5.2. ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС, ТЕХНОЛОГИЯ РАЗРАБОТКИ И ЭКСПЛУАТАЦИИ ПРИЛОЖЕНИЙ В СИСТЕМЕ "ЭЙДОС"
Все видеограммы, приведенные в данном разделе, получены на основе приложения системы "Эйдос", разработанного на основе данных об учащихся Краснодарского юридического института МВД РФ и обеспечивающего решение ряда задач рефлексивной АСУ качеством подготовки специалистов. Более подробно данное приложение описано в главе 6 данной работы. В наименованиях разделов с описаниями подсистем и режимов системы "Эйдос" указаны коды реализуемых ими базовых когнитивных операций системного анализа в соответствии с обобщенной схемой АСК-анализа (рисунок 2.16).
5.2.1. Начальный этап синтеза модели: когнитивная структуризация и формализация предметной области, подготовка исходных данных (подсистема "Словари")
|
|
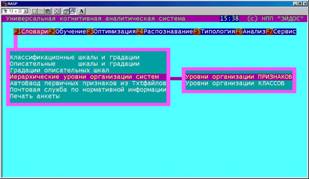
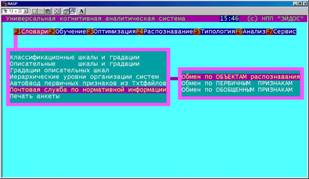
Подсистема "Словари" (рисунок 5.2) предназначена для формализации предметной области и включает следующие режимы: – классификационные шкалы и градации; – описательные шкалы и градации; |
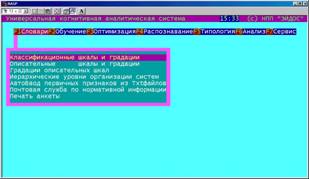
– градации описательных шкал;
– иерархические уровни организации систем;
– автоматический ввод первичных признаков из текстовых файлов;
– почтовая служба по нормативно-справочной информации;
– печать анкеты.
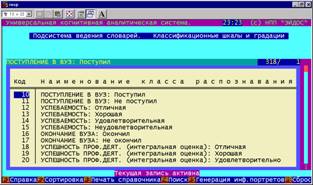
Классификационные шкалы и градации (БКОСА-1.1).
Классификационные шкалы и градации предназначены для ввода справочника будущих состояний активного объекта управления – классов.
|
|
Режим: "Классификационные шкалы и градации" (рисунок 5.3) обеспечивает ведение базы данных классификационных шкал и градаций классов: ввод; корректировку; удаление; распечатку (в файл); сортировку; поиск по базе данных. |
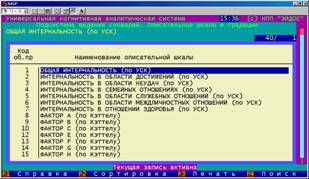
Описательные шкалы и градации (БКОСА-1.2)
Описательные шкалы и градации предназначены для ввода справочников факторов, влияющих на поведение активного объекта управления – признаков (рисунок 5.4).
|
|
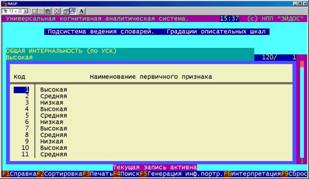
В этом режиме обеспечивается ввод, удаление, корректировка, копирование наименований описательных шкал и связанных с ними градаций. Характерной особенностью системы "Эйдос" является возможность использования неальтернативных градаций, |
|
Рисунок 5. 4. Режим: "Описательные шкалы и градации"(БКОСА-1.2) |
которых может быть различное количество по различным шкалам, причем это количество может быть любое (рисунок 5.5).
|
|
Справочник позволяет работать непосредственно с градациями (с учетом связей со шкалами), видеть их общее количество, а также просматривать и распечатывать процентное распределение ответов респондентов по градациям. |
|
|
Уровни организации систем (уровни Вольфа Мерлина) являются независимым способом классификации классов и факторов, что позволяет легко создавать и анализировать различные их подмножества как сами по себе, так и в сопоставлении друг с другом. |
|
|
В ставшей классической работе [182] В.С.Мерлин предложил интегральную концепцию индивидуальности, в которой рассматривал взаимодействие и взаимообусловленность различных уровней свойств личности: |
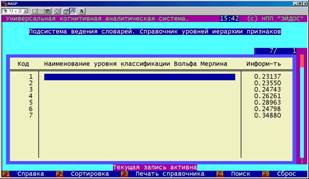
от генетически предопределенных, до социально-обусловленных и отражающих сиюминутное состояние.
В системе "Эйдос" предусмотрен аппарат, позволяющий классифицировать факторы таким образом, что становится возможным исследовать различные уровни их организации и взаимообусловленности.
|
|
Уровни организации классов предназначены для классификации будущих состояний активного объекта управления, как целевых и нежелательных с точки зрения самого объекта управления и управляющей системы, а также различных |
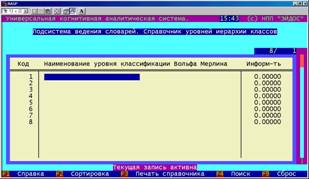
вариантов сочетаний этих вариантов.
Возможны и другие виды классификации.
|
|
Система "Эйдос" обеспечивает решение задач атрибуции анонимных и псевдонимных текстов (установления вероятного авторства), датировки текстов, определения их принадлежности к определенным традициям, школам или течениям мысли [152, 181]. |
|
Рисунок 5. 9. Автоматический ввод атрибутов из текстовых файлов |
Данный режим предназначен для автоматического ввода признаков текстов из текстовых файлов.
|
|
Работы, проводимые в системе "Эйдос", не требует одновременной работы многих пользователей с одними и теми же базами данных в режиме корректировки записей. |
Поэтому возможна эффективная организация распределенной работы по многомашинной технологии без использования ЛВС. Данный режим обеспечивает необходимую тождественность справочников на различных компьютерах.
|
|
Классификационные шкалы и градации в социально-психологических и политологических исследованиях представляют собой опросники (анкеты). После их ввода данный режим обеспечивает распечатку в файл (в поддиректорию "TXT"). |
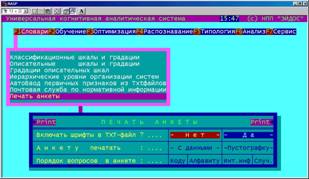
В системе "Эйдос" все текстовые и графические входные и выходные формы сохраняются в виде файлов, удобных для использования в различных приложениях под Windows.
|
|
Данная подсистема обеспечивает ввод и корректировку обучающей выборки, управление ею, синтез и адаптацию модели на основе данных обучающей выборки, экспорт и импорт данных с других компьютеров. |
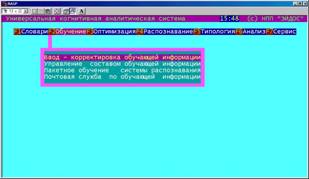
Ввод-корректировка обучающей информации (БКОСА-2.1)
|
|
Данный режим имеет двухоконный интерфейс, позволяющий ввести в обучающую выборку двухвекторные описания объектов. Левое окно служит для ввода классификационной характеристики объекта. В этом окне каждому объекту |
|
Рисунок 5. 13. Ввод-корректировка обучающей информации (БКОСА-2.1) |
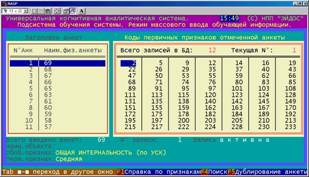
соответствует одна строка с прокруткой.
В правом окне вводится описательная характеристика объекта на языке признаков. Каждому объекту соответствует окно с прокруткой. Переход между окнами осуществляется по нажатию клавиши "TAB". Количество объектов в обучающей выборке не ограничено. Имеется практический опыт проведения расчетов с объемами обучающей выборки до 7000 объектов.
|
|
Данный режим предназначен для управления обучающей выборкой путем параметрического задания подмножеств анкет для обработки, объединения классов, автоматического ремонта обучающей выборки ("ремонт или взвешивание данных"). |
|
|
Выделение подмножества анкет для обработки может осуществляться логически и физически (рекомендуется 2-й вариант), это осуществляется путем сравнения с анкетой-маской. В ней задаются коды тех классов и признаков, которые |
обязательно должны присутствовать во всех анкетах обрабатываемого подмножества.
|
|
Данный режим предназначен для выявления слабо представленных классов (по которым недостаточно данных) и объединения нескольких классов в один. При этом производится переформирование справочника классов и автоматиче- |
|
Рисунок 5. 16. Статистическая характеристика обучающей выборки. Ручной ремонт |
ское перекодирование анкет обучающей выборки.
Автоматический ремонт обучающей выборки (ремонт или взвешивание данных) (БКОСА-2.2)
|
|
В данном режиме задается частотное распределение объектов по категориям, характерное для генеральной совокупности (или другое), затем автоматически осуществляется формирование последовательных подмножеств анкет обучающей выборки (с увели- |
чивающимся числом
анкет), максимально соответствующих заданному частотному распределению.
|
|
При этом используется метод последовательных приближений по минимаксному критерию: максимизация корреляции и минимизация максимального отклонения. Соответствующие графики представлены на рисунке 5.18. |
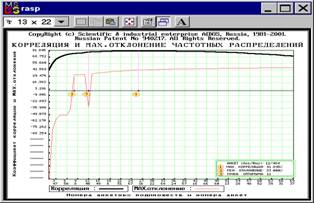
Система рекомендует оптимальное (по этим двум критериям) подмножество и позволяет исключить остальные анкеты из рассмотрения.
|
|
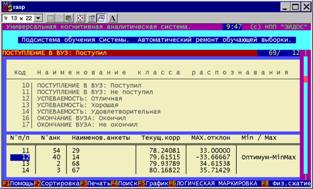
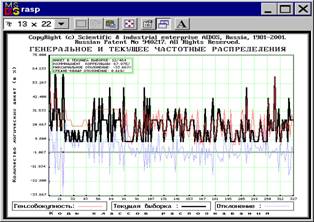
На рисунке 5.19 приведены графики частотных распределений объектов генеральной совокупности и выбранного подмножества обучающей выборки по категориям (классам), а также отклонение между этими распределениями. При достижении минимакса можно говорить об обеспечении структурной репрезентативности. |
|
Рисунок 5. 19. Автоматический ремонт обучающей выборки (генеральное и текущее распределения, отклонение) |
5.2.2. Количественный синтез модели: пакетное обучение системы распознавания (БКОСА-3.1)
|
|
Данный режим включает: расчет матрицы абсолютных частот, поиск и исключение из дальнейшего анализа артефактов, расчет матрицы информативностей, расчет матрицы условных процентных распределений, пакетный |
|
Рисунок 5. 20. Пакетное обучение системы распознавания (БКОСА-3.1) |
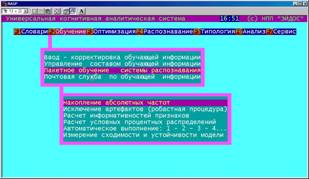
режим автоматического выполнения вышеперечисленных 4-х режимов, а также исследовательский режим, обеспечивающий измерение скорости сходимости и семантической устойчивости сформированной содержательной информационной модели.
Расчет матрицы абсолютных частот (БКОСА-3.1.1)
|
|
В данном режиме осуществляется последовательное считывание всех анкет обучающей выборки и использование описаний объектов для формирования статистики встреч признаков в разрезе по классам. На экране в наглядной форме |
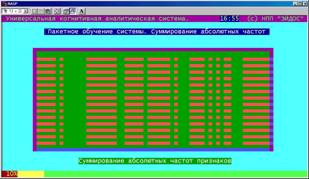
отображается стадия этого процесса, который может занимать значительное время при больших размерностях задачи и объеме обучающей выборки. Кроме того на качественном уровне красным отображается заполнение матрицы абсолютных частот данными: классы соответствуют столбцам, а признаки – строкам. Поэтому значительная фрагментарность данных легко обнаруживается еще на этой стадии. Данный режим обеспечивает полную "развязку по данным" и независимость времени исполнения процессов синтеза модели и ее анализа от объема обучающей выборки. Кроме того в данном режиме выявляются 4 типа формально-обнаружимых ошибок в исходных данных и по ним формируется файл отчета.
Исключение артефактов (робастная процедура) (БКОСА-3.1.2)
|
|
|
|
Рисунок 5. 22. Исключение артефактов невозможно, т.к. статистики нет |
Рисунок 5. 23. Исключение артефактов возможно, т.к. статистика есть |
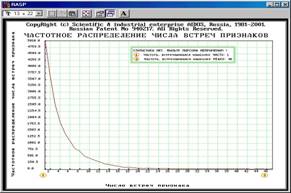
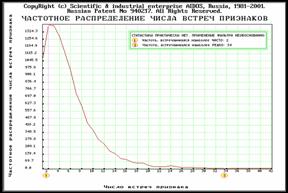
В данном режиме на основе исследования частотного распределения частот встреч признаков в матрице абсолютных частот, делаются выводы: об отсутствии статистики (рисунок 5.22) и невозможности обнаружения и исключения артефактов; о наличии статистики и возможности выявления артефактов (рисунок 5.23); рекомендуется частота, которая признается незначимой и характерной для артефактов, осуществляется переформирование баз данных с исключенными артефактами.
Расчет матрицы информативностей (БКОСА-3.1.3, 3.2, 3.3)
|
|
В этом режиме непосредственно на основе матрицы абсолютных частот с применением системной формулы Харкевича, рассчитывается матрица абсолютных частот, определяются значимость признаков, степень сформированности |
|
Рисунок 5. 24. Расчет информативностей признаков |
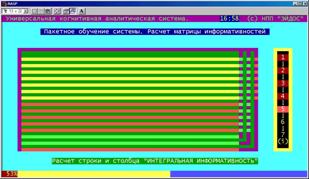
обобщенных образов классов, а также критерий Харкевича для всей матрицы информативностей в целом. На экране наглядно отображается стадия выполнения процесса и структура заполнения матрицы информативностей значимыми данными (на качественном уровне).
|
|
В этом режиме непосредственно на основе матрицы абсолютных частот рассчитывается матрица условных процентных распределений (процентные распределения ответов респондентов на вопросы анкеты в разрезе по классам – социальным категориям). |
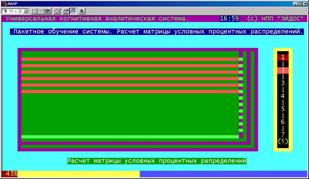
Автоматическое выполнение режимов 1-2-3-4. В данном пакетном режиме просто последовательно выполняются ранее перечисленные режимы обучения системы (кроме режима исключения артефактов).
|
|
В данном режиме после учета каждой анкеты обучающей выборки перерассчитывается матрица информативностей и в отдельной базе данных запоминаются информативности для заданных призна- |
|
Рисунок 5. 26. Скорость сходимости и семантическая устойчивость модели |
ков. Это позволяет измерять скорость сходимости и семантическую устойчивость модели.
|
|
В этом режиме задаются параметры, определяющие исследование скорости сходимости: порядок выборки анкет (физический; случайный; в порядке возрастания соответствия генеральной совокупности; в порядке |
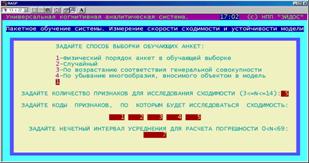
убывания степени многообразия, вносимого анкетой в модель), количество и коды признаков, по которым исследуется сходимость модели, а также интервал сглаживания для расчета скользящей погрешности.
|
|
|
|
Рисунок 5. 28. Сходимость модели по атрибуту: 1246, класс: 219 |
Рисунок 5. 29. Семантическая устойчивость модели по атрибуту: 1246, классы: 152, 153, 186, 187, 217, 218, 219 |
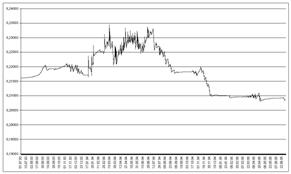
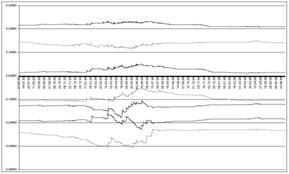
В работе [159], на примере прогнозирования фондового рынка, подробно рассматриваются вопросы сходимости и семантической устойчивости содержательной информационной модели.
|
|
В данном режиме обеспечивается экспорт и импорт обучающей информации при решении задач в системе "Эйдос" по многомашинной технологии. |
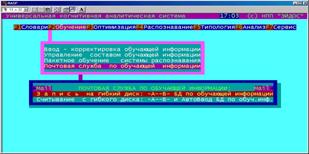
5.2.3. Оптимизация модели (подсистема "Оптимизация") (БКОСА-4)
|
|
В данной подсистеме различными способами реализуется контролируемое существенное снижение размерности семантических пространств классов и атрибутов при несущественном уменьшении их объема. |
|
Рисунок 5. 31. Оптимизация модели (подсистема "Оптимизация") |
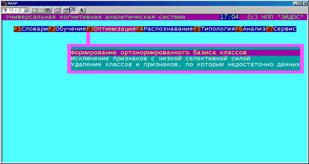
Формирование ортонормированного базиса классов (БКОСА-4.2)
|
|
|
|
Рисунок 5. 32. Список классов в порядке убывания степени сформированности образов |
Рисунок 5. 33. Парето-диаграмма степени сформированности обобщенных образов классов |
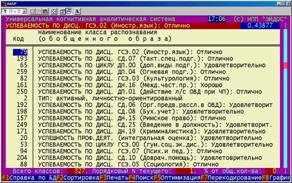
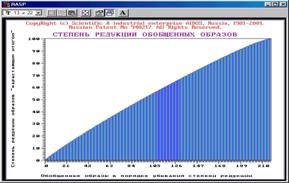
Прокрутка окна вправо позволяет просмотреть дополнительные характеристики. Образы классов хорошо сформированы. Пространство классов практически ортонормированно.
Реализовано три итерационных алгоритма оптимизации, относящиеся к методу последовательных приближений: путем исключения из модели заданного количества наименее сформированных классов; путем исключения заданного процента количества классов от оставшихся (адаптивный шаг); путем исключения классов, вносящих заданный процент степени сформированности от оставшегося суммарного (адаптивный шаг).
Критерий остановки процесса последовательных приближений – срабатывание одного из заданных ограничений: достигнуто заданное минимальное количество классов в модели; достигнуто заданное минимальное количество классов на признак (полнота описания признака).
Исключение признаков с низкой селективной силой (БКОСА-4.1)
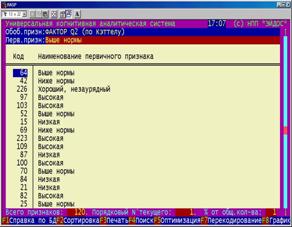
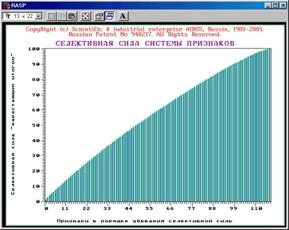
Реализовано три итерационных алгоритма оптимизации, относящиеся к методу последовательных приближений: путем исключения из модели заданного количества наименее значимых признаков; путем исключения заданного процента количества признаков от оставшихся (адаптивный шаг); путем исключения признаков, вносящих заданный процент значимости от оставшейся суммарной (адаптивный шаг). Критерий остановки процесса последовательных приближений – срабатывание одного из заданных ограничений: достигнуто заданное минимальное количество признаков в модели; достигнуто заданное минимальное количество признаков на класс (полнота описания класса).
Удаление классов и признаков, по которым недостаточно данных
Данный режим сходен с режимом выявления и исключения из модели артефактов.
5.2.4. Верификация модели (оценка ее адекватности) (БКОСА-5)
|
|
|
|
Рисунок 5. 36. Help режима измерения внутренней интегральной и дифференциальной валидности содержательной информационной модели |
Рисунок 5. 37. Отчет по результатам измерения внутренней интегральной и дифференциальной валидности содержательной информационной модели |
Данный режим исполняется после синтеза модели, копирования обучающей выборки в распознаваемую и пакетного распознавания. Он показывает средневзвешенную погрешность идентификации (интегральная валидность) и погрешность идентификации в разрезе по классам. Объект считается отнесенным к классу, с которым у него наибольшее сходство. Необходимо отметить, что остальные классы, находящиеся по уровню сходства на второй и последующих позициях не учитываются. Это обусловлено тем, что их учет привел бы к завышению оценки валидности модели. Классы, по которым дифференциальная валидность неприемлемо низка считаются не сформированными. Причинами этого может быть очень высокая вариабельность объектов, отнесенных к данным классам (тогда имеет смысл разделить их на несколько), недостаток достоверной информации по этим классам и т.д.
5.2.5. Эксплуатация приложения в режиме адаптации и периодического синтеза модели
Идентификация и прогнозирование (подсистема "Распознавание") (БКОСА-7)
|
|
Данная подсистема включает режимы ввода и корректировки распознаваемой выборки; пакетного распознавания; вывода результатов и межмашинного обмена данными. |
|
Рисунок 5. 38. Идентификация и прогнозирование (подсистема "Распознавание") |
|
|
|
В левом окне отображаются заголовки идентифицируемых объектов, в которых отображаются их коды и условные наименования, а в правом окне – описания объектов на языке признаков. В левом окне каждому объекту соответствует строка, а в правом – окно с |
|
Рисунок 5. 39. Двухоконный интерфейс ввода-корректировки распознаваемых анкет |
прокруткой. Переход между окнами происходит по нажатию клавиши "TAB".
|
|
В данном режиме каждая анкета распознаваемой выборки последовательно идентифицируется с каждым классом. |
|
|
Вывод результатов распознавания (идентификации и прогнозирования) возможен в двух разрезах: информация о сходстве каждого объекта со всеми классами; информация о сходстве каждого класса со всеми объектами. |
|
|
|
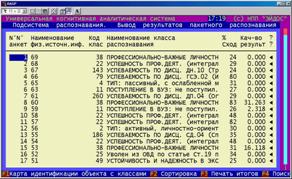
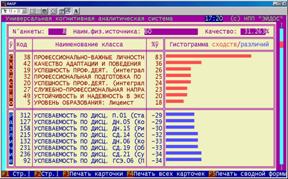
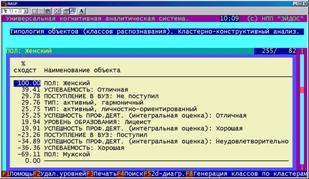
На рисунке 5.42 представлен обобщающий отчет по итогам идентификации, в котором в каждой строке дана информация о классе, с которым объект имеет наивысший уровень сходства (выражается в процентах). Качество результата идентификации – это эвристическая оценка качества, учитывающая максимальную величину сходства, различие между первым и вторым классами по уровню сходства и в (меньшей степени) общий вид распределения классов по уровням сходства с данным объектом.
На рисунке 5.43 представлена карточка результатов идентификации (прогнозирования), которая по сути дела представляет собой результат разложения вектора объекта в ряд по векторам классов. Эти карточки распечатываются в файл с полными наименованиями классов и содержат классы, с уровнем сходства выше заданного.
|
|
|
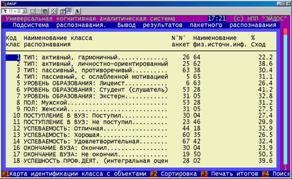
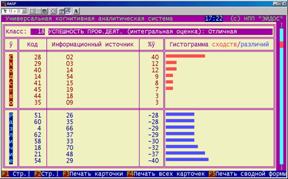
На рисунке 5.44 представлен обобщающий отчет по итогам идентификации, в котором в каждой строке дана информация об объекте, с которым класс имеет наивысший уровень сходства (выражается в процентах). Качество результата идентификации – это эвристическая оценка качества, учитывающая максимальную величину сходства, различие между первым и вторым объектами по уровню сходства и в (меньшей степени) общий вид распределения объектов по уровням сходства с данным классом.
На рисунке 5.45 представлена карточка результатов идентификации (прогнозирования), которая по сути дела представляет собой результат разложения вектора класса в ряд по векторам объектов. Эти карточки распечатываются в файл и содержат информацию по объектам, с уровнем сходства с классом выше заданного.
|
|
Данный режим обеспечивает запись на дискету распознаваемой выборки и считывание распознаваемой выборки с дискеты с добавлением к имеющейся на текущем компьютере. Этот режим служит для объединения информации по идентифицируемым объектам, |
введенной на различных компьютерах.
|
|
Данная подсистема обеспечивает типологический анализ классов и признаков. |
|
Рисунок 5. 47. Кластерно-конструктивный, семантический и когнитивный анализ (подсистема "Типология") |
|
|
|
Типологический анализ классов включает: информационные (ранговые) портреты; кластерно-конструктивный и когнитивный анализ классов. |
Информационные портреты классов (БКОСА-9.1)
|
|
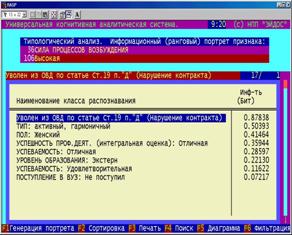
Информационный портрет класса представляет собой список признаков в порядке убывания количества информации о принадлежности к данному классу. Такой список представляет собой результат решения обратной задачи идентификации (прогнозирования). |
|
Рисунок 5. 49. Информационные (ранговые портреты) классов (БКОСА-9.1) |
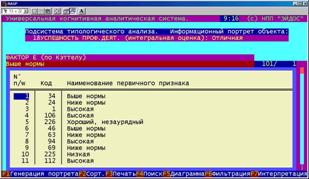
Фильтрация (F6) позволяет выделить из информационного портрета класса диапазон признаков (по кодам или уровням Мерлина) и, таким образом, исследовать влияние заданных признаков на переход активного объекта управления в состояние, соответствующее данному классу.
|
|
Данный режим обеспечивает: расчет матрицы сходства классов; генерацию кластеров и конструктов; просмотр и печать кластеров и конструктов; пакетный режим, обеспечивающий автоматическое выполнение |
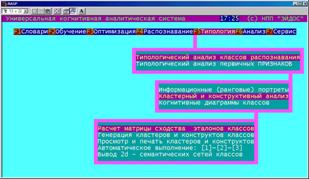
первых трех режимов при установках параметров "по умолчанию"; визуализацию результатов кластерно-конструктивного анализа в форме семантических сетей.
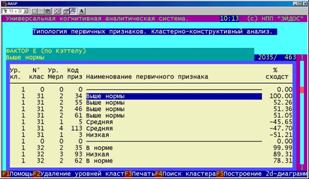
Расчет матрицы сходства эталонов классов (БКОСА-10.1.1)
|
|
В данном режиме непосредственно на основе оптимизированной матрицы информативностей рассчитывается матрица сходства классов. На экране в наглядной форме отображается информация о текущей |
|
Рисунок 5. 51. Расчет матрицы сходства эталонов классов (БКОСА-10.1.1) |
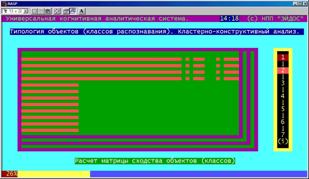
стадии выполнения этого процесса.
Генерация кластеров и конструктов классов (БКОСА-10.1.2)
|
|
В данном режиме задаются параметры для генерации кластеров и конструктов классов, позволяющие исключить из форм центральную часть конструктов (оставить только полюса), а также сформировать кластеры и конструкты для |
|
Рисунок 5. 52. Генерация кластеров и конструктов классов (БКОСА-10.1.2) |
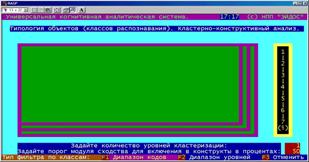
заданных (кодами или уровнями Мерлина) подматриц.
|
|
В данном режиме обеспечивается отображение отчета по конструктам и вывод его в виде текстового файла. Реализован режим быстрого поиска заданного конструкта и быстрый выход на него по заданному классу. |
|
Рисунок 5. 53. Просмотр и печать кластеров и конструктов атрибутов |
Автоматическое выполнение режимов 1-2-3
В данном пакетном режиме автоматически выполняются вышеперечисленные 3 режима с параметрами "по умолчанию". Выполнение пакетного режима целесообразно в самом начале проведения типологического анализа для общей оценки его результатов. Более детальные результаты получаются при выполнении отдельных режимов с конкретными значениями параметров.
Вывод 2d-семантических сетей классов (БКОСА-10.1.3)
|
|
В данном режиме в диалоге задаются коды от 3 до 12 классов (больше просто не помещается на мониторе при используемом разрешении), а затем на основе данных матрицы сходства классов отображается граф, в вершинах которого находятся классы, а ребра |
|
Рисунок 5. 54. Вывод 2d-семантических сетей классов (БКОСА-10.1.3) |
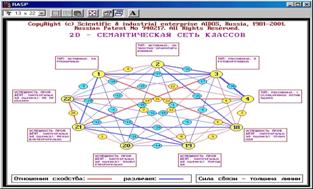
соответствуют знаку (красный – "+", синий – "-") и величине (толщина линии) сходства/различия между ними. Посередине каждой линии уровень сходства/различия соответствующих классов отображается в числовой форме (в процентах).
Когнитивные диаграммы классов (БКОСА-10.3.1, 10.3.2)
|
|
|
|
Рисунок 5. 55. Двухоконный интерфейс ввода задания на формирование когнитивных диаграмм (БКОСА-10.3.1) |
Рисунок 5. 56. Пример когнитивной диаграммы классов (БКОСА-10.3.2) |
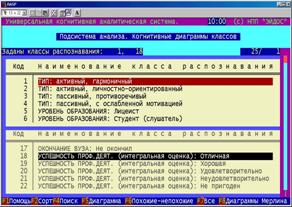
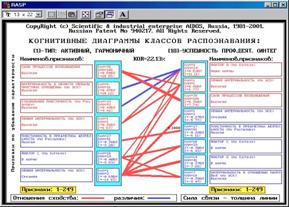
На рисунке 5.55 представлен двухоконный интерфейс ввода задания на формирование когнитивных диаграмм. Переход между окнами осуществляется по клавише "ТАВ", выбор класса для когнитивной диаграммы – по нажатию клавиши "Enter". В верхней левой части верхнего окна отображаются коды выбранных классов. Генерация и вывод когнитивной диаграммы для заданных классов выполняется по нажатию клавиши F5. Отображаемые диаграммы всегда записываются в виде графических файлов в соответствующие поддиректории. Имеются также пакетные режимы генерации диаграмм: генерацию когнитивных диаграмм для полюсов конструктов (F6), генерация всех возможных когнитивных диаграмм (F7), а также генерация диаграмм Вольфа Мерлина (F8).
При задании всех этих режимов имеется возможность задания большого количества параметров, определяющих вид диаграмм и содержание отображаемой на них информации.
|
|
В данном режиме обеспечиваются: формирование и отображение семантических портретов признаков, а также кластерно-конструктивный и когнитивный анализ признаков. |
Семантические портреты атрибутов (БКОСА-9.2)
|
|
|
|
Рисунок 5. 58. Семантический портрет признака (отчет) (БКОСА-9.2) |
Рисунок 5. 59. Семантический портрет признака (круговая диаграмма) |
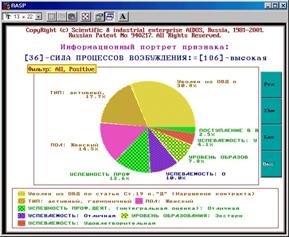
В данном режиме обеспечивается
формирование семантического портрета заданного признака и его отображение в
текстовой и графической формах (рисунки 5.58 и 5.59). Окно для просмотра
текстового отчета имеет прокрутку вправо, что позволяет отобразить
количественные характеристики. Графическая диаграмма выводится по нажатию
клавиши F5, и может быть непосредственно распечатана или записана в виде
графического файла в соответствующую поддиректорию.
|
|
В данном режиме обеспечивается: расчет матрицы сходства признаков; генерация кластеров и конструктов признаков: просмотр и печать результатов кластерно-конструктивного анализа; автоматическое выполнение перечисленных |
режимов; отображение результатов кластерно-конструктивного анализа в форме семантических сетей.
Расчет матрицы сходства атрибутов (БКОСА-10.2.1)
|
|
Стадия выполнения расчета матрицы сходства признаков наглядно отображается на мониторе. |
|
Рисунок 5. 61. Расчет матрицы сходства атрибутов (БКОСА-10.2.1) |
Генерация кластеров и конструктов атрибутов (БКОСА-10.2.2)
|
|
В данном режиме имеется возможность задания ряда параметров, детально определяющих обрабатываемые данные и форму вывода результатов анализа. |
|
Рисунок 5. 62. Генерация кластеров и конструктов атрибутов (БКОСА-10.2.2) |
|
|
|
В этом режиме отображаются результаты кластерно-конструктивного анализа. Имеются многочисленные возможности манипулирования данными. |
|
Рисунок 5. 63. Просмотр и печать кластеров и конструктов атрибутов |
Автоматическое выполнение режимов 1-2-3. Автоматически реализуются три вышеперечисленные режима.
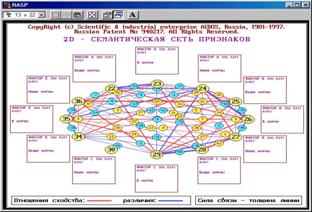
Вывод 2d-семантических сетей атрибутов (БКОСА-10.2.3)
|
|
Результаты кластерно-конструктивно-го анализа признаков отображаются для заданных признаков в наглядной графической форме семантических сетей. |
|
Рисунок 5. 64. Вывод 2d-семантических сетей атрибутов (БКОСА-10.2.3) |
Когнитивные диаграммы атрибутов (БКОСА-10.4.1, 10.4.2)
|
|
Это новый вид когнитивных диаграмм, не встречающийся в литературе. Частным случаем этих диаграмм являются инвертированные диаграммы Вольфа Мерлина. При их генерации имеется возможность задания ряда параметров, определяющих обрабатываемые |
|
Рисунок 5. 65. Когнитивные диаграммы атрибутов (БКОСА-10.4.1, 10.4.2) |
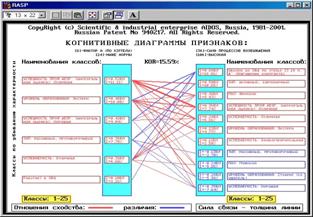
данные и форму отображения результатов.
|
|
В данной подсистеме реализованы режимы оценки анкет по шкале лживости; измерения внутренней интегральной и дифференциальной валидности модели; измерения независимости классов и признаков (стандартный анализ хи-квадрат), а также режим, |
|
Рисунок 5. 66. Анализ достоверности, валидности, независимости (подсистема "Анализ") |
обеспечивающий генерацию большого количества разнообразных 2d & 3d графических форм на основе данных матриц абсолютных частот, условных процентных распределений и информативностей.
Оценка достоверности заполнения анкет
В данном режиме исследуются корреляции между ответами в каждой анкете, эти корреляции сравниваются с выявленными на основе всей обучающей выборки и все анкеты ранжируются в порядке уменьшения типичности обнаруженных в них корреляций. Считается, что если корреляции в анкете соответствуют "среднестатистическим", которые принимаются за "норму", то анкета отражает обнаруженные макрозакономерности, если же нет, то возникает подозрение в том, что она заполнена некорректно.
|
|
В данном режиме реализован стандартный анализ хи-квадрат, а также рассчитываются коэффициенты Пирсона, Чупрова и Крамера, популярные в социологических и политологических исследованиях. На рисунке 5.67 приведен бланк задания на расчет матриц сопряженности. |
|
Рисунок 5. 67. Измерение независимости объектов и признаков (анализ c2) |
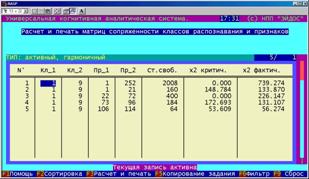
На основе этого задания рассчитываются и записываются в форме текстовых файлов одномерные и двумерные матрицы сопряженности для заданных подматриц. В отличие от матриц сопряженности, выводимых в известной системе SPSS, здесь они выводятся с текстовыми пояснениями на том языке, на котором сформированы классификационные и описательные шкалы, с констатацией того, обнаружена ли статистически-значимая связь на заданном уровне значимости. Необходимо также отметить, что в системе "Эйдос" не используются табулированные теоретические значения критерия хи-квадрат для различных степеней свободы, а необходимые теоретические значения непосредственно рассчитываются со значительно большей точностью, чем они приведены в таблицах (при этом численно берется обратный интеграл вероятностей).
|
|
|
|
|
|
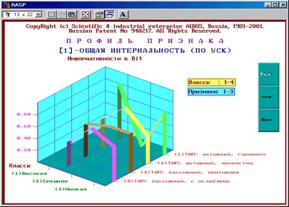
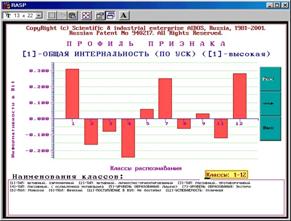
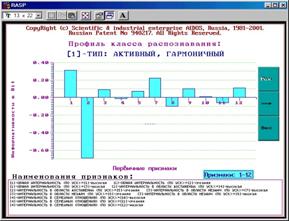
На рисунке 5.68 приведен фрагмент интерфейса задания на вывод графических форм и примеры некоторых из них. Всего система "Эйдос" версии 7.0 (последней на данный момент) позволяет генерировать и выводить 50 различных видов 2d & 3d графических форм.
|
|
Реальная эксплуатация ни одной специальной программной системы невозможна либо без тщательного сопровождения эксплуатации, либо без наличия в системе развитых средств обеспечения надежности эксплуатации. |
|
Рисунок 5. 69. Обеспечение надежности эксплуатации (подсистема "Сервис") |
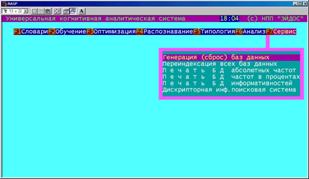
В системе "Эйдос" автоматически ведется архивирование баз данных; создаются отсутствующие базы данных и индексные массивы; распечатываются служебные формы, являющиеся основой содержательной информационной модели. Кроме того, по желанию пользователя отдельные базы данных просто могут быть сброшены, что необходимо для создания нового приложения.
|
|
Этот режим необходим для начала разработки нового приложения системы "Эйдос". |
|
|
Данный режим позволяет распечатать в текстовый файл матрицу абсолютных частот. Совершенно аналогично распечатываются базы условных процентных распределений и информативностей. |
|
|
В данную подсистему входит также интеллектуальная дескрипторная информационно-поисковая система, автоматически генерирующая нечеткие дескрипторы и имеющая интерфейс нечетких запросов на естественном языке. Отчет по результатам запроса содержит |
|
Рисунок 5. 72. Интеллектуальная дескрипторная информационно-поисковая система |
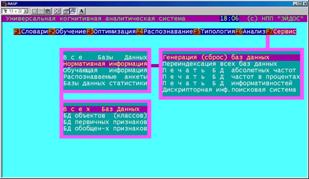
информационные объекты базы данных системы, ранжированные в порядке уменьшения степени соответствия запросу.