3.3. НЕКОТОРЫЕ СВОЙСТВА МАТЕМАТИЧЕСКОЙ МОДЕЛИ (СХОДИМОСТЬ, АДЕКВАТНОСТЬ, УСТОЙЧИВОСТЬ И ДР.)
Под сходимостью семантической информационной модели в данной работе понимается:
а) зависимость информативностей факторов (в матрице информативностей) от объема обучающей выборки;
б) зависимость адекватности модели (интегральной и дифференциальной валидности) от объема обучающей выборки.
Для измерения сходимости в смыслах "а" и "б" в системе реализован специальный исследовательский режим.
Под адекватностью модели понимается ее внутренняя и внешняя дифференциальная и интегральная валидность.
Под устойчивостью модели понимается ее способность давать незначительные различия в прогнозах и рекомендациях по управлению при незначительных различиях в исходных данных для решения этих задач.
3.3.1. Непараметричность модели. Робастные процедуры и фильтры для исключения артефактов
Предложенная семантическая
информационная модель является непараметрической, т.к. не основана на
предположениях о нормальности распределений исследуемой выборки.
Критерии для выявления артефактов есть только при большой статистике, когда же все частоты атрибутов малы, то невозможно отличить артефакт от значимого атрибута. При увеличении статистики частоты значимых атрибутов растут пропорционально объему выборки, тогда как частоты артефактов так и остаются чрезвычайно малыми, близкими к единице. В модели реализована процедура удаления наиболее вероятных артефактов, которая, как показывает опыт, существенно повышает качество (адекватность) модели.
3.3.2. Зависимость информативностей факторов от объема обучающей выборки
При учете в модели апостериорной информации, содержащейся в очередном объекте обучающей выборки, происходит перерасчет значений информативностей атрибутов. Иначе говоря изменяется количество информации, содержащейся в факте обнаружения у объекта данного атрибута о принадлежности объекта к определенному классу.
При этом значения информативностей атрибута "сходятся" к некоторому пределу в соответствии с двумя основными "сценариями":
1. Процесс "последовательных приближений", напоминающего по своей форме "затухающие колебания" (рисунок 3.13).
2. Относительно "плавное" возрастание или убывание с небольшими временными отклонениями от этой тенденции (рисунок 3.14). Других сценариев не наблюдается.
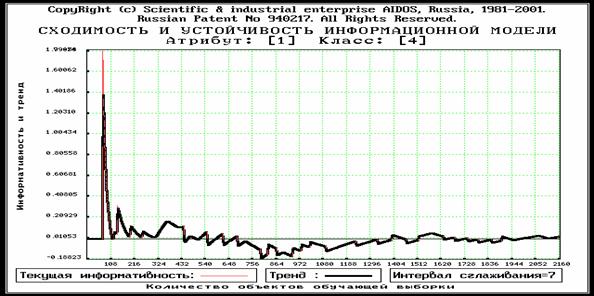
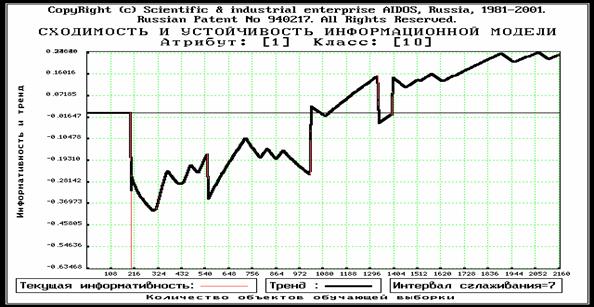
В любом случае при накоплении достаточно большой статистики и сохранении закономерностей предметной области, отражаемых обучающей выборкой, модель стабилизируется в том смысле, что значения информативностей атрибутов перестают существенно изменяться. При достижении этого состояния можно утверждать, что добавление новых примеров из обучающей выборки не вносит в модель ничего нового и процесс обучения продолжать нецелесообразно.
3.3.3. Зависимость адекватности семантической информационной модели от объема обучающей выборки (адекватность при малых выборках)
При экспериментальном исследовании характеристик предлагаемой модели было обнаружено следующее:
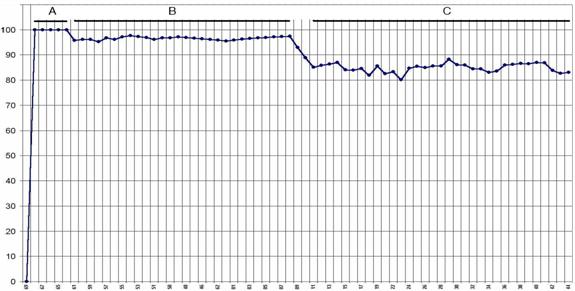
1. При малых выборках адекватность модели (внутренняя интегральная и дифференциальная валидность) равна 100% (рисунок 3.15, диапазон "А"). Это можно объяснить тем, что при малых объемах выборки все выявленные закономерности имеют детерминистский характер.
2. При увеличении объема исследуемой выборки происходит понижение адекватности модели (переход: А®В) и стабилизация адекватности на некотором уровне около 95-98% (рисунок 3.15, диапазон "В")
3. Учет в модели объектов обучающей выборки, отражающих закономерности, качественно отличающиеся от ранее выявленных, приводит к понижению адекватности модели (переход: В®С) и ее стабилизации на уровне от 80 до 90% (рисунок 3.15, диапазон "С").
4. Внутри диапазона "В" вариабельность объектов обучающей выборки по закономерностям "атрибут®класс" меньше, чем в диапазоне "С", т.е. объекты обучающей выборки диапазона "В" более однородны, чем "С".
|
|
|
Рисунок 3. 15. Зависимость адекватности модели от объема обучающей выборки |
Выявленные в модели причинно-следственные закономерности имеют силу для определенного подмножества обучающей выборки, например, отражающих определенный период времени, который соответствует детерминистскому периоду развития предметной области. При качественном изменении закономерностей устаревшие данные могут даже на некоторое время (пока модель не сойдется к новым закономерностям) нарушать ее адекватность.
В многочисленных проведенных практических исследованных модель показала высокую скорость сходимости и высокую адекватность на малых выборках. На больших выборках (т.е. охватывающих несколько детерминистских и бифуркационных состояний предметной области) закономерности с коротким периодом "причина-следствие" переформировываются заново, а с длительным (охватывающим несколько детерминистских и бифуркационных состояний) – автоматически становятся незначимыми и не ухудшают адекватность модели, если процесс апериодический, или сохраняют силу, если они имеют фундаментальный характер.
Из вышесказанного вытекает критерий остановки процесса обучения: если в модели ничего существенно не меняется при добавлении в обучающую выборку все новых и новых данных, то это означает, что модель адекватно отображает генеральную совокупность и продолжать процесс обучения нецелесообразно.
Здесь уместно рассмотреть один часто встречающийся вопрос, который
состоит в следующем. Если для формирования образов классов распознавания предъявлено настолько малое количество
обучающих анкет, что говорить об обобщении и статистике
не приходится, то как это может повлиять на качество
формирования этих образов и на достоверность распознавания? Если бы была статистика, то
как показывает опыт, около 95% анкет, формирующих образ оказывается типичными
для него, а остальные не типичными. Если этот образ формируется на основе
буквально одной - двух анкет, то вероятнее всего (т.е. с вероятностью около
95%) они являются типичными, и, следовательно, образ будет сформирован
практически таким же, как и при большой статистике, т.е. правильным. При увеличении статистики в этом случае информативности признаков, составляющих
образ практически не меняются). Но есть некоторая, сравнительно
незначительная вероятность (около 5%), что попадется нетипичная анкета. Тогда
при увеличении статистики образ быстро качественно изменится и "быстро
сойдется" к адекватному, "нетипичная" анкета будет
идентифицирована и ее данные либо будут удалены из модели, либо для нее
специально будет создан свой класс.
При незначительной статистике относительный вклад каждой анкеты в
некоторый образ, сформированный с ее применением, будет достаточно велик.
Поэтому в этом случае при распознавании Система уверенно относит анкету к этому
образу. При большой статистике Система также уверенно относит типичные анкеты к
образам, сформированным с их применением. Незначительное количество нетипичных
анкет могут быть распознаны ошибочно, т.е. не отнесены Системой к тем образам,
к которым их отнесли эксперты.
Наличие в системе классов распознавания очень сходных образов (по данным кластерно-конструктивного анализа) также может формально уменьшать валидность Системы. Однако фактически очень сходные образы целесообразно объединить в один, т.к. по-видимому, их разделение объективно ничем не оправдано, т.е. не соответствует действительности. Для осуществления данной операции предназначен режим: "Получение стат.характеристики обучающей выборки и объединение классов распознавания (ручной ремонт обучающей выборки)".
3.3.4. Семантическая устойчивость модели
Под семантической устойчивостью модели [141] в данном исследовании понимается ее свойство давать малое различие в прогнозе при замене одних факторов, другими, мало отличающимися по смыслу (т.е. сходными по их влиянию на поведение АОУ). Проведенные автором исследования и численные эксперименты показали, что предложенная модель обладает очень высокой семантической устойчивостью.
3.3.5. Зависимость некоторых параметров модели от ее ортонормированности
Изучим зависимость уровня системности, степени детерминированности и адекватности модели от ее ортонормированности. В связи с тем, что соответствующий научно-исследовательский режим, позволяющий изучить эти зависимости методом численного эксперимента, на момент написания данной работы находится в стадии разработки, получим интересующие нас зависимости путем анализа выражений (3.9) и (3.25), полученных в разделе 3.1.3.
При этом будем различать ортонормированность модели по классам и ортонормированность по атрибутам.
Зависимость адекватности модели от ее ортонормированности
Эта зависимость изучалась методом численного эксперимента. При этом были получены следующие результаты.
На 1-м этапе ортонормирования адекватность модели (ее внутренняя дифференциальная и интегральная валидность) возрастает. Это можно объяснить тем, что, во-первых, уменьшается количество ошибок идентификации с близкими, т.е. коррелирующими классами, и, во-вторых, удаление из модели малоинформативных признаков по сути улучшает отношение "сигнал/шум" модели, т.е. качество идентификации.
На 2-м этапе ортонормирования адекватность модели стабилизируется и незначительно колеблется около максимума. Это объясняется тем, что атрибуты, удаляемые на этом этапе, не являются критическим для адекватности модели.
На 3-м этапе ортонормирования адекватность модели начинает уменьшаться, т.к. дальнейшее удаление атрибутов не позволяет адекватно описать предметную область.
При приближении процесса ортонормирования к 3-му этапу или его наступлении этот процесс должен быть остановлен.
Зависимость уровня системности модели от ее ортонормированности
Рассмотрим выражение (3.9):
|
|
(3.9) |
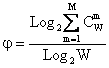
При выполнении операции ортонормирования по
классам из модели последовательно удаляются те из них, которые наиболее сильно
корреляционно связаны друг с другом. В результате в модели остаются классы
практически не коррелирующие, т.е. ортонормированные. Поэтому можно
предположить, что в результате
ортонормирования правила запрета на образование подсистем классов становятся
более жесткими, и уровень системности модели уменьшается.
Зависимость степени детерминированности модели от ее ортонормированности
Рассмотрим выражение (3.25):
|
|
(3.25) |
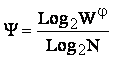
Так как каждый класс как правило описан более чем одним признаком, то при ортонормировании классов и удалении некоторых из них из модели суммарное количество признаков N будет уменьшаться быстрее, чем количество классов W, поэтому степень детерминированности будет возрастать.
При ортонормировании атрибутов числитель
выражения (3.25) не изменяется, а знаменатель уменьшается, поэтому и в этом
случае степень детерминированности
возрастает.
Таким
образом, ортонормирование модели
приводит к увеличению степени ее детерминированности.
По этой причине предлагается считать "истинной детерменированностью" предел, к которому стремится детерминированность, при корректном ортонормировании модели, т.е. при достижении максимума адекватности.