение
информационных и аналитических работ с различными объектами деятельности,
находящимися на различных структурных уровнях как самой организации, так и ее
окружения: персональный уровень; уровень коллективов (подразделений); уровень
организации в целом; окружающая среда (непосредственное, региональное,
международное окружение). Для достижения основной цели для каждого класса
объектов должны регулярно выполняться следующие работы: оценка (идентификация)
текущего состояния с накоплением данных (мониторинг); прогнозирование развития
(оперативное, тактическое и стратегическое); выработка рекомендаций по
управлению. Необходимо особо подчеркнуть,
что основная цель может быть достигнута только при условии соблюдения вполне
определенной наукоемкой технологии, основы которой изложены в данном исследовании.
Задачи, решаемые для достижения цели работы:
1. Мониторинг: оценка и идентификация текущего (фактического, актуального) состояния объекта управления; накопление данных идентификации в базах данных в течение длительного времени.
2. Анализ: выявление
причинно-следственных зависимостей путем анализа данных мониторинга.
3. Прогнозирование: оперативное,
тактическое и стратегическое прогнозирование развития объекта управления и
окружающей среды путем использования закономерностей, выявленных на этапе
анализа данных мониторинга.
4. Управление: анализ взаимодействия объекта управления с окружающей средой и выработка рекомендаций по управлению.
Таким образом, по мнению автора, управление является высшей, существующей на данный момент формой обработки информации.
Для достижения основной цели и решения задач управления необходимо выполнять работы по следующим направлениям: регулярное получение исходной информации о состоянии объекта управления; обработка исходной информации на компьютерах; анализ обработанной информации, прогнозирование развития объекта управления, выработка рекомендаций по оказанию управляющих воздействий на объект управления; разработка и применение (или предоставление рекомендаций заказчикам) различных методов оказания управляющих воздействий на объект управления.
Для этого необходима определенная организационная структура: научно–методический отдел включает: научно-методический сектор; сектор разработки программного обеспечения; сектор внедрения и сопровождения программного обеспечения; сектор организационного и юридического обеспечения; отдел мониторинга: сектор исследования объекта управления; сектор по работе с независимыми экспертами; сектор по взаимодействию с поставляющими информацию организациями; сектор по анализу информации общего пользования; отдел обработки информации: сектор ввода исходной информации (операторы); сектор сетевых технологий и Internet; сектор внедрения, эксплуатации и сопровождения программных систем; сектор технического обслуживания компьютерной техники; сектор ведения архивов баз данных по проведенным исследованиям; аналитический отдел имеет структуру, обеспечивающую компетентный профессиональный анализ результатов обработки данных мониторинга по объектам, которые приняты для контроля и управления.
Для выполнения работ по этим направлениям необходимо определенное обеспечение деятельности: техническое, программное, информационное, организационное, юридическое и кадровое. Детально подобная структура и виды обеспечения ее деятельности описаны в работе [92].
1.2.4.4. АСК-анализ, как технология синтеза и эксплуатации рефлексивных АСУ активными объектами
Применение АСК-анализа обеспечивает выявление информационных зависимостей между факторами различной природы и будущими состояниями объекта управления, т.е. позволяет осуществить синтез содержательной информационной модели, а фактически – осуществить синтез АСУ. Применение АСК-анализа в составе АСУ обеспечивает ее эксплуатацию в режиме непрерывной адаптации модели (на детерминистских этапах), а когда это необходимо (т.е. после прохождения точек бифуркации) – и ее нового синтеза.
Ниже приведена технология системы "Эйдос" как инструментария АСК-анализа:
Шаг 1–й: формализация предметной области (БКОСА-1): разработка описательных и классификационных шкал и градаций, необходимых для формализованного описания предметной области. Описательные шкалы описывают факторы различной природы, влияющие на поведение АОУ, а классификационные – все его будущие состояния, в том числе целевые.
Шаг 2–й: формирование обучающей выборки (БКОСА-2): информация о состоянии среды и объекта управления, а также вариантах управляющих воздействий поступает на вход системы. Работа по преобразованию этой информации в формализованный вид (т.е. кодирование) осуществляется специалистами, обслуживающими систему с использованием описательных и классификационных шкал. Вся эта информация представляется в виде специальных кодированных бланков, используемых также для ввода информации в компьютер. В результате ее формируется так называемая "обучающая выборка".
Шаг 3–й: обучение (БКОСА-3): обучающая выборка обрабатывается обучающим алгоритмом, на основе чего им формируются решающие правила (обобщенные образы состояний АОУ, отражающие весь спектр будущих возможных состояний объекта управления) и определяется ценность факторов для решения задач подсистем идентификации, мониторинга, прогнозирования и выработки управляющих воздействий.
Шаг 4–й: оптимизация (БКОСА-4): факторы, не имеющие особой прогностической ценности, корректным способом удаляются из системы. Данный процесс осуществляется с помощью итерационных алгоритмов, при этом обеспечивается выполнение ряда ограничений, таких как результирующая размерность пространства факторов, его информационная избыточность и т.п.
Шаг 5–й: верификация модели (БКОСА-5): выполняется после каждой адаптации или пересинтеза модели. На этом шаге обучающая выборка копируется в распознаваемую и осуществляется ее автоматическая классификация (в режиме распознавания). Затем рассчитываются так называемые внутренняя дифференциальная и интегральная валидности, характеризующие качество решающих правил.
Шаг-6: принятие решения об эксплуатации модели или ее пересинтезе. Если результаты верификации модели удовлетворяют разработчиков РАСУ АО, то она переводится из пилотного (экспериментального) режима, при котором управляющие решения генерировались, но не исполнялись, в режим экспериментальной эксплуатации, а затем и опытно–производственной эксплуатации, когда они реально начинают использоваться для управления. Иначе, т.е. если же модель признана недостаточно адекватной, то необходимо осуществить ее пересинтез, начиная с шага 1. При этом используются следующие приемы: расширение набора факторов, т.к. значимые факторы могли не войти в модель; увеличение объема обучающей выборки, т.к. существенные примеры могли не войти в обучающую выборку; исключение артефактов, т.к. в модель могли вкрасться существенно искажающие ее не подтверждающиеся данные; пересмотр экспертных оценок и, если необходимость этого возникает систематически, то и переформирование экспертного совета, т.к. причиной этого могла быть некомпетентность экспертов; объединение некоторых классы, т.к. по ним недостаточно данных; разделение некоторых классов, т.к. по ним слишком высокая вариабельность объектов по признакам, и т.д.
Шаг 7-й: идентификация и прогнозирование состояния АОУ (БКОСА-7).
Шаг
8-й: оценка качества идентификации состояния АОУ. Если
качество идентификации высокое, то состояние АОУ рассматривается как типовое, а
значит причинно-следственные взаимосвязи между факторами и будущими состояниями
данного объекта управления считаются адекватно отраженными в модели и
известными (т.е. если качество идентификации высокое, то считается, что объект
относится к генеральной совокупности, по отношению к которой обучающая выборка
репрезентативна). Поэтому в этом случае осуществляется переход на Шаг-9
(выработка управляющего воздействия и последующий анализ). Иначе – считается,
что на вход системы идентификации попал объект, не относящийся к генеральной
совокупности, адекватно представленной обучающей выборкой. Поэтому в этом
случае информация о нем поступает на Шаг-13, начиная с которого запускается
процедура пересинтеза модели, что приводит к расширению генеральной
совокупности, представленной обучающей выборкой.
Шаг 9-й: выработка решения об управляющем воздействии (БКОСА-9) путем решения обратной задачи прогнозирования [64].
Шаг 10–й типологический анализ классов и факторов (БКОСА-10): кластерно-конструктивный и когнитивный анализ, семантические сети, когнитивные диаграммы состояний АОУ и факторов [64].
Шаг
11-й: многофакторное планирование и принятие решения о применении
системы управляющих факторов (БКОСА-11).
Шаг
12-й: оценка адекватности принятого решения об управляющих воздействиях:
если АОУ перешел в заданное целевое состояние, то осуществляется переход на
вход адаптации содержательной информационной модели (Шаг- 2): в подсистеме
идентификации предусмотрен режим дополнения распознаваемой выборки к обучающей,
чтобы в последующем, когда станут известны результаты управления, этой
верифицированной (т.е. достоверной) оценочной информацией дополнить обучающую
выборку и переформировать решающие правила (обучающая обратная связь). Иначе,
т.е. если АОУ не перешел в заданное целевое состояние, переход на вход
пересинтеза модели (Шаг-1), при этом могут быть изменены и описательные, и
классификационные (оценочные) шкалы, что позволяет качественно расширить сферу
адекватного функционирования РАСУ АО.
Шаг
13–й (неформализованный поиск нетипового решения об управляющем
воздействии и подготовка данных для пересинтеза модели, как в случае, если
решения оказалось удачным, так и в противном случае).
Таким образом, предложена технология применения системы "Эйдос" как инструментария применения АСК-анализа, основанного на системной теории информации, ориентированной на синтез рефлексивных АСУ АО. В процессе эксплуатации системы "Эйдос" успешно решаются все задачи АСК-анализа: формирование обобщенных образов состояний АОУ на основе обучающей выборки (обучение); идентификация состояний АОУ на основе его параметров (распознавание); определение влияния входных параметров на перевод АОУ в различные будущие состояния (обратная задача прогнозирования); прогнозирование поведения АОУ в условиях полного отсутствия управляющих воздействий; прогнозирование поведения АОУ при различных вариантах многофакторных управляющих воздействий.
Кроме того, выявленные в результате работы рефлексивной АСУ причинно-следственные зависимости между факторами различной природы и будущими состояниями объекта управления позволяют, при условии неизменности этих закономерностей в течение достаточно длительного времени, построить АСУ с постоянной моделью классического типа.